國立臺中教育大學資訊工程學系碩士論文
聯邦雲中處理資料串流之
虛擬叢集系統
Virtual Clusters for Data Stream
Processing on Federated Clouds
指導教授:賴冠州 教授
研究生:李宜芳 撰
中華民國一百零四年七月
謝 辭
首先誠摯的感謝我的指導教授賴冠州教授,謝謝您在這兩年耐心的教 導,無論是專業領域的知識,還有做人的道理,求學期間總是不厭其煩 地指點我,給我正確的方向,直到最後都很感謝老師。 感謝黃國展教授、楊朝棟教授與許慶賢教授願意百忙之中抽空前來擔任 我的口試委員,給予碩士論文的指點與建議。特別感謝清華大學鍾武君 博士、張效維學長與古振浩學長,在我求學期間不斷地協助我解決實驗 所遇到的瓶頸。 感謝已經畢業的謝孟儒學長與劉建佑學長,在學期間在我研究中有缺 失時提醒我,迷惘時替我解惑,也謝謝我的同學郁鈞、俊豪、曉青、致 謀、旻映、承哲、立青、怡如、周董以及其他同學們,總是互相加油打 氣,一起努力,有你們的陪伴讓兩年的研究生活變得很精彩,另外也感 謝學弟政賢與厚貿的幫忙,讓實驗環境順利的運作。 最後,謹以此文獻給我的家人,謝謝你們的陪伴與支持,以及在天國 守護著我的爸爸,我很想你,也很愛你,謝謝你所給我的一切。I
摘要
近年來物聯網的興起,不僅將人與人之間能夠透過網路相互連結,甚 至物與物或人與物之間都可透過網路而有所連結,舉凡健康照護、金融、 氣候資料與 GPS 訊號等不同領域皆能透過感測器發送與蒐集資料。物聯網 的發展,持續產生了大量且連續的數據,這些數據則稱為海量資料,如何 處理這些海量資料,將這些資料以序列、不間斷的方式送出也是物聯網所 面臨的最大挑戰之一。 海量資料因規模大量且需講求效率,因此無法一次送入系統分析,而 是先將資料切割,利用 In-memory 技術加快處理之速度,我們稱為串流資 料之處理,這些處理需要大量計算與儲存資源,因此,雲端運算與物聯網 的結合,可滿足串流資料處理之需求。一般而言,In-Memory 技術由於運 算皆在記憶體裡面完成,因此記憶體之處理有可能會影響到串流資料處理 的效能,產生資源干擾之問題,同一時間會有多個工作需要資源,如何配 置資源給這些工作並改善效能是個值得考量的議題。本研究提出了 Memory Access Critical Path Scheduling(MACPS)排程方 法,根據剖析系統(Profiling System)所產生的資料資訊,以及監控系統所監 測之實體機器之動態資源,考量資源存取量配置虛擬資源以滿足串流處理 所需的要求並開發系統的效能。而為了去降低效能的影響,本研究模擬在 聯邦雲上進行排程方法之實驗,考慮五種排程方法,包含[27][29]等相關排 程文獻類比對照,探討在不同變因之下的效能,此研究不僅考慮到工作在 關鍵路徑之間的效率,同時也考慮到了資源存取干擾所帶來的影響。實驗 結果顯示,MACPS 能夠節省約三分之二的執行時間,且無論在跨雲或是 單雲的環境之下,效能始終比較好。 關鍵字:雲端運算、串流資料、虛擬叢集系統、資源配置、關鍵路徑。
II
Abstract
In recent years, the Internet of Things rise up luxuriantly, which make the link through the internet between people and people, people and object, object and object. A variety of different areas such as heal-care, financial, climate information and GPS information, all can send and collect data through sensors. The development of IoT bring large scale and continuous data, which is call Big Data. One of challenges in IoT is to deal with this high-volume streams of real-time data, data stream processing could provide insights into the underlying data patterns.
The system processes data by a fixed-size window in the batch fashion, it is known as stream processing which use in-memory technology to accelerate the process speed to satisfy the requirement of low latency and high feasibility. In general, in-memory technology execute operations in memory, the memory access may be affect the performance of stream processing and lead to resource interference problem, such as many tasks require resources, how to allocate to this task and improve the performance is the important issue.
In this study, we propose a resource scheduling approach, named Memory Access Critical Path Schedule (MACPS), for improving the performance of stream processing. The proposed approach could exploit the system performance by allocating the virtual resource to stream processing tasks according to the information generated by the profiling system. This work not only considers the tasks’ efficiency in critical paths, but also takes account of the effect of I/O interference. MACPS consider resource access data to satisfy the request of stream processing which consider 5 scheduler with different variable. To demonstrate the system improvement, this paper simulates the execution environment with single cloud and multi-cloud of applying MACPS.
Keywords: Cloud Computing, Big Data, Stream Processing, Resource Allocation,
Critical Path.
III
目錄
摘要... I 目錄... III 表目錄... IV 圖目錄... V 一、 緒論... 1 1.1 背景 ... 1 1.2 研究動機 ... 2 1.3 研究議題 ... 3 1.4 研究目標 ... 4 1.5 論文架構與內容 ... 5 二、 相關研究與文獻探討... 6 2.1 雲端運算 (Cloud Computing) ... 6 2.2 虛擬化技術 (Virtualization) ... 82.3 巨量資料與串流處理 (Big Data and Streaming Processing) ... 10
2.4 Spark RDD ... 13
2.5 Scheduling ... 16
三、 系統架構與演算法... 20
3.1 系統架構 ... 21
3.2 Memory Access Critical Path Scheduling ... 22
四、 效能評估... 33
4.1 實驗環境 ... 33
4.2 實驗結果 ... 35
五、 結論... 45
IV
表目錄
表 1. Transformations and actions available on RDDs in Spark ... 13
