第二章 文獻探討
第一節 資料倉儲
一、資料倉儲的定義
資料倉儲之父 Bill Inmon 在 1990 年首次對資料倉儲做了一個定義:
以主題導向的(subject-orient)、整合的(integrated)、隨時間變異的
(time-variant)及非暫存性的(nonvolatile)的資料蒐集,來支援管理的決策 (W. H. Inmon, 1994)。
資料倉儲系統主要的概念在於輔助查詢、擷取、篩選及整合相關資 訊。相對於傳統資料庫系統,除了內部儲存資料更具歷史性(資料的數量 及時間的涵蓋面增加)之外,其於資料查詢的層面,亦不同於傳統的被動 式查詢(當查詢時才做運算),而強調主動式查詢(當來源資料更動時,隨 即做出反應),因此當執行查詢時並不需要在資料來源處重新計算,而是 直接由資料倉儲中取出資訊(林存德,1999)。
二、資料倉儲的特性
根據定義可知,資料倉儲有下列四個特性:
(一) 整合性
資料倉儲是一個資料倉儲料整併後的集中儲存所,也就是將整個企 業組織分散在各地不同格式的資料,經轉換、合併或彙整進來。雖然轉 換及整併的動作需要耗費一些時間,但是只要整併完成後,資料倉儲就
可以對企業的所有部門,提供具有相同定義和一致表示方式的資料,以 幫助管理者更容易了解及掌控企業的營運,並進而輔助決策的制定(沈肇 基、張慶賀,2001)。
(二) 主題導向性
在一個企業組織裡,通常都會有各種不同性質的交易處理系統(例 如:生產管理系統、銷售管理系統、訂貨管理系統財務會計系統等),這 些系統都是屬於功能或處理導向的(functional or process oriented),它著重 在如何以最短的時間、最精確的方式,去處理一個事先指定好的動作(例 如新增一筆訂單或是列印一份報表等)。而資料倉儲則屬於主題導向的,
它著重在如何以最短的時間、最有彈性的方式,滿足管理者對於資訊的 需求。資料倉儲中的資料可以根據不同的主題或觀點來組合、彙整(沈肇 基、張慶賀,2001)。
(三) 隨時間變化性
交易處理系統所產生的作業性資料(operational data),其性質比較偏 向目前及短期間的歷史資料,而資料倉儲中存放的除了目前及短期間的 歷史資料外,還包含有長期間的歷史資料,通常會包含一個時間元素
(element of time),以利資料倉儲的分析或是不同時間點的比較。當資料 定期地加入到資料倉儲後,原本在資料倉儲中與該資料有時間相依 (time-dependent)關係的所有彙整資料都必須重新再計算,以保持資料的
一致性,因此資料倉儲中的資料是會隨著時間而變化的(沈肇基、張慶賀,
2001)。
(四) 非揮發性
對作業性資料而言,我們可以依需要隨時對它進行新增、刪除或修 改的動作,但在資料倉儲中,資料只能定期地被加進去,之後就不允許 再修改,因為資料倉儲中所儲存的是長期的歷史資料倉儲,所以也不允 許有刪除的動作,就以上的比較而言,資料倉儲的資料環境是比較穩定 的,只會增加資料,而不會減少資料所以可說是非揮發性的(沈肇基、張 慶賀,2001)。
三、資料倉儲的目標
資料倉儲著眼於滿足策略性的目標、支援策略性決策的資訊、支援 價值鏈的整合、強化工作能力、加速查詢反應時間、提昇資料品質、記 錄保留組織的內部知識、組合一系列的系統,並達到下列目標(戴文淵,
1998):
(一) 降低決策制定所耗成本。
(二) 較佳的使用者服務。
(三) 提供較佳的網站資源管理。
(四) 提供網站再造工程操作。
(五) 提供組織扁平化機會。
四、資料倉儲與資料庫的比較
資料倉儲系統連接許多網站運作中的資料庫,但有別於一般資料 庫,資料倉儲與資料庫之差異比較如表 2-1(戴文淵,1998)所示,一般 資料庫係以應用系統為導向進行發展設計,其資料來源固定、以明細為 主、缺乏歷史觀點、容易再更新、須正規化以方便存入、資料結構以關 連式表示;資料倉儲則以主題為導向進行發展設計,資料來源廣泛、有 歷史觀點、不容易再改變、不須正規化以方便資訊輸出、包括有詳細及 衍生性、匯總性、摘要性資料,可用多維度存取分析,資料以星狀結構 表示。
表 2-1 資料倉儲與資料庫比較
資料庫 資料倉儲
以應用系統為導向 以主題為導向
資料來源固定 資料來源廣泛,包含管理上廣泛的主題 資料缺乏歷史觀點 資料有歷史觀點,提供趨勢分析所需 資料容易再更新 資料不容易再改變
資料須正規化,方便資料存入 資料不須正規化,方便資訊輸出
