國立高雄大學亞太工商管理學系碩士在職專班
碩士論文
股票價格趨勢預測之研究
A study on stock price trends forecasting
研究生:林碁域
指導教授:陳宜伶 博士
誌謝
兩年的學業這麼一晃就過去了,當初入學想學的沒學到,倒是學到了更有價 值與效益的東西,算是柳暗花明吧。感謝諸位老師的教導、感謝一起合作過的同 學、感謝家裡的支持與父親的督促,就這樣吧。最後感謝一下高大,大地茫茫, 載德載物,我心惶恐,伏唯告之。兩年學程,如期已畢,唯苦唯艱,無怨無尤。 皇天后土,佑我高大,百業興旺,永念大德。 林碁域 謹誌 2016.7.21i
股票價格趨勢預測之研究
指導教授:陳宜伶博士 國立高雄大學亞太工商管理學系 學生:林碁域 國立高雄大學亞太工商管理學系碩士在職專班 摘要 股票市場是複雜多變的動態體系,其價格走勢直接影響著投資者的利益,因 而受到投資者們的廣泛關注。由於股價變化無常,投資者必然會遇到投資的風險, 因此投資時的規劃與預測之分析是非常重要的。本研究採用時間序列來預測分析 台灣上市公司之股價,以三家上市公司之股票為研究對象,比較三檔股票之預測 準確率,並模擬交易。結果顯示時間序列在預測當日股價下跌的趨勢有其準確性, 比較三檔股票的預測準確率則是股價波動較小之股票為佳,模擬交易的部分,其 中一檔股票獲利績效良好。此預測之結果與模擬之績效,可提供一般投資者、研 究者,或公司決策者之參考。 關鍵字:股票、股價、預測、時間序列ii
A study on stock price trends forecasting
Advisor: Dr. Yi-Ling Chen
Department of Asia Pacific Industrial and Business Management
National University of Kaohsiung
Student: Ji-Yu Lin
Department of Asia Pacific Industrial and Business Management
National University of Kaohsiung
Abstract
Stock market is a complex, changeful and dynamic system, and stock price trends affect the interest of investors, thus it attracts investors’ attention widely. Because stock price is fluctuating, and investors encounter inevitable risk, forecasting and analysis of investment planning is very important.
This research uses time series method to forecast the stock price of three Taiwan listed companies. Using time series to forecast the decreasing daily price trends is accurate. Comparing the accuracy of three stock price trends forecasting, the best one is less fluctuation in stock price. In simulating trading, one of the three objects is good performance. The empirical results provide the reference for investors, researchers, and policy makers.
iii
iv
目 錄
摘要...i 目錄...iv 表目錄...v 圖目錄...vi 第一章 緒論...1 第一節 背景與動機...1 第二節 研究目的及問題...2 第三節 研究流程...3 第二章 文獻探討...5 第一節 預測概說...5 第二節 股價預測相關文獻探討...11 第三章 研究方法...17 第一節 時間序列建模簡介...17 第二節 時間序列建模步驟...26 第三節 研究設計...29 第四章 研究結果...31 第一節 模式建構與交易模擬...31 第二節 交易模擬績效與預測準確比較...49 第五章 結論及建議...57 一、研究結論...57 二、後續研究與建議...57 參考文獻...59 一、中文文獻...59 二、英文文獻...60v
表目錄
表 3.2.1 理論 ACF 與 PACF 之特性...26 表 4.1.1 鴻海2016/03/01,09:01~10:00股價模式檢定之誤差表...33 表 4.1.2 鴻海 2016/03/01,10:01~10:10 股價預測表...33 表 4.1.3 鴻海2016/03/02,09:01~10:00股價模式檢定之誤差表...35 表 4.1.4 鴻海 2016/03/02,10:01~10:10 股價預測表...35 表 4.1.5 鴻海2016/03/03,09:01~10:00股價模式檢定之誤差表...37 表 4.1.6 鴻海 2016/03/03,10:01~10:10 股價預測表...37 表 4.1.7 佳格2016/03/01,09:01~10:00股價模式檢定之誤差表...39 表 4.1.8 佳格 2016/03/01,10:01~10:10 股價預測表...39 表 4.1.9 佳格 2016/03/02,09:01~10:00 股價模式檢定之誤差表...41 表 4.1.10 佳格 2016/03/02,10:01~10:10 股價預測表...41 表 4.1.11 佳格 2016/03/03,09:01~10:00 股價模式檢定之誤差表...43 表 4.1.12 佳格 2016/03/03,10:01~10:10 股價預測表...43 表 4.1.13 台泥 2016/03/01,09:01~10:00 股價模式檢定之誤差表...45 表 4.1.14 台泥 2016/03/01,10:01~10:10 股價預測表...45 表 4.1.15 台泥 2016/03/02,09:01~10:00 股價模式檢定之誤差表...47 表 4.1.16 台泥 2016/03/02,10:01~10:10 股價預測表...47 表 4.1.17 台泥 2016/03/03,09:01~10:00 股價模式檢定之誤差表...49 表 4.1.18 台泥 2016/03/03,10:01~10:10 股價預測表...49 表 4.1.19 模擬交易鴻海(2317)績效表(2016/03)...50 表 4.1.20 模擬交易佳格(1227)績效表(2016/03)...52 表 4.1.21 模擬交易台泥(1101)績效表(2016/03)...54vi
圖目錄
圖 1.1 研究流程圖...4
圖 2.1 預測方法分類圖...10
圖 3.2.1 AR (1)過程之 ACF 與 PACF...27
圖 3.2.2(a) AR(2)過程之 ACF 與 PACF...27
圖 3.2.2(b) ARIMA(2)過程之 ACF 與 PACF...28
圖 3.2.3 MA(0, 1)過程之 ACF 與 PACF...28
圖 3.2.4 三階段模式建構的流程與使用方法...29 圖 4.1.1 鴻海2016/03/01,09:01~10:00股價模式與走勢圖...32 圖 4.1.2 鴻海2016/03/01,09:01~10:00股價模式之殘差ACF與PACF圖...32 圖 4.1.3 鴻海2016/03/02,09:01~10:00股價模式與走勢圖...34 圖 4.1.4 鴻海 2016/03/02,09:01~10:00 股價模式之殘差 ACF 與 PACF 圖...34 圖 4.1.5 鴻海2016/03/03,09:01~10:00股價模式與走勢圖...36 圖 4.1.6 鴻海 2016/03/03,09:01~10:00 股價模式之殘差 ACF 與 PACF 圖...36 圖 4.1.7 佳格2016/03/01,09:01~10:00股價模式與走勢圖...38 圖 4.1.8 佳格 2016/03/01,09:01~10:00 股價模式之殘差 ACF 與 PACF 圖...38 圖 4.1.9 佳格2016/03/02,09:01~10:00股價模式與走勢圖...40 圖 4.1.10 佳格2016/03/02,09:01~10:00股價模式之殘差ACF與PACF圖...40 圖 4.1.11 佳格 2016/03/03,09:01~10:00 股價模式與走勢圖...42 圖 4.1.12 佳格2016/03/03,09:01~10:00股價模式之殘差ACF與PACF圖...42 圖 4.1.13 台泥2016/03/01,09:01~10:00股價模式與走勢圖...44 圖 4.1.14 台泥2016/03/01,09:01~10:00股價模式之殘差ACF與PACF圖...44 圖 4.1.15 台泥 2016/03/02,09:01~10:00 股價模式與走勢圖...46 圖 4.1.16 台泥2016/03/02,09:01~10:00股價模式之殘差ACF與PACF圖...46 圖 4.1.17 台泥2016/03/03,09:01~10:00股價模式與走勢圖...48