表 2. RDD 之 Case 1 之可能性 ... 28
表 3. RDD 之 Case 2 之可能性 ... 29
表 4. RDD 之 Case 3 之可能性 ... 30
表 5. RDD 之 Case 4 之可能性 ... 31
V
圖目錄
圖 1. 雲端運算服務架構圖 ... 7
圖 2. 全虛擬化 ... 9
圖 3. 半虛擬化 ... 9
圖 4. Big data 5 properties ... 10
圖 5. Spark streaming processing ... 12
圖 6. Spark RDD 示意圖 ... 15 圖 7. 雲端運算之資源配置策略 ... 16 圖 8. 虛擬叢集系統之資源配置 ... 17 圖 9. Communication skeleton 之範例 ... 18 圖 10. 非一致性記憶體系統示意圖 ... 19 圖 11. 資源干擾之示意圖 ... 20 圖 12. 軟體架構圖 ... 22 圖 13. LCT 與 EST 計算之範例圖 ... 24 圖 14. 關鍵路徑產生之範例 ... 26 圖 15. Case 1:Node 位於相同 RDD 但無相依賴性 ... 28 圖 16. Case 2:Node 位於相同 RDD 且有相依賴性 ... 29 圖 17. Case 3:Node 位於不同 RDD 且無相依賴性 ... 30 圖 18. Case 4:Node 位於相同 RDD 且有相依賴性 ... 30 圖 19. MACPS 之流程圖 ... 32 圖 20. 傅立葉轉換之 DAG(以 10 個 node 為例) ... 34 圖 21. 3 種標準差之常態分佈 ... 34 圖 22. 單雲-Task 總數 ... 35 圖 23. 跨雲-Task 總數 ... 36 圖 24. 單雲- Computation Time ... 37
VI 圖 25. 跨雲- Computation Time ... 38 圖 26. 單雲- Communication Data ... 39 圖 27. 跨雲- Communication Data ... 39 圖 28. 單雲- ReadData/WriteData ... 41 圖 29. 跨雲- ReadData/WriteData ... 41 圖 30. 單雲-常態分佈標準差 ... 43 圖 31. 跨雲-常態分佈標準差 ... 43
1
一、 緒論
1.1 背景
物聯網(Internet of Things)的興起,透過網路作為人與人、人與物與物 與物之間的溝通管道,透過感測裝置(Sensor)加以傳送、蒐集、監控與分析 資訊並整合到網路,進行分析管理。舉凡健康照護、金融企業、氣候資訊 或 GPS 訊號等不同領域,只要能透過網路串連,即為物聯網[1]。 而這些從各方蒐集之數據,是連續性且規模非常大,我們稱為巨量資 料、海量資料或是大數據(Big Data)。這些海量資料通常無法以傳統的方式 處理,因為需要大量的儲存空間與計算能力,而如何去分析這些資料、資 源又該如何分配等亦是各方關注的議題[2][7]。 雲端運算(Cloud computing)為一種計算模式,將硬體與系統軟體等運算 資源透過網路(Internet)提供服務給使用者,美國國家標準技術研究院 (National Institute of Standards and Technology, NIST)定義雲端運算有五種 基本特性[3]:(1) 自助需求式服務(On-demand self-service):使用者能夠依照不同的需求 索取計算資源,且不必與資源供應商互動。
(2) 廣泛的網路存取(Broad network access):透過標準機制讓使用者能夠在 不同的平台上使用。 (3) 資源池共享(Resource pooling):資源供應商的運算資源透過虛擬化技 術(Virtualization Technology)抽象化為資源池,能夠根據每個使用者不 同的需求動態分配其所需資源。 (4) 快速且彈性(Rapid elasticity):對於使用者來說,資源是無限制的供應 且能夠在任何的時間取得。 (5) 計量的服務(Measured service):使用者或供應商能夠透明的去限制、監 控與紀錄資源使用率。
2
雲端運算所提供的三種服務模式為:軟體及服務(Software as a Service)、 平台及服務(Platform as a Service)與基礎及服務(Infrastructure as a Service), 使用者不必透過第三方的許可,皆能依照不同的需求向供應商租用服務, 並且支付相對的花費。於企業而言,由於資訊發展快速,資料規模也越來 越大,因此企業常常購買大量設備以滿足高效能之計算資源之需求,然而 當面臨需求降低、設備老舊或不足以負荷大數據時,企業等同於虧損成本; 在雲端環境之下,企業只需要與雲端供應商租借所需之資源,並且簽訂服 務協議(Service Level Agreement)[4],當需求降低,供應商便收回不需要之 資源,也不必擔心有設備老舊必須汰換的問題,依照使用量支付供應商相 對費用,對於企業而言能夠節省大量成本[5]。 雲端運算與物聯網的結合,讓物聯網所產生之巨量資料能夠在雲端環 境在的資料中心進行分析,不僅滿足了大量資料所需之儲存空間與計算能 力需求,又能節省硬體與成本。
1.2 研究動機
一般而言,巨量資料有五種特性[6]:大量的(Volume)、多樣化(Variety) 、 快速(Velocity) 、價值性(Value)、準確性(Veracity)等,由於物聯網所產生之 巨量資料是連續性且需要即時分析,然而系統無法一次處理大規模之數據, 因此會將這些數據切割成資料流(Data stream)的方式送入系統裡分析,而 分析巨量資料則有兩種方式[8][9]:1.批次處理(Batch processing)、2.串流資 料處理(Real-time stream processing),兩者的不同在於前者將資料累積到一 定數量再進行分析;後者為快速的處理連續性的資料。無論是批次作業處理或是串流資料處理,所需面臨的第一個問題即是 海量資料所需的計算資源與儲存空間,以實體機器來儲存這些資料,有可 能會因為空間不足耗費更多的成本購買設備,又或者會因為供大於需而產
3 生之資源浪費,且還需考量到未來機器必須汰換的問題。而雲端運算環境 基於虛擬化技術,可提供大量計算資源,根據需求量來擴充或縮小所需之 資源規模,能夠完全的應付巨量資料的流動性、大規模、即時反應等特點。 為了提供資源給這些需要大量運算資源的環境,在實體的資源有限的 情況下,本研究選擇由數個獨立雲共同組成的聯邦雲來做為我們的環境, 相較於單雲,聯邦雲擁有較大的彈性與經濟效益。然而,在分析串流資料 的同時,我們面臨了兩個挑戰:(1)虛擬運算節點彼此之間的資源配置問題, (2)多個運行中的虛擬機器(Virtual Machine)請求會對彼此相關的資源存取 產生干擾(Memory interference)。 因此本研究去探討資源配置對於串流資料處理的影響,提升系統之效能, 創建出最適合串流資料之應用程式的虛擬叢集系統。 為了驗證本論文之方法,我們模擬在單雲與跨雲的環境之下,考慮五 種 排 程 方 法 分 別 在 五 種 變 因 如 : Task 個 數 、 Computation Time 、 Communication Data 、 ReadData/WriteData 與 常 態 分 佈 之 標 準 差 , 探 討 MACPS的效能,詳細過程將在第四章討論。
1.3 研究議題
物聯網所產生之大量資料,通常必須經由分析系統來取得我們所需之 資料,針對這些流動性高且講求及時處理之資料,資源的分配是相當值得 重視的。在雲端運算裡,資源配置處理主要透過網路配置可利用的資源給 有需求之雲端應用程式使用,主要針對在有限制之資源的雲端環境之中, 若是配置不當,很可能會造成應用程式飢餓(Starvation)的現象[10]。資源配 置問題需要避免當兩個應用程式在同一時間存取同一資源時所產生的資 源競爭,以及當資源有限或不足以供給有需求之應用程式形成資源之缺乏, 或是過度供給、供給不足等問題[11]。4 本研究觀察串流處理系統在分析動態的資料時,發現由於每單位時間 處理資料量多寡不一,因此需要動態的調整資源配置。然而,資源配置的 問題是一個NP-problem,並沒有哪一個演算法能夠適用於所有的情況,在 以往的文獻之中提出了許多演算法像是:0/1背包演算法(0/1 Knapsack algorithm)[12]、賽局理論(Game theory)[13],裝箱問題演算法(Bin-packing algorithm)[14]等來解決不同之資源排程問題,然而,資源配置之相關文獻 中並沒有考量到串流資料共享資源的多個虛擬機器(Virtual machine)彼此 之間會存在的資源競爭而所產生的資源干擾現象。因此本論文除了去考慮 每個工作(Task)的資源存取量之外,同時也考慮資料相依性之問題,而為了 最小化整體的處理時間,串流資料處理應用可以被表示為有向圖(Directed Acyclic Graph, DAG),其中點為Task而邊表示為資源存取量。
