國
立 交 通 大 學
財 務 金 融 研 究 所
碩 士 論 文
風險值衡量:變幅
DCC 模型的應用
Measuring the Value-at-Risk:An Application of Range-DCC model
研 究 生:洪慎慈
指導教授:周雨田 博士
鍾惠民 博士
風險值衡量:變幅 DCC 模型的應用
Measuring the Value-at-Risk:An Application of Range-DCC model
研 究 生:洪慎慈 Student:Shen-Tzu Hung 指導教授:周雨田 博士 Advisor:Dr. Yeutien Chou 鍾惠民 博士 Dr. Huimin Chung
國 立 交 通 大 學
財務金融研究所
碩 士 論 文
A Thesis
Submitted to Graduate Institute of Finance
College of Management
National Chiao Tung University
in partial Fulfillment of the Requirements
for the Degree of
Master
of
Science in Finance
June 2006
Hsinchu, Taiwan, Republic of China
風險值衡量:變幅 DCC 模型的應用
研究生:洪慎慈 指導教授:周雨田 博士
鍾惠民 博士
國立交通大學財務金融研究所
摘要
本研究針對不同財務資料特性所提出之風險值模型進行評比,包括考慮厚 尾性質的極值理論(extreme value theory;簡稱 EVT)風險值模型,以及利用 「時變」波動模型捕捉報酬具有條件異質變異特性的動態風險值模型。此外, 將變幅(range)概念引入風險值估計中,利用 Chou (2005)提出之 CARR (Conditional Autoregressive Range)模型估計波動性,得到變幅基礎下的風險值模型,並以美國S&P 500 股價指數與十年期財政部政府公債日資料做為研究
對象,進行變幅與報酬基礎下的風險值模型在風險值預測能力之比較,實證結 果顯示,變幅基礎下的風險值模型表現優於報酬基礎下的風險值模型。
最後,更將分析維度擴大至投資組合風險值的估計,探討不同相關係數估 計模型對投資組合風險值估計的影響,結果顯示Chou, Liu 和 Wu (2005)提出之 變幅基礎下的DCC(Dynamic Conditional Correlation)模型表現優於報酬基礎
下的 DCC 模型,可獲得較準確的投資組合風險估計值,證實變幅可做為資產
報酬風險評估之一良好指標。
Measuring the Value-at-Risk:An Application of
Range-DCC model
Student:Shen-Tzu Hung Advisor:Dr. Yeutien Chou
Dr. Huimin Chung
Graduate Institute of Finance
National Chiao Tung University
June 2006
Abstract
This paper investigates the Value-at-Risk models that were proposed with different characteristics of financial data, including the extreme value theory (EVT) Value-at-Risk model and the dynamic models considering the heteroscedasticity problem. In addition, we adopt the concept of range to the Value-at-Risk estimation. We use the Conditional Autoregressive Range (CARR) model of Chou (2005) to measure the volatility, and get the range-based Value-at-Risk model. We use the daily data of the stock indices of S&P 500 and the 10-year Treasury bond yield for empirical analysis. The empirical results indicate that the range-based models have the better performance than the return-based models in the Value-at-Risk evaluation. Finally, we expand the evaluation to larger dimentions for the portfolio situation, and examine the effect of different correlation estimating models on the Value-at-Risk measuring of a portfolio. We find that the range-based Dynamic Conditional Correlation (DCC) model gets more precise Value-at-Risk estimation than the return-based DCC model. In orter words, range data is a good tool for risk measuring of the asset return.
謝 辭
兩年的研究生涯即將告一段落,在這過程中要感謝的人實在太多,首先感 謝指導教授 周雨田老師和鍾惠民老師的耐心指導,以及感謝任職於中原大學國 貿系的巫春洲老師,在我遇到瓶頸時指引我撰寫的方向,並耐心的給予指正, 也感謝口試委員 朱家祥老師的建議與指教,讓這篇論文更具價值,在此,謹致 以最深的謝意。 在論文的撰寫過程中,我要感謝目前就讀於交大管科所博士班的劉炳麟學 長,學長給予的許多程式上的建議與指正,讓我在程式的撰寫過程中更加順利。 在研究所的求學旅程中,感謝交大財金所的伙伴們,有你們的陪伴,使得研究 所生活更加多采多姿,謝謝你們平常時的照顧。 最後,謝謝父親與母親的栽培,您的全力支持讓我能夠心無旁騖地完成學 業,您辛苦了,謝謝您。除此之外,感謝女友依依在程式上給我的協助,妳的 陪伴與鼓勵讓我更加茁壯與自信,謝謝妳! 洪慎慈 謹誌 國立交通大學財務金融研究所 中華民國九十五年六月目 錄
中文摘要... I 英文摘要... II 目 錄...IV 表目錄...VI 圖目錄... VII 第壹章、緒論...1 第一節 研究動機...1 第二節 研究目的...3 第貳章、文獻探討...5 第一節 風險值介紹...5 第二節 波動性模型的討論...7 第三節 極值理論的概念與相關應用的探討...9 一、 金融資產極值行為相關文獻...9 二、 尾部指數估計法... 11 三、 VaR-x風險值模型 ...12 四、 動態極值理論模型...13 第四節 相關係數估計模型...14 第參章、研究方法...17 第一節 極值理論...17 一、 Block Maxima模型...18 二、 Peak-Over-Threshold(POT)模型 ...20 三、 尾部指數之估計...22 第二節 風險值估計方法...24一、 靜態(非條件)風險值模型(unconditional Value-at-Risk model)..26
二、 動態(條件)風險值模型(conditional Value-at-Risk model)...32
第三節 投資組合風險值估計方法...35
一、 Moving Average 100(MA100)模型 ...37
二、 Exponential Weighted Moving Average(EWMA)模型...37
三、 Constant Conditional Correlation(CCC)模型 ...38
四、 Dynamic Conditional Correlation(DCC)模型...38
第四節 風險值模型評比準則...41
一、 保守性分析...42
三、 效率性分析...47 第肆章、資料分析...50 第一節 資料來源與取樣期間...50 第二節 資料的基本統計分析...50 第三節 極端資料分析...55 第伍章、實證結果...56 第一節 尾部指數估計結果的分析...56 第二節 單一資產回溯測試結果...58 一、 失敗率分析...59 二、 靜態與動態風險值模型比較...65 三、 個別年度(year by year)回溯測試...67 四、 極端事件風險捕捉能力的探討...68 五、 模型檢定分析...69 第三節 投資組合回溯測試結果...74 一、 動態投資組合風險值模型的比較...74 二、 DCC模型相對於MA100 與CCC模型的改善程度...78 第陸章、結論...82 參考文獻... 115
