國立臺中教育大學教育測驗統計研究所
教學碩士學位暑期在職進修專班碩士論文
指導教授:曾建銘 教授
指導教授:
陳桂霞 教授
小六數學科試題與性別的試題差別功能
(DIF)現象與能力指標達成率分析研究
研究生:莊學霖 撰
中華民國 九十九 年 八 月
中文摘要
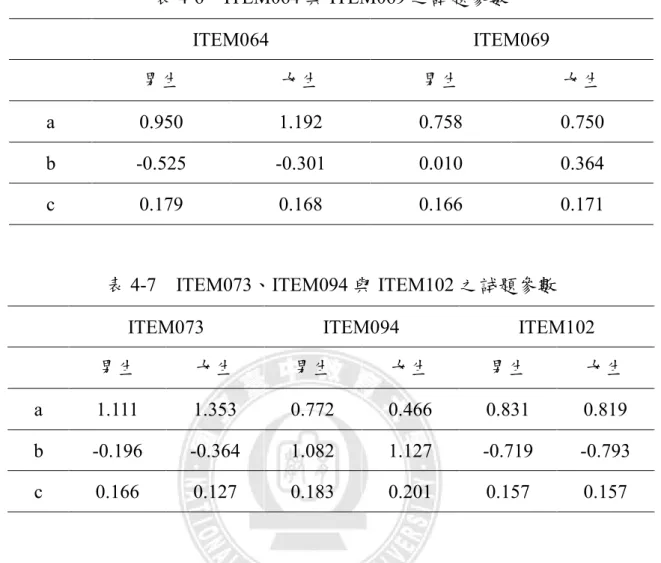
本研究利用 TASA 抽測所得資料分兩部分進行分析:1.以傳統測驗理論 (CTT)、試題反應理論(IRT)進行試題分析並統計學生在各項能力指標的平均答對 率;2.利用 Mantel-Haenszel 法、Crossing-SIBTEST 法、EZDIF ETS 分類法、EZDIF LR 法等四種方法檢測小六男女生在 2006 年 TASA 數學科試題中是否有 DIF 現 象。因受試樣本足夠,在設定=.01 的標準下,若該試題出現三種以上分析方法 檢測有 DIF 現象,即列入 DIF 試題,並將 Crossing-SIBTEST 法檢測出且
Mantel-Haenszel 法與 ETS 分類法未能檢測出的 DIF 試題列入,探討是否有 non-uniform DIF 的存在,並針對 DIF 試題做選項誘答力分析,推測 DIF 發生原 因,並探討不同 DIF 檢定方法的結果,顯示四種方法偵測 DIF 結果的一致性在 79.67%以上,其中 LR 法比對 Mantel-Haenszel 法與 ETS 分類法偵測出的結果一 致性最低。最後,根據研究結果探討男女生在學習成效上的差異並提出對教學 者、TASA 資料庫及未來研究的建議。 茲將研究結果摘述如下: 一、小六學生能力指標達成狀況,以「N_3_10」之平均達成率最低,而以「N_2_8」 之平均達成率最高。男生有 2 項能力指標的平均答對率高於女生達 5%以上, 而女生則有 1 項能力指標的平均答對率高於男生達 5%以上,針對此 3 項能 力指標進行獨立樣本 t 檢定,並考驗其顯著性。 二、在 103 題中有 7 題呈現 DIF,約佔總題數的 6.8%。整體而言,在 2006 TASA 小六數學科試題無法明顯判斷有利於男生或女生。 三、選項分析結果,DIF 試題中有 6 題的鑑別度優良,其中 1 題的鑑別度較差; 難度有 1 題對男女生均較困難,其他 6 題從適中到偏易,選項誘答力也大致 良好。
A DIF study and competence indicators achievement
of 6
thgrade students’mathematics test
Abstract
We used data from TASA (Taiwan Assessment of Student Achievement) and analyzed it with two different methods: 1. We used classical test theory (CTT) and item response theory (IRT) to test the difficulty of the questions and how the students performed and achieved the correct answers. 2. We used the following methods , Mantel-Haenszel, Crossing-SIBTEST, EZDIF ETS, and EZDIF LR to verify the questions of 2006 TASA mathematics test to see if DIF exist. The test sample was sufficient, so when =.01, if more than three methods verified the question was DIF, we assumed this question was DIF. If Crossing-SIBTEST tested the question was DIF while Mantel-Haenszel and ETS did not, we verified them to see if non-uniform DIF exist. We also performed the distraction analysis to find out why DIF occurs and what methods are feasible to verify DIF. It appears that the consistency rate of the four methods for DIF is over 79.67%; among them, the consistency between LR and Mantel-Haenszel and LR and ETS are the lowest. In the end, we proposed some suggestions to school instructors, TASA database administrators based on the competency differentiations between boys and girls for future research reference.
The conclusions of our study are listed below:
1. The achievement of competence indicators of 6th grade students:「N_3_10」has the lowest average achievement rate while 「N_2_8」has the highest. Boys’ correct rate is over 5% better than girls in two competence indicators while girls have only one.
We applied independent sample T to examine the three indicators and verified their significance.
2. 7 questions appeared to be DIF out of 103 which is about 6.8%. In whole, we cannot decide if the 2006 TASA 6th grade math test is favorable for the boys or the girls.
3. Conclusions of option analysis: 6 DIF questions have good discrimination, the other one does not. In tense of difficulty of the questions, only one question is difficult for both girls and boys; the rest of them are ranged between easy to medium. Averagely, option distraction is at a fair level.
Key words: TASA (Taiwan Assessment of Student Achievement), DIF (Differential
Item Functioning), Math Competence Indicators, Classical test theory (CTT) and Item response theory (IRT)
謝 辭
時光荏苒,四個暑期的求學過程即將告一段落,回首暑假時期的上課情景, 以及撰寫論文與投稿的歷程,箇中的滋味充滿了酸甜苦辣,而不捨與感謝的思緒 也不斷的湧上心頭。 首先,我最要感謝的是指導教授曾建銘老師,非常幸運的是我們在暑期的上 課期間,曾老師教授了我們一門課,老師認真、嚴謹又不失幽默的上課態度,以 及豐富、多元且實用的上課內容,讓我對 DIF 檢定這個領域有了更深入的瞭解; 在論文撰寫與投稿的指導方面,曾老師總是不厭其煩的回覆我的問題,仔細的檢 視我的論文內容,並且勉勵我要積極、不斷的努力,督促我一步步的朝著成功邁 進。其次,要感謝郭伯臣所長、陳桂霞教授、吳慧珉教授以及謝進昌教授在論文 口試時,透過彼此意見交流的過程,給了我許多精闢的指正與建議,令我對自己 的論文內容進行了更深一層的檢視,也能以更宏觀的角度來思考。另外,還要感 謝在這段期間所有老師的認真教學,讓我對於測驗理論的發展趨勢有更寬廣的視 野。 一路走來,身邊的朋友及親人們也給予我許多支持與鼓勵。意宗、再昇是論 文研究同一組的夥伴,我們彼此分享、討論、交流與扶持;雅娟、珮鈴是一起參 與口試的同伴,口試的順利完成少不了你們;爸爸、媽媽、老婆持續的關心與照 顧,以及同事們的溫暖陪伴,讓我滿載著信心與勇氣繼續努力;還有許多曾經給 予我協助以及幫我加油打氣的朋友,謝謝你們! 我的榮耀來自於大家,在此將這份榮耀與大家分享! 莊學霖 謹致 民國九十九年八月目 錄
第一章 緒論………..………...1
第 一 節 研究 背 景 與 動 機 …… … … …… … … …… … …. . 1 第 二 節 研 究 目 的 … … … . 5 第 三 節 待 答 問 題 …. .. … … … …… … … . . 5 第 四 節 名 詞 解 釋 … …. .. … … … … …… … … . . 6第二章 文獻探討………...9
第 一 節 九年 一 貫 數 學 領 域課 程 … …… … … …… … …. . 9 第二節 數學科測驗編製………15 第三節 BIB 量尺化設計………16 第四節 試題分析………...…17 第五節 數學表現在性別上的差異………...…22 第六節 DIF 的檢定方法………23第 三 章 研 究 方 法 … … … …… …… … … …… … . . .3 3
第一節 研究架構………..…33 第二節 研究流程………...34 第三節 研究對象………..35 第四節 研究工具………..38第四章 研究結果與討論………...41
第一節 試題分析………...41 第二節 能力指標達成狀況………..46 第三節 性別的試題差異功能(DIF)分析………..56 第四節 四種 DIF 檢測法結果之探討………..64第五節 DIF 試題選項分析………..………..65
第五章 結論與建議……….71
第一節 結論………..71 第二節 建議………..74參考文獻………77
壹、中文部分……….…………..………..77 貳、英文部分………..………..………….79表 目 錄