1.4 研究目標
本研究針對資源配置問題,開發了一個資源存取之關鍵路徑演算法 (Memory Access Critical Path Schedule, MACPS),透過剖析系統(Profiling system)所分析之應用程式之行為將 Tasks 以 DAG 圖呈現,此時會出現多 張相似的 DAG 圖,而我們利用 MACPS,去計算 Tasks 最長計算時間與最 早能夠開始執行之時間,藉由此兩個參數去決定關鍵路徑,同時考量了資 料區域性(Data locality)與實體機器之最快開始執行時間(Earliest start time), 將關鍵路徑之節點盡量配置到同一台實體機器,降低額外的溝通時間 (Communication time),避免其他 Tasks 存取此台實體機器之資源進而造成 資源衝突或搶奪的現象發生,除了考量了同一台實體機器上的虛擬機器之 間的資源存取干擾與各個實體機器之間的資料存取干擾,我們也在單雲以 及跨雲上之模擬環境下分析五個排程方法之效能。我們的目標為,創建出 最適合串流應用程式之虛擬叢集系統建置方式。
5
1.5 論文架構與內容
本論文的架構如下:第一章節引出本篇論文的研究背景與動機,說明所 面臨的挑戰,並簡略的說明改善之方法。第二章將說明與本篇論文相關之 技術,包含雲端運算,串流資料處理等。第三章將詳細說明本篇研究所使 用之系統架構與演算法。第四章將描述本文實驗環境,並以圖文展示系統 相關實驗與結果。最後,第五章為本論文之結論與未來展望。6
二、 相關研究與文獻探討
2.1 雲端運算 (Cloud Computing)
在本論文第一章背景中提到,美國國家標準技術研究院(NIST)定義在雲端 計算中的三種服務模式,如圖 1 所示為:
(1) 軟體即服務(Software as a Service,以下簡稱 SaaS):消費者可透過網路 瀏覽器或者程式介面使用雲端應用程式所提供的各種 SaaS 服務,而不 需要對服務進行更新或維護等作業;而供應商也可將軟體租借給企業 賺取佣金,且利用雲端運算可將開發及維護的人力降到最低。
(2) 平台及服務(Platform as a Service,以下簡稱為 PaaS):透過供應商提供 之執行環境或測試應用平台,消費者可以自行進行開發或應用,不需 要去管理底層的基礎設施,例如網路設定或作業系統等。常見的 PaaS 包括 Microsoft Azure、Google Engine、Amazon S3 等。
(3) 基礎架構及服務(Infrastructure as a Service,以下簡稱 IaaS):雲端服務 供應商會提供伺服器或相關周邊網路設備,透過虛擬化技術動態調整 資源,而消費者可根據自身需求向供應商租用,不必實際購買基礎設 施,即可隨時存取資料和取得計算能力,常見的 IaaS 服務供應商如 Amazon EC2、Amazon EBS、Google Compute Engine 等。
7 圖 1. 雲端運算服務架構圖 由 NIST 定義之四種不同的部屬類別: (1) 私有雲(Private cloud):提供給單一組織使用,例如企業或學校等,雲 端運算利用虛擬化來創造服務,其資料以及儲存設備可以完全由單一 組織所管理,可以更有效的對資源進行重新配置。 (2) 社群雲(Community cloud):提供給限定數目之個人或組織使用,由組 織內的成員或者是可藉由第三方來管理內部資料。 (3) 公有雲(Public cloud):提供給大眾使用,資源由雲端服務供應商所擁有, 使用者可以向供應商租用其資源,價格由供應商之計價系統所決定, 通常是”以量計價”,而為了資訊安全,有些供應商會限制使用者的存 取控制能力。 (4) 混合雲(Hybrid cloud):由兩個或以上的不同的雲端基礎架構所組成, 企業通常使用混合雲來讓內外部資訊能運用自如,可降低人力、硬體 與維護之成本,為企業帶來經濟效益。
8
2.2 虛擬化技術 (Virtualization)
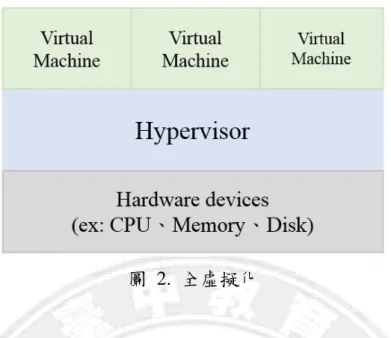
虛擬化技術不僅為雲端運算的關鍵,在 IaaS 階層上是一個非常重要的 角色。利用硬體虛擬化技術將資源抽象化為資源池,像是記憶體空間、虛 擬硬碟、虛擬 CPU 等等,讓企業能夠在現有的機器上增加效能、使用率與 彈性的同時減少 IT 成本。 虛擬化擁有三個特性[15],使其非常適合於雲端運算: (1) 分割性(Partitioning):虛擬化技術能將將單一實體機器的資源做切割, 並且提供給不同的應用程式或作業系統使用。 (2) 獨立(Isolation):每台虛擬機器皆獨立運作,彼此互不影響。 (3) 封裝(Encapsulation):封裝可以保護每一個應用程式,使他們不會干擾 到其他的應用程式。使用封裝時,虛擬機器可被抽象化為一個單一檔 案,讓其他應用程式容易識別。 而虛擬化技術又分為四種[16]: (1) 全虛擬化(Full virtualization) (2) 硬體輔助虛擬化(Hardware-assisted virtualization) (3) 部分虛擬化(Partial virtualization) (4) 半虛擬化(Para virtualization) 全虛擬化模擬全部的實體機器之硬體 I/O 以及 CPU 指令集,幾乎所有 的虛擬機器皆能運行在此虛擬化類型上,如圖 2 所示,例如 VirtualBox、 KVM(Kernel-based Virtual Machine)等。9
圖 2. 全虛擬化
硬體輔助虛擬化類似於全虛擬化,處理機(Processor)大廠 Intel/AMD 將 原有的 CPU 特權模式分為二個等級,速度比全虛擬化更快,例如 Linux KVM、VMware Fusion、VMware Workstation 等。
部分虛擬化技術虛擬機器給程式運作,相較於全虛擬化能更簡單的實 現,但是部分虛擬化不能模擬作為一個實體機器[17]。 半虛擬化提供特殊的 API 給虛擬機器,使其能控制實體硬體設備,相 較於全虛擬化技術,半虛擬化技術更有效率,因為虛擬機器能夠更直接地 去存取硬體,如圖 3 所示。例如 Xen、TRANGO 等[17]。 圖 3. 半虛擬化
10
而為了去管理雲端計算上各種不同的虛擬化方面,企業通常會使用管 理程序(Hypervisors),管理程序是一種機制,讓各種不同的作業系統能夠快 速且有效的獲得虛擬化資源[18]。
2.3 巨量資料與串流處理 (Big Data and Streaming Processing)
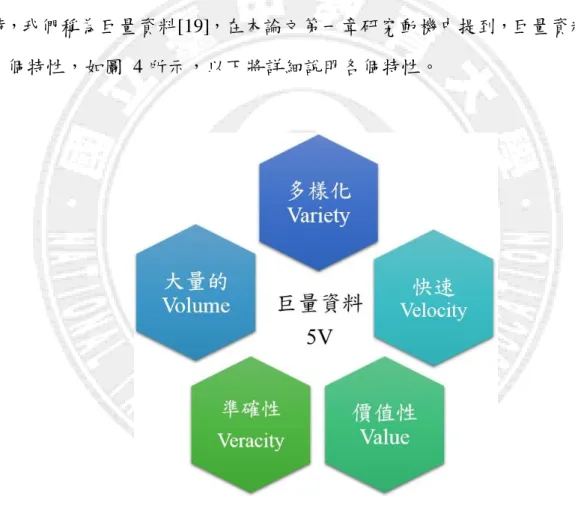
物聯網所產生之資料,來自於各個不同的領域,當這些資訊龐大到資 料庫系統無法一次送入系統內進行運算、分析、儲存成我們能解讀的資訊 時,我們稱為巨量資料[19],在本論文第一章研究動機中提到,巨量資料有 五個特性,如圖 4 所示,以下將詳細說明各個特性。
圖 4. Big data 5 properties
大量(Volume)的特性是巨量資料最具代表性的特徵,包含了所有的 Email、Twitter 訊息、照片、影片資料等。我們每分每秒都在產生這些資料, 累積起來甚至到達了兆位元組(Terabytes),這些越來越多的資料難以利用 傳統的資料庫去分析與儲存。通常分散式系統能夠在不同的區域上儲存部
11 分的資料,並且讓使用者透過軟體去匯集這些資料並使用它。 多樣化(Variety)的資料來源主要分為兩類,結構化與非結構化[20]。在 過去我們可以將結構化資料記錄到關聯式資料庫,但現在隨著網路的發展, 90%的資料已是非結構化[20],因此不能夠簡單的紀錄到表格,如何去分析 或儲存這些大量資料,又該如何彙整變成了重要的議題。 巨量資料的傳輸及產生是快速(Velocity)且連續的,如何回應這些資料 的速度也是一項挑戰,現今巨量資料已經能在產生的過程之中同時進行分 析,而不必透過任何的資料庫。 大數據的價值性(Value)是一項重要的特性,定義了蒐集資料所帶來的 附加價值,而此價值性取決於資料所代表的類型,例如資料型態是否為可 預期的,或是規則、不規則的資料等[6]。 在各種不同的資料型態之下,準確性(Veracity)的資料包含了兩個方面: 資料一致性以及資料可信度,要確保資料是可靠且可信的須符合下列幾項 要點[6]: 鏈結資料(Linked data)與資料的完整性,例如分散式資料。 資料的來源與真實性 資料與其來源之識別 電腦與儲存平台之可信度 可用性與時效性 責任制與信譽 巨量資料的處理又分為批次處理(Batch processing),以及串流資料處理 (Data stream processing)。批次處理是一次執行一連串不連續的資料,批次 資料允許先儲存起來,等到有特定事件發生或式電腦閒置的時候再去處理。 例如像是銀行在處理信用卡帳單時,消費者只會在特定日期收到整個月的
