國立臺中教育大學教育測驗統計研究所
教學碩士學位暑期在職進修專班碩士論文
指導教授: 曾建銘 博士
陳桂霞 博士
題組題與單選題混合測驗之 BIB 設計效果探究
研 究 生:張 雅 玲 撰
中華民國 九十九 年 八 月
誌謝
猶記得那年剛考上台中教育大學測驗統計研究所的我,心情是感到雀躍但也 徬徨,雀躍的是可以再邁向更進一層的學問,徬徨的是對此科系的陌生。幸運的, 遇到了一群認真的教授們、志同道合的夥伴們,讓我在這研究所的求學生涯中獲 益良多。 首先最要感謝的是指導教授曾建銘老師,老師總是很有耐心、不厭其煩的指 導我們,每次討論都耗費了老師許多寶貴的時間,但老師還是這麼的親切與認 真,最讓我深感敬佩的是老師對於做研究的智識與態度,持續不斷的給予建議, 口試完後依然再協助我修正論文,一路走來始終如一呢! 也非常感謝共同指導的陳桂霞老師及口試委員郭伯臣老師、凃柏原老師與李 信宏老師,仔細的審閱論文內容,提出了許多值得我深思與改進的意見,才得以 讓我的論文更加的完備。 再來還要感謝暄博學長,協助模擬資料的設定與指導,研究才能持續下去 呢!也感謝我的夥伴依穎,一同做模擬研究所耗費的時間與心力,真的是很辛 苦,還好有妳在一旁不時的給予意見,彼此互相討論,一起加油打氣,論文才得 以順利完成,只能說有妳真好啊! 最後還要謝謝我的另一半國祥,謝謝你給予我的精神支柱,有時還要忍受我 做研究時對你的冷落,謝謝你一路陪伴著我,讓我無後顧之憂,才能繼續向前邁 進。真的很謝謝所有幫助過我的師長與同學們,感謝大家! 張雅玲 謹誌 99.08.14摘要
本研究是利用電腦模擬資料,探討題組與單題混合測驗,在平衡不完全區塊 設計(balanced incomplete block design, BIB)下,設定當受試者能力分布為常態或 雙峰時,控制不同的施測人數、施測題數、題組題數比例、題組效果變異數此四 種變項,比較 BILOG-MG、SCORIGHT 此二種軟體估計受試者能力參數及試題 參數的精準度。研究中主要變項為:(一)施測人數為 5460 人和 7566 人﹔(二) 測 驗題數為 27 題和 45 題﹔(三) 題組比例分別佔總題數的 1/3 和 2/3(四) 題組效果 變異數分別為 0、0.5 和 1。 研究結果發現: 1. 受試者能力分布為常態時,不論用何者軟體估計參數的誤差值,都顯示 出人數越多或是題數越多估計越精準。 2. 受試者能力分布為雙峰時,不論用何者軟體估計參數的誤差值,都顯示 出人數越少或是題數越多估計越精準。 3. 受試者能力分布為常態時,比較兩種軟體估計參數的結果,均以 SCORIGHT此軟體估計能力參數、試題鑑別度和難度參數得到較低的估 計誤差值,估計較為精準。但試題參數中的猜測度較無規律性。 4. 受試者能力分布為雙峰時,比較兩種軟體估計參數的結果,均以 BILOG-MG此軟體估計試題參數中的難度與猜測度得到較低的估計誤差 值,估計較為精準。但受試者能力值與試題參數中的鑑別度較無規律性。 關鍵詞:平衡不完全區塊設計、題組
Abstract
This research is to estimate the root mean square error (RMSE) of ability parameters and item parameters by BILOG-MG and SCORIGHT when the ability distribution is normal or bimodal in balanced incomplete block design(BIB). The factors taken into consideration include the following: the sample sizes (5460 and 7566), the number of examinees (27 and 45), the proportion of the testlet items (1/3 and 2/3) and the
variances of the testlet effects (0, 0.5 and 1).
The results of this research show that:
1. The RMSE decreases as the sample size or the number of examinees increase when the ability distribution is normal.
2. The RMSE decreases as the sample size decrease or the number of examinees increase when the ability distribution is bimodal.
3. When the ability distribution is normal, compare with BILOG-MG and SCORIGHT simulation, the RMSE of the ability, the item discrimination and difficulty parameters are smaller under SCORIGHT simulation, but the RMSE of the pseudo-chance parameter is random.
4. When the ability distribution is bimodal, compare with BILOG-MG and
SCORIGHT simulation, the RMSE of the pseudo-chance and the item difficulty parameters are smaller under BILOG-MG simulation, but the RMSE of the ability parameters and the item discrimination are random.
目錄
第一章 緒論...01
第一節 研究動機...01 第二節 研究目的與問題...03 第三節 名詞解釋. ...04第二章 文獻探討...07
第一節 試題反應理論...07 第二節 題組反應理論...09 第三節 BIB 設計簡介 ...11 第四節 估計參數的軟體介紹...13第三章 研究方法...17
第一節 研究架構... ...17 第二節 研究工具...20 第三節 BIB 設計...21第四章 研究結果與討論...24
第一節 BIB 設計下 BILOG-MG 參數估計結果...24 第二節 BIB 設計下 SCORIGHT 參數估計結果...29 第三節 BILOG-MG 和 SCORIGHT 參數估計結果比較...34第五章 結論與建議...62
第一節 結論...62 第二節 改進建議...64參考文獻...66
中文部分...66 英文部分...67附錄一、常態與雙峰下,不同變項對 BILOG 參數估計之影
響...70
附錄二、常態與雙峰下,不同變項對 BILOG 參數估計之影
響...76
附錄三、常態與雙峰下,兩種軟體在不同變項的參數估計結
果...82
表次
表 2-1 BIB 設計範例...……….………12 表 3-1 BIB 設計表…….……….………21 表 3-2 題數設定一覽表…....……….………22 表 3-3 BIB 設計之變項對照表…….……….………23 表 4-1 常態下不同人數對 BILOG-MG 估計參數之比較………27 表 4-2 雙峰下不同人數對 BILOG-MG 估計參數值之比較………28 表 4-3 受試者能力分布為常態時,BILOG-MG 的估計結果………29 表 4-4 受試者能力分布為雙峰時,BILOG-MG 的估計結果………29 表 4-5 常態下不同人數對 SCORIGHT 估計參數值之比較………32 表 4-6 雙峰下不同人數對 SCORIGHT 估計參數值之比較..…………..…………33 表 4-7 受試者能力分布為常態時,SCORIGHT 的估計結果.………34 表 4-8 受試者能力分布為雙峰時,SCORIGHT 的估計結果.………34 表 4-9 常態下兩種軟體在不同受試人數中對參數估計值之比較(1)…….………37 表 4-10 常態下兩種軟體在不同受試人數中對參數估計值之比較(2)…….………38 表 4-11 常態下兩種軟體在不同受試人數中對參數估計值之比較(3)…….………39 表 4-12 常態下兩種軟體在不同受試人數中對參數估計值之比較(4)…….………40 表 4-13 雙峰下兩種軟體在不同受試人數中對參數估計值之比較(1)….…………43 表 4-14 雙峰下兩種軟體在不同受試人數中對參數估計值之比較(2)….…………44 表 4-15 雙峰下兩種軟體在不同受試人數中對參數估計值之比較(3)….…………45 表 4-16 雙峰下兩種軟體在不同受試人數中對參數估計值之比較(4)….…………46 表 4-17 常態下,兩種軟體估計結果之比較……….………61 表 4-18 雙峰下,兩種軟體估計結果之比較……….………61圖次