表 2-1 TASA2006 年數學科國小六年級測驗內容對照表...……....11 表 2-2 數學科國小六年級測驗各內容領域的題數分配百分比...15 表 2-3 BIB 13 題本等化設計區塊分配…………...………...……17 表 2-4 試題難易度等級表………...………...19 表 2-5 鑑別度評鑑標準表………..………...…20 表 2-6 總分為 k 之 22 列聯表………...26 表 3-1 各區塊抽樣人數………...………...38 表 4-1 試題分析表………...………...42 表 4-2 數學科小六各能力指標平均答對率………..……….…..46 表 4-3 獨立樣本 t 檢定暨 effect size………..………54 表 4-4 四種檢測法檢測出 DIF 試題之 p-value 值………..……56 表 4-5 ITEM036 與 ITEM055 之試題參數………62 表 4-6 ITEM064 與 ITEM069 之試題參數………63 表 4-7 ITEM073、ITEM094 與 ITEM102 之試題參數………63 表 4-8 四種檢測法之結果一致性………...…………....………...64 表 4-9 ITEM036 選項分析…………..…………...65 表 4-10 ITEM055 選項分析…………..…………...66 表 4-11 ITEM064 選項分析…………..…………...66 表 4-12 ITEM069 選項分析…………..…………...67 表 4-13 ITEM073 選項分析…………..…………...68 表 4-14 ITEM094 選項分析…………..…………...68 表 4-15 ITEM102 選項分析…………..…………...69圖 目 錄
圖 3-1 研究架構圖…………..………...33 圖 3-2 TASA 抽樣架構………...………...36 圖 3-3 區塊內能力配對隨機抽樣...………...37 圖 4-1 ITEM036 答對人數百分比曲線圖………...58 圖 4-2 ITEM055 答對人數百分比曲線圖………...59 圖 4-3 ITEM064 答對人數百分比曲線圖………...59 圖 4-4 ITEM069 答對人數百分比曲線圖………...60 圖 4-5 ITEM073 答對人數百分比曲線圖………...61 圖 4-6 ITEM094 答對人數百分比曲線圖………...61 圖 4-7 ITEM102 答對人數百分比曲線圖………...62第一章 緒論
本章共分為四節。分別討論本研究的研究背景與動機、研究目的與研究問 題,並對重要名詞提出釋義,茲分別敘述如下:第一節 研究背景與動機
近年來臺灣出生率遽降,少子化的情況日益嚴重,但每個孩子無論性別皆是 父母的心肝寶貝,對於子女的教育問題也愈來愈重視。而現代社會中,不論身份 是學生或是求職者,不論身處在學校、政府機關或公司行號中,測驗已變成生活 中的一部分。測驗的目的相當多樣性,從入學檢定、性向瞭解、資格審查到人才 篩選,皆須一個公平公正的測驗來做為依歸。然而測驗本身如果受到一些其他干 擾因素影響,如:性別差異、城鄉差距、家庭因素……等,而導致分數產生落差, 將會對受試者出現不公平的結果,因此,如何排除與測驗內容不相關的因素,而 此測驗可以真正測試出受試者的能力,是非常重要的。 兩性之間的學習成就差距是國際眾所關注的議題,一般人對男女生在能力差 異上常有些刻板印象,例如:「男生的數理能力較強,而女生則在語文和社會科 上表現較佳」,然而這是不變的定理?還是有經過科學驗證的結果呢?但對臺灣 學子而言,男女生的數理學習成就似乎沒有差異,而國內的男女國小學生在近幾 年的九年一貫的數學能力指標上的表現又是如何呢?「性別平等」議題近來備受 重視,男女生學習成就差距為國際間教育界所關注,一些國際性的學生學習成就 調 查 研 究 , 如 TIMSS(Trends in Mathematics and Science Study 的 簡 稱 ) 和 PISA(Programme for International Student Assessment 的簡稱),都專章報告男女學 生的學習成就。數學學科對於孩子在未來升學或邏輯思考上均有極大的影響,除 開環境及個人因素之外,不同性別是否左右數學科成就測驗,對身在教育第一線 的老師更需要充足的佐證資料來瞭解教學時的偏失並及時改進。以試題偏誤(item bias)為定義,但其字面上易給人負面的印象,因此有學者提出以 「試題差異功能」(differential item functioning,以下簡稱 DIF)一詞來代替(Holland & Thayer, 1988),意涵著試題發揮了不同的作用,不一定單指負面的功能。DIF 的定義,早先認定為:「在某個試題上,如果多數族群和少數族群的平均表現有 所不同時,該試題便具有 DIF 現象。」但這並未考量到能力相同與否的問題,可 能這兩族群本身能力就有所不同,才造成試題上表現有所差異(Lord, 1980)。若因 能力不同所造成的表現差異,只能稱之為「impact」。目前能被大多數學者所能接 受的 DIF 定義為:「來自不同的族群或團體,但能力相同的個人,在作答某試題 上的機率有所不同時,則該試題便具有 DIF 現象。」(余民寧,1993)。如果測驗 題目具有 DIF 現象,表示同一試題於兩團體或族群當中展現出不同的功能 (functioning),可能是因不同性別、族群或是地區性教學差異、生活經驗不同、資 源分配不均等等因素所造成的。一般而言,任何一個嚴謹的測驗在經過預試後, 若經由 DIF 的統計分析發現有 DIF 的問題存在,就要進一步作邏輯分析找出問題 所在,若發現此問題確實有偏誤,則以後應避免出類似問題。 測驗結果攸關考生的權益,因此測驗對不同背景的應試群體的公平性是測驗 發展機構關切的焦點之一,這也是試題差別功能(DIF)研究逐漸受重視的原因。數 學測驗對不同性別之受試者的「公平性」是不容忽視的重要課題,試題若有 DIF 現象,經過質性研究後若為試題偏誤,將影響測驗結果之判斷,甚至影響受試者 權益。DIF 反映的不只是適不適合的依據,而是可能包含某些課程或教學所須的 改變,這些隱藏在教學裡的問題,勢必影響臺灣的數學教育未來之發展。 良好的測驗需能反映出受試者在欲測量特質上的差異。如果測驗分數反映的 不是原先要測量的特質,而是其他無關變項,如不同的認知、語文能力,甚至種 族、性別等,則運用測驗結果作判斷時,就會產生偏誤的現象。例如數學測驗同 時測量受試者在計算和語文理解的能力,那麼以此測驗分數來代表受試者的計算 能力,對於語文理解能力低落的受試者就會產生不利的結果。因此有關測驗公平 性的研究成為測驗領域一項重要議題。
DIF 試題差異功能,或譯試題區辨功能,對於在欲測量特質上已相配對的不 同群體而言,DIF 是一種意料之外的測驗表現差異(Dorans & Holland, 1993);它 的存在,對於測驗結果的公平性可能有負面影響。試題反應理論(Item Response Theory)即將 DIF 定義為:在不同群體中,試題答對與答錯的機率不相等;亦即來 自不同次群體、具有相同能力的受試者,對於特定試題有不相等的答對與答錯機 率(Dorans & Holland, 1993)。
美澳等先進國家的教育系統,對於學生基本學習能力的表現水準,都有相當 深切的關懷及具體明確的認知,這些國家對於其學生的學術成就指標,例行性地 進行資訊的蒐集與統整。國內長期缺乏量化指標和標準化測量工具來檢視學生學 習成就的表現及其差異,以致無法確實瞭解課程實施的成效,亦不利於課程發展 之進行與相關教育政策之研擬。目前教育資料庫的建立普遍受到重視,「臺灣學 生學習成就評量資料庫(TASA)」即為其中一種。 臺灣學生學習成就評量資料庫(TASA),從 2005 年起採建置題庫模式,進行 組題每年對全國小四、小六、國二、高中二及高職二等五個年段,依人口密度進 行二階段分層抽樣,對國語文、英語文、數學、社會及自然等五科施行抽測(小四 英語文、社會除外),2005 年先行並對全國國小六年級學生的國、英、數三科抽 測,以瞭解全國國民中小學、高中職學生之學習成效,並建立年級、跨學科之學 生學習成就長期性的資料庫,可提供國內專家學者或學術單位進行基礎性研究(曾 建銘,2007)。 研究者將以性別為變項,針對不同性別之學生在「2006 年 TASA 小六數學試 題」之答題情形,探討數學試題是否存在某些因素,並造成在數學成就測驗產生 顯著差異,運用數種軟體進行 DIF 檢定,確認在 2006 年 TASA 小六數學試題中 是否有 DIF 試題。分析試題對於小學六年級男、女生兩群體是否呈現不公的試題 資訊,即具有相同能力的兩群體,理論上,他們的作答的答對率應該是大致相等 的,但在實際表現上,如果呈現有顯著的差異,我們稱此試題存在著差異功能。
達到顯著水準,該試題便被認為應該刪除或避免出現類似題目;但 DIF 只是統計 上的測量結果,並不是非得刪除該試題不可(Angoff, 1933);相反的,有 DIF 現象 的試題可能表示著某些課程或教學上所需要的改變(Harris & Carlton, 1993; Lane, Wane & Magone, 1996)。呈現 DIF 的單一試題,僅能表示該試題可能不適用在某 個測驗中,所能做的解釋有限,若想深入解釋測驗上是否因性別、區域、社經地 位或族群…等原因差異而導致的 DIF 現象,就應該將試題依照內容特徵適度的分 類,從不同類別試題的性質來分析了解及推測 DIF 發生的原因,以獲得較多心理 與教育面向的意涵(黃財尉、李信宏,1999)。DIF 的出現表示試題可能測到與測 驗擬測之構念無關(construct-irrelevant)的因素,試題的效度受到不利的影響。值 得我們進一步研究其造成的因素,若發現是偏誤的試題(biased item),則該刪除以 達考試的公平性。試題本身對於男女兩群體是否存在 DIF 的現象亦是為歐美測驗 界所關注的議題,因 TASA 之試題具有保密性,所以將只提供統計後具有 DIF 之 試題資訊,作為 TASA 研發試題時,對具有 DIF 的試題就內容對於男女兩群體是 否存在進行檢視,以確認該試題是否偏誤,若為偏誤試題,應該如何避免、修改 或刪除,以達到考試的公平性。 最後,根據上述研究之結果與發現,提出對教學者及未來研究的建議。
第二節 研究目的
基於上述之研究動機,本研究擬達成下列四項目的,敘述如下: 一、利用 2006 年 TASA 小六數學抽測所得之學生作答資料,進行試題分析並統 計學生在各項能力指標的平均答對率。 二、進行各個試題的 DIF 分析,探討試題對於小六男、女學生兩群體是否有差 異功能現象。三、探討 Mantel-Haenszel 法、Crossing-SIBTEST 法、ETS 分類法與 Logistic Regression 法等四種方法檢測結果之差異。
四、若有 DIF 試題,將對 DIF 試題做選項誘答分析,以瞭解產生 DIF 之可能原 因。
第三節 待答問題
根據前述研究動機與目的,本研究擬探討下列問題: 一、「2006TASA 小六數學成就測驗」試題在古典試題理論(CTT)之試題分析的試 題鑑別度、試題難度、測驗答對率、試題與總分間的相關為何? 二、「2006TASA 小六數學成就測驗」在試題反應理論(IRT)模式考驗下,試題難 度、鑑別度、試題參數、資料與模式適合度為何? 三、「2006TASA 小六數學成就測驗」試題在試題分析下的各項能力指標的平均 答對率及男、女生答對率的比較為何? 四、小六男、女學生兩群體在「2006TASA 小六數學成就測驗」試題中是否有(DIF) 差異功能現象?五、比較 Mantel-Haenszel 法、Crossing-SIBTEST 法、ETS 分類法與 Logistic Regression 法等四種方法之檢測結果有何差異?
