中英文語句語意推論 - 政大學術集成
116
0
0
全文
(2) 中英文語句語意推論 Textual Entailment Recognition for Chinese and English. 研 究 生:黃瑋杰. Student:Wei-Jie Huang. 指導教授:劉昭麟. Advisor:Chao-Lin Liu. 治 政 國立政治大學 大. 立. 學. ‧ 國. 資訊科學系 碩士論文. y. ‧. Nat. sit. A Thesis. er. io. submitted to Department of Computer Science. n. al National Chengchi University iv n. C. h e n g cofh itheUrequirements in partial fulfillment for the degree of Master in Computer Science. 中華民國一百零二年七月 July 2013.
(3) 致謝. 首先要感謝我的指導教授 劉昭麟老師,在研究所的求學生涯中,給予我諸 多建議,並細心且有耐心的指導研究的準則、態度與方向,在遭遇困難時, 提供適時的提醒與協助,敦促我順利完成論文研究。而老師的處事方法與. 政 治 大. 態度,在我人生的成長中更是獲益匪淺,深表感激,感謝老師在兩年之間. 立. 的照顧與提拔。. ‧ 國. 學. 再者要感謝三位口試委員 戴敏育老師、 吳世弘老師與 林川傑老師對. ‧. al. er. io. 果展示,並使我在修改的過程中有所收穫。. sit. y. Nat. 論文修改的建議,由於老師們的建議,使得本論文有更好的內容表達和成. n. iv n C 同時我要感謝 MIG 實驗室與大腦與語言實驗室的每一位伙伴的幫助, hengchi U 讓我的研究生涯因你們而豐富。感謝怡軒學姐、建良學長、家琦、瑞平、 柏廷、孫暐、嘉玲、柏誠及弘道,對我研究、論文寫作與實驗室總務各方 面的協助,讓我得以順利完成學業。也感謝曾經在 MIG 的大學部學弟妹們, 使我的求學生涯充滿歡笑與樂趣,包含育聖、孟蓁、翰臻、博允、思維、 繁辰與泓丞。並感謝曾與我共同合作的大腦與語言實驗室的各位,謝謝 李 佳穎老師、郁琳學姐、家如學姐、妤真學姐與羅明學長,在與你們的合作.
(4) 中獲益良多,是個相當難能可貴的經驗。 最後,僅將本文獻給我的家人,感謝父母給予生活上的照料及對我求 學態度的信任,使我在完成研究的過程中沒有後顧之憂,也感謝我的女友 在低潮時給予適時的鼓勵與支持,在有你們的陪伴下,得以順利地完成我 的碩士論文。. 立. 政 治 大. ‧ 國. 學. 黃瑋杰. ‧. 中華民國一百零二年七月. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v.
(5) 中英文語句語意推論. 摘要. 語句的推論在自然語言處理相關領域的研究,如資訊檢索、資料擷取、自. 政 治 大 動摘要或智慧型教學等,已經日趨重要。自 2005 年 Recognizing Textual 立. ‧ 國. 學. Entailment (RTE)競賽開始,此議題逐漸受到重視,而 Recognizing Inference. ‧. in Text (RITE-1)競賽亦開始針對中文語句推論的研究議題提供評估的平台。. sit. y. Nat. 本研究中我們建構一個根據文本分析設計各種函式計算推論關係的模型,. n. al. er. io. 並提出一套基於廣義知網的詞彙語意相似度計算方法,加強推論模型對句. iv. 子語意的理解能力,進而提升推論效果;此外根據過去機器學習的作法, C Un. hengchi. 依照上述的函式抽取詞彙語意、語法結構、POS 標記、詞彙覆蓋比例與詞 彙依賴關係等特徵,採用多種演算法訓練分類模型判斷推論關係。實驗結 果顯示我們的兩種系統在中文語句推論關係有不錯的效能,並在 NTCIR-10 RITE-2 競賽中獲得第二名的佳績,同時對機器學習分類模型效能的分析也 指出中英文語料於判斷推論關係時不同的特性與較有效果的特徵集。此外 我們透過閱讀測驗的實驗評估,瞭解推論系統於實際應用問題的效能,並.
(6) 指出未來我們可以推論系統為基底,發展閱讀測驗相關的智慧型教學系統, 輔助學生閱讀理解的能力與教師在閱讀測驗編輯的品質。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v.
(7) Textual Entailment Recognition for Chinese and English. Abstract. Recognizing Inference in Text (RITE) has become a serious issue in several. 政 治 大 Automatic Summarization, 立 or Intelligent Tutoring Systems (ITS). The research research areas, such as Information Retrieval (IR), Information Extraction (IE),. ‧ 國. 學. topic is getting more important since the First Recognizing Textual Entailment Challenge (RTE-1) was held in 2005. For Asian languages, Recognizing. ‧. Inference in Text (RITE-1) provides evaluation standards on recognizing. sit. y. Nat. entailment systems. In this research, we built a system based on textual analysis. er. io. and construct several heuristic functions to compute entailment in text. Besides,. n. v we proposed a method atol measure the similarity ibetween two Chinese words C. Un. i system’s performance. Moreover, e enhance based on E-HowNet and used ithto n g c h the machine learning techniques, such as SVM, J48 and Linear Regression are used to train classification models. We extracted features based on heuristic functions and other syntactic features. The experimental results indicated that our systems achieved great performances and received second places in NTCIR-10 RITE-2. The analysis of machine learning approaches also showed Chinese and English shared different linguistic characteristics and effective features on recognizing textual entailments. Besides, the experimental results of reading comprehensions showed that we can develop intelligent tutoring system based on this research..
(8) The intelligent tutoring system is able to enhance students the ability of reading understandings and help on generating quality reading tests.. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v.
(9) 目錄 1. 第一章 緒論 .................................................................................................. 1 1.1 1.2 1.3 1.4. 背景與動機 ................................................................................................................. 1 方法概述 ..................................................................................................................... 2 成果貢獻 ..................................................................................................................... 3 論文架構 ..................................................................................................................... 3. 2. 第二章 文獻回顧 .......................................................................................... 5. 治 政 大 2.1 中英文語句語意推論 ................................................................................................. 5 立 ............................................................................................. 7 2.2 詞彙語意相似度之計算 ‧ 國. 學. 3. 第三章 語料集及中英文辭典...................................................................... 8. ‧. 3.1 中文語料集 ................................................................................................................. 8 3.2 英文語料集 ................................................................................................................. 9 3.3 廣義知網(E-HowNet) ............................................................................................... 11. sit. y. Nat. al. iv n C 研究方法 ........................................................................................ 14 hengchi U n. 4. 第四章. er. io. 3.4 WordNet ...................................................................................................................... 12 3.5 教育部國語辭典 ....................................................................................................... 13. 4.1 系統元件 ................................................................................................................... 14 4.1.1 數字轉換模組 ................................................................................................ 14 4.1.2 簡繁轉換 ........................................................................................................ 15 4.1.3 中文斷詞與英文分詞 .................................................................................... 16 4.1.4 實體名詞(Named-Entity)標記與索引分析 ................................................... 16 4.1.5 否定詞、近義詞與反義詞搜尋 .................................................................... 17 4.2 經驗法則式推論模型 ............................................................................................... 22 4.3 機器學習之推論模型 ............................................................................................... 25. 5. 第五章 系統效能評估 ................................................................................ 31 5.1 經驗法則式推論模型實驗 ....................................................................................... 31.
(10) 5.1.1 參數調校 ........................................................................................................ 32 5.1.2 推論函式分析 ................................................................................................ 34 5.2 機器學習式推論模型實驗 ....................................................................................... 45 5.2.1 特徵組合搜尋 ................................................................................................ 45 5.2.2 分類模型效能評估 ........................................................................................ 48 5.2.3 特徵集對推論關係分類之影響 .................................................................... 54 5.3 NTCIR-10 競賽結果 .................................................................................................. 67. 6. 第六章 語句推論系統之應用.................................................................... 69 6.1 閱讀理解及語料集 ................................................................................................... 69 6.2 文本過濾 ................................................................................................................... 72 6.3 效能分析 ................................................................................................................... 73. 立. 政 治 大. ‧ 國. 學. 7. 第七章 結論與未來工作 ............................................................................ 78. ‧. 7.1 結論 ........................................................................................................................... 78 7.2 未來工作 ................................................................................................................... 81. y. sit. io. er. Nat. 8. 參考文獻 ........................................................................................................ 83 9. 附錄Ⅰ 經驗法則式推論模型參數調校及實驗.......................................... 88 a. n. iv l C n hengchi U 特徵集對推論關係分類之影響實驗 .............................................. 97. 10.附錄 II.
(11) 圖目錄. 圖 3.1 二元分類資料集 ........................................................................................................... 8 圖 3.2 RTE 語料範例 .............................................................................................................. 10 圖 3.3 廣義知網詞彙定義式 ................................................................................................. 11 圖 3.4 廣義知網分類結構 ..................................................................................................... 12. 政 治 大. 圖 3.5 相似詞與相反詞資料庫 ............................................................................................. 13. 立. 圖 4.1 原始語料之數字表達 ................................................................................................. 15. ‧ 國. 學. 圖 4.2 數字轉換模組結果 ..................................................................................................... 15 圖 4.3 實體名詞標記 ............................................................................................................. 17. ‧. 圖 4.4 專有名詞錯位 ............................................................................................................. 17. y. Nat. io. sit. 圖 4.5 否定詞範例 ................................................................................................................. 18. n. al. er. 圖 4.6 否定詞辭典 ................................................................................................................. 18. Ch. i Un. v. 圖 4.7 近義詞範例 ................................................................................................................. 19. engchi. 圖 4.8 展開式向量形式 ......................................................................................................... 19 圖 4.9 展開式樹狀結構 ......................................................................................................... 20 圖 4.10 否定詞例外 ............................................................................................................... 21 圖 4.11 反義詞範例 ............................................................................................................... 21 圖 4.12 經驗法則式推論系統架構與流程 ........................................................................... 21 圖 4.13 實體名詞位置比對範例 ........................................................................................... 25 圖 4.14 機器學習推論系統架構 ........................................................................................... 26 圖 4.15 詞彙依賴關係矩陣 M............................................................................................... 27.
