第二章 名詞定義與系統簡介
在本章中,我們將說明相關名詞的基本定義以及系統簡介。
2.1 基本定義
2.1-1 網站伺服器日誌(Web Server Log)
使用者藉由瀏覽器向網站提出一個網頁查詢的要求時,網站伺服器會處理這
些要求而與以回應,並記錄了一些重要的資訊到日誌檔案(Log File)中,因此
使用者瀏覽網站的行為模式,便可由網站伺服器日誌來獲得。
通常在日誌檔案中包含了:提出要求的機器位址( IP Address)或網域名稱,
提出要求的時間與日期,存取的方法( GET 或 POST) ,所要求的檔案位址名稱,
通訊協定,要求的結果(成功、失敗或錯誤) ,查詢的關鍵字,作業系統瀏覽器
的類型等相關資訊。本論文提出的網頁搜尋推薦系統架構在搜尋網站之上,使用
者可透過系統介面做會員登入,以關鍵字向搜尋網站查詢網頁,並在瀏覽網頁後
給回饋值。因此在本系統之網站伺服器日誌中還會記錄下會員編號、Session 編
號、查詢關鍵字及瀏覽網頁回饋值。例如圖 2.1 所示。
2.1-2 使用者查詢連線(User Query Session,簡稱 UQS)
本論文著重的焦點是在於探勘出使用者所提出的查詢以及其瀏覽網頁文章
的關聯,因此我們把日誌檔案中的記錄經過前置處理,取出用來表示使用者個別
查詢瀏覽行為的相關資訊。
我們在實作系統方面,允許使用者可以選擇以匿名或會員登入系統,這兩種
登入的模式會影響系統所提供網頁推薦的方式,我們會在第四章作詳細的說明。
當使用者以匿名方式登入時,系統使用 JSP 技術中 Session 的連線方式,以區分
出不同的使用者。每當使用者連線到伺服器系統時,系統會給予這個使用者一個
獨一無二的 Session 編號。Session 的有效執行時間則訂為 1.5 小時,也就是說當
使用者最後一次向系統發出要求後,再閒置了 1.5 小時之後,系統將自動消滅
Session。此後若使用者再度向系統提出要求時,則系統會重新設定一個新的
Session 編號給該使用者。若使用者以會員方式登入系統,系統也會給予這個使 用者一個獨一無二的 Session 編號,其目的在於表示出同一個使用者在不同時段
的查詢瀏覽記錄。
使用者查詢連線是指在一個 Session 有效執行期間內,單一使用者查詢的關
鍵字、查詢後瀏覽相關的網頁文章、以及瀏覽各文章後所給回饋值的集合。圖
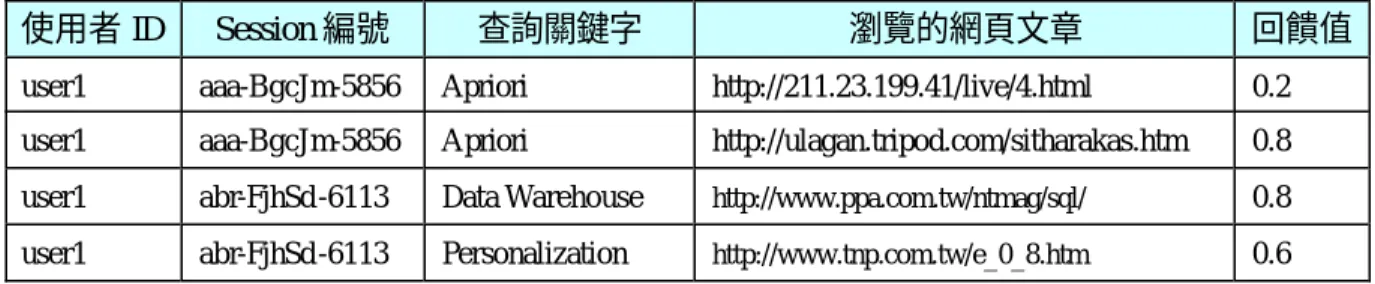
2.2 所示為圖 2.1 經過雜訊清除後的結果,其中有兩位使用者以會員方式進入系 統,其使用者 ID 分別為〝user1〞及〝user2〞,另一位使用者則以匿名方式登入
系統。以使用者 ID〝user1〞為例,〝user1〞在不同的時間進入系統兩次,因此
系 統 給 予 兩 個 不 同 的 Session 編 號 , 分 別 為 〝 aaa-BgcJm-5856 〞 以 及
〝abr-FjhSd-6113〞。以 Session 編號〝abr-FjhSd-6113〞為例,在這段期間內該使
用者查詢了兩個關鍵字,分別為〝Data Warehouse〞與〝Personalization〞,並記
錄下查詢後所瀏覽的網頁及其回饋值。這兩筆資料構成了使用者 ID 為〝user1〞,
Session 編號為〝abr-FjhSd-6113〞的一個使用者查詢連線,如圖 2.3 所示。
圖 2.2
140.122.76.107 - - [25/May/2002:03:39:41 -0500] user1 aaa-BgcJm-5856 "GET http://211.23.199.41/live/4.html 0.2 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=Apriori" "Mozilla/4.0 (compatible; MSIE 5.5;
Windows NT)"
