建構關鍵因子選擇的多品質特性田口方法算則
87
0
0
全文
(2) 誌謝 經過兩年的碩士生涯,終於完成此論文,過程幾經波折,承蒙指導教授的耐 心指教、碩士班的所有同學的鼓勵、學長姐和學弟妹的經驗分享與相伴、家人的 支持與經濟支援、某人的關心與並進,以及口詴委員的細心校稿指正,特別於此 表示感謝。研究期間瓶頸碰撞不少,有幸遇到好的老師們與同學們,使我的求學 過程更為豐富並能克服難關,感謝所有兩年來相遇的人事,謹以此論文表示最大 之謝意。. 楊捷允 謹致於 高雄 楠梓 中華民國一百年六月. i.
(3) 建構關鍵因子選擇的多品質特性田口方法算則. 指導教授:盧昆宏 博士 國立高雄大學亞太工商管理學系 研究生:楊捷允 國立高雄大學亞太工商管理學系. 摘要 使用傳統的田口方法進行品質改善時,適用於單一品質特性的製程最佳化 問題,然而顧客對於品質的需求往往不是單一特性的最佳即可。因此,開始有 研究學者提出一些算則方法,使傳統田口方法能解決多重品質特性的最佳化問 題。此外,當工程師或研究人員在選擇田口實驗中的製程關鍵參數時,一般藉 由討論及個人經驗之觀點來進行關鍵因子的決定,這樣的方式雖然簡便但卻缺 乏數字上的支持與客觀性。 本研究提出一個關鍵因子選擇下的多目標田口理想解算則,嘗詴藉由 DEMATEL 先找出製程中的關鍵控制因子,再透過 TOPSIS、模糊推論與田口方 法進行多品質特性產品製程的品質改善。本研究所提出之方法能以合理客觀的 方式挑選製程上的關鍵參數因子,並能藉由 TOPSIS 與模糊推論於田口方法上 的應用,觀察兩方法對於進行田口最佳化實驗時的完整性並確認所挑選之最佳 化製程參數水準的正確性。本研究以鑄造產業的脫蠟鑄造製程為案例,進行本 研究提出之算則的導入,欲驗證本研究所提出演算法之可行與有效。. 關鍵字:田口方法、多屬性決策、決策實驗室分析法、理想解類似度順序偏好 法、模糊推論、脫蠟鑄造. ii.
(4) Construct an Algorithm of Critical Parameters Selection for Multiple Quality Characteristics in Taguchi Method Advisor:Dr. Kuen-Horng Lu Department of Asia-Pacific Industrial Business Management National University of Kaohsiung Student:Jie-Yun Yang Department of Asia-Pacific Industrial Business Management National University of Kaohsiung Abstract The Taguchi method is suitable to the single quality characteristic but in generally, consumers’ demands of product quality characteristic are not only one. Because of this reason, many algorithms were proposed to aid the traditional Taguchi method to optimize the multiple quality characteristics. Moreover, engineers or investigators choose the critical parameters for Taguchi experiment usually by grouping discuss or their own subjective judgments that is lack of numerical proof and not objective enough. The algorithm proposed in this paper is a process to deal multiple quality characteristics in Taguchi method that could select critical parameters of manufacturing process. It aggregates DEMATEL、TOPSIS and Fuzzy Inference with Taguchi method to make critical parameters selection reasonable and observe the completeness between TOPSIS and Fuzzy Inference apply to Taguchi method. Furthermore, the algorithm could be able to confirm the accuracy of parameters’ levels of optimal manufacturing process. In this research uses a case lost wax casting procession to verify the feasibility and effectiveness of the algorithm.. Keywords:Taguchi Method, MADM, DEMATEL, TOPSIS, Fuzzy Inference, Investment Casting. iii.
(5) 目錄 頁碼 誌謝................................................................................................................................. i 摘要................................................................................................................................ii Abstract ........................................................................................................................ iii 目錄............................................................................................................................... iv 圖目錄........................................................................................................................... vi 表目錄..........................................................................................................................vii 第壹章 緒論................................................................................................................ 1 1.1 研究背景與動機........................................................................................... 1 1.2 研究目的....................................................................................................... 3 1.3 研究範圍與限制........................................................................................... 4 1.4 研究流程....................................................................................................... 4 第貳章 文獻探討........................................................................................................ 6 2.1 田口方法(Taguchi method)概述 .................................................................. 6 2.1.1 品質損失函數(Quality Loss Function)概念 ..................................... 7 2.1.2 品質特性分類與 S/N 比 ................................................................... 9 2.1.3 田口參數設計.................................................................................. 12 2.1.4 田口直交表...................................................................................... 13 2.1.5 田口方法步驟.................................................................................. 18 2.2 模糊集合理論............................................................................................. 18 2.2.1 模糊集合基本定義.......................................................................... 19 2.2.2 模糊語意變數與模糊數.................................................................. 21 2.2.3 模糊推論系統.................................................................................. 22 2.3 決策實驗室分析法..................................................................................... 24 2.3.1 DEMATEL 算則 ............................................................................. 25 2.4 多屬性決策與理想解類似度順序偏好法................................................. 26 2.4.1 多屬性決策...................................................................................... 27 2.4.2 理想解類似度順序偏好法.............................................................. 28 2.4.3 TOPSIS 算則 ................................................................................... 29 2.5 相關文獻比較............................................................................................. 31 2.5.1 田口方法與模糊田口...................................................................... 31 2.5.2 DEMATEL 相關文獻探討 .............................................................. 33 2.5.3 TOPSIS 相關文獻探討 ................................................................. 35 2.5.4 DEMATEL、TOPSIS 及田口方法之整合應用相關文獻........... 36 第參章 演算法則之建構.......................................................................................... 38 iv.
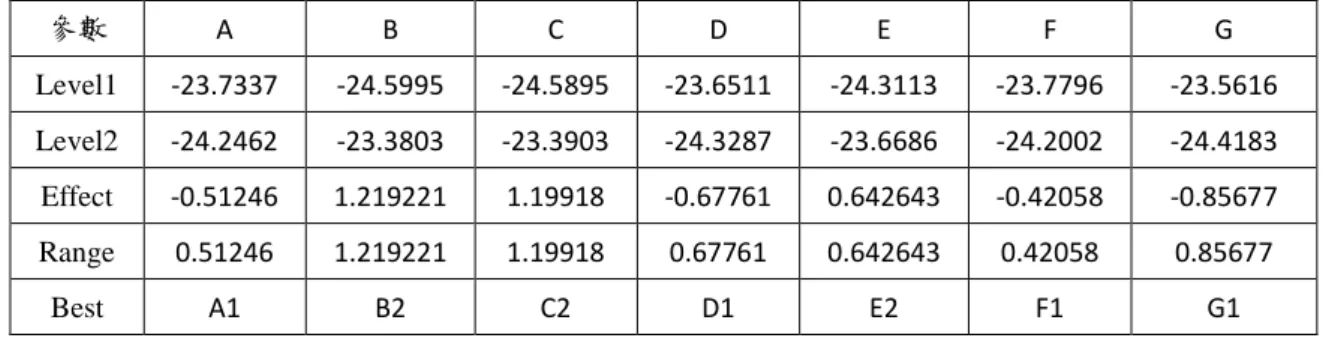
(6) 3.1. 算則建構..................................................................................................... 38. 第肆章 實例應用與驗證.......................................................................................... 44 4.1 脫蠟鑄造製程最佳化................................................................................. 44 4.2 小結............................................................................................................... 71 第伍章 結論與建議.................................................................................................. 73 5.1 結論............................................................................................................... 73 5.2 建議............................................................................................................... 74 參考文獻...................................................................................................................... 75. v.