vii
1
第一章 緒論
第一節 研究背景及動機
預測是一種預估未來事件的藝術與科學。人們之所以做預測,是恐懼未來的 不確定性,無法控制。預估的方式可透過:(1)歷史資料及數學模式、(2)主觀或 直覺、(3)結合數學模式及主觀調整等方式來逹成。在這個經濟成長遲緩的時代, 低利率、高通膨使得生存環境更加嚴苛,尤其我國的薪資還倒退了十幾年,如此 財務規劃更顯重要,不僅是為了將來謀劃,更重要是避免薪資成長率小於通貨膨 脹的現況,故預測在此經濟時代更顯其重要性。 股 票 就 是 公 司 為 了 籌 措 資 金 所 發 行 的 有 價 證 券 ,可 買 賣 、 抵 押 以 及 轉 讓 ,其 變 現 性 高 ,是 很 常 見 的 投 資 工 具 。 股 票 價 格 (簡 稱 股 價 )則 是 隨 著 該 公 司 的 營 運 發 展、國 家 經 濟 的 衰 榮 以 及 市 場 的 各 種 因 素 做 起 伏。 由 Eugene Fama 於 1970 年所提出效率市場假說,並依市場效率性質提出了三種型 態: (1) 弱勢效率市場:過去的股價、消息都不具參考價值,弱勢效率越高,利用過 去的資料來分析未來的股價是非常不準的。 (2) 半強式效率市場:於股價充分反應了所有的公開資訊,當半強式效率越高, 依賴財報、經濟政治情況來做基本面分析,是沒有什麼效果的。 (3) 強式效率市場:股價充分反應了所有已公開和未公開的訊息,但所謂的未公 開訊息,實際上是已公開,且反應在股價上。投資人即便擁有內線消息,也 無法獲得高額報酬。 然而這些論點更顯股市有跡難尋、不易預料,並非其任何一種型態能蓋括之。 近年來,我國的投資工具的種類越見繁多,其中股票市場(簡稱股市)自然是 社會大眾非常熟悉的投資工具之一,然投資股票瞭解其價格走勢為第一要務,而 影響股票價格(簡稱股價)的因素眾多,起伏不定、難以捉摸,所以投資人常透過 預測分析股票漲跌的各種方法,其也各有所長,舉凡技術分析、基本面分析、產2 業分析、籌碼動能、價值投資法,其最終目的也是想在如此充滿變數的系統中, 尋找出獲得報酬的蛛絲馬跡,以便尋此模式來獲利。 凡事預則立,不預則廢,有事先的計畫與準備,才能獲得最後的勝利。對股 票投資者而言,股市變化趨勢預測與利潤獲取有著直接之聯繫,預測愈準確,其 績效愈高;對上市公司來說,股票指數反映了該公司的經營情況以及未來發展趨 勢,影響著整個公司的利益,是分析和研究該公司的主要技術指標;對國家的經 濟發展而言,股票預測研究同樣具有其重要性,因此對股市預測之研究具有重要 性。另外,預測這門領域的學問,亦是古老的獨立學術領域,本研究使用時間數 列(Time Series) (亦稱時間序列)進行預測股票,把研究對象之數據收集起來並建 立出模型,期望能收到預測股價的效果,藉此讓投資策略更加清晰明瞭。
第二節 研究目的及問題
某事件在發生之前,人們常意識到該事件可能會發生,從意識到發生之間有 一段時間的間隔,稱之為前置時間,這段間隔讓人們可以預測並做準備、做好計 畫。前置時間如果很短,就無法做計畫,反之,如果前置時間長、而且也能掌握 一些確定會影響結果的因素,那麼就可做預測。在股票價格走勢方面,前置時間 可能是幾年或幾月,也可能是幾天或幾小時,甚至於只有分鐘,真可謂股市風雲、 瞬息萬變,所以建立預測模式、做有效率的計畫更顯得重要。 于宗先(1972)將預測定義如下:「預測是對未被觀察事項(未知) 的一種說明。 所謂未被觀察事項不僅指未來的事項,也指已發生的事項。如果所涉及的包括這 兩種事項,則稱為廣義的預測(Prediction);如果所涉及的僅是未來的事項,則稱 為狹義的預測(Forecasting)」。 投資股票為個人理財的重要工具之一,然而因股票價格隨市場機制波動卻也 造成投資上的風險,因此如何選擇適當的股票買賣時機以確保獲利,一直是股票 投資者所關心的議題。為什麼要預測股價?因為預測股價,可在合適的、合理的3 價格買賣操作順利進行,有效地控制資金的進出。然而股市裡似是 80%賠錢 20% 贏錢。原因在於大多數投資者不熟悉使用預測工具,隨著大盤起伏,盲目的進出、 失去了平常心、也失去了金錢的控管,這種案例也偶有所聞。 本研究以鴻海精密工業股份有限公司(鴻海)、佳格食品股份有限公司(佳格)、 台灣水泥股份有限公司(台泥)之股價為預測對象。 採 用 定量客觀的方法,不 只 預 測 股 價 , 也 要 觀 察 不 同 類 股 是 否 適 用 於 時 間 序 列 模 型 。 資 料 以當日每 1 分鐘的收盤價,並收集一個月的資料來進行作預測。 而若依照于宗先(1972)的 定義。本研究的預測係屬狹義的預測(Forecasting),為使用過去時間數列資料以 預測未來。本研究有 四 個 目 的 : (1)建立時間序列模型預測鴻海、佳格、台泥在相同時段的股價及走勢。 (2)建立三檔股票在相同時段的最佳配適模式。 (3)比較三檔股票預測的準確率,使投資者的方向更清楚,以利投資策略之施 行。 (4) 將預測之股價搭配投資策略,進行一個月的模擬交易。
第三節 研究流程
本研究流程,先確定研究主題,經過文獻的探討、建構研究方法、套裝軟體 使用和蒐集三家個案公司的股價資料,再建立預測股價的時間序列模型,並比較 三家個案公司預測結果的準確率,最後提出結論與建議(如圖 1.1)。4 圖 1.1 研 究 流 程 圖 研究背景及動機、目的 文獻探討與彙整 建立研究方法 預測模式 研究結果與分析 結論與建議 套裝軟體使用
5
第二章 文獻探討
全 球 經 濟 環境一直在快速變動,企業或組織的因應能力愈顯重要,並做出 正確的決策,已成為企業或組織決勝商場、維繫生存的關鍵,因此如何對未知事 象洞燭先機,即事先準確地預測已是重要課題。首先本章將簡述研究中之關鍵字 及相關資訊,以利研究主題之明確性。第一節-預測概說---定義、目的與需求、 方法、方法之選用、;第二節-相關文獻探討,分別敘述如下:第一節 預測概說
對於預測,每個人或許可能因觀察角度不同而有不同的看法,有人認為預測 所面對的是未知的世界,因此對預測的準確度及真實性感到懷疑。事實上,人類 對預測已愈能掌握,預測也愈來愈準確,尤其是在經濟事務方面。 一、預測定義何謂「預測」,美國英文傳統字典(American Heritage Dictionary of the English Language)將「預測」定義為:「預先估計或計算,以產生對未來的推測」,此定 義顯示「預測」含有相當程度的理性與資料分析。然而,除了理性分析性的預測 外,袁建中 等(2005)提出一些預測之另類選擇: 1. 不作預測:即矇住眼睛面對未來,指忽略小變動或預測「萬事如常」。 2. 任何事情都可能發生:認為未來完全是賭博,做什事也影響不了,也因 此試著做預測是沒有意義的。 3. 光榮的過往:這代表一種緬懷光榮過去而疏忽未來的態度。 4. 窗簾式預測:是一種判斷,依循一個固定軌跡前進,似如老式窗簾。 5. 危險行動:此法可描述成「壓下警鈴按鈕」,似火燒眉毛,問題或危機已 發生立即採取行動,以試圖減輕、暫緩危機的衝擊。 6. 天才預測:需費心找到一個「天才」,然後詢問其「直覺預言」。
6 每一個決策者不可避免地在其心中都有某一種預測,股票價格走勢預測者亦如是。 故每一個決策者在「做」或「不做」預測的議題上,根本沒有可以選擇「毫不做 預測」的充分理由。唯一的選擇是「是否該預測是經由理性與具體的方法而獲得」; 抑是「是否經由某人下意識深層的直覺所獲得」。股票價格走勢預測方式,一般 人往往是這六種方式擇其一、二,甚至六種綜合採用。 二、預測的目的與需求 2 年、5 年就是短期,而 20 年就是長期,以時間來區隔「短期規劃」與「長 期規劃」不妥的,正確的方式應該是:「行動前的前置時間」與「達成願望/願景 所需的作業時間」(袁建中等,2005)。另一個區別「短期規劃」與「長期規劃」 是方法是,「短期規劃」:規劃者無法等待額外的訊息,許多決定是需要適當下的 狀況而定,而「長期規劃」:規劃者可以等待訊息的狀況。林聽明與吳水丕(1981) 描述「短期規劃」以三個月為主、「中期規劃」以三個月至二年間、「長期規劃」 指兩年以上之預測規劃。以一般人在股票價格走勢預測之規劃為例,「短期規劃」 為 1 個月、「中期規劃」為半年內、與「長期規劃」為半年以上。本研究則採用 「行動前的前置時間」之「短期規劃」為研究之設計與規劃。 預測是無法避免。袁建中等(2005)為科技預測(Forecast technology)提出九項 目的,但此一系列預測的目的,不外乎是爭取最大的利益,抑或是將損失降至最 低。此一觀念即是規劃,亦即是處所有採取行動前的事情。規劃不是處理未來的 行動,而是處理現在的行動。未來是如何,取決於現在做了哪些行動,藉由選擇 當下最佳的規劃,可形成未來的輪廓,現在行動會影未來的結果。預測規劃的目 的就是達到「美好的未來」的願望/願景。此目的亦正是股票操作/投資者的終極 目的。 大部分的商業決策根本即在預測顧客的需求。以股票操作/投資者而言之, 即是如何規劃逢低買進、逢高賣出,因此預測需求,須先由可以利用的資訊中找 出可以利用的需求型式。對某一產品/服務的需求依出現之順序所形成的型式,