140.122.76.107 - - [25/May/2002:03:39:45 -0500] user1 aaa-BgcJm-5856 "GET http://ulagan.tripod.com/sitharakas.htm 0.8 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=Apriori" "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
140.122.76.107 - - [26/May/2002:10:08:35 -0500] user2 aak-EmkBs-1958 "GET http://bi.fast.com.tw/powerplay2.htm 1.0 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=OLAP" "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
140.122.76.125 - - [26/May/2002:10:08:55 -0500] kcj-HesVa-2512 "GET http://www.ebooks.com/epaper/ep04.htm 0.8 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=Data Mining" "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
140.122.76.107 - - [26/May/2002:10:10:15 -0500] user2 aak-EmkBs-1958 "GET http://zahedaan.usc.edu/~yishin/web/
0.6 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=Clustering" "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
140.122.76.106 - - [27/May/2002:09:20:45 -0500] user1 abr-FjhSd-6113 "GET http://www.ppa.com.tw/ntmag/sql/ 0.6 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=Data Warehouse" "Mozilla/4.0 (compatible;
MSIE 5.5; Windows NT)"
140.122.76.106 - - [27/May/2002:09:21:16 -0500] user1 abr-FjhSd-6113 "GET http://www.tnp.com.tw/e_0_8.htm 0.8 HTTP/1.0" 200 3547 "http://tw.google.yahoo.com/search/web_kimo?p=Personalization" "Mozilla/4.0 (compatible;
MSIE 5.5; Windows NT)"
雜訊清除
圖 2.1
使用者 ID Session 編號 查詢關鍵字 瀏覽的網頁文章 回饋值
user1 aaa-BgcJm-5856 Apriori http://211.23.199.41/live/4.html 0.2
user1 aaa-BgcJm-5856 Apriori http://ulagan.tripod.com/sitharakas.htm 0.8
user2 aak-EmkBs -1958 OLAP http://bi.fast.com.tw/powerplay2.htm 1.0