圖 3-1 研究流程圖………...17 圖 3-2 受試人數分別為 5460 人與 7566 人之常態分布統計圖………...18 圖 3-3 受試人數分別為 5460 人與 7566 人之雙峰分布統計圖………...19 圖 4-1 常態下兩種軟體在不同受試人數中,對受試者能力參數之估計誤差圖 41 圖 4-2 常態下兩種軟體在不同受試人數中,對試題鑑別度參數之估計誤差圖 41 圖 4-3 常態下兩種軟體在不同受試人數中,對試題難度參數之估計誤差圖….42 圖 4-4 常態下兩種軟體在不同受試人數中,對試題猜測度參數之估計誤差圖 42 圖 4-5 雙峰下兩種軟體在不同受試人數中,對受試者能力參數之估計誤差圖 47 圖 4-6 雙峰下兩種軟體在不同受試人數中,對試題鑑別度參數之估計誤差圖 47 圖 4-7 雙峰下兩種軟體在不同受試人數中,對試題難度參數之估計誤差圖….48 圖 4-8 雙峰下兩種軟體在不同受試人數中,對試題猜測度參數之估計誤差圖 48 圖 4-9 態下兩種軟體在不同題數中,對受試者能力參數之估計誤差圖……..…49 圖 4-10 常態下兩種軟體在不同題數中,對試題鑑別度參數之估計誤差圖….…49 圖 4-11 常態下兩種軟體在不同題數中,對試題難度參數之估計誤差圖...………50 圖 4-12 常態下兩種軟體在不同題數中,對試題猜測度參數之估計誤差圖....…...50 圖 4-13 雙峰下兩種軟體在不同題數中,對受試者能力參數之估計誤差圖.……51 圖 4-14 雙峰下兩種軟體在不同題數中,對試題鑑別度參數之估計誤差圖…….51 圖 4-15 雙峰下兩種軟體在不同題數中,對試題難度參數之估計誤差圖…….…..52 圖 4-16 雙峰下兩種軟體在不同題數中,對試題猜測度參數之估計誤差圖…….52 圖 4-17 常態下兩種軟體在不同題組數比例中,對受試者能力參數之估計圖…...53 圖 4-18 常態下兩種軟體在不同題組數比例中,對試題鑑別度參數之估計誤差 圖…....………...53 圖 4-19 常態下兩種軟體在不同題組數比例中,對試題難度參數之估計誤差圖 54 圖 4-20 常態下兩種軟體在不同題組數比例中,對試題猜測度參數之估計誤差 圖….………..………54 圖 4-21 雙峰下兩種軟體在不同題組數比例中,對受試者能力參數之估計誤差 圖…….………..………55 圖 4-22 雙峰下兩種軟體在不同題組數比例中,對試題鑑別度參數之估計誤差 圖…..………...……….…… 55 圖 4-23 雙峰下兩種軟體在不同題組數比例中,對試題難度參數之估計誤差 圖…..………...……….…….……56 圖 4-24 雙峰下兩種軟體在不同題組數比例中,對試題猜測度參數之估計誤差 圖..………...……….….………56 圖 4-25 常態下兩種軟體在不同題組效果變異數中,對受試者能力之估計誤差 圖…..………...……….….…57 圖 4-26 常態下兩種軟體在不同題組效果變異數中,對試題鑑別度之估計誤差 圖…...………..………..…57圖 4-27 常態下兩種軟體在不同題組效果變異數中,對試題難度之估計誤差 圖….………..58 圖 4-28 常態下兩種軟體在不同題組效果變異數中,對試題猜測度之估計誤差 圖…….………..………58 圖 4-29 雙峰下兩種軟體在不同題組效果變異數中,對受試者能力之估計誤差 圖…….………..…59 圖 4-30 雙峰下兩種軟體在不同題組效果變異數中,對試題鑑別度之估計誤差 圖…….………..……59 圖 4-31 雙峰下兩種軟體在不同題組效果變異數中,對試題難度之估計誤差 圖….……….….…60 圖 4-32 雙峰下兩種軟體在不同題組效果變異數中,對試題猜測度之估計誤差 圖….………..…60
第一章 緒論
本研究是以電腦模擬資料的方式,探討題組與單題混合測驗,在平衡不完全 區塊設計(balanced incomplete block design, BIB)下,兩種軟體對試題及能力參數 估計效果之比較。此章將針對研究動機、研究目的、研究問題與重要名詞解釋來 進行闡述。
第一節 研究動機
早在數千年前,中國為了選拔人才,早已有了考試制度,只是當時未建立理 論學派,直至近代的心理計量學才由國外發展起來。也隨著需求的不同,發展出 各式不同目的的測驗,像是入學考試、人格測驗、性向測驗、成就測驗等等,不 勝枚舉,所以我們的生活與測驗脫離不了關係。 而教育測驗內容中,又包含了許多不同種類的試題類型,像是選擇型試題測 驗與補充型試題測驗,其中選擇型試題更是被廣泛應用在國、內外各式測驗中。 但也觀察到測驗內容中,題組型的試題也普遍使用在各類的大型測驗中,例如: 我國的國中基本學力測驗、大學入學考試、托福測驗及國際學生評量計畫
(Programme for International Student Assessment,簡稱 PISA)等(許思雯,2008)。 主要是因為題組型的試題有較優於傳統的單選題測驗功能,Haladyna(1992) 提出題組能有效運用於測量不同類型的高層次思考,也可應用在各式測驗題型, 如是非題、選擇題或結構反應題。Ebel(1951)曾提出情境依賴試題組(context--dependent item set)減少了客觀式選擇題只能測量受試者記憶能力的限制,而測得 受試者較高層次的學習成果,基於上述原因所以題組型的試題已被廣泛應用於測 驗中。
在目前的測驗中,我們最迫切的是想了解學生學習成就表現及其差異,但是 因為國內長期缺乏量化指標和標準化測量工具,無法確實瞭解課程實施的成效, 對於課程發展之進行與相關教育政策之研擬進行也會遭遇困難。而臺灣目前在教
育研究工作上重要貢獻是建立「臺灣長期追蹤教育資料庫」 (Taiwan Education Panel Survey,簡稱TEPS),資料庫是不可或缺的,主要功能是適時提供正確、完 整的資料,經過適當的整合或分析這些資料之後,可以提供相關資訊,研究教育 的各項改變與成長進步,還能檢示教育的缺失,進一步探討教師的教學成效、學 生學習成長、行政效率等各方面的因素或是問題的癥結所在。多項議題的研究成 果是利用此資料庫的資料所完成的,若能仔細深究大型資料庫的功能與價值,可 以提供教育工作者作為改進的方向、教育方針的決策人員能做為未來政策方向規 劃或改進,因此了解教育資料庫所提供的資訊,是非常的重要。雖然上述TEPS 的經驗對於國內未來要建置大型資料庫提供了很多幫助,但是TEPS也只是眾多種 類的一種資料庫(彭森明,2003)。 在如此眾多種類的資料庫中,我們卻未找到針對全國國小、國中、高中學生 的學習成就做一長期性的研究,無法提供學生的學習成效,也尚無跨年級、跨學 科之學生學習成就長期性的資料庫,國內專家學者或學術單位也無法進行研究。 而國際間的互動日益密切與頻繁,需要能客觀的進行國際比較且量化,因此建置 一完整且客觀的學生學習成就資料庫極為迫切,因此而有了「臺灣學生學習成就 評量資料庫」 (Taiwan Assessment of Student Achievement ,簡稱 TASA )的產生 (TASA,2004)。
大型的教育測驗目的當然是想了解學生學習成效,但使用不同的測驗軟體來 估計不同的組卷方式,所獲得的學生能力參數及試題參數也會有所差異,而在荷 蘭的 PPON(Periodiek Peilingsonderzoek van het Onderwijs)、美國國家教育進展評 量(National Assessment of Educational Progress, NAEP)以及上述 TASA 的建置計畫 皆採用 BIB 設計(王暄博,2006)。但測驗內容若包含題組式的測驗,會違反試題 反應理論的局部試題獨立的假設,也會造成參數估計的誤差,而 BILOG-MG 是 適用試題反應理論,SCORIGHT 可用來估計題組題,因此試題中若是題組與單題
應理論為基礎,探討題組與單題混合測驗,在 BIB 設計不同測驗組合下,利用上 述二種軟體進行試題及能力參數估計效果之比較。希望能貢獻ㄧ己之力,提供 TASA 相關訊息,進行參數估計時的參考資料,以供國內外相關研究人員深入探 討學生學習成就方面的相關議題,來建立更完善、健全的資料庫。
第二節 研究目的與問題
本研究是利用電腦模擬資料,探討題組與單題混合測驗,在平衡不完全區塊 設計下,操弄不同的施測人數、測驗題數、題組比例、題組效果變異數此四種變 項,比較 BILOG-MG、SCORIGHT 此二種軟體估計受試者能力參數及試題參數 的精準度。在受試者能力分布為常態與雙峰的情形下,所要探討的研究目的如下:1. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同施測人數的情 況下,對受試者能力參數及試題參數估計的差異。 2. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同測驗題數的情 況下,對受試者能力參數及試題參數估計的差異。 3. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同題組比例的情 況下,對受試者能力參數及試題參數估計的差異。 4. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同題組效果變異 數的情況下,對受試者能力參數及試題參數估計的差異。 根據以上之研究目的,在受試者能力分布為常態與雙峰的情形下,本研究擬探討 之問題為: 1. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同施測人數的情 況下,對受試者能力參數及試題參數估計有何差異?
2. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同測驗題數的情 況下,對受試者能力參數及試題參數估計有何差異? 3. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同題組比例的情 況下,對受試者能力參數及試題參數估計有何差異? 4. 以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同題組效果變異 數的情況下,對受試者能力參數及試題參數估計有何差異?