7 予以重複觀察,即稱之為時間數列(Time Series)(楊明璧,2005)。五種常見的需求 時間數列基本型式如下: 1. 水平式(Horizontal):在固定不變的平均值周圍來回移動。 2. 趨勢性(Trend):在一段時間內水平值有系統的增加或減少的數列。 3. 季節性(Seasonal):即每天、每週、每月或每季重複相同需求增加或減少 的一種型式。 4. 循環性(Cyclical):指比較難預測,但在長時間下需求會呈現逐漸增加或 減少的現象。 5. 隨機性(Random):即需求的變異無法預測。 吳柏林(1999)指出,用上述 5 種需求之後 4 種來建構模式,基本上以相乘模式, 或相加模式考量之: 分析時間序列{Yt} = Tt × Ct × St × Rt (2.1) 分析時間序列{Yt} = Tt + Ct + St + Rt (2.2) 式中: Yt為時間序列, Tt、Ct、St、Rt分別為趨勢性、季節性、循環性、隨機性等變動 致於臺灣股市各股之時間數列,是以水平式、趨勢性、季節性、循環性、或隨機 性等型式變動,是需要規劃預測與分析究研的。 三、預測的方法 預測分析之所以重要,乃是由於它能作為解決多變的動態社會體系的基礎。 一般預測有三種特性(林茂文,2006): 1. 預測程序的連續性:由於周圍環境的動態性與多變性,合理的預測必須 不斷地調整資料和更新方法,而形成一種試誤循環的連續性預測程序, 始能使預測達到完善之境界。 2. 預測情況的不確定性:影響被預測事項的因素,往往很多且其相互影響 效應,不僅難於測度,而且也無法加以控制,以致未來預測的惰況是未
8 知的,也是不確定的。 3. 預測結果的真實性:在正常情況下,不論所用的資料如何正確,所用的 方法如何完善,但由於情況的不確定性,往往使得預測結果與事實真相 仍會有某種程度的差距。 預測方法非僅適用於某單一領域,在各領域的諸多預測方法之間,存在著許多相 似性。袁建中等(2005)指出四種預測方法: 1. 外插法:預測者從過去的現象推估出一種模式,此過去的資料是時間序 列。如,預測飛機未來的速度、經濟成長、…等。 2. 領先指標:採用一時間序列來獲得另一時間序列的未來行為資訊。如山 雨欲來風滿樓,當氣壓計下降通常是下雨的先兆,天氣預報員因此以某 一時間序列之氣壓資訊,預測未來之雨量。 3. 因果模型:上述外插法與領先指標法,只需找出過去與未來的相關性 (Correlation),而不需要知道未來所以承續過去之模型的因果因素。因果 模型即如其名,涵蓋「因與果」之間的資訊,如預測日蝕。 4. 機率法:前三種預測方法只產生一個單值預測,而機率法產生的一個範 圍可能值的機率分布,如預測明天下雨的機率是 30%。 綜言之,此四種預測方法均建立在過去的資料,時間序列,因此均屬於定量方法。 另楊明璧(2005)預測方法大致分為:定性(主觀)及定量(客觀)兩種。當在缺乏足夠 的歷史資料時,或擁有歷史資料卻有可能無法真實反映出某特定活動的影響;有 時候這些活動可能是未來才會發生,主觀的判斷法是可用的預測方法,其常用且 較為成功的方法為: 1. 銷售人員評估法:是由公司的銷售人員定期對未來需求作評估、整理彙 總而求出之預測值。此法似如股票名嘴、股市分析師。 2. 高階主管意見法:即綜合一位或多位管理人員的意見、經驗和技術上知 識,以求得一個單一預測。 3. 市場研究法:是以調查資料之蒐集來創造,並測試假設,以判別消費者
9 對產品/服務喜好的一種有系統之方法。 4. 德非法:指由一群匿名的專家達成共識的過程,三個臭皮匠勝過一個諸 葛亮。 股票價格走勢預測方法,一般人往往在這四種定性方法中擇其一、二,甚至四種 綜合運用。定量是以歷史數據的延伸或因果關係作為模型, 一般常用方法為: 1. 因果關係法,如廻歸分析。 2. 時間序列法,如(常用方法): (1) 成長模式:指數成長曲線、邏輯曲線、公貝茲曲線(Gompertz curve) 等 (2) 指數平滑法:將過去的資料,以特定的期數求移動平均值做為預測 值。 (3) 分解法:對時間數列四個特性:趨勢(T)、季節(S)、循環(C)、及隨機 (I)加以分析估計。 (4) ARIMA 模式(本研究採用之方法)。
(5) 類神經網路(Neural network):模擬人腦神經組織,經嘗試錯誤(Try and error)與修正記憶後得到自由模式(Model free),來做預測。
上述各種方法,將其分類(如圖 2.1)。定性及定量各有其優、缺點及其適用的時 間與範圍,使用者在預測前應先評估其適當性,以提高預測的品質。
10 圖 2.1 預測方法分類圖 四、如何選取預測方法 統計預測模式有很多種,如圖 2.1 所示。預測結果是否準確對系統經營、規 劃的成敗影響性很大。但在現實情況裡,要顧及成本及配合實務,如何選取合適 的預測方法?以下幾個因素可作為參考(吳柏林,1995): 1. 需要合種型式的預測--預測的型式有三種:點預測,區間預測及等第(rank) 預測。"2016 年經濟成長率為 2.24%"屬於點預測;"下周加權股價指數最 高點 95%信賴區間為 6500 至 6800",屬於區間預測;"第四季經濟景氣 指標將轉為紅燈或 A 級",屬於等第預測。 2. 要預測多久---這要看資料與決策的性質,有短期預測、中期預測、長期 預測。就以預測股價來說,只適合短期預測。 預測方法 定量(客觀)法 定性(主觀)法 1. 銷售人員評估法 2. 高階主管意見法 3. 市場研究法 4. 德非法 1. 成長模式 2. 指數平滑法 3. 分解法 4. ARIMA 5. 類神經網路 因果關係法 時間數列法 迴歸分析法
11 3. 要預測多少項目---整體而言,我們不須對影響系統之每項變數做預測。 過多變數的預測反而會模糊了系統的目標。在多變量模式建立過程中,4 個變數之系統結構已相當複雜。 4. 預測結果要準確到什麼程度---預測的準確性關係到管理決策的品質。但 精確度較高的預測,相對付出的成本與時間亦較高。 5. 系統結構是否轉變---由於系統結構性的轉變(Structure change),導致需求 或供給的時間序列走勢與過去迥異。預測者須配合動態變化的歷史演變, 建構符合目前狀況之模式。以預測股價來說,不同時段的模型自然不同, 若單以一種模型來預測一段時間之股價,準確率可能不高。 由於預測方法不斷的創新與進步,過去較偏向主觀經驗判定的定性預測,也 轉向較客觀之定量預測。影響定量預測快速發展的原因,主要有以下幾點(吳柏 林,1995): 1. 統計研究方法不斷的精進,更有效率的擷取、分析各種資訊。 2. 電腦功能不斷更新,快速處理龐大的數據,讓預測工作更容易即時完成。 3. 企業的規模及複雜性日益增加,人們很難迅速做出適當的決策,複雜的企 業結構使人們必須尋求較準確的預測模式。 4. 企業投注於研發的資源及資本支出的增加,若是錯估未來市場的供需程度, 將會造成不必要的損失甚至危及企業的生存。在這樣的危機意識之下,企 業體希望能用較佳的預測方法,將不確定性降到最低。
第二節 股票預測相關文獻探討
投資股票目的之一,是透過公開的市場交易機制,藉由股票的買進及賣出來 賺取其間的價差而獲取利潤,其操作方式包括現金買進、賣出,或是融資買進、 賣出及融券買進賣出等信用交易模式,然而希望藉由股票交易來獲利的目的卻是 一致的,因此,如何選擇股票投資標的以取得投資利益,一直是股票投資者關心12 的議題。股價預測的方法有很多,以國、內外的研究文獻為例,其中以時間序列 及類神經網路來進行預測,最多研究者使用,分別參考如下: 一、國外相關文獻 時間序列分析是建立在統計學、隨機過程理論的基礎上。早在 1920 年代及 1940 年代就有人提出時間序列分析的基本理論。時間數列分析最早是應用於工 程領域,直到 1970 年代才廣泛應用於統計學與經濟領域。之後 Box 與 Jenkins (1971)提出了以一系列自我迴歸移動平均模式(ARMA)為基礎,分析時間數列數 據的特徵和進行預測分析的可行方法,包括鑑定、估計、檢定與預測控制等步驟, 給時間序列分析的發展帶來了重大突破。Tiao & Box(1981)進一步將單變量時間 數列的 ARMA 模式發展到多變量時間數列的向量自我迴歸移動平均模式 (VARMA)。時間數列分析的另一個方面是非穩態型數列分析。由 ARMA 模式所 發展出非穩態數列的自我迴歸整合移動平均模式(ARIMA), Dickey & Fuller (1979)提出檢定時間數列非穩態與單位根的問題, Engle & Granger(1987)提出共 整合檢定等非穩態時間數列分析方法。Engle(1982)年提出自我迴歸條件異質變異 模式(ARCH)是時間序列分析中的一個非常重要的模式。
應用相關的時間序列於股票價格走勢預測之研究:Tang, Yang, & Zhou(2009) 結合新聞探勘與時間序列分析預測股價,該研究之研究對象為中國股票市場,研 究方法則是使用時間序列並結合新聞的有用訊息來預測股價,藉由新聞探勘的技 術,分析出的訊息能提升時間序列模式的準確度。結論顯示,預測股價趨勢的表 現良好。Adebiyi, Adewumi,& Ayo (2014)比較時間序列與人工神經網路於股價預 測,該研究以紐約股票市場為對象,研究方法則使用 ARIMA 模式及人工神經網 路,比較這兩種方法的預測準確率。結論顯示,人工神經網路的準確率優於 ARIMA 模式。Palit & Popovic(2000)利用人工神精網路預測非線性組合,該研究 之對像為溫度的時間序列資料,研究方法則使用指數平滑法、ARMA、ARIMA、 類神經網路、模糊類神精等方法來進行預測,比較平均誤差平方根(RMSE)、誤
