國立臺中教育大學數學教育學系碩士班碩士論文
指導教授:楊晉民 教授
結合頻譜與空間訊息設計於
高光譜遙測影像辨識之數學模型研發
研究生:張超群 撰
中華民國一○四年 七月
謝誌
首先要向黃一泓老師與廖元勳老師致上深深地謝意,感謝兩位口試委員的蒞 臨指導;感謝指導教授楊晉民老師兩年來的耐心教導,讓我可以順利完成碩士學 位;並感謝在取得碩士學位的路上,一起努力、彼此互相鼓勵的蔡松佑學長;以 及感謝同樣身為研究生,一同在為各自未來生涯努力的莉淳、夢舲、芷芸、雅雯、 益誠、閔馨、佩菁、萌禪、子婕。 在此要特別感謝一些我在學業上、學術上、職場上、人生上的前輩們,從前 輩們的言行身教上,讓我看到許多也受益匪淺,感謝甯平獻老師讓我學會如何善 用自己的哲學思維能力,讓自己的學習能力能夠變得更靈活、更有效率;感謝蘇 伊文老師的親身示範,讓我從您身上學習如何樂觀地看待世事,也感謝老師在我 情緒緊張的時候,就像強心針般地給予諸多的關心、支持與鼓勵;感謝李政軒老 師在這一年半以來的照顧,您的認真教學讓我受益良多,也感謝您不斷地給予鼓 勵,還要感謝您不吝地給予諸多協助;感謝呂佾澄老師從高中以來的照顧,雖然 遺憾的是,未能當成您學士與碩士學位的學弟,但仍然感謝您一直以來的關注; 感謝董玥君老師在國中時的照顧,畢業前與您的一番對話,學生仍銘記在心;最 後,感謝施議竺大哥,除了跟著您學習處理資訊硬體設備之外,也從您身上學習 到了許多職場上的經驗,每每與您在聚餐時的討論,都能學習到一些不同的價值 觀,也感謝您從認識到現在,不斷地給予勉勵。 感謝小玉、郁婷、品儀、淳芝、柏佑、家亨,雖然大學畢業之後,大家是各 奔南北,但是再忙也要抽空跟你們吃頓飯,感謝有你們的陪伴;感謝明華、哲毓、 品柔、慧君,謝謝你們讓我總在壓力大到一個極致時,能夠有個抒發的窗口;感 謝老媽跟老姊讓我可以不用擔心家務事,而專注在完成自己的學業;最後要感謝 現在使用的這台筆記型電腦,以及上一台已經壞了的筆記型電腦,雖然已經有一 台已經處理資料處理到燒壞了,但要不是有這兩台筆記型電腦冒著燒壞的風險, 幫我處理龐大的研究資料,恐怕這本碩士學位論文也無法寫成。 一晃眼兩年就過了,原以為不會完成的碩士學位,也就這樣意外地完成了, 萬般感激一直陪在身旁不斷給予陪伴的你/妳們。 張超群 謹誌 2015 年 7 月I
結合頻譜與空間訊息設計於
高光譜遙測影像辨識之數學模型研發
摘要
隨著科技的進步,全球每日的數據資料產生量與日俱增,對於資料處理的技 術需求相對地也越來越高,資料處理技術的提升,可幫助人類進行半自動化,或 全自動化的資料處理,省去人工處理資訊所需的大量時間與人力成本,並進一步 提供進行決策時的重要依據,因此,資料處理技術的改善是影響決策效率與決策 準確的關鍵,而在機器學習領域中,則是以利用分類器協助使用者進行自動化辨 識的元件,節省人力與物力,降低成本。 在遙測領域,由於高光譜影像之地表真實資訊取得不易,且需耗費相當多的 人力與物力,若能以少量的訓練樣本來訓練分類器,使得分類器能在影像資料分 類的過程中節省人力、物力,則是一項重要的議題。在高光譜影像資料,對於每 一個樣本,由感測器測得的光譜資料,稱為樣本在頻譜域(spectral domain)的訊息, 在畫面上的像素座標位置,即為樣本在空間域(spatial domain)的訊息,而高光譜 影像資料在空間域中具有叢聚性,也就是在空間域所意涵的地理分布中,相同類 別且在空間上相近的樣本,在圖像呈現上會形成一大塊或數塊區域。由於樣本之 間的空間訊息本身具有獨立性,也就是樣本在空間域具有唯一可識別(identifiable) 的性質,近年發展利用此一特性進行研究,其結果顯示,結合使用樣本之頻譜與 空間訊息的性質,確實有助於高光譜影像辨識。因此,本研究結合高光譜影像的 頻譜與空間訊息,利用有別於過去對於空間訊息的使用方式,設計頻譜與空間距 離分類器(spectral and spatial distance classifier, SSDC),希望能以少量樣本訓練分 類器,便可獲致令人滿意的辨識正確率;另外,再以相同運用空間訊息的方式, 設計頻譜與空間特徵萃取法(spectral and spatial feature extraction, SSFE),期望能 降低資料維度,以減緩高維度現象對分類器之辨識正確率的影響,並提升分類器 之辨識正確率。 研究結果顯示,本研究提出的分類器 SSDC 能以少量樣本訓練,便能獲致令 人滿意的辨識正確率,而本研究提出的特徵萃取法 SSFE,也確實能減緩高維度 現象的影響,並有效地提升分類器之辨識正確率。 關鍵字:小樣本、分類器、空間訊息、特徵萃取、高光譜影像II
Mathematical Model Integrating Spectral and
Spatial Information for Remotely Sensed
Hyperspectral Image Classification
Abstract
Hyperspectral image data with hundreds of measured bands potentially provide more accurate and detailed spectral information for classification. However, hyperspectral image with pixel location can provide additional accurate and detailed spatial information for classification, due to the data points of each class tended to form a cluster by its spatial information. Therefore, hyperspectral remote sensing image classification integrating spectral and spatial information is a popular issue in recent years.
Hence, in this study, two methods utilizing both spectral and spatial information from data on hyperspectral image classification are proposed, particularly for small sample size problems. The first one combines the concept of regularization spectral and spatial distance as two weights to design a classifier, named spectral and spatial distance classifier (SSDC). The second one is a dimensionality reduction method to extract features by introducing spectral and spatial information into the design of scatter matrices, named spectral and spatial feature extraction (SSFE).
The experimental results show that the proposed classifier SSDC can achieve remarkable performance on hyperspectral image classification even in small sample size scenarios. Moreover the proposed feature extraction method SSFE can achieve better classification accuracy than some existing feature exctration algorithms for most of the classifiers. In summary, the results of this study provide more efficient ways to integrate spectral and spatial information for hyperspectral image classification.
