國
立
交
通
大
學
電機學院 電機與控制學程
碩
士
論
文
應用線性迴歸模型於射頻 IC 特性預測
Prediction of RF IC characteristics
using regression models
研 究 生:黃哲賢
指導教授:周志成 教授
應用線性迴歸模型於射頻 IC 特性預測
Prediction of RF IC characteristics
using regression models
研 究 生:黃哲賢 Student:Che-Hsien Huang
指導教授:周志成 Advisor:Dr. Chi-Cheng Jou
國 立 交 通 大 學
電機學院 電機與控制學程
碩 士 論 文
A Thesis
Submitted to College of Electrical and Computer Engineering National Chiao Tung University
in partial Fulfillment of the Requirements for the Degree of
Master of Science in
Electrical and Control Engineering June 2012
Hsinchu, Taiwan, Republic of China
應用線性迴歸模型於射頻 IC 特性預測
學 生 : 黃 哲 賢 指 導 教 授 : 周 志 成
國立交通大學 電機學院 電機與控制學程 碩士班
摘 要
製程控制是半導體業很重要的一個環節。為了預測射頻 IC 特性,目前多半以人 工方式挑選變數,但此法不能同時監控多個參數以利晶圓挑選,故易導致良率偏低, 造成損失。本論文以統計學之線性迴歸分析作為預測射頻 IC 特性模型。本研究以現有 晶圓製程資料作為輸入變數,並以最終產品的測試結果作為輸出變數,透過有效的變 數選擇程序,即向前選擇法,並利用 F 檢定準則篩選出重要的輸入變數,以建立準確 且強健的預測模型。最後,我們利用測試資料來驗證預測模型的實際效用,結果顯示 準確率可達 92.5%以上,相較於原本的人工方式,良率因此獲得大幅改善。Prediction of RF IC characteristics
using regression models
Student: Che-Hsien Huang Advisor: Dr. Chi-Cheng Jou
Degree Program of Electrical and Computer Engineering
National Chiao Tung University
Abstract
Process control is a critical factor in semiconductor manufacturing. To predict IC characteristics, the present industry still relies heavily on human expertise. Manual selection for explanatory variables cannot deal with multi-variables effectively and thus often results in poor prediction accuracy. In this thesis, we adopt multivariate linear regression to predict RF IC characteristics. The wafer fabrication data provided by IC manufacturing company are taken as input variables, and the final function test data are target outputs. By adopting variable selection scheme, we are able to identify key input variables so as to enhance the model accuracy without losing robustness. Our study showed that the proposed approach can achieve 92.5% accuracy for the validation data. The yield rate was improved significantly.
誌 謝
感謝指導教授周志成老師的細心指導與教誨,不僅讓我在學習研究上得到札實的 訓練與知識,更讓我了解待人處事才是最重要的部份。同時感謝楊谷洋教授與孟慶宗 教授在口試時給予的指導,讓本論文能夠更完善。 感謝實驗室學弟小莊、阿陽、冰豬、承綱、志勇和駿程的課業與生活上的協助與 支持,讓我論文更能順利完成。 最後感謝太太雅閔的支持與體諒,女兒千綾與兒子千睿乖巧的配合,讓我事業、 學業,與家庭都能兼顧。 謝謝你們。目 錄
中文摘要 ……… i 英文摘要 ……… ii 誌 謝 ……… iii 目 錄 ……… iv 圖 目 錄 ……… vi 表 目 錄 ……… viii 第 1 章 序論... 1 1.1 研究動機與目的... 1 1.2 問題陳述... 3 1.3 系統架構... 4 1.4 論文架構... 6 第 2 章 半導體生產鏈實務介紹 ... 7 2.1 射頻 IC 封裝、測試流程 ... 8 2.2 WAT 參數 ... 8 2.3 最終測試參數... 10 2.4 功率增益... 10 2.5 靜態電流... 11 2.6 產品類型之挑選邏輯 ... 12 2.6.1 實驗階段 ... 12 2.6.2 量產階段 ... 13 第 3 章 線性迴歸分析... 15 3.1 線性關係原理... 15 3.2 皮爾森相關係數... 17 3.3 線性迴歸... 18 3.3.1 迴歸分析的概念 ... 18 3.3.2 最小平方法與迴歸方程式 ... 183.3.3 迴歸誤差與可解釋變異 ... 20 3.3.4 迴歸模型的顯著性考驗 ... 22 3.4 多元迴歸分析... 23 3.4.1 多元迴歸 ... 23 3.4.2 預測與解釋 ... 23 3.5 多元迴歸的統計原理 ... 25 3.5.1 多元相關 ... 25 3.5.2 多元迴歸方程式 ... 26 3.5.3 輸入變數的選擇程序 ... 27 3.5.4 預測誤差與估計問題 ... 28 第 4 章 實驗與討論... 31 4.1 實驗資料簡介與實驗流程 ... 31 4.1.1 皮爾森相關係數 ... 34 4.1.2 線性迴歸參數挑選 ... 37 4.1.3 線性多元迴歸解釋力檢驗 ... 38 4.1.4 建立線性多元迴歸模型 ... 42 4.2 線性迴歸預測結果比較 ... 42 4.2.1 C1 類型預測結果比較... 45 4.2.2 C2 類型預測結果比較... 46 4.2.3 C3 類型預測結果比較... 48 4.2.4 C4 類型預測結果比較... 50 4.3 成本與利潤評估... 54 4.3.1 C1 類型成本與利潤評估... 55 4.3.2 C2 類型成本與利潤評估... 56 4.3.3 C3 類型成本與利潤評估... 57 4.3.4 C4 類型成本與利潤評估... 58 4.4 補救措施... 59 第 5 章 結論... 61 參考文獻... 63
圖 目 錄
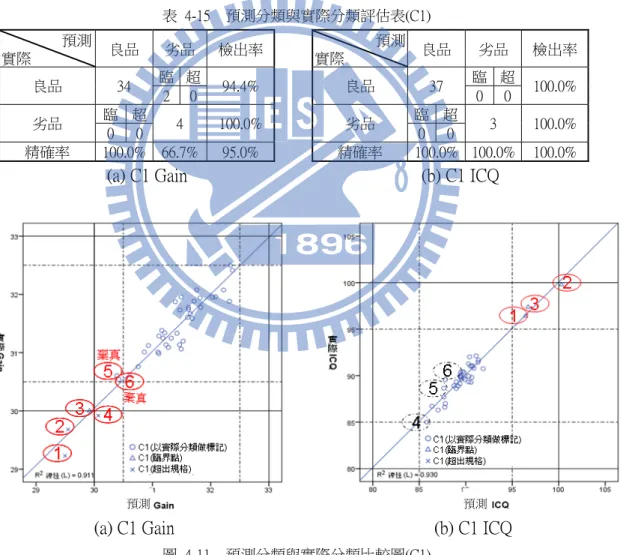
圖 1-1 先進製程控制(APC)概念圖 ... 1 圖 1-2 X 公司的人工預測方法 ... 2 圖 1-3 線性迴歸模型預測方法 ... 3 圖 1-4 系統流程圖 ... 4 圖 1-5 重要參數選擇流程 ... 5 圖 2-1 半導體產業體系架構 ... 7 圖 2-2 IC 封裝測試流程 ... 8 圖 2-3 8 吋晶圓測試鍵測試位置示意圖 ... 9 圖 2-4 收發器系統方塊圖 ... 10 圖 2-5 放大器方塊圖 ... 11 圖 2-6 多重設計專案晶圓(MPW)示意圖... 12 圖 2-7 實驗階段流程 ... 13 圖 3-1 Gain 與 WAT5 的散佈圖 ... 16 圖 3-2 x 與 y 關係散佈圖 ... 19 圖 3-3 迴歸分析各離均差概念圖示 ... 20 圖 3-4 迴歸分析多元相關概念圖示 ... 26 圖 4-1 最終測試結果 Gain 與 ICQ 產品特性散佈圖 ... 31 圖 4-2 Gain 與 ICQ 特性分佈圖 ... 32 圖 4-4 良率預測說明圖 ... 32 圖 4-5 實驗流程圖 ... 33 圖 4-6 Gain、ICQ 散佈圖與皮爾森相關係數 ... 34圖 4-7 Gain 與重要 WAT 參數(WAT2、5 和 14)散佈圖... 36
