建立資料倉儲與資料採礦實現洞察力行銷之研究--以個案公司為例說明
85
0
0
全文
(2) 致謝 在打下論文最後一個字之後,有很深刻的學生生涯告一段落,必 須告別一個身分的感觸。大學四年加上碩士兩年共六年的時間,季老 師給了我很多東西,除了學術上的指導,更多的是讓我累積經驗的機 會,從做中學,在錯中成長,我好像漸漸知道資訊管理原來是怎麼一 回事,以及從這越挖越深、越挖越廣的領域中獲得哪些樂趣,六年來. 政 治 大. 的這些收穫很珍貴也很珍惜,感謝季老師。. 立. ‧ 國. 學. 這篇論文能完成要感謝很多人的配合與幫忙;接觸資料採礦的時 間其實僅僅一年,它包含了太多領域的專業知識,尤其統計與數學,. ‧. 非本科系的我只能靠自修來自我充實,特別感謝台北大學資訊管理學. sit. y. Nat. 系的陳宗天老師,給予我對於資料採礦的悉心指導,耐心回答所有不. er. io. n. al 懂的邏輯和演算式,感謝陳老師。最後謝謝環域科技公司與台電公司 iv Ch. n engchi U. 在分析資料及專業知識上的幫助和訪談的配合。 謹以此成果獻給一路上支持我的家人和摯友們,尤其這段期間對 翔姈有諸多叨擾,感謝你們的包容,我愛你們。. 2.
(3) 摘要 提供以顧客為導向的服務、提升顧客價值成為各企業經營策略的 出發點,因此了解顧客特徵、需求、行為成為首要任務。 隨著經濟發展,台灣整體用電需求不斷攀升,同時電力產業亦須 面對全球燃料價格上漲的現況,政府邁向低碳經濟時代,推出一系列 相關政策,於我國電力結構中占有重要地位的台灣電力公司也開始思. 政 治 大. 考如何在需求及成本皆提升的環境下,繼續維持穩定供電,提供以用. 立. ‧ 國. 學. 戶為導向的服務。. 本文即以台電公司為個案,以資料倉儲與資料採礦技術進行【用. ‧. 戶區隔】了解台電用戶特徵、【選擇目標用戶】找出優先服務的用戶. sit. y. Nat. io. n. al 實現行銷活動 STP 分析過程之研究。 Ch. engchi. er. 對象及【產品定位】推薦適合目標用戶用電特徵之電價及優惠方案,. i Un. v. 關鍵詞:資料倉儲、資料採礦、洞察力行銷、市場區隔、STP. 3.
(4) Abstract Providing customer-oriented services and elevating customer value have became the starting point of business strategy. Therefore, understanding customer characteristics, requirements, and behavior has become the primary task. As the overall demand for electricity rises constantly in Taiwan along with economic development, electric power industries have to face. 政 治 大 government has launched 立various policies. Taiwan Power Company,. the surging fuel prices. To put low carbon economy into practice, the. ‧ 國. 學. which plays an important role in the electric power structure in Taiwan, started thinking about how to provide stable power and customer-oriented. ‧. services under the circumstances both demand and cost increase.. y. Nat. io. sit. Based on the case of Taiwan Power Company, this research. er. investigated customer segmentation - to understand customer. n. a. v. i customer, and l C - to find out then prior characteristic, customer targeting. hengchi U. product positioning - to recommend target customer appropriate tariff and preferential tariff treatment through data warehouse and data mining technology. The purpose of the research was to achieve STP analysis in marketing process.. Key words: data warehouse, data mining, insight driven marketing, STP. 4.
(5) 目錄 第一章、緒論 ____________________________________________ 8 第一節、研究背景____________________________________________________ 8 第二節、研究動機___________________________________________________ 10 第三節、研究目的___________________________________________________ 10 第四節、預期效益___________________________________________________ 11. 第二章、文獻探討 _______________________________________ 12 第一節、洞察力行銷:市場區隔、目標市場與產品定位___________________ 12 第二節、資料倉儲___________________________________________________ 25 第三節、資料採礦與演算法介紹_______________________________________ 31. 立. 政 治 大. 第三章、研究方法與設計 __________________________________ 44. ‧ 國. 學. 第一節、研究方法___________________________________________________ 44. ‧. 第二節、研究設計___________________________________________________ 45 第三節、研究架構___________________________________________________ 47. y. Nat. er. io. sit. 第四章、個案分析 _______________________________________ 49 第一節、我國電力環境現況___________________________________________ 49 第二節、個案分析___________________________________________________ 51 第三節、個案公司需求訪談___________________________________________ 57 第四節、STP 分析資料模型設計 _______________________________________ 61 第五節、STP 實做與分析 _____________________________________________ 69. n. al. Ch. engchi. i Un. v. 第五章、結論與建議 _____________________________________ 81 第一節、結論_______________________________________________________ 81 第二節、未來發展___________________________________________________ 83. 第六章、參考文獻 _______________________________________ 84. 5.
(6) 圖目錄 1、洞察力:企業獲得差異化競爭優勢的關鍵之路 ______________ 2、洞察力行銷帶來的改變 ___________________________________ 3、AMA 2004 年行銷概念圖 _________________________________ 4、不同市場區隔變數之實行難易程度_________________________ 5、合適/不合適的市場區隔變數之區隔結果 ____________________ 6、不同行銷策略下之目標市場選擇方式_______________________ 7、三種目標市場選擇策略 ___________________________________ 8、定位策略步驟 ___________________________________________ 9、啤酒市場的產品知覺圖 ___________________________________ 10、資料倉儲特性-整合性 ___________________________________ 11、資料倉儲特性-時間的變化性 _____________________________ 12、資料倉儲特性-不可更新性 _______________________________ 13、星狀模型 ______________________________________________ 14、資料立方體 ____________________________________________ 15、資料採礦步驟 __________________________________________ 16、每個群集可視為一機率分配______________________________ 17、單一鏈結分群結果示意圖________________________________ 18、研究流程圖 ____________________________________________ 19、研究架構圖 ____________________________________________ 20、執行步驟 ______________________________________________ 21、台灣發電結構(2012/1~4 月) ___________________________ al iv n 22、台灣電力公司組織架構圖 C h ________________________________ e n g_____________________________ chi U 23、資料倉儲-高壓用戶屬性主檔 24、資料倉儲-AMI 電表需量資料表 __________________________ 25、預處理-AMI 缺漏值補正 ________________________________ 26、預處理-AMI 資料存儲結構轉換 __________________________ 27、預處理-AMI 資料比例化前後數據 ________________________ 28、預處理-AMI 資料比例化前用電趨勢線 ____________________ 29、預處理-AMI 資料比例化後用電趨勢線 ____________________ 30、K-MEANS 分群結果 ____________________________________ 31、簡單貝氏機率分類建模結果______________________________ 32、STP 分析執行模式 ______________________________________ 33、系統架構設計 __________________________________________. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 6. 13 14 16 18 20 21 22 23 24 27 28 28 30 30 32 36 38 46 47 48 50 52 62 63 64 66 67 67 68 73 77 81 82.
(7) 表目錄 1、AMI 推動時程表 _________________________________________ 9 2、高低壓用戶佔比 __________________________________________ 9 3、AMA 針對行銷提出之定義 _______________________________ 15 4、單一鏈結名目資料之計算範例資料_________________________ 39 5、匹配矩陣 _______________________________________________ 40 6、資料採礦於各領域之應用_________________________________ 43 7、台電公司發電結構 _______________________________________ 53 8、台電公司燃料成本 _______________________________________ 54 9、北市區處訪談結果 _______________________________________ 58 10、北北區處訪談結果 ______________________________________ 59 11、總部業務處費率組訪談結果 ______________________________ 60 12、分析需求歸納 __________________________________________ 61 13、C4.5 用戶分類用戶篩選設定 _____________________________ 69 14、C4.5 用戶分類分析結果(部分) _________________________ 70 15、本月份用電度數、尖離比分析____________________________ 71 16、K-MEANS 用戶分群用戶篩選設定 ________________________ 71 17、K-MEANS 用戶分群分析結果 ____________________________ 72 18、用戶 A 計畫性減少優惠方案試算結果 _____________________ 74 19、各區營業處尖離比(由低至高)__________________________ 75 20、簡單貝氏機率分類用戶篩選設定__________________________ 76 21、簡單貝氏機率分類建模變數設定__________________________ 77 al v i n 22、建模結果-尖離比與方案參與關係 _________________________ 77 Ch U i e h ngc 23、簡單貝氏機率分類預測用戶篩選設定 _____________________ 78 24、簡單貝氏機率分類預測結果______________________________ 79 25、用戶 A 計畫性減少優惠方案一試算結果 ___________________ 79 26、用戶 B 計畫性減少優惠方案一試算結果 ___________________ 80. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表. 7.
(8) 第一章、緒論 第一節、研究背景 近年來,全球燃料價格上漲、用電量亦隨著經濟發展而攀升,台 電公司面臨如何提供民眾穩定用電的問題,因此不斷努力提升供電及 服務品質,並致力以用戶服務導向經營目標。 另一方面,政府為邁向「低碳經濟」 ,於民國 99 年推動智慧電網. 政 治 大. (Smart Grid)節能減碳策略,由行政院核定「智慧型電表基礎建設. 立. 推動方案」及各相關政府部門制定相關政策及計畫,故台電公司為因. ‧ 國. 學. 應國家策略之發展,陸續跟進智慧型電表基礎建設(AMI,Advanced. ‧. Metering Infrastructure)裝設。. Nat. io. sit. y. 智慧型電表基礎建設(AMI)主要由智慧型電表(Smart Meter)、. er. 通訊系統、電表資訊管理系統(MDMS, Meter Database Management. al. n. iv n C h e n g c h i U15 分鐘自動傳回該電表 System)所組成,可取代傳統人工抄表,每 所使用的用電度數。台灣 AMI 之設置對象可分為高壓用戶與一般家 庭之低壓用戶。依據經濟部能源局規劃,優先推動占全國用電量 58 %之高壓用戶 2,3000 戶預計於民國 101 年全部裝設完畢;低壓用戶 (戶數高達 1200 萬戶)由於用電量僅占 42%且投資金額較大,故將 以 50%約 600 萬戶為目標。推動時程請參閱下表 1。. 8.