kcj-HesVa -2512 Data Mining http://www.ebooks.com/epaper/ep04.htm 0.8 user2 aak-EmkBs -1958 Clustering http://zahedaan.usc.edu/~yishin/web/ 0.6 user1 abr-FjhSd -6113 Data Warehouse http://www.ppa.com.tw/ntmag/sql/ 0.8 user1 abr-FjhSd -6113 Personalization http://www.tnp.com.tw/e_0_8.htm 0.6
2.1-3 使用者側寫(User Profile,簡稱 UP)
當使用者以使用者 ID 登入系統時,系統會將該使用者的使用者查詢連線記
錄在使用者側寫資料中。同一使用者 ID,不同的 Session 編號,表示使用者側寫
中不同時間登入的使用者查詢連線。延續圖 2.2 範例,使用者 ID〝user1〞的使
用者側寫包含有兩個使用者查詢連線,如圖 2.4 所示。
2.1-4 使用者查詢交易記錄(User Query Transaction)
【定義 1】使用者交易記錄單位:在一個使用者查詢連線中,一個查詢關鍵
字以及所有對應到的瀏覽網頁和回饋值,形成一個使用者查詢交易記錄單位。一
筆使用者查詢交易記錄的表示為
<qi >(
dj,
fj)
+,其中 q
i為一個查詢關鍵字,瀏
覽的網頁文章為 d
j及其回饋值 f
j, 〝+〞號則表示網頁文章及其回饋值至少一組以
上。
根據定義 1,我們將某一段系統定義區間內,系統所蒐集到的使用者查詢連
使用者 ID Session 編號 查詢關鍵字 瀏覽的網頁文章 回饋值
user1 abr-FjhSd -6113 Data Warehouse http://www.ppa.com.tw/ntmag/sql/ 0.8 user1 abr-FjhSd -6113 Personalization http://www.tnp.com.tw/e_0_8.htm 0.6
圖 2.3
圖 2.4
使用者 ID Session 編號 查詢關鍵字 瀏覽的網頁文章 回饋值user1 aaa-BgcJm-5856 Apriori http://211.23.199.41/live/4.html 0.2
user1 aaa-BgcJm-5856 Apriori http://ulagan.tripod.com/sitharakas.htm 0.8 user1 abr-FjhSd -6113 Data Warehouse http://www.ppa.com.tw/ntmag/sql/ 0.8 user1 abr-FjhSd -6113 Personalization http://www.tnp.com.tw/e_0_8.htm 0.6
線轉換成一些使用者查詢交易記錄來表示。例如圖 2.5 所示,這些資料是兩位會
員使用者 ID 為 User1 及 User2,以及一位匿名使用者的使用者查詢連線資料,圖
2.6 則顯示經過處理之後,所得到的使用者查詢交易記錄。以使用者 User1 的查 詢關鍵字 q1 為例,其瀏覽的文章有 d1、d2 以及 d3,相關的回饋值為 1.0、1.0
以及 0.6,因此構成了一筆使用者查詢交易<q1> (d1 1.0) (d2 1.0) (d3 0.6)。
圖 2.5
交易編號 查詢交易內容
1 <q1> (d1 1.0) (d2 1.0) (d3 0.6) 2 <q2> (d2 0.8)
3 <q3> (d1 0.8) (d5 1.0)
4 <q4> (d4 0.8) (d5 0.8) (d6 0.2) 5 <q5> (d5 0.6) (d6 0.2)
6 <q1> (d3 0.2)