圖 4-8 ICQ 與重要 WAT 參數(WAT9、11 和 18)散佈圖... 36
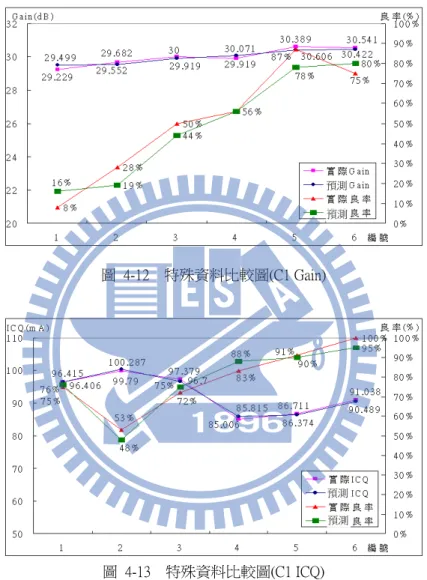
圖 4-9 解釋力比較圖 ... 39 圖 4-10 線性多元迴歸模型 ... 42 圖 4-11 圖例說明 ... 44 圖 4-12 預測分類與實際分類比較圖(C1) ... 45 圖 4-13 特殊資料比較圖(C1 Gain) ... 46 圖 4-14 特殊資料比較圖(C1 ICQ)... 46 圖 4-15 預測分類與實際分類比較圖(C2) ... 47 圖 4-16 特殊資料比較圖(C2 Gain) ... 48 圖 4-17 特殊資料比較圖(C2 ICQ)... 48 圖 4-18 預測分類與實際分類比較圖(C3) ... 49 圖 4-19 特殊資料比較圖(C3 Gain) ... 49 圖 4-20 特殊資料比較圖(C3 ICQ)... 50 圖 4-21 預測分類與實際分類比較圖(C4) ... 50 圖 4-22 特殊資料比較圖(C4 Gain) ... 51
圖 4-23 特殊資料比較圖(C4 ICQ)... 51 圖 4-24 預測結果評估比較圖(Gain) ... 53 圖 4-25 預測結果評估比較圖(ICQ) ... 53 圖 4-26 預測結果評估比較圖(合併後)... 53 圖 4-27 成本與利潤關係圖 ... 54 圖 4-28 補救措施流程圖 ... 59 圖 4-29 實際和預測利潤比較圖 ... 60
表 目 錄
表 3-1 迴歸模型的變異數分析摘要表 ... 23 表 4-1 皮爾森相關係數(Gain 與 20 個 WAT) ... 35 表 4-2 皮爾森相關係數(ICQ 與 20 個 WAT) ... 35 表 4-3 向前選擇法所得到的係數(C1 類型 Gain) ... 37 表 4-4 向前選擇法與向後移除法結果 ... 38 表 4-5 Gain 的向前選擇法與向後移除法模型的解釋力 ... 39 表 4-6 ICQ 的向前選擇法與向後移除法模型的解釋力... 39 表 4-7 Gain 與 WAT2、WAT5、WAT14 多元迴歸的模型顯著性考驗結果 ... 40 表 4-8 ICQ 與 WAT9、WAT11、WAT18 多元迴歸的模型顯著性考驗結果 ... 40 表 4-9 Gain 向前選擇法係數... 40 表 4-10 ICQ 向前選擇法係數... 41 表 4-11 Gain 之多元迴歸模型係數 ... 42 表 4-12 ICQ 之多元迴歸模型係數... 42 表 4-13 分類結果評估表 ... 43 表 4-14 圖例說明計算結果 ... 44 表 4-15 預測分類與實際分類評估表(C1) ... 45 表 4-16 預測分類與實際分類評估表(C2) ... 47 表 4-17 預測分類與實際分類評估表(C3) ... 48 表 4-18 預測分類與實際分類評估表(C4) ... 50 表 4-19 預測分類與實際分類評估表(Gain 與 ICQ 合併後整體結果) ... 52 表 4-20 成本評估表 ... 54 表 4-21 利潤評估表 ... 54 表 4-22 預測分類與實際分類成本比較表(C1) ... 55 表 4-23 預測分類與實際分類成本比較表(C2) ... 56 表 4-24 預測分類與實際分類成本比較表(C3) ... 57 表 4-25 預測分類與實際分類成本比較表(C4) ... 58第1章 序論
1.1 研究動機與目的
在半導體供應鏈,晶圓廠、封裝廠與測試廠當中,無不竭盡心力提高產能與良率, 有效的製程控制則是相當重要的環節。半導體產業界為此相繼提出及導入先進製程控 制(advanced process control, APC)的概念及方法[1]。
簡單描述 APC 的基本概念:一個 12 吋晶圓廠,每一片晶圓通常需要 300~400 道 製程,每一至數道製程之後,就會有量測機台(metrology),量測該製程的主要品質指標。 最後會產生晶圓允收測試(wafer acceptance test, WAT)參數,晶圓測試(circuit probing, CP) 良率等等資料[2]。因此如果由一組製程來看,這道製程必定有一台設備來執行製程, 有一輸入的工件 - 晶圓,透過一組設定的配方在此台設備中執行,其間尚有一些不可 控的因子,最後製程結束,晶圓取出。在這系統中,輸入的晶圓一定有變異存在,這 些可控/不可控的因子也會有雜訊與變異,因而產生晶圓的各種指標相對會有變異。而 提高良率的方法不外乎縮小產出晶圓的變異,以及管控製程中每個參數的變異二者。 圖 1-1 先進製程控制(APC)概念圖
本論文亦是先進製程控制的延伸,應用線性迴歸模型在射頻(radio frequency, RF)IC 特性預測。從晶圓廠製作晶圓完成後,WAT 參數即可代表此晶圓製程特性[3][4],但 是射頻 IC 和其他類型 IC(如類比或數位)較不同的地方,是射頻 IC 還必須考慮到干擾 或衰減問題,因此封裝時的打線長度和裸晶放置位置,亦會影響到特性。若將 WAT 參數和打線兩者都控制在特定範圍內,其實製作出來的 IC 特性是非常穩定。量產階段 時,在封裝廠,因為流程少,所以因素可以穩定控制,而晶圓廠製程繁複,WAT 參數 是在每道製程完成後才會測量,並無法隨時追蹤測試,當測量完,就算參數已經偏移, 只能調整後續製程參數,所以 WAT 參數主要用意是用來驗證製程穩定度,是否符合 交貨規格,此規格是晶圓廠所規範的製程規格,會比產品本身所要求的製程參數寬鬆 許多,因此參數偏移太多,將會嚴重影響 IC 特性。 在原本的方法中,為了能完全利用所有晶圓,會使用人工方式挑選 WAT 的重要 參數,將產品封裝成高良率,以達到高產能。而人工挑選,並無法同時監控多個參數 進行晶圓挑選,僅能使用晶片設計者認為和最終測試結果相關性最大的一個 WAT 參 數。 圖 1-2 X 公司的人工預測方法 如圖 1-2,X 公司的人工預測方法。左圖為輸入資料,每點代表一片晶圓資料, C1、C2、C3 及 C4 已經有足夠樣本數(140 筆),虛線圓圈則是本論文未探討的其他類型
人工預測
(因樣本小於 140 筆);右圖為輸出資料,每點亦代表一片晶圓資料。礙於人工預測, 所以只能透過 2 個輸入變數,預測 2 個輸出變數,目前晶圓預測所利用最主要的兩個 WAT 參數,是利用 WAT2 預測射頻增益(Gain)以及 WAT9 預測靜態電流(quiescent current, 簡稱 ICQ)。預測後的結果並不理想,很多 IC 都超出規格,因為封裝製程不可逆,也 無法挽救,只能報廢,造嚴重浪費。 如圖 1-3,本論文以線性多元迴歸分析理論為基礎,作實務應用。利用現有資料 WAT 參數,當成輸入資料,和最終測試結果當成輸出資料,透過有效的變數選擇程序, 找出重要的輸入變數,並利用這些輸入變數建立準確的線性迴歸模型,並利用此迴歸 模型進行晶圓封裝類型的預測,改善原本人工分類無法同時分析多變數的缺點,而預 測為劣品的晶圓,則可使用補救措施或套用其他類型的迴歸模型,以避免封裝後,仍 有低良率的問題。 圖 1-3 線性迴歸模型預測方法 1.2 問題陳述 在問題中,我們必需建立一個預測系統,使用於晶圓封裝以前,輸入數個重要的 WAT 參數(輸入變數),以判斷封裝後的產品特性(輸出變數),是否落於產品規範中, 進而使最終測試結果得到最佳良率。與原本使用方法最大不同處,是原本採用人工分 析,一個輸出變數只能採用設計者認為最有相關的一個 WAT 參數作 IC 類型挑選,而 本方法則是利用多變數線性迴歸模型作 IC 特性預測,並挑選類型,將會有更佳的解釋 力。 線性迴歸 模型 重要變數
在原始資料處理上會遇到一些困難,首先,資料可能是一個龐大的二維矩陣(矩 陣的各行代表是輸入變數,各列代表是樣本),當輸入變數很多時,大量的資料不管是 儲存、分析或運算都是相當大的負擔。所以,適當的變數選擇是必要的,即選擇對輸 出變數影響顯著的重要輸入變數。經由變數選擇,可以改善輸入變數的預測表現,加 快運算與分析速度,並且讓我們了解哪些預測變數對於結果較重要。 在實際應用上,輸入變數間經常存在著高度的相關性,即共變情形,也就是存在 冗餘的變數,使用這樣的資料去建立模型不但可能造成誤差,甚至影響對模型的詮釋, 因此,我們還要考慮如何有效地濾除多餘的輸入變數。 最後,若是資料中可能包含歧異值,即一些數值相當極端的樣本,歧異值對於資 料分析與模型建立都會產生影響,故必須適當的排除。 處理原始資料後,我們還必需從這些數據建立一套適合的模型,提供我們去研究 預測的輸出變數特性範圍,並且在多個輸入變數時,也要能同時滿足對每個輸出變數 的要求,找出適合的特性範圍。最後,利用預測的輸出變數作成本評估,輔助分類決 策[5]。 1.3 系統架構 預測可以說是迴歸分析重要的價值。考量問題特徵與現有可使用的資訊後,我們 藉由迴歸模型的建立,發展出一套預測系統。本系統的流程圖如圖 1-4 所示,主要包 含四個處理程序,分別是:原始資料、選擇重要變數、建立迴歸模型,與驗證特性範 圍。 圖 1-4 系統流程圖 原始 資料 選擇 重要變數 建立 迴歸模型 驗證 特性範圍
