跨國金融危機擴散效果之分析-以Copula模型為分析方法 - 政大學術集成
47
0
0
全文
(2) 謝辭. 漫長的碩士生活,對我我言,這是人生到現在最具挑戰性的三年,期間還做出了 先休學去當兵的決定。非常感謝毛老師一直以來對我的照顧,當初告知老師我決 定在碩士班一年級念完後就毅然決然踏入軍旅生涯,老師亦是相當的支持我,並 期許我重新回到學校完成學業的日子。退伍後,緊接著立即重新踏入校園生活, 一時之間,陌生的環境讓我非常的無所適從,覺得以前所學的一切似乎都遺忘殆 盡,幾乎喪失了所有的自信心,所幸的是,在老師的鼓勵、家人的支持以及朋友 的陪伴讓我逐步克服了重回校園後的種種挑戰。 感謝口試委員李沃牆老師及徐士勛老師不辭辛勞的來參加我的口試,老師們的指 導讓我能重新檢視自己論文不足的地方並在我解釋不夠清楚地的部分給予我相. 政 治 大. 當多且非常有幫助的建議。 感謝我的妹妹旭芹在我寫論文遇到不順利的時候,用妳的耐心鼓勵我並幫助我重 新找回奮鬥的自信心,感謝我最好的朋友承中一家人,我一個人來到這個陌生的 城市,所幸有你的陪伴以及你的家人給我的溫暖,讓我能撐過這一切。 最後,我尤其想感謝我的母親,雖然父親早逝,但您所給予我的愛一點也不比一 般家庭少,感謝您不斷支持我努力向學,在我不愛念書的青少年時期,您並沒有. 立. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 放棄我,只是不斷地以鼓勵的方式來表達您對我的關心,並盡您所能地給我最好 的學習環境,真的非常感謝您。. Ch. engchi. i Un. v. 民國一百零一年八月 莊旭明. ii.
(3) 目錄 中文摘要 ...................................................................................................................... 1 英文摘要 ...................................................................................................................... 2 第一章. 緒論 ............................................................................................................... 3. 第一節. 研究動機與目的 ........................................................................................ 3. 第二節. 研究範圍與資料來源 ................................................................................ 5. 第三節. 研究流程論文架構 .................................................................................... 6. 第二章. 文獻回顧 ....................................................................................................... 7. 第一節. Contagion ................................................................................................ 7. 第二節. Copula ..................................................................................................... 8. 立. 研究方法 ....................................................................................................... 9. 學. ‧ 國. 第三章. 政 治 大. Contagion 之測度檢定 ............................................................................. 9. 第二節. Copula 方法及其定理之介紹 ................................................................ 10. 第三節. 經驗累積分配函數(Empirical CDF) ..................................................... 12. 第四節. 實證模型建構 ......................................................................................... 13. sit. y. Nat. n. al. er. 實證結果與分析 ......................................................................................... 15. io. 第四章. ‧. 第一節. i Un. v. 第一節. 基本相關分析 .......................................................................................... 15. 第二節. Contagion 檢定結果 ............................................................................... 20. 第三節. Copula 模型選擇 .................................................................................... 24. 第五章. Ch. engchi. 結論 ............................................................................................................. 26. Appendix ..................................................................................................................... 27 A. Introduction of Copulas .................................................................................... 27 B. Syntax ................................................................................................................. 28 Reference .................................................................................................................. 41. iii.
(4) 圖目次 圖 4.1 不同國家報酬率的分散程度 ........................................................................ 16 圖 4.2 不同國家的資料散佈圖 ................................................................................ 18. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. iv. i Un. v.
(5) 表目次 表 3.1 不同分配下的 copula ................................................................................... 12 表 4.1 不同國家報酬率的各階動差 ....................................................................... 15 表 4.2 不同國家間的靜態相關係數分析 ............................................................... 15 表 4.3 金融風暴前後各個國家的平均報酬率與標準差(每日報酬率) ................. 17 表 4.4 檢定美國對其他國家是否產生蔓延效果 .................................................. 20 表 4.5 檢定全球金融危機時期美國對其他國家是否產生蔓延效果(一) .............. 20 表 4.6 檢定全球金融危機時期美國對其他國家是否產生蔓延效果(二) .............. 21 表 4.7 檢定全球金融危機後復甦期間美國對其他國家是否產生蔓延效果 ......... 21. 政 治 大. 表 4.8 檢定全球金融危機時期新加坡對其他國家是否產生蔓延效果 ................ 22. 立. 表 4.9 檢定全球金融危機時期台灣對其他國家是否產生蔓延效果 .................... 22. ‧ 國. 學. 表 4.10 檢定全球金融危機時期日本對其他國家是否產生蔓延效果 .................. 23 表 4.11 檢定全球金融危機時期泰國對其他國家是否產生蔓延效果 .................. 23. ‧. 表 4.12 兩兩國家間不同 copula 模型的配適程度 ................................................. 24. n. er. io. sit. y. Nat. al. Ch. engchi. v. i Un. v.
(6) 中文摘要. 本篇論文主要是想探討在 2008 年全球金融危機發生後,美國與亞洲國家股票市 場之間的相關性是否發生明顯的改變。藉由 2005 年至 2012 年美國、新加坡、台 灣、日本和泰國的股票市場資料,來觀察各國股票市場的相關性是否產生不對稱 的現象,首先檢定美國對其他四個國家有無產生蔓延效果,並藉由不同期間的資 料來檢定蔓延效果以看出各國之間是否在極端的情況下產生尾端相關性,最後, 再使用不同的關聯結構函數配適出最適合資料的模型。. 立. 政 治 大. 關鍵字:金融危機、關聯結構函數、蔓延效果、尾端相關性. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 1. i Un. v.
(7) Abstract. The main idea of this paper is to show whether or not that stock market between U.S and Asian country has been obviously changed after 2008 financial crisis. For the sake of observing if there is or not occurred inconsistence phenomenon in each country’s stock market, we use the information from U.S、Singapore、Taiwan、Japan and Thailand since 2005 to 2012. First, look in that if U.S has contagion affects to other four countries and, checkup the contagion effects through the information from. 政 治 大 model which is the most suitable for the information by using different Copula 立. different period to find the tail dependence in extreme situation. Finally, to dispose a. ‧. ‧ 國. 學. functions.. Key Word: financial crisis、copula、contagion effect、tail dependence. n. er. io. sit. y. Nat. al. Ch. engchi. 2. i Un. v.
(8) 第一章. 緒論. 第一節 研究動機與目的 一、研究動機 過去許多的實證文獻認為,透過持有各國股票資產組合是實務上分散風險的 主要策略之一;然而各國股市的相關性,隨著全球金融市場自由化與資訊的快速 流通,各國股票市場連結性越趨升高,使得國際投資組合的效益大幅降低,因此, 股票市場間的相關性對國際資產組合配置選擇的影響有多大,便成為一新的重要. 政 治 大. 實證議題。在近一二十年全球化對全世界各地經濟的影響已經是越趨明顯。時至. 立. 今日,世界各地的資金可以互通往來,管道也相當的多,使得每個國家很容易同. ‧ 國. 學. 時都擁有相當多個不同國家的資產,一旦其中一個國家發生重大金融危機,也就 很容易將此危機蔓延到其他國家。. ‧. 如次貸危機發生於 2007 年 4 月,以美國第二大次級房貸公司新世紀金融公. y. Nat. io. sit. 司破產事件為標誌,由房地產市場的泡沫化蔓延到信貸市場,進而演變為全球性. n. al. er. 金融危機。它暴露了金融業監管與全球金融體系根深蒂固的弱點。近年來許多美. Ch. i Un. v. 國抵押貸款發放是針對次級貸款(簡稱次貸)的借款人;而依照次級貸款的定義,. engchi. 這些所謂的借款人皆依照綜合標準評量過,其能力可能不足以償清貸款。當美國 房價在 2006 至 07 年度開始下降,抵押價值也下降,抵押違約率上升,而普遍由 金融公司持有的住房抵押貸款證券(Mortgage-Backed Security,簡稱 MBS) ,失 去了其大部分的價值。其結果是許多銀行持有的實質資本大幅下降,以致造成世 界各地信貸緊縮。 緊接著在 2008 年 9 月 14 日(星期日)為金融海嘯引爆的日期,創辦於 1850 年的投資銀行雷曼兄弟在美國聯準會拒絕提供資助後,正式宣告破產,而在同一 天美林證券宣佈被美國銀行收購。這兩件事揭開接下來這一星期全球股市大崩盤 的序幕。在 9 月 16 日,全世界最大的保險公司美國國際集團(AIG)因持有過 3.