(9) 表 1、AMI 推動時程表 實施年度. 高壓戶數. 低壓戶數. 民國 99 年. 300~500 戶. 民國 100 年. 2 萬 3000 戶. 1 萬戶. 民國 101 年 民國 102 年. --. 民國 103 年. --. 民國 104 年. --. 民國 105 年~. --. 100 萬戶 500 萬. 資料來源:經濟部能源局民國 99 年 6 月 28 日發布,標題:我國智慧型電表基礎 建設正式啟動. 用電量佔比. 58%. io. 資料來源:101 年台電公司. 99.81% 42%. er. Nat. 0.19%. y. ‧ 國. 用戶數占比. 低壓用戶. ‧. 高壓用戶. 學. 表 2、高低壓用戶佔比. sit. 立. 政 治 大. al. n. iv n C 在用電戶方面,台電公司資料顯示,台灣的高壓用戶(約 23,000 hengchi U 戶)僅佔全體用戶數的 0.19%,但用電量卻占台電售電量的 58%,如 上表 2 所示);因此,若能善加利用 AMI 智慧型電表所收集的用電 資料,台電公司資料倉儲將具備大量分析資料,做為高壓用戶動態負 載分析中屬性、需量、計量等不同類型資料分析之基礎,便能最佳化 資源配置、協調電能供需關係、引導電能消費行為、鼓勵用戶在負載 低時段合理用電,尖峰負載時少用電。有效管理高壓用戶用電行為、 9.
(10) 穩定供電及提高供電效率,以提供更佳的用戶服務。. 第二節、研究動機 台電公司過去所從事的電力負載管理相關研究因為資料有限,分 析資料顆粒度以月為單位,所涉及的成果都在某一特定範圍與時間, 屬於靜態式研究,如今有了 AMI 所收集的資料來源,可充分掌握用 戶特性、用電行為與趨勢等寶貴的資訊,未來負載管理相關分析可以. 政 治 大. 更廣更動態,以協助策略之研擬規劃。為實現用戶導向服務,提供穩. 立. ‧. ‧ 國. (供應面)。. 學. 定供電品質,台電應確實掌握用戶需求(需求面)並最佳化資源配置. io. sit. y. Nat. 第三節、研究目的. er. 本研究主要針對用戶需求面進行分析,試著回答以下問題:. n. al. . i n C U hengchi 台電用戶具備什麼特徵與行為?. v. 對台電公司而言,誰是目標用戶? 應該提供目標用戶什麼服務? 運用資料探勘之分群(Clustering) 、分類(Classification)方法, 提出洞察力行銷-STP 分析模型,探討如何運用台電公司現有用戶服 務資料倉儲(隸屬台電公司綜合研究所),針對高壓用戶實現負載管 理之分析。 10.
(11) 第四節、預期效益 由於過去受限於一至兩個月一次人工抄表的頻率,無法獲得即時 且精準的分析資料,再加上分析工具的缺乏,故相關分析只能產生較 為靜態的研究成果;今政策推廣 AMI 智慧電表裝設,透過自動傳回 每 15 分鐘一筆的用電資訊,大幅度增加資料來源的完整度與精確度, 本研究即以 AMI 智慧電表資料為基礎進行用戶負載有關研究,提升 研究品質與範圍。. 立. 政 治 大. 預期效益可分為公司與用戶兩方面,如下:. ‧ 國. 學. 1、公司面效益. ‧. 協助台電公司依據事實資料進行策略研擬:提出用戶區隔、. Nat. io. sit. y. 目標用戶選擇及產品/服務定位之分析模型,以事實資料分析用戶行. er. 為資訊、掌握用戶特性、用電習慣與趨勢,提供負載策略研擬之基礎。. al. n. iv n C hengchi U 抑低尖峰用電:透過用戶區隔分析了解用戶特徵與行為,以. . 電價優惠誘導用戶改變用電行為。. 2、用戶面效益 協助用戶合理化用電與最佳化資源配置:誘導用戶移轉尖峰 負載,朝向合理化用電,降低用電成本。. 11.
(12) 第二章、文獻探討 第一節、洞察力行銷:市場區隔、目標市場與產品定 位 1、洞察力行銷(SAP,2011) “洞察力:成長中的企業獲得差異化競爭優勢的關鍵之路。”在任 何行業中,將最具競爭力的企業與最不具競爭力的企業相比,前者的. 政 治 大. 員工受惠於洞察力的影響的比例是後者的 2 倍,相反的,後者將資料. 立. 共用視為喪失控制力的比例是前者的 2.5 倍;這說明了洞察力對競爭. ‧ 國. 學. 優勢具有正向推動關係。. ‧. 洞察力指的是對環境或任何情況做出預見的能力;因此,洞察力. Nat. io. sit. y. 結合了經驗與分析能力,幫助實現更好的決策。洞察力能夠幫助企業. n. al. er. 尋找機會,發現問題,從而基於這些發現採取修正的行動。其關係如 下圖 1 所示。. Ch. engchi. 12. i Un. v.
(13) 差異化競爭. 決策能力 洞察力 分析能力 經驗. 政 治 大 立資料來源:本研究整理. 圖 1、洞察力:企業獲得差異化競爭優勢的關鍵之路. ‧ 國. 學. 洞察力行銷(Insight Driven Marketing)的目地是企業透過對所. ‧. 掌握的顧客資料對顧客的價值或行為特徵進行深入分析,以獲得對顧. Nat. io. sit. y. 客的洞察力,並利用洞察的結果制定差異化的產品,建置“以顧客為. er. 中心”的行銷模式。透過對現有顧客的區隔,把企業的顧客作為資源. al. n. iv n C hengchi U 進行管理,建立基於各類顧客群的管理原則和具體方法,從而強化企 業的行銷能力與市場競爭力。對企業帶來的影響是上自策略下至流程 的整體性的改變。如下圖 2。. 13.
(14) 立. 政 治 大. 圖 2、洞察力行銷帶來的改變. ‧ 國. 學. 資料來源:“Insight: The Critical Path to Competitive Differentiation for Growing Companies”, SAP, IDC executive brief, 2011. ‧. 未來的市場行銷勢必以分析為策略的基礎,藉由顧客洞察力分析. sit. y. Nat. io. n. al. er. 以獲得每一位顧客的特徵與行為資訊,針對每個顧客制訂差異化的行 銷(Kotler, 2003)。. Ch. engchi. i Un. v. 2、市場行銷 依據早期美國行銷學會(AMA, American Marketing Association) 於 1960 年定義:行銷是引導物品與勞務從生產者流向消費者或使用 者的企業活動。 然而,至 1985 年進一步修正,認為:行銷是規劃與執行產品或 勞務的訂價、促銷與分配的一種過程,並創造交換行為,使個人與組 14.
(15) 織滿意。 直到 2004 年針對現代蓬勃發展的行銷活動給與新的意義:行銷 是組織的功能,行銷是企業一連串的活動,目的在創造價值、溝通價 值,與傳遞價值予顧客,同時經營顧客關係使組織與其利益關係人獲 利。整理如下表 3。 表 3、AMA 針對行銷提出之定義. 1960 年. 行銷是規劃與執行產品或勞務的訂價、促銷與分配的一種過 程,並創造交換行為,使個人與組織滿意。 行銷是組織的功能,行銷是企業一連串的活動,目的在創造價 值、溝通價值,與傳遞價值予顧客,同時經營顧客關係使組織 與其利益關係人獲利。. ‧. 2004 年. 動。. 學. 1985 年. 政 治定義大 行銷是引導物品與勞務從生產者流向消費者或使用者的企業活 立. ‧ 國. 年份. er. io. sit. y. Nat. n. 可以發現 AMA 對行銷的定義由單純的連繫產品 a v 、消費者的關係,. i l C n U hengchi 擴大範圍至訂價、促銷、使用者滿意導向,最終創造顧客價值及企業 獲利。其 2004 年提出行銷概念圖,如下圖 3 所示。. 15.
(16) 立. 政 治 大. ‧ 國. 學. 圖 3、AMA 2004 年行銷概念圖. ‧. 資料來源:現代行銷學理論與實務,范惟翔,新加坡商湯姆生亞洲私人有限公司 出版,2007. sit. y. Nat. 由 AMA 於 2004 年提出之定義可知,行銷活動是以創造價值為. er. io. n. al 始點,首以市場區隔(Segmentation) 、目標市場選擇(Targeting) 、 iv Ch. n engchi U. 產品(服務)定位(Positioning)做為開端。以下分別介紹。 2.1、市場區隔(Segmentation) 市場區隔的過程即是將大市場根據某些特定的區隔變數,如顧客 特徵、行為、喜好、需求等屬性,將大市場切割成幾個有明顯差異區 隔市場,針對每個區隔市場進行不同層次的策略制定、設計產品或其 行銷組合,增加產品豐富性以降低單一風險,以滿足不同區隔市場消. 16.
(17) 費者的需求,使企業因市場的區隔而增加獲利。 一般用來進行市場區隔的變數有以下幾類: 地理變數 人口統計變數:如年齡、生命週期、家庭形態、所得、職業、 教育程度、其他(宗教、種族、國籍) 。 生活型態:消費者對週遭環境的觀察與感受。如建設公司以. 政 治 大. 生活便利或遠離塵囂來吸引不同生活型態的顧客。. 立. 心理變數:指消費者的人格特質、習慣、態度。如 B&Q 的消. ‧ 國. 學. 費型態強調自我實現夢想的滿足感。. ‧. 產品相關的行為變數:如使用時機、為消費者帶來的利益、. Nat. io. sit. y. 使用狀態(分為過去使用、初次使用、未來使用) 、使用率、品牌忠. n. al. er. 誠度、消費者對產品的態度。. Ch. engchi. i Un. v. 市場區隔變數越能精確描述顧客心理、行為者行銷愈容易成功, 但相對的,卻越不容易收集與實行;不同的變數在實行市場區隔之難 易程度如下圖 4 所示。. 17.