資料以明細為主 有詳細含衍生性、匯總性、摘要性資料 資料量不大 資料量很大,可以分割
以主鍵或索引存取,資料結構 以關連式表示
索引存取及可用多維度存取分析,資料 結構以星狀結構表示
資料倉儲的實際價值在於資訊流動的管理,而非在於收集資料;一 種強調資料倉儲動態的名詞「資料倉儲系統,data warehousing」,其區別 在於位置(place)與活動(activity)或是資料結構與資料流動,倉儲位置就像 是貨物庫存的地方,倉儲活動則是一完整的流動配銷活動。
五、資料倉儲的架構
資料倉儲常用架構有三層式、兩層式及混合漸進式三種(W. H. Inmon, 1997),如下所述:
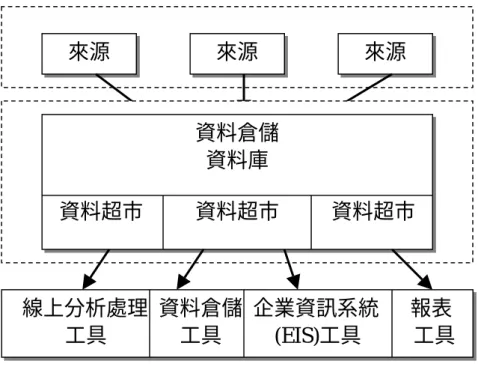
(一) 三層式架構:
理想的資料倉儲系統在設計上多採三層式的架構,如圖 2-1 所示,分 為資料來源、資料倉儲及資料超市(data mart)三層。資料來源端是企業營 運資料的來源處,這些資料可能分散在各個不同的地理區域,或公司的 各個部門。將這些來自不同來源端的資料進行資料前置處理的動作,確 保資料的純化與正確性後,整合匯入資料倉儲系統中。所以資料倉儲系 統可以說是整個企業資料的彙總處,提供一個日後線上分析處理的基礎。
基於企業不同事業單位的個別需要(如生產、業務、行銷等部門),可 將資料倉儲系統的資料再分成若干個資料超市,如此一來,資料倉儲部 分著重於資料的整合,而資料超市的部分則著重於使者分析查詢的需要。
三層式的架構最主要的缺點在於系統建置初期的成本過高,因此三
層式構較不適合小規模的企業,以及一些先期的開發研究。
圖 2-1 三層式資料倉儲架構
(二) 兩層式架構:
與三層式不同的是,兩層式沒有中央的資料倉儲資料庫,如圖 2-2 所示。就成本的角度來說,它是相當有吸引力的解決方案,不但硬體需 求較小,並且架構簡單而容易建置。
由於資料超市的硬體需求較小,企業在初期的投資成本比較低,所 以在企業規模不大或是資料量不大時,比較符合經濟效益。但是最大的 缺點是日後擴充規模的彈性不大,將使企業在系統設計上面臨兩難的局
資料 超市
資料 超市
資料 超市 資料倉儲
資料庫
線上分析處理 資料倉儲 企業資訊系統 報表 工具 工具 (EIS)工具 工具
來源 來源
來源
面,而且,將來新資料超市與既有資料超市的資料整合也是一大問題。
圖 2-2 兩層式資料倉儲架構
(三) 混合漸進式架構:
混合漸進式架構的資料倉儲系統改善了兩層式擴充彈性不大的缺 點,除了保有日後「升級」的彈性之外,更重要的是它的初期成本與兩 層式架構相差不大。換言之,如果企業日後確實有擴大其資料倉儲系統 的可能性,或是為減少開發初期風險的情形下,發展混合漸進式資料倉 儲系統是一個十分適合的解決方案,如圖 2-3 所示,混合漸進式亦採用兩 層式架構,但在第二層架構內不只是資料超市,而是資料倉儲與資料超 市的共存體,以方便日後調整架構的可能性。
資料倉儲 資料庫 來源 來源
來源
線上分析處理 資料倉儲 企業資訊系統 報表 工具 工具 (EIS)工具 工具
圖 2-3 混合漸進式資料倉儲架構 六、建構資料倉儲之注意事項
資料倉儲可活化傳統的資料庫系統作為資訊資源,亦可提供偶發式 的分析功能;資訊應用的最主要目標是將正確的資訊,以最有效的方式 適時的送到需求者手上。因此,在建構的過程中須注意以下幾點(李坤 龍,1997):
(一) 是否已充分了解決策需求,包括目前的資料需求,未來的可能需 求,以及將來所需要的彈性。
(二) 設計一個易於了解的資料架構,此架構必須要和資料來源及查詢 方式相配合。
(三) 資料存入倉儲中,必須確信資料保持清晰狀態。
來源 來源 來源
資料倉儲 資料庫
資料超市 資料超市 資料超市
線上分析處理 資料倉儲 企業資訊系統 報表 工具 工具 (EIS)工具 工具
(四) 撰寫指導說明書,讓使用者充分瞭解可供他們運用的資料有那些。
(五) 建立倉儲架構後,然後一次組合一個主題相關資料群。
七、資料倉儲的分類
資料倉儲系統在使用上,因各單位的狀況不同,在實施上乃有不同 的方式,不同的規模,不過一般可以區分為下列五大類(資通電腦,1996):
(一) 虛擬型
讓使用者在終端機或工作站上直接取用日常作業中的資料庫或檔 案,不過這種方式,通常只允許使用者對當時的企業資訊進行查詢或列 印的功能,而不讓使用者進行較複雜的資料分析。
(二) 部門分散型
