I
義 守 大 學
資 訊 工 程 研 究 所
碩 士 論 文
一種基於編譯器的保護返回位址的方法
Compiler-based approach to protect return
address
研究生:李宏哲
指導教授:楊吳泉博士
II
一種基於編譯器的保護返回位址的方法
Compiler-based approach to protect return
address
研究生:李宏哲
Student: Hong-Jhe Li
指導教授:楊吳泉
Advisor:Wu-Chuan Yang
義守大學
資訊工程研究所
碩士論文
A Thesis Submitted toDepartment of Information Engineering I-Shou University
In Partial Fulfillment of the Requirements For the Master Degree
in
Information Engineering July,2017
致謝
首先感謝我的指導教授楊吳泉老師,不論研究領域的相異,都無條件的支持我任 何的研究方向,並試著了解其中的價值與貢獻,也感謝老師一路走來的耐心教導, 從大學時期就跟著老師做專題開始,老師不只關心我們的課業,更關心我們的生 活狀態與條件,閒暇之餘不只討論研究、技術,更傳授許多人生經驗,讓其轄下 學生受益匪淺,教導方針自然放任,使得各個學生能找到自己的所長適性發展, 而不致於忙於應付課業、研究,匆忙畢業找不到人生方向,也感謝老師把我從一 個空有夢想的學生,提攜拉拔使我步步邁進到可以自我成長的地步,老師在學生 眼中有如第二個父親般的關懷學生,此形象將永遠深植我心。 再來要感謝實驗室的學長士瑞、賀源、書銘,在我的論文過程中給我很多幫助, 也提醒許多應該注意的事項,並時時關切我的進度狀況,有了他們的經驗分享傳 承讓我少走很多冤枉路,也使我的論文撰寫研究更為順利,再來要感謝我在台南 實習時的團隊,研究中不乏有大家提共建議的影子,某些不懂的地方,也是請益 團隊成員而得到的資源或是方向,使我的方向明確並與初衷並無二致。 最後要感謝我的家人,雖然在我的生涯中都是忙於工作無暇顧及我的課業,但在 我表現不佳的時候並不會過度責罵,只會適切的關心鼓勵我繼續前進,大學加上 碩士共讀了六年,離鄉背井從幾乎台灣最北端來到高雄讀書,除了學到學校教授 的知識以外,更學到自我獨立、團隊合作、責任心等等的重要性,雖遠在他鄉, 但家人不時的問候,不論是關懷近況或是生活費的支援從來都不曾缺少過,這著 實是我求學過程中不可或缺的助力之一,有了家人的支持、老師的栽培、學長的 傳承、實習團隊的幫助,才能成就現在的我,感謝多到無法盡書於此,當常繫於 心,伴我一生。III
一 種 基 於 編 譯 器 的 保 護 返 回 位 址 的
方 法
研究生:李宏哲
指導教授
:楊吳泉博士
義守大學資訊工程研究所
摘要
堆疊緩衝區溢位攻擊(Stack-based Buffer overflow attack) 一直都是軟體安全 頭痛的問題之一,到目前為止還是沒有有效的抑制方法,只能透過編譯器及作 業系統的支援促使程式運行狀態宛若處在黑箱之中,藉此使攻擊者無法得到必 要的資訊而進一步的利用弱點達到攻擊的效果。
本論文針對返回位址 (return address) 的保護為重點,核心思想為阻止返回 位址被惡意的資料所覆蓋,從而避免攻擊者控制指令指標(Instruction Pointer, IP) 來達到更動程式流程的目的。
實驗結果顯示,本論文提出來的保護方法可以確切的保護堆疊中的返回位 址不被惡意資料覆蓋,因此也提升了程式本身的安全性。
IV
Compiler-based approach to protect return
address
Student:Hong-Jhe Li Advisor:Dr.Wu-Chuan Yang
Department of Information Engineering
I-Shou University
Abstract
Stack-based buffer overflow attack has been one of the most tough problem of security vulnerability. There is no effectively solution to eliminated for now. Can only make your program runtime like a black box to avoid attacker exploit vulnerability by gathering necessary information of your program.
In this paper we provide a compiler-based solution to prevent Stack-based Buffer overflow attack on the function return address. To prevent override of return address means no control flow hijacked, and the integrity of the program.
Experiment shows that the approach we proposed could protect the return address in the stack buffer effectively therefore more secure software.
keywords: stack-based buffer overflow、return address protection、compiler-based
V
目錄
摘要 ... III Abstract ... IV 圖目錄 ... VII 表目錄 ... VII 第一章、緒論 ... 1 1.1. 研究背景 ... 1 1.2. 研究目的 ... 1 1.3. 論文架構 ... 2 第二章、背景知識 ... 3 2.1. 堆疊緩衝區溢位攻擊原理 ... 3 2.1.1. 呼叫慣例 ... 3 2.1.3. 函數組成 ... 4 2.1.4. Stack Frame ... 5 2.1.5. 堆疊佈局 ... 5 2.1.6. 攻擊實例 ... 6 2.2. 現行 Linux 緩解策略及繞過可能性 ... 8 2.2.1. 位址空間配置隨機載入 (ASLR) ... 8 2.2.2. 堆疊保護機制 (SSP) ... 9 2.2.3. 防止資料執行 (DEP) ... 10 2.2.4. 地址無關執行程式 (PIE) ... 11 2.2.5. 重定位唯讀 (RELRO) ... 11 2.2.6. FORTIFY_SOURCE ... 12 2.3. 程式編譯流程 ... 13 2.3.1. 前置處理 (Preprocessing) ... 13 2.3.2. 編譯 (Compilation) ... 14 2.3.3. 組譯 (Assembly) ... 14VI 2.3.4. 連結 (Linking) ... 14 2.4. 編譯細節 ... 15 2.4.1. 語彙分析 ... 15 2.4.2. 語法分析 ... 15 2.4.3. 語意分析 ... 16 2.4.4. 產生中介語言 ... 16 2.4.5. 目的碼的產生與最佳化 ... 17 第三章、實作降低漏洞可用性 ... 18 3.1. 為何選擇 LLVM ... 18 3.2. 緩解時機的選擇 ... 18 3.3. LLVM 後端流程與程式碼生成 ... 19 3.3.1. LLVM 後端流程 ... 19 3.3.2. BuildMI ... 20 3.4. 降低漏洞可利用性 ... 21 3.4.1. LLVM 修改實作 ... 22 3.4.2. 成果展示與說明 ... 23 3.4.3. 指令與暫存器的選用 ... 27 第四章、分析與討論 ... 29 4.1. 成本分析 ... 29 4.1.1. 指令成本分析 ... 29 4.1.2. 編譯成本分析 ... 29 4.2. 安全性影響分析 ... 30 第五章、結論 ... 31 參考文獻 ... 32
