第3章 水文分析
目 次
第 1 節 水文統計分析 ... 1
1. 1 總說 ... 1
1. 2 資料蒐集與分析方法前提條件之檢討 ... 1
1. 2. 1 水文資料週期性之檢討 ... 2
1. 2. 2 水文資料跳躍的檢討... 2
1.2.3 水文資料趨勢的檢討... 3
1.3 穩定性水文量頻率分析 ... 4
1.3.1 候選機率分布模式之列舉 ... 4
1.3.2 機率分布模式的母數推定 ... 6
1.3.3 候選機率分布模式的篩選 ... 9
1.3.4 機率水文量的偏差補正與穩定性評估 ... 10
1.3.5 機率分布模式之決定... 11
1.3.6 機率分布模式決定之相關補充事項 ... 13
1.4 非定常性水文量的頻率分析 ... 13
1.5 時系列變化特性的分析 ... 14
2014年 4 月 版
第 3 章 第 1 節-1
第 3 章 水文分析
第 1 節 水文統計分析 1. 1 總說
<概 說>
本節說明以第 2 章 水文.水理觀測 第 2 節 降水量觀測、第 3 節 水位觀測、第 4 節 流量觀測規定方法 所得、 第 5 節 「水文資料的整理.保存與品質管理」所規定方法,進行蓄積與管理水文資料等的統計分析 技術性事項。
一般河川規畫之執行須先設定河川管理設施等的設計或管理目標,通常根據過去所發生嚴重狀況或藉由 災害等頻率分析推定規模或目標。本節之水文頻率分析法,主要運用既有水文資料推定計畫規模頻率出現的 水文災害,並且推定不確定的水文災害發生頻率。
以往水文頻率分析,通常會假設水文資料之穩定性,但未來地球暖化可能帶來更大的氣候變化,水文頻 率分析方法也得跟著修正、改變,因此本節會說明如何確認分析之前提條件。
水文統計分析包含資料蒐集與分析方法之前提條件及檢討、水文頻率分析、時系列變化特性分析等。
資料蒐集與分析方法前提條件之檢討,除了說明水文統計分析的基本事項之外,也會檢討水文頻率分析 的前提條件是否已滿足。此外,水文頻率分析時,以下所述之穩定分析或是非穩定分析之適用選擇為基礎,
說明水文資料定常性檢討之方法。
水文頻率分析是根據水文諸量規模與其發生頻率的關係,用統計方法加以推定,並配合前述穩定性檢討 結果,選擇穩定性水文量之頻率分析或非穩定性水文量之頻率分析。
另外,本節也說明時系列變化特性分析時,用來分析週期性等時間變化特性的方法。
1. 2 資料蒐集與分析方法前提條件之檢討
<概 說>
應根據分析目的、分析方法、資料蒐集與整理難易等,選定可作為水文統計分析基礎的水文資料。水文 資料之選定與蒐集,應就如下各項目加以調查與檢討。
1) 水文資料的存在狀況
2) 觀測或記錄之方法、水文資料精確度、代表性等特性 3) 蒐集水文資料相關的時間、費用等作業程度
4) 其他調查成果資料
年最大值資料變動很大,不易由水文資料特性加以判斷,但若發現異常地大於或小於平均值的資料,應 調查當年氣象條件,判斷該水文資料妥當性,必要時得回頭查閱測定時的記事本,重新整理觀測值。
此外,水文頻率分析所使用水文資料的檢討項目主要有 1) 隨機性、2) 獨立性、3) 均質性、4) 穩定性。
1) 隨機性(Randomness)
所謂「隨機性」 ,主要是因為樣本本身會不斷變動。比如,人為調整流量所取得的資料已失去隨機性,須
去除調節效果。
第 3 章 第 1 節-2
[鍵入文字] [鍵入文字] [鍵入文字]
2) 獨立性(Independence)
所謂「獨立」 ,指樣本的各數據都不受其他數據影響。比如,本日的流量會受昨日的流量影響(昨日流量 大時,本日流量也較大) ,稱不上是「獨立」 。因此,進行水文資料隨機抽樣,通常得拉大抽樣間隔,才能達 到「獨立」的要求。
3) 均質性(Homogeneity)
「均質性」指所有樣本都可視為從一個母集團所取得。
4) 穩定性(Stationarity)
所謂「穩定性」 ,指樣本去除隨機變動後之成分,不會隨時間變化。非穩定性數據會有趨勢(長期變化傾 向) 、跳躍(急劇變化)或週期性等狀況。比如,流域本身會慢慢改變,是一種「趨勢」 。 「跳躍」則經常與自 然、人為條件突然改變有關。
穩定性不足時,應檢討水文資料之中去除週期成分與跳躍影響的資料趨勢有意義性,若判斷不具備有意 義性,可去除週期成分與跳躍影響的資料、以穩定性為前提的水文頻率分析。反之,若判斷具有意義性,實 施水文頻率分析時,可用含趨勢成分的非穩定性水文量頻率分析方法。
1. 2. 1 水文資料的週期性之檢討
<例 示>
水文資料是否有週期性,可用時系列相關圖評估樣本自己相關係數。判斷水文資料是否從獨立同一分布 取得樣本的方法是,以顯著水準 5%,從樣本{X
1, X
2, …,X
n}的自己相關係數判斷是否在可靠界限±1.96/√n 範圍內。若在預期週期 2~3 倍程度(或 40 倍步驟程度)的樣本自己相關係數,其中 2、3 個以上位於可靠界 限外,或者有 1 個遠離可靠界限
,就應放棄相關資料屬同一分布的假設。放棄之後就應根據調和分析等方法,進 行排除週期成分的水文頻率分析。1. 2. 2 水文資料跳躍的檢討
<例 示>
要判斷水文時系列資料是否「跳躍」 ,可實施 t-檢定或 Mann-Whitney 檢定。此外,觀察期間的長短有時會 影響能否確認水文資料是否有跳躍,因此最好同時確認是否有充足的水文資料觀測期間。不同的水文資料特 性,其所需要充分觀測期間長度也不同。若水文資料無充分觀測期間,就視為沒有跳躍。此外,若跳躍原因 已經很明顯,就需把觀測期間分割成幾個段落加以檢討。
比如,蒐集年降水量、洪水期降水量、月降水量、年最大日雨量、年最大時雨量等水文時系列資料時,
其中最穩定的就是年降水量。日降水量與時降水量等的年最大值變動很大,很難確認是否有跳躍,因此,即
使目的是分析年最大值,也最好利用能顯示年降水量等平均特性的資料進行檢討,若發現有顯著的跳躍,就
可把觀測期間切割成幾段,分別檢討。
第 3 章 第 1 節-3
1. 2. 3 水文資料趨勢的檢討
<例 示>
判斷水文時系列資料是否具有某種趨勢,有 Mann-Kendall 檢定與新記錄數檢定等方法。但其檢出力各有 不同,而水文資料很多不是只有單一趨勢,因此須以複數方法、複數對象期間實施評估。
1) Mann-Kendall 檢定
Mann-Kendall 檢定乃是不討論趨勢是線形還是非線形,只針對水文時系列資料趨勢實施檢定的非參數方 法。這項檢定的虛無假設 H
0與對立假設 H
1,如下:
H
0:n 個數據{X
1, X
2, …,X
n}獨立且具有相同機率分布。
H
1:n 個數據{X
1, X
2, …,X
n}非相同機率分布。
Mann-Kendall 檢定以公式(3-1-4)定義其統計量 Z
。s = ∑ ∑ sign(Xj− Xk)
n
j=k+1 n−1
k=1
(3-1-1)
sign(θ) = { 1 θ > 00 θ = 0
−1 θ < 0
(3-1-2)
Var(S) = 110(n(n − 1)(2n + 5) − ∑ ei(ei− 1)(2ei+ 5)
n
i=1
)
(3-1-3)
z =
{ s − 1
√Var(s) s > 0 0 s = 0
s + 1
√Var(s) s < 0