針對某一群使用者或某一部門,特別有價值的資料建立成資料倉 儲,這種供群組或部門使用的倉儲,我們通常稱為資料超市,其資料由 日常作業系統中抓取而來,然後會破壞其正常化(normalized)並且計算彙 總,再建成資料超市,這種方式讓決策支援的效率及可用性大大提高;
因為在部門的電腦中就可執行,同時由於部門的範圍較小,所以可以讓 企業組織很快地開始第一個資料倉儲的實施計劃。不過如果資料超市的 數目不斷增加,資料的重複性會很嚴重,而且管理會日趨複雜;另一個 缺點是資料超市的層面及彈性有限,所以難以滿足新的資訊需求。
(三) 分配型
將數個資料超市連接成一個分散型的資料倉儲,這方面的技術及經 驗仍非常粗淺有限,對初使用資料倉儲的單位,並不建議使用。
(四) 集中型(標準型)
這是最常被採用的方式,可以提供較複雜的資料分析及決策支援,
此一方式較易滿足新的資訊需求,也比較容易管理與維護。
(五) 雙層型
結合了集中型的資料倉儲及分散型的資料超市,綜合這兩種類型的 優點,以集中型開始建立資料倉儲應用的單位,在累積了許多經驗之後,
有可能演變為雙層型的方式。
八、資料倉儲的設計與規劃機制
資料倉儲的設計可分為三個不同的過程,分別為載入管理(load manager)、資料倉儲管理(warehouse manager)與查詢管理(query manager) (吳文宗,2000)。
(一) 載入管理
資料倉儲的應用可以去繁為簡,透過一個萃取、轉換、清理、載入 程序,將各個不同格式的資料檔案或資料庫,萃取所選取的資料,轉換 成正確的資訊,清除重複不需要的資料,轉至統一的資料倉儲資料庫,
以後企業內所有非線上異動處理(On-Line Transaction Processing, OLTP)
的需求,均可由此資料庫取得。
(二) 資料倉儲管理
此階段重點在資料模型的設計、資料轉入的頻率、資料更新的規則,
各種加總、彙總表格的處理,資料倉儲使用狀況的監督和管理,以調整 資料倉儲的效能,所有和資料倉儲有關的各種資訊均放在媒介資料檔案 內。
(三) 查詢管理
當資料統一轉至資料倉儲資料庫後,可以用各式的工具(Excel、
Access)來查詢資料,但須在授權的範圍內才允許。一般使用者可以依自 己需求查詢資訊、列印報表、作各種多維度的分析,將依賴資訊人員的 需求減至最低,期能充分發揮使用者操作需求(end user computing)的功 能。
九、資料倉儲的應用
由技術人員的角度來看,我們可以對資料倉儲進行查詢、列印報表,
並利用它來做計畫、分析、預測、模擬、建立模式、發出預警、財務、
會計的整合、比較等。所以它可以用在決策支援系統(DSS)、企業資訊系 統(EIS)、管理報表系統(MRS)及線上分析處理(OLAP)等方面(資通電腦,
1996a)。
由使用者的角度來看,資料倉儲可以用在利潤規劃與管理、預算編
列與管理、銷售/行銷績效分析、投資組合規劃、產品需求、製造組合及 財務整合等,這些都是過去的電子資料處理(Electronic Data Processing,
EDP)管理資訊系統(Management Information System, MIS)無法徹底做到 的地方(資通電腦,1996a)。
整體來說,資料倉儲的應用相當廣泛,因為它是所有應用的基礎,
以下以四種應用來進行說明,如圖 2-4 所示:
圖 2-4 資料倉儲的應用(資通電腦, 1996a)
(一) 動態報表查詢、隨機查詢
以強大的搜尋引擎,加上人性化的圖形介面,使用者不需要對資料 庫有詳盡的了解,即可自行取得所需的明細資料,或是透過容易理解的 介面,系統自動引導使用者產生報表數據所需的程式,並可透過資料庫 原生驅動程式(native API)或開放式資料庫連接介面(ODBC),連接企業資 料倉儲資料庫或企業資源規劃(Enterprise Resource Planning, ERP)資料 庫,做大量資料的查詢。使用者利用這種工具就可再被授權的範圍內,
報表 線上分析
處理 資料挖掘 預測
資料倉儲
分析 資料管理
查詢相關的資料。
(二) 線上分析處理
將資料倉儲的資料加以篩選、分類、彙總,產生極小的實體資料,
建構成多維立方體資料模型(Multi-Dimensional Data Cube, MDC),讓使用 者可以不同的主題和角度依其專業的直覺,即可操作並分析經營資訊,