表目錄
表 1. S&P 500 股價指數與十年期政府公債資料單根檢定 ...84
表 2. S&P 500 股價指數與十年期政府公債日報酬率敘述統計表 ...85
表 3. S&P 500 股價指數與十年期政府公債殖利率日變幅敘述統計表 ...86
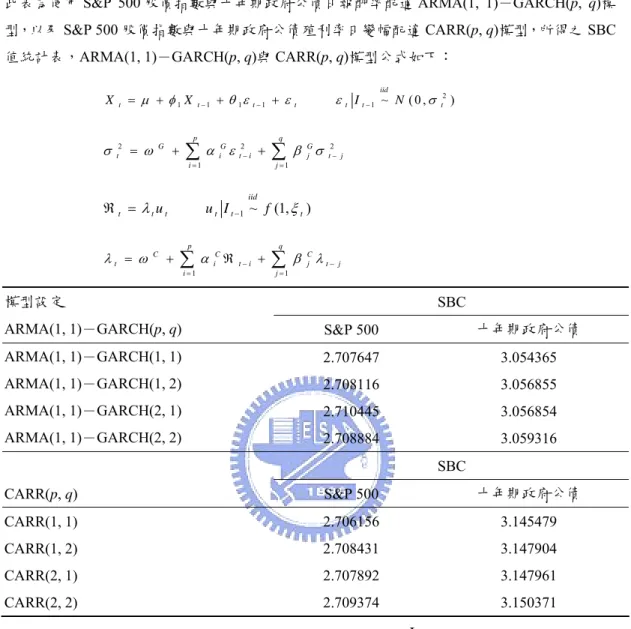
表 4. ARMA(1, 1)-GARCH(p, q)與CARR(p, q)模型SBC值統計表 ...87
表 5. ARMA(1, 1)-GARCH(1, 1)與CARR(1, 1)模型參數估計結果...88
表 6. S&P 500 股價指數與十年期政府公債日報酬率殘差項敘述統計表 ...89 表 7. S&P 500 股價指數與十年期政府公債日報酬率極端損失間距之累積分 配表...90 表 8. S&P 500 股價指數與十年期政府公債日報酬率分配尾部指數估計值 ...91 表 9. S&P 500 股價指數與十年期政府公債日報酬率 95%、97.5%、99%及 99.5%信心水準下靜態(非條件)風險值模型之穿透次數表 ...92 表 10. S&P 500 股價指數與十年期政府公債日報酬率 95%、97.5%、99%及 99.5%信心水準下動態(條件)風險值模型之穿透次數表 ...93 表 11. S&P 500 股價指數與十年期政府公債日報酬率在 95%、97.5%、99%及 99.5%信心水準下由靜態(非條件)風險值模型至動態(條件)風險值 模型的改善百分比表...94 表 12. S&P 500 股價指數與十年期政府公債日報酬率在 95%信心水準下風險 值模型之逐年穿透次數表...95 表 13. S&P 500 股價指數與十年期政府公債日報酬率在 99%信心水準下風險 值模型之逐年穿透次數表...96 表 14. S&P 500 股價指數與十年期政府公債日報酬率 31 個最大損失以及所有 損失在99%信心水準下各風險值模型的穿透百分比 ...97 表 15. S&P 500 股價指數日報酬在 95%信心水準下之風險值模型檢定分析...98 表 16. 十年期政府公債日報酬在 95%信心水準下之風險值模型檢定分析 ...99 表 17. S&P 500 股價指數日報酬在 99%信心水準下之風險值模型檢定分析.100 表 18. 十年期政府公債日報酬在 99%信心水準下之風險值模型檢定分析 ....101 表 19. 投資組合日報酬在 95%信心水準下動態風險值模型評比 ...102 表 20. 投資組合日報酬在 99%信心水準下動態風險值模型評比 ...103 表 21. 投資組合日報酬在 95%信心水準下搭配不同相關係數模型時之動態風 險值模型評比...104 表 22. DCC模型相較於MA100 與CCC模型在 95%信心水準下之投資組合風險 值模型估計準確性上的改善幅度...104 表 23. 投資組合日報酬在 99%信心水準下搭配不同相關係數模型時之動態風 險值模型評比...105 表 24. DCC模型相較於MA100 與CCC模型在 99%信心水準下之投資組合風險 值模型估計準確性上的改善幅度...105
圖目錄
圖 1. S&P 500 指數收盤價與十年期政府公債殖利率走勢圖 ...106 圖 2. S&P 500 股價指數與十年期政府公債報酬率直方圖vs常態分配圖...107 圖 3. S&P 500 股價指數與十年期政府公債報酬率QQ-plot...107 圖 4. S&P 500 日報酬率與條件波動性走勢圖 ...108 圖 5. 十年期政府公債日報酬率與條件波動性走勢圖...109 圖 6. S&P 500 股價指數報酬率殘差項QQ-plot... 110 圖 7. 十年期政府公債報酬率殘差項QQ-plot ... 110 圖 8. S&P 500 日報酬率與尾部指數估計值走勢圖 ... 111 圖 9. 十年期政府公債日報酬率與尾部指數估計值走勢圖... 112 圖 10. S&P 500 日報酬率vs各風險值模型在 99%信心水準下之風險估計值 . 113 圖 11. 報酬基礎下DCC模型、MA100 模型與CCC模型的樣本外相關係數估計 值... 114 圖 12. 變幅基礎下DCC模型、MA100 模型與CCC模型的樣本外相關係數估計 值... 114第壹章、緒論
第一節 研究動機 在進行投資決策過程中,期望報酬與風險一直為投資人最關心的兩項變 數。另一方面,近年來國際間交易活動日益熱絡,導致全球金融市場交易價格 波動性上升和不穩定,因此對於金融市場上的參與者來說,風險控管的能力越 來越重要,如何建立更具體可行的風險評量控管系統以有效管理涉險狀況,即 為目前學術界與實務界主要努力的目標之一。風險值(Value-at-Risk;簡稱 VaR) 的概念就是在這樣的背景之下被提出來的,風險值不僅概念簡單易懂,更可將 整個投資組合所面臨的各種風險暴露程度量化為單一數據來解釋,是一種相當 實用且可用於改善下方風險(downside risk)管理的風險控管工具。 所謂風險值乃為一風險估計值,測度投資組合面對市場風險下,當最壞的 情況發生時投資組合最大可能損失之額度,其中所指最壞的情況通常以機率分 配中的分位數(或稱為信賴機率水準)定義之。一般而言,風險值是評估一段 期間以既定的信心水準100( )%所計算出資產報酬的市場風險,或是此一資產 報酬在此期間可能發生的最大損失金額。Hull 和 White (1998)對風險值的定義 為:「我們有100( c )%的信心在未來 h 天內的損失不會超過 V 元」,其中V 值即 為風險值,此方法提供了實務上更明確的風險衡量方法。 c 雖然風險值估計模型不斷的發展,但究竟何者才是最適當的風險估計模型 可以適用於不同的金融市場與金融資產,目前尚無定論1。許多實證研究發現金 融資產之報酬分配具有厚尾(fat tail)的特性,而一般傳統風險值估計模型大 1 參照Hendricks (1996)有更深入探討。都假設報酬為常態分配,往往無法有效捕捉尾部分配的情況,因此可以直接經 由觀察樣本分配尾部極端值的情形來評估風險,期望能夠掌握真實的風險狀 態。然而很多運用極端值相關理論來探討風險值問題的研究,都無法獲得有效 率且估計簡便的風險評估方法,對此本研究將藉由Huisman, Koedijk和Pownall (1998)提出的風險值估計方法,探討其與一般傳統風險值估計方法的差異。 此外,也有許多研究將報酬波動性因時而異的特質納入考量,建立不同的 波動性模型來描述報酬變異數變化的特性,冀盼提升風險值模型估計的準確 性。Chou (2005)指出變幅(range)可做為報酬波動性的代理變數(proxy),且 其所發展的變幅基礎(range-based)下的波動性估計模型,在波動性估計上的 表現優於一般報酬基礎(return-based)下的波動性估計模型,本研究將進一步 探討變幅基礎下的波動性估計模型應用在風險值的估計時,是否可獲得較報酬 基礎下的波動性估計模型更準確的風險估計結果。 在全球各經濟體互動程度越來越頻繁的趨勢下,相較過去而言,財務風險 逐漸升高,資產間相關係數的預測在進行投資組合風險值的估計時,也越來越 重要,傳統的風險值評估模型往往假設資產報酬間的相關係數為一常數,以簡 化問題的處理並認為資產報酬間的相關性不會隨著時間的不同而改變,然而近 年來有許多研究指出資產報酬間的相關性並非固定不變,而會因市場結構的不 同產生改變,因此相關係數可視為時間的函數,自此許多關於資產報酬間共變 異數或相關係數的估計模型便成為被熱烈討論的議題,其中Engle (2002)所提出
的DCC(Dynamic Conditional Correlation)模型更為眾多相關係數模型中發展 相對完備且估計方便的模型,本研究亦將由此模型為基礎,進而應用至投資組
合風險值估計上,並探討 DCC 模型相較於其他模型,在投資組合風險值估計
上的差異。此外,本文也藉由 Chou, Liu 和 Wu (2005)所提出的變幅基礎下的 DCC 模型,探討應用至投資組合風險值估計上的情形,並與原始報酬基礎下的
DCC 模型比較,藉以檢視變幅基礎下的投資組合風險值模型和報酬基礎下的投 資組合風險值模型,在投資組合風險值估計上的相對表現。
第二節 研究目的
本研究以美國的金融市場資料為對象,探討此市場中不同投資組合可能面
臨的市場風險,並以S&P 500 股價指數與十年期財政部政府公債的日資料為主
要研究樣本,比較傳統的風險值估計方法與極值理論(extreme value theory;簡