可能原因為何?
第四節 名詞解釋
茲將本研究中出現的名詞說明如下:壹、 TASA
「臺灣學生學習成就評量資料庫(TASA)從 2005 年起採建置題庫模式,進行 組題每年對全國小四、小六、國二、高中二及高職二等五個年段,依人口密度 進行二階段分層抽樣,對國語文、英語文、數學、社會和自然等五科施行抽測(小 四社會、英語文除外),以了解全國國民中小學、高中職學生之學習成效,並建 立年級、跨學科之學生學習成就長期性的資料庫。貳、 數學成就(數學成就測驗上的表現)
在本研究中所稱「數學成就」或「數學成就測驗上的表現」係指學生在「TASA 小六數學成就測驗」上的答題情形。根據九年一貫之能力指標為內容來命題, 對小六學生施測後的表現進行分析,就學習階段而言,國民小學的學生在畢業 前,必須能熟練分數、小數的混合四則計算;能利用常用的量關係解決日常生 活的問題;能認識簡單幾何形體的幾何性質、並理解其面積與體積公式;能報 讀簡單統計圖形並理解其概念……等。參、 試題差異功能(Differential Item Functioning,DIF)
試題差異功能(DIF)是指兩組能力或表現相配比(comparable)的群體,在答題 上表現上所呈現的差異(Dorans & Holland, 1993),學者今多以 DIF 這個詞來取代 先前研究所謂的「試題偏誤」(item bias),並且對 DIF 與試題偏誤做進一步的區 分(Camilli & Shepard, 1994),不再視二者為同義詞。DIF 和因受試群體能力不同
所造成的表現差異要加以區別,若受試的群體沒有經過使能力相同的配組程 序,最後導致兩群體表現有所差異則稱為 impact。DIF 僅是統計分析或數量分析 的結果,DIF 是試題偏誤的必要但非充分條件,若試題呈現 DIF 現象,尚須經 學科專家做解釋與判斷後,才能確認該試題是否為「偏誤試題」(biased item)。
肆、 偏誤試題(biased item)
Camilli和Shepard(1994)曾進一步針對試題偏誤(item bias)與DIF作區分,認為 DIF僅是數量統計分析的結果,對於被檢定為DIF的試題做進一步的審視和判斷 後,若發現試題含有與測驗想要測得的構念無關(construct-irrelevant)的因素,而 造成試題的難度對不同背景的應試群體發生不相等的現象,才稱該試題為偏誤試 題(biased item)。 產生試題偏差的原因包括:1.測驗編製者僅以多數族群的團體為考慮施測對 象,造成編題時偏向以多數族群之特有文化、生活經驗、文化特色或風俗習慣為 欲測驗的題目內容,造成不利其他族群的受試結果;2.測驗抽樣的過程抽取了不 具代表性的樣本,造成某些不同族群的能力或潛在特質測量不利或不公平,間接 使測驗產生偏差的推論和預測結果;3.不同族群對測驗本身即產生不同反應結果 的差異現象,因此測驗所產生的差異結果便反應了試題本身具有不同的測量功 能。試題偏差種類包括:1.文化、種族、語言測驗偏差;2.社經地位測驗偏差; 3.性別測驗偏差;4.明星學校測驗偏差(余民寧,2006)。第二章 文獻探討
第一節 九年一貫數學領域課程
九年一貫課程改革的需求是基於二十一世紀是一個資訊爆炸、科學發達、社 會快速變遷、國際關係日益密切的新時代,而教育的本質是開展學生潛能、培養 學生適應與改善生活環境的歷程。因此,為培養具備人本情懷、統整能力、民主 素養、鄉土與國際意識,以及能進行終身學習之健全國民,而進行九年一貫新課 程之規劃(教育部,2006)。然而,在九年一貫數學領域課程實施之初。卻引起社 會的爭論,因而促成課程綱要之修訂。為了順應世界潮流、回應教育改革總諮議 報告書的建議,在教育的實施目標及社會的需求,並考量國際競爭力等因素,將 教科書定位為教師教學、學生自習及家長輔助學習的主要依據(教育部國教專業社 群網,2008)。 本節主要由教育部網站公佈的「2003年國民中小學九年一貫課程綱要」來說 明九年一貫數學領域的課程與教學目標、內容及能力指標,並依據TASA所公佈 的2006年數學科國小六年級試題來說明測驗內容。壹、課程與教學目標(教育部,2006)
課程目標的規劃不僅應反映數學學習的特性,亦應考量環境條件的限制。首 先是教學時數的限制。目前國民中小學數學領域教學的時數每週三至四節。然 而,數學領域新題材的學習(包括操作觀察、概念學習、新演算方法或應用問題解 題等),往往需要較寬裕的時間來融會貫通;而且,數學領域相較於其他領域學習 場所多樣化的特質,其學習仍以課堂活動為主體,家庭作業與溫習僅能輔助學 習,因此上課時數將直接影響數學教學的成效。 在既有限制之下,九年一貫數學領域的課程綱要,是由下列四個原則來界定: 一、參考施行有年且有穩定基礎的傳統教材。 二、採用國際間數學課程必備的核心題材。三、考慮數學作為科學工具性的特質。 四、現有學生能夠有效學習數學的一般能力。 具體而言,九年一貫數學學習領域的教學總體目標為: 一、培養學生的演算能力、抽象能力、推論能力及溝通能力。 二、學習應用問題的解題方法。 三、奠定下一階段的數學基礎。 四、培養欣賞數學的態度及能力。 其中,國民小學階段的目標為:第一階段(一至三年級):能掌握數、量、形 的概念。第二階段(四至五年級):能熟練非負整數的四則與混合計算,培養流暢 的數字感。在小學畢業前:能熟練小數與分數的四則計算;能利用常用數量關係, 解決日常生活的問題;能認識簡單幾何形體的幾何性質、並理解其面積與體積公 式;能報讀簡單統計圖形並理解其概念。
貳、內容及能力指標(教育部,2006)
數學領域將九年國民教育區分為四個階段:階段一為一至三年級,階段二為 四、五年級,階段三為六、七年級,階段四為八、九年級。另將數學內容分為數 與量、幾何、代數、統計與機率、連結等五大主題。 前四項主題的能力指標以三碼編排,其中第一碼表示主題,分別以字母 N、 S、A、D 表示「數與量」、「幾何」、「代數」和「統計與機率」四個主題;第二碼 表示階段,分別以 1, 2, 3, 4 表示第一、二、三和四階段;第三碼則是能力指標的 流水號,表示該細項下指標的序號。雖以主題與階段來區分,仍有若干能力指標 採跨主題方式同時編列,如「數與量」、「幾何」,以強調其連結,此類指標皆以 相關連結編碼註記。此外,數學內部的連結可貫穿前述四個主題,來強調解題能 力的培養;數學外部的連結則強調生活及其他領域中數學問題的察覺、轉化、解 題、溝通、評析諸能力的培養。具備這些能力,一方面增進學生的數學素養,能適切地應用數學,來提高生活品質,另一方面也能加強其數學的思維,有助於個 人在生涯中求進一步的發展。因此,我們仍沿用暫行綱要的方案,不對連結的能 力指標加以分段,各階段四個主題的能力要與連結的能力相配合培養,而連結的 能力經過各階段後會愈來愈強。連結的能力指標用三碼表示,第一碼表連結(C), 第二碼表察覺(R)、轉化(T)、解題(S)、溝通(C)、評析(E),而第三碼則是流水號。 茲列舉本研究測驗內容與九年一貫課程數學領域小學六年級能力指標之對 照表,如下表 2-1。 表2-1 TASA2006年數學科國小六年級測驗內容對照表 (依據九年一貫暫行綱要數學學習領域能力指標) 測驗 內容 能力指標 題號 N_2_2 N_2_2 延伸加、減、乘、除與情境的意義, 使能適用來解決更多的生活情境問 題,並能用計算器械處理大數的計 算。 M5_5、M12_3 N_2_4 N_2_4 能用四捨五入、進位、捨去等方式對 一個數量取概數,並利用概數作簡單 的估算。 M1_5、M5_4 N2_ N_2_6 在具體情境中,能以假分數或帶分數 描述具體的量,並能解決分數的合 成、分解以及簡單整數倍的問題。 M4_5、M7_5、M7_6 N_2 N_2_7 能以二位小數描述具體的量,並解決 二位小數的合成、分解及簡單整數倍 問題。 M1_6、M7_7、M8_2 N_2_8 N_2_8 能報讀(鐘面上的)時刻以及點算兩時 刻間的時間;能理解24時制並應用在 生活中。 M6_3 N_2_1 N_2_16 能知道先乘除後加減的約定,並 能用來列式及簡化計算式子。 M2_3、M8_1 N_2_1 N_2_18 能用時間的長短,描述一物體在固 定距離內的運動速率;能用距離, 描述一物體在固定時間內的運動速 率。 M5_6 數與 計算 N_3_3 N_3_3 在具體情境中,理解通分的意義並運 用通分解決異分母分數的合成、分解 問題。 M9_4、M9_5