VII
圖目錄
圖 1、堆疊緩衝區溢位攻擊... 3 圖 2、反組譯結果... 4 圖 3、輸入資料之前... 5 圖 4、輸入 AAAAAAAABBBBBBBB 之後 ... 5 圖 5、範例程式反組譯結果... 7 圖 6、堆疊變化示意... 7圖 7、Stack reading 示意圖[24] P4, Fig5 ... 10
圖 8、GCC 編譯過程分解[28] ... 13 圖 9、程式編譯流程[28] ... 15 圖 10、LLVM 後端流程 ... 19 圖 11、MC Layer 結構 ... 20 圖 12、原版 LLVM 編譯結果(同圖 5) ... 24 圖 13、改版 LLVM 編譯結果 ... 24 圖 14、改版 LLVM 對 Stack 影響-Prologue ... 25 圖 15、改版 LLVM 對 Stack 影響-Epilogue ... 26
圖 16、x86_64 ABI Registers[41] P21, Fig3.4 ... 27
表目錄
表 1、現行緩解策略簡表... 211
第一章、緒論
1.1. 研究背景
隨著物聯網(Internet of Things, IoT)時代的來臨,絕大多數的裝置都邁向智慧化 發展,更多的電腦技術進入到一般社會大眾的生活中,有鑑於此安全的思維與 意識更顯得不可忽略,電腦安全大致上可分類為三個區塊,分別為:密碼學、 網路安全以及系統安全,三者雖看似獨立實際上卻是互為支柱,其中軟體安全 便是關係著系統安全一個很重要的支項,除了作業系統本身的穩健性外,上面 運行的各種軟體也需要做好自己本身的安全防護,避免成為一個可被利用的破 口,進而讓軟體層面的危害,晉升到系統層面的威脅。 從軟體攻防的歷史演進來看[1][2],除了依賴作業系統提供更安全的執行環 境如:位址空間配置隨機載入(Address Space Layout Randomization, ASLR)[3]、 地址無關程式碼(Position Independent Code, PIC)、地址無關可執行文件(Position Independent Executable, PIE),另外也可透過編譯器本身提供的安全策略來達到 強固軟體的手段也不在少數,如:堆疊保護機制(Stack Smashing Protector, SSP)[4]、資料執行防止(Data Execution Prevention, DEP)[5]等,但是軟體攻防的 腳步卻絲毫沒有停歇的現象。
1.2. 研究目的
堆疊緩衝區溢位攻擊(Stack-based buffer overflow, Stack-based Bof)一直是系統安 全領域關注的題目,針對其攻擊特性的緩解(Mitigation)策略也不在少數,但許 多解決的策略仍有其缺陷或是限制[3][4][5],而一個好的防禦策略應該要能同時 兼顧效能以及安全性才有實作價值。為了達到這樣的目標與兼顧實作,本論文
2 針對使用廣泛的Linux 系統,審視目前 Linux 現行使用的緩解策略及繞過 (Bypass)方式,並參考其他文獻及論文實作方式,進一步提出一個相對輕量化且 增加漏洞利用難度的緩解策略。
1.3. 論文架構
本論文分為五章,本章先介紹研究背景與目的;第二章為相關知識的探討,其 中包括:堆疊緩衝區溢位攻擊原理、現行Linux 緩解策略及繞過的可能性及一 些為滿足攻擊條件的系統先備知識;第三章為研究方法及緩解策略實作;第四 章為實作結果分析與討論;第五章針對論文內容及貢獻作結論。3
第二章、背景知識
本章介紹所有Stack-based Bof 的必備知識、目前 Linux 主要發行版的緩解策略 及其繞過情境,最後概略介紹編譯器的編譯流程以便了解本論文的實作流程及 目的。
2.1. 堆疊緩衝區溢位攻擊原理
在現行的 x86 及 x64 系統下所有的區域變數都是存放在堆疊中,等待其運作 函式存取,緩衝區故而得名。當緩衝區資料越界時就有可能影響到其他資料的 完整性甚至可能更動整個程式控制流程,圖1 為經典的堆疊緩衝區溢位範例 [6]: 圖 1、堆疊緩衝區溢位攻擊 很容易就可以從程式碼得出,當使用者輸入超過20 個字元時,程式執行將 會出現超出預期的行為,透過詳細分析與安排之後,便可以將這些原本是不可 預期的程式錯誤行為轉換為任意命令運行(Arbitrary Command Execution, ACE)甚 至權限提昇(Privilege Escalation)等行為。2.1.1. 呼叫慣例
呼叫慣例(Calling convention)是函式呼叫者(Caller)以及被呼叫者(Callee)之間約 定的參數傳遞及堆疊平衡慣例,確保函式可以被正常的呼叫並回傳結果。通常 不同的作業系統及編譯器之間都有相異的呼叫慣例,或是有特定需求的架構、
4 及程式語言也會有相異的呼叫慣例[7]。 GCC on Linux x86 架構使用的呼叫慣例是 cdecl,其特點為所有的參數會被 由右至左放置到堆疊中,並且使用累加暫存器(AX)來傳遞函式的結果,並且都 是由呼叫者(Caller)來準備與收回被呼叫者(Caller)所需要使用到的堆疊空間。
2.1.2. x86 組合語言指令
圖 2、反組譯結果 圖 2 為圖 1 反組譯結果並擷取的主要程式片段,只需要了解 call、ret 兩個 指令即可: call 指令可分為兩個步驟: 1. 將下一行指令存到堆疊頂端 2. 跳往欲呼叫的函式位址 ret 指令的作用為將堆疊頂端的資料放入指令指標暫存器。2.1.3. 函數組成
在x86 與 x64 的結構下,組合語言層面的函數組成分為三個部分分別為: Prologue、Body、Epilogue,以圖 2 為例,前四行就屬於 Prologue 的範圍範5
疇,其作用在於將前一個 stack frame 的基底指標儲存在堆疊中,並創造出區 域變數會使用的空間大小; Body 則為函數的主體,主要執行函數本身的功能; Epilogue 則負責與 Prologue 相反的事務,並加上最後一行 ret 將指標暫存器 指向堆疊頂端的位址指引CPU 繼續執行[8][9]。
2.1.4. Stack Frame
我們將xSP 到 xBP 的範圍稱為 stack frame,裡面儲存著該函數的區域變數,以 便於CPU 使用基底暫存器(base register)加上偏移值(offset)來取得其位址。通常 每個函數都會有自己的 stack frame,其建立及銷毀也都依賴位於函數首部及尾 部的Prologue 與 Epilogue。
2.1.5. 堆疊佈局
圖 3、輸入資料之前 圖 4、輸入 AAAAAAAABBBBBBBB 之後 由圖3 與圖 4 的差異可得知,在 Linux x86_64 的環境下堆疊的資料寫入 是用little endian 的方式由低位址往高位址覆蓋[10]。同理,緩衝區溢位攻擊的 方向也應相同,所以緩衝區溢位攻擊,並無法影響到更低位址所儲存的資料。6
2.1.6. 攻擊實例
