應用模糊增強式學習技術於數位遊戲之研究
63
0
0
全文
(2) 誌謝 碩士班兩年的時間過得很快,在這兩年間我學到很多事情,也失去很多東西,我覺 得這兩年是我人生轉變最大的時期,面臨了許多困擾自己的問題,也因此改變我面對事 情的態度,並且在這段時間找到了我的人生目標與努力的方向。在這段時間中,最想感 謝的是我的指導教授丁一賢老師,從我一開始完全不知道要做什麼,慢慢的引導我找到 研究的方向,最終寫出論文,過程中我有許多時候都想要放棄,但是老師總是及時的拉 我一把,讓我可以完成我的學業,在此我想由衷的感謝老師,謝謝您。. 此外我也要感謝所有幫助過我的同學、學長姐、學弟妹以及朋友們。阿晟、科科、 瑋哥、譬司哥、大卜、大蘇兄,我很開心可以在求學的過程認識你們,當我有什麼困難 時你們都不吝給予幫助,希望在往後的人生路途中,我們還可以互相扶持、努力。也特 別感謝綠茶與阿珊,在我口試當天忙得不可開交時伸出援手,讓口試可以順利進行,謝 謝你們。而最感謝的朋友則是我的戰友們,小狗、小朱、書賓、子勛、思齊、肥與 J-Pow 的各位,在我人生最痛苦、難熬的階段,有你們的嘴砲與陪伴,讓我每天都過得很開心, 也才能專心的面對許多生活上的問題,也許大家都因為工作而慢慢疏遠,但我知道這份 友誼是不會因此被忽略的,你們永遠是我最重要的朋友。. 最後則是要感謝我的家人,父母親與哥哥,雖然每次事情很多而讓我心情不好時, 對你們的態度都很不好,但是你們還是包容我,為我打理一切,給予我家庭的溫暖,鼓 勵、支持我讓我可以無後顧之憂的完成學業,這份親情是我可以勇敢面對人生的最大原 因。最後再次感謝所有老師、朋友與家人,沒有你們的幫忙,我無法完成學業與這篇論 文,謝謝! 方永平 僅誌於 國立高雄大學 資訊管理學系 中華民國九十九年七月 I.
(3) 摘要 遊戲是人類生活上不可或缺的一項活動,近年來科技的蓬勃發展也帶起了數位遊戲 產業的龐大市場,數位遊戲會吸引人的原因除了其聲光效果之外,遊戲中玩家與非玩家 角色的互動也是一個非常重要的因素,為遊戲中的非玩家角色加入人工智慧技術可以讓 這些非玩家角色具有人類的思考能力,也因此可以讓遊戲與玩家的互動性更佳。. 數位遊戲中的環境是不斷在改變的,因此要為非玩家角色加入人工智慧通常會是一 個具有挑戰性的問題。在本研究中要將增強式學習技術應用在數位遊戲的非玩家角色 中,增強式學習技術是一種非監督式的學習方式,通常用於機械的自動化學習過程中, 增強式學習技術是一個不斷的試誤的學習過程,並且代理人會藉由去探索新環境來改變 其行為,是一種適用於未知環境下的學習方法。. 要將增強式學習技術應用在數位遊戲的非玩家角色中,其中最大的困難就在於增強 式學習必須要經過一段很久的時間去試誤學習,因此本研究利用模糊理論去改善傳統增 強式學習的效率,在實驗的過程中,成功的用模糊獎懲取代固定獎懲,讓學習的速度加 快,從實驗結果中也可以看出獎懲機制對於增強式學習結果的好壞有很大的影響,不同 類型的遊戲會需要不同的獎懲設定,找到適合的獎懲機制就能讓數位遊戲實際應用的可 能性提高。. 關鍵字:數位遊戲、遊戲人工智慧、增強式學習、模糊理論。. II.
(4) Abstract Game is one of the indispensable activities for humanity lives. In recent years, the development of technology also brought huge market to game industry. One of the appealing reasons in game is that the player can interact with the non-player-characters in game. Artificial intelligence is very important for these non-player-characters due to Artificial intelligence can let non-player-characters have more interactions with players.. The environment in digital games is changing continuously, so it is a challenge to add artificial intelligence in non-player-characters. In this research, we would like to use reinforcement learning in non-player-characters’ artificial intelligence. Reinforcement learning is a un-supervise learning method, and it is usually used in automatic machine learning process. Reinforcement learning is a trial-and-error process, and the agent will change his actions by exploring the new environment.. The most difficult to apply Reinforcement learning in digital games is that the method requires a long learning time . In this research, we use fuzzy theory to increase the learning efficiency. The results of this research experiment also prove the improvement of learning efficiency through using fuzzy reward to replace fixed reward. Different types of game need different settings of reward. In practice, the probability to apply reinforcement learning in digital games can be enhanced once the suitable reward mechanism has been found out.. key word:digital games、artificial intelligence for games、reinforcement learning、fuzzy theory. III.
(5) 論文目錄 第1章 緒論 ................................................................................................................................... 1 1.1 背景 ..................................................................................................................................... 1 1.2 動機與目的.......................................................................................................................... 6 1.3 研究假設 ............................................................................................................................. 7 1.4 研究流程與論文架構........................................................................................................... 8 第 2 章 文獻探討........................................................................................................................ 11 2.1 數位遊戲 .......................................................................................................................... 11 2.2 遊戲人工智慧 .................................................................................................................... 13 2.3 增強式學習........................................................................................................................ 15 2.4 本章小結 ........................................................................................................................... 19 第 3 章 模糊增強式學習 ............................................................................................................ 20 3.1 傳統增強式學習的缺點 .................................................................................................... 20 3.2 應用模糊理論於增強式學習之中 ...................................................................................... 22 3.3 模糊增強式學習之運算 ..................................................................................................... 23 第 4 章 實驗設計與實驗結果 ..................................................................................................... 25 4.1 實驗設計 .......................................................................................................................... 25 4.2 實驗環境與遊戲設計......................................................................................................... 27 4.4 前導實驗 ........................................................................................................................... 28 4.5 實驗結果 ........................................................................................................................... 38 4.6 遊戲呈現與遊戲結果......................................................................................................... 40 4.7 如何實際應用模糊增強式學習.......................................................................................... 45 4.8 本章小結 ........................................................................................................................... 48 第 5 章 結論 ............................................................................................................................... 49 5.1 摘要 .................................................................................................................................. 49 5.2 結論 ................................................................................................................................... 50 5.3 研究限制與未來研究......................................................................................................... 52 IV.
(6) 圖目錄 圖 一、. 全球遊戲市場產值圖 ............................................................................................2. 圖 二、. 增強式學習示意圖.................................................................................................5. 圖 三、. 坦克大戰遊戲畫面圖.............................................................................................6. 圖 四、. 研究流程圖.............................................................................................................9. 圖 五、. 增強式學習示意圖...............................................................................................15. 圖 六、. 黑與白遊戲畫面...................................................................................................18. 圖 七、. 實驗架構圖...........................................................................................................25. 圖 八、. 遊戲概念圖...........................................................................................................27. 圖 九、. 前導實驗圖...........................................................................................................28. 圖 十、. 增強式學習失敗圖...............................................................................................31. 圖 十一、. 三角隸屬函數圖...................................................................................................32. 圖 十二、. 前導實驗結果圖...................................................................................................33. 圖 十三、. 高斯隸屬函數圖...................................................................................................35. 圖 十四、. 模糊隸屬函數圖(s不同) ......................................................................................36. 圖 十五、. 模糊隸屬函數圖(m不同) ....................................................................................37. 圖 十六、. 模糊函數實驗結果圖...........................................................................................38. 圖 十七、. 遊戲編輯器...........................................................................................................40. 圖 十八、. 戰網示意圖...........................................................................................................41. 圖 十九、. 遊戲畫面圖...........................................................................................................42. 圖 二十、. 遊戲進行流程圖...................................................................................................43. 圖 二十一、實驗環境改變坦克學習圖...................................................................................50. V.
(7) 表目錄 表 一、. 遊戲分類表 ................................................................................................................2. 表 二、. 國內遊戲相關議題一覽表.......................................................................................11. 表 三、. 遊戲人工智慧方法比較...........................................................................................14. 表 四、. 獎懲函數...................................................................................................................24. 表 五、. 模糊獎懲函數...........................................................................................................24. 表 六、. 坦克移動策略表.......................................................................................................29. 表 七、. 獎懲函數...................................................................................................................30. 表 八、. 失敗的獎懲函數.......................................................................................................30. 表 九、. 危險變數例子...........................................................................................................32. 表 十、. 模糊獎懲函數...........................................................................................................33. 表 十一、實驗結果數據...........................................................................................................34 表 十二、成功次數表...............................................................................................................34 表 十三、實驗結果表...............................................................................................................51. VI.
