整合社群關係的OLAP操作推薦機制 - 政大學術集成
76
0
0
全文
(2) 整合社群關係的 OLAP 操作推薦機制 A Recommendation Mechanism on OLAP Operations Based on Social Network. 研 究 生:陳信固. Student:Hsin-Ku Chen. 指導教授:李蔡彥. 立. Advisor:Tsai-Yen Li 治 政 大. 碩士論文. Nat. er. io. A Thesis. sit. y. ‧. ‧ 國. 資訊科學系. 學. 國立政治大學. n. submitteda to Department of Computer v Science. i l C n National U h eChengchi n g c h i University. in partial fulfillment of the Requirements for the degree of Master in Computer Science 中華民國一百零一年七月 July 2012. II.
(3) 整合社群關係的 OLAP 操作推薦機制. 摘要. 近幾年在金融風暴及全球競爭等影響下,企業紛紛導入商業智慧平台,提 供管理階層可簡易且快速的分析各種可量化管理的關鍵指標。但在後續的. 治 政 推廣上,經常會因商業智慧系統提供的資訊過於豐富,造成使用者在學習 大 立 ‧ 國. 學. 階段無法有效的取得所需資訊,導致商業智慧無法發揮預期效果。本論文 以使用者在商業智慧平台上的操作相似度進行分析,建立相對於實體部門. ‧. 的凝聚子群,且用中心性計算各節點的關聯加權,整合至所設計的推薦機. sit. y. Nat. 制,用以提升商業智慧平台成功導入的機率。經模擬實驗的證實,在推薦. er. io. n. al 機制中考慮此因素會較原始的推薦機制擁有更高的精確度。 iv Ch. n U engchi. 關鍵詞:社群網路分析、推薦機制、社群偵測、商業智慧、網絡中心性. III.
(4) A Recommendation Mechanism on OLAP Operations Based on Social Network. Abstract In recent years, enterprises are facing financial turmoil, global competition, and. 政 治 大 the Business Intelligence platform to help managers get the key indicators of 立. shortened business cycle. Under these influences, enterprises usually implement. ‧ 國. 學. business management quickly and easily. In the promotion stage of such Business Intelligence platforms, users usually give up using the system due to. ‧. huge amount of information provided by the BI platform. They cannot. y. Nat. intuitively obtain the required information in the early stage when they use the. er. io. sit. system. In this study, we analyze the similarity of users’ operations on the BI platform and try to establish cohesive subgroups in the corresponding. n. al. organization. In addition,. v i n C wehalso integrate U the associated engchi. weighting factor. calculated from the centrality measures into the recommendation mechanism to increase the probability of successful uses of BI platform. From our simulation experiments, we find that the recommendation accuracies are higher when we add the clustering result and the associated weighting factor into the recommendation mechanism. Keywords : Social. Network. Analysis,. Recommendation. Community Detection, Business Intelligence, Network Centrality. IV. Mechanism,.
(5) 目錄 第一章 緒論 ............................................................. 1 1.1 前言 ............................................................................................................................. 1 1.2 研究動機 ..................................................................................................................... 2 1.3 研究目的 ..................................................................................................................... 3 1.4 研究方式 ..................................................................................................................... 4 1.5 論文架構 ..................................................................................................................... 6 第二章 相關研究 ......................................................... 7 2.1 推薦機制 ..................................................................................................................... 7 2.1.1 OLAP 推薦機制 ................................................................................................ 8 2.1.2 網頁推薦機制 ................................................................................................ 10 2.1.3 Page Rank 演算法 ........................................................................................... 10 2.2 社會網絡分析 ........................................................................................................... 11 第三章 研究方法 ........................................................ 13 3.1 研究假設 ................................................................................................................... 13 3.2 系統架構 ................................................................................................................... 14 3.3 使用者操作紀錄收集 ................................................................................................ 15 3.4 多維度操作紀錄正規化 ............................................................................................ 16. 立. 政 治 大. ‧. ‧ 國. 學. Nat. y. sit. n. al. er. io. 第四章 社群網絡分析 .................................................... 19 4.1 凝聚子群 ................................................................................................................... 19 4.1.1 Modularity Q 的計算 ...................................................................................... 20 4.1.2 社群切割(Subgroups) .................................................................................... 22 4.2 老手程度的判斷 ........................................................................................................ 23 第五章 推薦機制 ........................................................ 27 5.1 相似度判斷 ............................................................................................................... 27 5.2 候選項目篩選 ........................................................................................................... 29 5.3 推薦機制:最大信心度選擇 ................................................................................... 31 5.4 推薦機制:最大使用人次選擇 ............................................................................... 32. Ch. engchi. i n U. v. 5.5 推薦機制與參考關聯加權 ....................................................................................... 32 第六章 系統實作與實驗 .................................................. 34 6.1 程式語言、資料來源 ............................................................................................... 34 6.2 多維度分析推薦輔助系統功能模組說明 ................................................................ 34 6.2.1 操作紀錄正規化 ............................................................................................ 35 6.2.2 操作紀錄之相似度判斷 ................................................................................ 36 6.2.3 產生推薦候選項目集合 ................................................................................ 37 6.2.4 使用者分群 .................................................................................................... 38 V.
(6) 6.2.5 老手程度加權計算 ........................................................................................ 41 6.2.6 推薦項目產出 ................................................................................................ 42 6.2.7 使用者回饋機制 ............................................................................................ 42 6.3 多維度分析推薦輔助系統操作介面介紹 ............................................................... 43 6.3 模擬實驗 .................................................................................................................... 46 6.3.1 推薦機制:最大信心度選擇的模擬結果分析 ............................................ 47 6.3.2 推薦機制:最大使用人次選擇的模擬結果分析 ........................................ 48 6.3.3 推薦機制:最大信心度選擇加入參考關聯加權的模擬結果分析 ............ 49 6.3.4 推薦機制:最大使用人次選擇加入參考關聯加權的模擬結果分析 ........ 51 6.4 使用者實際操作回饋 ............................................................................................... 52 6.4.1 問卷的回饋與分析 ........................................................................................ 53 6.4.2 推薦機制的正確率分析 ................................................................................ 54 第七章 結論與未來發展 .................................................. 58 7.1 研究結論 ................................................................................................................... 58 7.2 未來發展 ................................................................................................................... 59 參考文獻 ............................................................... 61 附錄一:多維度分析平台推薦輔助系統實驗問卷 ............................. 64. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VI. i n U. v.
(7) 圖目錄 圖 1-1、商業智慧系統發展程序 .......................................................................................... 2 圖 圖 圖 圖 圖. 1-2、研究流程圖 .............................................................................................................. 4 3-1、系統架構圖 ............................................................................................................ 13 3-2、多維度分析平台操作介面 .................................................................................... 14 4-1、社會網絡圖形 ........................................................................................................ 18 4-2、Factions 演算法分群結果 ..................................................................................... 21. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 4-3、Girvan-Newman 演算法分群結果 ........................................................................ 22 4-4、Degree 的 Centrality measures 結果 ..................................................................... 24 4-5、Closeness 的 Centrality measures 結果 ................................................................. 25 4-6、Betweenness 的 Centrality measures 結果 ............................................................ 26 6-1、多維度分析推薦輔助系統流程圖 ........................................................................ 35 6-2、操作紀錄正規化處理流程圖 ................................................................................ 35 6-3、相似度判斷處理流程圖 ........................................................................................ 36 6-4、產生推薦候選項目集合流程圖 ............................................................................ 37 6-5、使用者分群的流程圖 ............................................................................................ 38 6-6、以節點 A 為起始點的最短路徑處理範例 ........................................................... 40. 圖 圖 圖 圖 圖 圖 圖 圖. 6-7、老手程度加權的流程圖 ........................................................................................ 41 6-8、推薦項目產出的流程圖 ........................................................................................ 40 6-9、使用者回饋的流程圖 ............................................................................................ 43 6-10、推薦系統參數設定介面 ...................................................................................... 44 6-11、推薦輔助系統登入畫面 ...................................................................................... 44 6-12、查詢操作正規化結果 .......................................................................................... 45 6-13、推薦結果 .............................................................................................................. 45 6-14、更多推薦的結果 .................................................................................................. 46. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VII. i n U. v.
(8) 表目錄 表 1.1、資訊系統專案導入成功比例圖 ...................................... 2 表 3-1、使用者於多維度分析系統的操作紀錄範例 ........................... 14 表 4-1、虛擬關聯分佈矩陣 ............................................... 19 表 6-1、操作紀錄分析與正規化的輸入與輸出 ............................... 36 表 6-2、產生推薦候選項目集合的輸入與輸出 ............................... 37 表 6-3、使用者分群的輸入與輸出 ......................................... 41 表 6-4、推薦機制:最大信心度選擇的模擬結果 ............................. 表 6-5、推薦機制:最大使用人次選擇的模擬結果 ........................... 表 6-6、推薦機制:最大信心度選擇加入參考關聯的模擬結果 ................. 表 6-7、最大信心度選擇的推薦機制加入參考關聯加權後的正確推薦順位比較 ... 表 6-8、推薦機制:最大使用人次選擇加入參考關聯的模擬結果 ............... 表 6-9、最大使用人次選擇加入參考關聯加權後的正確推薦順位比較 ........... 表 6-10、實驗人員的背景資料 ............................................ 表 6-11、OLAP 操作輔助系統的滿意度回饋統計 .............................. 表 6-12、實驗的推薦正確性測試結果 ...................................... 表 6-13、三種類型使用者的測試統計 ....................................... 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VIII. i n U. v. 48 48 49 50 51 51 53 53 55 55.