下面為一個可被 Stack-based Bof 攻擊的實例程式碼,後面章節的攻擊範例,都 以這段程式碼為目標: 1. #include <stdio.h> 2. void admin() { 3. system(“sh”); 4. } 5. void greeting() { 6. char name[4]; 7. get(name); 8. printf(“Hi, %s\n”, name); 9. } 10. void main(void) { 11. puts(“Hi ~”); 12. greeting(); 13. } 看似簡單的新手練習程式藏著一個呼叫系統指令 sh 的函數,以整個程式 的控制流程來看,想要執行危險函數 admin 根本不可能,因為程式本身並沒有 針對輸入做任何的條件判斷或是運算,但是此程式卻存在弱點 (Vulnerability) 並且為可利用(Exploitable) 的狀態。經過計算並輸入惡意資料便可成功執行危 險函數 admin,這也驗證了其指令指標(IP, Instruction Pointer) 可被輸入的資料 給汙染,並且對系統產生任意的行為。7 圖 5、範例程式反組譯結果 圖 5 為範例程式主要存在弱點之函數 greeting 的反組譯結果,顯而易見的 在組語第三行將堆疊空出0x10 也就是 16 位元組的空間,而第四行則是將寫入 的位址標明為RBP-0x4 開始,這樣便滿足 C 原始碼所宣告的 4 個位元組,又程 式邏輯上並沒有對gets 函式輸入做任何的限制,導致當輸入的資料超過 0x10 時,堆疊中的其他資料就會被覆寫。 圖 6、堆疊變化示意 圖 6 為 gets 執行後接收到 ABCD 的示意圖,可以明顯看出資料的寫入方 向為由上往下並且以little endian 的方式寫入堆疊區中,所以當資料超過 4 個位 元組時會首先覆蓋到saved-RBP 也就是等待函數還原後 RBP 指向的位址,通常 這個區塊被覆寫以後不會有立即的影響,在程式沒有使用基於RBP 位址的偏移 存取時而產生錯誤之前,程式仍然可以正常執行。
8 在Epilogue 清除堆疊空間之後,saved-RIP 會剛好處於 RSP 所指向的位 址,通常這個時候下一個指令便是ret,攻擊者便可透過資料覆寫的方式,改寫 saved-RIP,如此一來便可以控制 CPU 執行指令的方向。然而為了展示方便, 程式碼中已有一個名為admin 的危險函式做為攻擊者的目標,又因為一般情況 下編譯器不會幫你加上任何的緩解策略選項,所以函數的程式碼位址在每次執 行時期(Runtime)都是相同的。 總結來說只要覆蓋前面12 個位元組最後加上 admin 函數的位址 \x40\x06\x00(0x400600),便可將程式的執行流程劫持(Hijack)並導向 admin 函 式。
2.2. 現行 Linux 緩解策略及繞過可能性
本節介紹目前主流的 Linux 發行版都支援的緩解策略,包括第一章所提及的 ASLR、PIE、SSP 等。這些策略可以改善因為緩衝區溢位被攻擊的情形,即使 如此還是會因為發行版本效率問題或是安全政策的不同,而產生相異的情境。 預設不一定是開啟或是最安全的狀態,即使緩解策略全部開啟在某些特定情況 下還是可能透過以下情況被攻擊:程式碼重用攻擊(CRA, Code Reuse Attack)技 巧如ROP(Return-Oriented Programming)[11][12][13][14][15][16]或是其他類似的 攻擊:SROP (Sigreturn-Oriented Programming)[17]、JOP(Jump-OrientedProgramming)[18]、SOP(String-Oriented Programming)[19]、Data-Only Attack [20]等等。
2.2.1. 位址空間配置隨機載入 (ASLR)
作業系統提供的緩解方法包括ASLR 及 DEP。ASLR 的概念是程式執行時堆 疊、VDSO(Virtual Dynamically-linked Shared Object)以及載入的函式庫等,位於 資料區段的資料在記憶體中的位址,在每次運行時都會不同,使得程式運行狀
9
態如同至於黑盒之中使駭客無法輕易的利用現有函式庫的函式、修改特定區域 的資料或是執行位於緩衝區的惡意程式碼,管理者可以透過修改
/proc/sys/kernel/randomize_va_space 的數值來調整隨機載入的對象: 0:關閉 ASLR
1:只有堆疊(Stack), VDSO, Libraries 區域位址隨機 2:除了 1 以外加上推積(Heap)區域
倘若駭客可以在程式中找到任意位址洩漏漏洞,便可以利用程式碼區段不 會受ASLR 影響的特性計算出正確的函數位址,這部分保護機制目前在 Linux kernel 大於 2.6.8 才有支援。
儘管在所有的保護措施全部開啟(RELRO, Full-ASLR, PIE, SSP, DEP)的情況 下,仍然可以透過 offset2lib [21]的方式成功利用弱點。起因為,當所有保護開 啟時每個Linux 發行版中所使用到的標準函式庫,在記憶體中的相對位置是不 變的,且存在堆疊中的返回位址只有3*28的可能性,如此一來攻擊者便可以 先模擬一個類似的環境,再自行計算出可能的返回位址而達到攻擊的目的。
2.2.2. 堆疊保護機制 (SSP)
由編譯器提供的堆疊保護機制總共分為三個層級 --fno-statck-protector:不使用堆疊保護 --fstatck-protector:為區域變數中有 char 陣列類型的函數插入保護程式 碼 --fstack-protector-all:為全部的函數插入保護程式碼 所謂的保護程式碼,其實就是在char 陣列類型後面加上一個稱為 Canary 的亂數值,當資料緩衝區的資料越界時,這個數值必定會被破壞,在函數要結 束回傳結果前檢查該值的完整性,若被更動便認定發生緩衝區溢位攻擊,從而 觸發錯誤結束程式[22]。10
圖 7、Stack reading 示意圖[24] P4, Fig5
當被攻擊程式為32 位元程式時,Canary 的熵只有 24 位元,若是使用窮舉 攻擊仍是有機會攻擊成功。即使為64 位元程式其 Canary 的資訊量(Entropy)為 56 位元,但如果程式本身是透過 fork[23]函式產生的子行程時(通常是伺服端類 程式如:nginx, apache 等),便可利用其堆疊(Stack)狀態必為相同的特性,這意 味著存在於堆疊中的Canary 也會是一樣的,於是在溢出攻擊時,如圖 7 所 示,只消逐個位元組的猜測,並透過目標程式是否會崩潰(Crash)來判斷成功與 否,如此一來便形同將Canary 給『讀出來』一般輕鬆,複雜度由將指數等級 (256)降低至線性等級(7 × 28),此技巧被稱為 Stack reading[24]。若是存在任意讀
取漏洞或是在檢查Canary 之前可覆寫函數指標(function pointer)則此緩解策略也 會失效。
甚至有一種名為 Master Canary Forging 的攻擊技巧,迂迴式的透過堆積 (Heap)來靠近目標區塊,然後再引發一次 Stack-based Bof,只要溢位的長度夠 長便可將欲檢查的 Canary 給覆蓋成任意值[25]。
2.2.3. 防止資料執行 (DEP)
在Linux 上又稱為 NX Bit(No-eXecutable)或 W^X,將程式區段權限分為可讀、 可寫、可執行,並且可寫權限與可執行權限絕不同時存在,藉此杜絕攻擊者在
11
資料區段植入惡意程式碼後,透過Stack-based buffer overflow 攻擊影響程式流 程並執行之。但在IP 可控的情形下,駭客也可以選擇使用標準程式庫裡的函數 如mmap 來創造一段新的記憶體區段,並賦予同時具有可寫及可執行的權限, 在此區段中DEP 則無法發揮任何作用[26]。
