第6章 實驗架構與實驗結果
在 6.1 小節吾人將先介紹臺灣師大的中文大詞彙連續語音辨識系統[Chen et al.
2004; 2005],接著在 6.2 小節介紹及分析本論文所使用的公視晚間新聞(MATBN) 外場記者語料[Wang et al. 2005]和實驗的評估方式。在 6.3、6.4、6.5 及 6.6 小節 說明基礎實驗結果、改進以最小化音素錯誤鑑別式聲學模型訓練之結果、資料選 取方法於鑑別式訓練之實驗結果、非監督式訓練的實驗結果和實驗分析。
6.1 臺灣師大之中文大詞彙連續語音辨識系統
以下將分別介紹臺灣師大的中文大詞彙連續語音辨識系統統採用的前端處理 (Front-end Processing) 、 聲 學 模 型 (Acoustic Model) 、 詞 典 建 立 (Lexicon Construction)、語言模型(Language Model)以及詞彙樹複製搜尋(Tree-copy Search) 等部份。
6.1.1 前端處理
在本論文中使用梅爾倒頻譜係數特徵(MFCC)作為語音訊號的特徵參數。在求取 梅爾倒頻譜係數特徵時,將語音資料切割成一連串部分重疊的音框,每一個音框 由13維的梅爾倒頻譜係數特徵加上其一階與二階的時間軸導數(Time Derivatives) 所形成的39維語音特徵向量所組成。其中13維的梅爾倒頻譜係數特徵是由18個梅 爾頻譜上濾波器組(Filter Banks)的輸出經餘弦轉換求得。同時,為了降低通道效 應對語音辨識的影響,在此使用倒頻譜正規化法(Cepstral Normalization, CN)。
另外本論文還使用鑑別性特徵,所採用的是目前流行的線性鑑別分析(Linear Discriminant Analysis, LDA)[Duda et al. 1973] 和 異 質 性 線 性 鑑 別 分 析 (Heteroscedastic Linear Discriminant Analysis, HLDA)[Kumar 1997],異質性線性鑑 別分析(HLDA)是線性鑑別分析的一般化與去除多餘限制後的另一種線性特徵轉 換作法。線性鑑別分析假設各類別分布的變異量皆相同,因此在所有類別分布的
變異量為相同的情況下有最好的解。可是現實上大多的訊號特徵分布的變異量皆 為異質性,線性鑑別分析求出的基底矩陣就可能不是最佳的解,而異質性線性鑑 別分析就是拿掉這個假設,以求得較具鑑別性的語音特徵向量。本論文在做完異 質性線性鑑別分析之後還額外使用最大化相似度現性轉換(Maximum Likelihood Linear Transform, MLLT)[Gopinath 1998],其目的是為了配合目前我們在連續密 度隱藏式馬可夫模型所使用的對角化(Diagonal)之共變異矩陣。
6.1.2 聲學模型
聲學模型是採用傳統的連續密度隱藏式馬可夫模型(CDHMM),模型內狀態的轉 移情形只有兩種,一種是停留在原狀態,一種是由左至右跳到下一個相鄰的狀 態。模型的總數量有151個,其中包含了1個靜音模型(Silence),112個聲母模型 (INITIAL),以及38個韻母模型(FINAL)。每個模型的狀態數分別為3至6個不等,
每個狀態皆為高斯混合分布,其中每個高斯混合分布的分布個數分別為1至128 個不等。此外,聲母和韻母共有403種不同的音節組合。
6.1.3 詞典建立與語言模型訓練
在中文裡約有 7,000 個單字詞,新詞可由此 7,000 個單字詞合併產生,則可根據 字詞在語料中的統計特性,以自動化的方式產生新的複合詞(Compound Words)。
新 增 複 合 詞 的 自 動 產 生 方 式 如 下 面 所 述 : 對 於 語 料 中 任 意 相 鄰 的 兩 個 詞 )
,
(wi wj ,可以分別計算它們的前二連(Forward Bigram)機率Pf(wj |wi),與後二 連(Backward Bigram)機率Pf(wi|wj) ,並以前後二連(Forward and Backward
Bigrams) 的機率幾何平均(Geometric Average)FB(wi,wj)= Pf(wj|wi)Pb(wi|wj),作 為(wi,wj)是否合併的依據。文字語料先經由一個含有一至四字詞約六萬八千個 詞的詞典來斷詞,然後利用上述的公式,經數次的迭代以及不同的基準閥值
(Threshold)設定,產生約五千個二至十字詞的複合詞,使得最後的語音辨識詞典 約含有七萬二千個一至十字詞。本系統使用詞二連以及詞三連語言模型(Word Bigram and Trigram Language Models),並以從中央通訊社(Central News Agency,
CNA) 2001 與 2002 年所收集到的約一億七千萬個中文字語料作為背景語言模型 訓練時的訓練資料[LDC]。本論文中的語言模型使用 Katz 語言模型平滑技術,語 言模型訓練工具採用 SRI Language Modeling Toolkit (SRILM) [SRILM 2002]。
6.1.4 詞彙樹複製搜尋
本系統是採用由左至右(Left-to-right)且音框同步(Frame Synchronous)的詞彙樹複 製搜尋方式[Aubert 2002]。詞彙樹的架構如所示,樹中的每個分枝(Arc)代表一個 聲母(INITIAL)、韻母(FINAL)或靜音(Silence)模型。由樹的根節點(Root Node,
圖6-1的圓形實心點)走到樹的葉節點(Leaf Node,圖6-1的方形實心點)的某一條完 整路徑代表走完一個或一組發音相同的詞。而路徑上的每一個分枝正好對應到這 些詞的一組聲學模型。詞彙樹複製搜尋在執行時,每個音框會同時存在數棵詞彙 樹複製(Tree Copies),而每棵詞彙樹代表來自不同的語言歷史或限制(Language Model History or Constraint)。在同一棵詞彙樹裡,會進行隱藏式馬可夫模型狀態 層次(State Level)維特比(Viterbi)動態規劃搜尋。在詞彙樹搜尋中,只有在走到葉 節點時,才能確定所搜尋的一個完整詞為何。另外,當具有相同語言模型歷史之 不 同 詞 彙 樹 分 別 都 已 經 走 到 自 己 所 屬 那 棵 樹 的 葉 節 點 時 , 則 會 進 行 結 合 (Recombination),只保留其中分數最大者,並針對留下來的詞彙樹繼續執行詞彙 樹複製搜尋。然而,真正在實作時,並不需要產生如此多的詞彙樹,僅需建立一 棵詞彙樹作為參考之用,並分別記錄搜尋時存活下來之隱藏式馬可夫模型狀態節 點的相關資訊(如到目前為此所累積的分數及前一狀態為何)。另外一方面,由於 存活的狀態節點通常會隨著音框數呈指數倍成長,因而必須以光束剪裁(Beam Pruning)技術將分數較低的狀態節點做剪裁的動作。在對每個狀態節點執行光束 剪裁時,會依此節點所有可拜訪的葉節點之最大單連語言模型往前觀測分數