N_3_4 N_3_4 在具體情境中,解決分數乘以分數的 問題,進而形成分數倍的概念。 M13_6 _5 N_3_5 能延伸小數的認識到三位以上(小 數), 並解決 生活中 與小 數有關的 加、減、乘、除問題。 M9_8 N_3_ N_3_6 在具體情境中,能用分數、小數表示 除的結果(除的結果為有限小數)。 M2_5、M11_3 N_3_7 N_3_7 能用分數倍的概念,整合以分數為除 數的包含除和等分除的運算格式。(7 年級)。 M2_4、M6_1、M6_4、 M8_3、M8_4、M9_6、 M11_2、M13_8 N_3_14 能將各種柱體,變形成長方柱而計 算其體積,形成柱體之體積計算公 式。 M2_6、M10_2 N_3_15 N_3_15 能在情境中理解比、比例(包括正比 例和反比例)、比值、率(百分率、 ppm)的意義。 M1_7、M3_8、M4_2、 M6_2、M10_3、M11_4、 M12_4、M13_7 N_3_16 N_3_16 能用平均速率的概念描述一個物體 運動的狀態,並認識速率的普遍單 位米/秒、千米/時等,應用在生活 中。 M9_7 N_3_18 能察覺整數的因數、倍數、公因 數、公倍數。 M3_6、M3_7、M10_4 N_2_8 能報讀(鐘面上的)時刻以及點算兩時 刻間的時間;能理解24時制並應用在 生活中。 M7_3 N_2_10 N_2_10 能認識各種量的普遍單位,應用在 生活中的實測和估測活動,並培養 出量感(普遍單位:千米、毫米、公 升、毫公升、時、分、秒)。 M3_4、M5_3、M5_7、 M7_4、M10_5、M13_5 N_2_12 N_2_12 能知道同類量中二階單位之間的關 係及使用二階單位作描述,並利用 此關係作整數化聚。 M1_4 N_2_13 N_2_13 能以個別單位的方式(利用等物合 成複製後)描述面積、體積,並能用 乘法簡化長方形面積、長方體體積 之點算。 M4_6 N_2_ N_2_14 能在情境中,理解乘法交換律、等 號的對稱性、「<、=、>」的遞移 性、加法和乘法的結合律與分配 律,以及乘法和除法的相互關係。 M1_8 量與 實測 N_3_10 N_3_10 認識生活中使用的大的測量單位, 如:千公斤(公噸)、千公升(公秉)、 百平方米(公畝)、千平方米(公頃)。 M4_4
N_3_11 N_3_11 能以切割後,重新拼湊組合的方式 ( 幾 何 部 分 要 配 合 ) , 將 平 行 四 邊 形、三角形和梯形,變形成長方形 而計算其面積,形成面積之計算公 式。 M7_8 N_3_12 N_3_12 能對非直線形的平面區域,選定適 當的正方形單位,估計其概略面 積,並檢驗圓面積公式(πr2,r為圓 的半徑)。 M10_6、M13_4 N_3_14 N_3_14 能將各種柱體,變形成長方柱而計 算其體積,形成柱體之體積計算公 式。 M2_7 N_3_16 N_3_16 能用平均速率的概念描述一個物體 運動的狀態,並認識速率的普遍單 位米/秒、千米/時等,應用在生活 中。 M3_5、M12_5 N_3_17 N_3_17 能掌握米/秒 和千米 /時之 間 的關 係,並利用此關係作化聚。 M8_5、M9_3、M11_1 S_2_1 S_2_1 就給定的幾何形體,能確認並說出組 成要素的名稱,並在檢驗後適當地描 述其要素間的關係。 M1_2 S S_2_3 能透過實測察覺形體的性質。 M5_2 S_3_1 S_3_1 舊給定的幾何形體,能確認並說出組 成要素的名稱,並在檢驗後適當地描 述其要素間的關係。 M13_1 S_3_4 S_3_4 能利用構成要素間的可能關係,描述 複合形體要素間的可能關係。 M2_2、M6_5、M10_7、 M11_5、M11_6、M13_3 S_3_5 能利用形體的性質解決幾何問題。 M2_8、M3_2、M3_3、 M4_3、M5_8、M6_6、 M9_1、M10_8、M12_6、 M13_2 S_3_8 能瞭解平面圖形線對稱的意義。 M8_6 S_3_9 S_3_9 能辨識基本圖形間對應邊長成比例 時的形狀關係。(7年級) M12_7 幾何 S_3_10 S_3_10 能透過實測辨識三角形、四邊形、 圓的性質。 M8_7 D_2_4 能解讀現成資料之長條圖。 M1_3、M4_1、M7_2 D_3_1 D_3_1 能利用統計量,例如:平均數、中位 數等,來瞭解資料集中的位置。 M12_1 統計與 機率 D_3_3 能運用生活經驗來瞭解機會。 M9_2
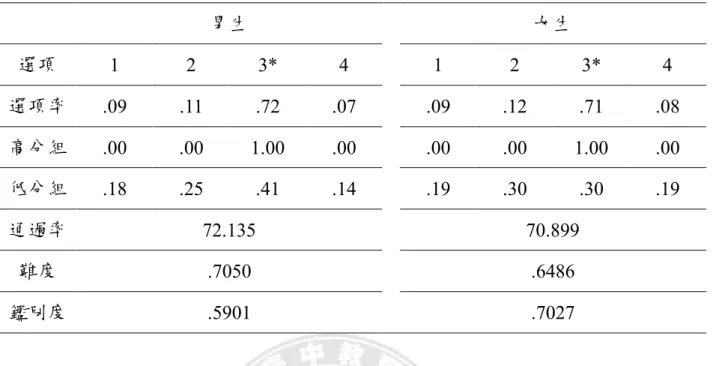
D_3_ D_3_4 能報讀生活中有序資料的統計圖 表。 M6_7、M12_8 D_3_ D_3_6 能解讀各式各樣的折線圖。 M4_7 D_3_7 D_3_7 能利用比值和百分率的概念,報讀相 關的統計圖表。 M10_1、M11_7 A_2_1 A_2_1 能將生活情境中簡單問題表徵為含 有△、□、甲、乙、?、…等的式子, 並能解釋式子與原問題情境的關係。 M1_1 A_2_2 A_2_2 能透過具體表徵,解決從生活情境問 題中列出的算式填充題。 M5_1、M7_1
A_3_1 A_3_1 能用x、y、…的式子表徵生活情境中 的未知量及變量。 M4_8、M6_8 A_3_2 A_3_2 能將生活情境中的問題表徵為含有 x、y、…的等式或不等式,透過生活 經驗檢驗、判斷其解,並能解釋式子 及解與原問題情境的關係。 M3_1、M8_8 代數 A_3_5 A_3_5 能察覺簡易數量模式與數量模式之 間的關係。 M2_1、M11_8
第二節 數學科測驗編製
2006 年 TASA 數學科國小六年級測驗內容,是以教育部所公布之「國民中小 學九年一貫課程暫行綱要」的能力指標為依據,同時參酌各版本的教材編製而 成。測驗內容皆側重學生生活數學經驗的連結,題目的設計,以數學概念理解、 程序應用、和問題解決能力為主要評量目標。測驗架構以數學內容及作業複雜度 兩個向度建構而成。數學內容區分為數與計算、量與實測、幾何、統計與機率、 以及代數等五個內容領域。 表 2-2 為 2006 年 TASA 數學科國小六年級測驗內容與題型的題數分配架構, 表中各內容領域所佔的題數比例,主要參酌課程綱要(暫綱與正綱)與現行教科書 的內容領域比重。國小六年級數學以「數與計算」、「量與實測」與「幾何」為主 要內容,「統計與機率」與「代數」相對比重較輕。 表 2-2 數學科國小六年級測驗各內容領域的題數分配百分比 選擇題 總題數% 數與計算 42 40.77 量與實測 20 19.41 幾何 22 21.35 統計與機率 10 9.70 代數 9 8.73 總題數 103 100.00第三節 BIB 量尺化設計
命題老師依據雙向細目表命題再經由臨床施測與學科及測驗專家的四次修 審題後,共計 13 個試題區塊(Block),每個區塊中包含 8 題試題,總共 104 題, 但因原始試題第 90 題答案出錯遭刪除,得到有效試題共 103 題測驗題。受限於 學生受測時間以四十分鐘為主的因素,無法使每位學生都能受測到所有試題,因 此本計畫中採用平衡不完全區塊(Balanced Incomplete Block, BIB)設計題本模 式,其優點為試題區塊與題本的配置方式,採螺旋式排列方式,可使每一個試題 區塊的施測次數相同(Van der Linden, Veldkamp, & Carlson, 2004),且 IRT 參數估 計時若採用同時估計法(concurrent calibration),則可減少等化程序所介入的額外 誤差(Kim, & Cohen, 1998; Kim, & Cohen, 2002; Kolen, & Brennan, 1995; Petersen, Cook, & Stocking, 1983; Stocking, & Lord, 1983)。因此研究中將原始測驗題 104 題 分為 13 個試題區塊(Block),每個區塊中包含 8 題試題,且區塊中的試題不重複, 然而原始試題第 90 題答案出錯遭刪除,故第 12 個試題區塊只有 7 題測驗題。BIB 設計最主要的特色或要求是能夠平衡各試題區塊的呈現次序,於是,每個區塊將 分別出現於不同題本前、中、後位置(即被包含於三個不同題本中),也就是說, 在這 13 份題本中,每一個區塊將出現三次。題本編製完畢後,將以一系統性序 列排序並束在一起(spiraled and bundled),如此就可確保每一份題本在施測樣本中 的出現頻率適切,而且呈現給受試的順序是均衡的。題本中的區塊分配情形,詳 見表 2-3(臺灣學生學習成就評量資料庫,2007)。