(9) 多信用違約的到期合約而被調低其信用評級,該保險集團自身也陷入了一場流動 性危機(liquidity crisis)。 這一場全球性的金融海嘯由美國本土爆發,直接衝擊到全球的經濟,不只對 其鄰近國家影響很大,連太平洋另一端的亞洲國家也深受其危害。本研究即是想 透過實證資料來印證及檢視當金融海嘯發生後,美國與亞洲國家究竟是否產生與 過往不同的互動關係。. 二、研究目的 在發生重大的危機時,對於一些新興的國家影響,尤其,近幾年,東南亞國. 治 政 協(簡稱東協)經濟活動發展越來越蓬勃,對於世界經濟所造成的影響亦不容小覷。 大 立 亞洲國家在面對當今世界第一大國美國金融體系崩壞時,美國對日本、台灣、新 ‧ 國. 學. 加坡以及泰國之間是否產生蔓延效果,之所以會選取這四個亞洲國家是因為日本. ‧. 近年來與東南亞國家的經濟活動越趨密切,而台灣與日本的經貿關係一直以來也. sit. y. Nat. 是相的緊密。由於亞洲國家大多擁有美國的資產,無論是股票、公債或是其他一. io. er. 些金融衍生性商品,都是以美元計價,故探討蔓延效果(contagion)的關係,是單 方面的影響,或是彼此互相影響的交互作用(interaction),以及大國對小國的影響,. al. n. iv n C 皆是需要考量近來的因素,本文所採用蔓延效果的檢定,是採用美國對新加坡、 hengchi U 台灣、日本和泰國的影響來做分析。. 有關國際股票市場相關性的文獻過去主要利用 Granger 因果關係(Granger causality)、向量自我回歸模型 (vector autoregressive model, VAR) 及衝擊反應函 數 (impulse response function) 等計量方法探討市場間外溢效果 (spillover effect)。 然而,全球在發生多次重大危機事件後,各國的股市透過金融面、實質面、政治 面或一般投資人等心理層面上的因素已日漸緊密連結。 若想配適出多變量的聯合機率分配(Multivariate joint probability distributions), 其相關的理論推導及計算上極為複雜,尤其當投資組合標的項目太多的時候,欲. 4.
(10) 準確估算出聯合機率分配幾乎是不可能的,通常處理的方式為假設標的資產報酬 率服從多變量常態分配(Multivariate normal distribution),並據以進行模擬工作。 本文則採用的關聯結構(copula)方法,此法最早由 Sklar(1959)所提出,直到 1999 年才開始被廣泛應用在財務領域中,近來相關的研究應用數量成長速度非常快速, 利用此方法可將上述的問題簡化處理,以配適出更符合實際資料的聯合機率分配 (joint probability distribution),進而更準確地衡量出銀行本身所可能面臨的風險。 本文強調探討在面臨不同衝擊的情況下,股票市場是否產生蔓延效果。若能了解 在危機發生時,是否產生蔓延的情況,除了有助於分散風險外,投資人亦可根據 這些結論進行投資決策及資產配置組合。. 立. 政 治 大. ‧ 國. 學. 第二節 研究範圍與資料來源. 本文採用台灣加權股價指數、美國標準普爾500指數(Standard & Poor’s 500)、. ‧. 日本日經指數、新加坡海峽指數以及泰國股票指數,並將各國的股票指數作自然. sit. y. Nat. 對數轉換,計算出日報酬率,以下論述皆以日報酬率來做分析。. n. al. 月1日至2012年3月13日,共有1836筆觀察值。. Ch. engchi. 5. er. io. 本研究所採用的原始數據皆取自於Datastream資料庫。研究期間為自2005年3. i Un. v.
(11) 第三節 研究流程論文架構. 基本統計分析. 檢定是否發 生蔓延效果?. 政 治 大. 立利用經驗累積分配整理報. ‧. ‧ 國. 學. 酬率資料. y. sit. io. n. al. er. Nat. 利用IFM法,將各種關聯 結構模型參數估計出來. Ch. engchi. i Un. 利用估計出的參數,生成 模擬值,去配適原始資料. 比較AIC或BIC的值,找出 配適最佳的關聯結構模型. 結論與經濟涵意. 6. v.
(12) 第二章. 第一節. 文獻回顧. Contagion. 當某一個股票市場發生嚴重的震盪,透過金融面、實質面、政治面、或投資 人產生從眾行為等均可能影響到投資決策的心理層面因素,可能會影響到其他國 家 的 股 票 市 場 , 進 而 改 變 共 移 性 , 稱 此 現 象 為 蔓 延 效 果 , 在 Forbes and Rigobon(1999)的研究提到,他們認為在過去如 1987 年美國股災、1994 年墨西哥 金融危機及 1997 亞洲金融風暴,之所以會蔓延到其他國家是因為不同國家本身. 政 治 大. 內部即存在相關性而不是 contagion 的發生。 Arestis et al.(2005), Chancharoenchai. 立. and Dibooglu(2006), and Pontines and Siregar(2009)分別使用了不同的模型來衡量. ‧ 國. 學. 1997-1998 年東亞所發生的金融危機是否產生了蔓延效果。. Arestis 使用了對稱的 GARCH 模型來檢定危機發生時是否發生結構改變,其. ‧. 結果發現亞洲金融危機對已開發國家的影響較沒有那麼大;但作者另外提出一點,. y. Nat. io. sit. 已開發國家,如日本,對其他亞洲國家所產生的蔓延效果更是明顯,不只發現了. n. al. er. 不同國家之間的相關結構發生明顯的變化,更發現在金融危機中,波動性變化更. Ch. i Un. v. 影響到東南亞的國家。Azad(2009)檢視了亞洲三個較大國家的股票市場,分別是. engchi. 中國、日本以及南韓在 1996-2006 年間的蔓延效果,該研究所獲得的結果是只有 日本與南韓之間確實存在蔓延效果。Yiu et al.(2010)研究了亞洲 11 個國家股票市 場和美國股票市場在 1993 到 2009 年間的動態相關性,該作者使用 DCC 模型發 現到在 2007 到 2009 年期間確實存在蔓延效果,此蔓延現象是從美國蔓延到亞洲, 但是在亞洲金融危機卻沒找到此關係,因此,該作者認為蔓延效果是從次貸危機 開始後才發生的現象。蔓延效果對於不同資產間的共變關係存在高度的正相關, 蔓延效果對資產組合多樣化所帶來分散風險的效果影響甚劇,可能會使得投資者 大幅低估該資產組合的風險,蔓延效果對於不管是投資人還是研究者都是一項必 須要納入風險考量的因素。 7.
(13) 本文主要是想研究不同國家再面臨突如其來的衝擊是否會產生蔓延效果,我 們就必須探討此等關係究竟是由一個國家直接傳染到另一個國家,還是兩個國家 產生相互影響的作用,甚至是三個以上不同國家之間的交互作用,為了要明確解 釋蔓延效果,文中採取動態分析並將關聯結構(copula)的概念導入模型裡面,以 確認不同國家間的蔓延效果。. 第二節. Copula. 關聯結構模型早期是被運用在統計分析上,近幾年則廣泛地運用在其他不同. 政 治 大 風險管理、價格訂定以及結構相關分析。首先運用關聯結構模型在風險管理上的 立. 的領域,尤其是財務工程上。一般而言,關聯結構模型的運用主要分成三個部分:. ‧ 國. 學. 文章是 Roncalli et al.(2001),文中,選擇 Gaussian-copula 和 Student-T-copula 來估 計資產組合的風險值。關聯結構模型運用在財務商品上的訂價則有 Ruicheng et. ‧. al.(2009)使用關聯結構模型模型來訂定 CDO(collateralized debt obligation)的價格,. sit. y. Nat. 這是一般最常使用關聯結構模型的文章。本文主要則是著墨在結構相關分析這個. n. al. er. io. 方向,關聯結構模型運用在結構相關分析可參考 Longin and Solnik(2001)使用. i Un. v. Gumbel copula 來檢定不同國家的股票市場是否存在相關性,Hu(2006), Steven and. Ch. engchi. Ng(2009)也曾運用混合的(mixed)copula 模型來探討不同國家股票市場與房地產 市場的結構相關,Lai and Tseng(2010)也曾利用 Gaussian copula 與 Clayton copula 建構 Mixture Copula 來估計中國與七大工業國股市間的一般相關性 (regular dependence)與極端相關性(extreme dependence),該文所得到的實證結果發現到中 國與其他股市同步崩跌的機率相當低,換句話說,可能隱含著中國可以做為全球 股票投資人的資金避風港。. 8.