第三節 名詞釋義
一、題組
就試題結構而言,題組是指包含一個段落、圖表或其他刺激材料,並在訊息 後跟隨著一些試題,受試者必須依賴相同的訊息,來作答反應一連串的問題(許思 雯,2008)。
二、資料庫
資料庫是蒐集原始資料,原始資料中可記錄各種的調查、評量或觀察結果以 及個人背景狀況等。這些資料原始可能記錄在簿冊裡,為了要加以保存,最後存 放在電腦檔案裡。這些資料或許是個人或各單位的描述,但經過統合整理分析 後,可以從中獲得一些因素之間的關係或因果。因此原始資料是資訊的來源,再 整合與分析延伸出來的資訊,更能加以利用。 一般說來,資料庫可分成兩類: (一)行政資料(administrative records): 行政資料指的是個人記錄,比如人事 資料、學生學籍資料、學校財政資料等。這些資料可利用電腦作統一管理,齊全(二)研究型資料(research-oriented database):這類型的資料可能是針對特定的 教育議題而收集的資料,也可用來探討多種不同議題的資料檔,國內的TEPS即是 一例,作為改進教育的方針(彭森明,2003)。
三、TASA
(TASA,2004
)「臺灣學生學習成就評量資料庫」 (Taiwan Assessment of Student
Achievement ,簡稱 TASA ) 是由一群測驗與學科專家共同研發「標準化成就測 驗」,來蒐集國內國小四年級、六年級、國中二年級、高中二年級及高職二年級 學生在國語、英語、數學、社會、自然這五個科目的學習成就表現,所建立之資 料庫。研究結果可作為教育決策單位政策調整及教師教學的參考依據,也可提供 國內外教育研究人員整體性且標準化的量化資料,作為探討學生學習成就的客觀 統計資料。
四、估計誤差
本研究將模擬 25 次的平均值作為估計誤差,若所計算出的估計誤差值越 小,代表估計越準確。將模擬生成的參數視為真值,及由 BILOG-MG 和
SCORIGHT 此二種軟體所估計出的能力與試題數值,計算均方根誤差(root mean square error, RMSE),本研究估計受試者能力參數誤差的公式計算如下:
N RMSE N i i i
1 2 ) ˆ ( ) ˆ , ( 其中,N:表示受試者人數; ) ,..., , , (1 2 3 N :表示受試者能力真值; ) ˆ ,..., ˆ , ˆ , ˆ ( ˆ 1 2 3 N :表示表示受試者能力估計值。另外本研究估計試題參數誤差的公式計算如下: L l l l l RMSE L i i i
1 2 ) ˆ ( ) ˆ , ( 其中,L:表示試題題數; ) ,..., , , (l1 l2 l3 lN l :表示試題參數真值; ) ˆ ,..., ˆ , ˆ , ˆ ( ˆ 3 2 1 l l lN l l :表示試題參數估計值。第二章 文獻探討
本研究主要探討不同的軟體在 BIB 設計測驗組合下,試題及能力參數估計的 差異比較。因此本章將分成三節加以說明:第一節說明試題反應理論;第二節題 組的介紹;第三節探討 BIB 設計;第四節主要使用的軟體介紹。
第一節 試題反應理論
試題反應理論(item response theory)建立在兩個基本概念上:(1)考生(examinee) 在某一測驗試題上的表現情形,可由一組因素來加以預測或解釋,這組因素叫作 潛在特質(latent traits)或能力(abilities);(2)考生的表現情形與這組潛在特質間的關 係,可透過一條連續性遞增的函數來加以詮釋,這個函數便叫作試題特徵曲線 (item characteristic curve,簡寫為 ICC)。
試題反應理論具有下列幾項基本假設,唯有在這些假設都成立的前提下,試 題反應模式才能被用來分析所有的測驗資料。將此四項基本假設介紹如下(Weiss & Yoes, 1991;余民寧,1992a):
(一)單向度(unidimensionality):
一般在教學現場所施測的測驗,影響學生作答的反應可能有許多因素存在, 試題反應理論中認為只要此測驗具有能夠影響測驗結果的一個「主要成份或因 素」(dominant component or factor),便算符合單向度假設的基本要求,各試題也 都是測量到同一共同的能力或潛在特質。 (二)局部獨立性(local independence): 當影響測驗表現的能力被固定時,考生在試題的作答情形是不互相影響的, 也就是說,在考慮考生的能力因素後,考生在不同試題上的反應間沒有任何關係 存在,表示在試題反應模式裡的受試者能力因素,是影響考生在測驗試題上做反 應的唯一因素。 (三)非速度測驗:
試題反應模式的基本假設是測驗的實施不是在速度限制下完成的;如果考生 的考試成績不理想,不是由於時間不夠答完所有試題所致,是因為能力不足所導 致的。 (四)知道——正確假設(know--correct assumption): 如果考生知道某一試題的正確答案,一定會答對該試題;也就是如果受試者 答錯某一試題,一定不知道該試題的答案,而不考慮人為的填答疏失錯誤。
因本研究的模擬題型為選擇題,根據 Hambleton,Zeal & Pieters(1991)的研究, 測驗題型若為四選一的選擇題,是較適合三參數對數模式。故採用試題反應理論 中三參數對數模式作為測驗資料分析的方法。以下為三個參數對數模式
(three-parameter logistic model),模式之簡介(Baker, 1992;Hambleton & Swaminathan,1985;Mislevy & Bock, 1990)如下所示:
( ) ) ( 1 ) 1 ( ) ( i i i i b a b a i i i e e c c P i1,2,,n 公式一 其中,Pi()表示任何一位能力為 的考生答對試題i或在試題i上正確反應的 機率;bi表示試題難度(difficulty)參數;n是該測驗的試題總數;e代表以底為 2.718 的指數;試題鑑別度(item discrimination) ai,是用來描述試題i所具有鑑別力大 小的特性。公式 一與二參數 對數形模式 相較,只多出一 個參數:機 運參數 (pseudo-chance parameter) ci。這個參數提供試題特徵曲線一個大於零的下限,表 示能力很低的考生答對某試題的機率。所以三個參數對數形模式是由二個參數對 數形模式延伸演變而來,是多增加一個參數ci,把低能力考生的表現好壞因素也 考慮在模式裡,而猜題可能是這些考生在某些測驗試題上唯一的表現行為(余民 寧,1992b)。 但是若題型為題組式的測驗,是具有局部試題依賴的特性,若使用試題反應
題參數會產生偏估的情況(Wainer,Sireci, & Thissen,1991;Wainer & Thissen,1996; Wainer & Lukhele,1997;Wainer&Wang,2000;Yen,1993) 。所以學者提出以題組 反應理論(testlet response theory,TRT)來分析題組的資料,其理論是由試題反應理 論所延伸出來的,詳細介紹請參照下節。
第二節 題組反應理論
約從 60 年代開始,是非題與選擇題的題型因過度強調學生的記憶能力,而 備受爭議,之後也歷經學校改革,希望能測量到學生高層次的思考能力。而 Ebel 曾在 1951 年提出情境依賴試題組(context-dependent item set),讓客觀式測驗題 型也能測量高階思考的能力與學習者較高層次的學習成果。
Haladyna(1992)在檢視許多情境依賴題組的研究後,也認為此種題型,不僅 適用在任何的測驗類型,如選擇題或建構反應題,還可以有效的測量到不同類型 的高層次思考。此外,Wainer 和Lewis (1990)也提到,在電腦化適性測驗
(Computerized Adaptive Test)中,單一試題的結構會產生情境效應(context
effects)、試題次序(item ordering)和內容平衡(content balancing)等問題。情境效應 的產生是指當某一試題的呈現會對次一試題的難度有所影響,若測驗建構的規則 未考慮試題的內容,就會產生依賴性(dependency)。一般測驗試題的編排應由簡 單排到困難,而試題次序的問題則是指違反了此規則。內容平衡問題係指電腦化 適性測驗在挑選試題時,可能會選擇到偏向某些主題,但這樣一來對於某些受試 者來說,或許是不公平的。 為了解決上述電腦化適性測驗所產生的問題,這些學者便提出以題組(testlet) 的方式來組織試題。他們認為以題組型來編製試題,可以解決電腦化適性測驗 中,單一試題所產生的問題。題組對於受試者而言,內容的呈現顯得較公平。有
上述這些優點,可以發現到題組的使用是越來越重要了(Lee, Brennan, & Frisbie, 2000)。 雖然不同學者使用不同名稱來稱此種測驗題型,如Ebel(1951)的解釋性作業 (interpretive exercises)、Cureton(1965)的超級試題(superitems)、Wainer 和 Kiely(1987)的題組(testlet)、或Yen(1993)的段落(passages) 等,但無論使用何種名 稱,這些學者皆認為此類的題型,能評量受試者分析思考和解決問題的能力,或 處理電腦化適性測驗中單一試題結構所造成的問題 (Allen & Sudweeks, 2001; Wainer & Lewis, 1990) 。
題組的定義也隨著不同學者的觀點而有所不同,例如Wainer 和Kiely(1987) 所提出的題組概念,是為了解決適性測驗所產生的選題問題,因此,他們將題組 (testlets)定義為,將一群和單一內容領域有關的試題組合成一個單位,此一單位 包含固定數量的預定路徑(predetermined paths),受試者便可依照此預定的路徑來 進行測驗。Wainer和Lewis(1990)提出將題組當成一個小測驗,小到能讓試題編製 者操弄,又大到可以包含題組本身的內容。 由於題組形式不僅可以適用於多種試題類型上,並能測量高層次思考,還能 解決電腦化適性測驗的單一試題結構問題,因此,目前許多大型的標準化成就測 驗或國家證照考試,皆採用該種測驗類型來評量學生的成就。如美國國家教育進 展評量(National Assessmentof Educational Progress,簡稱NAEP)、國際閱讀素養進 展研究(Progress in International Reading Literacy Study,簡稱PIRLS)、國際學生評 量計畫(Programme for International Student Assessment,簡稱PISA)等大型評量; 我國的國中基本學力測驗和大學入學考試;托福測驗或英語檢定測驗等,皆使用 了題組的測驗形式(許思雯,2008)。