(9) 第一章. 緒論. 本章主要在說明本研究的動機與目的,透過背景說明闡述本研究所要討論之主要目標, 並提出整個研究的流程步驟和架構。. 1.1 前言 依據 IDC 的商業智慧市場調查報告,亞太地區(不含日本) 2003 年在於商業智慧(Business. 政 治 大. Intelligence ,BI)的市場規模為 5.3 億美元;但在 2003 年到 2008 年的階段以 18.6%的比率. 立. 呈現一個複合性的成長,並在 2008 年突破 12 億美元。顯示企業在資訊科技發展從早期. ‧ 國. 學. 的自動化與電子化的推動,逐漸將重心轉移到思考如何整合企業內部資源與資訊。尤其 近幾年企業面臨著金融風暴、全球競爭、景氣循環縮短等影響下,企業經理人除了藉由. ‧. 以往的「經驗法則」作為決策的依據外,還必須能即時獲得所需的參考資訊才能夠為企. y. Nat. 業有效率的作出關鍵決策。但以早期資訊系統發展的情況,往往資訊的取得都是費時費. sit. 力,經由各系統負責人將局部資料以報表形式提供後,最後仍需進行彙總的整理後才能. n. al. er. io. 獲得所需的關鍵指標。因此企業管理階層如何在營運過程中快速取得所需的資訊,已是. i n U. v. 企業在資訊科技發展的一大重心,而商業智慧的技術即可提供企業作為一個解決方案。. Ch. engchi. 管理大師 Robert Kaplan 及 David Norton 說過:『如果你無法衡量它,你就無法有效 的管理它』。對於一個管理者來說,面對著企業以倍數在成長的資料,如何將雜亂的資 料轉換為企業經營上的實質效益,而商業智慧系統即是目前企業積極用來達成此目標的 一個解決平台。圖 1.1 表示是一般我們在導入商業智慧系統的三個過程,包含商業智慧 系統分析、商業智慧系統建置與商業智慧系統運用。一個商業智慧系統的導入,首先需 要透過需求訪談協助找出企業內部可量化管理的關鍵指標(KPI),並且定義該指標的計算 公式與該指標在管理層面所需要分析的面向(維度)。接下來依據定義的指標找尋其相對 的來源資料,並且利用資料轉換(ETL)的工具轉至倉儲系統內,最後在平台上建立各主 題的多維度分析模組,提供每個人依據職務的需求取得所需的相關資訊,讓企業能快速. 1.
(10) 反應外在的變化與企業的難題。 資料來 源分析. 資料轉換 程式設計. 企業需 求分析. 關聯主題 資料處理. 倉料倉 儲建置. 商業智慧 架構設計. 分析模 組建置. 系統操作. 效能維護. 立. 商業智慧系統 分析. 政 治 大 商業智慧系統 建置. 商業智慧系統 建置. 商業智慧系統 管理. 資料來源:資策會 2012. al. er. io. sit. y. ‧. ‧ 國. 學 圖 1-1、商業智慧系統發展程序. Nat. 1.2 研究動機. 系統推廣 主題擴充. v. n. 根據 CHAOS Summary 2009 報告,企業在導入資訊系統時的執行狀況如下. Ch. engchi. 專案導入結果. 定義. 成功(succeeding). 如期,如質,如預算. 不. 如. 預. i n U. 比例 32%. 期 雖然完成了,但時程不如預期,或超支、或 44%. (challenged). 刪減需求、或品質不佳等. 失敗(failed). 取消專案,或雖然做完了,卻從不使用。. 24%. 表 1.1、資訊系統專案導入成功比例圖 由表 1.1 中我們可以發現由於資訊系統專案的特性,無法成功完成專案目標的機率高達 76%,而商業智慧的專案又因為使用者的認知不足與系統的複雜度,更造成專案不成功 的比率高達 85%。在我們為客戶導入商業智慧專案的過程中,發現通常商業智慧專案失. 2.
(11) 敗的類型分為兩種,第一種我們歸類為建置不良的商業智慧系統,此種類型的專案因為 導入人員在需求訪談階段無法有效引導使用者,造成設計階段無法規劃出正確的模組架 構,而導致最後無法建置符合期望功能的系統;這樣的專案通常都是以建置大量的報表 來結束專案,而無法提供多維度分析平台應有的效益。第二種我們歸類為商業智慧系統 推廣不良,因為商業智慧的專案為了提供使用者一個具即時性與彈性的資料操作平台, 在建置的過程中盡可能會將以後會用到的指標與潛在指標內容都整合至模組內,但在導 入初期也常因為提供的資訊過多,因而導致對於模組不熟悉的使用者會望之怯步,慢慢. 政 治 大 統建置[8]、多維度系統開發方法論與資料採礦的運用以及演算法的研究,也有人研究怎 立 的造成此系統的僅侷限在特定的人員使用。目前商業智慧大部分的研究都在探討倉儲系. 麼提供商業智慧系統需求的分析模型,都是為了提升商業智慧專案成功的機率。在本研. ‧ 國. 學. 究中我們希望能從商業智慧系統的推廣方向著手,探討如何藉由輔助決策系統的方式提. er. io. sit. y. Nat. 1.3 研究目的. ‧. 升商業智慧在企業內推廣的成效。. 基於商業智慧專案在於企業推行的成功機率偏低,本研究探討如何建置即時的多維度分. al. n. v i n Ch 析模組的操作推薦系統。嘗試對商業智慧平台上使用者所建立的社群網絡進行分析,依 engchi U 據其操作的相似性對使用者作分群,並且將此結果運用在後續建立的多維度分析平台操 作推薦的輔助系統中,降低企業因為商業智慧系統推廣不佳而造成無法達到預期目標的 情況。本研究主要的研究目的如下: 一.. 降低使用者在商業智慧系統上學習的時間:在實務的 OLAP 專案上,我們建置 Cube 的類型主要會分為兩種,一種是給高階管理者使用,包含的內容會是企業 經營的主要指標,這種類型的 Cube 通常包含的量值與維度都不會超過 20 個, 因此使用者在使用上不會有太大的困難;但第二種類型是提供給專門提供分析 報告的人員使用,為了因應他們對資料的即時與有效性,往往我們在建置的過 程中會將所有可能分析到的重要面向與指標都整合在單一 Cube 中,以本次實驗 3.
(12) 的對象,我們在建置的卡友消費分析的 Cube 中包含的維度就高達一百三十二個, 對於系統的老手而言,他們可以很快速的從系統中取得所需的分析資料,但是 對於一般的使用者而言,他們可能需要花費大量的時間在找尋所需的維度或量 值。因此將藉由推薦系統的輔助,適時在操作的過程中提供建議,經由參考其 他相關使用者的操作紀錄,降低使用者在商業智慧系統上學習的時間。 二. 提昇群體間知識分享的成效:在 OLAP 系統中進行資料分析的過程中,我們通 常都是利用嘗試性的方法,對系統的所提供的維度與量值作測試性的操作後方. 政 治 大 這樣的模式會造成報表製作的效率不佳,因此將藉由此推薦系統的建置,讓使 立 能找到所需的資訊,最後在透過報表的討論才能夠達到知識分享的效果;但是. 用者在操作的過程中能檢視同群體的人員在分析相似問題時關心的面向,加速. ‧ 國. 學. 使用者資料檢索的效率。. ‧. 三. OLAP 推薦機制在實務上的驗證:以往研究的對象都是利用範例 CUBE 或者是小. y. Nat. 型的 Cube 進行問卷式的實驗,在本次的實驗中我們將會以實務上已經導入多維. er. io. sit. 度平台的企業做為研究對象,面對更複雜結構與包含更多維度的 Cube 來說,實 際能夠成功從一兩百個維度中找出適合的項目做為推薦的機率是非常低的,因. al. n. v i n Ch 此將藉由本次的實驗將會利用實務上的操作紀錄做為實驗資料,用以驗證這樣 engchi U 的 OLAP 推薦機制在實務上的幫助是否如預期。. 1.4 研究方式 基於上述研究目的,本研究首先會收集使用者在於多維度分析平台上的操作紀錄,並藉 由正規化方式將資料整理成可做分析使用的集合。我們將會利用社會網絡分析(Social Network Analysis,SNA)技術,依據使用者在商業智慧平台上資料檢索內容的相似度, 將使用者進行分群並且判斷子群內哪些人是生手哪些人是老手。最後,我們將把社群網 絡分析的結果運用在推薦輔助系統上。在使用者操作系統的過程中,系統會自動分析該. 4.
(13) 使用者目前的操作內容,與歷史資料進行相似度的比較,以找出可能的候選項目,最後 依據最大使用人次選擇方式作為候選項目選擇的判斷,實驗的過程中也將會將最大使用 人次選擇推薦機制與一般常用的依據支持度(Support)的推薦機制相比較。本研究之研究 方法步驟如圖 1-2 所示 確認研究目標. 相關研究探討. 資料蒐集與預處理. 學. ‧ 國. 立. 政 治 大 社會網絡分析. ‧ 實驗結果分析. n. al. Ch. engchi. i n U. 結論. 圖 1-2、研究流程圖. 5. er. io. sit. y. Nat. 建構多維度分析模組推薦系統. v.
(14) 1.5 論文架構 本研究共分七個章節,本章為研究概論,在說明研究的動機與目的;第二章將對相關研 究作介紹,主要是對社會網絡分析(Social Network Analysis)、網頁推薦機制與 OLAP 推 薦機制等相關研究作探討;第三章主要在介紹本研究問題的假設與資料收集的方法,首 先我們會先依據以往在實務上的經驗來定義此次研究的假設,接著會說明本次研究的系 統架構,然後會對資料的收集及資料正規化的處理作進一步的說明。第四章為社群網絡 分析,將說明如何對使用者進行分群,並且定義系統中使用者的老手程度。第五章,為. 政 治 大 為系統的實作與實驗結果的分析與討論;最後第七章介紹本論文的結論與未來的發展方 立. 推薦機制說明,將對操作相似度判斷、候選項目的篩選與推薦機制分別作說明;第六章. ‧. ‧ 國. 學. io. sit. y. Nat. n. al. er. 向。. Ch. engchi. 6. i n U. v.