(18) 立. 政 治 大. ‧ 國. 學. 圖 4、不同市場區隔變數之實行難易程度. ‧. 不同的區隔變數所區隔出的市場結果會得出不同意義,因此在進. sit. y. Nat. io. n. al 是良好的市場區隔必須具備以下幾個特性: Ch. engchi. er. 行市場區隔時,需考慮到該區隔方法是否有效。有效的市場區隔或者. i Un. v. 可測量性:區隔市場的規模、購買力和基本情況等是可以用 數字表示其大小、強弱與好壞,並且可以測量出其數值。 可接近性:區隔市場的客戶族群是行銷通路能夠接觸的到, 並且對其提供服務。如在學校附近設置安親班、文具用品店;商業辦 公大樓外食人口多,故多簡餐、咖啡店。 可辨別性:區隔市場要在概念上容易區分,對於不同的行銷. 18.
(19) 活動和方案應該要有顯著不同的反應。 可操作性:必須能夠設計出有效的行銷方案吸引所區隔出的 市場,並提出適合該區隔市場所需要的服務。 重要性/獲利性:區隔市場必須足夠大,或者大到能帶來足夠 的盈利,使公司有制訂行銷策略並投入資源滿足區隔市場需求的動 機。. 政 治 大. 成功的市場區隔變數可以將顧客聚合為群間相異、群內相似的特. 立. ‧ 國. 學. 定群體。如下圖 5 例子所示,以橫軸為購買太陽能熱水器的機率, 左圖以“變量 A:氣候"為區隔變數,而右圖以“變量 B:教育程度". ‧. 為區隔變數。. sit. y. Nat. 可以看出對於購買太陽能熱水器的潛在顧客而言,顧客所在的氣. er. io. n. al 候會明顯影響購買的機率,具有“所在氣候區越寒冷購買機率越大” iv Ch. n engchi U. 的現象;反觀右圖,不同教育程度的顧客對太陽能熱水器的需求並沒 有反映在購買機率上,可知教育程度對購買太陽能熱水器的潛在顧客 便不是一個有效區隔的變數,或稱他為不相關的描述性變數。. 19.
(20) 圖 5、合適/不合適的市場區隔變數之區隔結果 資料來源:“Marketing Engineering: Computer-Assisted Marketing Analysis. 政 治 大. Planning”, Gary L. Lilien, Arvind Rangaswamy, Addison Wesley, 1997. 立. ‧ 國. 學. 2.2、目標市場選擇(Targeting). 目標市場選擇即是在市場區隔之後對各種型態眾多顧客族群或. ‧. 區隔市場依企業策略進行評量,以確定哪些區隔市場是企業所需且值. sit. y. Nat. 得進入的目標市場,並選擇一個或多個顧客群做為企業的目標市場。. er. io. n. al 在選擇評估方面,需仔細比較各區隔市場是否具備購買力 、成長潛力、 iv Ch. n engchi U. 以及企業本身是否具有能力服務該群顧客、企業目標和資源的是否匹 配等因素。 目標市場的選擇可依行銷策略分為以下幾種方式:1.規模最大的 大眾行銷(無差異行銷)2.規模最小的一對一行銷(或稱微市場行銷、 本地行銷)以及介於兩者之間的 3.差異化行銷(區隔市場行銷)和 4.集中行銷(利基行銷)。如下圖 6 所示。. 20.
(21) 圖 6、不同行銷策略下之目標市場選擇方式. 無差異行銷. 政 治 大. 無差異行銷(undifferentiated marketing)或大眾行銷(mass. 立. ‧ 國. 學. marketing)的策略是專注於顧客的共同需求,而不是需求的差異性, 企業對整個市場提供相似的產品或服務,故有區隔市場間差異化小、. ‧. 同質性產品、低行銷成本等特徵。. sit. y. Nat. 差異化行銷. er. io. n. al 差異化行銷(differentiated marketing)的策略是決定幾個區隔市 iv Ch. n engchi U. 場作為目標市場,並依每個區隔市場之需求提供差異化的產品或服務, 甚至規畫不同的市場行銷策略。通常需要額外的市場研究、預測、銷 售分析以及通路管理等成本,才可能在目標市場內創造更大的銷售利 潤,相對無差異行銷之行銷成本高,因此企業必須在成本與銷售同時 增加之間求取平衡或做出取捨。 集中行銷. 21.
(22) 集中行銷(concentrated marketing)或利基行銷(niche marketing) 的策略在企業資源有限條件下,針對一個或多個區隔市場,集中資源 提供相同的產品或服務,追求該區隔市場的市場占有率及投資報酬率。 集中行銷策略的目的是瞭解這些區隔市場的需求,並且在所提供服務 的區隔市場上維繫著很好的聲譽,以便取得主導與強勢地位。 一對一行銷. 政 治 大. 一對一(one-to-one marketing)是指透過與顧客一對一的互動,. 立. 為其個別需求量身訂作,大量客製化;以大量生產的技術,提供低成. ‧ 國. 學. 本並趨近於個別訂製的產品與服務。. ‧. 各行銷策略如下圖 7 示意。. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 7、三種目標市場選擇策略 22.
(23) 資料來源:現代行銷學理論與實務,范惟翔,新加坡商湯姆生亞洲私人有限公司 出版,2007. 2.3、產品定位(Positioning) 產品定位是為了在目標市場之消費群心中建立與其他競爭者不 同的形象,根據目標市場所需,決定提供何種商品或服務,並設計合 適的市場行銷計畫;故產品定位也可以稱之為品牌效應,指企業利用 行銷手法將某一產品在目標客戶群的心目中建立相對於競爭產品而. 政 治 大. 言的形象、個性等差異處而形成購買偏好(Blattberg,2009)。. 立. ‧ 國. 學. 企業在做產品或品牌定位時需考慮的不只產品本身及消費者需 求,更重要是認清同樣位於市場上的現有競爭對象,因此,在制定定. ‧. 位策略時首要確認競爭者及其在市場上的定位,分析顧客次之,最後. sit. y. Nat. 才決定公司產品位置的選擇;一旦產品經過定位,隨著時間及市場的. er. io. n. al 變化需進行不斷的調整,因此有必要監控產品的位置,以評估定位策 iv Ch. n engchi U. 略。其定位策略步驟如下圖 8。. 圖 8、定位策略步驟 資料來源:現代行銷學理論與實務,范惟翔,新加坡商湯姆生亞洲私人有限公司 出版,2007. 23.
(24) 在認清競爭對象及消費者需求時,除了依靠管理者直觀的方法來 了解市場結構,亦可以應用知覺圖產品定位工具來幫助決策。知覺圖 由點、向量、縱橫兩軸三元素組成,分別代表該市場上產品、顧客感 官屬性與產品的基本屬性。如下圖 9 為啤酒市場之知覺圖。. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. iv n C hengchi U 9、啤酒市場的產品知覺圖. 圖. 資料來源:“Marketing Engineering: Computer-Assisted Marketing Analysis Planning”, Gary L. Lilien, Arvind Rangaswamy, Addison Wesley, 1997. 每個點分布在以啤酒口味(淡-濃)與價格(貴-便宜)所圍出的 二維空間中,不同品牌的啤酒依其產品本身屬性座落在不同象限中, 如圖中百威啤酒是屬於口味較濃且價格偏高的啤酒,點與點之間距離 越近代表代消費者心中兩者相似程度、互相替代的程度越高,因此兩. 24.
(25) 產品間競爭也越激烈;另外,向量標示出市場上消費者對不同啤酒的 感官資訊,如特殊場合適合喝的啤酒特徵是口味偏濃且價格偏高的, 如圖中 Beck’s 啤酒,而百威啤酒是男士心中最喜愛的啤酒。 由上例可知,知覺圖可以使管理者能夠將產品市場結構中的關鍵 要素進行歸納和形象化,進而進行策略的思考。. 第二節、資料倉儲. 政 治 大. W. H. Inmon 定義資料倉儲為支援管理決策過程的、主題導向的. 立. ‧ 國. 學. (subject orientation)、整合的(integrated)、穩定的(nonvolatile)、 隨時間不斷變化(time variant)的資料集合(Inmon, 2002)。. ‧. 另一位學者 Kimball 則提出資料倉儲中的資料是自日常交易系統. sit. y. Nat. 中抽取出來的,是一群靜態的、可支援決策的資料庫。. er. io. n. al 從技術的角度來看,具有下列三種觀點(Kimball, 2004): iv Ch. n engchi U. 資料倉儲是一個過程,而不是一個場所。 資料倉儲是一種架構,並不是一種產品。 資料倉儲是需要建造的,公司無法購買資料倉儲。. 資料倉儲集合了企業資料之基礎建設,可視為環境架構的核心, 以便讓使用者能快速、簡單的查詢資訊,以及各種分析來幫助管理者 策略的訂定,甚至更進一步延伸資訊成為企業知識。 25.
(26) 1、資料倉儲的特性 1.1、主題導向 資料倉儲是以企業關心的主題為導向進行資料的組織,所對於這 些有興趣的主題儲存、提供相關的資料作為分析及多維度的查詢。“主 題"是一個抽象的概念,主要將企業資訊系統中的資料綜合、歸類並 進行分析,它對應了企業中某一分析領域所涉及的分析對象。. 1.2、整合性. 立. 政 治 大. ‧ 國. 學. 資料倉儲的資料來自企業操作型的交易處理系統,再加上如前所 述,資料倉儲存儲資料的方式是以主題為導向,對於每一個主題所對. ‧. 應的資料來源分散在各個系統資料庫中,有許多重複且不一致的現象,. sit. y. Nat. 其中可能包括了上百種不同的資料結構、不同的格式、不同的屬性、. er. io. n. al 不同的命名等等;另外,資料倉儲在資料的應用上,有許多資料需要 iv Ch. n engchi U. 經過加總、轉換的處理而無法直接自來源資料取得。對資料倉儲的建 置而言,整合是一項最重要也最複雜的工程。如下圖 10。. 26.