(14) 第三章. 研究方法. 第一節 Contagion 之測度檢定 關於檢定是否發生 contagion,本文採用 Bradley et al.(2005)所介紹的方法。 其對 X 和 Y 之間的關係假設如下: Y = m(X) + σ(X)ε ε~(0,1)且 cov(ε, X)=0,因此,可以導出當 X=x 時,Y 和 X 的相關係數為: ρ(x) =. σX β(x) √σ2X β2 (x) + σ2 (x). 治 政 σ 為 X 的標準差,β(x) = m′(x),m(x) = E(Y|X 大= x),σ 立 定理 1.當以下情況發生時,表示 X 對 Y 有蔓延效果. 2 X. ρ(xL ) > ρ(xM ). = Var(Y|X = x)。. 學. ‧ 國. X. ‧. xM = FX−1 (0.5) 為 此 分 配 的 中 位 數 , FX (x) = Ρ(X ≤ x) of X and xL =. sit. y. Nat. FX−1 (0.025) 為此分配的下四分位數。. io. er. 檢定蔓延效果的步驟如下:. n. a lH0 ∶ ρ(xL) ≤ ρ(xM) (無蔓延效果) iv n C H1 ∶ h ρ(xL ) > ρ(xM ) (存在蔓延效果) engchi U. 檢定統計量: Z=. ρ̂(xL ) − ρ̂(xM ) ̂2ρ̂(xL ) + σ ̂2ρ̂(xM ) √σ. Z 為一標準常態分配。當α = 0.05,即Z ≥ z1−α = 1.645時,可以拒絕H0 , 作出確實存在蔓延效果的結論。一旦檢定出發生蔓延效果的結果,則可以推測出 該區間內的資料分配可能產生尾端相關(tail dependence)的現象。因此,就能透過 不同的關聯結構模型來配適出與原始資料最符合的模型。. 9.
(15) 第二節 Copula 方法及其定理之介紹 估計聯立系統之隨機變數本屬不易,原因之一是不同的隨機變數存在相異的 機率分配;而變數間之相關性亦是影響估計的重要因素。要聯合估計一變數集合 僅只於單一、簡單之多變量聯合分配(如常態),若是稍有不合理想之假設條件(如 missing data),在計算上,則會發生不易計算的結果,因此,本文主要著墨於關 聯結構模型來處理變數間相關性的問題。關聯結構理論(Copula theory)在財務經 濟之應用主要是在不同資產的價格或其報酬率之聯合分配的建構與相關程度的 衡量。由於金融波動與日俱增,且資產價格常出現特殊的變動,因此,過去對於. 政 治 大 低了分析的可信度。透過關聯結構函數之設計,可以把單變數的各個邊際分配與 立 不同資產間的報酬設定其聯合分配為多元常態的假設似乎偏離了真實性,也將降. ‧ 國. 學. 各變數之間的關聯結構形式分開考慮,經由此方法,分配的設定就變得非常有彈 性,更能接近真實的分配,藉由此較精確的描述,實證結果的可靠度也將有顯著. ‧. 的提升。若要檢視不同國家及不同市場之報酬的時間序列之間在發生極端事件的. sit. y. Nat. 關聯時,視各個時間序列為一聯合分配,可藉由關聯結構形式,將每一時間序列. n. al. er. io. 當成單變數的邊際分配。. i Un. v. Copula 是一個由多維變數映射至均勻分配(Uniform distribution)的函數,符. Ch. 號以表示,滿足以下三個條件:. engchi. 1. C:[0,1]n → [0,1] 2. C 是有著地(grounded)且遞增的函數; 3. C 的所有邊際函數Ci 滿足:Ci (u) = (1, … ,1, u𝑖 , 1, … ,1). u ∈ [0,1] ;. 假如F1 , … , Fn 是𝑋1 , … , 𝑋𝑛 單變量的累積分配函數,則C[F1 (x1 ), … , Fn (xn )]是表 示一多變量的累積分配函數其邊際函數為F1 , … , Fn。由以上定義可以了解 Copula 是一個聯合機率分配的函數,在實際應用上,下述的 Sklar’s 定理,可謂是 Copula 最重要的定理。. 10.
(16) 定理2:Sklar’s Theorem 若F(. )是一個 n 維的累積機率分配函數,且其邊際函數是連續函數F1 , … , Fn , 則可以找到唯一的 Copula 使得: 𝐹(𝑥1 , … , 𝑥𝑛 ) = C(𝐹1 (𝑥1 ), … , 𝐹𝑛 (𝑥𝑛 ))………(1) 利用上述定理我們能將一個多維的分配,拆成單維的邊際函數及相關結構. F ( x1 ,..., xn ) C ( F1 ( x1 ),..., Fn ( xn )) (dependent structure)兩個部分,推導如下: F ( x1 ,..., x n ) C ( F1 ( x1 ),..., Fn ( x n )) C (u1 ,..., u n ) F ( x ) i i x1 ...x n x1 ...x n u1 ...u n xi ..(2) i c(u1 ,..., u n ) f i ( xi ) c(u~ ) f i ( xi ). f ( x1 ,..., x n ) . i. i. 政 治 大. 其中f(x1 , … , xn )為F(. )的機率密度函數. 立. , i 1,..., n. 學. ũ = (u1 , … , u2 ) c(ũ)為 Copula 的密度函數. ‧. ‧ 國. ui Fi ( xi ). y. Nat. 由式(2)顯示:可將一個聯合機率密度函數f(x1 , … , xn )拆解成兩部分,前一. er. io. sit. 部分c(ũ)為 Copula 的密度函數,用以規範變數X1 , X2 , … , X n 之間的關聯結構,即 決定變數間共同移動(co-movement)的關係,可視為相關性結構部分;後一部分. al. n. iv n C f ( x ) 則為單純的邊際機率密度函數之乘積。也就是說,可以先決定每個個別 hengchi U i. i. i. 隨機變數𝑋𝑖 的(不同)邊際分配函數Fi (xi ), i=1,2,…,n,並分別進行其個別邊際分配 函數之配適及參數之估計(這部份可以利用一般的統計估計方法:動差法、最大 概似估計法…)後,再另外配適出合適的相關性結構(Copula 函數),即可求得其 聯合機率分配。利用先將邊際分配及關聯結構分開個別處理,再加以整合的過程, 可得出更有彈性且更有效的探討各變數間的共同移動關係,並進而估得更合適的 聯合機率分配。在極端的情況下,當各變數之間獨立時,可以得到 𝐶(𝑢1 , … , 𝑢𝑛 ) = 𝑢1 × … × 𝑢𝑛 。. 11.
(17) 表 3.1. 不同分配下的copula. Copula. Gaussian Student-t. Distribution. Parameter range. 𝐶𝑋,𝑌 (𝑢, 𝑣) = ∅𝜌 (∅−1 (𝑢), ∅−1 (𝑣)). 𝜌 ∈ (−1,1). 𝜌=0. 𝐶𝑋,𝑌 (𝑢, 𝑣) = 𝑇𝜌,ʋ (𝑡 −1 (𝑢), 𝑡 −1 (𝑣)). 𝜌 ∈ (−1,1). 𝜌=0. 𝑎 ∈ (0,1). 𝑎=1. 𝑎 ∈ (−1, ∞). 𝑎→0. 1 𝑎. 1. Gumbel. Independence. 𝐶𝑋,𝑌 (𝑢, 𝑣) = 𝑒𝑥𝑝 ( − [(−𝑙𝑜𝑔𝑢)𝑎 + (−𝑙𝑜𝑔𝑣)𝑎 ] ). 1. Clayton. 𝐶𝑋,𝑌 (𝑢, 𝑣) = (𝑢−𝑎 + 𝑣 −𝑎 − 1)−𝑎. 表格中描述不同關聯結構函數的分配、參數範圍以及獨立的條件。. 立. 政 治 大. 學. ‧ 國. 第三節 經驗累積分配函數(Empirical CDF) 累積分配函數的順序統計量定義如下:. ‧. 𝑛. Nat. 1 𝐹𝑛 (𝑦) = ∑ 𝐼(𝑦𝑖 ≤ 𝑦) 𝑛. sit. y. 𝑖=1. al. n. 函數為 1,(𝑦𝑖 ≤ 𝑦)不成立時,指標函數為 0。. Ch. engchi. er. io. 表示存在 n 個觀察值,且存在一個指標函數𝐼(𝑦𝑖 ≤ 𝑦),當(𝑦𝑖 ≤ 𝑦)成立時,指標. i Un. v. 文中,將原始資料透過累積分配函數轉換成不同國家的的邊際分配,再透過 此分配來配適出最佳的關聯結構函數。. 12.