7 <q2> (d1 0.8) (d2 1.0) 8 <q3> (d2 1.0) (d5 1.0) 9 <q4> (d4 0.6) (d5 0.8) 10 <q5> (d5 0.8) (d6 0.2) 11 <q1> (d2 0.8) (d3 0.2) 12 <q2> (d1 0.6) (d3 0.2) 13 <q3> (d1 0.8) (d5 1.0) 14 <q4> (d4 0.8) (d6 0.2) 15 <q5> (d5 1.0)
圖 2.6 處理
使用者 ID:User1
<q1> d1 1.0
<q1> d2 1.0
<q1> d3 0.6
<q2> d2 0.8
<q3> d1 0.8
<q3> d5 1.0
<q4> d4 0.8
<q4> d5 0.8
<q4> d6 0.2
<q5> d5 0.6 aaa-BgcJm-5856
<q5> d6 0.2 使用者 ID:User2
<q1> d3 0.2
<q2> d1 0.8
<q2> d2 1.0
<q3> d2 1.0
<q3> d5 1.0
<q4> d4 0.6
<q4> d5 0.8
<q5> d5 0.8 adj-BhkSy -8118
<q5> d6 0.2 Anonymous
<q1> d2 0.8
<q1> d3 0.2
<q2> d1 0.6
<q2> d3 0.2
<q3> d1 0.8
<q3> d5 1.0
<q4> d4 0.8
<q4> d6 0.2 abe-GnmOst-1758
<q5> d5 1.0
2.1-5 二分圖(Bipartite Graph)
查詢關鍵字及其對應瀏覽的網頁間具有多對多的關係,因此我們以二分圖的 方式來表示它們之間的關聯。
【定義 2】令 UT 為所有使用者查詢交易所形成的集合,Q 為 UT 中查詢關
鍵字所形成的端點集合,D 為 UT 中網頁文章所形成的端點集合,則 E 為邊所形
成 的 集 合 且
E⊆Q×D。 若 在 UT 中 存 在 一 筆 使 用 者 查 詢 交 易 包 含
{
<qi >(dj, fj)} ,則(q
i, d
j)
∈E,以 ei,j表示。因此 G(UT)=(Q, D, E)形成一個關鍵 字集合 Q 與網頁集合 D 的瀏覽關聯二分圖。
以圖 2.6 之資料為例,查詢關鍵字集合 Q 為{q
1,q
2,q
3,q
4,q
5},網頁文章集合 D 為
{d
1, d
2, d
3, d
4, d
5, d
6},圖 2.7 顯示 Q 和 D 的瀏覽關聯二分圖。以查詢交易編號 1 為例,下了查詢關鍵字 q
1並瀏覽文章 d
1,則存在有一個邊 e
1,1連接 q
1及 d
1所對
應的節點。
圖 2.7
q1 q2 q3
q4 q5
d1 d2 d3
d4 d5
d6
e1,1
2.1-6 二分圖中關鍵字節點 q
i的鄰居(neighbor)
【定義 3】在一個瀏覽關聯二分圖 G(UT)=(Q, D, E)中,若存在一個邊 e
i,j∈E連接 q
i及 d
j,則 q
i及 d
j稱為彼此相鄰(adjacent)。對於任一 q
i∈Q,qi的鄰居為
與 q
i相 鄰 的 網 頁 文 章 節 點 所 形 成 的 集 合 , 以 Neighbor(q
i) 表 示 , 即
( )
{
D E}
Neighbor
( q
i)
=d
kd
k ∈ ∧q
i, d
k ∈。
以圖 2.7 的二分圖為例,與 q
3相鄰的節點有 d
1、d
2及 d
5,因此 q
3的鄰居
Neighbor(q3
)={d
1, d
2, d
5}。
2.1-7 二分圖中兩關鍵字節點 q
i與 q
j的相似度(similarity)
【定義 4】以 Sim(q
i, q
j)表示兩關鍵字節點 q
i與 q
j的相似度:
( )
) q ( )
q (
) q ( )
q (
q , q
j i
j i
j
i Neighbor Neighbor Neighbor Neighbor
Sim ∪
= ∩
其中 Neighbor(q
i)由定義 3 得知為 q
i在二分圖中鄰居所形成的節點集合,”
∩”
代表集合運算符號”交集”,”
∪” 代表集合運算符號”聯集”,絕對值符號代表集