Keywords: classifier, feature extraction, hyperspectral image, small sample size,
III
目錄
圖目錄 ... IV 表目錄 ...V 第一章 介紹 ... 1 第一節 緒論... 1 第二節 架構... 3 第二章 相關文獻 ... 5 第一節 高光譜遙測影像資料 ... 5 第二節 空間訊息的使用 ... 9 第三節 樣本情境與維度現象 ... 11 第四節 分類器 ... 13 第五節 特徵萃取法 ... 19 第三章 頻譜與空間距離分類器 ... 25 第一節 頻譜與空間距離分類器設計 ... 25 第二節 實驗設計 ... 27 第三節 實驗結果 ... 34 第四章 頻譜與空間特徵萃取法 ... 49 第一節 頻譜與空間特徵萃取演算法設計 ... 49 第二節 實驗設計 ... 52 第三節 實驗結果 ... 55 第五章 結論與建議 ... 71 第一節 結論... 71 第二節 建議... 72 參考文獻 ... 73IV
圖目錄
圖 1 多光譜影像與高光譜影像示意圖組 ... 1 圖 2 Indian Pines 高光譜影像圖 ... 6 圖 3 Salinas 高光譜影像圖 ... 7 圖 4 Pavia University 高光譜影像圖 ... 8 圖 5K £ K
K £ K
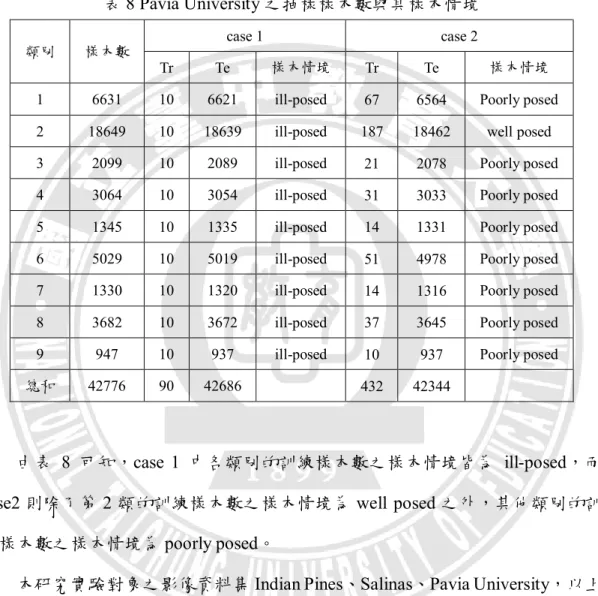
window 示意圖組 ... 10 圖 6 neighborhood system 示意圖組 ... 10 圖 7 Hughes phenomenon 示意圖 ... 12 圖 8 SVM 解最佳化邊界概念示意圖 ... 14 圖 9 ABC 運作流程圖 ... 17 圖 10 SSDC 使用頻譜與空間訊息方式之概念示意圖 ... 26 圖 11 分類器研究之實驗架構與流程 ... 28 圖 12 SSDC 之調配參數®
®
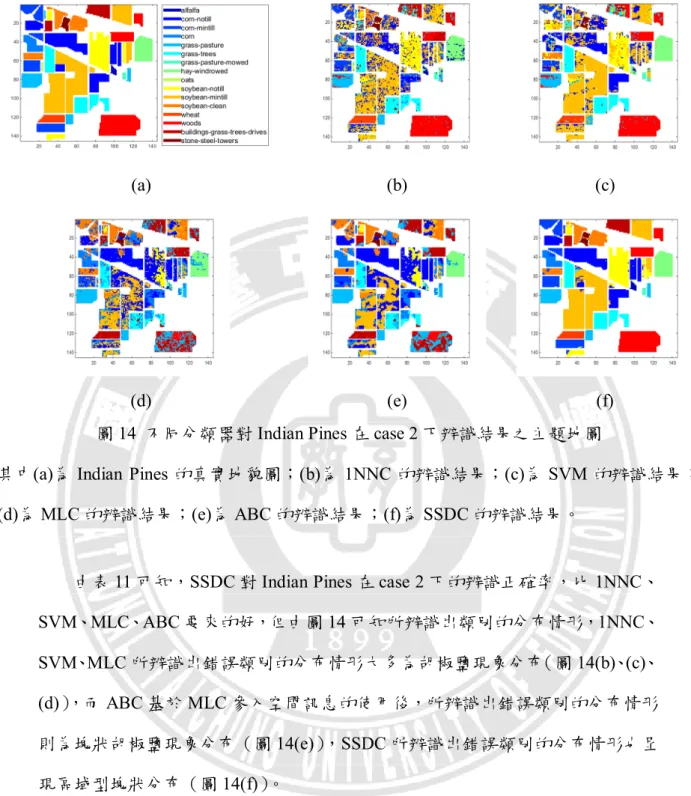
的變化對於抽樣資料集辨識結果之折線圖 ... 35圖 13 不同分類器對 Indian Pines 在 case 1 下辨識結果之主題地圖 ... 42
圖 14 不同分類器對 Indian Pines 在 case 2 下辨識結果之主題地圖 ... 43
圖 15 不同分類器對 Salinas 在 case 1 下辨識結果之主題地圖 ... 44
圖 16 不同分類器對 Salinas 在 case 2 下辨識結果之主題地圖 ... 45
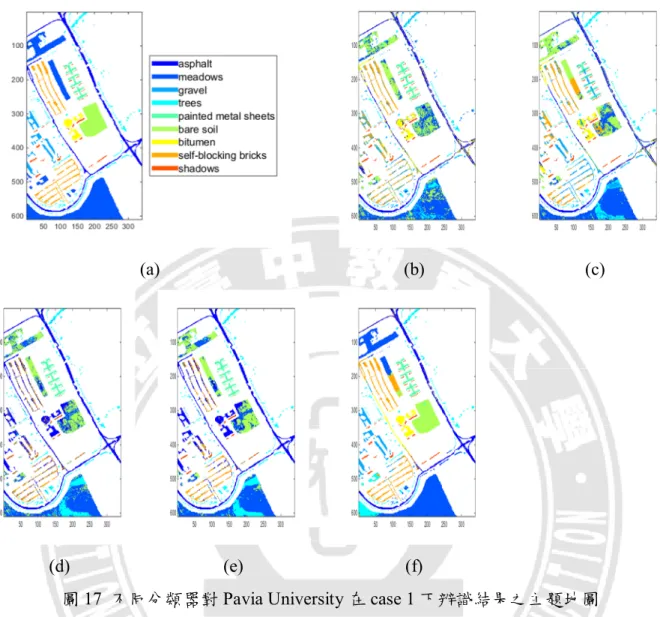
圖 17 不同分類器對 Pavia University 在 case 1 下辨識結果之主題地圖 ... 46
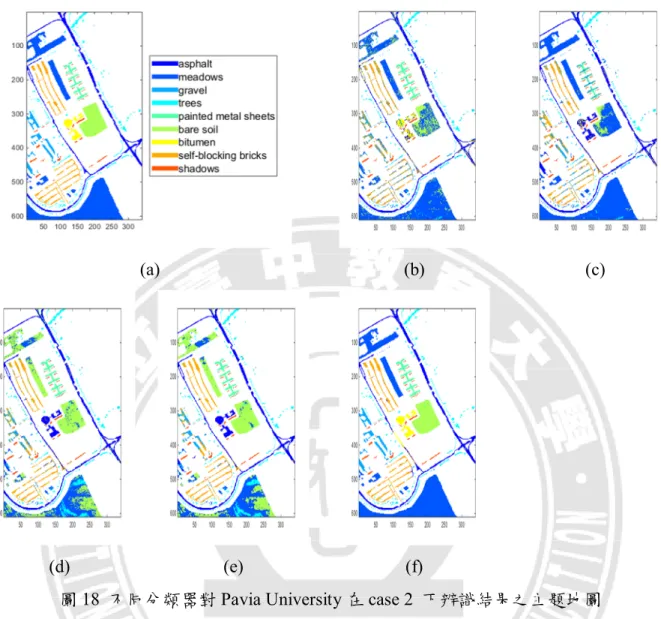
圖 18 不同分類器對 Pavia University 在 case 2 下辨識結果之主題地圖 ... 47
圖 19 SSFE 使用頻譜與空間訊息方式之概念示意圖 ... 50 圖 20 特徵萃取法研究之實驗架構與流程 ... 53 圖 21 不同特徵萃取法搭配 1NNC 對抽樣資料集降維後其辨識結果之線性圖 . 56 圖 22 不同特徵萃取法搭配 SVM 對抽樣資料集降維後其辨識結果之線性圖 ... 58 圖 23 不同特徵萃取法搭配 MLC 對抽樣資料集降維後其辨識結果之線性圖 ... 60 圖 24 不同特徵萃取法搭配 ABC 對抽樣資料集降維後其辨識結果之線性圖 ... 62 圖 25 不同特徵萃取法搭配 SSDC 對抽樣資料集降維後其辨識結果之線性圖 .. 64
V
表目錄
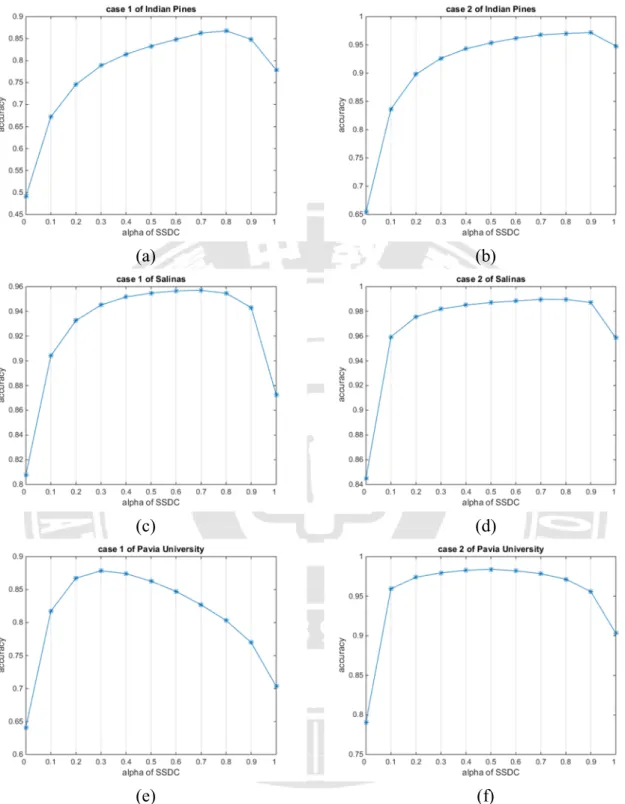
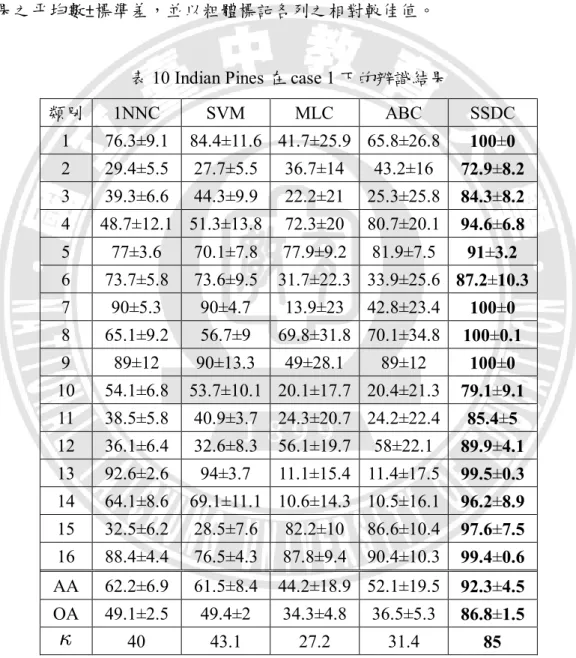
表 1 符號表... 3 表 2 Indian Pines 高光譜影像資料中各類別所含樣本數 ... 6 表 3 Salinas 高光譜影像資料中各類別所含樣本數 ... 8 表 4 Pavia University 高光譜影像資料中各類別所含樣本數 ... 9 表 5 SSDC 演算法 ... 27 表 6 Indian Pines 之抽樣樣本數與其樣本情境 ... 29 表 7 Salinas 之抽樣樣本數與其樣本情境 ... 30 表 8 Pavia University 之抽樣樣本數與其樣本情境 ... 31 表 9 混淆矩陣示意表 ... 32表 10 Indian Pines 在 case 1 下的辨識結果 ... 36
表 11 Indian Pines 在 case 2 下的辨識結果 ... 37
表 12 Salinas 在 case 1 下的辨識結果 ... 38
表 13 Salinas 在 case 2 下的辨識結果 ... 39
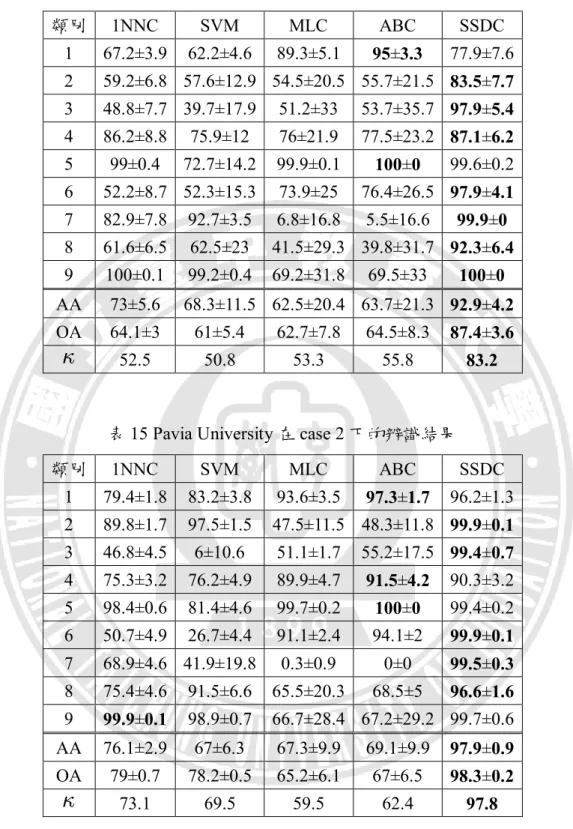
表 14 Pavia University 在 case 1 下的辨識結果 ... 40
表 15 Pavia University 在 case 2 下的辨識結果 ... 40
表 16 SSFE 演算法 ... 52
表 17 在 case 1 下對 Indian Pines 使用最佳維度數之辨識結果比較 ... 67
表 18 在 case 2 下對 Indian Pines 使用最佳維度數之辨識結果比較 ... 67
