國 立 交 通 大 學
電機與控制工程學系
碩 士 論 文
低功耗相位式快取記憶體
之高效能管線設計
High-Performance Pipeline Design
for Low-Power Phased Cache
研 究 生:薛智文
指導教授:周志成 博士
林進燈 博士
i
低功耗相位式快取記憶體
之高效能管線設計
High-Performance Pipeline Design
for Low-Power Phased Cache
研 究 生:薛智文
Student:Chih-Wen Hsueh
指導教授:周志成
Advisor:Dr. Chih-Cheng Chou
林進燈
Co-advisor : Dr. Chin-Teng Lin
國立交通大學
電機與控制工程學系
碩士論文
A Thesis
Submitted to Department of Electrical and Control Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering
July 2007
Hsinchu, Taiwan, Republic of China
低功耗相位式快取記憶體
之高效能管線設計
High-Performance Pipeline Design
for Low-Power Phased Cache
學生:薛智文
指導教授:周志成、林進燈教授
國立交通大學電機與控制工程研究所
中文摘要
隨著可攜式產品的應用日趨廣泛及全球能源觀念抬頭,低功率消耗成為微處理器研究 中重要的一環。而快取記憶體佔了處理器一半左右的面積及功率消耗,依據Amdahl 定律, 如果能改善快取記憶體的功率消耗,就能帶給處理器可觀的低功率消耗的效果。快取記憶 體一但失誤,需要花費大量的時間及能量跟外部記憶體存取,因此命中率嚴重影響效能及 功率消耗,快取記憶體中為了提升命中率而增加的集合關聯性設計(set associative cache), 卻會造成多餘的功率消耗,因此相位式快取記憶體設計能去除不需要的集合關聯式記憶體 存取,改善這個缺失,但卻會造成雙倍存取時間的缺失,造成效能下降。 本論文針對相位式資料快取記憶體,改良處理器管線,加速讀取指令其運作,以分擔 相位式快取記憶體中的Tag 存取相位,改善其耗時雙週期的缺點,去除管線暫停,只增加 6%成本就達到 44%低功率消耗又不增加時間負擔的設計理念。結合相位式快取及快速存取 管線設計,並達到整體最高效益。為了驗證該演算法的正確性,本論文設計中結合本實驗 室的嵌入式處理器,做為該資料快取記憶體的驗證平台,並整合成為一顆嵌入式低功耗處 理器晶片。此晶片採用TSMC 0.18 μm 1P6M 製程,以 Cell-based 方式設計,晶片面積約 2.1x2.1 mm2,最大操作頻率在100MHz,平均功耗 16mW。ii
High-Performance Pipeline Design
for Low Power Phased Cache
Student:Chih-Wen Hsueh
Advisor: Chih-Cheng Chou
Co-advisor: Chin-Teng Lin
Department of Electrical and Control Engineering
National Chiao Tung University
Abstract
Low power and high performance design issues have played an important role among various portable systems and applications. In embedded processors, the cache design almost occupies half chip area and power consumption. According to Amdahl’s Law, if we could reduce the power consumption of cache, the embedded processor can significantly save more power. The cache miss results in the penalty of thousands of cycles waiting and power consumption due to the increasing external memory accesses. Generally, the set associative cache design could increase the hit ratio, but also induces remarkable power consumption. On the other hand, the phased cache design can largely improve the power consumption which set associative cache wasted, but phase cache requires double access cycles compared with traditional one-access-cycle cache design.
In this thesis, we take advantages of the improved pipelined architecture without stalling and low-power phase cache to achieve high-performance and low-power embedded processor design. From experimental results, the proposed architecture could reduce 44% power consumption compared with traditional one-access-cycle cache and eliminate pipeline stalls incurred by phased cache with only 6% gate count overhead.
To verify the pipeline architecture, a RISC embedded processor is employed to be the verification platform for the proposed cache controller and pipeline design. The chip fabricated in TSMC 0.18 μm 1P6M CMOS process can operate at 100 MHz, where the whole chip area is 2.1x2.1 mm2. The average power consumption is around 16 mW.
誌 謝
兩年的研究所生涯隨著論文的完成劃上了句號,這兩年間,要感謝許多人的鼓勵和幫 忙,使我獲得充實的專業能力並順利完成研究所的學業。 首先要感謝的是我的指導教授-林進燈老師。林老師是國內十分傑出的一位教授,在不 同領域內都有相當好的研究成果。感謝老師提供了很理想的研究環境、豐富的資源及正確 的引導,使我在研究上非常順利。在老師悉心的指導下,讓我學習到解決問題的能力及做 研究應有的態度,使我獲益良多。 在學校裡,范倫達教授時常關心我學業上的研究,時常與我討論論文方向及進度。在 實驗室裡,仁峰學長給予我最直接的教導,不管遇到課業上或研究上的問題,常常去請教 仁峰學長,感謝學長不厭其煩地教導,使我增進了對積體電路設計上的專業知識,開拓了 我的視野。也感謝實驗室所有的夥伴,經翔、紹航學長,德瑋、俊傑、靜瑩以及實驗室的 學弟妹,感謝大家在研究上及生活上的互相扶持及鼓勵。 最後要感謝家人媽媽、哥哥的支持,讓我能專心於學術上的研究,渡過所有難關,謝 謝! 人生值得感謝的人其實很多,感謝老天、感謝許多親人、朋友和同學,在生命的旅途 中,因為有你們,因為我們彼此珍惜、相互扶持,才能有無比的力量iv
目 錄
中文摘要 ... i
Abstract ... ii
誌 謝 ... iii
目 錄 ... iv
圖 目 錄 ... viii
第一章 序論 ... 1
1.1 簡介 ... 1
1.2 論文架構 ... 11
第二章 相位式快取記憶體之高效能管線設計 ... 12
2.1 相位式快取記憶體之高效能存取管線架構與原理 ... 12
2.1.1 快取記憶體控制器及高效能存取管線架構設計 ... 12 2.1.2 快取記憶體控制器及高效能存取管線之原理與演算法 .... 15 2.1.3 相位式快取記憶體及高效能存取管線之分析及改善 ... 172.2 相位式快取記憶體之高效能存取管線之效能分析 ... 24
2.2.1 相位式快取記憶體之高效能存取管線設計之功率分析 .... 24 2.2.2 Simplescalar 功率及週期分析 ... 29 2.2.3 高效能之記憶體存取管線設計分析 ... 322.3 結語 ... 34
第三章 低功耗嵌入式處理器設計 ... 35
3.1 低功耗嵌入式處理器架構 ... 35
3.1.1 低功耗嵌入式處理器核心 ... 35 3.1.2 低功耗嵌入式處理器指令集架構 ... 383.2 功率感知之匯流排編碼解碼器 ... 43
3.2.1 功率感知之匯流排編碼解碼器原理 ... 43 3.2.2 功率感知之匯流排編碼解碼器效果 ... 443.3 具有使用者可調性主從式指令快取記憶體控制器 ... 44
3.3.1 主從式快取記憶體控制器原理 ... 44 3.3.2 主從式快取記憶體效果 ... 463.4 軟體開發環境 ... 47
3.4.1 組譯器 ... 47 3.4.2 模擬器 ... 483.5 測試驗證 ... 50