(27) 立. 政 治 大. 圖 10、資料倉儲特性-整合性. ‧ 國. 學. 1.3、隨著時間不斷變化(時間差異性). ‧. “時間”在資料倉儲中是重要的元素,可視為資料的戳記,每一筆. sit. y. Nat. 資料是在某時刻產生的快照,累積快照使資料倉儲保留了每個時間點. er. io. n. al 活動和事件的歷史記錄;故資料倉儲往往累積了 i v 5~10 年長時間的資 Ch. n engchi U. 料,並且以時間為資料表主鍵,一筆正確的快照資料一旦被累積就不 會被修改,如下圖 11 所示。. 27.
(28) 政 治 大 資料來源:Building the Data Warehouse, William H. Inmon, Wiley, 3 edition, 2002. 立 圖 11、資料倉儲特性-時間的變化性. ‧ 國. 學. 1.4、不可更新性. ‧. 傳統作業處理環境會不斷新增、刪除、修改每筆資料,如顧客基. Nat. io. sit. y. 本資料,但在資料倉儲中只有載入與存取兩種動作。當快照轉換到資. n. al. er. 料倉儲內,其內容就不會再被改變,以確保資料所反應當時的狀況。 如下圖 12。. Ch. engchi. i Un. v. 圖 12、資料倉儲特性-不可更新性 資料來源:Building the Data Warehouse, William H. Inmon, Wiley, 3 edition, 2002. 28.
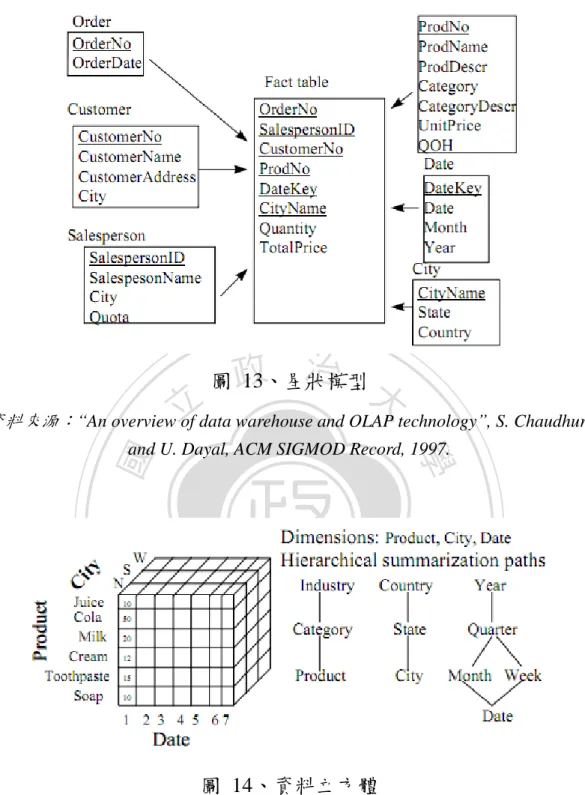
(29) 2、資料倉儲的應用 在應用上,資料倉儲可以作為線上分析處理(Online Analytical Processing,縮寫為 OLAP)和資料採礦(Data Mining)的資料來源。 OLAP 主要功能在於操作靜態資料倉儲的資料,以星狀模型(Star - Schema)方式作為資料儲存的結構,見圖 13,將資料組成資料立 方體(Cube)來做儲存,見圖 14。. 政 治 大. 星狀架構是由事實資料表(Fact Table) 儲存各維度資料表的主鍵,. 立. 以及欲觀察的測量值(Measure) ,這些測量值通常具有可累加的特性;. ‧ 國. 學. 及一連串記錄各個資料表屬性的維度資料表(Dimension Tables)所. ‧. 組成。. Nat. io. sit. y. 這樣的資料結構讓使用者可以方便的進行多種組合、多種角度、. er. 動態多維度分析,並提供視覺化操作、上捲(Roll - Up) 、下鑽(Drill. al. n. iv n C h and - Down)、切片及切丁(Slice e nDice)以及轉軸(Pivot)等資料操 gchi U 作功能與展示介面。. 29.
(30) 政 治 大. 圖 13、星狀模型. 立. 資料來源:“An overview of data warehouse and OLAP technology”, S. Chaudhuri. ‧. ‧ 國. 學. and U. Dayal, ACM SIGMOD Record, 1997.. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 14、資料立方體 資料來源:“An overview of data warehouse and OLAP technology”, S. Chaudhuri and U. Dayal, ACM SIGMOD Record, 1997.. 關於資料倉儲於資料採礦的應用詳見下個章節,3、資料採礦與 演算法介紹。. 30.
(31) 第三節、資料採礦與演算法介紹 1、資料採礦 前一章節所介紹的 OLAP 主要是透過以定義好的靜態資料進行 動態多維度的檢視,與 OLAP 不同的是,資料採礦著重在運用演算法, 在資料中找出隱藏的規則,並利用這樣的規則來預測未來。 隨著資料庫技術的迅速發展與成熟,以及資料庫管理系統的廣泛. 政 治 大. 應用,企業累積的資料越來越多,對公司而言資料是一大資產,如何. 立. 從資料中得到有價值的資訊便成為一大課題。目前的資料庫系統可以. ‧ 國. 學. 高效率地實現資料新增、查詢、修改、統計等功能,但無法發現資料. ‧. 間存在的關係和規則,亦無法根據現有的資料預測未來的發展趨勢。. Nat. io. sit. y. 資料採礦(Data Mining)便是從大量的、不完全的、有雜訊的、. er. 模糊的、隨機的實際應用資料中,找出隱含在其中的、人們事先不知. al. n. iv n C hengchi U 道的、但又是潛在有用的資訊和知識的過程(Jiawei Han, 2000)。 1.1、資料採礦的步驟,參考下圖 15: 資料清理(消除噪音或不一致資料) 資料整合(多種資料來源可以組合在一起) 資料選擇(從資料庫中擷取與分析任務相關的資料). 資料變換(資料變換或統一成適合的形式;如,資料彙總) 資料採礦(使用智慧方法擷取資料模式) 31.
(32) 模式評估(根據某種衡量方法,識別提供的知識是否真正有 效) 知識表示(提供視覺化結果,向用戶提供資料採礦後的知 識)。 知識表示 模式評估. 治 政 資料探勘 大 學. ‧ 國. 立資料變換. 資料選擇. 資料倉儲. ‧. 資料清理. sit. y. Nat. 資料整合. er. io. 資料庫. n. al. i n C U hengchi 圖 15、資料採礦步驟. v. 1.2、資料採礦的種類: 依活動內容的不同,資料採礦可分為:分類(Classification) 、推 估(Estimation)、預測(Prediction)、同質分組或關聯規則(Affinity Grouping or Association Rule)、群集化(Clustering)、描述及視覺化 (Description and Visualization) (Michael J. A. Berry, Gordon S. Linoff,. 32.
(33) 2001)。 另外,以採礦方法分類,資料採礦可分為監督式資料採礦 (Supervised Data Mining)與非監督式資料採礦(Unsupervised Data Mining)兩種。 監督式資料採礦 屬於由上而下(top - down)的方法,通常是在已知要預測的目. 政 治 大. 標下進行,以演算法找出資料所屬類別的規則,並以此規則預測新資. 立. 料所屬類別。分類、推估、預測三類資料採礦屬之。. ‧ 國. 學. 非監督式資料採礦. ‧. 屬於由下而上(bottom - up)的方法,演算法在資料間發現規則,. Nat. 化、描述及視覺化三類資料採礦屬之。. n. al. 2、演算法介紹. Ch. engchi. er. io. sit. y. 並讓使用者決定是否採用採礦後的規則。同質分組或關聯規則、群集. i Un. v. 2.1、K-means 分群演算法 K-Means 演算法是 J. B. MacQueen 於 1967 年所提出。是把 N 個 物件分為 K 個聚集,使類別內具有較高的相似度,而類別間的相似 度最低,其中相似度根據一個聚集中物件的平均數(被看作聚集的重 心)來計算。. 33.
(34) K-Means 演算法的處理流程如下。首先,隨機地選擇 K 個物件, 每個物件初始地代表了一個聚集中心,對剩餘的每個物件,根據其與 各個聚集中心的距離,將它賦給最近的聚集。然後重新計算每個聚集 的平均數。 這個過程不斷重複,直到目標函式收斂。目標函式的定義如下:. 政 治 大. 立. 此處 E 是資料集中所有物件平方誤差的總和。. ‧ 國. 學. k 表共分為 k 群。. ‧. ci 為第 i 群資料集合。. Nat. n. al. Ch. engchi. sit er. io. mi 是資料群 ci 的平均數。. y. p 指包含於 ci 中的所有資料點。. i Un. v. 這個目標函式以達到 E 最小為目標,表示各群內資料盡可能的相 似,群間資料盡可能的獨立。對處理大資料集,該演算法是相對可伸 縮的和高效率的。 其進行的步驟如下: 使用者給定分群數 k 系統隨機指派群中心. 34.
(35) 系統產生初始分群結果 系統產生新的群中心 系統修正分群邊界 重複第三和第四步驟直到資料不再變動 但 K-Means 在應用上有一定的限制,其一,使用者必須事先給 定分群群數(即 k 值) ;其二,K-Means 收斂的依據是各群的平均數,. 政 治 大. 因此若資料存在少量的極端值將會對平均數產生極大的影響,使分群. 立. 結果產生誤差。. ‧ 國. 學. 2.2、EM 分群演算法. ‧. EM(全名為 Expectation Maximization,期望值最大)演算法是. sit. y. Nat. 以 K-Means 為基礎加以改善及擴充的方法。EM 不強調將個別資料分. er. io. n. al 配給一個特定的群集,而是根據資料與群集之間隸屬關係發生的機率 iv Ch. n engchi U. 來分派,換句話說,在聚集之間沒有嚴格的界線。其目標函式是以加 權後的衡量值來計算。 每個聚集都可以用機率分配來做數學描述,整個資料集可視為這 些分配的混合,如圖 16 中有兩個群集,分別遵循高斯分配 g(m1,σ1) 和 g(m2, σ2),並具有各自的平均數與標準差。. 35.