表 19 在 case 1 下對 Salinas 使用最佳維度數之辨識結果比較 ... 68
表 20 在 case 2 下對 Salinas 使用最佳維度數之辨識結果比較 ... 68
表 21 在 case 1 下對 Pavia University 使用最佳維度數之辨識結果比較 ... 69
1
第一章 介紹
第一節 緒論
在遙測影像領域中 ,遙測載具 搭載感測器(sensor)所能記錄的光學影像 (optical image)隨著科技進步而越來越精細,從原來頻段較窄、感測器數量較少的 多光譜影像(multispectral image)(圖 1 下),發展到頻段較寬、感測器數量較多的 高光譜影像(hyperspectral image)(圖 1 上), 圖 1 多光譜影像與高光譜影像示意圖組 (節錄自[4]) 並且從單純使用空中飛行載具遙測地表影像,發展至使用衛星遙測高或超高解析 (high/very high spatial resolution)的地表影像,以改善了過去必須實際去現場勘查的類別確認方式。高解析影像大多為使用單一波段的全色態影像(panchromatic)與 使用多個波段的多光譜影像,相較於高光譜影像,雖然高解析影像所記錄影像上 樣本的頻譜資料細緻度相較低,但善用高解析影像的解析度,將兩者影像資料融 合(fusion) [45]後,能夠讓使用者直接從螢幕上標定類別,省去必須前往實地標定 類別所耗費的人力與物力。然而,即使如此,決定類別的方式也仍舊需要人工判 定,因此無論是過去或現今的科技發展水準,能否使用少量樣本訓練分類器,使
2 其在遙測影像辨識時,便可取得令人滿意的辨識正確率,以減低人工判定的成本, 仍然是遙測影像辨識領域中重要議題之一。 因應科技的發展,雖然能從不同的平台(空中飛行載具、衛星)有效地取得 影像的頻譜資料,但單獨使用影像的頻譜資料,對於直接使用者與決策者的幫助 始終有限[16]。高光譜影像資料的每一個樣本,皆同時具有頻譜與空間訊息,除 了最常被使用的頻譜訊息,空間訊息的使用也是影像處理的重要關鍵[7], [58]。 由遙測載具搭載感測器所測得的光譜資料,即稱為樣本的頻譜訊息;樣本在圖像 上的座標(coordinate)資料,即為樣本的空間訊息,然而高光譜影像的空間訊息具 有叢聚性,相同類別的樣本在空間分布上會形成一大或數塊子區域,為了更有效 處理高光譜影像資料,將樣本在圖像上的座標資料,經處理或轉換後,提供影像 分類等資料處理使用。因此,近年來有許多研究發展,將高光譜影像的空間訊息 使用於影像的處理與辨識。 對於結合頻譜與空間訊息之相關研究,較多研究對於空間訊息的使用方式, 僅用於探測樣本在圖像位置之近鄰樣本,也就是說,此類空間訊息的使用方式對 於分類器之辨識結果的影響力較屬於間接性,仍然只有頻譜訊息為直接性地被使 用於分類器的辨識運算過程。然而,比起單純地使用高維度頻譜訊息於高光譜影 像處理(hyperspectral image processing)設計,從高光譜遙測影像攫取空間訊息應 用於高光譜影像處理設計,能達到更好的辨識結果[1], [20],對於空間訊息的使 用方式,除了較多研究用於探測樣本在圖像位置之近鄰樣本之外,亦有研究將頻 譜與空間訊息直接性地導入分類器的設計[25],而本研究利用高光譜影像資料在 空間域中樣本間彼此獨立之性質,結合頻譜與空間訊息,進行分類器開發。除此 之外,高光譜遙測影像本身使用大量波段紀錄頻譜訊息,導致形成龐大的資料量, 雖然記錄詳細,卻也同時增加了電腦在計算時所需要瞬間記憶體的負荷量,為減 緩該問題,可以使用維度降低方法(dimensionality reduction),而此方法大致可分 為特徵選取法(feature selection)與特徵萃取法(feature exctration),其中以特徵萃取 法較廣為人使用,因此,本研究結合頻譜與空間訊息,進行特徵萃取演算法開發。
3
第二節 架構
本研究結合高光譜遙測影像的頻譜屬性資料與空間座標資料於分類器設計 與特徵萃取演算法開發,在本章之後:第二章相關文獻主要介紹本研究選定的高 光譜遙測影像資料、資料之樣本情境與維度現象,以及本研究選定實驗比較對象 之分類器與特徵萃取法;第三章為本研究之分類器研究,介紹本研究提出分類器, 說明其實驗架構與設計,並呈現實驗結果;第四章為本研究之特徵萃取法研究, 介紹本研究提出特徵萃取法,說明其實驗架構與設計,並呈現實驗結果;第五章 則綜合本研究之分類器研究與特徵萃取法研究之實驗結果,提出結論與未來研究 發展建議;於下表列出本論文常用符號表,並於本論文末條列本研究之參考資料。 表 1 符號表 符號 說明L
L
樣本資料的類別數N
N
樣本資料的總樣本數N
(i)N
(i) 樣本資料中第ii
類的樣本數d
d
樣本資料的維度數p
p
樣本資料的最佳化維度數,其中1 · p · d1 · p · dx
x
樣本資料,其中x 2 R
x 2 R
d£1d£1X
X
樣本資料構成矩陣,其中X = [x
X = [x
11; : : : ; x
; : : : ; x
NN] 2 R
] 2 R
d£Nd£Ny
y
投影後樣本資料,其中y 2 R
y 2 R
d£1d£1Y
Y
投影後樣本資料構成矩陣,其中Y = [y
Y = [y
11; : : : ; y
; : : : ; y
NN] 2 R
] 2 R
p£Np£N¹
¹
樣本資料的總樣本平均¹
(i)¹
(i) 樣本資料的第ii
類樣本平均§
(i)§
(i) 樣本資料於第ii
類的共變異矩陣4
p(x)
p(x)
樣本x
x
的機率函數(或稱樣本x
x
的先驗機率、邊際機率)p(!
