報告題名:危險都市
Danger County
作者:詹勳成、王韋傑、陳港才、唐秉宏、徐昀靖、余宗憲、曾少羿 系級:統計四甲 學號:D0482028、D0433036、D0425788、D0482135、D0597309、 D0693677、D0408678 開課老師:魏裕中 課程名稱:統計專題(一) 開課系所:統計學系 開課學年:107 學年度 第一學期摘
要
現今台灣因高度經濟成長與都市化,衍生的犯罪問題也越來越多。本研究欲 設計一個整合性平台,供使用者選擇自身關心的變數,經由中華民國內政部警政 署提供的資料,並透過統計運算各筆資料,最後以視覺化地圖呈現台灣各城市的 治安排名。 本研究使用 Shiny 套件建立一個互動式介面,其中分為前端的 UI 與後端的 Server 兩大部分,UI 用來描繪網頁的呈現方式,Server 則為後端伺服器,使用者 於前端勾選欲關注的細項變數,後端則以勾選的變數資料進行主成分分析,並計 算出各城市的排名,依設定好的區段將所有縣市分為三個等級,並以顏色來表示, 再利用Leaflet 套件將顏色繪製於台灣地圖上,最後傳送到前端的介面顯示。 這次的研究,我們運用了我們在統計系所學習到的專業知識,建構一個可提 供個人需求來進行統計分析的系統,利用淺顯易懂的互動式介面,即可讓使用者 得到大筆資料經過複雜的統計分析後最後的結果。 關鍵字: 視覺化地圖、Shiny、主成分分析、LeafletAbstract
The measurement and evaluation of crime is an important issue, especially for the developed country. In this research, crime data from the National Police Agency are used to analyze and construct a user-friendly platform. Users can choose the items of crime that they care about, and the ranks of public security for each city in Taiwan are shown via a visual map.
Shiny package in R program is adopted to construct the integrative platform. Two modules are essential, including UI for the front-end and Server for the back-end. Based on the items of crime and year that user selects in the front-end, the comprehensive data analysis runs in the back-end. The principal component analysis method is adopted and the values for evaluating the dangerous are provided. Finally, the level of danger is displayed on the Taiwan map by Leaflet package.
In this project, we use the expertise learned from the Department of Statistics in the college. We provide an interactive interface to make the statistical results easily and clearly.
Keyword:visual map, Shiny, principal component analysis, Leaflet
目 錄
第一章 緒論 ... 5 第一節 研究動機與背景 ... 5 第二節 研究目的 ... 6 第二章 資料蒐集 ... 7 第一節 資料蒐集與篩選 ... 7 第二節 資料彙總 ... 9 第三章 研究流程 ... 10 第一節 統計分析 ... 11 一、選擇統計分析方法 ... 11 二、主成分分析 ... 11 (一)主成份分析特點和定義變數 ... 12 (二)主成份分析步驟 ... 13 (三)範例 ... 13 第二節 UI 架構 ... 16 一、介紹及用途 ... 16 二、實務操作 ... 17 (一)介面呈現 ... 17 (二)程式碼及解釋各自用途 ... 18 第三節 Server ... 21 一、介紹及用途 ... 21 二、實際操作 ... 21 (一)資料檢視 ... 22 (二)buttom 裡的結構... 24 (三)myMap 裡的結構 ... 26 第四節 資料地圖化 ... 28 一、介紹及用途 ... 28 二、實際操作 ... 28 第四章 研究成果 ... 29 第一節 介面指引 ... 30 第二節 臺中歷年犯罪變動 ... 31 第五章 結論及討論 ... 33 第一節 結論 ... 33 第二節 討論 ... 34 附錄一 程式碼 ... 35 附錄二 工作分配表 ... 41 附錄三 社會責任認知與心得 ... 42圖目錄
圖 1 網頁提供資料分類 ... 7 圖 2 Shiny 架構 ... 10 圖 3 陡坡圖 ... 15 圖 4 UI 內容架構 ... 17 圖 5 整體介面 ... 18 圖 6 Server 架構 ... 22 圖 7 檢視資料圖 ... 23 圖 8 危險程度標籤 ... 29 圖 9 區塊顯色與文字敘述 ... 29 圖 10 結果顯示範例 ... 31 圖 11 歷年臺中表現圖 ... 32表目錄
表 1 原始 37 個細項變數 ... 8 表 2 細項變數重新命名表 ... 9 表 3 勾選選項表 ... 9 表 4 原始資料表 ... 14 表 5 標準化資料後計算相關矩陣表 ... 14 表 6 特徵值和特徵向量表 ... 15 表 7 主成份的變異數 (解釋能力) 表 ... 15 表 8 第一主成份得點表 ... 16第一章 緒論
第一節
研究動機與背景
在1960 前,台灣的經濟還未起飛,當時主要靠美國援助,1960 至 2000 年間透過十大建設以及相關經濟措施,造成台灣經濟起飛奇蹟年代,當時的 經濟起飛,讓台灣成為亞洲四小龍,台灣民間中都可以聽到口耳相傳「台灣 錢淹腳目」,當時的起飛造就現在台灣成為全球第22 大經濟體[1],現今的台 灣高度經濟成長與都市化,造成貧富差距的擴大,所得不均相對的也衍生出 犯罪問題出現,犯罪問題包含暴力犯罪、搶奪、偷竊、毒品、性侵害...,這 些的犯罪會造成社會成本,社會成本直接影響到國家與城市的發展,我們應 該去了解這些不同犯罪的占比和原因來提供給台灣政府有效解決意見。 此外,現今的台灣新聞報導或網路資訊中,都可透過不同組織機構調查 去了解台灣哪些城市是宜居城市,不同組織調查有不同的調查結果,像《BBC 》「2018 世界宜居城市排行榜」[2]、國際宜居城市獎[3]、美國人力資源諮詢公 司美世公布2018 生活品質調查結果[4],分別都調查出台北、台中、高雄為宜 居城市,在宜居城市評比中,犯罪率和犯罪類型是相當重要的評比關鍵之一, 我們可以透過不同城市的犯罪率調查和哪些城市最主要犯罪類別和形式,提 供一個頁面平台,讓台灣人民了解台灣縣市的治安調查,去評比他們心目中 治安最好的宜居城市,治安相對不好的縣市可能因為治安評比提供一個改進 動力方向。 調查犯罪類別中,分別調查「暴力犯罪」、「竊盜犯罪」、「其他治安相關」、 「道安事故」、「道安舉發」、「酒後駕車」六大面向,這六大面向在治安中是 重大的指標,運用警政署提供的統計資料[5],將不同的犯罪細分類整理成六 大面向,透過統計運算各筆資料,各個城市中犯罪類別資料透過數據分析, 以客觀的分析提供淺顯易懂的圖示顯示平台。第二節 研究目的
現今的台灣,過度的貧富差距而造成犯罪治安,以及一個城市是否宜居 的其中一項重要指標也是治安,這些犯罪治安因素對於台灣的經濟發展而引 發的犯罪面向以及最適合宜居的城市息息相關,想要了解台灣犯罪相關資料 的學者和人民,往往在網路上搜尋就像茫茫大海裡找尋他們所要尋找的犯罪 資料,這些犯罪資料在網路上所呈現方式可能都是以各個縣市為單位直接以 數字數據的方式呈現,沒有整合性的資料,會造成使用者查詢全台灣各個縣 市比較犯罪以及治安相關資料會相對耗時以及無效率,所以我們想要運用我 們統計專業,去設計一個整合性平台,把所有資料透過統計彙整在整個平台 裡,使用者可以依自己所要了解的資料點選,直接跑出使用者所需要的資料, 提供一個有效率簡而易懂平台。 在這平台上,為了讓使用者可以選擇他們所想要了解的項目以及年分, 我們提供各項的犯罪分類勾選、台灣近十年來的年份選項,我們所提供的年 分間距不管是10 年還是 1 年都可以完全依照使用者所要觀看年分區調整,是 為了讓使用者方便分析他所需要在不同年份不同結果的比較,當使用者勾選 出所要的犯罪分類,以及所要觀看的年分間距,將經過統計整理的數據直接 呈現台灣地圖上,民眾可以運用台灣地圖各縣市顏色顯示,即時了解各縣市 犯罪狀況以及嚴重程度,同時也可以直接觀察各個縣市犯罪比較,這個平台 不只提供給民眾了解整個台灣犯罪現況,也提供同個城市在不同時間點比較 出來犯罪治安的嚴重程度。 在政府方面,犯罪的嚴重程度會使當地的居民因為治安差而造成推力, 遷移目前所居住的城市,當一個城市人口流失代表這城市的競爭力可能會漸 漸流失,剛好透過這個平台,可以給地方政府做為一個犯罪治安改進檢討的 一份資料依據,讓台灣整個社會發展越來越好,以成為治安最好的國家為目 標邁進。第二章 資料蒐集