稱EVT)所發展出來的各種風險值估計方法是否存在差異?亦考慮條件波動性 會因時而異的動態風險值估計模型在風險值估計上是否優於未考慮條件波動變 異性的靜態模型?另外,若以變幅做為對波動性估計的代理變數時,其表現如 何?最後,我們也會討論不同的相關係數估計模型對投資組合風險值估計的影 響,並討論預測資產報酬間相關性的正確與否,對於投資組合報酬風險值的評 估確實有相當大的影響。 本文的貢獻在於建立可以描述資產報酬具異質變異性與極端事件叢聚特性 的風險值模型,更可簡化風險值的估計過程並在小樣本情形下提升風險值估計 的準確性。除此之外,亦嘗試使用變幅的觀念代替報酬變異數來描述波動性, 以檢視變幅基礎下風險值模型的績效表現。值得說明的是,在過去應用極值理 論估計資產報酬風險值的研究中,大多只考慮單一資產的估計情況,鮮少研究 是以投資組合為研究對象來估計風險值,本文首次嘗試將極值理論的估計概念 應用在投資組合的風險值估計上,探討在極值理論架構下之投資組合風險值模 型的績效表現,並驗證當無法精確估計資產間相關係數時,對於投資組合風險 值估計的準確性可能造成的影響,由此也可以了解相關係數模型在風險值估計 中的重要性。
本文架構如下:第一章為緒論,介紹本文的研究重點。第二章為文獻探討, 第三章主要闡釋研究方法的設計,第四章為資料分析,說明研究過程中的分析 對象及基本統計性質,第五章為實證結果,主要說明本研究的發現,第六章為 本研究之結論。
第貳章、文獻探討
第一節 風險值介紹
1995 年四月,巴塞爾銀行監理委員會(Basel Committee on Banking Supervision)發佈一項諮詢文件,主要在修正 1988 年巴塞爾資本協定(Basel Accord)的內容,該文件即為眾所皆知的「1996 年巴塞爾資本適足協定修正
案」,或者藉由其正式施行之年度-1998 年,而稱其為「BIS 98」,主張金融機
構必須以風險值來衡量市場風險並藉以決定資本適足性之問題,且在其內部模 型 基 準 規 定 (an Internal Model-Based Approach to Market Risk Capital Requirement)中,准許銀行可自行選用本身發展的內部模型(internal model) 來計算市場風險值,決定銀行的必要資本額,並且必須以回溯測試(backtesting) 檢驗模型的信賴程度,以決定必要資本的提列乘數。風險值模型發展至今,最 常見的估計方法可區分為四類:歷史模擬法(historical simulation method)、蒙 地 卡 羅 模 擬 法 (Monte Carlo simulation method )、 變 異 數 - 共 變 異 數 法 (variance-covariance method)、以及極值理論,然而這些模型之優劣並無一致 性的結果。 根 據 Jorion (2000) , 歷 史 模 擬 法 為 一 種 無 母 數 方 法 ( nonparametric method),假設資產過去的價格變化會在未來評估期間再出現,而可以利用過去 實際資產價格變動資料來推估未來價格可能的變動情形;此法只需要將過去一 段期間的資產報酬資料做排序,取其信心水準相對應的分位數,即可求得風險 估計值。歷史模擬法的優點為概念易於了解且計算非常簡單,直接取實際資料 的狀況來進行分析,不需對資料賦予任何統計分配上的假設,因此減少模型假 設錯誤的風險,亦即降低模型風險,此法的缺點在於當歷史資料樣本數不足時,
便難以計算風險值,另外,若是未來的市場結構與過去明顯不同時,歷史模擬 法所估計的風險值將不適合用來反應未來的情況。Danielsson 和 de Vries (2000) 指出,以歷史資料求出的風險值在樣本數小的時候會有嚴重的誤差,因為小樣 本下極端事件的數量可能很少,如此一來以樣本內的資料估計樣本外事件的發 生機率,很可能會發生估計上的偏差,所以歷史模擬法必須仰賴多年的歷史資 料做為樣本。Goorbergh 和 Vlaar (1999)則分別測試視窗長度為 250、500、1,000 及 3,038 筆的樣本資料,也同樣獲得歷史模擬法會嚴重受到歷史資料多寡影響 的結論。
Jorion (2000)指出蒙地卡羅模擬法屬於參數法(parametric method),其基本 觀念是假設資產報酬型態符合某一過程(process),依據所設定的價格變動過 程,大量模擬未來各種可能發生的情境,再建構投資組合的損益分配圖,並推 估其風險值。蒙地卡羅模擬法的優點在於可以處理任何金融商品,解釋投資組 合所面臨的各種不同風險,即使是非線性價格風險、波動風險或模型風險都可 以使用,缺點在於需面對龐大的計算時間成本,根據 Jorion (2000)的估計,若 以1,000 條價格路徑模擬由 1,000 項資產所構成之投資組合,所需的價格路徑次 數將超過一百萬條。另外,若所假定的資產價格模型與財務變數或風險因子的 隨機模型不合適,則模擬的結果也將與實際狀況差異甚大,產生模型假設錯誤 的風險,這些都是蒙地卡羅模擬法進行實務推廣上所面臨的缺點。 J. P. Morgan 於 1994 年提出 RiskMetrics 風險值估計法,其計算方法主要以 變異數-共變數矩陣(variance-covariance metrics)來計算風險值,故又稱為變 異數-共變數法,此法為參數法的典型代表,假設資產報酬率為常態分配、各 觀察值間相互獨立以及市場變數變動與資產價格變動呈線性關係。對於這種方 式的風險值計算,其著重的重點在於資產報酬變異數與共變異數的估計,最早 是使用固定權數的加權方式,即給予過去不同期別的變數相同的權重,故又稱
為簡單移動平均(simple moving average)模型,之後 J. P. Morgan 又提出以指 數加權移動平均(Exponential Weighted Moving Average;EWMA)模型來估計
變異數-共變異數矩陣,EWMA 模型在估計變異數時,主要假設近期市場波動 對於未來變異數的估計有較大的影響力,因而得到較大的權重;而對於較遠期 的資訊,則會隨著時間的增加而賦予較小的權重係數,且呈現指數型態的衰退 方 式 , 藉 此 一 設 計 可 以 捕 捉 變 異 數 波 動 性 的 叢 聚 效 果 , 所 謂 波 動 性 叢 聚 (volatility clustering)是指大波動伴隨著大波動,小波動伴隨著小波動的特性, 而J. P. Morgan 的 EWMA 模型在考慮指數型態權數之後,改善了固定權數方式 之不合理的假設,相較於固定權數模型更能正確估算資產報酬之變異數-共變 異數矩陣,因此EWMA 模型為 RiskMetrics 法的核心模型。 第二節 波動性模型的討論 由前文可知,使用變異數-共變異數法估計風險值時,其著重的重點在於 資產報酬變異數與共變異數的估計,因此資產報酬變異數與共變異數估計的準 確性在風險值估計方法中扮演相當重要的角色,然而過去許多文獻證實金融資 產報酬往往存在異質變異性(heteroscedasticity)問題,如French, Schwert和 Stambaugh (1987)、Bollerslev, Engle和Wooldridge (1988)、Ballie和DeGennaro (1990)以及Andersen和Bollerslev (1997)等,皆觀察到資產報酬率分配變異數隨
時間改變的情形,此外亦有相關文獻認為條件波動性變異具叢聚的現象,Engle
(1982)更將此波動性異質變異的性質予以模型化而提出自我迴歸條件異質變異 (Autoregressive Conditional Heteroscedasticity;ARCH)模型,並配適於英國市 場資料獲得實證上的支持,Bollerslev (1986)修正其模型,而提出一般化自我迴 歸條件異質變異(Generalized Autoregressive Conditional Heteroscedasticity; GARCH)模型,使得條件變異數的動態結構更具彈性,在參數估計上也可以更