表 2-3 BIB 13 題本等化設計區塊分配 區塊位置 題本序號 區塊一 區塊二 區塊三 S1 M1 M2 M5 S2 M2 M3 M6 S3 M3 M4 M7 S4 M4 M5 M8 S5 M5 M6 M9 S6 M6 M7 M10 S7 M7 M8 M11 S8 M8 M9 M12 S9 M9 M10 M13 S10 M10 M11 M1 S11 M11 M12 M2 S12 M12 M13 M3 S13 M13 M1 M4
第四節 試題分析
構成測驗最基本的單位是試題,有良好的試題才有良好的測驗。但必須先透 過試題質與量的分析,才能評鑑試題的好壞,也就是做邏輯與統計分析。試題分 析在測驗編製過程中,目的在透過客觀的量化分析,找出每個試題所具有的統計 特徵,以供教師瞭解自編測驗試題的特性,作為評鑑測驗的標的,更可以協助教 師做為改進教學和診斷出學生的學習困難,作為補救教學之依據。試題分析的重 要性有以下幾點:1.可作為改進學生學習的參考,教師可逐題澄清學生的錯誤概 念、矯正不當的學習方法;2.作為實施補救教學的依據,教師針對學生感到困難 的地方對症下藥,設計出有效的校正方案;3.作為修改課程的依據,幫助教師評 鑑學習成果與課程內容是否適合學生;4.增進教師編製測驗的經驗,試題的難度、 鑑別度、選項誘答力等資訊,都可提供教師修訂或刪改試題的依據;5.增進測驗題庫運用的功能,經過試題分析留下的試題具有優良試題特徵,日後,教師可從 題庫中隨機抽取適合的試題,有系統的組成新的測驗(余民寧,2006)。由上述可 知,作為評鑑整份測驗良窳,進而改進教學方法,試題分析是絕對必要的過程。 以下將進一步說明質與量的分析:
壹、質的分析
每一份不同的測驗均有其不同的目的和適用的範圍,因此在編製試題時,應 配合測驗的目的與命題的基本原則,才能編出適當的試題。可就試題的內容請學 者專家或資深教師,對內容審查、有效命題原則及教學目標等評鑑工作,此為試 題在質的方面做的邏輯分析(余民寧,1997)。貳、量的分析
試題經過質的分析後,僅只確定試題是否符合測驗的基本原則。但為避免測 驗中出現過難或鑑別度過低的試題,所有命完的試題均須經過預試,再根據預試 結果進行測驗統計分析,以確定各個試題的有關量的分析數值(曾建銘,2006)。 以下將本研究相關之量的分析方法逐一介紹: 一、難易度(古典測驗理論) 難易度適當的試題是構成優良測驗的必要條件。常用的試題難度分析方法有 三(簡茂發,1991): (一) 10000 N R P 其中 P 表試題難度,R 表答對該題人數,N 表全體受試人數。例如:一個數 學測驗,若有 200 名受試者,其中一題答對人數為 150 人,則此題的難度為 200 150 P ×100%=0.75。 (二) 2 L H P P P PH為高分組答對該題人數的百分比,PL為低分組答對該題人數的百分比 全體受試者中,從分數最高部分往下取 27%為高分組,從分數最低部分往上取 27%為低分組。例如:一個語文測驗,共有 200 位受試者,其中一題高分組答對 人數為 160 人,低分組答對的人數為 40 人,則此題的難度為 0.5 2 2 . 0 8 . 0 P P 值介於 0 與 1 之間,數值愈大表示題目愈容易;相反地,數值越小則題目越難。 (三)以等距量尺分析
此為美國教育測驗服務社(Educational Testing Service,ETS)另創的一種具有等 距量尺特性的難度指數,以△(Delta)表示。它是以 13 為平均數,4 為標準差,下 限為 1,上限為 25 的標準分數。其公式為 △= 13 + 4Z。△值越大表示越困難; 相反的,愈小表示越容易。其求法係根據答對某試題的人數百分比與答錯該題的 人數百分比,使前者在右,後者在左,找出二者在常態分配曲線橫軸上的分界點, 此點的相對位置以標準差為單位表示(曾建銘,2007)。例如:某一試題的答對人 數為 16%,即 P=0.16,則可知相對應的 Z 值為 1,帶入公式,則其△值為 13+4(1)=17。 關於如何利用難度值來挑選試題,美國的測驗學者 Ebel & Frisbie(1991) 將試題難度區分為五個等級,如下表 2-4: 表 2-4 試題難易度等級表 難易度(P) 難易度等級 80 . 0 P 極容易 60 . 0 80 . 0 P 容易 40 . 0 60 . 0 P 難易適中 20 . 0 40 . 0 P 困難 P 20 . 0 極困難 一般測驗學者均建議挑選難度接近 0.5 的試題中等難度的試題,也就是難易
適中的試題,因為此試題的鑑別度可達到最大。不過在實際的情況下,要選出每 一題的難度都接近 0.5 是有困難的,因此,有學者主張以 0.4 到 0.8 之間的難度範 圍做為選題標準(Chase, 1978),但平均而言,整份測驗的平均難度值還是以接近 0.5 為佳。 二、鑑別度 試題的鑑別度高低與測驗的信度和效度有密切的關係,若要增進測驗診斷與 評量的功能,因此良好的鑑別度對試題相當重要。鑑別度的分析方法有二: (一)試題反應與測驗總分的關聯性: 若試題為選擇題,考生的作答反應則為答對或答錯之二分變項;而對整份測 驗而言總分可視為連續變項,兩者之間的關係可用點二系列相關係數(rpb)來表示 其內部一致性的高低,即該試題的鑑別度。 (二)鑑別度指數 D: L H P P D 其中 D 表示鑑別度指數,PH與PL之定義同難度所述。由鑑別度的定義可知, 鑑別度高的試題可以清楚地分辨能力高與能力低者,但該如何判定鑑別度的高 低?根據 Noll、Scannell & Craig(1979)的看法,至少要達 0.25 以上,低於 0.25 者 即為鑑別度不佳或品質不良之試題。美國測驗學者 Ebel(1979)曾提出一套鑑別度 判斷的標準如表 2-5,供試題命題者作為選題的參考。 表 2-5 鑑別度評鑑標準表 鑑別度 試題評鑑 0.40 以上 非常優良 0.30~0.40 優良,但需小幅度修改 0.20~0.30 尚可,但需部分修改 0.19 以下 劣,需要大幅修改或刪除
三、難度、鑑別度與猜測度 在試題反應理論中,若以三參數模式為例,模式中有三個參數:a、b、c,代 表的是試題的鑑別度、難度與猜測度。一般而言,鑑別度只取正,值愈大代表鑑 別度愈大;難度值則通常介於-3~3 之間,同樣地,值愈大代表試題愈難(與古典 測驗理論的難度相反);猜測度則介於 0~1 之間,值愈大代表試題猜測度愈大, 選項的多寡往往影響猜測度的大小。
參、選項分析
選擇題的選項包括正確選項與誘答選項,正確選項必須明確,而誘答選項則 需有一定的誘答力,為了判斷試題編製的好壞與各選項是否符合性質,則必須進 行選項分析。選項分析可以讓施測者了解每道試題的選項是否符合命題原則,並 進一步提供試題分析的指標。因此,經過試題的選項誘答力分析,可協助教師改 進編製試題的技巧及了解學生的答題情形,更可進一步調整或改變教學策略 (Ha1adyna, 1994)。 選項分析是比較高分組與低分組對正確與誘答選項的選答率,如果分析的結 果符合下面兩項原則,則表示該試題的所有選項是合理有效的(郭生玉,2004): 一、正確選項的選答率,高分組必須高於低分組。 二、每一個誘答選項應有一位低分組的受試者選答,而低分組的選答率則須高於 高分組。肆、試題分析的功能