(Unigram Language Model Look-ahead Score)[Aubert 2002]及聲學往前觀測分數 (Acoustic Look-ahead Score)[Chen et al. 2004; 2005]做為剪裁與否的依據。此外,
在每個音框,利用存活的詞彙樹複製樹其葉節點(代表可能的候選詞)所儲存的語 言模型歷史、開始音框、結束音框及其聲學解碼的分數等資訊,建立如第二章所 提到的詞圖。而後使用更高階的語言模型,如詞三連(Trigram)或詞四連(Fourgram) 語言模型,抑或採用更複雜的聲學模型,如三連音素(Triphone),進行詞圖重評 分(Word Graph Rescoring)搜尋[Ortmanns et al. 1997],找出最佳的詞序列。在本論 文中,詞彙樹複製搜尋階段是採用詞二連語言模型,詞圖搜尋階段則是使用詞三 連語言模型。
6.2 實驗語料與評估方式
6.2.1 實驗語料之說明
本實驗主要使用的語料庫為 MATBN 新聞語料,為中央研究院資訊所口語小組 (SLG)[SLG]耗時三年與公共電視台(PTS)[PTS]合作錄製完成。錄製的對象為公視 晚間新聞,其每天的長度皆為一個小時,收錄了 200 天(約 200 小時)的新聞語料,
其中包含 2001 年的新聞 30 小時、2002 年 146 小時及 2003 年 24 小時。所有的 台灣
颱風 大
學 ㄉ_ㄚ
ㄚ ㄒ_ㄩㄝ
ㄩㄝ ㄊ_ㄞ
ㄞ Null_ㄨㄢ ㄨㄢ ㄈ_ㄥ
ㄥ
台灣
颱風 大
學 ㄉ_ㄚ
ㄚ ㄒ_ㄩㄝ
ㄩㄝ ㄊ_ㄞ
ㄞ Null_ㄨㄢ ㄨㄢ ㄈ_ㄥ
ㄥ
圖 6-1 詞彙樹範例
新聞語料都有正確的人工轉寫以及其它的標註資訊(如:音樂、背景雜訊、停頓、
語助詞、呼吸、強調語氣、反覆、不適當的發音等),所有的人工轉寫與標注均 使用 DGA&LDC 的轉寫器(Transcriber)[Barras et al. 2001]來完成。
每天的新聞約含有二十多則報導,每則報導為一完整主題。除了語音資料,
文字語料在其它應用上也有很大的價值(如資訊檢索、文件摘要等)。此新聞語料 大致上可分內場及外場兩個部份,內場部分主要為主播(Studio Anchors)的語料,
外場部分則可分為採訪記者(Field Reporters)與受訪者(Interviewees)的語料。在篩 選實驗語料時,考量新聞的特性,主播多為同一人所擔任。如表 6-1 所示,葉明 蘭主播的語料在本語料庫中約佔了所有主播語料的 85%,這將使得實驗偏向語者 相依(Speaker-dependent)的環境,加上女性主播約佔了所有主播語料的 94%,也 造成了性別相依(Gender-dependent)的問題。如果使用主播語料的話,缺少足夠的 變異來提供良好的訓練與客觀的評估,故本實驗不採用主播語料。此系統可檢索 語句的統計資訊,如語者資訊、語音長度、所含背景雜訊、說話速度及正確轉譯 文 句 等 資 訊 , 適 合 用 來 分 析 且 定 義 出 實 驗 的 訓 練 集(Training Set)與評估集 (Evaluation Set)。目前本研究初步地只選擇外場採訪記者部份作為實驗語料,在
表 6-1 主播語料分布表 語者姓名 性別 句數
(句)
語音總長度
(秒) 所含語音百分比(%) 余佳璋-主播 男 36 452.20 0.50 林建成-主播 男 427 5,298.10 5.70
某主播一
_PTSND20020226 女 1 7.90 0.008 洪蕙竹-主播 女 89 1,407.40 1.50 洪蕙竹-氣象主播 女 155 1,443.60 1.50
徐惠玲-主播 女 225 3,208.20 3.40 馬紹-主播 男 35 465.60 0.50 黃明明-主播 女 175 2,932.60 3.10 葉明蘭-主播 女 5,101 78,584.70 83.60 蘇怡如-氣象主播 女 17 213.80 0.20
未來將會納入受訪者的部份。
本研究所使用外場記者的語料總共約 26 小時,其中 24.5 小時(5774 句,再 切成 34,672 個短句供聲學模型訓練之用)做為聲學模型訓練的語料,1.5 小時(292 句)則為辨識評估的資料。訓練語料由 2001 及 2002 年的新聞中篩選出不含語助 詞(Particle)的語料,為了建立性別平衡(Gender-balanced)的訓練環境,男、女語 料分別篩取 12.2 小時。為了準確客觀地評估研究方法,我們採用由中研院從 2003 年語料庫中所選定的外場記者語料作為評估語料,部份語音片段含有語助詞,關 於訓練語料及測試語料詳細的資訊可見表 6-2。
表 6-2 外場記者訓練與測試語料分布表 性別 訓練語料總長(分) 評估語料總長(分)
男生 766.69 21.68
女生 766.79 65.23
表 6-3 語助詞出現次數統計表
語者型別
所含語音百分比 (%)
語助詞出現次數 (句)
每句平均語助詞出 現次數(次)
外場採訪記者 48.69 877 0.07
外場受訪者 29.33 18,991 2.03
內場主播 21.98 771 0.12
表 6-4 外場受訪者訓練與評估語料分布表 性別 訓練語料總長(分) 評估語料總長(分)
男生 269.03 25.91
女生 259.22 10.53
而在外場受訪者部份,由於有較多的語助詞出現,如表6-3所示,因此如果直接 只採用不含語助詞的外場語料的話,測試資料(只從2003年的語料擷取)將會非常 的稀少。而訓練資料(從2001及2002年的語料擷取)為了要顧及性別平衡的因素,
也會有訓練資料量不足的問題,所以本論文就沒有使用外場受訪者的語料。另外 所有語料的詳細統計資訊可經由師大資工語音實驗室[NTNU 2004]所開發的公 視新聞語料檢索系統獲得。此系統可檢索語句的統計資訊,如語者資訊、語音長 度、所含背景雜訊、說話速度及正確轉寫文等內容,極為適合用來篩選聲學模型 訓練所需的語料。
6.2.2 實驗評估方式