2.2.4. 地址無關執行程式 (PIE)
PIE 需借助 ASLR 的支援,其旨在讓程式碼區段也可以在每次載入時位址不相 同,想藉此杜絕程式碼重用攻擊相關的技巧。但若程式存在任意位址洩漏漏 洞,此緩解策略也是無法發揮作用,並且使用此方法會造成程式執行效率降 低,對大型的程式來說並不全然適用[27]。2.2.5. 重定位唯讀 (RELRO)
重定位唯讀 (RELRO, RELocation Read-Only)是一種強化 ELF(Executable and Linking Format) 中一個稱為惰性符號解析 (Lazy Symbol Binding) 的緩解措 施。程式啟動時外部函數的位址仍屬未知,如定義在 libc 中的函數 gets, printf, … 等等,只有動態連結的 ELF 才需要解析外部函數,靜態連結則直接 包含了所有的函數實作。
函數第一次被呼叫時,透過動態解析器 (dynamic resolver) 與 link_map 來 計算函數位址,並利用全域偏移表 (GOT, Global Offset Table) 及程序繫結表 (PLT, Procedure Linkage Table) 來達到惰性解析的目的,以減少符號解析的開銷 [28]。
問題在於原本用意良善的解析機制是為了增加效率,至此卻淪為攻擊者利 用的利器,只要攻擊者將能控制傳入解析器中的結構,便可隨心所欲地得到目 標函數的位址加以利用,或是更暴力的將 GOT 上已解析過的函數改寫成對攻 擊者有利的危險函數,並徑直呼叫之。
12 RELRO 分為三種類型,分別為: No RELRO Partial RELRO Full RELRO 第一種顧名思義是不採用 RELRO 機制,當啟用第二種時,ELF 的.dynaic、.dynsym、.dynstr 等區段(segment) 為唯讀,此項為 GCC 的預設 值,當啟用第三種型態時,所有的 symbol 會在載入時解析完成、GOT 唯讀、 沒有 link_map 和 resolver 的指標。 雖然看似 RELRO 提供的保護使安全性提升了不少,但是在特定的條件底 下仍然可以用一種被稱為 Leakless[29] 的攻擊技巧所突破,進而讓弱點 (Vulnerability) 變得可利用(Exploitable)。
2.2.6. FORTIFY_SOURCE
在編譯時加入選項 –D_FORTIFY_SOURCE={1|2},當選項被設定時編譯器會 在巨集展開前插入檢查危險函數的巨集,藉此在巨集展開後使程式裡的危險函 數被取代或是偵測,但只是純粹檢查置換並不足夠,並且在某些情況下也有可 能對程式的穩定性造成影響[30][31][32]。13
2.3. 程式編譯流程
想要將軟體安全的問題自動化解決,必定得先了解二進制執行檔的生成過程, 再來決定應該將緩解策略實作在哪一個階段為最恰當的[28],GCC 編譯過程如 圖8,以下針對 GCC 各階段分析,探討緩解實作的適當時機。 圖 8、GCC 編譯過程分解[28]2.3.1. 前置處理 (Preprocessing)
首先是原始檔 (*.c) 和相關的標頭檔(*.h),如 stdio.h 等被前置處理器 cpp 編 譯成一個 .i 檔,對於 C++ 程式來說,他的原始程式檔的副檔名可能是 .cpp 或 .cxx 標頭檔的副檔名可能是 .hpp,而前置處理之後副檔名是 .ii。 前置處理主要處理那些原始檔程式中以 “#” 開始的前置處理指令,如: “#include”、”define” 等。 將所有的 “define” 移除,並展開所有的巨集定義。 處理 “#include” 前置處理指令,將包含的檔站插入到該前置處理指定 的位置。(這個過程是遞迴進行的,意味著包含的檔案可能還包含其他14 的檔案。) 刪除所有的註解 “//” 和 “/* */”。 添加行號和檔案名稱標示,比如 #1 “a.c” 1,便於編譯時編譯器產生除 錯用的行號資訊,及用於編譯時產生編譯錯誤或警告時能夠顯示行 號。 保留所有的 #pragma 編譯器指令,留著之後給編譯器使用。 經過前置處理後的 .i 檔不包含任何巨集定義,因為所有的巨集已經被展 開,並且包含的檔案也已插入 .i 檔。所以當我們無法判斷巨集定義是否正確或 標頭檔包含是否正確時,可以查看前置處理後的檔案來確定問題。
2.3.2. 編譯 (Compilation)
編譯過程就是把前置處理完的檔案進行一系列的詞法、語法及語意分析並最佳 化後產生相應的組合語言程式碼檔案,這個過程往往整個程式建構的核心部 分。詳細的步驟將在 下一大節補充。2.3.3. 組譯 (Assembly)
組譯器是將組合語言轉換成機器可以執行的指令。每一個組語語句幾乎都對映 著一條機器指令,所以組譯器的組譯過程相對於編譯器來的簡單,並沒有複雜 的語法,也沒有語意,也不需要做指令最佳化,只是根據組語指令和機器指令 的對照表一一翻譯即可。2.3.4. 連結 (Linking)
連結的主要處理的內容就是把各個模組之間相互引用的部分正確的銜接起來, 連結過程包括位址和記憶體配置 (Address and Storage Allocation)、符號解析 (Symbol Resolution) 和重定位 (Relocation) 等步驟。15
2.4. 編譯細節
編譯過程包括語彙分析、語法分析、語意分析、中介語言產生以及目的碼最佳 化及產生,大致流程如圖9。 圖 9、程式編譯流程[28]2.4.1. 語彙分析
如圖 9 所示,原始碼 (source code) 先透過掃描器 (Scanner) 進行語彙分析 (lexical analysis),並運用類似有限狀態機(Finite State Machine) 的演算法,將原 始碼的字元順序切割成記號 (Token)。詞法分析產生的記號一般可被分類為幾 類:關鍵字、識別字、字面量(literal,包含數字、字串等) 和特殊符號(如加 號、等號)。
2.4.2. 語法分析
語法分析(Grammar Parser) 將對記號行分析,進而產生語法樹(Syntax Tree)。分 析過程採用上下文無關語法(Context-free Grammar) 的分析方法。語法樹是以運
16
算式(Expression) 為節點的樹,例如 C 語言的一個語句就是一個運算式,而複 雜的語句就是很多運算式的組合。
2.4.3. 語意分析
語意分析(Semantic Analysis) 由語意分析器(Semantic Analyzer) 完成,與法分析 僅是完成對運算式與法層面的分析,但並不了解其真正的意義。如C 語言中兩 個指標做除法是無意義的,但是這個語句在語法上是合法的。編譯器所能夠分 析的語意是靜態語意(Static Semantic),是指在編譯階段(Compile time)可以確定 的語意,相對應的是動態語意 (Dynamic Semantic) 就是只有在運行階段 (Runtime) 才能確定的語意。 靜態語意通常包含宣告和類型的匹配與類型的轉換等等。如當一個浮點數 型別的運算式指定給一個整數型別的運算式時,其中隱式的浮點數轉整數過程 是語意分析器所負責的工作,經過語意分析階段後,整個語法樹的運算式都會 被標定類型,如果有些類型需要做隱式轉換,語意分析器會在語法樹中插入對 應的轉換節點。
2.4.4. 產生中介語言
在編譯器中往往有多層次的最佳化過程,原始碼最佳化器(Source CodeOptimizer) 會在原始法的層級進行最佳化,如 Copy Propagation 會將除去純粹 的傳遞數值變數,取而代之的是原本的數值; Code Folding 將具有確定性的運算 式計算出確切的值並且取代原本的運算式; Dead Code Elimination 移除對程式執 行結果並無任何影響的程式碼,等最佳化方法。