(36) 立. 政 治 大. 圖 16、每個群集可視為一機率分配. ‧ 國. 學. 資料來源:資料探勘 - 概念與方法(Data Mining: Concepts and Techniques, 2/e), Jiawei Han, Micheline Kamber, CS, 2008.. ‧. EM 首先對整個資料集的混合模型進行初始的估計,反覆根據資. sit. y. Nat. 料集產生的混合密度對每個資料點重新計算目標函式值,每個資料點. er. io. n. al 都賦予一個機率以假設它是特定群集的成員,具有該群集屬性的可能 iv Ch. n engchi U. 性。演算法邏輯步驟描述如下:. E-step 期望值(Expectation)步驟:用以下機率將每個物件 Xi 指派到聚集 Ck。 ). ) ( ). 其中 p(xi | Ck)服從常態分配(即高斯),此一步驟是針對每個 群集計算資料點 xi 的隸屬機率。 36.
(37) M-step 最大化(Maximization)步驟:尋找一個讓條件最大化 的機率模型,利用前面得到的機率估計重新估計模型參數。. 𝑚. 1 k. n. n. xi P(xi. i 1. Ck ). j P(xi. Cj ). EM 演算法比較簡單且容易實現。在實務中,它收斂很快,但是 可能達不到全域最佳。. 政 治 大. 2.3、單一鏈結分群演算法. 立. ‧ 國. 學. 單一鏈結演算法(Single linkage clustering)又稱最短距離法,屬 於階層法(Hierarchical method)中的聚合(agglomerative)分群法,. ‧. 繼承其分群之後不做重新分群、分群之後的結果可以用樹狀圖呈現等. sit. y. Nat. io. al. n. 意如圖 17。. er. 特性,分別計算兩個群集中距離最近的兩個項目的距離,分群結果示. Ch. engchi. i Un. v. 其品質受限於:一旦群集間互相聚合就不能再回頭修正,也就是 說,如果某個聚合決策在後來證明不是好的選擇,該方法無法退回並 更正。. 37.
(38) 圖 17、單一鏈結分群結果示意圖 演算法邏輯步驟:. 政 治 大. 將所有資料視為單獨群集。. 立. ‧. ‧ 國. 集。. 學. 依據距離衡量函式所衡量出的距離大小聚合兩個最接近的群. 繼續聚合相近的群集直到得到目標群集數。. io. sit. y. Nat. er. 距離衡量函式的方法會因資料型態有所不同,有以下幾種:. al. n. iv n C hengchi U 若資料型態為可數連續或離散型資料,其相似度距離可以:相關 係數(Correlation coefficient) 、歐幾里得距離、曼哈頓距離、Minkowski 距離來衡量計算,以相關係數、歐幾里得距離兩種計算方法最常使 用。 相關係數:. (. )( 38. ).
(39) 其中 x1~xn 表 x 群集中的資料點,y1~yn 表 y 群集中的資料點。 歐幾里得距離: (. ). (. ). 其中 i 和 j 表示一對觀測到的資料點,xkj 表第 k 個變數的 i 值, k=1~n 個變數。. 若資料型態為不可數名目行資料,其相似度距離則以匹配衡量法 計算。計算範例如下:. 立. 政 治 大. ‧ 國. 學. 下表 4 有 A~D 五組織,分別針對 F1~F8 八種特徵進行調查,若 具備該特徵以 Y 紀錄,反之以 N 紀錄。. ‧. 表 4、單一鏈結名目資料之計算範例資料. sit. y. Nat. n. al. er. io. Essential Features? (Yes or No) F3. F4. i U nF5. N. N. Y. N. Y. N. Y. N. F1. CF2h. Organization A. Y. Y. Organization B. N. Organization C Organization D. v. F6. F7. F8. Y. Y. Y. Y. N. N. Y. Y. Y. Y. Y. Y. N. N. N. N. N. Y. Y. Y. Y. engchi. 完成資料收集後,對兩兩組織進行比較,計算匹配值。以 A、B 兩組織為例,F1~F8 特徵中 F1 與 F5 兩筆記錄不同,其餘 F2、F3、 F4、F6、F7、F8 等 6 筆記錄相同,故 A、B 兩組織匹配值為 6/8。以 39.
(40) 相同方式兩兩計算可得一對稱的匹配矩陣,見表 5。 表 5、匹配矩陣 A. B. C. D. A. 1. B. 6/8. 1. C. 2/8. 0. 1. D. 7/8. 5/8. 3/8. 1. 2.4、C4.5 分類演算法. 政 治 大 J.Ross Quinlan 於 1993 年提出,是決策樹的一種,所產生的決策 立. ‧ 國. 學. 樹為多元樹。C4.5 的目標是找出哪一種規則最能夠減低分類結果的. ‧. 亂度 (Entropy,熵值)。計算資訊增益率(Gain Ratio)來決定決策. sit. y. Nat. 樹建立過程中以哪個分類屬性作為較上層的分類節點。. n. al. er. io. 熵值計算:. Ch. engchi. i Un. v. 其中 X 表事件,k 為事件發生的結果種類,Cp 為發生該結果的機 率值。 資訊增益率 : ( ). ( ). ( ) 其中 X 表事件,A 為事件結果的屬性,E(S)為結點分割後整 40.
(41) 體的熵值。訊增益率越大代表該節點分割後的子集合中類別越單純, 類別代表性及解釋性高,所得的分類結果越好。. 2.5、CART 分類演算法 CART 全名為 Classification and Regression Tree,分類與迴歸樹, 於 1984 年由 L. Brieman 提出。與 C4.5 相異處在於 CART 為二元樹, 並以吉尼指標(Gini index)做為建樹的準則。 吉尼指標. 立. 政 治 大. ‧ 國. 學 ‧. 其中 D 代表決策樹某節點,pj 表節點 D 中第 j 個類別的機率。. Nat. sit. n. al. er. io. 果越好。. y. Gini 值越小代表該節點分割後的子集合中類別越單純,所得的分類結. Ch. engchi. i Un. v. 2.6、簡單貝氏分類演算法. 貝氏分類方法是以貝氏定理為基礎所作的延伸應用,計算類別的 條件機率,在統計學裡有廣泛地應用。特別適用於當輸入的屬性維度 多時,並以屬性間互相獨立為前提假設,儘管這項假設過於理想與簡 單,但它往往能解決複雜的現實世界中的分類預測問題。 運作原理是透過訓練樣本學習與記憶分類所使用屬性間的關係,. 41.
(42) 再用學習得到的規則對未歸類的資料進行分類預測,因此具有只需要 少量的訓練資料就能準確的估計資料屬性歸類的優點。 計算各屬性的條件機率 貝氏定理: ) ( ). ). ) ( ) 屬性獨立:. 政 治 大. 立. ‧ 國. 學. ). ). 分類預測模型. ‧. ). n. Ch. engchi. ). er. io. al. ( ). sit. y. Nat. 𝑚. i Un. v. 3、資料採礦於商業應用. 早期關於資料採礦的研究多著重於技術面,如針對不同型態資料 的處理、演算法的效率性及有用性、以及隱私權與資料安全性方面的 議題。隨著資料採礦技術的成熟,越來越多關於商業應用的討論議 題。 一項 META Group 顧問公司調查顯示,自 1996 年以來,越來越. 42.
(43) 多企業投入資料採礦及知識發現技術,包括 Amazon 與 Yahoo 兩大具 前瞻性的企業,皆投入資金進行顧客區隔、尋找目標顧客、提高並維 持顧客保留、交叉銷售等研究,所應用的產業範圍更拓及零售、保險、 金融、電信、證券(Lach, 1999)。各領域應用情形如下表 6。 表 6、資料採礦於各領域之應用 應用領域. 應用. 說明. 政 治 大 交叉銷售(Cross-selling) 立. 類同定位(Affinity positioning) 零售. 為顧客找到更多產品. 顧客關係管理 確認顧客價值,並發展 (Customer relationship management)方案獲取最大收入. ‧ 國. 學. 銀行. 有效的定位產品. 舉力(Lift). 確認有效的市場區隔. 顧客流失(Churn). 確認顧客可能的流動率. n. al. Ch. engchi. y. i Un. 電話行銷. 線上資訊(Online information). 人力資源管理. 顧客流失(Churn). 確認顧客可能的流動 率. er. 顧客流失(Churn). 確認保單應受調查. sit. 詐欺偵測(Fraud detection). io. 電信. Nat. 保險. ‧. 信用卡管理. v. 幫助電話行銷員容易 取得資料 確認潛在的員工流動 率. 資料來源:“資料探勘- Introduction to Business Data Mining”,郭志隆、張芳菱(譯), 麥格羅‧希爾(民 97). 可知資料採礦已廣泛的應用於各行業領域,幫助了解顧客區隔、 找出目標客群、定位產品,甚至延伸於顧客關係管理,了解顧客流動 並確保顧客忠誠。 43.
(44) 第三章、研究方法與設計 第一節、研究方法 本研究的研究方法,主要採取個案研究法並加以系統實作進行。. 1、個案研究法 個案研究是社會科學研究之方法之一。Yin(1985)認為個案研 究是一種實證研究,在現實生活環境中研究當前的現象。. 政 治 大. 並提出個案研究法的特性如下:. 立. ‧ 國. 學. 在自然環境(natural setting)中進行現象的研究。 使用多種資料收集方法。. ‧. 分析單位(資料收集的對象)可能是一個(單一個案)或多. sit. y. Nat. 個(多個案)實體。. er. io. n. al 對於每一個實體都深入瞭解其複雜性。 iv Ch. n engchi U. 個案研究比較適合運用在問題仍屬探索性階段,且尚未有前 人研究可循的情況下,甚至分類性研究及假設或命題的提出。 沒有變數操弄(manipulation)、實驗設計或控制。 研究當前的現象,解決當前的問題。 個案研究比較適合研究「為什麼」或「如何做」的問題,並 且可以做為未來相關研究的基礎。. 44.