3.5.1 有限長度脈衝響應(Finite Impulse Response) ... 50
3.5.2 餘弦轉換(Discrete Cosine Transform) ... 51
3.5.3 索比爾運算(Sobel operator) ... 52
3.6 可程式邏輯閘陣列(FPGA) 驗證 ... 54
3.7 結語 ... 54
第四章 晶片實現與結果驗證 ... 55
4.1 晶片製作 ... 55
4.1.1 設計流程 ... 55 4.1.2 合成結果 ... 56 4.1.3 佈局與封裝 ... 56第五章 結論與展望 ... 61
參考文獻 ... 62
附錄 ... 64
vi
圖 目 錄
圖 1-1 : ARM 920T 消耗功率比例圖 ... 1 圖 1-2 : 關聯性記憶體命中率及消耗功率分析圖 ... 2 圖 1-3 : 相位式快取記憶體控制與傳統快取記憶體控制比較圖 ... 3 圖 1-4 : Sentry tag 快取記憶體架構 ... 4 圖 1-5 : 區塊預測關聯式快取記憶體 ... 6 圖 1-6 : 低功率消耗關聯式資料快取記憶體分析 ... 9 圖 2-1 : 相位式資料快取記憶體管線流程圖 ... 12 圖 2-2 : 相位式快取記憶架構 ... 12 圖 2-3 : 高效能低功率消耗相位式資料快取記憶體管線流程圖 ... 13 圖 2-4 : 高效能低功率消耗相位式快取記憶體的架構圖 ... 13 圖 2-5 : 快取記憶體執行相位比較圖 ... 14 圖 2-6 : 高效能低功率消耗相位式快取記憶體演算法 ... 17 圖 2-7 : 512 block 之集合關聯式記憶體位址組成 ... 19 圖 2-8 : critical path 時間模擬結果 ... 20 圖 2-9 : 處理器管線前饋圖 ... 20 圖 2-10: 管線 REG 級前饋改善圖 ... 22 圖 2-11: Sentry tag 架構與相位式架構降低功率消耗比較圖 ... 28 圖 2-12: Sentry tag 架構與相位式架構降低功率消耗比例關係圖 ... 28 圖 2-13: Sentry tag 架構與相位式架構功耗跟命中率之關係圖 ... 28 圖 2-14: Simplescalar 軟體介面 ... 29圖 2-15: 2-Way 時 Sentry tag 與相位式架構降低功耗比較 ... 30
圖 2-16: 4-Way 時 Sentry tag 與相位式架構降低功耗比較 ... 30
圖 2-17: 8-Way 時 Sentry tag 與相位式架構降低功耗比較 ... 31
圖 2-18: 總周期改善比例與讀取指令比例 ... 32 圖 2-19: 快取記憶體讀取周期改善比例 ... 32 圖 2-20: 管線改良之分析圖...32 圖 2-21: 高效能相位式快取記憶體設計改善比較圖…...34 圖 3-1 : 處理器組成架構圖 ... 36 圖 3-2 : 處理管線流程圖 ... 36 圖 3-3 : MACHR 指令運算 ... 42 圖 3-4 : 匯流排編碼架構流程圖 ... 43 圖 3-5 : 多媒體傳輸編碼效果比較 ... 44 圖 3-7 : 主從式快取記憶體操作演算法 ... 45 圖 3-8 : 主從式快取記憶體的效能提升示意圖 ... 46 圖 3-9 : 組譯器(Assembler)流程圖 ... 47 圖 3-10:圖形化介面組譯器(Assembler) ... 48
圖 3-11:利用倒寫管線以便用高階語言的寫法描述管線。 ... 49 圖 3-12:圖形化介面模擬器(simulator) ... 50 圖 3-13:FIR RTL 模擬及 simulator 執行結果 ... 51 圖 3-14:1-dimension 8-by-8 DCT 演算法 ... 51 圖 3-15:2-dimention 8-8DCT RTL 模擬及 simulator 執行結果 ... 52 圖 3-16:Sobel 模擬結果 ... 53 圖 3-17:處理器 FPGA 模擬 Sobel 結果圖 ... 54 圖 4-1 :晶片設計流程 ... 55 圖 4-2 :佈局圖 ... 57 圖 4-3 :腳位圖 ... 57 圖 4-4 :打線圖 ... 58 圖 4-5 :處理器 Post-sim 模擬 DCT 結果圖 ... 60 圖 4-6 :處理器 Post-sim 模擬 Sobel 結果圖 ... 60
viii
表 目 錄
表 1-1:集合預測架構與相位式快取記憶體架構時間及功耗分析 ... 7
表 1-2:集合關聯式記憶體之低功耗設計分析 ... 8
表 2-1:各種定址模式範例、意義及使用頻率 ... 16
表 2-2:傳統、Sentry tag 架構、phase 架構功率公式比較表 ... 26
表 2-3:標準效能評估程式介紹 ... 30 表 2-4:整合設計效能、功率比較 ... 33 表 2-5:本設計與其他低功耗快取設計分析比較 ... 34 表 3-1:資料搬移指令列表 ... 39 表 3-2:算數邏輯運算指令列表 ... 40 表 3-3:跳躍指令列表 ... 40 表 3-4:SIMD 指令列表 ... 41 表 3-5:其他指令列表 ... 42 表 4-1:合成的結果 ... 56 表 4-2:晶片設計規格 ... 58 表 4-3:快取記憶體功率計算 ... 59
第一章 序論
1.1 簡介
隨著可攜式的產品應用日趨廣泛,普遍於人們的日常生活之中,如手機、PDA 數位相機,MP3 player 等等,帶給人們生活上很大的便利,於是也佔了市場上很 大的一環。可攜式的產品相當重視其使用時間長短的表現,但是電池能源技術的 成長卻相當緩慢,以至於電池能源部分佔了可攜式產品相當大的重量,如NOKIA 6100 系列,電池重量佔了將近 30%的重量。越長的使用時間也意味著電池所佔 的比例越大,於是在能源無法提供更多的情形下,必須將電源使用的更有效率, 所以低功率消耗便成為近代嵌入式處理器中,相當重要的研究。 處理器的低功率消耗設計相當廣泛,從 P=fcV2中,不論是管線(pipeline)設 計的複雜程度,暫存器的數目或快取記憶體的模式,到指令集架構的編排及匯流排的變動(bus activity)都是可以從中改善以獲得不錯的效益[1]。根據 Amdahl 定 律,改善部份佔全體的比例,深深決定設計改良能帶來多少效益。也就是改善的
單位效率還要乘以全體比例,才是全體的改良效率。
一般來說,快取記憶體是處理器中經常使用的單元,佔了處理器五成的功率 消耗,如圖1-1 [1],例如 Arm920T,快取記憶體佔了功率消耗 46%,StrongArm-1, 快取記憶體佔了功率消耗43%,所以快取記憶體的低功率消耗設計是個值得研究 的部份,可以從中獲得不錯的報酬率。 為了降低處理器中快取記憶體功耗的研究相當多元[2][3][4],可以從提升快 取命中率來降低整體功耗,或者 SRAM cell 的低功耗設計,又或者從快取架構 上來著手,例如 直接定址快取記憶體(Direct Mapping cache)、集合關聯性快取記 憶體(Set associative cache)和完全關聯性快取記憶體(Fully associative cache)[5]。
其中快取記憶體相當重視命中率(hit ratio),因為 1 次的快取 MISS 必須到外 部記憶體存取正確的資料,平均需要花費數倍到數十倍存取週期,而外部的記憶 體存取相對於晶片內部快取記憶體除了耗費更多的存取時間之外,所耗費的能量 也是晶片內部快取記憶體的數倍,所以提高命中率在效能及功耗上都能獲得改善, 其中最基本、簡單的方法就是使用集合關聯式快取記憶體,例如完全關聯式快取 記憶體,4-way 集合關聯式快取記憶體,都能有效改善快取衝突性失誤(conflict miss),提高命中率,但這個技術當然也有相對上的缺失,例如,4-way 集合關聯 式快取記憶體,會在1 次存取中,同時啟動 4 個 way 集合,讀取 4 筆資料,如 圖1-2,再將命中的集合區塊資料讀取到處理器使用,也就是在這 4 個集合中, 最多只會有一筆區塊資料是我們所需要的,最少有3 個以上的區塊存取是浪費的, 這就是很值得改善的空間。 圖 1-2 :關聯性記憶體命中率及消耗功率分析圖
針對以上提出來的現象,已有相當多的研究試著解決集合關聯式快取記憶體
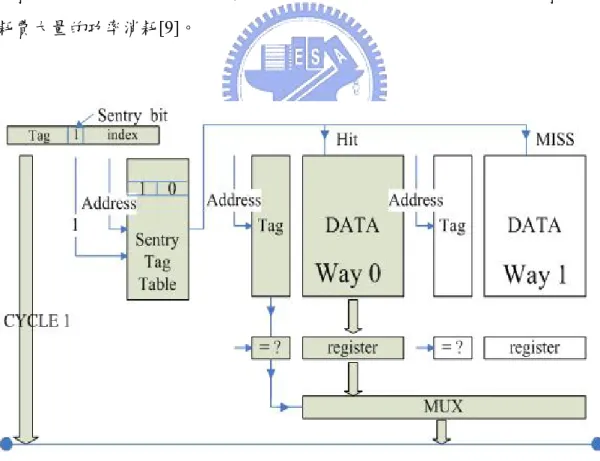
不必要的功率消耗,其中早期提出的觀念是相位式快取記憶體(Phased cache) [6][7],如圖 1-3 所示[10],藉由先執行快取記憶體中 Tag 的存取及比對判別出不 需要執行的way 集合,也就是 Cache MISS 的 Way 集合的資料存取,藉由這個 快取記憶體控制的演算法,可以將集合關聯式記憶體中不必要的集合資料區塊存 取完全的省略掉,避免不必要的功率消耗。但此設計有個嚴重的缺失,因為將原 本快取記憶體一個步驟就提取出Tag 跟資料的做法,變成分兩步驟執行,第一步 驟先執行Tag 的存取,比對記憶體位址是否正確,第二步驟在將正確的資料讀取 出來,也就是需要耗費2 倍的記憶體存取時間,而這多出來的時間浪費,會造成 管線暫停,降低效能,處理程式所花費的時間越多也代表著需要耗費更多的功率 消耗,所以雖然此演算法能省下快取記憶體約略40%-70%左右的功率消耗(依關 聯式設計集合數多寡影響),但也造成多出的管線暫停及管線功率消耗。 圖 1-3 : 相位式快取記憶體控制與傳統快取記憶體控制比較圖
因此也有相當多的研究試著去改善相位式快取記憶體在時間上的缺失,例如
Sentry tag architecture [8],這篇論文試著將相位式快取記憶體中的兩個步驟,濃 縮在1 個記憶體存取時間內完成,這樣就能達到相位式快取記憶體中避免不必要 的集合資料存取,又能改善相位式快取記憶體需要耗費兩個記憶體存取時間的缺