(8) 第1章 緒論 1.1 背景 遊戲是人類社會中深受喜愛的一種活動,自古以來人類一直將遊戲視為一項重要 娛樂項目,蔡淑苓(2004) 在 《遊戲理論與應用:以幼兒遊戲與幼兒教師教學為例》一 書中提到,遊戲是非常古老且普遍的人類活動行為,並且受到中今中外的哲學家與教 育學家所重視,不論是幼兒時期或是學生時期,遊戲都扮演著成人活動的一種練習準 備,在遊戲中學習成長讓人格更具完善。長久發展以來,遊戲不再是只有幼年時期所 需求,有更多各種不同的類型的遊戲來滿足不同年齡層的需求,如團康遊戲、桌上型 紙牌遊戲、數位遊戲等等。總而言之,不論是什麼類型的遊戲,都是一種吸引人且重 要的人類行為表現。. 遊戲吸引人的原因有很多,其中有學者認為是因為遊戲可以達到放鬆與休閒的原 因(Epstein,1999),另外有一個很大的原因是因為透過遊戲可以與人互動交流、競賽, 藉由遊戲的過程與同好交流溝通,達到舒解壓力與取得娛樂感。由遊戲的本質來看, 遊戲的過程代表著一種邏輯思考的過程,通常可以將遊戲求勝的過程公式化成難解的 數學邏輯問題,因此如果解開遊戲中的各種問題,就代表著解開了一些數學邏輯上的 問題,也因此越來越多的許多學者在研究遊戲相關的議題。. 近年來由於科技的蓬勃發展,數位遊戲 (digital games) 也成為人類生活中一個很重 要的娛樂項目,數位遊戲以遊戲平台來分的話,大致可以分成電視遊戲(TV game)、電 腦遊戲(PC game) 、 手機遊戲(Mobile game) 等三種,若以遊戲型態來分,則可以分成單 機或線上兩種遊戲型態。目前而言,以線上遊戲為大宗。根據資策會資訊市場情報中 心(MIC )預估 (2008) ,台灣線上遊戲市場規模在 2008 年將超過新台幣 100 億元,且每 年仍將維持 8 至 9% 的成長率,且預估在 2010 年時規模將可達到 120 億元左右。就 全球市場而言,台灣經濟研究院產經資料庫研究(2008 年 12 月 ) 指出 ( 圖一 ) ,全球的線 上遊戲產值高達54.11 億美金,並逐年上升中,又以中國地區成長最大。行政院 (2009) 也視數位內容產業為文化產業中的一塊重要拼圖,為近年來非常重視的一個產業方 1.
(9) 圖 一、全球遊戲市場產值圖 ( 資料來源 : 台灣經濟研究院產經資料庫, 2008 年 12 月 ). 數位遊戲可以除了帶來許多感官的刺激,也讓遊戲更具多樣性,每一種不同的遊 戲類型都有不同的玩家所喜好,遊戲公司為了迎合玩家的胃口,同時也創造出許多不 同的數位遊戲類型。若要以遊戲內容來做分類的話,Aha 等學者在 2005 年將數位遊戲 簡單的分類為冒險遊戲(adventure) 、即時戰略遊戲 (real-time strategy) 、團隊運動遊戲 (team sports)等七種類型,如表一所示。 表 一、遊戲分類 表 (資料來源 :Aha,2005) 類別. 代表遊戲. 描述. 桌上型. 西洋棋、象棋、五子棋等. 棋類或牌類、通常為 n*n 的地圖. 冒險. 猴島小英雄. 解題類型. 團隊運動. 足球遊戲、籃球遊戲等. 即時或多人合作. 經營. 模擬城市. 城市或團隊管理. 角色扮演. 太空侵略者. 即時單人角色. 回合式. 文明帝國. 回合基礎遊戲. 即時戰略. 魔獸爭霸. 即時、經營. 2.
(10) 數位遊戲吸引人的因素除了聲光效果之外,最主要的原因還是玩家可以在遊 戲互動中得到娛樂的效果,通常稱這些在遊戲中與玩家互動的非玩家角色為 NPCs(non-player characters) , NPCs 可以是玩家的敵人或朋友,但是不管如何,要 是這些NPCs反應不合理,或是單調無趣,玩家因此失去耐心,玩過一兩次之後就 不會有新鮮感,甚至會成為一個公式化的行為,也就會讓遊戲失去遊戲性,如早 期任天堂公司於1985 年發行的著名的遊戲瑪俐歐 ( 日文:マリオ; 英文 : Mario ; 或 中文 譯:馬力歐、瑪莉、瑪俐歐 等等) ,遊戲中的怪物 (NPCs) 行動模式是不變 的,當玩家玩過多次以後就會知道要如何閃避敵人,久而久之就會開始覺得厭 倦,進而對這款遊戲不感興趣。許多研究因此就會想為這些NPCs建置人工智慧, 讓NPCs 具備自行思考的能力,也就是說讓 NPCs 會根據玩家的行為做出一些合理 的反應,當玩家與NPCs 產生互動時, NPCs 就會有更人性化的表現,增加遊戲的 樂趣與耐玩性。. 早期的遊戲人工智慧研究大部份致力於桌上型遊戲 (board game) 上,例如研發 可以與玩家對戰的西洋棋或象棋的NPCs等,這樣的人工智慧發展的結果是為了挑 戰人類,如IBM 的深藍 (Deep Blue) ,可以打敗世界西洋棋的冠軍,因此追求的是 可以和玩家有同等級的思考能力,追求的是一種且完美不會失敗的人工智慧 (Ghory,2004)。. 但在目前數位遊戲中的人工智慧大部份尋求的並非永遠無法擊敗的人工智 慧,而是想讓NPCs 具有人類思考模式的行為 (Livingstone,2004) ,因此玩家才可以 與其互動,從中得到樂趣,如果一個無法擊敗的NPCs反而會讓玩家失去信心,使 玩家覺得遊戲太過困難且不有趣,數位遊戲需要的是有能夠適應環境,能與玩家 之互動的人工智慧,因此本研究想要建置在NPCs上的人工智慧是一種可以依據目 前狀態而改變的學習模式,玩家在遊戲中改變不同的玩法時,NPCs也會做出相對 應的對策。. 3.
(11) 數位遊戲的人工智慧都在早期都是以規則基礎 (rule-based) 的方式來建置(Bourg, 2004) ,例如以第一人稱射擊遊戲來做例子,當玩家走到 NPCs 一定範圍時, NPCs 就會開槍反擊,像這樣一條一條的規則去定下所有 NPCs 會做出的行為,因此要寫 出一個非常人性化的NPCs人工智慧,可能需要上萬行的程式碼,在某些情況下, 玩家可能會覺得NPCs 的行為是不合理的 (Spronck等人,2006) ,這樣的人工智慧也 就被稱為弱的人工智慧(weak AI) 。強的遊戲人工智慧 (strong AI) 如基因演算法或 類神經網路等(Buckland,2005) ,可以讓 NPCs 做出更多合理化的行為,但是大部份 這類型的方法都需要在環境已經給定的基礎之下,並無法在一個未知的環境下使 用,但是遊戲的環境卻常常在改變,對NPCs來說,玩家不同的行為讓遊戲環境變 得不可預測,如果要讓NPCs能夠隨環境改變而跟著做出反應,需要能夠在未知環 境下運行的演算法,因此在眾多的人工智慧技術中,增強式學習可說是最適合 NPCs 的一種 (Szita,2007) 。. 增 強 式 學 習 (reinforcement learning) 為 一 種 非 監 督 式 學 習 (unsupervised learning),所謂的非監督式學習是一種機器學習方式,非監督式學習法則的特色 是在訓練過程只需提供輸入資料,而期望的輸出理想值卻不需要設定,代理人會 自去學習調整(Sutton and Barto 1998) 。. 增強式學習通常用在未知的環境之下,利用試誤 (trial-and-error) 與延遲獎懲(delay reward)的機制,不斷的去探索環境來找到最佳解,其學習的流程如圖二,增強式 學習通常包含兩個角色,環境(environment)代表需要解決問題的所有外在因子, 而代理人(agent) 則負責與環境互動學習,代理人所做出的行動 (action) 會改變整體 環境的狀態 (state) ,在不同的狀態下代理人會依照獎懲 (reward) 去做出應對的行 動,在多次學習過程中學習到最佳策略的方法(Sutton and Barto,1998)。. 4.
(12) 圖二中的t代表時間,st代表目前時間點的狀態,st+1 代表下一時間點的狀態, rt代表目前時間點的獎懲值,rt+1 代表下一時間點的獎懲值,本示意圖將會在本論 文的 2.3 節之中詳細介紹 。通常將增強式學習公式化成馬可決策過程 (Markov decision process )問題。增強式學習的精神為如同人類小時候試誤學習時的過程, 利用過去的經驗來做判斷,進而達到學習的效果。. 圖 二、 增強式學習示意圖 t:時間. 當遊戲中 NPCs 加入增強式學習的人工智慧技術後,就可藉由一次又一次與玩 家互動經驗中,瞭解玩家的習性,藉此學習到如何反應玩家的行為,增強式學習 同時是一種漸進式的學習,不會讓遊戲初始的難度太高,玩家也不會感到太大壓 力,進而提高遊戲的吸引力。. 5.
(13) 1.2. 動機與目的. 由前一節的研究背景中提到, 數位遊戲中NPCs的人工智慧是遊戲非常重要的一 環,有好的人工智慧技術就可以讓遊戲與玩家更具互動性,本研究期待將增強式學習 技術加入數位遊戲的人工智慧中,讓NPCs可以藉由經驗來學習,並做出應對的行動。. NPCs 的行動路線在遊戲中是一個很重要的因素,在許多類型的遊戲中, NPCs 都 必須要藉由移動路徑來跟玩家互動,如 : 戰略型遊戲,不論是回合制或是即時制, NPCs 都要藉由接近或遠離玩家來達成他的目標 ( 攻擊或逃跑 ) ;第一人稱射擊遊戲中, NPCs也要有避開玩家攻擊與利用阻礙物的能力,藉由不同的路線移動來達到他的目 標;角色扮演類型遊戲的NPCs如果只會在地圖上隨機亂走,玩家也會因此感到無趣。 能夠讓NPCs有聰明的行動路線,對於遊戲來說是一個非常重要因素,並且可以應用到 許多類型的遊戲上。本研究將以坦克類型遊戲來做實驗,坦克類型遊戲是一個傳統的 射擊遊戲類型,最早為發表於1985 年任天堂主機上的遊戲 ( 圖 三) 。. 圖 三、 坦克大戰 遊戲畫面圖 ( 資料來源 :http://zh.wikipedia.org/ 遊戲製作發行 : 南宮夢, 1985). 在遊戲中玩家需要控制玩家坦克去對抗電腦的坦克 (NPCs) ,在射擊類型遊戲中, 往往會有許多危險區塊或路線,如果可以定義其危險的程度,當連續多次走到特定的 危險區塊時就提高該地區的危險程度,讓NPCs快速的理解到該地區是非常危險的,不 6.