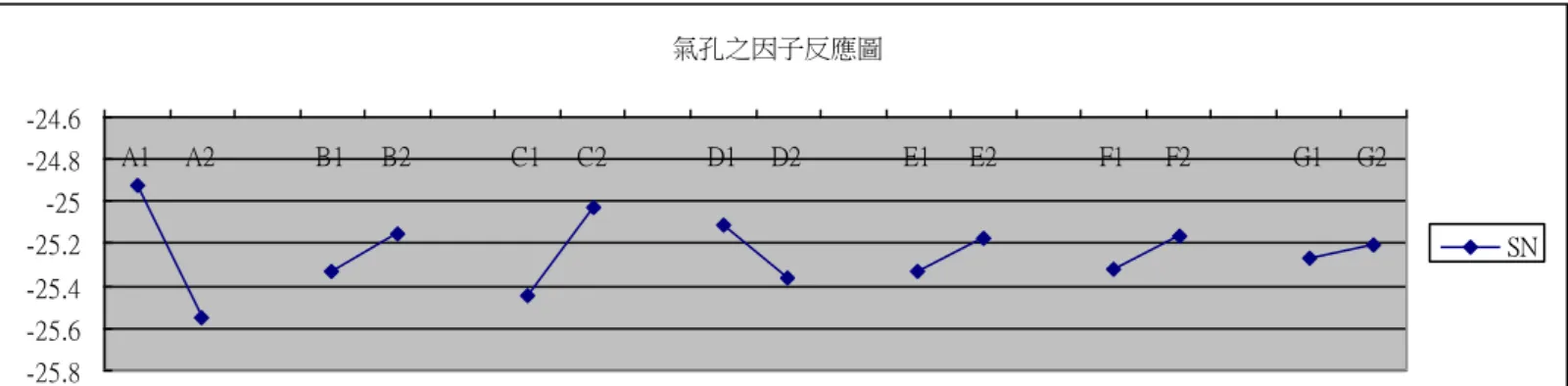
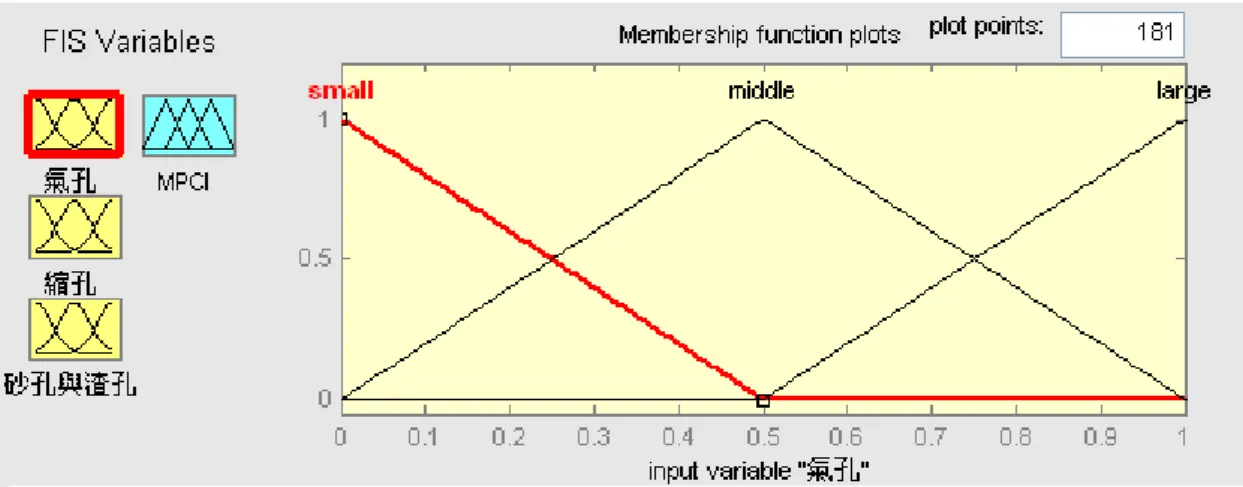
(7) 圖目錄 頁碼 圖 1-1 研究流程圖......................................................................................................... 5 圖 2-1 品質損失函數.................................................................................................... 7 圖 2-2 田口參數圖...................................................................................................... 12 圖 2-3 田口方法流程圖.............................................................................................. 18 圖 2-4 三角形歸屬函數圖........................................................................................... 19 圖 2-5 梯形歸屬函數圖............................................................................................... 20 圖 2-6 高斯歸屬函數圖............................................................................................... 20 圖 2-7 語意變數之模糊數.......................................................................................... 22 圖 2-8 模糊推論系統架構圖.................................................................................... 22 圖 2-9 多屬性決策方法分類....................................................................................... 28 圖 3-1 算則架構流程圖.............................................................................................. 39 圖 4-1 脫蠟鑄造流程................................................................................................... 45 圖 4-2 脫蠟鑄造製程參數因果圖............................................................................... 52 圖 4-3 參數效果下的氣孔反應圖............................................................................... 55 圖 4-4 參數效果下的縮孔反應圖............................................................................... 55 圖 4-5 參數效果下的砂孔與渣孔反應圖................................................................... 56 圖 4-6 氣孔品質特性之歸屬函數............................................................................... 61 圖 4-7 縮孔品質特性之歸屬函數............................................................................... 61 圖 4-8 砂孔與渣孔孔品質特性之歸屬函數............................................................... 61 圖 4-9 脫蠟製程案例之多重品質特性衡量指標(MPCI) .......................................... 62 圖 4-10(一)脫蠟鑄造製程案例之品質特性模糊規則 ............................................... 62 圖 4-10(二)脫蠟鑄造製程案例之品質特性模糊規則 ............................................... 63 圖 4-11 脫蠟鑄造製程案例之模糊推論過程............................................................. 64 圖 4-12 脫蠟鑄造製程之 TOPSIS 參數分析反應圖 ................................................. 66 圖 4-13 脫蠟鑄造製程之 MPCI 參數分析反應圖 ..................................................... 68. vi.
(8) 表目錄 頁碼 表 2-1 品質特性損失函數與 S/N 比 .......................................................................... 11 表 2-2 田口參數的三種型態 ...................................................................................... 13 7 表 2-3 L 8 (2 ) 的直交表 ............................................................................................... 15. 表 2-4 選擇直交表之建議........................................................................................... 17 表 2-5 語意變數型式................................................................................................... 21 表 3-1 影響程度尺度表............................................................................................ 40 表 4-1 脫蠟鑄造製程參數及說明............................................................................ 46 表 4-2 脫蠟鑄造製程之品質特性與說明.................................................................. 47 表 4-3 脫蠟鑄造製程各參數間影響程度之直接關係矩陣.................................... 48 表 4-4 脫蠟鑄造製程參數之標準化直接關係矩陣................................................... 49 表 4-5 脫蠟鑄造製程參數之直接/間接矩陣表 ......................................................... 50 表 4-6 脫蠟鑄造製程參數之中心度與原因度........................................................... 51 表 4-7 脫蠟鑄造製程關鍵參數之實驗水準............................................................... 53 表 4-8 氣孔、縮孔、砂孔與渣孔之 S/N 比 ............................................................. 54 表 4-9 參數效果下的氣孔反應表.............................................................................. 54 表 4-10 參數效果下的縮孔反應表............................................................................. 55 表 4-11 參數效果下的砂孔與渣孔反應表 ................................................................. 56 表 4-12 脫蠟鑄造製程個別品質特性下的田口最佳參數水準組合........................ 56 表 4-13 脫蠟鑄造製程之多重品質特性特行衡量指標數據..................................... 65 表 4-14 脫蠟鑄造製程之 TOPSIS 參數分析反應表 ................................................. 66 表 4-15 脫蠟鑄造製程之 TOPSIS 品質特性衡量指標 ANOVA 分析表 ................. 67 表 4-16 脫蠟鑄造製程之 MPCI 參數分析反應表 .................................................... 68 表 4-17 脫蠟鑄造製程之模糊推論 MPCI 變異數分析 ............................................ 69 表 4-18 最佳參數水準下的 SN 比預測值與實驗值 ................................................. 70 表 4-19 最佳參數水準驗證實驗與原始參數水準數據比較 .................................... 71. vii.
(9) 第壹章. 緒論. 全球化所造成的世界工廠競爭,致使企業對於核心能耐的不斷提升,不敢有 絲毫的鬆懈。不論生產之速度、成本、品質及效率都是企業核心競爭力的重點標 的,其中產品與服務的品質,更關係著顧客的滿意度與忠誠度,對企業之信譽和 永續經營具有舉足輕重之影響。雖然品質的改善多少意味著成本的增加,但研究 學者及業界近來在品質改善與改善所需負擔之額外成本的平衡上已投入了諸多 心力且成果豐碩,目前對於以最經濟的方法來生產製造具符合顧客滿意之產品或 服務,已經不再是遙不可及的目標。田口方法在品質改善上已在各家學者研究與 實務中被多次證實是一能以低成本之方式創造高品質產品的方法,本研究便欲利 用決策實驗室分析法、理想解類似度順序偏好法建置多目標田口實驗的一套算 則。期望提供改善時一個系統化的流程方法,使製程參數之選擇更為客觀合理, 並能處理非單一品質特性之問題。本章將闡述本研究之背景與動機、研究目的、 研究範圍及限制,最後,介紹本研究之流程。. 1.1 研究背景與動機 由於品質改善有助於企業競爭力的提升,因此,相關之研究一直是被廣為探 討的議題。實務上有效管理及控制品質的方法很多,一般常見的有統計製程管制 (Statistic Process Control)、可靠度工程、實驗設計(Design Of Experiment)、失效 模式與效應分析(Failure Mode and Effects Analysis)、品質機能展開(Quality Function Deployment)、田口方法…等。品質管制活動可分為線外(off-line)品質管 制和線上(on-line)品質管制,線外品質管制是關於產品和製程發展的品質改善活 動而線上品管是透過對於生產線上製造流程的監控來確認產生的品質水準,線上 品質管制大多和生產線上的機台或品檢員有關,較不易以低成本的方式改進,線 外品質管制則是一種以低成本為基礎考量,提升產品品質的方式[28]。田口方法 即是為了達成上述目標而設計的方法,透過此方法,工程師能夠得到合適的參數 設計組合,並使生產的產品變異降低,達到預設之目標。傳統的田口方法在製程 1.
(10) 上的應用,大都僅止於單一品質特性的最佳化,但在實務上的產品通常有多於一 個的品質特性,此時工程師也不會只追求單一品質特性的最佳化設計。多重品質 特性的產品其品質特性可能會存在關聯影響的關係,意即當找出品質特性目標 A 的最佳解時的一組設計變數,對於品質特性目標 B 可能並非一良好的解。反之, 當此組設計變數設計點移動至品質特性目標 B 為最佳解時,品質特性目標 A 卻 非一良好的解,故兩品質特性目標間將需有所取捨,這時大都依賴工程師的經驗 與分析,以進行最佳參數組合的選擇,一旦發現不合期望或非最佳解時再對參數 予以修正。這樣的方式除了不具客觀性外,重複的錯誤嘗詴與分析也將造成時 間、原料及人力的成本浪費;因此 Ames、Artiles、Tai 等學者自 1992 年開始, 詴圖以田口方法的品質損失函數求解多品質特性問題的最佳化;Tong 和 Su 則在 1997 年開始透過模糊理論,發展一套系統化的程序來解決多重品質特性問題。 多重品質特性選擇所遭遇的困境近似於多屬性決策問題,文獻上所提出的方 法也多有相似之處,其中決策實驗室分析法(Decision Making Trial and Evaluation Laboratory)為一能將複雜龐大的系統進行清楚的分群及表達關聯性的方法,由於 工程師或管理者在進行田口實驗時往往透過集思廣益的方式來做實驗參數的選 擇,但這樣的方式即使經過多數決的篩選也多為主觀之意見,對於關鍵參數的選 擇難免有失偏頗。因此本研究在決定實驗參數前先透過 DEMATEL 方法,使能 夠客觀的挑選關鍵之參數;而理想解類似度順序偏好法(Technique for Order Preference by Similarity to Ideal Solution) 能同時考量每個方案距正理想解與負理 想解的距離,並以距正理想解最近且距負理想解最遠為最佳方案的多屬性決策方 法;另再應用模糊推論方法求解田口最佳實驗參數。最後透過兩結果的驗證實驗 與貢獻度之比較,觀察本案例中兩方法對於田口實驗之完整性;這些方法分別與 田口品質方法的結合應用並不少見,但整合 DEMATEL 、TOPSIS、模糊推論與 田口方法進行多品質特性產品製程的品質改善及比較的文獻相對較少;本研究即 嘗詴藉由 DEMATEL 先找出製程中的關鍵控制因子,再透過 TOPSIS、模糊推論 與田口方法進行多品質特性產品製程的品質改善進而得到最佳化參數之設計,以 2.