13 差平方和(SSE)、平均絕對誤差(MAE)及平均誤差平方(MSE)的預測結果。結論顯 示,模糊類神經的表現最好。 一、國內相關文獻: 應用 ARIMA 相關的時間序列於股票價格走勢預測之研究:曹耀均、薛舜仁 (2011)以自我迴歸整合移動平均法在指數股票型基金之預測效果研究,該研究以 預測 ETF(台灣 50)收盤價為目標,且深入探討,檢視何種移動平均法(MA)的配 適位階對 ETF 最為適當。結論顯示,ARIMA(自我迴歸整合移動平均)預測能適 用於任何型態的資料,如金融、觀光、產品銷售等,因此對於一組複雜而且不知 道時間序列型態的數據相當適合。結論顯示,週資料預測的準確率約 50%~60% 左右,月資料僅 40%~50%左右,所以 ARIMA 並非完全適合用於 ETF 此金融商 品的型態資料。 蔡正修(2007)以台灣上市電子類股價指數走勢預測之研究,該研究主要是預 測電子股隔月之收盤價,進而觀察股價走勢,冀望能得到較高的準確率給投資者 做參考。研究方法則使用迴歸分析、時間序列和倒傳遞神經網路及適應性網路模 糊推論系統,建構預測模式來分析比較。結論顯示,時間序列的 ARIMA 模式最為 準確,適合用於投資決策作參考。 楊踐為、李家豪、類惠貞(2007)應用時間序列分析法建構台灣證券市場之預 測交易模型,該研究以時間序列分析法建立 ARIMA 與 ARIMA-GARCH 模型, 來 探 索 股 價 之 間 的 關 係 , 並 預 測 股 價 , 且 同 時 利 用 ARIMA 模 型 與 ARIMA-GARCH 模 型 預 測 結 果 , 進 行 模 擬 交 易 , 探 討 ARIMA 模 型 與 ARIMA-GARCH 模型可否獲得超額報酬。結論顯示,ARIMA-GARCH 模型比 ARIMA 模型還準確,兩模型都相當穩定。模擬交易的結果顯示,在考慮交易成 本的情形下,投資績效顯著地高於買入持有投資資策略的投資績效,同時風險也 較低。 陳執中(2006)台股加權指數隔月收盤價預測之研究,該研究使用了迴歸分析、
14 時間序列、類神經網路來預測台股加權指數隔月之收盤價。將三種模式比較後發 現,時間序列分析的模式較另兩種方法來的好。結論顯示,ARIMA 為較佳的方 法,推估原因為研究資料較適合時間序列分析,預測方法的使用應以資料特性而 決定,並無絕對優良的方法。 謬昆陵(2008)台灣上市鋼鐵類股價指數預測之研究,該研究對象為台灣上市 鋼鐵類股月收盤價,研究方法則使用迴歸分析、時間序列、倒傳遞類神經網路及 適應性網路模糊推論系統,預測鋼鐵類股隔月收盤價,來作比較分析。結論顯示, ARIMA 模式為最佳,但預測模式之優劣,取決於當時資料的特性與型態,並無 決對的結論。 連偉志(2011)台灣股價指數時間序列之研究,該研究對象為台股的加權平均 指數。研究方法則是建立時間序列模型單變量 ARIMA 模式、多變量 ARIMA 模 式、以及向量自我回歸模式,找出預測最準確的模型,並且探討匯率、國際股市 與台灣股票市場的相關性。結論顯示,最好的是單變量 ARIMA 模式,對台股影響 力最大的是美股。 吳行正(2008)台股加權指數於時間序列模型最適解之探討,該研究之目的是 在股票市場中,找出影響股價的因素,哪些變數受到股價影響。研究方法則是建 立時間序列單變量 ARIMA 模型和多變量 ARIMA 模型,比較日資料、月資料的 最市預測能力,並找出最能影響台股波動之變數。結論顯示,單變量 ARIMA 模 型以 ARIMA(8, 1, 7)-GARCH(3, 2)為日資料最適模型,ARIMA(2, 1, 3)-ARCH(2) 為月資料最適模型,最能影響台股的變數則是匯率市場。 王衍智(2004)台灣股票選擇權日內價格訂價模型研究--比較時間序列方法與 基因規劃方法,該研究以股票選擇權為對象。研究方法則是建立時間序列 ARMA 模型和使用基因演算法,來處理股票選擇權交易資料,比較不同模型找出最合適 者。結論顯示,ARMA 模型的績效最好,適應性最好的是時間序列模型。 涂雲懷(2010)台灣匯率預測模型在多頭或空頭市場之預測能力--總體經濟因 素及時間序列模型的比較,該研究以新台幣兌換美元的短期匯率為對象,研究方
15 法則使用時間序列,建構 ARIMA(p, d, g)和 GJR-GARCH(m, n)模型來預測匯率走 勢,並檢定短期匯率之波動,再以月交易資料來探討時間序列模型是否適用於匯 率,最後比較時間序列模型和經濟數據模型的預測準確度。結論顯示。運用 ARIMA(3, 1, 0)和 GJR-GARCH(1, 1)模型來預測匯率為最適,月資料所建構之模 型具有波動不對稱性和槓桿效果,經濟數據模型在空頭市場預測能力較好。 另外使用類神經網路表現較佳之文獻:蘇哲宇(2013)台灣加權股價指數整合 性預測之研究,該研究將台灣加權股價指數作為研究對象, 並利用技術指標作 為解釋變數,運用時間序列、倒傳遞類神經網路以及經驗模態分解法建立台灣加 權股價指數隔日收盤價之預測模型,並比較六個模型的優劣。結論顯示,統計方 法之預測優於倒傳遞類神經網路。 黃琦年(2004)統計方法與類神經網路應用於國內開放式股票型基金投資績 效分類及投資報酬率預測之研究,該研究之研究對象為股票型共同基金,目的是 建構績效分類模式及報酬分類模式,研究方法則使用倒傳遞神經網路、改良式倒 傳遞神經網路及統計方法。結論顯示,在預測的部分以改良式倒傳遞神經網路效 果最好。 吳月明(2006) 股票報酬率預測模式績效之研究-倒傳遞類神經網路與灰預測 之應用。該研究以台灣 50 之成份股為研究對象,目的是比較倒傳遞類神經網路 與灰預測模式,何者預測能力較佳。研究方法則是使用類神經網路、倒傳遞類神 經網路、灰預測模式及利用財務比率。結論顯示,倒傳遞類神經網路的預測效果 最好。 陳志龍(2006)運用類神經網路與技術指標預測股票型基金漲跌及交易時機 之研究--以臺灣 50 指數股票型基金為例,該研究以台灣 50 為研究對象,使用倒 傳遞類神經網路預測台灣 50 的漲跌趨勢,且利用規則式類神經網路與技術指標 判斷台灣 50 的買賣時機。結論顯示,類神經網路結合技術指標,有助於投資者 買賣時機。 尚有其他方法者,鍾任明、李維平、吳澤民(2007)運用文字探勘於日內股價
16 漲跌趨勢預測之研究,該研究整合歷史股價交易資料與新聞,建構台股個股日內 股價漲跌之預測模型。且利用文字分類器在財經新聞中,選出關鍵的訊息來協助 預測。研究方法則使用倒傳遞類神經網路,並模擬交易。結論顯示:預測漲跌有 81.4%的準確率,季報酬率則有 5.33%。 林茂文(2006)由於時間序列分析重視數據而不重視理論,常被認為是缺乏理 論的計量,但時間序列分析在應用方面,比迴歸方程與聯立方程組更好。再者計 量軟體的廣泛應用與電腦技術的進步,提升了人們處理數據的能力,使時間序列 分析持續的發展與重視,日後漸成為主流的計量分析方法。
17
第三章 研究方法
時間序列所能反映自然、與社會現象的發展過程和規律性,而進行預測其發 展趨勢。它是將某種統計指標的數值(如股價),按時間先後順序排到所形成的數 列,這數列是一組觀測值,這組數據經過一段時間定記錄期量測可以獲得,例如 上市、上櫃之股價就是很典型的時間序列的數據,這些數據代表了每天、每月觀 測得來,或是取自多年以前的一組數據。最重要的是,在做時間序列分析的時候, 要去嘗試預測未來的數據。時間數列的模型可以解釋過去的數據之意義,也可以 預測未來的結果。是否能做出成功的預測,對商場或科學領域十分重要。第一節 時間序列建模簡介
由文獻探討得知,有不少研究者於股票價格走勢預測方法中使用時間序列, 而此時間序列為離散型時間序列(Discrete time series),即股價每分鐘一個觀察值, 通常以{Zt}表示,即在時間為 t1、t2、…、tn 之觀察值𝐳𝐭𝟏、𝐳𝐭𝟐、… 𝐳𝐭𝐧。此時間數列亦是一個隨機過程(Stochastic process),倘此隨機過程為穩態(Stationary),則 {Zt}須滿足其過程中的期望值、變異數與自共變異數不變,即:
E[Zt]= μ ,Var[Zt] = Var[Zt+k] = γ0 ,Cov(Zt, Zt+k) = γk (3.1a)
ρk = γk / γ0 (3.1b) ∅𝐤𝐤 = 𝟏 𝛒𝟏 𝛒𝟐
…
𝛒𝐤−𝟐 𝛒𝟏 𝛒𝟏 𝟏 𝛒𝟏…
𝛒𝐤−𝟑 𝛒𝟏⋮
𝛒𝐤−𝟏 𝛒𝐤−𝟐⋮
𝛒𝐤−𝟑⋮ … ⋮ ⋯ ⋮
…
𝛒𝟏 𝛒𝐤 𝟏 𝛒𝟏 𝛒𝟐…
𝛒𝐤−𝟐 𝛒𝐤−𝟏 𝛒𝟏 𝟏 𝛒𝟏…
𝛒𝐤−𝟑 𝛒𝐤−𝟐⋮
𝛒𝐤−𝟏 𝛒𝐤−𝟐⋮
𝛒𝐤−𝟑⋮ … ⋮ ⋯ ⋮
…
𝛒𝟏 𝟏 ⁄ (3.1c)18
式中:μ 是期望值、γ0是變異數、與 γk、ρk與∅𝐤𝐤分別是落差 k 期之變異
數、自相關函數(Auto-Correlation Function, ACF)與偏自相關函數 (Partial Auto-Correlation Function, PACF),t 是任意時間、k 是落差。
其中,如{at}為白噪(White noise)過程是一個最簡單的穩態隨機過程、最簡單的時
間數列,即期望值為零、變異數為一定值與自共變異數為零,其模式為: E[at]= 0 ,Var[at] = 𝛔𝐚𝟐,Cov(at, at+k) = 0
at ~ WN(0, 𝛔𝐚𝟐) (3.2)
一般白噪符合常態分配,即稱此隨機過程為高斯過程(Gaussian process)。 分析時間數列須注意,其本身乃統計相關而非統計獨立,即前幾期觀察值、 當期、與後幾期觀察值,有某種程度的關係性存在,其間之相關程度以 ACF 及 PACF 衡量之。在實際情況,ACF 與 PACF 之理論值是未知的,可從觀察值(即 是樣本)中估計之,即是樣本 ACF 與 PACF。一般稱 ACF 與 PACF 即是樣本 ACF 與 PACF。一組時間數列{Zt},其樣本平均值為𝐳̅、落差 k 期的ACF為𝛒̂𝐤 與 PACF
為𝛒̂𝐤𝐤 分別如下(Wei, 2006): 𝛒̂𝐤 = 𝛄̂𝛄̂𝐤 𝟎 = ∑𝐧−𝐤𝐭=𝟏(𝐙𝐭−𝐙̅)(𝐙𝐭+𝐤−𝐙̅) ∑𝐧𝐭=𝟏(𝐙𝐭−𝐙̅)𝟐 = 𝛒̂−𝐤 k = 0, 1, 2…. (3.3) 式中𝐳̅ = ∑𝐧𝐭=𝟏𝐳𝐭⁄𝐧 ∅̂𝐤+𝟏,𝐤+𝟏 = 𝛒̂𝐤+𝟏−∑𝐤𝐣=𝟏∅̂𝐤𝐣𝛒̂𝐤+𝟏−𝐣 𝟏−∑𝐤𝐣=𝟏∅̂𝐤𝐣𝛒̂𝐣 (3.4a) ∅̂𝐤+𝟏,𝐣 = ∅̂𝐤𝐣 − ∅̂𝐤+𝟏,𝐤+𝟏 ∅̂𝐤,𝐤+𝟏− 𝐣 j = 1, 2, 3,….k (3.4b) ACF 與 PACF 在預測模式之建構時,模式判定上扮演決定性角色。
