國立臺灣大學文學院語言學研究所 碩士論文
Graduate Institute of Linguistics College of Liberal Arts
National Taiwan University Master Thesis
台灣華語自然語料中無聲捲舌音及齒音之聲學研究 An Acoustic Study on Voiceless Retroflex and Dental
Sibilants in Taiwan Mandarin Spontaneous Speech
莊育穎 Yu-Ying Chuang
指導教授:馮怡蓁 博士 Advisor: Janice Fon, Ph.D.
中華民國 九十八 年 七 月
誌謝
哆啦 A 夢有一個叫「任意門」的道具,可以帶我們到任何想去的地方。如
果碩士學位是我欲前往之地,那這本碩士論文就是我的「門」。只不過,哆啦 A
夢的任意門只需輕轉門把,即可到達夢想之處,而我的這扇門,不僅不易開啟,
走到門前的道路更是迂迴漫長且佈滿荊棘。
還記得三年前剛入學時,雄心壯志編織著美好遠景,這扇門就在伸手可及 處。但是漸漸地,修課做研究佔據生活後,這扇門似乎不斷往後退,心理上及實 際上皆離我越來越遠。等到真正著手進行論文的時候,猛一抬頭,才發現門已是 在幾乎看不見的遠方,就好像是在那海拔四千公尺的玉山山頂上。幸運地,玉山 雖不易攀爬,一路上有許多溫暖的手持續帶給我力量,支持我前進。
首先,要感謝台大語言所的所有師長,帶領我進入語言學研究的領域。尤其 感謝我的指導教授馮怡蓁老師:謝謝老師是我的助力也是阻力,總是恐嚇中帶鼓 勵,加油中挾威脅地提攜著我;謝謝老師看透且揪出了我做學問的劣根性,苦口 婆心地讓我了解研究應有的方法及態度;謝謝老師耐心仔細地教導,不厭其煩地 與我反覆討論,助我渡過瓶頸;謝謝老師啟發我對口語語料庫的興趣,指引我該 前進的方向且讓我有往下個目標邁進的勇氣。
非常感謝我的兩位口試委員鄭靜宜老師及小笠原奈保美老師。謝謝兩位老師 百忙之中不辭勞苦地參加口試,且給予我修改論文的指導及意見,使我在聲學量 測及語音方面皆有更寬廣的認識及視野。另外,特別感謝中研院陳克健老師提供 線上斷詞系統的使用,讓我能更有效率地完成論文。
感謝實驗室的大家。謝謝Sally 學姊總是在一旁鼓勵我,替我加油打氣;謝
謝Shelly 學姊很有耐心地幫我聽語料及和我討論;謝謝 Chris 學姊貼心地聽我訴
苦且每每提供有效的解決方法;謝謝盈潔和慧茹在語料的處理上幫了我許多忙。
也感謝所上所有人好好的大家 ─ 乃欣學姊、芷誼學姊、文琦學姊、惠如學姊、
季樺學姊、立心學姊、佩玥 ─ 謝謝大家在各方面支持著我完成論文。還要感謝 一直和我在一起歡笑流淚的同學兼死黨們,Ruby、Angela、Susu、姚姚,有了大 家的陪伴,這一路走來雖然艱辛卻不孤獨。
最後,我要感謝我的家人。謝謝阿公不斷地提醒我何時要畢業;謝謝爸爸媽 媽無微不至的照顧、賠小心的呵護及風雨無阻的娃娃車接送;謝謝老哥總是給我 繪圖設計上專業的建議;謝謝小貓喔逼適時地吵鬧替我趕走瞌睡蟲。大家的支持 與關懷永遠是我最強而有力的後盾。
現在,終於我走到門前,手中緊握著鑰匙,到了要開啟這扇門的moment 了。
懷著感謝的心情,我將穿過這扇門,往另一扇更高更厚的門前進。
摘要
本研究旨在探討無聲捲舌音及齒音在台灣華語中的表現。過去的研究可以概 括分為兩大類:以自然語料所做的社會語言學研究以及運用實驗材料所進行的聲 學測量。由於研究材料和方法的限制,先前並未有從聲學角度探討自然語料的研 究。有鑑於此,本研究以自然語料為研究材料,並且以聲學測量為研究方式來分 析無聲捲舌音及齒音在台灣華語中的呈現。本研究共有十五位男女發音人,皆出 生於台北或高雄。每位發音人參與約三十分鐘的訪談。在訪談語料中,所有的無 聲捲舌音及齒音皆挑選出來並進行量測。本研究所採用的聲學測量是取頻譜的重 心頻率值,且一併分析了四個因素,包括兩個社會因素:地區和性別,及兩個語 言因素:重音程度及詞類。研究結果顯示,地區和性別皆有顯著影響。就性別因 素而言,女生對於捲舌音和齒音的區分較為男生明顯。而就地區因素而言,男女 生呈現不同的趨勢:台北女生的區分程度比高雄女生大,然而台北男生的區分程 度卻比高雄男生小。至於兩個語言因素,結果亦發現兩者皆有顯著影響。在重音 的情況下,捲舌音和齒音的區分程度較大;而相似的結果也出現在實詞的情況下。
再者,研究結果顯示捲舌音化與齒音化這兩個音韻過程在台灣華語有著不同的功 能。捲舌音化與社會因素(性別和地區)息息相關,而齒音化卻是與語言因素(重音 程度和詞類)有相互關聯。進一步詮釋,本研究發現在台灣華語中,捲舌音化是呈 現外在語言因素的不同;反之,齒音化能呈現語言內部的分類及差異。
關鍵詞:捲舌音,齒音,重音,詞類,自然語料,台灣華語
ABSTRACT
The present study investigated the realizations of voiceless retroflex and dental sibilants in Taiwan Mandarin. Past studies on this issue are mainly of two tracks – sociolinguistic studies on spontaneous speech and acoustic studies on experimental data.
In this study we would like to examine sibilant realizations in spontaneous speech from the acoustic perspective. Fifteen speakers of both genders from two regions, Taipei and Kaohsiung, were recruited and each speaker contributed 30-minute-long speech data.
All retroflex and dental sibilant tokens were labeled, and the centroid frequency of each sibilant was measured to determine its realization. Effects of four factors were looked into, including two social factors, region and gender, and two linguistic factors, prosodic prominence and word class. Results showed that both region and gender played determinant roles. Females generally made larger sibilant contrasts than males, but inconsistency was observed for cross-regional comparisons. While Taipei females distinguished sibilants better than Kaohsiung females, the opposite was observed for male speakers. As for the effects of linguistic factors, it was also found that sibilant realizations in Taiwan Mandarin were indeed subject to both prosodic prominence and word class. In particular, the strengthening effect was shown in linguistically prominent conditions – prosodically prominent and content word conditions, in which speakers tended to make greater sibilant distinctions. Our results further implicated distinctive functions for the processes of retroflexion and dentalization in Taiwan Mandarin.
Retroflexion characterized speaker group discrepancies, while dentalization reflected different levels of linguistic prominence. In this regard, degrees of retroflexion were sensitive to extra-linguistic differences, whereas degrees of dentalization were sensitive to language-internal categorization.