(12) 圖 4.16 經過五步的詞彙依賴關係,M ∪ M2 ∪ M3 ∪ M4 ∪ M5 ........................................ 27 圖 5.1 經驗法則式推論模型近義詞效能比較:RITE-1 繁體中文語料 ............................ 35 圖 5.2 經驗法則式推論模型近義詞效能比較:RITE-2 繁體中文語料 ............................ 35 圖 5.3 經驗法則式推論模型近義詞效能比較:RITE-1 簡體中文測試語料 .................... 37 圖 5.4 經驗法則式推論模型近義詞效能比較:RITE-2 簡體中文測試語料 .................... 38 圖 5.5 經驗法則式推論模型系統效能:MSR 測試語料 .................................................... 41 圖 5.6 經驗法則式推論模型系統效能:RTE-1 測試語料.................................................. 41. 政 治 大 圖 5.8 經驗法則式推論模型系統效能:RTE-3 測試語料.................................................. 42 立 圖 5.7 經驗法則式推論模型系統效能:RTE-2 測試語料.................................................. 42. ‧ 國. 學. 圖 5.9 分類模型準確率比較:RITE-2 繁體中文訓練語料 ................................................ 49 圖 5.10 分類模型準確率比較:RITE-2 簡體中文訓練語料 .............................................. 49. ‧. 圖 5.11 分類模型準確率比較:MSR 訓練語料 .................................................................. 50. sit. y. Nat. 圖 5.12 分類模型準確率比較:RTE 訓練語料 ................................................................... 50. n. al. er. io. 圖 5.13 詞彙覆蓋比例於推論關係分類之影響:RITE-1 繁體中文測試語料 .................. 55. i Un. v. 圖 5.14 詞彙覆蓋比例於推論關係分類之影響:RITE-2 繁體中文測試語料 .................. 55. Ch. engchi. 圖 5.15 詞彙覆蓋比例於推論關係分類之影響:RITE-1 簡體中文測試語料 .................. 56 圖 5.16 詞彙覆蓋比例於推論關係分類之影響:RITE-2 簡體中文測試語料 .................. 56 圖 5.17 詞彙覆蓋比例於推論關係分類之影響:MSR 測試語料 ...................................... 57 圖 5.18 詞彙覆蓋比例於推論關係分類之影響:RTE-1 測試語料.................................... 57 圖 5.19 詞彙覆蓋比例於推論關係分類之影響:RTE-2 測試語料.................................... 58 圖 5.20 詞彙覆蓋比例於推論關係分類之影響:RTE-3 測試語料.................................... 58 圖 5.21 近義詞於推論關係分類之影響:RITE-1 繁體中文測試語料 .............................. 59 圖 5.22 近義詞於推論關係分類之影響:RITE-2 繁體中文測試語料 .............................. 60 圖 5.23 近義詞於推論關係分類之影響:RITE-1 簡體中文測試語料 .............................. 60.
(13) 圖 5.24 近義詞於推論關係分類之影響:RITE-2 簡體中文測試語料 .............................. 61 圖 5.25 語法結構於推論關係分類之影響:RITE-1 繁體中文測試語料 .......................... 63 圖 5.26 語法結構於推論關係分類之影響:RITE-2 繁體中文測試語料 .......................... 63 圖 5.27 語法結構於推論關係分類之影響:RITE-1 簡體中文測試語料 .......................... 64 圖 5.28 語法結構於推論關係分類之影響:RITE-2 簡體中文測試語料 .......................... 64 圖 5.29 語法結構於推論關係分類之影響:MSR 測試語料 .............................................. 65 圖 5.30 語法結構於推論關係分類之影響:RTE-1 測試語料............................................ 65. 政 治 大 圖 5.32 語法結構於推論關係分類之影響:RTE-3 測試語料............................................ 66 立 圖 5.31 語法結構於推論關係分類之影響:RTE-2 測試語料............................................ 66. ‧ 國. 學. 圖 5.33 RITE-2 競賽近義詞效能比較 ................................................................................... 68 圖 6.1 閱讀測驗形式 ............................................................................................................. 70. ‧. 圖 6.2 推論系統形式轉換 ..................................................................................................... 71. sit. y. Nat. 圖 6.3 文章人工過濾前 ......................................................................................................... 72. n. al. er. io. 圖 6.4 文章人工過濾後 ......................................................................................................... 73. i Un. v. 圖 6.5 國小中文閱讀測驗透過經驗法則式推論模型實驗結果 ......................................... 76. Ch. engchi. 圖 6.6 國中英文閱讀測驗透過經驗法則式推論模型實驗結果 ......................................... 76 圖 6.7 國小中文閱讀測驗透過機器學習分類模型實驗結果 ............................................. 77 圖 6.8 國中英文閱讀測驗透過機器學習分類模型實驗結果 ............................................. 77.
(14) 表目錄. 表 3.1 中文訓練語料集統計 ................................................................................................... 9 表 3.2 測試語料集數量統計 ................................................................................................... 9 表 3.3 MSR 語料集統計 ........................................................................................................... 9 表 3.4 RTE 語料集統計 .......................................................................................................... 11. 政 治 大 表 4.2 英文特徵集 ................................................................................................................. 30 立. 表 4.1 中文特徵集 ................................................................................................................. 29. ‧ 國. 學. 表 5.1 RITE-2 繁體中文訓練語料參數設定 ......................................................................... 33 表 5.2 RITE-2 簡體中文訓練語料參數設定 ......................................................................... 33. ‧. 表 5.3 MSR 訓練語料參數設定 ............................................................................................. 33. sit. y. Nat. 表 5.4 RTE 訓練語料參數設定 .............................................................................................. 33. n. al. er. io. 表 5.5 經驗法則式推論模型實驗結果(無近義詞):RITE-1 繁體中文測試語料 ............. 36. i Un. v. 表 5.6 經驗法則式推論模型實驗結果(近義詞):RITE-1 繁體中文測試語料 ................. 36. Ch. engchi. 表 5.7 經驗法則式推論模型實驗結果(無近義詞):RITE-2 繁體中文測試語 ................. 37 表 5.8 經驗法則式推論模型實驗結果(近義詞):RITE-2 繁體中文測試語料 .................. 37 表 5.9 經驗法則式推論模型實驗結果(無近義詞):RITE-1 簡體中文測試語料 ............. 39 表 5.10 經驗法則式推論模型實驗結果(近義詞):RITE-1 簡體中文測試語料 ............... 39 表 5.11 經驗法則式推論模型實驗結果(無近義詞):RITE-2 簡體中文測試語料 ........... 39 表 5.12 經驗法則式推論模型實驗結果(近義詞):RITE-2 簡體中文測試語料 ............... 40 表 5.13 經驗法則式推論模型實驗結果:MSR 測試語料 .................................................. 43 表 5.14 經驗法則式推論模型實驗結果:RTE-1 測試語料................................................ 43 表 5.15 經驗法則式推論模型實驗結果:RTE-2 測試語料................................................ 44.
(15) 表 5.16 經驗法則式推論模型實驗結果:RTE-3 測試語料................................................ 44 表 5.17 中文特徵集編號表 ................................................................................................... 46 表 5.18 英文特徵集編號表 ................................................................................................... 46 表 5.19 RITE-2 繁體中文訓練語料特徵組合搜尋 ............................................................... 47 表 5.20 RITE-2 簡體中文訓練語料特徵組合搜尋 ............................................................... 47 表 5.21 MSR 訓練語料特徵組合搜尋 ................................................................................... 47 表 5.22 RTE 訓練語料特徵組合搜尋 .................................................................................... 48. 政 治 大 表 5.24 繁體中文測試語料經線性回歸演算法之推論效能 ............................................... 52 立 表 5.23 測試語料使用之分類模型 ....................................................................................... 49. ‧ 國. 學. 表 5.25 簡體中文測試語料經線性回歸演算法之推論效能 ............................................... 52 表 5.26 MSR 測試語料經線性回歸演算法之推論效能 ....................................................... 53. ‧. 表 5.27 RTE 測試語料經 SVM 演算法之推論效能 ............................................................. 53. sit. y. Nat. 表 5.28 RITE-2 繁體中文訓練語料參數設定 ....................................................................... 67. n. al. er. io. 表 5.29 RITE-2 競賽結果(無近義詞) .................................................................................... 67. i Un. v. 表 5.30 RITE-2 競賽結果(近義詞) ........................................................................................ 67. Ch. engchi. 表 5.31 RITE-2 中文推論模型之特徵組合- SVM ................................................................ 68 表 5.32 RITE-2 競賽結果(機器學習) .................................................................................... 68 表 6.1 閱讀測驗語料集統計 ................................................................................................. 72 表 6.2 閱讀測驗實驗參數設定 ............................................................................................. 74 表 6.3 閱讀測驗實驗特徵組合 ............................................................................................. 74.
(16) 1. 第一章. 1.1 背景與動機. 立. 緒論. 政 治 大. 由 2005 年開始,兩個句子間推論的議題,經由 First Recognizing Textual Entailment. ‧ 國. 學. Challenge(RTE-1)競賽的舉辦[13],逐漸受到重視,而後更舉行了 RTE-2 與 RTE-3 的競. ‧. 賽,該競賽主要的目標語料為英文,並且針對多項子議題進行題目設計。2011 年 NTCIR-9 也首次提供一個推論系統的評估標準(Recognizing Inference in Text, RITE)[12],針對日文. y. Nat. er. io. sit. 與中文的語料集,幫助亞洲學者專注於相關議題的研究上。在 RITE 當中,推論系統的 能力主要是區辨兩個句子間的推論關係,系統能分類 Yes(Y)或 No(N)兩種推論的結果;. n. al. Ch. i Un. v. 以下這組例子,『尼泊爾毛派叛亂份子在新國王大壽前夕發動攻擊』與『尼泊爾毛派叛. engchi. 亂分子在新國王華誕前夕發動攻擊』,便是我們預期能由推論系統辨別出具有推論關係 的句對。2013 年,NTCIR-10 再次舉辦 RITE 競賽[34],我們則參與了此次的競賽,並獲 得不錯的成績。 語句的理解與推論已經在自然語言處理當中,逐漸地受到重視,近年來已有許多相 關的研究發展語句推論系統。語句的推論已被知道可以應用在數個不同的議題當中,如 問答系統,可以增進跨訊息的資料擷取(Information Access);如資訊檢索(Information Retrieval),將 Query 展開,追求高度召回率(high-recall)的檢索系統;如自動摘要(Text. 1.