失,如圖1-4 所示[8]。其將一部分的 Tag bits 存放在 Sentry tag cache 這個 table 之中,這樣再處理快取記憶體存取時,先經由Sentry tag cache table 快速存取出 部分Tag bits,與記憶體位址做比對,經由此步驟可以有效過濾部分不必要的集 合存取,又只需要增加短暫Sentry tag cache table 存取時間。藉由使用內容定址 記憶體CAM(Content Addressable Memory) 9-T cell 來實現 Sentry tag architecture 所需的高速存取需求,但CAM 採用的是類似 Full associative cache 的存取方式, 也就是對記憶體內部每筆資料都做比對,需要驅動所有 CAM cell,也就是需要 耗費大量的功率消耗[9]。
但其實深入探討可以看出此設計仍有改善的空間,這些設計必須使用快速的
特殊記憶體元件將2 個步驟濃縮在一個記憶體存取時間內,除了有可能會降低記 憶體存取頻率之外,因為使用快速的記憶體元件CAM,因為 CAM 會隨著面積、 區塊增加而增加存取時間的性質,因此CAM 有著面積、區塊上的限制,不得不 只能紀錄2-4bit 的 Tag bit,也因為比對的 Tag bit 數少,不能完全的過濾掉不必 要的資料存取,只能降低約略相位式快取記憶體八成的功率消耗,且考慮到CAM 快速存取但必須全部比對需要驅動所有cell 且單位面積比約為 SRAM 兩倍大[9], 耗費的單位功率損耗比 SRAM 多出 1 倍以上,所以此特殊記憶體單元設計也耗 費掉可觀的功率消耗。
另外因為 Sentry tag architecture 在過濾快取記憶體非必要執行集合的效果 是機率性的,隨著測試程式的不同,區域性(locality)的不同,會影響其降低功率 消耗的效果,不像Phased cache architecture 過濾快取記憶體非必要執行集合的效 果是 100%,所以因為資料快取記憶體的區域性相對於指令快取記憶體較低, Sentry tag architecture 使用在資料快取記憶體上的效率是比使用在指令快取記憶 體上的效果較差。
除了相位式的方法,還有一種也是以降低集合關聯式快取記憶體的功率消耗
為目標的設計,Way-predicting set-associative cache [10],有別於相位式快取記憶 體經由Tag 快取部份存取比較後的訊息,此記憶體經由 MRU(Most Resent Used) 演算法來預測命中的Way 集合的訊息,因此在執行快取讀取時,只需同時執行 預測命中的way 集合的 Tag 及資料的存取,即可達到避免不需要的 WAY 集合的 存取,降低功率消耗,如圖 1-5[10]所示,因為此演算法為事先預測,於是在執 行快取存取時,已有關聯式記憶體集合命中、失誤的訊息,只需要單一週期存取,
不會造成時間上的負擔。但此設計也有必需付出的代價,若是預測的訊息錯誤,
不但要多付出 1 個記憶體存取週期去存取其他 way 集合的資料,且完全沒有降 低功率消耗,所以依然會增加平均處理時間,且降低功率消耗的效率也不如相位
因此預設率的高低決定此設計的效果,在指令快取記憶體中也因為指令的區 域性,連續性高,因此猜測率高,降低功率消耗效果與相位式快取記憶體相近, 但在資料快取記憶體中會因為預測率降低,降低功率消耗的效果變差,也增加了 處理時間。此外預測率也會隨著關聯性快取記憶體的集合數增加而降低。 另外此設計有個問題需要來思考的,就快取處理時間上來分析,集合預測的 演算法確實能將快取處理時間降到平均一個周期左右,但從管線的角度來思考, 在指令快取記憶體中,預測命中時,在快取處理時花一個週期的處理時間,但若 下一筆快取存取預測失誤,卻需要花兩個周期的處理時間,就管線流程的角度, 此時反而會造成管線暫停。雖然能降底整體快取處理時間,但因為其處理週期的 不確定性,反而造成整體的週期增加,因此其時間上的效果在指令快取中,是沒 有效果的。
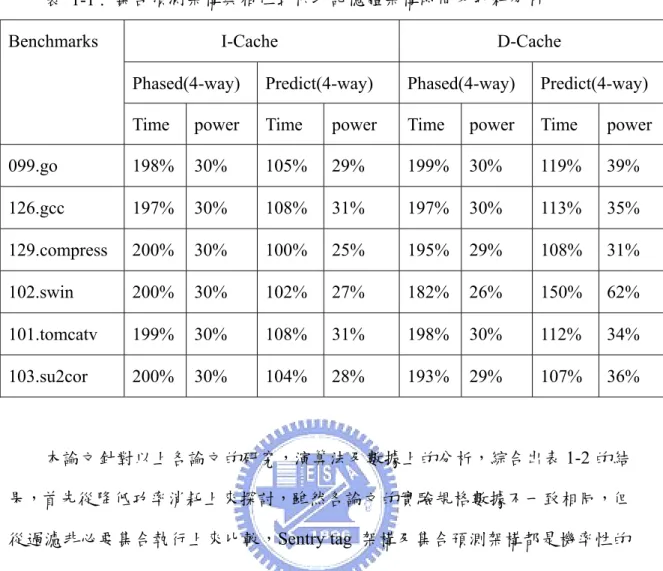
就如表 1-1 [10]顯示 Phased cache 與 way prediction cache 的比較一樣,可以 看出Phased cache 需要花費較多的快取處理時間,但功率消耗較 way prediction cache 為低。
表 1-1 : 集合預測架構與相位式快取記憶體架構時間及功耗分析 Benchmarks I-Cache D-Cache
Phased(4-way) Predict(4-way) Phased(4-way) Predict(4-way) Time power Time power Time power Time power 099.go 198% 30% 105% 29% 199% 30% 119% 39% 126.gcc 197% 30% 108% 31% 197% 30% 113% 35% 129.compress 200% 30% 100% 25% 195% 29% 108% 31% 102.swin 200% 30% 102% 27% 182% 26% 150% 62% 101.tomcatv 199% 30% 108% 31% 198% 30% 112% 34% 103.su2cor 200% 30% 104% 28% 193% 29% 107% 36% 本論文針對以上各論文的研究,演算法及數據上的分析,綜合出表1-2 的結 果,首先從降低功率消耗上來探討,雖然各論文的實驗規格數據不一致相同,但 從過濾非必要集合執行上來比較,Sentry tag 架構及集合預測架構都是機率性的 過濾非必要執行集合,而相位式快取記憶體架構卻能100%過濾非必要執行資料 集合部分,雖然與Sentry tag 架構及集合預測架構相比無法省略 Tag 部分的執行, 考量到Sentry tag 架構需花費 CAM cell 的 Sentry tag cache 的功率消耗,而集合 預測架構在失誤時需要耗費的大量功率消耗,相位式快取記憶體架構在降低功率
消耗的效果仍是比其他設計較為有效。
從處理時間週期上去探討,Sentry tag 架構增加了 Sentry tag cache 的處理、 資料比較的時間,集合預測架構增加了失誤時增加的 10%~20%快取處理週期, 而相位式快取記憶體架構需要增加1 週期的處理時間,因此容易造成管線暫停, 增加處理時間。在處理週期上相位式快取記憶體需要花費最多的處理時間。
綜合深入探討分析,相位式快取記憶體可以最有效的降低功率消耗,且準確 率最高,但卻有耗時的缺點,而Sentry tag 架構可以改善相位式耗時的缺點概念 很好,但卻有特殊元件的限制及時間和功率上的小缺失,而預測集合關聯式快取 記憶體雖然能使用事先預測的方法降低功率消耗,卻有猜測率失誤的風險及付出 的代價。因此若是能結合最低功率消耗的相位式快取記憶體的概念,又能使用事 先的判斷來改善其耗時的缺點,但又能維持判斷率的100%命中,就能達到低功 率消耗且不影響效能的高效能低功率消耗快取記憶體控制器設計。 表 1-2 : 集合關聯式記憶體之低功耗設計分析 Conventional Cache Sentry tag Cache Way Prediction Cache Phased Cache 降低快取 功耗效果
Low(0%) Middle(34%) Middle(30%~40%) High(44%)
快取延遲/ 暫停
Low(1 cycle) Low(1 cycle) Middle(1~2 cycle) High(2 cycles)
設計複雜 度/成本 Low High (CAM) Middle Middle 本論文提出一個將相位式快取記憶體改善的另一途徑,將此相位式快取記憶 體與前級管線結合,分擔相位式快取記憶體的Tag 存取步驟,在快取記憶體存取 級之前級就判別出Tag 比對的結果,這樣就能省略 MISS 的集合資料存取,有效 降低五至七成左右的功率消耗,且在快取記憶體處理前得得到命中、失誤的訊息, 於是能在正常處理時間內完成所需資料的存取,不會造成管線暫停,改善相位式 快取記憶體耗時的缺失。
圖1-6 為高效能低功率消耗相位式快取記憶體管線設計的原理,比照其他設 計將相位式濃縮至單一週期的原理達到低功率消耗卻不造成時間負擔的效果,本 設計理念亦以此為目標,因此提出將其提前一級去執行相位式中之Tag 存取比對 的步驟,就能在讀取快取資料時依前級比對的訊息驅動所需執行之集合的動作, 又不會延後快取存取資料的時間點,這樣就不會影響管線的執行,達到目標。 圖 1-6 : 低功率消耗關聯式資料快取記憶體分析 如圖1-6 所示,此設計原理因與管線結合記憶體讀取優化來達到高效能的效 果,在設計上能改善資料快取記憶體的效能,對於指令快取記憶體卻沒有另外設 計,除了考量到指令快取記憶體多為L1 直接映射快取記憶體(Direct-Mapped cache)設計,較少集合關聯式設計而且最多也是 2-Way 集合關聯式快取記憶體設 計,且指令快取命中率高,相反的資料快取記憶體,命中率較低,資料被取代性 高,有較高衝突性失誤,需要使用較深的關連性快取記憶體設計,2-Way、8-Way 以上的集合關聯式快取記憶體架構來降低失誤率,所以針對快取記憶體降低關聯 式快取記憶體功率消耗的相位式設計,在資料快取記憶體上的使用是較指令快取 記憶體實用的,詳細會在2.1.3 節有介紹說明。