Keywords: retroflex sibilant, dental sibilant, prosodic prominence, word class, spontaneous speech, Taiwan Mandarin
TABLE OF CONTENTS
CHAPTER 1 INTRODUCTION... 1
1.1 Linguistic background ... 1
1.2 Motivation ... 3
1.3 Aims of study... 8
1.4 Significance ... 10
1.5 Organization ... 12
CHAPTER 2 LITERATURE REVIEW ... 14
2.1 Phonological variations in Taiwan Mandarin... 14
2.2 Voiceless retroflex and dental sibilants in Mandarin... 16
2.2.1 Articualation ... 16
2.2.2 Acoustic measurements ... 17
2.3 Sociolinguistic studies on retroflex sibilants in Taiwan Mandarin... 20
2.3.1 Gender and region ... 21
2.3.2 Hypercorrection... 22
2.4 Prosodic prominence ... 24
2.5 Word class... 28
2.6 Summary... 30
CHAPTER 3 METHODS... 32
3.1 Participants ... 32
3.2 Data collection... 33
3.3 Recording equipment... 34
3.4 Data processing procedure... 34
3.4.1 Text transcription... 34
3.4.2 Word segmentation and word class labeling ... 35
3.4.3 Stress labeling... 37
3.5 Retroflex and dental sibilants ... 40
CHAPTER 4 RESULTS ... 46
4.1 Overall distribution... 46
4.1.1 Valid tokens ... 47
4.1.2 Invalid tokens ... 50
4.2 Valid canonical sibilant tokens ... 56
4.3 Word class... 67
4.4 The interaction between stress and word class... 72
4.5 Substituted valid sibilant tokens... 75
4.6 Sibilant deleted tokens... 82
CHAPTER 5 DISCUSSION ... 86
5.1 Sibilant realizations in spontaneous speech... 86
5.2 The effects of social and linguistic factors ... 87
5.2.1 Stress realizations by different speaker groups ... 88
5.2.2 Sibilant type and vowel context ... 94
5.2.3 The effect of word class... 98
5.3 The interaction between stress and word class... 99
5.4 Retroflexion and dentalization in Taiwan Mandarin ... 102
CHAPTER 6 CONCLUSION ... 106
REFERENCES ... 109
APPENDIX I ...114
APPENDIX II...115
LIST OF FIGURES
Figure 1.1 The demographic distributions of the four major ethnic groups (Min, Hakka, Mainlander, Aborigine) in Taipei and Kaohsiung (Yang, 2008)... 2 Figure 1.2 The production of (a) [ß] and (b) [s] from the Mandarin Phonetics Textbook (NTNU Mandarin phonetics committee, 2003)... 5 Figure 1.3 The X-ray slides of the production of (a) [ß] and (b) [s] from Ladefoged et al.
(1984)... 5 Figure 3.1 The waveform, spectrogram, tonal contour, stress labeling (tier 1) and
syllable labeling (tier 2) of the utterance ‘I did not know why, it’s just…’. 39 Figure 3.2 The waveform, spectrogram, tonal contour, stress labeling (tier 1) and
syllable labeling (tier 2) of the utterance ‘There is a small amount of Indian curry, the kind that is very spicy.’. ... 40 Figure 3.3 The spectra of retroflex and dental sibilants taken from the the syllable shi
‘thing’ and si ‘in charge’ respectively, produced by (a) 10 male and (b) 10 female speakers. The solid line in each spectrum indicates 2000 Hz. ... 42 Figure 3.4 (a) The waveform and the spectrogram of the syllable sai‘game’. The dashed lines indicate the frication portion, where the solid lines indicate the 10 ms in the middle of the frication. (b) The spectrum extracted from the middle 10 ms of the frication. The centroid frequency was calculated from the range above 2000 Hz, indicated by the dashed line... 44 Figure 3.5 The spectrogram of the syllable cai ‘vegetable,’ with the frication and the
aspiration parts being labeled... 45 Figure 4.1 The waveform and the spectrogram of the word jiushi ‘that is,’ where the
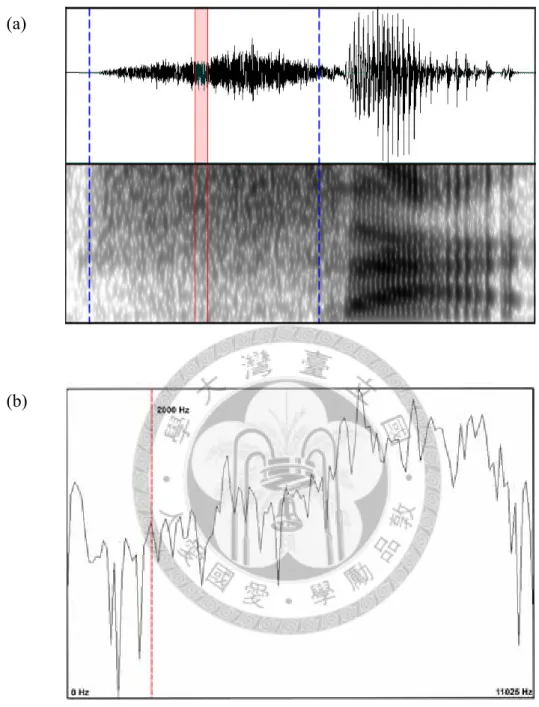
retroflex sibilant [ß] is voiceless in (a) and voiced in (b)... 49 Figure 4.2 The waveform and the spectrogram of the word jiushi ‘that is,’ where the
retroflex sibilant [ß] is deleted. ... 51 Figure 4.3 The waveform and the spectrogram of the word dagaishi ‘perhaps,’ where
the retroflex sibilant [ß] is soft. ... 52 Figure 4.4 The waveform and the spectrogram of the word chuanzhuo ‘clothing,’ where the retroflex sibilant [tßH] is affected by microphone noise... 53
Figure 4.5 The waveform and the spectrogram of the word tongche ‘to commute,’
where the production of the second syllable is incomplete and only the retroflex sibilant [tßH] is uttered. ... 53 Figure 4.6 The waveform and the spectrogram of the phrase zai nage ‘at that,’ where the dental sibilant [ts] is pronounced wrongly and replaced by the voiceless stop [t]... 54 Figure 4.7 The waveform and the spectrogram of the phrase wo zhi zhidao ‘I only know that…,’ where the retroflex sibilant [tß] overlapped with the speaker’s laughter. ... 55 Figure 4.8 The waveform and the spectrogram of the phrase wo shi zai ‘I was at…,’
where the dental sibilant [ts] is replaced by a glottal stop... 55 Figure 4.9 The mean centroid frequency of three sibilant types (c: aspirated affricate; s:
fricative; z: unaspirated affricate) in the S2 and S3 conditions for speakers of both genders (F: females; M: males) from Taipei and Kaohsiung... 64 Figure 4.10 The mean centroid frequency of three sibilant types (c: aspirated affricate; s:
fricative; z: unaspirated affricate) followed by rounded and unrounded vowels of both female and male speakers... 67 Figure 4.11 The mean centroid frequency of content and function word unaspirated
affricates (z type) in unrounded vowel context of speakers from Taipei and Kaohsiung. ... 69 Figure 4.12 The mean centroid frequency of content and function word fricatives (s type)
in the rounded vowel context of both female and male speakers from Taipei and Kaohsiung. ... 70 Figure 4.13 The mean centroid frequency of content and function word fricatives (s type)
in the rounded vowel context of each Taipei male speaker... 71 Figure 4.14 The mean centroid frequency of content and function word fricatives (s type)
in the rounded vowel context, with speaker CZX and JXW excluded from Taipei male group. ... 72 Figure 4.15 The mean centroid frequency of S1, S2 and S3 retroflex fricatives (s type)
in the unrounded vowel context of the two word classes. ... 74 Figure 4.16 The mean centroid frequency of S0 and S2 dental unaspirated affricates (z
type) in the unrounded vowel context of the two word classes. ... 75
Figure 4.17 The mean centroid frequency of canonically realized dental/retroflex sibilants and substituted dental sibilants in rounded vowel context of Kaohsiung females... 82 Figure 5.1 The mean frication duration of three sibilant types. ... 96 Figure 5.2 The mean centroid frequency of the dental unaspirated affricate of the
syllable zi in different stress levels and word class conditions... 101
LIST OF TABLES
Table 2.1 The three pairs of retroflex and dental sibilants in Mandarin... 17
Table 2.2 Relative levels of stress in Pan-Mandarin ToBI (Peng, et al., 2007)... 28
Table 3.1 The number of subjects in each speaker group... 33
Table 3.2 The mean Min-to-Mandarin ratio for each speaker group... 33
Table 3.3 The parts of speech and the corresponding word class categories. ... 37
Table 3.4 Modified criteria for levels of prosodic prominence. ... 38
Table 4.1 The distribution of all sibilant tokens in the corpus... 47
Table 4.2 The overall valid token distribution of (a) Taipei male (b) Taipei female (c) Kaohsiung male and (d) Kaohsiung female groups (R: retroflex; D: dental; c: aspirated affricate; s: fricative; z: unaspirated affricate)... 57