(17) Summarization),計算句子的語意關連度,消除多餘的句子,提高摘要品質;又或者智 慧型的教學系統(Intelligent Tutoring),判斷學生的作答是否可以推論至一組相關的正確 答案,進行答案建議並加強學習的效果。除此之外,我們希望藉由本研究,提出一套基 於廣義知網的中文詞彙語意相似度計算方法,透過詞彙表達式的剖析與結構比對,計算 兩個中文詞彙在語意上的相似程度,並且透過實驗分析比較此方法對於推論關係判斷的 效能差異。. 1.2 方法概述. 立. 政 治 大. 中文 RITE 的基礎已有許多相關的研究成果,NTCIR-9 的 Baseline 系統是由字元數的覆. ‧ 國. 學. 蓋比例來產生推論結果;而現在的方法多以統計方法抽取特徵,訓練機器學習的推論模 型,兩者都已經可以達到不錯的正確率。但我們由上方的例子可以發現,經由近義詞的. ‧. 判定,可以增加兩個句子的詞彙覆蓋比例,並且我們認為較高的覆蓋比例可以視為具有. Nat. sit. y. 較多的資訊交集,而具有推論的關係,因此假設判定詞彙語意的關係(近義詞),能有效. n. al. er. io. 地增進推論系統的能力。為了達到上述的詞彙語意相似的判定,我們希望透過一套知識. i Un. v. 表達系統,如廣義知網(Extended-HowNet, E-HowNet)[4],提出方法計算詞彙之間的語意. Ch. engchi. 相似度,判斷近義詞關係,藉以提升句子之間詞彙覆蓋的比例。具備近義詞判定的能力 後,我們對文本進行分析,設計多種函式,透過覆蓋比例、實體名詞(Named-Entity)標 記、否定詞與反義詞等資訊建立多項評比標準來判定推論關係,建構經驗法則式推論模 型。除此之外,我們根據經驗法則式推論模型的函式抽取語言特徵,並增加語法結構及 詞彙依賴關係等特徵,採用不同的機器學習演算法訓練分類模型進行推論關係的判斷, 最後比較各種分類模型之間的效能差異,也與經驗法則推論模型的結果進行分析比較。 同時我們透過相同的經驗法則式推論模型對英文語料進行推論效果的評比,並在機器學 習的部分增加不同的語法結構特徵來訓練分類模型;我們蒐集到兩種不同類型的英文語 2.
(18) 料,因此也嘗試不同語料所訓練的分類模型進行推論關係判斷,分析相同語言的特性是 否可以具有相仿的推論效果。. 1.3 成果貢獻 在本研究中,我們提出了兩種方法建構推論系統,並且在中文語料的推論關係判斷上有 著相當不錯的效能,尤其是我們以對文本分析建構的經驗法則式推論模型,透過幾項語 言特性的計算函式便能夠達到相當好的判斷效果,而機器學習方法所建構的分類模型與. 政 治 大. 特徵集也提供相仿的效能,並加上我們提出語法結構特徵的使用,對中英文語料都有些. 立. 微的效能提升。. ‧ 國. 學. 並且我們以廣義知網為基礎,建構中文詞彙語意相似度的計算方法,判斷兩個中文. ‧. 詞彙是否為近義詞,藉以提昇推論關係的效果。此方法在經驗法則式推論模型中,與詞 彙覆蓋比例的計算混合使用,在 NTCIR-10 競賽的結果中提升不少系統效能,但在其他. y. Nat. er. io. sit. 測試語料中則也有些微的效能下降,說明透過此方法計算詞彙語意的相似度具有潛在的 功效,讓我們在近義詞判定的方法建構上有著不錯的開端,未來能持續發展近義詞的判. n. al. Ch. i Un. v. 定方法,除了有機會提升推論系統的效能外,也有助於自然語言處理相關研究的發展。. engchi. 我們也透過中英文閱讀測驗的回答,評估推論系統的效能,該實驗指出我們的推論 系統在適當的文章過濾後,能夠提供不錯的閱讀測驗正確率,未來也將依賴本研究提出 之推論系統發展閱讀測驗相關的智慧型教學系統,以實際應用呈現本研究的成果。. 1.4 論文架構 本論文共分為六章,第一章為緒論,說明研究背景、動機、目的、問題描述及論文架構; 第二章探討過去語句推論關係的相關研究,包含各種中英文語句推論關係的方法,如機. 3.
(19) 器學習、知識為基底(Knowledge-based)、邏輯推論等作法,以及各種語言特徵的擷取與 詞彙語意分析等內容;第三章說明我們蒐集的中英文語料集,以及用來輔助推論系統的 各式辭典;第四章則說明本研究提出的系統架構與兩種方法,包含文本的前處理元件, 以及經驗法則式推論模型與機器學習分類模型的設計;第五章設計實驗方法與進行測試 語料預測結果,藉由數據分析,說明各個模型對中英文語料的推論能力,並驗證我們提 出的幾項語言特徵在推論關係判斷中的成效,最後說明 RITE-2 的競賽成績;第六章總 結本研究的成果與發現,並提出目前不足之處以及未來改善的方向,以利後續的研究與 應用。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 4. i Un. v.
(20) 2. 第二章. 文獻回顧. 本節針對過去 RITE 及 RTE 競賽中英文語句推論的研究及 WordNet[31]與知網(HowNet). 政 治 大. 在詞彙語意相似度計算方法進行回顧。. 立. ‧ 國. 學. 2.1 中英文語句語意推論. ‧. 過去 RITE 相關研究多採用機器學習的方法,透過不同的特徵擷取與機器學習演算法來 建構系統,例如使用 SVM、決策樹(Decision Tree)等演算法,或使用投票(Voting)綜合多. y. Nat. er. io. sit. 種分類器等方式來預測推論關係。Cao[18]等人透過機器學習的演算法與特徵項來建構系 統,他們將一般常見的語句資訊擷取出來做為特徵,而他們更致力於自己開發的自然語. n. al. Ch. i Un. v. 言處理工具,針對實體名詞標記、日期與數字處理,提升文字中資訊擷取的能力,研究. engchi. 結果顯示具備良好的實體語意名詞標記技術,能有效獲得語句中的資訊。Wu[24]等人亦 透過機器學習演算法,利用機器翻譯效能評估的 BLEU[15][16]分數及句子長度做為特徵 訓練分類器,在 RITE-1 的簡體中文競賽中也有不錯的表現。而 Zhang[33]等人提出加入 語意相關特徵處理,透過上下位詞、同義詞與反義詞等資訊,來進行語意的推論,並使 用多種機器學習的演算法,透過投票的機制更能有效地提升推論關係判斷的準確率。Lin 與 Hsiao[10]則提出經由機器翻譯的語句後,以英文的文本進行特徵的擷取,針對英文詞 彙的校對位置做為特徵,提供一種不同的思維來處理語句推論的問題。除了機器學習的 方法外,Shih[7]等人以知識為基底建構語句推論的系統架構,透過既有的知識表達,進 5.
(21) 行字詞分析、句型語法分析與實體名詞標記,依據制訂的規則計算語句間的關連程度。 Day[22]等人則建立一套結合機器學習與以知識為基底的語句推論系統,並且除了前面 提到的各種語言特徵外,更以詞彙的依賴關係計算特徵,並加入其他的語意資源輔助語 句間的推論效果。綜合以上研究的結果發現由詞彙的分析、實體名詞標記與語法結構等 語言特徵所建構的模型,於 RITE-1 競賽皆能獲得一個高於平均的評分。 英文相關的研究始於 RTE 競賽,也發展出各種作法來提升語句推論的效果。 Adams[23] 的 研 究 採 用 詞 彙 覆 蓋 (Lexical Overlap) 的 相 似 度 判 斷 推 論 關 係 , 並 加 入. 政 治 大. WordNet 以拓展詞彙的鏈結關係來達到更佳的相似度計算效果,但這樣的系統仍然過於. 立. 簡易,在 RTE 競賽中的僅能獲得中等的成績,而需要更多的語言資訊輔助來提升推論. ‧ 國. 學. 效果,但此種較容易計算推論關係的作法提供我們一個不錯的嘗試機會。而同樣地,機. ‧. 器學習的分類器仍然在語句推論中是經常被運用的一種技術,Hickl[6]等人透過詞彙對 齊(Textual Alignment)擷取可能指出推論關係的詞彙特徵,以及加上如句子極性(Polarity). y. Nat. er. io. sit. 或否定標記等語意特徵和標記詞彙之間的依賴關係來計算特徵,最後採用分類器預測推 論關係,否定標記及詞彙依賴關係的語法結構特徵在推論關係的判斷上也具有不錯的效. n. al. Ch. i Un. v. 果;並且 Hickl 等人的研究更指出,額外的語料蒐集將可以有效地提升英文語句推論關. engchi. 係的系統效能,但此項工作的仍屬於較為困難的工作。Tatu[21]等人則是使用邏輯形式 的推論系統,該研究指出透過邏輯的使用,可以進行更多因子之間的關連性推導,而有 效地判定否定意義、數量形式與時間表達,判定語句之間的推論關係;Tatu 的研究指出 此項方法在推論關係的判斷上具有一定的成效,但在邏輯角色的標記工作上則是相對較 困難的部分。因此我們採用詞彙覆蓋比例、否定標記、詞彙語意分析及語法結構等語言 特徵建構推論模型,在一般性的新聞語料中可以獲得較好的效能,而針對研究議題所設 計的語料則相對缺乏特定領域的語言特徵處理,無法取得良好的推論效能。. 6.