(11) 期能以最低成本最高效率的方式對關鍵因子進行改善與調整,並避免不必要之浪 費。 鑄造這項工藝的歷史悠久,在技術上已相當成熟,儘管現在科技發達,但這 項技術仍因可生產型狀複雜之工件及可大量生產等優點傳承至今無法取代。而鑄 造的方法約略可區分為金屬模型鑄造法、離心鑄造法、精密或包模鑄造法及連續 鑄造法,其中精密或包模鑄造法的脫蠟鑄造因熔點及碳化的溫度低且有產品尺寸 精密度高、製程可局部自動化等優點使得此法為多數業者所使用。本研究也將利 用脫蠟鑄造流程為研究案例,驗證本研究方法的可行性與可用性;關於脫蠟鑄造 流程及其控制因子與品質特性將於第肆章詳述。. 1.2 研究目的 本研究擬整合決策實驗室分析法、理想解類似度順序偏好法與模糊推論建置 多目標田口實驗,制定一套「多品質特性的田口實驗決策分析算則」,提供實行 多目標田口改善時一個系統化的流程方法,具體而言,本研究有以下主要目的: 1.. 挑選更客觀、合理與重要的關鍵參數。經由 DEMATEL 的應用達到降低實 驗次數和時間的效果,並使得挑選的關鍵參數更為客觀合理。. 2.. 建構一套能夠有效處理多重品質特性的演算法則。本研究欲透過 DEMATEL 找出關鍵參數,再分別藉由 TOPSIS 與模糊推論求得多品質特性產品製程的 最佳化參數設計。. 3.. 實例研究。透過案例驗證本研究的演算法則,本研究以鑄造產業的脫蠟鑄造 製程為例,欲驗證本研究所提出之演算法的可行性與有效性。. 4.. 實驗結果比較(TOPSIS 與模糊推論) 。藉由實例驗證結果觀察本案例中兩方 法與田口方法之結合應用後所呈現的完整性。. 3.
(12) 1.3 研究範圍與限制 本研究旨在整合決策實驗室分析法、理想解類似度順序偏好法建置多目標田 口實驗的最佳化參數,制定一套能夠有效處理多重品質特性的演算法則,而在演 算法則的建構及驗證實驗上可能有以下限制: 1.. 本研究僅藉由專家意見廣義的挑選品質特性及可能影響這些特性的控制因 子,接著才進行 DEMATEL 作關鍵因子選擇。. 2.. 生產線上有許多製程參數需設定其參數水準之組合,本研究以脫蠟鑄造製程 為案例進行最佳參數水準的選擇和探討. 3.. 本研究探討之品質特性目標值皆為已知且特性明確(望大、望目、望小), 故並未探討品質的「動態特性」。. 1.4 研究流程 本論文研究流程架構如圖 1.1 所示,其部分內容簡要說明如下述: 一. 選定研究主題 針對研究之背景、動機和目的加以界定其研究範圍與限制。 二. 文獻回顧和數據資料收集 整合 DEMATEL、模糊理論、TOPSIS 以及田口方法等各種多重品質特性相關 文獻,並透過專家意見調查收集脫蠟鑄造之重要參數與品質特性之水準以及實驗 進行時所需要的相關數據。 三. 演算法則之建構 透過相關文獻的收集來決定研究方法,經整合後發展出「關鍵因子挑選下多 目標田口理想解」的演算法則,用於解決多重品質特性之參數最佳化。 四. 實例應用與驗證 依案例公司所提供之實例來進行改善,以驗證本論文研究之演算法則的可行 性及有效性。 五. 結論與建議 4.
(13) 透過本研究之演算法則進行案例驗證後,做出最後結論,並提供建議給予後 續研究者和工程師未來研究改善的方向。. 選定研究主題. 相關文獻回顧. 實例應用與驗證. 演算法則之建構. 結論與建議. 圖 1-1 研究流程圖. 5.
(14) 第貳章 文獻探討. 2.1. 田口方法(Taguchi method)概述 田口方法或稱田口品質工程是由田口玄一(Taguchi Genichi)博士於1950年. 代所開發,倡導利用直交表(Orthogonal Array)及品質損失函數(Quality Loss Function)來設計品質實驗,此方法對於實驗結果的再現性很高、配置實驗的伸 縮性大、實驗次數較少、實驗配置容易且解析方法較簡便,由於以上優點,該實 驗方法在日本迅速普及。日本人將田口博士的學問稱為品質工程(Quality Engineering),歐美各國在1980年代開始接受此方法並稱之為田口方法[1]。 田口方法與穩健設計(Robust Design)的概念相同,為一種將製程參數最適化以 進行品質改善的方法,田口博士以設計開發者的立場將品質定義為「產品出售後 帶給顧客的損失」,強調在產品或製程設計時就考慮品質問題,運用穩健性設計 找到使產品變異縮小的設計或製程參數組合,使得產品品質的問題對社會所造成 的平均損失成本最小[21]。一般品質管制活動可分為線外(off-line)品質管制和 線上(on-line)品質管制,線外品質管制是關於產品和製程發展的品質改善活動而 線上品管則是透過對於生產線上製造流程的監控來確認產生的品質水準[36] ,當欲以低成本方式增進產品品質時線外品質管制常被認為是一個有效的方法, 而田口實驗設計即是達成此目的的常見應用方式[28]。 田口博士將品質工程分成三個設計階段[4、19]: (1) 系統設計(System Design): 檢視各種可能達成「理想機能」的系統或技術,並從中挑選出最適當者,例 如:選定系統所需的材料、零件或選擇一個適當的製造程序。 (2) 參數設計(Parameter Design): 是田口品質工程的核心項目,用以最佳化「系統設計」,透過實驗確定相關 控制因子水準組合,其目的在使產品對於雜訊因子(Noise Factor)干擾的敏感 度最低,以減少產品品質變異提升系統穩健性。 6.
(15) (3) 允差設計(Tolerance Design): 主要是藉由調整公差範圍,以達最佳化設計參數,當產品品質未能滿足顧客 要求,則必頇增加製造成本來降低品質變異減少損失,因此允差設計是一種 追求成本與品質平衡的方法。 田口方法為結合品質損失概念的實驗設計方法,即「每一個產品使用期間對 社會所造成的損失最小」。所謂好品質的產品,每次使用都要正確的表現其目標 績效(Target Performance),同時也不可有任何危害社會的副作用。因此,理想 的產品品質應該是對社會的損失為零。如圖2-1所示若產品功能偏離目標值愈 遠,則表示變異愈大,對社會所造成的損失也就隨之增大,換句話說,品質簡而 言之就是對於目標績效表現的無變異或極小變異[15、35]。. 圖 2-1 品質損失函數. 2.1.1 品質損失函數(Quality Loss Function)概念 田口博士對於品質的定義是以社會損失為基礎,不同於以往以不良率或是製 程能力係數等來評估品質,田口方法以成本的考量為原則,利用損失(即成本) 來做產品品質的評價,所以更容易被了解及接受。 田口博士利用泰勒展開式來定義品質損失函數,茲說明如下[1]: 損失函數 L( y ) 是將品質與金錢結合起來的函數,品質好,則損失就少。對一 個目標值是m的品質特性,假設其特性值為y,當 y m 時可知產品的損失為 7.
(16) 最小,故將損失當成零,即 L(m) 0 ,在數學上此點的斜率為零,也就是 L(m) 0 。品質特性值y比目標值m大或小時,其損失會增加且y越偏離m,則. 損失相對也越大。 將損失函數 L( y ) 在目標值m的周圍,以泰勒(Tayler)展開式展開則可將損 失函數展開如下: L( y) L(m y m). L(m) . (2-1). L(m) L(m) L(m) ( y m) ( y m) 2 ( y m) 3 1! 2! 3!. (2-2). 將 L(m) 0 及 L(m) 0 代入上式得到. L( y ) . L(m) L(m) ( y m) 2 ( y m) 3 2! 3!. (2-3). 由於 ( y m) 3 此項相當於當 y m 時,會有特性值越偏離目標值反而損失越小之 不符合損失函數定義的情況,因此不予考慮。又根據泰勒展開極限理論,高階的 項目可以省略刪除,所以 ( y m) 4 以上的項目可省略,所以損失函數近似於特性 值與目標值之差的平方,稱之為二次損失函數。. L( y ) . L(m) ( y m) 2 K ( y m) 2 2!. (2-4). 公式(2-4)為對稱型望目損失函數(Symmetric Quality Loss Function)其中K為一常 數品質特性係數,若是超出上下規格的損失係數不相等時,稱之為非對稱型望目 損失函數(Asymmetric Quality Loss Function),故此函數可表示為:. K 2 ( y m) 2 , y m (2-5). K1 ( y m) 2 , y m. 8.
(17) 此外,當品質特性值反應值愈小愈佳時,用 m=0 來近似,二次損失函數變為(2-6) 式,並稱為望小特性損失函數:. L( y) K y 2. (2-6). 相反的,若當品質特性值為愈大愈佳時,則用 1 代替y值,此時二次損失函數 y 如(2-7)式,並稱為望大特性損失函數: L( y ) K. 1 y2. (2-7). 2.1.2 品質特性分類與 S/N 比 田口方法中的品質特性可分為望小特性(the smaller-the better)、望大特性 (the larger-the better)及望目特性(the nominal-the better)。以下為簡略之說明 [12]: (1)望小品質特性 若品質特性值具有一個規格上限(Upper Specification Limit;USL),且為非負 數值,其值愈小愈好的特性稱之為望小品質特性。此類的品質特性如產品缺點數。 (2)望大品質特性 若品質特性值具有一個規格下限(Lower Specification Limit;LSL),且為非負 數值,其值愈大愈好的特性稱之為望大品質特性。此類品質特性如手機待機時間。 (3)望目品質特性 此類品質特性通常有一個理想的目標值,且規格上限與規格下限,在此目標值的 兩側。當產品的特性值偏離此一目標值時,產品的功能就會發生退化。此類品質 特性如尺寸特性。 在通訊上,S/N比定義為[1]:. log(. 信號的強度 )db 雜音的強度. 9. (2-8).