(15) 第二章. 相關研究. 本研究的目的是在對線上分析處理 (On-Line Analytical Processing,OLAP)系統的使用者 行為進行分析,經由推薦輔助系統提升企業在於商業智慧專案的推廣。研究的過程中, 參考的觀念技術包含在 OLAP 上的使用者行為預估[9][13]與推薦技術[17][19][21]、網頁 推薦機制[12]與資料探勘[6][14]等;此外,我們也會利用社群網絡分析(Social Network Analysis,SNA)的技術[15][16],依據使用者在 OLAP 系統上操作的相似度,將一個大網 絡分割為多個同質的凝聚子群,並且識別每個人在各社群中的專家程度,並且反應至推. 政 治 大. 薦系統的加權係數中,以提昇推薦的精確度;後續我們將對這些相關研究作進一步的探. 立. 討。. ‧. ‧ 國. 學. 2.1 推薦機制. 日常生活中我們在做決定時,通常會參考外部的建議後,才做出最後的選擇;舉例來說,. y. Nat. er. io. sit. 在決定看哪部電影或者是買甚麼車時,我們可能會上搜尋引擎查詢別人的評價或者是參 考此領域專家的文章,而做出最適當的決定。不過當能參考的資訊過多的時候,反而不. n. al. Ch. i n U. v. 知道哪些資訊是有效,也因此有許多技術與研究用來協助我們在巨量資料中取得所需的. engchi. 資訊,而推薦機制就是其中一個經常被使用的輔助方式。一般的推薦機制主要是以資訊 過濾為基礎,利用歷史經驗來分析使用者的行為模式,進行喜好的預測來降低資料過載 的情形。在一個推薦系統中,將會依據使用者的操作習慣,協助使用者在眾多物件篩選 出候選的物件,然後推薦符合使用者需要的資訊。一般的推薦系統主要分為三種類型: . 內容式資訊過濾推薦系統. Content-Based Filtering Systems. . 協同式資訊過濾推薦系統. Collaborative Filtering Systems. . 混合式資訊過濾推薦系統. Hybrid approaches. 不同的推薦系統著重於解決不同的推薦問題,而相關研究的探討範圍包括:資料取 得的方式、推薦系統的應用領域、推薦方法的革新等。下面將個別作說明:. 7.
(16) . 內容式資訊過濾(Content-based Filtering)[9][20]:系統首先會收集使用者資訊, 像是該使用者曾經瀏覽過的網頁及這些網頁的屬性(例:關鍵字或類型等),並 分析過去使用者的資訊,每個項目皆會有屬於自己的屬性標籤,而所有項目集 合起來就是一個使用者的喜好主檔。在進行推薦的時候,我們會依據各項目相 對於使用者的主檔資訊作匹配,判斷哪個項目最適合做為推薦。此過濾方式通 常運用文件自動分類的方法,並適合用在處理半結構化的文件上,且最常被使 用在有限屬性的項目上,像是書籍與電影上。. . 協同式資訊過濾(collaborative Filtering)[5][7]:依據擁有共同經驗之群體的喜好, 來推薦使用者感興趣的資訊。利用合作的方式提供個人對於資訊的評分,而評. 政 治 大. 分不一定只能侷限於感興趣的部分,不感興趣資訊的部分也相當重要。此方式. 立. 在進行推薦時,首先依據使用者對於項目的評比建置使用者的主檔,然後利用. ‧ 國. 學. 統計或者是機器學習的方式來建立各使用者所屬的群集,我們稱之為「最同好 群(Nearest Neighbors)」,最後藉由同好群集內的成員所喜好的項目作推薦,. . ‧. 過程中會結合權重的觀念來產生有順序的推薦項目。. 混 合 式 資 訊 過 濾 (Hybrid approaches) : 結 合 Content-based Filtering 與. y. Nat. n. al. er. io. sit. collaborative Filtering 兩種方式,即本研究採行方式。. i n U. v. 在本研究中,我們將會利用內容式資訊過濾的方式,找出相似度一致的項目做為推薦的. Ch. engchi. 候選項目;此外我們在協同過濾上我們將會利用社群網絡分析的技術,對使用者進行同 質資訊需求的分群取代一般的個人背景與使用者喜好的收集,我們將會找出候選項目中 哪幾個項目,在相同子群內的使用頻率或使用人次最高做為推薦的標的。下列我們將先 介紹幾個在 OLAP 推薦上相關的研究,後續將會對社群網絡分析上的相關研究作說明。. 2.1.1 OLAP 推薦機制 線上分析處理 (On-Line Analytical Processing,OLAP)是一種提供使用者存取資料倉儲的 前端應用,協助決策者快速且有效率的從巨量資料中取得決策所需的資訊。藉由資料模 型(Cube)的建置,提供決策者可以利用多維度的觀點,依據不同的主題與面向來對資料 進行分析。在資料操作上,利用維度階層上向下探勘(Drill-Down)與向上彙總(Roll-Up). 8.
(17) 的功能,有效率的切換資料的面向且取得一致性的決策資訊。在 OLAP 系統中主要分為 兩個部分: . 維度(Dimension):檢視一個問題時所用的分析面向,如時間、區住地與學歷等, 通常都是描述性的項目。而維度的使用方式又分為報表維度與條件式維度。報 表維度指的是我們一般放置於報表的行列資訊,主要是用來呈現此維度各成員 的量值彙總資訊,提供的操作方式包含鑽研(Drill-Down 與 Roll-Up)與樞紐 (Pivot)等。而條件式維度,主要是用來界限報表呈現的內容,例如檢視 2009 年北美的銷售數字中的『2009 年』與『北美』 ,主要的操作方式是切面(Slice)。. . 量值(Measure):檢視一個問題時所用的彙總資訊,如金額、次數與庫存等,通 常都是量化的項目。. 立. 政 治 大. ‧ 國. 學. 線上分析處理系統為了能提供系統操作者取得全面性的資料,通常在建置的過程中, 都會將分析問題所需的維度與相關屬性以及各主題所需分析的量值全都納入系統內,用. ‧. 以提供決策者可有效率的檢視企業 KPI。但也因為這樣的特性,通常會導致新手使用者 發生難以下手的情況。因此,有許多的論文就對於如何在 OLAP 系統上提供使用者協助。. y. Nat. sit. 下列幾篇論文也是在對於 OLAP 系統上輔助方式進行探討。. er. io. 在 Carsten Sapia(1999)的研究[9]中,作者利用內容式資訊過濾(Content-based Filtering). al. n. v i n Ch 上每一個查詢都代表著一種商業問題,而在相似商業的問題處理時會有相似的模式 engchi U. (Balabanovic & Shoham, 1997) 方式做使用者行為的預測,Carsten Sapia 認為 OLAP 系統. (Patterns)。因此他將 OLAP 上的操作(MDX 查詢語句)正規化為集合的表示式,做為此查 詢的 Query Prototype。作者將正規化後的集合,經由『維度的層級(Level)差異』與『維 度的功能(Result 或 Selection Dimension)』兩個面向,計算兩個查詢語句的相似度。最後 再以相似度的判斷結果,預測該使用者下一步操作。不過在此研究中,存在因忽略認同 度而產生『最相似的查詢等同是最適合推薦的項目』的錯誤,單純以資料本身的相似度 作為判斷,有可能此查詢本身是錯的,但只因它最相似而誤認為最適項目。因此在本研 究中會先以相似度高低找出候選的項目,然後進行認同度進行投票後,找出最適合的推 薦項目來改善此問題。 在 Chen & Hsu (2008)的研究[20]中,作者進行生手推薦機制、老手推薦機與分群推 薦機制的比較。作者認為 OLAP 系統上的使用者應該有生手與老手間之分,生手在此研 9.
(18) 究中將考慮在所有的使用者的操作紀錄,計算出使用頻率最高的三個項目進行推薦。但 隨著使用者在系統操作經驗的累積,使用者在系統上的推薦需求反而是以往不曾使用過 的項目,以提升使用者對於系統功能的使用率。作者利用 K-Means 分群演算法依據使用 者行為的相似性進行分群,提升推薦分析資料的精確度。 不過此研究主要是推薦各個 Cube 使用頻率最高的前三名項目,不過實際上 OLAP 系統的操作是一個序列的操作,需要經由多個相關的項目組合才能取得一個有效的結果。 但是在同一個 Cube 上使用頻率最高的三個項目組合起來,絕大部分不會是我們問題解 決所需的資訊,因此在本研究中,我們依據使用者當下的操作內容的相似度判斷,並且 整合社群關係的推薦機制來找出最適合的推薦項目。. 立. 2.1.2 網頁推薦機制. 政 治 大. ‧ 國. 學. 隨著網際網路的發展與網路頻寬的普及,人們可以快速獲取所需資訊的管道日益擴增。. ‧. 但伴隨著網站數目大幅度的成長,如何在巨量資源中找到有價值的資訊就變成最迫切的 議題;也因有搜尋引擎的發明,藉由關鍵字的查詢有效的縮小資料範圍。搜尋的過程中,. Nat. sit. y. 使用者會輸入所需資訊的關鍵字,但由於網路資源實在太多,且單一關鍵字通無法明確. er. io. 描述出真的資訊需求。因此搜尋引擎查詢的過程中,通常會藉由演算法計算各頁面符合. al. v i n Ch 使用者評分(User Rating)的方式是一種經常見的推薦方式,是以使用者的角度來 engchi U n. 的機率並且排序後呈現結果,避免查詢的結果發生方向偏離的情況。. 進行推薦。藉由使用者上傳對於各項目的評分後,經由公式的計算統計評分的結果。像 是雅虎拍賣網站,在每次交易後讓買家與賣家互相評分,協助後續其他人在交易時很容 易知道對方的信任評分。但是此種方式僅限於在於票選項目很少的時候,才可以讓使用 者對於全部項目進行評分,然後再依據評分結果進行推薦。但在網際網路這樣可能的候 選項目是幾千幾萬個的情況下,要讓使用者對於每個項目進行評分幾乎是不可能。因此, 就有許多論文研究各種演算法,依據使用者的歷史操作紀錄,模擬每個人對於各網頁的 喜好進行評分,最後再依據統計的結果進行推薦。. 2.1.3 Page Rank 演算法. 10.