時間數列中之自我迴歸整合移動平均 (Autoregressive Integrated Moving Average,ARIMA)為最常見之分析模式,此模式係根據過去的歷史資料,求得一 個合適的機率模式,用來表示這些資料和時間之相關性,一旦模式建立後,便可
19
對未來的狀況做一較為準確地預測。ARIMA 模式整合三個時間數列:自我迴歸 (Auto-Regressive,AR) 模式、移動平均(Moving Average,MA)模式、及差分 (Difference)處理,以下分別述之。 一、p 階自我迴歸 AR(p) 時間序列{Zt}在時間為 t1、t2、… tp…、tn之觀察值分別為zt1、zt2、…ztp… ztn,倘當期觀察值以過去 p 期觀察值的加權,及當期之隨機誤差所組成,稱之 為 p 階自我迴歸,以 AR(p)表示之,其模式為: żt = φ1żt−1+ φ2żt−2 +…+ φpżt−p + at (3.5a) 式中żt = zt - μ
為求簡示,常利用後移運算子(Backward shift operator) B 來表示時差(Time lag), 如,以zt 為例,落後一期的觀察值 zt-1,則 zt-1 = Bzt、落後二期的觀察值 zt-2,則 zt-2 = Bzt-1 = B2zt、….以此類推,AR(p)模式藉由後移運算子 B,將(3.5)式改寫為 żt - φ1żt−1- φ2żt−2 -…- φpżt−p = at zt - φ1Bżt - φ2B2żt-…- φpBpżt = at (1 - φ1B- φ2B2-…- φpBp) żt = at φp(B)
𝐳̇
𝐭 = at (3.5b) 式中:φp(B) = (1 - φ1B- φ2B2-…- φpBp), φi為自迴歸係數,C 為常數項,at ~ WN(0, 𝛔𝐚𝟐)。 Wei (2006)指出∑𝐩𝐣=𝟏|𝛗𝐣 | < ∞,AR(p)是可逆的(Invertible),此過程為穩態之條件: φp(B) = 0 之所有根必須落於單位圓之外。 當模式參數估計完成後,自然是從事預測,此亦是本研究的目的,茲簡單進 行 AR(1)模式預測之推導,由(3.5)式知 AR(1): 𝐳̇𝐭 = φ1𝐳̇𝐭−𝟏+ at ż̂t(1) = φ1żt , ż̂t(2) = φ1ż̂t(1) = φ12żt , …., ż̂t(n) = φ1nżt ,20 ż̂t(n) = φ1nżt , ẑt(n) = μ + φ1n(zt− μ) (3.6) 式中,𝐳̂𝐭(𝐧)是預測至時間 n。 二、q 階移動平均 MA(q) 時間數序{Zt}在時間為 t1、t2、… tp…、tn之觀察值分別為zt1、zt2、…ztp… ztn,倘當期觀察值以過去 q 期的隨機誤差的加權,及當期之隨機誤差所組成, 稱之為 q 階移動平均,以 MA(q)表示之,其模式為: żt = at - θ1at-1 - θ2at-2 -…- θqat-q (3.7a) 𝐳̇𝐭 = θq(B) at (3.7b) 式中:θq(B) = (1 - θ1B- θ2B2-…- θqBq), θi為移動平均係數,at ~ N(0, 𝛔𝐚𝟐)。 Wei(2006)指出 1 + 𝛉𝟏𝟐 + 𝛉𝟐𝟐 +….+ 𝛉𝐪𝟐<∞,有限的 MA(q)模式是穩態的;此過程 θq(B) = 0 之所有根必須落於單位圓之外,則是逆性的。總之,AR(p)過程均可轉
換成MA(∞)過程,同理,任可逆 MA(q)過程可轉換成 AR(∞)過程,即穩態 AR(p) 過程與可逆性MA(∞)過程之間,存在對偶(Duality)關係。茲簡單進行 MA(1)模式 預測之推導,由(3.7)式知 MA(1): 𝐳̇𝐭 = at - θ1at-1 ż̂t(1) = - θ1at = - θ1{żt− ż̂t−1(1)}, ẑt(1) = μ - θ1{zt− ẑt−1(1)}, (3.8a) ż̂t(2) = - θ1at+1 = 0 ,..., ẑt(n) = μ (3.8b) 式中,𝐳̂𝐭(𝟏)是第 1 個預測值,𝐳̂𝐭(𝐧)至時間 n。
21 當 MA(1)執行第 1 個預測值時,以(3.8a)式計算之。然在第 2 個(含)預測後,其預 測值均為μ。 三、(p, q)階自我迴歸移動平均 ARMA(p, q) 時間序列{Zt}在時間為 t1、t2、… tp…、tn之觀察值分別為zt1、zt2、…ztp… ztn,倘當期觀察值以過去 p 期觀察值的加權,及當期之隨機誤差,並結合過去 q 期的隨機誤差的加權,及當期之隨機誤差所組成,稱之為(p, q)階自我迴歸移動 平均 ARMA(p, q),其模式即(3.5)式加上(3.6)式為: żt = φ1żt−1+ φ2żt−2 +…+ φpżt−p + at - θ1at-1 - θ2at-2 -…- θqat-q (3.9a) φp(B) żt= θq(B)at (3.9b) 式中:φp(B) = 1 - φ1B- φ2B2-…- φpBp ,θq(B) = 1 - θ1B- θ2B2-…- θqBq, φi、 θi為係數,C 為常數項,at ~ N(0, 𝛔𝐚𝟐)。 Wei (2006)指出因為 ARMA(p, q)模式為可逆的,則θq(B) = 0 之所有根必須落於 單位圓之外;為了穩態的,則φp(B) = 0 之所有根必須落於單位圓之外。故各係 數: -1< φi < 1; -1< θi < 1 (3.10)
同時,當ARMA(p, 0) = AR(p);ARMA(0, q) = MA(q)。茲簡單進行 ARMA(1, 1) 模式預測之推導,即是 AR(1)與 MA(1)結合地預測,由(3.9)式知 ARMA(1, 1):
żt = φ1żt−1+ at - θ1at-1 ż̂t(1) = φ1żt - θ1{żt− ż̂t−1(1)} ẑt(1) = μ + φ1(zt− μ) - θ1{zt− ẑt−1(1)} (3.11a) ż̂t(2) = φ1ż̂t(1), ż̂t(3) = φ1ż̂t(2) = φ12ż̂t(1),…, ż̂t(n) = φ1n−1ż̂t(1) ẑt(n) = μ + φ1n−1{ż̂t(1)}, n ≧ 2 (3.11b) 當 ARMA(1, 1)執行第 1 個預測值時,以(3.11a)式計算之。然在第 2 個(含)預測後,
22 以(3.11b)式計算之。 四、(p, d, q)階自我迴歸整合移動平均 ARIMA(p, d, q) 上述三個模式,AR(p)、MA(q)、ARMA(p, q),建構在穩態過程的基礎上, 即其過程中滿足期望值、變異數與自共變異數不變的條件,然而時間數列的變動 趨勢並不一定呈現穩態過程,此模式顯得過於理想化。如在匯率、期貨、股票等 資料中,其間時間數列走勢常呈現高者愈高、低者愈低。此資料沒有固定的平均 值,且趨勢飄浮不定,因此若時間數列呈現非穩態過程,則可採用差分方式處理, 將非穩態過程的時間數列化為穩態過程。時間數列{Zt}經過差分以產生穩態過程 的序列稱之為(p, d, q)階自我迴歸整合移動平均模式,ARIMA(p, d, q)模式為 φp(B)(1 – B)d zt = θ0 + θq(B)at (3.12) 式中:d 為差分階次,θ0為參數,at ~ N(0, 𝛔𝐚𝟐)。 Wei (2006)指出穩態的 AR 模式運算子φp(B) = (1 - φ1B- φ2B2-…- φpBp),與可逆 的MA模式運算子θq(B) = 1 - θ1B- θ2B2-…- θqBq並非適用各一般因子。當 d = 0 與 d>0,參數 θ0扮演非常不同的角色,d = 0 時,此過程為是穩態的,則 θ0 = μ(1 - φ1B- φ2B2-…- φpBp) (3.13)
d≧1,參數θ0稱之為確定的趨勢項(Deterministic trend term)。總之,ARIMA(p, d,
q)模式,當 p = 0,則為稱為整合移動平均(Integrated Moving Average),IMA(d, q) 模式。茲簡單進行 ARIMA(1, 1, 1)模式預測之推導,即是差分 1 階次與 ARMA(1, 1)結合地預測,由(3.12)式知 ARIMA(1, 1, 1): 1 階差分: ∆żt = żt - żt−1 ARMA(1, 1): żt = φ1żt−1+ at - θ1at-1
23 1 階差分結合 ARMA(1, 1),即 ARIMA(1, 1, 1): ∆żt= φ1∆żt−1+ at - θ1at-1 , (zt – zt-1) – μ = φ1{(zt -1 – zt-2) – μ}+ at - θ1at-1 , ẑt(1) = zt + μ + φ1{(zt – zt-1) – μ}- θ1{zt− ẑt−1(1)} (3.14a) ẑt(2) = ẑt(1)+ μ + φ1{(ẑt(1) – zt) – μ} (3.14b) ẑt(3) = ẑt(2)+ μ + φ1{(ẑt(2) –ẑt(1)) – μ} ,…., ẑt(n) = ẑt(n − 1)+ μ + φ1{(ẑt(n − 1) –ẑt(n − 2)) – μ} (3.14c) n ≧ 3 當 ARMA(1, 1, 1)執行第 1 個預測值時,以(3.14a)式計算之、第 2 個預測值時, 以(3.14b)式計算之。然在第 3 個(含)預測後,以(3.14c)式計算之。 五、參數估計與模式檢定