第一節 資料蒐集與篩選
為了蒐集完整的資料,我們從中華民國內政部警政署中的警政統計查詢 網提供的資料,網頁提供的資料共7 大類別如下圖 1。 圖 1 網頁提供資料分類 總共有 86 個細項變數,經過討論和表決後,我們決定使用和我們日常 生活較為有關的「治安直接相關案類」和「道路交通案件」兩大類作為本次研 究的變數。 本研究以台灣各個縣市作為一個地區單位,因此將台灣共 22 個直轄市 和縣市納入評比,但因後來地圖切割沒辦法顯示金門縣和連江縣2 處,且因 身為離島的連江縣和金門縣資料的數值皆趨近於0,因此刪除連江縣與金門 縣,最終選擇台灣除去金門縣與連江縣之20 個直轄市和縣市做為研究對象。 此外,由於台灣於民國103 年實施縣市合併,因此資料有分為縣市合併 前後,我們最後決定使用合併之後的制度,因此若是升格過後的直轄市,其 資料為縣市合併前縣與市的資料加總。 另外為了確保資料具有時間的一致性,因此我們在挑選資料變數皆先確 認每個變數的各年分資料有無缺失,此外因為107 年尚未結束,因此年資料 尚未完整,最後我們挑選最近一年106 年開始以年為單位近十年的資料。 選 擇 研 究 的 變 數 類 別最終我們蒐集到了37 個時間與地點皆一致細項變數,將 37 個細項變數 簡單分為「治安直接相關案類」、「道路交通案件」兩大分類,各細項的原始 變數名稱列於表 1。 表 1 原始 37 個細項變數 治安直接相關案類 道路交通案件 暴力犯罪總數* 事故概況* 故意殺人 肇事件數 擄人勒贖 死亡人數 強盜 受傷人數 搶奪 肇事原因 重傷害 總件數* 重大恐嚇取財 超速 60 公里以下 強制性交總數 飆車 竊盜總數* 違規停車 重大竊盜 不依規定轉彎 普通竊盜 闖紅燈 汽車竊盜 取締未繫安全帶 機車竊盜 取締未戴安全帽 一般傷害 其他原因 一般恐嚇取財 取締件數 詐欺(9403 以前含背信) 移送法辦件數 對幼性交(10512 前歸暴力犯罪) 肇事件數 性侵害 死亡人數 受傷人數 *為欲刪除之細項(刪除原因為與其他變數資料相似)
第二節 資料彙總
原始的 37 個細項變數中,有些與其他變數資料相似因此刪除了變數共 4 項,最後使用之細項變數為 33 個,再來,為了讓視覺化頁面呈現的時候, 使用者可以清晰了解各選項,且有些變數名稱相同,因此對部分變數重新命 名(表 2),最後加上六大分類整合,共 33 個勾選選項。 表 2 細項變數重新命名表 治安直接相關案類 道路交通案件 故意殺人 車禍件數(原為肇事件數)* 擄人勒贖 車禍死亡人數(原為死亡人數)* 強盜 車禍受傷人數(原為受傷人數)* 搶奪 道路交通事故(原為肇事原因)* 重傷害 一般道路超速(原為超速 60 公里以下)* 重大恐嚇取財 飆車 強制性交(原為強制性交總數)* 違規停車 重大竊盜 違規轉彎(原為不依規定轉彎)* 普通竊盜 闖紅燈 汽車竊盜 未繫安全帶(原為取締未繫安全帶)* 機車竊盜 未戴安全帽(原為取締未戴安全帽)* 一般傷害 其他原因 一般恐嚇取財 取締件數 詐欺(原為詐欺(9403 以前含背信))* 移送法辦件數 對幼性交(原為對幼性交(10512 前歸暴力犯罪))* 性侵害 酒後車禍件數(原為肇事件數)* 酒後車禍死亡(原為死亡人數)* 酒後車禍受傷(原為受傷人數)* *為名稱有更動者(更動原因為原始名稱太過拗口) 表 3 勾選選項表 暴力犯罪 竊盜犯罪 其他治安相關 道安事故 道安舉發 酒後駕車 故意殺人 重大竊盜 一般傷害 車禍件數 一般道路超速 取締件數 擄人勒贖 普通竊盜 一般恐嚇取財 車禍死亡人數 飆車 移送法辦件數 強盜 汽車竊盜 詐欺 車禍受傷人數 違規停車 酒後車禍件數 搶奪 機車竊盜 對幼性交 道路交通事故 違規轉彎 酒後車禍死亡 重傷害 性侵害 闖紅燈 酒後車禍受傷 重大恐嚇取財 未繫安全帶 強制性交總數 未戴安全帽 其他原因第三章 研究流程
一般來說,統計分析都由研究者選定研究項目,並做統計分析,但此一研究 是針對大眾個別有興趣的項目做研究,故,為讓使用者能更方便的瞭解結果,不 須自行讀取繁雜的統計資料,我們將使用Shiny 套件[6]來製做一個便於使用者使 用的介面。 Shiny 套件是一個以 R 語言開發且提供建立互動式網頁的工具,其分為 UI和 Server 兩大部分,UI 用以描繪網頁的編排與呈現方式,Server 則為後端伺服
器,將統計資料進行數據分析得到結果後,再傳至前端 UI 來顯示結果。其架構 如下。 圖 2 Shiny 架構 在UI 部分,我們分了四部分,選擇年份、資料顯示、變數選擇及關於。「選 擇年份」是一拉條,以供使用者來選取有興趣的年份區間;「資料顯示」則是在 後端Server 得到的結果顯示區塊;「變數選擇」有六大分類:暴力犯罪、竊盜犯 罪、其他治安相關、道安事故、道安舉發以及酒後駕車,使用者可複數勾選自己 有興趣的變數項目,然後點選下方「開始查詢」來讓後端進行對於選取的年份和 變數來分析,將結果打進資料顯示區;「關於」則是顯示此專題的指導老師與組 員們的資訊。
而在Server 部分,該程式碼中需包含 input 與 output 兩個函數鍵結前端與後
端的指令動作,將選取年份與選取變數設定為 input 的投入要素,然後將 output 設為資料分析後的結果數據。
Shiny
UI
選擇年份
資料顯示
變數選擇
關於
Server
input
output
第一節 統計分析
一、選擇統計分析方法
本研究為了解台灣中各縣市的犯罪情況,分析民國 97 年至 106 年 不同省份的各項犯罪件數作考慮標準,利用「R shiny」製作互動介面程 式,讓使用者挑選不同的年份和犯罪事項,運用統計分析方法計算出一 個指標為台灣各縣市排序。 為計算出合適的指標,需要選擇一種適合的統計方法。其中迴歸分 析是最常使用的統計方法,利用各變數的數據可以簡易地建立模型作解 釋,但一般的線性迴歸模型需要考慮模型有否符合基本假設 (變數共線 性、殘差同質性、殘差常態一致性和殘差獨立性),使用者選擇的變數所 建立的模型可能不能符合線性迴歸基本假設,造成模型估計不穩定而誤 判結果。 考慮各種統計分析方法,本研究運用多變量分析[7]中的主成份分析(Principal components analysis, PCA) 計算出合適的指標,因此本研究採 用主成份分析作資料計算和整合。
二、主成分分析
主成份分析於 1901 年由皮爾森(Karl Pearson)提出,再由侯特齡 (Hotelling) 在 1933 年加以修改發展出來的統計方法,適用在設立指標 的根據上。 其統計方法把原本的多個變數由線性組合轉換成新的變數(主成份) ,主成份之間互相獨立,消弭變數之間的相關影響,再以合理的準則決 定取用多少主成份,保留原有變數的資訊(主成份中保留最大變異數), 以少數變數代表多個變數,以達致資料降維、縮減和精簡的作用。(一)主成份分析特點和定義變數 主成份分析可選擇資料的共變異數矩陣(S),Covariance matrix)或相 關矩陣(R),Correlation matrix)進行主成份分析,本研究利用相關矩陣進 行計算特徵向量(Eigenvector)和特徵值(Eigenvalues),以下以多維主成份 分析為例說明此統計分析法的理論,其中分析有以下特點。 1. 原始資料集變數 �𝑿𝑿 = [𝑥𝑥1, 𝑥𝑥2, ⋯ , 𝑥𝑥𝑝𝑝] = � 𝑋𝑋11 𝑋𝑋12 … 𝑋𝑋1𝑛𝑛 𝑋𝑋21 𝑋𝑋22 … 𝑋𝑋2𝑛𝑛 ⋮ ⋮ ⋮ ⋮ 𝑋𝑋𝑛𝑛1 𝑋𝑋𝑛𝑛2 … 𝑋𝑋𝑛𝑛𝑝𝑝 ��, n 為樣本數,p 為變數。 2. 把觀察值投影至新的多維軸線上,新的變數為(主成份)(𝑌𝑌1, 𝑌𝑌2, ⋯ , 𝑌𝑌𝑝𝑝)
利用此計算出來的數值為主成份得點(Principal components scores)。
3. 主成份(𝑌𝑌1, 𝑌𝑌2, ⋯ , 𝑌𝑌𝑝𝑝)和原始變數([𝑥𝑥1, 𝑥𝑥2, ⋯ , 𝑥𝑥𝑝𝑝])的線性組合(Linear
combination)均值為 0。
4. 主成份(𝑌𝑌1, 𝑌𝑌2, ⋯ , 𝑌𝑌𝑝𝑝)和原始變數([𝑥𝑥1, 𝑥𝑥2, ⋯ , 𝑥𝑥𝑝𝑝])的總平方和(Total
sum of square) 和 總 變 異 數 (Total variance) 相 等 。 ( ∑ 𝑉𝑉𝑉𝑉𝑉𝑉(𝑋𝑋𝑝𝑝𝑗𝑗 𝑗𝑗)=