(45) 研究結論的好壞與研究者的整合能力有相當大的關係。 改變研究對象與資料收集方法可以發展一些新的假說。 個案法不預設研究變數、及何者為自變數、依變數。. 2、採取個案研究之原因 根據前述電力產業現況描述,可知目前仍以台電公司為主要供電 來源,幾乎以獨佔者姿態立足市場,故以台電公司為個案研究對象進. 政 治 大. 行分析與推論可充分代表市場現況,因此採以個案研究法,從中收集. 立. ‧ 國. 學. 台電公司內部負載管理想法與需求,並深入探討執行面與影響面等實 務運作方面的見解,方能奠立具可行性與務實性的研究結果,進而有. ‧. 效推行。. io. sit. y. Nat. n. al. er. 第二節、研究設計. C 1、研究對象之選擇h. engchi. i Un. v. 本研究主要配合 AMI 之裝設時程,如表 1,預計今年(民國 101 年)底可完成高壓用戶 23,000 戶之裝設進度,再加上高壓用戶雖佔 總體用戶只有 0.19%,但用電量卻占台電售電量的一半以上(58%), 見表 2。 故以(1)用戶資料完整性以及(2)分析成效與影響程度為優先 考量,決定選擇台電公司高壓用戶為研究對象。 45.
(46) 2、研究流程. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. i n C U 圖 h 18、研究流程圖 engchi. v. 資料來源:本研究整理. 本研究流程規劃如上圖 18,首先確定研究目標與問題,針對目 標進行環境背景與洞察力行銷理論兩方面之文獻探討,另一方面透過 訪談與資料收集了解個案公司現況,初步了解內部需求後以資料採礦 技術進行 STP 分析。. 46.
(47) 第三節、研究架構. 立. 政 治 大. al. sit. iv n C h e nSQL 19 所示,本研究以 h i U2008 Business Intelligence g cServer n. 如上圖. er. io. 資料來源:本研究整理. y. ‧. ‧ 國. 學. Nat. 圖 19、研究架構圖. 為分析工具,既有用戶服務資料倉儲為基礎,進行台電公司高壓用戶 洞察力行銷之實作與分析,因此研究架構包含:1.洞察力行銷 - 市場 區隔、目標市場選擇、產品定位,2.資料倉儲,3. 資料採礦 - 分群、 分類方法等三大部分。詳細執行步驟如下圖 20 所示。. 47.
(48) 政 治 大. 圖 20、執行步驟. 立資料來源:本研究整理. ‧ 國. 學. 執行步驟說明:. ‧. 個案公司背景分析,並進一步訪談相關單位,收集需求資訊。. sit. y. Nat. 納入訪談需求意見,藉由 STP 分析模型了解如何以資料倉儲. er. io. n. al 與資料採礦技術實現市場區隔之洞察力行銷。 iv Ch. n engchi U. S:根據資料採礦之分群、分類功能進行市場區隔,解釋與評 估用戶區隔結果。T:針對各個用戶區隔進行用電行為之 KPI 試算, 如尖峰用電量、尖離比,以找出若干目標市場。P:試算並推薦目標 用戶合適的優惠方案,藉由優惠電價吸引用戶願意調整用電行為,以 達到尖峰用電移轉效果。 歸納分析結果並提出建議。. 48.
(49) 第四章、個案分析 第一節、我國電力環境現況 近來福島核災滿周年,核電廠安全與核廢料問題成為討論話題, 不少民間團體聯合提出廢核要求,對於核四是否順利運作的問題有不 少爭論。 “針對廢核要求,台電公司表示,台灣若立即廢核,會有停限電. 政 治 大. 之可能。” (中央社,2012/3/11). 立. ‧ 國. 學. 1、電力供給面-台灣發電結構. 台灣用電用電需求攀升,逐漸高於目前所能供應的電量。在電力. ‧. 供應面,台電統計民國 101 年 1~4 月份發電結構資料顯示,目前台灣. sit. y. Nat. io. al. n. 2012)。. er. 用電來自台電供電佔 78.4%,其於 21.6%來自購電(台灣電力公司,. Ch. engchi. i Un. v. 台電供電又以火力發電為主要供電來源,佔總發購電 54.1%,其 次為核能發電,佔 20.3%,再生能源發電第三,佔 2.5%,以抽蓄水 力發電最少,僅佔 1.5%。 購電來源以民營火力發電為最大宗,佔 18.1%;汽電共生次之, 佔 2.6%;民營再生能源發電最少,佔 0.9%,包含託營水力發電(0.3%) 、 民營水力發電(0.1%) 、民營風力發電(0.5%) 、太陽能發電(0.0%)。. 49.
(50) 政 治 大. 圖 21、台灣發電結構(2012/1~4 月). 立資料來源:本研究整理. ‧ 國. 學. 2、電力需求面-台灣用電結構. ‧. 經濟部能源局資料顯示,台灣主要用電需求來自:工業及能源部. sit. y. Nat. io. al. n. 2012/1). er. 門用電最多占 54.49%,服務業部門次之占 19.37%。 (經濟部能源局,. Ch. engchi. i Un. v. 台灣為獨立能源系統的海島國家,能源供給的先天條件極為脆弱, 自主能源匱乏,目前約 99.4%的能源仰賴進口,且欠缺有效的能源備 援系統,由上圖 21 可知,目前台灣供電依然以台電公司為主 (78.4%)。. 50.
(51) 第二節、個案分析 1、個案公司簡介 台灣電力公司,全名台灣電力股份有限公司(Taipower,簡寫為 TPC) ,於民國 35 年成立,負責台灣本島、澎湖、金門、馬祖的電力 需求,為台灣國營電力事業,先後發展水力、火力、多能源等供電來 源;民國 75 年起,因政治經濟環境改變,國內用電需求大增,台電. 政 治 大. 始意識供應與需求平衡問題,直到今日,不斷思考並調整需求管理策. 立. 略。. ‧ 國. 學. 近年來,在能源來源的限制下,加以國際能源價格上漲、用電需. Nat. sit. n. al. er. io. 加強供電品質. y. 開發多元電源. 推動節能減碳. ‧. 求攀升的情況下,台電提出以下未來發展目標:. Ch. engchi. i Un. v. 落實顧客服務 善盡社會責任 以因應台灣經濟與社會的發展,提供穩定、高品質的電力,在執 行上,除了積極配合政府相關政策推動各種電力建設外,更注重質量 並重的電力服務。 公司組織架構如下圖 22: 51.
(52) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 22、台灣電力公司組織架構圖 資料來源:台灣電力公司網站 52.
(53) 2、個案公司發電結構 台電供電可分火力、核能、再生能源、水力三大類。各項供電資 訊如下表 7 所示: 表 7、台電公司發電結構 發電度數. 發電佔比. (百萬度). (%). 發電方式. 水力發電. 水力抽蓄. 火力發電. 合計 燃油. 20,333. 31.1. 燃氣. 13,265. 合計. 13,271. 20.3. 合計. 1,656. 慣常水力. 1,320. ‧ y. 0.5. 太陽能. 3,865. 0.0. 51,250. Nat. 333. sit. 20.3 2.5. er. 風力. al iv 資料來源: n C h 101 年 5 月號台電月刊 engchi U. n. 台電發電量合計. 2.7. io. 再生能源發電. 1.5. 學. 核能發電. 54.1. ‧ 國. 燃煤. 立. 954 治 政 35,368 大 1,770. 2.0. 78.4. 承前述,火力發電為主要電力來源,佔台電總發購電量 54.1%, 由上表數據可知,火力發電主要以燃煤與燃氣為大宗,分別佔 31.1% 及 20.3%,以燃油最少,僅 2.7%(台灣電力公司,2012)。煤、天然 氣、石油皆屬化石燃料,所對應的燃料成本整理如下表 8:. 53.
(54) 表 8、台電公司燃料成本 燃料種類. 成本(元/度). 發電佔比(%). 媒. 1.4790. 31.1. 天然氣. 3.1263. 20.3. 石油. 5.5657 資料來源:101 年 5 月號台電月刊. 2.7. 觀察各燃料成本與發電佔比的對應關係,發現成本與發電量呈現 負相關,可知台電公司在火力發電管理上,以成本低者為優先供電來 源。. 學. ‧ 國. 立. 政 治 大. 3、負載管理思維. ‧. 電力是一種不具型體的能量形式,不像石油、瓦斯可以事先儲存,. y. Nat. er. io. sit. 台電電力調度中心必須時時刻刻掌握用電需求,確保電廠的發電產能 永遠要高於當下的用電量 a ,以避免缺電的問題(天下雜誌,2012/3/7)。. n. iv l C n hengchi U 因此,在用電尖峰時段,台電必須備足機組與發電系統以供應尖峰用 電需求,在離峰時段則必須保養與維運停擺的設備,顯示台電平時有 四到七成的發電機組,都是閒置的。此處所指尖峰時段一般為六到九 月的夏季,此為每年的用電高峰期,而上午十時至下午五時之間則為 每日的用電尖峰時段。. 面對不斷攀升的用電需求,尖峰時間用電量不斷攀升,台電公司 必須備足發電機組,並且使用更多化石燃料,啟動相對成本高昂的發 54.