(18) 第四節 實證模型建構 假設所有累積分配函數皆可微分,根據Sklar’s定理,則可將一個二維聯合分 配拆解成兩個一維的邊際分配及一個關聯結構函數: 2 ∂2 F(R1,t , R 2,t ) ∂ C (F1 (R1,t ), F2 (R 2,t )) f(R1,t , R 2,t ) = = ∂R1,t ∂R 2,t ∂R1,t ∂R 2,t. ∂2 C(u1,t , u2,t ) ∂Fi (R i,t ) = ×∏ = c(u1,t , u2,t ) × ∏ fi (R i,t ) ∂u1,t ∂u2,t ∂R i,t i=1,2. i=1,2. 其中f(R1,t , R 2,t )為F(R1,t , R 2,t )的PDF;C (F1 (R1,t ), F2 (R 2,t ))及c(u1,t , u2,t )分別. 政 治 大. 為 Copula 的 聯 合 CDF 與 PDF , 用 來 捕 捉 變 數 R1,t 及 R 2,t 間 的 共 移 性. 立. (co-movement); Fi (R i,t )與fi (R i,t )分別為邊際分配的CDF與PDF,且ui,t = Fi (R i,t )。. ‧ 國. 學. 兩邊取對數後,可以計算出的t期的對數概似函數值(log-likelihood function value) logf(R1,t , R 2,t ) = logc(u1,t , u2,t ) + logf1 (R1,t ) + logf2 (R 2,t ). ‧. io. 可獲得各參數估計值。其中,θ = (θc , θ1 , θ2 )。. n. al. Ch. er. L(θ) = Lc (θc ) + L1 (θ1 ) + L2 (θ2 ). sit. Nat. 對數概似函數: MAX. y. 令θc , θ1 及θ2 分別為c(u1,t , u2,t ), f1 (R1,t )及f2 (R 2,t )中的參數,透過極大化下列. i Un. v. 若模型參數過多,估計的結果有時會無法收斂。在此,我們使用Joe and. engchi. Xu(1996)提出的兩階段估計法(inference for the margins. IFM),即將邊際分配與關 聯結構函數中的參數分兩階段估計,第一階段採最大概似估計法(Method of Maximum Likelihood Estimation. MLE)分別估計出各個邊際分配的參數: T. θ̂1 = argmax ∑ logf1 (R1,t ; θ1 ) t=1 T. θ̂2 = argmax ∑ logf2 (R 2,t ; θ2 ) t=1. 再用邊際模型中所估計出的參數值,轉換各市場報酬率為累積機率 ûi,t = Fi (R i,t ; θ̂i ),再以第二階段估計關聯結構函數中的參數: 13.
(19) T. θ̂c = argmax ∑ logc(û1,t , û2,t ; θc ) t=1. Joe(1997)證明兩階段估計法(IFM)較最大概似估計法(MLE)便利且同具有效 性(efficiency) ,缺點是,兩階段估計法需假定在兩邊際分配及關連結構函數間 無共同參數,Patton(2006)證明兩階段估計法會產生漸近一致(consistent),但有效 率損失(inefficient)的情況。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 14. i Un. v.
(20) 第四章. 實證結果與分析. 第一節 基本相關分析 本文是採用五個不同國家股票市場的日資料,分別是美國、日本、新加坡、 台灣和泰國,期間為 2005 年 3 月 2 日到 2012 年 3 月 13 日,資料取自於 Datastream 資料庫。並計算出其報酬率,其公式為100 ×. Pt −Pt−1. %,由於本研究中的資料皆. Pt−1. 以報酬率來分析,故若該國的股票市場為休假日時,以報酬率為 0 來分析並不影 響到分析的結果。為了觀察原始資料是否具有對稱性或不對稱性的現象,文中,. 學. 表 4.1. ‧ 國. 治 政 我先不採用任何的 copula 去配適資料,透過觀察原始資料的散佈情況,來達到 大 立 此目的。 不同國家報酬率的各階動差. Japan. Thailand. 0.018. 0.0297. 0.0227. 0.0034. 0.0344. 變異數. 2.0470. 1.7438. 1.8249. 偏態係數. -0.05151. -0.06012. -0.28876. 峰態係數. 9.708284. sit. io. n. 表 4.2. al. 2.5740. er. 平均數. y. Taiwan. Nat. Singapore. ‧. US. 2.0046. -0.30458. -0.75969. 9.718639. 13.51631. Taiwan. Japan. Thailand. v ni. C h e n g c3.044537 4.970942 hi U. 不同國家間的靜態相關係數分析 US. US. Singapore. 1. 0.2695. 0.1311. 0.1166. 0.2189. Singapore. 0.2695. 1. 0.5826. 0.5812. 0.5594. Taiwan. 0.1311. 0.5826. 1. 0.5745. 0.4198. Japan. 0.1166. 0.5812. 0.5745. 1. 0.4058. Thailand. 0.2189. 0.5594. 0.4198. 0.4058. 1. 上述兩表將五個國家的基本統計性質表達出來。 15.
(21) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4.1 不同國家報酬率的分散程度 16.
(22) 圖 4.1 為五個國家股票市場報酬率的時間序列,藉此,我們可以觀察到各國股市 報酬率隨著時間變化的波動程度,由圖中可知,在金融海嘯過後,各國的報酬率 明顯有波動變大的趨勢,尤其是在金融海嘯發生那段期間的波動,更是明顯的變 大。. 金融風暴前後各個國家的平均報酬率與標準差(每日報酬率). Singapore. 2005-2008. 2008-2012. 0.018. 0.0078. 0.0283. (2.0470). (0.8375). (3.2711). 0.0297. 立. 治 政 0.0319 大. (1.5415). 0.0034. 0.0119. (2.5740). (1.5913). (2.1114) -0.0051. y. al. -0.0051. n. 0.0344. 0.0370. ‧. (1.8249). io. Thailand. 0.0086. Nat. Japan. 0.0227. (2.1853). 學. Taiwan. (1.3074). ‧ 國. (1.7438). 0.0275. (2.0046). Ch. sit. US. 2005-2012. er. 表 4.3. n U i e n g(1.5872) h c. iv. (3.5683) 0.0744 (2.4239). 表格中數據皆以百分比來表示,括號內為變異數。 此表格以 2008 年雷曼兄弟投資銀行申請破產那天為分界點,將五個國家不同時 期報酬率的平均數與變異數分別計算出來,可以發現到,金融海嘯發生後,各國 股票報酬率的分散程度均有上升的現象。. 17.
(23) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 18. i Un. v.
(24) 立. 政 治 大. ‧. ‧ 國. 學. n. 圖. er. io. sit. y. Nat. al. iv n C 4.2 h 不同國家的資料散佈圖 engchi U. 本圖為五個國家中,不同兩國間日報酬率的資料散佈圖,從圖中可以看出哪些國 家在極端值上有明顯的相關,以台灣和日本的圖為例,在資料在兩端有發生較密 集的結果,即表示在極端的情況下有產生相關性較強的現象。. 19.
(25) 第二節 Contagion 檢定結果 本節所介紹的是美國對新加坡、台灣、日本和泰國,在金融危機發生時,是 否有發生傳染的現象。文中採用 Bradley et al.(2005)所介紹的方法,藉此來判斷 contagion 是否有發生。. 表 4.4 檢定美國對其他國家是否產生蔓延效果 Market. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. Singapore -0.0218. 0.0115. 0.0096. 0.0111. Japan. 0.0061. 0.013. Thailand. 0.0119. 0.0116. Contagion. -14.0607. NC. 0.4753. NC. 0.00079952 0.016. 0.2572. NC. 0.0016. 0.5627. NC. 0.0013 治 0.0137 政 大. 立. ‧ 國. 0.0132. 0.0143. 學. Taiwan. 0.2249. ̂ 𝒁. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). ̂(𝒙𝑳 ) 𝝆. 此表所使用的資料為 2005 年 3 月 1 日至 2012 月 13 日,從表 4.4 的結果可知,. ‧. 在我們所觀察的這段期間裡,美國對新加坡、台灣、日本和泰國並沒有發生傳染. Nat. n. al. er. io. sit. y. 的現象。C:Contagion,即發生蔓延效果;NC: No Contagion,即未發生蔓延效果。. i Un. v. 表 4.5 檢定全球金融危機時期美國對其他國家是否產生蔓延效果(一) Market. ̂(𝒙𝑴 ) 𝝆. Singapore 0.4441. Ch. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). e 𝝆̂n(𝒙g𝑳)c h i 𝝈̂𝝆̂(𝒙 ) 𝑳. ̂ 𝒁. Contagion. 0.0194. -0.0656. 0.0160. -20.2792. NC. Taiwan. -0.7985. 0.0186. -0.0678. 0.0153. 30.3770. C. Japan. -0.6747. 0.0173. -0.0348. 0.0201. 24.1566. C. Thailand. 0.3469. 0.0181. -0.0589. 0.0124. -18.4667. NC. 資料的期間為 2007 年 9 月 12 日至 2009 年 9 月 11 日,此表格是以 2008 年雷曼 兄弟破產那日取前後各一年的資料來分析,此時可看出,美國對台灣和日本有產 生蔓延效果,但對新加坡和泰國則無蔓延效果。. 20.