由上述可知題組在測驗中所扮演的角色愈趨重要,故本研究中試題的類型加 入了題組,以符合現今的測驗的趨勢。
試題反應理論分析題組式測驗所造成參數偏估的問題。Bradlow 等人(1999)將 Birnbaum(1968)所提出的二參數模式(two-parameter logistic model, 2PLM)加入一 個隨機效果,而演變成二參數題組模式(two-parameter testle model, 2PTM),而後 Bradiow、Wainer 和 Du (2000)將二參數題組模式加入猜測度參數,成為三參數題 組模式(three-parameter testle model,3PTM)。所以題組反應理論是由試題反應理論 演變,三參數題組模式計算方式為: )] ( exp[ 1 )] ( exp[ ) 1 ( ) ( ) ( i jd i j i i jd i j i i i i b a b a c c P 公式二 jd(i) ~ N(0,2rd(i)) 其中,j代表第 j位受試者能力參數,ai、bi、ci分別代表第i題試題的鑑別 度、難度參數及猜測度,jd(i)是指第 j個人在第d(i)個題組上的隨機效果。 ) ( 2 i rd 可視為題組效果的變異程度,當題組效果2rd(i)愈大,表示題組內試題 的依賴比例愈高。當猜測度為 0 時,公式二則會縮減為二參數題組模式,當猜測 度為 0 且鑑別度參數為 1 時,公式二又可再縮減為 Wang & Wilson(2005)所提出 的 Rasch 題組模式。又當題組效果為 0 時,Rasch 題組模式又可縮為單參數模式。 以上這些題組反應模式的公式,是可用以估計受試者的能力值及受到題組所影響 的程度。
第三節 BIB 設計簡介
BIB 設計是將試題分成若干試題區塊,區塊間與區塊內的試題皆不重複,受 試者只需接受若干試題區塊的試題,且不同受試者可能接受部分相同、完全相 同、或完全不同的試題區塊。最後,將所有受試者的作答反應資料堆疊進行分析,以達到能力估計的目的。BIB 設計如表2-1。 表2-1 BIB 設計範例 題本序號 區塊(k1) 區塊(k2) 區塊(k3) S1 M1 M2 M4 S2 M2 M3 M5 S3 M3 M4 M6 S4 M4 M5 M7 S5 M5 M6 M1 S6 M6 M7 M2 S7 M7 M1 M3 表2-1為BIB 設計的一個範例,在此設計中,有7 個題本(S1~S7);7 個試題 區塊(M1~M7)。BIB 設計中試題區塊序號的組合不重複,如:S1 題本是由試題 區塊M1、M2、M4 組合而成,則表中其他題本(S2~S7)就不會再出現試題區塊M1、 M2、M4 的組合(曾玉琳、王暄博、郭伯臣、許天維,2006)。 BIB 設計的優點為試題區塊與題本(booklet)的配置方式,使用螺旋(spiral)式 排列方式,可使每一個試題區塊的施測次數相同(van der Linden, Veldkamp &Carlson, 2004;Nemhauser & Wolsey, 1999)。
美國的NAEP 和荷蘭的PPON(Periodiek Peilingsonderzoek van het Onderwijs) 即依據BIB 設計的原則。這個設計假設題庫中的試題被區分為數個區塊,並利用 這些試題區塊編製成題本,題本根據最小單位,經由螺旋排序並束在一起(spiraled and bundled)的方式確保每一試題區塊出現的次數均等。在區分試題區塊的過程不 需為隨機分配,但必須考量受試者可以有足夠的時間作答完所有的試題,並確定 試題對受試者是實用的。另外,根據NAEP 1998 年的技術性報告中指出,每一試 題在施測時,大約需要500 個測試樣本(Allen, Donoghue & Schoeps, 2001)。
1. 每一個題本內的試題區塊數要相同; 2. 試題區塊作結合要組合成最小的題本數; 3. 每一個試題區塊出現在所有題本的次數要相同。 不過這只是BIB 設計必須符合的三項基本限制,但在實際實施測驗時,還需注意 試題的內容、編排、形式及作答時間等等。 BIB設計的優缺點 (一)BIB 設計的優點 1. 試題區塊與題本採螺旋式排列,雖然有非共同試題的題本,但依然可進行等化 的連結或分析; 2. 不會有某些區塊出現的次數較多,因此不會造成有些題目過度曝光。 3. 每題試題的作答人數均相等,試題平均分配施測; 4. 若需進行題本公布時,不會公布到所有的定錨試題。 (二)BIB 設計的缺點 1. 不易尋找到題本與試題區塊的配置方式; 2. BIB 設計等化要達到較佳的等化效果,必須要有夠多的施測人數及定錨試題 數。(王暄博,2006) 本研究測驗即採用BIB設計進行模擬研究,將試題分成若干試題區塊,使用 每個題本配置若干個試題區塊來進行施測。
第四節 估計參數的軟體介紹
一、BILOG-MG
BILOG-MG由Mislevy & Zimowski & Muraki & Bock所發展的套裝軟體,是適 用於二元計分試題對數模式,能處理單參數、二參數及三參數模式的資料,作為
計,將所有題本之作答結果全部放置一起,然後同時進行參數估計,如此一來, 所有試題參數估計值便會放在相同的量尺上,而且受試者能力估計值也可在相同 量尺作比較。
在試題參數的估計上,是使用邊際最大概似估計(Margin Maximum Likelihood Estimate,簡稱 MMLE)法;而在能力參數的估計上,使用的估計方法最大概似估 計法、期望後驗(Expected a Posteriori,簡稱 EAP)估計法和最大後驗(Maximum a Posteriori,簡稱 MAP)估計法三種(趙素珍,1997、1998)。
IRT 模式的軟體中提供三種估算受測者能力的方法,介紹如下(Zimowski, Muraki, Mislevy, & Bock, 2003;楊孟麗、譚康榮、黃敏雄,2003):
1.最大概似估計法(Maximum Likelihood Estimation,簡稱MLE)是根據原始 的資料,估算出最有可能的母群體參數。也就是以現有的資料所呈現的模式,利 用統計方法找出最有可能出現這種答題模式的受試者的能力值。若試題中和受試 者的能力相當的題數較多或少時,該受試者能力的測量標準誤就會跟著較小或較 大。MLE 的缺點:當受試者全部答對或全部答錯測驗中的所有試題時,MLE 將 無法估算其能力程度。
2. Expected A Posteriori 估算(簡稱EAP) 能克服上述缺點,就算是受測者答對 或答錯所有的題目,可由EAP 估計其受試者能力。其方法是利用測驗的答題模式 來「修改」受測者先前假定的能力分布後,得到的新分布中的平均值,。而EAP 的 缺點是:它所估得的值較集中在母群體的平均值附近,但若其標準誤很小時,這 個誤差也很小。
3. Maximum A Posterior 估算(簡稱 MAP) 與 EAP 相類似,即使受試者得滿 分或得零分,也可以估算其相對的能力。其方法用的是新分布的眾數,除了最大 概似估算法(MLE)中的資料分布之外,也將參數原有(或假定)的分布納入考 量。但 MAP 也較偏向集中於母群體的平均值,誤差比 EAP 稍大。
題參數及能力參數的估計方法。
二、SCORIGHT
SCORIGHT(Wang, Bradlow, & Wainer, 2005)是一種很普遍的計算機程式,適 用試題反應理論的模式,試題內容可以各自獨立,或是題組,或是單一試題和題 組的組合,可用於二元或多元計分的試題模式,能分析包含題組的試題反應資 料。在估計參數方面,SCORIGHT 是使用馬可夫鍊蒙地卡羅(Markov chain Monte Carlo,簡稱 MCMC)的估計方法。
以下對於 MCMC 的估計方法做概略的簡述,MCMC 是屬於一種貝氏的估計 法,此優點為若取得後驗樣本的分配,即可容易完成推論。此方法是透過重複抽 樣的方式,獲得一個平穩分布,也就是馬可夫鍊(Markov chain )。Wainer、Bradlow 和 Wang(2007)以二參數題組模式來檢視 MCMC 的演算過程,以Λ代表模式的參 數,以 a1,………,aJ 代表試題鑑別度、b1,…….,bJ 代表難度參數等,θ1,……,θI 表受試者能力參數,γ1d(1),……, γId(J) 表題組參數,以及影響參數分配的(μa, σa2)、 (μb,σb2) 與σγ2,估計步驟如下: 步驟 1. 選擇一個起始的向量, ( 0) t ,t代表佚代數,將t設為 0,根據 Wainer 等人指出 MULTILOG 與 BILOG 軟體的估計結果可以提供給 MCMC 很 好的起始值,能夠加速收斂到穩定分配。 步驟 2. 選擇某參數的組合1,並藉由條件分布 ( 1 , () ) 1 t Y p ,抽取更新值(1t1), 估計第t次的值,其中 () 1 t 代表這個向量包含1這些參數,Y 代表所 觀察的向量資料。 步驟 3. 選擇某參數的組合2,並藉由條件分布 ( , ) ) 1 ( 1 ) ( , 2 1 2 t t Y p ,抽取更新 值 ( 1) 2 t ,估計第t次的值,其中 () , 2 1 t 代表這個向量包含1和2這些 參數,而 (t1)是由步驟 2 更新 所得到的值。
步驟 4. 從條件分配 ( () , , 1( 1), (2 1)) 2 1 t Y t t p 中抽取 ( 1) , 2 1 t ,並讓t t1 步驟 5. 若t M(特別指定的佚代數),再從步驟 2 重複這些順序,直到t M才停 止。 最後使用 F 檢定,來確認是否達到收斂,並計算後驗分配的平均數,來進行 推論。(引自顏秀聿,2009)
第三章 研究方法
第一節 研究架構
本研究是利用電腦模擬資料,探討探討題組與單題混合測驗,在平衡不完全