∑ 𝑉𝑉𝑉𝑉𝑉𝑉�𝑌𝑌𝑝𝑝𝑗𝑗 𝑗𝑗�, 𝑗𝑗 = 1,2, ⋯ , 𝑝𝑝) 5. 首項主成份的變異數(𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌1) = 𝜆𝜆1, 𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌2) = 𝜆𝜆2, ⋯ , 𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌𝑝𝑝) = 𝜆𝜆𝑝𝑝) 比原始變數(𝑉𝑉𝑉𝑉𝑉𝑉(𝑋𝑋1), 𝑉𝑉𝑉𝑉𝑉𝑉(𝑋𝑋2), ⋯ , 𝑉𝑉𝑉𝑉𝑉𝑉(𝑋𝑋𝑝𝑝))的變異數百分比大。 6. 主成份之間相關獨立(𝐶𝐶𝐶𝐶𝑉𝑉�𝑌𝑌𝑖𝑖, 𝑌𝑌𝑗𝑗� = 0, ∀𝑖𝑖 ≠ 𝑗𝑗, 𝑖𝑖, 𝑗𝑗 = 1,2, ⋯ , 𝑝𝑝)。 7. 第一主成份的變異數(解釋能力)最高,其次為第二主成份、第三主成 份,如此類推。(𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌1) = 𝜆𝜆1 > 𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌2) = 𝜆𝜆2 > ⋯ > 𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌𝑝𝑝) = 𝜆𝜆𝑝𝑝)
(二)主成份分析步驟 以下利用數學方程式說明主成份分析的步驟。 1. 計算相關矩陣: 𝐑𝐑 = ⎣ ⎢ ⎢ ⎡𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋1 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋1, 𝑋𝑋2) … 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋1, 𝑋𝑋𝑗𝑗) 2, 𝑋𝑋1) 1 … 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋2, 𝑋𝑋𝑗𝑗) ⋮ ⋮ ⋱ ⋮ 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋𝑖𝑖, 𝑋𝑋1) 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋𝑖𝑖, 𝑋𝑋2) … 1 ⎦ ⎥ ⎥ ⎤ 2. 計算特徵值(𝜆𝜆𝑗𝑗)、特徵向量(𝑉𝑉𝑖𝑖𝑗𝑗)和主成份(𝑌𝑌𝑗𝑗): 𝐑𝐑𝐑𝐑 = 𝜆𝜆𝐑𝐑 |𝐑𝐑 − 𝜆𝜆𝐼𝐼𝑝𝑝| = �� 1 − 𝜆𝜆 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋1, 𝑋𝑋2) … 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋1, 𝑋𝑋𝑗𝑗) 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋2, 𝑋𝑋1) 1 − 𝜆𝜆 … 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋2, 𝑋𝑋𝑗𝑗) ⋮ ⋮ ⋱ ⋮ 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋𝑖𝑖, 𝑋𝑋1) 𝐶𝐶𝐶𝐶𝑉𝑉(𝑋𝑋𝑖𝑖, 𝑋𝑋2) … 1 − 𝜆𝜆 �� = 0 𝑆𝑆𝐶𝐶𝑆𝑆𝑆𝑆𝑆𝑆: 𝜆𝜆1, 𝜆𝜆2, ⋯ , 𝜆𝜆𝑝𝑝 𝐑𝐑𝑉𝑉𝑖𝑖𝑗𝑗 = 𝜆𝜆𝑗𝑗𝑉𝑉𝑖𝑖𝑗𝑗, 𝑆𝑆𝐶𝐶𝑆𝑆𝑆𝑆𝑆𝑆: 𝑉𝑉1, 𝑉𝑉2, ⋯ , 𝑉𝑉𝑝𝑝 𝑌𝑌𝑗𝑗 = � � 𝑉𝑉𝑖𝑖𝑗𝑗 𝑝𝑝 𝑗𝑗 𝑛𝑛 𝑖𝑖 𝑋𝑋𝑖𝑖, 𝑖𝑖 = 1,2, ⋯ , 𝑛𝑛𝑗𝑗 = 1,2, ⋯ , 𝑝𝑝 3. 主成份的變異數(解釋能力),決定取用多少主成份並計算出主 成份得點(𝑆𝑆𝑆𝑆𝐶𝐶𝑉𝑉𝑆𝑆𝑖𝑖𝑗𝑗): 第j 主成份(𝑌𝑌𝑗𝑗)解釋全體原來變數的變異數(解釋能力)比例為 𝑉𝑉𝑉𝑉𝑉𝑉(𝑌𝑌𝑗𝑗) ∑ 𝑉𝑉𝑝𝑝𝑗𝑗 𝑉𝑉𝑉𝑉(𝑌𝑌𝑗𝑗)= 𝜆𝜆𝑗𝑗 ∑ 𝜆𝜆𝑝𝑝𝑗𝑗 𝑗𝑗, 𝑗𝑗 = 1,2, ⋯ , 𝑝𝑝 計算主成份得分前需要標準化原始資料,第ij 主成份得分為 𝑆𝑆𝑆𝑆𝐶𝐶𝑉𝑉𝑆𝑆𝑖𝑖𝑗𝑗 = � � 𝑉𝑉𝑖𝑖𝑗𝑗 𝑝𝑝 𝑗𝑗 𝑛𝑛 𝑖𝑖 𝑍𝑍𝑖𝑖𝑗𝑗, 𝑖𝑖 = 1,2, ⋯ , 𝑛𝑛,𝑗𝑗 = 1,2, ⋯ , 𝑝𝑝 (三)範例 以下利用實際例子說明主成份分析的步驟,假設使用者選擇民國
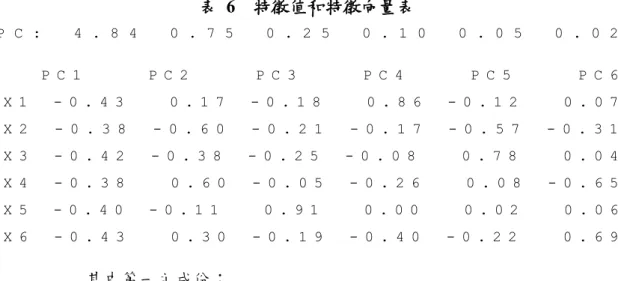
106 年中故意殺人(X1)、重大竊盜(X2)、一般傷害(X3)、車禍件數(X4)、 一般道路超速(X5) 和取締件數(X6)六個變數,運用 R 軟體運算主成份 分析: 1. 分割出使用者挑選的年份和變數的資料,把原始資料變數標準化,計 算出相關矩陣。 表 4 原始資料表 X1 X2 X3 X4 X5 X6 新北市 36 7 1877 323 206844 12962 臺北市 56 9 2424 21682 474833 10633 桃園市 35 0 276 30872 200814 8425 臺中市 42 1 710 46793 273135 13041 臺南市 39 2 1067 18458 46373 8220 高雄市 64 4 1455 48629 233383 12547 ... 表 5 標準化資料後計算相關矩陣表 X1 X2 X3 X4 X5 X6 X1 1.00 0.71 0.82 0.86 0.79 0.91 X2 0.71 1.00 0.93 0.45 0.74 0.67 X3 0.82 0.93 1.00 0.61 0.79 0.79 X3 0.86 0.45 0.61 1.00 0.69 0.94 X4 0.79 0.74 0.79 0.69 1.00 0.77 X5 0.91 0.67 0.79 0.94 0.77 1.00 2. 計算特徵值、特徵向量和主成份。
表 6 特徵值和特徵向量表 P C : 4 . 8 4 0 . 7 5 0 . 2 5 0 . 1 0 0 . 0 5 0 . 0 2 P C 1 P C 2 P C 3 P C 4 P C 5 P C 6 X 1 - 0 . 4 3 0 . 1 7 - 0 . 1 8 0 . 8 6 - 0 . 1 2 0 . 0 7 X 2 - 0 . 3 8 - 0 . 6 0 - 0 . 2 1 - 0 . 1 7 - 0 . 5 7 - 0 . 3 1 X 3 - 0 . 4 2 - 0 . 3 8 - 0 . 2 5 - 0 . 0 8 0 . 7 8 0 . 0 4 X 4 - 0 . 3 8 0 . 6 0 - 0 . 0 5 - 0 . 2 6 0 . 0 8 - 0 . 6 5 X 5 - 0 . 4 0 - 0 . 1 1 0 . 9 1 0 . 0 0 0 . 0 2 0 . 0 6 X 6 - 0 . 4 3 0 . 3 0 - 0 . 1 9 - 0 . 4 0 - 0 . 2 2 0 . 6 9 其中第一主成份: Y1 = −0.43×故意殺人 −0.38×重大竊盜 −0.42×一般傷害 −0.38×車禍 件數 −0.40×一般道路超速 −0.43×取締件數 3. 主成份的變異數 (解釋能力),取用主成份的準則。 圖 3 陡坡圖 表 7 主成份的變異數 (解釋能力) 表 P C 1 P C 2 P C 3 P C 4 P C 5 P C 6 S t a n d a r d d e v i a t i o n 2 . 2 0 0 . 8 7 0 . 5 0 0 . 3 1 0 . 2 2 0 . 1 5
P r o p o r t i o n o f V a r i a n c e 0 . 8 1 0 . 1 2 0 . 0 4 0 . 0 2 0 . 0 1 0 . 0 0 C u m u l a t i v e P r o p o r t i o n 0 . 8 1 0 . 9 3 0 . 9 7 0 . 9 9 1 . 0 0 1 . 0 0 根據主成份的變異數(解釋能力)表,第一主成份可以解釋八成多原 始資料 (0.806),第二主成份可以解釋一成多原始資料(0.1247),而如果 取用第一和第二主成份可以解釋 93%(0.9307)的原始資料,取用第一、 第二、第三主成份可以解釋 97%(0.97225) 的原始資料。本研究取用主 成份考慮凱莎原則 (Kaiser),取用特徵值大於 1 的主成份,表示取用可 以解釋較多原始資料的主成份。觀察陡坡圖中只有第一主成份的特徵值 大於1,所以只取第一主成份作後面部份的分析,下面列出第主成份得 點,利用主成份得點為台灣縣市排序。 表 8 第一主成份得點表 新北市 -3.64 南投縣 1.24 臺北市 -5.20 雲林縣 1.40 桃園市 -1.00 嘉義縣 1.39 臺中市 -2.73 屏東縣 0.14 臺南市 -1.01 臺東縣 1.69 高雄市 -4.03 花蓮縣 1.02 宜蘭縣 1.37 澎湖縣 2.00 新竹縣 1.01 基隆市 1.00 苗栗縣 1.27 新竹市 1.69 彰化縣 0.38 嘉義市 2.00
第二節
UI 架構
一、介紹及用途
以下的圖表為UI 的內容架構: 圖 4 UI 內容架構 雖然說 UI 是將前端操作介面的資料傳到後端伺服器使用,但在排 版及建立介面時,大多不須使用後伺服器的計算功能,只需將固定格式 的程式碼輸入,即可建立起UI 的介面。其中,需要經由 Server 計算, 並將得到的結果以圖像化方式呈現,只有PART-(c)的部分,該部分需使 用Leaflet 套件[8]將於本章第四節討論。
二、實務操作