(22) 2.2 詞彙語意相似度之計算 在詞彙語意的分析中,如何能判斷同義詞、反義詞、上位詞或下位詞等詞彙間的關係? WordNet 是一個線上的英文辭典,WordNet 提出一套知識表達的方法,將詞彙分成各種 同義詞集(Synset),並提供簡短的語意說明,根據詞彙的分類建置為一套具有蘊含關係 的層次結構,因此使用者可以根據這些資訊來做文本的分析與人工智慧應用。Budanitsky 與 Hirst[5]便以 WordNet 為基礎,提出數種詞彙間語意的相似度計算的方法,藉以比較. 政 治 大 中文為主要語言的一套知識表達系統,透過義原的組合來闡述詞彙語意,同時知網可由 立. 詞彙之間的語意關係。而中文則有由董振東等人所發展的知網(HowNet)[1],這是以簡體. ‧ 國. 學. 使用者自由的分析使用,來獲得近義詞、反義詞與其他詞彙關係。劉群[3]等人的研究便 是瞭解知網中用以描述詞彙的義原間的關連性,並提出兩種資料結構來解析定義的表達. ‧. 式,除此之外,亦提出一套基於義原群相似的詞彙語意相似度計算方法。而廣義知網. sit. y. Nat. (E-HowNet)是一套基於知網的知識本體與語意定義機制所建構的知識表達系統,主要收. io. al. n. 徵。. er. 納繁體中文的常用詞彙,並修改知網部分的定義方式,讓詞彙的表達式更符合語意表. Ch. engchi. i Un. v. 我們的研究將透過經驗法則建構一套語句推論模型,並且加上機器學習的分類模型, 透過多種的方式提升系統的推論能力,並對於廣義知網做分析與應用,檢視詞彙間的相 似關係,以提升系統對於句子語意的理解,接下來我們將提出幾項方法來建置推論系 統。. 7.
(23) 3. 第三章. 語料集及中英文辭典. 本節說明此研究所使用的中英文語料集及中英文辭典,首先說明語料內容,並列出每項. 政 治 大. 語料的相關統計數據,接著介紹廣義知網、WordNet 及教育部國語辭典,這些辭典將用 來輔助推論關係的判斷。. 立. ‧ 國. 學. 3.1 中文語料集. ‧. 我們經由參與 NTCIR 的競賽,取得 RITE 的訓練(Dev.)與測試(Test)語料集,語料為推論. y. Nat. er. io. sit. 關係二元分類(Binary Classification),並且包含繁體中文與簡體中文兩種語言。圖 3.1 為 繁體中文二元分類的資料內容,每筆資料皆有一個編號記錄,並包含兩個句子-t1 與 t2,. n. al. Ch. i Un. v. 而 label 代表的是 t1 的內容是否能推論出 t2 中的假設,Y 表示成立,N 則反之。我們共. engchi. 取得了 NTCIR-9 RITE-1 和 NTCIR-10 RITE-2 的訓練與測試語料,表 3.1 及表 3.2 為訓練 與測試語料集的數量統計。. 圖 3.1 二元分類資料集. 8.
(24) 表 3.1 中文訓練語料集統計 來源. NTCIR-10 繁體中文 簡體中文. 語言 類別. Dev.. Dev.. Y. 716. 528. N 總和. 605. 286. 1321 814 表 3.2 測試語料集數量統計. NTCIR-9 繁體中文 簡體中文. 語言. Test. Y. 450. N 總和. 450. 立. 治 Test 政Test 263 大479. Test 422. 402. 359. 407. 881. 781. ‧ 國. 900. 144. 學. 類別. NTCIR-10 繁體中文 簡體中文. 3.2 英文語料集. ‧ sit. y. Nat. Microsoft Research Paraphrase Corpus(MSR Corpus)於 2004 年由 Quirk 等人提出,語料集. io. er. 共包含 5801 個英文句對,並且標記兩個句子之間是否相關聯,Quirk 等人並將其切割為. al. 訓練集與測試集。MSR Corpus 自網際網路上數千則新聞擷取,歷時 18 個月完成,每個. n. iv n C U 句對皆由兩位專家來判定是否屬於語意上的等價 Yes(Y)或 No(N); h e n g c h i,並給予一個二元標記 當兩個評定出現歧異時,將由第三方的評定來標記此句對,表 3.2 為 MSR 語料集的統 計。 表 3.3 MSR 語料集統計 來源. MSR. 類別. Dev.. Test. Y. 2753. 1147. N 總和. 1323. 578. 4076. 1725. 9.
(25) 立. 政 治 大. ‧. ‧ 國. 學 圖 3.2 RTE 語料範例. y. Nat. er. io. sit. RTE 為一項英文語句推論競賽,始於 2005 年,主要目標是為了解決越來越多的文 本應用的需求,包含文本蘊含意義分析與語意推理關係的判定,因此提出此項通用的評. n. al. Ch. i Un. v. 估標準,藉以拓展對此問題的系統發展與研究方法,並且該競賽提供之語料具備廣泛的. engchi. 應用面向,諸如問答系統(Question Answering, QA)、資訊檢索(Information Retrieval, IR)、 文件比較(Comparable Documents, CD)、閱讀理解(Reading Comprehension, RC)、機器翻 譯(Machine Translation, MT)和訊息抽取(Information Extraction, IE)等類別;語料內容包含 兩個句子,t 與 h,value 則指出 t 推論至 h 的結果為 TRUE 或 FALSE,圖實驗語料 3.2 為 RTE 語料的範例,task 標籤為此句對所屬的範疇。我們總共蒐集了 RTE-1、RTE-2 與 RTE-3 三次競賽的語料,並且將三個訓練語料綜合成一個獨立的訓練語料,使我們訓練 模型時的文本數量大為增加,表 3.4 為 RTE 語料的統計資訊。. 10.
(26) 表 3.4 RTE 語料集統計 來源. RTE-1. RTE-2. RTE-3. 類別. Dev.. Test. Dev.. Test. Dev.. Test. TRUE. 283. 400. 400. 400. 412. 410. FALSE 總和. 284. 400. 400. 400. 388. 390. 567. 800. 800. 800. 800. 800. 3.3 廣義知網(E-HowNet) 廣義知網是中央研究院資訊所詞庫小組於 2003 年與董振東先生合作,將中研院詞庫小. 政 治 大. 組辭典(CKIP Chinese Lexical Knowledge Base)與知網做連結。詞庫小組針對定義的架構. 立. 做了一些修改,並增加以簡單概念取代義原,讓更為複雜的詞彙語意能以較簡單的表達. ‧ 國. 學. 式來呈現,因而更精準地表達知識含意;在廣義知網中,義原與簡單概念是做為描述詞 彙的最基本元素。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 3.3 廣義知網詞彙定義式 圖 3.3 為廣義知網中詞彙定義式的例子,包含讀音、拼音與詞性等資訊,但在本研 究中著重於詞彙表達知識的擷取,而廣義知網包含兩種概念的表達式,概念式 (TopLevelDefinition)與展開式(BottomLevelExpansion),當中皆由義原或簡單概念來定義 詞彙。在廣義知網的技術報告中提到,概念式實為較精簡的表達模型,他們將複雜的表 達式以廣義知網內既有的詞彙來表示,而展開式則是將該精簡化的表達式全數展開至義. 11.
(27) 圖 3.4 廣義知網分類結構 原及簡單概念來呈現,更可以表達最深層的詞彙語意[9]。因此,我們希望透過展開式的 解析,擷取詞彙間的語意關係。. 立. 政 治 大. ‧ 國. 學. 廣義知網延伸知網的基礎架構,所以同樣建置了分類(Taxonomy)的概念,提供詞彙 間階層式的架構,如圖 3.4 顯示廣義知網中的分類結構,皆由事物或關連等類別往下拓. ‧. 展。因此我們可以經由階層式的樹狀結構計算義原之間的距離來瞭解詞彙的相似、相反. sit. n. al. er. io. 3.4 WordNet. y. Nat. 或上下位詞的關係。. Ch. i Un. v. WordNet 是由普林斯頓大學所發展的一套線上電子辭典,自 1985 年開發維護至今,當. engchi. 中收錄大量的英文詞彙,包含動詞、名詞、副詞和形容詞等詞性。WordNet 的設計本身 已經將英文詞彙以同義詞集(Synset)作為分類,每項分類代表個別的一個語意概念,各 個同義詞集在 WordNet 中透過概念語意與詞性作為鏈結。而 WordNet 經由同義詞集的分 析,可以取得詞彙的反義詞(Antonym)、上位詞(Hypernym)和下位詞(Hyponym)。在這裡 我們採用 WordNet 2.1 的版本加入到本研究當中,使用 JAWS 工具對 WordNet 的辭典解 析,我們直接透過 JAWS 來獲得指定詞彙的同義詞集與反義詞集,在後面的章節我們會 說明如何使用同義詞與反義詞來建構推論系統。. 12.
(28) 3.5 教育部國語辭典 教育部於 1994 年開始建構網路版的重編國語辭典修訂本[2],該辭典經由數位專家學者 編撰而成,歷經數次的檢索系統更新與內容修訂,使用者可透過檢索系統搜尋指定詞彙, 辭典內容包含詞彙讀音、拼音、相似詞與相反詞等資訊。我們透過授權取得教育部相似 詞與相反詞的辭典,圖 3.5 示意為辭典內容範例,相似詞辭典共包含 16005 個繁體中文 詞彙,相反詞辭典包含 8625 個繁體中文詞彙。 相似詞 高興; 得意、痛快、開心、快樂、快活、歡樂、歡喜、歡躍、喜悅、興奮、怡悅、愉 快、樂意、願意 相反詞 高興; 敗興、悲傷、悲哀、煩悶、難過、苦惱、沮喪、傷心、掃興、憂愁、厭惡、鬱 悶、不快、生氣. 立. 政 治 大. Nat. n. al. er. io. sit. y. ‧. ‧ 國. 學. 圖 3.5 相似詞與相反詞資料庫. Ch. engchi. 13. i Un. v.