Table 4.3 The number and percentage (in paranthesis) of S2 fricative (s type) sibilant tokens in the rounded context contributed by each Taipei male speaker... 71
Table 4.4 The overall substituted token distribution of (a) Taipei male (b) Taipei female (c) Kaohsiung male and (d) Kaohsiung female groups (R: retroflex; D: dental; c: aspirated affricate; s: fricative; z: unaspirated affricate). The categorization of R/D is provided in Note at the bottom of this table... 78
Table 4.5 The overall sibilant deleted token distribution and the deletion rate (in the parenthesis) of (a) Taipei male (b) Taipei female (c) Kaohsiung male and (d) Kaohsiung female groups (R: retroflex; D: dental; c: aspirated affricate; s: fricative; z: unaspirated affricate)... 84
Table 5.1 The degree of sibilant contrast made by different speaker groups. ... 89
Table 5.2 The comparisons of sibilant contrast degrees between (a) genders in the same region and (b) regions of the same gender... 90
CHAPTER 1 INTRODUCTION
1.1 Linguistic background
With the spread of Chinese population, Mandarin has been brought to many areas
around the world. Gradually, it develops into a number of dialects in different areas, due
to factors such as geographical separation or contact with local languages. These
dialects differ from Standard Beijing Mandarin, or Putonghua, in various linguistic
aspects. Such a process of dialect formation is seen in many regions or areas where
Chinese people populate.
Taiwan is of no exception. Before the arrival of Mandarin, Taiwan was essentially
a multi-lingual society, owing to the composition of different ethnic groups. In the early
twentieth century, a number of languages were spoken in Taiwan, including Min, Hakka,
several indigenous languages, and even Japanese because of political occupation. In late
1940s, Mandarin officially came to Taiwan with the immigrants from Mainland China.
At that time, in order to strengthen its authority, the government then implemented
Mandarin-only policy, in which people were required to use Mandarin as the sole
language in public occasions. Under such a social context, a lot of people in Taiwan
started to learn and speak Mandarin, and eventually became bilinguals, or even
trilinguals.
Among all the ethnic groups in Taiwan, the majority of people are of Min origin.
To be specific, about 73.3% of people in Taiwan are Min people, 13% of them are
Mainlanders,1 12% are Hakka, and 1.7% are Austro-Polynesian aborigines (S. Huang,
1993). A more recent demographic survey further revealed the slightly divergent
compositions of ethnic groups in different regions (Yang, 2008). Take Taipei and
Kaohsiung, the two metropolitan cities in Taiwan, for example. Figure 1.1 summarizes
the distributions of the four major ethnic groups in these two cities. As can be seen, the
general trend patterns similarly in both areas; that is, Min people have far bigger
population than the other ethnic groups.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Taipei Kaohsiung
Others Aborigine Mainlander Hakka Min
Figure 1.1 The demographic distributions of the four major ethnic groups
(Min, Hakka, Mainlander, Aborigine) in Taipei and Kaohsiung (Yang, 2008).
1 Mainlanders refer to those who came to Taiwan with the government from Mainland China after World
Given the fact that a large number of people in Taiwan belong to the Min ethnic
group, it is not surprising that Min is spoken much more frequently than the other local
languages. In fact, about 80% of people in Taiwan are Mandarin-Min bilinguals (S.
Huang, 1993). Regardless of the great number of Min speaking population in Taiwan, it
should be noted that the actual usage of Mandarin and Min, nevertheless, was found to
differ across regions in Taiwan (Ang, 1997). Generally speaking, Mandarin is more
often spoken than Min in the Taipei area. Nevertheless, the usage of Min increases in
cities southern to Taipei. In particular, the usage of Min even exceeds that of Mandarin
in Southern Taiwan. It is a general trend that as one goes further south, the dominance
of Min in the mixed code use is more frequently observed (Liao, 2000). These findings
all convince us that Taiwan is by no means a linguistically homogeneous society, and
the regional discrepancy in terms of Mandarin and Min usage characterizes one of such
features.
1.2 Motivation
When Min native speakers learned to speak Mandarin, some linguistic features of
Min would inevitably be carried over to their Mandarin speech. One of the most salient
phonological features being identified at the early stage was the deretroflexion of
retroflex sibilants. There are four retroflex sibilants in Mandarin, including three
voiceless sibilants [tß], [tßH], [ß], and one voiced sibilant [Ω]. Specifically, deretroflexion
depicts the process that voiceless retroflex sibilants [tß], [tßH] and [ß], phones
non-existent in Min, are substituted by voiceless dental sibilants [ts], [tsH] and [s],
phones existent in both Mandarin and Min. The substitution pattern for the voiced retroflex sibilant [Ω], however, varies more, mainly due to the lack of a direct
corresponding voiced non-retroflex sibilant in Mandarin and Min. Some common substituents include [z], [l] and [n] (Chan, 1984).
The realizations of retroflex sibilants, nevertheless, are actually much more
complicated than mere substitution. Deretroflexion is so notorious a feature that in
Chinese education, students in Taiwan are explicitly taught to learn the “standard”
pronunciation. Starting from elementary schools, students are asked to pay extra
attention to retroflex sounds when learning phonetic symbols2. It has always been
highlighted that retroflex sounds are produced with the tongue curled up. Similar
instructions can also be seen in the Mandarin phonetics textbook at college levels.
Textbook demonstration of the “standard” retroflex articulation of [ß] was shown in
Figure 1.2(a), which, in comparison with dental articulation of [s] in Figure 1.2(b), has a
clearly curled-up tongue blade and further retracted place of articulation.
2 The phonetic symbols here refer to Zhuyinfuhao, the sound transcription system officially used in Taiwan. Getting to know these symbols and making use of them are emphasized in the first two years of
Figure 1.2 The production of (a) [ß] and (b) [s] from the Mandarin Phonetics Textbook (NTNU Mandarin phonetics committee, 2003).
Figure 1.3 The X-ray slides of the production of (a) [ß] and (b) [s] from Ladefoged et al. (1984).
However, midsagittal X-ray data provided by Ladefoged et al. (1984) showed that
even for Standard Beijing Mandarin, retroflex sounds are not produced with a curled-up
tongue (see Figure 1.3). Instead, retroflex sibilants in Mandarin, just like dental sibilants,
are produced with the upper surface of the tongue; in other words, the tongue is not
curled up. In effect, the two sets of sibilants differ more crucially in terms of
constriction position and tongue shape. With respect to such an official overcorrection
(a) (b)
(a) (b)
of retroflex pronunciation in Taiwan Mandarin, the realizations of retroflex sibilants
thus drew many researchers’ attention, in terms of how and when Taiwan Mandarin
speakers would use retroflex sibilants and also how the contrast between retroflex and
dental sibilants was made.