前一段所描述的最佳化方法在語法樹上應用相較困難,所以原始碼最佳化 器往往會將整個語法樹轉換成中介碼 (IR, Intermediate Representation),他是語 法樹的順序表示,通常與機器和執行環境無關 (Target-Independent)。中介碼有
17
很多類型,常見的有:三位址碼 (Three-address Code) 和虛擬碼 (Pseudo Code)。
2.4.5. 目的碼的產生與最佳化
原始碼最佳化產生器所產生的中介碼標示著之後的過程都屬於編譯器後端。編 譯器後端主要包括程式碼產生器(Code Generator)、目的碼最佳化器 (Target Code Optimizer)。程式碼產生器將中介碼轉換成目的碼的整個過程,非常的倚 賴目的機器,因為不同的機器有著不同長度的暫存器、整數資料類型等。最後 目的碼最佳化器對目的碼進行最佳化,如選擇適當的定址方式、使用位移來替 代乘法運算等等。
18
第三章、實作降低漏洞可用性
現行的緩解策略會被實作到主流Linux 發行版中的原因有很多,除了安全考量 以外效能及穩定度都是參考指標,有時理論上可行完美,但實務上卻無法實行 或是在實作粒度上進行輕量化處理的同時安全性又不能因此而降低。 此章節透過程式原始碼經過編譯、連結等步驟,直到形成二進制檔案的脈 絡中,找尋適當的緩解解策略實作契機,力求在有效率並且不影響程式原本行 為,甚至可以與其他緩解策略共存的前提下運作。3.1. 為何選擇 LLVM
本論文選擇使用前端Clang[33]加上後端底層虛擬機( Low Level Virtual Machine, LLVM) [34]的組合來實作緩解措施,而非目前主流 Linux 所使用的 GCC。雖 然其三段式架構前端(Frontend)、最佳化器(Optimizer)、後端(Backend) 與 GCC 並相差無幾,但 LLVM 的設計也包含了最佳化階段的整合,你不只可以將自己 的Pass 加入編譯,也可以同時使用 LLVM 所提供的 Pass,與 GCC 不同的是 LLVM 同時也是一個編譯器開發框架 (Framework)。Clang 加上 LLVM 的組合 也於2010 年達到了 Self-hosting。同時 LLVM 也是眾多編譯器安全解決方法實 作的首選[35][36][37]。
3.2. 緩解時機的選擇
從第二章的介紹可以知道,一般來說可以很簡單的將編譯拆分成三個部分:前 端、IR 層及後端,想要在前端的部分修改程式原始碼來達到安全的目的,只能 透過類似FORTITY_SOURCE 的作法實作在巨集展開階段,或者是使用語法樹 來做分析。但是如前一章節所述,語法樹其實不容易被用於分析,所以才會使 用IR 來進行最佳化的操作,但礙於在 IR 層並不能肆意的執行插入任意組合語19 言,如此一來直接修改LLVM 原始碼便成為實作的唯一選項。
3.3. LLVM 後端流程與程式碼生成
本節概略介紹LLVM 的後端流程,在流程中尋找並定位出我們可以修改的層級 部分,一方面配合二進制檔案的生成,達到不影響原生功能的運作下加入額外 的組合語言指令以達到漏洞緩解的效果。3.3.1. LLVM 後端流程
圖 10、LLVM 後端流程 圖 10 為 LLVM 後端流程示意圖,左邊虛線之下屬於 IR 編譯成 MachineInstr20
的範圍,此步驟由LLVM 中的 TargetMachine 類別負責,右半部分的虛線之上 是以Machine Code Layer 為核心,整合了組譯與反組譯等二進制檔案操作的相 關功能。
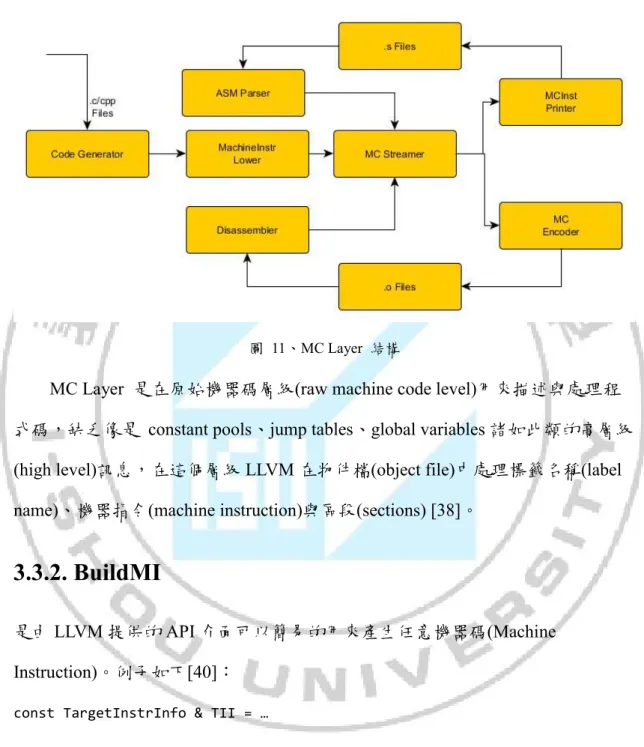
圖 11、MC Layer 結構
MC Layer 是在原始機器碼層級(raw machine code level)用來描述與處理程 式碼,缺乏像是 constant pools、jump tables、global variables 諸如此類的高層級 (high level)訊息,在這個層級 LLVM 在物件檔(object file)中處理標籤名稱(label name)、機器指令(machine instruction)與區段(sections) [38]。
3.3.2. BuildMI
是由LLVM 提供的 API 介面可以簡易的用來產生任意機器碼(Machine Instruction)。例子如下[40]:
const TargetInstrInfo & TII = … MachineBasicBlock &MBB = … DebugLoc DL;
MachinInstr *MI = BuildMI(MBB, DL, TII.get(X86::MOV32ri), DestReg).addImm(42);
21 以上的片段程式碼在x86 架構下會被轉譯成『mov DestReg, 42』。
3.4. 降低漏洞可利用性
表 1、現行緩解策略簡表 緩解策略 針對問題 緩解實作媒介 ASLR 降低程式運行時期資料區段狀態透明度 作業系統(Linux >= 2.6.8) PIE 降低程式運行時期指令區段狀態透明度 編譯器(需要 ASLR 支援) SSP 增加堆疊緩衝區溢位攻擊利用難度 編譯器 DEP 增加指令插入攻擊難度 編譯器 RELRO 增加符號解析機制利用難度 編譯器 FORTIFY SOURCE 降低堆疊緩衝區溢位攻擊發生 編譯器透過第二章的介紹可了解到 Stack-based Bof 的成因以及目前 Linux 發行版 所使用的緩解策略不足之處如表 1 所示。歸根究底還是因為指令指標可以被攻 擊者控制所導致的一連串問題,假設可以讓指令指標不被輸入資料所影響,則 將可解決此問題所帶來的安全性危害。本章節透過描述問題成因以及預想的防 禦方式來設計組合語言指令的使用並透過修改LLVM 來達到實作目的。 既然一切都因儲存在堆疊中返回位址而起,那麼我們便在各個函式的 Prologue 中加入額外組合語言程式碼,將欲 return 之位址先行儲存一份,等到 函式執行完成以後在Epilogue 時徑直將指令覆蓋,如此一來即便原本儲存在堆 疊內的指令指標受到Bof 的影響,卻也在函式結束前被復原並正確的回歸原本 的執行流程,如此一來便可以在某種程度上避免指令指標可被惡意資料污染而 產生安全疑慮的窘境。 雖然如此的確可以正確保護當前 Stack Frame 的返回位址,可是每個函示 的 Stack Frame 都是堆疊在同一個堆疊中,意思是指要溢位的長度夠大,卻也
22 可能影響到下一個 Stack Frame 的返回位址,為了預防這種事情發生,除了預 先儲存返回位址以外,還需要另外加上編碼及解碼機制,解編碼機制部分參考 [39],與該論文實作相異的是,其直接描述了利用 XOR 解編碼的概念並未進 一步的嘗試還原返回位址。透過覆蓋返回位址加上解編碼機制便可順利地抵禦 攻擊並增加程式的可執行利率,如此一來便可將實作步驟總結如下: 在 Prologue 取出堆疊頂端的返回位址 取出區段暫存器隨機值 將兩值進行 XOR 操作編碼 在區域變數空間佈置完成後存入返回位址 在區域變數空間清除前取出返回位址 取出區段暫存器隨機值 將兩值進行 XOR 操作解碼 放入堆疊頂端
3.4.1. LLVM 修改實作