(14) NPCs 學習時間,讓 NPCs 行動表現的更具智 慧,所以本研究將利用模糊函數來表示危險程度,讓NPCs可以利用快速的學習與反 應,同時利用模糊函數的定義,也可以控制NPCs學習的速度,讓遊戲具有難度調整的 功能,讓玩家依自己程度來調整或挑戰,增加遊戲的耐玩性。. 總而言之,本研究的動機希望能夠將增強式學習應用在數位遊戲 NPCs 的人工智慧 中,並且改善其效率,具體而言本研究的目的為: I.. 應用增強式學習技術於數位遊戲的 NPCs 之中 本研究將利用遊戲編輯器製作出坦克對戰類型的遊戲環境,並在遊戲中加入 增強式學習機制的NPCs,並探討其成效。. II.. 利用模糊理論提昇增強式學習效率 將模糊邏輯理論應用在改善增強式學習的效率上,並且期望能夠利用模糊邏 輯理論來達成數位遊戲調整難度的機制。. 1.3 研究假設 根據之前的探討,本研究提出以下幾點的研究假設: I.. 本研究假設在傳統數位遊戲中加入增強式學習技術可以讓遊戲中的 NPCs 具有學 習的能力,會依據玩家不同的行為來做出不同的反應,並可適應遊戲環境的改變 進行調整。. II.. 本研究假設在傳統的增強式學習技術中加入模糊理論可以提高其學習效率. 7.
(15) 1.4 研究流程與論文架構 本研究流程如圖四。本論文想要將增強式學習應用在遊戲之中,並且改善它的效 率,因此研究的流程為:. 1.. 首先在背景與 動機 下界定研究範圍。. 2.. 在界定的研究範圍中,進行相關文獻的蒐集,並針對所得的文獻的探討,文 獻共分成遊戲、遊戲人工智慧與增強式學習的文獻三部份。. 3.. 從文獻探討中確定本研究目標。. 4.. 用實驗來印證研究假設,實驗共分成兩部份為前導實驗與遊戲實驗,實驗的 內容主要在於應用增強式學習技術在數位遊戲,以及應用模糊理論來提高增強 式學習技術效率。. 5.. 透過結果與討論來修改實驗中所建置的各個參數,反覆的調整不同的參數來 應用在遊戲之中,並找出最適合本研究的數值 。. 6.. 最後再綜合所有實驗結果做出結論,並探討本研究的實際應用在數位遊戲上的 可行性與策略,以及未來進行研究的建議。. 8.
(16) 圖 四、 研究流程圖. 9.
(17) 本論文架構如下,. 第一章 緒論: 從遊戲的本質探討瞭解到互動性對於遊戲是非常重要的,而人工智慧技術是讓數 位遊戲增強互動性的一個方法,從此一背景下界定研究的範圍,並提出研究的假設, 確定研究流程。. 第二章 文獻探討: 對過去的研究 文獻做統整, 探討在遊戲方面目前學者的研究成果,以及目前與 遊戲相關的人工智慧之研究,與增強式學習方面的研究成果,以及增強式學習應用 在遊戲的研究探討。. 第三章 模糊增強式學習: 對於模糊增強式學習的深入研究,包括傳統增強式學習的缺點與解決方法,模 糊理論如何應用在增強式學習之中,以及既有的模糊理論應用探討,最後是本研究 中如何將模糊理論實際應用。. 第四章 實驗設計與實驗結果: 為本研究實驗部份,內容包括了整體遊戲的設計概念,模糊增強式學習如何應用在 本論文的遊戲之中,與前導實驗所做出的參數值設定,與前導實驗結果的探討,以 及本研究所做出的遊戲實際情形,與應用增強式學習技術在此遊戲的結果及討論。. 第五 章 結論: 結論與未來研究,討論本研究實驗所呈現的結果,並探討如何應用本研究之結果到 實際的數位遊戲之中,最後提出未來可進行之研究。. 10.
(18) 第2章 文獻探討 本章將討論數位遊戲、遊戲人工智慧與增強式學習技術的文獻,目前與數位遊戲有關 的研究中,大多數文獻主要在研究數位教學與遊戲中玩家行為,但也有少部份的研究 在探討遊戲中的人工智慧,在遊戲的人工智慧方面,也有不少研究在於如何應用增強式 學習技術於數位遊戲的人工智慧中,以下各節將依序詳細討論。. 2.1 數位 遊戲 簡國斌(2010)在其碩士論文中整理了國內碩士論文對於數位遊戲相關的研究 結果(表二) 表 二、國內遊戲相關議題一覽表 (資料來源:簡國斌碩士論文,2010). 學年. 研究生. 學校系所. 90. 陳慶峰. 南華大學資訊管理所碩士論文. 91. 林青嵐. 91. 張武成. 93. 楊斐羽. 95. 李豐良. 95. 李炯龍. 96. 曾世绮. 96. 蘇榮章. 97. 鄭羽汎. 97. 陳亭光. 97. 蔣昱雯. 論文名稱. 研究方法. 從心流(flow)理論探討線上遊戲 個 案 訪 談 法 、 文 獻 分 析 參與者之網路使用行為 法、問卷調查法 靜宜大學資訊管理所碩士論文 玩家對多人線上角色扮演遊戲產 文獻分析法、問卷調查法 品屬性偏好之研究 淡江大學資訊管理所碩士論文 線上遊戲軟體設計因素與使用者 文獻分析法、問卷調查法 滿意度相關聯之研究 元智大學資訊傳播所碩士論文 將傳統遊戲的玩性因素導入電子 焦點團體訪談、專家訪談 遊戲設計之研究 法 國立交通大學工業工程與管理所 動作型電腦遊戲設計因素探討 問 卷 調 查 法 、 類 神 經 網 博士論文 路、基因演算法 國立臺北教育大學玩家與遊戲設 集換式牌類遊戲之遊藝功能要素 文獻分析法、專家訪談 計所碩士論文 分析─以魔法風雲會為例 佛光大學資訊教育所碩士論文 驗證遊戲吸引人之要素:內容分 內容分析、參與觀察法 析『魔獸世界』 國立政治大學資訊管理所碩士論 數位教育遊戲設計與評估指標之 文獻分析法、問卷調查法 文 研究 開南大學資訊管理所碩士論文 線上遊戲設計:個案探討與內容 個案研究、內容分析 分析 國立臺灣大學資訊管理所碩士論 基於使用者經驗之多準則評分遊 文 獻 分 析 法 、 多 穩 額 評 文 戲推薦系統 分、協同過濾 國立臺北教育大學傳播與科技所 數位遊戲學習教材評鑑指標之研 文獻分析法、德懷術 碩士論文 究 11.
(19) 從表中可以看出,以往與遊戲相關的研究大部份著重在於遊戲的本質與數位教學為 主,且目標大部份探討的是以幼兒為主,如《遊戲理論與應用:以幼兒遊戲與幼兒教師 教學為例》( 蔡淑苓,2004)、《 幼兒遊戲-以 0~8 歲幼兒園實務為導向 》(James E. Johnson, 2005)、《幼兒教育》(朱敬先,2005)等書,皆是由幼兒時期的遊戲行為來探討遊戲對 於正常人成長過程的影響。在朱敬先《幼兒教育》一書中提到,遊戲理論又可以分成 精力過剩論、鬆弛論、本能實踐論、復演論、生活實踐論、自我表現論、學習論、心理 分析論等八種論點,但不管那一種論點都是支持遊戲對於人成長是有正向的影響,因此 也就會有研究探討怎樣的遊戲會吸引人去玩,在《遊戲理論與應用:以幼兒遊戲與幼兒 教師教學為例》(蔡淑苓,2004)一書中提到,遊戲可以吸引人的原因不外乎遊戲是一個 社交行為的縮影,在遊戲中可以與人交流互動,並從遊戲中學習到如何應對。. 近年來電腦技術的成長快速,也帶動了數位遊戲的發展(詳細介紹請見第一章),數 位遊戲吸引人的地方不只是其聲光效果佳,同時也未脫離遊戲的本質,因此遊戲的互動 仍然是很重要的一個因素,除了玩家與玩家的互動外,玩家在數位遊戲中也會與許多非 玩家角色 NPCs 互動,這些 NPCs 的行為模式也就顯的格外重要,例如角色扮演遊戲中, 劇情的發展就是一個非常重要的因素,如果可以藉由玩家與遊戲中的 NPCs 互動情形來 決 定 不 同 的 遊 戲 內 容 , 就 可 以 大 幅 的 提 高 遊 戲 的 吸 引 力 , 在 這 方 面 , Barber 和 Kudenko(2001)就做過自動劇情產生器,在這篇研究中,他們成功的創造一個自動劇情 產生器,讓遊戲會依照玩家不同的行為產生不同的劇情,就可以讓每個人遊戲的過程不 一樣,藉此讓遊戲可以有無限多的內容,增強遊戲的耐玩性。. 除了遊戲內容之外,NPCs 的行為表現也是一個重要的因素,如果 NPCs 表現不合 常理或是非常單調,就會大幅降低遊戲的吸引力,在遊戲中加入簡單的在因此就需要遊 戲的人工智慧讓 NPCs 更具人性化的行為表現。. 12.