Although a great number of studies have been conducted to investigate the
realizations of retroflex sounds in Taiwan Mandarin from various perspectives, several
gaps on this issue could still be observed. First of all, there is a gap of merging direction
being studied. Because the substitution of retroflex sibilants with dental counterparts
was first recognized as a salient feature, most studies focused on the deretroflexion
process in Taiwan Mandarin (M.-C. Li, 1995; C. C. Lin, 1983; Rau & Li, 1994). Few,
however, have paid attention to the realizations of dental sibilants. Although the general
assumption is that dental sibilants are the unmarked segments and the process of turning
marked into unmarked ones is linguistically universal, it is still interesting to investigate
when and how such a process will be reversed. In the case of Taiwan Mandarin, the
substitution of retroflex sibilants for dental ones has been observed from time to time
(e.g., Chung, 2006). It is worthwhile to study the mechanism behind such a
phenomenon.
Second, there is a gap of research materials and research methods. Early studies are
mostly impressionistic, and results are often derived from perceptual observations
(Chan, 1984; Kubler, 1985; M.-C. Li, 1995; C. C. Lin, 1983; Rau & Li, 1994). However,
sound perception is easily affected by various factors, such as ambient segments,
individual voice quality, suprasegmental effects, etc. Later studies on this issue started
to adopt a more objective way and acoustically measured retroflex and dental sibilants
(Jeng, 2006; Tse, 1988, 1998). Nonetheless, the measurements are so far limited to
experimental data. Under reading and citation conditions, subjects tend to be very aware
of their own pronunciation, so retroflex and dental sibilants are usually found to be
clearly distinguished. These totally different results thus create a mismatch between
recent experimental studies and previous impressionistic ones on this issue.
Third, there is a gap of factors being examined. Even though the deretroflexion
phenomenon has long been recognized and discussed, most studies are sociolinguistic
research that centers on a number of extra-linguistic factors such as gender, social class,
education level, etc. (M.-C. Li, 1995; C. C. Lin, 1983; Rau & Li, 1994). Few of them
really focus on linguistic variables. Considering the fact that interview is the most
frequent method for conducting sociolinguistic studies and also the fact that results are
mostly derived from spontaneous speech in the interview, a lot of information regarding
this issue will be masked if linguistic factors are not taken into consideration. For
example, the copula verb shi is such a high-frequency word in Mandarin. Given its low
semantic information and high frequency of use, it is predictable that its onset
consonant will hardly be realized as the canonical retroflex sibilant [ß] in natural speech.
Therefore, the results of simply averaging over the token numbers could possibly cause
difficulty for interpretation.
Given the gaps noted above, in this study, we intend to investigate both dental and
retroflex sibilants more thoroughly and completely, by acoustically measuring the
sibilant realizations in spontaneous speech, with several linguistic factors being
controlled for and looked into.
1.3 Aims of study
With regard to the gaps on retroflex and dental sibilants discussed above, we would
like to investigate the realizations of both sibilants more thoroughly in the present study.
Specifically, three research goals are tempted to be achieved.
Our first research goal is to adopt acoustic measurements to investigate the
realizations of voiceless retroflex and dental sibilants in spontaneous speech. As
mentioned previously, most of the past studies focused on the deretroflexion process.
Moreover, due to limitation of research methods, a great number of sociolinguistic
studies were based on impressionistic observations. Although several acoustic studies
did appear later, they only examined experimental data. Therefore, in this study, we
intend to objectively determine the issue of retroflex and dental sibilants in spontaneous
speech by taking acoustic measurements. One thing to be noticed is that in order to adopt the same measurement to all sibilants, we exclude the voiced retroflex sibilant [Ω]
in this study mainly because it is no longer typically realized as a fricative in Taiwan
Mandarin (Chan, 1984). Thus, the present study focuses on six voiceless retroflex and dental sibilants – [tß], [tßH], [ß] and [ts], [tsH], [s].
Second, social factors, gender and region, are of interest. Considering that gender
is a common factor examined in many sociolinguistic studies, in this study we are
particularly interested to see how the realizations of retroflex and dental sibilants are
influenced by regional diversity, since it is a factor that has not yet been looked into on
this issue. As aforementioned, Taipei differs from other regions in that the use of
Mandarin dominates. On the contrary, the use of Min actually exceeds that of Mandarin
in other southern cities. To examine regional differences, we thus select Taipei and
Kaohsiung, the metropolitan city in Northern and Southern Taiwan, respectively. We
would like to see whether different speaker groups have their specific realizations for
retroflex and dental sibilants.
The third research goal is to see whether the realizations of retroflex and dental
sibilants are subject to the influence of linguistic factors. In particular, we will examine
one phonological factor – prosodic prominence, and one morpho-syntactic factor – word
class. As commonly believed, prosodic prominence and word class in effect exhibit high
correlation, i.e., content words are more likely to receive prosodic prominence, while
function words tend to be prosodically reduced. This leads to the assumption that
prosodic prominence and content words signify the strengthening condition, whereas
prosodic non-prominence and function words signify the reduction condition. However,
exceptions can still be anticipated. For instance, function words do receive prominence
under situations such as contrastive stress; on the other hand, content words are also
very likely to be reduced to a great degree in the fast speech condition. In this regard, it
is worthwhile to examine how the effect of prosodic prominence interact with that of
word class, and it is predicted that different degrees of distinction between retroflex and
dental sibilants can be observed in diverse conditions.
1.4 Significance
The significance of this study includes the following three aspects. First of all,
although studying retroflex and dental sibilants in Taiwan Mandarin is not uncommon,
or even seems to be out-dated, this study differs from previous ones in that it has better
controls in both social and linguistic perspectives. A great number of social factors on
this issue have been thoroughly examined. More often than not, the results, however, are
hardly generalizable. Taiwan is in effect a heterogeneous society. Therefore, the lack of
control regarding subject background, Min proficiency, etc. will introduce unwanted
effects and thus make explanations difficult. Likewise, linguistic effects should not be
neglected, especially when phonological variations are studied. Not all linguistic units
are of equal status in a language, and our articulation will always reflect such
linguistically internal discrepancies. Nonetheless, previous studies rarely, if not never,
take into account the effects of linguistic factors. It is known that deretroflexion is a
general phenomenon found in Mandarin spoken in Taiwan, but whether it is true in all
speech contexts or exactly how this process interacts with other linguistic factors still
remains unknown. Keeping these insufficiencies in mind, in this study we try our best to
explore both social and linguistic factors in a more controlled way, in hope of obtaining
more specific and less confounding results.
In addition, this study should be regarded as the first corpus-based study on the
issue of retroflex and dental sibilants. Using data from a speech corpus has a number of
advantages. For example, it is natural speech that is of interest. Natural speech is
gaining attentions nowadays due to the fact that it better represents the authentic process
of producing and perceiving language. Also, a speech corpus permits objective
measurements. With the advancement of digital recording techniques, a lot of sound
realizations can be acoustically determined, and thus, some flaws or inaccuracies of
transcription-based analyses can be avoided. Most importantly, by using a speech
corpus, a large number of data can be incorporated. A quantitative study has its merits,
for it is much more representative and has higher generability. The present corpus-based
study is thus considered pioneering in that it quantitatively and objectively looks into
the realizations of retroflex and dental sibilants in spontaneous speech.