(i))
p(!
(i))
樣本x
x
為第ii
類的機率函數(或稱第ii
類的先驗機率、邊際機率)p(xj!
(i))
p(xj!
(i))
樣本x
x
在第ii
類的條件機率(或稱第ii
類的後驗機率)p(!
(i)jx)
p(!
(i)jx)
樣本x
x
屬於第ii
類的條件機率(或稱樣本x
x
的後驗機率)S
BS
B 樣本資料的組間共變異矩陣S
WS
W 樣本資料的組內共變異矩陣W
W
樣本資料的特徵向量構成投影矩陣,其中W 2 R
W 2 R
d£pd£pkx
m¡ x
nk
kx
m¡ x
nk
樣本x
x
mm與樣本x
x
nn的歐式距離5
第二章 相關文獻
本章節主要對於本研究相關文獻與資料進行回顧,第一節介紹本研究使用的 高光譜遙測影像資料:Indian Pines[5]、Salinas 與 Pavia University[30];第二節探 討過去研究較常使用空間訊息的方式;第三節介紹資料之樣本情境:ill-posed、 poorly-posed、well posed[53],與維度現象:Hughes phenomenon[22];第四節介紹
分 類 器 :
k
k
-Nearest neighborhood classifier[38] 、 support vector machine[59] 、 maximum likelihood classifier[50]、adaptive bayesian contextual classifier[48];最後第五節則介紹特徵萃取法:linear discriminant analysis(LDA)[49]、nonparametric weighted feature extraction(NWFE) [8] 、 cosine-based nonparametric feature
extraction(CNFE)[33]、spectral and spatial linear discriminant analysis(SSLDA)[29]。
第一節 高光譜遙測影像資料
由於國、內外高光譜遙測影像資料取得不易,本研究使用被公開於網路上提 供研究用途的高光譜遙測影像資料:Indian Pines[5]、Salinas[30],以及 Pavia University[30] , 前 兩 者 是 經 由 Airborne Visible/Infrared Imaging Spectrometer
(AVIRIS) sensor 測得影像資料,後一者則是經由 Reflective Optics System Imaging
Spectrometer (ROSIS) sensor 測得影像資料,以下分別介紹此三個高光譜遙測影
像資料。
壹、 Indian Pines 高光譜影像資料
Indian Pines 高光譜影像資料為來自於印第安那州西北部之農業用地的譜遙 測影像圖,使用 AVIRIS sensor 搭載 224 個頻譜感測器子頻譜儀,影像大小為145 £ 145
145 £ 145
(圖 2),其中包含 16 個類別(表 2),原始檔為 220 維有效頻譜,排 除 部 分 紀 錄 會 受 水 吸 收 影 響 的 頻 譜 , 將 資 料 維 度 降 至 200 維 , 亦 即145 £ 145 £ 200
145 £ 145 £ 200
的資料矩陣。6 (a) (b) (c) (d) (e) (f) 圖 2 Indian Pines 高光譜影像圖 其中(a)為真實地貌圖;(b)為第 4 個頻譜影像圖;(c)為第 45 個頻譜影像圖;(d)為第 77 個頻譜影像圖;(e)為第 113 個頻譜影像圖;(f)為第 144 個頻譜影像圖。 表 2 Indian Pines 高光譜影像資料中各類別所含樣本數 編號 名稱 數量 編號 名稱 數量 1 alfalfa 46 9 oats 20 2 corn-notill 1428 10 soybean-notill 972 3 corn-mintill 830 11 soybean-mintill 2455 4 corn 237 12 soybean-clean 593 5 grass-pasture 483 13 wheat 205 6 grass-trees 730 14 woods 1265 7 grass-pasture-mowed 28 15 buildings-grass- trees-drives 386 8 hay-windrowed 478 16 stone-steel-towers 93
7
貳、 Salinas 高光譜影像資料
Salinas 高光譜影像資料為來自於加州西北部,薩利納斯之農業用地的遙測 影像圖,該影像使用 AVIRIS sensor 搭載 224 個頻譜感測器子頻譜儀,影像大小 為512 £ 217
512 £ 217
(圖 3),其中包含 16 個類別(表 3),原始檔為 224 維有效頻譜, 排除部分會被水吸收的頻譜,將資料維度降至 204 維,亦即512 £ 217 £ 204
512 £ 217 £ 204
的 資料矩陣。 (a) (b) (c) (d) (e) (f) (g) 圖 3 Salinas 高光譜影像圖 其中(a)為真實地貌圖;(b)為第 3 個頻譜影像圖;(c)為第 47 個頻譜影像圖;(d) 為第 93 個頻譜影像圖;(e)為第 117 個頻譜影像圖;(f)為第 156 個頻譜影像圖; (g)為第 201 個頻譜影像圖。8 表 3 Salinas 高光譜影像資料中各類別所含樣本數 編號 名稱 數量 編號 名稱 數量 1 brocoli-green-weeds-1 2009 9 soil-vinyard-develop 6203 2 brocoli-green-weeds-2 3726 10 corn-senesced- green-weeds 3278 3 fallow 1976 11 lettuce-romaine-4wk 1068 4 fallow-rough-plow 1394 12 lettuce-romaine-5wk 1927 5 fallow-smooth 2678 13 lettuce-romaine-6wk 916 6 stubble 3959 14 lettuce-romaine-7wk 1070 7 celery 3579 15 vinyard-untrained 7268 8 grapes-untrained 11271 16 vinyard-vertical-trellis 1807
參、 Pavia University 高光譜影像資料
Pavia University 高光譜影像資料為來自於北義大利,帕維亞大學的遙測影像 圖,該影像使用 ROSIS sensor 搭載 103 個頻譜感測器子頻譜儀,影像大小為610 £ 340
610 £ 340
(圖 4),其中包含 9 個類別(表 4),檔案為610 £ 340 £ 103
610 £ 340 £ 103
的資料 矩陣。 (a) (b) (c) 圖 4 Pavia University 高光譜影像圖 其中(a)為真實地貌圖;(b)為第 37 個頻譜影像圖;(c)為第 83 個頻譜影像圖。9 表 4 Pavia University 高光譜影像資料中各類別所含樣本數 編號 名稱 數量 1 asphalt 6631 2 meadows 18649 3 gravel 2099 4 trees 3064
5 painted metal sheets 1345
6 bare soil 5029 7 bitumen 1330 8 self-blocking bricks 3682 9 shadows 947
第二節 空間訊息的使用
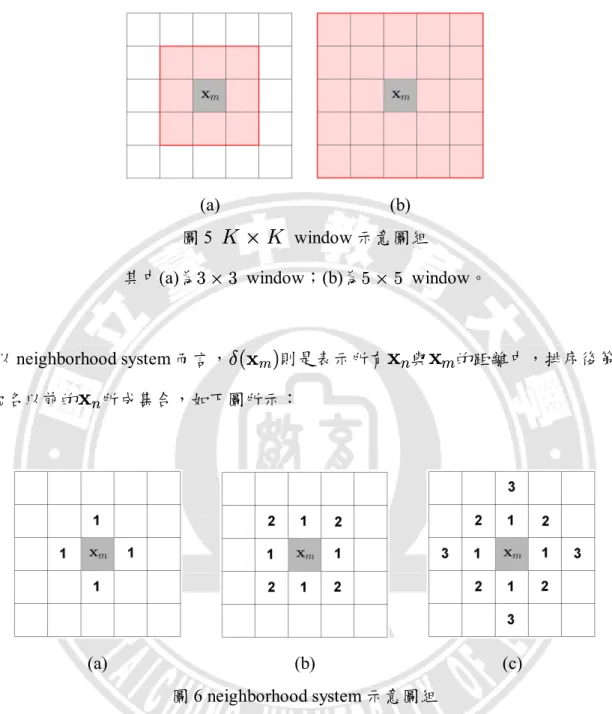