(29) 4. 第四章. 研究方法. 本節說明我們的研究方法,首先敘述推論系統所使用的元件;根據過去的經驗,語料經. 政 治 大. 過適當的前處理後,能獲得較佳的推論效果。接著我們提出兩種方式進行推論關係的判. 立. 定,第一種為經驗法則式的推論模型,透過對語料的觀察與分析,提出幾個簡單語言現. ‧ 國. 學. 象的計算方法,對兩個句子之間的推論程度給予評分,第二種則使用機器學習的演算法,. er. io. sit. y. Nat. 4.1 系統元件. ‧. 藉由數學模型自動分析與學習語料中的語言現象,並針對這些現象做推論關係的分類。. 在這個小節中,將說明建構兩種系統時所需要使用的元件,這些元件將被用來對文本做. n. al. Ch. i Un. v. 前處理,期望提升文本的一致性與推論關係的判斷。以下介紹的元件包含中文斷詞、英. engchi. 文分詞、中英文數字轉換模組、實體名詞標記與詞彙語意分析。. 4.1.1 數字轉換模組 中文的數字有多種的表示方法,如圖 4.1 為一筆中文語料,兩個句子都包含相同的時間 與數字,但其表示的格式卻不盡相同;因此具有相同標記的時間或數字,卻使用不同的 文字形式表達,可能造成推論系統解析文字時造成誤解。為了解決上述的問題,我們透 過正規表達式(Regular Expression)的使用,擷取句子當中特定的時間或數字表示的句法 結構,將其轉換為統一的時間或數字格式,減少系統於解析文本字串時造成的錯誤使 14.
(30) t1:京都議定書規定在二零一二年之前,將可能造成溫室效應的廢氣排放量降到比 一九九零年低百分之五點二 t2:京都議定書規定在2012年以前,將可能造成溫室效應的廢氣排放量降到比 1990年低5。2% 圖 4.1 原始語料之數字表達 t1:京都議定書規定在 2012 年之前,將可能造成溫室效應的廢氣排放量降到比 1990 年低 5.2% t2:京都議定書規定在 2012 年以前,將可能造成溫室效應的廢氣排放量降到比 1990 年低 5.2%. 政 治 大. 圖 4.2 數字轉換模組結果. 立. 用,圖 4.2 為圖 4.1 轉換後的結果。. ‧ 國. 學. 同樣地,英文亦有時間與數字表達形式的不同,但我們並未針對英文的格式制定正. ‧. 規表達式的規則做轉換,而直接使用公開的工具 YAGO-NAGA Javatools[32]來做轉換。. sit. y. Nat. 在英文中,日期則是較常有較大變化的部分,所以我們僅針對日期的部分做轉換,希望. io. al. er. 在接下來的英文分詞或字串比對時,降低時間表達方式不一致的情況,藉以提升字面上. n. 相似的程度來增加推論效果。. 4.1.2 簡繁轉換. Ch. engchi. i Un. v. 由於我們將使用公開的工具進行中文斷詞與實體名詞標記,並且這些工具被設計成對簡 體中文文本有較佳的效果,因此必須將繁體中文的語料進行簡繁轉換,以獲得較佳的斷 詞與實體名詞標記結果。我們設計一套自動化的簡繁詞彙轉換的流程,透過 Microsoft Word 既有的套件進行轉換,同時我們未對此程序進一步的設計與改進,所有簡繁轉換 的品質皆以 Microsoft Word 的結果為準。. 15.
(31) 4.1.3 中文斷詞與英文分詞 中文句子有別於英文的句子,並非以空格做為詞彙之間的分隔,因此中文句子在不同的 詞彙組合中,可能產生不同的斷詞結果,而有不同的意義。為了取得較佳的斷詞結果, 我們採用三種斷詞器的結果。第一種為中研院的 CKIP 斷詞器[11],這是一組以繁體中 文為詞庫的工具,多為臺灣地區使用。第二種為 LingPipe[19],它是由 Alias-i 這家公司 所開發的一套自然語言處理工具,包含多種自然語言處理的模組,如實體名詞標記、中 文斷詞與 Part-of-Speech(POS)標記等,LingPipe 所提供的中文斷詞模組,亦可直接處理. 政 治 大. 繁體中文。第三種為史丹佛斷詞器(Stanford Word Segmenter)[29],這是一組以簡體中文. 立. 語料所建構而成的斷詞器,因此我們的語料仍須要由繁體中文轉為簡體中文後才可以獲. ‧ 國. 學. 得較佳的斷詞結果。我們最後選擇由史丹佛斷詞器來做為本研究的斷詞工具,語料透過. ‧. 簡繁的轉換後,再將其丟入史丹佛斷詞器來取得斷詞結果。. sit. y. Nat. 英文句子具有類似的需求,我們希望將句子切割至詞彙或符號等較小的單元,獲得. io. er. 更精確字面上所包含的資訊,以提升推論系統理解更細微的字面資訊。由於我們並非英. al. iv n C h e n g Tokenizer)[28]進行英文的分詞 詞的功能,我們採用史丹佛分詞器(Stanford 。分詞的同時, chi U n. 文母語的使用者,對英文的分詞或語法結構熟悉程度不足,因此避免自己去實現英文分. 我們將結果進行詞形還原(Lemmatization),對詞彙的使用正規化,預期可以加強字串的 比對效果。. 4.1.4 實體名詞(Named-Entity)標記與索引分析 無論在中文或英文的語句中,經常包含特殊的專有名詞,如人名、地名或組織名;而這 些專有名詞在推論的過程中,我們將其視為重要的資訊。因此我們為了使電腦理解語句 中所包含的重要資訊,必須擷取出句子中所包含的專有名詞,這種技術即是實體名詞標 記。本研究中,我們並不著力於該技術的研究,所以透過既有工具的使用,來擷取實體 16.
(32) 名詞。Gao[14]等人於 2005 年提出簡體中文的斷詞與實體名詞標記的方法,並發展出一 套工具 S-MSRSeg,我們採用此工具來擷取句子中的專有名詞,圖 4.3 是一個標記的範 例,我們將於後面的小節說明這些實體名詞如何被使用來檢驗語句的推論關係。英文的 實體名詞標記則使用史丹佛實體名詞標記(Stanford Named Entity Recognizer)[26],我們 採用的標記模型是由 CoNLL-2003 的語料訓練而成,可以針對人名、地名、組織名與其 他可能的實體名詞做標記,但我們移除第四個部份的實體名詞,而著重於人名、地名與 組織名的分析與應用。. 政 治 大 立Ex2:伏明霞出生於武漢. Ex1:思科是全球最大軟體公司. ‧ 國. 學. 圖 4.3 實體名詞標記. 主詞與受詞的交換往往讓句子的意義有所不同,並且實體名詞在本研究中被視為一. ‧. 項重要的資訊,而圖 4.4 則顯示一組由於實體名詞在句子中位置不同造成的歧義狀況;. Nat. sit. y. 因此除了標記句子中的實體名詞外,我們同時分析實體名詞出現於句子中的索引,藉以. n. al. er. io. 瞭解實體名詞於該句中可能代表的可能是主詞或受詞,讓推論系統較有效地掌握句子的 意義,並提升推論效果。. Ch. engchi. i Un. v. t1:美國尤其擔心,恐怖分子或「流氓國家」可能以購買或偷竊的方法取得俄國的 武器級鈽 t2:俄國尤其擔心,恐怖分子或「流氓國家」可能以購買或偷竊的方法取得的美國 武器級鈽 圖 4.4 專有名詞錯位. 4.1.5 否定詞、近義詞與反義詞搜尋 經常地我們使用一些具有否定意義的詞彙來表達句子反向的意思,圖 4.5 為一組使用否 定詞彙的效果,儘管 t1 及 t2 使用了近乎完全相同的詞彙,但「不」的使用讓兩個句子擁. 17.
(33) 有完全相異的意思。因此我們認為否定詞對句子之間推論關係的判斷是非常重要的角色, 而擷取否定詞成為一項重要的工作;我們將廣義知網裡所有的定義展開式,抓取展開式 中包含功能詞(Function Word) 「not」的詞彙,接著經由人工過濾的方式挑選適當的否 定詞組成一部辭典用以擷取句子中的否定詞,圖 4.6 為辭典包含的否定詞。英文的否定 詞 , 我 們 則 是 使 用 史 丹 佛 剖 析 器 (Stanford Parser)[27] 產 生 詞 彙 的 依 賴 關 係 (Dependency)[25],擷取依賴關係標記為「neg」的詞彙組合,將其視為否定詞的使用。 t1:2012 年 12 月 21 日是世界末日 t2:2012 年 12 月 21 日不是世界末日. 立. 政 治 大 圖 4.5 否定詞範例. Nat. io. er. 圖 4.6 否定詞辭典. sit. y. ‧. ‧ 國. 學. 無 未 不 沒有 非. al. iv n C hengchi U 且詞彙之間都具有相似的意義,我們稱這些詞彙為近義詞(Near-synonym),如圖 4.7 所 n. 日常生活的談話或寫作,經常會運用不同的詞彙描述相同的行為、情緒或事物,並. 示,「大壽」與「華誕」在意義上都是指「生日」的意思,卻使用兩種不同的詞彙來描 述。而本研究提出的作法便是希望由字面上的覆蓋程度來進行推論關係的驗證,我們認 為句子之間具有較高的詞彙覆蓋比例時,能夠說明推論關係的程度高低,而近義詞的擷 取能夠將相似意義的詞視為相同的詞彙,增加詞彙覆蓋的比例,亦有機會提升推論關係 的判斷能力。因此我們以廣義知網為基礎,提出兩種方法計算中文詞彙之間的語意相似 程度,並且給予兩個詞彙相似程度的信心值,信心值由 0 至 1 表示由相似程度最低到最 高,我們將設立門檻值界定兩個詞彙是否為近義詞,同時教育部國語辭典也被用來判定. 18.