試題經過質的分析,對試題內容進行檢測後,再透過量的分析,可分析出每 道試題的統計特徵,幫助命題者了解試題的品質,若經過測驗後,確認該試題為 優良試題,則可納入題庫,作為日後編製試卷時使用。試題在經過質與量的分析後,可以讓命題者知道試題是否具備預期的測量功能,以及試題的資訊:如難度、 鑑別度、猜測度、試題特徵曲線、選項誘答力等,教師可利用這些資訊與教材內 容及教學目標相結合,作為日後實施測驗的參考依據。未來可從題庫中選出適切 的試題,自編出一份測驗,不但可節省時間,人力、物力的花費,而且選出的試 題均為經過試題分析的優良試題。老師更可憑此作為加強學生學習盲點的參考、 作為實施補救教學的依據、修改課程內容,提供更符合學生需求的學習內容。
第五節 數學表現在性別上的差異
影響學生數學文字題解題能力低落可能為閱讀困難、數學句法及符號理解發 生障礙、解題策略或計算能力不佳等其中一種或兩種以上之能力。 在數學文字題解題表現方面,許多研究者也探討了性別此變項。Henney(1970) 研究四年級國小學童,女生在文字題後測之閱讀分測驗上的平均得分顯著高於男 生(引自陳世杰,2005)。陳濱興(2001)研究國小四年級學童,女生在數學解題歷程 之理解題意上優於男生。蕭美琪(2003)研究國小二年級學童,發現男女學童在乘 法解題各歷程中與整合認知能力等方面的表現沒有差異。 國內學者曾對大學聯考或標準化測驗的試題進行 DIF 調查(王振世,1997; 陳明終,1996;簡茂發等,1995;戴麗紅,1994),調查結果一致指出有相當高比 例的試題被鑑定為呈現 DIF,舉一個最嚴重的例子來說,例如戴麗紅(1994)指出 八十二年大學聯考國文科的二十六個試題(含作文)中,96%的試題被檢定為呈現 性別 DIF。 在數學成就測驗上,因男、女性別而產生的差異表現,一直是教育及心理研 究者關心的議題。許多研究聚焦在試題本身特徵對受試者的影響,其重點在於受 試者在受測過程中的認知運作是否相同(Ryan & Chiu, 2001)。有部分研究結果發現某些因素(如試題的內容、形式、認知背景等)對不同性別受試者有不同的影響, 如:Harris & Carlton(1993)、Lane, Wang & Magone(1996)、O'Neil & McPeek(1993) 等人發現代數題對女生較有利;但亦有研究指出不同的結果(Becker, 1990;Wang & Lane, 1996;Zhang & Manon, 2000)。由此可見在數學測驗中,因性別產生有關 的 DIF 現象之研究結果存在著歧異性。
第六節 DIF 的檢定方法
壹、DIF 的定義
有關 DIF(Differential item function)的研究最初在 1960 年代,美國的人權運 動興起,重視機會均等,測驗公平性乃受到廣泛注意。當時是稱為試題偏誤(item bias)(Angoff, 1993),由於試題偏誤中的「偏誤」一詞涵蓋許多不同的意義:光以 字面上來看,可能代表某些違背事實或真理的隱喻;若站在統計的觀點上,則代 表某一估計值偏離所欲測量的真正數值。因為「偏誤」一詞可能代表多種意涵, 加上牽涉到價值判斷,所以心理計量上的客觀研究有必要對此用語加以釐清,因 此有學者提出以「試題差異功能」(Differential Item Functioning,以下簡稱 DIF) 一詞來代替(Holland&Thayer, 1988),意涵著試題發揮了不同的功用,不一定單指 負面的功能(余民寧、謝進昌,2006)。Camilli 和 Shepard(1994)進一步針對試題偏 誤與 DIF 做區分,認為 DIF 僅是統計分析的結果,而對被檢定為 DIF 的試題做更 詳 盡 的 審 視 和 判 斷 後 , 若 發 現 試 題 含 有 與 測 驗 本 身 欲 測 量 的 構 念 無 關 (construct-irrelevant)的因素,而造成試題的難度對不同背景的應試群體不相等, 方可稱該試題為偏誤試題(biased item)。對於在欲測量特質上已相配對的不同群體 而言,DIF 是一種意料之外的測驗表現差異(Dorans&Holland, 1993)。
group) , 另 一 個 用 來 與 焦 點 組 答 題 表 現 作 對 照 的 群 體 稱 為 參 照 組 (reference group)。參照組和焦點組之受試者配組的依據稱為配組變項(matching variable)或 配 組 效 標 (matching criterion) , 接 受 調 查 或 檢 定 的 試 題 稱為 受 評 試題 (studied item)。其中焦點組是研究者所感興趣的群體,參照組則是用以對照的另一群體。 (盧雪梅,2000)我們常是以總測驗分數或分測驗分數作為焦點組和參照組的配對 標準,有些人對 DIF 的看法認為:「在某個試題上,如果多數族群和少數族群在 測驗上的表現有所差異,該試題便顯現出 DIF 的現象」。然而真是如此嗎?因為 有可能原本這兩個族群的能力本來就不同,因此才導致在某個試題(測驗)上表現 產生差異(Lord, 1980),上述的情況只能稱做 Impact,並不能說試題有 DIF 的存在。 目前,比較令心理統計學者所接受的 DIF 的定義為:來自不同族群,但能力相同 的個人,如果在某個試題上的答對機率有所不同時,則該試題便顯現出 DIF 的現 象(余民寧,1993)。 有關檢定 DIF 的解釋是很重要的,因為不正確的解釋會造成極大誤解,其解 釋仍必須考慮其測驗目的來加以區別。例如:當某一測驗被檢測出有 DIF 試題時, 並非要將所有 DIF 試題均移除,有時亦有好的理由將之留下,因此,我們應注意 的是所有統計並非定論,檢查出 DIF 試題後必須再經由專家學者加以分析,以判 斷該試題是否偏誤,亦或是教學者在教法上出現偏差所導致。另外,分組時的配 對標準是否公平、可信賴且有效,如果配對時發生偏誤,那麼這個檢定 DIF 的分 析過程則會有瑕疵。再者,DIF 試題可能包含某些課程或教學所須的改變,這些 隱藏的問題值得教育工作者加以留意。
貳、IRT 取向的 DIF 檢定方法
IRT 取向的 DIF 方法是屬程序分類架構中的潛在變項且有特定函數關係形式 的方法,主要檢定焦點組與參照組的試題參數是否有差異,亦即檢定兩組的試題反應函數是否相同,目前最普遍的 IRT 取向的檢驗 DIF 方法是比較試題參數估計 值,主要有 Lord χ2考驗法(Lord,1980)、兩組受試之 IRF 或 ICC 間區域量數法、 概率比檢定法(likelihood ratio test,簡稱 LR-IRT)等。
參、非 IRT 取向的 DIF 檢定方法
IRT 取向的 DIF 方法,Lord 的卡方考驗和 LR-IRT 考驗均只提供兩團體統計 是否達顯著上的資訊,無法進一步提供差異程度上的訊息,而 ICC 區域量數法雖 提供兩團體間差異程度,但其在檢定效能上仍須更多研究評估。另外,IRT 取向 的 DIF 方法須符合 IRT 模式的各項嚴格假設,不僅需要大量樣本且實施程序上費 時費力,實際應用上比較不方便,因此有非 IRT 取向的 DIF 方法產生。
一、Mantel-Haenszel 法(簡稱 M-H 法,Holland & Thayer, 1988)
M-H 法是由 Mantel 與 Haenszel 於 1959 年發展出來,期間不斷演變,經過 Landis,Hyman 與 Kock(1978)加以改良,使成可調整層次的卡方(chi-square)統計 量,稱為 CMH(Cochran-Mantel-Haenszel)統計量,後由 Holland 和 Thayer(1988) 應用到 DIF 研究中,才形成一完整的 DIF 試題的檢定法,此法不僅具有統計上強 而有力的考驗指標,且 ETS 也發展出一套解釋 DIF 嚴重程度的分類系統,是一 種少數兼具量與質的 DIF 試題檢定方法(余民寧、謝進昌,2006)。 利用 M-H 法進行試題 DIF 分析,首先是在實施測驗後,選定配對的準則(the criteria for matching),然後依此準則將受試者分為焦點組與對照組兩組。焦點組 的受試者是研究者較關心想要瞭解的對象,而對照組則是相對於焦點組,作為比 較之用。例如:研究者的興趣是想要瞭解某數學試題是否對男學生較為有利,則 焦 點 組 便 是 由 男 學 生 組 成 , 而 女 學 生 則 組 成 對 照 組 。 M-H 法 屬 於 列 聯 表 (contingency tables)的分析法,檢定通常以測驗總分做為配對變項。此法,包含共 同勝算率(common odds ratio)及 M-H 卡方統計值的計算,其方法乃根據 k+1 個分