此評估法則是採用美國國家標準與技術中心(National Institute of Standards and Technology, NIST)[NIST]所訂立的評估標準來進行正確答案的詞序列與辨識詞序 列的比較。此評估標準需要使用動態規畫(Dynamic Programming)來做詞序列比對 (也就是第二章所提到的編輯距離(Edit or Levenshtein Distance))。由於在中文會有 斷詞不一致的問題,因此在本論文的實驗中主要是以字為比對單位。令H 為正 確答案詞序列與辨識詞序列比對後相同(Match)的字的個數、I 為辨識詞序列多餘 插入(Insertion)的字的個數、 N 為正確答案詞序列的字的個數,則語音辨識系統 的正確率(Accuracy)的計算方式為 − ×100%
N I
H ,而錯誤率(Error Rate)則為 1-正
確率。在進行動態規畫比對時,替代(Substituion)錯誤的懲罰權重(Penalty Weight) 為 10 分,插入及刪除的權重則皆為 7 分。因為中文是以字(Character)為單位,所 以在以下的實驗數據中,都是以字錯誤率(Character Error Rate, CER)來呈現實驗 結果。
6.3 基礎實驗結果
本小節主要是比較不同的語音特徵以及不同的聲學模型訓練方法對外場記者語 料辨識字錯誤率的影響。所比較的語音特徵有三種,包含梅爾倒頻譜特徵加上倒 頻譜正規化法(MFCC+CN)、線性鑑別分析加上最大化相似度線性轉換與倒頻譜 正規化法(LDA+MLLT+CN)及異質性線性鑑別分析加上最大化相似度線性轉換 與倒頻譜正規化法(HLDA+MLLT+CN)。其次,所比較不同的聲學模型訓練方法 也是有三種,包含最大化相似度(ML)估測法、最大化交互資訊(MMI)估測法以及 最小化音素錯誤(MPE)鑑別式訓練[Povey 2004]。本小節使用最小化音素錯誤 (MPE)鑑別式訓練來比較三種不同的語音特徵,其實驗結果可參考圖6-2和表 6-5,其中Baseline是利用最大化相似度(ML)估測法訓練10次所得到的字錯誤率 (CER)。其次,使用異質性線性鑑別分析加上最大化相似度線性轉換與倒頻譜正 規化法(HLDA+MLLT+CN)來比較三種不同的聲學模型訓練方法,其實驗結果可 參考圖6-3和表6-6,Baseline是利用最大化相似度(ML)估測法訓練10次所得到的 字錯誤率。由上述之比較可以得知在基礎實驗中,目前最好的語音特徵與模型訓 練方法分別為為異質性線性鑑別分析加上最大化相似度線性轉換與倒頻譜正規 化法(HLDA+MLLT+CN)與最小化音素錯誤(MPE)鑑別式訓練。所以接下來的實 驗中,都是以最小化音素錯誤(MPE)與異質性線性鑑別分析加上最大化相似度線 性轉換及倒頻譜正規化法(HLDA+MLLT+CN)訓練10次為比較對象,其字錯誤率 (CER)為20.77%。
20 21 22 23 24 25 26 27
0 1 2 3 4 5 6 7 8 9 10 訓練次數 字錯誤率(%)
MPE MFCC+CN MPE LDA+MLLT+CN MPE HLDA+MLLT+CN
圖 6-2 比較不同的語音特徵(使用最小化音素錯誤訓練)
表 6-5 比較不同的語音特徵(使用最小化音素錯誤訓練) CER(%) MPE
MFCC+CN
MPE LDA+MLLT+CN
MPE
HLDA+MLLT+CN Baseline 26.60 24.25 23.64 Itr01 25.68 23.32 22.82 Itr02 25.58 22.95 22.44 Itr03 25.43 22.64 22.28 Itr04 25.13 22.50 21.79 Itr05 25.06 22.31 21.48 Itr06 24.90 22.10 21.24 Itr07 24.97 22.01 21.10 Itr08 24.96 21.95 21.06 Itr09 24.89 21.65 20.97 Itr10 25.05 21.50 20.77
20 21 22 23 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) ML HLDA+MLLT+CN
MMI HLDA+MLLT+CN MPE HLDA+MLLT+CN
圖 6-3 比較不同的聲學模型訓練方法(使用異質性線性鑑別分析)
表 6-6 比較不同的聲學模型訓練方法(使用異質性線性鑑別分析) CER(%) HLDA+MLLT+CN
ML
HLDA+MLLT+CN MMI
HLDA+MLLT+CN MPE Baseline 23.64
Itr01 23.58 23.28 22.82
Itr02 23.62 22.89 22.44
Itr03 23.52 22.58 22.28
Itr04 23.64 22.28 21.79
Itr05 23.64 22.16 21.48
Itr06 23.66 22.10 21.24
Itr07 23.68 22.08 21.10
Itr08 23.68 21.88 21.06
Itr09 23.62 21.81 20.97
Itr10 23.70 21.75 20.77
6.4 改進最小化音素錯誤之實驗結果
本小節主要是呈現第三章所描述過去學者對最小化音素錯誤(MPE)訓練的正確 函數之改進以及吾人所提出之改進的訓練方法的實驗結果,分為三個子小節呈現 實驗數據。6.4.1 小節呈現最小化音素錯誤正確率改進之實驗,6.4.2 小節為本論 文提出之改進方法於最小化音素錯誤訓練的實驗結果,最後 6.4.3 小節則是本論 文所提出之以統計式方法去近似訓練語句的事前機率於最小化音素錯誤訓練之 實驗結果。
6.4.1 最小化音素錯誤訓練正確率函數改進之實驗
最小化音素錯誤鑑別式訓練之不同正確率函數有最小化音素音框錯誤(MPFE)訓 練、最小化音框音素錯誤(MFPE)訓練、以狀態為基礎的最小化貝氏風險(s-MBR) 以及最小化散度(MD)鑑別式聲學模型訓練。其中最小化音框音素錯誤又有一個 改進方式(記作 MFPE_nosil),就是在詞圖中收集統計值時不考慮靜音(Silence)的 影響,那麼在詞圖中只要有遇到靜音詞段,則其音素音框正確率設為 0[Povey et al.
2007]。有關最小化音素錯誤鑑別式聲學模型訓練之不同減損函數公式可以參考 錯誤! 找不到參照來源。。
在使用最小化音素錯誤(MPE)訓練聲學模型時,一定要搭配使用重要的平滑 技術,即 I-平滑技術(I-smoothing,詳見 2.3.4 小節之說明),不然其效能便沒有辦 法完全發揮,甚至會比最大化交互資訊(MMI)估測的效能還要差[Povey et al.