本論文所設計的快取記憶體與高效能存取管線設計具有以下特性: 1. 降低快取記憶體功率消耗: 將快取記憶體分成兩個相位,事先處理Tag 與記憶體位址的比對,判別 出關聯式記憶體所需的集合區塊命中、失誤訊息,將失誤的關連性記憶體集 合關閉,達到低功率消耗的效果。 2. 改善相位式快取記憶體耗時兩倍記憶體時間的缺失: 因為相位式快取記憶體將存取Tag 跟資料分成兩步驟依序執行,雖 然能有效降低快取記憶體的功率消耗,但卻需要花費2 倍的讀取記憶體的時 間,因此本設計將相位式資料快取記憶體結合管線分擔Tag 比對判別的相位 步驟,雖然仍需耗費2 倍記憶體時間,但提早一級執行此步驟,與一般資料 快取記憶體同時完成資料存取的執行,所以在時間上並沒有造成負擔,改善 相位式快取記憶體耗時造成的管線暫停的缺點,達到較高效能。 3. 設計單純、低成本: 此設計只需增加些微管線硬體電路及快取記憶體控制器成本,佔整體不 到10%的 gate count。 且有別於Sentry tag 架構快取記憶體控制器,需要使用特殊設計快取記 憶體單元,如CAM 或者加入其他邏輯單元,來改善相位式快取記憶體耗時 的缺點,須準備2 種晶片內記憶體單元及其控制單元,且這些快速記憶體單 元在面積上及功耗上皆比 SRAM 高出數倍,本設計因為不需將相位式濃縮 至單一週期,所以可以採用傳統一般 SRAM 記憶體作為資料快取記憶體, 除了不增加製作難度,且不會造成面積及功耗上的取捨。 為了驗證該演算法的正確性、可行性及可靠性,本論文設計中結合本實驗室 的嵌入式處理器,做為該資料快取記憶體控制器及管線的驗證平台,並整合其他 低功耗設計成為一顆嵌入式處理器晶片。此晶片採用 TSMC 0.18 μm 製程,以 Cell-based 方式設計,晶片面積約 2.1x2.1 mm2,最大操作頻率在100 MHz,平均 功率消耗為 16 mW。
1.2 論文架構
本篇論文中,第二章介紹低功率消耗相位式資料快取記憶體控制器及管線設 計,從硬體架構到效能測試有詳細的說明。第三章介紹快取記憶體控制器其平台 設計,從嵌入式處理器架構到開發工具製作、低功耗設計的整合和測試程式驗證。 第四章介紹晶片實現的過程,包含模擬驗證方法及結果,晶片製作。最後,在第 五章做總論。第
含其2.
IF第二章
本章介紹高 其原理、架2.1 相位
1.1 快取記
F ID REG相位式
高效能之低 架構、效能測位式快取
記憶體控制
圖 2-1 : 相 圖 2-2 :相位 Reg file G式快取記
低功率消耗相 測試、特點取記憶體
制器及高效
相位式資料快 位式快取記 ALU記憶體之
相位式快取 點及比較。體之高效能
效能存取
快取記憶體 記憶架構 ALU WB之高效能
取記憶體控制能存取管
取管線架構
體管線流程 L1T cac B/MEM1能存取管
制器及其管管線架構
構設計
圖 Tag he HIT Miss管線設計
管線的設計構與原理
L1 D cac MEM2 Ma mem計
,包 Data che ain moryREG 取記 Dat 就會 圖 2-3 : 高 圖 2 圖 2-1 為 G 讀取暫存 記憶體首先 a cache 的存 會造成管線 高效能低功 2-4 : 高效 為傳統低功率 存器數值、A 先讀取Tag c 存取,因此 線暫停一個週 功率消耗相位 效能低功率消 率消耗相位 ALU 計算記 ache 的數值 此記憶體指令 週期。. 位式資料快 消耗相位式 位式資料快取 記憶體位址 值,比對命 令需要耗費 快取記憶體 式快取記憶體 取記憶體管 址再到相位式 命中失誤訊息 費兩個週期 管線流程圖 體的架構圖 管線流程圖 式快取記憶 息之後,下 ,如果有資 圖 圖 ,從 IF、I 憶體,相位式 下一週期在執 資料相依發生 ID、 式快 執行 生,
圖2-2 為低功率消耗相位式快取記憶體控制器 MEM1 與 MEM2 級的架構圖, 將ALU 運算的記憶體位址分為 Tag 部分及 index 部分,依照 index 從 Tag cache 讀 取出每一個Way 集合的 Tag 區塊數值,再將其與記憶體位址中的 Tag 部份做比 對,然後將命中的訊息作為Data cache 驅動與否的判斷,以圖為例,在 MEM2 級只有Way1 的 Data cache 會被驅動,其餘則會被關閉,降低功率消耗。
圖2-3 為高效能之低功率消耗快取記憶體控制器與管線的架構圖。此控制器 仿照相位式快取記憶體分為Tag 讀取比對相位及資料讀取相位,且將 Tag 讀取比 對相位提前至管線的前一級跟 ALU 平行去執行判斷,然後在 WB/MEM 級執行 命中的區塊資料存取,跟圖2-1(a)相位式快取記憶體管線比較,可以將快取記憶 體存取時間點提前,得到較高的效能。 圖2-4 為高效能相位式快取記憶體控制器在 ALU 級的改良架構圖,在此級 我們就依照REG 級得到的 index 數值讀取出 Tag cache 中每一個 Way 集合 的 Tag 數值跟ALU 單元在此級運算出來的記憶體位址做比對,判斷出命中的集合區塊 並在 WB/MEM2 級驅動之,其餘失誤的區塊就會被關閉,達到相位式快取記憶 體相同低功率消耗效果。 雖然本設計在相位式快取記憶體的處理時間上,仍然需要兩個週期才能分別 完成Tag 存取比對及資料存取,但在管線的處理流線上,如圖 2-5 所示,經由管 線的提早執行快取的步驟,可以跟傳統快取處理器達到相同的時間點上存取的目 標,因此不會像改良前的相位式快取記憶體般,因為需要多花費一個週期才能得 到所要的資料,會造成管線暫停,降低處理速度。除此之外,因為提早運作 L1 快取的 Tag 比對得到的資訊,在命中時可以去除非必要執行的功率消耗,若判 別為失誤時,更能提早處理下一級的記憶體存取,提高效能。因此若以L1 快取 記憶體需時 1-cycle,主要記憶體需時 4-cycles 為例,在我們提出的設計架構下, 在 L1 失誤的情形下,可以將總記憶體存取所需時間從傳統的 5-cycles 改善至 4- cycles 的處理時間,進一步提升效能。
圖 2-5 :快取記憶體執行相位比較圖
因此為了在ALU 級執行 Tag cache 的存取,我們必須要 ALU 級前一級就獲 得Tag 存取所需要的資訊,也就是快取記憶體位址,於是本管線在 REG 級即須 計算出快取記憶體位址,但原本應該是ALU 級才產生的記憶體位址若要在 REG 級就計算出,勢必需要再管線上做些改變才能達到此目標。
2.1.2 快取記憶體控制器及高效能存取管線之原理與演算法
為了達到以上功能,本設計需要在 ALU 級之前獲得存取快取所需的位址資 訊,依照記憶體存取指令分為直接定址、間接定址、暫存器定址等等模式去分析, 隨著定址模式的不同以及指令集架構的設定決定而有所不同,若採用簡單定址模 式如暫存器定址的指令集,因為記憶體存取指令不需經過運算,即可直接將暫存 器數值做為記憶體位址,若是採用此指令集架構,則無須對處理器管線作任何改 變即可提早獲得記憶體位址,實現本設計要求。 在此本設計利用記憶體位址計算簡單的特性,如表2-1,只需進行 Reg+direct 運算或者直接是 Reg 或者 direct 的數值來計算記憶體位址,因為不需進行複雜 的運算,因此可以將此步驟提前至REG 級運算,針對特定記憶體指令增加硬體求。
表2-1 : 各種定址模式範例、意義及使用頻率
位址模式 範例指令 意義 使用頻率百分比
立即值 Load R4,#3 R4<-Mem[3] 39%(gcc),43%(Tex) 位移 Load R4,3(R1) R4<-Mem[R1+3] 40%(gcc),32%(Tex)
暫存器間接 Load R4,(R1) R4<-Mem[R1] 11%(gcc),24%(Tex) 如上表 2-1 所示,分別顯示位址模式及其意義和使用頻率,從頻率上可以看 出此三種定址模式在記憶體指令中使用的多寡,可以包含75%~99%的記憶體指 令,是每一個架構應該具有的定址模式[5]。 因此本設計針對記憶體的存取指令設計,利用其運算簡單的特性,來改善相 位式快取記憶體架構,在指令集中可以使用在此三大類定址模式,來提早執行記 憶體位址的運算,達成我們的需求。 演算法流程如圖2-6 所示,本圖架構以五級管線為例,分為 Fetch、Decoder、 Register、ALU/Tag cache、WB/Data cache 五級,一開始指令從 Fetch 級輸出 Program Count 值至指令記憶體讀取出指令後,在 Decoder 級除了判別指令運算 碼及其指令組成位元分佈,也針對記憶體相館的指令作判斷,輸出訊號給 REG 級做不同的處理。到了REG 級會依造指令解碼產生的暫存器碼讀取相對的暫存 器數值,讀取完畢後,若是記憶體相關指令會依照解碼產生的訊息對讀取出來的 暫存器數值做不同的運算,有可能是暫存器加上暫存器或者暫存器加上直接定值 又或者是直接定值,產生出快取記憶體位址供Tag 快取記憶體做為存取所需要的 訊息。在ALU/Tag cache 級會依照指令的型態做不同的運算,若非記憶體相關的 指令,則經由ALU 做算數(arithmetic)或邏輯(logic)運算即可,若是記憶體相關指 令,ALU 單元負責運算出完整的記憶體位址與快取記憶體讀取出來的 Tag 值做 比對,將命中、失誤的訊息傳到下一級。而在WB/Data cache 則處理 REG 的寫 回或者命中的快取記憶體資料存取。
圖 2-6: 高效能低功率消耗相位式快取記憶體演算法
2.1.3 相位式快取記憶體及高效能存取管線之分析及改善
本設計要達到降低功率消耗又能兼顧效能的設計,需要對管線作出些改變, 雖然能符合我們要求的目標,但也需要去克服一些困難以及必須犧牲的方面。 從益處、壞處分別去分析本設計 益處: 1. 降低功率消耗: 使用相位式快取記憶體,有效降低關聯性記憶體造成的 功率浪費 2. 提高效能: 改善相位式快取記憶體造成的管線暫停以及在 L1 快取記憶 體失誤發生時,提早處理下一級之記憶體單元,降低總處理週期 3. 設計單純不複雜: 不需使用其他高速元件,不造成額外負擔,只增加約 6~7%左右的管線硬體成本
Algorithm
Instruction Decoder:Decode the instruction and Detect cache access instruction
Register File:
Get the Rs,Rt register value/ Calculate cache access
ALU:
Get memory address
Cache Tag Access
W B / Cache Data Access
address : index value
=?