在以 ACF 與 PACF 確定模式後,為建立 ARIMA(p, d, q)模式,(3.12)式中之 各個參數須予以估計之,即是完成μ、 θ0、 𝛔𝐚𝟐、φi與θi之計算。參數估計的方
法,一般以動差法(Moments Method)、最小平方估計法(Least Squares Estimation, LSE),與最大概似估計法(Maximum Likelihood Estimation, MLE)三種。其中, MLE 由英國統計學家費雪(R. A. Fisher)於 1912 ~ 1922 年提出,其主要的觀念是 假定所有抽出的樣本資料,為所有可能樣本中出現機率最大的樣本;因此 MLE 即根據母體機率密度函數,求得一估計式使其聯合機率密度函數 P, (Joint Probability Density Function) (即概似函數)的值最大;而此估計值應很接近母體參 數(Aldrich, 1997)。以 ARMA(p, q)之 MLE 為例(Wei, 2006)
𝐳̇𝐭 = φ1𝐳̇𝐭−𝟏+ φ2𝐳̇𝐭−𝟐 +…+ φp𝐳̇𝐭−𝐩 + at - θ1at-1 - θ2at-2 -…- θqat-q (3.15a)
式中:𝐳̇𝐭 = zt – μ,at ~ N(0, 𝛔𝐚𝟐)
24 at = θ1at-1 + θ2at-2 +…+ θqat-q + 𝐳̇𝐭 - φ1𝐳̇𝐭−𝟏- φ2𝐳̇𝐭−𝟐 -…- φp𝐳̇𝐭−𝐩 (3.16) 參數μ、𝛔𝐚𝟐、φ 與 θ 是最大概似之函數, lnL*(μ, 𝛔𝐚𝟐, φ, θ) = - 𝟐𝐧ln2π𝛔𝐚𝟐 - 𝐒∗(𝛗,𝛍,𝛉)𝟐𝛔 𝐚 𝟐 (3.17) 式中 S*(μ, φ, θ) = ∑𝐧𝐭=𝟏𝐚𝐭𝟐(𝛍,𝛗, 𝛉|𝐙∗, 𝐚∗,𝐙) (3.18) (3.18)式稱之為條件平方和函數。設假 ap = ap-1 =…= ap+1-q = 0,從 t ≧ (p + 1)計算 起,則(3.18)式變為: S*(μ, φ, θ) = ∑𝐧𝐭=𝐩+𝟏𝐚𝐭𝟐(𝛍,𝛗, 𝛉|𝐙) (3.19) 此式廣泛運用於電腦程式中,計算出參數μ、φ 與 θ 之估計值,𝛍̂、𝛗̂與𝛉̂;續之, 計算出參數𝛔𝐚𝟐之估計值,𝛔̂ 𝐚 𝟐: 𝛔̂𝐚𝟐 = S*(𝛍̂、𝛗̂、𝛉̂) / N(d.o.f) (3.20) 式中:N(d.o.f)為自由度的數目。如此即可計算得 ARMA(p, q)模式之參數。 當完成ACF 與 PACF 確定模式,及 ARIMA(p, d, q)模式參數之估計後,即 須進行模式之檢定,此為預測續效,即是查看預測誤差大小。預測誤差之衡量:
1. 預測誤差--即某時期下的預測值與實際的觀察值間之差:
Et = Rt - Ft (3.21)
式中:Et =第 t 期預測誤差,Rt =第 t 期實際的觀察值,Ft=第 t 期預測值
2. 預測誤差的累積和(Cumulative Sum of Forecasting Errors, CFE)--衡量總 預測誤差:
CFE = ΣEt (3.22)
3. 預測誤差的平均:
𝐄̅ = CFE / n (3.23)
25 MSE = ∑𝐄𝐭𝟐/𝐧 (3.24) 5. 標準差(Standard Deviation) σ = √∑[𝐄𝐭− 𝐄]̅𝟐 (𝐧 − 𝟏) ⁄ (3.25)
6. 平均絕對差(Mean Absolute Error, MAE)
MAE =Σ|Et| / n (3.26)
7. 平均絕對誤差百分比(Mean Absolute Percent Error, MAPE)
MAPE =[Σ|Et| /Dt]100 / n (3.27)
8. 均方根誤差(Root Mean Square Error, RMSE)
RMSE =√∑ 𝐄𝐭𝟐
𝐧
⁄ (3.28)
如果 MSE、σ、MAE 很少,預測值一般會非常接近實際的觀察值;若數值 很大,表示預測誤差較大的可能性高。MAE 是衡量預測誤差的一個最為常用的 方式(楊明璧,2005)。Chai 與 Draxler (2014)指出用 RMSE 與 MAE 時,以 RMSE 績效為佳。另外誤差亦稱之為殘差,時間數列分析最重要的事情是,殘差必須是 白噪音(石村貞夫,2005)。
9. AIC 與 BIC--Akaike (1973, 1974)指出評估模式配適品質(Goodness of Fit) 二 種 模 式 資 訊 準 則 ,AIC (Akaike’s Information Criterion) 與 BIC (Bayesian Information Criterion)
AIC(M) = n ln𝛔̂𝐚𝟐 + 2M (3.29) BIC(M) = n ln𝛔̂𝐚𝟐 – (n – M)ln(1 – M/n) + M ln n + M ln [(𝛔̂𝐳 𝟐/𝛔̂𝐚 𝟐 − 𝟏)/𝐌] (3.30) 式中:n 為樣本數、M 為參數個數、𝛔̂𝐚𝟐是最大概似估計𝛔 𝐚 𝟐之估計值、
26
𝛔̂𝐳 𝟐為數列之樣本變異數。
第二節 時間序列建模步驟
根據Box & Jenkins 提出建立一個合適之ARIMA模式,需經過下列三步驟, 主要是利用數列資料的ACF和PACF型態來判斷應採用何種ARIMA模式,其後再 估計此模式的參數,並檢定預測殘差值,以診斷該模式是否正確。若不符合統計 檢定,則再行修正模式,重新估計檢定。
1. 模式識別(Identification):決定 p, d, q 值,利用樣本估計的 ACF 和 PACF 作為判斷依據。由 ACF 判斷時間數列{Zt}是否為穩態過程,若 ACF 不會
很快消失,但以線性方式逐漸遞減,表示資料為非穩態過程,可用差分使 非穩態過程轉為穩態過程。當{Zt}已經是穩態過程後計算其 ACF 和 PACF,
其研判方法如下表 3.2.1,及 AR(1)、AR(2)與 MA(1)之 ACF 和 PACF 參考 圖 3.2.1, 3.2.2,與 3.2.3 所示。 表 3.2.1 理論 ACF 與 PACF 之特性 模式 ACF PACF AR(p) 逐漸消失(指數遞減或正弦波遞減) p 階後立即消失 MA(q) q 階後立即消失 逐漸消失(指數遞減或正弦 波遞減) ARMA(p,q) 指數遞減或正弦波遞減 指數遞減或正弦波遞減
27 圖 3.2.1 AR (1)過程之 ACF 與 PACF (a) φ1>0 ACF 1 -1 1 (a) φ1>0 PACF -1 (b) φ1<0 ACF 1 -1 1 (b) φ1<0 PACF -1 (a) φ1>0, φ2>0 ACF 1 -1 1 (a) φ1>0, φ2>0 PACF -1 (b) φ1>0, φ2<0 ACF 1 -1 1 (b) φ1>0, φ2<0 PACF -1
28
圖 3.2.2(a) AR(2)過程之 ACF 與 PACF
圖 3.2.2(b) ARIMA(2)過程之 ACF 與 PACF
(d) φ1<0, φ2<0 ACF 1 -1 1 (c) φ1<0, φ2>0 PACF -1 (c) φ1<0, φ2>0 ACF 1 -1 1 (d) φ1<0, φ2<0 PACF -1 1 (a)θ1>0 ACF -1 (a)θ1>0 PACF 1 -1 1 (b) θ1<0 PACF -1 (b) θ1<0 ACF 1 -1
29
圖 3.2.3 MA(0, 1)過程之 ACF 與 PACF
2. 參數估計(Estimation):在 p、d、q 次序決定後,接下來就是估計參數值, 以決定各項落遲變數對預測序列之影響程度。 3. 模式檢定(Diagnostic):模式認定及估計完成後,接下來檢查誤差項是否符 合常態、同質變異、無自我相關之白噪的隨機過程。如果不為白噪音,表 示模式配適不佳,須重新認定及估計。整個步驟過程說明如下(圖 3.4)所 示。 圖 3.2.4 三階段模式建構的流程與使用方法
第三節 研究設計
袁建中等(2005)所示:「短期規劃」與「長期規劃」,應該是:「行動前的前 置時間」與「達成願望/願景所需的作業時間」。本研究探討的是預測短期股價, 作為進出賣買之決策,即是進出賣買行動前的前置時間,作為預測時間;針對研 究對象,選取其數據,時段為民國 105 年 3 月 1 日至民國 105 年 3 月 31 日。預 測規劃之該時段正處於一個台股大盤上漲的趨勢,加上權值股及金融股的拉抬, 不少類股也紛紛上漲,適合投資者短期操作。在操作期間需選擇財務結構良好的 公司之股票,被套住的時候,投資者亦莫驚慌,畢竟該公司之股東權益報酬率是 不錯的,長期持有也能有所獲。預測規劃這一個月的數據顯示,每日 13:30 分產 模式識別 參數估計 模式檢定 預測 識別方法 ACF 與 PACF 估計方法 MLE 檢定方法 穩態 R2 , R2 RMSE, MAPE, MAEMaxAPE, MaxAE 標準化 BIC
30 生大量的成交量,不論當天是收高或收低,短線的投資者都不願意抱股票過夜, 頻繁的進出所損失的手續費、證交稅是很可觀的。因此,本研究除了利用時間數 列來預測該時段研究對象之股價,並且搭配投資策略來測試短期的操作能否獲利。 在預測規劃上,以每日的 10:01 利用前一小時(即 09:01 ~ 10:00)的數據來建立模 式,並進行股價及走勢預測,本研究之投資策略為,進場條件:預測走勢平穩、 向上則進場,進場時間 10:05,買入一張。出場條件:進場當天的 13:30,若當天 股價≧手中持有股票 0.5 元,就出場,否則必須一直持有。進行一個月的測試與 分析,來評估研究對象股價時間數列之模式與預測之準確性。
31
第四章 研究結果