精簡(parsimony)2,這類模型不但可以估算資產報酬的條件變異數,也能夠 解釋金融資產報酬所產生的波動性叢聚現象,對於資產報酬未來的風險狀況更 能掌握,關於ARCH與GARCH模型在財務與經濟上的應用及說明,可參考 Bollerslev, Chou和Kroner (1992)的整理。由於波動性具異質變異的性質,故利用 變異數-共變異數法來估計風險值時,若假設資產報酬波動性為常數將會產生 嚴重的估計誤差,因此有動態(條件)波動性風險值模型被發展出來,常見的 作法,基本上是將GARCH的特性納入模型之中,利用條件波動性模型來估計未 來波動情況,進而預測風險值,J. P. Morgan所提出主要用來估計變異數-共變 異數模型之變異數矩陣的方法,亦即EWMA模型,可視為GARCH模型的特例 之一。Berkowitz和O’Brien (2002)特別針對六家銀行的內部風險值模型與時間數 列風險值模型進行比較,發現由於時間數列風險值模型對於市場上波動性的掌 握較內部模型更具彈性,能及時捕捉市場真實情況,故在風險值估計表現上並 不會比這六家銀行現行使用的內部評估模型差,因此認為銀行在使用其內部模 型評估風險時,最好可以搭配時間數列風險值模型做為輔助的評估工具。 在衡量時間數列風險值模型時,關於資產報酬波動性方面,除了如同ARCH 或GARCH模型可以利用報酬平方項衡量波動性之外,也可以利用變幅當做波動 性的代理變數,並定義變幅為某一固定取樣期間內,對數化資產價格最高價 (high)與最低價(low)的價差3。財務文獻上亦有許多論述支持使用變幅的 觀念來衡量波動性,Parkinson (1980)指出,相較於傳統歷史波動性的衡量方法, 使用變幅來預測股價的波動性,會比只有使用收盤價資訊來進行波動性預測的 表現為佳,但是在Parkinson (1980)的實證研究上卻無法得到一致性的佐證用以 支持其推論,另一方面,Chou (2005)認為變幅在波動性的估計能力方面之所以 無法彰顯,並不代表變幅無法當做波動性的代理變數,而是因為過去模型對波 2 ARCH(∞)在某些條件下,可以轉換為GARCH(1, 1),則參數估計可以更精簡。 3 參照Brooks (2004), ch8.6, p.444~445 有進一步說明。
動性的動態結構刻畫得不夠完備,因此將變幅的觀念納入GARCH模型而提出自 我迴歸條件變幅(Conditional Autoregressive Range;CARR)模型,此模型巧妙 的結合GARCH模型刻畫波動性的動態過程與變幅特有的屬性,把單位時間內價 格變動的極端值情形表現在模型的動態結構當中,可以適當的描述變幅的動態 結構,使得變幅在波動性的預測上相對於傳統GARCH模型更具有優勢,Chou (2005)並利用S&P 500 股價指數資料實證結果支持CARR模型確實較GARCH模 型更能獲得準確的波動性估計值。 相較於傳統的GARCH 模型,CARR 模型主要著眼於變幅條件均數的動態 過程,而GARCH 模型則是採用報酬平方項為代理變數,屬於二階動差函數的 探討,故不如CARR 模型利用一階動差來建構模型簡便,為了更加了解這兩種 模型在波動性估計上的優劣,本研究將針對此兩種波動性模型在風險值估計上 的表現進行完整的比較,探討 CARR 模型是否能夠如同其在波動性預測上較 GARCH 為優的表現一樣,同時在風險值估計上亦可獲得較準確的估計值。 第三節 極值理論的概念與相關應用的探討 一、金融資產極值行為相關文獻 目前為止有許多文獻皆發現金融資產報酬的分配型態並非服從常態分配的 假設,而有所謂極值(extreme value)行為及厚尾特性,所謂厚尾係指報酬分 配的極端值發生頻率較常態分配為高,Danielsson和de Vries (2000)指出, RiskMetrics模型基於條件常態分配之假設並不適用於極端報酬之分析,因為在 此假設下,會低估極端事件的次數而影響風險值估計的準確性,Duffie和Pan (1997)指出,假設市場因子之機率分配為常態之模型假設與市場實際情況差距
甚遠4,特別是當市場因子之機率分配具有厚尾現象時,發生極端狀況的頻率較 常態分配為高,將使得變異數-共變異數法產生低估風險值的問題,Bollerslev (1986)亦提供實證證明在預測金融資產報酬時,即使考慮了資產報酬異質波動 的情形,以條件波動性模型來估計金融資產報酬的波動性,亦無法完全捕捉金 融資產報酬厚尾的現象,造成在高信心水準之下時會低估資產市場風險值的結 果 , 由 此 可 見 金 融 資 產 報 酬 其 實 存 在 極 端 下 方 風 險 , 或 稱 額 外 下 方 風 險 (additional downside risk),亦即風險在經濟蕭條或動盪較大的特別時期會變得 更大、更難以掌控,Barone-Adesi, Bourgoin和Giannopoulos (1998)亦藉由GARCH 模型來配適資產報酬分配的異質變異性,並結合歷史模擬法來估計GARCH模型 下的殘差值分配以估算風險值,雖然解決報酬隨時間變動的自我相關性與異質 變異問題,但缺點如前所述,利用歷史模擬法來推估未來損益機率分配型態, 當歷史資料不足或是無法包含極端值時,此時歷史資料所形成的機率分配就無 法反應所有的可能情況,因此必須在大樣本的情況下才能獲得準確性的估計值。
Jansen和de Vries (1991), Loretan和Phillips (1994)以及Longin (1996)皆研究 股市的極值行為,並實證發現金融資產的極值分配為具有厚尾的分配型態。許 多財務研究更進一步將金融資產的極值行為應用到風險管理議題的探討,運用 極值理論估計金融資產的極值行為並進而提升風險值估計的準確性,Neftci (2000)利用美國四種利率及匯率資料為研究對象5,實證發現不論是樣本內或是 樣本外的結果,採用極值理論風險值模型所估計的99%信心水準下風險值,皆 較一般傳統常態假設下風險值模型的估計值準確,且可獲得較小的平均失敗誤 差6,代表其所估計之風險值較接近實際報酬大小,而Huisman, Koedijk和Pownall (1998)、Pownall和Koedijk (1999)、Danielsson和de Vries (2000)等,亦比較常態
4 Duffie和Pan (1997)以S&P 500 股價指數 1986 年至 1996 年之日報酬資料為例說明此結果。 5 此四種利率資料為三個月期國庫券利率、兩年期、五年期及七年期政府公債利率;四種匯率
資料則為美元對德國馬克、法國法郎、英國英鎊及日本日圓的匯率。
假設下風險值模型與極值理論風險值模型在風險估計上的表現,都證實極值理 論風險值模型的估計表現確實優於常態假設下的風險值模型,而後也有越來越 多的研究開始對極值理論之下的風險值模型進行探討。 二、尾部指數估計法 應用極值理論來做為風險值估計方法有一個很大的優點,即不需對資產報 酬真實分配型態配適任何假設,而是直接觀察極端值的情形來判斷真實風險狀 況,Longin (1996)指出資產報酬真實分配的尾部形狀即反應在其尾部指數(tail index)估計值上,它決定了分配函數尾部消失的速度,若原本分配函數其尾部 越厚,則消失速度越慢,尾部指數也越大,此外,尾部指數估計值的倒數又稱 為形狀參數(shape parameter),他提到極值分配中Frechet型態的形狀參數亦反 應原本分配存在有限動差的最高階次7,若形狀參數估計值越大代表原本分配存 在越高階次的動差函數,例如當形狀參數估計值等於2 即代表原本分配存在一 階及二階動差,因此極值理論可在不需了解極值的正確分配下,藉由尾部型態 的估計了解金融資產的極值分配,進而估計風險值。 在應用極值理論估計資產報酬分配尾部指數時,依據Longin (1996)的分類 可分為母數估計法與無母數估計法,Jansen和de Vries (1991)、Koedijk, Stork和 de Vries (1992)、Danielsson和de Vries (1997)指出,無母數估計法在估計尾部指 數時,由於不需假設極值是來自於何種極限分配而較母數估計法在估計上顯得 有效率,然而在無母數估計法的估計式中,Longin (1996)以及Kearns和Pagan (1997)皆證明Hill估計式為一個較好的尾部指數估計法,Longin (1996)將NYSE
股價指數由1885 至 1990 年近一世紀的日資料,藉由極端值分配來配適,並利
用母數估計法中的最大概似估計法(maximum likelihood method)、迴歸方法
(regression method)以及無母數估計法中的Hill估計式與Pickand估計式8估計極 端值分配中的尾端係數,結果顯示Hill估計式為一較有效率的尾部指數估計方 法,並發現極端報酬的近似分配為Frechet分配。
然而如同McNeil和Frey (2000)所提到的,利用Hill估計式來估計尾部指數時
會面臨到兩個問題:(1)小樣本下的Hill估計式容易產生偏誤以及(2)最適尾
部觀察數目決定不易。因此Huisman, Koedijk, Kool和Plam (2001)針對Hill估計式 的兩個問題,提出一個修正Hill尾部指數的估計式,Hill修正式除了在小樣本下 具有不偏性外,也不需在求算尾部指數時事先決定尾部觀察數目,並用分配模
擬的方式證明修正Hill估計式對資產報酬服從Burr分配9、柯西(Cauchy)分配
或是t分配(student’s t)而言,仍可得到一無偏誤的尾部指數估計值,此外在其
實證分析中,根據匯率資料的實證結果10,亦顯示修正Hill估計式在尾部指數估
計上較Hill估計式準確。Huisman, Koedijk, Kool和Palm (1998)亦利用修正Hill估 計式檢視前述之匯率資料其非條件分配(unconditional distribution)的情形,發 現匯率報酬率資料有近似於t分配的情形。