way0 way1 tag
Memory address Enable Hit way
壞處:
1. Critical path :對管線 REG 級增加計算流程,提高此管線級成為 Critical path 的風險,有可能造成時脈降低
2. Data Hazard : 需要在 REG 級使用暫存器的數值計算記憶體位址,若與上 一指令有資料相依,會造成資料危障
3. 只能改善相位式資料快取記憶體的效能: 只能改善資料快取記憶體造成 的管線暫停,對指令快取記憶體沒有效能改善。
以下將針對益處壞處的部份做出分析及改善方法
首先針對此設計對管線的改變,造成的問題,如Critical path、Data Hazard, 將在此小節,針對問題提出改善的方法,將傷害降到最低 z Critical path 部分 本設計需在管線中加入計算單元來提早計算此記憶體位址,可能是單純的加 法運算,來處理的記憶體位此的計算,才能提供ALU 級時的 Tag 快取記憶體存 取,因此本設計在REG 級中,在讀取完暫存器數值之後,加入加法器來做記憶 體位址計算,這樣就能在ALU 級前獲得所需的記憶體位址,但加入此加法器勢 必會對原本的管線產生影響,增加此管線級成為critical path 的風險。 考量到不希望因為增加的計算負擔造成此級成為critical path ,也就是有可能 降低處理器時脈的風險,本設計也提出許多對應的方法:將加法器所需要處理的 位元數盡可能降到最低,這樣就能將REG 級所增加的時間不至於太多,超過原 本的critical path(ALU 級)。 記憶體位址分成兩部分,分別為Tag、Index 部分,如圖 2-7 所示,Tag 部分 用來比對判斷關聯式記憶體中是否有命中的主記憶體中的資料,Index 部分用來 讀取快取記憶體的位址中的資料。傳統的快取記憶體會一次擷取整段記憶體位址 來運作,使用記憶體位址中Index 讀出關聯式記憶體中的資料,在將這些資料跟 計憶體位址中的Tag 部份做比對,來判斷命中與否。
因為讀取快取記憶體中的Tag 或資料只需要 Index 數值即可,所以為了降低 REG 級中加入的運算增加時間造成 critical path 的風險,所以在 REG 級中只去計 算記憶體位址中的Index 數值也就是較低的位元部份,大約可以減少一半的加法 時間,將增加的時間負擔降到最低。其餘的記憶體位址則在ALU 運算出完整的 數值,以供利用。
圖 2-7 : 512 block 之集合關聯式記憶體位址組成
本設計以 TSMC 0.18um cell-base 製程實作,經 Cadence tools 加入 time constrain 模擬結果分析時脈,結果如圖 2-8 顯示,左邊為 ALU 級的最長週期、 右邊為REG 級的最長周期,最長周期仍是以 ALU 級的運算為主,REG 級仍沒 有成為critical path ,並沒有造成時脈上的降低,証明其實作上是可行的。
REG 級因為增加運算及選擇,造成 REG 級的處理週期增加,但可以選擇 Critical path 極大的處理器,例如 DSP,因為要在 1 個週期完成乘加,增加效能, 所以此時REG 級加入加法器也不會超過 DSP 的 critical path ,所以也不會對處 理器最高時脈產生影響。 因為本設計會隨著處理器的管線設計,架構,處理器應用需求,而有所不同, 在此不詳加考慮、討論,隨著處理器設計者去抉擇。本論文以實驗室處理器驗證 以第一種方法,即可解決此問題。
Index
32 9 8 0
Tag
圖 2-8 critical path 時間模擬結果 z Data Hazard 部分 在管線執行部分,因為需要提前處理記憶體指令相關的資料,所以在執行記 憶體相關的指令時,會因為資料尚未寫入暫存器而發生讀取之暫存器錯誤數值的 資料危障,如圖2-9 所示。 圖 2-9 : 處理器管線前饋圖
Cycle n
I D
REG
ALU
WB
LD r0,4,r1
Add r1,r2,r3 LD r0,4,r1
Add r1,r2,r3 LD r0,4,r1
Add r1,r2,r3 LD r0,4,r1
I F
Cycle n+1
Cycle n+2
Cycle n+3
r1 have
data hazard
r1 have no
data hazard
在正常的管線級中,Add r1,r2,r3 指令在 ALU 級產生的數值,需要前饋 (Forwarding)給下一週期的 ALU 級,去計算 LD r0,4,r1 的記憶體位址,以避免資 料危障,這樣LD 指令才能再 WB 級處理記憶體的存取,但是在我們的演算法中, 本設計需要在REG 級中計算記憶體位址的前半部的位元,但此時 r1 的值不但尚 未寫入REG 級中,甚至仍未經過 ALU 級的計算,也就是在 Cycle n+1 時,本設 計需要再REG 級計算 r1+4 的數值,但此時 r1 的數值正在 ALU 級中計算,此時 REG 級中讀取的 r1 數值是錯誤的,因此會發生資料危障,發生資料危障會造成 管線暫停,增加總處理週期,造成效能的下降。 因此為了解決管線中因為記憶體相關指令提前計算而產生的資料危障,本設 計也為此提出兩種解決方法,希望藉此能解決問題。 1. 藉由編譯器最佳化,避開資料危障的發生: 將會發生資料危障的部份,經由編譯器的重新編排,將發生資料危障的指令 經由slot 的技術,插入不相干的指令,在不影響指令效能及結果下,執行最佳化。 例如 以下為 FIR 的一段程式,在 LH R4 in(R3)指令前,執行的 ADDI R3, R3, #1 因為跟LH 指令有資料相依的危險,會發生資料危障,可藉由指令順序改善,避 開因為讀取指令產生的資料危障。
INT: ADDI R1, R0, #40 INT: ADDI R1, R0, #40 ... ... LOOP2: LOOP2: ADDI R2, R2, #-1 ADDI R2, R2, #-1 ADDI R3, R3, #1 ADDI R3, R3, #1 LH R4 in(R3) LH R5 coeff(R2) LH R5 coeff(R2) LH R4 in(R3) MAC R6, R4, R5 MAC R6, R4, R5
2. 增加 REG 級前饋路徑
另外本系統也提供簡單的前饋系統去改善,加入特定的指令去前饋,例如 如 果記憶體相關指令之前的指令有資料相依的情形發生,則我們使用之前REG 級 中加入的加法器去做運算提供REG 級前饋資料,從 REG 級前饋至 REG 級就不 會有資料危障的發生,如圖 2-10 所示,因為只有加法器單元,所以也只針對使 用加法來計算記憶體位址的指令有前饋的效果,反之若不為加法的資料相依,也 就是使用到乘法或邏輯位移的記憶體位址運算,則無法提供前饋,只能使用編譯 器最佳化來避免資料危障。 圖 2-10: 管線 REG 級前饋改善圖 本管線設計中LH R4 ,in (R3) 會跟 ADDI R3,R3, #1 發生資料危障,但因為 記憶體相關指令LH 之前所處理的指令是為 ADDI,是可以使用 REG 級中的加法 器去運算其Index 部分所需要的位元的加法,再將計算的數值回饋至 LH 指令在 REG 級中執行的 R3+1 的低位元部份的加法,並不會造成資料危障的發生。但此 方法只能解決因為特定排序的資料危障,若是乘法指令在記憶體指令之前所造成 的資料危障,則必須經由編譯器來解決或者暫停管線。
Cycle n
I D
REG
ALU
WB
LD r0,4,r1
Add r1,r2,r3 LD r0,4,r1
Add r1,r2,r3 LD r0,4,r1
Add r1,r2,r3 LD r0,4,r1
I F
Cycle n+1
Cycle n+2
Cycle n+3
r1 have no
data hazard
r1 have no
z Instruction cache 部分 本論文提出之管線設計只改善資料快取部份效能,沒有針對指令相位式快取 記憶體效能提升之改善去設計,有以下幾點原因 1. 指令快取記憶體增加相位式設計對於效能並沒有太大的影響: 因為指令快取記憶體所增加的相位週期會隨著管線的持續進行,而只在初始 及發生指令跳躍時才會影響一個週期效能,並不是每次存取指令快取記憶體都會 造成管線暫停,相較於相位式資料快取記憶體每次存取都有可能造成管線暫停而 言,相位式指令快取記憶體本身可改善的空間不大,不如不要增加設計負擔。 2. 指令快取記憶體之關連性深度較資料快取記憶體淺: 指令快取記憶體因為指令有較佳的區域性及時間性,所以命中率本來就很高 ,最高可達到95%~98%左右的命中率,因此指令快取記憶體通常在關連性快取 記憶體設計中,常見的通常直接使用直接定址快取記憶體設計或者最多只會使用
到2-Way 關聯性設計左右,例如TMS320C6211 只搭配4KB的direct mapped L1 指令快取記憶體,因此本設計重點在於改善關聯性快取記憶體設計之功率消耗上
2.2 相位式快取記憶體之高效能存取管線設計效能分析
2.2.1 相位式快取記憶體之高效能存取管線設計之功率分析
在功率計算方面,仿效先前提到的論文中,以快取記憶體的驅動次數作為粗 估功耗的公式的參數,來推導本設計估計功率消耗的公式,並加入面積的參數來 評估各設計詳細的功率消耗。al
convention
tag
sentry
atio
ctivity
ACT
ACT
R
A
=
−
(1)在公式(1)中[8],ACTsentry-tag 表示在 Sentry tag 架構下,需要驅動的集合 次數,ACTconventional 表示在傳統快取記憶體架構中,需要驅動的集合次數。 並以兩者的驅動次數比例做為評斷功率消耗的比例。