在原始資料部份,為實際量產資料,每筆資料都是已經封裝、測試後的完整資料, 包含輸入變數和輸出變數,輸入變數與輸出變數皆為連續變數。輸入變數部份,每包 資料有 20 個 WAT 參數,每個 WAT 參數,都是晶圓 5 個區域測量的平均值,由於變 異量極小,所以只用平均值分析。輸出變數部份,由於封裝後不可逆,所以每筆資料 都只有一種類型的輸出變數,在驗證模型時,只能使用和原始資料同一類型的線性迴 歸模型作驗證,並無法驗證其他類型的模型,每筆資料包含 Gain、ICQ 的最終測試結 果,此數值代表一片晶圓封裝完 IC 之後,所測量 IC 的平均值,由於變異稍大,所以 驗證資料時,會將規格範圍往內縮一個標準差,以維持高良率水準。 我們把資料分成兩份,一份為訓練資料,4 類型各別有 140 筆,另一份為驗證資 料,4 類型各別有 40 筆。訓練資料是用來建立迴歸模型及找出特性範圍,而驗證資料 用來確認模型所預測的特性。 如之前 1.2 問題陳述,原始資料可能是龐大的二維陣列資料,且包含著冗餘輸入 變數,所以必需經過重要變數選擇來改善資料品質,從而提高後續探勘過程的精確度 和性能,首先利用皮爾森相關係數,觀察輸入變數和輸出變數的相關性,再進一步利 用線性迴歸向前選擇法或向後移除法來取捨變數,選擇重要變數來分析。 X1 X2 … Xm S1 S2 . . . Sn 向前選擇法 向後移除法 X1 X2 … Xa S1 S2 . . . Sn 圖 1-5 重要參數選擇流程 在建立迴歸模型中,我們利用選擇後的重要變數建立線性迴歸模型,合計有 4 個 類型,每個類型有 2 個輸出變數,總共 8 個模型。 最後,我們利用驗證資料來確認所找到的特性範圍。判斷特性範圍的優劣可以從
兩個方面來衡量:(1)驗證資料在特性範圍的表現,即比較預測的輸出變數和驗證資料 實際特性在特性範圍中的落點,並比較準確率。(2)將預測的輸出變數和驗證資料轉換 為成本評估方式,比較兩者相異的資料所使用的成本。 1.4 論文架構 本論文共分為五章。第一章序論為問題描述與說明作本研究的動機與目的以及研 究的方向;第二章為半導體生產鏈實務介紹,簡單介紹從晶圓到 IC 成品之製作流程; 第三章介紹線性迴歸方程式的原理;第四章為實驗與討論,介紹線性迴歸結果,並比 較預測後產品特性和成本評估,第五章為結論,針對本論文之優缺點作總結。
第2章 半導體生產鏈實務介紹
近幾年來,隨著電子科技、網路等相關技術的進步,以及全球電子市場消費水準 的提昇,個人電腦、多媒體、工作站、網路、通信相關設備等電子產品的需求量激增, 帶動整個世界半導體產業的蓬勃發展,而在台灣,半導體業更儼然成為維繫國家經濟 動脈的一個主力。基本上半導體製造為一垂直分工細密且高附加價值的產業,其快速 的成長也會帶動其他週邊產業的繁榮,下圖所示為一典型的半導體產業體系架構[6]。 圖 2-1 半導體產業體系架構 在這個體系中,半導體製造,也就是一般所稱的晶圓加工,是資金與技術最為密 集之處,伴隨著晶圓加工的上游產業則包括產品設計、晶圓製造、以及光罩製造等, 下游產業則更為龐大,其中包括一般所稱半導體後段製程的 IC 封裝、測試、包裝,以 及週邊的導線架製造、連接器製造、電路板製造等,結合緊密的產業體系。2.1 射頻 IC 封裝、測試流程
本論文要探討的部份,為晶圓製作完成,經過封裝、測試,至成品分料等半導體 後段流程,如圖 2-2 所示,步驟依序為:A. 由晶圓廠製作晶圓; B. 在晶圓的切割道 或特定位置測量製程監控(process control monitor, PCM)電晶體,並紀錄成 WAT 參數, 以確認晶圓量產規格是否符合規範; C. 封裝廠將晶圓切割成晶片; D. E. 將晶圓切 割成裸晶(die); F. 將裸晶置於導線架上; G. 封裝為 IC 成品; H. 在測試廠依據 IC 規格書測試 IC,以保證出廠 IC 功能完整性; I. 依據測試結果,作 IC 分類,分成各 種等級產品[7]。 圖 2-2 IC 封裝測試流程 2.2 WAT 參數 WAT 參數是一種在晶圓切割道上測試電晶體以驗證晶圓是否擁有正常工作能力 的一項測試。測量對象為單一電晶體(如單一的 NMOS 或 PMOS…,而非已組合的邏輯 電路),所以並無法得知邏輯電路是否設計正確,而只是非常單純的測試在各項製程中 最終測試 分料/成品 封裝 IC 封裝廠 測試廠 F G H I PCM測試 測得WAT參數 晶圓 晶圓切割 取裸晶 裸晶 晶圓廠 封裝廠 A B C D E
是否有無出錯,以及導致最小單位的電晶體既無法正常的工作[8]。 測試的電晶體並非晶圓上的晶片,而是埋設於晶圓上每個晶片與晶片之間切割道 中的電晶體。每個晶片與晶片之間的空隙稱作切割道,晶片切割時就會沿著切割道切 除。晶圓廠會在設計階段就在所有切割道上製作測試元件,切割道上面的元件稱作測 試鍵(test key),這樣就可以有效利用切割道的空間,並測試每個切割道上面的電晶體, 去推測附近晶片中的元件電性是否完美。
在切割道上會有許多接點,每個接點會有編號如 pad 1、2、…、pad12 等。Pad 將 元件的各端點連接至晶圓表面。每一組測試鍵會標上標題,分別代表不同的元件如 PMON、NMOS,甚至是不同規格(不同的通道寬度與通道長度)。在同一個標題上,不 同的接點有各種的規格(如通道寬度、通道長度...等)。測試鍵種類很多,如多晶矽等效 條寬、隔離漏電、接觸電阻、飽和電流、通道形成電壓、金屬層厚度、寬度或電阻... 等,用以檢驗晶圓廠製程控制程度,是否符合 IC 設計規格[9]。 測試時機則是晶圓廠每段製程結束後,依照規格書提供的位置與規格在顯微鏡下 找到元件,再分別利用探針給予測試鍵電壓與電流,並測量數據。 因為 WAT 所測試的項目中,包含了許多破壞性測試,若是直接測試製造完成的 晶片,必定會破壞晶片,影響產品出廠時的良率,另外在切割道上製作電晶體,亦算 是利用空間,因測試後再切割晶圓時,切割道也會被切除,並不會造成浪費。 本論文討論的是 8 吋晶圓,分別在晶圓上、中、下、左與右等五個區域,測量測 試鍵。如圖 2-3,可經由測試此五區域上的電晶體,去推測附近晶片中的元件電性是 否正常。 圖 2-3 8 吋晶圓測試鍵測試位置示意圖
2.3 最終測試參數
本論文討論的 IC 是射頻功率放大器(radio frequency power amplifier, 簡稱 PA),如 圖 2-4 收發器(transceiver)系統方塊圖中,PA 工作在系統的發射端,功用是將無線裝置 中的低功率射頻訊號轉換成高功率訊號,再透過天線將此訊號發射[10]。 此產品通常須要有最佳效能、高線性輸出(P1dB)、輸入與輸出端有良好反射損失 (return loss)、良好輸出增益與最佳散熱,與低待機電流。 圖 2-4 收發器系統方塊圖 而量產測試時,會考量到成本,並無法完整測試 IC 全部的特性,只能選擇最需 要控制的項目作測試,而本類型 IC 主要測試的電性參數分別是功率增益和靜態電流。 2.4 功率增益 代表放大器對信號放大能力的參考量。輸出量與輸入量之比為放大倍數,取對數 後的分貝數(dB)即增益。輸出功率與輸入功率相比稱為“功率增益”。電壓比或電流 比則為電壓增益或電流增益。
如圖 2-5 放大器方塊圖所示,將放大器當為待測物(device under test, 簡稱 DUT), 其中包含一個輸入 x,一個輸出 y,還有一個測試結果–Gain,Gain 為一個沒有單位的
轉換函數。此轉換函數可以表示成 G,如( 2-1 )式。 圖 2-5 放大器方塊圖 ) ( ) ( f x f y G ( 2-1 ) 或等效成更常用的方程式G | ,如下所示: dB dB dB dB y f x f G| ( )| ( )| ( 2-2 ) 2.5 靜態電流 靜態電流簡單的說法,一顆 IC 從電源流到地的電流,通常是指 VCC 流到地的電 流。也有人稱為待機電流。靜態電流分成三種: 1. 工作中的靜態電流:正常工作或有負載時的靜態電流,一般而言,較難測量到 靜態電流,因為整顆 IC 都在運作,消耗的電流遠比靜態電流大,所以較少會去紀錄這 種靜態電流。 2. 無負載的靜態電流:IC 正常工作但負載之電流為 0 時的靜態電流,用待機電 流來稱呼這種靜態電流最貼切,行動裝置最需考慮此靜態電流,例如手機有一些元件 平時都是處於待機狀態,但是電源 IC 還是開啟,若電源管理 IC 的靜態電流低,用於 行動裝置就可讓待機時間更久。 3. 關機的靜態電流:IC 關機時的靜態電流,此時電源管理 IC 是關閉的,雖然 IC 沒有啟動但是 VCC 還是有電壓,IC 內部還保留小部份電路繼續運作等待喚醒,所以 還是會有很小的電流。 而本 IC 在最終測試時的靜態電流則採用無負載時的電流,雖然在測試環境中, 有很多 IC 同時測試,空氣中充滿各種干擾訊號,但是只要外在訊號夠低,約低於