三、VaR-x 風險值模型
另一方面,Huisman, Koedijk 和 Pownall (1998)指出大部分金融資產之報酬
分配較常態分配具有厚尾的特性,而採用 t 分配來配適資產報酬分配可較常態 分配更能夠捕捉高狹峰的分配型態,因此其假設資產報酬分配服從 t 分配,並 將形狀參數,亦即反應原本分配存在的最高階次動差的概念與 t 分配結合,首 先利用修正Hill 估計式來估計尾部指數值,並依據尾部指數估計值與 t 分配自 8 Hill估計式的計算公式可參考本文後面的研究方法,Pickand估計式則參照Pickand (1975)說明。 9 Burr分配的累積分配函數為F(x) =1−(x2 +1)−2且其形狀參數等於4。
10 Huisman, Koedijk, Kool和Plam (2001)利用美元對法國法郎、德國馬克、英國英鎊、瑞士法郎
由度大小反向的關係,求得原始報酬在 t 分配假設下之自由度估計值,進一步 估計風險值,稱之為VaR-x 風險值估計法,同時指出當運用 VaR-x 法來估計風 險值時,除了可以免除需事先決定一最適尾部觀察數目之繁雜的程序之外,對 於樣本數不足或是必須將資料切割成為小樣本時,亦提供一個良好的不偏估計 的特性,此外,他們利用美國S&P 500 與十年期政府公債的資料實證發現,使 用VaR-x 估計法在風險值估計準確性上的表現亦較常態法為佳。 四、動態極值理論模型 Jorion (2000)提到,使用極值理論估計法來估計風險值時,雖然極值法可以 捕捉資產報酬的厚尾型態,但由於極值理論假設報酬的發生過程為來自獨立且 相同的分配型態(independently and identically distributed;簡稱 ),此假設 與金融資產報酬數列普遍存在異質變異數的情況不符,由於極值理論估計法忽 略了金融資產報酬數列之異質性問題,可能會得到不正確的風險估計值。此外, Goorbergh 和 Vlaar (1999)比較歷史模擬法、變異數-共變異數法及尾部指數等 數種估計方法,以估計荷蘭股價指數與道瓊工業指數之風險值,而由於未能處 理波動性叢聚現象,使得採用尾部指數估計方法的結果不佳。為了同時解決金 融資產具厚尾與波動異質性問題,McNeil 和 Frey (2000)提出了時間數列模型結 合極端值分配的概念,利用GARCH 模型與極值理論的結合形成動態(條件) 風險值估計模型,其方法為先利用GARCH 模型來估計資產報酬的波動性,再 以極值理論架構下的無母數Hill 估計式估計 GARCH 模型殘差項的尾部型態, 最後根據尾部極限分配計算殘差項百分位數(percentile)以求得動態(條件) 風險值,McNeil 和 Frey (2000)的實證結果顯示此模型比忽略厚尾分配或是隨機 波動的估計方法更好。Bystrom (2004)亦比較結合 GARCH 模型以及極值理論下 一般化極值分配(generalized extreme value distribution;GEV)與一般化柏拉圖 分配(generalized Pareto distribution;GPD)所形成的動態風險值估計模型,發
. . . di i
現 GARCH-GEV 與 GARCH-GPD 模型在風險值估計績效表現上皆較其他非條 件及常態假設下模型佳;結合極值理論與GARCH 模型所得到的動態(條件) 風險值估計模型,一方面可以使風險估計模型動態化,事先預測下一期樣本外 波動性情況,另一方面利用GARCH 模型的樣本內波動性配適值來標準化原始 報酬率資料,使其滿足極值理論風險值估計架構下的獨立同態分配( )假 設。由於動態極值理論風險值模型結合了波動性模型與極值理論的優點,可用 以捕捉極端下方風險的情況,故應為一較精確的風險值估計方法。 . . . di i
Pownall 和 Koedijk (1999)提出結合 EWMA 模型與 VaR-x 估計法的條件 VaR-x 風險值估計模型,並實證發現此動態(條件)VaR-x 模型在風險值估計 的準確性上,較靜態(非條件)VaR-x 模型與 J. P. Morgan 所提出的 RiskMetrics
模型有很大的改進,尤其在亞洲金融風暴期間,此差異更加顯著。然而Pownall
和Koedijk (1999)所使用的估計模型並未採用 McNeil 和 Frey (2000)的建議,先 將原始報酬資料標準化,而是直接使用原始資料來估計尾部指數,可能存在如
上所述的估計偏誤問題,且其波動性預測模型亦為較不具彈性的EWMA 模型,
可能存在改進空間,因此本文在應用極值理論估算金融資產報酬風險時,將延 續Pownall 和 Koedijk (1999)所提出的風險值估計模型,進一步結合 McNeil 和 Frey (2000)的建議,利用 GARCH 模型對原始資料事先進行過濾(標準化)的 動 作 , 在 波 動 性 預 測 上 亦 採 用 較 具 彈 性 的 GARCH 模 型 配 適 , 推 導 出 GARCH-VaR-x 風險估計模型,此作法可以簡化條件風險值的估計過程並提升 估計的準確性。 第四節 相關係數估計模型 如同第一節所述,在變異數-共變異數風險值估計方法中,影響風險值估 計準確與否的一個主要因素為對於變異數-共變異數矩陣估計的準確性,第二
節的波動性模型討論中曾提及,當我們在估計單一資產報酬的風險值時,若想 精確的估計其風險狀況,則必須能確實掌握此資產報酬市場波動的變化情形, 我們也已經於第二節對於波動性的估計模型做了詳細的探討。本節主要針對風 險值估計標的為一投資組合時,對於其資產報酬間共變異數估計方法的探討。 較早的作法中,常認為資產報酬間的相關性並不會隨著時間的移動有顯著改 變,因此往往假設資產報酬間相關係數為一常數,然而近年有許多研究文獻指 出,金融資產報酬間的相關性並非固定的且是時間的函數,Bollerslev, Engle 和 Wooldridge (1988)利用美國國庫券、債券及股票報酬資料實證發現條件變異數 -共變異數矩陣存在強烈的自我相關情形,並拒絕變異數-共變異數矩陣為常 數的假設,自此有越來越多有關資產報酬間相關係數變化情形的研究,開始嘗 試模型化資產報酬間相關係數或是共變異數的動態過程(dynamic process),試 圖 捕 捉 資 產 報 酬 間 的 真 實 互 動 情 況 , 因 而 發 展 出 各 式 各 樣 的 多 元 變 數 (multivariate)波動模型,例如 Bollerslev, Engle 和 Wooldridge (1988)提出 VECH 模型、Bollerslev (1990)提出 CCC(Constant Conditional Correlation)模型以及 Engle 和 Kroner (1995)提出的 BEKK 模型等,然而到目前為止所發展的多元模 型皆存在一些問題,有些是模型假設上的不甚合理,有些則是變數過多導致參 數估計上並不容易等等。
在Engle (2002)、Engle 和 Sheppard (2001)以及 Cappiello, Engle 和 Sheppard (2003)一系列文章中,提出可以使用 DCC 模型來估計資產報酬間的條件相關係
數,此作法不僅解決了前面提到的諸多問題,在Engle (2002)的實證研究中也證
明DCC 模型不論是在股價、債券殖利率或是匯率資料上,相較於其他如 BEKK
模型、MA100 估計式、EWMA 模型以及 Orthogonal GARCH 模型等,皆有相 當好而且穩定的估計表現,而在Engle 和 Sheppard (2001)裡,除了對於 DCC 模
型設定上的統計特性進行更深入探討之外,亦採用S&P 500 與道瓊工業指數的
Vlaar (2003)使用美國與德國的股價指數及公債資料進行研究,發現使用 DCC 模型所得到的概似函數值較CCC 模型及 J. P. Morgan 的 RiskMetrics 模型大,在 相關係數估計上具相對效率性,Yang (2005)以日本對亞洲四小龍的股市報酬相 關性為研究標的,結果發現國際股票市場間相關性隨著時間劇烈變化,且各市 場的波動情況似乎存在傳染效果,同時相關係數和波動性間亦存在著高度相 關,此情形將會減低國際分散投資的效益。 Chou, Liu 和 Wu (2005)延伸原始 DCC 模型,提出以變幅為基礎下的 DCC 模型,有別於原始報酬基礎下的DCC 模型,他們對於波動性的估計採用 CARR 模型來處理,與原始 DCC 模型之下配適 GARCH 模型為波動性估計模型的處 理方法不同,並利用美國S&P 500、NASDAQ 以及十年期財政部政府公債資料 實證發現,變幅基礎下的 DCC 模型在共變異數的估計上,顯著優於報酬基礎 下的DCC 模型,推論以變幅基礎之下的 DCC 模型捕捉資產報酬間的共變異數 情形,較報酬基礎下的 DCC 模型更準確。因此本文實證研究中亦擬進一步比 較這兩種相關係數估計模型在投資組合風險值估計上的表現。