(一)介面呈現 UI 與 Server 中的所有資訊都要相互對應,只要有一項資訊 沒有對應到,雖然網頁會出來以及網頁中的介面是完整的,但 只要勾選變數後按開始查詢時,圖1 當中標註為 c 的地方是無 法跑出東西來的。其中圖1 中的 a、b、c、d 及 e 的標註是與上 述的程式碼相對應的。以下為介面示意圖:圖 5 整體介面 以下介紹UI 程式碼及所對應的介面。 UI 內主要包含以下三個東西: 側邊目錄 sidebar<-dashboardSidebar(<->) 資料顯現 body<-dashboardBody(<->) 整個頁面及標題 dashboardPage(<->,sidebar,body) (二)程式碼及解釋各自用途 以下我們來介紹UI 內的程式碼: 1. PART-(a) sidebar<-dashboardSidebar(<->):「dashboardSidebar」是個可 隱藏的介面,藉由按下”≡”這符號,使這個介面隱藏起來,讓主 要畫面變的更大。「sidebarMenu」是類似目錄的型態,主要是 讓使用者知道主程式的使用介面在哪裡,在”關於”這一目錄裡 面為創作者的名字及引用的資料來源為何。「menUItem」為目 錄名稱。「tabItems」、「tabsetPanel」以及「tabPanel」都是為了 讓主要畫面跟「menUItem」裡頭的目錄名稱相互對應。 #a (左邊側欄) UI=sidebar <- dashboardSidebar({ sidebarMenu( menUItem(iconv("主程式",to="UTF-8"), tabName =
"QPF_analysis0601", icon = icon("area-chart") ), menUItem(iconv("關於",to="UTF-8"), tabName = "about", icon = icon("book",class="fa fa-address-book")))})
UI=body <- dashboardBody({
tabItems(tabItem("QPF_analysis0601",
2. PART-(b)
「sliderInput」是拉條,裡頭的 min=97 和 max=106 為我們
這次所採用的年份,而value 裡頭的數值為我們預定的年份範 圍,而使用者如果要看其他年份的話,直接拉到相對應的年份 位置上即可。「flUIdRow」是為了將主要畫面分割為圖1 的(b)、 (c)以及(d)三個板塊,是用來讓使用者清楚操作介面,並且讓使 用者自由變換年份及資料變數。 #b (選擇年份) flUIdRow(column(width = 12, tabsetPanel( tabPanel(sliderInput("slider2",label = h3("選擇年份"), min = 97,max = 106, value = c(99,100,101,102,103),width=1048))))), 3. PART-(c)&(d) 「checkboxGroupInput」為我們這次所收集的六大類別, 六大類別再在「choices」裡頭分成各類小細項,以供使用者進 行勾選,之後只要按下「actionButton」裡頭開始查詢,所勾選 的變數便能在圖5 中標註為 c 的地方呈現給使用者看。 #c (呈現畫面) flUIdRow(column(width = 10,
box(leafletOutput('myMap', width = "100%", height = 1087),width = NULL, solidHeader = TRUE, height = 1090)),
#d (變數選擇及其細項)
column(width = 2,
checkboxGroupInput("in1", "暴力犯罪", choices = c("故意殺人","擄人勒贖"…),selected = c(1, 2, 3, 4)), checkboxGroupInput("in2", "竊盜犯罪", . . actionButton("zoomButton", "開始查詢")))))), 4. PART-(e) 「dashboardPage」是將前面的兩大架構共同結合成供使用 者使用的頁面,而頁面的精緻程度能從Server 裡面的程式碼加 以修改。「dashboardHeader」就是這次專題及這頁面的標題。 #e (主架構及主題) UI=dashboardPage( dashboardHeader(title = "危險都市"),sidebar,body)
第三節
Server
一、介紹及用途
Server 的用途是將選取年份與選取變數設定為統計分析方法的運 算參數,並將計算結果以圖像化的方式展現。而圖像化還需透過Leaflet 套件,故將於下一節討論。二、實際操作
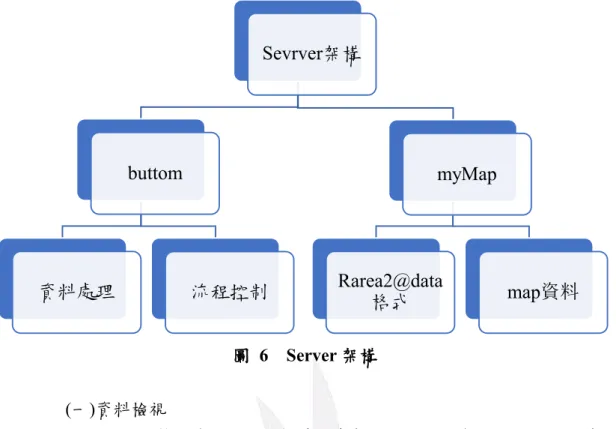
如上節所述,建立起UI 後,接著將 Server 的架構分成兩部分(如下) 解釋,一為buttom,另一個為 myMap。 #Server 架構Server <- function(input, output) {
buttom<-eventReactive(input$zoomButton,{↔}) output$myMap <- renderLeaflet({↔}) } 其中,內置函數「eventReactive」與「renderLeaflet」,分別對應(位 於UI 的)「actionButton」與「leafletOutput」。 「eventReactive」函數是通過操作按鈕 (即 actionButton)觸 發命令,該命令即為您所勾選的變數和選擇的年份。 「renderLeaflet」函數是將觸發命令所整理、計算後的資料傳至 「myMap」這個參數裡,並透過「leafletOutput」圖像化資訊。
下圖為Server 架構,資料處裡、Rarea2@data 格式、map 資料下都
還有小項目,但圖中不再細分,因依下圖區塊尋找已足夠方便,過細反 而難找。
圖 6 Server 架構
(一)資料檢視
在初步整理資料,並分析時,其實不用使用到資料檢視這個環節,
但在後期要套用在Server 與 UI,或更進一步要串連 Server 與 UI 時常會
遇到資料屬 性 不合的問題 、 對照資 料 排序時的繁瑣 步驟還 有降低 「myMap」參數錯誤的可能性,以下提醒一些要注意的資料屬性,以及 使用「renderPrint」與「verbatim-TextOutput」來檢視資料的便利性,但 若不看不懂此段,亦可跳過此段,並使用固定年分及特定變數慢慢檢查。 其中「renderPrint」函數是將您所勾選的變數和選擇的年份,經過 整理或計算後以文字檔的方式回傳至「verbatimTextOutput」所在的 box 裡,故可以直接透過選擇年分及變數,改變如同下一頁的圖7 所呈現的 資料。 #傳資料的指令 renderPrint(list(class(as.vector(unlist(buttom()))),butto m())) buttom()又等於 list(Ind.v,YY,Year.x,Y.sum.pca.point,rank(Y.sum.pca.point)) 故,按順序來說,圖 7 的資料為 class、Ind.v、YY、Year.x、 Y.sum.pca.point、rank,分別代表 buttom()的資料屬性、選取的變數、選 取的年分、選取變數及年分後所對應的資料、PCA 分數得點、分數得點 的排序。 Sevrver架構 buttom 資料處理 流程控制 myMap Rarea2@data 格式 map資料
圖 7 檢視資料圖 提醒: myMap 所使用的參數屬性須為 numeric。 變數選擇僅有一個時,PCA 分數得點無意義,故須有流程控制。 PCA 分數得點有時會多一個負號,於事後 rank 及地圖顯色上 會與實際涵義相反,須多加注意。 若要檢查「選取變數及年分後所對應的資料」是否正確,可拿 圖中的資料與原始資料對照。
Ind.v(選取的變數)與 YY(選取的年分)的 input 皆為變數(指令
如下),以此方式檢視資料,較便利。
#選變數
df = data.frame(subject=c("故意殺人","擄人勒贖","強盜 ",…),id=c(1:33))
Ind.v<-(df %>% filter(subject %in% c(input$in1,input$in2,…)) %>% select(id))
#選年分
dff=data.frame(subjectt=c("Y7","Y8","Y9",…),idd=c(97:106)) YY<-(dff %>% filter(idd %in% (input$slider2[1]:
(二)buttom 裡的結構 此段裡,將詳細說明 buttom 的結構,裡頭包含了資料處裡以及流 程控制兩個部分,文中的指令僅為部分而非全部,以「…」省略相同、 類似的地方,並以解釋指令用意為主,若想參考完整的指令請至附錄查 看。 1. 資料處理 資料處理的部分又分為選變數、選年分、表格整理、選擇年分及變 數後的資料。以下解釋或提醒須注意部分。(符號註解:管線運算子 「%>%」的用途是將左側的運算結果傳遞至右側函數的第一個參數。) (1) 選變數與選年分的結構差不多,皆是建立一個資料框架(df/ dff),並透 過管線運算子「%>%」配適您於 UI 所勾選的變數或選擇的年分 (即 input$...) ,最後選擇資料框架(df/ dff)您所需要的部分 (如 select(id),即 是選擇變數所對應到的編號) 。 #選變數 df = data.frame(subject=c("故意殺人","擄人勒贖","強盜 ",…),id=c(1:33))