區塊設計(balanced incomplete block design, BIB)下,當受試者能力分布為常態或 雙峰時,操弄不同的施測人數、測驗題數、題組比例、題組效果變異數此四種變 項,比較 BILOG-MG、SCORIGHT 此二種軟體估計受試者能力參數及試題參數 的精準度。
-3.000 -2.000 -1.000 0.000 1.000 2.000 3.000 V1 0 100 200 300 400 次 數 Mean = 1.30326E-4 Std. Dev. = 0.986792 N = 7,566 -2.000 -1.000 0.000 1.000 2.000 V1 0 50 100 150 200 250 300 次 數 Mean = 0.00249 Std. Dev. = 0.917468 N = 5,460 設定模擬資料如下: (一)人數:因 TASA 計畫的受測人數 10000 人與 7500 人兩種,本研究欲探 討減少人數是否會對參數估計精準度造成影響,故設定此研究之模擬 施測人數為 5460 人、 7566 人。 (二)試題長度:題本施測題數為27題、45題,每個題本配置的試題區塊數 3。 所以每個試題區塊數的試題數為9題、15題。 (三)受試者群能力分布:截尾常態分布N(0,1) ,範圍− 3 ~ 3。 雙峰分布,範圍− 3 ~ 3。(王暄博,2006) 在不同受試人數中,隨機各選取一筆原始資料,分別 將能力值繪製成常態與雙峰分布統計圖,如圖3-2與 3-3。 圖3-2受試人數分別為5460人與7566人之常態分布統計圖
-3.000 -2.000 -1.000 0.000 1.000 2.000 3.000 V1 0 50 100 150 200 250 次 數 Mean = 0.00857 Std. Dev. = 1.149398 N = 5,460 -3.000 -2.000 -1.000 0.000 1.000 2.000 3.000 V1 0 50 100 150 200 250 300 次 數 Mean = 8.59459E-5 Std. Dev. = 1.195938 N = 7,566 圖3-3受試人數分別為5460人與7566人之雙峰分布統計圖 (四)題組效果變異數:0、0.5、1 (五)題組比例:前三分之一題數為題組,後三分之二題數為單題 前三分之二題數為題組,後三分之一題數為單題
第二節 研究工具
本研究所使用的主要軟體為 BILOG-MG、SCORIGHT 及 MATLAB 軟體,簡 介如下:
一、BILOG-MG
BILOG-MG 由 Mislevy & Zimowski & Muraki & Bock 所發展,能處理單 參數、二參數及三參數模式的資料,是適用於估計二元計分試題對數模式之能力 及試題參數的軟體。本研究採用此軟體估計受試者的能力參數及試題參數。
二、SCORIGHT
SCORIGHT(Wang, Bradlow, & Wainer, 2005)適用於二元計分或多元計分的試 題類型,或是試題反應理論的模式,也可分析題組型的試題資料。本研究採用此 軟體估計受試者的能力參數及試題參數。
三、MATLAB 軟體
MATLAB 是由 Math Works 公司於 1984 年所開發出來的一套數學軟體,功能 眾多且編輯簡易,能做為系統模擬、矩陣運算、繪製圖像等等,應用的領域十分 廣泛。本研究透過此軟體模擬 BIB 設計下的受試者的能力參數、試題參數和作答 反應,並進行資料檔案的轉換。
第三節 BIB 設計
壹、BIB 設計
表 3-1 BIB 設計表 題本 序號 區塊 (k1) 區塊 (k2) 區塊 (k3) 題本 序號 區塊 (k1) 區塊 (k2) 區塊 (k3) S1 M1 M10 M11 S14 M1 M4 M12 S2 M6 M8 M11 S15 M6 M10 M13 S3 M2 M6 M12 S16 M3 M7 M13 S4 M7 M9 M10 S17 M8 M9 M12 S5 M2 M7 M11 S18 M2 M4 M10 S6 M4 M6 M7 S19 M3 M5 M6 S7 M1 M7 M8 S20 M5 M8 M10 S8 M1 M6 M9 S21 M2 M5 M9 S9 M11 M12 M13 S22 M4 M9 M13 S10 M5 M7 M12 S23 M1 M5 M13 S11 M3 M9 M11 S24 M2 M8 M13 S12 M3 M10 M12 S25 M4 M5 M11 S13 M1 M2 M3 S26 M3 M4 M8資料來源:van der Linden & Veldkamp & Carlson,2004
表3-1 BIB設計係依據van der Linden, Veldkamp & Carlson(2004),共包含26 個題本,每個題本包含3 個試題區塊,共有13 個試題區塊。在單一題本中出現 的成對試題區塊次數只有1次,每一試題區塊在題本中出現的次數共為6次,次數 均相同。
貳、題數設定
因本研究想以模擬資料比較 BILOG-MG、SCORIGHT 此二種軟體,在不同 測驗題數變化的情況下對受試者能力及試題參數估計的差異,所以本研究模擬每 個題本施測試題分別為 27 題、45 題, 每個題本包含 3 個試題區塊數,故每個試 題區塊之試題數分別為 9 題、15 題;總試題長度分別為 117(9×13)題、195(15×13) 題。依上述題數將資料整理如表 3-2: 表 3-2 題數設定一覽表 題本施測題數 題本區塊數 試題區塊題數 總試題長度 27 3 9 117 45 3 15 195
參、人數設定
本研究欲探討減少人數是否會對參數估計精準度造成影響,因此設定此研究 之模擬施測人數為 5460 人、 7566 人。故可得每個題本受測人數分別為 210(5460/26)人、291(7566/26)人。肆、各模擬資料變項設定
關於試題參數和受試者能力參數之產生,分述如下。 一、試題參數的產生 1.鑑別度參數:為截尾常態分布,平均數為1,標準差為0.25,將範圍界定於 0.5 ~1.5 ,記為N(1,0.25)。 2.難度參數:為截尾常態分布,平均數為0,標準差為1,將範圍界定於− 3 ~ 3, 記為N(0,1)。 3.猜測度參數:為截尾常態分布,平均數為 0.125,標準差為 0.0625,將範圍 界定於 0 ~ 0.25 ,記為 N(0.125,0.0625)。 二、能力參數的產生受試者能力分布為截尾常態分布(truncated normal distribution),平均數為0, 標準差為1,將範圍界定於− 3 ~ 3,記為N(0,1)。
受試者能力分布為雙峰分布,取自兩個常態分布平均數各為2與-2、標準差皆 為1隨機產生,再標準化組成,其平均數為0,標準差為1,將範圍界定於-3~3。 就以下述表格 3-3 做整體說明:
表 3-3 BIB 設計之變項對照表 軟體 BILOG-MG SCORIGHT 題本所含的題數 27 題、45 題 題本所含的區塊數 3 個 題本試題長度 117 題、195 題 題組比例 前三分之一題數為題組,後三分之二題數為單題 前三分之二題數為題組,後三分之一題數為單題 施測人數 5460 人、7566 人 受試者能力分布 常態截尾分布 N(0,1),範圍-3~3 雙峰分布,取自兩個常態分布平均數各為2與-2、標準差皆 為1隨機產生,再標準化組成,其平均數為0,標準差為1, 將範圍界定於-3~3。 鑑別度(a)-截尾常態分布N(1,0.25), 範圍0.5 ~ 1.5 難度(b)-截尾常態分布 N(0,1) , 範圍− 3 ~ 3 試題參數分布 猜測度(c)-截尾常態分布 N(0.125,0.0625) , 範圍 0 ~ 0.25 每一情形模擬次數 25 次 (能力及試題參數設定值的資料來源:王暄博,2006)
第四章 研究結果與討論
本研究以 RMSE 作為參數估計之誤差,依此來評斷比較 BILOG-MG、 SCORIGHT 此二種軟體估計受試者能力參數及試題參數的精準度。因此,本章共 分為三節,第一節為 BIB 設計下 BILOG-MG 估計結果,第二節為 BIB 設計下 SCORIGHT 估計結果,第三節為 BILOG-MG 與 SCORIGHT 估計結果綜合比較。 詳述如下。
第一節 BIB 設計下 BILOG-MG 估計結果
此節主要是探討當受試者能力分布為常態和雙峰分布情形下,以 BILOG-MG 此軟體進行各項參數估計,是否會受到人數、題數、題組數和題組效果變異數的 不同,而影響各項參數估計的精準度。 為了比較上述四種變項對參數估計的影響,將在 BIB 設計中 BILOG-MG 估 計結果之 RMSE 整理成表 4-1、4-2 及附錄一,結果與討論如下: 一、受試者能力分布為常態 (一) 以不同施測總人數來看,總人數分為5460人和7566人情形下,固定測驗 題數、題組比例及題組效果變異數時,可以歸納出不論是受試者能力值或試題參 數中的鑑別度、難度與猜測度,受試者人數較多的各項估計誤差值均比受試者人 數較少的值為低,因此可推論人數越多估計越精準,此結果與預期結果和王暄博 (2006)相符合。 (二) 以不同施測題數來看,題數分為 27 題和 45 題的情形下,固定測驗人數、 題組比例及題組效果變異數時,可以歸納出若改變題數,不論是受試者能力值或 試題參數,估計誤差值均隨著題數增加而減少,因此可推論題數越多估計越精 準,與預期結果相符。 (三) 以不同題組比例來看,題組比例為1/3和2/3的情形下,固定測驗人數、隨著題組比例的增加而增加。但由數據可以歸納出估計誤差值並不隨著題組比例 增加而增加,即題組比例增加,受試者能力參數及試題參數中試題鑑別度與難度 估計誤差並無顯著差異,而試題猜測度估計誤差還大多隨著題組比例增加而減 少。推論或許題組比例的增加,並不會影響BILOG-MG的估計結果。 (四) 以不同題組效果變異數來看,題組效果變異數為0、0.5和1的情形下, 固定測驗人數、題數及題組比例時,可以歸納出改變題組效果變異數,受試者能 力參數估計誤差會隨著變異數增加而增加,即題組效果變異數為0時,受試者能 力參數估計誤差最小,與預期結果相符。但從題組效果變異數來看試題參數時, 發現改變題組效果變異數時,對於試題鑑別度參數並無一致的結果。不過當題組 效果變異數為0時,試題猜測度參數的估計誤差最小;當題組效果變異數為0.5時, 難度參數的估計誤差大多為最小。 二、受試者能力分布為雙峰 (一) 以不同施測總人數來看,總人數分為 5460 人和 7566 人情形下,固定測 驗題數、題組比例及題組效果變異數時,可以歸納出不論是受試者能力值或試題 參數中的鑑別度、難度,受試者人數較少的各項估計誤差值均比受試者人數較多 的值低,即人數越少估計越精準。但猜測度的部份是人數越多估計越精準,但猜 測度的估計誤差也僅只有約 0.001~0.003 的差距而已。 BILOG-MG 在受試者能力分布為雙峰時,估計結果大多是受試者人數較少的 各項估計誤差值較小,推測原因可能是受試人數較少時,所產生估計誤差的標準 差較小,數值較為集中,所以較為準確。 (二) 以不同施測題數來看,題數分為27題和45題的情形下,固定測驗人數、 題組比例及題組效果變異數時,可以歸納出若改變題數,受試者能力或試題參 數,估計誤差值均隨著題數增加而減少,因此可推論題數越多,估計越精準,符 合預期的估計結果。