如上所述,本研究預測規劃,選取研究對象之股價數據,時段為民國 105 年 3 月 1 日至民國 105 年 3 月 31 日,投資策略是預測短期股價。在該時段每日 的 10:01 利用前一小時的數據,即是 09:01 至 10:00 時段,進行預測模式建立, 觀看股價走勢,符合進場條件則進場。若不符合出場條件,則必須持有,進行一 個月的交易模擬。因篇幅限制,本研究只附上 3 檔股票 3/1~3/3 之數據與預測及 模擬交易。(數據來源:元大證券的看盤軟體, yeswin 越是贏)第一節 模式建構與交易模擬
由於統計軟體不斷精進,當人們在使用SPSS-20進行時間序列分析時,已不 需要經過模式識別、參數估計、模式檢定這三個步驟(如圖3.4)來逐項求得最佳配 適模式,SPSS-20裡的Expert Modeler會直接透過數據,建構出一個最佳配適模式 (IBM Manual, 2012)。本研究使用SPSS統計軟體,理由在於它具有豐富的統計分 析的手法,而且是世界性普及的手法,可用性也是採用的理由之一。 一、個案研究一(研究對象:鴻海) 模擬一 預測規劃:自105年3月1日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(0,1, 0),其模式檢定各項誤差在7.6% ~10.9%,如表4.1.1所示。 模式與預測結果如圖4.1.1。圖4.1.2其模式之ACF與PACF, 由該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符 合時間序列基本要求。 預測分析:走勢向上(如圖4.1.1)。股價預測結果77.5 ~ 77.6元(如表4.1.2)。 選擇10:05進場買入1張,股價為77.3元。
32
買賣決策:當日13:30之股價大於等於買入價的0.5元則賣出,否則持有。 13:30股價為77.7元,故持有,俟日後一併賣出。
圖4.1.1 鴻海2016/03/01,09:01~10:00股價模式與走勢圖
33
表4.1.1 鴻海2016/03/01,09:01~10:00股價模式檢定之誤差表
MAE MAPE RMSE
0.076 0.098 0.109 表4.1.2 鴻海2016/03/01,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 77.5 77.5 77.5 77.5 77.6 77.6 77.6 77.6 77.6 77.6 UCL 77.7 77.8 77.9 78.0 78.0 78.1 78.2 78.2 78.2 78.3 LCL 77.3 77.2 77.2 77.1 77.1 77.0 77.0 77.0 76.9 76.9 模擬二 預測規劃:自105年3月1日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(1, 0, 0),其模式檢定各項誤差在5.9% ~ 8.3%,如表4.1.3所示。模 式與預測結果如圖4.1.3。圖4.1.4其模式之ACF與PACF,由 該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符合 時間序列基本要求。 預測分析:走勢向上(如圖4.1.3)。股價預測結果78.5 ~ 78.6元(如表4.1.3)。 選擇10:05進場買入1張,股價為78.5元。 買賣決策:當日13:30之股價大於等於買入值的0.5元則賣出,否則持有。 13:30股價為79.5元,將本日、與0301日買入之股票賣出,獲 利為2800元。
34
圖4.1.3 鴻海2016/03/02,09:01~10:00股價模式與走勢圖
35
表4.1.3 鴻海2016/03/02,09:01~10:00股價模式檢定之誤差表
MAE MAPE RMSE
0.059 0.075 0.083 表4.1.4 鴻海2016/03/02,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 78.5 78.5 78.5 78.5 78.5 78.5 78.6 78.6 78.6 78.6 UCL 78.7 78.7 78.8 78.8 78.8 78.8 78.9 78.9 78.9 78.9 LCL 78.3 78.3 78.3 78.3 78.3 78.3 78.3 78.3 78.3 78.3 模擬三 預測規劃:自105年3月3日9點01分至10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(0, 0, 3),其模式檢定各項誤差在5.0% ~ 7.5%,如表4.1.5所示。模 式與預測結果如圖4.1.5。圖4.1.6其模式之ACF與PACF,由 該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符合 時間序列基本要求。 預測分析:走勢向下(如圖4.1.5) ,不進場。股價預測結果80.2 ~ 80.1元 (如表4.1.6)。 買賣決策:當日13:30之股價大於等於買入值的0.5元則賣出,否則持有。 13:30股價為80.5元,故持有。
36
圖4.1.5 鴻海2016/03/03,09:01~10:00股價模式與走勢圖
37
表4.1.5 鴻海2016/03/03,09:01~10:00股價模式檢定之誤差表
MAE MAPE RMSE
0.050 0.062 0.075 表4.1.6 鴻海2016/03/03,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 80.2 80.2 80.2 80.1 80.1 80.1 80.1 80.1 80.1 80.1 UCL 80.3 80.4 80.4 80.4 80.4 80.4 80.4 80.4 80.4 80.4 LCL 80.0 80.0 79.9 79.9 79.9 79.9 79.9 79.9 79.9 79.9 二、個案研究二(研究對象:佳格) 模擬一 預測規劃:自105年3月1日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(1, 1, 0),其模式檢定各項誤差在4.4% ~ 9.7%,如表4.1.7所示。模 式與預測結果如圖4.1.7。圖4.1.8其模式之ACF與PACF,由 該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符合 時間序列基本要求。 預測分析:走勢平穩(如圖4.1.7)。股價預測結果83.0元(如表4.1.8)。選擇 10:05進場買入1張,股價為83元。 買賣決策:當日13:30之股價大於等於買入值的0.5元則賣出,否則持有。 13:30股價為83.2元,故持有,俟日後一併賣出。
38
圖4.1.7 佳格2016/03/01,09:01~10:00股價模式與走勢圖
39
表4.1.7 佳格2016/03/01,09:01~10:00股價模式檢定之誤差表
MAE MAPE RMSE
0.044 0.053 0.097 表4.1.8 佳格2016/03/01,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 83.0 83.0 83.0 83.0 83.0 83.0 83.0 83.0 83.0 83.0 UCL 83.2 83.2 83.3 83.3 83.4 83.4 83.4 83.4 83.5 83.5 LCL 82.8 82.8 82.7 82.7 82.6 82.6 82.6 82.6 82.5 82.5 模擬二 預測規劃:自105年3月2日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(1, 0, 0),其模式檢定各項誤差在6.3% ~ 9.1%,如表4.1.9所示。模 式與預測結果如圖4.1.9。圖4.1.10其模式之ACF與PACF,由 該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符合 時間序列基本要求。 預測分析:走勢向下(如圖4.1.9)。股價預測結果83.4 ~ 83.3元(如表4.1.10)。 不進場。 買賣決策:當日13:30之股價大於等於買入值的0.5元則賣出,否則持有。 13:30股價為83.5元。將0301買入之股票賣出,獲利500元。
40
圖4.1.9 佳格2016/03/02,09:01~10:00股價模式與走勢圖
41
表 4.1.9 佳格 2016/03/02,09:01~10:00 股價模式檢定之誤差表
MAE MAPE RMSE
0.063 0.075 0.091 表4.1.10 佳格2016/03/02,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 83.4 83.4 83.4 83.4 83.3 83.3 83.3 83.3 83.3 83.3 UCL 83.6 83.6 83.6 83.6 83.6 83.6 83.6 83.6 83.6 83.6 LCL 83.2 83.2 83.1 83.1 83.1 83.1 83.1 83.1 83.1 83.1 模擬三 預測規劃:自105年3月3日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(0, 1, 0),其模式檢定各項誤差在4.9% ~ 10.1%,如表4.1.11所示。 模式與預測結果如圖4.1.11。圖4.1.12其模式之ACF與PACF, 由該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符 合時間序列基本要求。 預測分析:走勢向上(如圖4.1.11)。股價預測結果83.5 ~ 83.6元(如表 4.1.12)。選擇10:05進場買入1張,股價為83.5元。 買賣決策:當日13:30之股價大於等於買入的0.5元則賣出,否則持有。 13:30股價為83.8元,故持有,俟日後一併賣出。