Ind.v<-(df %>% filter(subject %in%
c(input$in1,input$in2,input$in3,…)) %>% select(id))
#選年分
dff =
data.frame(subjectt=c("Y7","Y8","Y9",…),idd=c(97:106)) YY<-(dff %>% filter(idd %in%
(input$slider2[1]:input$slider2[2])) %>% select(subjectt)) (2) 表格整理的部分,於讀檔後,為便於分析以陣列呈現,在此著重於 AA 即 function(L)的意思。函數裡 Year$Y6*L[10]+Year$Y5*L[9]+…,可 拆成變數 Year 及 L。Year 是以年分(97~106)劃分的資料,選取「$」的 子集合有 Y0 至 Y9,其中 Y0 旁的數字「0」代表年分 100 的資料,是 以個位數字下去命名,以方便辨認之用。L 是用邏輯判斷的方式檢查, list 裡的變數是否屬於 YY 年分選取所得到的資料,屬於 YY 者命名為 「True」,反之為「False」,以此方式命名原因是「True」代表的數字是 1,「False」代表的數字是 0,故 Year$Y6*L[10]+Year$Y5*L[9]+…這一 串式子,意即 AA 函數,可以幫忙選出並相加您於 UI 所勾選的年分資 料。順帶一提,map 切割縣市的資料中,並沒有金門縣與連江縣故,須 注意您所使用的資料中是否有這兩個地方。
#表格整理
data <- read.csv("d:/專題原始資料.csv", header=T, sep=",") year.array<-array(apply(as.matrix.noquote(data[5:26,2:331]), 2,as.numeric),dim=c(22,33,10)) colnames(year.array)<-c("故意殺人","擄人勒贖","強盜",…) rownames(year.array)<-c("新北市","臺北市",…,"金門縣","連江縣") Year<-list(Y6=year.array[,,1],Y5=year.array[,,2],Y4 = year.array[,,3],…) L<-ifelse(list("Y7","Y8","Y9",…)%in%(YY$subjectt),T,F) AA <- function(L){ Year$Y6*L[10]+Year$Y5*L[9]+Year$Y4*L[8]+… } (3) 選擇年分及變數後的資料主要是透過前兩項所提到的選變數、選年 分及表格整理個別對應到的結果Ind.v、YY 、AA 所做的總整理並命名 為「Year.x」,且在下一節做的資料分析,皆是以這個整理完的資料做計 算。 #選擇年分及變數後的資料 Year.x<-AA(L)[,Ind.v$id] 2. 流程控制 在資料整理完後做流程控制的用意很簡單,因為下一節裡的資料分 析,我們是採用PCA 來縮減資料維度,以便在最後的地圖顯色時使用。 然而,重點在於 PCA 是用來縮減資料維度時所使用的,所以當我們選 取的變數僅有一個的時候,採用 PCA 並沒有意義,故以下面的方式控 制選取變數為1 個時,將不同年分的該變數總和即可。其中 Ind.v 是您 選取變數所對應的編碼,實屬向量,故可直接length( )函數檢視 Ind.v 長 度是否為1(即選取變數是否為 1),並藉此方式,控制流程。 #流程控制 if(length(Ind.v)<=1){做 A}else{做 B}
(三)myMap 裡的結構
myMap 可分為兩的部分,一是將 buttom 裡的資料整理成分割縣市
所需的資料格式Rarea2@data,另一則是將 Rarea2@data 套用在 leaflet( )
函數裡。由於myMap 的結構大致上是固定的,所以本段將提醒一些需 要更改或需要注意之事項,其餘維持不變即可。 1. Rarea2@data 格式 Rarea2@data 格式裡需要更改的,只有標成粗黑體字的三個部分 city2、Rank、Rank_YY.csv。分三點如下。 #Rarea2@data 格式 city2=as.vector(unlist(buttom()))
COUNTYENG=c ("New Taipei City","Taipei City"…)
Rank=floor(rank(city2))
TWN = readOGR ({↔}) %>% spTransform({↔}) list<-c ("New Taipei City","Taipei City",…) Rarea2<-subset(TWN, COUNTYENG %in% list) aa=as.data.frame(cbind(COUNTYENG,(P_N))) aa[,2]=as.numeric(as.character(aa[,2])) colnames(aa)=c("COUNTYENG","P_N") bb <-as.data.frame(read.table("Rank_YY.csv",header = TRUE,sep = ",") cc <-as.data.frame(read.table(↔)) Rarea2@data<-left_join(Rarea2@data, aa,by=c("COUNTYENG")) Rarea2@data<-left_join(Rarea2@data, bb,by=c("P_N")) Rarea2@data<-left_join(Rarea2@data, cc,by=c("COUNTYENG")) pal=colorFactor("Reds",levels = c("普通","不良","危險")) labels <- sprintf(↔)%>% lapply(htmltools::HTML)
(1) city2 是要對應 buttom 裡的 PCA 分數得點,要特別注意的是資料屬性須為
numeric,如同本節第一段資料檢視所提及,而原因是此資料是要用於排
序並顯色之用,所以若為類別變數,則無法排序、顯色。
(2) Rank為city2 的資料排序,而 floor( )是為了避免選取變數只有一個,且
遇到案件發生數量一樣,進而排序出現取平均值的情況發生(此一情況,會造 成地圖無法顯色)。
提,Rank_YY.csv 須與指令檔案放在同意件夾裡才能開啟。
2. map 資料
map 資料同樣是使用管線運算「%>%」將左側的運算結果傳遞至
右側的參數,過程依序為leaflet ( )、addTiles ( )、setView ( )、addLegend
( )、addProviderTiles ()、addPolygons ( ),但主要提到的只有 setView ( ),
而addLegend ( )、addProviderTiles ()、addPolygons ( ),且於下節才述明,
第四節
資料地圖化
一、介紹及用途
Leaflet 套件在整個研究流程中具有串連的功用,如同前兩節所提 到的一樣,Leaflet 套件的資料來源,是 UI 即前端操作介面所勾選的 變數、選擇的年分,接著在由統計分析方法家於後端伺服器加以運算, 接著將運算結果套用在Leaflet 函數裡,並以圖像化的方式加以呈現。二、實際操作
首先我們把主成分分析的結果輸入,然後利用我們從內政資料平 臺(OPEN DATA)所取得的直轄市、縣市界線(TWD97 經緯度)的shp 檔 [9],而後將原先主成分分析的縣市與行政區域分塊的縣市做串連後, 將各縣市的主成分分析做rank()對每個縣市的主成分分析得點做排名, 以此來獲得各縣市的排名(1-5 列為危險,6-15 列為不良,16-20 列為 普通),並利用 colorFactor()來決定地圖分級顏色以及 sprintf()來控制 我們想要提供的資訊,再者就可以設定我們想要的地圖呈現方式。 接著我們利用 setView(120.9739,23.5,zoom=8)來設定地圖中心區 域以及地圖縮放大小,其中(120.9739,23.5)為臺灣經緯度原點的座標, 並 且 透 過 addLegend() 來 讓 顯 示 地 圖 上 有 顏 色 排 名 注 釋 以 及 addPolygons()來控制顯示資料時的字體大小。 最 後 我 們 把 Leaflet 在 UI 的 資 料 顯 示 區 與 Server 利 用 renderLeaflet 函數來做串連,通過前述的例子再點一次「開始查詢」 後得到下圖。如此一來,使用者可以透過鼠標游移到感興趣的縣市來 直接得到該縣市的危險程度,抑或是透過顏色來瞭解該區域的危險程 度。 #map 資料 map<- Rarea2@data %>%leaflet ( ) %>% addTiles ( ) %>% setView (120.9739, 23.5, zoom = 8) %>% addLegend ( {↔} ) %>% addProviderTiles ( {↔} ) %>% addPolygons ( {↔} ) (1) setView ( )的用途是定位,裡頭數字(120.9739, 23.5)是中心點, 而zoom 則是放大的尺寸,若想調整 map 的長寬,則須至 UI 的leafletOutput( )調整。 (2) addLegend ( )是地圖右上角的標籤。如下圖。 圖 8 危險程度標籤 (3) addProviderTiles ( )是畫分等直線,即縣市界線的劃分。 (4) addPolygons ( )是區塊的顯色還有文字的添加。如下圖。 圖 9 區塊顯色與文字敘述