(3-1-4)
在此,ei代表數據{X
1, X
2, …,X
n}按升序排列時,相同值連續出現的個數,n 代表其組數。在此若顯著水 準為α,標準常態變量 Z 為︱Z︱>z
1-
α/2時,假設 H
0就被棄卻。這裡的 z
1-
α/2乃是相當於標準常態分布的超過 機率α/2 之位數。此外,S>0 時,代表水文時系列資料 Xi 走高,S<0 時,走低。
2) 新記錄次數檢定
水文時系列資料固定維持獨立同一分布時,可把最初記錄當作新記錄,之後只需計算新記錄被更新的次 數。該數字理論上可用下列公式算出來,因此可和觀測值所得到的新記錄次數比較,評估其穩定性。
1 +
12+
13+ ⋯ +
1n≈ 1ogn + γ (3-1-5)
在此,n 代表觀測次數(以年最大值為對象時,指觀測年數)、γ代表尤拉常數,約為 0.577216。時系列
若呈增加傾向,代表觀測值所得到新記錄次數超過理論值;呈現減少趨勢,代表新記錄次數少於理論值。比
如,顯著水準為 5%時,相對於 n=25、50、100 的新記錄次數的上限值分別為 7、8、9。
第 3 章 第 1 節-4
<參考資料>
水文時系列資料穩定性分析詳細做法,可參考下列資料。
1) 徐宗學、竹內邦良、石平博:日本的平均氣溫.降水量時系列之跳躍與趨勢相關研究,水工學論文集,
第 46 卷,pp.121-126,2002。
2) Salas, Jose R.:Analysis and Modeling of Hydrologic Time Series, Chap. 19, Handbook of Hydrology, (Ed. ) D. R.
Maidment, McGraw-Hill, New York, pp. 19. 1-19.72, 1993.
3) 飯山由利子、西村和夫、澀谷政昭:檢定新記錄次數的檢出力,應用統計學,Vol. 24 No. 1,pp. 13-26, 1995。
4) 關靜香、加藤琢朗、志村光一、山田正:以新記錄出現理論針對荒川水系大雨發生頻率的研究,土木 學會的 55 屆學術演講會,Ⅱ-155,2000。
5) 竹內啟,藤野和建:運動數理科學-增進歡樂的數字判斷方法(應用統計數學系列),p.181,共立出 版,1988。
6) P. J. Blockwell.R. A. Davis 著者,逸見功.田中稔.宇佐美嘉弘.渡邊則生譯:入門時系列分析與預 測,p.431,謝皮出版,2004。
1.3 穩定性水文量頻率分析
<標 準>
穩定
性為前提的水文量發生頻率分析,應依如下順序實施。1) 候選機率分布模式之列舉 2) 機率分布模式的母數推定 3) 候選模式篩選
4) 機率水文量偏差補正與穩定性評估 5) 機率分布模式之決定
1.3. 1 候選機率分布模式之列舉
<例 示>
水文頻率分析之候選模式,因應分析對象之水文資料予以列舉
。<例 示>
1) 水文時系列資料依一定區間予以分割,彙集各該區間所含最大值的水文資料,區分之最大值,一般又 稱為極值資料。極值資料呈現 3 種極值分布型態,可用 1 個公式表示之,就是一般極值分布(GEV)。
一般極值分布形狀母數為 0 時是 Gumbel 分布,以 x 為變量,各自的機率密度函數 f(x)與機率分布函數 F(x)如下。
a) Gumbel 分布
f(x) =exp{−
x−ξ α }
α exp [−exp {−x−ξα }]
(3-1-6)
F(x) = exp [−exp {−x−ξα }](3-1-7)
b) 一般極值分布
第 3 章 第 1 節-5
f(x) =
α1{1 −
k(x−ξ)α}
1 k−1
exp [− {1 −
k(x−ξ)α}
1/k] (3-1-8)
F(x) = exp [− (1 − k
x−ξα)
1/k] (3-1-9) 在此,ξ:位置母數、α:尺度母數、k:形狀母數,k=0 時為 Gumbel 分布。此外,一般極值分布 k
>0 時,有上限值。
x≦ξ+α/k (3-1-10)
2) 閥值超過資料(POT:peaks over threshold)乃是全部取出超過閥值的獨立峰值資料。年最大值資料不 會使用比其他年度最大值為大的排位第二或第三高數據,而且不同年度某些狀況不為洪水,若能選擇 適當的臨界值,就能排除像這樣具有不同特性的水文資料。選定臨界值常用方法是運用樣本平均超過 函數。以下舉例說明指數分布與一般 Pareto 分布。
一般 Pareto 分布的形狀母數為 0 時,就是指數分布;以 x 為變量,各自的機率密度函數 f(x)、機率分 布函數 F(x)如下。
a) 指數分布
f(x) =
exp{−x−ξ α }
α
(3-1-11) F(x) = 1 − exp {−
x−ξα} (3-1-12)
b) 一般 Pareto 分布
f(x) =
α1{1 −
k(x−ξ)α}
1 k−1
(3-1-13)
F(x) = 1 − (1 − k
x−ξα)
1/k(3-1-14)
在此,ξ:位置母數、α:尺度母數、k:形狀母數,k=0 時為 Gumbel 分布。此外,一般極值分布 k
>0 時,有上限值。
x≦ξ+α/k (3-1-15)
3) 如所周知,誤差會隨常態分布改變。此外,一定期間內的日降水量等短時間降水量,多半可用指數分 布加以說明。配合指數分布變化的兩種變量和,可用γ(伽瑪)分布加以說明。類似這樣先掌握各分 布的特徵與過去的例子,就可在進行對象水文資料分析時列舉適宜的分布。以下舉例說明常態分布、
Pearson Ⅲ型分布機率密度函數 f(x)與機率分布函數 F(x)。
a) 常態分布
f(x) =
√2πσ1exp {−
12(
x−μσ)
2} (3-1-16)
第 3 章 第 1 節-6
F(x) =
√2πσ1∫
−∞xexp {−
12(
x−μσ)
2} dt (3-1-17)
在此μ為平均,σ為標準偏差。特別是μ=0,σ=1 時,稱為「標準常態分布」 ,有其機率分布函數的 數表。
b) Pearson Ⅲ型分布
若形狀母數γ不是 0,進行如下的變數變換,
α =
γ42, β =
12σ|γ|, ξ = μ −
2σγ, γ ≠ 0 (3-1-18)
每個正負的γ之中,x 的分布範圍、機率密度函數 f(x),以及機率分布函數 F(x),可用下列公式說明。
γ>0 時,x 的分布範圍為ξ≦x<∞
f(x) =
(x−ξ)α−1exp{−(x−ξ)/β}βαΓ(α)
(3-1-19) F(x) = G (α,
x−ξβ) /Γ(α) (3-1-20) γ<0 時,x 的分布範圍為-∞<x<ξ
f(x) =
(ξ−x)α−1exp{−(ξ−x)/β}βαΓ(α)
(3-1-21) F(x) = 1 − G (α,
ξ−xβ) /Γ(α) (3-1-22) 在此,G(α, z)是不完全γ函數
G(α, z) = ∫ t
0z α−1exp(−t) dt (3-1-23) γ接近 0 時,Pearson Ⅲ型分布漸近於常態分布;γ=2 時,為指數分布。
1.3. 2 機率分布模式的母數推定
<例 示>
採用分析對象之水文資料求取候選模式母數時,應配合樣本大小,使用適宜的推定法。其方法包括積率 法、L 積率法、最尤法等
。小樣本(樣本大小<30)時,常使用L 積率法