(18) 田口博士藉此定義並延伸損失函數之觀念將其創造成參數設計中使用的S/N比。 基本上由損失函數可以看出,若調整品質特性之平均值到目標值上,可使損失減 少,且平均值之調整甚為容易,故將平均值視為「有用的信號」,而品質特性之 變異的增加將使損失增大,故將變異視為「有害的信號」,所以田口之S/N比定 義為:. log(. 有用的信號 )db 有害的信號. (2-9). 而S/N比的推算,是將損失函數直接取對數值轉換而得,主要在於減少交互作用 的產生,並增強穩健設計中加法性(additive model)模式的成立。依據不同的品質 特性,將有不同的轉換公式茲就以各類品質特性之損失函數與S/N比整理如下表 [11]:. 10.
(19) 表 2-1 品質特性損失函數與 S/N 比 品質 函數圖. 損失函數. S/N比. 特性 L(y). STB = 10 log10 ( L( y) K y 2. 望小. 1 n 2 yi ) n i 1. y. (2-10). L(y). L( y ) K. 望大. 1 y2. 1 n 1 LTB = 10 log10 ( 2 ) n i 1 yi. y. (2-11). NTB 10 log10 (. L(y). L( y) K ( y m) 2. 望目. (2-12) y. 11. y2 ) s2.
(20) 2.1.3 田口參數設計 當我們在應用田口實驗方法於產品或製程之前,可以先繪出影響品質特性的 參數圖(圖2-2),依此作為產品或製程之參數的設計方向,其中y表示產品品 質特性,而致使品質特性偏離目標值的可能參數分別為控制因子、信號因子、雜 訊因子,各參數之說明整理如表2-2。. 雜訊因子 Noise factors. 信號因子. 產品/製程. 品質特性(y). Signal factors. Product/process. Quality characteristcs. 控制因子 Control factors 圖 2-2 田口參數圖. 12.
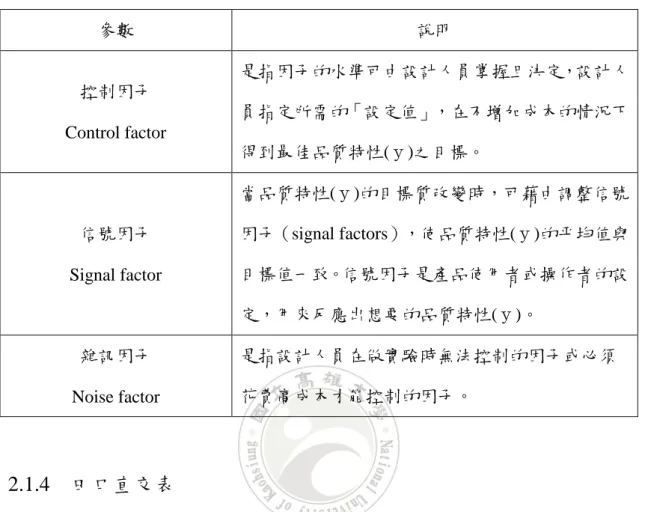
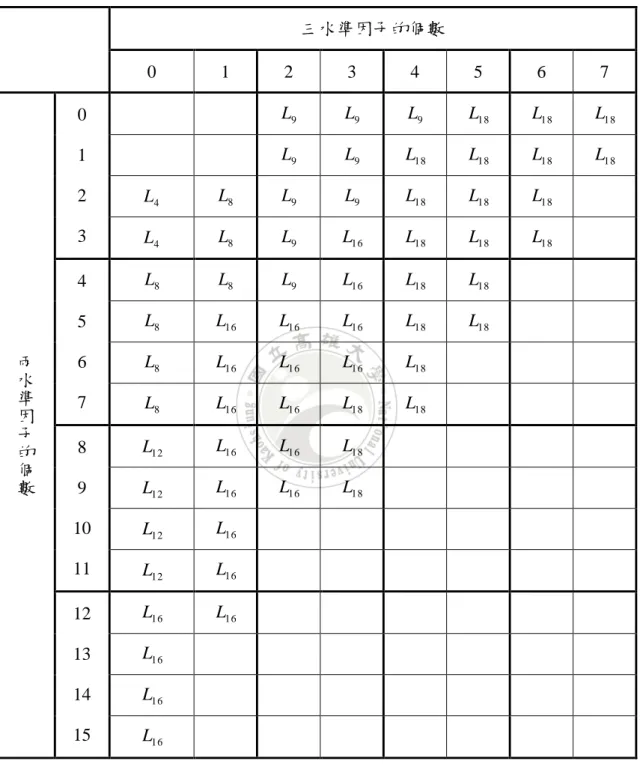
(21) 表 2-2 田口參數的三種型態. 參數. 說明 是指因子的水準可由設計人員掌握且決定,設計人. 控制因子 員指定所需的「設定值」,在不增加成本的情況下 Control factor 得到最佳品質特性(y)之目標。 當品質特性(y)的目標質改變時,可藉由調整信號 信號因子. 因子(signal factors),使品質特性(y)的平均值與. Signal factor. 目標值一致。信號因子是產品使用者或操作者的設 定,用來反應出想要的品質特性(y)。. 雜訊因子 Noise factor. 是指設計人員在做實驗時無法控制的因子或必頇 花費高成本才能控制的因子。. 2.1.4 田口直交表 直交表是田口實驗方法中參數設計主要的配置方法,不同於傳統實驗方法為 一次改變一個因子,其餘因子保持固定的單因子實驗,直交表的配置實驗是利用 全因子(Complete Factorial)實驗中的部份因子(Fractional Factorial)實驗進行因 子、水準配置。如:進行一個七因子各兩水準實驗,若進行全因子實驗,則頇執 行128次實驗組,若利用田口直交表配置時,則僅頇執行8次實驗組。這是因為各 水準間所執行實驗組數為相同(2個)且對稱所致。因此,經由直交表的直交特性 做實驗有下列兩優點: (1) 由於存在直交性,對任一因子的任一水準而言,其他因子的高低水準都是成 對出現,因此,經計算以後,其他因子的影響效果將會互相抵消,而可增加 實驗的再現性。 (2) 經濟效益的增加,因為直交表的應用使得所需做的實驗數減少,因此,大量 13.
(22) 的減少了時間與成本[20]。 典型的一個直交表是以 L a (b c ) 來命名,L代表直交表(Latin square),共有a組實 驗,最多可容納b個水準的因子c個,亦即代表一個a列c行的直交表;有些直交表 可以容納兩水準的因子,此時以 L a (b c d e ) 來表示,它代表共有a組實驗,最多 可容納b個水準的因子c個及d個水準的因子e個。表2-3為 L 8 (2 7 ) 的直交表,而一 般常見的直交表有以下系列,: (1) 2 K 系列: L 4 (2 3 ) 、 L 8 (2 7 ) 、 L16 (215 ) 、 L 32 (2 31 ) 、 L 64 (2 63 ) (2) 3 K 系列: L 9 (34 ) 、 L 27 (313 ) 、 L 81 (340 ) (3) 4 K 系列: L16 (4 5 ) 、 L 64 (4 21 ) (4) 5 K 系列: L 25 (5 6 ) (5) 2 K 3 K 系列: L18 (21 37 ) 、 L 36 (211 312 ) 、 L 36 (2 3 313 ) 、 L 54 (21 325 ) (6) 2 K 4 K 系列: L 32 (21 4 9 ) (7) 2 K 5 K 系列: L 50 (21 511 ) 水準數 行數. L8 (27 ) 列數(實驗次數) 表示直交表. 行數 . 1 列數 1 水準數 1. (2-13). 14.
(23) 7 表 2-3 L 8 (2 ) 的直交表. Exp. A. B. C. D. E. F. G. 1. 1. 1. 1. 1. 1. 1. 1. 2. 1. 1. 1. 2. 2. 2. 2. 3. 1. 2. 2. 1. 1. 2. 2. 4. 1. 2. 2. 2. 2. 1. 1. 5. 2. 1. 2. 1. 2. 1. 2. 6. 2. 1. 2. 2. 1. 2. 1. 7. 2. 2. 1. 1. 2. 2. 1. 8. 2. 2. 1. 2. 1. 1. 2. 而直交表的配置步驟法則分為下列兩種: 一、無交互作用的一般配置 當實驗的各因子水準數皆相同,且因子間不存在交互作用時: (1) 計算所有因子自由度之和。 (2) 選取自由度不小於因子自由度之和且詴驗次數最少之相同水準數直交 表。 (3) 將所有因數任意配置於直交表之行上。 (4) 由因數所配置行上的數字1,2 或3,決定各詴驗的水準組合。 (5) 以隨機順序進行全部之詴驗。 二、有交互作用的一般配置 當因子間存在交互作用時,需對所有可能的水準組合進行實驗: (1) 計算所有因子與交互作用自由度之和。 (2) 選取自由度不小於因子自由度之和且詴驗次數最少之相同水準數直交 表。 15.
(24) (3) 選定一交互作用,將其相關之兩因子任意配置於直交表之行上,然後依 據「交互作用配行表」將此交互作用配置於直交表之行上。 (4) 重複步驟(3)直到所有交互作用之因子皆配置完為止。 (5) 將剩餘因子任意配置於直交表剩餘之行上。 (6) 以隨機順序進行全部之詴驗。 因此,使用直交表配置因子實驗時,並不是對所有組合進行,而是以直交表 所決定之特定組合條件為對象來進行實驗。田口博士在品質工程的研究中推薦使 用被稱為混合系的 L12 、 L18 、 L36 ,一般在選擇直交表時可採用表2-4之建議,例 如,當實驗之2水準因子有5個,3水準因子有2個,則最少需要使用到 L16 直交表。 [1]。. 16.
(25) 表 2-4 選擇直交表之建議 三水準因子的個數 0. 兩 水 準 因 子 的 個 數. 1. 2. 3. 4. 5. 6. 7. 0. L9. L9. L9. L18. L18. L18. 1. L9. L9. L18. L18. L18. L18. 2. L4. L8. L9. L9. L18. L18. L18. 3. L4. L8. L9. L16. L18. L18. L18. 4. L8. L8. L9. L16. L18. L18. 5. L8. L16. L16. L16. L18. L18. 6. L8. L16. L16. L16. L18. 7. L8. L16. L16. L18. L18. 8. L12. L16. L16. L18. 9. L12. L16. L16. L18. 10. L12. L16. 11. L12. L16. 12. L16. L16. 13. L16. 14. L16. 15. L16. 17.