第四章 研究成果
第一節
介面指引
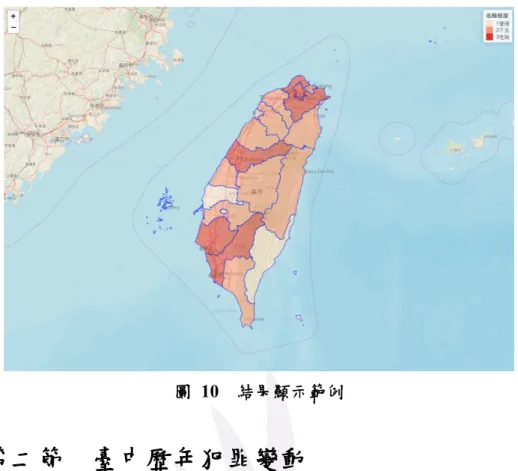
經由上章節的研究流程,我們設計出一互動式網頁提供使用者可以在主 介面選取單一年份或多個年份,並勾選自己想要觀察的變數,且在查詢之後 可以透過資料視覺化來清晰地查看結果,下面就讓我們利用主成份分析時採 用的例子(p12)來一一展示操作步驟。 步驟一、選取年份 在網頁開啟後可以看到上方有選擇年份的捲軸,用以提供使用者自 行拖曳感興趣的年份區間,或是將捲軸收起後,點選感興趣的年份兩下, 即會自動選擇。圖為單選106 年的年份。 步驟二、變數選擇 在網頁右側的變數選擇欄中,勾選「故意殺人」、「重大竊盜」、「一 般傷害」、「車禍件數」、「一般道路超速」和「取締件數」這六個變數。 步驟三、開始查詢 在確認選取年份以及變數選擇後,在變數選擇欄的最下方有開始查 詢的按鈕,點下去後,Server 就會對所選擇的年份以及變數做出主成份 分析排名以及將其結果視覺化。 步驟四、查看結果 經由上述步驟後,結果將會顯示在網頁左下方的框架中。結果畫面 的中央是臺灣各縣市的顯色狀況,右上方則是對各顏色所代表的危險程 度解釋。以顏色深淺可以看出,臺北市、新北市、臺中市、臺南市、高 雄市被繪成最深的紅色,即說明這五個城市在使用者選擇感興趣的條件 下呈現危險的情況。圖 10 結果顯示範例
第二節
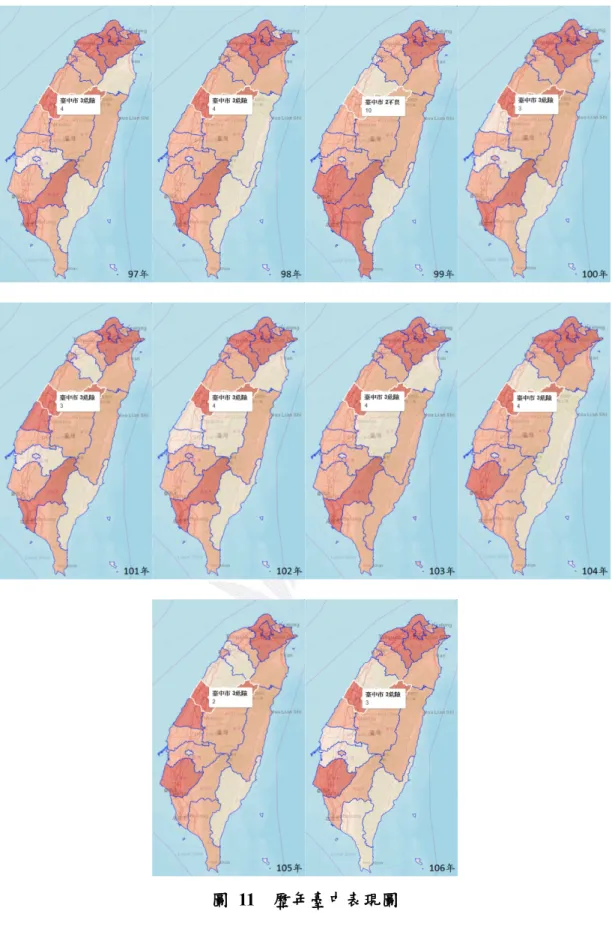
臺中歷年犯罪變動
身為在逢甲就學的學生,抑或是即將來臺中工作、就讀的人們,臺中的 危險程度是和我們息息相關的因素,故我們利用做出來的Shiny 互動式網頁 對於臺中在所有危險變數下歷年(97-106)的危險程度表現做分析。但由於「重 大恐嚇取財」在 102、103、104、106 這四年度中,各縣市的表現皆為零, 以及「對幼性交」一項在105 年度 12 月後不歸類在暴力犯罪項中,致使 106 對幼性交一項的各縣市表現皆為零,避免資訊上的缺失造成無法比較的狀況 ,因此,我們只採用除這兩項之外的所有變數。 下圖群為利用互動式網頁所取得的歷年臺中危險程度視覺化表現,我們 可以發現臺中只有在 99 年時,沒有顯現代表危險的深紅色,而其餘年皆為 危險狀況的分佈,甚至在105 年時,危險程度排名躋升至全國第二,透過圖 群的表現我們可以道出臺中的危險程度很高,並不建議一般民眾在此居住。第五章 結論及討論
第一節
結論
我們的專題研究先從小組討論研究方向,參考警政署犯罪案件統計網收 集數據資料,篩選及改名變數再選擇臺灣於97 年到 106 年間改制後的 20 個 縣市,而離島的連江縣、金門縣的資料由於較不完整所以不予計入,藉由R 程式語言裡的套件:Shiny 架構 UI 及 Server,再將資料視覺化及地圖化,設 計出一套系統,使用者可以選擇想要觀察的年份及變數,資料會以 PCA 的 主成分在後端系統分析,再將 20 個縣市以顏色深淺呈現在地圖上,立即看 出各縣市的危險程度。 本次的專題研究,可以發現我們變數前三大分類屬於犯罪統計,後三大 分類屬於道安統計,所以我們綜合了 33 個變數用程式實驗了臺灣近十年間 的結果變化,結果顯示出97 年到 106 年 10 張地圖分級,包括臺中市在內, 臺北市、新北市、桃園市、台南市、高雄市,六個都市被繪成紅色的重疊率 較高,可以說明主要以都市化程度較高的六都在近十年間,他們的危險程度 較其他縣市來的高。 除了上述的實驗方向,使用者可以依照想要觀察的不同面向,可能是從 都市化程度、城鄉差距、貧富差距、人口密度及經濟發展多種議題去探討, 或是交通方面的道安問題,根據不同研究目的所使用的變數不同,程式對應 出的結果也不盡相同,交叉比對選擇自己想要的變數,研究結果就不會只有 單一方向,並呈現出相對綜合性的分析結果。 我們的研究成果展示了近十年臺灣各縣市犯罪的趨勢變化,依據現有公 開數據,依照使用者的需求選取想要的多個變數,經過後端統計分析,呈現 淺顯易懂的綜合性評比,或是由某些特定變數作評比中,可以知道每個縣市 對特定變數呈現的危險程度,想要甚麼資料的呈現都方便使用者選取,這也 是我們的程式想給使用者更為人性化的一面。第二節
討論
本次研究提供了更方便、有效的系統,讓使用者可以依照自己的需求去 選擇關心的變數,而研究成果雖然可以看出臺灣 20 個縣市的危險程度,但 只以縣市做為分析單位仍然過於粗略,若使用者想從更多社會議題為參考面 向,就需要各鄉鎮或鄰里及偏遠地區更精細的資料蒐集;而警政統計查詢網 公開的資料中,例如金門縣、連江縣,還有少部分資料登記不詳,也無鄉鎮 鄰里及偏遠地區的統計資訊,未來政府及警政署的開放平台若能提供更多詳 細資料,便有利於我們更新更精細的資料呈現在地圖上。 而研究成果是將各縣市分析後的資料依照排名分為普通、不良、危險三 個等級,起初以Server 架構地圖右上角的標籤時,三個等級的排序錯亂而並 不是以危險程度依序由上而下,因為 R 程式會以中文筆劃多寡由少至多排 序,所以我們在三個等級前分別加入數字,R 程式會以數字排序「1 普通」、 「2 不良」、「3 危險」呈現在地圖右上角的標籤;顯色方面,排名縣市時想 以漸層色呈現在地圖上,但由於顏色區隔太小導致顏色過於相近不易辨識, 所以我們將 20 個縣市的排名以 3 種顏色由淺至深分組歸類,讓使用者更利 於辨識結果。 現在是個科技及網路發達的時代,大部分民眾都會使用3C 類的科技產 品來連線上網,舉凡蒐集資料、教學式平台互動、網路購物...等等,都能用 網路達到目的,甚至是國家的資訊都能在網路世界輕鬆獲取,形成一個全球 性公共空間,卻也延伸出許多網路犯罪議題,而目前警政統計查詢網的資料 只有登記現實面的犯罪細分類統計,暫無網路犯罪的細分類統計,希望政府 能增加更多網路犯罪資料,利於我們將來更新程式後給予使用者更多元性的 犯罪資料。附錄一 程式碼
library(shiny) library(ggplot2) library(shinydashboard) library(leaflet) library(dplyr) library(rgdal)server <- function(input, output) { buttom<-eventReactive(input$zoomButton,{ #選變數 df = data.frame(subject=c("故意殺人","擄人勒贖","強盜","搶奪","重傷害","重大恐嚇取財","強制 性交","重大竊盜","普通竊盜","汽車竊盜","機車竊盜","一般傷害","一般恐嚇取財","詐欺","對幼性交","性 侵害","車禍件數","車禍死亡人數","車禍受傷人數","道路交通事故","一般道路超速","飆車","違規停車","違 規轉彎","闖紅燈","未繫安全帶","未戴安全帽","其他原因","取締件數","移送法辦件數","酒後車禍件數","酒 後車禍死亡","酒後車禍受傷"),id=c(1:33))
Ind.v<-(df %>% filter(subject %in%
c(input$in1,input$in2,input$in3,input$in4,input$in5,input$in6)) %>% select(id)) #選年分
dff =
data.frame(subjectt=c("Y7","Y8","Y9","Y0","Y1","Y2","Y3","Y4","Y5","Y6"),idd=c(97:106) )
YY<-(dff %>% filter(idd %in% (input$slider2[1]:input$slider2[2])) %>% select(subjectt))
#表格整理
data <- read.csv("d:/107.csv", header=T, sep=",") year.array<-array(apply(as.matrix.noquote(data[5:26,2:331]),2,as.numeric),dim=c(22,33,10)) colnames(year.array)<-c("故意殺人","擄人勒贖","強盜","搶奪","重傷害","重大恐嚇取財","強制性 交","重大竊盜","普通竊盜","汽車竊盜","機車竊盜","一般傷害","一般恐嚇取財","詐欺","對幼性交","性侵 害","車禍件數","車禍死亡人數","車禍受傷人數","道路交通事故","一般道路超速","飆車","違規停車","違規 轉彎","闖紅燈","未繫安全帶","未戴安全帽","其他原因","取締件數","移送法辦件數","酒後車禍件數","酒後 車禍死亡","酒後車禍受傷") rownames(year.array)<-c("新北市","臺北市","桃園市","臺中市","臺南市","高雄市","宜蘭縣","新 竹縣","苗栗縣","彰化縣","南投縣","雲林縣","嘉義縣","屏東縣","臺東縣","花蓮縣","澎湖縣","基隆市"," 新竹市","嘉義市","金門縣","連江縣") Year<-list(Y6=year.array[,,1],Y5=year.array[,,2],Y4=year.array[,,3],Y3=year.array[,,4],Y2=ye