本研究主要設計空間訊息的使用方式,以用來設計分類器與特徵萃取法,因 此於本節探討過去研究對於空間訊息的使用方式,其中較常見的使用方法有K £ K
K £ K
window[9], [10], [16], [26], [29], [41], [62], [63]、neighborhood system[7], [40], [42], [48]、Gibbs’ distribution[24], [35], [36], [37], [39]。然而公式(2.1),以集 合形式說明大多數的研究對於空間訊息的使用方式如下:±(x
m) = fx
njx
n2 A
C(x
m) ; 8n 2 Ng
±(x
m) = fx
njx
n2 A
C(x
m) ; 8n 2 Ng
(2.1)
其中以x
x
mm為中心,在給定空間域之限制條件A
A
CC(x
(x
mm)
)
下,±(x
±(x
mm)
)
表示所有符 合限制條件的近鄰樣本x
x
nn之集合。以K £ K
K £ K
window 為例,在空間域中,以x
x
mm 所在位置為中心展開K £ K
K £ K
window 的區域範圍 ,±(x
±(x
mm)
)
表示在所有位在 window 內的x
x
nn所成集合,如圖 5 所示:10
(a) (b)
圖 5
K £ K
K £ K
window 示意圖組其中(a)為3 £ 33 £ 3 window;(b)為5 £ 55 £ 5 window。
以 neighborhood system 而言,
±(x
±(x
mm)
)
則是表示所有x
x
nn與x
x
mm的距離中,排序後第k
k
名以前的x
x
nn所成集合,如下圖所示:(a) (b) (c)
圖 6 neighborhood system 示意圖組
其中(a)為 first-order system;(b)為 second-order system;(c)為 third -order system。
而 Gibbs’ distribution 的基礎模型[23]如下:
p(x) =
1
Z
e(
¡Px2»VC(x))
p(x) =
1
Z
e(
¡Px2»VC(x))
(2.2)
其中
Z
Z
為標準化常數(normalizing constant),»»
為族類(set of cliques)集合,V
V
CC為使用樣本xx之座標資料進行運算的空間域函數,而 Gibbs’ distribution 的使用可
11 綜合前述過去研究對於空間訊息的使用方式,皆僅用於探測樣本在空間域之 近鄰樣本,然而,比起單純使用高維度頻譜訊息,從高光譜遙測影像資料攫取空 間訊息應用於高光譜影像處理的設計,可能達到更好的辨識結果,因此本研究利 用高光譜影像資料在空間域中樣本間彼此獨立之性質,設計不同於過去使用空間 訊息之方式,以進行分類器設計與特徵萃取演算法開發。
第三節 樣本情境與維度現象
本研究設計不同於過去使用空間訊息之方式,目標結合頻譜與空間訊息開發 分類器,使分類器能以少量樣本訓練,便可獲致令人滿意的辨識正確率;並且開 發特徵萃取法,除了用來降低資料維度,以減緩高維度現象對分類器之辨識正確 率的影響之外,目標對於不同類別樣本間,找到最佳的資料分離量,以利於分類 器進行辨識,提升辨識正確率。因此本節說明利用少量樣本訓練分類器的樣本情 境,以及高維度資料進行辨識時的維度現象。壹、 樣本情境
對於樣本數N
N
、各類樣本數N
N
(i)(i)與樣本維度數d
d
,根據三者之間的關係可劃 分成三種樣本情境[53]:(1) ill-posed(N
N
(i)(i)< N < d
< N < d
):由於N < d
N < d
,樣本所成的 共變異矩陣為奇異(singularity problems)不可逆矩陣,對於整體而言,較難有好的 辨識結果;(2) poorly posed(N
N
(i)(i)< d < N
< d < N
):雖然訓練樣本總數充足,但由於N
(i)< d
N
(i)< d
,樣本所成的共變異矩陣仍為奇異不可逆矩陣,對於各類而言,較難有 好的辨識結果;(3) well posed(d < N
d < N
(i)(i)< N
< N
):由於d < N
d < N
(i)(i),樣本所成的共變 異矩陣為可逆矩陣,表示不論對於整體或各類的辨識結果,皆有相當程度的可信 度,並且是較為理想狀態的樣本情境。由於情境(1)與情境(2)下,各類樣本數的不12
足,導致各類樣本所成的共變異矩陣皆為奇異不可逆矩陣,因此,情境(1)與情境 (2)合稱為小樣本(small sample size, SSS)問題。本研究設計空間訊息的使用方式,
目標以少量樣本訓練分類器,便可獲致良好辨識正確率,換句話說,希望結合空 間訊息的使用,能改善在小樣本情境下訓練分類器,使得辨識正確率表現不佳之 情形。
貳、 維度現象
由於高光譜影像資料屬高維度資料(high dimensionality data),當資料維度數 過高時,會有 Hughes phenomenon[22],如圖 7 所示,對於不同樣本數
m
m
,當辨 識複雜度(維度數)n
n
提高時,雖然辨識正確率也會相對地提高,但是到達某個 程度時,辨識正確率反而開始呈現下降的現象。 圖 7 Hughes phenomenon 示意圖 (節錄自[22]) 本研究設計空間訊息的使用方式,目標除了降低資料維度,以減緩高維度現 象之外,並且對於不同類別樣本間,找出最佳的資料分離量之特徵空間,並將資 料投影至該特徵空間,以利於分類器進行辨識,提升其辨識正確率。13
第四節 分類器
本研究設計空間訊息之使用方式,結合頻譜與空間訊息進行分類器設計,然 而,在辨識領域中,較為基礎的分類器有
k
k
-nearest neighborhood classifier(k
k
NNC) [38]、support vector machine(SVM)[59]、maximum likelihood classifier (MLC)[50],由於
k
k
NNC、SVM、MLC 皆為單純使用頻譜訊息進行辨識的分類器設計,因此, 本研究選定k
k
NNC、SVM、MLC 作為比較對象之分類器,與本研究提出之分類 器進行實驗,探討有無使用空間訊息之分類器,其辨識結果之比較;而 adaptive Bayesian contextual classifier(ABC)[48]為以 MLC 為原型,結合頻譜與空間訊息的分類器設計,因此,本研究選定 ABC 作為比較對象之分類器,與本研究提出之 分類器進行實驗,探討不同空間訊息使用方式之分類器,其辨識結果之比較。因 此,本節將介紹本研究選定實驗比較對象之分類器:
k
k
NNC、SVM、MLC、ABC。壹、 kk -Nearest Neighborhood Classifier(kk NNC)
k
k
NNC[38]是基於貝式法則(Bayes’ rule)設計的分類器,並且使用無參數的距 離計算,在所有分類器中,處理方式淺顯易懂也容易操作,至今仍被使用作分類 器開發的指標性比較之一[44], [60], [63]。其判斷樣本點類別的方式如下:! = arg max
i=1;:::;Ln
p(!
(i)jx)
o
! = arg max
i=1;:::;Ln
p(!
(i)jx)
o
(2.3)
而公式(2.3)的條件機率p(!
p(!
(i)(i)jx)
jx)
可表示為公式(2.4)p(!
(i)jx) =
p(xj!
(i))p(!
(i))
p(x)
p(!
(i)jx) =
p(xj!
(i))p(!
(i))
p(x)
(2.4)
其中p(x) =
k
N V
p(x) =
k
N V
(2.5)
p(xj!
(i)) =
k
(i)N
(i)V
p(xj!
(i)) =
k
(i)N
(i)V
(2.6)
p(!
(i)) =
N
(i)N
p(!