。1) 積率法
通常,積率法簡單講就是推定機率分布模式的母數時,假定其原點與平均值周邊的積率也就是平均值、
分散、變率,各自等於從樣本取得的樣本平均、無偏分散、無偏應變率等,以之推定分布模式的母數。
機率分布模式機率密度函數為 F(x)時,其中的平均μ、變方σ
2與應變率γ公式分別如下:
第 3 章 第 1 節-7
μ = ∫ xf(x)dx
∞
−∞
(3-1-24) α
2= ∫ x
2f(x)dx − μ
2∞
−∞
(3-1-25) γ = ∫ x
3f(x)dx/σ
3∞
−∞
(3-1-26) 另一方面,由樣本{X
1, X
2, …, X
n}取得的樣本平均μ̂
x、無偏變方σ̂
x2、無偏變率為γ̂
x分別為
μ̂
x= 1 n ∑ x
in
i=1
(3-1-27) σ̂
x2= 1
n − 1 ∑(x
i− x̅)
2n
i=1
(3-1-28) γ̂
x= 1
(n − 1)(n − 2)σ̂
x3∑(x
i− x̅)
3n
i=1
(3-1-29)
f(x)為 2 母數時,(3-1-24)與(3-1-25)左邊置換成(3-1-27)與(3-1-28)解開連立方程式,算出母數。有 3 個母數 時,(3-1-24)、(3-1-25)與(3-1-26)左邊置換成(3-1-27)、(3-1-28)與(3-1-29)解連立方程式,算出母數。此外,3 種母 數時有各種可補正變率的方法。
2) L 積率法
水文資料數據有 明顯偏差之處理,主要有 PWM(probability-weighted moments)與L積率(L Moments)
這 2 種方法。L積率特徵在於用順序統計量的線形和加以表現, (L是 linear combinations 的縮寫) 。 X
j(j=1, 2,…,n)為樣本所取得順序統計量(X
1≧X
2≧X
3…,≧X
n)時,PWM 定義如下。
β
r= E{X[F(X)]
r} ∫ xF
1 rdt
0
(3-1-30) 計算 PWM 樣本推定值有 2 種方法,其中最單純的是機率分布函數 F(x)搭配「位置標繪」。
β̂
r= 1
n ∑ x
j[1 − j − 0.35 n ]
n r
i=1
(3-1-31)
另一種無偏推定值之推求方法,如下。
第 3 章 第 1 節-8
β̂
r= 1
n ∑ (n − j r ) x
j(n − 1 r ) = 1 r + 1
n−r
j=1
∑ (n − j r ) x
j( n r + 1)
n−r
j=1
(3-1-32) 本公式 r=0、1、2、3 時,實際上如下所示。
β̂
0= X̅ (3-1-33)
β̂
1= ∑ (n − j)x
jn(n − 1)
n−1
j=1
(3-1-34)
β̂
2= ∑ (n − j)(n − j − 1)x
jn(n − 1)(n − 2)
n−2
j=1
(3-1-35)
β̂
3= ∑ (n − j)(n − j − 1)(n − j − 2)x
jn(n − 1)(n − 2)(n − 3)
n−3
j=1
(3-1-36) 採用算出為 PWM,L 積率可用下列公式推求。
λ
1= β
0(3-1-37) λ
2= 2β
1− β
0(3-1-38) λ
3= 6β
2− 6β
1+ β
0(3-1-39) λ
4= 20β
3− 30β
2+ 12β
1− β
0(3-1-40) r
2= λ
2/λ
1(L−CV) (3-1-41) r
3= λ
3/λ
2(L−skewness) (3-1-42) r
4= λ
4/λ
2(L−kurtosis) (3-1-43) 把這些 L 積率代入各機率分布模式之母數與 L 積率關係的連立方程式,即可求得各機率分布模式的母數。
a) Gumbel 分布
α = λ
2/log2 , ξ = λ
1− αγ (3-1-44) 在此,γ代表歐拉常數,約 0.577216。
b) 一般極值分布 (GEV)
k ≈ 7.8590c + 2.9554c
2, c =
3+r23
−
log2log3(3-1-45) α =
(1−2−kλ)Γ(1+k)2k(3-1-46) ξ = λ
1− α{1 − Γ(1 + k)}/k (3-1-47) c) 指數分布
α = 2λ
2, ξ = λ
1− α (3-1-48) 已知下限值ξ時
α = λ
1− ξ (3-1-49)
d) 一般 Pareto 分布
第 3 章 第 1 節-9
k =
1−3r1+r33
(3-1-50) α = (1 + k)(2 + k)λ
2(3-1-51) ξ = λ
1− (2 + k)λ
2(3-1-52)
已知下限值ξ時
k =
(λλ3−ξ)2
− 2 (3-1-53) α = (1 + k)(λ
1− ξ) (3-1-54) e) 常態分布
μ = λ
1, σ = √πλ
2(3-1-55) f) Pearson Ⅲ型分布
α ≈
z+0.1882z1+0.2906z2−0.0442z3, z = 3πr
32, for 0 < |r
3| <
13(3-1-56) α ≈
0.36067z−0.59567z2+0.25361z31−2.7886z+2.56096z2−0.77045z3
, z = 1 − |r
3|, for
13< |r
3| < 1 (3-1-57) 有α時,可使用如下公式。
γ =
√α2sign(γ
3)λ
1, σ = λ
2√απΓ(α)/Γ(α +
12), μ = λ
1(3-1-58) 3) 最尤法
機率密度函數 f(x)=f(x;θ),母數向量為θ時,尤度函數公式如下:
L(θ) = L(θ, X
1, X
2, … , X
n) = ∏ f(X
j, θ)
n
j=1
(3-1-59) 最大母數向量
L(θ̂) = max
θ L(θ) (3-1-60) 為推定值此即為最尤法,通常取尤度函數自然對數的最大對數尤度函數,就能算出最尤推定量。
1.3. 3 候選機率分布模式的篩選
<例 示>
候選模式是否適合用來分析對象水文資料的評估方法,可採用 SLSC(Standard Least Square Criterion) 。SLSC 定義為如下公式。
SLSC =
|S√ξ299−S01|
,ξ
2=
n1∑ (s
ni=1 i− s
i∗)
2(3-1-61)
在此,s
99與 s
01分別是非超越機率 0.99 與 0.01 時的該機率分布之標準變量,n 代表樣本大小,s
i為以推定母
數之順序統計量變換得到的標準變量,s
i∗為以機率分布模式所算出對應位置標繪位數得到的標準變量。
第 3 章 第 1 節-10
[鍵入文字] [鍵入文字] [鍵入文字]
SLSC 值越小,適合度越高,用這樣的判斷基準進行篩選。SLSC 若小於 0.04,多半代表能滿足適合度。
就標繪位置而言,解決方案的公式很多。由水文資料取得的順序統計量(X
1≧X
2≧X
3…,≧X
n)第 i 個值 的超過機率 pi,可統一用下列公式說明。
pi =
n−2α+1i−α(3-1-62) 在此,n:樣本大小,α:決定標繪位置的常數,有不同的提案,Weibull:0、Blom:0.375、Cunnane:0.4、