(34) t1:尼泊爾毛派叛亂份子在新國王大壽前夕發動攻擊 t2:尼泊爾毛派叛亂分子在新國王華誕前夕發動攻擊 圖 4.7 近義詞範例 詞彙:漲價 展開式: {BecomeMore|增多:domain={economy|經濟},theme={price({object|物體})}} 向量表示: [BecomeMore|增多, domain, economy|經濟, theme, price, object|物體] 圖 4.8 展開式向量形式. 政 治 大 中文近義詞。而英文的部分,我們則透過既有的工具使用 WordNet 抓取英文詞彙的同義 立. ‧ 國. 學. 詞集(Synset),並未針對英文詞彙多加設計同義詞或近義詞的搜尋方法。 廣義知網當中,每個詞彙都透過義原(Sememe)、功能詞(Function Word)或語意角色. ‧. (Semantic Role)組成表達式,說明該詞彙的語意,表達式共分為兩種-概念式與展開式,. Nat. sit. y. 展開式皆以最基礎的義原說明詞彙語意,而展開式若有部分的表達式能轉換為廣義知網. n. al. er. io. 內的既有詞彙時,則會直接使用該詞彙代替其中的表達式而轉換為概念式,因此我們選 擇使用展開式做為相似度計算的基底。. Ch. engchi. i Un. v. 第一種方法,我們將詞彙的展開式進行剖析,將義原、功能詞和語意角色擷取出來, 轉換成向量的形式,如圖 4.8 所示。接著透過餘弦相似度(Cosine Similarity)計算兩個詞 彙語意組成的相似程度,由 0 到 1 的分數表示相似程度低至高,公式如下所示:. SimCos (𝐴, B) =. ∑𝑛𝑖=1 𝐴𝑖 × 𝐵𝑖 √∑𝑛𝑖=1(𝐴𝑖 )2 × √∑𝑛𝑖=1(𝐵𝑖 )2. ,. (1). 公式(1)中的 A 及 B 分別為兩個詞彙展開式轉換出來的向量集合。 展開式中使用到的每個義原及語意角色,都屬於 2.2 節提及的廣義知網分類架構中 19.
(35) 立. 政 治 大 圖 4.9 展開式樹狀結構. ‧ 國. 學. 的某個節點,而每個節點與節點之間大多具有上下位的關係,並且在鄰居節點之間往往 也具有類似的意義,因此我們認為展開式其實是一種樹狀的結構,說明該詞彙的組成與. ‧. 成分比例。第二種方法中,我們首先將展開式轉換成樹狀的結構,如圖 4.9 所示;從樹. Nat. sit. y. 狀結構可以瞭解義原、功能詞與語意角色之間的關連性,透過元素之間的關係組成,找. n. al. er. io. 出詞彙與詞彙的相似程度。由圖 4.9 的樹狀結構,我們擷取以每一個節點做為根節點(Root). i Un. v. 的子樹(Subtree),找出兩個詞彙共用的子樹數量,並定義一個公式計算詞彙的相似程度,. Ch. engchi. 其分數將由 1 至 0 表示相似程度的高低,公式如下: Sim_Subtree(𝑆, 𝑇) =. |𝑆𝑢𝑏𝑡𝑟𝑒𝑒𝑆 ∩ 𝑆𝑢𝑏𝑡𝑟𝑒𝑒𝑇 | , |𝑆𝑢𝑏𝑡𝑟𝑒𝑒𝑆 |. (2). 公式(2)中的 S、T 代表來源的詞彙與欲比較的詞彙,Subtree 則為子樹的集合。 否定詞在句子表達中,我們認為僅能視為可能造成意義相反,但不一定是完全表達 相反的情況,如圖 4.10 顯示了一個例外的狀況,否定詞的使用並沒有達到反向的效果, 而仍是說明「信任史懷哲的善心」這件事實。反義詞則是另一項表達反向意義的詞彙使 用,圖 4.11 顯示一組反義詞使用的句子範例,可以發現以詞彙覆蓋比例計算時,原先獲 20.
(36) 得較高比例的句對,將因為反義詞的使用而產生截然不同的意義;因此我們希望解決這 個類型的問題,讓系統可以偵測反義詞的使用,並適當地調整推論關係的判斷。我們加 入教育部國語相反詞辭典,用來搜尋句子當中的反義詞。同樣地,我們並未針對英文設 計反義詞的搜尋方法,而是透過既有的工具,經由 WordNet 搜尋反義詞;我們並不直接 使 用指定的英文詞彙找尋反義詞,而首先對欲搜尋的英文詞彙找尋同義詞,再由這些 同義詞取得更多的反義詞,希望增加反義詞的數量,提升反向意義的判斷。. 學. t1:一九九一年波斯灣戰爭結束時 t2:波斯灣戰爭發生於 1991 年. ‧. ‧ 國. 治 政 大 由於史懷哲的品德良好,你不能不信任他的善心。 立 圖 4.10 否定詞例外 圖 4.11 反義詞範例. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4.12 經驗法則式推論系統架構與流程. 21.
(37) 4.2 經驗法則式推論模型 圖 4.12 為經驗法則式推論模型的系統架構與運行流程,首先將語料讀入系統後,透過數 字轉換模組將數字正規化,接著進行中文斷詞或英文分詞,並標記實體名詞與解析句法 結構,最後通過我們提出的計算方法與門檻值設定,計算推論關係的評分,由 0 至 1, 並根據門檻值獲得欲判斷的句子推論關係。 完成 4.1 節的元件之後,我們利用多種的分數評比,評估一個句子的意義是否能夠. 政 治 大. 推論至另一個句子;我們提出一個簡單的概念為計算推論關係的基礎,認為句子當中每. 立. 一個詞彙都表示一項資訊,當兩個句子裡相同的詞彙比例夠高時,則相信這兩個句子包. ‧ 國. 學. 含等價的資訊量,因而具有推論的關係。. ‧. 將經過數字轉換後的句子進行中文斷詞或英文分詞,以 t2 產生的詞彙集合做為基底, 計算兩個句子詞彙重疊的比例,如下方公式(3)。公式(3)中 T1 及 T2 分別為兩個句子斷詞. y. Nat. al. er. io. iv n ∩ 𝑇2 | e(𝑇n1,g𝑇2c) =h|𝑇i 1 U 𝑓𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 ,. n. 相同比例的高低。. sit. 或分詞後的詞彙集合,透過該公式計算兩個句子所使用相同詞彙的比例,由 1 到 0 顯示. Ch. |𝑇2 |. (3). 但公式(3)要求詞彙的完全相同才納入計算,如此一來可能遺漏掉部分相同的縮寫詞 彙或因為各種原因被斷詞器斷開的情況,因此我們稍稍修改了公式(3),加入詞彙部分相 同的計算;而近義詞的使用,也減少了字面上的比對相同的機會,降低詞彙的重疊比例, 因此近義詞的判斷也加入到公式(3)的修改,使之成為公式(4)。公式(4)中𝑐(𝑤1 , 𝑤2 )為計 算詞彙部分相同的分數,由 0 至 1 表示完全不相同到完全相同,若兩個詞彙完全相同或 為近義詞,則給予完全相同的分數;若兩個詞彙僅部分相同,我們依照兩個詞彙相差的 字元數來調整詞彙重疊比例。透過調整後的公式,我們預期可以增加詞彙比對相同的機 22.
(38) 會,增加句子之間的重疊比例,掌握更多句子中的資訊。. 𝑓′𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 (𝑇1 , 𝑇2 ) = 1, 𝑐(𝑤1 , 𝑤2 ) = {1 − log||𝑤1 | − |𝑤2 || , 0,. ∑𝑤2 ∈𝑇2 ∑𝑤1 ∈𝑇1 𝑐(𝑤1 , 𝑤2 ) , |𝑇2 | 𝑤1 = 𝑤2 or 𝑤1 , 𝑤2 are near synonyms 𝑤1 ⊂ 𝑤2 , 𝑒𝑙𝑠𝑒. (4). 我們以公式(4)做為計算語句推論關係的基礎,設立門檻值判斷句子之間的推論關係,. 政 治 大. 如公式(5),E 為推論關係判別的門檻值。接下來我們會加上各種輔助的計算方法改善系. 立. 學. 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 = 𝑓′𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 (𝑇1 , 𝑇2 ),. 𝑅𝑒𝑙𝑎𝑡𝑖𝑜𝑛𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡. Y, ={ N,. 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 ≥ 𝐸 , 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 < 𝐸. ‧. ‧ 國. 統的推論能力。. Nat. y. (5). er. io. sit. 如果只使用詞彙重疊比例來計算推論關係,我們僅能掌握句子中的資訊含量,而無 法真正的得知句子所包含的內容與重要性,因此透過前一小節提到的實體名詞標記,將. n. al. Ch. i Un. v. 句子中的人名、地名和組織名擷取出來,並把這些詞彙認定為重要的資訊,倘若兩個句. engchi. 子無法同時取得這些詞彙的交集,便認為這兩個句子較難以具有推論關係。根據上述的 假設,我們加入一個函數調整推論關係的計算,如公式(6)。 𝑁𝐸𝑡2 為 t2 中擷取出的實體 名詞,fNEPenalty 則會判斷𝑁𝐸𝑡2 中的元素會被包含於 t1,當每一個元素不包含在 t1 時,則給 予一次範圍 0 至 1 的α懲罰分數。因此推論關係的判斷加入該函式,變成公式(7)。 𝑓𝑁𝐸𝐷𝑖𝑓𝑓 (𝑡1 , 𝑡2 ) = ∑ 𝑓𝑁𝐸𝑃𝑒𝑛𝑎𝑙𝑡𝑦 (𝑛, 𝑡1 ) 𝑛∈𝑁𝐸t2. 𝑓𝑁𝐸𝑃𝑒𝑛𝑎𝑙𝑡𝑦 (𝑛, 𝑡1 ) = {. 𝛼, 𝑛 𝑖𝑠 𝑛𝑜𝑡 𝑎 𝑠𝑢𝑏𝑠𝑡𝑟𝑖𝑛𝑔 𝑜𝑓 𝑡1 , 0, 𝑒𝑙𝑠𝑒. 23. (6).