12
消費累積帳單或是企業在發法薪資時,會在每個月的固定日期統一計算後 方法等皆屬於批次作業。
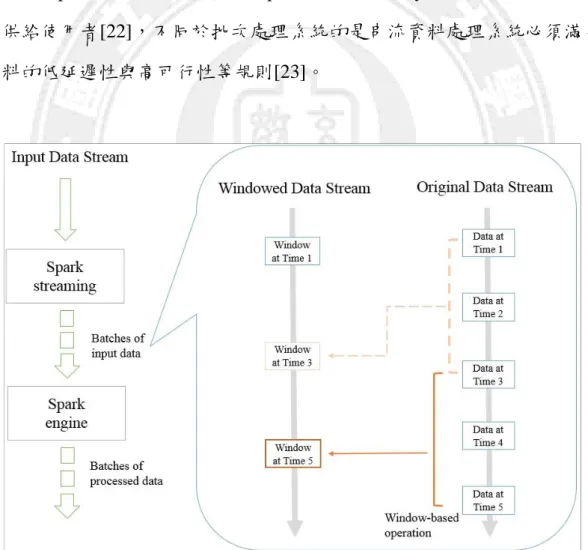
一個典型的資料串流處理系統,最有名的莫過於 Apache Spark,為 UC Berkeley AMP lab 所開發的平行計算框架,基於 Hadoop Map 與 Reduce 的 分佈式計算,不同於 MapReduce 的是 Spark 使用 in-memory 技術,它接收 即時且連續的資料串流並將他們切割成小區塊(Block),每個區塊的資料會 以一個 Window 為單位滑行送入 Spark engine 分析並得出結果[21],如圖 5 所示。而 Spark 將工作之間的運算過程與結果皆存在記憶體裡,不必去使 用 Hadoop 分佈式文件系統(Hadoop distributed file system),以即時的速度 提供給使用者[22],不同於批次處理系統的是串流資料處理系統必須滿足 資料的低延遲性與高可行性等規則[23]。
13
2.4 Spark RDD
RDD,全名為 Resilient Distributed Datasets,為 Spark 之核心概念,Spark 對於 RDD 的描述為” A R e s i l i e n t D i s t r i b u t e d D a t a s e t ( R D D ) , t h e b a s i c a b s t r a c t i o n i n S p a r k . R e p r e s e n t s a n i m m u t a b l e , p a r t i t i o n e d c o l l e c t i o n o f e l e m e n t s t h a t c a n b e o p e r a t e d o n i n p a r a l l e l ” [25],他是一個容錯且平行的資料結構,允許使用者將資料儲存 到磁碟以及記憶體,目的是能夠有效率的重複運用這些資料。 不同於現存的 in-memory 儲存裝置,RDD 物件是一個被封裝的狀態, 若要從原先的狀態轉換成另一種狀態,那麼會使用另外一個 RDD 來封裝 轉換過後的資料,使用者僅能從 RDD 封裝上辨識裡面的資料,而無法直 接得知裡面的資料結構。RDD 基於 coarse-grained 轉換之介面,將 operation 分為兩類,如表 1,transformations 主要產生 RDD,並且將 RDD 轉換成另 外一個 RDD;而 action 表示對 RDD 的操作[24]。
表 1. Transformations and actions available on RDDs in Spark
圖 6 為 Spark RDD 示意圖,Spark 將一個 job 切成好幾個 RDD,每個 RDD 裡會有固定大小及數目之 partition,透過程式碼內容決定進行何種轉 換,如圖 6 之 stage1,RDD A 進行 map 轉換至 RDD B,並且進行 shuffle,
14
在進行 shuffle 前之階段為一個 stage,因此一個 job 裡會有好幾個 stage, stage 中會有多個 RDD 以及 partition 分別做不一樣的動作。RDD 擁有以下 五個特性[25]:
Partition list:
當 input data 進來時,RDD 會將資料分成 n 個 partition,我們可以 稱這 n 個 partition 為 n 個 task,需要 n 個 core 執行,使用者可以 自己定義 partition 之切割量,但必須要注意的是一個 partition 最 大只能到 128MB,一旦超過 RDD 便會自己分割成兩個 partition。 在 spark 裡之預設值為每個 RDD 有 2 個 partition。
A function for computing each split:
RDD 會透過程式碼內容進行相對應的轉換,如圖 6 之 stage1 所 示,當 RDD 確定執行 map 轉換的動作,所有 mapRDD 裡的 partition 便是統一執行相同的 map 動作。
A list of dependencies on other RDDs:
透過 RDD 關係我們可以得知其相依賴關係,透過此資訊,我們也 能得到 task 之間的相依賴關係。
Optionally, a Partitioner for key-value RDDs:
若有使用到 hash-partition,RDD 會分割出額外的 RDD 來放置相 對應的 key value。
Optionally, a list of preferred locations to compute each split on: 通常 RDD 會將資料處理完畢之後再進行轉換,如果有必要,RDD 會儲存各分頁資料的位置。
RDD 在進行轉換之後便會記錄轉換過程,我們可以由此得知他們之間的 相依賴關係,此關係取決於 data locality,因此,RDD 之相依賴性又分為兩 種:
15 Narrow Dependency(窄依賴):
每一個 RDD 只會映射到另外一個 RDD,如圖 6 之 stage1,在進 行 map 時,每個 partition 一對一映射到 RDD B 之 partition,因此 資料會來自於同一地點。 Wide Dependency(寬依賴): 每一個 RDD 會分散給不同的 RDD,例如 RDD E 所執行之 join, 將尚未排序的資料重組,資料會在不同地點搬移。 圖 6. Spark RDD 示意圖 圖 6 為程式碼之執行順序,因此箭頭會往右執行,而 RDD 的過程會 是與執行順序相反,他必須由最後往前推導,紀錄 RDD 之間父與子的關 係,稱為血統關係(lineage),透過此 lineage,當 RDD 的 partition 遺失時, 我們可以重新計算記憶體的資料,恢復遺失的 partition,達到容錯機制,同 時我們也能得知 task 之間的相依賴性,透過這個特性來進行排程。
16
2.5 Scheduling
雲端運算的資源雖然是無上限,但是基於pay-as-you-go之服務模式, 使用者所租用之資源還是受限的,因此資源配置在雲端運算上長久以來被 廣泛的研究,期望能夠達到增進效能、降低複雜度或者是節省電源以達到 綠色運算等,利用不同的方法或演算法來達到不同的目的,然而資源配置 之問題屬於NP Problem,沒有一個演算法能適用於所有的情況,只能夠針 對某一類議題去探討。Vinothina, V, R et al.[11] 介紹了各種不同的資源配 置策略,講述了資源配置對於雲端運算之重要性,並且討論他們之間所面 臨的挑戰。同時,Vinothina, V, R et al.也將雲端上的資源配置做分類,如圖 7所示。雲端運算資源是”以量計價”,因此資源配置的最佳化對於消費者來 說,不僅能夠更加節省成本之外,且能很好的運用資源。一個好的資源配 置應避免的幾項要素,包括了當兩個應用程式在同一時間存取同一資源時 所產生的資源競爭,以及當資源有限或不足以供給有需求之應用程式形成 資源之缺乏,或是過度供給、供給不足等問題。 圖 7. 雲端運算之資源配置策略17
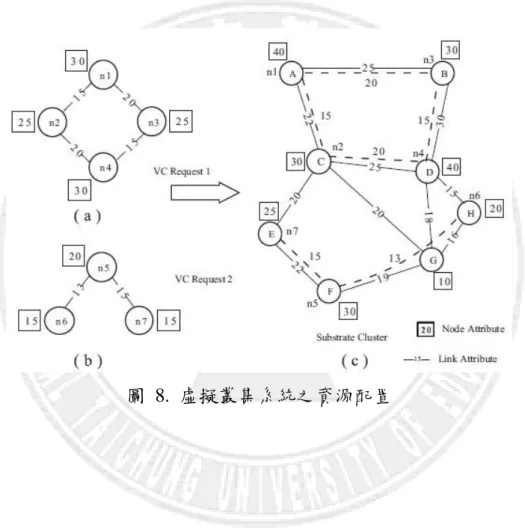
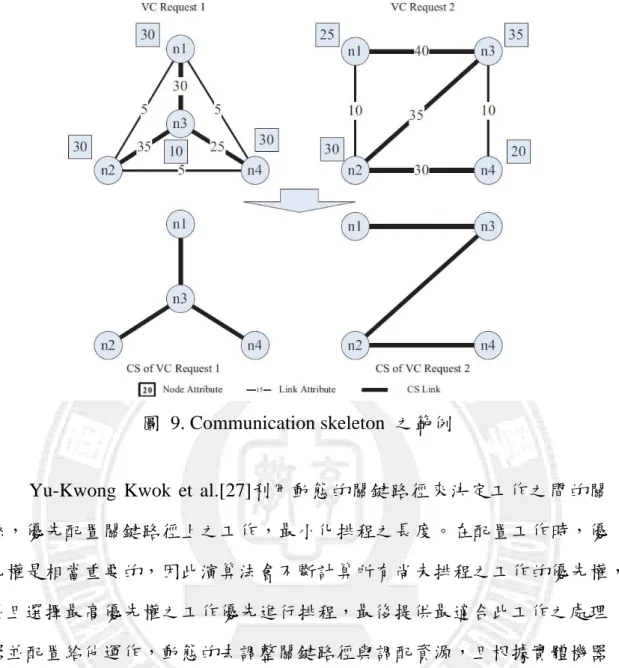
Xiaohui Wei et al.[26]探討虛擬叢集(Virtual Cluster)之資源配置,提出 了Partial mapping之概念,利用網路拓譜的概念,將分散式架構上的計算節 點集合為一張無向圖,如圖 8所示,再根據演算法留住重要的link與nodes, 實現partial MAPPING,依照communication skeleton來作為資源配置之依據, 如圖 9所示,重要性較高的工作應該要優先被配置並且保證他們能擁有完 整的資源,避免其他的子工作影響到整體工作的執行。
18
圖 9. Communication skeleton 之範例