題數及題組效果變異數時,可以歸納出受試者的能力參數估計誤差大多隨著題組 數增加而減少,即題組比例增加,受試者能力參數估計誤差較為準確,與預期的 結果相同。但其他估計誤差值並不隨著題組比例增加而減少,即題組比例增加, 試題參數估計誤差並無一定的規律。推測可能是因為題組比例的增加,並不會影 響BILOG-MG的估計試題參數結果。或是能力分布為雙峰時,所造就的估計結果。 (四) 以不同題組效果變異數來看,題組效果變異數為0、0.5和1的情形下, 固定測驗人數、題數及題組比例時,可以歸納出改變題組效果變異數,受試者能 力參數估計誤差會隨著變異數增加而增加,即題組效果變異數為0時,受試者能 力參數估計誤差最小,與預期結果相符。但從題組效果變異數來看試題參數時, 發現改變題組效果變異數時,對於鑑別度參數的估計誤差並無一致的結果;在題 組效果變異數為0.5時,難度參數估計誤差最小;任一題組效果變異數,對於猜測 度參數的估計誤差來說,估計誤差僅只有些微的差距,大多相等。此結果與能力 分布為常態時,相類似,或許改變題組效果變異數對於BILOG-MG的估計結果差 異不大。
表 4-1 常態下不同人數對 BILOG-MG 估計參數值之比較 RMSE(SD) 題 數 題 組 比 例 題 組 效 果 變 異 數 人數 能力值 鑑別度 難度 猜測度 5460 0.402(0.014) 0.495(0.072) 0.360(0.112) 0.049(0.004) 0 7566 0.388(0.009) 0.489(0.095) 0.227(0.085) 0.047(0.004) 5460 0.438(0.022) 0.521(0.064) 0.337(0.104) 0.050(0.005) 0.5 7566 0.416(0.011) 0.475(0.079) 0.207(0.066) 0.047(0.004) 5460 0.449(0.018) 0.503(0.077) 0.320(0.108) 0.051(0.004) 1/3 1 7566 0.430(0.013) 0.478(0.095) 0.216(0.085) 0.050(0.004) 5460 0.408(0.020) 0.513(0.062) 0.368(0.125) 0.049(0.004) 0 7566 0.390(0.011) 0.492(0.094) 0.236(0.094) 0.046(0.004) 5460 0.424(0.018) 0.519(0.069) 0.320(0.073) 0.051(0.003) 0.5 7566 0.406(0.008) 0.477(0.090) 0.195(0.042) 0.047(0.004) 5460 0.443(0.020) 0.536(0.075) 0.320(0.067) 0.050(0.004) 27 2/3 1 7566 0.418(0.014) 0.489(0.088) 0.207(0.083) 0.049(0.004) 5460 0.327(0.017) 0.439(0.057) 0.247(0.047) 0.047(0.004) 0 7566 0.312(0.007) 0.415(0.064) 0.171(0.063) 0.044(0.004) 5460 0.354(0.015) 0.439(0.065) 0.212(0.045) 0.048(0.004) 0.5 7566 0.342(0.010) 0.382(0.078) 0.158(0.024) 0.048(0.017) 5460 0.377(0.017) 0.426(0.064) 0.222(0.046) 0.049(0.004) 1/3 1 7566 0.371(0.015) 0.395(0.077) 0.181(0.046) 0.047(0.005) 5460 0.328(0.013) 0.430(0.072) 0.251(0.067) 0.047(0.003) 0 7566 0.309(0.008) 0.398(0.077) 0.180(0.079) 0.043(0.003) 5460 0.332(0.019) 0.434(0.086) 0.224(0.069) 0.047(0.004) 0.5 7566 0.319(0.007) 0.372(0.066) 0.151(0.030) 0.044(0.003) 5460 0.333(0.012) 0.426(0.052) 0.204(0.040) 0.048(0.005) 45 2/3 1 7566 0.321(0.007) 0.390(0.061) 0.164(0.077) 0.045(0.003)
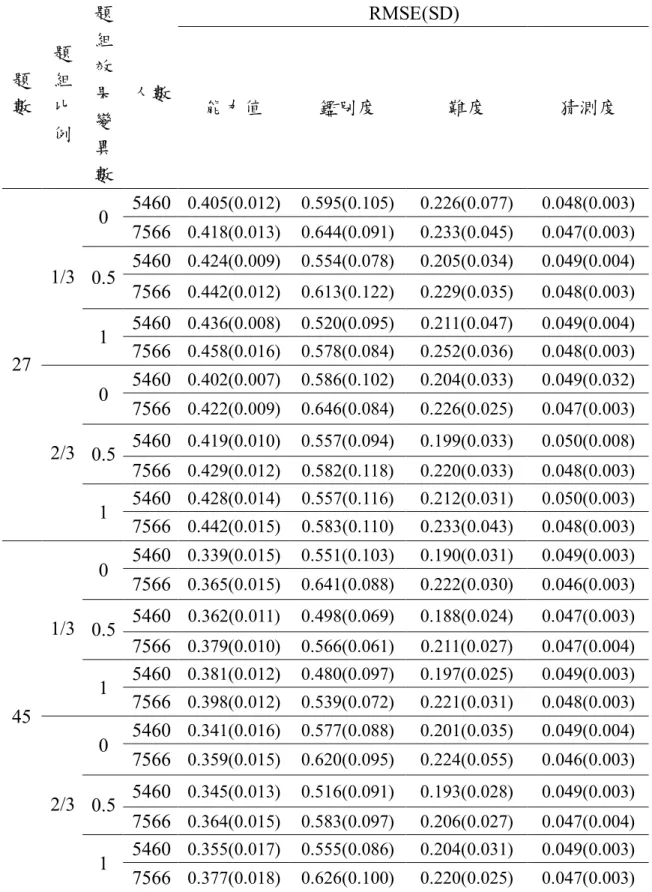
表 4-2 雙峰下不同人數對 BILOG-MG 估計參數值之比較 RMSE(SD) 題 數 題 組 比 例 題 組 效 果 變 異 數 人數 能力值 鑑別度 難度 猜測度 5460 0.405(0.012) 0.595(0.105) 0.226(0.077) 0.048(0.003) 0 7566 0.418(0.013) 0.644(0.091) 0.233(0.045) 0.047(0.003) 5460 0.424(0.009) 0.554(0.078) 0.205(0.034) 0.049(0.004) 0.5 7566 0.442(0.012) 0.613(0.122) 0.229(0.035) 0.048(0.003) 5460 0.436(0.008) 0.520(0.095) 0.211(0.047) 0.049(0.004) 1/3 1 7566 0.458(0.016) 0.578(0.084) 0.252(0.036) 0.048(0.003) 5460 0.402(0.007) 0.586(0.102) 0.204(0.033) 0.049(0.032) 0 7566 0.422(0.009) 0.646(0.084) 0.226(0.025) 0.047(0.003) 5460 0.419(0.010) 0.557(0.094) 0.199(0.033) 0.050(0.008) 0.5 7566 0.429(0.012) 0.582(0.118) 0.220(0.033) 0.048(0.003) 5460 0.428(0.014) 0.557(0.116) 0.212(0.031) 0.050(0.003) 27 2/3 1 7566 0.442(0.015) 0.583(0.110) 0.233(0.043) 0.048(0.003) 5460 0.339(0.015) 0.551(0.103) 0.190(0.031) 0.049(0.003) 0 7566 0.365(0.015) 0.641(0.088) 0.222(0.030) 0.046(0.003) 5460 0.362(0.011) 0.498(0.069) 0.188(0.024) 0.047(0.003) 0.5 7566 0.379(0.010) 0.566(0.061) 0.211(0.027) 0.047(0.004) 5460 0.381(0.012) 0.480(0.097) 0.197(0.025) 0.049(0.003) 1/3 1 7566 0.398(0.012) 0.539(0.072) 0.221(0.031) 0.048(0.003) 5460 0.341(0.016) 0.577(0.088) 0.201(0.035) 0.049(0.004) 0 7566 0.359(0.015) 0.620(0.095) 0.224(0.055) 0.046(0.003) 5460 0.345(0.013) 0.516(0.091) 0.193(0.028) 0.049(0.003) 0.5 7566 0.364(0.015) 0.583(0.097) 0.206(0.027) 0.047(0.004) 5460 0.355(0.017) 0.555(0.086) 0.204(0.031) 0.049(0.003) 45 2/3 1 7566 0.377(0.018) 0.626(0.100) 0.220(0.025) 0.047(0.003)
為了讓研究結果更加清楚易懂,故將上述結果整理成表4-3~4-4,如下: 表4-3 受試者能力分布為常態時,BILOG-MG的估計結果 總人數 總題數 題組數 效果變異數 能力參數 增加而降低 增加而降低 無一定規律 減少而降低 鑑別度 增加而降低 增加而降低 無一定規律 無一定規律 難度 增加而降低 增加而降低 無一定規律 為0.5時最小 猜測度 增加而降低 增加而降低 增加而降低 為0時最小 表4-4 受試者能力分布為雙峰時,BILOG-MG的估計結果 總人數 總題數 題組數 效果變異數 能力參數 減少而降低 增加而降低 減少而降低 減少而降低 鑑別度 減少而降低 增加而降低 無一定規律 無一定規律 難度 減少而降低 增加而降低 無一定規律 為0.5時最小 猜測度 增加而降低 增加而降低 增加而降低 無一定規律
第二節 BIB 設計下 SCORIGHT 估計結果