(19) 由 Google 創始人 Brin 和 Page (1998)所提出的 Page Rank[11]便是其中最為著名的一個評 分演算法,此方法將查詢結果依據實用性作為排名的一個主要因素,用以表現網頁的相 關性與重要性。Page Rank 演算法中具有兩個特性: . 頁面連結越多代表此網頁越重要:利用網頁間連結的特性,每一個頁面的連結 都代表使用者對於此頁面投一認同票,因此連結越多代表此頁面重要性越高。. . 如果此網頁被重要的網頁連結時,則此網頁也是很重要的網頁。. 此研究利用投票方式取代傳統以資料出現頻率判斷項目的好壞,以往在判斷推薦項 目的適合程度時,都只利用『點選的次數』作分析,這樣的方式卻很容易造成只以『點』 的方式判斷推薦項目的好壞。而在 OLAP 系統上的操作與網頁上的瀏覽行為相似,都存. 政 治 大. 在以 Session 為導向[10]的特性(Newman, 2006);因此我們在設計 OLAP 推薦輔助機制上. 立. 亦可參考 Page Rank 演算法中的兩個特性,可以透過鏈結關係進行認同投票,將同情境. ‧ 國. 學. 下操作人次最多的項目視為最適合推薦的標的,此外我們亦會依據每個人的老手程度, 對使用者的認同票進行加權,用以取代以往一人一票的方式。. ‧ sit. y. Nat. 2.2 社會網絡分析. er. io. 社會網絡分析(Social Network Analysis,SNA)的研究,主要是在探討人與人之間互動關. al. v i n Ch 產生的影響,以及關聯間存在的『潛在結構』[3](Latent e n g c h i U Structure)。在社會網絡中,主 n. 係(Newman, 2003; Wasserman & Faust, 1994) [15][16]所建立的社會結構對於特定個體所. 要是由『節點(Node)』、『關聯紐帶(Relation)』、『連結(Link)』三個要素組成。 . 節點:亦稱為社會個體(Social Entities),它是社會網絡中的最小單位,例如: 個人、部門、公司、國家..等;而節點在不同的關係型態下,可以同時屬於不 同的網絡。在本研究中,我們會將在 OLAP 系統上的每一個使用者視為此網絡 中的節點。. . 連結:亦稱為社會整合程度,說明的是社會個體與網絡關聯的互動程度與類型, 通常包含關係的強度、方向等。在本次研究中,我們會利用推薦採納的結果來 建立使用者間的連結,當今日使用者 A 接受我們的推薦項目時,我們會針對在 候選項目篩選時關聯的使用者與使用者 A 間建立一個正向的連結,反之我們也 會建立一個表示為此使用者參考這些使用者的一個反向連結。 11.
(20) . 關聯紐帶:社會個體間因為某種連結而產生的互動,並且因同質性的特徵造成 影響;而同質性一般可從內容來定義。例如:因在同一個部門一起工作所構成 的同事關係與常見因血緣或是婚姻所造成的情感關係。在本次的研究中,我們 將會利用資訊需求的相似程度建立起一個虛擬部門的關聯。. 在社會網絡中,我們通常會用密度(Density)來描述網絡中節點彼此之間的互動狀況。在 W.D. Nooy (2005)的凝聚子群分析研究[16]中,密度越高的群體代表節點關係越密切,也 表示著此子群內的節點因為某種的關聯而形成一個社群。對於社群的詮釋,可能會因不 同研究目的而有所不同。參考 M. E. J. Newman (2006)提出的研究[18],我們認為在 OLAP. 政 治 大. 系統上操作行為相仿者,他們在實際的企業組織屬同一部門的機率比較大,相對其操作. 立. 對於推薦上的幫助比較有效益,因此在本次的實驗上我們會將行為相似的人歸屬於同一. ‧ 國. 學. 社群。在大部分社群網絡的研究中[4],都會利用網絡中心性[2](Brass & Burkhardt, 1992) 來判斷節點在『潛在結構』的網絡重要性,節點在群組中的中心性越高相對代表具有越. ‧. 高的影響力。Freeman(1979)的研究[1]則指出代表中心性概念的三種形式為程度中心性、. Nat. sit. y. 中介中心性及接近中心性。程度的中心性主要是在觀察網絡中節點間活絡的程度,存在. n. al. er. io. 越多關聯的節點表示其非正式權力與影響力相對也高;接近中心性主是要衡量出社會網. i n U. v. 路的全域中心性,並藉此判斷此節點與其他節點的接近程度,與其他節點的總距離越短. Ch. engchi. 表示此節點的接近中心性愈高;在中介中心性中,主要是在觀察節點間的關聯間是否都 存在以某個節點作為中介的橋樑,該節點在社會網絡中通常扮演著資訊串聯的角色,掌 握著資訊流通的關鍵位置。在後續的研究中,我們將會利用社會網絡分析的分支度 (Degree)中心性,利用操作紀錄被其他人參考的次數來找出哪些人在多維度分析平台中 屬於老手,並且在進行推薦的時候進行關聯加權。. 12.
(21) 第三章. 研究方法. 本章為問題定義與研究方法的說明,一共分為三節。第一節,將會就在此次研究過程中 所提出的假設作說明;第二節,將會對本研究所提出的推薦系統架構作介紹;第三節與 第四節,我們將會針對此次研究過程來源資料的收集與預處理作說明。後續我們會將正 規化後的資料做為後續社群網絡分析與操作推薦機制使用,最後,我們會在第六章中對 提供的推薦系統進行實驗分析與驗證。. 立. 3.1 研究假設. 政 治 大. ‧ 國. 學. 首先,本研究將先針對多維度分析系統之特性進行說明,以作為本研究所提操作推薦機 制之前提,而本研究在建立線上分析操作推薦模型時,也將以下列假設作為模型資料建. y. Nat. 操作的順序不影響推薦的結果:在 OLAP 系統上的操作,雖然每筆記錄都是一個有. sit. 1.. ‧. 立的基礎。. n. al. er. io. 順序性的結果,但在本次研究中在進行相似度的判斷時將會忽略此順序性。因為在. i n U. v. OLAP 的系統中,他對於『維度-性別』 、 『維度-年齡』 、 『量值-平均消費金額』三物. Ch. engchi. 件進行下列的操作都可取得各年齡層的男女消費能力的分析的結果:. 2.. . 選擇『維度-性別』、選擇『維度-年齡』、最後選擇『量值-平均消費金額』. . 選擇『維度-年齡』、選擇『維度-性別』、最後選擇『量值-平均消費金額』. . 選擇『量值-平均消費金額』、選擇『維度-年齡』、最後選擇『維度-性別』. . 選擇『維度-性別』、選擇『量值-平均消費金額』、最後選擇『維度-年齡』. 在線上分析系統上的使用者是有老手與生手之分:在線上分析系統的使用者中,我 們認為同領域的族群所作的操作紀錄,應該要比不同族群所作的操作在進行推薦時 候來的重要。而在相同的族群內又區分為老手與生手,通常在一個族群中老手的比 率是比較低的,但是其操作紀錄對於推薦機制上的影響比重卻應該比生手來的更重. 13.
(22) 要,此因素更應該被凸顯於推薦的結果上。. 3.2 系統架構 本研究根據多維度分析系統使用者的操作行為,提出一套基於查詢相似度判斷與使用者 關聯度判斷為基礎的 OLAP 系統推薦機制。圖 3-1 為本次研究的個人化多維度分析平台 推薦的模型架構,此一模型可視為使用者在前端操作介面與資料庫資料中的一個中間層 (Middleware)。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3-1、系統架構圖 系統在使用者對多維度分析系統進行操作的過程中,主動記錄使用者的所有查詢紀錄, 並且解析個別的查詢描述式用以進行正規化,並且將結果保存於操作紀錄的資料庫中; 系統依據記錄下來的資料,經由相似性與使用者分群與老手程度的判斷,最後將推薦的 項目以清單的方式提供使用者作為參考。使用者在取得推薦項目清單後,將會對提供的 項目進行系統反饋,用以提供系統進行人員關聯強度的學習,提升後續的推薦準確率。 在本章節我們將說明在研究中如何收集分使用者的操作紀錄,並且將每筆記錄依據特定 14.
(23) 模式正規化成可用於分析的查詢物件集合。在第四章,我們將依據整理出來的集合作社 群網絡的分析,將使用者依據業務的同質性作分群,並且利用中心性作為每個使用者在 個別社群中的老手程度進行判斷。最後在第五章,我們將會把利用正規化的結果進行相 似度的判斷找出推薦的候選項目,並且利用設計的推薦機制進行各候選項目推薦適合度 的判斷。. 3.3 使用者操作紀錄收集. 政 治 大 方案進行使用者行為分析。在多維度分析的系統上,使用者操作的是如圖 3-2 所示的視 立. 本研究是以建置於微軟的 Microsoft SQL Server 2008 Analysis Services 服務上的商務智慧. ‧. ‧ 國. 學. 覺化介面。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3-2、多維度分析平台操作介面 使用者在多維度分析系統上的所有操作,系統都會轉換成一筆可用於 Cube 上作查詢的 MDX 語句。MDX(Multidimensional Expressions),是一種對於 OLAP 系統中建立的分析 模型進行查詢的語法。它的結構類似我們在一般關聯式資料查詢資料時所使用 T-SQL, 但是不同的地方是 T-SQL 對資料的操作是一種只包含行列的二維查詢,但是 MDX 則是 利用切片(Slicing)方式對資料做操作。因此在研究過程中我們將會保存每筆操作紀錄的 MDX 查詢語句,以做為分析過程中所需的大量實驗數據。在操作紀錄的收集上,本研 15.