找出改善的重點,釐清事件的真相。各種管理角度的交叉分析、資料排 名、預算及實際值的比較、例外管理等,均可在瞬間完成。使用者有需 求時,只須利用工具就能找到資料,排隊等待資訊人員寫程式的盛況將 不再出現。
(三) 資料挖掘
企業的歷史資料通常都以百萬筆或千萬筆計,要分析起來相當困 難,加上專業經理人可能加入的主觀因素,將會導致分析的偏差,而錯 失企業銳變的契機。因此利用資料挖掘工具,從龐雜的資訊中抽取有用 的知識,以期公正客觀的統計分析模式,快速且正確地探知企業的經營 資訊,找出正確的銷售模式、客戶關係、採購模式,進而增加企業利潤、
減少支出,正確地掌握經營動態。如資料挖掘的深度和廣度能持續延伸 下去,未來資料挖掘的應用必是企業競爭的利器。
(四) 動態預測(forecasting)
擷取現有經營資訊,假設未來市場狀態或企業目標,系統即可自動
模擬出以時間序列為橫軸的變化曲線,使用者還可調整各項資源,模擬 出達成企業目標的最佳資源規劃組合。
第二節 資料挖掘
一、資料挖掘的意義
(一) 資料挖掘的起源
從 1980 年代開始,所有大企業都建立其客戶、競爭者及其產品的資 料庫。這些資料形成一個具有潛力的「金礦」,包含大量的資料及許多隱 藏且不容易挖掘的資訊。利用資料挖掘演算法可以找出資料中具有規則 性的特點,並把焦點集中在最重要的部份。再加上網路使用持續的成長,
與資料庫之連結越來越容易,也加速了資料挖掘技術的成長。現在不論 是市場專家或是政策決定者都想從這項新技術中取得競爭優勢(樓玉 玲,1998)。
(二) 資料挖掘的定義
根據 Frawley, Piatetsky-Shapiro 及 Matheus (1991)對資料挖掘的 定義是在資料庫中挖掘出非顯然的、前所未知的及潛在的可能有用資訊 之過程。Berry 及 Linoff (1997)對資料挖掘的定義則是利用自動或半自 動的方式對大量資料做分析,以發現出有意義的關係或法則。
Fayyad(1996)認為資料庫知識發現流程(Knowledge Discovery in
Database process, KDD process)是說明在資料庫中取得知識的過程,因此 對於不確定、不完整及有干擾性的資料要預先處理,而資料挖掘只是資 料庫知識發現流程中的一步驟。
(三) 資料庫知識發現流程
資料庫知識發現的流程,包含下列幾個步驟(Fayyad,1996):
1.建立目標資料集:應用相關的先前知識,選擇出目標的相關資 料。
2.資料淨化與先前處理:過濾資料雜質、處理缺漏資料、定義資 料型態與綱要等。
3.資料轉換:資料範圍縮小與資料投射,包含對於目標及任務找 出有用的代表資料,並利用多維度法或資料轉換法來減少變 數或找出不變的資料代表。
4.選擇模型與方法來作資料挖掘:找出資料關連性。
5.資料挖掘:根據問題的種類來進行資料挖掘。
6.結果說明:對結果解釋與評估,以及決定結果呈現方式。
二、資料挖掘的方式
(一) 資料挖掘的方法
資料挖掘是利用資料來建立一些模擬真實世界的模型(model),利用 這些模型來描述資料中的型樣(pattern)以及關係(relation)。這些模型可讓
決策者從對資料型樣與關係的了解得到決策時所需之資訊,而從資料的 型樣分析中則可進行預測。
在建立模型的過程中,資料挖掘使用了許多既有之統計分析與塑模 (modeling)的方法,如預測模型(迴歸、時間數列)、資料庫分割(database segmentation)、連接分析(link analysis)、偏差偵測(deviation detection)
等等。一般而言,資料挖掘的方法如下(M. J. A. Berry & G. Linoff, 1997):
1.分類(classification):依據分析對象的屬性加以分類,並建立 類組。例如,將信用申請者的風險屬性,區分為高度風險申 請者、中度風險申請者及低度風險申請者。在分類所使用的 技巧有決策樹(decision tree),記憶基礎推理(memory based reasoning)等。
2.推估(estimation):經由既有連續性數值之相關屬性資料,以獲 致某一屬性未知之值。例如按照信用卡申請者之教育程度與 行為,推斷其信用卡的消費量。這種推估方式通常利用統計 方法上之相關分析、迴歸分析及類神經網路方法來進行。
3.預測(prediction):根據對象屬性之過去觀察值來預測該屬性未 來值。例如由顧客過去刷卡消費量來預測其未來之刷卡消費 量。預測所使用的技巧包括迴歸分析、時間數列分析及類神