(20) 2.2 遊戲人工智慧 在過去遊戲人工智慧的相關研究中,以研究桌上型遊戲 (board game) 與猜謎 (puzzle) 為 最多,桌上型遊戲如西洋棋、象棋、圈圈叉叉等,這類型的遊戲通常不可能全用暴力 法將所有狀態空間計算出來,當找出較好的演算法代表著解決一個難解的數學問題, 也因此有許多的學者在研究(Epstein,1999) 。而 Ghory(2004) 試圖對增強式學習應用在桌 上型遊戲做一個公式化的研究,其結果讓許多研究應用在各種不同的桌上型遊戲上。. 在數位遊戲上通常是用規則基礎 (rule-based) 的方式去寫入 NPCs 的人工智慧,但如此一 來則需要大量的程式碼來完成許多複雜的行為,且會有許多不合理的行為發生,因此 也有許多學者在這方面在研究,Aha (2003) 利用案例基礎 (case-based) 方式,對戰略類 型遊戲魔獸爭霸 二 做一個更佳的 NPCs 人工智慧 ,他認為在這款遊戲中的建築順序關 鍵,因此將所有可能的建築順序排成一個階層結構,因此可以整理出許多建築序列,不 同的序列就可以當成不同的案例,因此根據案例就可以寫出許多條規則,最後就讓NPCs 依照案例規則來建築,擊敗玩家,雖然此一方法效果卓越,但是卻被玩家的一些特例所 擊敗,比如說玩家一開始不蓋任何建築,直接農民快攻等等不合常理的玩法。因此, 在同一款遊戲之下, Ponson(2004) 等人則是用基因演算法去改善 Aha 研究的缺失之處, 就可以有效的解決這些特例情形 ,並且提高成攻率,讓NPCs更具挑戰 。另外 Jin(2008) 等人則是用類神經網路的方法去加強運動類型遊戲 NPCs 的人工智慧,讓複雜的遊戲人 工智慧簡化成幾個不同的行為模式,這些研究的其優缺點如表三。. 這些方法的共通缺點為必須在已知的環境之下, 事先 設定好許多環境的因素才能執 行,而如果環境即時改變,如果玩家的行動改變了環境狀態,就會有較遭的結果產 生,增強式學習可以讓代理人(agent)在未知的環境下學習,但目前用在數位遊戲中的 研究並不多, McPartland(2008) 將增強式學習利用在第三人稱的射擊遊戲之中,讓 NPCs 可以學習到最佳的行動路線,以及攻擊玩家的時機與地點。另外, Wender(2008) 等人則是將增強式學習利用在策略遊戲之中,讓 NPCs 選擇啟始點時適應不同的環境與 玩家的行動,讓NPCs 的行為更聰明。而 Björnsson(2004) 等人則是將增強式學習應用在 養成策略遊戲之中,且讓玩家可以直接對NPCs做一些簡單的控制,縮短學習的時間。 13.
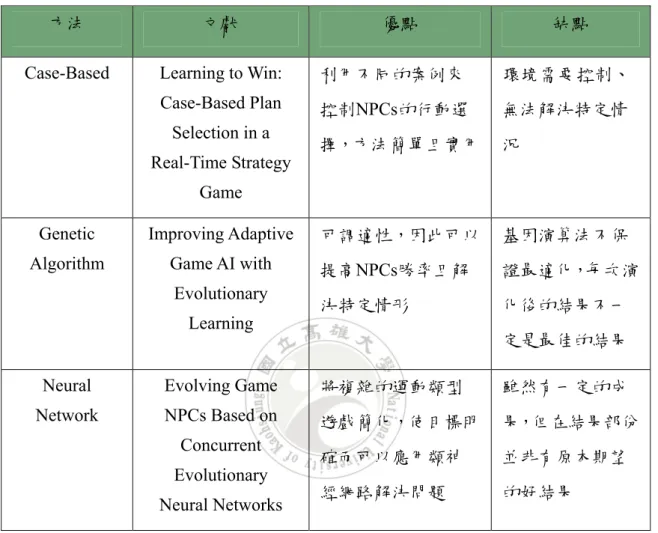
(21) 表 三、遊戲 人工智慧方法比較 (資料來源:本研究整理). 方法. 文獻. Case-Based. Learning to Win:. 利用不同的案例來. 環境需要 控制、. Case-Based Plan. 控制NPCs的行動選. 無法解決特定情. 擇,方法 簡單且實用. 況. 可調適性,因此可以. 基因演算法不保. 提高NPCs勝率且解. 證最適化,每次演. 決特定情形. 化後的結果不一. Selection in a Real-Time Strategy. 優點. 缺點. Game Genetic. Improving Adaptive. Algorithm. Game AI with Evolutionary Learning. 定是最佳的結果. Neural. Evolving Game. 將複雜的運動類型. 雖然有一定的成. Network. NPCs Based on. 遊戲簡化,使目標明. 果,但在結果部份. 確而可以應用類神. 並非有原本期望. 經網路解決問題. 的好結果. Concurrent Evolutionary Neural Networks. 14.
(22) 2.3 增強式學習 增強式學習是種與環境互動中,不斷的嘗試不同的行動,找尋最佳策略的一種學習方 法。增強式學習通常包含兩個角色,環境(environment)代表需要解決問題的所有外在 因子,而代理人(agent) 則負責與環境互動學習,代理人所做出的行動 (action) 會改變整 體環境的狀態(state) ,在不同的狀態下代理人會依照獎懲 (reward) 去做出應對的行動, 在多次學習過程中學習到最佳策略的方法,其流程就如之前所看過的圖五,t代表時間, 當代理人感知到環境(目前狀態)時,選擇不同的動作,動作又會改變環境,並得到獎懲, 進入到下一個時間點,代理人感知到下一時間點狀態,並且選擇動作得到下一時間點的 獎懲。. 圖 五、 增強式學習示意圖. 增強式學習其實就是模擬生物在學習事物的情形,比如說小孩子剛開始學騎腳踏 車,一開始會不知道怎樣驅動,也不知道傾斜多少度會跌倒,但是每次失敗跌倒後,自 然後吸取教訓,再反覆的練習,跌倒了許多次之後,就知道該如何平衡,也知道如何轉 彎而不會跌倒,藉由過去的經驗不斷的強化自身的能力,就是增強式學習技術的主要精 神。. 15.
(23) 增強式學習通常可以公式化為馬可決策過程,增強式學習又可以分成主動式 (active) 增 強式學習與被動式(passive)增強式學習,其主要的差別在於,被動式增強式學習的代 理人用固定的策略(fixed policy) 去學習其效用值 (utility value) ,效用值所代表的意義為 在該狀態下達到目標與其他狀態的相對比較值,通常值越大代表此一狀態離目標越接 近,選擇到此一狀態的機率也越大。主動式學習則是需要不停的探索環境去找到其策 略(Melenchuk,2000)。. 被動式學習的方法通常分成三種, LMS(least mean squares) 、ADP(adaptive dynamic programming) 與 TD(temporal difference learning) 三種,這三種方法中最佳的是 TD 方法 (Russell and Norvig,2003) 。 LMS 方法為隨機選取行動,再計算到達目標的所有獎懲 值,然後再算出其各個狀態下達到目標的效用值平均數,其缺點為需要非常久的計算 時間(Russell and Norvig,2003) ; ADP 方法則是在給定特定估計模式之下,每次行動後 重覆的計算每一個狀態的效用值,但在狀態空間大的情形下會難以計算(Russell and Norvig,2003) ; TD 方法結合了蒙地卡羅方法 (Monte Carlo ) 與動態規劃方法(dynamic programming)的概念,其公式如公式一:. V(s) ← V(s ) + α(R(s) + γV(s' ) - V(s) ). (1). V(s)代表效用值, α 是學習函數, γ 是獎賞折扣值,s代表狀態,R(s)為在此狀態的 獎懲值,其主要概念為藉由過去的經驗去調整預期可以到達目標的效用值(Russell and Norvig,2003)。. 16.
(24) 主動式增強式學習最有名的演算法為 Q-Learning 與 SARSA algorithm 兩種,兩種演 算法皆是建立在TD 方法基礎之上的演算法,藉由試誤與延遲獎懲來不斷的重複計算 Q-value(state-action value) , Q-value 是在某一狀態與行動對 (State -Action pairs) 到達目標 之相對比較值,Q-value越大代表選擇此一狀態與行動對於達到目標的機會越大,因此 以Q-value大小來決定各個狀態與行動的機率值,讓代理人可以藉由過往經驗選擇目前 環境下最佳的行動。 Q-Learning 是由 Watkins 在 1989 年提出,是一種無策略演算法 (off-policy) 的演算法,而其公式如 公式二(Sutton and Barto,1998) :. Q(s, a) ← Q(s, a ) + α(R(s) + γmaxQ(s' , a' ) - Q(s, a) ). (2). SARSA 是 State-Action-Reward-State-Action 的縮寫,在 1994 年的 Rummery 提出,是 一種有策略性(on-policy)的演算法,其公式如公式三:. Q(s, a) ← Q(s, a ) + α(R(s) + γQ(s' , a' ) - Q(s, a) ). (3). s 代表現在環境狀態, a 代表代理人的行動, s’ 是下一時間點的狀態, a’ 是下一時 間點的動作,因此Q(a,s) 代表在狀態 s 下進行行動 a 的期望價值, R(s) 是在狀態 s 下的實 際價值,maxQ(a’,s’) 代表著在所有下一時間點預期的 Q-value 最大值, α 是學習函數, 用於控制學習收斂速度,一般會將此值預設為1 , γ 是獎懲的折扣值,通常是一個小於 1 的常數。而 Q-Learning 與 SARSA 最大的差別在於 SARSA 是在某些特定的策略下執 行,而Q-Learning則是完全沒有任何策略的運用,因此必需要計算下一次行動中最大 的Q-value(Sutton and Barto,1998)。. 17.