Gringorten:0.44、Hazen:0.5 等。
計算 SLSC 時,最常用的是標繪位置大多適合各種分布的 Cunnane 標繪。此外,小樣本時,可使用 Weibull 標繪。此外,也可搭配以 SLSC 評估適合度,以適合的機率紙標繪,確認模式的適合度。
<例 示>
確認機率分布模式適合度的方法有使用 Gumbel 機率紙與指數機率紙,如下:
1.3. 4 機率水文量的偏差補正與穩定性評估
<例 示>
以滿足一定層級適合度的機率分布模式為對象,必要時用重複取樣法、針對機率分布模式的機率水文量 偏差補正,評估其穩定性,主要有 jackknife 法與 bootstrap 法。
圖 3-1-1 使用 Gumbel 機率紙
(極值資料)
圖 3-1-2 使用指數機率紙
(POT 資料)
第 3 章 第 1 節-11
jackknife 法做法是,大小為 n 個之樣之中,欠缺第 i 號 1 個的數據數 n-1 個樣本,都對 i 製作(成立 n 套),
然後根據這些樣本所算出統計量,計算無偏佐值及其周邊推定誤差。
另一方面,bootstrap 法是從大小為 n 個樣本,容許其重複地任意取出 n 個的複數樣本,再根據這些樣本求 得的統計量,算出無偏估值及其周邊推定誤差。
jackknife 法計算次數少,所完成的樣本數、無偏估值與推定誤差都只有 1 個值;相對的,bootstrap 法完成 的樣本數可任意設定,所做成不同樣本數會導致不同的無偏估值與推定誤差。用這兩種方法算出偏差補正量,
bootstrap 法偏差補正量會變成 jackknife 法偏差補正量的(n-1)/n,n 若非極小,這個差就會很小。
jackknife 法具體順序如下。大小為 n 樣本的各項數據分別是 X
1,X
2,…,X
n。利用這些數據推定其母集團特性 的統計量為
Ψ ̂ = Ψ(X
1,X
2,…,X
n) (3-1-63) 大小為 n 個樣本之中,使用只欠缺第 i 號 1 個數據的數據數 n-1 樣本統計量為
Ψ ̂
(i)= Ψ(X
1,X
2,…,X
i-1, Xi+1,…, X
n) (3-1-64) Ψ ̂
(i)之 i=1,2,…n,即有 n 個。 (?)
Ψ ̂
(i)的平均值即為
Ψ ̂
(∙)= 1
n ∑ Ψ ̂
(i)n
i=1
(3-1-65) 偏差推定值公式如下。
BIAS ̂ = (n − 1)(Ψ̂
(∙)− Ψ ̂ ) (3-1-66) 以此公式補正統計量偏差的 jackknife 推定值,公式如下。
Ψ ̃ = Ψ̂ − BIAS ̂ = nΨ̂ − (n − 1)Ψ̂
(∙)(3-1-67) 此外,jackknife 法得出的推定誤差分散為:
VAR ̂ = n − 1
n ∑(Ψ ̂
(i)− Ψ ̂
(∙))
2n
i=1
(3-1-68) 相對於不適用 jackknife 時的統計量具有 1/n 級序偏差,(3-1-67)之中的 jackknife 推定值偏差只有 1/n
2級序,
可見以 jackknife 法補正偏差是有效的。
1. 3. 5 機率分布模式之決定
<例 示>
滿足適合度基準,可使用機率分布模式之方法。
選擇機率分布模式,應從滿足適合度基準之中,選出具有良好穩定性的機率分布模式。此時乃以本節 1.3.4
所算出機率水文量推定誤差分散平方根的推定誤差為指標,選出其中相對較小的機率分布模式。
第 3 章 第 1 節-12
對應於超越機率或非超越機率之機率水文量或任意規模之變量,具對應超越機率或非超越機率,可由其 所使用的機率分布模式推定出來。
要計算對應於任意規模變量 x 的非超越機率 F(x),只需簡單帶入機率分布函數 F(x)的 x。超越機率可用 1-F 計算出來。超越機率的倒數乃是重現期間(return period)。
Return Period =
1−F1(3-1-69) 計算機率水文量所使用機率分布函數 F(x),加入變量 x 解出公式帶入非超越機率 F,就能算出機率水文量。
年最大值等極值資料為對象的分布機率水文量之案例如下。
1) Gumbel 分布
x(F) = ξ − α ∙ log (− log(F)) (3-1-70) 2) 一般極值分布
x(F) = ξ + α{1 − (− log(F))
k}/k (k ≠ 0) (3-1-71) 超過 POT 臨界值的變量以及代表其非超越機率分布函數 G(x)及年最大值資料機率分布函數 F(x)之間,有 下列公式的關係。
F(x) = exp{− λ(1 − G(x))} (3-1-72) 在此,λ是超越臨界值事件的年間發生率。用這個公式解 G(x),就能以下列公式算出對應於年最大值資 料非超越機率 F 的非超越機率 G,置換成(3-1-12)與(3-1-14)的 F(x)而計算 x,即為(3-1-74)與(3-1-75),如此就能 算出對應於年最大值為對象重現期的機率水文量。
G = 1 +
log (F)λ(3-1-73) 3) 指數分布
x(F) = ξ − α ∙ log (−
log(F)λ) (3-1-74) 4) 一般 Pareto 分布
x(F) = ξ + α {1 − (−
log(F)λ)
k} /k (k ≠ 0) (3-1-75) 5) 常態分布
常態分布的機率分布函數逆函數不會顯示出來,因此可用標準常態分布表或誤差函數的逆函數等方式算
出機率水文量。
第 3 章 第 1 節-13
1. 3. 6 機率分布模式決定之相關補充事項
<例 示>
本節 1.3.5 機率分布模式選定時若難以判斷,可一併參考使用赤池資訊量基準(AIC)評估法。
AIC 公式定義如下。
AIC = 2m − 2MLL (3-1-76) 在此,m 為母數向量的次元數(母數的數)。MLL 為最大對數尤度
MLL = ∑ log[f(X
i, θ̂]
n
i=1
(3-1-77) 母數向量θ̂為最尤推定量,但若運用 L 機率推定母數時,可取代其母數向量。
一般而言,母數數目較多時,會有更好的分布適合度。AIC 較重視母數的數目,這部分和只重視適合度的 其他規準不同。AIC 值越小,可判斷為越好的模式。
<參考資料>
遵照本基準實施水文頻率分析時,可參考下列資料。
1) 岩井重久,石黑政儀:應用水文統計學,森本出版,1970。
2) 角屋睦:水文統計論,土木學會水理委員會 水工學系列,64-02,p.59,1964。
3) 高橋倫也:極值統計學,統計數理研究所公開講座,p.57,2008。
4) 寶馨:水文頻率分析的進步與將來展望,水文.水資源學會誌,Vol. 11 No. 7,pp. 740-756,1998。
5) 水文.水資源學會編集:水文.水資源手冊,pp.238-248 7.3 水文頻率分析,朝倉書店,1997。
6) Stedinger, J.R., R.M. Vogel, and E. Foufoula-Georgiou: Frequency Analysis of Extreme Events,Chap. 18, Handbook of Hydrology, (Ed.) D. R. Maidment, McGraw-Hill, New York,pp.18.1-18.66,1993.