(26) 表 4.6 檢定全球金融危機時期美國對其他國家是否產生蔓延效果(二) Market. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. ̂ (𝒙𝑳 ) 𝝆. ̂ 𝒁. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). Contagion. Singapore -0.9876. 0.0092. -0.3310. 0.0195. 30.4711. C. Taiwan. -0.4269. 0.0190. -0.1471. 0.0133. 12.0353. C. Japan. 0.1489. 0.0201. 0.2912. 0.0180. 5.2756. C. Thailand. -0.9972. 0.0095. -0.6011. 0.0170. 20.3462. C. 資料的期間為 2008 年 3 月 12 日至 2009 年 3 月 13 日,此表格是以 2008 年雷曼 兄弟破產那日取前後各半年的資料來分析,此時可看出,美國對新加坡、台灣、 日本和泰國皆有發生蔓延效果。. 立. 政 治 大. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. ̂ (𝒙𝑳 ) 𝝆. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). 學. Market. ‧ 國. 表 4.7 檢定全球金融危機後復甦期間美國對其他國家是否產生蔓延效果 ̂ 𝒁. Contagion. 0.1632. 0.0146. -23.0875. ‧. NC. Taiwan. 0.2257. 0.0098. 0.1114. 0.0083. -8.8658. NC. Japan. 0.0117. 0.0153. 0.0328. 0.0098. Thailand. 0.2257. 0.0905. 0.0189. n. Ch. engchi U. sit. 1.1649. er. io. al. 0.0105. y. 0.0059. Nat. Singapore 0.5277. v ni. -6.2515. NC NC. 資料的期間為 2009 年 3 月 9 日至 2011 年 4 月 29 日,此表格是以 2008 年雷曼兄 弟破產後,選擇 S&P500 指數最低點的那日到指數最高的那日所做的分析,此時 可看出美國對新加坡、台灣、日本和泰國皆沒有發生蔓延效果。 由上述四個表格,可以得到一個結論,選取資料的範圍若是越靠近全球金融 危機所發生的時間,其發生蔓延效果的可能性也就越大,表示資料在極端的情況 下所存在的相關性較為明顯,即資料可能存在尾端相關性,因此,才繼續使用不 同的 copula 模型來找出配適資料最佳的模型。但在面臨衰退時,可以檢定出美 國對其他國家可能會有蔓延效果,然而,在景氣復甦的時候,美國對其他國家並 沒有發生蔓延效果。 21.
(27) 表 4.8 檢定全球金融危機時期新加坡對其他國家是否產生蔓延效果 Market. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. ̂ (𝒙𝑳 ) 𝝆. ̂ 𝒁. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). Contagion. US. 0.9971. 0.0188. -0.3450. 0.0300. -37.9521. NC. Taiwan. 0.7502. 0.0195. -0.1947. 0.0178. -35.8197. NC. Japan. 0.6887. 0.0248. -0.2079. 0.0177. -29.4488. NC. Thailand. 0.6917. 0.0176. -0.2439. 0.0120. -43.8909. NC. 資料的期間為 2008 年 3 月 12 日至 2009 年 3 月 13 日,此表格是以 2008 年雷曼 兄弟破產那日取前後各半年的資料來分析,此時可看出,新加坡對美國、台灣、. 政 治 大. 日本和泰國皆沒有發生蔓延效果。. 立. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. ̂ (𝒙𝑳 ) 𝝆. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). 學. Market. ‧ 國. 表 4.9 檢定全球金融危機時期台灣對其他國家是否產生蔓延效果 ̂ 𝒁. Contagion. -0.0620. 0.0240. -5.7333. ‧. NC. Singapore 0.9897. 0.0195. -0.8391. 0.0142. -75.7414. NC. Japan. 0.6153. 0.0255. -0.1820. 0.0119. Thailand. -0.9248. -0.5682. 0.0195. n. Ch. engchi U. sit. -28.3221. er. io. al. 0.0266. y. 0.0263. Nat. 0.1423. US. v ni. 10.8214. NC C. 資料的期間為 2008 年 3 月 12 日至 2009 年 3 月 13 日,此表格是以 2008 年雷曼 兄弟破產那日取前後各半年的資料來分析,此時可看出,台灣對美國、新加坡和 日本皆沒有發生蔓延效果,但對泰國有產生蔓延效果,會造成這樣的結果可能是 美國先將蔓延效果傳染到台灣,接著台灣再蔓延到泰國。. 22.
(28) 表 4.10 檢定全球金融危機時期日本對其他國家是否產生蔓延效果 Market. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. ̂ (𝒙𝑳 ) 𝝆. ̂ 𝒁. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). Contagion. 0.7416. 0.0289. -0.0569. 0.0242. -21.1766. NC. Singapore 0.7154. 0.0197. -0.1708. 0.0129. -37.6215. NC. Taiwan. 0.7921. 0.0189. -0.2146. 0.0124. -44.6172. NC. Thailand. 0.6003. 0.0189. -0.1261. 0.0124. -32.1308. NC. US. 資料的期間為 2008 年 3 月 12 日至 2009 年 3 月 13 日,此表格是以 2008 年雷曼 兄弟破產那日取前後各半年的資料來分析,此時可看出,日本對美國、新加坡、. 政 治 大. 台灣和泰國皆沒有發生蔓延效果。. 立. 𝝈 ̂ 𝝆̂(𝒙𝑴 ). ̂(𝒙𝑴 ) 𝝆. ̂ (𝒙𝑳 ) 𝝆. 𝝈 ̂ 𝝆̂(𝒙𝑳 ). 學. Market. ‧ 國. 表 4.11 檢定全球金融危機時期泰國對其他國家是否產生蔓延效果 ̂ 𝒁. Contagion. -0.3140. 0.0233. -37.3865. ‧. NC. Singapore 0.8086. 0.0203. -0.1671. 0.0199. -34.3395. NC. Taiwan. 0.6878. 0.0198. -0.1366. 0.0178. Japan. 0.5860. -0.1208. 0.0200. n. Ch. engchi U. sit. -30.9648. er. io. al. 0.0257. y. 0.0257. Nat. 0.9833. US. v ni. -21.7068. NC NC. 資料的期間為 2008 年 3 月 12 日至 2009 年 3 月 13 日,此表格是以 2008 年雷曼 兄弟破產那日取前後各半年的資料來分析,此時可看出,泰國對美國、新加坡、 台灣和日本皆沒有發生蔓延效果。 由表 4.8、表 4.9、表 4.10 和表 4.11 的結果,可以推論出在金融海嘯期間之 所以只有美國對其他國家產生蔓延效果其主因可能是因為這次的全球金融海嘯 是由美國本土所爆發,因此,其他國家間彼此並沒有產生蔓延效果。. 23.
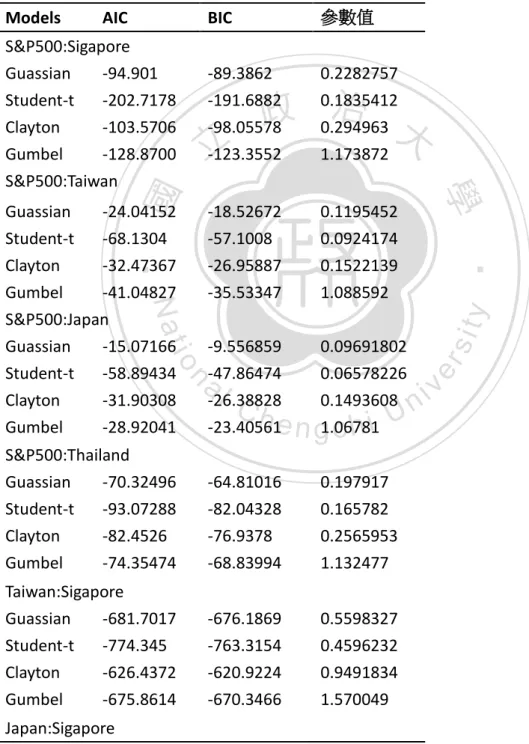
(29) 第三節 Copula 模型選擇 在使用copula模型配適之前,我們將原始資料轉換成經驗累積分配函數 (empirical communicative distribution function),並將此函數視為該資料的邊際分 配,然後使用不同的copula模型來配適它們,並透過IFM法來估計其對應的參數。. 表 4.12 兩兩國家間不同copula模型的配適程度 BIC. 參數值. -89.3862 -191.6882 -98.05578 -123.3552. 0.2282757 0.1835412 0.294963 1.173872. -24.04152 -68.1304 -32.47367. -18.52672 -57.1008 -26.95887. 0.1195452 0.0924174 0.1522139. Gumbel -41.04827 S&P500:Japan Guassian -15.07166 Student-t -58.89434 Clayton -31.90308 Gumbel -28.92041. -35.53347. 1.088592. -9.556859 -47.86474 -26.38828 -23.40561. 0.09691802 0.06578226 0.1493608 1.06781. S&P500:Thailand Guassian -70.32496 Student-t -93.07288 Clayton -82.4526. -64.81016 -82.04328 -76.9378. 0.197917 0.165782 0.2565953. Gumbel. -74.35474. -68.83994. 1.132477. Taiwan:Sigapore Guassian -681.7017 Student-t -774.345 Clayton -626.4372 Gumbel -675.8614. -676.1869 -763.3154 -620.9224 -670.3466. 0.5598327 0.4596232 0.9491834 1.570049. Nat. y. ‧ 國. ‧. Guassian Student-t Clayton. 立. 政 治 大. 學. S&P500:Sigapore Guassian -94.901 Student-t -202.7178 Clayton -103.5706 Gumbel -128.8700 S&P500:Taiwan. io. n. al. Ch. engchi. Japan:Sigapore. 24. sit. AIC. er. Models. i Un. v.