經網路方法。
4.關聯分組(affinity grouping):考量範圍包括所有物件,以決定 那些相關物件應該聚集在一起。例如超市中相關之盥洗用品
(牙刷、牙膏、牙線),放在同一展示區。關聯分組在客戶行 銷中,可用來確認交叉銷售(cross selling)的機會,以設計 出吸引人的產品群組。
5.同質分組(clustering):將異質母體進一步區隔為較具同質性之 群組。同質分組相當於行銷術語中的區隔化(segmentation)。
其所使用的技巧包括 k-means 法及 agglomeration 法。
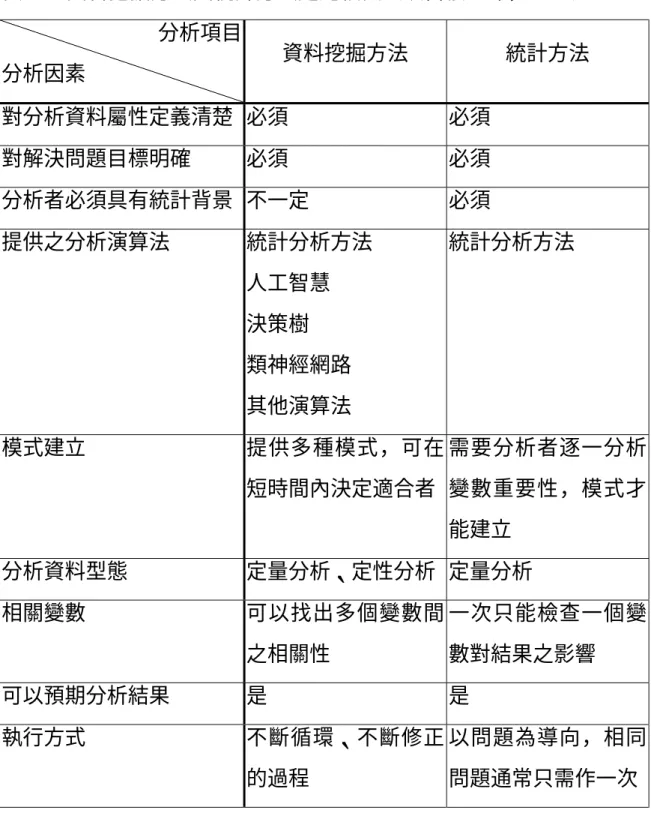
(二) 資料挖掘方法與統計方法之比較
資料挖掘方式與傳統統計方法間雖具有相關性,但兩者並不相同,
其比較如表 2-2。
表 2-2 資料挖掘方法與統計方法之比較表(改自樓玉玲,1998)
分析項目
分析因素 資料挖掘方法 統計方法
對分析資料屬性定義清楚 必須 必須 對解決問題目標明確 必須 必須 分析者必須具有統計背景 不一定 必須 提供之分析演算法 統計分析方法
人工智慧 決策樹 類神經網路 其他演算法
統計分析方法
模式建立 提供多種模式,可在 短時間內決定適合者
需要分析者逐一分析 變數重要性,模式才 能建立
分析資料型態 定量分析、定性分析 定量分析 相關變數 可以找出多個變數間
之相關性
一次只能檢查一個變 數對結果之影響
可以預期分析結果 是 是
執行方式 不斷循環、不斷修正 的過程
以問題為導向,相同 問題通常只需作一次
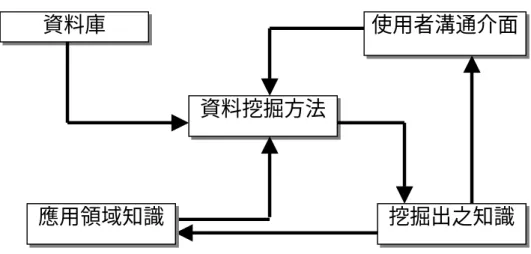
三、資料挖掘的架構
資料挖掘的架構分為下列五大項,使用者介面、資料庫、應用領域 知識、挖掘出知識的處理及資料挖掘方法,如圖 2-5 所示。
圖 2-5 資料挖掘架構(Frawley, Piatetsky-Shapiro, and Matheus, 1991)
有關圖 2-5 資料挖掘的五大項目敘述如下:
(一) 使用者溝通界面:使用者通常不知道資料庫設計方式及不具有使 用程式語言的能力,因此無法了解自己能從資料庫中得到何種資 訊。所以使用者的溝通模式與使用者可能遭遇的問題,值得我們 考量。
(二) 資料庫:分為兩類,一為資料庫的設計與管理問題,原始資料是 否正確與資料過時的處理;二為資料庫種類不同所造成資料型態 在資料挖掘的困難(樓玉玲,1998)。
(三) 應用領域知識:在資料挖掘過程中,加入許多領域知識較能挖掘 出更具意義的結果。並輔助資料挖掘之進行、判斷及解讀。
(四) 挖掘出的知識表達及後續處理:如何使挖掘出的知識,明確的表 達讓使用者最容易,並使用所挖掘出來的資訊。
資料庫 使用者溝通介面
資料挖掘方法
應用領域知識 挖掘出之知識
(五) 資料挖掘方法:依處理方式不同,可分為類神經網路、統計及數 學模式及歸納學習等,其各具優缺點。
四、資料挖掘與資料倉儲的關係
資料倉儲本身是一個龐大的資料庫,由企業或組織既有之作業資料 料庫中整合收錄而來的資料,資料經由整合才置放於資料倉儲中,企業 或組織的決策者則利用這些資料作決策。因此,將資料由作業資料庫轉 換及整合至資料倉儲的過程,是建立一個資料倉儲的最核心,故將作業 中的資料轉換成有用的策略性資訊是整個資料倉儲的重點。
資料倉儲所具備的資料皆為整合性資料(integrated data)、詳細和彙總 性資料(detailed and summarized data)、歷史性資料、媒介資料(metadata),
為建立如此有價值的資料倉儲集合,則需資料挖掘的技術來成功地探測 資料的世界,以挖掘出對決策有用的資料與知識,這也是建立資料倉儲 與使用資料挖掘的最主要目標。
此外,資料倉儲與資料挖掘的結合,也可發生在資料倉儲建立完成 之後,再讓資料挖掘技術有效率地進行。因此,資料挖掘亦可謂是從巨 大資料倉儲中找出有用資訊之一種過程與技術。
五、資料庫相關議題
資料挖掘是在資料庫中挖掘出隱含的、前所未知的及可能有用的資 訊。所以資料挖掘與資料庫議題有密切關係,且建立在資料庫領域的發
展上。因此,資料庫種類、設計方式與管理得當與否,會影響資料挖掘 出來的品質。
資料庫相關議題分為兩類,一為資料庫設計與管理問題,二為不同 資料庫型態與資料種類問題,茲敘述如下(楊亨利、林幸怡,1998):
(一) 資料庫設計與管理問題