(24) 究將利用 Microsoft SQL Server 2008 所提供的 Profiler 功能,記錄每筆使用者在於多維度 分析平台上所進行的查詢內容。表 3-1 的資料就是我們所記錄下來的所有使用者在多維 度分析系統上所做的操作紀錄,後續我們將會藉由內容的觀察,將每筆資料解析為可做 為分析使用的資料。 表 3-1、使用者於多維度分析系統的操作紀錄範例. 政 治 大. 立. ‧. ‧ 國. 學 sit. y. Nat. io. er. 3.4 多維度操作紀錄正規化. 經由 Profiler 所記錄下來的操作都是一連串複雜的 MDX 語法,無法運用在研究中進行. n. al. Ch. i n U. v. 相似度的判斷。因此在本研究中,參考 Carsten Sapi [9]的作法,將每筆操作記錄的正規. engchi. 化成一個可運用的項目集合。在本研究中,我們藉由觀察資料庫內的資料屬性,撰寫一 隻適當的解析程式來剖析每筆操作結果,將每次的操作紀錄拆分為四個部分:Cube 名 稱、維度-報表 、維度-過濾條件與量值四個部分,最後再經由簡化的方式將每筆的操作 紀錄正規化為一個有限的維度集合(={df,..dr, M})。在此表示式中我們把量值也視為一個 特殊的維度。下面是一個 MDX 範例,在後續我們將會依據正規化的方式將此查詢 MDX 進行拆解:. 16.
(25) 1.. 步驟一:分析此次操作的 Cube:由於多維度分析有一個特性,他一次只能對單一 的 Cube 操作,而不像是一般的 SQL 的語法可以利用 JOIN 的方法串連多個資料表 作查詢,因此我們只要利用 FROM 字串協助定位出此次操作 CUBE 的位置,然後 我們可以利用 [ 與 ] 作為識別 CUBE 字串的起始與結束座標點。因此在此範例中, 首先我們知道 FROM 的位置是第 95 個字元,那我們將找到的位置加上 FROM 字 串的長度 5 後,第 100 個字元就是 CUBE 字串的起始位置,另外我們再從 100 作為 起始點找出最接近的 ] 的位置視為結束點(107),由此兩點的定位我們就可以很明 確取得此次操作的 CUBE 名稱為[卡友消費分析]。. 2.. 步驟二:分析此次操作的量值:觀察多維度分析操作的記錄中,我們發現量值一定. 政 治 大. 是以 Measure 為開頭的字串,因此我們可以利用[Measures].找出每個量值的起始位. 立. 置,接下來我們可以利用 ] 找出各量值得結束位置,以此範例來說[消費人數]的起. ‧ 國. 3.. 學. 始位置為 20 與 25。. 步驟三:分析此次操作的過濾維度:在多維度分析系統的查詢語句中,過濾的條件. ‧. 式與 T-SQL 相似,會出現於 WHERE 的描述式中,但是它是對維度以 SLICE 方式 進行查詢過濾。因此在解析的過程中,我們將會利用 WHERE 字串協助定位出過濾. y. Nat. sit. 維度的起始位置,接下來我們可以利用維度的形式 [Dimsnsion].[Level].&[Member]. n. al. er. io. 的特性,利用 [ 、.&[ 與 ] 等字串的位置找出每個過濾維度的起始與結束的位置。. i n U. v. 以此範例為例,我們利用 WHERE 與 [ 可以找出過濾維度([特約商].[主產業. Ch. engchi. 別].&[TT])的起始位置為 119,然後我們可以利用&[與最靠近的] 找出結束點位置為 136,因此我們就可以取得此次操作的過濾維度為[特約商].[主產業別].&[TT]。 4.. 步驟四:分析此次操作的 報表維度:在多維度分析系統中,報表維度通常是以下 列兩種形式出現 . [Dimsnsion].[Level].&[Member]. . [Dimsnsion].[Level].[(All)].ALLMEMBERS. 且報表維度也一定會出現於 WHERE 前面,因此我們可以利用此兩個特徵,分析得 到此操作中的報表維度為[清算日].[清算日 年].&[2008 年]與[清算日].[清算日 年].&[2008 年]。 5.. 經過系統的解析後將會拆分為下列四類型的物件 . Cube 名稱:[卡友消費分析] 17.
(26) . . 報表維度名稱: . [清算日].[清算日 年].&[2008 年]. . [清算日].[清算日 年].&[2009 年]. 過濾維度名稱 . . [特約商].[主產業別].&[TT]. 量值名稱:[消費人數]. 但是在推薦機制的相似度判斷中,所有的操作內容都是百分之百相同的情況是非常的低 的。因此系統將會再進一步的此結果進行簡化,我們將維度中特定成員(member)的資訊 給刪除後,做為正規化後的最小單位,並且將每個查詢式以下列表示式呈現. 政 治 大. Þ = ( Cube , Ds = {s1,…,si} , Dr = {r1,…,rj} , Mm = {m1,…,mk}). 立. Ds 表示此次操作所包含的過濾維度集合. ‧ 國. Mm 表示此次操作所包含的量值集合. 學. Dr 表示此次操作所包含的報表維度集合. ‧. 因此此次的解析結果正規化後將如下 Cube 名稱:[卡友消費分析]. . 報表維度名稱:[清算日].[清算日 年]. . 過濾維度名稱:[特約商].[主產業別]. . 量值名稱:[消費人數]. n. Ch. engchi. sit er. io. al. y. Nat. . i n U. v. Þ = ([卡友消費分析],{ [清算日].[清算日 年]},{[特約商].[主產業別]},{[消費人數]}),這樣 的項目集合也將會作為後續相似度判斷計算時所使用。. 18.
(27) 第四章. 社群網絡分析. 在使用商業智慧平台的社會網絡中,使用者就是此社會網絡中的節點,而網絡中各種關 聯所建立出來的連結將會影響到推薦的方式與準確性。在商業智慧平台系統中,相同部 門的使用者存在相同的背景與資訊需求,產生的推薦項目也相對較能符合期望。在本研 究中,為了增加此因素在於 OLAP 推薦機制的通用性,我們依據推薦反饋所建立的連結 作為網絡中的聯結,建立取代原本組織關係的虛擬人際關係。圖 4-1 即是我們依據此連 結關聯所產生的社會網絡圖形。在此圖中連結上的數字表示的是兩節點之間的關聯程度,. 政 治 大. 程度越高的表示的是兩者之間的同質性越高,其屬於相同部門的可能性越高。. 立. ‧ 國. 學. 30. 使用者A. 使用者C. n. al. 8. 使用者I. 50. sit. 40. y. 80. er. io 20. 使用者H. ‧. Nat. 使用者B. 80. 70. 90. 使用者D. Ch. engchi U. 使用者E. 50. v ni. 60. 使用者G. 使用者F. 圖 4-1、社會網絡圖形. 4.1 凝聚子群 表 4-1 中,我們對每個使用者依據在集團中相對應的實際組織單位進行編碼,例如 EC 開頭的表示為電子商務部門;然後我們從錄製的資料中找出兩千筆資料,逐筆拿出來跟 另外的一萬四千筆操作紀錄作比較,當有完全相似操作的人時,系統會自動將兩個使用. 19.
(28) 間增加一條連結,而所有人之間建立的連結結果統計於關聯分佈矩陣表上,我們可發現 在相同部門的使用者之間,於推薦上的採納程度會比不同部門間的推薦高。 表 4-1、虛擬關聯分佈矩陣. 政 治 大. 立. 在本研究中,我們利用 UCINET 對系統使用者進行虛擬組織的分群,並且在社群中找出. ‧ 國. . 學. 相對的老手。本研究執行的步驟如下:. 計算網絡中最適合的社群數:依據 Newsman and Girvan 的方法,計算在符合最. ‧. 小連結數(Ties)情況下各社群數的 Modularity Q 值,找出 Modularity Q 最大的 做為最適合的分割社群數。. y. Nat. 社群切割(Subgroups):我們依據 Girvan and Newsman 演算法,利用邊中性的結. sit. . al. n. . er. io. 果區分出 N 個社群。. i n U. v. 識別社群中的老手:依據中心性的分析結果,我們採用分支度中心度〈In-degree〉. Ch. engchi. 來判斷各節點在於社群中相對的重要性與影響力。 上述步驟的進一步說明如下:. 4.1.1 Modularity Q 的計算 Newman and Girvan(2006)提出來的模組性(Modularity)[2318]是社群網絡中用來表達的 一種結構特徵,可用來衡量網路結構品質的一個指標。其核心概念為社群內的包含大量 的關係連結,而在社群間存在少數的連結。因此假設一個社群模組性(Modularity)越高表 示社群內的節點存在高關係強度,相對是好的分割。Modularity Q 的基本定義如下: . 今日有一個 n 個節點的社會網絡, 如果節點. 與節點. 表示的是此相鄰矩陣內的元素,. 之間有連結,且節點. ;其他 20. 不為節點.