(26) 2.1.5 田口方法步驟 田口方法實驗是以實驗手段來決定參數之設計,其目的是尋求最佳的製程或 產品機能,並進一步維持此一機能的穩健性(Robust)。綜合前述之田口方法介 紹,田口方法的實驗設計步驟整理如圖2-3所示[19]。 Step 1 定義問題並選定品質特性. Step 6 依直交表配置所對應的參 數組合進行實驗. Step 2 判定理想機能. Step 7 計算直交表中每組實驗的 S/N 比. Step 3 列出影響品質特性之因子. Step 8 繪製回應表與回應圖,並 推測最適參數水準組合. Step 4 決定各種因子及變動水準. Step 9 進行資料分析. Step 5 選定合適的直交表. Step 10 確認實驗的新設計值 圖 2-3 田口方法流程圖. 2.2 模糊集合理論 「模糊集合理論」主要是用以將模糊概念量化的學問,起源於美國加州大學 柏克萊分校的Zadeh 教授,於1965 年發表「fuzzy set」之論文,首先提出模糊集 合理論,成為模糊理論的開端,並有越來越多的學者投入於相關研究,使得模糊 數學迅速發展,成為數學中的一門新學問,模糊集合(fuzzy set)是描述事件發 生的可能性集合,意思是說集合中的事件屬於此集合的程度有大小之分,而不是 明確的―是‖或 ―不‖屬於此集合[23]。模糊理論將傳統數學從二值邏輯(binary logic)擴展到連續多值(continuous multi-value),利用歸屬函數(membership function)描述一概念的特值,亦即使用0和1間的數值來表示一個元素屬於某一 概念的程度,這個值稱為元素對集合的歸屬度(membership grade) ;當歸屬度為1 18.
(27) 時,表示元素百分之百屬於這個概念,當歸屬度為0 時,則表示該元素完全不屬 於這個概念,介於兩者之間者則表示於完全屬於及完全不屬於之間[8]。. 2.2.1 模糊集合基本定義 模糊集合的表示方法有很多種,以下為最常使用的一種表示方法:. ~ A ( x, A~ ( x)) x U . (2-14). 其中 為一模糊集合, A~ () 為歸屬度函數,x為元素,U為論域(universe of discourse),一般情況之下歸屬度會界定在0和1之間,(2-14)式的完整解釋為:當 x在U的範圍內,會對應到一個介於0到1之間的數值 A~ ( x) 。所有這種x所成的 集合就是一個模糊集合[2]。 一般可將歸屬函數分為離散型及連續型歸屬函數,基於研究資料類型與目的 本研究將採用功能較佳的連續型歸屬函數,故在此不對間斷型多做贅述;而常用 的連續型歸屬函數的型態則有三角形歸屬函數、梯形歸屬函數及高斯歸屬函數等 [18],函數與圖形如下所示: 一.. 三角形歸屬函數:. 0 x a x a a x b b a A~ x = c x b x c c b 0 c x . (2-15). A~ x. X b c a 圖 2-4 三角形歸屬函數圖 資料來源:Chen and Hwang (1992) 19.
(28) 二. 梯形隸屬函數:. 0 x a x a a x b b a A~ x =1 b x c d x c x d d c 0 d x. (2-16). A~ x 1.0. 0. a. b. c. d. X. 圖 2-5 梯形歸屬函數圖 資料來源:Chen and Hwang (1992). i.. 高斯歸屬函數:. ( x m) 2 2 2 . A~ x exp . (2-17). A~ x. 1.0. 0. X. 圖 2-6 高斯歸屬函數圖 資料來源:Chen and Hwang (1992). 20.
(29) 一般而言歸屬函數的選擇並無一定的定理或公式,通常是根據經驗或統計方法來 加以確認,較難具有強制性,然而在應用模糊控制時,利用三角形及梯形來進行 歸屬函數的規劃幾乎都能得到令人滿意的結果,相關的應用文獻也多,因此本研 究也將選用三角形歸屬函數與模糊語意進行S/N比之模糊化。. 2.2.2 模糊語意變數與模糊數 根據 Zadeh教授在1975年所提出有關語意變數的文獻,係將模糊的概念引入 口語變數中,並應用在現實生活裡。所謂語意變數是用來表達資料所代表的大小 程度,其表示的方式是以自然語言來表示。一般而言,一個語意變數的論域內想 要分割的語意項之數目,通常是以奇數項為主,語意項數量越多,空間的分割就 顯得越細膩,所需要建立的控制規則數量亦相對地增加,一般控制模式較常採用 的方法是分割為二到五個語意項,為求嚴謹,在語意變數的選擇上本研究將把指 標資料分割為五個語意項。下表為語意變數項常用之分割型式 [10] [49]: 表 2-5 語意變數型式 語意變數為二. 語意變數項數為三. 語意變數項數為五 極低度. 低度 低度. 低度. 中度. 中度. 高度 高度 高度 極低度. 21.
(30) 模糊數為一個模糊集合,其歸屬函數頇滿足下列條件[25]: (1)正規化模糊子集(Normality of A Fuzzy Subset)。 (2)凸模糊子集(Convex Fuzzy Subset)。 (3)區段連續(Piecewise Continuous)。. 語意變數主要是用來建立模糊控制規則及進行模糊推論,一般用來建立模糊 控制規則及進行模糊推論的語意變數有三角形、梯形與混合形三種型態,本研究 將使用的語意變數為三角形型態,使用方式例如可將成對比較影響分為―無相關 (NO)‖、―低相關(L)‖、―中度相關(M)‖、―高相關(H)‖、―極高相關(VH)‖進行模 糊處理,如圖2-7所示:. 圖 2-7 語意變數之模糊數. 2.2.3 模糊推論系統 模糊推論系統主要包含定義輸入變數、模糊化、知識庫、模糊推論和解模糊 化,能夠有效處理不確定性的知識與訊息[5],該系統的架構如圖2-8所示。. 輸入變數. 模糊化. 模糊推論. 解模糊化 output. Input 知識庫. 圖 2-8 模糊推論系統架構圖. 22.
(31) 1. 定義輸入變數與輸出變數 首先需選擇適當的受控變數,此變數可為單一變數或多個變數構成之集合;輸 出、入變數的論域應在0到1之間。 例如,於本研究所定義之輸入變數為個別品質特性S/N比的正規化後數值,輸出 變數為多重品質特性衡量指標(Multiple Performance Characteristics Index,MPCI)。 2. 變數模糊化 (Fuzzification) 輸入變數需要先經過模糊化的過程,將明確的數值轉換成模糊數值,才可進入模 糊法則進行模糊推論,而將變數的數值以適當的比例轉換到另一論域的過程稱為 模糊化。 3. 知識庫 (Knowledge Base) 知識庫包含所應用領域的知識與參與控制的目標,主要由資料庫與規則庫組成: (1) 資料庫(Data Base) 提供處理模糊數據的相關定義,包含論域的切割、輸入與輸出變數的選擇、歸屬 函數型式的決定等。 (2) 規則庫(Rule Base) 規則庫是藉由一群語言推理規則描述推理目標與推理方法;而人類的經驗及語言 時常充滿不確定性,利用模糊理論能夠適度的處理這類語意變數,以模糊規則 (Fuzzy Rule)的形式將人類的知識或經驗更明確的表達出來。 4. 模糊推論引擎 (Fuzzy Inference Engine) 模糊推論引擎是整個模糊系統的核心,它可以藉由近似推論或模糊推論的進行, 來模擬人類的思考決策判斷,以達到解決問題的目的。有關近似推理運算方面的 研究非常多,目前最常用的為Mamdani 的模糊推論法[36],其規則如下:. R1 if x1 is A1 and x 2 is B1 then y is C1 R2 if x1 is A1 and x 2 is B2 then y is C 2 5.. 解模糊化(Defuzzification) 23.
(32) 解模糊化的目的在於將模糊化的模糊集合轉化至普通集合,然而解模糊化並沒有 一定的方法,也有許多學者在這方面投入了相當多的相關研究,如:最佳等級排 序、比較函數、加權平均法、重心法、面積法、α-cut、Hamming距離、模糊均值 與幅度法、模糊數積分法…等;本研究將延用Doraid Dalalah研究中所使用的重 心法(Center of Gravity)進行解模糊化,而此法也是最普遍被使用的方法;重心 法是求模糊推論結果面積的重心,並以其對應的元素為輸出操作量。其連續值與 間斷值的公式如下[8][46]:. 連續值:. X def . x ( x)dx ( x)dx ~ A. (2-18). ~ A. 間斷值:. X def . x * ( x) ( x) ~ A. (2-19). ~ A. 2.3 決策實驗室分析法 決策實驗室分析法(DEMATEL)源自 1973 年的日內瓦 Battelle 研究中心,當 時此方法是用於釐清有關種族、饑餓、環保、能源等世界性複雜且困難的問題所 發展出來的方法。該方法是根據目標事物的具體特徵來確認變數/屬性之間的因 果關係,並反映出系統本質與發展趨勢,DEMATEL 可以提升對特殊問題的瞭 解 、 將糾結複雜的問題加以集 群以及藉由層級結構來識別可行方案 [45] 。 DEMATEL 是一個以圖形化為基礎的方法,使用此方法能幫助決策者將多個衡量 指標區 分為 原因 (cause) 與效 果 (effect) 使其 能更輕 易瞭 解因 果的 關係, 此外. 24.