ar.array[,,5],Y1=year.array[,,6],Y0=year.array[,,7],Y9=year.array[,,8],Y8=year.array[, ,9],Y7=year.array[,,10]) L<-ifelse(list("Y7","Y8","Y9","Y0","Y1","Y2","Y3","Y4","Y5","Y6")%in%(YY$subjectt),T,F) # 邏輯判斷 AA <- function(L) { Year$Y6*L[10]+Year$Y5*L[9]+Year$Y4*L[8]+Year$Y3*L[7]+Year$Y2*L[6]+Year$Y1*L[5]+Year$Y0 *L[4]+Year$Y9*L[3]+Year$Y8*L[2]+Year$Y7*L[1] } #選擇年分&變數後的資料 Year.x<-AA(L)[,Ind.v$id] #流程控制 if(length(Ind.v)<=1){做 A}else{做 B} if(length(Ind.v$id)<=1){ Year.x<-Year.x[-(21:22)] qu<-quantile(Year.x) boundary<-matrix(qu);rownames(boundary)=c("Q0","Q1","Q2","Q3","Q4") boundary;Y.sum.pca.point<-Year.x*(-1) }else{ Year.x<-Year.x[-(21:22),] Y.z<-scale(Year.x,center=T,scale=T) #共變異矩陣 Y.z[is.na(Y.z)] <- 0 Y.pca<-prcomp(Y.z) Y.pca.rot<-(Y.pca$rotation)[,which(Y.pca$sdev^2>=1)] Y.pca.rot.m<-as.matrix(Y.pca.rot) #sum(pca) Y.sum.pca<-numeric(length(Ind.v$id));for(i in 0:(length(Ind.v$id)-1)){Y.sum.pca[i+1] <- sum(Y.pca.rot.m[i+1,])} #如 qwe<-matrix(c(1,2,1,2,4,3,5,1,6),3,3);ewq<-c(2,1,1);qwe*ewq Y.pca.point<-t(Y.z)*Y.sum.pca Y.sum.pca.point<-numeric(20);for(i in 0:19){Y.sum.pca.point[i+1] <- sum(Y.pca.point[,i+1])} qu<-quantile(Y.sum.pca.point) boundary<-matrix(qu);rownames(boundary)=c("Q0","Q1","Q2","Q3","Q4") boundary<-sort(boundary,decreasing=T) } return(Y.sum.pca.point)
})
output$myMap <- renderLeaflet({ city2=as.vector(unlist(buttom())) Rank=floor(rank(city2))
COUNTYENG=c("New Taipei City","Taipei City","Taoyuan City","Taichung City","Tainan City",
"Kaohsiung City","Yilan County","Hsinchu County","Miaoli County","Changhua County",
"Nantou County","Yunlin County","Chiayi County","Pingtung County","Taitung County",
"Hualien County","Penghu County","Keelung City","Hsinchu City","Chiayi City")
TWN = readOGR("COUNTY_MOI_1070516.shp", layer = "COUNTY_MOI_1070516", use_iconv = T, encoding="UTF-8") %>% spTransform(CRS("+proj=longlat +datum=WGS84"))
list<-c ("New Taipei City","Taipei City","Taoyuan City" ,"Hsinchu County", "Hsinchu City","Miaoli County" , "Taichung City","Changhua County" , "Yunlin County" ,"Chiayi City" ,"Chiayi County","Tainan City" , "Kaohsiung City","Pingtung County" ,"Taitung County","Hualien County", "Keelung City","Yilan County" ,"Nantou County","Penghu County") Rarea2<-subset(TWN, COUNTYENG %in% list)
aa=as.data.frame(cbind(COUNTYENG,(Rank))) aa[,2]=as.numeric(as.character(aa[,2])) colnames(aa)=c("COUNTYENG","Rank")
bb <-as.data.frame(read.table("Rank_YY.csv", header = TRUE, sep = ",")) cc <-as.data.frame(read.table("County_Chinese.csv", header = TRUE, sep = ",")) Rarea2@data<-left_join(Rarea2@data, aa,by=c("COUNTYENG")) Rarea2@data<-left_join(Rarea2@data, bb,by=c("Rank")) Rarea2@data<-left_join(Rarea2@data, cc,by=c("COUNTYENG")) #品質好壞比對顏色 右上角資訊比對英文拼音順序 pal=colorFactor("Reds",levels = c("1 普通","2 不良","3 危險"))
labels <- sprintf( "<strong>%s</strong> <strong>%s</strong> <br/>%g ", Rarea2@data $C_NAME, Rarea2@data$YY, Rarea2@data $Rank)%>% lapply(htmltools::HTML)
map<- Rarea2@data %>% leaflet() %>% addTiles() %>%
setView(120.9739, 23.5, zoom = 8) %>%
addLegend(pal = colorFactor("Reds",levels = c("1 普通","2 不良","3 危險")), value= c("1 普通","2 不良","3 危險"), opacity = 1,title = "危險程度")%>% addProviderTiles("Esri.WorldStreetMap",options = providerTileOptions(opacity = 0.35)) %>%
addPolygons(data=Rarea2 , fillColor = pal(Rarea2@data$YY) ,weight = 1,
smoothFactor = 0.5, opacity = 1.0, fillOpacity = 0.5,label = labels, labelOptions = labelOptions(noHide = FALSE, style = list("font-weight" = "normal",
padding = "3px 8px"), textsize = "15px"),
highlightOptions = highlightOptions(color = "white", weight = 2,bringToFront = TRUE)) return(map) }) } #側邊設計 ui=sidebar <- dashboardSidebar({ sidebarMenu(