-20dBm,其實已經不影響 IC 靜態電流。但如果較敏感的 IC,還可以單獨將一台測試 機放到電波隔離室(shielding room)作 IC 特性量測,以避免干擾。
2.6 產品類型之挑選邏輯 2.6.1 實驗階段
隨著積體電路製程進步到深次微米的時代,光罩製作的成本可達到一、兩百萬美 金之多。多重設計專案晶圓(multiple project wafers, MPW)或稱晶梭晶圓(shuttle wafer), 可以將不同的設計放在同一組光罩裡,進而降低整體製造的成本。然而,因為晶片設 計複雜度的不同,每個設計都有其所需要的製程,例如某一個設計需要一層複晶(poly) 及四層的金屬層,而某個較複雜的設計可能需要更多層的金屬層。而且,不同製程的 設計雖然無法從同一片晶圓中切割生產出來,但是它們可以放在同一組光罩中來降低 整體製造的成本。如圖 2-6 多重設計專案晶圓示意圖,在晶圓中 A、B、…、I 為不同 設計者所設計,而光罩卻是各設計者所共用,但晶圓並無共用,可分別依照不同需求, 調整製程參數。 圖 2-6 多重設計專案晶圓(MPW)示意圖 在實驗階段,設計者會利用晶圓廠定期提供的晶梭,和其他設計者共同使用光罩 來生產多重設計專案晶圓,以驗證電路設計,並封裝成樣品 IC 提供產品驗證。實驗階 段流程,如圖 2-7,A. 設計者調整多種製程參數,在晶圓廠製作成各種類型的晶梭晶
圓,B. 封裝廠負責切割晶圓成各顆獨立的裸晶,C. 封裝時,可調整各種打線長度及 方式,或裸晶位置,以因應產品規格需求。D. 測試廠測試產品,驗證規格。如果規格 符合需求,則確認製程參數與打線方式,並移轉到量產。若不符合需求,必須檢討電 路設計、製程參數,或打線方式,再回到 A 重新製作。 圖 2-7 實驗階段流程 2.6.2 量產階段 經過實驗階段驗證電路、製程參數,和打線方式之後,接著即開始量產階段。量 產時,會由多重設計專案的光罩改製成量產光罩,要求晶圓廠製作晶圓時,控制製程 參數,並且要求封裝廠固定打線方式。 若將製程參數和打線方式控制在設計者要求範圍內,其實製作出來的產品是非常 穩定。但是實驗階段在每個流程中,是經由工程人員精準控制參數。量產階段時,並 非如此作業,是由產線作業員同時照顧數台機器,雖然封裝廠會定時追蹤打線方式, 遇到嚴重錯誤會通知工程人員,但是 WAT 參數並無法隨時測試追蹤,而是等晶圓即 將製作完成才會測量,當測量完參數,就算參數已經偏移,並無法再調整製程,將晶 打線1 打線2 C D
S1
S2
S3
B A 量產 重製 開始圓調回正軌,所以 WAT 參數,在晶圓廠的主要用意只是用來區分製程穩定度是否有 符合交貨規範,所以亦會比設計者所要求的製程參數寬容許多。
綜合上述兩種問題,在晶圓廠製作完晶圓,並測量 WAT 參數後,必須再利用挑 選的方式,將 IC 調整成高良率,以最少成本製作出最多產品。
第3章 線性迴歸分析
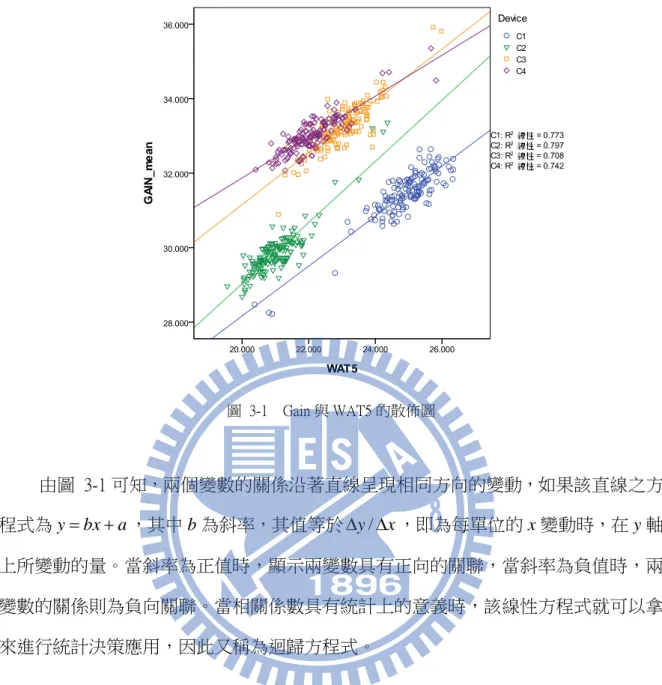
線性關係分析是將兩個變數的關係以直線方程式的原理來估計關聯強度,例如積 差相關就是用來反應兩個連續變數具有線性關係強度的指標[11]。 相關係數則是兩個連續變數之間線性關聯強度的指標,相關係數越大,表示線性 關聯越強,反之,相關係數越小,表示線性關聯越弱,此時可能是變數間沒有關聯, 或是呈現非線性關係。 迴歸分析則是運用變數間的關係來進行解釋與預測的統計技術,在線性關係假設 成立的情況下,迴歸分析是以直線方程式來進行統計決策與應用,又稱為線性迴歸。 一般來說,我們對於兩個變數的關係先以相關係數去檢驗線性關聯的強度,當相關達 到統計顯著水準,表示線性關係是有意義的,便可進行迴歸來進行統計決策。這就是 為何許多學者把相關與迴歸是唯一個整合、連續的概念,以 MRC(multiple regression and correlation)來統稱之。 3.1 線性關係原理 兩個連續變數間的共變關係可能有多種形式,其中最簡單也是最常見的關聯型態 是線性關係。所謂線性關係,是指兩個變數的關係呈現直線般的共同變化,數據的分 佈可以被一條最具代表性的直線來表達的關聯情形。例如本論文中 Gain 和 WAT5 兩個 變數,當 WAT5 越高者,Gain 也可能越高,兩個變數的關係是同方向的變動關係。如 果我們收集了許多筆 Gain 與 WAT5 的資料,並以散佈圖的方式來表現,可以得到圖 3-1。圖中 X 軸為 WAT 參數、Y 軸為最終測試結果 Gain,象限內的點為每一個樣本在 兩個變數上的成對觀察值,其散佈情形顯示出兩變數的關聯,稱為散佈圖(scatter plot)。圖 3-1 Gain 與 WAT5 的散佈圖 由圖 3-1 可知,兩個變數的關係沿著直線呈現相同方向的變動,如果該直線之方 程式為ybxa,其中 b 為斜率,其值等於 /y x,即為每單位的 x 變動時,在 y 軸 上所變動的量。當斜率為正值時,顯示兩變數具有正向的關聯,當斜率為負值時,兩 變數的關係則為負向關聯。當相關係數具有統計上的意義時,該線性方程式就可以拿 來進行統計決策應用,因此又稱為迴歸方程式。 值得注意的是,雖然直線方程式反應了兩個連續變數共同變動的線性函數關係, 但該線性方程式只是一個假設的概念,而且在一群分散的配對觀察值中,也可以不同 方法求得多條不同的線性方程式,因此,線性關係是否存在,如何求得「最佳」的迴 歸方程式來代表這些觀察值的關係等問題,必須透過統計程序來回答。也只有當我們 能夠證實線性關係有其存在的合理基礎(也就是具有顯著的相關),我們才能運用迴歸 方程式來進行應用的工作。 在統計學上,雙連續變數間的線性關係強度,可以利用相關的概念,以數學模型 來說明兩個連續變數線性關係的方向與強度。所得到的用以描述相關情形的量數,稱 為相關係數。反應母體的兩變數關連情形的相關係數以希臘字母 ρ(rho),樣本資料所
計算得到的相關係數則以小寫英文字 r 表示。 3.2 皮爾森相關係數 共變數的數值無法直接用比較的原因,是變數具有不同的單位,因此若能將單位 去除,標準化後的共變數將具有可比較性,其可理解性亦增加。而去除單位的影響, 即是取得兩變數的標準差作為分母,將共變數除以兩個變數的標準差,得到一個標準 化的關聯係數,稱為積差相關係數,由於是由皮爾森(Pearson)所提出,因此稱為皮爾 森相關係數(Pearson's product moment correlation coefficient, 簡稱 Pearson's r)[12]。
x y xy y x SS SS SP Y Y X X Y Y X X s s y x r
2 2 , cov ( 3-1 ) 近一步的,相關係數數值雖可以反應兩個連續變數關聯情形的強度大小,但相關係數 是否具有統計上的意義,則必須透過統計考驗來判斷。 2 1 2 0 0 N r r s r t r ( 3-2 ) 在( 3-2 )式當中,分子為樣本統計量的相關係數 r 與母體相關係數0的差距,分 母為抽樣標準誤sr。一般來說,研究者所關心的式樣本相關是否顯著不等於 0,也就 是說從樣本得到的 r 是否來自於相關為 0 的母體,即H0 :XY 0(0 0),因此分子 為r0。如果研究者想要從樣本得到的 r 是否來自於某一相關(例如 0.5)的母體,也可 以利用以H0:XY 0.5的虛無假設考驗來檢驗,此時分子為r0.5。 分子與分母兩個相除後,得到 t 分數,配合 t 分配,即可進行統計顯著性檢驗。 相關係數 t 檢定的自由度為N 2,因為兩個變數各取一個自由度進行樣本變異數估 計。依據中央極限定理,當樣本數越大,抽樣標準誤越小,樣本數越小,抽樣標準誤 越大,在同樣相關係數強度下,提高樣本數可以更容易拒絕虛無假設,達到顯著水準, 使得統計檢定力提高。3.3 線性迴歸 線性關係是社會科學研究的重要概念,相關分析的目的在描述兩個連續變數的線 性關係強度,而迴歸則是在兩變數之間的線性關係基礎上,進一步來探討變數間的解 釋與預測關係的統計方法。 一般在介紹相關分析時,均會特別提醒,一個顯著的相關係數,僅能說明兩個變 數之間具有一定程度的線性關聯,而無法確知兩個變數之間的因果關係。如果研究者 目的在於預測,亦即取用某一變數去預測另一個變數,或是關心實驗的控制(因),是 否影響某一被觀察的變數(果),研究者則可使用迴歸分析,透過迴歸方程式的建立與 考驗,來檢測變數間關係以進行預測用途。 3.3.1 迴歸分析的概念 從相關的原理可知,當兩個變數之間具有顯著的線性關係,可以用相關係數來反 應此一線性關係以一最具代表性的直線來表示,建立一個線性方程式,研究者即可以 透過此一方程式,代入特定的 x 值,求得一個 y 的預測值。此種以單一輸入變數 x 去 預測輸出變數 y 的過程,稱為簡單迴歸(simple regression)。如( 3-3 )式,稱為 y 對 x 的迴 歸分析。 a bx y' ( 3-3 ) 在簡單迴歸中,其數學原理與相關的計算相同,均以兩個連續變數的共變數為基 礎,計算變數間標準化的關聯強度。惟相關係數計算之時,同時考慮兩個變數的變異 情形,屬於對稱性設計,以xy表示。但迴歸則由於目的在取用某一變數去預測另 一變數的變化情形,x、y 兩個變數各有其角色,在迴歸係數的計算中,x、y 變數為不 對稱設計,以xy或yx表示。 3.3.2 最小平方法與迴歸方程式 在線性關係中,若變數之間的關係是完全相關時(即r 1),x 與 y 的關係呈一直 線,兩個變數的觀察值可以完全的被方程式y' bxa來涵蓋,其中 b 為斜率,a 為截