2
2
1
1
2
2
2
2
2
1
)
1
(
2
1
)
1
(
1
W
S S S S S S S SW
HR
W
HR
W
HR
W
HR
HR
W
HR
W
HR
Ave+
⎟
⎠
⎞
⎜
⎝
⎛ −
=
×
−
+
−
×
+
=
×
×
−
+
⎟
⎠
⎞
⎜
⎝
⎛
+
−
×
×
=
(2)公式(2)[8]為 Sentry tag 架構計算集合平均驅動次數的公式,WAve 表示集合
平均驅動次數,HR 表示 Hit Ratio,W 代表集合數,S 表示 Sentry tag bit 大小, 影響到過濾的非必要執行集合的機率,公式分為命中時及失誤時分開計算,因為
本設計根據演算法及前述論文的計算方式,並參考Phased cache、Sentry tag cache 演算法推導出本設計消耗功率的公式表(3),以面積及驅動次數作為評量功 率的標準,將快取記憶體中的Tag 跟 Data 兩部分面積做為功率基本單位,在累 計其驅動2 者的次數做統計平均。
Other
ratio
enable
D
M
power
Data
ratio
enable
T
M
power
Tag
Way
ratio
Miss
ratio
enable
D
H
power
Data
ratio
enable
T
H
power
Tag
Way
ratio
Hit
cache
Power
)
_
_
_
_
_
_
_
_
(
_
)
_
_
_
_
_
_
_
_
(
_
_
+
×
+
×
×
×
+
×
+
×
×
×
=
(3) Power_cache : 快取記憶體總功率消耗 Hit_ratio : 快取記憶體命中率,隨著測試程式不同改變 Miss_ratio : 快取記憶體失誤率,數值為 1-Hit_ratio Way : 集合,快取的區塊個數 Tag_power : 快取記憶體中 Tag 部分功率消耗,隨快取記憶體大小而變,可利用 Cadence tools SRAM 模組測量
Data_power : 快取記憶體中 Data 部分功率消耗,隨快取記憶體大小
而變,可利用 Cadence tools SRAM 模組測量
H_T_enable_ratio: 命中時,Tag 部分驅動的機率,依照設計有不同計算的 方式 H_D_enable_ratio: 命中時,Data 部分驅動的機率,依照設計有不同計算 的方式 M_T_enable_ratio: 失誤時,Tag 部分驅動的機率,依照設計有不同計算的 方式 M_D_enable_ratio: 失誤時,Data 部分驅動的機率,依照設計有不同計算 的方式
Other : 其他單元的功率消耗,在此表示 Sentry tag cache 使
如表2-2 所示,本表以 4KB ,4-way(Way=4) ,8-bit Tag bit(tag= 8), 2 bit Sentry tag bit(S=2), 32-bit data bit(data=32) 的快取架構做為例子來比較,另外此圖表假 設單位CAM 所耗的 power 為單位 SRAM 的兩倍[9]作為評估功率消耗的比較。
表 2-2 : 傳統、Sentry tag 架構、phase 架構功率公式比較表 Convention Sentry tag Phased cache/
This Work Hit_power Way(tag+data) (tag +data) +(Way-1)
*(tag+data)(1/S^2) +Way*CAM*S
Way*tag + data
Miss_power Way(tag+data) Way*(tag+data)(1/S^2) +Way*CAM*S Way*tag Power: Hit*Hit_power + Miss*Miss_power H* Way(tag+data) +M*Way(tag+data)
H*(tag +data) * (1+(Way-1)/ S^2) +M*( tag +data) +Way*CAM*S H*( Way*tag + data) +M*Way*tag Power : (4-way) (95%Hit) 100% 51% 39%
Tag 跟 Data 分別表示 tag cache 跟 data cache 相位所消耗的功率,依快取記 憶體大小不同而變化。將快取記憶體功率消耗分成命中時的功耗及失誤時的功率
消耗,會依照快取記憶體使用的演算法而有所不同,以 4-Way 集合關聯性快取 記憶體為例,傳統設計需要同時驅動4 個 way 的 tag cache 及 data cache 部份, 而Sentry tag 架構在命中時約需消耗 1.75 個 way 的 tag 加 data 的 power,在失 誤時約需消耗1 個 way 的 tag 加 data 的 power,可比傳統快取記憶體架構省下 約49%的功率消耗,此結果與 Sentry tag 架構論文數據大致相似。而使用 Phased cache 架構,雖然在處理 tag 部分都需要驅動 4 個 way 集合,但命中時只需要處
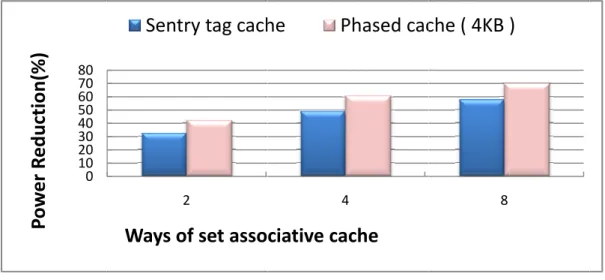
理1 個 Way 集合 的 data cache 部分,失誤時則不需要驅動任何一個 data cache 部 分,於是可以比 Sentry tag 架構 省下較多的功率消耗,大約能省下 61%左右的 功率消耗。 因為主要是針對集合關聯性快取記憶體降低功率消耗的設計,所以不同的集 合關聯性快取記憶體條件下省略的功率消耗當然也是不同,如圖 2-11 所示在相 同參數不同集合關聯數條件下,代入公式(表 2-1)去統計,以傳統的快取記憶體 架構的功率消耗為標準,在2-Way 關聯性快取記憶體條件下,Sentry tag cache 可 以省下約32%的功率消耗,Phased cache 可以省下約 42%左右的功率消耗,而在 4-Way 關聯性快取記憶體條件下,Sentry tag cache 可以省下約 48%的功率消耗, Phased cache 可以省下約 61%左右的功率消耗,而在 8-Way 關聯性快取記憶體 條件下,Sentry tag cache 可以省下約 57%的功率消耗,Phased cache 可以省下約 70%左右的功率消耗,可以看出集合數越多越能達到降低功率消耗的效果,另外 Phased cache 跟 Sentry tag 架構 在越多集合關聯性下,降低功率消耗的差距雖然 有變小,如圖2-12 所示,在 2-Way associative 條件下,Phased cache 降低功率 消耗約為Sentry tag 的 1.3 倍左右,4-Way 集合關聯性時約為 1.23 倍,8-Way 集 合關聯性時約為1.22 倍,16way 、32-Way、64 way 集合關聯性 時皆為 1.21 倍 左右,表示在集合關聯性數越多的情形下 Phased cache 降低功率消耗的效果依 然是Sentry tag cache 120% 上下,並不會隨著 Way 數增加而有明顯效率變差。 測試程式的命中率不同,依照公式及演算法推演,也會帶來不同的效果,如
圖 2-13 所示,命中率越高降低功率消耗越低,但相位式快取記憶體過濾非必要 執行集合的效果是一樣的,只是需要驅動的集合次數增加,因此在降低功率消耗
圖2-11:Se 圖2-12: S 圖2-13: S 0 10 20 30 40 50 60 70 80
Po
w
e
r
R
e
duction(%)
1.16 1.181.2 1.22 1.24 1.26 1.281.3 1.32Ra
tio
0 10 20 30 40 50 60 70 80 Power Reduction (%) entry tag 架 Sentry tag 架 Sentry tag 架 2Ways of
Sentr
6 8 2 2 4 6 8 3 2 2Ratio of P
50 架構與相位 架構與相位 架構與相位 2f set asso
ry tag cach
4Ways of s
Phased /Se
Sentry tag 位式架構降低 位式架構降低 位式架構功率 4ciative ca
he
P
8set associ
entry tag c
75 Hit ra cache 低功率消耗 低功率消耗 率消耗跟命 4che
Phased cac
16ative cach
cache pow
90 tio (%) Phased ca 耗比較圖 耗比例關係圖 命中率之關係 8che ( 4KB
32he
wer reduct
ache (4KB 4w 圖 係圖)
64tion
95 way)2.2.2 Simplescalar 功率及週期分析
本論文仿照其他論文分析測量,採用 Simplescalar[11],圖 2-14 來模擬本設 計 及 Sentry tag architecture 演 算 法 在 處 理 標 準 效 能 評 估 程 式 SPEC95 及 SPEC2000 (Standard Performance Evaluation Corporation )[12]的效果,隨機取用七 種測試程式,包含整數標準效能評估程式及浮點數標準效能評估程式,表 2-3 有 各標準效能評估程式的簡介,模擬結果如圖2-15、2-16、2-17 所示,大致與推導 相似,降低功率損耗平均結果分別為 Phased cache 2-Way:44%, 4-Way:62%, 8-Way:71% ,Sentry tag architecture 2-Way:34%, 4-Way:49%, 8-Way:58%,與 Sentry tag paper 所提結果 4-Way 46%差距不大。