(33) DEMATEL 的因果圖內是有方向性的,如此一來系統內各指標之間的相互影響關 係與程度便能更具體化與結構化[26]。. 2.3.1. DEMATEL 算則. DEMATEL進行的步驟如下[6]: Step1. 藉由專家訪談、腦力激盪、問卷等方式定義要素(指標)並判斷之間的關 係,同時需決定尺度量表。. Step2. 建立直接相關矩陣(Direct Relation Matrix) 在 n 個評估要素中,依其影響程度與關係兩兩比較,得到 n n 矩陣,稱為 直接關係矩陣,以 Z 表示之。在矩陣中的每一個 Z ij ,代表要素 i 對要素 j 之影響程度,並將其對角要素 Zij 設為 0,如式 2-20 所示. C1 C2 Cn C1 C Z ij 2 Cn. 0 Z 12 Z 1n Z 0 Z 2n 21 Z n1 Z n 2 0 . (2-20). Step3. 建立正規化直接關係矩陣(Normalizing the direct relation matrix) n. 令 S max ( Z ij ) ,將直接關係矩陣Z除以S,可得到標準化直接關係矩陣 1i n. X, 即 X . j 1. Z 。 S. (2-21). Step4. 計算直接/間接矩陣(Direct/Indirect Matrix) 在獲得標準化直接關係矩陣 X 後,可經由公式 2-22 轉換為直接/間接矩陣 T, 其中,I 為單位矩陣。. T lim ( X X 2 X k ) X ( I X ) 1 k . 25. (2-22).
(34) Step5. 計算中心度及原因度 計算直接/間接矩陣T各列與各行之總和,分別以 Di 及 R j 表示。 Di 表示該要 素直接或間接影響其他要素之總和, R j 表示該要素被其他要素影響之總 和,即令 t ij (i,j=1,2,...,n)為T中元素,其D值與R值可由下列式子得到:. Di j 1 t ij (i, j 1,2,..., n). (2-23). R j i 1 t ij (i, j 1,2,..., n). (2-24). n. n. 並計算 Di R j 稱為中心度(Prominence),表示要素間的關聯強度, Di R j 稱 為原因度(Relation),表示要素影響及被影響的強度。 Step6. 繪製因果圖(Causal diagram) 分別以 Di R j 為橫軸, Di R j 為縱軸,將各要素繪於此座標軸內,繪製出 因果圖。. 2.4 多屬性決策與理想解類似度順序偏好法 時代的轉變下,許多產品已不再以大量的標準化生產為優先,而是由產品的 設計端便開始投入顧客滿意的考量以及商品的獨特與實用性,故為了滿足消費者 要求與產品的各種預設特性,單一屬性的決策選擇已無法滿足目前的所有需求, 因而多屬性決策(Multiple Attribute Decision Making, MADM)的方法漸漸的受 到重視並發展。多屬性決策方法是最常被應用在「評估」與「選擇」方案問題的 最佳解。而理想解類似度順序偏好法便是多屬性決策問題中的解決方法之一。. 26.
(35) 2.4.1 多屬性決策 多屬性問題對於管理者而言是常見的,對於具有多個欲達成屬性目標之相同 產品,如何選擇合適的方案成為最佳解即為此類問題。 Hwang 及 Yoon(1981)認為多屬性決策方法為決策者在多個質化或量化的 評估準則下,對一組有限、可數且數目不大的已知可行方案進行評估,以決定各 方案之優劣或執行的優先順序;在處理多個屬性的評估和抉擇時,當遇到屬性間 相互衝突而無法衡量出最佳方案時,就需要使用多屬性決策方法來加以分析比 較,找出最佳方案組合[27]。 多屬性決策涵蓋各種屬性問題的選擇方案,而這些屬性通常相互矛盾,以實 際的觀點來看,多屬性決策問題的選擇方案通常已被預先決定,而―屬性‖一詞是 被用以作為―目標‖或―準則‖之意。MADM 問題有一些常見的特徵,如:這些屬 性通常彼此互相矛盾、各屬性的衡量單位不同、每個屬性的相關重要性通常可用 一權重組合表示。目前有很多 MADM 的解決方法都是可用的,且這些方法都有 其特色和適用性[41]。多屬性決策問題與解決方法,若依決策者所提供的偏好資 訊加以分類,可將多屬性決策方法分為三類[48]:1.無法獲得決策者的偏好資訊, 2.可獲得決策對環境的偏好資訊,3.可獲得決策者對屬性的偏好資訊;Hwang 及 Yoon(1995)所提出的多屬性決策方法之分類圖,如圖 2-9 所示。. 27.
(36) 可獲得決策者 資訊的型態. 資訊的顯 著特性. 無法獲得決策 者的偏好資訊. 多 屬 性 決 策 方. 主要的分 類方法 絕對優勢法 (dominance). 悲觀的 (pessimistic) 可獲得決策者 對環境的偏好 資訊. 法 法. 小中求大法 (maximin). 樂觀的 (optimistic). 大中求大法. 標準的水準 (standard level). conjunctive method disjunctive method. 序數 (ordinal). lexicographic method elimination by aspect. 基數 (cardinal). 簡單加權法. 可獲得決策者 對屬性的偏好 資訊. (maximax). weighted product TOPSIS ELECTRE median ranking. 圖 2-9 多屬性決策方法分類 根據其研究與分類,當決策者的主要屬性偏好資訊已知且資訊的特性為基數 時,理想解類似度順序偏好法(Technique for Order Preference by Similarity to Ideal Solution)將是最合適的解決方法[41]。. 2.4.2 理想解類似度順序偏好法 理想解類似度順序偏好法(TOPIS)是 Hwang and Yoon 於 1981 提出用以處理 多屬性決策之方法,TOPSIS 同時考量每個方案距正理想解與負理想解的距離, 並以距正理想解最近且距負理想解最遠為最佳方案[42]。所謂正理想解(Positive. 28.
(37) Ideal Solution, PIS)乃是由各選代方案效益性評估值最大者,成本性評估值最小者 所構成之解,反之負理想解(Negative Ideal Solution, NIS)乃是由各選代方案效益 性評估值最小者,成本性評估值最大者所構成之解[16]。Tong and Su 於 1997 的 文章更說明了田口的損失函數圖形近似於 TOPSIS 的曲線圖形,且認為當在處理 田口實驗的多目標最佳解問題時可以 TOPSIS 方法作為績效表現之評估與衡量 [41]。. 2.4.3. TOPSIS 算則. TOPSIS 之運算步驟如下[14]: 於本論文中,因有多個品質特性,故設多準則決策問題的方案集合. {a i i 1, 2........, m} ,而評估準則集合為 {g g j 1, 2......, n} Step1. 建構評估矩陣, D [ xij ]mn. 1 x11 x12 x1j x1n 2 x 21 x 22 x 2 j x 2 n D i xi1 xi 2 xij xin m x m1 x m 2 x mj x mn . (2-24). 其中 A i 表示第i個方案, X j 表示第j個績效評估準則, xij 表示第i個方案對第j個品 質特性的績效值,此值必頇是可量化的指標。 Step2. 正規化評估矩陣, R [rij ]mn. rij . r11 r12 r1j r1n r21 r22 r2 j r2 n xij , R m r r r r i 1 i 2 ij in xij2 i 1 rm1 rm 2 rmj rmn . 29. (2-25).
(38) 將各個參數組合對各個品質特性之績效值作正規化處理,其中 rij 表示正規化之品 質特性決策矩陣(R)的績效值。 Step3. 建立加權後正規化評估矩陣, V [vij ]mn. w1r11 w2 r12 w j r1j wn r1n w1r21 w2 r22 w j r2 j wn r2 n vij w j rij ,V w1ri1 w2 ri 2 w j rij wn rin w1rm1 w2 rm 2 w j rmj wn rmn . (2-26). n. 其中 vij 表是加權後績效值, w j 為第j個品質特性的權重,且 w j 1 。 j 1. Step4. 決定正理想解( v )與負理想解( v ). min v j B , max v j C i 1,2,..., m v , v ,..., v ,...v . v max vij jB , min vij j C i 1,2,..., m v1 , v2 ,..., v j ,...vn. (2-27). v. (2-28). i. i. i. ij. i. 1. ij. 2. j. n. 其中 B 是屬於望大的屬性集合,而 C 是屬於望小的屬性集合。. Step5. 計算各參數組合與正理想解和負理想解的距離,分別為 S 與 S . S i . S i . n. (v j 1. ij. v j ) 2. i 1, 2, ..., m. (2-29). ij. v j ) 2. i 1, 2, ..., m. (2-30). n. (v j 1. Step6. 計算各組參數組合對正理想解的相對接近程度. 30.
(39) Ci . S i S i S i. 0 Ci 1. i 1, 2, ..., m. (2-31). 當一組方案比另一組方案更接近理想解並不表示就為最佳方案組合;頇同時 考慮方案與正理想解和負理想解的距離,依此近似度來判斷,如此,。令 C i 表 示方案 i 距正理想解 v 的相對近似度,若方案 i 為正理想解,則 C i 1 ;若方案 i 為負理想解,則 Ci 0 。故當 C i 值越接近 1 表示其方案越接近正理想值。. Step7. 方案排序 評估方案的優先順序乃是依 C i 值大小來排序, C i 愈接近 1 時,表示第 i 組 參數組合之方案的優先順序越高,反之, C i 愈接近 0 時,表示第 i 組參數組合之 方案的優先順序越低。. 2.5 相關文獻比較 本節將各相關文獻中,應用各種多屬性決策方法來解決多重品質特性產品及 製程最佳化做一整理比較,並挑選部份較具代表性的方法彙整如下列各小節。. 2.5.1 田口方法與模糊田口 魏振育(2010) 整合FMEA、DEMATEL及TRIZ理論等方法,建構「失效模式 與決策分析之算則」 ,該研究算則建構流程包含三個階段:(1)功能需求之瞭解與 失效分析、(2)關鍵失效模式分析及(3)改善與驗證,藉以歸納出產品/製程中的主、 次要失效問題,尋找關鍵失效模式,進而提出適當的改善措施[17]。 蔡宗倫(2009) 結合模糊理論、理想解類似度順序偏好法(TOPSIS)、灰關聯 分析(GRA)來整合多重品質特性的問題;先利用模糊理論處理經由田口實驗後所 得之 S/N 比值,以便於比較單位標準不同的品質特性,接著結合 TOPSIS 與 GRA 建構「模糊理想解」與「模糊灰關聯」兩套演算法則,分別運算處理得到顯著影 響參數與關聯度進行最佳參數組合的排序,透過所得之起始最佳參數解與整體最 佳參數解比較分析,如此,可取得客觀的綜合性判斷,也可了解到數據資料多寡 31.