Finally, results of this study can benefit the burgeoning field of information
processing and signal recognition. In recent years, people start to get interested in
human-machine interactions. Therefore, machines are designed to both produce and
perceive speech. Since our study focuses on different sound realizations in distinct
linguistic categories, our results, if applicable, can help machines make more precise
predictions and better recognition of human spontaneous speech. Moreover, if different
linguistic behaviors are indeed consistently found between genders and among dialects,
social factors can also be set as separate parameters to enhance the overall processing
speed and accuracy. In this way, speech recognition techniques will definitely be better
improved and more widely applied in various fields in the upcoming future.
1.5 Organization
The organization of the following chapters is as followed. In Chapter 2, reviews of
literature on retroflex and dental sibilants in Taiwan Mandarin, along with a number of
relevant issues, are discussed. Chapter 3 introduces the methods for conducting this
study, in terms of data collection, data processing, and sibilant measurements. Chapter 4
presents the statistical analyses and results. Discussion is provided in Chapter 5, and
conclusion in Chapter 6.
CHAPTER 2 LITERATURE REVIEW
In this chapter, past studies on retroflex and dental sibilants in Taiwan Mandarin
are discussed. Section 2.1 summarizes the overall phonological variation, resulting from
contact with Min, in Taiwan Mandarin. Section 2.2 reviews studies of voiceless
retroflex and dental sibilants, in terms of their articulation and acoustic correlates.
Sociolinguistic studies are presented in Section 2.3, in which the effects of gender,
region, and the phenomena of hypercorrection are particularly highlighted. Section 2.4
reviews studies on prosodic prominence, and the effect of word class is discussed in
Section 2.5.
2.1 Phonological variations in Taiwan Mandarin
Given the fact that about 80% of the people in Taiwan are Mandarin-Min bilinguals
(S. Huang, 1993), Min, among all the local languages in Taiwan, should therefore be
considered to play the most crucial role in shaping Mandarin and propelling the
emergence of such a Mandarin dialect in Taiwan. Indeed, according to early research, a
great number of linguistic characteristics being identified are specific to Min-accented
Mandarin (Cheng, 1985; Kubler, 1985). In terms of phonology, some sounds in
Standard Beijing Mandarin were found to be altered, substituted, added, or deleted (Ing,
1984, 1985). It was even reported that Mandarin in Taiwan is actually developing in a
trend towards the resemblance with Min, from which we should be able to see the great
influence of Min (Dong, 1995).
For decades, phonological variations in Taiwan Mandarin have been consistently
brought up and extensively studied. Commonly noted variations include the
monophthongization of diphthongs, the merging of syllable-final nasals, the
disappearance of neutral tone and several sandhi processes, etc. (Dong, 1995; Ing, 1984;
Kubler, 1985). As for consonant variations, deretroflexion is by far the most frequently
discussed topic. Most research attributes deretroflexion to the influence of Min, which
has only dental sibilants but no retroflex counterparts (Y.-H. Lin, 1988).
Lin (1983) took the lead to systematically investigate the realizations of retroflex initials, followed by Chan (1984), who conducted a sociolinguistic study on [Ω] in
Taiwan, and Rau and Li (1994) and Li (1995), who examined the phonological variants of [tß], [tßH] and [ß]. On contrary to what has been observed (e.g., Kubler, 1985, etc.), in
all these studies, retroflex sibilants are still present in the speech of Taiwan Mandarin
speakers, though the occurrence strongly depends on various social factors. In other
words, instead of total deretroflexion as observed in early studies, speakers, at least for
those in latter studies, still have the phonological representations of retroflex sibilants.
As a matter of fact, total deretroflexion should be better considered as one of the salient
features of Taiwanese Mandarin, which is a stigmatized variety of Mandarin that is
heavily Min-accented and spoken mainly by the aged native Min speakers who acquire
Mandarin as their second language (Hsu, 2006). Taiwan Mandarin, on the other hand,
should refer to the variety of Mandarin, still influenced by Min but not stigmatized, and
spoken by comparatively younger generation in Taiwan. In our study, it is Taiwan
Mandarin that is of interest.
2.2 Voiceless retroflex and dental sibilants in Mandarin
2.2.1 Articualation
There are three pairs of voiceless retroflex and dental sibilants in Mandarin. Their
romanization letters and corresponding phonetic symbols are shown in Table 2.1.
According to the articulatory data of [ß] and [s] (Ladefoged & Wu, 1984), contradictory
to the general assumption that a curled-up tongue is involved in the production of retroflex sibilants, [ß] in Mandarin, just like its dental counterpart [s], is also produced
with the upper surface of the tongue approaching the alveolar region. As shown in Figure 1.3, [ß] and [s] are distinguished in the following three aspects. First, [ß] clearly
has a further back constriction point than [s]: the constriction is roughly in the center
region of the alveolar ridge for [ß], while it is anterior to the alveolar ridge for [s]. In
addition, sublingual cavity, the space under the tongue, is present in the production of
[ß], but not [s]. Finally, the tongue is slightly grooved when [s] is produced.
Unfortunately the articulatory data for the other two affricate pairs are not available, but
assuming that they only differ from the fricative pair in manner of articulation, we
should be able to predict that the general articulation patterns resemble that of fricative
sibilants.
Table 2.1 The three pairs of retroflex and dental sibilants in Mandarin.
Sibilant type Place of
articulation
Aspirated
affricate Fricative Unaspirated affricate Retroflex ch [tßH] sh [ß] sh [tß]
Dental c [tsH] s [s] s [ts]
2.2.2 Acoustic measurements
In search of acoustic cues for classifying fricatives, early studies made use of
spectral analyses. Examination of power spectra has yielded several reliable
measurements, inclusive of frication duration, amplitude, and spectral peaks (Behrens &
Blumstein, 1988; Hughes & Halle, 1956; Manrique & Massone, 1981). A more recent
and common method is spectral moments analysis, which applies statistical calculations
to the power spectra (Forrest, Weismer, Milenkovic, & Dougall, 1988). These moments
are mean/centroid (M1), standard deviation (M2), skewness (M3) and kurtosis (M4). In
particular relation to sibilants, it has been indicated that M1 is a very robust cue
(Jongman, Wayland, & Wong, 2000). Specifically, the mean or centroid frequency is
negatively correlated with the length of the front cavity — the shorter the cavity anterior
to the constriction position, the more energy fall on the high-frequency region in the
spectra, thus resulting in higher M1 value.
In Mandarin, there are three series of sibilants: dental, retroflex, and alvelopalatal.
Acoustic studies also started early in order to identify their spectral characteristics (e.g.,
Svantesson, 1986; Tse, 1988). Recently, Li (2008) measured these three fricative
sibilants with spectral moments analyses. The moment values were calculated from the
40 ms window in the middle of the frication, which is considered to be the most steady
portion of the frication noise. Results showed that centroid frequency (M1) alone is
sufficient to separate retroflex and dental sibilants, for they contrast crucially in place of
articulation.
As for Taiwan Mandarin, Tse (1998) studied retroflex and dental sibilants in
experimental settings, in order to determine how merged each sibilant pair is in the
speech of young people in Taiwan. The measurement he took was the lower limit of the
energy concentration region in the power spectra. His acoustic results demonstrated that
young people still distinguish retroflex and dental sibilants in their speech, and the
degree of distinction interacts with gender effect. Moreover, he also found that the unaspirated affricate [tß] merges with its dental counterpart [ts] to a greater extent than
the other two retroflex sibilants. Jeng (2006) also examined the realizations of retroflex
and dental sibilants acoustically. She took four spectral moments, along with duration
measurements. It was also found that centroid frequency could effectively distinguish retroflex and dental sibilants. In addition, the aspirated affricate pair [tßH] and [tsH] have
particularly lower M1 values than the other two pairs, owing to the fact that frication
diminishes during aspiration. In terms of duration, the frication of retroflex sibilants is
in general shorter than that of dental sibilants. Another interesting finding in this study
was that context plays a role. That is, retroflex sibilants become less retroflexed in a
more natural (question-answer) context than in a less natural (reading) context.