由以上公式推導,數據分析皆能證明 Phased cache architecture 在相同條件下, 降低功率損耗的效果是比Sentry tag architecture 較為優異。
而Phased cache 跟 Way-prediction cache 的比較,圖 1-6 已有其比較結果, 由圖1-6 可以看出 Phased cache 在降低功耗的效果也是比 Way-prediction cache 優異。
Item com li95 gzip gcc amm pars bzip P Rd ti (%) P Rd ti (%) ms mpress95 5 p mp ser p2 0 10 20 30 40 50 60 b P ower R e d uc ti on (%) 0 10 20 30 40 50 60 70 b P ower R e d uc ti on (%) 表 SPEC CINT95 CINT95 CINT2000 CINT2000 CFT2000 CINT2000 CINT2000 圖15: 2-圖2-16: 4-bzip2 comp zip2 comp Sentry 表 2-3 : 標準 Descrip A in-me Xlisp in 0 Compre 0 C Progr Compu 0 Word P 0 Compre Way 時 Se Way 時 Se p.95 gzip p.95 gzip y tag cache 準效能評估 ption emory versi nterpreter. ession ramming La utational Ch Processing ession entry tag 與 entry tag 與 gcc SPEC 95 & Sentry t gcc SPEC 95 & Phased C 估程式介紹 ion of the co anguage Co emistry 與相位式架構 與相位式架構 li95 p & 2000 tag cache li95 p & 2000 Cache (4KB 4W ommon UN ompiler 構降低功耗 構降低功耗 parser am parser am Way) NIX utility. 耗比較 耗比較 mp avg mp avg
果, 位式 期平 2-19 少快 並非 週期 要兩 間會 加入 少相 果是 P Rd ti (%) 另外也使 ,使用依序 式快取記憶 平均8%的執 9 所示。分析 快取讀取的 非每次讀取 期決定,如 兩週期的讀 會被R5 讀取 入本高效能 相位式快取 是在合理的 LH R4 ,0( LH R5 ,0( MAC R6, 0 20 40 60 80 bz P ower R e d uc ti on (%) 圖2-17: 8-使用 Simple 序執行(in ord 憶體的效果 執行時間, 析此結果, 的管線級數, 取相位式資料 如以下程式為 讀取時間,但 取時間掩飾 能管線設計雖 取記憶體造成 的範圍之內。 (R2) (R3) R4, R5 zip2 comp Sentry ta Way 時 Se scalar 模擬 der issue), ,如圖 2-18 相對就是減 雖然本設計 去除管線暫 料快取記憶 為例,在相 但只有R5 的 飾掉,因此這 雖然能改善 成的週期增 。 .95 gzip ag cache entry tag 與 擬此設計改善 分別量測 8 所示,在 減少了快取 計將相位式 暫停,但因為 憶體皆會造成 相位式資料快 的讀取會造 這兩個讀取 善相位式快取 增加,但從管 gcc SPEC 95 & Phased Cach 與相位式架構 善相位式快 測相位式快取 在平均 20%的 取記憶體讀取 式增加的1 週 為未改善前 成管線暫停 快取記憶體 造成管線兩週 取指令只有一 取記憶體造 管線及程式指 li95 p & 2000 he (4KB 8Way 構降低功耗 快取記憶體 取記憶體與 的讀取指令 取時間的3 週期延遲融 前的相位式記 停,必須視資 體下,雖然 R 週期的暫停 一個管線暫 造成的管線暫 指令架構考 parser am y) 耗比較 體時間效能的 與本設計改良 令中改善了總 9%左右,如 融入管線中 記憶體管線 資料危障的距 R4 跟 R5 都 停,R4 的讀取 暫停週期,所 暫停,能完全 考量,此數據 mp avg 的效 良相 總週 如圖 ,減 線中, 距離 都需 取時 所以 全減 據結
圖2-18: 總周期改善比例與讀取指令比例 圖2-19: 快取記憶體讀取周期改善比例
0 10 20 30 40
ammp bzip2 comp.95 gzip gcc li95 parser avg
%
SPEC 95 & 2000 Improvement of total cycles Data cache access of total instruction 0 20 40 60ammp bzip2 comp.95 gzip gcc li95 parser avg
%
SPEC 95 & 2000 Improvement of cache access cycles
2.2.3 高效能之記憶體存取管線設計分析
圖2-20 : 管線改良之分析圖 從圖2-20 來分析此管線設計的使用,若是單純只加入此高效能之記憶體存取 管線設計,如圖2-20 上半部管線,在 ALU 級就能獲得快取資料,在時間數據上, 從上面的改善37%管線暫停的數據中分析,可以得到只有 37%的 load 指令在 2 個週期以內會造成管線暫停,也就是有63%的讀取資料指令不急著在 2 週期內讀 取到資料,由此我們推測37%指令中只有一半的會在 1 個周期內造成管線暫停, 也就是18%左右,也就是約略能加速 4%左右的整體效能。但若是結合相位式快 取設計,除了能降低40%~70%左右的功率消耗,又能改善相位式快取記憶體耗 時的缺點,在20%load 程式中,改善 37%快取讀取時間,改善 8%的整體時間。 因此本設計結合相位式快取設計可以得到最大的效益,如表2-4 所示。 表 2-4 : 整合設計效能、功率比較 相位式快取 高效能存取管線 功率 執行時間 傳統 X X 100% 100% 相位式快取設計 O X 40% 108% 高效能存取管線 X O 100% 96% 本論文設計 O O 40% 100% ALU/MEM WB/MEM2 ALU Tag compare Data cache HIT MISS REG Index Rs/Rd•Phased cache with pipeline modified
40% power &100% time ALU/MEM WB ALU L1 cache REG Index Rs/Rd
•Conventional cache with pipeline modified
100% power & 96% time
ALU/MEM WB/MEM2 ALU Tag compare Data cache HIT MISS REG Index Rs/Rd
•Phased cache with pipeline modified
40% power &100% time ALU/MEM WB ALU L1 cache REG Index Rs/Rd
•Conventional cache with pipeline modified
從優 體模 38% 右的 達到 降低 功耗 快取 /暫停 設計 度/硬 成本
2.3
結
本章節針 優缺點去分 模擬結果, %左右的快取 的功率消耗 到此效果, Conv Cach 低快取 耗效果 Low 取延遲 停 Low (1 cy 計複雜 硬體 本 Low 0 50 100 150 200 % C 圖結語
針對相位式快 分析,改善及 從解決相位 取處理時間 耗,只需針對 跟其他設計 表 2-5 : 本 ventional he S C w(0%) M w ycle) L ( w H ( Cac Conventional C 圖 2-21: 高 快取記憶體 及測試,再從 位式快取記 間,也就是改 對管線增加 計比較在功 本設計與其他 Sentry tag Cache Middle(34% Low (1 cycle) High (CAM) che access cyc Cache 高效能相位 體及高效能存 從功率及效 記憶體造成的 改善8%的 加些微硬體電 功耗、效能 他低功耗快 Way Predictio Cache %) Middle( Middle (1~2 cyc Middle cles Phased Cach 位式快取記憶 存取管線設 效能上去評量 的管線暫停 的整體效能, 電路,增加 、成本上都 快取設計分析 on (30%~40%) cle) Po he This 憶體設計改 設計描述其原 量,使用S 停中,如下圖 ,又能降低 加約6%的硬 都較為優秀 析比較 Phased Cache ) High(44%) High (2 cycles) Middle ower consum s work (4Way 改善比較圖 原理及其架 Simplescalar 圖 2-21,改 低40%至 70 硬體成本,即 ,如表2-5 This Wor ) High(44% Low (1 cycle) Middle (6% area ption 8KB) 架構, r 軟 改善 %左 即可 。 rk %) a)第三章 低功耗嵌入式處理器設計