(i)) =
N
(i)N
(2.7)
14
V
V
是以x
x
為中心畫出區域範圍的面積、體積或超體積,k
k
是指區域V
V
涵蓋的訓 練樣本點總數,k
k
(i)(i)則是區域V
V
中第ii
類訓練樣本點總數。結合公式(2.4) ~ (2.7), 可將公式(2.3)整理成公式(2.8)! = arg max
i=1;:::;L½
k
(i)k
¾
! = arg max
i=1;:::;L½
k
(i)k
¾
(2.8)
由公式(2.8)可知,k
k
NNC 計算樣本之間的距離判斷其他樣本是否存在區域範 圍V
V
內,並以區域範圍V
V
內樣本總數k
k
中,比較各類樣本數k
k
(i)(i)所占比重,決定樣 本點類別。貳、 Support Vector Machine(SVM)
SVM[59]是目前眾所周知的分類器[61],因為能夠以少量訓練樣本訓練辨識 器,獲得令人滿意的辨識正確率,而廣被應用於文字辨識、影像辨識領域[28], [55], [56], [64]。SVM 主要概念以存在類別邊界附近的訓練樣本作為支撐,找出類別 的最佳化邊界,在以最佳化邊界線作為分類的依據(圖 8)。 圖 8 SVM 解最佳化邊界概念示意圖 SVM 解最佳化邊界的方法種類繁多[12],本研究採用的是
C
C
- support vector classification(C
C
-SVC)[15], [18],給定訓練樣本x
x
mm2 R
2 R
dd; m = 1; : : : ; N
; m = 1; : : : ; N
,在兩15 類問題中
y 2 R
y 2 R
NN,其中y
y
mm2 f1; ¡1g
2 f1; ¡1g
,而原始C
C
-SVC 解最佳化邊界問題,其 方式如下:min
w;b;»(
1
2
w
Tw + C
NX
i=1»
m)
min
w;b;»(
1
2
w
Tw + C
NX
i=1»
m)
(2.9)
subject to y
m(w
TÁ(x
m) + b) ¸ 1 ¡ »
m»
m¸ 0; m = 1; : : : ; N
subject to y
m(w
TÁ(x
m) + b) ¸ 1 ¡ »
m»
m¸ 0; m = 1; : : : ; N
公式(2.9)為解決資料之兩類別問題的方法,其中此處所指w
w
為向量,y
y
mm為記 錄樣本m
m
存在於邊界正負向的係數,»
»
mm為與邊界差距的常數,C
C
為與邊界差距的 調整參數。然而 SVM 最初設計適用對象為線性可分割(linearly separable)的資料, 其w
w
表示如下:w =
NX
m=1y
m®
mx
mw =
NX
m=1y
m®
mx
m(2.10)
假若資料為非線性不可分割(non-linearly inseparable)時,SVM 則利用核函數 (kernel function)[34], [54]將資料投影至高維度空間,或理論上無限維度空間,增 強資料的分散程度,使得資料投影後成為線性可分割,以利於類別辨識,而其方 法主要使用投影矩陣Á(x
Á(x
ii)
)
將x
x
ii投影至不同維度空間,並且經最佳化過程推導後, 其w
w
表示如下:w =
NX
m=1y
m®
mÁ(x
m)
w =
NX
m=1y
m®
mÁ(x
m)
(2.11)
將公式(2.11)代入公式(2.9)後,利用 Lagrange Multi pliers 轉換,推導出
C
C
-SVC 解 最佳化邊界的對偶型(dual form)公式如下:min
®=
½
1
2
®
TyKy® ¡ 1
T®
¾
min
®=
½
1
2
®
TyKy® ¡ 1
T®
¾
(2.12)
subject to y
T® = 0
0 · ®
m· C; m = 1; : : : ; N
subject to y
T® = 0
0 · ®
m· C; m = 1; : : : ; N
16 其中1 = [1; : : : ; 1]1 = [1; : : : ; 1]TT、
y = [y
1; : : : ; y
N]
Ty = [y
1; : : : ; y
N]
T,K = Á(x)K = Á(x)TTÁ(x)Á(x)為核函數矩陣,並 且常見的核函數如下[13]: 1. linear:k(x
k(x
mm; x
; x
nn) = x
) = x
mTmTx
x
nn (或x
x
mmx
x
nTTn) 2. polynomial:k(x
k(x
mm; x
; x
nn) = (x
) = (x
TmmTx
x
nn+ a)
+ a)
bb (或(x
(x
mmx
x
nTTn+ a)
+ a)
bb) 3. radial-basis:k(x
m; x
n) = exp
n
¡kxm¡xnk 2 2¾2o
k(x
m; x
n) = exp
n
¡kxm¡xnk 2 2¾2o
4. sigmoidal:
k(x
k(x
mm; x
; x
nn) = tanh(ax
) = tanh(ax
TmmTx
x
nn¡ b)
¡ b)
(或tanh(ax
tanh(ax
mmx
x
nTTn¡ b)
¡ b)
)其中此處所指
a
a
、bb
、¾
¾
皆為核函數的控制參數。而 SVM 的最佳化邊界為解決兩類問題的資料分割方法,要從解決兩類問題 擴展至解決多類問題,則必須採用一對一(one-against-one, OAO)或一對多(one-against-all, OAA)的方式,以協助解決多類問題[3]。
參、 Maximum Likelihood Classifier(MLC)
MLC[50] 是 高 斯 最 大 概 似 分 類 器 (Gaussian maximum likelihood classifier,
Gaussian MLC)亦稱為貝式分類器(Bayes classifier)[27],其判斷樣本類別的非線性
分類器,其判斷方式如下:
! = arg max
i=1;:::;Ln
p(xj!
(i))p(!
(i))
o
! = arg max
i=1;:::;Ln
p(xj!
(i))p(!
(i))
o
(2.13)
而公式(2.13)的條件機率p(xj!
p(xj!
(i)(i))
)
是第ii
類的機率函數,且機率分布為高斯分布 (Gaussian distribution)如下: p(xj!(i)) = q 1 (2¼)d¯¯§(i)¯¯ exp (¡(x ¡ ¹(i))T§(i)¡1(x ¡ ¹(i)) 2 ) p(xj!(i)) = q 1 (2¼)d¯¯§(i)¯¯ exp (
¡(x ¡ ¹(i))T§(i)¡1(x ¡ ¹(i)) 2 )
(2.14)
由公式(2.14)可知,條件機率p(xj!
p(xj!
(i)(i))
)
為指數族機率函數,由於指數族機率函數 對於取自然對數,其結果不變。因此,對公式(2.14)取自然對數後,在進行最大 概似計算,可推導出為公式(2.13)之對偶型公式如下:! = arg max
i=1;:::;Ln
ln
³
p(xj!
(i))p(!
(i))
´o
= arg max
i=1;:::;Ln
x
TW
(i)x + x
Tw
(i)+ a
(i)o
! = arg max
i=1;:::;Ln
ln
³
p(xj!
(i))p(!
(i))
´o
= arg max
i=1;:::;Ln
x
TW
(i)x + x
Tw
(i)+ a
(i)17
由於形似二次方程式,因此可別稱為 quadratic discriminant classifier(QDC) [2], [19], [32], [38], [48], [50], [51], [57],而其中
W
(i)= ¡§
(i)¡1W
(i)= ¡§
(i)¡1(2.16)
w
(i)= 2§
(i)¡1¹
(i)w
(i)= 2§
(i)¡1¹
(i)(2.17)
a
(i)= ¡ ln
¯
¯
¯§
(i)¯
¯
¯ + 2 ln p(!
(i)) ¡ ¹
(i)T§
(i)¡1¹
(i)a
(i)= ¡ ln
¯
¯
¯§
(i)¯
¯
¯ + 2 ln p(!