(55) 電設備以因應尖峰時刻發電,導致成本居高不下。 面對這樣的用電環境,不斷增購發電設備雖然可滿足尖峰時段用 電,但卻造成離峰時段更多機組閒置的情況,隨之而來的是閒置機組 日常維護的成本開銷,可見此法治標不治本,有效的方式應是降低尖 峰時間用電量,即降低該時段的電力負載,倡導用戶節約用電,亦搭 配時間電價、優惠方案等策略,以電費優惠為誘因,鼓勵用戶用電轉 移尖峰時段至離峰時段。. 立. 政 治 大. 目前除了政府政策加持、AMI 智慧電表積極推廣與裝設,台電. ‧ 國. 學. 公司方面應著重思考負載管理還能如何調整,以解決穩定供電與成本. ‧. 居高不下的問題 。目前電力公司為了滿足用戶的用電需求,避免尖. Nat. sit. n. al. er. io. 差距。. y. 峰時段供電不足,正積極的推廣尖峰負載管理,減少尖、離峰負載的. Ch. engchi. i Un. v. 4、負載管理實施內容. 針對負載管理,台電公司提出兩大策略方向: 針對電價基礎(Price-Based)制訂 電業根據各個時段之供電成本或價值,訂定各種隨時間變動之差 別費率,用戶可根據電業公佈之不同時段費率,決定是否在某些特定 時段減少用電以避免支付較高之電價,如季節電價、時間電價。. 55.
(56) 針對激勵基礎(Incentive-Based)制訂 用戶根據與電業事先約定之生效條件,於電力系統高載期間或電 力供應調度需要時,配合降低用電以獲得電費扣減或補償,如減少用 電方案、需量反應計畫,以及儲冷式空調、空調冷氣週期性暫停用電 優惠電價等措施。 各項負載管理辦理內容如下(台電公司網站,2011): 時間電價. 立. 政 治 大. 時間電價將一日時間分為尖峰、離峰、半尖峰時段,依不同時段. ‧ 國. 學. 發電成本不同,分別訂定各時段電價,尖峰費率最高,半尖峰費率次. ‧. 之,離峰費率最低。以時間電價反映不同時段之供電成本差異,借流. Nat. sit. er. io. 季節電價. y. 動電費之費率高低鼓勵用戶轉移尖峰負載到離峰以減輕電費負擔。. al. n. iv n C hengchi U 季節電價將全年畫分成夏月電費(6/1~9/30)與非夏月電費(其 他月份),每年夏月期間流動電費費率高於其他非夏月期間流動電費 費率。 減少用電方案 分為計畫性與臨時性兩種方案類型。計畫性減少用電方案係指, 符合特定條件的用戶於台電所指定的期間內(通常為夏月或尖峰時 段),依契約內容抑低用電;臨時性減少用電方案為當電力公司系統 56.
(57) 供電不足時,請用戶配合暫停部分用電。 此兩種方案實施方式皆為用戶與台電公司簽訂契約,若用戶於約 定或臨時通知的時段確實減少用電,則流動電費可享有優惠。 需量反應計畫 用戶配合緊急通知時減少用電,可選擇抑低用電前 15 分鐘、30 分鐘或前 1 小時通知之抑低用電方式,視依約降載量程度享有基本與. 政 治 大. 流動電費折扣。適用於經常契約容量 500 瓩以上之高壓或特高壓用戶. 立. 學. ‧ 國. 選用。. 儲冷式空調系統. ‧. 為抑低成長快速冷氣負載,台電公司鼓勵企業用戶或辦公大樓裝. Nat. 價的電力及優惠折扣,轉移尖峰負載。. n. al. . er. io. sit. y. 置夜間儲冷、白天釋冷的儲冷式空調系統,充分利用夜間離峰時段廉. i n C U hengchi 空調系統週期性暫停用電. v. 為抑低造成夏季尖峰的冷氣負載,對中央空調系統用戶,若達到 每運轉 60 分鐘暫停 15 分鐘,便給予用戶電費優惠。. 第三節、個案公司需求訪談 AMI 電表上線後,為更有效進行負載管理,找出重點目標用戶 為首要工作,故選以與用戶直接接觸的前線單位為需求訪談對象:北. 57.
(58) 市區處大用戶服務專員、北北區處大用戶服務專員;以及業務處訪談 對象:總部業務處費率組。. 1、北市區處大用戶服務專員 表 9、北市區處訪談結果 項目. 訪談回覆 用戶希望台電告知選用二段式或三段式電費何者較為划. 政 治 大. 算,目前業務處僅有 Excel 檔案可進行試算,但試算結果 1.. 立. 是較粗略的估計值,且專員要自行輸入很多參數,使用不. 資料來源:本研究整理. Nat. y. ‧. ‧ 國. 學. 便。. er. io. sit. 承上表 9,項目 1.說明:. 由於過去缺乏詳細用電資料,僅得知每月尖離峰總用電度數,因 a. n. iv l C n hengchi U 此大用戶服務專員在流動電費試算上只能粗略估算,被動的由用戶提 出試算需求後給予建議。未來以 AMI 每 15 分鐘一筆的資料做為試算 基礎,可確實掌握各大用戶用電行為,針對不同行為者進行差異化管 理,將各類用戶用電資料套用各時點時間電價費率,以及該用戶可能 簽訂之各契約條件,主動給予方案建議。 需求歸納: (1)用戶分群、分類(2)流動電費試算(3)減少用 電方案試算。 58.
(59) 2、北北區處大用戶服務專員 表 10、北北區處訪談結果 項目 1.. 訪談回覆 建議 AMI 資料處理時應填補缺漏資料。 系統分析用戶群的用電方案選擇,要能以電費試算結果呈. 2. 現才較有說服力。. 政 治 大. 建議可依照供電饋線和變電所區隔用戶,並分析區隔用戶. 立. 3.. 學. ‧ 國. 之用電行為及尖峰用電抑低移轉之試算。 資料來源:本研究整理. ‧. 承上表 10,項目 1.說明:. y. Nat. er. io. sit. AMI 於收集時,會因資料傳輸問題導致該用戶於某時點資料的. n. al 缺漏,導致資料在後續分析時,如分群、分類,造成分析結果偏差, iv Ch. n engchi U. 因此應設計資料填補的機制。 項目 2.說明:. 用戶分群、分類後資訊僅能表達該群/類特性,尚不足以提供用 戶服務的決策資訊,因此應整合後續電費試算,以突顯分群、分類後 用戶面與公司面的效益。 項目 3.說明: 不同使用者會有不同的分析需求,北北區處大用戶服務專員主要 59.
(60) 以饋線別與用戶所屬變電所為條件管理並服務各大用戶,因此再進行 分群、分類前應予以使用者資料篩選的功能。 需求歸納:(1)填補資料缺漏值(2)分析流程可設計為【資料 篩選】→【分群、分類】→【電費試算】。. 3、總部業務處費率組 表 11、總部業務處費率組訪談結果 項目. ‧ 國. 學. 1.. 立. 治 政 訪談回覆 大. 是否能以單一條件篩選出用戶,再進行分群。. ‧ sit. y. Nat. 是否能於分完群後,依照群組的屬性條件,找出資料中其. al. iv n C 的用戶分群,藉由這些用戶群的特質找出其他尚未參加方 hengchi U n. 2.. er. io. 他有相同特質的潛在用戶,例如對目前有參加「計減一」. 案的用戶,並向其推薦該措施。 資料來源:本研究整理. 承上表 11,項目 1.說明: 同北北區處訪談結果之項目 3.說明。 項目 2.說明: 目前計畫性減少用電方案參與狀況不一,某些用戶主動參與方案 60.
(61) 爭取電費折扣,但某些用戶可能因為相關資訊不全,尚未考慮方案的 簽訂,故總部業務處費率組提出是否藉由分群、分類分析歸納出相同 性質的用戶,再進一步從中探討各群/類用戶參與方案的情形,主動 推薦那些尚未加入方案的用戶,以電費折扣為誘因,達到尖峰用電抑 低的效果。 需求歸納:分析流程可設計為【資料篩選】→【分群、分類】→. 政 治 大. 【優惠方案參與情況分析】→【電費試算】→【推薦優惠方案】。. 立. ‧ 國. 學. 4、用戶區隔分析需求歸納 歸納以上訪談結果如下表 12:. ‧. n. al. er. io. 需求內容. sit. y. Nat. 單位. 表 12、分析需求歸納. i Un. v. 北市區處 大用戶服務專員. (1)用戶分群、分類分析需求 (2)流動電費試算需求 (3)減少用電方案試算需求. 北北區處. (1)資料預處理 - 填補缺漏值. 大用戶服務專員. (2)分析流程可設計為【資料篩選】→【分群、分類】 →【電費試算】. 總部業務處 費率組. (1)分析流程可設計為【資料篩選】→【分群、分類】 →【優惠方案參與情況分析】→【電費試算】→【推薦優 惠方案】。. Ch. engchi. 資料來源:本研究整理. 第四節、STP 分析資料模型設計 1、資料倉儲 61.
(62) 本研究分析資料來源為台電用戶服務資料倉儲(隸屬單位:台電 綜合研究所) ,依據前述研究需求找出倉儲中相關資料欄項,以高壓 用戶屬性主檔,及 AMI 電表需量資料表為資料來源,其中前者高壓 用戶屬性主檔提供用戶基本屬性資料,共計 123 欄位,目前有 24,185 戶高壓用戶資料,而後者 AMI 電表需量資料提供用戶用電行為資料。 兩表之實體資料模型圖如下圖 23 及圖 24:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 23、資料倉儲-高壓用戶屬性主檔 資料來源:台電綜合研究所提供 62.
(63) 立. 政 治 大. ‧ 國. 學. 圖 24、資料倉儲-AMI 電表需量資料表. Nat. sit. y. ‧. 資料來源:台電綜合研究所提供. er. io. 2、資料超市. n. al 在後續分析的資料應用上,可直接抓取高壓用戶屬性主檔進行分 iv Ch. n engchi U. 群、分類,但 AMI 電表需量資料表的儲存結構不利分析,故需經過 結構調整與轉換,以資料倉儲-AMI 電表需量資料表為基礎,抽取並 轉換資料,建置為資料超市。 缺漏值補正 資料預處理首先設計 AMI 每 15 分鐘一筆用電度數資料缺漏值之 填補機制。資料倉儲中與用電度數相關欄位有五項,除了 AMI 資料. 63.