42
圖4.1.11 佳格2016/03/03,09:01~10:00股價模式與走勢圖
43
表 4.1.11 佳格 2016/03/03,09:01~10:00 股價模式檢定之誤差表
MAE MAPE RMSE
0.049 0.059 0.101 表4.1.12 佳格2016/03/03,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 83.5 83.5 83.5 83.5 83.5 83.5 83.5 83.5 83.5 83.6 UCL 83.7 83.8 83.9 83.9 84.0 84.0 84.1 84.1 84.2 84.2 LCL 83.3 83.2 83.2 83.1 83.1 83.0 83.0 83.0 82.9 82.9 三、個案研究三(研究對象:台泥) 模擬一 預測規劃:自105年3月1日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
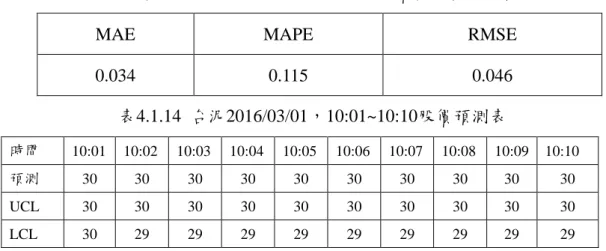
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(0, 1, 0),其模式檢定各項誤差在3.4% ~ 11.5%,如表4.1.13所示。 模式與預測結果如圖4.1.13。圖4.1.14其模式之ACF與PACF, 由該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符 合時間序列基本要求。 預測分析:走勢向下(如圖4.1.13)。股價預測結果30元(如表4.1.14)。不 進場。 買賣決策:當日 13:30 之股價大於等於買入的 0.5 元則賣出,否則持有。 13:30 股價為 29.85 元。
44
圖4.1.13 台泥2016/03/01,09:01~10:00股價模式與走勢圖
45
表 4.1.13 台泥 2016/03/01,09:01~10:00 股價模式檢定之誤差表
MAE MAPE RMSE
0.034 0.115 0.046 表4.1.14 台泥2016/03/01,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 30 30 30 30 30 30 30 30 30 30 UCL 30 30 30 30 30 30 30 30 30 30 LCL 30 29 29 29 29 29 29 29 29 29 模擬二 預測規劃:自105年3月2日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
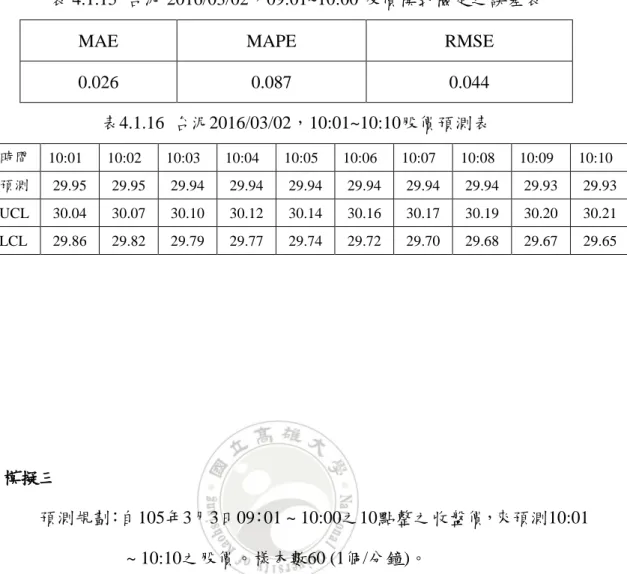
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(0, 1, 0),其模式檢定各項誤差在2.6% ~ 8.7%,如表4.1.15所示。 模式與預測結果如圖4.1.15。圖4.1.16其模式之ACF與PACF, 由該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符 合時間序列基本要求。 預測分析:走勢向下(如圖4.1.15)。股價預測結果29.95 ~ 29.93元(如表 4.1.16)。不進場。 買賣決策:當日 13:30 之股價大於等於買入的 0.5 元則賣出,否則持有。 13:30 股價為 29.85 元。
46
圖4.1.15 台泥2016/03/02,09:01~10:00股價模式與走勢圖
47
表 4.1.15 台泥 2016/03/02,09:01~10:00 股價模式檢定之誤差表
MAE MAPE RMSE
0.026 0.087 0.044 表4.1.16 台泥2016/03/02,10:01~10:10股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 29.95 29.95 29.94 29.94 29.94 29.94 29.94 29.94 29.93 29.93 UCL 30.04 30.07 30.10 30.12 30.14 30.16 30.17 30.19 30.20 30.21 LCL 29.86 29.82 29.79 29.77 29.74 29.72 29.70 29.68 29.67 29.65 模擬三 預測規劃:自105年3月3日09:01 ~ 10:00之10點整之收盤價,來預測10:01 ~ 10:10之股價。樣本數60 (1個/分鐘)。
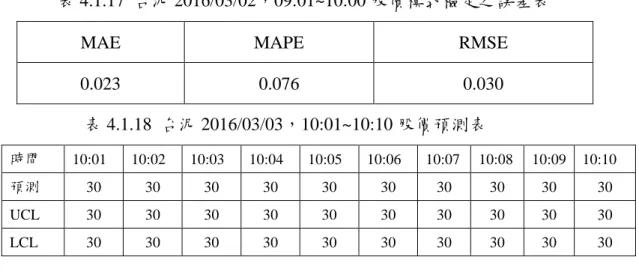
建模型式:ARIMA(p, d, q)。經Expert Modeler分析,模式為ARIMA(1, 0, 0),其模式檢定各項誤差在2.3% ~ 7.6%,如表4.1.17所示。 模式與預測結果如圖4.1.17。圖4.1.18其模式之ACF與PACF, 由該圖顯示其殘差值均在信賴界限內,即殘差為白噪音,符 合時間序列基本要求。 預測分析:走勢向下(如圖4.1.17)。股價預測結果30元(如表4.1.18)。不 進場。 買賣決策:當日13:30之股價大於等於買入的0.5元則賣出,否則持有。 13:30股價為30.4元。
48
圖4.1.17 台泥2016/03/03,09:01~10:00股價模式與走勢圖
49
表 4.1.17 台泥 2016/03/02,09:01~10:00 股價模式檢定之誤差表
MAE MAPE RMSE
0.023 0.076 0.030 表 4.1.18 台泥 2016/03/03,10:01~10:10 股價預測表 時間 10:01 10:02 10:03 10:04 10:05 10:06 10:07 10:08 10:09 10:10 預測 30 30 30 30 30 30 30 30 30 30 UCL 30 30 30 30 30 30 30 30 30 30 LCL 30 30 30 30 30 30 30 30 30 30
第二節 交易模擬績效與預測準確比較
在建構了三檔股票三天的模式與預測分析,配合投資策略。其中三檔股票一 個月同時段的ARIMA(p, d, q)模式均不同,但模式檢定各項誤差(MAE、MAPE、 RMSE)均在10%以內,且各模式之ACF與PACF圖顯示其殘差值均在信賴界限內, 即殘差為白噪音,符合時間數列基本要求。就結果而論,鴻海公司的交易績效對 操作短線的投資者是相當好的,手中僅持有1張股票也降低了被套住的風險。在 此模擬投資某公司績效之三表中,同時列出識別之模式(即ARIMA(p, d, q))、估 計之參數(φi 、θj )、與模式之檢定(RMSE)。 在預測準確方面,一般都以MAE、MAPE、RMSE做為判斷的指標, Chai 與 Draxler (2014)則是認為使用RMSE比MAE好,RMSE比MAE有更好的評估誤差性 能,因此本研究在最後選擇使用RMSE作為判斷的指標。比較了三檔股票的RMSE, 台泥的準確率比起另外三檔股票還要準,一個月的RMSE都維持在10%以下,模 式配式的情況良好,也顯示出該檔股票在短時間的波動較小。在建立模式的方面,50 每天同時段的模式不盡相同,表示每天大盤的情況都不一樣,需要天天建模,才 能達到預測與控制的目的,也凸顯出軟體的進步,透過數據在幾秒鐘內就能建立 一個不同的模式,給投資者在當天參考。儘管ARIMA模式在預測股價走勢向上 的情況並不理想,但是在預測走勢向下的情況卻非常準確,能讓投資者選擇逢低 買進或是避免被套住,也降低了投資的風險。 模擬交易進行一個月的以後,鴻海公司:獲利9800元及手中持有1張股票。 表4.1.19 模擬交易鴻海(2317)績效表 時間 模式 參數 檢定 投資策略 績效 2016/3/1 9:01~10:00 ARIMA(0,1,0) RMSE=0.109 10:05 進場買 入一張 77.3 元 無 2016/3/2 9:01~10:00 ARIMA(1,0,0) φ1 =0.849 RMSE=0.083 10:05 進場買 入一張 78.5 元 將本日、1 日 買入之股票買 出 獲利 2800 元 2016/3/3 9:01~10:00 ARIMA(0,0,3) θ3 =-0.553 RMSE=0.075 不進場 無 2016/3/4 9:01~10:00 ARIMA(0,1,0) RMSE=0.083 10:05 進場買 入一張 81.1 元 將本日買入之 股票買出 獲利 1800 元 2016/3/7 9:01~10:00 ARIMA(1,0,1) φ1 =0.687 θ1 =-0.495 RMSE=0.088 10:05 進場買 入一張 81.1 元 無 2016/3/8 9:01~10:00 ARIMA(0,1,0) RMSE=0.118 不進場 無 2016/3/9 9:01~10:00 ARIMA(0,1,0) RMSE=0.098 不進場 無 2016/3/10 9:01~10:00 ARIMA(1,0,0) φ1 =0.821 RMSE=0.097 10:05 進場買入 一張 82.9 元 無