(25) 增強式學習的學習方式是去找到每個狀態的最佳行動,因此需要多方嘗試,但是 如果隨機去嘗試,就等同於不去選擇已知的最佳行動,這樣隨機的行為就與基本精神 相違背,因此解決問題與探索新知(exploitation. and. exploration)就成為增強式學習的. 兩難問題,通常會運用ε-greedy 演算法來解決, ε-greedy 也是 greedy 演算法的一種,只 是在其過程中會有一定機率利用隨機的方式去探索,這樣不但可以符合找最佳行動的 基本精神,也會試圖的去探索是否有更佳的行動(Bianchi , 2007) 。例如,設定另一參數 p=0.5,而代理人在每一次決定行動時,會隨機決定一個 0~1 的變數q,當q>p=0.5 時, 就選擇隨機探索產生行動,反之,當q≤p=0.5 時就從之前經驗算出最佳的行動。. 增強式學習已經有許多應用與研究,比較常看到應用在機械的學習與控制,也有一些 研究是應用在遊戲之中,目前應用增強式學習最有名的遊戲為善與惡(Black & White) 這款遊戲,善與惡是由 Lionhead Studios 在 2001 年所研發製作,是一款經營類型的遊 戲,在善與惡這款遊戲中玩家伴演造物者的角色,而玩家可以控制一名神祇生物,此 生物會跟著玩家所做出的不同決定,而改變其行為跟長相,這樣的一個機制受到玩家 的好評,也因此這一款遊戲在2005年推出續作善與惡二代,圖 六 為該遊戲二代之畫 面。. 圖 六、 黑與白遊戲畫面 ( 資料來源 : http://lionhead.com/Jobs.aspx). 18.
(26) 2.4 本章小 結 由以上三節得知,數位遊戲最吸引人的地方不單單只是其聲光效果,如果可以增加遊 戲與玩家的互動性,就可以讓遊戲更具可玩性。在遊戲人工智慧的發展中,大部份的 遊戲都已經具備基本的人工智慧,如路徑搜尋或是碰撞偵測等,或是用條件規則基礎 來為遊戲的NPCs加入人工智慧,但是這樣的遊戲並不能滿足目前玩家的需求,如果可 以用強的人工智慧讓NPCs行對更人性化,就能讓遊戲更吸引玩家。. 強的人工智慧如基因演算法及類神經網路等,有許多的研究已經有效的將此類方法應 用在數位遊戲之中,可是在市面的遊戲中仍不常見,最主要的問題如之前幾節所論, 數位遊戲中的環境變化太大,因為玩家特性而存在著許多需要考慮的因素,如果沒辦 法有效的解決環境的因素,建置強的人工智慧所需要的成本太大,反而不實用。. 但是由文獻中可以發現,數位遊戲的 NPCs 需要的人工智慧,並非是無懈可擊的人工 智慧,一個不犯錯的NPC 只會降低玩家的信心,而不能為遊戲加值,因此 數位遊戲# 不需要一個完美的人工智慧,而是要能夠學習互動的人工智慧,並且是可以因應遊戲 環境的需求來做調整學習的人工智慧,增強式學習正好具備以上的特性,也因此本研 究將以增強式學習做為研究的重點。. 文獻中也可以看出,雖然增強式學習在許多領域已經被廣為應用,但是在數位遊戲之 中仍然還未有許多研究,其最主要的問題就是因為傳統的增強式學習通常需要很長的 一段時間來學習,這樣並不能符合數位遊戲的需求,因此本研究將設法改進此一缺 點,下一章將探討本研究如何解決這問題以及如何應用在遊戲之中。. 19.
(27) 第3章 模糊增強式學習 傳統增強式學習已經在各個領域廣為研究,但其效率不好的缺點也讓增強式學習 技術常常無法被實際應用,因此有許多學者在研究用各種不同的方法去縮短增強式學 習的學習時間,本研究則是應用模擬理論來提高傳統增強式學習的效率,以下各節將 會詳細介紹傳統增強式學習的缺點,以及本研究如何將模糊理論運用在增強式學習技 術之中,並提高其效率。. 3.1 傳統 增強式學習的缺點 增強式學習的特色為不斷的試誤過程去找到最佳解,但其付出的代價就是需要很 長的一段時間讓代理人去學習(Epstein,2009),有許多學者研究如何去縮短傳統增強式 學習的學習時間,像是將階層式增強式學習,將所有狀態空間表示成一個階層式的狀 態空間,所以代理人就不必去計算下一時間點狀態所對應的所有Q-value值,先從下一 階層中的狀態空間去運算,藉此降低其運算時間,讓增強式學習更具有效率。 Ponsen(2006)嘗試等人將此應用在數位遊戲之中,將代理人的移動先分成達到目標或 遇到敵人此一階層,再決定代理人會選擇移動的方位,這樣的方法有效的提高學習的 效率。. 也有研究利用模糊理論來提高增強式學習的學習效率。模糊理論是利用數學模式 去解決人類語言學中語義不清的問題,最初是由Lotfi Zadeh 在 1965 年所提出,例如溫 度問題,當有人表示天氣太冷,但實際上的溫度度數卻沒有明確的表達,不同人對於 冷熱有不一樣的概念,而這些表達不清的模糊區域就無法以傳統的二元分法來做判斷, 因此為了解決這些模糊的灰色地帶問題,就需要用到模糊集合理論(fuzzy set theory)來解 決。模糊集合理論捨棄原本二元的分法,而以從屬度(membership degree)來做判斷,例 如剛剛的溫度問題,將溫度表達成冷暖等等區間,10℃在冷區的從屬度為 0.9,而在熱 區的從屬度為 0.1 這樣的方式來對溫度做區閣,數字越高代表越符合這個區域的特性, 而這些數值則形成所謂的 模糊從屬函數 (fuzzy membership function ),模糊理論 常常應 20.
(28) Seo(2000)等人做過將模糊邏輯應用在增 強式學習上的研究,在該研究中是將狀態轉換成模糊狀態,因此可以將所有狀態分成許 多狀態區塊,也就能提高傳統增強式學習的學習效率。. 這些研究都有效改善增強式學習效率不佳的問題,但是其學習過程卻是有所限制,因 為在增強式學習的過程中,最重要的是獎懲機制的設定,就算有效的降低狀態空間的運 算,沒有一個適當的獎懲機制設定,傳統增強式學習也有可能會無法學到最佳策略,甚 至是一個發散的結果,也就是根本就找不到所謂的最佳策略,因此增強式學習在獎懲的 設定通常會需要依照不同的需求來制定,這樣的限制也限制的增強式學習研究的一般 化,同樣的結果在另外的研究中因為獎懲的問題可能就不適用,但是如果改善獎懲的 設定,或許可以造成不同的學習效果,因此本論文著眼於獎懲機制上的改變,嘗試利 用模糊邏輯理論於獎懲機制之中,讓原本固定的獎懲變成模糊化的獎懲,不再是固定 的獎懲數值,不但讓學習速度更快,也讓學習更加合理。. 如果可以讓遊戲的 NPCs 具有增強式學習的人工智慧,並且用模糊邏輯理論去改善其 效率,這樣一來可以讓許多的遊戲實際的應用,也使遊戲NPCs行為更有變化,如此一 來不但簡化了遊戲程式碼的複雜度,還可以讓遊戲NPCs行為更人性化,甚至因應不同 玩家的程度來改變難度,讓遊戲更具耐玩性。. 21.
(29) 3.2 應用模糊理論於增強式學習之中 如上一節所討論,在增強式學習中最重要的因素就是奨懲的設定,所以本研究將原本 固定的獎懲改成模糊獎懲機制,在傳統的增強式學習中,原本獎懲的設定會給一個基 本的固定值,當代理人做出行動時如果可以接近目標,就給予獎勵值,但是如果越接 近目標則會給予越高的獎勵值使Q-value 值提高,反之,則可能給予懲罰,讓 Q-value 降低,這樣的機制考慮了目前狀態與目標狀態的差距,獎懲值的大小會直接影響到學 習的結果,如果一開始設定了一個很高的獎勵值,代理人可能會因為獎勵值過高而快速 學到某條策略,但是這樣卻忽略了其他可能的策略,如果獎勵太低又會讓代理人學習的 曲線變的很平緩,要經過很久才能學習到最佳的策略,但是其中很重要的一點就是當獎 勵越高,對於學習的效率是有正向影響的,只是其結果可能會不好。. 本研究的想法是讓獎懲的機制不再是由固定的數值去做調整,而是由另一個模糊隸屬 函數來控制。 加入了模糊獎懲的機制就可以讓代理人在學習的過程中,不單只是依照 目標與現在狀態差距而去調整獎懲值,也會考慮到策略在不同情形下的獎勵,如此一來 就可以將獎懲值設定成較高的數值,再將獎懲值乘上一個模糊值,根據該條策略的模糊 隸屬程度來改變獎懲值,也因此可以有效的改變傳統增強式學習的效率,同時也不因為 數值的加減變動過大,最後導致無法學習到最佳策略的結果。. 在加入了模糊函數之後還可以利用模糊函數的調整,來達成不同的學習行為,例如 遊戲中的最終魔王可能就會需要快速學習能力,因此就可以調整模糊函數讓這種類型的 NPC 可以快速的學習,而其他像是魔王身邊的小兵這種 NPCs 可能就不能有那麼強大的 學習能力,除此之外,利用不同的模糊函數或許可以用來調整難度,增加遊戲的可玩性。. 22.