合中的元素個數。以圖 2.7 的二分圖為例,關鍵字節點 q
1與 q
3的相似度計算方
式如下:
Neighbor (q1
)={d
1, d
2, d
3} Neighbor (q
3)={ d
1, d
2, d
5}
Neighbor (q1
)
∩Neighbor (q3)={d
1, d
2} |Neighbor (q
1)
∩Neighbor (q3)|=2
Neighbor (q1
)
∪Neighbor (q3)={d
1, d
2, d
3, d
5} |Neighbor (q
1)
∪Neighbor (q3)|=4
Sim(q1
,q
3)=|Neighbor (q
1)
∩Neighbor (q3)|/|Neighbor (q
1)
∪Neighbor (q3)|=2/4
=0.5
2.1-8 關聯式規則
關聯式規則可用來表示交易資料庫中資料項出現的關聯性。例如在圖 2.8 中
之例,第二筆資料中同時有 q
2及 d
2,因此可以列出『若有 q
2則有 d
2』及『若有
d
2則有 q
2』兩個關聯式規則,分別表示為 q
2→d
2及 d
2→q
2。在本論文中,我們要 找出一個關鍵字和瀏覽文章集合的關聯,因此僅考慮前提是單一個查詢關鍵字且
結論為網頁文章集合的關聯規則。
在以往關聯式規則的推導中,大部份僅考慮資料項是否同時出現在一筆交易
記錄中的關聯。在此論文中,我們考慮資料項出現在交易記錄中有不同關聯值,
因此在找出關聯規則時能提供更多有關資料項關聯比重的資訊。例如圖 2.8 所示
範例,每一筆交易資料包含一個查詢關鍵字以及對應瀏覽的網頁文章為其資料
項,其中查詢關鍵字在該筆交易記錄中的關聯值皆設為 1.0,使用者所給予的瀏
覽網頁回饋值則視為各網頁資料項在該筆交易記錄中的關聯值。
交易編號 查詢交易內容
1 (q
11.0) (d
11.0) (d
21.0) (d
30.6) 2 (q
21.0) (d
20.8)
3 (q
31.0) (d
10.8) (d
51.0) 4 (q
11.0) (d
30.2)
5 (q
21.0) (d
10.8) (d
21.0) 6 (q
31.0) (d
21.0) (d
51.0) 7 (q
11.0) (d
20.8) (d
30.2) 8 (q
21.0) (d
10.6) (d
30.2) 9 (q
31.0) (d
10.8) (d
51.0)
圖 2.8
在計算關聯規則的支持度與確信度時,我們將資料項關聯值列入計算,其計
算方式如下。
【定義 5】以 sup(X)表示資料項 X 在查詢交易記錄中的支持度:
N ) X.weight(T sup(X)
N
1 i
∑
i=
=
, 其 中 N 表 示 使 用 者 查 詢 交 易 記 錄 的 總 數 ;
X.weight(T
i)表示資料項 X 在第 T
i筆交易記錄中的關聯值。若 X 沒有出現在第
T
i筆交易記錄中,則 X.weight(T
i)=0。
【定義 6】 以 sup(X, Y
1,… ,Y
k)表示資料項集合 {X, Y
1,… ,Y
k}的支持度:
N ) .weight(T Y
) X.weight(T )
Y , , Y sup(X,
N
1 i
k
1 j
j j
i k
1
∑ ∏
= =
∗
=
K
,其中 N 表示使用者
查詢交易記錄的總數;X.weight(T
i)表示資料項 X 在第 T
i筆的交易記錄中的關聯
值;Y
j.weight(T
i)表示資料項 Y
j在第 T
i筆的交易記錄中的關聯值。
【定義 7】以 sup 與 conf 表示關聯規則 X→Y
1,… ,Y
k(k≥ 1)的支持度與確信度:
) Y , , Y sup(X, )
Y , Y (X
sup
→ 1K
k = 1K
ksup(X) ) Y , , Y sup(X, )
Y , Y
conf(X 1 k 1 K k
K =
→
以圖 2.8 之資料為例,q
2→d