Possibly due to the feature of deretroflexion in Taiwan Mandarin, the issue on the
degree of retroflexion particularly arouses the interests of researchers in Taiwan. The
relationship between acoustic parameters and the degree of retroflexion has been
discussed with experimental manipulations. Tse (1989) once measured the frequency (Hz) and intensity (dB) of the second formants of the mid back unrounded vowel [µ],
an allophone that only occurs following retroflex sibilants in Mandarin. Tse
hypothesized that the more retroflex a sibilant is, the higher the frequency and the stronger the intensity of [µ]’s F2 would be. Although his results were far from
satisfactory due to the small number of subjects, a slight trend compatible with his
hypothesis was still observed. In addition to measuring the following vowels, sibilants
are directly measured as well. Jeng (2006) asked subjects to perform four degrees of
retroflexion – the most retroflexed, moderately retroflexed, slightly retroflexed, and
non-retroflexed. Spectral analyses indicated that the former three retroflex versions
differ from each other only to a small extent. On the other hand, the non-retroflexed
version is significantly distinguished from those retroflex ones. Such a result further
implies that there is a continuum between the realizations of retroflex and dental
sibilants, in which acoustic measurements are able to authentically reflect sibilants’
place of articulation along this continuum.
2.3 Sociolinguistic studies on retroflex sibilants in Taiwan Mandarin
According to Labov (1972), during the course of language change, there are three
stages involved in the change of language forms, which are the origin of the change, the
propagation of the change, and the completion of the change. It is in the second stage
(propagation) that more and more people start to adopt new variant forms, and it is also
in this stage that “social significance is inevitably associated with the variant and with
its opposition to the older form” (p. 123). As a result, to study language variation, a
great number of studies start with the investigation of variants in social contexts.
Frequently examined social factors for the issue of retroflex and dental sibilants include
gender, age, socio-economic status, education level, etc.
2.3.1 Gender and region
Gender is the most frequently examined factor in most previous sociolinguistic
studies, and it also has a very salient effect. For example, in Lin’s (1983) study on
college students in Taiwan, gender is found to be the strongest factor, in which the
correct usage of retroflex sibilants for females greatly outnumbers that for males.
Subsequently, Li (1995) examined the realizations of [tß], [tßH], [ß] in Taiwan Mandarin.
Instead of using binary retroflex/non-retroflex distinction, she recognized the
intermediate variants of the three retroflex sibilants which, according to her, are the
realizations somewhere between retroflex sibilants and dental sibilants. Her results
suggested that gender effectively interacts with speech contexts. To be specific, women
retroflex more in the formal speech, but they actually substitute dental variants for
retroflex sibilants more often than men in the casual speech. Li explained her finding
with the well-established sociolinguistic theory. That is, in general, women are
comparatively conservative speakers and tend to use more standard forms than men.
However, in the course of sound change, usually women, instead of men, play the
leading role (e.g. Labov, 1990). As a result, it is not difficult to understand why more
vernacular forms are found in women’s daily conversation.
Compared to gender, region is a much less studied factor on this issue. The only
study that touches upon its effect is Lin’s study (1983). In particular, Lin roughly
divided his subjects into Taipei group and non-Taipei group, based on the subjects’
residency prior to the age of 14. Broad categorization this might be, the effect is rather
salient. Regardless of gender, when speaking Mandarin, native Min speakers from
Taipei have higher percentage of producing correct retroflex sibilants than those from
other regions. Moreover, discrepancies were shown even for native Mandarin speakers.
That is, native Mandarin speakers from Taipei also have more correct retroflex
production than native Mandarin speakers from other areas. This finding illustrates that
region is indeed a potentially effective factor that deserves being pursuing in greater
detail.
2.3.2 Hypercorrection
Labov (1972) studied the /r/ pronunciation of New York residents in relation to
their social classes. Significantly, he found that the usage of rhotic /r/ (considered to be
the prestigious form) of people from the lower middle class exceeds that of people from
the upper middle class in formal conditions. A more detailed investigation was done in
Labov’s another study (1990), in which he discussed the complicated relationship
between gender and social class. Particularly, he discovered that females constitute the
high percentage of using rhotic /r/ of the lower middle class New Yorkers. Males are
also doing the same, though on a smaller scale. The lower middle class, as well as
females, are both categorized as linguistically insecure groups, therefore propelling
them to use more standard forms. Such insecurity acts upon speakers’ consciousness
level and urges them to hypercorrect their speech in order to gain security.
The phenomenon noted above is parallel to the realizations of retroflex sibilants in
Taiwan Mandarin. To be specific, most past studies, either sociolinguistic or acoustic,
all showed a strong gender effect in terms of using retroflex sibilants. In addition,
retroflex production is found more often in the formal context, in the speech of people
of higher education level and higher income, etc. All these could serve as evidence for
the fact that retroflex sounds are considered to be prestigious in Taiwan Mandarin.
Therefore, people hypercorrect their pronunciation by using more retroflex sibilant
tokens.
In early studies, while most attentions were directed to the detretroflexion process,
researchers did notice that some non-retroflex tokens are pronounced as retroflexed one,
especially in reading tasks (e.g., M.-C. Li, 1995; C. C. Lin, 1983). Most researchers
explained this by stating that Taiwan Mandarin speakers have both dental and retroflex
repertoire in their phonological systems, but they simply activate them wrongly during
their productions. Chung (2006), however, held a rather different perspective. Instead of
having wrong activation, Chung regarded retroflexion of dental sounds to be a
hypercorrection process. Because retroflex sibilants have always been prestigious in
Taiwan Mandarin, to obtain authority and mark formality, people hypercorrect their
speech to such an extent that they even mistakenly retroflex dental sibilants. The
hypercorrection phenomenon unravels Taiwan Mandarin speakers’ attitudes towards
retroflex and dental sibilants, which should be facilitating in explaining how they are
realized and contrasted in natural speech.
2.4 Prosodic prominence
Studies on prosodic prominence started early, due to the fact that it serves crucial
linguistic functions. In English, for example, prominence at the word level contrasts
lexical meaning (e.g., INcline vs. inCLINE); at the sentence level, locations of prosodic
prominence enable speakers to convey different meanings or elements of focus (e.g., he
HIT John vs. HE hit John vs. he hit JOHN). To understand what constitutes perceptual
saliency of prosodic prominent elements, Lieberman (1960), as an first attempt,
measured a number of dimensions on stressed syllables, in which he identified three
acoustic correlates, including fundamental frequency, amplitude and duration. While
these three cues should be more or less considered to be closely associated with
suprasegmental features, more recent studies start to pay attention to the relationship
between prosodic structure and fine-grained phonetic details. Specifically, researchers
are interested in how prominence, defined at the suprasegmental level, influences
phonetic features at the segmental level.
One of the early identified cues in the segmental level is vowel quality. In
particular, vowels are articulated with greater gestural efforts in stressed or accented
positions. This effect has been saliently verified both from the articulatory perspective
(e.g., Beckman & Edwards, 1994; de Jong, 1995) and from the acoustic perspective
(e.g., Cho, 2005; van Bergem, 1993). Similarly for consonants, it is discovered that in
prosodically prominent conditions, greater distinction could be observed. For example,
in terms of voicing, voiced and voiceless stops are better contrasted in the accented
condition, which is reflected in a number of acoustic measurements such as VOT as in
English (Cole, Kim, Choi, & Hasegawa-Johnson, 2007), or degree of prevoicing in
Dutch (Cho & McQueen, 2005). Such a prosodic effect on segmental realizations is
commonly referred to as prosodic strengthening, depicting the phenomenon that
linguistic contrasts are maximized or maintained in prosodically stronger conditions.