數組(k 代表試題數,k=1……k),形成 k+1 個 22 列聯表在 k 個分數層中,各個 分數層之受試者答題表現可整理成一個 2×2 的列聯表,如表 2-6。 表 2-6 總分為 k 之 22 列聯表 得分 答對(1) 答錯(0) 合計 參照組(R) Ak Bk nRk 組 別 焦點組(F) C k Dk nFk 合計 m1k m0k Tk Tk代表得分為k的總人數,nRk與nFk分別代表參照組與焦點組的人數, m1k為答對試題的人數,m0k為答錯試題的人數。MH法的虛無假設(null hypothesis) 即是在考驗這k+1個分數組的參照組和焦點組的共同勝算率參數(αMH)是否等於 1.0。,αMH的估計值如下: k k k k k k k k MH T C B T D A ˆ Mantel 與 Haenszel 於 1959 年曾提出一卡方統計數來考驗 αMH=1.0 的虛無假設: 2 MH 2 ) 5 . 0 ) ( ( k k k k k k A Var A E A 上述公式中,-0.5是為了提升χ2 MH的間斷分配使之趨近於連續卡方分配,其 中E(Ak)和Var(Ak)的定義分別為:
k k Rk k T m n A E 1 ,
1
2 0 1 k k k k fk Rk k T T m m n n A Var 在虛無假設下,χ2 MH是自由度為1的卡方分配,拒絕虛無假設表示該試題呈現DIF現象。實際應用上,為了方便說明DIF的分析結果,通常將ˆMH值轉換為另一種 型式的DIF量數,稱為MH D-DIF(ΔMH),轉換公式如下:MH D-DIF=-2.35ln
ˆMH
MH D-DIF是以ETS(Educational Test Service)的難度量尺Δ(delta)指標來解釋 相同能力的參照組與焦點組在某試題上難度的差異值,正的MH D-DIF值則表示 試題對於參照組相對較為困難,即是有利於焦點組;負的MH D-DIF值表示該試 題對於參照組相對較為簡單,即有利於參照組(余民寧、謝進昌,2006)。 進行統計分析時,顯著性考驗的結果容易受到樣本因素的影響,當樣本人數 多時,即使是微小的差異,也會達到統計上的顯著性,但並不見得具有實質上的 差異,因而ETS的DIF嚴重程度分類系統,乃同時根據顯著性考驗結果(α=.05顯著 水準)與MH D-DIF值來對試題進行DIF程度分類(盧雪梅,2000)。試題之MH D-DIF 值如果未顯著異於0或絕對值小於1.0,則歸類於A類DIF;MH D-DIF的值顯著大 於1.0或絕對值如果大於1.5,則歸類於C類DIF;其餘的試題,則歸於B類DIF(Doran & Holland, 1993)。A類代表未顯著或輕度的DIF,B類代表中度DIF,C類代表重度 DIF。 二、羅吉式迴歸分析法 羅吉式迴歸分析法(Logistic Regression,LR)根據測驗總分和組別預測答題表 現,其基本模式如下:
z
z e e u 1 1 公式中的P表示受試者在該試題正確作答的機率,Z則根據研究者對DIF類型 的假定來決定模式,模式I: z=0 1 2G3(G)、模式Ⅱ:z=0 1 2G、 模式Ⅲ:z=0 1 ,式中的θ是受試者被觀察到的能力,是一個連續變項,通常 以測驗總分來代表。G是組別,通常以0和1來編碼,G=0代表參照組;G=1則為焦 點組,θG是θ和G的乘積。迴歸係數0為截距係數;1為能力值θ對試題答對率的 影響;2是指兩受試群體在該試題表現上的差異,3是指兩受試群體和能力值之 間的交互作用,LR是應用最大概似法(maximum likelihood estimate;MLE)來估計模式中的迴歸係數(盧雪梅,1999)。 LR 檢定的步驟是比較模式Ⅰ與模式Ⅱ,以檢定3是否異於 0,以自由度為 1 的卡方分配考驗之,若拒絕3=0 的假設,表示組別與能力的交互作用效果顯著, 試題呈現 non-uniform DIF;若3=0 的假設未被拒絕,則繼續比較模式Ⅱ與模式 Ⅲ,也是以自由度為 1 的卡方分配考驗之,若拒絕2=0 的假設,表示試題出現 uniform DIF。 三、SIBTEST 法
SIBTEST 偵 誤 程 序 是 一 種 兼 具 潛 在 變 項 (latent variable) 與 無 參 數 模 式 (non-parametric)的 DIF 檢定方法(Dorans&Potenza, 1994),除了受試者能力間的差 異不會因樣本抽樣不同而產生偏差的優點外,更因其不用考慮於參數模式中資料 適合度(data fitting)問題所產生的費時費力情形,因此 SIBTEST 法是一種相對降 低偵誤成本的有效方法(Shealy&Stout, 1993a, 1993b;Dorans&Potenza, 1994;Ryan &Fan, 1996;Ryan&Chiu, 1997)。SIBTEST 法是根據 IRT 所發展出的一套偵誤程 序,但並未涉及試題參數的估計,而是基於相同配對分數的受試者擁有相同潛在 能力的假設,因此是以配對子測驗的分數做為分組計算的依據。應用 SIBTEST 法須先將試題分為兩部分,一部分由無 DIF 試題組成,稱為有效部分測驗(valid subtest),做為配組準據,另一部分稱為可疑部分測驗(suspect subtest),這部分的 試題將接受 DIF 檢定。
SIBTEST的實際操作程序(Shealy & Stout, 1993a; Roussos & Stout, 1996)如 下:首先,設 Ugij 代表組別g(焦點組或參照組)中第j個受試者於第i題的得分情
形,假定第1題至第n題為有效部分測驗集合(沒有DIF試題的集合),從第n+1題到 第N題為可疑部分測驗集合(被懷疑有DIF試題的集合),則焦點組與參照組第j個受 試者作答的有效部分測驗分數X與可疑部分測驗分數Y可分別表示如下:
n i gij gj U X 1
N n i gij gj U Y 1 其中Xgj的分數從0分至n分,形成n+1個組別(cell),則所有的受試者可依得分 情形而分配至每個組別之中,因而便可計算每個組別所包含參照組與焦點組成員 得到k分的人數:JRk與JFk(k=0,l,...,n),然後計算每一組受試者於可疑部分測 驗之平均得分。
Rk J j Rj Rk RK Y J Y 1 1 k=0, 1, 2……n
Fk J j Fj Fk FK Y J Y 1 1 k=0, 1, 2……n 進而得到DIF估計值 ˆ ˆ ( ) 0 Fk Rk n k k U
P Y Y ,其中
n k Fk Rk Rk Fk k J J J J p 0 / ˆ 。Shealy & Stout(1993b)證明ˆU是DIF指標U的不偏估計量。接下來計算在有 效部分測驗中獲得k分的受試者於可疑部分測驗得分的變異數:
2 2 1 1 ) , ( ˆ
gk J j gk gj gk Y Y J g k Y ,g代表焦點組F或參照組R。 最後定義DIF統計檢定量 ) ˆ ( ˆ ˆ U U B ,其中分母部分為: 2 / 1 0 2 2 2 1 ˆ ( , ) 1 ˆ ( , ) ˆ ) ˆ ( ˆ
n k Rk Fk k U Yk F J R k Y J P 在樣本數夠大的情況下,此統計量B的分配趨近於標準常態N(0,1),因此,依 照適當的顯著水準就可以實施統計考驗,檢定可疑部分測驗之DIF試題。 上述的DIF估計值ˆU與統計檢定量B的推導,乃是假設兩組受試者目標能力θ 的分配相等;然而,有可能試題本身沒有DIF現象,檢定量B卻因兩組受試者本身 在目標能力θ分配上的差異而變得較大,進而誤導以為試題有DIF的現象。為了避 免此種現象產生,在SIBTEST中可以採用迴歸校正(regression correction)的程序, 將兩個團體中的受試者依照相同能力等級做配對,再比較他們在某一題或多題的 表現是否有差異。這種校正法可以避免因為測驗所產生的測量誤差,以及存在於團體間不同能力分配(impact)所造成的第一類型錯誤率膨脹(Bolt, 2000)。 迴歸校正的原理和方法可參閱Shealy & Stout(1993a)。經由迴歸校正後,DIF 估計值ˆU被定義為: ( * *) 0 Fk Rk n k k U