7) 林敬大,立川康人,椎葉充晴,萬和明,Kim Sunmin:導入以 SLSC 評估水文頻度模式適合度的統計 假設檢定,土木學會論文集 B1(水工學),Vol.68 No.4,pp. 1381-1386,2012。
8) 葛葉泰久:擬定治水計畫時的統計方法-SLSC 與本益比相關考察-,土木學會論文集,Vol.66 No.1,
pp. 66-75,2010。
1. 4 非定常性水文量的頻率分析
<例 示>
無法視為定常的水文量頻率分析考慮如下順序之方法。
1) 檢討有無水文資料周期性或跳躍狀況,無這種狀況的才可當作水文資料。
2) 水文時系列資料統計特性之時間變化,可推定帶入模式機率分布模式的母數,進行機率評估。比如,
處理年最大值等極值資料的一般極值分布情況,或處理 POT 資料的一般 Pareto 分布情況,都可用位置 母數、尺度母數與形狀母數等 3 種母數表示。其中,考慮位置母數與尺度母數會隨時間變化之模式。
ξ(t) = β
0+ β
1t 或 ξ(t) = β
0+ β
1t + β
2t
2(3-1-78)
第 3 章 第 1 節-14
α(t) = exp (β
3+ β
4t) (3-1-79) 用最尤法解這些母數中的參數,以推定代表時系列變化的機率分布模式。
<參考資料>
將時系列資料具有統計特性的時間變化帶入模式而完成機率分布模式,詳細做法參考下列資料。
1) Coles, S.:An Introduction to Statistical Modeling of Extreme Values, Springer, p.208, 2001.
2) 高橋倫也:極值統計學,統計數理研究公開講座,p.57,2008。
1. 5 時系列變化特性的分析
<概 說>
很多水文現象具有長時間某種程度規則性,且其平均與分散等統計特性會緩慢變化。時系列分析乃是以 定量方法了解這種時間變化特性的分析法,具體做法如下。
時系列現象的變化狀態,大體上有長期性傾向變化(趨勢) 、週期性變化、持續性變化以及偶然性變化等 幾種。若要從定量角度說明這些特性,有各自不同的分析方法。
若要處理受氣候變化等影響,分析對象水文資料統計特性經年不斷變化的水文頻率分析,可參考本節 1.4 非穩定性方法。
此外,水文資料統計特性會因為觀測期間不同而出現經年性變化的顯著性改變,因此須慎重評估設定不 同觀測期間的優劣。
<例 示>
要掌握時間經過過程之水文時系列資料狀態改變傾向,可參考下列 1 種或組合之方法。
1) 將經過時間與對應水文資料值整理成圖(時系列圖) ,可直接看出其變化狀態。
2) 從資料的值算出移動平均值,看出其時間變化傾向。
3) 以任意的時間區分將資料分成幾個群,每個群都算出觀測值平均值、分散以及系列相關係數等的統計 量,由此推定的母集團特性值,比較各群的值。
4) 製作時系列相關圖,了解有無週期性變化與持續性變化傾向。
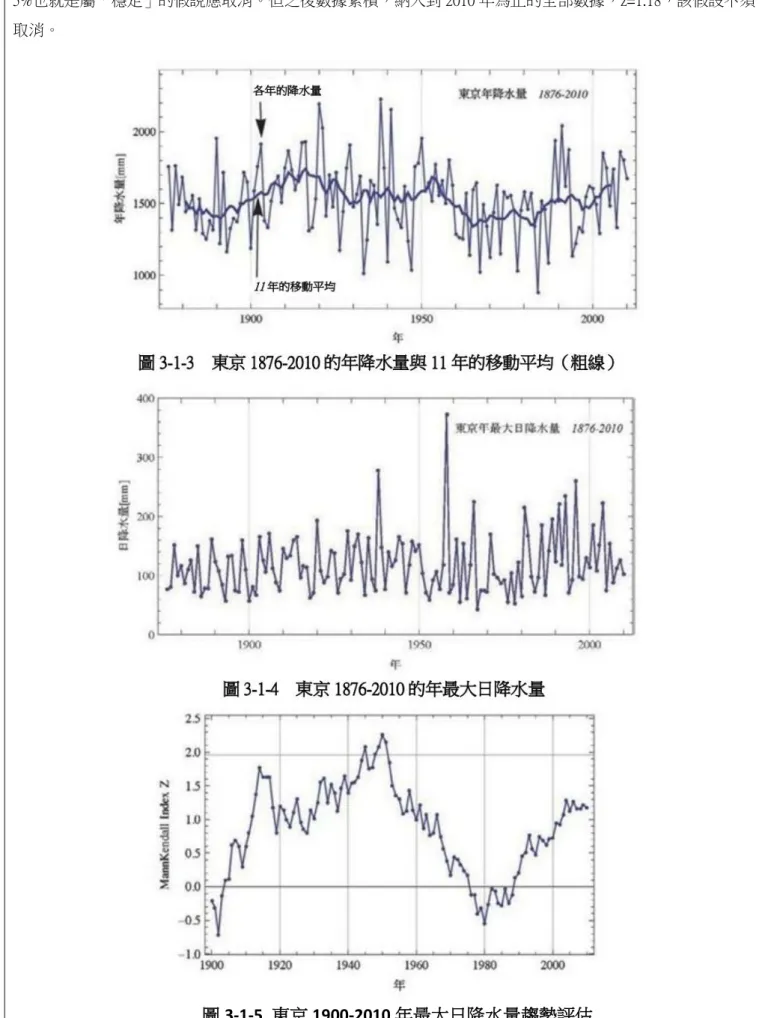
圖 3-1-3 是從 1876 到 2010 年為止東京年降水量的 11 年移動平均。
在此,若實施全部期間 Mann-Kendall 檢定,z=-0.36,未達顯著水準 5%之棄卻假說,因此稱不上是有顯著 的減少傾向。
圖 3-1-4 代表同期間年最大日雨量演變。
圖 3-1-4 是開始實施觀測後 25 年的水文資料。1900 到 2010 年以 Mann-Kendall 實施檢定的結果,如圖 3-1-5
所示。
第 3 章 第 1 節-15
由此圖可以發現,橫軸在 1950 年附近變成 Z>1.96。這顯示,1876 年到 1950 年為止數據判斷為顯著水準 5%也就是屬「穩定」的假說應取消。但之後數據累積,納入到 2010 年為止的全部數據,z=1.18,該假設不須 取消。
圖 3-1-5 東京 1900-2010 年最大日降水量趨勢評估
第 3 章 第 1 節-16
圖 3-1-6 是東京 1876 到 2010 年為止月降水量相關圖,明顯出現 12 個月的週期性。
圖 3-1-6 東京 1876-2010 年月降水量相關圖
相關圖模式形狀特徵也就是時系列變化特徵,大致如圖 3-1-7 分類。
圖 3-1-7 時系列變化的模式
① 幾乎完全的週期性 (a) ② 持續性 (衰減傾向) (c) 週期性與偶發性的混合型 (a') ③ 純偶發性 (d)
週期性與持續性的混合型 (b)
此外,若週期性理由不明確,以相關圖作為完全週期性之判斷基準,應考慮水文資料全部期間內含有好 幾個週期。
若要更詳細地探討時系列變化特性,可以下列方法 1 種或組合,實施基礎分析。
1) 套用時間相關 1 次式或多次式的迴歸分析,推定傾向變化曲線(趨勢) 。
第 3 章 第 1 節-17
2) 藉由週期分析(或週期圖分析)等方法,找出週期變化成分特性。
3) 利用相關圖分析或其他方法,求出週期成分變化及持續性變化特性。
4) 原先的時系列變化可分為以上述 1)或 3)求出來的規格性變化成分,以及剩下的不確定性變化成分。後
者可分析其分布特性與生成特性。
第 3 章 水文分析 第 2 節 逕流分析 目 次
第 2 節 逕流分析 ...1
2. 1 總說 ...1
2.1.1 逕流分析的目的 ...1
2.1.2 逕流模式的種類與特徵 ...1
2. 2 洪水涇流計算 ...2
2.2.1 總說 ...2
2.2.2 洪水涇流模式之選定 ...3
2.2.3 水文資料及流域特性資料之蒐集與整理 ...3
2.2.4 洪水涇流模式構造之決定與計算輸入的雨量 ...4
2.2.5 洪水涇流模式的常數分析與驗證 ...6
2.2.6 洪水流量計算 ...7
2. 3 低水流量演算 ...7
2.3.1 總說 ...7
2.3.2 蒸發散量計算 ...7
2.3.3 取水與還原量等的推定 ...8
2.3.4 積雪與融雪量的推定 ...9
2. 4 主要逕流模式例示 ...10
2014 年 04 月 版
第 3 章 第 2 節-1
第 3 章 水文分析
第 2 節 逕流分析
〈概 說〉
本節說明河川等調查進行逕流分析必要之技術性事項。