第參章、研究方法
本章將介紹本文所採用的研究方法,共分為四個部分,第一部分介紹極值
理論的概念與尾部指數估計方法,介紹極值理論的主要概念Block Maxima 模型
與Peak-Over-Threshold 模型,以及修正 Hill 估計式,修正 Hill 估計式為一種近 期發展的無母數尾部指數估計方法;第二部分說明風險值估計方法,包括本研 究納入評量的靜態與動態風險值模型;第三部分介紹投資組合風險值的估計方 法;第四部分則說明回溯測試的設計。 第一節 極值理論 風險值估計模型的主要精神在於估計投資組合在最壞的狀況下,可能的最 大損失金額,因此如何將報酬機率分配的尾端特性真實的呈現出來,才是風險 值估計模型所應該考量之最重要的問題。許多金融資產報酬率的分配已被驗證 存在較常態分配厚尾的現象,因此使用平均數與變異數將無法正確描繪出報酬 分配的機率特性,而藉由觀察樣本值尾部分配厚尾的程度,將能夠捕捉預期極 端事件發生的機率。極值理論便是在探討分配的尾部特性,由於極值理論不需 對原始報酬做任何分配上的假設,特別著重於機率分配尾端的描述,有助於正 確估計資產報酬分配厚尾的程度。此外,Longin (1996)指出極值理論中重要的 參數估計值-尾部指數,亦即反應此一機率分配厚尾的程度,也是極值理論研 究中一個相當重要的發現及良好的特性。以下前兩段分析將依序介紹極值理論
目前為止較廣為探討的兩種概念Block Maxima 模型與 POT 模型,第三段分析
則介紹Huisman, Koedijk, Kool 和 Plam (2001)所提出的修正 Hill 尾部指數估計 式,其具有小樣本下不偏以及不需事先決定尾部觀察數目的優點,為一估計相 當準確且簡便的尾部指數估計式,亦為本研究主要採用之尾部指數估計方法。
一、Block Maxima 模型 Block Maxima 模型主要探討時間資料隨機變數中,每段期間(如:每年或 每月)極端值的分配。假設有一平穩的隨機數列 (例如:每日的 股價報酬率或匯率報酬率),服從某一累積機率分配且彼此統計獨立,令 為 隨機變數X 之機率密度函數; 為隨機變數X 之累積機率密度函數,並定義 此數列之最大值為Y ,且 為 的累積機率分配,如下: n X X X1, 2,L, X f X F
{
n}
n =max X1,X2,L,X FYn Yn[
]
n X n n Y x F x X x X x X prob x Y prob x F n ) ( ) , , , ( ) ( ) ( 2 1 = < < < = < = L (1) (因為X1,X2,L,Xn彼此獨立且服從同一累積機率分配) 由於極值分配 的真正型態亦無從獲悉,因此極值理論著重於極大值與極小值的漸近分配(asymptotic distribution)型態的研究。依據 Fisher 和 Tippett
在 1928 年的研究,可知經過標準化的極大值統計量 n Y F n n n Y y α β − = 會有弱收斂
(weakly converge)的傾向,其中αn為規模參數(scale parameter),αn >0,
相當於標準差;βn為位置參數(location parameter),相當於平均數,且其漸進 分配趨近於一個非退化極限分配(non-degenerate limiting distribution)H,以數 學式表現如下:
[
+]
→ ∈ℜ = + = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ≤ − ∞ → x x H x F x F x Y prob n n n X n n Y n n n n n , ) ( ) ( ) ( lim β α β α α β (2)H 稱為極值分配(extreme value distribution),它必須是以下三種標準極值分配 的其中一種,分別為Gumbel 分配、Frechet 分配以及 Weibull 分配:
型一:Gumbel 分配 ℜ ∈ − = − y e y FY y n( ) exp( ) (3) 型二:Frechet 分配 0 , 0 0 0 ) exp( ) ( > ⎩ ⎨ ⎧ ≤ > − = α α y y y y F n Y (4) 型三:Weibull 分配
(
)
, 0 0 0 1 ) ( exp ) ( < ≥ < ⎩ ⎨ ⎧ − − = −α α y y y y F n Y (5) 其中,α稱為形狀參數,主要決定分配尾部消失的速度及有限動差的最大 階數,故為決定尾部的分配型態中最重要的參數。然而極值分配若以前述三種 型態表示,在統計應用上會造成不便,因此Jenkinson 於 1955 年導出可涵蓋上述三種分配的一般化極值分配(generalized extreme value distribution;GEV)。 令標準化極大值統計量之極限分配定義為:
( )
⎪ ⎩ ⎪ ⎨ ⎧ = − > ⋅ + ≠ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⋅ + − = − − 0 ) exp( 0 1 , 0 ) 1 ( exp 1 γ γ γ γ γ y Y e y y y F n (6) 其中γ 稱為尾部指數(tail index),為形狀參數α的倒數, α γ = 1 。依據Longin (1996)的歸納,當γ =0時,表示GEV 屬於第一類型 Gumbel 分配,例如常態分 配、指數分配、Gamma 分配、Lognormal 分配等屬之,這類分配稱為中等尾部 (medium-tailed)的分配,分配尾端消失是以指數(exponential)的形式遞減。 當γ >0時,表示GEV 屬於第二類型 Frechet 分配,例如柏拉圖(Pareto)分配、 t 分配、柯西分配、Burr 分配和 Loggamma 分配等屬之,此類分配為厚尾或長 尾(long-tailed)分配,尾部以次冪(power)的形式衰退,故衰退的速度比常 態分配慢。由於多數財務資料都屬於厚尾分配,因此在財務領域上這個分配特別受到矚目與探討。當γ <0時,表示 GEV 屬於第三類型 Weibull 分配,例如 均勻(uniform)分配及 Beta 分配等都包含在內,此類分配屬於薄尾或短尾 (short-tailed)分配,尾部衰退速度比前兩類更快。此外,第一與第三類型分 配的動差皆存在,不過第二類型分配的動差卻是受形狀參數α所影響,α的值 代表有限動差存在的最大階數,也就是說階次大於α的動差是不存在的,比較 小的α就代表分配是較厚尾的,因此當α >4時,分配的平均數、變異數、偏 態與峰態係數才會存在。 H 函數的極限分配 一般化極值分配(GEV)
( )
⎪ ⎩ ⎪ ⎨ ⎧ = − > ⋅ + ≠ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⋅ + − = − − 0 ) exp( 0 1 , 0 ) 1 ( exp 1 γ γ γ γ γ y Y e y y y F n 0 = γ γ >0 γ <0 型一 型二 型三Gumbel Frechet Weibull ℜ ∈ − = − y e y FY y n( ) exp( ) ⎪⎩ ⎪ ⎨ ⎧ ≤ > − = 0 0 0 ) exp( ) ( y y y y F n Y α
(
)
0 0 1 ) ( exp ) ( ≥ < ⎩ ⎨ ⎧ − − = − y y y y F n Y α 0 > α α <0 例:常態分配 指數分配 Gamma 分配 Lognormal 分配 例:柏拉圖分配 t 分配 柯西分配 Loggamma 分配 例:均勻分配 Beta 分配 二、Peak-Over-Threshold(POT)模型 Peak-Over-Threshold 模型的核心,敘述樣本中超過某特定門檻值的尾部分 配,可以用一般化柏拉圖分配(generalized Pareto distribution;GPD)來描述。 GPD 分配是比 GEV 分配發展較晚的模型,主要觀念在考慮資料超過某一個門檻值以上的情況,以期能夠了解這些極端值的狀況,進而避免在估算風險值時, 遺漏了這些重要的訊息。 假設有一平穩的隨機數列 n,皆服從某一累積機率分配 且彼 此統計獨立,我們有興趣的是 大於某一個高的門檻值 u 的分配情況,稱為餘 額分配(excess distribution),可以得到餘額分配函數 如下: X X X1, 2,L, FX i X u F ) ( 1 ) ( ) ( ) ( ) , ( ) ( ) ( u F u F y u F u X prob u X y u X prob u X y u X prob y F X X X u − − + = > > + ≤ = > ≤ − = (7) 其中 且 , 是 的最右極端點。這裡需特別強調的是, 此函數只描述樣本中超過門檻值 u 的分配,而非整個樣本的行為。