(29) . 在社群網路分群過程中,各個節點都有一個所屬的社群,我們以 、. 分別表. 示節點 v 與節點 w 所屬的社群,因此兩個有連結的節點會落在同一個社群的機 率如下: 其中 . 其他. 假設我們以 m 表示網絡中所有關聯的個數,則 m=. 。因此我們可以. 將原本的公式調整如下 δ. 政 治 大 假設 表示為節點 v 的分支度(Degree)中心性,也就是說節點 v 有 立 個連結。假設網絡是隨機的情況下節點 v 與節點 w 的在同一個網絡的機率為 ,因此在隨機網絡中的 Modularity 為:. ‧. δ. 通常我們會將分割社群的 Modularity 與隨機網絡的 Modularity 比較,判斷在此. y. Nat. . 學. ‧ 國. . δ. iv. n. al. er. io. sit. 社群組合下結構特性的程度。因此我們將原本 Modularity 的定義調整後如下: (1). n U engchi 如果 Q 為 0 的時候,表示社群內的關聯數與隨機網絡一樣,相對的其結構特性不強。根. Ch. 據下列的計算結果,我們可以發現在此網絡中最適合組織社群叢集數目為 3。 Partition w/ 3 clusters: Q = 0.216 Partition w/ 4 clusters: Q = 0.202 Partition w/ 8 clusters: Q = 0.099 Partition w/ 9 clusters: Q = 0.066. 21.
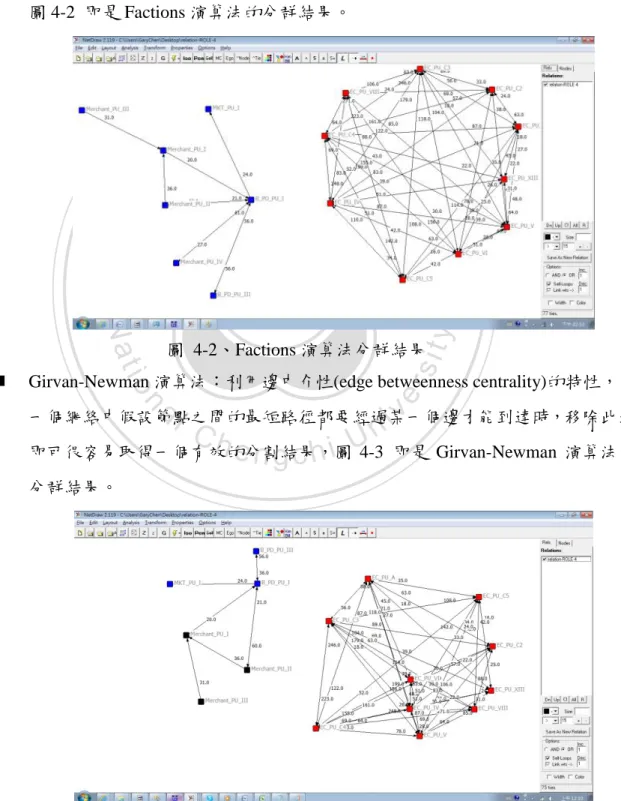
(30) 4.1.2 社群切割(Subgroups) 在此研究中,我們對 UCINET 提供的子群分割演算法 Factions 與 Girvan-Newman 演算 法的作比較: . Factions 演算法:是使用 Tabu 搜尋方法進行社群的辨識,所依循的原則是尋 求集合內各個行動者之截面(profile)的最小「組內平方差和」 (Moody,2001 ), 圖 4-2 即是 Factions 演算法的分群結果。. 立. 政 治 大. y. ‧. ‧ 國. 學 sit. Nat. n. al. er. Girvan-Newman 演算法:利用邊中介性(edge betweenness centrality)的特性,在. io. . 圖 4-2、Factions 演算法分群結果. i n U. v. 一個網絡中假設節點之間的最短路徑都要經過某一個邊才能到達時,移除此邊. Ch. engchi. 即可很容易取得一個有效的分割結果,圖 4-3 即是 Girvan-Newman 演算法的 分群結果。. 22.
(31) 圖 4-3、Girvan-Newman 演算法分群結果 由結果的比較,我們可以發現利用 Factions 作組織社群的分派上,只能夠有效的識別電 子商務與實體通路的這種比較大分類的使用者類型,但是 Girvan-Newman 演算法中,我 們在實體通路上,進一步能有效區分特約商管理部門與經營管理部門的使用者,因此在 此次研究,我們將會利用 Girvan-Newman 演算法作為分群依據。 下列是邊 e 中介性的計算公式: ;. (2). σst(e)表示的網絡中所有節點 s 到節點 t 的最短路徑中,經過邊 e 的加總個數,因此計算 過程中,. ;. (3). 學. ‧ 國. 立. 政 治 大. :表示節點 到節點 的最短路長度. :表示節點. ‧. :表示節點 到節點 的最短路長度 到節點 的最短路長度. Nat. sit. y. :表示節點 到節點 的最短路徑數. n. al. er. io. :表示節點 到節點 的最短路徑數. Ch. 因此在分群的過程中,將依據下列的步驟進行:. engchi. i n U. v. 1.. 步驟一:計算網絡 G 中所有邊的中介性. 2.. 步驟二:移除中介性最高的邊,將網絡 G 拆分為 與. 3.. 步驟三:重複步驟 1 與步驟 2,值到滿足 Modularuty Q 計算出的最適合社群數. 4.2 老手程度的判斷 在商業智慧平台的使用上,有一些人在部門中相對重要且具影響力,通常這樣的人 都是部門中對於系統使用比較久且比較了解系統功能的人。因此這樣的人在於推薦的判 斷上,其操作相對於部門內新人應該來的更重要。而在網絡中通常我們都利用分支度 (Degree)中心性、緊密度(Closeness)中心性、中介(Betweenness)中心性三種指標來評估一. 23.
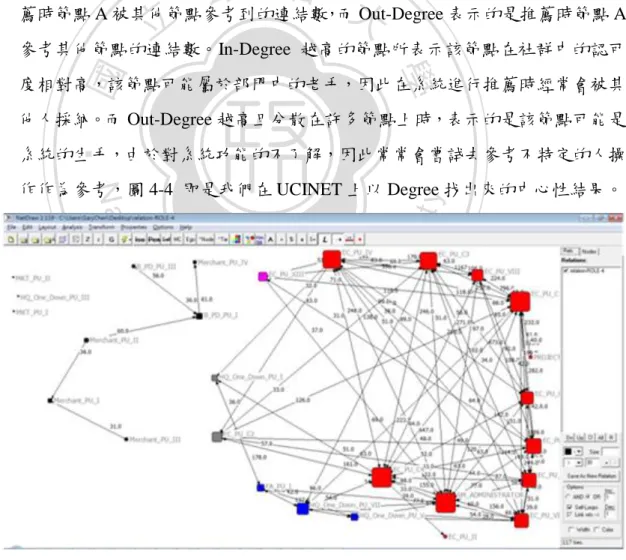
(32) 個節點的重要性。 . 分支度(Degree)中心性:主要是利用每個節點的連結數目作為中心性的判斷, 假設有一個節點與其他節點的連結越多的時候,表示該節點在網絡中相對於其 他節點更為活絡,相對其擁有較高的中心性。假設一個社會網絡的節點個數為 N 時,我們計算節點 v 分支中心性的公式如下: ,. (4). 節點 與節點 之間有連結 節點 與節點 之間無連結 Degree 可依據連結的方向分為 In-Degree 與 Out-Degree,In-Degree 代表的是推. 治 政 薦時節點 A 被其他節點參考到的連結數,而大 Out-Degree 表示的是推薦時節點 A 立 參考其他節點的連結數。In-Degree 越高的節點所表示該節點在社群中的認可 ‧ 國. 學. 度相對高,該節點可能屬於部門中的老手,因此在系統進行推薦時經常會被其 他人採納。而 Out-Degree 越高且分散在許多節點上時,表示的是該節點可能是. ‧. 系統的生手,由於對系統功能的不了解,因此常常會嘗試去參考不特定的人操. n. al. er. io. sit. y. Nat. 作作為參考,圖 4-4 即是我們在 UCINET 上以 Degree 找出來的中心性結果。. Ch. engchi. i n U. v. 圖 4-4、Degree 的 Centrality measures 結果 . 緊密度(Closeness)中心性:Closeness 著重的是該節點與其他節點的靠近程度,. 24.
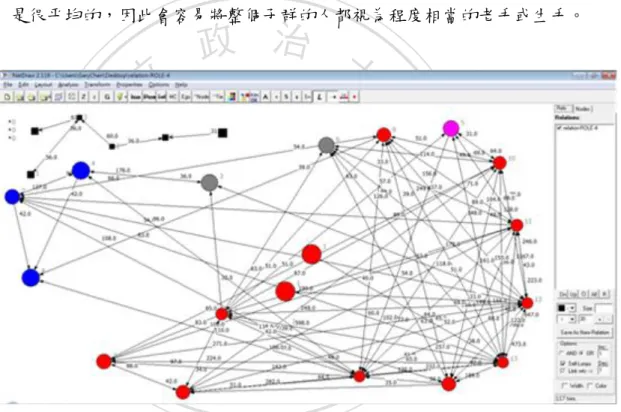
(33) 值介於 0 到 1 之間,值越高表示該節點與越容易到達其他節點,相對表示此節 點與其他節點之間的密度高。我們在計算節點 v 的緊密度中心性公式如下: ,. (5). :表示節點 與節點 最短路徑之連結數 圖 4-5 是我們在 UCINET 上以 Degree 找出來的中心性結果,在結果中發現此 指標雖然能區分出哪些人可能會是老手,但是在老手之間的程度卻無法有效的 區分出來。尤其當子群內的節點數比較少的時候,彼此間互動所建立的連結數 是很平均的,因此會容易將整個子群的人都視為程度相當的老手或生手。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4-5、Closeness 的 Centrality measures 結果 . 中介(Betweenness)中心性:在網絡中任兩個節點間一定存在一個最短路徑 (geodesics),假設一個節點經常在最短路徑上面表示越多節點需要經由他才能 到 達 其他 節點 。通 常這 樣 的節 點扮 演的 是橋 樑 的角 色, 其 In-Degree 與 Out-Degree 的值會很平均。計算節點 v 的中介中心性公式如下: (6) :表示任兩個節點間的最短路徑中經過 的次數. 25.