逕流分析所使用的逕流演算模式種類繁多,而且不斷有新的逕流模式與分析方法。因此,本節主要說明以河 川等調查進行逕流分析時通用的技術性事項,並舉例說明在河川等調查之中有實際運用成績的代表性逕流演算模 式。
2.1 總說
2.1.1 逕流分析的目的
〈概 說〉
藉由河川等調查之逕流分析目的,主要有以下幾種 1) 為擬定河川相關計畫或河川管理設施設計之流量計算 2) 預測實況時的河川流量(特別是洪水時的流量)
3) 計算長期的河川流量
4) 流域或氣候變化所導致水循環的變化的預測
5) 水文觀測不充分的流域長期或洪水時河川流量的計算 6) 為更進一步了解逕流現象的內涵
本節除非特別說明,否則主要在說明 1) 為擬定河川相關計畫,或河川管理設施設計之流量計算以及 3) 計算 長期河川流量的相關逕流分析。
〈參考資料〉
逕流分析的目的分類及其詳細內容,可參考下列資料
1) 池淵洲一,椎葉充晴,寶馨,立川康人;ACE 水文學(ACE 土木學工程系列),pp.125-126,朝倉書店,
2006。
2) 日本學術會議:回答 河川逕流量演算模型.設計洪水量驗證相關學術評價,P.3,2010。
〈必須〉
逕流量分析的方法與順序應依分析的目的與能利用的資料等條件,適切設定。
2.1.2 逕流模式的種類與特徵
〈例 示〉
逕流模式可以從許多不同觀點做不同的分類。代表性之分類方法及特徵如下。
1) 根據預測期間分類
‧短期逕流模式 ‧長期逕流模式
短期逕流模式又稱為洪水演算模式,計算幾小時到幾天的逕流現象。通常是以一小時或更短時間單位計算幾
天內的河川流量。此時逕流模式主要部份是在坡面逕流過程,以及在河道網之中的水流模式化。通常短期流出模
式不會導入蒸發散過程。反之,長期逕流模式得適切地把積雪.融雪蒸發散過程反映到模式裡面。
第 3 章 第 2 節-2
2) 根據降雨─逕流的應答過程分類
‧應答模式 ‧概念模式 ‧物理模式
應答模式乃是由輸出入應答關係所構成降雨逕流關係式的模式。
概念模型則是概念性地掌握現象而構成降雨流出關係式模式。若有過去長期間的降雨與河川流量水文資料並 且適切地設定演算模式常數,就能較精準地預測河川流量。這種模式具有計算負荷小的特徵。
物理模式乃是由物理法則之基礎公式建構的降雨逕流關係式之模式,可呈現土地利用或流域環境的變化。
3) 從模式空間構成方法之角度分類 ‧集中常數系模式(集中型模式) ‧分布常數系模式(分布型模式)
集中常數系模式乃是進行某對象地點流量計算時,將對象地點上游流域為單位的逕流過程,用整個流域加以 以平均化的模式。
分布常數系演式乃是納入降雨時的時空觀測數據,並將地形.地質.地被等地域資訊分布納入考量而計算水 文量時空分布構造的模式。
〈參考資料〉
逕流模式的分類及特徵詳細內容,可參考下列資料。
1) 池淵洲一,椎葉充晴,寶馨,立川康人;ACE 水文學(ACE 土木學工程系列),pp.125-126,朝倉書店,
2006。
2) 日本學術會議:回答 河川逕流量演算模式.計畫洪水量驗證相關學術評價,P.3,2010。
2.2 洪水涇流計算 2.2.1 總說
〈概 說〉
計算洪水逕流量通常順序如下 1) 選定逕流模式
2) 蒐集與整理水文資料、流域特性資料 3) 決定逕流模式構造並算出輸入的降雨量 4) 逕流演算模式的常數分析與驗證 5) 計算流量
但有時因為受到洪水逕流分析目的與能利用的水文觀測資料制約,或所使用逕流演算模式等有所限制,這些
順序有時會簡略化。比如運用合理化公式時,3) 、4)可省略。
第 3 章 第 2 節-3
2.2.2 洪水逕流模式之選定
〈標 準〉
洪水演算模式應依洪水逕流量分析目的或是有無必要之水文資料,加以選定,並視必要加以改良。
譬如水環境健全化檢討之際,若須預測流域都市化之流量影響,必須選定能清楚顯示流域變化前後流出特性 的逕流模式。
〈例 示〉
選定洪水演算模式時,大多得充分地將模式是否耐用(不同洪水狀況模式仍能適用)以及實際運用的成績納入考 量。
合理化公式有許多應用在土地利用的常數標準值調查案例,常被用來計算無過去流量資料小流域的洪峰流 量,具有實用之業績。
貯蓄函數法在計算日本對洪水流量方面具有很高的重現性,很受廣泛利用。
水桶模式適用在世界各國多樣化氣候條件以及擁有流域特性的流域,用來進行逕流量預測,但須根據過去的 水文資料測試大部分常數是否有誤。
一般而言,模式常數較多,重現性較高,但耐用性會降低。已有人開發出很多種分布常數系模式,且適用在 運動方程式之物理公式時不會降低耐用性。
2.2.3 水文資料與流域特型資料之蒐集與整理
〈概 說〉
以洪水為對象的水文資料及流域特性資料,為提高逕流分析精密度應儘可能蒐集。此外,蒐集來的資料須整 理,應適合所使用的逕流量模式構造。
〈標 準〉
基本上應盡可能對分析對象區域內或附近的雨量、水位、流量觀測記錄加以蒐集,每次洪水都須整理確認資 料存在與否。
雨量資料有時只靠對象河川流域內的雨量資料,無法適切地重現雨量時空間分布,因此,基本上應在該周邊 地區蒐集包含降雨原因在內的該周邊地區所能得到的全部雨量資料。
流量資料應清楚說明流量的觀測方法。
〈標 準〉
若觀測流量受儲水池等調節之人為影響或洪水時外水氾濫等偶發性影響,應配合逕流分析目的,選擇適當方 法,避開上述不良影響。
〈例 示〉
製作流域平均雨量與觀測流出水位的時系列變化圖,藉此可掌握每次洪水降雨和逕流量關係之特徵。
第 3 章 第 2 節-4
〈建 議〉
必要時應整理水文資料稽核時所可能利用的相關資料。
天氣圖等氣象資訊、雷達雨量、淹水災情或土砂災害等災害記錄,可用來掌握雨量資料的精確度。在觀測所 之外地點,特定時間所調查到的水位、流量、水位痕跡等,則可幫助觀測所掌握流量資料的精確度。
〈建 議〉
必要時應蒐集整理該流域的地形、地質、土地利用、土地被覆等資料,並活用於流域分割妥當性檢討或逕流 模式常數分析、逕流量計算結果分析等。
2.2.4 洪水逕流模式構造之決定與計算輸入的雨量
〈標 準〉
洪水逕流演算的基本方法是,將該河川流域分割成幾個逕流演算的基本單位(小流域或小區塊等),然後用河道 模式連結起來加以計算。此時需注意洪水流的傳播以及河道貯蓄的影響等。
〈標 準〉
洪水逕流演算時用來追蹤河道洪水波的河道計算方法,是選出可和流域基本單位之逕流模式精確度整合的方 法、就河川洪水波傳播之水理量變化能獲知的一次元分析方法。