在資料庫設計與管理問題中,除了資料庫本身設計問題之外,還包 括雜訊(noise)處理、不完整資料(incomplete)與資料有效性問題。處 理這些問題就是要避免造成垃圾進、垃圾出(garbage in, garbage out)的 原因並加以處理。
如果在正確度不高的資料中進行挖掘,其挖掘出的資訊品質必定不 良。而在真實世界因為有些原因,造成無法像實驗設計中的資料一樣完 整與正確,例如:在收集時未能獲取完整資料,或之後的維護與更新工 作未能確實,造成當資料進行挖掘時存有誤差,所以資料庫設計與管理 工作,對資料挖掘有很大的影響。
1.資料庫設計不良
資料庫技巧發展至今已趨成熟,其中關聯式資料庫使用最為普遍,
但依然無法確保資料庫的品質。在我們使用資料庫時,仍然可發現資料 重覆儲存所產生的一致性問題,或未將不相關資料分開儲存,使得在資 料挖掘時受到與主題無關的資料干擾,而造成資料挖掘出來的結果沒有
意義。這是因為資料庫設計不良所致,造成資料挖掘的困難,目前研究 中仍然無法以其他方法改善。
2.雜訊處理
所謂雜訊(noise)乃指資料庫中不正確或不確定資料,這是由於資 料收集中所發生的疏失,或因資料輸入時的人為過失造成。因為資料挖 掘目的就是要在資料庫中找出一些現象與規則,若連資料的正確性都有 問題,可想而知的,挖掘出來的結果必定不足採信,因此雜訊對資料挖 掘的影響非常大。
而雜訊與正確的少量資料(spare data)在判斷上十分不易,並非資 料出現次數少就代表不正確。目前研究中都以統計方法處理,將資料出 現的正確頻率正確表現出來,讓使用者了解資料分布情形,或者利用統 計檢定公式,將未落入信賴區間的資料以雜訊處理。
3.不完整資料
所謂資料不足是指資料應輸入而未輸入,造成資料輸入不完整而有
null 值產生。由於因應需求不同,各資料屬性值的重要性亦有所不同,若 在關鍵屬性上缺乏足夠的資料數目,將無法進行資料挖掘。目前解決方 法有三種,若是影響不大的資料值,可利用預設值(default value)填補。
當此資料非常重要,足以影響整個決策過程時,可與使用者利用交談方 式,由使用者自行決定該數值。此外,亦可設定 unknown 值(W. J. Frawley,
1991)。
因資料庫中的資料為累積的歷史性資料,當在發生的時間點,如果 無法將資料正確的輸入,其後資料的追蹤處理將非常困難。若因為處理 資料挖掘而將資料事後輸入設定值,或由使用者自行決定數值,將導致 不可預期的結果出現,而無法將事實表達出來,對資料挖掘而言毫無意 義。因此,若資料庫中的關鍵屬性空白資料數量過多時,應考慮放棄這 次的資料挖掘,或當空白資料出現於非關鍵屬性時,應將此屬性排除於 考量範圍之外,以維持資料的可信度。
此外,對於 unknown 資料的處理,其所隱含的意義可能依不同的應 用領域而有所改變,unknown 值的意義可能表示實際不知道,或是可能 資料未登錄。
4.資料時效性
所謂資料時效性是指資料庫中資料隨時間變遷時,未加以更新,造 成資料內容過時的情形。當資料庫記錄為某時間點的狀態資料,必須部 份資料隨時間做資料更新,若資料庫管理未能做好維護工作,則挖掘出 來的資料將是過時資料,為不正確之資訊。雖然資料庫中的部份屬性是 永不改變的,如性別、生日及身分證字號等,但對資料挖掘而言,較富 意義的資料值往往是會隨時間變化而更新其內容的資料(W. J. Frawley, 1991)。因此,資料挖掘必須考慮所挖掘的資料時效性。
(二) 不同資料庫型態與資料種類問題 1.不同資料種類問題
資料可分為定量(quantitative)與定性(qualitative)資料,定量資 料是指有關數值資料,如應用於科學實驗所得之資料或衛星資料判讀,
而其依特性又可分為連續性與非連續性資料。定性資料為一般企業界所 使用之文字資料,但當然亦會有部份是定量資料,如年齡及薪資等。
若為純定量資料,則較容易處理,因為純粹是數學或統計問題。為 了歸類需要,於連續資料處理上,通常利用統計方法,將資料依全距、
平均值及標準差等切割出資料範圍。
對於定性資料處理,需加入人工智慧中的學習機制,才能於其中歸 納整理出有系統、有意義的資料。目前的研究中,是和先前定義好的模 式(pattern)相互比較,若兩者相符,再根據既定的規則往下走。另一種 定性資料的處理,則以抽象化的模式處理,每一個定性的屬性,其值依 專家意見分門別類,分別歸屬於更高一層抽象層次定義之中(W. J.