Balkema 和 de Haan (1974)以及 Pickands (1975)提出理論,指出連續分配函數 中,當選取 的門檻值 u 逐漸增加,則餘額分配函數 會向GPD 收斂,可以數學式表示: u X y≤ F − ≤ 0 XF ≤∞ XF FX X F u F 0 ) ( ) ( sup lim , 0 = − − ≤ ≤ → Fu y G y u X y X u F F β α (8) 換句話說,即使面對一個不知名的連續分配,只要其門檻值 u 取得夠高, 超過門檻值的餘額分配Fu就是 GPD,即當u→ XF時,Fu(y)≅Gα,β(y),其中 GPD 的分配,Gα,β(y),以兩個參數來表示: ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ = − ≠ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + − − − 0 1 0 1 1 ) ( 1 , α α β α β α β α y e y y G (9) 式中β >0是規模參數,而α是重要的形狀參數,用來描述尾部的衰退速度。 當α =0時, 的尾部會以指數的形式衰退,屬於中等尾部的分配,譬如說常 態、指數、Gamma、Lognormal 等,都是這一類分配。當 X F 0 > α 時,原本的分配
X F 尾部呈現次冪消失,屬於厚尾分配,如柏拉圖分配、Loggamma 分配、柯西 分配、t 分配等,相似之前的 Frecht family;而許多財務資料,其參數為α >0, 是屬於這一類的分配。當α<0時, 屬於短尾分配,例如均勻分配及Beta 分 配屬於此類。 X F u F 函數的極限分配 一般化柏拉圖分配(GPD) ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ = − ≠ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + − − − 0 1 0 1 1 ) ( 1 , α α β α β α β α y e y y G 0 = γ γ >0 γ <0 型一 型二 型三
Gumbel Frechet Weibull ℜ ∈ − = − y e y FY y n( ) exp( ) ⎪⎩ ⎪ ⎨ ⎧ ≤ > − = 0 0 0 ) exp( ) ( y y y y F n Y α
(
)
0 0 1 ) ( exp ) ( ≥ < ⎩ ⎨ ⎧ − − = − y y y y F n Y α 0 > α α <0 例:常態分配 指數分配 Gamma 分配 Lognormal 分配 例:柏拉圖分配 t 分配 柯西分配 Loggamma 分配 例:均勻分配 Beta 分配 三、尾部指數之估計 由前文敘述我們已經知道,應用極值理論來做為風險值估計方法不需對資 產報酬真實分配型態做任何假設,而是直接藉由觀察極端值的情形來判斷真實 風險狀況。而且資產報酬真實分配尾部厚薄的程度即反應在其尾部指數估計值 γ 上,因為尾部指數的大小反應其報酬分配機率密度函數尾端接近於零的速 度,當分配尾部越厚時,其分配的機率密度函數尾部接近零的速度就越慢,所 求得的尾部指數值也就越大;反之,當分配尾部越薄時,其分配的機率密度函數尾部接近零的速度就越快,所求得的尾部指數值也就越小。由此可知,欲清 楚了解資產報酬分配尾部的型態,必須準確估計出尾部指數估計值的大小。 最常被應用以估計尾部指數之估計式為Hill 於 1975 年所提出之 Hill 估計 式,此估計式具有易於求算且漸近不偏的特性。假設從一未知的厚尾分配中抽 取一組n 個正值且彼此獨立之樣本,令 為第i個順序統計量(order statistics) 並且 , 。假設從分配之右尾選擇 k 個觀察值以估計尾 部指數,則Hill 尾部指數估計式可表示如下: ) (i X ) 1 ( ) (i ≥ X i− X i =2 L, ,n ( ) 1 ln
(
( 1))
ln(
( ) 1 k n X j n X k k k j − − + − =∑
= γ)
(10) 其中,n 為資料總數目,k 為尾部資料總數目,根據 Huisman, Koedijk, Kool 和 Plam (2001)指出,γ(k)為條件柏拉圖分配之最大概似估計式,且Hill 估計式之 困難處在於最適尾部觀察數目 k 的決定。由於 k 的選定對於尾部指數之估計不 偏性極為重要,Dacorogna, Muller, Pictet 和 de Vries (1995)提出 Hill 尾部指數估 計偏誤值(bias)之漸近分配函數為: ) 1 ( 1 ) (x = −ax−α +bx−β F (11) 其中α,β >0且 a 與 b 皆為實數。Hall (1990)證明在 k 給定下,Hill 尾部指數估 計值之漸近期望值與變異數各為:(
)
α β α β β α α β α γ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − ≈ − n k a b k E ) ( 1 ) ( (12)(
( ))
12 α γ k k Var ≈ (13) 由(12)與(13)式可知,若從點估計之不偏性觀點分析,則 k 值越小越好;相反的 若從點估計之有效性觀點分析,則 k 值越大越好。以上的說明顯示 Hill 尾部指 數估計值隨 k 值的改變存在偏誤與有效性的抵換關係,同時,由(12)式可發現 當 時,Hill 尾部指數估計值均存在偏誤的現象。Dacorogna, Muller, Pictet 和de Vries (1995)利用模擬方式指出尾部指數估計值並不受0 >
k
以即使β 的假設值產生偏誤並不會對α估計值造成很大的影響。
根據上述分析,Huisman, Koedijk, Kool 和 Plam (2001)提出修正式解決 Hill
估計式的 k 值選擇問題,作法為在(12)式中加入α =β限制式,使得漸近偏誤與 k 存在一線性關係,則(10)式可進一步轉換如下: κ ε β β γ(k)= 0 + 1k+ (k) , k =1,L, (14) 其中,β0與β1為迴歸參數,ε(k)為迴歸殘差項。根據(14)式,當 k 值接近於 0 時,可以得到一個具不偏性的尾部指數估計值,所以(14)式不需選擇最適尾部 觀察數目來估計尾部指數,而是透過輸入不同的 k 值產生不同的尾部指數估計 值γ 的過程,來解決偏誤與有效性的抵換關係,進而得到一個小樣本下具有不 偏性的尾部指數估計值β0,因此(14)式可以普通最小平方法(ordinary least squares;OLS)進行估計,所得到的截距項參數估計值 即為小樣本下的尾部
指數不偏估計值。Huisman, Koedijk, Kool 和 Plam (2001)透過模擬過程發現,尾 部觀察值個數 0 ˆ β κ 的選擇並不影響修正後 Hill 尾部指數的估計,建議採用κ =n 2 即可以獲得準確的估計結果。 相較於僅使用單一的Hill估計值,修正Hill估計值乃使用許多(在不同的k 下)傳統Hill估計值計算而得的加權平均值,以推估尾部的型態。因此修正Hill 估計值可視為一組傳統Hill估計值的加權平均,權重乃是使用普通最小平方法 所求得。11 第二節 風險值估計方法
11 Huisman, Koedijk, Kool和Plam (2001)曾提到,由於ε(k)存在異質變異問題,故建議使用加權
最小平方法(weighted least squares;WLS)來估計(14)式中的迴歸參數,因此本研究在迴歸參 數估計上亦採用WLS法來估計,避開ε(k)的異質變異問題。
雖然風險值的觀念簡單易懂,估計方法卻有不同的方式。一般而言,風險 值的衡量方法可區分為參數法(parametric method)與無母數法(non-parametric method)兩類,較常見的歷史模擬法屬於無母數法,而變異數-共變異數法與 蒙地卡羅模擬法則屬於參數法,另外還有一種由極值分配統計理論發展出來的 極值理論風險值評估法,可在不需了解金融資產報酬的正確分配下,藉由尾部 型態的估計而了解金融資產的尾部分配進而估計風險值,亦為目前廣泛運用於 研究金融資產極端情形的重要方法。 假設 為資產在時間 t 時之價格,在連續複利假設下,資產在時間 t 時的 預期報酬率(以百分比表示)為 t P ) ln (ln 100 ln 100 1 1 − − − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × = t t t t t P P P P X ,則給定 投資期間及原始投資金額V0後,投資組合的預期價值Vt為: ) 1 ( 0 t t V X V = + (15) 由於目的僅在探求某一特定信心水準(100( )%)下,投資組合在 t+1 時之最 低價值( ),因此只需找出會造成投資組合價值為 的預期報酬率 : c * 1 + t V Vt*+1 * 1 + t X (1 * ) (16) 1 0 * 1 + + = + t t V X V 假定投資組合平均報酬率為µ ,則投資組合相對風險值為: (1 ) (1 * ) (17) 1 0 0 + − + + =V V Xt VaR µ 經簡化可得: ) ( * 1 0 −µ − = V Xt+ VaR (18) 由(18)式可知,若欲獲得準確的風險估計值,對於 的估計相當重要。 在信心水準100( )%下,在時間 t 預測時間 t+1 之資產報酬率 可以表示為: * 1 + t X c Xt*+1