(40) 對兩套法則可靠性的影響。並利用顯示器製程案例來驗證演算法則的有效性與可 靠性,進一步幫助公司在產品設計初期就可兼顧品質管制,同時也可節省時間和 成本[14]。 徐瑞富(2005)針對BGA 208L(某種封裝製程)之封裝成型製程作研究,依據實 務經驗選出影響金線偏移的主要製程參數,接著依此主要製程參數給予適當的因 素水準去從事封裝成型,再由x-ray量測各個製程條件下的金線偏移量,最後利用 田口方法來尋求最佳的製程參數組合,以減低封裝時的金線偏移[9]。 廖文基(2008)在半導體封裝製程上考慮錫球之上、下墊片半徑、高度、材料, 印刷電路板之楊氏係數、質量密度、厚度,基板之楊氏係數、厚度、錫球配置、 構裝尺寸,晶片之尺寸、厚度,封膠之楊氏係數、厚度等因子,進行單一因子分 析,以評估各因子對構裝結構抗衝擊可靠度的影響,然後將上述各因子利用田口 品質設計,建立直交表進行實驗,並經誤差統合,找出最佳化的參數組合,以提 升TFBGA(半導體構裝製程) 構裝體之可靠度[13]。 陳明佑(2002)利用田口方法中處理單品質特性的方法,依照品質特性的特性 分別計算出SN 比,再運用滿意函數將SN 比轉為滿意值,並藉由多元線性迴歸 方程式來建構滿意函數與製程參數間的關係,最後結合目標規劃、模糊理論以及 偏好函數求出最佳解,在選取最適因子水準時,則假設因子水準間的變動是呈線 性關係,運用內差法來求得最佳因子水準,使在因子水準的選取上更具有彈性 [12]。 Jeyapaul et al. (2005)回顧近代對於應用田口方法在多重品質特性上所使用的 各種方法,其中包含迴歸分析、主成分分析、資料包絡法(DEA)、模糊多屬性決 策、模糊邏輯應用、灰關聯分析、類神經網絡…等;並說明使用者在選擇方法上 可以就使用者本身的偏好與熟悉度選擇方法,但應注意的是方法背後的假設與所 探討問題的適用性[28]。 Lin 等,結合田口理論和模糊理論來解決多重品質特性的放電加工製程問 題,發展出一套可以處理具模糊性設計目標之多重品質特性的演算法[33]。 32.
(41) 綜合以上文獻與其它本研究所涉獵之文章可知,相對於傳統的田口方法只能 處理單一品質特性問題,近期對於能夠解決多目標品質特性的田口方法更為重 視,各種算則更是百家爭鳴;自 1997 年 Tong and Su 透過模糊理論發展系統化的 程序來解決多目標決策問題[28],往後許多學者便開始投入結合模糊理論和田口 方法的研究,然而最後也驗證了此方式在解決多重品質特性問題時,可避免因品 質特性的不同而造成的衝突以及不知如何判斷各品質特性間重要性大小的問題。. 2.5.2. DEMATEL 相關文獻探討. 關於決策實驗室分析法,無論在工業或服務業上的應用可說是不勝枚舉,也 有許多學者提出修正的 DEMATEL,使此方法在使用上更為合理與合適,以下列 舉近期應用此研究方法的文章做為參考。 李宗偉(2009)提出最大平均熵差法(Maximum Mean De-Entropy, MMDE)解決 DEMATEL 在設定門檻值時易發生的共識問題,並驗證此法對於 DEMATEL 的門 檻值設定是合適且有效的[3]。 胡雪琴(2003)利用 DEMATEL 方法將問題間的複雜度解構與量化,透過此方 法後可採用經驗累積的類似基模,作為主要及核心問題的處理模式以提供企業解 決問題的參考依據[7]。 Hiroyuki and Katsuhiro (2005)提出一個修正的 DEMATEL 方法,該方法加入 了各因素的不確定性結構的優先考量,稱為―隨機性決策實驗室分析 法‖(stochastic DEMATEL),此法既使當探討的系統結構中存在不確定性,也能正 確描述結構中的因子特性,此外,隨機的重要性組合能夠描述來自結構不確定性 的優序風險增加問題,並可將決策者的樂觀與悲觀態度納入決策優序中考量計算 [38]。 Seyed-Hosseini et al. (2006)認為 FMEA(失敗效用模式分析)在 RPN(風險優先 數)的排序上存在未考慮各元素間的間接相關性,以及所探討的系統中可能包含 更多其他元素或子系統的問題,因此作者先利用 DEMATEL 解決以上問題,並. 33.
(42) 經過實際案例驗證 DEMATEL 能夠有效且完整的補足 FMEA 的缺陷(DEMATEL 能處理間接相關問題並且能夠對龐大複雜的系統進行元素的分群與排序) [37]。 Lin and Wu(2004)認為日常生活案例中人們的偏好判斷通常是含糊不清的, 因此提出在 DEMATEL 方法中加入模糊化的概念,依此彌補傳統上使用片斷值 的不適用,也利用一個實證研究確定此方法的可用性與有效性[32]。 Yang and Tzeng(2010)指出大多重要性評估方法是藉由可加性與獨立性假設 下的權重設定來驗證指標間的重要性,但事實上加法模式的使用並不總是可行 的,因此作者提出先以 DEMATEL 使具複雜因果關係的系統結構化與可視化, 並獲得指標間的影響關聯,再透過超級矩陣的正規化來計算網絡分析法 ANP(analytic network process)權重以獲得指標間的相對重要性,最後利用台灣知 名 3C 零售商的供應商選擇為例,證明該研究所提出之方法在重要性評估中更為 合理適用[47]。 Tseng(2009)學者說明 ANP 是一個相對較新的 MCDM 問題處理方法並能夠 處理所有類型的交互作用系統,而 DEMATEL 不僅能將指標間的因果關係轉換 為結構模型還能被用來解決指標群中的內部相依問題,因此該學者結合 ANP 與 DEMATEL 方法來協助馬尼拉的專家小組找出較重要的管理議題與關聯指標來 管理該城市的都市固體廢物[44]。 Lin et al. (2010)利用 DEMATEL、ANP、TOPSIS 探討車輛通訊系統(VTS)的 各種需求項目,並藉由 DEMATEL 來建立關係矩陣,ANP 衡量權重,TOPSIS 找 出最佳解的運算流程,找出下一個世代的 VTS 應該具備的項目,以此滿足消費 者之需求[31]。 綜合以上文獻與其它本研究所涉獵之文章,對於 DEMATEL 的應用可歸結 以下幾項特點: 1.. DEMATEL 對於複雜龐大的系統,能達到資料縮減、關鍵指標選擇以及指標 間的關聯表達等成效。. 34.
(43) 2.. 無論指標間是否具有交互作用 DEMATEL 方法皆可使用。. 3.. 對於多屬性決策問題(MADM),DEMATEL 在此領域的應用上為合適且合理 的。. 4.. DEMATEL 在多屬性決策問題上之演算過程能使賦權過程更為合理化。. 5.. 經過模糊語意後的 DEMATEL 在實際案例中是較合理客觀的指標挑選方式。. 2.5.3. TOPSIS 相關文獻探討. TOPSIS 為處理多屬性決策的方法之一,在多目標決策分析中已被認為是一 種有效的方法。該方法已經在土地利用規劃、物料選擇評估、項目投資、醫療衛 生等眾多領域得到成功的應用,且明顯提高了多目標決策分析的科學性、準確性 和可操作性。 Negi 引用模糊理論於傳統的 TOPSIS 法來加以延伸利用,在其研究中,每一 方案的評估值及權重皆以梯形模糊數表示,在方案與模糊正理想解和負理想解之 間距離的計算,採兩模糊數之隸屬函數交集的最高相似度來做運算,最後再以各 方案對正理想解之相對近似值的大小予以優劣排序[34]。 Tsaur 應用 TOPSIS 於航空業服務品質之評估,其研究中,航空公司的各項 評估值準則之評比以模糊數表示,透過去模糊化的方式將模糊數轉為明確值,再 以 TOPSIS 對航空的服務品質進行評估[43]。 魏巧晴利用簡易的 QFD 原則,以模糊運算求得顧客需求對工程或設計屬性 的重要度,最後以 TOPSIS 方法做概念設計選擇方案的排序,而排序結果將作為 選擇設計參數的重要參考[16]。 由以上文獻探討可知 TOPSIS 是決策分析中常見的工具,而模糊觀念的引入 將使此工具在應用上更具說服力,此外 TOPSIS 的無差異曲線與田口的品質損失 函數曲線十分類似,所以當在研究田口的多重品質組合最佳解時十分適合使用 TOPSIS 作為績效表現衡量的檢索[41]。. 35.
(44) 2.5.4. DEMATEL、TOPSIS 及田口方法之整合應用相關文獻. 本節將介紹 DEMATEL 與 TOPSIS 的結合應用及 TOPSIS 與田口方法的結合 應用,故歸納分類如下: 一、DEMATEL 與 TOPSIS 的結合應用 這兩種方法的結合由Doraid Dalalah於2009年提出作為解決多屬性決策問題 的新方法,該方法尚未被其他學者延續探討;Doraid Dalalah混合DEMATEL與 TOPSIS的原理是利用修正的模糊DEMATEL算則,以專家群的因果評估分類方式 衡量指標準則之權重,所產生的準則權重再被代入模糊TOPSIS中作權重使用, 而成為一個新的混合模型,該模型的最佳解選擇與TOPSIS相同,不同之處僅在 於模糊化的處理,由於模糊化,故最佳解的選擇為離正模糊理想解(Fuzzy Positive Ideal Solution , FPIS)最近且離模糊負理想解(Fuzzy Negative Ideal Solution , FNIS) 最遠[24]。 另有一透過模糊網絡層級分析鏈結 DEMATEL 與 TOPSIS 的解題模式被提 出:Jui-Kuei Chen、I-Shuo Chen(2010)提出一個解決多屬性決策問題的演算程序, 其方法由 DEMATEL、模糊網絡層級分析(FANP)和 TOPSIS 構成此解題模式,並 且藉由此模式作者建立一個針對台灣高等教育創新表現評估的輔助系統[22]。 二、TOPSIS 與田口方法的結合應用 Tong and Su(1997)首先提出藉由模糊理論結合 TOPSIS 與田口方法應用在多 重品質特性的處理上,此方法能夠減少衡量回應權重的不確定性,此外還能同時 處理間斷與連續的資料類型,除提出此算則外作者也以電漿化學氣相沉積製程 (PECVD)為案例驗證此方法[41]。. Tong et al. (2003)應用 TOPSIS 與田口方法在電子封裝轉移成形的製造情境 最佳化上,並透過製程模擬驗證此方式之有效[40]。 Liao(2003)使用 PCR(製程能力比)-TOPSIS 以最佳化田口的多回應問題,該 方法先計算 SN 比,再計算每個實驗的 SN 比的 PCR,最後進行 TOPSIS 求得最. 36.