要如何在如茫茫大海的 LLVM 程式碼中找到正確的修改位置,可以從官方的文 件下手[41]。文件中寫道在 LLVM 中 x86 的 PEI(Prologue-Epilogue Inserter)分成 三種:Function with a Frame pointer、Frameless with a Small Constant Stack Size、 Frameless with a Large Constant Stack Size,目前一般的架構下都是屬於第一種, 於是我們就可以在 LLVM 原始碼中找到 lib 中 CodeGen 這個目錄,裡面就存在 著一個 PrologueEpilogueInserter.cpp 的實作檔案,透過程式碼本身的註解可以知 道,這個檔案中對 Prologue 與 Epilogue 的更動都是從一個叫 FrameLowering 的 namespace 中透過兩個函數分別為 emitPrologue 與 emitEpilogue 所完成的。其中 Lowering 指的就是降階,也就是高階轉往低階的意思,例如從 High-Level IR(HIR)降階至 Medium-High-Level IR(MIR),至於在這裡的使用代表的是從高階
23
層的表示方法降階至組合語言的階段,而Frame 指的就是 Stack Frame。而 LLVM 將所有的架構都分類成不同的資料夾,如此一來便可以很容易地在 X86 的分類 下找到X86FrameLowering.cpp 這個實作檔案,並在檔案中找到函數 emitPrologue 與emitEpilogue。
誠如2.1.3 所描述的 Prologue 與 Epilogue 的功能,Prologue 的作用相對簡 單,只要負責將RBP 存入堆疊中,並創造區域變數空間與確保堆疊的對齊即 可,所以只需要將想要加入的組合語言所對應之BuildMI 指令加到 emitPrologue 函數開始處與結尾處即可達到效果。
emitEpilogue 的部分則是對應到前面所提到的 Function with a Frame Pointer 這個類別,因為目前的實作只對這個部分作處理,所以透過註解可以在判斷式 中找到hasFP(是否具有 Frame Pointer),便可將指令加入 Epilogue 的開頭。 Epilogue 的另外一項重要功能就是回收 Prologue 所創造的區域變數空間,通常 都是使用ADD 這個指令來達成,在函式的程式碼中可以看到將類似的程式碼 做合併(merge)的註解,由此可以看段這裡就是 Epilogue 的結尾,於是乎將剩餘 的指令安排於此處便可以達到我們想要的效果。
3.4.2. 成果展示與說明
下列實驗使用與2.1.6 相同的 C 原始碼,使用的是 LLVM 5.0-beta 版在 Docker 中的 Ubuntu 16.04 編譯24 圖 12、原版 LLVM 編譯結果(同圖 5) 圖 13、改版 LLVM 編譯結果 圖 13 框起來的部分就是改動過的 LLVM 所新增的組合語言指令,實驗步 驟如下: 使用原版 LLVM 編譯存在弱點程式碼 使用自行撰寫的攻擊程式進行攻擊(攻擊成功)
25 使用改版的 LLVM 編譯存在弱點的程式碼 使用自行撰寫的攻擊程式進行攻擊(攻擊失效) 透過實驗可以得知上述對LLVM 的改動確實可以正確抵擋住經典的堆疊緩 衝區溢位攻擊,當攻擊發生並且確實影響到返回位址的數值時,會因為後半部 XOR 操作解碼而導致返回位址變成無效位址,如此一來便可讓程式引發中斷藉 此抵擋攻擊順利進行。 圖 14、改版 LLVM 對 Stack 影響-Prologue 圖 14 為改版後的 LLVM 對堆疊的影響 Prologue 部分,step 0 為尚未有任
26
何指令執行時的模擬狀況,step 1 為執行第一行組合語言指令也就是 mov r11, QWORD PTR [rsp]之後的狀態,以此類推。直到第七行指令結束,整個 Prolouge 程序也結束了,可以看到堆疊中除了原本該有的 RBP 及 saved-RIP 外,還多了一項 Encoded saved-saved-RIP,這便是我們自行存放的編碼過後之返 回位址。
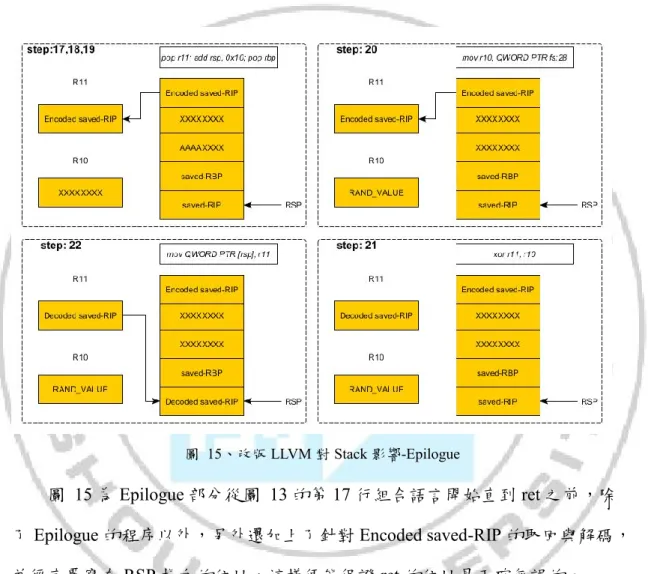
圖 15、改版 LLVM 對 Stack 影響-Epilogue
圖 15 為 Epilogue 部分從圖 13 的第 17 行組合語言開始直到 ret 之前,除 了Epilogue 的程序以外,另外還加上了針對 Encoded saved-RIP 的取回與解碼, 並徑直覆寫在RSP 指向的位址,這樣便能保證 ret 的位址是正確無誤的。
透過圖 14 與圖 15 可得知修改後 LLVM 的堆疊狀態,如第二章的先備知 識所描述,Prologue 與 Epilogue 為每個函數組成的重要組件,同理可得,每個 在程式中運行的函數都具有這兩個部分,透過LLVM 源碼的修改,便可在不影 響堆疊本身正確性的前提下,保護開發者自行撰寫的任何函數。
27
3.4.3. 指令與暫存器的選用
圖 16、x86_64 ABI Registers[42] P21, Fig3.4
在圖 13 中可以看到改版後的 LLVM 所加入的額外組合語言程式碼,其中 除了使用RSP 這個 x64 標準堆疊指標以外還使用了 R11、FS、RAX 等暫存 器,從圖 16 中可得知 R11 為臨時暫存器並且跨函數之間不需要保留值,所以
28 一開始在讀取返回位址時便選用R11 來存放,至於 RAX 雖然在圖 16 中被標示 為回傳值暫存器,但因為程序還處在Prologue 之前,所以 RAX 仍然可被用來 當臨時暫存器使用,至於FS 為區段暫存器,通常為作業系統內部使用,並且 提供一些系統必備的功能,例如Canary[4][22]也是使用 FS:0x28 的數值來做為 隨機值。
一開始就用mov 指令而非 pop 來取得返回位址的原因是,pop 指令會影響 到堆疊指標(RSP)的降低,若使用 pop 來取得返回位址,則就必須額外使用 push 來平衡原本的堆疊指標,故使用mov 取值的方式來取得返回位址。而後面的 push rax 與 pop r11 都有類似的意義,push rax 是為了在 Prologue 準備好區域變 數空間之後將編碼過的返回位址放入堆疊區的頂端以避免緩衝區溢位的攻擊, 而相反的pop r11 是為了在 Epilogue 回收區域變數空間之前取回編碼過的返回 位址,並在函數ret 之前將之解碼且放回堆疊頂端。在圖 16 中可以看到 R10 是使用在靜態鏈結指標,但因為C/C++ 類語言並不支援函數嵌套,並且 R10 也符合無須跨函數保留得性質,所以R10 完全可以當作臨時暫存器來使用。後 段在解碼返回位址之前是使用R11 而非一開始的 RAX,是因為 RAX 被用來當 作函數回傳值的暫存器,所以就使用R11 而非 RAX。 所以藉由上述之實驗方法及成果說明可以得知,本論文所提出之實作方 法,足以達到針對堆疊緩衝區溢位攻擊之緩解效果,餘下的緩解策略所帶來之 成本(overhead)及其缺點將在第四章分析與討論說明之。
29
第四章、分析與討論
4.1. 成本分析
前面的章節提到過,目前會被主流Linux distribution 或硬體所實現的緩解策 略,都有一個共通點,對程式本身運行的效率並不會影響太大,倘若有疑慮則 像ASLR、RELRO、PIE 乃至 SSP、FORTIFY_SOURCE 都有強度等級可供選 擇,讓開發者在開發到釋出階段可以自由的選擇,因為他們影響到的不只是執 行時期的效率,而是在編譯時期就已經發揮影響了,一個好的緩解策略,除了 增加安全強度之外,其本身不應該是開發者或是使用者需要特別注意的項目。4.1.1. 指令成本分析
以指令數增加的角度來看共有35 位元組(byte)的增長,因為適用於動態連結所 以編譯時間幾乎沒有增長且總長度的增幅並沒有超過一個page(4 KB)所以在靜 態的二進制檔案大小方面並無任何增加的情況。4.1.2. 編譯成本分析