(64) 外,高壓用戶屬性主檔會記錄該用戶於該月份總用電度數,以及該月 份離峰時段用電總和、半尖峰時段用電總和、尖峰時段用電總和等, 記錄於主檔是為方便台電電費計算而用,因此加總某用戶於某月分 AMI 所記錄的各筆資料會與主檔總用電數度值相等,並且記錄該總 值分布於離峰、半尖峰、尖峰時段之用電度數。示意圖如下圖 25:. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. iv n C h e n g c h缺漏值補正 25、預處理-AMI i U. 圖. 資料來源:本研究整理. 承上,可知總用電度數(x)與 AMI 電表度數總和(Sum(y)) 之差值即為資料缺漏總值,此差值依據該時段佔總用電度數比例給予 一加權乘數,平均分配給該時段缺漏值。以上圖 25 數值為例,若用 戶 A 於 2012 年 1 月 AMI 表中共缺漏 5 筆資料,其中 3 筆(a、b、c) 發生於尖峰時段,離峰與半尖峰各佔 1 筆(d、e) ,加總 AMI 資料表 64.
(65) 中用戶 A 於 2012/1 用電度數為 298,000,數值補正計算如下: 總用電度數 - AMI 本月分用電總和 = 300,000 - 298,000 = 2,000 尖峰時段缺漏值補正數值 = 2,000 * (110,000/300,000) * (1/3) = 244.4. 半尖峰時段缺漏值補正數值 = 2,000 * (100,000/300,000) * (1/1) = 666.6. 立. 政 治 大. 離峰時段缺漏值補正數值. ‧ 國. 學. = 2,000 * (90,000/300,000) * (1/1) = 600. ‧. 故資料缺漏值 a、b、c 填補為 244.4,缺漏值 d 填補為 666.6,缺. sit. y. Nat. io. n. al. er. 漏值 e 填補為 600。. . C 資料存儲結構轉換 h. engchi. i Un. v. 資料缺漏補正後,為適用分群、分類分析,將原分散於 AMI 電 表需量資料各列的用戶用電資料,轉存為單筆完整用戶用電資料,如 下圖 26 所示:. 65.
(66) 立. 政 治 大. ‧ 國. 學. 圖 26、預處理-AMI 資料存儲結構轉換. ‧. 資料來源:本研究整理. sit. y. Nat. 資料比例化. er. io. n. al 比例化公式:某時點用電度數 / Max(該資料列所有用電度數) 。 iv Ch. n engchi U. 比例化後數值將介於 0~1 間,目的在於消去資料間量值的差距,使資 料趨勢容易被比較。 如下圖 27 及圖 28 用戶 A、B 之數據及趨勢線所示,發現比例 化前用戶 A 於各時間點用電量皆高於用戶 B,在分群、分類上容易被 視為不同群/類,但經資料比例化後(見圖 29),可得 A、B 兩用戶 在用電行為趨勢是上相似的。. 66.
(67) 圖 27、預處理-AMI 資料比例化前後數據 資要來源:本研究整理. 60. 立 40. sit. n. al. er. io. 20. y. Nat. 30. ‧. ‧ 國. 學. 50. 政 治 大. 10. Ch. engchi. i Un. v. 0 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 圖 28、預處理-AMI 資料比例化前用電趨勢線 資料來源:本研究整理. 67. 11. 12.
(68) 1.2. 1. 0.8. 0.6. 0.4. 0.2. 立. 0 3. 4. ‧ 國. 2. 5. 6. 7. 8. 9. 學. 1. 政 治 大 10. 11. 12. 圖 29、預處理-AMI 資料比例化後用電趨勢線. ‧. 資料來源:本研究整理. sit. y. Nat. 因此,在資料預處理時,同時保留原始用電資料與比例化後用電. er. io. n. al 資料,可提供使用者在分析上視需求選擇較適當的資料形式。 iv Ch. n engchi U. 資料超市現況 據台電綜合研究所提供資料,目前取得 AMI 資料筆數共計 85,708 筆,共計有 1,190 戶高壓用戶,資料時間範圍橫跨 2011/7/1 ~ 2011/8/30 及 2012/1/2 ~ 2012/1/30 共 3 個月份。. 68.
(69) 新增用電行為指標【尖離比】 用電行為指標:尖離比 = 尖峰用電量 / 離峰用電量(陳宗天, 台電綜研所會議簡報,100 年 12 月 16 日)。尖離比越高表示用戶用 電集中在尖峰時段,反之,尖離比越低表示用電分散在離峰時段。此 處尖峰時段定義為每日早上 7 時~下午 5 時,其餘時間屬離峰時段。 以尖離比來識別用戶,比值越高者越為優先改善對象,優先鼓勵. 政 治 大. 調整用電行為。於分析應用上可做為目標用戶選擇的依據,或做為用. 立. 學. ‧ 國. 戶分群、分類的屬性之一。. 第五節、STP 實做與分析. ‧. 本研究分為三個分析面向:用戶分布分析(以 C4.5 為例) 、用戶. sit. y. Nat. io. n. al 例),探討各資料採礦模型於 STP 之應用。 Ch. engchi. er. 行為分析(以 K-MEANS 為例)、建議優惠方案(以貝氏機率分類為. i Un. v. 1、用戶分布分析 表 13、C4.5 用戶分類用戶篩選設定 分類模型. C4.5. 資料來源. 高壓用戶屬性主檔. 日需量 測試資料. 2011/7/18 30% 69.
(70) 分類變數. 區處別、行業別、經常契約容量、尖離比. 觀察變數. 計畫性減少用電方案類別. 條件篩選後共 1,172 戶 資料來源:本研究整理. 承上表 13 各參數設定,30%資料為測試資料,得母體 821 戶, 挑選高雄區營業處為分析對象,共 62 戶,觀察該區營業處所轄用戶,. 政 治 大. 參與計畫性減少用電方案情形如下表 14 所示。. 立 經常契約. 無. 容量. 計. 一. 二. 計. 總. 三. 四. 計. 3. 1. 0. 3. (81.03%). (6.9%). (3.45%). (1.72%). (6.9%). n. Ch (28.57%). sit. io. a1l. 1. 0. (16.67%). i n U e(14.29%) n g c h i(14.29%) 0. y. 46. 高雄區 31,400 3 0 9,420~ 營業處 (33.33%) (8.33%) 大於 31,400. 計. er. Nat. 小於. ~9,420. 計. ‧. ‧ 國. 區處. 學. 表 14、C4.5 用戶分類分析結果(部分). 0. (8.33%). v1. (28.57%). 3. 53 7. (33.33%). 0. 2. (14.29%). 資料來源:本研究整理. 由分析結果可得,高雄區營業處所轄之高壓用戶簽訂經常契約容 量大多低於 9,420,且參與計畫性減少用電方案情形尚不普遍(佔約 20%) 。進一步以分析高雄區營業處,經常契約容量小於 9,420 之用戶 (共 53 戶),以本月份用電度數與尖離比觀察其用電情況。. 70.
(71) 表 15、本月份用電度數、尖離比分析 本月份用電度數. 戶數佔比. 平均尖離比. ~1,200,000. 66%. 1.92. 1,200,000~2,500,000. 13%. 1.17. 2,500,000~3,800,000. 11%. 1.22. 3,800,000~5,000,000. 6%. 1.15. 5,000,000~. 4%. 1.00. 資料來源:本研究整理. 政 治 大. 由上表 15 統計,此區隔(高雄區營業處、經常契約容量小於 9,420). 立. 7 月份用電度數主要分布於 1,200,000 度以下,佔 66%,平均尖離比. ‧ 國. 學. 為 1.92,顯示尖峰用電量為離峰用電量 1.92 倍,用電行為存在可改. ‧. 善的空間。得此資訊,高雄區營業處大用戶服務專員可針對該用戶群. y. Nat. n. al. er. io. sit. 試算各別適用之優惠方案,以誘導降低尖峰用電需量。. 2、用戶行為分析 C h. engchi. i Un. v. 依上例延伸分析,觀察該區隔用電行為,並選擇出優先改善之目 標用戶。 表 16、K-MEANS 用戶分群用戶篩選設定 分群模型. K-MEANS. 資料來源. 比例化後日需量. 用戶篩選條件. 高雄區營業處、經常契約容量小於 9,420、本月分 用電度數小於 1,200,000 71.
(72) 日需量. 2011/7/18. 測試資料. 30%. 群數. 3. 條件篩選後共 48 戶 資料來源:本研究整理. 承上表 16 各參數設定,同以 30%資料為測試資料,篩選後得母. 政 治 大. 體 33 戶,以 K-MEANS 分為三群,觀察各群用戶用電行為(見表 17),. 立. 並繪製用電曲線圖(見圖 30)。. ‧ 國. 學. 表 17、K-MEANS 用戶分群分析結果. 尖離比 0.85. ‧. 19. sit. y. al. 群3. er. 群2. n. 戶數. io. 群1. 33 戶. Nat. 母體. i 尖離比 n C戶數 U hengchi 13. 1.29. 資料來源:本研究整理. 72. v. 1. 戶數. 尖離比 1.
數據
Outline
相關文件
「公告品名成份規格」欄位預設帶入公告資料,請依
、專案管理廠商及監造單位相關資料送政府採購法主管機關
推理論證 批判思辨 探究能力-問題解決 分析與發現 4-3 分析文本、數據等資料以解決問題 探究能力-問題解決 分析與發現 4-4
例如,參閱:黃啟江,《因果、淨土與往生:透視中國佛教史上的幾個面 相》〈第六章·從佛教研究法談佛教史研究書目資料庫之建立〉,(台北:臺 灣學生書局,2004 年),頁 237-252; Yasuhiro
• 不過,如果是為調查及懲處嚴重不當行為(並不限於罪案)的目的而使用 的個人資料,則受《 私隱條例》第58條所豁免 ,以致有關資料不受保障資
利用 BeautifulSoup 將網頁資料以 html.parser 儲存 (
In our AI term project, all chosen machine learning tools will be use to diagnose cancer Wisconsin dataset.. To be consistent with the literature [1, 2] we removed the 16
Angel: Interactive Computer Graphics 4E © Addison-Wesley 2005 1..