2007]。因為減損函數的不同,使得所收集的統計值之範圍也會不盡相同,所以 I-平滑技術的參數(記作 Tau)就需要重新調整。最小化音素錯誤(MPE)訓練的 I-平 滑技術參數最佳化設定為 10[郭人瑋 2005],其他不同減損函數的訓練也試了許 多組實驗設定,在此只呈現最佳設定的實驗結果,其實驗結果可參考圖 6-4 和表 6-7。由實驗結果得知最小化音素錯誤(MPE)訓練與其他改進方法的結果差不多,
只有最小化散度(MD)和最小化音素音框錯誤(MPFE)訓練的結果稍微差了一點。
20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%)
MPE MPFE MFPE MFPE_nosil s-MBR MD
圖 6-4 最小化音素錯誤訓練正確率改進之實驗結果
表 6-7 最小化音素錯誤正確率改進之實驗結果 CER(%) MPE
Tau=10
MPFE Tau=10
MFPE Tau=100
MFPE_nosil Tau=100
s-MBR Tau=250
MD Tau=50 Baseline 23.64
Itr01 22.82 23.05 22.70 22.80 22.82 23.11 Itr02 22.44 22.62 22.35 22.44 22.52 22.62 Itr03 22.28 22.22 22.00 22.08 22.03 22.32 Itr04 21.79 21.89 21.66 21.78 21.74 22.35 Itr05 21.48 22.19 21.50 21.52 21.48 22.12 Itr06 21.24 22.24 21.45 21.47 21.35 21.93 Itr07 21.10 22.16 21.55 21.37 21.22 21.92 Itr08 21.06 22.09 21.36 21.23 21.11 22.06 Itr09 20.97 22.08 21.18 21.29 21.05 21.90 Itr10 20.77 22.05 21.06 21.05 20.97 21.97
6.4.2 本論文提出的時間音框正確率函數之實驗
本子小節呈現本論文針對最小化音素錯誤訓練(MPE)的缺點而改進的最大化時 間音框正確率函數(MTFA)訓練之實驗數據。因最小化音素錯誤訓練沒有給予刪 除錯誤(Deletion Error)適當的懲罰(Penalty),而吾人所提出之時間音框正確率函 數有考量到刪除錯誤的懲罰,所以在字辨識錯誤率上,確實比最小化音素錯誤來 的好。事實上,本論文所提出的時間音框正確率函數並不是要減少刪除錯誤的個 數,而是要讓詞圖中某詞段因受到刪除錯誤的影響,而減少其收集的正確率統計 値,以利聲學模型訓練的強健。實驗結果可參考表 6-8,其中刪除錯誤的懲罰權 重(Penalty Weight)以 Lo( ρ )表示。由實驗數據顯示出在前幾次的迭代訓練中,有 有考慮不同懲罰權重的刪除錯誤之時間音框正確率函數都會稍微比最小化音素 錯誤來得好。不同的刪除錯誤懲罰權重設定會有不同的刪除錯誤懲罰的效果,由 表 6-8 的數據顯示,太大( ρ =0.8)或太小( ρ =0.1)的刪除錯誤懲罰權重設定在一開 始的訓練上會有比較不明顯的效果,但都比最小化音素錯誤訓練來得佳,可是在 第 10 次的訓練上比最小化音素錯誤訓練的字錯誤率要高一點。最好的刪除錯誤 懲罰權重設定(Lo=0.5)的時間音框正確率函數在第 10 次的訓練上比最小化音素 錯誤(MPE)訓練的辨識字錯誤率好 0.05%,相對字錯誤率將低約 0.1%,訓練次數 1 到 10 次的字錯誤率曲線圖請參考圖 6-5。
為了能使時間音框正確率函數能充分地懲罰刪除錯誤,且也是為了要和原始 音素正確率的値域同為-1 到 1 之間,本論文使用一個常見的 S 型函數來平滑時間 音框正確率函數,記作 MSTFA。其中 S 型函數有兩個參數可調整,在本實驗中 只調整α(alpha),而 β 設為零(β=0)。實驗結果可以參考圖 6-6,實驗數據顯示 出使用S 型函數來充分地懲罰刪除錯誤確實可以達到不錯的效果,在每次迭代訓 練中都會比最小化音素錯誤(MPE)訓練來得好,最好的設定(ρ 0.1,= α =0.5)在 第 10 次的訓練上可以比最小化音素錯誤的辨識字錯誤率好 0.31%,相對字錯誤 率降低約 1.5%,訓練次數 1 到 10 次的字錯誤率曲線圖請參考表 6-9。
20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE MTFA Lo=0.5
圖 6-5 最大化時間音框正確率函數(MTFA)最佳設定( ρ =0.5) 與最小化音素錯誤(MPE)之比較結果
表 6-8 最大化時間音框正確率函數(MTFA)之實驗結果 CER(%) MTFA
ρ=0.1
MTFA ρ=0.3
MTFA ρ=0.4
MTFA ρ=0.45
MTFA ρ=0.5
MTFA ρ=0.55
MTFA ρ=0.6
MTFA ρ=0.8 Baseline 23.64
Itr01 22.85 22.73 22.71 22.73 22.74 22.73 22.75 22.80 Itr02 22.35 22.33 22.31 22.30 22.36 22.33 22.29 22.39 Itr03 22.07 22.13 22.11 22.12 22.14 22.15 22.16 22.19 Itr04 21.65 21.50 21.57 21.60 21.56 21.57 21.58 21.69 Itr05 21.26 21.14 21.25 21.21 21.26 21.28 21.24 21.34 Itr06 20.98 20.97 21.00 21.00 21.09 21.17 21.11 21.23 Itr07 20.91 20.87 20.94 20.99 21.09 21.13 21.16 21.19 Itr08 20.87 20.81 20.85 20.79 20.82 20.78 20.82 20.93 Itr09 20.84 20.74 20.81 20.78 20.85 20.86 20.92 20.90 Itr10 20.82 20.80 20.81 20.80 20.72 20.79 20.83 20.93
20 20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE MSTFA Lo=0.1 Alpha=0.5
圖 6-6 最大化 S 型時間音框正確率函數(MSTFA)最佳設定( ρ=0.1,α=0.5) 與最小化音素錯誤(MPE)之比較結果
表 6-9 最大化 S 型時間音框正確率函數(MSTFA)之實驗結果 CER(%) MSTFA
ρ =0.1
= α 0.5
MSTFA ρ =0.2
= α 0.5
MSTFA ρ =0.5
= α 0.5
MSTFA ρ =0.1
= α 1
MSTFA ρ =0.2
= α 1
MSTFA ρ =0.5
= α 1 Baseline 23.64
Itr01 22.88 22.82 22.82 22.83 22.82 22.77 Itr02 22.37 22.40 22.34 22.37 22.40 22.38 Itr03 22.06 22.10 22.10 22.02 22.09 22.05 Itr04 21.52 21.56 21.58 21.41 21.60 21.56 Itr05 21.23 21.29 21.47 21.30 21.39 21.52 Itr06 21.05 21.03 21.27 21.06 21.26 21.32 Itr07 20.89 20.90 21.11 20.80 20.91 21.19 Itr08 20.50 20.69 20.97 20.54 20.84 20.98 Itr09 20.58 20.69 20.82 20.57 20.63 21.03 Itr10 20.46 20.68 20.87 20.65 20.72 21.10
6.4.3 考慮事前機率之實驗