此節主要是探討當受試者能力分布為常態和雙峰分布情形下,以 SCORIGHT 此軟體進行各項參數估計,是否會受到人數、題數、題組數和題組效果變異數的 不同,而影響各項參數估計的精準度。 為了比較上述四種變項對參數估計的影響,將在 BIB 設計中 SCORIGHT 估 計結果之 RMSE 整理成表 4-5、4-6 及附錄二,結果與討論如下: 一、受試者能力分布為常態 (一) 以不同施測總人數來看,總人數分為5460人和7566人情形下,固定題數、題組比例及題組效果變異數時,可以歸納出不論是受試者能力值或試題參 數,估計誤差值均隨著受試者人數增加而減少,即人數越多估計越精準,與預期 結果相符。 (二) 以不同施測題數來看,題數分為 27 題和 45 題的情形下,固定人數、題 組比例及題組效果變異數時,可以歸納出若改變題數,不論是受試者能力值或試 題參數,估計誤差值均隨著題數增加而減少,即題數越多估計越精準,與預期結 果相符。 (三) 以不同題組比例來看,題組比例為1/3和2/3的情形下,固定人數、題數 及題組效果變異數時,可以歸納出受試者能力參數及試題猜測度參數估計誤差隨 著題組比例增加而減少,即題組比例增加,估計誤差較小,估計較為準確。但試 題鑑別度及難度參數估計誤差較沒有一定的規律,上述結果與顏秀聿(2009)相類 似,或許增加題組比例,對於試題參數估計的影響不大。 (四) 以不同題組效果變異數來看,題組效果變異數為0、0.5和1的情形下, 固定人數、題數及題組比例時,可以歸納出改變題組效果變異數,受試者能力參 數與試題參數中的鑑別度估計誤差會隨著變異數增加而增加,即題組效果變異數 為0時,受試者能力參數和鑑別度估計誤差最小。但從題組效果變異數來看試題 參數時,發現改變題組效果變異數時,對於試題參數中的難度與猜測度估計誤差 並無一致的結果,上述結果也與顏秀聿(2009)相類似。 二、受試者能力分布為雙峰 (一) 以不同施測總人數來看,總人數分為 5460 人和 7566 人情形下,固定題 數、題組比例及題組效果變異數時,可以歸納出不論是受試者能力值或試題參數 中的鑑別度、難度,受試者人數較少的各項估計誤差值均比受試者人數較多的值 低,即人數越少估計越精準。但猜測度的部份主要是以人數越多估計越精準。 SCORIGHT 在受試者能力分布為雙峰時,估計結果大多是受試者人數較少的各項
分布影響所致。 (二) 以不同施測題數來看,題數分為 27 題和 45 題的情形下,固定人數、題 組比例及題組效果變異數時,可以歸納出若改變題數,受試者能力或試題參數, 估計誤差值均隨著題數增加而減少,推測題數越多,估計越精準,與預期結果相 符。 (三) 以不同題組比例來看,題組比例為 1/3 和 2/3 的情形下,固定人數、題 數及題組效果變異數時,可以歸納出若改變題組比例,受試者的能力值和試題參 數中的鑑別度、難度及猜測度的參數估計誤差均隨著題組數增加而減少,即題組 比例增加,所有的參數估計誤差均較為準確,與預期的結果相符,或許是在受試 者能力為雙峰下,應增加題組比例,並以 SCORIGHT 來估計參數。 (四) 以不同題組效果變異數來看,題組效果變異數為 0、0.5 和 1 的情形下, 固定人數、題數及題組比例時,可以歸納出改變題組效果變異數,受試者能力參 數、難度及猜測度估計誤差大多會隨著變異數增加而增加,即題組效果變異數為 0 時,受試者能力參數、試題難度、猜測度估計誤差幾乎為最小,與預期結果相 符。但從題組效果變異數來看試題參數時,發現改變題組效果變異數時,對於鑑 別度參數的估計誤差會隨著變異數增加而減少,即題組效果變異數為 1 時,鑑別 度參數估計誤差最小,或許表示鑑別度受到題組效果變異數的影響較大。
表 4-5 常態下不同人數對 SCORIGHT 估計參數值之比較 RMSE(SD) 題 數 題 組 比 例 題 組 效 果 變 異 數 人數 能力值 鑑別度 難度 猜測度 5460 0.371(0.007) 0.283(0.021) 0.197(0.022) 0.056(0.013) 0 7566 0.370(0.007) 0.225(0.022) 0.134(0.017) 0.044(0.005) 5460 0.396(0.009) 0.317(0.027) 0.187(0.024) 0.055(0.009) 0.5 7566 0.396(0.006) 0.246(0.019) 0.139(0.016) 0.048(0.007) 5460 0.416(0.008) 0.338(0.025) 0.198(0.021) 0.055(0.011) 1/3 1 7566 0.414(0.008) 0.270(0.023) 0.159(0.023) 0.049(0.008) 5460 0.371(0.005) 0.284(0.026) 0.194(0.022) 0.049(0.006) 0 7566 0.371(0.007) 0.222(0.015) 0.127(0.013) 0.042(0.004) 5460 0.387(0.007) 0.307(0.030) 0.188(0.023) 0.052(0.009) 0.5 7566 0.389(0.006) 0.228(0.018) 0.141(0.016) 0.044(0.004) 5460 0.402(0.009) 0.344(0.036) 0.202(0.027) 0.051(0.008) 27 2/3 1 7566 0.400(0.009) 0.248(0.023) 0.149(0.013) 0.044(0.003) 5460 0.297(0.004) 0.253(0.017) 0.166(0.015) 0.050(0.006) 0 7566 0.292(0.004) 0.189(0.014) 0.124(0.013) 0.042(0.005) 5460 0.330(0.005) 0.293(0.018) 0.170(0.021) 0.052(0.008) 0.5 7566 0.325(0.005) 0.220(0.011) 0.123(0.016) 0.042(0.003) 5460 0.355(0.008) 0.330(0.020) 0.179(0.027) 0.052(0.007) 1/3 1 7566 0.348(0.007) 0.247(0.017) 0.137(0.016) 0.045(0.005) 5460 0.299(0.004) 0.271(0.016) 0.180(0.020) 0.046(0.006) 0 7566 0.292(0.003) 0.194(0.007) 0.123(0.016) 0.041(0.003) 5460 0.305(0.004) 0.292(0.018) 0.167(0.017) 0.047(0.005) 0.5 7566 0.299(0.004) 0.217(0.013) 0.122(0.008) 0.041(0.002) 5460 0.312(0.005) 0.319(0.014) 0.173(0.022) 0.048(0.009) 45 2/3 1 7566 0.305(0.005) 0.238(0.018) 0.124(0.014) 0.041(0.002)
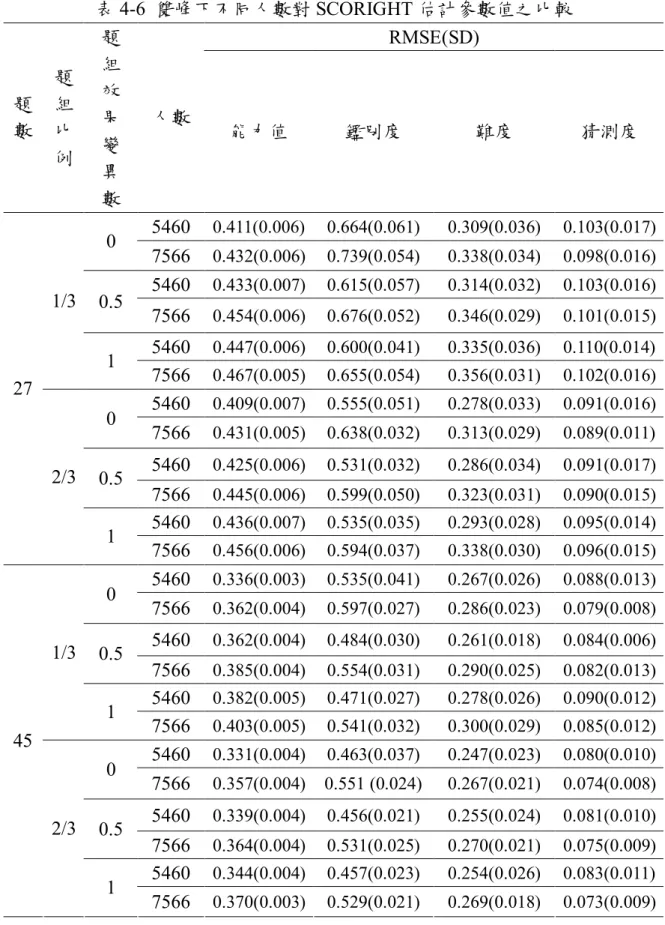
表 4-6 雙峰下不同人數對 SCORIGHT 估計參數值之比較 RMSE(SD) 題 數 題 組 比 例 題 組 效 果 變 異 數 人數 能力值 鑑別度 難度 猜測度 5460 0.411(0.006) 0.664(0.061) 0.309(0.036) 0.103(0.017) 0 7566 0.432(0.006) 0.739(0.054) 0.338(0.034) 0.098(0.016) 5460 0.433(0.007) 0.615(0.057) 0.314(0.032) 0.103(0.016) 0.5 7566 0.454(0.006) 0.676(0.052) 0.346(0.029) 0.101(0.015) 5460 0.447(0.006) 0.600(0.041) 0.335(0.036) 0.110(0.014) 1/3 1 7566 0.467(0.005) 0.655(0.054) 0.356(0.031) 0.102(0.016) 5460 0.409(0.007) 0.555(0.051) 0.278(0.033) 0.091(0.016) 0 7566 0.431(0.005) 0.638(0.032) 0.313(0.029) 0.089(0.011) 5460 0.425(0.006) 0.531(0.032) 0.286(0.034) 0.091(0.017) 0.5 7566 0.445(0.006) 0.599(0.050) 0.323(0.031) 0.090(0.015) 5460 0.436(0.007) 0.535(0.035) 0.293(0.028) 0.095(0.014) 27 2/3 1 7566 0.456(0.006) 0.594(0.037) 0.338(0.030) 0.096(0.015) 5460 0.336(0.003) 0.535(0.041) 0.267(0.026) 0.088(0.013) 0 7566 0.362(0.004) 0.597(0.027) 0.286(0.023) 0.079(0.008) 5460 0.362(0.004) 0.484(0.030) 0.261(0.018) 0.084(0.006) 0.5 7566 0.385(0.004) 0.554(0.031) 0.290(0.025) 0.082(0.013) 5460 0.382(0.005) 0.471(0.027) 0.278(0.026) 0.090(0.012) 1/3 1 7566 0.403(0.005) 0.541(0.032) 0.300(0.029) 0.085(0.012) 5460 0.331(0.004) 0.463(0.037) 0.247(0.023) 0.080(0.010) 0 7566 0.357(0.004) 0.551 (0.024) 0.267(0.021) 0.074(0.008) 5460 0.339(0.004) 0.456(0.021) 0.255(0.024) 0.081(0.010) 0.5 7566 0.364(0.004) 0.531(0.025) 0.270(0.021) 0.075(0.009) 5460 0.344(0.004) 0.457(0.023) 0.254(0.026) 0.083(0.011) 45 2/3 1 7566 0.370(0.003) 0.529(0.021) 0.269(0.018) 0.073(0.009)