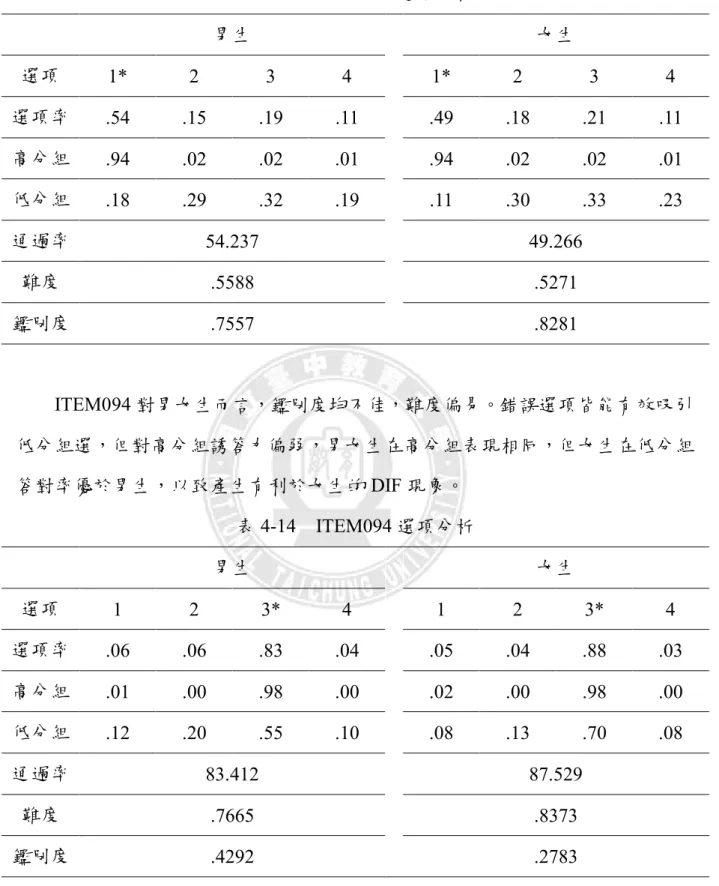
P Y Y , * Rk Y 、 * Fk Y 為去除 impact 所產生的膨脹 效果後,所得到修正的Y值平均值。(YRk* YFk*)是兩組受試者在可疑部份測驗試題 之得分的調整平均數的差異,這差異分數可以是單一試題得分或一組試題得分的 差異。如果無DIF存在,U值將會是0。DIF大小可依SIBTEST的效果量來分為三 類,依據β值歸類為C、B、A三類的不同DIF嚴重程度,C類是 值大於等於0.088, 屬於嚴重DIF試題,建議應刪除。B類則為:0.059 <0.088,為中度DIF試題, 可以重新審定或編修之後再使用。A類是 值小於0 . 059,為輕度DIF試題,通常 可以被忽略(Roussos & Stout, 1996)。Crossing-SIBTEST法是SIBTEST檢定方法的修正方法,且沒有限制在一個能 力參數上。Li 和 Stout (1996)修正原有的 SIBTEST 程序,使其能有效偵察出 non-uniform DIF的試題,並以Crossing DIF 來取代non-uniform DIF的詞彙。
Crossing DIF的假設考驗為H0 :cro 0 vs. H0: cro 0
其中cro的估計值被定義為:
n k k Fk Rk k k Rk Fk cro pk Y Y pk Y Y 1 * * 1 0 * * ) ( ˆ ) ( ˆ ˆ 接著考驗沒有DIF的虛無假設(H0 :cro 0),其統計值為: ) ˆ ( ˆ ˆ cro cro cro ,其 中 分母部分為: 2 / 1 2 2 2 1 1 0 ) , ( ˆ 1 ) , ( ˆ 1 ˆ ) ˆ ( ˆ
F k Y J R k Y J p Fk Rk k n k k k k cro c c c k 為有Crossing DIF情形時,有效部分測驗的分數。 ˆ2( , ) g k Y 為有效部分測 驗分數為k時,群體g(參照組R或焦點組F)中受試者在可疑部分試題分數的樣本變 異數。當沒有DIF發生時,Crossing -SIBTEST的統計值cro也接近於N(0,1)分配, 因此,可以依照所設定之適合的顯著水準來實施統計考驗,檢定出有DIF現象的 試題。肆、本研究採用的 DIF 檢定法
非 IRT 取向的 DIF 程序如 Mantel-Haenszel 法、羅吉式迴歸分析法與 SIBTEST 法,在各組人數約 200 到 250 人時,即可以得到適當的結果(盧雪梅,1999),曾 建銘(2005)曾利用實徵資料和模擬資料針對 IRT 和非 IRT 的 DIF 偵測方法進行 DIF 試題偵測,研究結果發現兩者並無太大差異,其中以 SIBTEST 偵測效果最好, 考量運用 IRT 模式偵測 DIF 不但原理複雜,需要提供大量樣本(1000 人以上)且實 施程序上又有費時費力的缺點,建議在 DIF 偵測上可運用非 IRT 模式之方法,實 施程序比較簡單,容易應用於實際中,不要大樣本,效能令人滿意,並且提供 DIF 的顯著性假設檢驗。本研究之小六男生達 4164 名,女生人數 3921 名,受試 樣本足夠,但基於計算簡單、實施容易且效能也令人滿意,故採非 IRT 取向的 DIF 程序。非 IRT 取向的 DIF 方法通常以測驗總分做為配組變項,但當兩組受試 者能力分配差異較明顯時,測驗總分無法有效的將兩組受試能力配對比較,能力 差異與 DIF 產生混淆,易發生第一類型錯誤。故本研究先採用試題分析軟體 BILOG-MG3.0 估計所有受試者之能力值,再根據每個試題區塊內之男、女生的 能力值分布情形,在該區塊抽取能力值相對應之相等人數,以降低犯第一類型錯 誤的機率,避免 impact。
第三章 研究方法
第一節 研究架構
研究者向 TASA 提出申請,共釋出數學科有效試題 103 題,8085 名小六受試 學生。本研究先求出男女生在各項能力指標之平均達成率,再對試題做 DIF 檢定 分析,若出現 DIF 試題,則對其進一步做選項分析,最後依據研究結果提出建議。 本研究之研究架構如圖 3-1 所示: 圖3-1 研究架構圖 2006TASA 小六數學科 試題及作答結果資料 分析整體學生各項能力指標 之平均達成率及性別間差異 檢定 DIF 試題 M-H 法 Crossing- SIBTEST 法 ETS 分類法 不同 DIF 檢定方法之檢定結果 DIF 試題之選項分析 LR 法 性別 DIF 試題分析第二節 研究流程
本研究詳細的研究流程說明如下: 1.依據當今社會眾所關注之議題引發研究動機並決定研究方向。 2.設定研究主題,並擬定研究的流程草案。 3.建構研究目的並據以衍生出待答問題。 4.蒐集相關文獻,並據以撰寫研究背景及文獻探討。 5.向「臺灣學生學習成就評量資料庫(TASA)」申請2006年小六數學科的作答資料。 6.依據九年一貫數學領域五大主題將數學科試題予以區分為五個測驗內容,以便 針對DIF試題進行分析。 8.依據研究目的與研究問題繪製研究架構圈。 9.將申請到的2006TASA小六數學科考生原始作答反應資料加以整理,並利用 BiLog-MG3.0估計受試者的能力值,以便作進一步分析。 10.根據作答情形,分析整體學生各項能力指標之平均達成率及性別間差異。 11.將兩族群能力指標達成率差異達 5%以上做獨立樣本 t 檢定,並依 effect size 公 式分析顯著情形。 12.了解本研究中所運用分析 DIF 試題的檢定方法(M-H 法、Crossing-SIBTEST 法、ETS 分類法及 LR 法)原理。 13.熟悉M-H法、Crossing-SIBTEST法、ETS分類法及LR法所應用到的統計套裝軟 體程式(如:SPSS、SIBTEST、EZDIF),將資料輸入檢測出具有性別DIF現象之試 題。 14.繪製DIF試題區塊答對人數百分比曲線圖輔助佐證DIF現象之說明。 15.針對具有性別DIF現象之試題,利用試題測驗分析程式 Tester 2.0 分析各題通 過率、難度、鑑別度及高低分組的各題選項填答率。 16.彙整研究結果並進行研究討論,最後提出研究結論與建議。第三節 研究對象
壹、TASA 抽樣架構
為能確保「臺灣學生學習成就評量資料庫」所抽取之樣本具有全國代表性, 且因臺灣各縣市人口多寡各異,為充分顯現教改後臺灣學生學習成就實際情形, 故採二階段隨機抽樣設計。第一階段採分層叢集隨機抽樣,根據縣市、鄉鎮人口 密度及班級數等三個變項進行分層,抽取樣本學校名單。第二階段則根據所抽取 到之樣本學校,對每一層以學生個人為單位,在排除在家教育者與 12 類障礙類 別等特殊學生,以進行簡單隨機抽樣。其中縣市依照行政區分為 25 個縣市;人 口密度則以全縣人口平均數為基準,將鄉鎮(市、區)依照人口密度分為 4 群;至 於學校規模則以 24 班以下及 25 班以上為基準,分為 2 群,見圖 3-2(臺灣學生學 習成就評量資料庫,2007)。 根據上述之二階段隨機抽樣設計,經向 TASA 提出申請「2006 年學生學習成 就評量」小六數學科施測結果釋出資料,2006 年全國總共抽選 8179 名小六數學 科受試學生,刪除作答資料不全者 81 名及無法判斷性別者 13 名,合計有效樣本 共 8085 名,其中男生人數 4164 名,女生人數 3921 名。試題處理方面,因原始 試題第 90 題答案出錯而遭到刪除,得到有效試題共 103 題。符合以下條件之ㄧ 者為無效樣本: 一、資料不全,以致無法判斷性別者; 二、未做答或連續跳答超過 4 題者; 三、若選項為 1、2、3、4,但答案卻寫 5、6、7…或跳答總合超過 5 題者。圖 3-2 TASA 抽樣架構 陳 XX 李 XX 蔡 XX 樣本學校 第 二 階 段 : 簡 單 隨 機 抽 樣 …… …… 全國樣本 臺中縣 臺北市 臺東縣 大雅鄉 沙鹿鎮 霧峰鄉 25 班以上 24 班以下 第 一 階 段 : 分 層 隨 機 抽 樣 豐原市 …… …… 25 縣市 學校規模 鄉鎮人口密度 … … …