本子小節呈現吾人所提出之統計式方法來近似事前機率(Prior Probability)於最小 化音素錯誤(MPE)訓練之實驗結果。在本實驗中,某語句之事前機率的算法是使 用某詞圖中所有可能詞序列的前向分數(Forward Score)再正規化所有訓練語句的 前向分數,如式(3.28)所示。為了不讓事前機率支配統計值的收集,在實作上使 用刻度法(Scaling)來平滑事前機率値,其統計值的收集數學式可表示為(以正貢獻 為例):
κ z Z
z q
e s t
z q z
qm num
qm γ t γ P O
γ
lattice z
q
q
MPE 1
1
)
~( ) , 0 max(
) (
,
⎥⋅
⎥⎦
⎤
⎢⎢
⎣
=
∑
⎡∑ ∑
= ∈W =
(6.1)
其中κ為刻度法的參數。
實驗結果可以參考表 6-10,由實驗數據顯示出考慮事前機率的影響,確實對 辨識字錯誤率有效果,但其效果不是非常的明顯。在最佳設定(κ=10)的實驗中,
可參考圖 6-7,前幾次的迭代訓練中都有比最小化音素錯誤(MPE)訓練好,在第 10 次訓練上只有 0.01%的進步。
表 6-10 考慮事前機率於最小化音素錯誤(MPE)訓練之實驗結果 CER(%) Prior
= κ 3
Prior
= κ 5
Prior
= κ 8
Prior
= κ 10
Prior
= κ 12
Prior
= κ 15
Prior
= κ 20 Baseline 23.64
Itr01 22.56 22.80 22.78 22.80 22.74 22.79 22.79 Itr02 22.26 22.25 22.26 22.31 22.28 22.34 22.33 Itr03 21.67 21.83 21.95 21.98 22.01 22.01 22.10 Itr04 21.54 21.50 21.55 21.57 21.75 21.69 21.78 Itr05 21.44 21.32 21.27 21.36 21.43 21.41 21.53 Itr06 21.34 21.27 21.26 21.23 21.25 21.18 21.34 Itr07 21.42 21.10 21.01 21.01 21.18 21.10 21.37 Itr08 21.33 21.00 21.01 20.98 20.98 21.03 21.29 Itr09 21.22 20.91 20.91 20.95 20.95 20.99 21.25 Itr10 21.08 20.82 20.80 20.76 20.77 20.76 21.16
20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10 訓練次數 字錯誤率(%) MPE MPE Prior Kappa=10
圖 6-7 考慮事前機率的最佳設定(κ=10) 與最小化音素錯誤(MPE)訓練之比較
0 1000000 2000000 3000000 4000000 5000000 6000000
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 正規化熵值 音框個數
圖 6-8 所有訓練語句的正規化熵值分布圖
6.5 本論文提出的資料選取方法之實驗結果
本小節將呈現以正規化熵值為基礎的資料選取方法於鑑別式聲學模型訓練之實 驗結果,包含最大化交互資訊(MMI)估測(6.5.1小節)、最小化音素錯誤(MPE)訓 練(6.5.2小節)以及最大化S型時間音框正確率函數(MSTFA)(6.5.3小節)。首先,本 論文分析所有訓練語料的正規化熵值分布,其分布圖如圖6-8所示,橫軸代表正 規化熵值(Normalized Entropy),縱軸代表時間音框的個數(Frame Number),利用 異質性線性鑑別分析(HLDA+MLLT+CN)之語音特徵與最大化相似度(ML)估測 法訓練10次之後的聲學模型,對每一個音框算出其正規化熵值就可以求得此分布 圖。在約25小時的訓練中,所有的時間音框總數為9183883個時間音框。從分析 的數據中可以得知大部分時間音框的正規化熵值都集中在0.1以內(其時間音框總 數為3561021個,佔所有時間音框總數的38.77%),代表的意思就是大部份的時間 音框都是可以完全辨識正確或完全辨識錯誤,只有少部分的時間音框是非常混淆 的(Confused)。事實上,因為最大化相似度(ML)訓練10次之後所得到的字錯誤率 為23.64%,其音素錯誤率會再更低一點,所以時間音框的正規化熵值集中在0.1 以內,吾人認為大部份都是完全辨識正確,少部份則是完全辨識錯誤。完全辨識 正確的時間音框在最大化相似度訓練中已貢獻非常多了,在鑑別式訓練中,其統 計值就不再是那麼的重要,因此可以捨棄。由4.2小節的描述,以正規化熵值為 基礎的時間音框資料選取方法有兩種,一種是硬性選取(Hard Selection,記作 HS),另一種為軟性選取(Soft Selection,記作SS)。本實驗嘗試將兩種選取方法結 合(記作HS+SS)。
6.5.1 資料選取方法於最大化交互資訊估測
本子小節呈現資料選取方法於最大化交互資訊(MMI)估測之實驗結果。其最大化 交互資訊的 I-平滑技術參數最佳化設定為 10[郭人瑋 2005]。所使用的時間音框 資料選取方法為硬性選取(HS),其實驗結果可以參考表 6-11。最佳門檻值(記作
21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MMI MMI HS Thr=0.05
圖 6-9 硬性資料選取最佳設定(HS Thr=0.05) 與最大化交互資訊估測之比較
表 6-11 硬性資料選取方法(HS)於最大化交互資訊估測之實驗結果 CER(%) MMI HS
Thr=0.05
MMI HS Thr=0.06
MMI HS Thr=0.08
MMI HS Thr=0.1
MMI HS Thr=0.25 Baseline 23.64
Itr01 22.95 22.96 22.91 22.84 22.89 Itr02 22.28 22.33 22.33 22.29 22.38 Itr03 22.21 22.18 22.06 22.11 22.33 Itr04 21.90 21.92 21.85 21.84 21.96 Itr05 21.77 21.86 21.88 21.94 22.08 Itr06 21.84 21.82 21.78 21.99 22.03 Itr07 21.88 21.90 21.92 21.92 21.90 Itr08 21.83 21.97 21.87 22.07 21.84 Itr09 21.95 22.20 22.27 22.46 21.76 Itr10 22.10 22.70 22.87 23.12 22.06
Thr) 設 定 為 0.05( 其 時 間 音 框 總 數 為 4214360 個 , 佔 所 有 時 間 音 框 總 數 的 45.88%),其曲線圖可參考圖 6-9。資料選取方法可以加快收斂速度,但在第 10 次的訓練上卻沒有比最大化交互資訊估測的字錯誤率來得低,但其結果是差不多 的。可能的原因將在 6.5.2 小節分析。
6.5.2 資料選取方法於最小化音素錯誤訓練
本子小節呈現資料選取方法於最小化音素錯誤(MPE)訓練之實驗結果。其最小化 音素錯誤的 I-平滑技術參數最佳設定為 10[郭人瑋 2005]。所使用的時間音框資 料選取方法為硬性選取(HS)及軟性選取(SS),其實驗結果可以參考表 6-12 及表 6-13。其硬性選取固定門檻值(記作 Thr)最佳設定為 0.05(其時間音框總數為 4214360 個,佔所有時間音框總數的 45.88%),如圖 6-10 所示,硬性資料選取方 法應用在最小化音素錯誤(MPE)訓練確實可以加快收斂速度,但在第 10 次的訓 練上卻沒有比最小化音素錯誤的字錯誤率來得低,其效果是差不多的。軟性資料 選取的實驗結果曲線圖可以參考圖 6-11,其效果與最小化音素錯誤訓練差不多,
沒有特別明顯的進步。針對硬性資料選取方法會加快收斂速度及在第 10 次的訓 練上與最小化音素錯誤訓練之結果會差不多的原因,吾人猜想其可能的因素有兩 個,茲分述如下:
1. 以下為針對加快收斂速度之猜想,鑑別式聲學模型訓練的目標函數(MMI or MPE)是使用延伸波氏重估演算法(Extended Baum-Welch, EBW)來作模型參 數的最佳化,其中 EBW 有一個控制收斂速度的常數D ,s D 値越大則收斂s 速度越慢,D 値越小則收斂速度越快。在過去的文獻中,有學者在實作上s 是使用如下的公式可以得到最好的效果[Povey 2004]:
} ,
2
max{ smin sden
s D E γ
D = ⋅ (6.2)
其中Dsmin為連續密度隱藏式馬可夫模型(CDHMM)中的某個狀態s,在模型 參數調整時為確保共變異矩陣(Covariance Matrix)為正定(Positive Definition)
時的最小值。E 為可調整的常數,γsden為狀態s在所有訓練語料中所收集的 統計值(負貢獻)。由式(6.2)可知控制收斂速度的常數D 與訓練資料量的多寡s 有關,因此當我們使用資料選取方法時,勢必會減少訓練資料量,那麼統計 值的收集便會減少,所以D 的値就會變小,因此收斂速度會加快。 s
事實上,EBW 的模型參數調整公式如下(以平均値向量為例),類似式 (2.52):
s den s num s
s s den
s num
s
s γ γ D
μ D O θ O μ θ
+
−
+
= −
} {
)}
( ) (
{ (6.3)
在訓練資料量一樣的情形下,即沒有做資料選取,分子分母項的統計值沒有 變動,那麼D 的大小會影響收斂速度。但在使用資料選取方法調整時,控s 制收斂速度的常數D 雖然變小,但其調整的響影力也隨著其分子分母項的s 統計值減少而變小。所以吾人的猜想是錯的,會加快收斂速度的原因應該是 利用以正規化熵值為基礎的資料選取方法選到了具有鑑別力的時間音框樣 本(Frame Samples),即比較混淆的時間音框樣本,以幫助鑑別式模型訓練較 快達到收斂。
2. 以下為在第 10 次會有差不多效果的猜想,在鑑別式訓練的目標函數一樣的 情形下,不管有沒有使用資料選取方法,其目標函數的區域最佳値(Local Optimal)應該是一樣的。因此造成以正規化熵值的資料選取方法與最小化音 速錯誤訓練在第 10 次的辨識率差不多。
事實上,目標函數的區域最佳値是與訓練資料量有關的,以最小化音素 錯誤(MPE)訓練的目標函數為例:
∑ ∑
= ∈= Z
z
z i W
z i
MPE λ p W O AW W
F
z
1 i
) , ( )
| ( )
(
W
(6.4)
當訓練資料量變動時,即Z 變動(變大或變小),那麼目標函數的値就會有所 變動。所以此猜想也是錯的,那麼為什麼資料選取方法在第 10 次的訓練沒 有比最小化音素錯誤訓練來的好呢,其原因就是使用以正規化熵值的資料選
20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE MPE HS Thr=0.05
MPE HS Thr= 0.08de
圖 6-10 硬性資料選取方法固定門檻值最佳設定(HS Thr=0.05) 及動態最佳設定(HS Thr=0.08de)與最小化音素錯誤之比較
表 6-12 硬性資料選取方法於最小化音素錯誤訓練 CER(%) MPE HS
Thr=0.05
MPE HS Thr=0.06
MPE HS Thr=0.08de
MPE HS Thr=0.1
MPE HS Thr=0.15 Baseline 23.64
Itr01 22.63 22.55 22.43 22.55 22.53 Itr02 22.05 22.02 21.80 21.94 21.88 Itr03 21.60 21.66 21.45 21.70 21.74 Itr04 21.40 21.44 21.34 21.53 21.54 Itr05 21.19 21.24 20.94 21.27 21.39 Itr06 20.92 20.95 20.82 21.28 21.41 Itr07 20.91 21.06 20.73 - -
Itr08 21.22 21.17 20.74 - - Itr09 21.08 21.18 20.65 - - Itr10 21.29 21.02 20.63 - -
20.50 21.00 21.50 22.00 22.50 23.00 23.50 24.00
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE MPE SS w=0.5
圖 6-11 軟性資料選取方法門檻值最佳設定(SS w=0.5) 與最小化音素錯誤之比較
表 6-13 軟性資料選取方法於最小化音素錯誤訓練 CER(%) MPE MPE
SS w=1
MPE SS w=0.5
MPE SS w=2
MPE SS w=1.5 Baseline 23.64
Itr01 22.82 22.84 22.88 22.91 22.86 Itr02 22.44 22.40 22.43 22.36 22.37 Itr03 22.28 22.21 22.25 22.11 22.12 Itr04 21.79 21.65 21.73 21.62 21.60 Itr05 21.48 21.34 21.31 21.34 21.31 Itr06 21.24 21.33 21.18 21.48 21.37 Itr07 21.10 21.29 21.29 21.18 21.24 Itr08 21.06 21.00 21.06 21.15 21.13 Itr09 20.97 21.02 20.93 20.97 21.02 Itr10 20.77 20.94 20.89 21.04 21.08
取方法只選出有鑑別力的時間音框資料樣本,訓練資料量減少,以致模型參 數的訓練會遭遇到過度訓練(Over-training)的問題,因此資料選取方法在第 10 次的訓練就沒有比最小化音素錯誤訓練來得好。
由以上兩點的分析,說明了以正規化熵值為基礎的資料選取方法確實是有用的,
能選出在事後機率定義域中離決定邊界較近的時間音框樣本,也因為這些時間音 框樣本本身比較混淆,所以對鑑別式訓練會特別有幫助。
另一方面,吾人使用隨機選取(Random Selection)方法作為比較來驗證以正規 化熵值為基礎的資料選取方法是有用的,而不是亂選的。實驗結果可以參考圖 6-12 和表 6-14,其中隨機選取(記作 MPE Random)方法在每一次的迭代都隨機選 取所有時間音框總數的 45.88%。
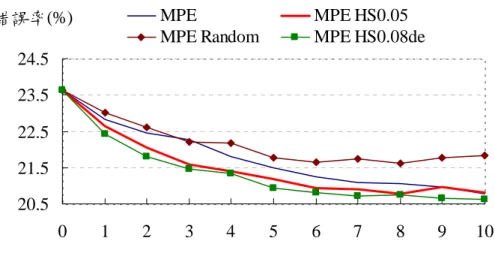
為了想要加快收斂速度且要避免因使用資料選取方法而會遇到過度訓練的 問題,本論文使用隨迭代次數的增加而減少門檻值設定的方法(記作 MPE HS 0.08de)來解決此問題,其實驗結果可以參考圖 6-10、圖 6-12、表 6-12 及表 6-14,
由其曲線圖得知,使用門檻值遞減的方法確實能克服過度訓練的問題,而且在每 一次的迭代訓練中都比最小化音素錯誤訓練來得好,在第 10 次的迭代中之辨識 字錯誤率比 MPE 好 0.14%。
另外,本論文使用了另一個測試集(Testing Set,1.5hrs 包含 307 句,與 292 句為同一時期的資料)來驗證以熵値為基礎的資料選取方法的一般性,其實驗結 果可以參考圖 6-13 及表 6-15,由曲線圖得知其資料選取方法確實能夠加快收斂 速度。
20.5 21.5 22.5 23.5 24.5
0 1 2 3 4 5 6 7 8 9 10
訓練次數
字錯誤率(%) MPE MPE HS0.05
MPE Random MPE HS0.08de
圖 6-12 以隨機選取作為比較對象
表 6-14 以隨機選取作為比較對象之實驗結果 CER(%) MPE MPE
HS 0.05
MPE HS 0.08de
MPE Random Baseline 23.64
Itr01 22.82 22.63 22.43 23.02 Itr02 22.44 22.05 21.80 22.62 Itr03 22.28 21.60 21.45 22.22 Itr04 21.79 21.40 21.34 22.16 Itr05 21.48 21.19 20.94 21.76 Itr06 21.24 20.92 20.82 21.66 Itr07 21.10 20.90 20.73 21.74 Itr08 21.06 20.79 20.74 21.62 Itr09 20.97 20.97 20.65 21.78 Itr10 20.77 20.80 20.63 21.84