Since stressed and accented syllables are indeed in prosodically strong positions, it is
conceivable that the strengthening effect could be generally observed for both vocalic
and consonantal segments.
As opposed to prominence, reduction is a stress level that generally refers to a
diminishing process of acoustic cues resulting from articulartory economy in
prosodically non-prominent position. One common phenomenon of reduction is the
assimilation effect. Specifically, in reduced conditions, segments usually become more
similar to their surrounding segments and they are also more likely to lose their original
distinctive phonetic features. van Bergem (1993), for instance, suggested that vowels in
non-stressed, unaccented syllables move towards a position similar to the preceding and
following consonants, instead of merely centralizing. As for consonants, the reduction
process is basically comparable with that of vowels (van Son & Pols, 1999). In the
perceptual aspect, Duez (1995), in a study of voiced stops in French spontaneous speech,
indicated that prosodic prominence had an effect on consonant identification. In
particular, voiced stops occurring in non-prominent syllables are significantly less
successfully recognized than those in prominent syllables.
As for prosodic prominence in Mandarin, Chao (1968) proposed three levels of
stress, including contrasting stress, weak stress, and normal stress. Accordingly,
contrastive stress signifies the condition where speakers intend to contrast certain
elements in the sentence. For instance, in the sentence Bushi Huang xiansheng, shi
WANG xiansheng ‘It’s not Mr. Huang; it’s Mr. Wang.’, it can be seen that the speaker
puts emphasis on the surname Wang. The syllable to be contrasted is thus said to
possess contrastive stress. Contrastive stress is generally realized with a wider pitch
range and longer duration, and usually with increased loudness. Weak stress is
particularly associated with neutral tone syllables by Chao. A great number of
grammatical suffixes in Mandarin (e.g., -de ‘possessive marker’) are of neutral tones.
Moreover, neutral tones also have the function of distinguishing lexical meaning (e.g.,
dong1xi1 ‘east and west’ vs. dong1xi0 ‘thing’). According to Chao, the name “neutral tone” is given because the original tonal range is “flattened to practically zero” (p.44),
and the pitch height of the neutral tone syllable actually depends on the tone of its
previous syllable. As opposed to contrastive stress, neutral tone syllables are relatively
short in duration. Additionally, other identified acoustic features include low intensity,
vowel centralization, and consonant weakening, as mentioned by Chao and in other
researchers (e.g., Shi, 1994). As for normal stress, by Chao’s definition, syllables that
have neither contrastive stress nor weak stress belong to this category.
In addition to the three stratifications of stress, Chao (1968) further stated that
stress in Mandarin is manifested primarily by pitch range enlargement and duration
lengthening, and only secondarily by loudness. Later studies took Chao’s idea and
conducted a number of experiments to testify his observations. For example, in his
acoustic study on sentence stress in Mandarin, Jin (1996) found that pitch and duration
are truly the two most relevant correlates of sentence stress, with pitch ranked even
higher than duration. The systemization of stress levels is found in Pan-Mandarin ToBI,
developed by Peng, et al. (2007). Four levels of stress are identified. These four levels
and the corresponding depictions are shown in Table 2.2.
Table 2.2 Relative levels of stress in Pan-Mandarin ToBI (Peng, et al., 2007).
Stress Description
S0 syllable with lexical neutral tone
S1 syllable that has lost its lexical tonal specification (e.g., in a weakly-stressed position)
S2 syllable with substantial tone reduction (e.g. undershooting of tonal target with duration reduction)
S3 syllables with fully realized lexical tone
As can be seen, the stratification of stress in Pan-Mandarin ToBI is actually similar
to that of Chao’s (1968), except for dividing weak stress into two levels (S0 and S1),
depending on whether the syllable is lexically specified as a neutral tone syllable. In
addition, it is obvious that tonal realizations are taken as the sole criterion for
identifying stress in Pan-Mandarin ToBI. Nonetheless, it should be noted that there are
studies indicating that although pitch is an important cue for stress, it is not a necessary
cue. For instance, Shen (1993) utilized natural speech and modified the acoustic
parameters in order to see whether stress perception is harmed in lack of the F0 cue.
Results of perceptual experiments showed that without F0 information, listeners are still
able to identify stress locations. In this regard, it was concluded by Shen that in
Mandarin, no one cue is indispensable; instead, stress prominence is marked by the
integration of all relevant correlates.
2.5 Word class
word and function word. By definition, content words, also termed open-classed words,
are semantically informative elements, while function words, or close-classed words,
are grammatically required elements. The common assumption is that prominence is
usually with content word, whereas non-prominence is with function word. Nonetheless,
it is still worth noticing that although the relationship between prominence level and
word class is rather clear, this generalization is definitely not foolproof. As stated by
Bolinger (1972), sentence accent is not determined by syntax, but information focus. As
a result, even with syntactic category distinction, accent is still not predictable.
There are studies investigating the effect of word class on speech production and
phonological variation. For example, van Bergem (1993) looked into Dutch vowel
production in experimental settings. He found that word class, interacting with stress, is
very influential in determining how vowels are realized. Specifically, for the same
vowel, a stressed content word condition has more distinctive vowel realizations than an
unstressed content word condition, which in turn has better realizations than function
word condition. In studying /t/ and /d/ deletion in English spontaneous speech,
Raymond et al. (2006) also pinpointed the influence of word class on such a
phenomenon. In particular, for content words, deletion is more likely to occur in longer
words; such an effect, on the contrary, is not found for function words.
While word class generally exerts an effect on speech production, it does not seem
to play a crucial role in speech perception. For instance, Cutler and Foss (1977)
examined how stress and word class affected sentence processing. They found that
given the same stress level, there are no significant differences in terms of subjects’
performance for content words and function words. In the identification test of French
voiced stops, Duez (1995) did not see any effect of word class either. Voiced stops in
content words, surprisingly, are not easier to be recognized than those in function words.
Although the discrepancy between production and perception studies is indeed puzzling,
and it does not seem to be satisfactorily explained yet, it still does not hurt our
prediction that word class could have an effect on the realizations of retroflex and dental
sibilants in Taiwan Mandarin. In this regard, the investigation of word class and its
interaction with stress should be both interesting and worthwhile.
2.6 Summary
In this chapter, past studies on the realizations of retroflex and dental sibilants in
Taiwan Mandarin were discussed, from both acoustic and sociolinguistic perspectives.
In general, a gap can be observed; that is, acoustic studies focus on experimental data,
whereas sociolinguistic studies most frequently investigate spontaneous speech. It is one
of our main goals to fill this gap by acoustically studying the issue on retroflex and
dental sibilants in spontaneous speech.
Previous research relevant to the four factors that are to be examined in this study
was presented as well. For social factors, gender exerts a strong effect on the
realizations of retroflex and dental sibilants, while the effect of region factor is much
less examined and still remains unclear. As for linguistic factors, both factors of
prosodic prominence and word class are active in speech production, but neither of them
has been examined on the sibilant realizations in Taiwan Mandarin. As a result, in this
study, we are going to investigate these four factors all together, and try to uncover
interesting interactions among them.
CHAPTER 3 METHODS
This chapter introduces the methods for conducting the present study. Section 3.1
to Section 3.3 describes participants, data collection, and recording equipment in this
study. Section 3.4 focuses on data processing procedure, in terms of transcription, word
segmentation, and stress labeling. Section 3.5 illustrates the labeling and the acoustic
measurements of retroflex and dental sibilant tokens.