c I X X prob( t+1 ≤ t*+1 t)=1− (19) 上式中 表示在t 時的資訊集合,若在時間 t 時,預測資產報酬在 t+1 時的累積 機率分配,並以 表示,則可以寫成: t I ) (• F c X F( t*+1)=1− (20) 因此,Xt*+1亦可由累積機率分配F(•)之反函數表示,即: ) 1 ( 1 * 1 F c Xt+ = − − (21) 將(21)式所得 估計值代回(18)式,即可得到風險估計值,故風險值的各種估 計方法,可視為對報酬的累積機率分配函數與反函數的估算。然而資產報酬機 率分配往往是未知的,因此有許多風險值估算方法皆建立在預期報酬機率分配 的假設上。以下將循序介紹本文實證研究中所討論之風險值估計方法,並依模 型之靜態及動態特性分開解釋。 * 1 + t X
一、靜態(非條件)風險值模型(unconditional Value-at-Risk model)
靜態風險值模型主要假設資產報酬來自於相同的機率分配- ,且機率 分配並不隨著時間而改變。由此可知,靜態風險值模型主要的缺點是未能將隨 時間變動的波動性變數納入考慮,因此無法反應市場新舊資訊的不同。本研究 所採用的靜態風險值模型包括歷史模擬法、靜態(非條件)變異數-共變異數 法、以及極值理論架構下的VaR-x 法,其估計方法分述如下。 ) (• F
(一)歷史模擬法(Historical Simulation method;HS)
歷史模擬法主要藉由投資組合價值變動的歷史資料建構實際的報酬分配,
等於其歷史報酬分配的型態,認為過去價格變化的趨勢會一再地重複,因此歷 史模擬法不需針對金融資產的分配預做任何假設,也不需估計任何的參數,故 視為無母數系統的風險值估計方法之一。至於投資組合風險估計值的求算可將 過去歷史報酬由小到大排序,獲得投資組合之歷史報酬分配,再配合所欲觀測 的信心水準(100( )%),找出在 t+1 期時相對應的分位數(quantile)即 , 代入(18)式即可求得相對於平均報酬之風險估計值。例如有 500 筆投資組合歷 史報酬,在99%的信心水準下,預期會有 5 筆觀察值超過 ,則 估計值 將會落在依損失大小排序後的第6 筆觀察值上。 c Xt*+1 * 1 + t X Xt*+1 由於歷史模擬法的概念易懂、計算簡便且可避免模型設定的風險,故在許 多文獻上皆廣為應用,然而在使用歷史模擬法估測風險值時,必須考量資料觀 察值的樣本數目是否足夠用以模擬未來可能的價格變化,並涵蓋可能發生的極 端事件,以及投資組合風險因子之間的報酬分配是否為獨立且相同分配,這些 皆是能否準確估計風險的重要因素。 (二)靜態(非條件)變異數-共變異數法(unconditional variance-covariance method) 除了使用歷史報酬分配來推估 之外,另一種作法為事先假設 為某 特定統計分配,並利用此統計分配可被特定參數描述的特性來求算 。J. P. Morgan 於 1994 年首先在 RiskMetrics 提出以變異數-共變異數法來計算風險 值,常態分配的假設是此作法使用的重要假設之一,即假設市場報酬率為聯合 常態分配,另一個假設為獨立性,即假設個別觀察值之間彼此獨立,讓這個模 型較容易推算,最後就是假設市場變數變動與資產價格變動呈線性關係。在估 * 1 + t X F(•) * 1 + t X
計風險值方面,假設投資組合報酬率平均數為µ ,變異數為 ,所需要做的是 算出實際資料的平均數與變異數估計值 2 σ µˆ與 ,再配合給定信心水準下之標準 常態分配臨界值 ,得到: 2 ˆ σ ∗ N µ σˆ ˆ * 1 =− + ∗ + N Xt (22) 再將 代入(18)式,即可得到相對風險估計值 。本文實證研究中皆假 設 ,並不失一般性。 * 1 + t X 0 σˆ ∗ N V 1 0 = V 由於此處在求算µˆ與 時,是假設機率分配不會隨著時間而改變的靜態模 型,故不需對 2 ˆ σ µˆ與σˆ2做預測,並假設其等於歷史估計值,即µˆ = X 與 , 再加上報酬分配為常態的假設後,(22)式可改寫為: 2 2 ˆ =s σ X s N Xt*+1 =− ∗ + (23) 因此在本研究中將這種估計方法命名為Delta-Normal 法,即為一般傳統常態分 配估計法。
(三)靜態(非條件)VaR-x 估計法(unconditional VaR-x method)
在 Delta-Normal 法中,對於 的估計是假設報酬分配為常態下的估計值, 然而Huisman, Koedijk 和 Pownall (1998)所提出的 VaR-x 風險值估計法則是假設
資產報酬分配服從t 分配,因此在估計 之前,必須先決定t 分配的自由度( ∗ N ∗ N ν) 大小。他們指出 t 分配中決定分配尾部厚薄的因素在於自由度的多寡,而自由 度的大小亦反應 t 分配動差存在的數目,表示在 t 分配下形狀參數即等於自由 度,因此可藉由極值理論中可描述胖尾型態之Frechet 分配函數中的尾部指數的 估計,來決定t 分配自由度的大小。VaR-x 風險值估計法主要先利用(14)式之修 正Hill 估計式估計尾部指數,再依據尾部指數與自由度之倒數關係(γ =1ν ) 求得 t 分配之自由度與 t 分配的尾部機率分配,進而計算出風險值。以下詳細
說明VaR-x 法估計風險值的步驟: 1. 先利用(14)式之修正 Hill 估計式求出歷史報酬分配左尾的尾部指數估計值 。 0 ˆ β 2. 求算樣本期間內歷史報酬分配之平均數估計值µˆ = X 與標準差估計值 s = σˆ 。 3. 設定 t 分配的自由度數目等於尾部指數估計值βˆ0的倒數。 0 ˆ 1 ˆ β ν = ,其中νˆ 為 t 分配自由度估計值。 4. 找出自由度為νˆ 之標準化 t 分配,在信心水準為 100( )%之下的臨界值 。 由於 c S∗ ) 2 ˆ ˆ , 0 ( ~ − ∗ ν ν t S ,故在將 轉換成實際報酬率的臨界值 時,須採用 轉換因子 ∗ S Xt*+1 2 ˆ ˆ ˆ − = Φ ν ν σ ,得到 * µˆ。 1 =− Φ+ ∗ + S Xt 5. 將上述 代入(18)式中,即可求得在 100( )%信心水準下報酬率的相對風 險值估計值為 。 * 1 + t X c Φ = − ∗ S V x VaR 0 如 Jorion (2000)所述,若極值理論估計法忽略了金融資產報酬率數列之異 質性問題時,可能會得到不正確的風險估計值,為解決此問題,本研究在使用 修正Hill 估計式估計尾部指數時,將納入 McNeil 和 Frey (2000)所提出來的觀 念,先利用波動性模型配適資產報酬的產生過程以解決資產報酬波動性異質變 異的問題,並獲得符合 型態之標準化殘差數列,以進行尾部指數的估計。 以下說明如何產生符合 型態之標準化殘差數列,假設資產報酬率 的動態 模型為: . . . di i . . . di i Xt t t t t Z X =µ +σ (24) 其中,Xt為第 t 日的資產報酬率,條件期望值µt =E(Xt It−1),條件變異數 ) ( 1 2 − = t t t Var X I σ ,Zt表第t 日的標準化殘差,為一個平均數等於 0、變異數等
於1 且獨立同分配的白噪音過程(white noise process)。本研究在條件期望值µt 的估計上將利用自我迴歸移動平均(autoregressive moving average;ARMA)模
型來描述資產報酬率的一階自我相關行程,稱為 ARMA(m, n)模型;然而在條
件波動性σt的估計上則設定兩種形式之估計模型做探討並比較其表現優劣,分
別為報酬基礎下之GARCH(p, q)模型,以及變幅基礎下之 CARR(p, q)模型。因 此結合條件均數方程式(mean equation)與條件波動性方程式(volatility equation)後可形成 ARMA(m, n)-GARCH(p, q)模型以及 ARMA(m, n)- CARR(p, q)模型,模型設定如下所示。 ARMA(m, n)-GARCH(p, q)模型: ) , 0 ( ~ 2 1 1 1 t iid t t t n j j t j m i i t i t X I N X µ φ θ ε ε ε − σ = − = − + + + =