此部分使用在 Docker 中的 Ubuntu 16.04 硬體設備為:Intel® Core™ i5-6300U CPU @ 2.40GHz、4GB RAM。 表 2、編譯時間比較表 編譯一千次總和(秒) 最大值(秒) 最小值(秒) 眾數(秒) 原版 LLVM 105.75 0.13 0.08 0.11 (440 次) 0.10 (418 次) 改版 LLVM 108.83 0.14 0.09 0.11 (547 次)
30 對軟體來說,編譯時間也會是一個效率關鍵,當需要使用大量應用時,軟 體本身的編譯部屬時間過長,也會降低服務的效率與品質,所以好的緩解策略 對執行及編譯時的效率定然不能影響幅度太大。這裡使用Linux time 指令量測 原版LLVM 編譯時間與改版 LLVM 編譯時間,使用 2.1.6 範例原始碼,編譯時 間差異如表1 所示。可從表中看出對時時間的影響最大值與最小值都只有 0.01 秒的差距,可見在編譯時間上的影響差距甚小,甚至可以忽略。
4.2. 安全性影響分析
透過第三章的實驗便可得知,緩衝區溢位攻擊確實能以此緩解策略阻擋,但是 卻也因為需要阻擋攻擊,該程式會產生錯誤而退出,這對系統或是程式本身需 要保證流程的正確性來說是很大的缺失,不過有賴現在的環境發展都是傾向於 雲端分散式服務,好處是可以透過雲端基礎設施的資源來增加錯誤容忍率。 一次的攻擊只要引發錯誤隨即會被自然中斷,本身的服務並不需要花費太 多額外的成本檢查,只需要重新啟動服務及可,這對當的前雲端環境來說小事 一樁,假若再搭配上Docker, lxc 等等的容器(Container)類應用,更可以擴大容 錯機制,做到快速啟動大量服務的效果,如此一來即便因為攻擊引發的程式中 斷,也可以很快地被復原,而不易被前端使用者察覺,或是影響服務業務。31
第五章、結論
基於堆疊的緩衝區溢位(Stack-based Buffer overflow)攻擊一直是 CVE[43]的常 客,各種各樣的系統、軟體等都曾被發現有這樣弱點(Vulnerability),雖然現在 已經有很多的緩解策略(Mitigation)及強固化政策(Hardening policy),試圖去抑制 弱點(Vulnerability)的存在或是降低其可被利用性(Exploitable),但仍是無法的完 全制止類似攻擊的發生。 本論文所提出的概念與基於編譯器的緩解策略實作,利用修改LLVM 的方 式達到加入額外組合語言程式碼的目的,並搭配解編碼機制來抑制攻擊的產 生,縱使弱點(Vulnerability)確實存在,也無法被利用(Exploit)來對系統做進一步 的危害,而是會自然的引發程序錯誤而中斷執行。 是優點也是缺點,中斷軟體執行的確中斷了攻擊者的攻擊流程,卻也阻斷 了正常程式的運行,理想的安全策略不應該影響發開、維運的正常執行,在4.2 也提出了一個可行的解決辦法,雖然並不是完美的解決方案,卻也是可行的方 法之一。一個好的安全策略,不僅要照顧到安全性的提升,更要兼顧效能與程 式本身的正確性,於此在確保程式正確性的方面是CFI(Control Flow Integrity)[37]等類似方法的主要方向之一,但在實作效能上以目前的運算能力來 說仍在無法普及化的範疇,需透過輕量化或是降低粒度(Granularity)的方式來達 到目標。整體而言此方法雖然不是最好,卻是一個有效可用的解決方法。
32
參考文獻
[1] C. Cowan, P. Wagle, C. Pu, S. Beatte, J. Walpole., “Buffer overflows: Attacks and Defenses for the Vulnerability of the Decade., available via
https://css.csail.mit.edu/6.858/2012/readings/buffer-overflows.pdf, DARPA Information Survivability Conference and Exposition, 2000, view in 2017. [2] Haroon Meer, “Memory Corruption Attacks The (almost) Complete History”
available via ,
https://media.blackhat.com/bh-us-10/whitepapers/Meer/BlackHat-USA-2010-Meer-History-of-Memory-Corruption-Attacks-wp.pdf, Black Hat 2010 USA., view in 2017.
[3] PaX-Team, “PaX ASLR(Address Space Layout Randomization)” available via
https://pax.grsecurity.net/docs/aslr.txt, 2003, view in 2017.
[4] Perry Wagle, Crispin Cowan “StackGuard: Simple Stack Smash Protection for GCC” available via,
https://ece.uwaterloo.ca/~vganesh/TEACHING/S2014/ECE458/Stackguard.pdf, Immunix Inc., 2003, view in 2017.
[5] PaX-Team, “PaX non-executable pages” available via
https://pax.grsecurity.net/docs/noexec.txt, view in 2017.
[6] Aleph One, “Smashing The Stack For Fun And Profit” available via
http://www-inst.eecs.berkeley.edu/~cs161/fa08/papers/stack_smashing.pdf, Phrack Magazine, vol.7 no.49, 1996.
[7] Wikipedia, “calling convention” available via
https://www.wikiwand.com/en/X86_calling_conventions, view in 2017. [8] Wikipedia, “Prologue”, available via
33
https://en.wikipedia.org/wiki/Prologue, view in 2017. [9] Wikipedia, “Epilogue”, available via
https://en.wikipedia.org/wiki/Epilogue, view in 2017. [10] Gustavo, “anatomy of a program in memory”, available via
http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/, view in 2017.
[11] Erik Buchanan, Ryan Roemer, Stefan Savage, Hovav Shacham, “Return-oriented Programming Exploitation without Code Injection” available via
https://www.blackhat.com/presentations/bh-usa-08/Shacham/BH_US_08_Shacham_Return_Oriented_Programming.pdf, Black Hat 2008 USA., view in 2017.