〈例 示〉
洪水逕流演算的河道計算方法,大致區分為水理學追蹤法與水文學追蹤法。
水理學追蹤法乃是運用差分法與特性曲線法等數值計算法,得出一次元開水路水流運動方程式數值,使用這 種方法前提是需有河川斷面水理學特性相關資訊。開水路流水運動方程式因所考量到的項目不同,會有包括所謂 不定流計算的動態波模式至擴散波模式、運動波模式等不同選項。
水文學追蹤法可將河水流入河道區間與流出之對應關係公式化,又分以下三種。
1) 利用某河道區間內水理連續方程式與運動方程式(貯蓄函數)的方法 2) 設定洪水波傳播速度(延遲時間)的方法
3) 利用洪水流水位相互關係的方法
1) 方法有貯蓄函數法、Muskingum 等。水庫內的洪水追蹤法之中,有相當於河道區間水體水面同步升降時可 使用貯蓄函數法之水庫模式。這些常數都能從河道區間的橫斷面形狀等水理學資訊取得。
2 ) 方法有運用 Manning 公式與 Chezy 公式,計算合理式洪水集流時間的方法,以及運用水庫中傳播速度的 方法。在限定水理與水文學資訊條件下,能用這種方法簡易計算。
3) 在洪水演算對象地點以外地點實施水位預測,或進行即時洪水預測等所使用的方法。
〈參考資料〉
用集中常數系模式所形成洪水逕流演算進行河道計算的方法,可參考如下資料。
1) 土木學會水理委員會;水理公式集﹝1999 年﹞,pp.119-125,丸善,1999。
第 3 章 第 2 節-5
依貯留函數法及 Muskingum 法之河道計算關於常數之水理學的推定法,可參考下列資料。
2) 橋本宏,藤田光一;洪水追蹤法(其 2)─洪水追蹤模式的適用界線與未知參數推定法計算河道方法的詳 細內容,可參考以下資料。
3) 池淵洲一,椎葉充晴,寶馨,立川康人;ACE 水文學(ACE 土木學工程系列),pp.125-126,朝倉書店,
2006。
〈必 須〉
逕流模式的雨量以各逕流模式流域為基本單位之各面積平均雨量輸入。計算面積平均雨量之際,應將流域內 的地形性降雨地區分布特性,不同年代不同降雨觀測所網、缺測狀況等納入考量,選出最適切的方法。
〈例 示〉
計算面積平均雨量的方法有等雨量線法、徐昇氏法、算術平均法、支配圈法、高度法、代表係數法等。
〈參考資料〉
等雨量線法、徐昇氏法、算術平均法、支配圈法、高度法的內容,可參考下列資料。
1) 日本學術會議:回答 河川演算模式.設計洪水量驗證相關的學術評估,pp.27-28。
代表係數法詳細內容,可參考下列資料。
2) 木村俊晃:土木技術資料,以相關關係分析為基礎的流域平均雨量演算法,2-5,pp.173-179,1960。
〈例 示〉
判斷雷達雨量計分析處理數據比地上雨量計觀測雨量算出的雨量具有更高精密度,可進行幾何補正而當作輸 入值。
另外,研究從「再分析數據」也就是利用過去觀測的氣象資訊與氣象數值模式,詳細分析過去氣象的同化分 析結果,由此抽樣選出降雨量的方法。
〈例 示〉
進行即時洪水預測而必須輸入逕流模式的預測雨量時,從該地點降雨預測值算出面積平均雨量,然後加以輸 入,或是輸入氣象數值預測結果。
〈參考資料〉
進行即時洪水預測詳細內容,可參考下列資料。
1) (財)河川情報中心:中小河川的洪水預測入門,2002。
〈標 準〉
洪水逕流演算時,標準做法是,流域內雨水損失與保留機能的部分另外計算,以直接逕流量(表面逕流量+中間
逕流量)成份作為計算對象。一次洪水的總有效降雨量等於直接逕流量成分的總量。直接逕流量成份演算的標準方
法是,將觀測水文歷線的基底逕流量成分分離出來。逕流量成分的分離方法則有在洪水上湧點水平分離法、水文
歷線遞減部轉折點與洪水上湧點連線分離法等。
第 3 章 第 2 節-6
〈參考資料〉
逕流量成分分離的詳細做法,參考下列資料。
1) 土木學會水理委員會;水理公式集﹝1999 年版﹞,p.36,丸善,1999。
〈例 示〉
有效降雨相關常數可用觀測資料所取得洪水期間的水收支算出來。
此外,若從水收支等認定有降雨初期貯留在凹地等的效果,可把這部分納入有效降雨量計算。
〈參考資料〉
計算有效降雨順序詳細做法,參考下列資料
1) 日本學術會議:回答河川演算模式.計畫洪水量驗證相關的學術評估,pp.5-6。
2.2.5 洪水逕流模式的常數分析與驗證
〈概 說〉
洪水演算模式的常數分析與驗證須先有洪水現象,因此,應先找出超過過去記錄的洪峰流量預測,以及從大 洪水到中小洪水、可用來進行水文歷線重現等的逕流演算的觀測資料。
是否有適宜地完成常數分析,可用比較觀測流量與計算流量的方式加以確認。
驗證用的洪水現象最好選出與常數用分析不同的洪水現象,但若大洪水等現象數目有限,若該演算模式已經 在許多流域擁有驗證過的實績,可省略驗證步驟,而以針對更多洪水現象實施常數分析,提升其精確度。
〈必 須〉
洪水演算模式的常數分析非常依賴觀測資料精確度,因此,若判斷流域平均雨量等的輸入值或觀測流量精密 度太低,就不可列入常數分析對象。
〈標 準〉
洪水演算模式常數分析時,若想以大洪水洪峰流量重現這樣的逕流演算加以重現,標準做法是選定能讓複數
洪水洪峰流量適度重現的洪水。但若研究個別洪水現象等特定目的,不在此限。
第 3 章 第 2 節-7
〈建 議〉
洪水演算模式常數分析之際,應盡可能納入更多的洪水狀況。
〈例 示〉
計算流量與觀測流量之適合度的定量數值指標,重點在洪峰流量附近誤差的評估基準、相對基準、相對平方 基準、Nash-Sutcliffe 效率等。
〈參考資料〉
訂定可用來顯示適合度的各數值指標,可參考下列資料。
1) 望月邦夫:淀川治水計畫以及系統工學研究,京都大學博士論文,1970。
2) 角屋睦,永川明博:流出分析手法(其 11),農業土木學會誌,第 48 卷 第 11 號,pp.841-856,1980。
3) Nash J. E and Sutcliffe, J.V. : River Flow Forecasting Through Conceptual Models Part I-A Discussion of Principles, Journal of Hydrology, 10, pp. 282-290,1970.