Yu-Kwong Kwok et al.[27]利用動態的關鍵路徑來決定工作之間的關 係,優先配置關鍵路徑上之工作,最小化排程之長度。在配置工作時,優 先權是相當重要的,因此演算法會不斷計算所有尚未排程之工作的優先權, 並且選擇最高優先權之工作優先進行排程,最後提供最適合此工作之處理 器並配置給他運作,動態的去調整關鍵路徑與調配資源,且根據實體機器 之節點能夠最早開始執行時間以及最晚開始執行時間做為配置之依據,重 複去計算節點之優先權。 Menglan Hu et al.[28] 講述計算型工作大致上可被分類為三類:不可分 割(Indivisible Task)、模組化分割(Modularly Task)與任意分割(Arbitrarily Task),其中不可分割之工作只能在單一處理器上處理,而模組化分割可以 分散被多個處理器平行執行,但會存在溝通與同步之問題,任意分割之工 作則是可以分成任意大小之數量平行處理。排程策略主要將Deadlines作為 門檻值來決定不可分割工作與模組化分割之工作之排程,以最小化工作之 總執行時間。
19
Weijia Song et al. [14] 將資源配置的問題模擬為裝箱問題,其中箱子 為Server而每一台虛擬機器為將要被打包的物體,此文獻根據過去的統計 資料預估所有應用程式之資源需求量與所有實體機器之負載,基於資源需 求與綠色運算(Green computing),利用裝箱問題演算法,透過最佳化Server 數量動態配置資料中心之資源。
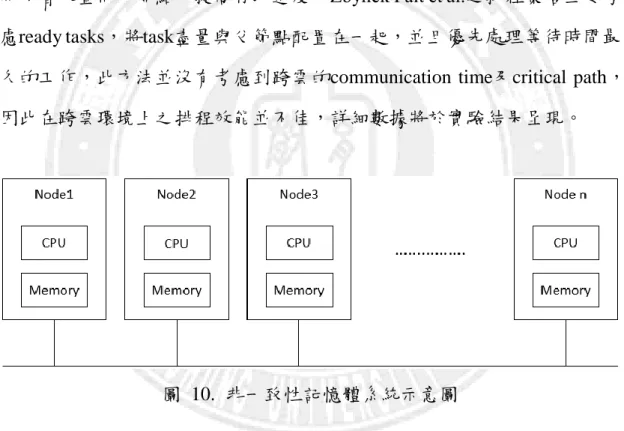
Zbynĕk Falt et al.[29]在非一致性記憶體系統(NUMA)上探討平行資料 串流系統之task scheduling。Numa 系統如圖 10所示,相較於對稱式多處理 器(SMP)之設計,NUMA系統每一個CPU能夠各自管理部分的系統記憶體, 將兩者放置同一節點,提高存取速度。Zbynĕk Falt et al.之排程策略主要考 慮ready tasks,將task盡量與父節點配置在一起,並且優先處理等待時間最 久的工作,此方法並沒有考慮到跨雲的communication time及critical path, 因此在跨雲環境上之排程效能並不佳,詳細數據將於實驗結果呈現。
20
三、 系統架構與演算法
此章節分為兩個部分,一是介紹本研究所採用的雲端運算系統架構, 二是公式及演算法, Memory Access Critical Path Scheduling (MACPS)分為 4 個部分,Earliest Start Time 計算,Longest Competition Time 計算,Data Locality 定義與計算及 MACPS 演算法本體。
在 Input 是大量 Data stream 的前提之下,系統資源會不斷的被存取, 而不只是記憶體,網路傳輸也是主要的一個考量原因,過去的資源配置之 文獻雖然有考慮到資源存取,但是過去文獻所探討的對象是批次資料,然 而在物聯網的環境底下,資料是以即時且連續性的方式進來,因此資源會 不間斷地被存取,在這種考量之下,我們所考慮的就不單單只是頻寬與計 算方面,還有考慮到資源存取的特性。一般而言,存在於同一個實體機器 或虛擬機器內之 Task,常會因為需要資源而產生彼此干擾或衝突的現象, 如圖 11 所示: 圖 11. 資源干擾之示意圖
21
同一台實體機器上存在正在運行中的 Task A、B 與 C,此時若 Task A 需要 Task B 之資料,然而當 Task B 執行完畢時,由於 Task C 需要 I/O, 因此會霸佔住記憶體資源,使得 Task A 無法順利讀取所需資料,否則會產 生干擾的問題,進而讓執行時間往後延遲。因此我們必須來決定哪一個 Task 能夠優先處理,優先使用資源,以避免上述之情況。 本研究利用關鍵路徑之排程方法,針對串流處理之應用程式來設計較 適合的雲端叢集系統的建置方式,最佳化串流處理之效能,以下將說明細 節與架構。
3.1 系統架構
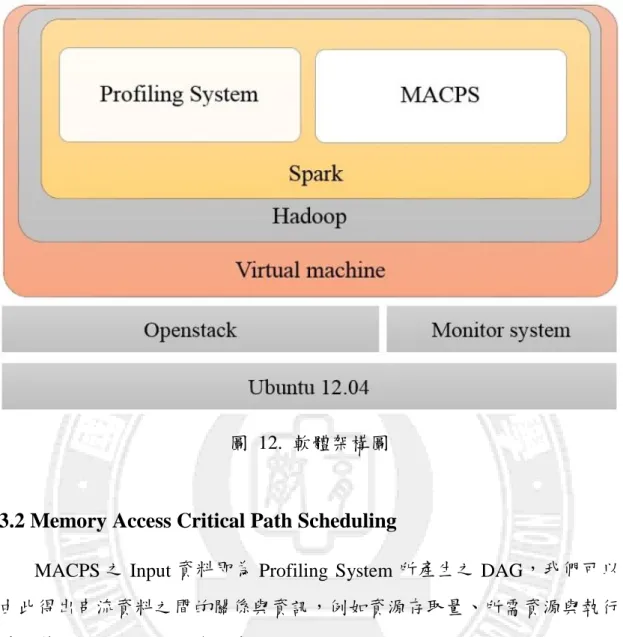
圖 12 為本研究之軟體架構圖,從底層的 Ubuntu 12.04 版本,接著在 其上建置 Openstack、虛擬機器,並且在虛擬機器上架設 Hadoop 2.2.0 版與 Spark 1.0.2 版用以分析大量數據,接著採用我們自己開發之剖析系統 (Profiling system),用於剖析應用程式之行為,並將其視為我們的 Input 之 一,而實體機器之相關資訊則是透過監控系統(Monitor system)來即時監控, 本研究建構於虛擬叢集之上,所以 Input task 需得先經由 MACPS,考慮 Data locality 與資料相依賴率等特性,在根據關鍵路徑上之 Tasks 關係,配 置到實體機器裡。22
圖 12. 軟體架構圖
3.2 Memory Access Critical Path Scheduling
MACPS 之 Input 資料即為 Profiling System 所產生之 DAG,我們可以 由此得出串流資料之間的關係與資訊,例如資源存取量、所需資源與執行 時間等,並且依照這些資訊來進行排程。 我們將實體機器與 Task 分別定義為(1)、(2)。 𝑃𝑀𝑠 = {𝑃1, 𝑃2, 𝑃3, … … 𝑃𝑝−1, 𝑃𝑝} 𝑇𝑎𝑠𝑘𝑠 = {𝑇1, 𝑇2, 𝑇3, … … 𝑇𝑡−1, 𝑇𝑡} (1) (2)
23
Algorithm MACPS
Input: Resource , Job information
Output: Task allocation
Begin
1: Clear buffer
2: Get data structure from input 3: For each node
4: get longest competition time by getLCT(node) 5: get earliest start time by getEST(node)
6: end for
7: While nodes haven’t allocated 8: For each node
9: If input edge finished then
10: input edge -=1
11: If input edge ==0 then
12: node ready
13: end if
14: end if
15: end for
16:For each ready node
17: get next node with max NP by formula (4) 18: If lock PM for CurNode!=Null then 19: allocate node to Loca PM
20: UnLock PM
21: else
22: If node’s parent == null then
23: allocate node to PM considering earliest start time 24: else
25: allocate node to PM with min PM_EST considering formula (5) 26: get NextStageReady Node
27: If (Max NP – NextStageReady Node NP by formula 1) < (NextStageReady Node Input Edge Length/Min Banswidth) then
28: If PM is locked
29: unlock PM
30: lock CurNode PM for NextStageReady node
31: lock PriorityPM = NextStageReady Node Input Edge Length/Min Banswidth
24
33: If PM is locked
34: unlock PM
35: lock CurNode PM for NextStageReady node
36: lock PriorityPM = Data LocalityCurNode, NextStageReady Node/Min Banswidth
37: end for
38: end while
資源配置之排程方法說明如下: 演算法第 3~6 行:
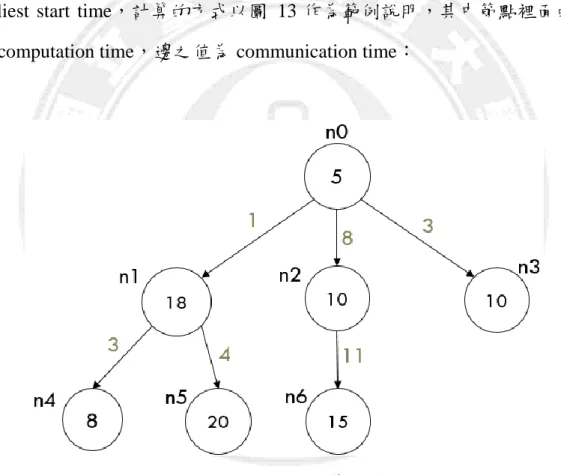
首先,我們針對所有的 Input data 計算其 longest competition time 與 earliest start time,計算的方式以圖 13 作為範例說明,其中節點裡面的值 為 computation time,邊之值為 communication time:
圖 13. LCT 與 EST 計算之範例圖
下列為LCT之程式碼,程式會從n0節點開始遞迴計算,舉例來說n5因為沒 有子節點,便傳回值20,而n1之LCT為n4與n5之LCT + communication time + n1 computation time取最大值等於42,以此類推由下往上推算各個節點的 LCT。
25 int getLCT(node)
{
if (node’s child == null) return node computation time; else
return node computation time + Max(getLCT(node’s child)+ edgenode,node’s child)
}
下列為EST之程式碼,由n0往下遞迴計算,以圖 13所示,n0之EST為5,n1 之EST為n0 EST + communication + n1 computation time等於24,以此類推 往下計算。
int getEST(node) {
if (node’s parent == null)
return node computation time; else
return node computation time + Max(getEST(node’s parent)+ edgenode,node’s parent)
}
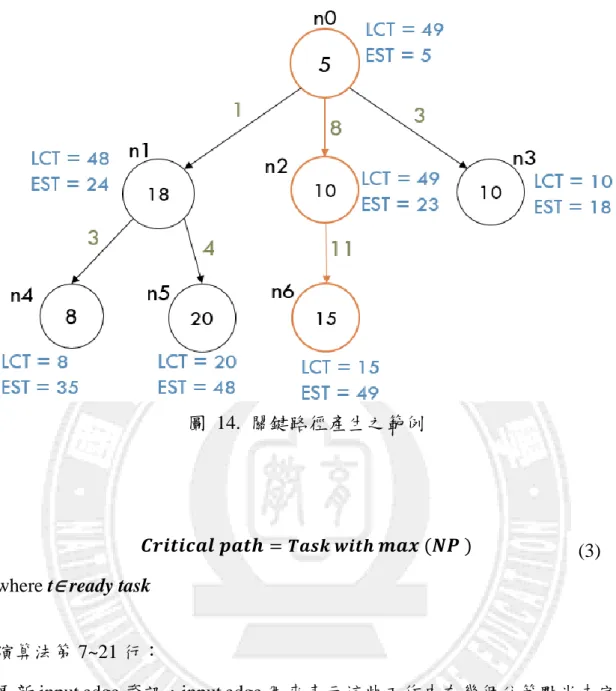
由上述計算結果我們可以得到每個節點之LCT與EST,並且透過公式(3)與 (4)來得到其中的critical path,如圖 14之範例所示,我們可以得到critical path為中間的路徑。
26
圖 14. 關鍵路徑產生之範例
𝑪𝒓𝒊𝒕𝒊𝒄𝒂𝒍 𝒑𝒂𝒕𝒉 = 𝑻𝒂𝒔𝒌 𝒘𝒊𝒕𝒉 𝒎𝒂𝒙 (𝑵𝑷 ) where t∈ ready task
演算法第 7~21 行:
更新 input edge 資訊,input edge 用來表示這些工作中有幾個父節點尚未完 成工作,這時會找出一群 ready task,我們利用公式(4),算出 NP 值,最高 NP 值之 ready task 可以優先執行: 𝑵𝑷 = 𝒏𝒐𝒅𝒆 𝑬𝑺𝑻 + 𝒏𝒐𝒅𝒆 𝑳𝑪𝑻 − 𝒏𝒐𝒅𝒆 𝒄𝒐𝒎𝒑𝒖𝒕𝒂𝒕𝒊𝒐𝒏 𝒕𝒊𝒎𝒆 演算法第 22~25 行: 接著我們再去觀察,這些 ready task 是否有預留資源可以給他們使用,若 是有則直接放入此資源(即實體機器),若是沒有,我們就去尋找此 ready task (4) (3)
27
是否存在 Parent,若是此 ready task 上面還存在 parent task,則我們依照公 式(5)放入 parent task 所在之實體機器:
𝑷𝑴_𝑬𝑺𝑻 = 𝑷𝑴 𝒂𝒗𝒂𝒊𝒍𝒂𝒃𝒍𝒆 𝒕𝒊𝒎𝒆 + 𝒄𝒐𝒎𝒎𝒖𝒏𝒊𝒄𝒂𝒕𝒊𝒐𝒏 𝒕𝒊𝒎𝒆
若是此 ready task 上面並沒有任何的 parent task,便直接將此 task 放入最快 可以滿足其需求之實體機器。
演算法第 26~38 行:
考慮下一階段會 ready 之 node,並且評估這些 node 配置到其他的實體機 器,是否會延遲整體的執行時間,若會,則資源會先預留給他(即 lock PM), 而 lock 之優先權取決於此 ready node 放到其他實體機器所造成之延遲時 間,延遲時間越高,表示優先權越高,越能提早拿到資源進行運算;若是 這些 node 放到其他實體機器並不會造成整體執行時間的影響,那麼根據 公式(6)來考慮 data locality 之轉換是否會造成整體執行時間之延遲,若會, 則我們 lock PM 預留資源。
公式(6)之 Task0 表示目前已經配置好之 Task,Task1 則表示下一次可 ready 之 task。
𝑫𝒂𝒕𝒂 𝑳𝒐𝒂𝒄𝒍𝒊𝒕𝒚𝒕𝟎,𝒕𝟏 =𝟏(𝑹𝒆𝒂𝒅𝑫𝒂𝒕𝒂𝒕𝟎∩ 𝑹𝒆𝒂𝒅𝑫𝒂𝒕𝒂𝒕𝟏) + 𝟐(𝑾𝒓𝒊𝒕𝒆𝑫𝒂𝒕𝒂𝒕𝟎∩ 𝑾𝒓𝒊𝒕𝒆𝑫𝒂𝒕𝒂𝒕𝟏) +𝟑(𝑾𝒓𝒊𝒕𝒆𝑫𝒂𝒕𝒂𝒕𝟎∩
𝑹𝒆𝒂𝒅𝑫𝒂𝒕𝒂𝒕𝟏) +𝟒(𝑹𝒆𝒂𝒅𝑫𝒂𝒕𝒂𝒕𝟎∩ 𝑾𝒓𝒊𝒕𝒆𝑫𝒂𝒕𝒂𝒕𝟏)
當 Spark 之 RDD 進行轉換時,會需要跨資源傳送資料,因而產生執行 時間之延遲,data locality 可分為四個 case,並且依照公式(6)之 4 個參數來 (5)
28 討論可能性: Case 1: 兩個 task 彼此之間沒有程式的相依賴關係,但是卻在同一個 RDD 裡 圖 15. Case 1:Node 位於相同 RDD 但無相依賴性 表 2. RDD 之 Case 1 之可能性 ReadData1 ∩ ReadData2 可能性為?%,表示不確定是否讀取同一塊記憶 體之資料。 WriteData1 ∩ ReadData2 可能性為?%,有可能會存取到同一塊記憶體, 也同時不可能,機率為?% WriteData1 ∩ WriteData2 可能性為?% ReadData1 ∩ WriteData2 可能性為?%
29 Case 2: 兩個 task 之間有程式的相依賴關係,且在同一個 RDD 裡 圖 16. Case 2:Node 位於相同 RDD 且有相依賴性 表 3. RDD 之 Case 2 之可能性 ReadData1 ∩ ReadData2 可能性為?%但是機率偏高,他們之間有程式依 賴性,有可能讀取同一塊記憶體之資料,但是 做不一樣的處理。
WriteData1 ∩ ReadData2 相較起來可能性為 100%,代表兩個 node 都存 取到同一塊記憶體之資料。
WriteData1 ∩ WriteData2 可能性為?%但機率偏高,有可能兩個 node 皆寫 到同一塊記憶體資料,只是做不一樣的處理。
ReadData1 ∩ WriteData2
可能性為?%且機率偏低,因為一個是從上面讀 取,一個則是往下讀寫,代表兩個 node 是錯開 的,但又在同一塊 RDD 內且有程式相依賴性。
30 Case 3: 兩個 task 之間並沒有依賴關係,且分別在不同的 RDD 裡 圖 17. Case 3:Node 位於不同 RDD 且無相依賴性 表 4. RDD 之 Case 3 之可能性 ReadData1 ∩ ReadData2 可能性為 0% WriteData1 ∩ ReadData2 可能性為 0% WriteData1 ∩ WriteData2 可能性為 0% ReadData1 ∩ WriteData2 可能性為 0% Case 4: 兩個 task 之間有依賴關係,但是在不同的 RDD 裡 圖 18. Case 4:Node 位於相同 RDD 且有相依賴性
31 表 5. RDD 之 Case 4 之可能性 ReadData1 ∩ ReadData2 可能性為?%,有可能讀取同一份記憶體資 料。 WriteData1 ∩ ReadData2 可能性為?%但機率偏高,因為一個向下寫 入,一個往上讀取,但因為是不一樣的 RDD,所以無法斷定是 100%。 WriteData1 ∩ WriteData2 可能性為?%,有可能寫入同一份記憶體資 料。 ReadData1 ∩ WriteData2 可能性為 0%,一個從上面讀取,一個向 下寫入資料。 我們將以上四種 case 之可能性為?%設為 x,機率為?%但機率偏高之狀況 設為 1.5x,?%且機率偏低作為 0.5x,100%作為 2x,將四個狀況相加: ReadData1 ∩ ReadData2 = x + 1.5x + 0 + x = 3.5x WriteData1 ∩ ReadData2 = x + 0.5x + 0 + 0 = 1.5x WriteData1 ∩ WriteData2 = x + 1.5x + 0 + x = 3.5x ReadData1 ∩ WriteData2 = x + 2x + 0 + 1.5x = 4.5x 所得出之結果即為公式(6)之 α 值,α 值越高代表將 tasks 放在不同之實體 機器上會拉長整體執行時間,如上述之例子來說: α1 = 3.5x , α2 = 1.5x , α3 = 3.5x , α4 = 4.5x 圖 19 表示了 MACPS 執行之流程。
32
33
四、 效能評估
4.1 實驗環境
本研究之主體為資源配置,目標為創建出最適合串流處理應用程式之 虛擬叢集系統,為了驗證方法,本文模擬單雲與跨雲的環境,採用傅立葉 轉換之 DAG 作為 input job 來使實驗更接近實際狀況,如圖 20,並且參考 [30]在 Unicloud 上所評估之網路速度頻寬如表 6 所示,並且透過 5 種變因 如: Task 個數 Computation Time Communication Data ReadData/WriteData 常態分佈之標準差 來討論以下五個方法之效能:
1.