(39) 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 = 𝑓′𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 (𝑇1 , 𝑇2 ) − 𝑓𝑁𝐸𝐷𝑖𝑓𝑓 (𝑡1 , 𝑡2 ),. (7). 在先前曾提到否定詞對語句推論造成可能的影響,因此我們增加系統對否定詞的擷 取,並設計簡單的規則判斷否定詞對計算推論關係的影響,適當地調整推論關係的評分。 我們認為兩個句子若包含不同數量的否定詞時,則較容易有不同意義的產生,而降低推 論關係的可能性,因此再度加入一個函式針對否定詞做推論分數的調整,如下方公式(8) 所示。Negation 表示句子當中包含的否定詞集合,β為否定詞數量不相等時用以調整的. 政 治 大 𝛽, |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛 | ≠ |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛. 懲罰分數,其值介於 0 到 1,並將推論關係的判斷延伸成公式(9)。. 立. 𝑡2 |. 𝑡1. 𝑓𝑛𝑒𝑔𝑎𝑡𝑖𝑜𝑛 (𝑡1 , 𝑡2 ) = {. 0, 𝑒𝑙𝑠𝑒. (8). ,. ‧ 國. 學. 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 = 𝑓′𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 (𝑇1 , 𝑇2 ) − 𝑓𝑁𝐸𝐷𝑖𝑓𝑓 (𝑡1 , 𝑡2 ) − 𝑓𝑛𝑒𝑔𝑎𝑡𝑖𝑜𝑛 (𝑡1 , 𝑡2 ),. (9). ‧. Nat. sit. y. 除了否定詞外,句子之間若存在反義詞,我們認為這樣是更加顯示兩個句子之間可. n. al. er. io. 能不具有推論的關係,因此我們嘗試分析句子之間的反義詞包含狀況,若包含反義詞,. i Un. v. 則給予較重的懲罰分數,大幅調整推論關係的判斷。公式(10)顯示反義詞判斷的函式,. Ch. engchi. Antonym 表示一個詞彙透過 4.1 節提出的方法獲得的反義詞集合,γ則是反義詞存在時 的懲罰分數,其值為 1 至 2,而判斷推論關係的公式則變成公式(11)。 𝑓𝑎𝑛𝑡𝑜𝑛𝑦𝑚 (𝑇1 , 𝑇2 ) = {. 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 =. 𝛾, {𝑤1 ∈ 𝐴𝑛𝑡𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 } , 1, 𝑒𝑙𝑠𝑒. 𝑓′𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 (𝑇1 , 𝑇2 ) − 𝑓𝑁𝐸𝐷𝑖𝑓𝑓 (𝑡1 , 𝑡2 ) − 𝑓𝑛𝑒𝑔𝑎𝑡𝑖𝑜𝑛 (𝑡1 , 𝑡2 ) 𝑓𝑎𝑛𝑡𝑜𝑛𝑦𝑚 (𝑇1 , 𝑇2 ). (10). ,. (11). 前一小節曾提及主詞與受詞位置可能影響句子語意上的,因此我們在前處理便標記 出實體名詞的索引,並且我們認為當推論分數較高時,代表句子之間的詞彙使用非常相 24.
(40) 近,此時若實體名詞發生錯位,則較容易影響兩個句子語意的相似程度,如圖 4.13,因 此增加一個函式判斷索引值的迥異,藉以調整推論關係的評分,如公式(12)。公式中 i 代表實體名詞於句子中的位置,m 和 n 為 NE_Order 的索引值,δ為範圍 1 到 2 的懲罰 分數,λ為使用該函式的推論分數門檻值。透過上述的各種語言資訊的使用,最後合併 成一項推論關係的計算公式(13),將推論關係的程度以 0 至 1 的分數顯示高低,我們預 期該方法能有效地判定語句間的推論關係。 t1:台灣出口至印度成長 28.6% t2:印度從台灣出口成長率可達 28.6%. 政 治 大. 𝑁𝐸_𝑂𝑟𝑑𝑒𝑟𝑡2 = [台灣:0, 印度:1]. 立. 𝑁𝐸_𝑂𝑟𝑑𝑒𝑟𝑁𝐸𝑡2 𝑖𝑛 𝑡1 = [台灣:1, 印度:0]. ‧ 國. 學. 圖 4.13 實體名詞位置比對範例 ∏ 𝑖𝑚 ,𝑖𝑛 ∈𝑁𝐸𝑂𝑟𝑑𝑒𝑟 𝑁𝐸. 𝑓𝑁𝐸𝑂rder𝑃𝑒𝑛𝑎𝑙𝑡𝑦 (𝑖m , 𝑖𝑛 ),. 𝑎𝑛𝑑 𝑚 <𝑛 𝑡 2 𝑖𝑛 𝑡1. y. Nat. sit. io. n. al. 𝛿, 𝑖𝑛 − 𝑖𝑚 < 0 and 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 > 𝜆 , 1, 𝑒𝑙𝑠𝑒. er. 𝑓𝑁𝐸𝑂rder𝑃𝑒𝑛𝑎𝑙𝑡𝑦 (𝑖𝑚 , 𝑖𝑛 ) = {. 𝑆𝑐𝑜𝑟𝑒𝑒𝑛𝑡𝑎𝑖𝑙𝑚𝑒𝑛𝑡 =. (12). ‧. 𝑓𝑁𝐸𝑜𝑟𝑑𝑒𝑟 (𝑡1 , 𝑡2 ) =. Ch. i Un. v. 𝑓′𝑤𝑜𝑟𝑑𝑜𝑣𝑒𝑟𝑙𝑎𝑝 (𝑇1 , 𝑇2 ) − 𝑓𝑁𝐸𝑒𝐷𝑖𝑓𝑓 (𝑡1 , 𝑡2 ) − 𝑓𝑛𝑒𝑔𝑎𝑡𝑖𝑜𝑛 (𝑡1 , 𝑡2 ). engchi. 𝑓𝑎𝑛𝑡𝑜𝑛𝑦𝑚 (𝑇1 , 𝑇2 ) × 𝑓𝑁𝐸𝑜𝑟𝑑𝑒𝑟 (𝑡1 , 𝑡2 ). ,. (13). 4.3 機器學習之推論模型 圖 4.14 為使用機器學習演算法建構的推論模型系統架構,同樣使用 4.1 節的元件進行前 處理,接著擷取我們認為可以增加推論效果的語文資訊,做為訓練模型的特徵集合;最 後我們採用三種不同的分類演算法訓練分類模型,分別是支持向量機(Support Vector Machine, SVM)[8][17]、Weka J48 決策樹(J48 Decision Tree)與 Weka 線性回歸(Linear Regression)[20],透過不同類型的分類器獲得推論關係的結果。 25.
(41) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4.14 機器學習推論系統架構. sit. y. Nat. 前一小節說明了經驗法則式推論模型所使用的函式,我們針對這些函式進行數值化. io. er. 的轉換,做為訓練推論模型的特徵;這些特徵包含詞彙覆蓋比例、實體名詞數量、實體. al. iv n C hengchi U 項目。除此之外,我們希望加深推論模型對語法結構的認識,因此加入剖析樹(Parsing n. 名詞相似度、實體名詞錯位數量、句子長度、否定詞數量、近義詞數量、反義詞數量等. Tree)分析、POS(Part-of-speech)動詞標記與詞彙依賴關係(Word Dependency)等元素,計 算其相似度做為特徵,希望提高推論模型的能力。 我們透過史丹佛剖析器(Stanford Parser)取得句子的剖析樹,並且我們認為使用整個 剖析樹分析句法結構相似度容易增加計算的難度,因為句子之間可能僅有部分的結構具 有共通性即可具備推論的關係,因此以每一個節點做為根節點(ROOT)擷取其下層節點 形成的子樹,使用這些子樹來計算兩個句子結構的相似程度。同樣地,POS 標記由史丹 佛剖析器獲得,我們認為動詞在句子中扮演較重要的角色,因其指出整個句子的事件與 26.
(42) 動作意圖,因此特意將被標註成動詞的詞彙抓取出來,以兩個句子個別的動詞數量與相 似度做為特徵,期望讓分類器學習動詞使用在推論關係上的影響力。 史 丹 佛 剖 析 器 亦 能 根 據 剖 析 樹 的 生 成 , 產 生 詞 彙 之 間 依 賴 的 關 係 (Stanford Dependencies)[25][30],我們將依賴關係中的詞彙做為節點,將句子中的詞彙關係視為一 個有向圖(Directed Graph),並化做矩陣形式如圖 4.15。我們發現一個矩陣內可以顯示的 資訊並不充沛,如此稀疏的矩陣中,我們難以找到句子之間包含相同關係的詞彙組合, 因此以相鄰矩陣(Adjacency Matrix)的概念做進一步的運算;例如一個矩陣 M,可以經由. 政 治 大. 矩陣相乘獲得節點到節點之間移動所需要的步數,因此計算 M3 便能瞭解任一個節點經. 立. 過三步移動後的位置。我們將這樣的移動視為依賴關係的延伸,便能找出更多潛在的詞. ‧ 國. 學. 彙依賴關係,並且將不同移動步數的矩陣結果聯集,獲得更豐富的依賴關係。圖 4.16. ‧. 回歸. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. v n1 i. al. 中國. 0. ROOT. 0. C0h. 0. ROOT. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. sit er. 0. 中國. y. 香港. n. 回歸. 年. io. 香港. 1997. Nat. 1997 年. 原句:1997 年香港回歸中國. 0 e n g 0c h i U 0. 0 圖 4.15 詞彙依賴關係矩陣 M 原句:1997 年香港回歸中國. 1997. 年. 香港. 回歸. 中國. ROOT. 1997 年. 0. 0. 0. 1. 0. 1. 0. 0. 0. 1. 0. 1. 香港. 0. 0. 0. 1. 0. 1. 回歸. 0. 0. 0. 0. 0. 1. 中國. 0. 0. 0. 1. 0. 1. ROOT. 0. 0. 0. 0. 0 2. 3. 0 4. 圖 4.16 經過五步的詞彙依賴關係,M ∪ M ∪ M ∪ M ∪ M. 27. 5.