低功率消耗相位式快取記憶體控制器及其管線設計硬體地位上不能單獨存 在運作,需搭配一個處理器設計。因此,本論文也製作出一個32 位元嵌入式處 理器核心,以呈現完整的應用。以下章節將說明此處理器的特性、指令集、軟體 開發環境及可搭配的其他設計作一介紹。3.1 低功耗嵌入式處理器架構
3.1.1 低功耗嵌入式處理器核心
此處理器以低功耗為設計考量方向,主體以RISC 架構為主,分別增加指令 快取記憶體、資料快取記憶體控制器及匯流排編碼解碼器來降低處理器功率消耗 的主要部份: 快取記憶體及匯流排傳輸,指令快取記憶體設計為具有使用者可調 性主從式指令快取記憶體控制器[13],資料快取記憶體設計為本設計架構,匯流 排編碼解碼器為功率感知之匯流排編碼解碼器設計[14]。希望能結合各自降低功 率消耗的設計理念發展成一顆以低功耗為訴求的嵌入式處理器。 本論文設計的低功率消耗嵌入式處理器擁有七級管線架構的設計[15]。當一 個指令透過程式計數器(Program counter),指令快取控制、讀取,將指令抓取 進入處理器內部後,會先對該指令進行解碼,接著到暫存器提取所需要的資料到 ALU 中執行,最後將結果存回暫存器或記憶體中。記憶體周邊裝置的存取透過 快取控制處理器來規劃,周邊裝置(或 IP)可利用標準的 APB 規格掛上匯流排, 將外部的取樣訊號透過 APB 匯流排,將資料存取於內部快取記憶體及外部主要 記憶體之間,或內部運算的結果送到周邊裝置上輸出,架構如圖3-1。圖 3-1 :處理器組成架構圖
圖3-2 :處理管線流程圖
Instruction Fetch /
Program Counter / Branch Prediction
MS-Cache
Instruction Decoder
Register File/ Cache address generator
ALU Cache tag comparison
W B / Cache Data Access
Main memory
BUS
Load Instruction Fetch /
Program Counter / Branch Prediction
MS-Cache
Instruction Decoder
Register File/ Cache address generator
ALU Cache tag comparison
W B / Cache Data Access
Main memory
BUS
Load
BUS Encoder/Decoder
圖3-2 簡介此處理器管線的流程,此處理器擁有七級管線架構,七級管線包 含程式計數/分支預測/指令抓取模組、指令快取記憶體模組(2 級)、指令解碼模組、 暫存器模組、算數邏輯單元模組/快取 Tag 級以及寫回/快取資料級,以下分別描 述其主要的工作簡述如下:
Program Counter/Branch Predict/ Instruction Fetch:在硬體架構最上層,目的 是把程式計數器加一,並處理跳躍,最後決定程式計數器的值。再把程式計數器 的值,轉成程式記憶體的位址,送進指令快取記憶體去抓取指令。其中,由於有 些指令在ALU 級時會需要處理指令中的程式計數器值,所以必須把程式計數器 值一級一級地傳下去,因此,程式計數器值會傳進下一級的暫存器。在處理跳躍 指令時,為了避免浪費跳躍指令發生後一個指令被抓取,設定兩個訊號做為防止 跳躍發生時的指標,用以表示現在的管線是否在 Stall 狀態,決定要不要執行該 級動作。 MS-I-cache : 依照 PC 值讀取相對應的資料,若發生失誤,則至主記憶體搬 移數筆資料取代。採用相位式設計,先經過Tag 存取比對,再讀取命中的資料。 並針對跳躍的指令加強,提高命中率。 Instruction Decoder:這一級的目的是把指令依照對應的指令碼去做解碼,指 令中有兩個來源暫存器的位置,一個目的暫存器的位置。這些位置可以對下一級 的暫存器組取得來源運算元並提供未來ALU 級寫回的目的位置。 Register File : 處理核心有 16 個通用暫存器。處理核心有額外的 16 個中斷 暫存器來處理外部中斷、內部優先權中斷、與其他IP 狀態設定所使用的暫存器, 暫存器組為 2 讀 1 寫的格式,負責提供解碼器所解碼出的來源運算元值,並將 ALU 級算出的目的運算元寫回。在此模組中,有很多連接 ALU 級模組的輸出信 號,目的是把這些 ALU 級要用到的信號經由管線級送往 ALU 級中,利用這些 信號來完成Data forwarding 的動作。此外針對記憶體相關指令,特別計算其記憶
ALU/ Tag Cache access:本級功能是計算出邏輯或運算值,為了 Data forwarding 的實作,Data memory 及 Write back 這兩級隱含在 ALU 級內。Data forwarding 的機制是利用前面一級一級傳回的信號實作而成,目的是為了減少 RAW hazard。此級也平行記憶體相關指令,讀取 Tag cache 的數值跟計憶體位址 做比對,判別快取命中失誤等訊息。
Write-Back/ Data Cache access:由 ALU 或 Memory 寫回 Reg File 的動作,或 由ALU 寫入 cache 及 Memory。若為記憶體相關指令則依命中的訊息驅動集合的 資料存取。
除了以上基本的管線模組設計外,還有一些特殊硬體設計需求被強調出來,
包含以下五種說明:
SIMD support (Single-Instruction stream ,Multiple-Data stream):
支援8/16 bit SIMD 指令集架構,加速特定多媒體運算,如 8-bit 圖形 運算,16bit 語音運算。
Bit Reverse:針對 FFT 運算所增加的 memory 定址模式[16],例如位址
(01101)可被轉成(10110)的位置儲存。 一個指令週期完成乘加運算。
良好的 Data Forwarding 機制。
Condition Branch:預測採用 Prediction-untaken 方法設計。
3.1.2 低功耗嵌入式處理器指令集架構
處理器指令集共分五大類:資料搬移、算數邏輯運算、跳躍指令、SIMD 指 令及其他類指令,列表如下:
處理器共提供Direct、Reg to Reg、Indirect、Displacement (base add)、Index, Bit-Reverse 六大類的定址模式。
表 3-1 :資料搬移指令列表 資料搬移指令 :
Instruction Op code Example Mode
MOVRC 000001 MOV rd,data Direct
MOVRR 000010 MOV rd,rs Reg-Reg
MOVRM 000011 MOV rd,address Direct
MOVMR 000100 MOV address,rs Direct
MOVMRR 000101 MOV @rs2,rs Indirect
MOVRRM 000110 MOV rd,@rs Indirect
MOVARR 100010 MOV rd(a),rs(b) Reg-Reg
MOVB 101111 MOVB rd,base(rs) Displacement
MOVI 110000 MOVI rd,rs1(rs2) Index
MOVREVRM 101010 MOV rd,address Bit Reverse
MOVREVMR 101011 MOV address,rs Bit Reverse
MOVREVMRR 101100 MOV @rs2,rs Bit Reverse
MOVREVRRM 101101 MOV rd,@rs Bit Reverse
表 3-2:算數邏輯運算指令列表 算數與邏輯運算指令 :
Instruction Op code Example
ADDRR 001000 ADD rd,rs1,rs2
SUBRR 001010 SUB rd,rs1,rs2
MULRR 001100 MUL rd,rs1,rs2
SUBRC 001001 SUB rd, data
MULRC 001011 MUL rd, data
MACR 100111 MAC rd,rs1,rs2
MACC 110001 MAC rd,rs1,data
ANDRR 001110 AND rd,rs1,rs2 ORRR 001111 OR rd,rs1,rs2 XORRR 010000 XOR rd,rs1,rs2 INVR 010001 INV rd,rs 表 3-3:跳躍指令列表 跳躍指令 :
Instruction Op code Example
JMP 010010 JMP address
JMPR 010011 JMP @rs
JBE 010100 JBE rs1,address
JNE 010101 JNE rs1,address
JMB 010110 JMB rs1,address
JLB 010111 JLB rs1,address
JBER 011000 JBER rs1,rs2,address
JNER 011001 JNBR rs1,rs2,address
JMBR 011010 JMBR rs1,rs2,address
JLBR 011011 JLBR rs1,rs2,address
CALL 100011 CALL address
RET 011110 RET