(i)) ¡ ¹
(i)T§
(i)¡1¹
(i)(2.18)
¹
(i)¹
(i)為第ii
類樣本平均數,§
§
(i)(i)為第ii
類共變異矩陣。而 MLC 的計算過程中,必須注意當遇到樣本數不足時,也就是資料的樣本數小於維度數時,在計算第
ii
類共變異反矩陣§§(i) ¡1(i) ¡1,容易遇到奇異解(singular)的情況。
肆、 Adaptive Bayesian Contextual Classifier(ABC)
ABC[48]是基於 Markov random fields(MRF),並且使用 iterative conditional
mode(ICM)將 MLC 修改而成的分類器,其分類器運作流程如圖 9 所示。
圖 9 ABC 運作流程圖 (節錄自[48])
以下依照圖 9 之順序說明 ABC 之運作流程,首先令
``
為紀錄 ABC 之重複執 行次數,則首次執行 ABC(` = 1
` = 1
)時,先求出初始樣本平均¹¹(i)11(i)與變異矩陣§§(i)1(i)1 , 亦即統計估計值ÁÁ1(i)1(i) = f¹= f¹1(i)(i)1 ; §; §(i)1(i)1 gg,分別為公式(2.19)與公式(2.20)¹
(i)1=
P
N(i) n=1x
(i) nN
(i)¹
(i)1=
P
N(i) n=1x
(i) nN
(i)(2.19)
18
§
(i)1=
P
N(i) n=1(x
(i) n¡ ¹
(i) 1)(x
(i) n¡ ¹
(i) 1)
TN
(i)§
(i)1=
P
N(i) n=1(x
(i) n¡ ¹
(i) 1)(x
(i) n¡ ¹
(i) 1)
TN
(i)(2.20)
在以ÁÁ(i)1(i)1 為 MLC 之參數依據進行辨識。 接著圖 9 粗體箭頭引導方向為 ABC 執行重複步驟之流程,在執行重複步驟 (` > 2
` > 2
)時,將前次(` ¡ 1
` ¡ 1
)重複執行時,MLC 所辨識出類別為半監督式類別訊息 (semi-supervised information),提供給 maximum a posteriori (MAP) classifier 進行辨識,其公式如下:
! = arg max
1·i·L
n
ln j§(i)` j + (X(s) ¡ ¹(i)` )T(§(i)` )¡1(X(s) ¡ ¹(i)` ) + 2m¯ o ! = arg max
1·i·L
n
ln j§(i)` j + (X(s) ¡ ¹(i)` )T(§(i)` )¡1(X(s) ¡ ¹(i)` ) + 2m¯ o
(2.21)
其中,¯
¯
為控制的固定係數,並且為 ABC 之控制參數,m
m
為在給定空間域限制 條件範圍內,MLC 所辨識出半監督式類別與第ii
類不同類之事件發生數。然而, 再以 MAP 所辨識出類別作為半監督式類別訊息,計算第``
次執行之估計加權值 如下:w
`n(i)=
p(x
(i) njÁ
(i) (`¡1))p(i(s)j^i(@s))
P
L j=1p(x
(i) njÁ
(j) (`¡1))p(j(s)j^
j(@s))
w
`n(i)=
p(x
(i) njÁ
(i) (`¡1))p(i(s)j^i(@s))
P
L j=1p(x
(i) njÁ
(j) (`¡1))p(j(s)j^
j(@s))
(2.22)
其中p(xp(xmm(i)(i)jÁjÁ(i)11(i)))為以ÁÁ(i)1(i)1 為統計參數的高斯函數模型之機率值,
p(i(s)j^i(@s))
p(i(s)j^i(@s))
則 意指該樣本在空間域中,給定範圍內為第ii
類的機率值,其機率模型基於 Gibbs distribution 可表示成公式(2.23)p(i(s)j^i(@s)) =
1
Z
exp
8
<
:
¡¯
X
s02c(s)f1 ¡ ±(i(s) ¡ i(s
0))g
9
=
;
p(i(s)j^i(@s)) =
1
Z
exp
8
<
:
¡¯
X
s02c(s)f1 ¡ ±(i(s) ¡ i(s
0))g
9
=
;
(2.23)
其中Z
Z
為分配係數(partition coefficient),且P
s02c(s)f1 ¡ ±(i(s) ¡ i(s
0))g
P
s02c(s)
f1 ¡ ±(i(s) ¡ i(s
0))g
意指在給定範圍內,異於第
ii
類之事件發生數,再接著計算第``
次的統計估計值,亦即 樣本平均¹
¹
(i)`(i)` 與變異矩陣§
§
(i)`(i)` ,分別為公式(2.24)與公式(2.25)¹
(i)`=
P
N(i) n=1x
(i) n+
P
M(i) m=1w
(i) `my
(i) mN
(i)+
P
M(i) m=1w
(i) `m¹
(i)`=
P
N(i) n=1x
(i) n+
P
M(i) m=1w
(i) `my
(i) mN
(i)+
P
M(i) m=1w
(i) `m(2.24)
19
§(i)` = PN(i)
n=1(x
(i)
n ¡ ¹(i)` )(x(i)n ¡ ¹(i)` )T +
PM(i)
m=1w
(i)
`m(y
(i)
m ¡ ¹(i)` )(ym(i)¡ ¹(i)` )T
N(i)+PM(i) m=1w (i) `m §(i)` = PN(i) n=1(x (i)
n ¡ ¹(i)` )(x(i)n ¡ ¹(i)` )T +
PM(i)
m=1w
(i)
`m(y
(i)
m ¡ ¹(i)` )(ym(i)¡ ¹(i)` )T
N(i)+PM(i)
m=1w
(i)
`m
(2.25)
其中,
N
N
(i)(i)為第ii
類訓練樣本x
x
(i)(i)的樣本數,M
M
(i)(i)為第ii
類測試樣本y
y
(i)(i)的樣本數。 在以Á
Á
(i)`(i)` 為 MLC 之參數依據進行辨識。 結束重複執行時,則以最後一次的 MLC 之辨識結果,提供 post-processing (PP) classifier 進行辨識,其公式如下:! = arg max
1·i·Lf2mg
! = arg max
1·i·Lf2mg
(2.26)
其中m
m
為在給定範圍內,MLC 所辨識出半監督式類別與第ii
類不同類之事件發生 數。第五節 特徵萃取法
本研究設計空間訊息之使用方式,結合頻譜與空間訊息進行特徵萃取演算法 開發,一般而言,降低資料維度可使用特徵選取、特徵萃取兩種方法,較常使用 的是區辨分析特徵萃取(discriminant analysis feature extraction, DAFE),或稱線性 區辨分析(linear discriminant analysis, LDA) [38], [49], [57],其方法主要找出具有資料最大分離量所對應之特徵向量構成投影矩陣
W
W
,再利用投影矩陣,將樣本 在頻譜域的樣本資訊投影至特徵子空間,以利於進行影像辨識Y = W
TX
Y = W
TX
(2.27)
其中特徵萃取法大致上可分成三種類型[63]:(1)非監督式(unsupervised) 特徵萃 取法:使用所有樣本訊息的特徵萃取法設計;(2)監督式(supervised) 特徵萃取法: 僅使用類別已知樣本訊息的特徵萃取法設計;(3)半監督式(semi-supervised) 特徵 萃取法:同時使用類別已知樣本訊息與類別未知樣本訊息的特徵萃取法設計。 本研究以 LDA 為原型,進行演算法開發,因此,本研究選定同樣以 LDA 為 設 計 原 型 的 特 徵 萃 取 法 作 為 實 驗 比 較 對 象 : nonparametric weighted feature20
extraction(NWFE)[8]、cosine-based nonparametric feature extraction(CNFE)[33]、
spectral and spatial linear discriminant analysis(SSLDA)[29],其中 NWFE、CNFE 為
單純使用頻譜訊息,便能減緩高維度現象,並同時有效地提升分類器之辨識正確 率的監督式特徵萃取法,故選定 NWFE、CNFE 作為比較對象之特徵萃取法,與 本研究提出特徵萃取法進行實驗,探討有無使用空間訊息的特徵萃取法設計,對 於提升分類器辨識正確率的成效,而 SSLDA 結合空間訊息的使用,以 LDA 為 原型,設計半監督式特徵萃取法,故選定 SSLDA 做為比較對象之特徵萃取法, 與本研究提出特徵萃取法進行實驗,探討空間訊息的使用方式,對於提升分類器 辨識正確率的成效。因此,本節首先介紹本研究設計特徵萃取法的原型:LDA, 以及本研究選定為實驗比較對象之特徵萃取法:NWFE、CNFE、SSLDA。
壹、 Linear Discriminant Analysis(LDA)
LDA[49]是典型的子空間分析方法(subspace analysis method),並且被廣泛地
在運用在臉部辨識之相關研究[43], [47], [65]。然而,有許多關於特徵萃取法的研 究,其設計是基於 LDA 分析資料分離量之模式變化而來[6], [8], [11], [17], [21], [29], [31], [33], [43], [46], [47], [65]。LDA 從樣本的頻譜訊息裡,找出具有能夠區 辨資料類別之最大分離量的特徵空間,藉由投影至特徵空間將不同類別的資料分 離,以便進行資料辨識。首先利用公式(2.28)找出區辨樣本類別的最大分離量
W = arg max
W½
W
TS
BW
W
TS
WW
¾
W = arg max
W½
W
TS
BW
W
TS
WW