Frawley, 1991)。
2.不同資料庫型態問題
資料庫的發展技術由階層式資料庫(hierarchical database)、網路式 資料庫(network database)到目前廣為大家所使用的關聯式資料庫
(relational database),其發展已非常成熟。現在簡化並改善關聯式資料
庫的缺點,而有所謂的物件導向資料庫(object-oriented database)、為了 處理多媒體資料而發展的多媒體資料庫(multi-media database)、為了處 理時間而發展出來的時間性資料庫(temporal database)等。資料挖掘其 目的是希望在資料庫中挖掘出有用的資訊,因此要隨資料庫種類來發展 出適合該資料庫的資料挖掘方法論。
第三節 線上分析處理
一、線上分析處理的意義
線上分析處理就是一種快速擷取多維資訊和了解企業整體概況的工 具,不但不需要設定特定角度和觀點,而且不需要設定資料層級就可以 最快速的方法瀏覽並分析資料。線上分析處理可滿足企業上對大量的多 維度資訊做分析比較或預測模擬之需求,令企業組織可經由線上分析處 理以洞察營運狀況或藉以協助決策分析。
二、多維度資訊的意義(多度空間的資料分析)
多維度的概念令人聯想起愛因斯坦,讓我們想起他所提出的曲線空 間-時間、平行宇宙與數學公式積分等看法。更令人感到興奮的是,
Microsoft SOL Server 2000 的分析服務被認為可以使用快速、彈性且簡便 的方式,分析大量的資料。
針對任一事物所能觀察的角度應是多元的,因此資料應皆具備多度
空間的性質。要對資訊進行通透且全面的分析與處理,即需要兼顧資料 於各個角度各個空間中所呈現象微的價值,利用線上分析處理即能達到 面面俱到的要求。
三、線上分析處理的分析方式
線上分析處理於資料分析的過程中,包括下列的分析方式:
(一) 下探(drill-down)
線上分析處理除了從多維角度瀏覽資料外,亦注重細部資料中所隱含 資訊的發掘。使用者於資料分析的過程中,必先瀏覽概括性的資料,並 且對整體的情況有大致的瞭解後,即對細部的資料愈加地重視。因此,
為了能取得更為詳盡的資訊,線上分析處理針對此概括性資料發揮下探 的能力。例如,從整個公司的銷售開始,使用者可以下探分區域的銷售、
再區分業務辦公室、再區分出個別的業務員之銷售成績(見圖 2-6)(莊瑞 杰,1997)。
產品 第一季 玩具 $1.9 服飾 $2.3 電子 $5.2 化妝品 $1.1
圖 2-6 下探
點選其中一類可查看更深入的資料 銷售業績(千萬元)
電子產品 第一季 第二季 第三季 VCR $1.4
錄影機 $0.6 電視機 $2.0 CD 唱盤 $1.2
(二) 上捲(roll-up)
根據維度層級的關係,縮小成摘要性資料。例如圖二下方為某工廠 一~三月產品生產量,甲工廠與乙工廠生產量互有高低,若欲尋找每季各 工廠生產量的趨勢情形,可經由上捲功能查詢第一季至第四季的生產量 摘要(如圖 2-7),便可發現長期以來,乙工廠生產量明顯高於甲工廠。
單位(千個) 第一季 第二季 第三季 第四季
甲工廠 78 45 34 56
乙工廠 90 67 87 91
單位(千個) 一月 二月 三月
甲工廠 30 26 22
乙工廠 28 30 32
圖 2-7 上捲
(三) 切片及切丁(slicing and dicing)
在線上分析處理系統中是以多維度資料的瀏覽來擷取資料,而多維 度的概念可由立方體的模型來比擬。在資料的分析上,同樣的資料對不 同的使用者來說,會因其所持的觀點不同而代表不同的意義。從不同的 觀點來分析資料可比擬為不斷地切割立方體方式來呈現,所以稱為切片 及切丁(S. Chaudhuri and U. Dayal, 1997)。
(四) 轉軸(pivot)
若以報表為例,報表是一個二維度的資料空間,而轉軸則是使用者 觀看報表的角度從橫的基準移到縱的基準。例如可以將報表中月份的軸 移到直的方向上(由上到下排列),同時將產品維度移到橫的方向上(由左 向右排列),然後還可以將同一產品別再按業務部門區分,或反過來先以 業務部門別之後再按產品區分(圖 2-8) (S. Chaudhuri and U. Dayal, 1997)。
銷售業績(千萬元) 第一季 產品
業務部門 1 業務部門 2
電子產品 $5.2 $8.9 玩具 $1.9 $0.75 服飾 $2.3 $4.6 業務部門 1
化妝品 $1.1 $1.5
電子產品 $8.9
玩具 $0.75
服飾 $4.6
業務部門 2
化妝品 $1.5
圖 2-8 轉軸
一個成功的線上分析處理系統必須具有高度的彈性,能夠隨時面對 使用者新的需求。然而,要發揮線上分析處理的功效,仍是得依賴其所 支援的資料庫,而且具備龐大的資料量與好的資料品質,才能分析出高
價值的實用資訊,因此線上分析處理與資料倉儲的聯結是最佳組合。另 外,資料倉儲配合線上分析處理系統,從各種不同角度所分析的結果顯 示出相關資料的差異性,如此一來,使用者可以比較並評量不同的策略,
以及決策後會造成什麼樣的結果,達到更多元及宏觀的資訊分析需求。
四、立方體(cube)的意義
立方體是線上分析處理資料庫的主要物件,使用者必須依實際需求 來建立自己的立方體,例如:與銷售有關的立方體和與庫存有關的立方 體等。立方體包含以下元件(方盈,2001)
(一) 資料來源(data source):