(30) 3.3 模糊增強式學習之運算 本研究將模糊獎懲取代傳統增強式學習的固應獎懲,以下本論文就以坦克對戰遊戲 為例,解釋如何將固定的獎懲值換成模糊獎懲值,在坦克對戰遊戲中,NPC 坦克因應 不同的環境與玩家的行動,可能會有數條不同的路線(策略)選擇,每當選擇一條路徑的 結果可能會被玩家擊敗,或是順利抵達目標,因此獎懲的數值可能是+1 與-1,但是當 NPC 坦克在同樣的情形下不斷的被擊敗時,可能因為狀態(玩家所做的行為與地圖的所 有因素)是一樣的,所以其懲罰值是不變的,但是這樣的情形並不符合常理,連續的在 某條路線上被擊倒應該要有更大的懲罰值,相對的,連續成功的達到目標也應該有更大 的獎勵值。. 因此如果可以給每個策略不同的模糊值,而這個模糊值可以依據每次的結果去運 算,就可以避免以上的問題,所以本研究將獎懲值就設定為+10*F 或-10*F,F 為該條路 線的模糊隸屬值(fuzzy membership value,詳細介紹在第四章),為範圍介於 0~1 的一個 小數值,如此一來當 F=1 時,就會有很高的獎懲值,讓 NPC 坦克可以很快的學習到該 條路線是否危險,但是 F=0 時,將不會有任何獎懲值,也就是該次結果可能只是偶然, 不能提供 NPC 坦克做為學習的參考,其步驟如下所示:. 1. 回合開始。 2. NPC 坦克根據各路線的 Q-value 選擇此回合之路線。 3. NPC 坦克撞到炸彈或順利走到終點。 4. 計算各路線危險值 X,並轉換成對應各路線的危險函數值 F。 5. 將獎懲值乘上其對應的 F 值。 6. 重新計算各條路線的 Q-value 值。 7. 回合結束,如果還未學到唯一一條路線,則回到步驟 1。. 23.
(31) 以本研究的實驗為例(詳細介紹請見第四章),原本的獎懲如表四,如果將其模糊化 就變成表五所示。. 表 四、獎懲函數 狀態 s. R(s). 坦克撞到炸彈,該條策略. -10. 坦克撞到炸彈,別條策略. +5. 坦克順利走到終點,該條策略. +20. 坦克順利走到終點,別條策略. -10. 表 五、模糊獎懲函數 狀態 s. R(s). 坦克撞到炸彈,該條策略. -20*F. 坦克撞到炸彈,別條策略. +10*F. 坦克順利走到終點,該條策略. +40*F. 坦克順利走到終點,別條策略. -20*F. 接著下一章將詳細介紹完整實驗設計與實驗結果,也就可以看出當把原本的固定 獎懲(表四)變成模糊獎懲(表五)後,其效率因此可以大幅提升。. 24.
(32) 第4章 實驗設計與實驗結果 本章將介紹本研究的實驗部份,本研究實驗共分成兩部份,第一部份是前導實 驗,在前導實驗中將找出最適合坦克對戰遊戲類型的模糊增強式學習參數,並應用在 第二部份的遊戲實驗中,在本章的實驗中可以看出應用模糊理論提高傳統增強式學習 的效率,並且探討不同的模糊隸屬函數在於不同類型遊戲的應用。. 4.1 實驗 設計 本研究如圖七,共分成兩部份,第一部份為前導實驗,藉由簡單的遊戲路徑行為 模擬,找出最適合此遊戲的增強式學習,再將其加入第二部份實際的遊戲之中。. 圖 七、實驗架構圖 25.
(33) 前導實驗中的步驟如下: 1.. 實驗平台: 開發實驗平台,前導實驗的平台主要是讓本研究可以測試增強式學習在 坦克對戰類型遊戲中的應用情形,藉由路線的選擇來測試增強式學習與模糊理 論的實用性。. 2.. 增強式學習: 在前導實驗平台上的 NPC坦克 加上具有增強式學習技術之人工智慧,讓 NPC坦克在多次的嘗試之後,可以經由經驗學習來選擇路線避開炸彈。. 3.. 模糊理論: 在增強式學習中加上模糊函數來調整獎懲值的設定,使原本的固定獎懲變 成模糊獎懲。. 4.. 數據分析: 實驗後把本次實驗所得到的結果回饋到各參數中,不斷的嘗試不同的值來找 出最佳函數。. 26.
(34) 4.2 實驗環境與遊戲設計 本研究中規劃設計出一個坦克對戰射擊遊戲,遊戲中有玩家可以自行操控的坦克 以及具有模糊增強式學習人工智慧的NPC坦克,其遊戲規則如下:. NPC坦克要從任意大小的地圖中某一啟始點出現,目標為到達某些終止點,玩家 可以從任意處攻擊NPC坦克,但是在地圖中會有些玩家不可擊破的牆壁,這些牆壁可 能是隨機產生或是玩家設定,因此,NPC坦克就會藉由這些牆壁來躲過玩家的攻擊, 並且學到最安全的一條路線來擊敗玩家,其過程如圖八所示。. 圖五為一個 N*N 大小的地圖,紅色框框所示就是 NPC 坦克,而玩家則是在地圖下 方黑色框框中的坦克,可以左右自由移動,紅色 S 點代表 NPC 坦克的初始出現地點, A1~A5 代表可以阻擋玩家攻擊的牆,紅色箭頭代表 NPC 坦克的目標,只要移動通過最 下面的底線,就算 NPC 坦克勝利。. 圖 八、遊戲概念圖 本研究的實驗平台 的軟硬體設備如下: OS: Windows Vista Home Premium CPU:Intel Core 2 Duo processor T5500(1.6GHz,2MB L2 cache) RAM:2GB Software:Adobe Flash CS3 Pro 27.
(35) 4.3 前導實驗 1.. 加入增強式學習. 在製作遊戲之前,本研究先做了一個前導實驗,想利用的簡單的實驗平台來找出最適 的函數,再將此一實驗結果運用在實際製作的遊戲之中,前導實驗利用flash與action script 2.0 當成實驗平台設計工具,創造了一個在 3*3 地圖中具有簡化 SARSA 演算法學 習能力的NPC坦克,如圖九。. 圖 九、前導實驗圖. 在此實驗中設定了一個 3*3 的地圖,在地圖的右上方為 NPC 坦克的啟始點(紅色框白色 S字處) ,而地圖的左下方則是終止點 (老鷹圖處) , NPC 坦克只能往左或往下走,因此 會有六種不同的策略,如表六。. 28.
(36) 表 六、坦克移動策略表 Step 1. Step2. Step 3. Step 4. Policy A. left. left. down. down. Policy B. left. down. Left. down. Policy C. left. down. down. left. Policy D. down. left. Left. down. Policy E. down. left. down. left. Policy F. down. down. Left. left. 同時在地圖中會有些玩家可以自由設定位置的炸彈 (紅色與黑色炸彈) ,當 NPC 坦克碰撞到這些炸彈就會被摧毀,該回合即結束,此外,若 NPC 坦克走到終止點也算 一回合結束,每次回合結束就會用SARSA 演算法去計算其 Q-value 值,當坦克被摧毀 對該條路線Q-value值就會給予懲罰降低,而其他路線則給予獎勵提高,反之,若坦克 走 到 終 點 時 , 該 條 路 線 Q-value 值 則 會 得 到 獎 勵 , 其 他 路 線 會 加 予 懲 罰 , 將 各 個 Q-value 值的大小計來算出不同條路線的選取機率, Q-value 值越大則會代表著選到該 路線的機會越大,直到只剩下一條路線時,該遊戲才會結束,再將其數據紀錄之。. SARSA演算法公式如公式四:. Q(s, a) ← Q(s, a ) + α(R(s) + γQ(s' , a' ) - Q(s, a) ). (4). 設定 α , γ =1. 並將此實驗的公式簡化如公式五:. Q(s, a) ← Q(s' , a' ) + R(s). (5). 29.