(30) Guassian. -699.2558. -693.741. 0.5656796. Student-t Clayton Gumbel. -772.433 -679.974 -659.6043. -761.4034 -674.4592 -654.0895. 0.5189742 1.001234 1.568005. Thailand:Sigapore Guassian -648.7833 Student-t -688.8887 Clayton -573.0836 Gumbel -620.666. -643.2685 -677.8591 -567.5688 -615.1512. 0.5485647 0.4821687 0.892334 1.534499. -704.6798 -762.6527 -672.9362 -657.2347. -699.165 -751.6231 -667.4214 -651.7199. 0.5674675 0.5287613 0.9988312 1.567155. Taiwan:Thailand Guassian -331.7657 Student-t -349.0558 Clayton -291.623 Gumbel -326.8565. 立 -326.2509. Taiwan:Japan. n. al. Ch. engchi. y. 0.3815811 0.2872136 0.5470461 1.293436. sit. -277.8543 -283.5609 -271.8106 -255.1772. er. io. -283.3691 -294.5905 -277.3254 -260.6920. ‧. Nat. Guassian Student-t Clayton Gumbel. -338.0262 -286.1082 -321.3417. 0.4099304 0.3285712 0.5621398 1.332634. 學. Thailand:Japan. 政 治 大. ‧ 國. Guassian Student-t Clayton Gumbel. i Un. v. 本表格將五個國家以兩兩為例,分別用不同的關聯結構函數來配適所得到的AIC 值和BIC1值,並以此數值判斷出哪種關聯結構函數配適最佳。 由表4.12的結果可知,在經由不同的copula模型下,所算出的AIC值與BIC值, 可以得到,無論是哪兩個國家的相關性判斷,Student-t關聯結構函數所得到的AIC 與BIC數值皆比其他模型都還要來得低,因此,使用Student-t關聯結構函數來配 適資料,皆比文中其他所使用的模型還要來得適合。. 1. 在模型的選取上,一般都以 AIC (Akaike Information Criterion)或 SIC (Schwartz Information Criterion),也稱為 BIC,Bayesian nformation Criterion)當準則來選取。 25.
(31) 第五章. 結論. 本研究旨在探討美國對亞洲國家是否發生蔓延效果,藉由不同期間的資料來 檢視蔓延效果的發生與否,並透過關聯結構(copula)來刻劃亞洲在面臨美國產生 重大金融危機時,其股票指數報酬率與其他國家所產生的共變關係,一般來說, 資產報酬率常常產生厚尾(fat tails)的現象,過去文獻大多將資產報酬設定為聯合 常態分配的假設下來衡量其相關性,並忽略到尾部相關性,此假設將嚴重低估資 產報酬在極端事件下的相關程度。當參數之間存有不同的分配,或其分配型態必. 政 治 大 上的實證結果得知,選取資料的範圍若是越靠近全球金融危機所發生的時間,其 立. 須個別估計時,copula函數可以有效地針對多個參數之不同分配進行整合。由以. ‧ 國. 學. 發生蔓延效果的可能性也就越大,表示資料在極端情況下所存在的相關性較為明 顯,即資料可能存在尾端相關性,本文以關聯結構(copula)方法,來配適不同國. ‧. 家報酬率的分配。透過AIC與BIC的數值,我們可以知道T-Copula的配適程度最. sit. y. Nat. 佳,即表示資料可能存在對稱性與厚尾的現象。. n. al. er. io. 總結而論,可以發現到不論是哪兩個國家,其股票市場都有呈現出在資料尾. i Un. v. 端具有較強烈的相關性,即可以推論出,當世界經濟面臨大漲或大跌的情況時,. Ch. engchi. 這些國家很容易產生同步現象,這表示,過去使用同時持有不同國家的資產來避 免在危機發生時的避險方法,所能得到的益處已經沒有過去那麼好。原因是,在 現今這個全球化的時代,各國的資金能自由地在世界各地流動,而且每個國家同 時可能持有許多不同國家的資產,一旦全球危機發生時,就會容易受到其他國家 的影響。. 26.
(32) Appendix. A. Introduction of Copulas 1. Gaussian copula 其函數形式如下: CX,Y (u, v) = ∅ρ (∅−1 (u), ∅−1 (v)). (1). 其中 (∅. −1 (u),. ∅. −1 (v)). ∅−1 (u). =∫. ∅−1 (v). ∫. −∞. −∞. −(x 2 − 2ρxy + y 2 ) exp { } 2(1 − ρ2 ) 2π√1 − ρ 1. 治 政 且∅ 為常態分配聯合密度函數的反函數。Gaussian 大 copula 多半可用來處理 立 多元變數的相依性,但比較不易描繪資料尾端的相關結構。 −1 (u). ‧ 國. 學. 2. Student’s t copula. ‧. 其函數形式可表示如下:. y. (2). sit. io. n. al t. −1 (u) ʋ. t−1 ʋ (v). er. 其中. Nat. CX,Y (u, v) = Tρ,ʋ (t −1(u), t −1 (v). ni C ∫ −∞ h −∞ U engchi. Tρ,ʋ = (t −1 (u), t −1 (v)) = ∫. v. x 2 − 2ρxy + y 2 (1 + ) ʋ(1 − ρ2 ) 2π√1 − ρ2 1. −. ʋ+2 2. 且t −1 (u) 為 Student’s t 聯合分配函數的反函數,ʋ 為自由度,當樣本數趨 近於無窮大時,Student’s t 分配會收斂常態分配。相較於 Gaussian copula,Student’s t copula 更能捕捉資料的厚尾特性以及資料尾端之結構性相關,隨著自由度越小, 其尾端相關性越大,當自由度為 1 時,該 copula 亦可稱為 Cauchy copula。因為 Student’s t copula 為對稱分配,主要用來描述多元變數間雙尾之雙關結構。 3. Archimedean Copulas (1)Gumbel copula Gumbel copula 可以反映資料有明顯的右尾相關性結構之非對稱型態的 copula 函. 27.
(33) 數,適合用來解釋市場同時大漲時之報酬率相關程度,其函數形式如下: 1. 1. a. CX,Y (u, v) = exp ( − [(−logu)a + (−logv)a ] ). (3). (2)Clayton copula 與 Gumbel copula 相較,Clayton copula 為較能反映左尾相關性結構之非對稱型 態的 copula 函數,對變數在分配下尾處的變化十分敏感,故能快速捕捉到下尾 相關的變化,可用於描述具下尾相關特性的變數間之相關;但對變數在分配上尾 處的變化則不敏感,僅能考量單尾極端事件發生機率。可以捕捉市場同步崩跌時 之報酬率的相關性,其函數形式如下: 1. CX,Y (u, v) = (u−a + v −a − 1)−a. 立. ‧. ‧ 國. 1. Copula. (4). 學. B. Syntax. 政 治 大. ### R code from vignette source 'nacopula-pkg.Rnw'. y. Nat. io. sit. ###################################################. n. al. er. ### code chunk number 1: preliminaries. Ch. i Un. v. ################################################### op.orig <-. engchi. options(width = 70, ## SweaveHooks= list(fig=function() par(mar=c(5.1, 4.1, 1.1, 2.1))), useFancyQuotes = FALSE, prompt="R> ", continue="+. "). Sys.setenv(LANGUAGE = "en") if(.Platform$OS.type != "windows") Sys.setlocale("LC_MESSAGES","C") ## if(Sys.getenv("USER") == "maechler")# take CRAN's version, not development one: 28.