(45) 佳解,該研究指出對於多回應問題 PCR-TOPSIS 是可以產生滿意解的方法[30]。 Tong et al. (2004)利用主成分分析(PCA)與 TOPSIS 研究較少被探討的動態多 回應問題的田口實驗設計,並提出一個解決此問題的最佳程序,其中 SN 比和系 統敏感度被用來評估各種回應之績效,而 SN 比和系統敏感度的值經過主成分分 析獲得無共相關性的集合,最後以 TOPSIS 找到多回應問題的最佳解[42]。 Kuo et al. (2008)為多個加工程序的流程製造系統透過系統模擬、TOPSIS 與 網絡層級分析(ANP)結合田口式直交表等工具,找出此系統各工作站的最適派工 法則,並驗證此最適派工法則具堅耐性[29]。. 37.
(46) 第參章. 演算法則之建構. 本研究整合 DEMATEL、TOPSIS 及田口等方法,為建構一套「失效模式與 決策分析之算則」的決策分析演算法則。本章內容將逐一陳述「失效模式與決策 分析之算則」建構流程所包含的三個階段:(1)現況問題了解與資料收集;(2)算 則建構;(3)決定最佳參數組合與驗證。. 3.1 算則建構 本研究欲串聯 DEMATEL、TOPSIS 及田口方法成為一套「多品質特性的田 口實驗決策分析算則」,提供實行多目標田口改善時一個系統化的流程方法。 算則的建構大致上可分為三個階段,流程架構如圖 3-1 所示: 1. 了解研究問題之現況與資料收集 決定欲研究主題後,到現場收集相關資料與專業工程人員提供之資訊,結合 相關文獻來選定研究方法。 2. 算則模型之建構 根據文獻整合 DEMATEL、TOPSIS 及田口方法,建立一演算法則之模型。 3. 決定最佳參數組合與驗證 應用實例來驗證所建構之演算法則的可行性與正確性,將獲得之最佳參數組 合與現狀進行分析比較。. 38.
(47) 問題陳述. 訂定製程參數與品質特性. 資料收集 階段 I. 進行決策實驗室分析法找 出關鍵參數. 選擇直交表與 S/N 比公式並計算各品 質特性 S/N 比形成品質特性矩陣. 建構模糊推論系統求算多 重品質特性衡量指標 (MPCI). 進行 TOPSIS 演算程序 求算 TOPSIS 值. 階段 II. 分別計算 TOPSIS 與模糊推論 結果之 S/N 比 分析、預測與驗證. 圖 3-1 算則架構流程圖. 39. 階段 III.
(48) I. 現況問題了解與資料收集 步驟一:問題陳述 針對欲研究之主題描述其製程概況以及面臨之問題。 步驟二:訂定製程參數與品質特性 根據所選定之研究主題整合其相關資料,並到現場勘查了解其現狀,與專業 工程人員進行討論交流來決定欲控制的實驗參數與品質特性。 步驟三:資料收集 在參數及品質特性選定後,準備開始專家訪談進行製程參數相關性矩陣之資 料收集。 II. 算則模型之建構 步驟四:進行決策實驗室分析法(DEMATEL)找出關鍵參數 4-1: 建立控制因子(參數)的直接關係矩陣 Zij 將已決定的控制因子給予專家參考並進行專家訪談,本研究採用四點尺度 量表作為訪談內容的評量,依此獲得兩兩參數間影響程度,如表 3.1 所示, 接著依據專家所提供之意見,將訪談結果整理成品質特性的直接關係矩陣 Zij。 表 3-1. 影響程度尺度表. 評估尺度. 影響程度. 0. 沒有影響. 1. 稍微影響. 2. 有影響. 3. 影響很大. 40.
(49) 4-2: 計算標準化直接關係矩陣 X n. 令 S max ( Z ij ) ,將直接關係矩陣 Z 除以 S,可得到標準化直接關係矩陣 1i n. X,即 X . j 1. Z 。 S. 4-3: 直接/間接矩陣 T 依公式 2-21 計算將直接關係矩陣 X 轉換為直接/間接矩陣 T 4-4: 計算中心度及原因度 計算直接/間接矩陣 T 的各列與各行總和(公式 2-22、2-23),分別以 及 表 示。並計算 Di R j 為中心度(Prominence),表示要素間的關聯強度, Di R j 為原因度(Relation),表示要素影響及被影響的強度。 4-5: 繪製因果圖並找出關鍵參數. 步驟五:選擇直交表與 S/N 比公式並計算各品質特性 S/N 比,形成品質特. 性之矩陣 5-1: 由評估之關鍵參數與品質特性選擇直交表與. 公式,進行此步驟時需考慮. 因子數、各因子水準數、因子交互作用及實驗時可能遭遇的困難。 5-2: 根據 5-1 所得之資訊計算總自由度以確定實驗次數最小值,算法如下: 1. 計算因子自由度=因子水準數-1。 2. 兩因子交互作用自由度=兩因子個別自由度的乘積。 例:A×B 的自由度=A 的自由度×B 的自由度。 3. 實驗次數=總自由度+1。 例如參數設定時,當有 A、B、C、D 四因子,且皆為二水準,其中含交互作 用 A×B,則其總自由度=4×(2-1)+(2-1)×(2-1)=5,所以其所需的最小實驗次數 為 5+1=6 次,接著再依(2-13)的直交表特性選擇適合的直交表進行實驗。 5-3: 根據望小、望大、望目的品質特性,分別套用公式(2-10)、(2-11)、(2-12)計 算其品質特性 S/N 比值。 41.
(50) 5-4: 依各品質特性在田口實驗中所得之 S/N 比作為品質特性矩陣(Q). Q11 Q12 Q1n Q Q Q 2n Qij 21 22 Qm1 Qm 2 Qmn 其中,i 為 1~m 個田口實驗參數組合;j 為 1~n 個品質特性; Qij 為實驗組合 i, 品質特性 j 下的 S/N 比之值。 步驟六:進行 TOPSIS 演算程序 依據轉換後之模糊品質特性的 S/N 比值進行 TOPSIS 分析,以獲得各因子的 回應值與起始最佳參數組合,其分析步驟如下: 6-1:建構評估矩陣, D [ xij ]mn 。(此處即等於矩陣 Qij ) 6-2:正規化矩陣, R [rij ]mn 。(2-25) 6-3:加權後正規劃評估矩陣 V vij. . w j rij. . 6-4:決定理想解( v )與負理想解( v )。(2-27、2-28) 6-5:計算各參數組合與正理想解和負理想解的距離為 S 與 S 。(2-29、2-30) 6-6:計算各組參數組合對正理想解的相對接近程度, C i 。(2-31) 6-7:方案排序,選取 TOPSIS 方法下初步最佳參數水準組合。. 步驟七:建構模糊推論系統求算多重品質特性衡量指標(MPCI) 此步驟旨在建構一模糊推論系統,將品質特性進行模糊推論求得多重品質特 性衡量指標。 7-1:決定輸入與輸出變數,並將變數正規化。 本研究的正規化方式如下:. 42.
(51) 1.先將各品質特性 S/N 比以公式 3-1 轉為 Z 值,其中 X ij 為個品質特性之 S/N 比,μ 為某個品質特性下所有 S/N 比的平均數,σ 為某個品質特 性下所有 S/N 比的標準差。. Z ij . X ij . (3-1). . 2.將所得之 Z 值對應標準常態分配表以獲得其機率。 7-2:變數模糊化。 7-3:制定模糊規則。 7-4:模糊推論與解模糊化。 7-5:輸出 MPCI。 7-6:排序 MPCI 值,選取模糊推論下初步最佳參數水準組合。 III. 決定最佳參數組合與驗證 步驟八:結果分析與驗證 將步驟六與步驟七所得之參數組合代入田口直交表中計算 S/N 比以進行參 數反應值分析,並將反應結果製成反應表與反應圖來獲得田口實驗上的最佳參數 水準組合,最後利用變異數分析(ANOVA)檢視各因子所佔變異的百分比(貢獻度) 及各參數水準組合(變異來源)在統計上對於實驗結果造成之差異是否具顯著性。 步驟九:確定最佳參數水準組合 透過以上實驗設計與算則流程雖然已可獲得實驗的最佳參數水準組合,但尚 需預測結果與驗證實驗結果相近,並經實驗證實新的參數水準組合下的績效較原 有參數水準組合的績效佳,方能確定本實驗之加法性成立以及最佳實驗參數水準 組合之獲得。. 43.
數據


+7

相關文件
Hong Kong Education Department (1998).Review Report on the Pilot Project on the Grow with Guidance System – Development of Whole School Approach to Guidance. Hong Kong:
In this paper, by using Takagi and Sugeno (T-S) fuzzy dynamic model, the H 1 output feedback control design problems for nonlinear stochastic systems with state- dependent noise,
(2007), “Selecting Knowledge Management Strategies by Using the Analytic Network Process,” Expert Systems with Applications, Vol. (2004), “A Practical Approach to Fuzzy Utilities
由於 DEMATEL 可以讓我們很有效的找出各準則構面之因果關係,因此國內外 有許多學者皆運用了 DEMATEL
Sharma (1999), “An Intergrated Machine Vision Based System for Solving the Non-Covex Cutting Stock Problem Using Genetic Algorithms,” Journal of Manufacturing Systems, Vol..
Kuo, R.J., Chen, C.H., Hwang, Y.C., 2001, “An intelligent stock trading decision support system through integration of genetic algorithm based fuzzy neural network and
A decision scheme based on OWA operator for an evaluation programme: an approximate reasoning approach. A decision scheme based on OWA operator for an evaluation programme:
Then, these proposed control systems(fuzzy control and fuzzy sliding-mode control) are implemented on an Altera Cyclone III EP3C16 FPGA device.. Finally, the experimental results