(37) 而在此實驗中的獎懲函數值如表七,其中各值大小為本研究自訂,因應本實驗給予每 條路線的初始值為五十,因此在設定函數數值時,以加減十來測試,在多次實驗之後, 發現對於撞到炸彈或順利走到終點此兩種狀態應該給予較高的獎懲值,相對的其他兩種 情形則需要比較低的獎懲值,因此在本實驗中分別設定為撞到炸彈或走到終點之獎懲值 的一半,也就如表七所示。. 表 七、獎懲函數 狀態s. R(s). 1.坦克撞到炸彈,該條策略. -10. 2.坦克撞到炸彈,別條策略. +5. 3.坦克順利走到終點,該條策略. +20. 4. 坦克順利走到終點,別條策略. -10. 在實驗的過程中,本研究發現講懲的設定與增強式學習的效率有很大的關係,如果提 高獎懲值將對提高效率有正向的影響,但是如果設定不當,將造成無法學習到最佳策略 的結果,如表八,當坦克順利撞到炸彈後別條策略的獎懲提高到 10,就會造成如圖十 所示,當回合數非常大時仍然無法學到最佳策略(本研究以一百回合當做最大值,超過 則認為此設定失敗)。 表 八、失敗的獎懲函數 狀態s. R(s). 1.坦克撞到炸彈,該條策略. -10. 2.坦克撞到炸彈,別條策略. +10. 3.坦克順利走到終點,該條策略. +20. 4. 坦克順利走到終點,別條策略. -10. 30.
(38) 圖 十、 增強式學習失敗圖. 並且發現如果以固定的獎懲值,將無法表現出路線的危險程度,當某一路線不斷 的撞到炸彈時,增加固定的值並不合理,應該要以模糊函數來計算獎懲值,如果一直 撞到炸彈時,代表此一策略是非常危險的, 應該要給予更高的懲罰 。. 2.. 加入模糊理論. 經由實驗的結果,本研究用模糊理論來改善此一實驗。首先,用某一危險函數來 做計算, Xi 為該條路線的危險變數,初始值為 0 ,當碰到炸彈時該路線危險變數為 Xi=Xi+1 ,若連續碰到兩次則 Xi=Xi+2 ,若連續碰到三次則 Xi=Xi+3 ,最多 +3 ,也就是 說如果同一條路線中連續碰撞多次炸彈,就代表該路線非常危險,危險變數累加速度 越快,反之,其他j=i 條路線的危險變數 Xj=Xj-1 ,且一樣有累加的效果,最多 -3 。. 31.
(39) 舉例來說,選擇同一條路線上的九回合結果如表 九( 炸彈可移動所以同條路線會有 碰撞或沒碰撞到的情形). 表 九、危險變數例子 回合. 1. 2. 3. 4. 5. 6. 7. 8. 9. 結果. +. +. +. -. -. +. -. +. +. X改變量. 1. 2. 3. 1. 2. 1. 1. 1. 2. X 總量. 1. 3. 6. 5. 3. 4. 3. 4. 6. +:代表坦克撞到炸彈 -:代表坦克順利走到終點. 如果將原本固定的獎懲改變成模糊獎懲,用危險變數 X 來代表危險程度,模糊隸 屬 函 數 (fuzzy membership function) 則 利 用 最 基 本 的 三 角 隸 屬 函 數 (Pieczy ski and Obuchowicz 2004)( 圖 十一) ,而 f=µ(x) 的算式如算式六:. if x ≥ 10 ⎧1, ⎪10 − x ⎪ , if 0 < x < 10 μ (x) = ⎨ ⎪ 10 if x = 0 ⎪⎩0,. 圖 十一、三角隸屬函數圖. 32. (6).
(40) 此一算式所計算出來的危險模糊函數來替代原本固定的獎懲值,新的模糊獎懲函數如 表 十,因為 f 期望值為 0.5 ,所以新的模糊獎懲函數 R’ 為原本固定獎懲函數 R 二倍再乘 R. 上 f ,例如原本第一條獎懲為 -10 ,新的獎懲值就為 -20*f ,以此類推。. 表 十、模糊獎懲函數 狀態 s. R(s). 1. 坦克撞到炸彈,該條策略. -20*f. 2. 坦克撞到炸彈,別條策略. +10*f. 3. 坦克順利走到終點,該條策略. +40*f. 4. 坦克順利走到終點,別條策略. -20*f. 兩個實驗結果比較如圖十二及表十一。可以看出加入模糊獎懲後,NPC坦克只要 約 26 回合就可以學到唯一的一條路線,比起原本未加入前的固定獎懲快了約 20 回合,明顯的提高學習效率。. 圖 十二、前導實驗結果圖. 33.
(41) 表 十一、實驗結果數據. ID. E1. E2. 1. 58. 29. 2. 52. 28. 3. 54. 24. 4. 59. 25. 5. 55. 26. 6. 52. 32. 7. 56. 27. 8. 54. 28. 9. 47. 30. 10. 59. 23. mean. 54.6. 25.6667. success rate. 0.56. 0.67. E1: 固定獎懲 E2: 模糊獎懲 表十一中的成功率(success rate)代表在所有回合中,成功走到終點的機率(成 功走到終點次數/總回合次數),如果以每十回合來看 E1 實驗的成功次數,則如 表十二所示。. ID\回合. 1~10. 1 2 3 4 5 6 7 8 9 10 mean. 5 3 1 2 2 2 3 3 2 3 2.6. 表 十二、成功次數表 11~20 21~30 31~40. 5 2 3 6 2 2 2 4 3 4 3.3. 6 5 4 4 3 5 7 3 3 3 4.3 34. 8 5 4 6 4 7 5 5 7 6 5.7. 41~50. 51~60. 61~70. 10 8 10 8 9 9 8 10 9 10 9.1. 10 10 10 10 10 10 9 9 10 10 9.8. 10 10 10 10 10 10 10 10 10 10 10.
(42) 在此一實驗中可以看出,模糊理論確實可以明顯的提高增強式學習的效率,而 且不只是提高效率,也許可以利用模糊邏輯來控制其難易度的調整,因此實驗 除 了 使 用 基 本 的 三 角 隸 屬 模 糊 函 數 , 也 利 用 了 高 斯 隸 屬 函 數 (Gaussian. membership function ) 來比較兩者的差別 (Pieczy ski and Obuchowicz 2004) 。高 斯隸屬函數算式如公式七: ⎡ 1 x−c m⎤ μ a ( x, c, s, m ) = exp ⎢− ⎥ ⎣⎢ 2 s ⎦⎥. (7). x 為 危 險 函 數 值 , c 為 中 央 值 (centre) , s 為 寬 度 值 (width) , m 為 模 糊 因 子 (fuzzification factor) ,其型狀如圖十三所示 (c=5,s=2,m=2):. 圖 十三、高斯隸屬函數圖 在此實驗中希望 X 的值不要超過 5 ,也就是如果從 0 開始計算,在連續撞到 第三次時,其危險程度就為最高,因此 固定中央值 c=5 ,也就是說當 x≧5 其危 險函數值 f=µ(X)=1 ,另外如果改變二個參數值 (s,m) ,就可以改變,隸屬函數的 圖型,如果只改變 s 的話,如圖十四所示 ( 以 c=10 , m=5 , s=2,3,4,5,6,7) :. 35.
(43) 圖 十四、模糊隸屬函數圖 (s 不同 ). 36.
(44) 如果只改變 m 的話,如圖十五所示 ( 以 c=10 , s=5 , m=3,5,7) :. 圖 十五、模糊隸屬函數圖 (m 不同 ) 高斯隸屬函數所呈現的表現較符合本研究所期望的智能表現,本研究所期 望的智能表現並非是直線提高其危險程度,而是要根據不同的需求,去改變其 學習的效果,例如如果 目前希望一個後知後覺的 NPC ,那應該要如圖十四中 6 號 曲線 (黃色) 所呈現的結果,相反的如要一個學習能力很強大的 NPC ,就要 s 與. m 兩值都提高,如圖十四中 1 號曲 線的結果 ( 或是更加垂直 ) 。因此本研究期望 可以利用不同參數值的隸屬函數,可以用來做為調整難度的機制。. 37.
(45) 4.5 實驗結果 根據前三節所討論,本研究想探討不同模糊隸屬函數參數值與不同的獎懲值大小設定 對於結果的影響,將不同的值代入實驗中,並紀錄 NPCs 坦克需要多少回合才能學到唯 一的路線,得到的結果中發現,原本預期依照不同的模糊參數值 (s 與 m 值 ) , NPCs 會有 不同的行為模式,藉此可以調整遊戲的難度,但經過實驗發現,模糊參數值的調整並 不能達到原本的預期,在不同的參數設定下,只會影響數據的穩定性,而不會形成不 同的行為表現,反而是不同的獎懲設定對於 NPCs 行為模式影響程度較大,如圖十六所 示及說明。. 圖 十六、模糊函數實驗結果圖. 圖十中,從所有結果挑出 s=3,5 與 m=3,5 來呈現, 1 號( 藍色 ) 線條代表模糊參數值 m=3 與 s=3 的四種不同獎懲值下的結果,同理, 2 號( 紅色 ) 線條是 m=3 與 s=5 的四種結果, 3 號( 綠色 ) 線條是 m=5 與 s=3 的四種結果, 4 號( 黑色 ) 線條是 m=5 與 s=5 的四種結果。而. A,B,C,D 四 點 則 是 代 表 在 該 模 糊 參 數 下 的 四 種 獎 懲 值 ( 參 考 4.3 節 ) , 分 別 為 (40,20,20,10) 、 (40,20,20,0) 、 (40,15,20,10) 與 (40,20,20,5) ,其中第一個數值為坦克順利 走到終點,該條策略所增加的值,第二個數值為坦克順利走到終點,別條策略所減少 38.