2.2.6 洪水流量計算
〈概 說〉
流量計算應將降雨輸入同時率定的逕流模式之中。
2.3 低水流量演算 2.3 .1 總說
〈概 說〉
低水流量逕流量分析一般的順序,基本上和洪水逕流分析順序相同。以下說明與洪水逕流分析不同的項目。
〈概 說〉
1950 年代之後的流量記錄較多;雨量記錄必須長期持續,低水流量計算因此常被用來作為流量未觀察期間的 流量資料之補充(復原)。
〈標 準〉
通常低水流量逕流量分析標準是以日單位或半旬為單位。
〈標 準〉
日平均流量(m
3/s)變換成逕流量高(mm/day)時,應掌握日雨量、日流量之日界,並記錄計算逕流量時的注意事 項。譬如,自記水位記錄的觀測所,其日流量乃是從凌晨 1 到 24 時為止毎正時的流量平均;水位標的觀測所,則 通常是 6 時與 18 時的平均流量。
2.3 .2 蒸發散量計算
〈標 準〉
第 3 章 第 2 節-8
計算低水流量逕流量時通常得輸入降雨和融雪,減掉損失的量乘以時間就是逕流量,這種做法稱為追蹤計算。
所謂「損失」 ,指水因為蒸發散而往大氣移動、流域貯蓄量變化,深層地下水帶水層而往流域外流失。以河川流域 為計算對象時,通常可把最後的流失忽略不計,又,1 水文年開始與結束時,可不必考慮其流域貯蓄量變化,而 將那一年之間的損失全部視為蒸發散。為了能讓 1 水文年的水收支平衡,基本上應採用推定蒸發散量的方法。
〈標 準〉
蒸發散量的計算方法,基本上是可能蒸發散量,或觀測蒸發量乘以從水收支得出的係數。
水收支不明時,可根據過去的調查案例,運用可適用該流域的係數。
但若所實施觀測精確度高於上述作法,也可加以運用。
〈例 示〉
假設能充分供地表水分下的可能蒸發散量,其推定有許多種公式可用。比如由氣溫與緯度所決定日照量推定 的 Hamon 公式,Thornthwaite 公式等經驗公式,以及需更詳細微氣象觀測資訊的 Penman 公式、Penman-Moteith 公式 等。觀測蒸發散量,可運用氣象廳等所觀測蒸發皿的總蒸發量。
〈參考資料〉
推定可能蒸發散量的詳細做法,可參考以下資料。
1) 土木學會水理委員會;水理公式集 ﹝1999 年﹞,pp.16-18,丸善,1999。
〈例 示〉
從河川流域水收支算出日本平均年降雨損失量,全國平均約 500mm、北海道約 400mm、瀨戶內.九州約 600mm。
〈參考資料〉
由河川流域水收支計算全國平均年降雨損失量的詳細做法,可參考以下資料。
1) 建設省技術研究會(編輯);利水計畫掌握流況之研究,第 23 屆建設省技術研究會報告,p.4,1970。
2.3.3 取水與還原量等的推定
〈概 說〉
以利水計算為目的低水流量逕流量演算時,應先大致算出水庫調節,或上游取水.還原等無人為影響的自然 流量,建立可預測這種自然流量的逕流演算模式。
〈標 準〉
基本上以水庫調節或取水與還原量等觀測值加以利用。
若無觀測資料,應從許可水權量以及河川區域內水收支等資訊加以推定。若這些資訊也無法加以運用,應準
用其他河川所完成的調查事例。
第 3 章 第 2 節-9
〈建 議〉
若無農業用水取水量實測值,可用下列方法推定其取水量 1) 水收支法
假定無農業用水取水計算之河川流量與同一地點觀測流量的差,當作純農業用水取水量(=農業用水取水量─
還原水量) 2) 減水深法
水田以外其他農耕地減水深乘以其面積,算出農業用水量,當作取水量。
〈參考資料〉
土地改良事業設定減水深計畫值,可參考下列資料。
1) 土地改良事業計畫設計基準「計畫 農業用水(水田)」 ,1993 年 5 月,農林水產省構造改善局,pp.33-56。
2.3.4 積雪與融雪量的推定
〈概 說〉
有融雪流出的河川流域推定其降雪、積雪與融雪量,一般是把融雪算入降雨,計算其流出。
〈標準〉
降水觀測通常不會區分降雪還是降雨,通常是由降水時的地面氣溫觀測值推定該地點的地面氣溫,判別降雪 與降雨。
積雪量通常是降雪量減掉融雪量。
融雪量可用只靠氣溫就能推定融雪量的「積算暖度法(degree-day 法)」 ,若要算出更高精確度,可用積雪量的熱 收支加以計算。
〈參考資料〉
積算暖度法詳細作法,可參考下列資料。
1) 土木學會水理委員會;水理公式集 ﹝1999 年﹞,pp.27,丸善,1999。
〈例 示〉
積雪量分布可根據衛星與飛機的遙測資訊,推定積雪區域,然後由推定積雪密度估計積雪量。這項方法也可 用來驗證從降雪量算出積雪量分布與融雪量推定之妥當性。
根據積雪量熱收支所推定的融雪量,可用積雪表面的輻射收支、顯熱‧潛熱收支、降雨所帶來的熱量、積雪 底面來自土壤的熱傳導等加以計算。這些方法可使用氣象廳 AMEDAS (自動數據探測系統)等依氣象觀測值所推定 出來的的簡易熱收支法「日射量.氣溫.降水量之融雪模式」 。
〈參考資料〉
「日射量.氣溫.降水量融雪模式」的詳細作法,可參考下列資料。
1) 土木學會水理委員會;水理公式集 ﹝1999 年﹞,pp.27-28,丸善,1999。
第 3 章 第 2 節-10