3.1 Participants
This study utilized part of the speech data from the Mandarin-Min bilingual corpus
constructed by Fon (2004). The data of fifteen speakers were selected for analyses in
this study. These fifteen speakers, including both males and females, are all
Mandarin-Min bilinguals from either Taipei City/County or Kaohsuing City/County.
None of them lived or stayed in places other than Taipei or Kaohsiung for over six
months prior to the age of eighteen. They were at the age of 20 to 35 years old at the
time of recording. Each speaker’s age is given in Appendix I. The numbers of speakers
in each group are displayed in detail in Table 3.1.
As for language proficiency, each participant’s Mandarin and Min recordings were
listened to and judged by three additional bilinguals, who were proficient in both
Mandarin and Min. Each judge assigned a score to indicate the language proficiency for
each participant, on a scale ranging from 1 (the least proficient) to 7 (the most
proficient). The average proficiency scores for each speaker’s Mandarin and Min are
provided in Appendix I. Generally speaking, almost all speakers are proficient in
Mandarin, but they do differ in Min proficiency levels. In order to compare Min
proficiency among different speaker groups, each speaker’s Min score was divided by
his/her Mandarin score as a means of normalization. The average Min-to-Mandarin ratio
for each speaker group is shown in Table 3.2.
Table 3.1 The number of subjects in each speaker group.
Region
Gender Taipei Kaohsiung
Male 4 4
Female 3 4
Table 3.2 The mean Min-to-Mandarin ratio for each speaker group.
Region
Gender Taipei Kaohsiung
Male 1.03 0.91 Female 0.79 0.78
3.2 Data collection
In the bilingual corpus of Fon (2004), the form of interview was adopted. Each
speaker had two thirty-minute conversations in Mandarin and Min respectively with one
interviewer. The interviewers themselves are also fluent Mandarin-Min bilinguals, who
used either of the two languages solely to converse with the interviewees during the
recording. The interviewer would ask open questions which were related to speakers’
personal experiences or opinions on several issues. There were preset questions, but
spontaneous questions were asked as well, with the goal to elicit maximum responses
from the speakers. Frequently discussed topics included habits, movies and TV
programs, food, traveling experiences, student or career lives, etc. In this study, only
Mandarin data of the selected fifteen speakers were processed and analyzed. The
recording length and discussed topics for each speaker are summarized in Appendix II.
3.3 Recording equipment
The recording equipment was SONY DAT recorder PCM-M1. Subjects wore a
SHURE SM10A head-mounted microphone during the recording. Each recording was
later digitalized and downsampled with the 22 kHz sampling rate, by using Cool Edit
Pro (Version 2) software.
3.4 Data processing procedure
3.4.1 Text transcription
Each recording was first transcribed in Chinese characters, and then romanized into
hanyupinyin. Syllable labeling was done by using Praat computer software (Boersma &
Weenink, 2008). In each thirty-minute recording, there were about 7,500 syllables. The
total syllable numbers contributed by each speaker are shown in Appendix II.
3.4.2 Word segmentation and word class labeling
The definition of a word in Chinese is not as clear-cut as that in most Western
languages. Due to the influence of Chinese writing system, in which every syllable has
its corresponding character, Chinese people often confuse the notion of word with that
of syllable, considering that every syllable is a word. However, it has been shown that
Modern Chinese consists of a great number of bisyllabic or multisyllabic words.
Therefore, a word may be composed of one syllable, two syllables, or even three or
more syllables. Accordingly, a word should better be defined as “a unit in the spoken
language characterized by syntactic and semantic independence and integrity”. (C. N. Li
& Thompson, 2005, p. 13).
There have been debates over how to identify Chinese word boundaries. For
example, certain grammatical morphemes (e.g., -le ‘perfective aspect suffix’) are hard
to be classified, for some consider them to be separate words, whereas others regard
them as part of the preceding words. Compound words (e.g., zhongwenfenciguifan
‘Chinese segmentation standard’) belong to an ambiguous category, in which they can
be either treated as an independent unit or can be subdivided into several smaller units.
Furthermore, people also have different ideas towards the word boundaries of specific
constructions (e.g., V-not-V) in Mandarin. To solve the word segmentation problem, in
this study, we adopted the segmentation criteria developed by Academia Sinica, Taiwan,
of which their definition of word is applicable with respect to both linguistics and
information processing (C.-R. Huang, Chen, Chen, Wei, & Chan, 1996). For instance,
according to their criteria, grammatical suffixes are regarded as separate morphemes. In
addition, long compound words should be segmented; thus, zhongwenfenciguifan are
subdivided into zhongwen ‘Chinese’ fenci ‘segmentation’ guifan ‘standard’. Finally,
V-not-V structure is segmented (e.g., xihuan bu xihuan ‘like it or not’).
The word segmentation of our corpus data first used the Online Word Segmentation
System developed in the National Digital Archive Program, Taiwan (Chen, 1998). After
the automatic text segmentation by the system, we hand-checked each segmented word
and its corresponding labeled part of speech. The original part of speech coding of the
online system was very specific. For instance, it distinguished different types of verb,
such as transitive verb (e.g., chi ‘eat’), intransitive verb (e.g., zoulu ‘walk’), etc.
However, our ultimate goal was just to classify all words into two major word classes –
content word and function word; therefore, the broad labels such as “noun” or “verb”
would be sufficient. In this regard, the part of speech coding was modified when we
checked the segmentation data. All parts of speech identified in our study, with their
corresponding word class categories, are shown in Table 3.3.
Table 3.3 The parts of speech and the corresponding word class categories3. Word class Part of Speech Example
Adjective zhuyao ‘main’
Adverb qishi ‘actually’
Measure word zhong ‘kind’
Noun zhuozi ‘desk’
Numeral modifier henshao ‘few’
Numeral san ‘three’
Content word
Verb chifan ‘eat’
Aspect marker zhe ‘progressive marker’
Conjunction suoyi ‘so’
DE de ‘nominalizer’
Discourse marker jiushishuo4 ‘well’
Determiner zhe ‘this’
Negation bu ‘not’
Preposition zai ‘at’
Postposition zhilei ‘something like that’
Pronoun wo ‘I’
Function word
SHI shi ‘coverb’
3.4.3 Stress labeling
As noted previously, in Pan-Mandarin ToBI (Peng, et al., 2007), four levels of
prosodic prominence are identified (see Table 2.2), and the criteria are generally based
on tone solely, possibly due to the influence of Chao’s observation that pitch is the
3 There were several categories that did not belong to either content word class or function word class.
These categories included “Filler,” “Foreign word,” and “Truncated word/sound.”
4 The Academia Sinica Corpus is a text-based corpus, and its data source is mainly from written materials.
Therefore, the Online Segmentation System labels jiushishuo as an adverb, approximately equal to ‘that is to say’ in English. However, in spoken Mandarin, jiushishuo has been grammaticalized and became a discourse marker. In this regard, jiushishuo is considered as a discourse marker and thus categorized as

![Figure 1.2 The production of (a) [ ß] and (b) [s] from the Mandarin Phonetics Textbook (NTNU Mandarin phonetics committee, 2003)](https://thumb-ap.123doks.com/thumbv2/9libinfo/9605145.631241/16.892.203.692.141.384/figure-production-mandarin-phonetics-textbook-mandarin-phonetics-committee.webp)




![Figure 4.1 The waveform and the spectrogram of the word jiushi ‘that is,’ where the retroflex sibilant [ ß] is voiceless in (a) and voiced in (b)](https://thumb-ap.123doks.com/thumbv2/9libinfo/9605145.631241/60.892.143.753.130.754/figure-waveform-spectrogram-jiushi-retroflex-sibilant-voiceless-voiced.webp)