20.50 21.00 21.50 22.00 22.50 23.00 23.50 24.00
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE Testing Set MPE HS Thr=0.08
圖 6-13 硬性資料選取方法(固定門檻值 HS Thr=0.08) 於最小化音素錯誤訓練在另一測試集
表 6-15 硬性資料選取方法於最小化音素錯誤訓練在另一測試集 CER(%) MPE
Testing Set
MPE HS Thr=0.08 Baseline 23.80
Itr01 22.38 22.37 Itr02 22.06 21.33 Itr03 21.48 21.14 Itr04 21.24 20.90 Itr05 21.15 20.95 Itr06 20.86 20.90 Itr07 20.80 20.86 Itr08 20.70 21.06 Itr09 20.74 21.24 Itr10 20.84 21.07
6.5.3 資料選取方法於最大化S 型時間音框正確率函數
在 6.4.2 小節中,考慮刪除錯誤的最大化 S 型時間音框錯誤率函數(MSTFA)相對 於最小化音素錯誤(MPE)訓練有明顯的效果。所以本子小節將呈現資料選取方法 於最大化S 型時間音框正確率函數(MSTFA)之實驗結果。其最大化 S 型時間音框 正確率函數的 I-平滑技術參數最佳化設定為 10。所使用的時間音框資料選取方 法為硬性選取(HS)、軟性選取(SS)以及結合硬性和軟性選取(HS+SS),其實驗結 果分別可以參考表 6-16、表 6-17 和表 6-18。其硬性選取最佳門檻值(記作 Thr) 設定為 0.05,如圖 6-14、圖 6-15 和圖 6-16 所示,資料選取方法應用在最大化 S 型時間音框正確率函數確實可以加快收斂速度,但在第 10 次的訓練上卻沒有比 最大化 S 型時間音框正確率函數的字錯誤率來得低。另外,如圖 6-15 所示,軟 性資料選取方法比硬性選取效果來得好,在第 10 次的訓練上跟最大化 S 型時間 音框正確率函數的字錯誤率差不多。最後,結合硬性與軟性選取(HS+SS)的實驗 結果似乎沒有比較好,沒有加成性的效果。
20 20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE MSTFA MSTFA HS Thr=0.05
圖 6-14 硬性資料選取方法(HS Thr=0.05)與最大化 S 型時間音框正確率函數 之比較
表 6-16 硬性資料選取方法(HS)於最大化 S 型時間音框正確率函數 CER(%) MPE MSTFA MSTFA HS
Thr=0.05 Baseline 23.64
Itr01 22.82 22.88 22.46 Itr02 22.44 22.37 21.87 Itr03 22.28 22.06 21.40 Itr04 21.79 21.52 21.38 Itr05 21.48 21.23 21.08 Itr06 21.24 21.05 21.03 Itr07 21.10 20.89 21.02 Itr08 21.06 20.50 21.15 Itr09 20.97 20.58 20.86 Itr10 20.77 20.46 21.43
20 20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) MPE MSTFA MSTFA SS w=0.8
圖 6-15 軟性資料選取方法最佳化設定(SS w=0.8, Lo=0.1, Alpha=0.5) 與最大化S 型時間音框正確率函數之比較
表 6-17 軟性資料選取方法(SS)於最大化 S 型時間音框正確率函數 CER(%) MPE MSTFA
Lo=0.1 Alpha=0.5
MSTFA SS w=0.1
Lo=0.1 Alpha=0.5
MSTFA SS w=0.5
Lo=0.1 Alpha=0.5
MSTFA SS w=0.8
Lo=0.1 Alpha=0.5
MSTFA SS w=1 Lo=0.1 Alpha=0.5 Baseline 23.64
Itr01 22.82 22.88 22.88 22.88 22.81 22.75 Itr02 22.44 22.37 22.35 22.28 22.26 22.25 Itr03 22.28 22.06 21.98 21.88 21.81 21.83 Itr04 21.79 21.52 21.45 21.41 21.42 21.45 Itr05 21.48 21.23 21.21 21.16 21.21 21.27 Itr06 21.24 21.05 21.15 20.99 20.98 20.94 Itr07 21.10 20.89 - - 20.73 20.65 Itr08 21.06 20.50 - - 20.78 20.78 Itr09 20.97 20.58 - - 20.53 20.56 Itr10 20.77 20.46 - - 20.75 20.86
表 6-18 結合硬性和軟性資料選取方法(HS+SS) 於最大化S 型時間音框正確率函數 CER(%) MSTFA
HS Thr=0.05 SS w=0.1
Lo=0.1 Alpha=0.5
MSTFA HS Thr=0.05 SS w=0.5
Lo=0.1 Alpha=0.5
MSTFA HS Thr=0.05 SS w=0.8
Lo=0.1 Alpha=0.5
MSTFA HS Thr=0.1
SS w=0.5 Lo=0.1 Alpha=0.5
MSTFA HS Thr=0.1
SS w=0.8 Lo=0.1 Alpha=0.5 Baseline 23.64
Itr01 22.55 22.56 22.55 22.53 22.49 Itr02 21.79 21.77 21.73 21.72 21.85 Itr03 21.49 21.55 21.46 21.45 21.63 Itr04 21.28 21.61 21.31 21.38 21.56 Itr05 20.98 21.20 21.00 21.03 21.11 Itr06 20.96 21.26 20.98 20.90 21.28 Itr07 21.10 21.06 21.39 21.14 21.02 Itr08 21.18 21.28 21.49 21.14 21.34 Itr09 21.03 21.23 21.95 21.07 21.26 Itr10 21.39 21.73 21.97 21.37 21.21
20 20.5 21 21.5 22 22.5 23 23.5 24
0 1 2 3 4 5 6 7 8 9 10 訓練次數 字錯誤率(%) MSTFA MSTFA HS+SS
圖 6-16 結合硬性和軟性資料選取方法最佳化設定(HS Thr=0.1, SS w=0.5, Lo=0.1, Alpha=0.5)與最大化 S 型時間音框正確率函數之比較
6.6 非監督式之實驗結果
本小節將呈現非監督式最大化相似度、非監督鑑別式訓練以及資料選取方法於非 監督鑑別式訓練之實驗結果。使用的實驗語料為公視新聞外場記者的部份(共 34672 句,約 24.5 小時),其中 200 句(約 11 分鐘)用來訓練初始模型(Initial Model),
其他的 34472 句(約 24 小時)當成大量未轉譯的語料。本實驗共使用兩種語音特 徵,一為梅爾倒頻譜特徵加上倒頻譜正規化法(記作 MFCC+CN),另一為異質性 線 性 鑑 別 分 析 加 上 最 大 化 相 似 度 線 性 轉 換 與 倒 頻 譜 正 規 化 法 ( 記 作 HLDA+MLLT+CN)。初始模型(Initial Model)使用較少的高斯模型個數(約 3100 個,依 11 分鐘的訓練量來決定其個數),使用 HTK Toolkit 的 Hinit 和 HRest 函數 來訓練初始的聲學模型。其初始模型的字錯誤率還蠻高的,實驗結果可參考表 6-19,表示用少量的訓練語料(如 11 分鐘)來訓練此初始的聲學模型會使模型不夠 強健。當有大量未轉譯的語料時,我們應該提高模型的複雜度以訓練出較強健的 模型,也就是增加高斯模型的個數,這個部份是使用 HHed 函數來實作,分裂後 的高斯模型個數約 13500 個,其實驗結果可參考表 6-19。