(34) ##. require("copula", lib="~/R/Pkgs/CRAN_lib"). ################################################### ### code chunk number 2: acopula-family ################################################### require(copula) ls("package:copula", pattern = "^cop[A-Z]") copClayton copClayton@psi copClayton@psiInv # the inverse of psi(), psi^{-1}. 治 政 copClayton@V0 # "sampler" for V ~ F() 大 立 ################################################### ‧ 國. 學. ### code chunk number 3: ex1-definition. ‧. ###################################################. sit. y. Nat. (theta <- copJoe@tauInv(0.5)). io. al. er. C3joe.5 <- onacopula("Joe", C(theta, 1:3)). n. ###################################################. Ch ### code chunk number 4: ex1-str. engchi. i Un. v. ################################################### str(C3joe.5) # str[ucture] of object ################################################### ### code chunk number 5: ex1-U3 ################################################### require(lattice) set.seed(1) dim(U3 <- rnacopula(500, C3joe.5)) ################################################### 29.
(35) ### code chunk number 6: ex1-splom-def (eval = FALSE) ################################################### ## splom2(U3, cex = 0.4) ################################################### ### code chunk number 7: ex1-splom ################################################### ## NB: 'keep.source=false' is workaround-a-bug-in-R-devel-(2.13.x)--- and more "splom" print( splom2(U3, cex = 0.4). 立. ). 政 治 大. ‧ 國. 學. ###################################################. ‧. ### code chunk number 8: ex1-explore1. sit. y. Nat. ###################################################. io. er. round(cor(U3, method="kendall"), 3). al. n. ###################################################. ni Ch ### code chunk number 9: ex1-explore2 U engchi. v. ################################################### c(pnacopula(C3joe.5, c(.5, .5, .5)), pnacopula(C3joe.5, c(.99,.99,.99))) ################################################### ### code chunk number 10: ex1-explore3 ################################################### prob(C3joe.5, c(.8, .8, .8), c(1, 1, 1)) ################################################### ### code chunk number 11: ex2-explore4 30. 2 x.
(36) ################################################### c(copJoe@lambdaL(theta), copJoe@lambdaU(theta)) ################################################### ### code chunk number 12: NAC_3d-ex ################################################### ( C3 <- onacopula("A", C(0.2, 1, C(0.8, 2:3))) ) ################################################### ### code chunk number 13: NAC_3d-ex2. 治 政 ################################################### 大 立 stopifnot(identical(C3, ‧ 國. 學. onacopula("A", C(0.2, 1, list(C(0.8, 2:3, list())))). ‧. )). sit. y. Nat. ###################################################. io. al. er. ### code chunk number 14: AMH-V01. n. ################################################### copAMH@nestConstr. Ch. engchi. i Un. v. copAMH@V01 ################################################### ### code chunk number 15: ex2-definition ################################################### theta0 <- copClayton@tauInv(0.2) theta1 <- copClayton@tauInv(0.5) theta2 <- copClayton@tauInv(0.8) c(theta0, theta1, theta2) C_9_clayton <- onacopula("Clayton", 31.
(37) C(theta0, c(3,6,1), C(theta1, c(9,2,7,5), C(theta2, c(8,4))))) C_9_clayton ################################################### ### code chunk number 16: U9-prepare-splom ################################################### set.seed(1) U9 <- rnacopula(500, C_9_clayton). 學. ‧ 國. 治 政 j <- allComp(C_9_clayton)# copula component "numbers": 大 1:9 but in "correct order" 立 (vnames <- do.call(expression, lapply(j, function(i) substitute( U[I], list(I=0+i))))). ‧. ###################################################. sit. y. Nat. ### code chunk number 17: ex2-splom-def (eval = FALSE). io. er. ###################################################. al. ## splom2(U9[, j], varnames= vnames, cex = 0.4, pscales = 0). n. iv n C ################################################### hengchi U ### code chunk number 18: ex2-splom ################################################### print( splom2(U9[, j], varnames= vnames, cex = 0.4, pscales = 0) ) ################################################### ### code chunk number 19: ex2-explore1 ################################################### round(cor(U9[,9],U9[,7], method="kendall"), 3) 32.
(38) ################################################### ### code chunk number 20: ex2-explore2 ################################################### c(pnacopula(C_9_clayton, rep(.5,9)), pnacopula(C_9_clayton, rep(.99,9))) ################################################### ### code chunk number 21: ex2-explore3 ################################################### prob(C_9_clayton, rep(.8,9), rep(1,9)). 治 政 ################################################### 大 立 ### code chunk number 22: ex2-explore4 ‧ 國. 學. ###################################################. ‧. c(copClayton@lambdaL(theta0),. sit. y. Nat. copClayton@lambdaU(theta0)). io. al. er. c(copClayton@lambdaL(theta1),. n. copClayton@lambdaU(theta1)) c(copClayton@lambdaL(theta2),C h. engchi. i Un. v. copClayton@lambdaU(theta2)) ################################################### ### code chunk number 23: outerpower-def ################################################### str(opower) ################################################### ### code chunk number 24: opwer-def2 ################################################### thetabase <- copClayton@tauInv(.5) 33.
(39) (opow.Clayton <- opower(copClayton, thetabase)) ################################################### ### code chunk number 25: opwer-def3 ################################################### theta0 <- opow.Clayton@tauInv(2/3) # will be 1.5 theta1 <- opow.Clayton@tauInv(.75) # will be 2 opC3 <- onacopula(opow.Clayton, C(theta0, 1, C(theta1, c(2,3)))) ################################################### ### code chunk number 26: U3-ex. 治 政 ################################################### 大 立 U3 <- rnacopula(500, opC3) ; stopifnot(dim(U3) == c(500,3)) ‧ 國. 學. ###################################################. ‧. ### code chunk number 27: opower-splom-def (eval = FALSE). sit. y. Nat. ###################################################. io. er. ## splom2(U3, cex = 0.4). al. n. ###################################################. ni Ch ### code chunk number 28: opower-splom U engchi. v. ################################################### print( splom2(U3, cex = 0.4) ) ################################################### ### code chunk number 29: opower-explore1 ################################################### round(cor(U3, method="kendall"), 3) ################################################### 34.
(40) ### code chunk number 30: opower-explore2 ################################################### rbind(th0 = c(L = opow.Clayton@lambdaL(theta0), U = opow.Clayton@lambdaU(theta0)), th1 = c(L = opow.Clayton@lambdaL(theta1), U = opow.Clayton@lambdaU(theta1))) ###################################################. 治 政 ### code chunk number 31: sessionInfo 大 立 ################################################### ‧ 國. 學. toLatex(sessionInfo()). ‧. ###################################################. sit. y. Nat. ### code chunk number 32: copula-version (eval = FALSE). io. al. packageDescription("copula")[c("Date", "Revision")]. n. ## my.strsplit(. er. ###################################################. Ch. n engchi U. iv. ). ################################################### ### code chunk number 33: copula-version ################################################### pd <- lapply(packageDescription("copula")[c("Date", "Revision")], function(ch) gsub("\\$",'', ch)) cat(pd[["Revision"]], "-- ", sub("^Date: +", '', pd[["Date"]]), "\n", sep="") ################################################### ### code chunk number 34: finalizing ################################################### options(op.orig) 35.
(41) ################################################### ### code chunk number 35: fitCopula ################################################### function (copula, data, method = "mpl", start = NULL, lower = NULL, upper = NULL, optim.control = list(NULL), optim.method = "BFGS", estimate.variance = TRUE) { if (method == "ml") fit <- fitCopula.ml(data, copula, start, lower, upper,. 治 政 optim.control, optim.method, estimate.variance) 大 立 else if (method == "mpl") ‧ 國. 學. fit <- fitCopula.mpl(copula, data, start, lower, upper,. ‧. optim.control, optim.method, estimate.variance). sit. y. Nat. else if (method == "itau"). io. er. fit <- fitCopula.itau(copula, data, estimate.variance). al. else if (method == "irho"). n. iv n C fit <- fitCopula.irho(copula, estimate.variance) h edata, ngchi U. else stop("Implemented methods are: ml, mpl, itau, and irho.") fit } 2. Contagion clc num_target = 101; X = Data(:,i); Y = Data(:,j); Sorted_X = sort(X); 36.
(42) Sorted_Y = sort(Y); X_Target = linspace(prctile(X,2.5),prctile(X,97.5),num_target); Weight = zeros(length(X),1) %OptimalPieceNum ~= 18 if use optknt function for i = 1 : num_target AddToTarget = 1 - (X - X_Target(i)).^2; AddToTarget(AddToTarget < 0) = 0; Weight = Weight + AddToTarget; end %Weight = ones(length(X),1);. 立. 政 治 大. %Get Function sp = m (Quadratic, local polynomial fitting). 學. ‧ 國. %Local Correlation of X<-->Y (Quadratic). ‧. MISE_Main = zeros(length(X),1);. y. sit. io. er. while 1 == 1. Nat. CurrentBandWidth = 1;. al. n. disp(CurrentBandWidth). i Ch Vector = Sorted_X(1 : CurrentBandWidth : end);U n engchi. v. try sp = spap2(Vector,3,X,Y,Weight); catch CurrentBandWidth = CurrentBandWidth + 1; continue end MISE_Main(CurrentBandWidth). =. var(fnval(sp,X))).*Weight); CurrentBandWidth = CurrentBandWidth + 1; 37. sum(((fnval(sp,X)-Y).^2. +.