[12] Nergal, “The advanced return-into-lib(c) Exploits: PaX case study”, available via
http://phrack.org/issues/58/4.html#article, Phrack, vol. 11 no. 58, 2001, view in 2017.
[13] H. Shacham, “The geometry of innocent flesh on the bone: return-into-libc without function calls”, available via
https://cseweb.ucsd.edu/~hovav/dist/geometry.pdf, ACM CCS, 2007, view in 2017.
[14] Stephen Checkoway, Lucas Davi, Alexandra Dmitrienko, Ahmad-Reza Sadeghi, Hovav Shacham, Marcel Winandy, “Return-Oriented Programming without Returns”, available via
https://www2.cs.uic.edu/~s/papers/noret_ccs2010/noret_ccs2010.pdf, ACM CCS, 2010, view in 2017.
[15] Minh Tran, Mark Etheridge, Tyler Bletsch, Xuxian Jiang, Vincent Freeh, Peng Ning, “On the expressiveness of return-into-libc attacks”, available via
34
https://astojanov.files.wordpress.com/2011/09/tran_raid11.pdf, RAID’11, 2013, view in 2017.
[16] Ryan Roemer, Erik Buchanan, Hovav Shacham, Stefan Savage, “Return-Oriented Programming: Systems, Languages, and Applications”, available via
https://cseweb.ucsd.edu/~hovav/dist/rop.pdf, Manuscript, 2009, view in 2017. [17] Remi Mabon, “Sigreturn Oriented Programming is a real Threat”, available via
http://cs.emis.de/LNI/Proceedings/Proceedings259/2077.pdf, Lecture Notes in Informatics, Gesellschaft fr Informatik, Boon, 2016, view in 2017.
[18] Tyler Bletsch, Xuxian Jiang, Vice w. Freeh, Zhenkai Liang, “Jump-Oriented Programming: A New Class of Code-Reuse Attack”, available via
https://www.comp.nus.edu.sg/~liangzk/papers/asiaccs11.pdf, ACM Symp. Computer and Communications Security, 2011, view 2017.
[19] Mathias Payer, “String Oriented Programming – Circumventing ASLR, DEP and Other Guards”, available via
https://nebelwelt.net/publications/files/1128c3.pdf, Chaos Community Congress, 2011, view in 2017.
[20] Laszlo Szekeres, Mathias Payer, Tao Wei, and Dawn Song., “SoK: Eternal War in memory”, available via
https://nebelwelt.net/publications/files/13Oakland.pdf, IEEE International Symposium on Security and Privacy, 2013, view in 2017.
[21] Hector Marco-Gisbert, Ripoll, “On the Effectiveness of Full-ASLR on 64-bit Linux, available via
https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf, DeepSec, 2014, view 2017.
35
“detection and prevention of buffer-overflow attacks”, available via
https://www.usenix.org/legacy/publications/library/proceedings/sec98/full_paper
s/cowan/cowan.pdf, USENIX Security Symposium, 1998, view in 2017. [23] Linux manual, “Linux Programmer’s Manual - Fork”, available via
http://man7.org/linux/man-pages/man2/fork.2.html, view 2017.
[24] Andrea Bittau, Adam Belay, Ali Mashtizadeh, David Mazieres, Dan Boneh, “Hacking Blind”, available via
http://www.scs.stanford.edu/brop/bittau-brop.pdf, Security and Privacy (SP), 2014 IEEE Symposium, view in 2017.
[25] Koike Yuki, “Hunting Birds”, available via
https://www.npca.jp/works/magazine/2015_1/, Code Blue, 2015, view in 2017. [26] Wikipedia, “W^X”, available via
http://en.wikipedia.org/wiki/W∧X, view in 2017.
[27] Maythias Payer, “Too much PIE is bad for performance”, available via
https://nebelwelt.net/publications/files/12TRpie.pdf, ETH Zurich Technical Report, 2012, view in 2017.
[28] 俞甲子, 石凡, 潘愛民, “程式設計師的自我修養 – 連結. 載入. 程式庫”, 碁峰資訊股份有限公司, 2009.
[29] A. D. Federico, A. Cama, Y. Shoshitaishvili, C. Kruegel, G. Vigna. “How the elf ruined Christmas”, available via
https://www.usenix.org/conference/usenixsecurity15/technical-sessions/presentation/di-frederico, 24th USENIX Security Symposium, 2015,
view 2017.
[30] Redhat, “Enhance application security with FORTIFY_SOURCE”, available via
36
[31] Fedora,”Compiler Time Buffer Checks (FORTIFY_SOURCE)”, available via
https://fedoraproject.org/wiki/Security_Features?rd=Security/Features#Compile_
Time_Buffer_Checks_.28FORTIFY_SOURCE.29, view in 2017. [32] Linux manual, “FEATURE_TEST_MACROS(7)” available via
http://man7.org/linux/man-pages/man7/feature_test_macros.7.html, view in 2017.
[33] Clang Project. Clang – A C Language Family Frontend for LLVM, view in 2017. [34] Low-Level Virtual Machine Project. “LLVM”, available via
http://llvm.org/, view in 2017.
[35] Jannik Pewny, Thorsten Holz, “Control-Flow Restrictor: Compiler-based CFI for iOS”, available via
https://hgi.rub.de/media/emma/veroeffentlichungen/2013/10/02/CFI-compiler-acsac13.pdf, Annual Computer Security Applications Conference, 2013, view in 2017.
[36] Kuznetsov, V., Payer, M., Szekerrs, L., Candea, G., Sekar, R., Song, D., “Code-Pointer Integrity”, available via
http://dslab.epfl.ch/pubs/cpi.pdf, OSDI, 2014, view in 2017.
[37] M. Zhang, R. Sekar, “Control flow integrity for COTS binaries”, available via
http://seclab.cs.sunysb.edu/seclab/pubs/usenix13.pdf, USENIX Security Symposium, 2013, view in 2017.
[38] LLVM Project., “the-mc-layer”, available via
http://llvm.org/docs/CodeGenerator.html#the-mc-layer, view in 2017. [39] Kaan Onarlioglu, Leyla Bilge, Andrea Lanzi, “G-Free: Defeating
Return-Oriented Programming through Gadget-less Binaries”, available via
37
2017.
[40] LLVM Project., “using-the-machineinstrbuilder”, available via
http://llvm.org/docs/CodeGenerator.html#using-the-machineinstrbuilder-h-functions, view in 2017.
[41] LLVM Project, “Prologue/Epilogue Code Insertion”, available via
http://llvm.org/docs/CodeGenerator.html#prolog-epilog-code-insertion, view 2017.
[42] Michal Matz, Jan Hubicka, Andreas Jaeger, Mark Mitchell, “System V
Application Binary Interface AMD64 Architecture Processor Supplement Draft”, available via https://uclibc.org/docs/psABI-x86_64.pdf, 2014, view in 2017. [43] CVE, “Common Vulnerabilities and Exposures”, available via
![圖 7、Stack reading 示意圖[24] P4, Fig5](https://thumb-ap.123doks.com/thumbv2/9libinfo/8931808.268023/19.892.121.762.102.435/圖7Stackreading示意圖24P4Fig5.webp)
![圖 16、x86_64 ABI Registers[42] P21, Fig3.4](https://thumb-ap.123doks.com/thumbv2/9libinfo/8931808.268023/36.892.120.750.122.998/圖-x-abi-registers-p-fig.webp)