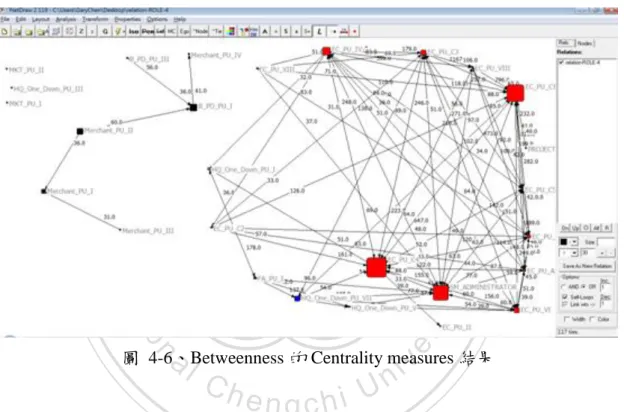
(34) :表示任兩個節點的最短路徑的數量 :表示網絡中節點的個數. 圖 4-6 是我們在 UCINET 上以 Betweenness 找出來的中心性結果。在商業智慧 平台上,老手通常對於系統的操作與功能上都很了解,相對 Out-Degree 的數值 通常都會偏低。如果採用此指標通常會讓老手的中心性降低,因此在此研究中 將不考慮此指標。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. v. 圖 4-6、Betweenness 的 Centrality measures 結果. Ch. engchi. i n U. 最後我們將三種中心性的結果與利用同部門使用者互評的結果比對後,發現 In-degree 的結果是最符合我們在商業智慧平台上做為老手程度判斷的指標,他在每個子群中可以 有效的識別使用者對於系統的熟悉度。因此在後續的推薦機制上我們將會以此方式作為 投票加權的判斷。. 26.
(35) 第五章. 推薦機制. 在第三章,我們將蒐集回來的資料正規化處理整理成可供分析用的集合,在本章我們將 會藉由相似度的判斷與推薦機制設計提供使用者在系統操作過程所需的建議。多維度分 析系統上的推薦機制通常分為兩種類型:內容相似度推薦與同好推薦。我們將同時考慮 內容過濾與協同過濾兩種技術,提供混合式的推薦機制。在內容過濾方面,我們將會利 用相似度的判斷縮小候選項目的範圍,後續我們將會依據支持度(Support)與最大使用人. 政 治 大 的結果反應至兩個推薦機制上。而在第六章中,我們也將會以兩個推薦機制的結果進行 立 次選擇兩種推薦機制挑選出機率越高的項目作為推薦;最後我們也將會把社群網絡分析. ‧. ‧ 國. 學. 比較。. 5.1 相似度判斷. y. Nat. sit. 如果我們每次在作推薦時,都把所有的操作紀錄都納入考慮時,將可能因為資料量大造. n. al. er. io. 成系統的效能不彰。因此在資料的過濾上,我們會將正規化後的操作項目集合,利用相. i n U. v. 似度的計算公式,取出與此次操作相同且操作項目數大於此次操作的資料作為推薦用的. Ch. engchi. 候選集合。由於相似度主要是利用涵蓋度(inclusion ratio)的概念作判斷,依據 MDX 查詢語句 與 在於 Cube、維度與量值上差異作為相似度的判斷,因此計算出來的相 似度是不可逆的。舉例來說當查詢 是查詢 的子集合時,查詢 相對於查詢 是完全 相似的,但是查詢 相對於查詢 是部分相似的。Cube 操作的差異(. :在多維度分. 析平台上我們一次只能對一個 Cube 進行資料的操作,因此假設使用者存取的目標 Cube 不同時,此兩筆的操作是無相關的,因此操作的 Cube 是否相同是決定兩個查詢是否相 似的最大要素。 與 操作相同的 與 操作不同的. 27.
(36) 查詢 相對於查詢. 在於操作內容的涵蓋率判斷上,會先計算查詢. 目個數做為分母;分子部分我將依據兩查詢在過濾維度( 三個部分的操作相同個數,因此假設查詢 包含查詢. 中包含的操作項. 、報表維度(. 與量值(. 中所有的操作項目時,我們會認. 為查詢 完全相似於查詢 。下列為系統用以判斷查詢 Þ 1 對於查詢 Þ 2 之間涵蓋率的 公式:. 表示的是兩個查詢在過濾維度(Ds)間的相同個數. 政 治 大 表示的是兩個查詢在報表維度(Ds)間的相同個數 立. ‧ 國. 學. 表示的是兩個查詢在量值的相同個數. ‧. 下列是我們利用三個正規化後查詢,計算相對於查詢(Þ 1)相似度的例子. Nat. y. [卡友消費分析] ,. sit. Þ1=(. io. al. n. { [產品別].[產品類別],[卡友維度].[年收入級距]}, {[消費人數]}) Þ2=(. Ch. [卡友消費分析] ,. engchi. er. {[清算日].[清算日 年],[供應商].[區域]},. i n U. v. {[清算日].[清算日 年] ,[供應商].[區域] ,[供應商].[區域]}, { [產品別].[產品類別],[卡友維度].[年收入級距]}, {[消費人數], [消費金額]}) Þ 2 相對於 Þ 1 的相似度計算如下: | Þ 2- Þ 1| = △Ct * (△Ds + △Dr + △Mm) =. 1* ( (2/5) + (2/5)+ (1/5)). =. 1. 百分之百相似. 28.
(37) Þ3=(. [供應商分析] , {[清算日].[清算日 年],[供應商].[區域]}, { [產品別].[產品類別] }, {[消費金額]}). Þ 3 相對於 Þ 1 的相似度計算如下: | Þ 3- Þ 1| = △Dc*(△Ds + △Dr + △Mm ) = 0*( 2/5+1/5+1/5) 相似度零. =0 Þ4=(. [卡友消費分析] ,. 政 治 大 { [產品別].[產品類別],[卡友維度].[年收入級距]}, 立 {[清算日].[清算日 年] },. ‧ 國. 學. {[消費人數]}, [消費金額]}) Þ 4 相對於 Þ 1 的相似度計算如下:. io. al. n 5.2 候選項目篩選. y. 相似度百分之八十. sit. 0.8. Nat. =. 1*( 1/5+2/5+1/5). er. =. ‧. | Þ 4- Þ 1| = △Dc+△Ds + △Dr + △Mm. Ch. engchi. i n U. v. 在進行完查詢相似度的判斷後,我們可以從歷史操作紀錄的資料庫中取得許多筆完全相 似的紀錄。在第三章中,我們認為順序在於 OLAP 系統上的操作是不會影響最後資訊取 得的結果,因此假設今日有一個操作的查詢包含 A、B 與 C 三個項目時,另外有一個操 作的查詢包含了 A、B、 C、D 與 E 五個項目時,我們會認為包含 A、B、 C 與 D 四個 項目的操作跟包含 A、B、 C 與 E 四個項目的操作都可能會是最適合推薦的下一步,也 因此我們會認為項目 D 與項目 E 會是此次推薦的候選項目。因此在實做上,我們會將 所有符合的操作項目集合作聯集,並且扣除此次的操作項目後,產生推薦的項目的候選 清單。下面是一個候選項目清單的產生範例。假設使用者有一個 q1= ( [卡友消費分析] ,. 29.
(38) {[清算日].[清算日 年],[供應商].[區域]},{ [產品別].[產品類別],[卡友維度].[年收入級 距]},{[消費人數]}),假設在歷史資料庫中相對於 q1 完全相似的操作紀錄有下列三筆: =(. [卡友消費分析] ,. {[清算日].[清算日 年] ,[供應商].[區域] ,[卡友維度].[教育程度] , [卡片維度].[發卡來源] [卡友維度].[年齡級距] }, { [產品別].[產品類別],[卡友維度].[年收入級距]}, {[消費人數]}). 政 治 大 {[清算日].[清算日 年] ,[供應商].[區域] ,[卡友維度].[教育程度] , 立. =(. [卡友消費分析] ,. { [產品別].[產品類別],[卡友維度].[年收入級距] ,. ‧ 國. 學. [產品別].[產品金額級距]},. [卡友消費分析] ,. y. Nat. =(. ‧. {[消費人數]}). er. io. sit. {[清算日].[清算日 年] ,[供應商].[區域] ,[卡友維度].[教育程度] , [卡友維度].[教育程度]},. al. n. v i n Ch { [產品別].[產品類別],[卡友維度].[年收入級距]}, engchi U. {[消費人數], [消費金額], [消費次數]}) 聯集此三個查詢的項目集合為. = ( [卡友消費分析] , {[清算日].[清算日 年] ,[供應商].[區域] ,[卡友維度].[教育 程度] , [卡片維度].[發卡來源] ,[卡友維度].[年齡級距] , [產品別].[產品類別], [產品 別].[產品金額級距], [卡友維度].[年收入級距], [消費人數], [消費金額], [消費次數]}) 排除本次操作的項目後,即為本次推薦的所有候選項目。以上述例子中,下列項目[卡 友維度].[教育程度] , [卡片維度].[發卡來源] ,[卡友維度].[年齡級距], [產品別].[產品金額 級距], [消費金額], [消費次數] 都是後續可能的推薦項目。. 30.