(46) ,Y軸為當坦克學到唯一一條路線所需的回合數。. 從圖中可以看出,改變不同的模糊函數,並不能藉由函數的改變來改變學習的模式 的不同,但是當s與m兩者參數都增加的情型下,會讓NPCs坦克的學習效果越一致,也 就是不受到不同獎懲設定的影響。另外,改變獎懲的大小會直接影響學習的表現(學習 的快與慢),當坦克撞到炸彈,別條策略所增加的值越少,學習越快,這也是合理的行 為,但是如果太少雖然學的比較快,但也表示坦克就會減少嘗試其他路線的機會,如此 一來當環境改變時NPC坦克可能就不懂得如何應變,因此從以上結果可以看出,不同的 需求會有不同的參數值,換句話說,在不同類型的遊戲環境下,會有不同的參數設定。. 雖然從結果可以看出模糊函數並不能改變行為模式,但是整體而言,模糊獎懲的結 果會比固定獎懲更有效率(學習的回合數較少),因此雖然從實驗結果無法得到調整難度 機制的方法,但是利用模糊獎懲的增強式學習還是會比固定獎懲的傳統增強式學習更有 效率。此外,如果是不同類型的遊戲,可能需要不同的學習曲線,像是第一人稱射擊遊 戲與即時戰略類型中,NPCs 需要的可能是比較穩定的學習曲線,讓 NPCs 可以從與玩 家互動中穩定的學習,不會讓玩家突然覺得強度變化太大,不可預測;但是像是運動或 動作類型遊戲可能需要變化較大的學習曲線,這類型的遊戲對於強度的敏感度較低,畢 竟人類本來就會有失誤的情形產生,在這種類型遊戲中,如果 NPCs 突然做變強或變弱 並不會讓玩家覺得奇怪,反而只會覺得 NPCs 只是產生失誤,但是整體而言並不會造成 影響。. 39.
(47) 4.6 遊戲呈現與遊戲結果 在實際的遊戲上,本研究利用魔獸爭霸三的編輯器做出一個實際可以玩的遊戲, 魔獸爭霸三為 Blizzard公司 在 2000 年所發表製作的遊戲,遊戲中附有遊戲編輯器 (world. editor ,圖十 七) 來讓玩家自己設計自己想要的關卡,可以發表在遊戲官方伺服器戰網 (Battle net ,圖十 八) 之上,讓所有玩家玩到自己設計的圖,因為其功能非常齊全,因 此受到玩家的愛戴,創造出許多小遊戲,如圖如當下很紅的 Dota 、 TD 等等小遊戲都是 從玩家自行設計進而發表在戰網上面,許多遊戲甚至成為經典且被視為一種新的遊戲 類型 ,如 Dota類型遊戲,原是為Defend of the Ancient ,是一名歐洲玩家eul所自行設計 出的新遊戲類型,玩家分成兩邊陣營控制英雄去攻打對方軍營,該遊戲融合了許多要 素,如升級系統、道具系統、技能系統等,擁有龐大的玩家群,雖然在魔獸爭霸資料片 時停止更新,但是因此有非常多的玩家按照這樣此類型設計去研發新圖,像是國外的. Dota allstar與Dota chaos,國內的真三國無雙、信長的野望等等,甚至還有遊戲公司專 門獨立研發此一類型的遊戲,如 League of Lengends(Riot games , 2009) 、 Heros of. Newerth(S2 games,2010) 、與中國自行研發的夢三國 (杭州電魂,2010) 等等遊戲。. 圖 十七、 遊戲編輯器. (資料來源:魔獸爭霸 III 截圖,版權所有:Blizzard). 40.
(48) 圖 十八、 戰網示意圖. (資料來源:魔獸爭霸 III 截圖,版權所有:Blizzard) 根據之前所提的遊戲概念,本研究製作了一個坦克對戰的遊戲 ( 如圖十 九) ,在這 一遊戲中,玩家可以控制在下方的玩家坦克移動且攻擊,會有 NPC 坦克從上面出現, 並且會有隨機的牆 ( 圖十四中藍色的橫槓 ) 出現來阻擋玩家的攻擊, NPC 坦克會利用模 糊增強式學習技術不斷的學習到玩家的攻擊行為,進而利用牆壁來躲開玩家的攻擊, 當 NPC 坦克往下走到玩家的基地時,玩家將會受到攻擊,並降低生命值,而當玩家成 功擊敗 NPC 坦克時就會提高自身的分數,當玩家 生命值 就結束,分數最高的玩家就是此一遊戲的贏家。. 41. 降低成零時遊戲.
(49) 圖 十九、遊戲畫面圖. (資料來源:魔獸爭霸 III 截圖,版權所有:Blizzard) 本實驗讓 NPC 坦克具有模糊增強式學習的人工智慧,一開始 NPC 坦克會隨機選擇 路線並且紀錄路線到路線資料庫內,當 NPC 坦克被玩家擊敗或是成功走到最底部,就 算本回合結束,接著下一回合開始 NPC 坦克會從隨機或是從路線資料庫中選擇出這回 合要執行的路線,如果是由隨機選擇路線的話,則會判斷是否是一條新的路線,新的路 線就再將這條路線紀錄起來到資料庫內,其流程圖如圖二十。. 42.
(50) 圖 二十、遊戲進行流程圖. 43.
(51) 在此實驗中,使用 ε-greedy 演算法來決定 NPC 是否決定探索新路線,設定的機率 為 10%,而路線的選擇機制則是利用前導實驗所做出的結果,使用 SARSA 演算法的模 糊增強式學習,模糊隸屬函數是使用高斯隸屬函數,參數為 c=10、s=5 以及 m=5,每條 新產生的路線都會給予路線的選擇值 t,其初始值設定為 50,每回合結束後都會做重複 運算,此值就會決定路線被選擇出來的機率大小,也就是說當 NPC 坦克在此條路線被 擊敗時,就會根據 SARSA 演算法去懲罰此條路線,減少 t 值,反之則會增加 t 值。. NPC 坦克會學習到如何利用地型避開玩家的攻擊,因實驗需求,本實驗設定一面牆讓 NPC 坦克必能成功避開攻擊並成功抵達目標,也就是玩家一定會因為生命被扣完而結 束遊戲,最後再以玩家所取得的分數來當勝負的判別。遊戲完成之後,再將此遊戲放到 戰網上讓玩家下載,在遊戲的過程中可以發現,玩家對於 NPC 坦克會避開攻擊感到很 有趣,且為了取得更高分會想盡辦法去擊敗 NPC 坦克,如果想要挑戰不同的難度或玩 法,也可以藉著改變牆的位置或是改變增強式學習的獎懲值設定,讓 NPC 坦克可以有 不同的表現,玩家因此可以與 NPC 坦克鬥智產生樂趣。. 44.
(52) 4.7 如何實際應用模糊增強式學習 從本研究得知,模糊增強式學習確實是可以應用在坦克類型遊戲之中,但是數位遊 戲有很多類型,在不同的遊戲類型可能會有不同的應用情形。. 1.. 第一人稱遊戲類型 例如在第一人稱射擊遊戲中就可以本研究所做的路徑搜尋功能,第一人稱射擊遊戲. 中的 NPCs 跟坦克對戰類型遊戲有異曲同工之妙,NPCs 都需要知道去避開危險,找到 一條安全且可以擊敗的玩家的路徑,不同的是第一人稱射擊遊戲通常會更複雜,會有更 多因素來影響 NPCs 的決定,例如與玩家的距離、武器的不同、是否要與玩家硬碰硬等 等,要將更多的因素加入路線危險程度的考慮,但是同樣的是可以讓模糊增強式學習成 為 NPCs 選擇路徑的一個依據,讓 NPCs 有更具人性化的行動表現。. 2.. 角色扮演類型 如果是以目前最熱門的線上角色扮演類型的遊戲,或許可以將模糊增強式學習技. 術應用在敵方 NPCs 的出招模式上,在此類型的遊戲中,最吸引玩家的過程通常是集合 許多玩家一起去打敗強大的敵方頭目(NPCs)來取得稀有的物品獎勵,而不同的 NPCs 可 能就會有不一樣的行為模式,雖然同樣的一個 NPC 可能會有許多不同的行為,但是不 同的行為通常會是隨機產生的,因此玩家在玩過幾次後通常會知道 NPC 會有哪幾種行 為,該如何避開 NPC 的招式,所以玩過幾次後打頭目 NPC 的過程就變成有固定的模式 且不斷重複的無趣過程,遊戲公司也必須要一直出更多不同的場景與不同的 NPCs 來因 應玩家的需求,因此如果能讓 NPCs 都具有模糊增強式學習的人工智慧,讓 NPCs 可以 學習到玩家的行為,進而選擇不同的行為模式,就可以讓遊戲變得更有趣,延長遊戲的 壽命。. 45.
數據



+4


Outline
相關文件
又到了回顧年度成績的時刻,Google 於 12 月 1 日公布台灣「Google Play 2020 年 度最佳榜單」,總共有 16 款應用程式與 20 款遊戲上榜。因應
從視覺藝術學習發展出來的相關 技能與能力,可以應用於日常生 活與工作上 (藝術為表現世界的知
學生在專注理解遊戲時, 不自覺的要理 解文字提供的線索, 閱讀的目的明確而 有意義, 有助練習認字讀句。..
運用學校的區角圖片,讓 兒童從「找不同」的遊戲
蔣松原,1998,應用 應用 應用 應用模糊理論 模糊理論 模糊理論
本研究考量 Wal-mart 於 2005 年方嘗試要求百大供應商需應用 RFID 技術 於商品上(最終消費商品且非全面應用此技術,另 Wal-mart
H2-7:不同 Facebook 得知管道的 Facebook 遊戲使用者在 Facebook 遊戲動機有顯著 差異。. H2-8:不同 Facebook 平均每次使用時間的 Facebook
譚志忠 (1999)利用 DEA 模式研究投資組合效率指數-應用