用來定義立方體的資料來源並且連接資料來源的資料庫。例如:可 透過 ODBC 介面定義立方體的資料來源為 Oracle 資料庫上的資料。
(二) 維度(dimension):
維度將立方體內的資料映射成不同層次的資料表示方式,而維度不 外分為人、事、時、地、物等。例如:將銷售資料按時間區分的話就可 區分為日、月、季、年等層次;若按顧客的年齡來分析的話則可依每十 歲一個階層來加以分析。
(三) 量值(measure):
量值一般是立方體資料內的數值欄位(亦可為非數值欄位),也是在整 個分析過程中使用者最感興趣的項目。例如:銷售金額、產品價格、庫
存量等。
(四) 分割(partition):
立方體可以實際需求將它儲存在不同的分割下,例如:將每年的銷 售資料分別儲存在不同的分割下。將立方體的資料分成 partition 的最大 好處是為了查詢效能的考量,因為可以將不同的分割存放在不同的硬碟 上,這樣便能增加查詢的速度。
(五) 角色(role):
角色是用來管理使用者存取立方體內資料的權限控制,分析服務是 以 NT 伺服器的使用者和使用群組帳號來建立立方體的角色,因此並不 需要在分析服務外再另建管理使用者帳號。
五、線上分析處理的資料儲存模式
線上分析處理服務提供了多維式(Multi-dimensional OLAP,
MOLAP)、關聯式(Relational OLAP, ROLAP)及混合式(Hybrid OLAP, HOLAP)三種儲存模式,此三種模式分別有其優缺點,其間的差別在於佔 用的儲存體和查詢效能間的抉擇,詳細說明如下(方盈,2001),三者之優 缺點比較請參考表 2-3(林裕仁,1999):
(一) 多維式線上分析處理:
立方體的內部資料和彙總資料皆擺放在線上分析處理的資料庫內,
以多維度的資料架構(multi-dimensional structure)來儲存。這樣的結果雖然
需要耗費大量的儲存容量,但是卻可以提昇查詢的效率。
(二) 關聯式線上分析處理:
立方體的內部資料和彙總資料皆擺放在原有的關聯資料庫管理系統
(RDBMS)上。此種架構可以使用既有的硬體設備和軟體工具來建立自己 的線上分析處理系統,其好處是可以降低成本,不過在資料查詢的效能 上會打些折扣。
(三) 混合式線上分析處理:
立方體的內部資料在原有的關聯資料庫管理系統上,但彙總資料則 以多維度架構的方式儲存在線上分析處理資料庫上。此種架構的好處是 資料不必重複地儲存在線上分析處理資料庫和關聯資料庫管理系統上,
但查詢效能上會比多維式線上分析處理差一點。
表 2-3 MOLAP、ROLAP、HOLAP 之優缺點比較(改自林裕仁,1999)
優點 缺點
多維式 (MOLAP)
查詢速度極快。
硬體設備要求較低。
簡單、好用,使用者不需有資 訊技術背景亦會使用。
分析、評比、數學功能強。
易於維護。
資料建構(load)速度慢。
由於建檔速度慢一般的多維 式資料庫不能太大。
架構缺乏彈性,如果需變更設 計,必須重新建置資料庫。
對資料比較挑剔,不是每種資 料都適用於多維式線上分析 處理。
資料重複性高、專屬性技術與 開放性較差。
關聯式 (ROLAP)
彈性較佳,變更設計較易,可 支援中大型資料倉儲需求。
適應性良好,對資料較不挑剔 建檔速度較快。
開放式技術,開發人才與工具 較好找。
查詢速度一般較多維式線上 分析處理慢。
SQL 查詢是對非資訊背景的 人員一項挑戰。
SQL 有些先天限制,難以執行 許多複雜的查詢。
對硬體設備要求比較高。
混合式 (HOLAP)
查詢速度介於多維式與關聯 式線上分析處理兩者之間。
建檔速度極快,擴展性佳,可 支援大型資料庫。
資料模組設計彈性佳,適用元 件實體模型(ER Model)。
微觀查詢速度極慢。
SQL 有些先天限制,難以執行 許多複雜的查詢。
六、微軟的分析服務軟體(Microsoft Analysis Services)
在 SQL Server 7.0 時稱為線上分析處理服務(OLAP Services)的資料 倉儲系統,在 SOL Server 2000 將其更名為分析服務(Analysis Services),
基本上都是資料倉儲的觀念與應用,其伺服器端架構如圖 2-9 所示。分析 服務將資料倉儲內的資料處理後,轉換成為一多維架構的儲存方式,這 種架構可提供使用者快速且複雜的查詢。例如:當提出以下的查詢問題 時:
「2000 年電腦類的書籍在台北地區的銷售金額為多少?」
此為一多維架構的查詢。以線上分析處理的術語來看,年、產品類 別、地區稱為維度,銷售金額則為量值,如果將(年、產品類別、地區) 當做一個座標,則該座標所對應的量度值就是答案。
使用者透過分析管理員(Analysis Manager)來管理整個線上分析處理 資料庫。另外,如果覺得分析管理員的功能無法滿足需求的話,亦可透 過系統所提供的程式設計介面,建立自己的管理介面來管理以及控制分 析服務伺服器。
圖 2-9 微軟的分析服務伺服器端架構 關聯資料庫
(RDBMS)
立方體
決策支援物件 分析管理員 線上分析處理
管理機制 客製化應用程式
分析服務 伺服器
轉軸表 (Pivot Table)
用戶端 客製化應用程式 媒介資料
(Metadata)
HOLAP
ROLAP
ROLAP MOLAP 微軟管理控制台
(Microsoft Management Console, MMC)