Next Ready Tasks & Data locality2.
Data locality 3. Next Ready Tasks4. Critical Paths & Resource EST 5. Locality-aware task scheduling
34 圖 20. 傅立葉轉換之 DAG(以 10 個 node 為例) 圖 21. 3 種標準差之常態分佈 0 50 100 150 200 250 300 350 400 0 20 40 60 80 100 120 次數 機率 (%) 標準差 = 0.1 標準差 = 0.2 標準差 = 0.3
35
本實驗採用三種不同標準差的常態分佈,表示 1000 次當中落在區間 的平均次數,將其視為 data locality 所產生的機率,藉以探討在不同應用 程式的工作行為下,每個不同的排程方式所表現出的效能。
表 6. UniCloud Network Speed
Sites NTCU-NTCU NTCU-PU
Network Speed 120Mb/s 42 Mb/s
4.2 實驗結果
圖表中 MACPS 之數線表示只考慮 Next Ready Tasks 與 Data
locality,DL 則表示只考慮 Data locality,只考慮 Next Ready Tasks 排程方 法以 NRT 表示,[27]中之 Critical Paths & Resource EST 策略,在圖表中 表示為 CP,最後,數線 LA 則表示[29]之 Locality aware task scheduling 策 略。利用以上五種排程方法來探討 5 個不同變因與環境之效能,每一個 變因之變動值皆執行 10 次取平均值,結果如下: 圖 22. 單雲-Task 總數 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 1 0 1 5 2 0 2 5 3 0 3 5 4 0 Exe cutio n tim e (s) # of tasks MACPS DL NRT CP LA
36 圖 23. 跨雲-Task 總數 測量此變因時,環境之預設值為: VM 個數 10 VM 所需記憶體 2G Computation Time 30~50 s Task 所需資源 200~300 MB 頻寬 單雲: 10~15 MB 跨雲: 1~4 MB ReadData/WriteData 200~300 MB Communication Data 200~500 MB 常態分佈平均值 0.5 標準差 0.1 圖 22 為在單雲環境上改變 task 數量之結果,由於 task 在數量 40 以上 記憶體不足,因此沒有繼續量測。結果顯示 execution time 會隨著 task 數 量增加而呈現指數成長,原因為 task 數量增加,更有可能無法配置同一機 器給多個 task,使得一些 task 被迫配置到其他實體機器,因而產生跨 PM 0 5000 10000 15000 20000 25000 30000 35000 1 0 1 5 2 0 2 5 3 0 3 5 4 0 Executi o n time (s) # of tasks MACPS DL NRT CP LA
37
溝通的機率,造成執行時間延長。另外,LA 方法是應用於單機多核心之環 境,沒有考慮到跨雲頻寬較低,因此當工作數量逐漸增加,LA 策略之實驗 結果與其他方法相較之下,指數成長的幅度較大。在單雲環境上 MACPS 之方法優於 LA 方法,節省約一半的執行時間,相較於 CP 之策略,則是 節省了三分之一的執行時間。NRT 方法主要考慮 next ready task,由於在單 雲環境下頻寬較高,因此 communication time 所佔的時間比較高,因此在 大多情況下 NRT 優於 DL;跨雲環境上 MACPS 相較於 LA 方法與 CP 方 法皆節省了一半之執行時間,DL 方法考慮 data locality 特性,在跨雲頻寬 少的情況下,data locality 轉換需要較高的時間,所以 DL 主要的精神在於 優化 data locality 之轉換時間。 圖 24. 單雲- Computation Time 0 1000 2000 3000 4000 5000 6000 7000 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 Exe cutio n tim e (s) Computation time (s) MACPS DL NRT CP LA
38 圖 25. 跨雲- Computation Time 測量此變因時,環境變數之預設值為: VM 個數 10 Task 個數 10 VM 所需記憶體 2G Task 所需資源 200~300 MB 頻寬 單雲: 10~15 MB 跨雲: 1~4 MB ReadData/WriteData 200~300 MB Communication Data 200~500 MB 常態分佈平均值 0.5 標準差 0.1 圖 24 由於 computation 之總量增加,因此成類線性成長。在單雲環境 上 data locality 之影響較小,因此本研究之方法與 NRT 較能接近。圖 25 為 跨雲,因為 computation 不受跨雲與不跨雲之影響,而 LA 並沒有考慮到 critical path,因此在效能上略遜於 CP 策略。 0 1000 2000 3000 4000 5000 6000 7000 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 Exe cutio n tim e (s) Computation time (s) MACPS DL NRT CP LA
39 圖 26. 單雲- Communication Data 圖 27. 跨雲- Communication Data 0 500 1000 1500 2000 2500 3000 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 Exe cu tio n t im e (s ) Communication data (MB) MACPS DL NRT CP LA 0 2000 4000 6000 8000 10000 12000 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 Execu tio n tim e (s ) Communication data (MB) MACPS DL NRT CP LA
40 測量此變因時,環境變數之預設值為: VM 個數 10 Task 個數 10 VM 所需記憶體 2G Computation time 30~50 s Task 所需資源 200~300 MB 頻寬 單雲: 10~15 MB 跨雲: 1~4 MB ReadData/WriteData 200~300 MB 常態分佈平均值 0.5 標準差 0.1 圖 26 在單雲環境下,communication 量增加,然而頻寬約 15MB,因此每 個區間的每個 task 僅增加 3~4 秒,才會呈現線性成長;圖 27 跨雲之頻寬 約 4MB,每個區間的每個 task 約增加 10 秒,由結果圖顯示以指數成長, 換句話說,communication data 的變因與頻寬有非常大的關係。另外,NRT 之方法主要盡量縮短 critical path 之執行時間,當 communication 量增加, 效能會更好,對於跨雲來說,此方法更加顯著。
41 圖 28. 單雲- ReadData/WriteData 圖 29. 跨雲- ReadData/WriteData 0 200 400 600 800 1000 1200 5 0 / 5 0 1 0 0 / 1 0 0 1 5 0 / 1 5 0 2 0 0 / 2 0 0 2 5 0 / 2 5 0 3 0 0 / 3 0 0 3 5 0 / 3 5 0 4 0 0 / 4 0 0 4 5 0 / 4 5 0 5 0 0 / 5 0 0 Execu tio n tim e (s ) ReadData/WriteDara (MB) MACPS DL NRT CP LA 0 2000 4000 6000 8000 10000 12000 14000 16000 5 0 / 5 0 1 0 0 / 1 0 0 1 5 0 / 1 5 0 2 0 0 / 2 0 0 2 5 0 / 2 5 0 3 0 0 / 3 0 0 3 5 0 / 3 5 0 4 0 0 / 4 0 0 4 5 0 / 4 5 0 5 0 0 / 5 0 0 Exe cuyio n tim e (s) ReadData/WriteData (MB) MACPS DL NRT CP LA
42 測量此變因時,環境變數之預設值為: VM 個數 10 Task 個數 10 VM 所需記憶體 2G Computation time 30~50 s Task 所需資源 200~300 MB 頻寬 單雲: 10~15 MB 跨雲: 1~4 MB Communication Data 200~500 MB 常態分佈平均值 0.5 標準差 0.1 圖 28 由於頻寬高,所以 data 轉換之時間不高,以至於實驗結果呈現線性 成 長 , 另 外 , DL 在 300MB 時 超 越 NRT , 理 由 是 因 為 DL 在 ReadData/WriteData 變因之下有較高效能,此方法之首要目的在改善由 RDD 轉換所造成的執行效能延遲,因此在 RDD 轉換量越高,效能越好, 而跨雲頻寬較低,因此執行時間之延遲會升高,如圖 29。
43 圖 30. 單雲-常態分佈標準差 圖 31. 跨雲-常態分佈標準差 0 100 200 300 400 500 600 700 800 MACPS DL NRT CP LA Exe cutio n tim e (s) 標準差 = 0.1 標準差 = 0.2 標準差 = 0.3 0 500 1000 1500 2000 2500 MACPS DL NRT CP LA Exe cutio n tim e (s) 標準差 = 0.1 標準差 = 0.2 標準差 = 0.3
44 測量此變因時,環境變數之預設值為: VM 個數 10 Task 個數 10 VM 所需記憶體 2G Computation time 30~50 s Task 所需資源 200~300 MB 頻寬 單雲: 10~15 MB 跨雲: 1~4 MB ReadData/WriteData 200~300 MB Communication Data 200~500 MB 常態分佈平均值 0.5 如圖 30 所示,當標準差越高,代表 data locality 之分布越平均,因此在低 標準差的時候 data locality 會分布在某幾個特定的 tasks 上,表示 MACPS 與 DL 可以在這種情況下產生更有效的排程,因此 MACPS 與 DL 之實驗 結果會與標準差成正比。另外,其他的方法呈現反比或是均標的原因為 data locality 的分布較平均的話,在其他方法的排程策略上,出現剛好兩個或以 上有 data locality 關係的 tasks 排到同個資源的可能性較高。
圖 31 所示之跨雲與單雲的分別在於頻寬的不同,因此呈現的差距與總執 行時間較高。
實驗結果顯示,LA 之方法由於在單機多核心的系統上進行排程機制, 沒有考慮到溝通量與 critical path,因此不太適用於雲端的環境上;而 CP 之策略則是沒有考慮到 data locality 的特性,相較之下,同時考慮 Data locality 與 Next ready tasks,無論在單雲或跨雲上,效能始終比較好,這是 因為 Task 在讀取所需資料時,若是兩者來源為不同記憶體,則會造成傳輸 時間的上升,執行時間之延遲等,因此此特性為必須考慮之要點。
45
五、 結論
物聯網透過網路將遍布各地之感測裝置來收集資料,資料量急遽的成 長而形成巨量資料,這些資料必須透過分析處裡來取得我們所需之資訊, 而傳統的資料中心已經無法應付這些大量數據,因此將巨量資料儲存在雲 端運算之資料中心裡,利用雲端運算的靈活度與快速佈署資源等特性來達 到”智慧化”之理想。 感測裝置所匯集而成之巨量資料,通常必須切割為 data stream,利用 分析系統來取得我們所需之資訊,與批次處理不同的是,這些大規模且連 續性之資料要求即時且準確率高之分析結果,因此資源之分配對於串流資 料來說是非常重要的。 本研究主要探討串流資料處理之資源配置,透過剖析系統所分析出工 作之間的相互關係與資訊,形成多個有向圖,計算所有 tasks 之 longest competition time 與 earliest start time 來決定關鍵路徑,並且考量關鍵路徑 上的 task、next ready task 與 data locality 特性,配置優先權較高之 task,解 決虛擬節點的資源配置問題並且降低資源競爭與干擾的現象。為了驗證我們的方法,本研究模擬單雲以及跨雲之環境,採用傅立葉 轉換之 DAG 作為 input job 以及三種不同標準差的常態分佈,視為 data locality 產生的機率,探討五種排程方法:(1) 考慮 Next Ready Tasks 與 Data locality,(2) 只考慮 Data locality 特性,(3)