距,此時 x 與 y 的關係不必預測,代入 x 即得 y,或代入 y 即得 x。而我們可以取任何 兩個點,即可求出方程式的截距與斜率。
但是,當兩個變數之間的關係未達到完全相關時(即r1),x 與 y 的關係是分佈
在同一區域內,無法以一條直線來表示,而必須以人為的方式求取一條最具代表性的 線,此線稱為最適合線(best-fit line)或迴歸線(regression line),必定通過兩個變數的平均 數。 圖 3-2 x 與 y 關係散佈圖 以圖 3-2,圖中穿越各配對觀察值散佈區域的斜線即為迴歸線。而直線之所以能 夠用來反應 x 對 y 的預測關係,係因為各配對資料觀察值在迴歸線上的預測值具有最 小的離差(稱為迴歸殘差)。 更具體來說,對於某一個配對觀察值(x, y),如果將 x 值代入方程式,得到的數值 為對y變數的預測值,記為 ' y ,兩者的差值y 稱為殘差(residual),表示利用迴歸方y' 程式無法準確預測的誤差,最小平方法即為求取殘差的平方和最小化
'
2 min
y y 的 一種估計迴歸線的方法,利用此種原理所求得的迴歸方程式,稱為最小平方迴歸線 (least square regression line) [13]。3.3.3 迴歸誤差與可解釋變異 1. 迴歸誤差 迴歸分析使用最小平方法,自 x 與 y 兩個變數的原始觀察值(xi,yi)當中,尋求一 條最佳迴歸預測線y' bxa。一旦方程式建立之後,代入一個x 值,可以獲得一個i 預測值 ' i y ,在完全相關的情況下,該值等於原始配對值y ;但是在非完全相關的情況i 下, ' i y 與y 之間存在一定的差距,是迴歸無法解釋的誤差部份(e)。每一個原始配對值i (x 與i y )可用i yi bxiae來表示,eyi' yi。 對於特定的x 所對應的觀察值i y ,其與 y 變數的平均數 y 的距離是所謂的離均i 差,離均差的平方 2 ) (yi y 是計算 y 變數變異數的重要數據。利用迴歸方程式代入x 所i 獲得的預測值 ' i y ,與 y 變數平均數的離均差(yi' y)應非常接近於原始值與平均數之離 均差錯誤! 物件無法用編輯功能變數代碼來建立。,兩者的差距即是迴歸所不能涵蓋的誤差 部份,如圖 3-3。 xi x y ) , (x y ) , (xi yi ) , (xi yi x y x y x a b y . . 誤差 原始離均差 迴歸離均差 圖 3-3 迴歸分析各離均差概念圖示 2. 迴歸解釋變異量 迴歸誤差表示以迴歸方程式進行解釋的誤差情形,相對來說,沒有誤差的部份表 示以迴歸方程式取代平均數來表示 y 變數離散性,所可以有效解釋的程度。換句話說, 原始 y 觀測值的離均差可以拆解為迴歸預測值離均差(即可以解釋的部份)與誤差(即無 法解釋的誤差部份),即原始離均差=迴歸值離均差+誤差,其中:
' ' ) ( ) (yi y yi y yi yi e ( 3-4 ) 移項後得到: ) ( ) ( i' i i' i y y y y y y ( 3-5 ) 將上式改以 SS 形式表示,得到下列關係式: e reg i i i i t y y y y y y SS SS SS
( )2
( ' )2
( ')2 ( 3-6 ) 兩邊同除SS 後得到: t 2 2 ' 2 2 ' ) ( ) ( ) ( ) ( 1
y y y y y y y y SS SS SS SS i i i i i t e t reg ( 3-7 ) 令: PRE SS SS SS SS R t reg t e 1 2 ( 3-8 ) 此時 2 R 稱為迴歸可解釋變異量比,表示使用 x 去預測 y 時的預測解釋力,即 y 變數被自變數所削減的誤差百分比。 2 R 又稱為迴歸模型的決定係數, 2 R 開方後可得 到 R,稱為多元相關,為輸出變數數值 y 與預測值 'y 的相關係數。R 反應了由輸入變2 數與輸出變數所形成的線性迴歸模式的適配度, 2 R 為 0 之時,表示輸入變數與輸出變 數之間沒有線性關係。在簡單迴歸時,R 。 r 3. 調整迴歸解釋變異量 以 2 R 來評估整體模式的解釋力的一個問題,是R 無法反應模型的複雜度(或簡效2 性)。如果研究者不斷增加輸入變數,雖然不一定增加模型解釋力,但是 2 R 並不會減 低( 2 R 為輸入變數數目的非遞減函數),導致研究者為了提高模型的解釋力,而不斷的 投入輸入變數,每增加一個輸入變數,損失一個自由度,最後模型無關的輸入變數過 多,自由度變數失去了簡效性。 為了處罰增加輸入變數所損失的簡效性,在 2 R 公式中將自由度的變化作為分子 與分母項的除項加以控制,得到調整後 2 R ,可以反應因為輸入變數數目變動的簡效性 損失的影響,如( 3-9 )式。) 1 ( ) 1 ( 1 1 2 N SS p N SS df SS df SS adjR t e t t e e ( 3-9 ) 從( 3-9 )式可以看出,當輸入變數數目(p)越多, 2 adjR 為越小,也就是對於簡效性損失 的處罰越大。如果研究者的目的在於比較不同模型的解釋力大小時,各模型的輸入變 數數目的差異會造成簡效程度的不同,宜採用調整後 2 R 。當使用逐步迴歸或階層迴歸 等多層次迴歸分析時,輸入變數數目不斷變動,也需使用調整後 2 R 來反應模型解釋力。 另外,當樣本數越大,對於簡效性處罰的作用越不明顯。一般來說,如果樣本數 較少時,輸入變數數目對於 2 R 估計的影響越大,應採用調整後 2 R 來描述模型的解釋 力。如果樣本數越大, 2 R 與調整後R 就會逐漸趨近而無差異。 2 總結上述的討論,在多元迴歸分析時,均應採用考慮了模型簡效性的調整後 2 R 來 反應模型解釋力,對於模型的意義才有較為正確的解讀。在簡單迴歸時,因為輸入變 數僅有一個,調整前與調整後的數據不會有所差異。 3.3.4 迴歸模型的顯著性考驗 前面已經說明了 y 變數離均差平方和可以拆解成迴歸離均差平方和與誤差平方 和,若將兩項各除以自由度,即可得到變異數,相除後得到 F 統計量,配合 F 分配, 即可進行迴歸模式的變異數分析考驗,用以檢驗迴歸模型是否具有統計的意義。此時 的對立假設為「迴歸可解釋變異量比不同於 0」。如果無法推翻「迴歸可解釋變異量比 等於 0」之虛無假設,則該 2 R 數值即使再高,也沒有統計上的意義。 由於 2 R 的基本原理是變異數,因此對於R 的檢定可利用 F 考驗來進行。F 考驗2 公式與摘要表如下: ) 1 ( 1 , p N SS p SS df SS df SS MS MS F e reg e e reg reg e reg p N p ( 3-10 )
表 3-1 迴歸模型的變異數分析摘要表 變異來源 SS df MS F 迴歸效果 SSr p SSr dfr MSreg MSe 誤差 SS e N p1 SSe dfe 全體 SS t N 1 3.4 多元迴歸分析 3.4.1 多元迴歸 通常一個研究中,影響輸出變數的輸入變數不只一個,此時需建立一套包含多個 輸入變數的多元迴歸模型,同時納入多個輸入變數來對輸出變數進行解釋與預測,稱 為多元迴歸[14]。例如三個輸入變數對一個輸出變數的多元迴歸方程式則為: a x b x b x b y 1 1 2 2 3 3 ' ( 3-11 ) 此一方程式可知,以三個輸入變數去預測 y 變數的分數,可得三個迴歸係數b1、b2和 3 b ,這三個迴歸係數即代表以三個變數去預測 y 的權數。由於多元迴歸必須同時處理 多個迴歸係數,計算過程較為繁複。除此之外,由於輸入變數之間彼此所具有的共變 數關,會影響迴歸係數的計算,因此必須加以控制。同時多個輸入變數雖為輸出變數 之「因」,但是其彼此之間又可能存在不同的順序、因果關係,導致對於這些輸入變數 的處理,還需考慮其次序,使得多元迴歸的運作益顯複雜。 3.4.2 預測與解釋 多元迴歸分析在探討一組輸入變數如何能夠最有效的解釋輸出變數的變異。基於 預測或解釋的不同目的,多元迴歸可被區分為預測型迴歸與解釋型迴歸兩類。在預測 型迴歸中,研究者的主要目的在實際問題的解決或實務上的應用;而且解釋型迴歸的 主要目的則在瞭解現象的本質與理論關係,也就是探討輸入變數與輸出變數的關係。 我們在此作如此的區分,並不是意味著預測與解釋是截然不同的兩套作法或不同的研 究設計,而是從統計操作的角度來看,當研究者的目的有所不同時,在分析的作法上