¾
(2.28)
其中S
S
BB為組間(between)共變異矩陣,S
S
WW為組內(with-in)共變異矩陣,分別定義 如下:S
B=
LX
i=1N
(i)(¹
(i)¡ ¹)
T(¹
(i)¡ ¹)
S
B=
L
X
i=1
N
(i)(¹
(i)¡ ¹)
T(¹
(i)¡ ¹)
(2.29)
S
W=
LX
i=1 N(i)X
m=1(x
(i)m¡ ¹
(i))
T(x
(i)m¡ ¹
(i))
S
W=
LX
i=1 N(i)X
m=121 而公式(2.28)利用 Rayleigh quotient 推導出其對偶型公式,如公式(2.31):
S
BW = ¸S
WW
S
BW = ¸S
WW
(2.31)
其中¸
¸
為特徵矩陣。由公式(2.31)可知,利用解特徵值的方式,能找出具有能夠區 辨資料類別之最大分離量的特徵空間。最後使用公式(2.27),將樣本的頻譜資料 投影至特徵空間。由於 LDA 在資料處理的過程中,使用類別已知的訓練樣本之 訊息,為監督式特徵萃取法。貳、 Nonparametric Weighted Feature Extraction(NWFE)
NWFE[8] 基 於 LDA 分 析 資 料 分 離 量 的 方 法 , 並 結 合 nonparametric
discriminant analysis(NDA)[31]的概念發展而來,其結構上與公式(2.28)相同。然 而,NWFE 設定其
S
S
BB= S
= S
N WBN WB 與S
S
WW= S
= S
N WWN WW ,分別定義為如公式(2.32)與公式 (2.33): SN WB = L X i=1 p(!(i)) L X j=1; j6=i N(i) X m=1 ¸(i;j)m N(i)(x (i) m ¡ M (j)(x(i)m))T(x(i)m ¡ M(j)(x(i)m))
SN WB = L X i=1 p(!(i)) L X j=1; j6=i N(i) X m=1 ¸(i;j)m N(i)(x (i) m ¡ M (j)
(x(i)m))T(x(i)m ¡ M(j)(x(i)m))
(2.32)
SN W W = L X i=1 p(!(i)) N(i) X m=1 ¸(i;i)m N(i)(x (i) m ¡ M (i)(x(i) m)) T(x(i) m ¡ M (i)(x(i) m)) SN W W = L X i=1 p(!(i)) N(i) X m=1 ¸(i;i)m N(i)(x (i) m ¡ M (i)(x(i) m)) T(x(i) m ¡ M (i)(x(i) m))
(2.33)
其中,以第ii
類第m
m
個樣本為中心,對第jj類別的加權平均M(j )(x(i) m) M(j )(x(i)m)之加權¸
(i;j ) m¸
(i;j )m 計算如下:¸
(i;j)m=
dist(x
(i) m¡ M
(j)(x
(i) m))
¡1P
N(j) t=1dist(x
(i) t¡ M
(j)(x
(i) m))
¡1¸
(i;j)m=
dist(x
(i) m¡ M
(j)(x
(i) m))
¡1P
N(j) t=1dist(x
(i) t¡ M
(j)(x
(i) m))
¡1(2.34)
而
dist( ² )
dist( ² )
為距離函數,且第jj類的加權平均M
M
jj(x
(x
(i)mm(i))
)
與其加權w
w
mkmk(i;j )(i;j )計算如下:M
j(x
(i)m) =
N(j)X
k=1w
mk(i;j)x
jkM
j(x
(i)m) =
N(j)X
k=1w
mk(i;j)x
jk(2.35)
w
mk(i;j)=
dist(x
(i) m¡ x
(j) k)
¡1P
Nj t=1dist(x
(i) t¡ x
(j) k)
¡1w
mk(i;j)=
dist(x
(i) m¡ x
(j) k)
¡1P
Nj t=1dist(x
(i) t¡ x
(j) k)
¡1(2.36)
22 另外使用公式(2.37)調整
S
S
WWS
W= 0:5S
W+ 0:5diag(S
W)
S
W= 0:5S
W+ 0:5diag(S
W)
(2.37)
由公式(2.31)找出最佳化投影向量,最後以公式(2.27)將樣本的頻譜資料投影至特 徵空間。由於 NWFE 在資料處理的過程中,使用類別已知的訓練樣本之訊息, 為監督式特徵萃取法。參、 Cosine-based Nonparametric Feature Extraction(CNFE)
CNFE[33]基於 LDA 分析資料分離量的方法,結合 NDA 的概念,並且以
cosine distance 設計其加權值計算。在結構上同樣地以公式(2.28)為基礎,求出最
佳化特徵空間,但不同之處在於樣本平均的計算方式,在公式(2.29)與公式(2.30) 中,LDA 所使用的樣本平均為類別平均(class mean);在公式(2.32)與公式(2.33) 中,NWFE 所使用的樣本平均為加權平均(weighted mean);然而,CNFE 則循 NDA 計算樣本平均的方式,使用區域平均(local mean),設定
S
S
BB= S
= S
CNBCNB 與S
S
WW= S
= S
CNWCNW , 並分別定義如公式(2.38)與公式(2.39) SCNB = L X i=1 p(!(i)) L X j=1; j6=i N(i) X m=1w(i;j)m (x(i)m ¡ Mk(j)(x(i)m))T(x(i)m ¡ Mk(j)(x(i)m))
SCNB = L X i=1 p(!(i)) L X j=1; j6=i N(i) X m=1
w(i;j)m (x(i)m ¡ Mk(j)(x(i)m))T(x(i)m ¡ Mk(j)(x(i)m))
(2.38)
SC NW = L X i=1 p(!(i)) N(i) X m=1 wm(i;i)(x (i) m ¡ M (i) k (x (i) m)) T (x(i)m ¡ M (i) k (x (i) m)) SC NW = L X i=1 p(!(i)) N(i) X m=1 wm(i;i)(x (i) m ¡ M (i) k (x (i) m)) T (x(i)m ¡ M (i) k (x (i) m))
(2.39)
其中 ,以第ii
類第m
m
個樣本為中心, 對第jj類別的k
k
個最 近鄰所成區域平均M
k(j)(x
(i)m)
M
k(j)(x
(i)m)
之計算如下:M
k(j)(x
(i)m) =
1
k
kX
n=1K
n(j)(x
(i)m)
M
k(j)(x
(i)m) =
1
k
kX
n=1K
n(j)(x
(i)m)
(2.40)
Kn(j)(x(i)m ) Kn(j)(x(i)m )意指從第jj類樣本中,找出與第ii
類第m
m
個樣本x
(i) mx
(i)m第jj類的第n
n
個近鄰 樣本。而 CNFE 基於餘弦模型設計加權方式,如公式(2.41)與公式(2.42):23
w
(i;j)m= 1 ¡
(³
(i;j) m)
rP
N i t=1(³
(i;j) m)
rw
(i;j)m= 1 ¡
(³
(i;j) m)
rP
N i t=1(³
(i;j) m)
r(2.41)
³
m(i;j)=
¯
¯
¯(x
(i)m¡ M
k(j)(x
(i)m))(x
(i)m¡ ¹
(i))
T¯
¯
¯
°
°
°x
(i)m¡ ¹
(i)°
°
°
³
m(i;j)=
¯
¯
¯(x
(i)m¡ M
k(j)(x
(i)m))(x
(i)m¡ ¹
(i))
T¯
¯
¯
°
°
°x
(i)m¡ ¹
(i)°
°
°
(2.42)
與 NWFE 相同地,CNFE 亦使用公式(2.37)調整S
S
WW,之後使用公式(2.31)求出最 佳化投影矩陣W = [w
W = [w
11; : : : ; w
; : : : ; w
pp] 2 R
] 2 R
d£pd£p,其中d
d
為樣本維度數,p
p
為最佳化樣 本維度數,再由公式(2.43)調整投影向量w
w
w
m=
w
mp
w
T mS
ww
m; m = 1; : : : ; p
w
m=
w
mp
w
T mS
ww
m; m = 1; : : : ; p
(2.43)
最後由公式(2.27)將樣本的頻譜資料投影至特徵空間。因 CNFE 在資料處理的過 程中,使用類別已知的訓練樣本之訊息,為監督式特徵萃取法。肆、 Spectral and Spatial Linear Discriminant Analysis(SSLDA)
SSLDA[29]是基於 LDA 分析資料分離量的方法,結合空間訊息的處理,所 設計而成的特徵萃取法 。 SSLDA 首先承 襲 LDA 之公式(2.28) ,並設定其
S
B= S
SSLDBS
B= S
SSLDB 與S
S
WW= S
= S
WWSSLDSSLD,以及S
S
TSSLDSSLDT= S
= S
BSSLDSSLDB+ S
+ S
SSLDWSSLDW ,其定義分別如 公式(2.44)、公式(2.45)與公式(2.46)S
SSLDB=
1
N
LX
i=1N
(i)(¹
(i)¡ ¹)
T(¹
(i)¡ ¹)
S
SSLDB=
1
N
LX
i=1
![圖 9 ABC 運作流程圖 (節錄自[48])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7438388.108879/25.892.139.772.190.923/圖9ABC運作流程圖節錄自48.webp)