為了讓研究結果更加清楚易懂,故將上述結果整理成表4-7~4-8,如下: 表4-7 受試者能力分布為常態時,SCORIGHT的估計結果 總人數 總題數 題組數 效果變異數 能力參數 增加而降低 增加而降低 增加而降低 減少而降低 鑑別度 增加而降低 增加而降低 無一定規律 減少而降低 難度 增加而降低 增加而降低 無一定規律 無一定規律 猜測度 增加而降低 增加而降低 增加而降低 無一定規律 表4-8 受試者能力分布為雙峰時,SCORIGHT的估計結果 總人數 總題數 題組數 效果變異數 能力參數 減少而降低 增加而降低 增加而降低 減少而降低 鑑別度 減少而降低 增加而降低 增加而降低 增加而降低 難度 減少而降低 增加而降低 增加而降低 減少而降低 猜測度 增加而降低 增加而降低 增加而降低 減少而降低
第三節 BILOG-MG 與 SCORIGHT 估計結果比較
這節主要是探討 BILOG-MG 和 SCORIGHT 兩種軟體在 BIB 設計不同測驗組 合下,試題及能力參數估計效果之比較 。將在 BIB 設計中 BILOG-MG 和 SCORIGHT 的估計結果整理成表 4-9~4-16 及附錄三,並繪製成圖 4-1~4-32,結 果與討論如下: 一、受試者能力分布為常態 (一)比較兩種軟體在不同的受試者人數中,對參數估計誤差的影響,可以歸 納出 SCORIGHT 此軟體估計受試者能力參數與試題參數中的鑑別度與難度均得 到較小的估計誤差值,估計較為精準。但試題猜測度的估計誤差較無規律性。
(二)比較兩種軟體在不同的題數中,對參數估計誤差的影響,可以歸納出 SCORIGHT此軟體估計受試者能力參數與試題參數中的鑑別度與難度均得到較 小的估計誤差值,估計較為精準。但試題猜測度的估計誤差較無規律性。 (三)比較兩種軟體在不同的題組比例中,對參數估計誤差的影響,可以歸納 出SCORIGHT此軟體估計受試者能力參數與試題參數中的鑑別度與難度均得到 較小的估計誤差值,估計較為精準。但試題猜測度的估計誤差較無規律性。 (四)比較兩種軟體在不同的題組效果變異數中,對參數估計誤差的影響,可 以歸納出SCORIGHT此軟體估計受試者能力參數與試題參數中的鑑別度與難度 均得到較小的估計誤差值,估計較為精準。但試題猜測度的估計誤差較無規律性。 綜合上述討論均發現所得的結果是一致的,或許是因為BILOG-MG在估計參 數時,會忽略含有題組的試題,所以導致SCORIGHT的估計較為準確,而在試題 猜測度方面,可能是因為此兩種軟體所估計出的誤差值均很低,無法比較出差異 性。 二、受試者能力分布為雙峰 (一)比較兩種軟體在不同的受試者人數中,對參數估計誤差的影響,可以歸 納出 BILOG-MG 此軟體估計試題參數中的難度與猜測度均得到較小的估計誤差 值,估計較為精準。但受試者能力值與試題參數中的鑑別度較無規律性。 (二)比較兩種軟體在不同的測驗題數中,對參數估計誤差的影響,可以歸納 出 BILOG-MG 此軟體估計試題參數中的難度與猜測度均得到較小的估計誤差 值,估計較為精準。但受試者能力值與試題參數中的鑑別度較無規律性。 (三)比較兩種軟體在不同的題組比例中,對參數估計誤差的影響,可以歸納 出 BILOG-MG 此軟體估計試題參數中的難度與猜測度均得到較小的估計誤差 值,估計較為精準。但受試者能力值與試題參數中的鑑別度較無規律性。 (四) 當受試者能力分布為雙峰時,比較兩種軟體在不同的題組效果變異數
難度與猜測度均得到較小的估計誤差值,估計較為精準。但受試者能力值與試題 參數中的鑑別度較無規律性。 綜合上述討論均發現所得的結果是一致的,BILOG-MG 在受試者能力為雙峰 的情形下,估計試題參數中的難度與猜測度均得到較小的估計誤差值,推斷或許 可能是因為 BILOG-MG 所採的的估計法會在事後分布做調整,SCORIGHT 在估 計法方面不會有此現象,或許這是導致 BILOG-MG 估計參數較為精準的原因。
表 4-9 常態下兩種軟體在不同受試人數中對參數估計值之比較(1) RMSE(SD) 題 數 題組 比例 題 組 效 果 變 異 數 人數 軟 體 能力值 鑑別度 難度 猜測度 B 0.402 (0.014) 0.495 (0.072) 0.360 (0.112) 0.049 (0.004) 5460 S 0.371 (0.007) 0.283 (0.021) 0.197 (0.022) 0.056 (0.013) B 0.388 (0.009) 0.489 (0.095) 0.227 (0.085) 0.047 (0.004) 0 7566 S 0.370 (0.007) 0.225 (0.022) 0.134 (0.017) 0.044 (0.005) B 0.438 (0.022) 0.521 (0.064) 0.337 (0.104) 0.050 (0.005) 5460 S 0.396 (0.006) 0.246 (0.019) 0.139 (0.016) 0.048 (0.007) B 0.416 (0.011) 0.475 (0.079) 0.207 (0.066) 0.047 (0.004) 0.5 7566 S 0.396 (0.009) 0.317 (0.027) 0.187 (0.024) 0.055 (0.009) B 0.449 (0.018) 0.503 (0.077) 0.320 (0.108) 0.051 (0.004) 5460 S 0.416 (0.008) 0.338 (0.025) 0.198 (0.021) 0.055 (0.011) B 0.430 (0.013) 0.478 (0.095) 0.216 (0.085) 0.050 (0.004) 27 1/3 1 7566 S 0.414 (0.008) 0.270 (0.023) 0.159 (0.023) 0.049 (0.008)
表 4-10 常態下兩種軟體在不同受試人數中對參數估計值之比較(2) RMSE(SD) 題 數 題組 比例 題 組 效 果 變 異 數 人數 軟 體 能力值 鑑別度 難度 猜測度 B 0.408 (0.020) 0.513 (0.062) 0.368 (0.125) 0.049 (0.004) 5460 S 0.371 (0.005) 0.284 (0.026) 0.194 (0.022) 0.049 (0.006) B 0.390 (0.011) 0.492 (0.094) 0.236 (0.094) 0.046 (0.004) 0 7566 S 0.371 (0.007) 0.222 (0.015) 0.127 (0.013) 0.042 (0.004) B 0.424 (0.018) 0.519 (0.069) 0.320 (0.073) 0.051 (0.003) 5460 S 0.387 (0.007) 0.307 (0.030) 0.188 (0.023) 0.052 (0.009) B 0.406 (0.008) 0.477 (0.090) 0.195 (0.042) 0.047 (0.004) 0.5 7566 S 0.389 (0.006) 0.228 (0.018) 0.141 (0.016) 0.044 (0.004) B 0.443 (0.020) 0.536 (0.075) 0.320 (0.067) 0.050 (0.004) 5460 S 0.402 (0.009) 0.344 (0.036) 0.202 (0.027) 0.051 (0.008) B 0.418 (0.014) 0.489 (0.088) 0.207 (0.083) 0.049 (0.004) 27 2/3 1 7566 S 0.400 (0.009) 0.248 (0.023) 0.149 (0.013) 0.044 (0.003)
表 4-11 常態下兩種軟體在不同受試人數中對參數估計值之比較(3) RMSE(SD) 題 數 題組 比例 題 組 效 果 變 異 數 人數 軟 體 能力值 鑑別度 難度 猜測度 B 0.327 (0.017) 0.439 (0.057) 0.247 (0.047) 0.047 (0.004) 5460 S 0.297 (0.004) 0.253 (0.017) 0.166 (0.015) 0.050 (0.006) B 0.312 (0.007) 0.415 (0.064) 0.171 (0.063) 0.044 (0.004) 0 7566 S 0.292 (0.004) 0.189 (0.014) 0.124 (0.013) 0.042 (0.005) B 0.354 (0.015) 0.439 (0.065) 0.212 (0.045) 0.048 (0.004) 5460 S 0.330 (0.005) 0.293 (0.018) 0.170 (0.021) 0.052 (0.008) B 0.342 (0.010) 0.382 (0.078) 0.158 (0.024) 0.048 (0.017) 0.5 7566 S 0.325 (0.005) 0.220 (0.011) 0.123 (0.016) 0.042 (0.003) B 0.377 (0.017) 0.426 (0.064) 0.222 (0.046) 0.049 (0.004) 5460 S 0.355 (0.008) 0.330 (0.020) 0.179 (0.027) 0.052 (0.007) B 0.371 (0.015) 0.395 (0.077) 0.181 (0.046) 0.047 (0.005) 45 1/3 1 7566 S 0.348 (0.007) 0.247 (0.017) 0.137 (0.016) 0.045 (0.005)