應有必要的權宜作法與偏重。 1. 分析策略的差異 由於預測型迴歸的重點在於問題的解決與實際的預測,因此如何從一組複雜的輸 入變數中,找出最關鍵者,以建立一套最佳的迴歸方程式,產生最理想的預測分數, 即成統計分析師最重要的任務。為了能夠產生一個最佳的預測方程式,研究者通常會 蒐集一系列對於輸出變數具有潛在解釋力的輸入變數,然後藉由相關強弱等統計程 序,決定這些輸入變數何者應保留、何者應排除。 在操作上,預測型迴歸最常用的變數選擇方式是逐步迴歸法。逐步迴分析可以滿 足預測型迴歸所強調的目的:以最少的變數來達成對輸出變數最大的預測力。因為逐 步迴歸法是利用各輸入變數與輸出變數的相關係數的相對強弱來決定哪些輸入變數應 納入、何時納入迴歸方程式,而不是從理論取捨的觀點來決定模型中的輸入變數。 相對的,解釋型迴歸的主要目的,在於釐清研究者所關心的變數間關係,以及如 何對於輸出變數的變異提出一套具有最合理解釋的迴歸模型。因此,不僅在選擇輸入 變數必須慎重其事、詳加斟酌,同時每一個被納入分析的輸入變數都必須仔細檢視它 與其它變數的關係,因此對於每一個輸入變數的個別解釋力,都必須予以討論與交代, 此時,最重要的訊息除了整體迴歸模型的解釋力,還有各項輸入變數的標準化迴歸係 數(beta 係數),以作為各輸入變數影響力的比較之用,至於方程式為何,已經不是重 要的問題,因此,一般學術上所使用的多元迴歸策略,多為同時迴歸法,也就是不分 先後順序、不作取捨,一律將研究者所選用的輸入變數納入迴歸方程式,透過統計分 析,來決定各變數的相對重要性。 2. 理論的角色 除了分析策略上的差異,理論所扮演的角色在兩種迴歸應用上也有明顯的不同。 基本上,理論基礎是學術研究非常重要的一環,藉由理論,研究者得以決定哪些變數 適合用來解釋輸出變數、如何影響輸出變數,一旦分析完成之後,在報告統計數據之 餘,也必須回到理論的架構下,來解釋研究發現與數據的意義,因此,在解釋型迴歸, 理論的重要性不僅在於決定輸入變數的選擇與安排,也影響研究結果的解釋。
相對的,預測型迴歸由於不是以變數關係的釐清為目的,而是以建立最佳方程式 為目標,因此輸入變數的選擇,所考慮的是要件是否具有最大的實務價值,而非基於 理論上的適切性。理論在預測型迴歸中,多被應用於說明迴歸模型在實務應用的價值, 以及有效達成問題解決的機制,以期在最低的成本下,獲致最大的實務價值。 值得注意的是,不論在預測型迴歸或解釋型迴歸,如果當輸入變數具有理論上的 層次關係,必須以不同的階段來處理不同的輸入變數對於輸出變數的解釋時,可以利 用階層迴歸分析的區組選擇程序,依照理論上的先後次序,逐一檢驗各組輸入變數對 於輸出變數的解釋。階層迴歸的優點在於輸入變數的選擇較具彈性以及理論上的合理 性,適用範圍大。 3.5 多元迴歸的統計原理 3.5.1 多元相關 在迴歸分析中,多元相關(multiple correlation; 以 R 表示)的數學定義是輸出變數的 迴歸預測值
y 與實際觀測值的相關: Y Y R ' ( 3-12 ) 多元相關的平方稱為 2 R ,表示 y 被 x 解釋的百分比。在簡單迴歸時,由於僅有一 個輸入變數,因此對於輸出變數的解釋僅有一個預測來源,此時多元相關 R 的數值恰 等於輸入變數與輸出變數的積差相關係數, 2 R 則表示該輸入變數對於輸出變數的解釋 力,如圖 3-4(a)所示。在兩個輸入變數的多元迴歸,對於輸出變數的解釋除了來自於 1 x ,還有x2,此時多元相關不是x1與 y 的相關或x2與 y 的相關,而是指x1與x2整合 後與輸出變數的相關。由於輸入變數之間(x1與x2之間)具有相當程度的相關,因此多 元迴歸中的多元相關,並非任何一個輸入變數與輸出變數的相關,而需扣除輸入變數 共變的部份[15][16]。 多元共線性問題,如圖 3-4(b)中,兩個輸入變數彼此相互獨立,r12為 0,而各自 與輸出變數的相關明顯,r 與y1 r 不為 0,此時多元相關平方為y2 r 與y1 r 兩個相關的平y2 方和,屬於最單純且最理想的一種狀況,也就是:2 2 2 1 2 12 . y y y r r R ( 3-13 ) 但是在圖 3-4(c)與(d)中,兩個輸入變數之間具有相關,r12不為 0,因此多元相關 平方需將r1y與r2y兩個相關的平方和扣除重疊計算的區域。同時由於三者之間關係的 不同,在重複面積的扣除上也會產生不同的作用,此一現象顯示多元迴歸受到輸入變 數間關係的影響甚鉅,這種多個輸入變數間的多重相互關係稱為多元共線性問題。利 用下式可說明多元共線現象存在的多元相關平方關係: 2 2 2 1 2 12 . y y y r r R ( 3-14 ) 以圖 3-4(d)為例,x1與x2之間具有高度的關聯,而x1變數對於 y 變數的解釋也幾 乎完全被輸入變數間的相關所涵蓋,呈現高度共線性。在進行多元迴歸分析時,x1變 數的解釋力會因為不同的變數選擇程序而產生不同的結果,形成截然不同的結論。 圖 3-4 迴歸分析多元相關概念圖示 3.5.2 多元迴歸方程式 多元迴歸方程式的計算,也是利用最小平方法,先透過輸入變數間的線性整合, 然後導出最能解釋整合後輸入變數與輸出變數關係的線性方程式,使殘差值達到最小。 斜率與截距的計算,多元迴歸方程式的斜率,反應了各輸入變數對於輸出變數的 淨解釋力,也就是當其他輸入變數維持不變的情況下,各輸入變數的單純影響力,公 y x1 x2 x1 x2 y y y x1 x2
式如下: 2 12 2 1 2 12 1 2 1 SP SS SS SP SP SP SS b y y ( 3-15 ) 2 12 2 1 1 12 2 1 2 SP SS SS SP SP SP SS b y y ( 3-16 ) 2 2 1 1 12 . y bx b x ay ( 3-17 ) 由( 3-15 )式與( 3-16 )式中,分母相同,分子則為各輸入變數對輸出變數的解釋效 果。分子越大,表示該輸入變數每單位的變動對於輸出變數的變化解釋較多,解釋力 較大。 3.5.3 輸入變數的選擇程序 多元迴歸分析包含了多個輸入變數,基於不同的目的,可以採用不同的輸入變數 選擇程序以得到不同的結果[17]。各種程序的性質與原理說明如下: 1. 同時分析法 最單純的變數處理方法,是將所有的輸入變數同時納入迴歸方程式當中來對輸出 變數進行影響力的估計。此時,整個迴歸分析僅保留一個包含全體輸入變數的回歸模 型。除非輸入變數間共線性過高,否則每一個輸入變數都會一直保留在模型中,即使 對於輸出變數的邊際解釋力沒有達到水準,也不會被排除在模型之外。 在解釋型迴歸,由於每一個輸入變數對於輸出變數的影響都是探討對象,因此不 論顯著與否,都有學術上的價值和意義,因此多採用同時法來處理變數的選擇。 2. 逐步迴歸分析 此一方法的特色是輸入變數並非同時被取用來進行預測,而是依據解釋力的大 小,逐步的檢視每一個輸入變數的影響,稱為逐步分析法[18]。在操作上,還可區分 為三種程序。 (1) 向前選擇法(Forward Selection) 輸入變數的取用順序,以具有最大預測力且達統計顯著水準的輸入變數首先被選 用,然後依序納入方程式中,直到所有達顯著的輸入變數均被納入迴歸方程式[19]。
(2) 向後移除法(Backward Removal) 與向前選擇法相反的程序,所有的輸入變數先以同時分析法的方法納入迴歸方程 式的運算當中,然後逐步的將未達統計顯著水準的輸入變數,以最弱、次弱的順序自 方程式中予以排除,直到所有未達顯著的輸入變數均被淘汰完畢為止[20]。 (3) 逐步分析法(Stepwise) 綜合向前選擇法與向後移除法,迴歸分析先依向前選擇法,逐步納入最具預測效 力的輸入變數,但是每納入一個輸入變數後,即利用向後移除法檢驗在方程式中的現 有輸入變數,若有任何未達顯著的輸入變數便將被淘汰,依此原則交叉循環進行檢測, 直到所有保留在方程式中的輸入變數都是達到顯著水準、淘汰的輸入變數為不顯著的 變數為止[21]。此法兼俱向前選擇法與向後移除法的優點[22]。 3.5.4 預測誤差與估計問題 預測型迴歸的主要目的在利用迴歸方程式進行實務的預測,當方程式確立之後, 下一個工作是進行預測的工作,此時,最重要的問題是如何估計預測的誤差,並利用 標準誤的概念與區間估計方法,來說明預測值存在的可信賴區間(範圍)。 在迴歸分析中,運用標準誤的概念所進行的區間估計有兩個重要的概念需要事先 建立,首先,在不同的輸入變數的數值下,進行迴歸預測的誤差有所不同,因此在進 行預測分數的估計時,在不同的輸入變數測的誤差有所不同,因此在進行預測分數的 估計時,在不同的輸入變數數值下需採用不同的標準誤。一般在迴歸分析報表中,會 提供一個迴歸模型的估計標準誤,該數據可以說是整體模型估計標準誤的一個總體估 計數(平均標準誤),可用以反應整體模型的估計能力,但在實際進行預測數值的計算 時,不宜採用整體模型估計標準誤。 預測值的估計,根據研究目的的不同區分成兩種,分別為對於輸出變數平均數的 估計標準誤,以s 表示;另外是對於個別觀察值估計標準誤,則以 sy表示。區間估計 的通式為:
t s Y /2,df ( 3-18 ) dfsy t Y /2, ( 3-19 ) 1. 平均數估計標準誤 平均數估計標準誤是用來反應以輸入變數的分數去預測輸出變數平均數的估計 誤差的程度。當只有一個輸入變數的簡單迴歸中,平均數估計標準誤公式如下:
X i x y SS x x N s s 2 2 . 1 ' ( 3-20 ) 其中 2 . x y s 為以 c 預測 y 的估計變異誤
SSres/dfres
,也就是殘差變異數,x 為第 i 個 x 觀i 察值, x 為 x 變數平均數,SS 為 x 變數離均差平方和。 x 由上述數據可知,當 x 分數離開平均數越遠,估計標準物越大。也就是說,當 x 越趨近於極端分數時,樣本數越來越少,因此估計標準誤較大,相對的,在平均樹附 近的 x 值去預測 y ,預測誤差越小。此一現象也即是中央極限定理的概念(在母體標準 差為定值的情況下,樣本數越大,抽樣誤差越小)。 如果是多元迴歸,以多個輸入變數去預測 y 變數時,在不同的輸入變數的組合情 況下,對於 y 平均數的估計區間原理相同,但是標準誤的計算就相對複雜。但如果運 用統計軟體(例如 SPSS、SAS)來計算,可以省略計算上的繁複。 2. 個別分數估計標準誤 如果迴歸分析的目的在預測個別觀察值的得分,所使用的估計標準誤為個別分數 估計標準誤。在只有一個輸入變數的簡單迴歸中,個別分數估計標準誤公式如下:
X i x y y SS X X N s s 2 2 . 1 1 ' ( 3-21 ) 由( 3-21 )式可知,個別分數估計標準誤的計算增加了一個單位的迴歸模型變異誤,因 此對於個別分數的預測標準誤大於平均數的估計標準誤。 對於個別分數的估計,此節所介紹的標準誤與整個迴歸模型的估計標準誤sy.x相當接近。當樣本數越大,x 各數值下的個別分數估計標準誤會趨近於迴歸模型的估計
標準誤sy.x,因為樣本數若夠大,在每一個 x 觀察值下的樣本數接近且呈現常態,抽
樣分配也就相似。這就是為何一般在樣本數夠大的情況下,可以利用迴歸模型的估計 標準誤sy.x來代替s ,而y' sy.x可以說是s 的平均值。但是當樣本數很小時,個別分數y'
第4章 實驗與討論
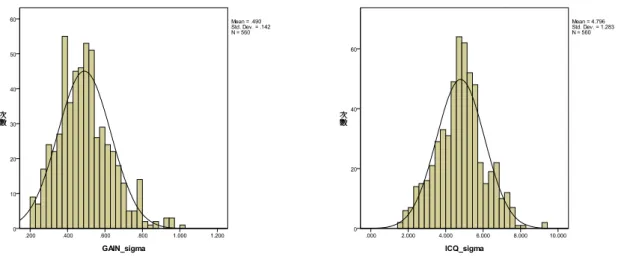
4.1 實驗資料簡介與實驗流程 本實驗所使用的數據是從晶圓自動化生產製程中所記錄的測試數據 WAT。首先 利用射頻 IC 設計觀念,在晶圓廠提供的 55 個 WAT 參數中,挑選出 20 個與射頻 IC 相 關的 WAT 參數,分別稱為 WAT1、WAT2、…、WAT20,此即為輸入變數。此外,還 有利用最終測試所測試的 Gain 與 ICQ,兩個輸出變數。 輸入變數與輸出變數皆為連續變數,資料包含 4 個類型產品,每個類型有 180 筆 樣本,4 個類型輸出變數 Gain 與 ICQ 產品特性散佈圖如圖 4-1 所示,而每一點代表一 片晶圓最終測試結果之平均值,方框實線部份所包圍為良品範圍,超出方框則屬廢品, 虛線部份則是平均值加上標準差,用以規範一片晶圓的平均值,超出虛線,卻未超出 實線,屬臨界值。本實驗主要目的是:由 20 個 WAT 參數中,找出影響產品特性的重 要 WAT 參數,並利用這些參數建立線性迴歸方程式,預測 IC 的特性範圍。如圖 4-2 為統一預測後規格範圍,將預測 Gain 的標準差統一設定為 0.5,而預測 ICQ 的標準差 統一設定為 5。 圖 4-1 最終測試結果 Gain 與 ICQ 產品特性散佈圖圖 4-2 Gain 與 ICQ 特性分佈圖
預測良率是利用常態機率分配(normal probabiity distribution)來估計,常態分配是連 續機率分配中最重要的機率分配,定義常態分配是鐘形曲線,方程式如式( 4-1 )所示。 2/2 2 2 1 ) ( x e x f ( 4-1 ) 其中μ為平均值,σ為標準差,此條常態曲線所定義的高度稱為機率密度函數 (probability density function,pdf)[23]。如圖 4-3,若要預估 Gain 的良率,可由式( 4-1 )
求得常態分配圖 f( x),再將 f( x)累積成常態累積分配圖,此圖例中 Gain 良品規格為 30~33dB,所以取得 30dB 累積的比例為 0.16,而 33dB 累積的比例為 1.0,兩者相減則 為 30~33 dB 所累積的比例,為 84%,此即為預估良率。 30, 0.16 33, 1.00 0.00 0.25 0.50 0.75 1.00 1.25 28 28.5 29 29.5 30 30.5 31 31.5 32 32.5 33 Gain 平均值 = 30.5, 標準差=0.5 , 良率 = 84 % 比 例 f(x) f(x)累積 圖 4-3 良率預測說明圖
實驗流程如圖 4-4 所示,資料經過重要參數選擇,利用向前選擇法挑選重要 WAT 參數,接著,利用挑選過的重要參數建立適合的迴歸模型,並找出輸出變數的產品特 性範圍,最後利用驗證資料來測試所找到的產品特性範圍。 圖 4-4 實驗流程圖 我們首先將 4 個類型產品分別命名為 C1、C2、C3 與 C4 等類型。並分別將 4 個 類型產品 180 個樣本資料隨機分成兩份,一份為 140 個樣本的訓練資料,另一份為 40 個樣本的驗證資料。訓練資料經過皮爾森相關係數觀察輸出變數 Gain 與 ICQ 相關性, 如圖 4-5,以確認並排除參數間存在共變關係,接著,利用線性迴歸向前選擇法挑選 重要參數,並且再觀察重要參數間,使否存在共變關係。 原始 資料 選擇 重要參數 建立 迴歸模型 驗證 特性範圍
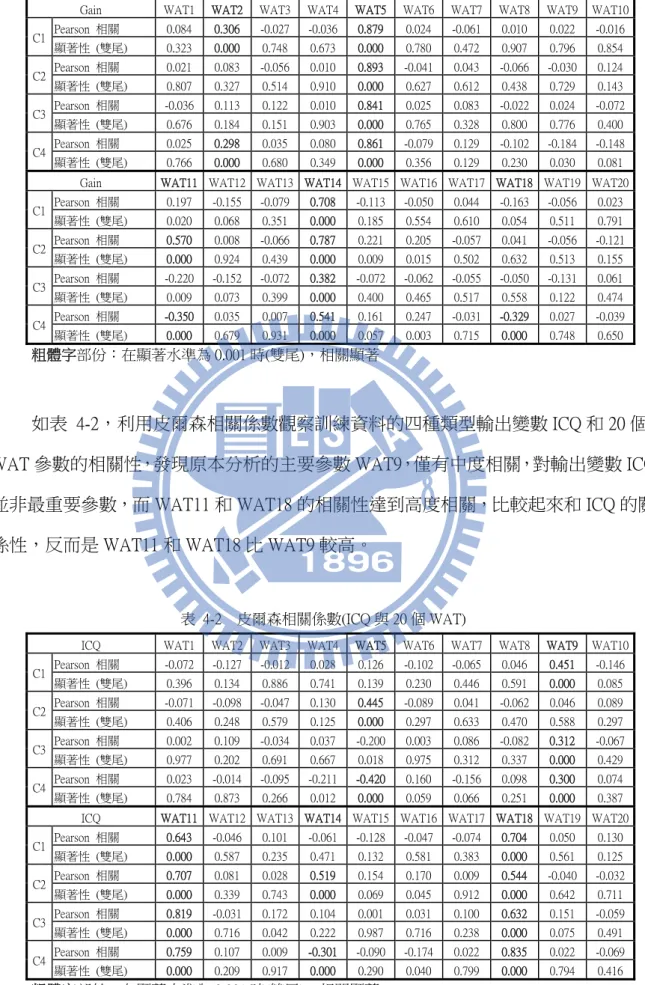
4.1.1 皮爾森相關係數 相關係數是兩個連續變數之間線性關聯強度的指標,相關係數越大,表示線性關 聯越強,反之,相關係數越小,表示線性關聯越弱,此時可能是變數間沒有關聯,或 是呈現非線性關係。 如圖 4-5,利用皮爾森相關係數(R)觀察訓練資料的四種類型輸出變數 Gain 和 ICQ 的相關性,結果兩者相關性都很低,所以可以排除兩參數有共變關係,並將兩個輸出 變數當成個別輸出變數獨立分析。 圖 4-5 Gain、ICQ 散佈圖與皮爾森相關係數 針對四種類型 140 個訓練資料樣本,分別觀察輸出變數 Gain、ICQ 與 20 個 WAT 參數的相關性,並挑選顯著水準 p<0.01 的 WAT 參數,p 值越小表示實驗觀測值為隨 機反應的機會很低,亦即拒絕虛無假設 H0,由此可觀察出相關性最高的 WAT 參數。 如表 4-1,利用皮爾森相關係數觀察訓練資料的四種類型輸出變數 Gain 和 20 個 WAT 參數的相關性,發現原本使用的主要參數 WAT2 僅有低度相關,對輸出變數 Gain 並非最重要參數,而 WAT5 和 WAT14 的相關性達到高度相關,比較起來和 Gain 的關 係性,反而是 WAT5 和 WAT14 比 WAT2 高。
類型 R C1 0.023 C2 0.482 C3 0.118 C4 0.401
表 4-1 皮爾森相關係數(Gain 與 20 個 WAT)
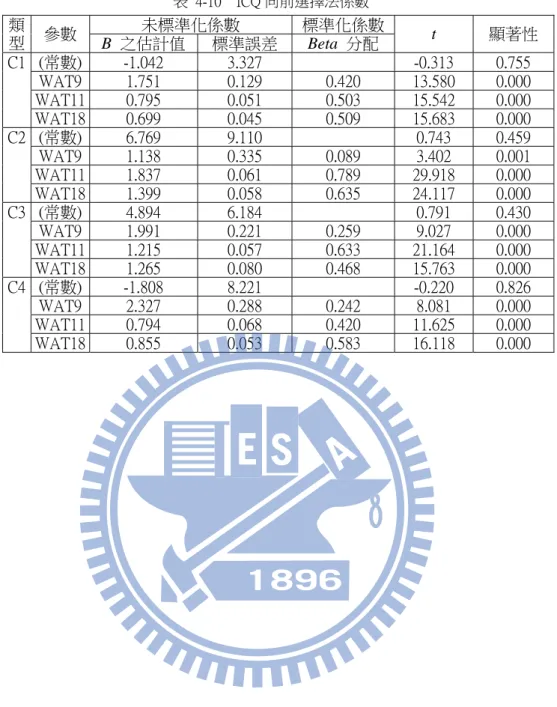
Gain WAT1 WAT2 WAT3 WAT4 WAT5 WAT6 WAT7 WAT8 WAT9 WAT10 Pearson 相關 0.084 0.306 -0.027 -0.036 0.879 0.024 -0.061 0.010 0.022 -0.016 C1 顯著性 (雙尾) 0.323 0.000 0.748 0.673 0.000 0.780 0.472 0.907 0.796 0.854 Pearson 相關 0.021 0.083 -0.056 0.010 0.893 -0.041 0.043 -0.066 -0.030 0.124 C2 顯著性 (雙尾) 0.807 0.327 0.514 0.910 0.000 0.627 0.612 0.438 0.729 0.143 Pearson 相關 -0.036 0.113 0.122 0.010 0.841 0.025 0.083 -0.022 0.024 -0.072 C3 顯著性 (雙尾) 0.676 0.184 0.151 0.903 0.000 0.765 0.328 0.800 0.776 0.400 Pearson 相關 0.025 0.298 0.035 0.080 0.861 -0.079 0.129 -0.102 -0.184 -0.148 C4 顯著性 (雙尾) 0.766 0.000 0.680 0.349 0.000 0.356 0.129 0.230 0.030 0.081 Gain WAT11 WAT12 WAT13 WAT14 WAT15 WAT16 WAT17 WAT18 WAT19 WAT20 Pearson 相關 0.197 -0.155 -0.079 0.708 -0.113 -0.050 0.044 -0.163 -0.056 0.023 C1 顯著性 (雙尾) 0.020 0.068 0.351 0.000 0.185 0.554 0.610 0.054 0.511 0.791 Pearson 