(43) 便是圖 4.15 的矩陣計算移動五步後的結果,我們透過這樣的矩陣,分析句子之間詞彙依 賴關係相似的程度,並以該數值做為一項特徵。 而英文的語料中,我們認為既有的工具可以提供更好的實體名詞標記與剖析樹解析, 因此對於英文實體名詞的特徵擷取分為更細緻的類別,分別計算人名、地名與組織名的 相似度。除此之外,我們針對剖析樹提出新的特徵,利用詞彙依賴關係,企圖找出兩個 句子的主詞-動詞-受詞結構(Subject-Verb-Object Structure, SVO Structure);我們抓取依賴 關係中的 subj 與 dobj 關係,取得句子中的主詞、動詞與受詞,並將其進行排列組合獲. 政 治 大. 得可能的 SVO 結構集合,根據集合內容,轉換為兩個特徵值,第一個以布林形式表達. 立. 兩個句子間是否有相同的 SVO 結構,第二個則為兩個句子擁有相同 SVO 結構的比例。. ‧ 國. 學. 最後表 4.1 與表 4.2 個別列出用以訓練模型的中英文特徵集合與其定義,再透過不. ‧. 同種類的分類演算法訓練模型進行推論關係的判斷,我們預期這些特徵也能達到與經驗. n. al. er. io. sit. y. Nat. 法則式推論模型的相仿效果。. Ch. engchi. 28. i Un. v.
(44) 表 4.1 中文特徵集 𝑓Overlap. 𝑓Negation𝑡. 見公式(4). 1. |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡1 |, |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 |. 𝑓Negation𝑡. 2. 𝑓NEPosDiff. 見公式(12). 𝑓Antonyms. |{𝑤1 ∈ 𝐴𝑛𝑡𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }|. 𝑓NENotExist. |𝑛|𝑛 ∈ 𝑁𝐸t2 , n ∌ 𝑁𝐸t1 |. 𝑓Synonyms. |{𝑤1 ∈ 𝑆𝑦𝑛𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }|. 𝑓Length𝑡. 句子字元數. 𝑓LenBool. 1, 𝑓Length𝑡1 > 𝑓Length𝑡 2 { 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. 𝑓SubtreeSim. 見公式(2). 𝑓NESim. |𝑁𝐸𝑡1 ∩ 𝑁𝐸𝑡2 | |𝑁𝐸𝑡2 |. 𝑓NE𝑡1 𝑓NE𝑡2. 𝑓NegSim. |𝑁𝐸𝑡1 | |𝑁𝐸t2 |. |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡1 ∩ 𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 |. |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛 | 政 𝑓 治 |{𝑤大∈ 𝑆𝑦𝑛𝑜𝑛𝑦𝑚 |𝑤 𝑡2. |Dep𝑡1 ∩ 𝐷ep𝑡2 | |Dep𝑡2 |. 𝑓𝑉erb𝑡2. |POSVerb𝑡2 |. 𝑤2. 1. ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }|. |𝑇2 |. 𝑓VerbSim. ‧ 國. |POSVerb𝑡1 |,. 1. |POSVerb𝑡1 ∩ POSVerb𝑡2 |. 學. 𝑓𝑉erb𝑡1 ,. 立. SynRatio. |POSVerb𝑡2 | 𝑓𝑁𝑒𝑔𝐵𝑜𝑜𝑙. ‧. 1, |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡1 | ≠ |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 | { 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. io. sit. y. Nat. n. al. er. 𝑓DepSim. Ch. engchi. 29. i Un. v.
(45) 表 4.2 英文特徵集 𝑓Overlap. 𝑓Negation𝑡. 見公式(4). 1. |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡1 |, |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 |. 𝑓Negation𝑡. 2. 𝑓NEPosDiff. 見公式(12). 𝑓Antonyms. |{𝑤1 ∈ 𝐴𝑛𝑡𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }|. 𝑓NENotExist. |𝑛|𝑛 ∈ 𝑁𝐸t2 , n ∌ 𝑁𝐸t1 |. 𝑓Synonyms. |{𝑤1 ∈ 𝑆𝑦𝑛𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }|. 𝑓Length𝑡. 句子字元數. 𝑓SVOMatch. 1, 𝑠 ∈ 𝑆𝑉𝑂𝑡2 𝑎𝑛𝑑 𝑠1 ∈ 𝑆𝑉𝑂𝑡1 { 1 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. 𝑓SubtreeSim. 見公式(2). 𝑓NegSim. |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡1 ∩ 𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 | |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 |. 𝑓SVORatio. 𝑓SynRatio. |𝑆𝑉𝑂𝑡1 ∩ 𝑆𝑉𝑂𝑡2 | |𝑆𝑉𝑂𝑡2 | |𝑁𝐸𝐿𝑜𝑐𝑡1 ∩ 𝑁𝐸𝐿𝑜𝑐𝑡2 |. 立. |𝑁𝐸𝐿𝑜𝑐𝑡2 |. NEPersonSim. 𝑡1. ∩ 𝑁𝐸𝑃𝑒𝑟𝑠𝑜𝑛𝑡2 |. |𝑁𝐸𝑃𝑒𝑟𝑠𝑜𝑛𝑡2 |. ‧ 國. |𝑁𝐸𝑂𝑟𝑔𝑡1 ∩ 𝑁𝐸𝑂𝑟𝑔𝑡2 |. 𝑓𝑁𝑒𝑔𝐵𝑜𝑜𝑙. |𝑁𝐸𝑂𝑟𝑔𝑡2 | 𝑓AntRatio. 1, |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡1 | ≠ |𝑁𝑒𝑔𝑎𝑡𝑖𝑜𝑛𝑡2 | { 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. 學. ‧. |{𝑤1 ∈ 𝐴𝑛𝑡𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }| |𝑇2 |. y. Nat. io. sit. 𝑓NEOrgSim. 政 𝑓 治 |𝑁𝐸𝑃𝑒𝑟𝑠𝑜𝑛 大. n. al. er. 𝑓NELocSim. |{𝑤1 ∈ 𝑆𝑦𝑛𝑜𝑛𝑦𝑚𝑤2 |𝑤1 ∈ 𝑇1 , 𝑤2 ∈ 𝑇2 }| |𝑇2 |. Ch. engchi. 30. i Un. v.
數據

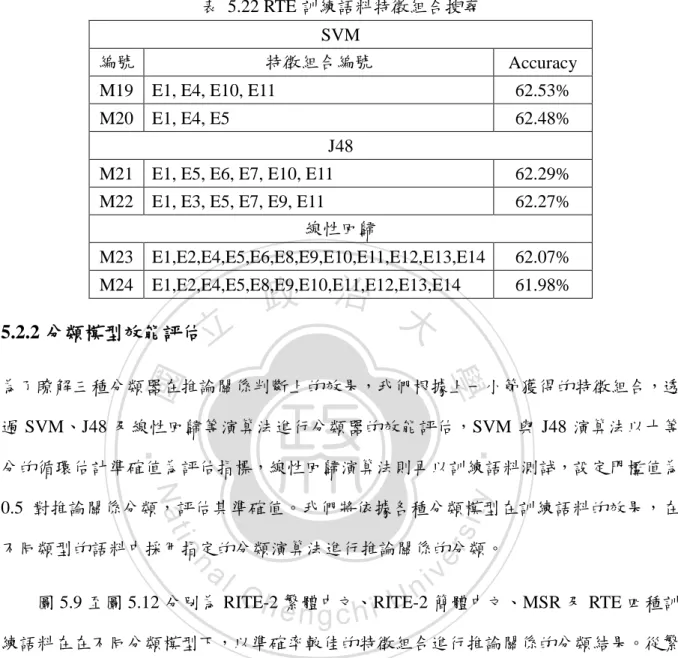
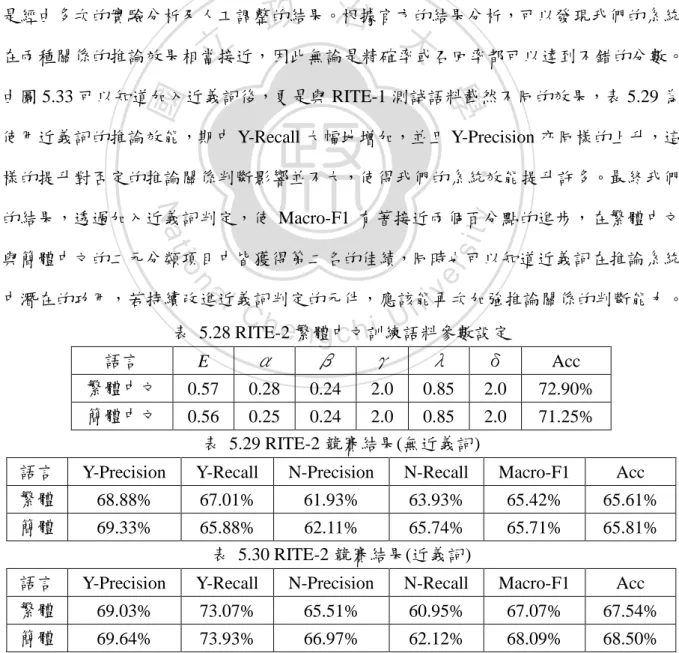
相關文件
人之初 性本善 性相近 習相遠 苟不教 性乃遷 教之道 貴以專 昔孟母 擇鄰處 子不學 斷機杼 竇燕山 有義方 教五子 名俱揚 養不教 父之過 教不嚴 師之惰 子不學 非所宜 幼不學 老何為
學習語文必須積累。語文能力是在對語文材料大量反復感受、領悟、積累、運用的過程中
“Transductive Inference for Text Classification Using Support Vector Machines”, Proceedings of ICML-99, 16 th International Conference on Machine Learning, pp.200-209. Coppin
主頁 > 課程發展 > 學習領域 > 中國語文教育 > 中國語文教育- 教學 資源 > 中國語文(中學)-教學資源
指導語 8:請將以下國語點字標點符號讀出來? (5 個題目). 指導語 9:請將以下英文字母讀出來?
喜而告其妻曰﹕我有家當矣。妻問安在?持卵示 之,曰﹕此是,然須十年,家當乃就。因與妻計
Does your daughter like to drink apple juice.. She eats breakfast
個人、社會及人文教育 |英國語文教育| 藝術音樂教育 | STEM 教育 全球意識與文化敏感度 |體驗學習| 接觸大自然