只考慮
Next Ready Tasks,(4) Critical Paths & Resource EST 與(5)Locality aware task scheduling 等分別在 五 種 變 因 如 : Task 個 數 、 Computation Time 、 Communication data 、 ReadData/WriteData 與常態分佈之標準差之下所表現出的效能影響,實驗 結果顯示 Memory Access Critical Path Scheduling 無論在單雲或是跨雲環境 之下,效能始終是最好的。46
參考文獻
[1]. Luigi Atzori, Antonio Iera, and Giacomo Morabito. "The Internet of Things: A survey", Computer Networks, Vol.54, Issue 15, pp.2787-2805, October 2010. [2]. Jayavardhana Gubbia, Rajkumar Buyyab, Slaven Marusic, and Marimuthu
Palaniswami. "Internet of Things (IoT): A vision, architectural elements, and future directions", Future Generation Computer Systems, Vol.29, Issue 7, pp.1645-1660, September 2013.
[3]. Mell, Peter, and Tim Grance. "The NIST definition of cloud computing", NIST Special Publication 800-145, September 2011.
[4]. Attila Kertesz, Gabor Kecskemeti, and Ivona Brandic, “An SLA-based resource virtualization approach for on-demand service provision”, Proceedings of the 3rd international workshop on Virtualization technologies in distributed computing, ACM, pp. 27-34, June 2009.
[5]. Michael Armbrust, Armando Fox, Rean Griffith, Anthony D. Joseph, Randy Katz, Andy Konwinski, Gunho Lee, David Patterson, Ariel Rabkin, Ion Stoica, and Matei Zaharia.“Above the Clouds: A Berkeley View of Cloud Computing”, Communications of the ACM, Vol.53, Issue.4, pp.50-58, April 2010.
[6]. Yuri Demchenko, Paola Grosso, Cees de Laat, and Peter Membrey. "Addressing big data issues in scientific data infrastructure", Collaboration Technologies and Systems (CTS), 2013 International Conference on. IEEE, 2013.
[7]. Karthik Kambatla, Giorgos Kollias, Vipin Kumar, and Ananth Grama. “Trends in big data analytics”, Journal of Parallel and Distributed Computing, Vol.74, Issue 7, pp.2561-2573, July 2014.
[8]. K Bhoola, K Kruger, J Peick, P Pio and NA Tshabalala .“Big Data analytics”, Actuarial Society of South Africa’s 2014 Convention, pp.22–23, October 2014.
47
[9]. Rajeev Gupta, Himanshu Gupta, and Mukesh Mohania .“Cloud Computing and Big Data Analytics: What Is New from Databases Perspective? ”, Big Data Analytics. Springer Berlin Heidelberg, pp.42-61, 2012.
[10]. Alvin AuYoung, Bzrent N. Chun, Alex C. Snoeren, and Amin Vahdat. “Resource Allocation in Federated Distributed Computing Infrastructures”, Proceedings of the 1st Workshop on Operating System and Architectural Support for the On-demand IT InfraStructure. Vol.9. 2004.
[11]. Vinothina, V, R. Sridaran, and Padmavathi Ganapathi. “A survey on resource allocation strategies in cloud computing”, International Journal of Advanced Computer Science and Applications 3.6, pp.97-104, 2012.
[12]. Goudarzi, Hadi, and Massoud Pedram. “Multi-dimensional SLA-based resource allocation for multi-tier cloud computing systems”, Cloud Computing (CLOUD), 2011 IEEE International Conference on. IEEE, 2011.
[13]. Zexiang Mao, Jingqi Yang, Yanlei Shang, Chuanchang Liu, and Junliang Chen, “A game theory of cloud service deployment”, 2013 IEEE World Congress on Services (SERVICES), pp. 436-443, June 2013.
[14]. Weijia Song, Zhen Xiao, Senior Member, IEEE, Qi Chen, and Haipeng Luo. “Adaptive Resource Provisioning for the Cloud Using Online Bin Packing”, IEEE TRANSACTIONS ON COMPUTERS, Vol.63, No.11, November 2014.
[15]. Judith Hurwitz, Robin Bloor, Marcia Kaufman, and Fern Halper. “Cloud Computing For Dummies”, November 2009.
http://www.dummies.com/how-to/content/how-to-use-virtualization-with-cloud-computing.html.
[16]. VMware. “Understanding Full Virtualization, Paravirtualization, and Hardware Assist ”, 2014.
48
http://en.wikipedia.org/wiki/Virtualization [18]. TechTarget Network, “What is hypervisor?”
http://searchservervirtualization.techtarget.com/definition/hypervisor [19]. O’REILLY, “What is big data? ”
https://beta.oreilly.com/ideas/what-is-big-data
[20]. DATAFLOQ, “Why The 3V’s Are Not Sufficient To Describe Big Data”, https://datafloq.com/read/3vs-sufficient-describe-big-data/166
[21]. Apache Spark, “Spark Streaming Programming Guide”,
https://spark.apache.org/docs/1.2.1/streaming-programming-guide.html [22]. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and
Ion Stoica. “Spark: cluster computing with working sets”, Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, Vol.10, 2010.
[23]. Stonebraker, Michael, Uǧur Çetintemel, and Stan Zdonik, “The 8 requirements of real-time stream processing”, ACM SIGMOD Record, Vol.34, Issue 4,pp.42-47, December 2005.
[24]. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, and Ion Stoica. "Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing", Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, 2012.
[25]. Spark, "RDD",
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RD D.
[26]. Xiaohui Wei, Hongliang Li, Kun Yang, Senior Member, IEEE, and Lei Zou, "Topology-aware Partial Virtual Cluster Mapping Algorithm On Shared Distributed Infrastructures", IEEE Transactions On Parallel And Distributed
49
Systems, Vol.25, Issue.10, pp.2721-2730, 2014.
[27]. Yu-Kwong Kwok,and Ishfaq Ahmad. "Dynamic Critical-Path Scheduling: An Effective Technique for Allocating Task Graphs to Multiprocessors", IEEE Transactions on Parallel and Distributed Systems, Vol.7, No.5, pp.506-521, May 1996.
[28]. Menglan Hu, and Bharadwaj Veeravalli. "Dynamic Scheduling of Hybrid Real-Time Tasks on Clusters", IEEE Transactions On Computers, Vol.63, N0.12, December 2014.
[29]. Zbyněk Falt, Martin Kruliš, David Bednárek, Jakub Yaghob, and Filip Zavoral. "Locality aware task scheduling in parallel data stream processing." Intelligent
Distributed Computing VIII. Springer International Publishing, pp.331-342,
2015.
[30]. 謝孟儒.“聯邦雲中基於賽局理論之分散式排程方法”, 國立臺中教育大學 資訊工程學系碩士論文, 7 月 2014.