2之支持度與確信度分別為:
2 . 9 0
) 0 . 1 0 . 1 8 . 0 0 . 1 ) ( d , sup(q )
d q
sup( 2 → 2 = 2 2 = ∗ + ∗ =
6 . 0 0
. 3
) 0 . 1 0 . 1 8 . 0 0 . 1 ( ) sup(q
) d , sup(q )
d q ( conf
2 2 2 2
2 → = = ∗ + ∗ =
而 q
1→d
2, d
3之支持度為與確信度分別為:
035 . 9 0
) 8 . 0 2 . 0 0 . 1 8 . 0 2 . 0 0 . 1 ) ( d , d , sup(q )
d , d q
sup( 1 → 2 3 = 1 2 3 = ∗ ∗ + ∗ ∗ =
11 . 0 0
. 3
) 8 . 0 2 . 0 0 . 1 8 . 0 2 . 0 0 . 1 ( )
sup(q ) d , d , sup(q )
d , d q ( conf
1 3 2 1 3
2
1 → = = ∗ ∗ + ∗ ∗ =
2.2 系統架構簡介
本論文提出以合作式推薦的方法來提供適於使用者需求的網頁搜尋推薦系
統,系統主要可分為四大部分,架構圖如圖 2.9 所示,其中第一、二、三部份是
屬於離線(off- line)作業;第四部份是屬於線上(on- line)處理。
第一部份為資料前置處理:此部份的工作是將網站伺服器日誌過濾移除一些
不必要的資訊,保留所需要的相關資訊,例如使用者 ID、Session 編號、查詢關
鍵字、瀏覽網頁文章位址名稱及回饋值等,並記錄使用者側寫以及產生使用者查
詢交易記錄。
第二部份為資料群集分析:根據使用者查詢交易記錄建構出查詢關鍵字與網
頁文章的瀏覽關聯二分圖,探勘出二分圖中關鍵字及網頁聚落的分佈情形,產生
使用者查詢喜好聚落,再根據查詢喜好聚落將使用者查詢交易記錄做分割
(partition)。
第三部份為關聯規則推導:針對每個使用者查詢喜好聚落對應的查詢交易記
錄分割,探勘出查詢關鍵字與網頁文章間確信度高的關聯規則。
第四部份為合作式查詢推薦系統:採取線上處理的模式,當使用者提出推薦
網頁的要求時,系統會根據使用者所屬查詢喜好聚落,並以先前探勘出之查詢關
鍵字與網頁文章的關聯規則,推薦相關網頁給使用者。
本系統以類似代理人( Agent)的身份,架構在使用者與搜尋引擎系統之間,
使用者可透過本系統向搜尋引擎發出查詢關鍵字,並接收搜尋引擎所傳回的網頁
資訊。因此系統可以記錄使用者查詢了哪些關鍵字,且瀏覽了哪些網頁文章等等
相關資訊,以形成使用者側寫,並產生使用者查詢交易記錄。
系統將蒐集來的使用者查詢交易資料,運用資料群集技術將查詢關鍵字做分
群,並根據各關鍵字聚落,產生查詢關鍵字與網頁文章的關聯規則。依據分群結
果,一個使用者的查詢資料可能包括多個關鍵字聚落,以反應一個使用者能有多
方面的查詢喜好。
當使用者以會員方式登入系統並向系統提出推薦的要求時,系統會依使用者
側寫中的查詢資料,推薦其所屬關鍵字聚落中高度相關的網頁文章給使用者,即
藉由合作式過濾方式來達到網頁推薦的功能。當使用者以匿名方式使用系統,亦
可要求推薦查詢的功能。系統則依使用者所下查詢關鍵字,推薦該關鍵字所屬聚
落中高度相關的網頁文章。
系統架構圖:
資料前置處理
使用者個人側寫
資料群集分析
建構出瀏覽 關聯二分圖 建構出瀏覽 關聯二分圖
群集分析群集分析 二
分 圖
1 2 k
使用者交易記錄分割SUT
離線作業
網頁搜尋推薦引擎 網頁搜尋推薦引擎
中文Yahoo搜尋引擎 中文Yahoo搜尋引擎
查詢 瀏覽 回饋 推薦
網頁 查詢
網頁文章 關鍵字
線上處理
合作式查詢推薦系統
Apriori演算法 Apriori演算法 關鍵字與網頁
的關聯規則
使用者 即時更新 資料雜訊清除
取出使用者查詢連線 資料雜訊清除 取出使用者查詢連線
關聯規則推導
1 2
}
k產生並記錄 產生並記錄
網站伺服器 日誌
使用者查詢交易記錄
查詢喜好聚落