(39) 但是在實際的商業運作上,找出來的可能候選項目的量可能是幾百幾千個,這樣反而會 造成使用者因自行過濾有效項目,而造成提供的建議內容無法達到預期的效果。為了解 決此問題,後續我們將對過濾出來的項目依據最大信心度與最大使用人次選擇兩種推薦 機制,對於每個項目計算一個分數,依據分數的高低決定哪些項目最適合作為推薦。. 5.3 推薦機制:最大信心度選擇 在 Agrawal 關聯法則[27]中,主要是用來找尋資料庫中資料之間的關係,依據最小支持. 政 治 大 率項目集合做為關聯的規則,而掃描的過程中將從兩個項目的集合開始,持續的找尋下 立. 度(Support)與最小信賴度(Confidence)的門檻,對資料進行掃描找出符合門檻限制的高頻. ‧ 國. 學. 一級的候選項目集合,直到不再出現新的候選項目集合為止。此推薦機制參考關聯法則 中的最大信心度選擇(Most-Confident Selection)觀念而來,主要是以”相同情境下各候選. ‧. 項目被操作過的次數”作為判斷依據,主要是找出使用頻率最高的操作項目作為推薦標. . 候選項目符合最小支持度(Minimum Support). al. er. 操作內容與本次操作內容百分之百相似的. io. . sit. y. Nat. 的。在此機制中,系統會統計符合下列兩個限制的資料筆數作為分母:. n. v i n Ch 接下來我們會逐一計算在在此次的操作內容前提下,各個候選項目出現的次數(Support) engchi U 作為分母,計算每個候選項目的適合推薦的分數。因此,當一個項目信心水準越高的情 況,表示此項目的使用頻率高,相對推薦成功的機率會比較高的。下列為最大信心度選 擇機制在計算候選項目 b 在操作項目集合為 A 時分數的公式:. (8) A:在此次操作項目的集合 b :候選推薦項目 :表示在包含 操作項目集合時,同時也操作過項目 :表示在包含 操作項目集合的操作次數. 31. 的次數.
(40) 5.4 推薦機制:最大使用人次選擇 在最大信心度選擇的推薦機制上,我們是利用每個項目的頻率做為推薦的判斷依據,但 當某個候選項目的操作頻率是很高不過卻是集中少數人的操作上時,此時推薦的成效是 非常不好。因此在最大使用者人次選擇的推薦機制上,我們會認為在推薦上同部門中存 在比較多的人對此候選項目的認同會比候選項目被操作的次數來的重要。此機制主要是 以”相同情境下各候選項目操作過的人次”作為判斷依據,找出最多人使用的操作項目 作為推薦標的。在此推薦方式中,系統會先統計所有候選項目曾經操作過的人數作為分. 政 治 大 項目曾經使用過的人數作為分子。因此,當一個項目使用過的人數越多的情況,表示此 立. 數計算時的分母,接下來系統會將之前所列出來的候選項目逐一去判斷,計算每個候選. ‧ 國. 學. 項目是越多人關注的,相對推薦成功機率會是比較高的。下列為最大使用人次選擇機制 在計算各候選項目分數時的公式:. ‧. n. Ch. engchi. sit. 的人次. er. io. al. y. Nat. A:在此次操作項目的集合 b :候選推薦項目 :操作過集合 與項目 :操作過集合 的人次. (9). i n U. v. 5.5 推薦機制與參考關聯加權 在上述兩種推薦機制中,我們認為每個人操作所佔的重要性是一樣的;但實際上,是否 相同部門與人員對於系統的熟悉程度都應該影響其在候選項目重要性的判斷。舉例來說, 有四個人甲、乙、丙、丁,甲是採購部門的新人,而丁是甲在採購部門的同事,乙與丙 是另外一個行銷單位的同事,採購單位會比較著重於銷售商品的成本,但是行銷單位會 著重於產品銷售的數量與金額。但由於行銷單位的同仁數相對於採購單位來的多,因此 資料庫的操作紀錄也會相對的多;而這樣的情況很容易造成推薦的結果錯誤。而相同的 在同部門中,通常會有部分的人對於系統的功能是比較了解的,因此該人員的操作紀錄 也應該提高其加權,讓他的操作能有效的反應至推薦結果上。因此,我們將會把凝聚子. 32.
(41) 群的社群結果與參考關係加權加入原有推薦機制,並且作了下列的改善: . 相同社群內的使用者,其操作紀錄在於候選項目判斷上才會有效。. . 使用者在該社群中分支度(In-Degree)越高,候選項目判斷上的加權越高。. 下列為各使用者加權係數的計算公式: 使用者 與推薦對象不屬於同一社群 (10). 其他. 因此,我們將兩個推薦機制做下列的調整: . 政 治 大. 推薦機制 最大信心度選擇調整後公式如下:. 立. (11). ‧ 國. ‧. er. io. sit. y. 推薦機制最大使用人次選擇調整後公式如下:. Nat. . 學. n:表示為曾經同時操作過項目集合 A 與候選項目 b 的使用者集合 :使用者 i 操作過項目集合 A 的次數 :使用者 i 同時操作過項目集合 A 與候選項目的次數 :使用者 i 的老手加權係數. (12). n:表示為曾經同時操作過項目集合 A 與候選項目 b 的使用者集合 :使用者 i 操作過項目集合 A 的加權人次 :使用者 i 同時操作過項目集合 A 與候選項目 b 的加權人次 :使用者 i 的老手加權係數. n. al. Ch. engchi. 33. i n U. v.
(42) 第六章. 系統實作與實驗. 本章節將簡略說明實作推薦機制之資料來源、開發環境及程式語言,在 6.2 節裡則概略 的介紹多維度分析推薦輔助系統的操作介面,並在 6.3 節我們會將收集的操作資料分成 十組進行推薦機制的驗證以及兩種推薦機制的實驗結果。最後在 6.4 節上,我們會將此 次設計的推薦輔助系統提供給實際的使用者作使用,藉由問卷與系統操作紀錄的分析來 驗證此推薦機制的效果,與收集使用者對於推薦系統的回饋,以做為後續研究使用。. 政 治 大 在多維度分析推薦輔助系統的實作上,所使用的程式語言為 Visual C#與 T-SQL,並使用 立 6.1 程式語言、資料來源. ‧ 國. 學. Visual Studio 2010 整合式開發環境 (Integrated Development Environment,IDE)與 SQL Server Management 作開發。開發與實驗的作業系統為 Windows 2003 R2 64 位元,CPU. ‧. 為 Intel® Core™ i3 CPU M 330 2.13GHz,記憶體為 8GB。. 在本次實驗中,我們將以某家已經導入多維度平台一年半的公司為研究對象。該公. y. Nat. sit. 司在導入商業智慧專案的初期,我們採用對部門種子員工進行需求訪談與後續小團體的. er. io. 教育訓練,並且經由半年的推廣後才能在實體通路經營部門達到預期的導入效益。在第. al. n. v i n Ch 用者的數量更多,第一階段的指導模式已經無法適用。在本研究中,我們收集此公司使 engchi U 二階段的導入目標為電子商務單位,由於建置的 Cube 所包含的維度更為複雜與系統使. 用者在商業智慧平台上五十六未使用者一個月的操作紀錄,以做為實驗分析的資料,範 圍包含電子商務、供應商管理與經營管理三個單位的所有操作,總計一萬八千六十九筆。 後續我們將會依據第三章的方法,將所有操作紀錄轉換成可分析的結果集合,以做為後 續實驗使用。在下一節我們將就多維度分析推薦輔助系統的幾個主要功能模組作說明。. 6.2 多維度分析推薦輔助系統功能模組說明 圖 6-1 為多維度分析推薦輔助系統的處理流程圖,此推薦輔助系統主要包含操作紀錄正 規化、操作相似度判斷、產生推薦候選項目集合、使用者分群、老手程度加權計算與推 薦項目產出六個功能模組,在後續章節中我們將會對每一個功能作詳細的說明。. 34.
(43) OLAP查詢. MDX. 正規化的操 作項目集合. 操作紀錄正規化. 操作相似度判斷. 完全相似的操作紀錄. 呈現於推薦 輔助系統. 最高分的五 個推薦項目. 老手程度加權 & 候選項目評分. 候選 項目集合. 產生推薦候選 項目集合. 使用者所屬之群集. 使用者分群. 學. 圖 6-1、多維度分析推薦輔助系統流程圖. ‧. ‧ 國. 立. 政 治 大. 6.2.1 操作紀錄正規化. y. Nat. sit. 圖 6-2 為此資料正規化處理的流程圖,對 SQL Server Profiler 所錄製的操作紀錄進行分. er. io. 析,將收集到的每一筆操作記錄,轉換成一組記錄著操作時間、操作使用者與操作項目. al. n. v i n Ch 轉換成過濾維度、報表維度與量值三種類型的項目集合。 engchi U. 的集合。分析的過程中,我們將會依據第三章的資料正規化的方式,將原始複雜的 MDX. 操作紀錄正規化. 查詢語句 MDX. 操作Cube解析. 維度-過濾 解析. 維度-報表 解析. 量值 解析. 正規後的操 作項目集合. 圖 6-2、操作紀錄正規化處理流程圖 根據分析得到的結果,我們可以了解此使用者目前的操作內容,用以跟歷史資料庫比較 用。表 6-1 是此功能模組的輸入與輸出的結果。. 表 6-1、操作紀錄分析與正規化的輸入與輸出 35.
數據

+2
相關文件
澳門整體的收入中位數由 2005 年至 2011 年都有著明顯的升幅(見圖十三及表五) , 當中博彩業的收入中位數在六年間的升幅達 50.02%,而在 2005 年和 2011 年均
第二十四條 學、術科測 試辦理單位應遴聘具有 下列資格之一者,擔任 學科測試及術科測試採 筆試非測驗題方式之監 場人員:. 一、
一、成績計算:以術科實作及面試之原始分數計算,術科實作成績佔 70%,面試成績佔 30% (術 科實作原始分數*70%+面試原始分數*30%,分數四捨五入至小數點第 2
是以法國物理學家 Augustin Fresnel 命名的。.
從幾何上看,一個在區間上的每一點都連續的函數,其函數 圖形沒有分斷。直觀上,這樣的連續圖形我們可以一筆劃完
2.核對該場地懸掛之評鑑合格崗位 數證明文件,如發現場地、崗位 數或崗位配置不符時,應立即反
0830-0930 第一順位 第二順位 第三順位 0940-1040 第四順位 第五順位 第六順位 1050-1150 第七順位 第八順位
學生已在 2000 年版小學數學課程學習單位 4N4「倍數和因數」中認識因