(43) if (CurrentBandWidth >= length(X)) break end end MISE_Main(MISE_Main == 0) = Inf; BestSplineNum_Main = find(MISE_Main == min(MISE_Main)); Vector = Sorted_X(1 : BestSplineNum_Main : end); sp =spap2(Vector,3,X,Y,Weight); %sp = spap2(3,3,X,Y,Weight);. 治 政 %If you want to calculate the value, use fnval(sp,X_Interpolate) 大 to get Y 立 %value ‧ 國. 學. %If you want to see the result, use fnplt function. y. sit. io. al. er. Beta = sp_diff;. Nat. sp_diff = fnder(sp);. ‧. %Get Function Beta (differentiate function m):. n. %Local Correlation of X<-->Residual variance (= VAR(Y|X = x)) (Linear, %local polynomial fitting). Ch. engchi. i Un. v. MISE_VarY = zeros(length(X),1); CurrentBandWidth = 1; while 1 == 1 disp(CurrentBandWidth) Vector = Sorted_X(1 : CurrentBandWidth : end); try sp_VarY = spap2(Vector,2,X,(Y-fnval(sp,X)).^2,Weight); %sigma^2 catch CurrentBandWidth = CurrentBandWidth + 1; 38.
(44) continue end MISE_VarY(CurrentBandWidth) = sum(((fnval(sp_VarY,X)-(Y-fnval(sp,X))).^2 + var(fnval(sp_VarY,X))).*Weight); CurrentBandWidth = CurrentBandWidth + 1; if (CurrentBandWidth >= length(X)) break end end. 治 政 MISE_VarY(MISE_VarY == 0) = Inf; 大 立 BestSplineNum_VarY = find(MISE_VarY == min(MISE_VarY)); ‧ 國. 學. Vector = Sorted_X(1 : BestSplineNum_VarY : end);. ‧. sp_VarY = spap2(Vector,2,X,(Y-fnval(sp,X)).^2,Weight); %sigma^2. n. al. er. io. Std_X = std(X);. sit. y. Nat. %sp_VarY = spap2(20,2,X,(Y-fnval(sp,X)).^2); %sigma^2. Ch. engchi. i Un. v. %Use this to evaluate Rho value of value x0: Xm = prctile(X,50); %Median Beta_Xm = fnval(Beta,Xm); Rho_Xm = (Std_X*Beta_Xm)/(Std_X^2*Beta_Xm^2 + fnval(sp_VarY,Xm)).^0.5 Sigma_Xm = fnval(sp_VarY,Xm) ^ 0.5 Xl = prctile(X,2.5); %(0.025) Beta_Xl = fnval(Beta,Xl); Rho_Xl = (Std_X*Beta_Xl)/(Std_X^2*Beta_Xl^2 + fnval(sp_VarY,Xl)).^0.5 Sigma_Xl = fnval(sp_VarY,Xl) ^ 0.5 39.
(45) Z = (Rho_Xl - Rho_Xm) / (fnval(sp_VarY,Xm) + fnval(sp_VarY,Xl)).^0.5 if (Z > 1.65) disp('Contagion') else disp('Not Contagion') end. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 40. i Un. v.
(46) Reference. 賴亦豪、江福松、林煌傑 (2010),極端報酬下亞洲股市之蔓延效果:應用 Copula 分析法,《經濟與管理論叢》,6(2), 247-270。 賴柏志 (2004),關聯結構(copula)在信用風險管理之運用,金融風險管理季刊。 Ang, A., and Chen, J. (2002), “Asymmetric Correlations of Equity Portfolios,” Journal of Financial Economics, 63, 443-494. Arestis, P., Caporale, G.M., Cipollini, C., Spagnolo, N. (2005),“Testing for Financial Contagion Between Developed and Emerging Markets During the 1997 East Asian Crisis,” International Journal of Finance and Economics, 10(4), 359-367. Azad, S. (2009),“Efficiency, Cointegration and Contagion in Equity Markets: Evidence from China,”Japan and South Korea Asian Economic Journal,23(1),. 立. 政 治 大. ‧. ‧ 國. 學. 93-118. Bradley, B. and Taqqu, M., (2005),“How to Estimate Spatial Contagion between Financial Markets,”Finance Letters, 3 (1), 64-76. Bradley, B. and Taqqu, M., (2005),“Empirical evidence on spatial contagion between financial markets,”Finance Letters, 3 (1), 77-86. Chancharoenchai, K. and Dibooglu, S. (2006),“Volatility Spillovers and Contagion. n. al. er. io. sit. y. Nat. During the Asian Crisis: Evidence from six Southeast Asian Stock Markets,”Emerging Markets Finance and Trade, 42(2), 4-17. Chollete, L., Pena, V., and Lu, C. C. (2011),“International diversification: A copula approach,”Journal of banking and Finance, 35, 403-417. Duan, J. C., Gauthier G., Sasseville, C., and Simonato, J. G. (2006),“No Contagion, Only Independence: Measuring Stock Market Comovements,”Journal of Finance, 57(5), 2223-2261. Forbes, K. and Rigobon, R. (1999),“No Contagion, Only Independence: Measuring Stock Market Comovements,”Journal of Finance, 57(5), 2223-2261. Hong, Y., Tu, J., and Zhou, G. (2007),“Asymmetries in Stock Returns: Statistical Tests. Ch. engchi. i Un. v. and Economic Evaluation,”Journal of Multivariate Analysis, 20, 1547-1581. Hu, L. (2006),“Dependence patterns across financial markets: a mixed copula approach,”Applied Financial Economics, 16(10), 717-729. Joe, H. and Xu, J. J. (1996),“The Estimation Method of Inference Functions for Margins for Multivariate Models,”Technical Report, No. 166, Department of Statistics, University of British Columbia. Joe, H. (1997), “Multivariate Models and Dependence Concept, ” London: Chapman and Hall. 41.
(47) Lai, Y. H. and Tseng, J. C. (2010),“The Role of Chinese Stock Market in Global Stock Markets: A safe Haven or a Hedge?”International Review of Economics and Finance, 19, 211-218. Longin, F. A. and Solnik, B. (2001),“Extreme Correlation of International Equity Markets,”Journal of Finance, 56(2), 649-676. Pontines, V. and Siregar, R.Y. (2009),“Tranquil and Crisis windows, heteroscedasticity, and contagion measurement: MS-VAR application of DCC procedure,”Applied Financial Economics, 19(9), 745-752. Roncalli, T., Bouye, E., Durrleman, V., Nikeghbali, A., and Riboulet, G., (1959),“Copulas: an open field for risk management,”Warwick Business School Financial Econometrics Research Centre, Universal of Warwick, working Paper. Ruicheng, Y., Xuezhi, Q., and Tian, C., (2009),“CDO pricing using single factor copula model with stochastic correlation and random factor loading,”Journal of Mathematical Analysis and Applications, 350(1), 73-80.. 政 治 大 Sklar, A. (1959),“Fonctions de repartition a n dimensions et leurs marges,”Publication 立 s de l’Institut de Statistique de l’Universite de Paris, 8, 229-231. ‧. ‧ 國. 學. Steven, S. and Ng, W. L. (2009),“The Effect of Real Estate Downturn on the Link between REITs and the Stock Market,”Journal of Real Estate Portfolio Management, 15(3), 211-219. Yiu, M. S., Ho, W.Y., and Choi, D. F. (2010),“Dynamic correlation analysis of. n. al. er. io. sit. y. Nat. financial contagion in Asian markets in global financial turmoil,”Applied Financial Economics, 20(4), 345-354.. Ch. engchi. 42. i Un. v.
(48)
數據
Outline
相關文件
In my opinion, the financial statements give a true and fair view of the financial position of the HKSAR Government Scholarship Fund as at 31 August 2021, and of its
The above information is for discussion and reference only and should not be treated as investment
Warrants are an instrument which gives investors the right – but not the obligation – to buy or sell the underlying assets at a pre- set price on or before a specified date.
Quality Assessment and Compliance – SMC/IMC composition Major observations:. SMC did not comprise all the stakeholders as managers as required in the
HR policies (such as staff recruitment and performance management) not endorsed by SMC/IMC. SMC/IMC has not clearly set out criteria and guidelines on approving
Visit the following page and select video #3 (How warrant works) to show students a video introducing derivative warrant, then discuss with them the difference of a call and a
The current yield does not consider the time value of money since it does not consider the present value of the coupon payments the investor will receive in the future.. A more
Administrative Science Quarterly Journal of Accountingand Economics Journal of Accounting Research Journal of Applied Psychology Journalof Financial Economics.. Journal of Finance