在本實驗中迭代方法只用在最大化相似度(ML)的聲學模型訓練上,一共做 了三次迭代,每一次的迭代中都作 10 次的最大化相似度聲學模型訓練,其實驗 流程可參考圖 6-17,其實驗結果可以參考表 6-20、表 6-21、表 6-22、圖 6-19、
圖 6-20 和圖 6-21。由實驗數據顯示出初始模型的字錯誤率在第一次的迭代中的 第一次模型訓練就大幅下降,之後的訓練就很緩慢的下降,到第三次迭代時,就 可以看出快要收斂了。
信心度評估的實驗數據顯示只有少量的進步,其門檻值(記作 Conf)隨著迭代 次數的增加而遞減,實驗結果顯示出信心度評估有一點點的幫助,其信心度的分 析圖可以參考圖 6-18,由圖中可以知道大部分的詞段之信心度都介於 0.9 到 1 之 間,這也表示以事後機率為基礎的信心度評估相當不準,所以信心度評估在本實
使用200句(11分鐘)語料來 訓練初始聲學模型
用目前訓練好的聲學模型去辨識34472句(24小時),
並且產生詞圖
使用前向-後向演算法求得每一個詞段的信心度,
並產生第一名詞序列
利用含信心度的第一名詞序列(34472句)及200句,
重新訓練目前的聲學模型(ML 10次)
用目前訓練好的聲學模型去辨識34472句(24小時),
並且產生詞圖
使用前向-後向演算法求得每一個詞段的信心度,
並產生第一名詞序列
使用鑑別式訓練(MPE),信心度評估 及資料選取方法來作聲學模型參數的調整 迭代3次
使用200句(11分鐘)語料來 訓練初始聲學模型
用目前訓練好的聲學模型去辨識34472句(24小時),
並且產生詞圖
使用前向-後向演算法求得每一個詞段的信心度,
並產生第一名詞序列
利用含信心度的第一名詞序列(34472句)及200句,
重新訓練目前的聲學模型(ML 10次)
用目前訓練好的聲學模型去辨識34472句(24小時),
並且產生詞圖
使用前向-後向演算法求得每一個詞段的信心度,
並產生第一名詞序列
使用鑑別式訓練(MPE),信心度評估 及資料選取方法來作聲學模型參數的調整 迭代3次
圖 6-17 非監督鑑別式訓練之流程
驗中才會幫助不大。接著就使用最小化音素錯誤(MPE)訓練法則來訓練聲學模 型,其實驗結果可參考表 6-23 和圖 6-22。由實驗數據可以得知鑑別式訓練在非 監督的情況下仍然是有幫助的。
最後,資料選取方法(記作 FS)應用在非監督鑑別式聲學模型訓練上的實驗可 以參考表 6-23 和圖 6-22,其效果並不如預期。效果不好的可能原因是非監督的 作法本身就會遇到辨識錯誤的問題,那麼應用資料選取方法在非監督式的訓練便 可能沒有什麼幫助。
0 1000000 2000000 3000000 4000000 5000000 6000000 7000000 8000000
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 信心度值 音框個數
圖 6-18 信心度評估之分布圖
表 6-19 初始模型的實驗結果
CER(%) MFCC+CN HLDA+MLLT+CN HRest 58.95 58.37 HHed 58.31 57.80
40 45 50 55
0 1 2 3 4 5 6 7 8 9 10 訓練次數 字錯誤率(%) ML MFCC+CN ML HLDA+MLLT+CN
圖 6-19 最大化相似度模型訓練第一次迭代之實驗結果
表 6-20 最大化相似度模型訓練第一次迭代之實驗結果 CER(%) MFCC+CN
Conf=0
MFCC+CN Conf=0.9
HLDA+MLLT+CN Conf=0
HHed 58.31 57.80
Itr01 46.97 46.75 42.76 Itr02 45.87 45.62 41.66 Itr03 45.37 45.29 40.83 Itr04 44.73 44.78 40.56 Itr05 44.46 44.60 40.42 Itr06 44.41 44.38 40.51 Itr07 44.35 44.22 40.37 Itr08 44.07 44.17 40.35 Itr09 44.07 44.28 40.20 Itr10 44.04 44.11 40.20
35.5 37.5 39.5 41.5 43.5
0 1 2 3 4 5 6 7 8 9 10 訓練次數 字錯誤率(%) ML MFCC+CN ML HLDA+MLLT+CN
圖 6-20 最大化相似度模型訓練第二次迭代之實驗結果
表 6-21 最大化相似度模型訓練第二次迭代之實驗結果 CER(%) MFCC+CN
Conf=0
HLDA+MLLT+CN Conf=0 ML1_Itr10 44.04 40.20
Itr01 40.43 37.00 Itr02 40.00 36.47 Itr03 39.56 36.26 Itr04 39.45 36.24 Itr05 39.24 36.16 Itr06 39.16 35.93 Itr07 38.98 35.90 Itr08 38.93 35.75 Itr09 38.79 35.59 Itr10 38.68 35.56
32.8 33.8 34.8 35.8 36.8 37.8 38.8
0 1 2 3 4 5 6 7 8 9 10 訓練次數 字錯誤率(%) ML MFCC+CN Conf=0.8
ML HLDA+MLLT+CN Conf=0.8
圖 6-21 最大化相似度模型訓練第三次迭代之實驗結果
表 6-22 最大化相似度模型訓練第三次迭代之實驗結果 CER(%) MFCC+CN
Conf=0
MFCC+CN Conf=0.8
HLDA+MLLT+CN Conf=0
HLDA+MLLT+CN Conf=0.8
ML2_itr10 38.68 35.56
Itr01 37.31 37.40 33.90 33.80 Itr02 37.24 37.14 33.61 33.59 Itr03 37.14 36.79 33.47 33.35 Itr04 36.75 36.82 33.20 33.19 Itr05 36.63 36.64 33.16 33.14 Itr06 36.61 36.68 33.14 33.03 Itr07 36.64 36.66 33.19 33.06 Itr08 36.65 36.73 33.10 32.95 Itr09 36.65 36.62 32.93 32.97 Itr10 36.62 36.42 33.00 32.91
33.5 34 34.5 35 35.5 36 36.5
0 1 2 3 4 5 6 7 8 9 10
訓練次數 字錯誤率(%) ML MFCC+CN MPE MFCC+CN
MPE FS MFCC+CN
圖 6-22 非監督鑑別式聲學模型訓練之實驗結果(MFCC+CN)
表 6-23 非監督鑑別式聲學模型訓練之實驗結果(MFCC+CN) CER(%) ML
MFCCCN Conf=0.5
MPE MFCC+CN
Conf= 0
MPE MFCC+CN
Conf= 0.5
MPE MFCC+CN
Conf= 0.7
MPE FS MFCC+CN
Conf= 0.5 ML3 itr10 36.42 36.42 36.42 36.42 36.42 Itr01 35.65 35.51 35.58 35.68 35.63 Itr02 35.61 34.91 34.86 34.95 35.13 Itr03 35.50 34.61 34.61 34.75 34.98 Itr04 35.49 34.43 34.42 34.63 34.82 Itr05 35.50 34.38 34.40 34.51 34.82 Itr06 35.52 34.14 34.23 34.33 34.73 Itr07 35.33 34.06 34.23 34.10 34.58 Itr08 35.41 33.87 34.08 34.31 34.43 Itr09 35.33 34.18 34.19 34.20 34.46 Itr10 35.38 34.24 34.14 34.39 34.51