相關 0.570 0.008 -0.066 0.787 0.221 0.205 -0.057 0.041 -0.056 -0.121 C2 顯著性 (雙尾) 0.000 0.924 0.439 0.000 0.009 0.015 0.502 0.632 0.513 0.155 Pearson 相關 -0.220 -0.152 -0.072 0.382 -0.072 -0.062 -0.055 -0.050 -0.131 0.061 C3 顯著性 (雙尾) 0.009 0.073 0.399 0.000 0.400 0.465 0.517 0.558 0.122 0.474 Pearson 相關 -0.350 0.035 0.007 0.541 0.161 0.247 -0.031 -0.329 0.027 -0.039 C4 顯著性 (雙尾) 0.000 0.679 0.931 0.000 0.057 0.003 0.715 0.000 0.748 0.650 粗體字部份:在顯著水準為 0.001 時(雙尾),相關顯著 如表 4-2,利用皮爾森相關係數觀察訓練資料的四種類型輸出變數 ICQ 和 20 個 WAT 參數的相關性,發現原本分析的主要參數 WAT9,僅有中度相關,對輸出變數 ICQ 並非最重要參數,而 WAT11 和 WAT18 的相關性達到高度相關,比較起來和 ICQ 的關 係性,反而是 WAT11 和 WAT18 比 WAT9 較高。
表 4-2 皮爾森相關係數(ICQ 與 20 個 WAT)
ICQ WAT1 WAT2 WAT3 WAT4 WAT5 WAT6 WAT7 WAT8 WAT9 WAT10 Pearson 相關 -0.072 -0.127 -0.012 0.028 0.126 -0.102 -0.065 0.046 0.451 -0.146 C1 顯著性 (雙尾) 0.396 0.134 0.886 0.741 0.139 0.230 0.446 0.591 0.000 0.085 Pearson 相關 -0.071 -0.098 -0.047 0.130 0.445 -0.089 0.041 -0.062 0.046 0.089 C2 顯著性 (雙尾) 0.406 0.248 0.579 0.125 0.000 0.297 0.633 0.470 0.588 0.297 Pearson 相關 0.002 0.109 -0.034 0.037 -0.200 0.003 0.086 -0.082 0.312 -0.067 C3 顯著性 (雙尾) 0.977 0.202 0.691 0.667 0.018 0.975 0.312 0.337 0.000 0.429 Pearson 相關 0.023 -0.014 -0.095 -0.211 -0.420 0.160 -0.156 0.098 0.300 0.074 C4 顯著性 (雙尾) 0.784 0.873 0.266 0.012 0.000 0.059 0.066 0.251 0.000 0.387 ICQ WAT11 WAT12 WAT13 WAT14 WAT15 WAT16 WAT17 WAT18 WAT19 WAT20 Pearson 相關 0.643 -0.046 0.101 -0.061 -0.128 -0.047 -0.074 0.704 0.050 0.130 C1 顯著性 (雙尾) 0.000 0.587 0.235 0.471 0.132 0.581 0.383 0.000 0.561 0.125 Pearson 相關 0.707 0.081 0.028 0.519 0.154 0.170 0.009 0.544 -0.040 -0.032 C2 顯著性 (雙尾) 0.000 0.339 0.743 0.000 0.069 0.045 0.912 0.000 0.642 0.711 Pearson 相關 0.819 -0.031 0.172 0.104 0.001 0.031 0.100 0.632 0.151 -0.059 C3 顯著性 (雙尾) 0.000 0.716 0.042 0.222 0.987 0.716 0.238 0.000 0.075 0.491 Pearson 相關 0.759 0.107 0.009 -0.301 -0.090 -0.174 0.022 0.835 0.022 -0.069 C4 顯著性 (雙尾) 0.000 0.209 0.917 0.000 0.290 0.040 0.799 0.000 0.794 0.416 粗體字部份:在顯著水準為 0.001 時(雙尾),相關顯著
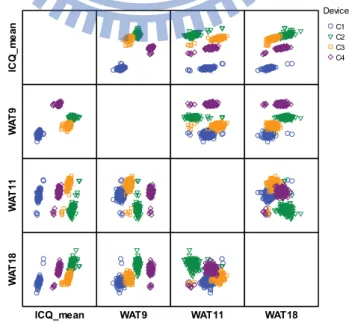
如圖 4-6 進一步用散佈圖表示,和 Gain 關係性較高的參數 WAT2、WAT5 和 WAT14 之間的相互關係,除了由 R 可得知相關性以外,亦可由散佈圖形狀看出,輸出變數 Gain 和輸入變數 WAT5 或 WAT14 比輸出變數 Gain 和輸入變數 WAT2 更有相關性。
圖 4-6 Gain 與重要 WAT 參數(WAT2、5 和 14)散佈圖
如圖 4-7 進一步用散佈圖表示,和 ICQ 關係性較高的參數 WAT9、WAT11 和 WAT18 之間的相互關係,除了由 R 可得知相關性以外,亦可由散佈圖形狀看出,輸出 變數 ICQ 和輸入變數 WAT11 或 WAT18 比輸出變數 ICQ 和輸入變數 WAT9 更有相關性。
4.1.2 線性迴歸參數挑選 1. 向前選擇法 向前選擇法是以各輸入變數當中,與輸出變數相關最高者首先被選入,其次為未 被選入的輸入變數與輸出變數有最大的偏相關者,也就是能增加最多的解釋力( 2 R )的 預測變數。在實際執行時,必須選定選入的臨界值作為門檻,本實驗以 F 考驗的顯著 水準p0.05為臨界值,如果模型外的變數所增加的解釋力最大者的 F 考驗值的顯著 性小於 0.05 即可備選入模型中。 C1 類型輸出變數 Gain 的向前選擇法,執行結果如表 4-3,與輸出變數 Gain 相關 最高者為 WAT5(顯著性p 0, Beta 0.879),所以首先被選入迴歸方程式(模式 1)。 此時,尚有 19 個預測變數,各變數與輸出變數的偏相關(排除其他輸入變數的效果)以 WAT2 的 0.641 最高,而其預測力也達到 0.05 的顯著水準(t9.762, p0.000),因此 是第二個被選入模型的變數。
選入後,模型 2 即同時包含了兩個輸入變數 WAT5 和 WAT2,Beta係數分別為
0.879 與 0.305,兩者 t 考驗均達顯著性水準。此時,模型外尚有 18 個輸入變數,其中 還有 WAT14 的偏相關(0.730)顯著性(0.000)小於 0.05,因此成為第三個被納入的變數,
納入後的模型 3,三個輸入變數 WAT5、WAT2 和 WAT14 的Beta係數分別為 0.705、
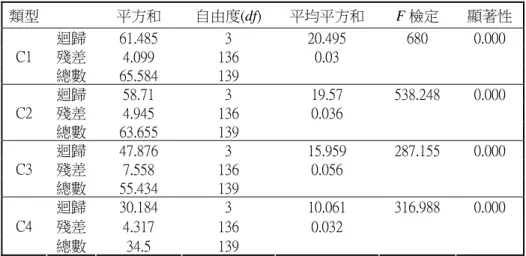
0.300 和 0.318,其中以 WAT5 相對重要性最高。此時,模型外的 17 個變數的偏相關係 數均未達 0.05 的統計顯著性,因此選擇變數程序終止,留下最佳預測力的三個輸入變 數於方程式中。 表 4-3 向前選擇法所得到的係數(C1 類型 Gain) 未標準化係數 標準化係數 模式 B 之估計值 標準誤差 Beta 分配 t 顯著性 (常數) 14.764 0.770 19.179 0.000 1 WAT5 0.670 0.031 0.879 21.692 0.000 (常數) 5.363 1.131 4.741 0.000 WAT5 0.670 0.024 0.879 28.138 0.000 2 WAT2 0.628 0.064 0.305 9.762 0.000 (常數) 3.163 0.796 3.973 0.000 WAT5 0.538 0.019 0.705 27.584 0.000 WAT2 0.617 0.044 0.300 13.979 0.000 3 WAT14 1.034 0.083 0.318 12.450 0.000
![表 3-1 迴歸模型的變異數分析摘要表 變異來源 SS df MS F 迴歸效果 SS r p SS r df r eregMSMS 誤差 SS e N p 1 SS e df e 全體 SS t N 1 3.4 多元迴歸分析 3.4.1 多元迴歸 通常一個研究中,影響輸出變數的輸入變數不只一個,此時需建立一套包含多個 輸入變數的多元迴歸模型,同時納入多個輸入變數來對輸出變數進行解釋與預測,稱 為多元迴歸[14]。例如三個輸入變數對一個輸出變數的多元迴歸方](https://thumb-ap.123doks.com/thumbv2/9libinfo/8474516.183678/33.892.122.751.145.342/多元迴歸分析多元迴歸通常研究需建立個輸入變數來對輸出變數進.webp)