menuItem(iconv("主程式",to="UTF-8"), tabName = "QPF_analysis0601", icon = icon("area-chart") ),
menuItem(iconv("關於",to="UTF-8"), tabName = "about", icon = icon("fa-address-book",class="fa fa-address-book") ) )}) #每個側邊設計對應的內容 ui=body <- dashboardBody({ tabItems(tabItem("QPF_analysis0601", fluidRow(column(width = 12, tabsetPanel( #左邊側欄 1--tab1 tabPanel(sliderInput("slider2",label = h3("選擇年份"), min = 97, max = 106, value = c(99,100,101,102,103),width=1048)) ) )
),
fluidRow(column(width = 10),
column(width =2,h4("變數選擇")), fluidRow(column(width = 10,
box(leafletOutput('myMap', width = "100%", height = 1087),width = NULL, solidHeader = TRUE, height = 1090)),
column(width = 2,
box(width = NULL, status = "warning", checkboxGroupInput("in1", "暴力犯罪", choices = c( "故意殺人","擄人勒贖","強盜","搶 奪","重傷害","重大恐嚇取財","強制性交"), selected = c(1, 2, 3, 4) ), checkboxGroupInput("in2", "竊盜犯罪", choices = c( "重大竊盜","普通竊盜","汽車竊盜 ","機車竊盜"), selected = c(1, 2, 3, 4) ), checkboxGroupInput("in3", "其他治安相關", choices = c( "一般傷害","一般恐嚇取財","詐欺 ","對幼性交","性侵害"), selected = c(1, 2, 3, 4) ), checkboxGroupInput("in4", "道安事故", choices = c( "車禍件數","車禍死亡人數","車禍受 傷人數","道路交通事故"), selected = c(1, 2, 3, 4) ), checkboxGroupInput("in5", "道安舉發", choices = c( "一般道路超速","飆車","違規停車 ","違規轉彎","闖紅燈","未繫安全帶","未戴安全帽","其他原因"), selected = c(1, 2, 3, 4) ),
checkboxGroupInput("in6", "酒後駕車", choices = c( "取締件數","移送法辦件數","酒後車 禍件數","酒後車禍死亡","酒後車禍受傷"), selected = c(1, 2, 3, 4) ), actionButton("zoomButton", "開始查詢") )) ) )# tabsetPanel )#tabItem )#dashboardBody }) #主架構 ui=dashboardPage( dashboardHeader(title = "危險都市"), sidebar, body )
附錄二 工作分配表
成員 負責項目
詹勳成 PCA 指令、Server 及 UI 串聯、Server 內文
王韋傑 UI、撰寫目的動機 陳港才 PCA 指令、PCA 解釋 唐秉宏 UI、撰寫資料蒐集及篩選 徐昀靖 Leaflet、地圖顯色解釋、撰寫研究成果部分 余宗憲 Leaflet、研究結論 曾少羿 UI、UI 內文
附錄三 社會責任認知與心得
姓 名 詹勳成 學 號 D0482028 社會責任認知與心得 這學期過的很快,不知不覺就到了期末,同時,專題也到了尾聲,雖然過程挺難熬的, 但回頭想想,還是覺得挺值得的。 在這專題裡,除了製作類似網站的互動式視覺化平台外,更多讓人覺得辛苦的是和同儕 之間的溝通。在談論溝通這件事之前,得先說說shiny這套件。我想,組內的成員也都是沒有 接觸過,但每個人付出多少時間、花多少心思,去了解這套件。其實,多少看得出來,尤其 每次週四要分配工作時,特別明顯。剛開始時,覺得還好,但越到後期,越不想接觸那些看 起來就沒花什麼心思在專題上的人,所以導致後來出現了一些很麻煩的問題。但是為了繼續 推前進度,我還是得解決那惱人的問題。所以,我真心感到哀怨,也覺得我有滿腹怨言,畢 竟專題是大家的,有人可以準時完成發派的任務,但有人不行,那問題究竟出在哪?後來我 把專題丟一旁,冷靜思過後,開始意識到,我是不是拿著「專題是大家的」這樣一件是情, 去強迫其他人,按時完成任務,或許強烈意識「這專題是我的」只有我而已,也造成我過分 看中結果,而沒注意他人的付出,或許下次,我該試著放寬心,與其他人溝通,也能省下那 些多餘的煩惱。 所以我說「意識到沒辦法強迫別人改變,但可以試著溝通」是在這次專題裡, 我覺得較大的收穫。而,除了這主觀上的心得外,我想另外還要談談客觀的責任問 題,在資料處理分析的過程,或許會想說刪掉什麼資料後會比較好做,但問題是, 我們要做的是互動式視覺化平台,是要給其他人使用的東西,並不是單純自己要 看,想了解而已,既然是要給及他人使用,資料處理就不能馬虎,畢竟這也算是一 種責任,別人使用我們的平台,我們就不能欺騙對方,所以我們得坐的就是盡量保 持資料的客觀以及完整程度。另外,我想也並不單純是這次專題我們需要做到而 已,在往後若一樣有繼續從事統計資料分析的相關行業,保持資料的客觀以及完整 程度,是每位資料處理者都須具備的基本責任。同樣的道理,當其他人具備這樣的 責任感,我們在使用別人處理的資料時,才能用的安心。姓 名 王韋傑 學 號 D0433036 社會責任認知與心得 在一個社會中,分別由不同政府、企業、機構及個人組成,每個角色在社會都相當重要, 我們取之於社會,用之於社會,相同的我們也應該肩負社會責任回饋社會,像是政府的社會 責任是提供好的環境給國民,企業和機構在環境社會責任是提供自然環境永續發展,當一個 企業在追求企業利潤時可能會因為生產而造成污染以及碳排放,他們的社會責任盡可能減 少碳排放、努力地減少地球的污染以及積極的去增加森林,在社會方面,企業機構應該提供 給弱勢族群更多機會在這個社會上生存下去,而現在的我們雖然只是個大學生,在社會上可 能是一個很渺小的個體,但許多個體聚集起來的力量或許可能很強大,我們現在應該把自己 照顧好,不應作奸犯科,反而產生更多社會成本讓社會照顧我們,在更進一步,我們大學期 間所學的專業運用在未來的專長領域為社會貢獻,我們所肩負的社會責任可能會因為年紀 的增長而越來越重,但相對的能為社會貢獻的能力就越來越多,我相信我現在能肩負好我自 己的社會責任,繼續地走下去。 在這次的專題報告中,從最初的迷惘到做出一份專題,讓我感受最深的就是成就感與 感動,剛開始我們的想法是做出一個能夠可以給社會一個幫助的研究,但往往找尋主題方向 時候最難,我們花最久時間是討論主題以及方向,最後我們想出可以透過一個介面查詢到台 灣的犯罪治安資料,我們覺得犯罪治安在我們生活中有著很大的影響,希望能透過這次的專 題研究,運用自己在大學所學的統計技能去做出一個有意義能以及有價值的研究成果,相對 的也可以透過這次的專題去發現自己有所學習不足的地方,讓自己有機會補足專業能力。 對我來說幾個月前當我面對專題時他就像一個陌生的東西,我對於寫程式這一方面很 不在行,可能會懷疑自己的實力是否可以完成這份專題,但透過每個禮拜的專題時間,吸收 學習到不同的資訊以及討論我們各自的想法,我從不太熟悉,到後來完全了解做出一份專 題,發現自己沒有想像中的差,驗證出只要努力就可以達成目標。
姓 名 陳港才 學 號 D0425788 社會責任認知與心得 每一家企業、個人都活在社會中,取之於社會,用之於社會,大家也應該對社會負責。 對於企業,在生產和銷售過程中注意環保事項、訂立產品合理價格、提供充足貨源、繳 交政府規定的賦稅等,對生產者、分銷商、消費者、政府和市民大眾等持分者負上社會責任。 由個人而言,以個人學識、財富和力量貢獻社會、在生活上關注環保事宜,身體力行執 行在生活各方面、履行公民應有的義務與責任,定時繳交政府規定的個人賦稅,參興選舉過 程,利用選票讓社會變得更好。 在我們學生身上也應該把社會責任背負在肩上,努力讀書把知識把握在手。編制報告和 論文時要列出所有引用的資料來源,不可以抄襲別人的知識產權,把報告完整、正確、合理 呈現發佈。 作為學生,經歷多份報告的折磨,同學們做報告都有豐富的經驗,但面對大四專題還是 十分棘手,要求事項比以前各種報告都要高,要做的分析深度也到了專業等級,媲美碩博士 學術論士和專業學術文章,這樣要求對於我們來說困難重重。 剛開始與指導老師討論時,討論了幾個星期才把主題定論好。後續就要尋找適合的資料 來分析,在台灣各處網站、資料庫都不太能尋覓到合適的資料,最後從中華民國內政部警政 署中的警政統計查詢網找到七零八落的資料,經過多日的處理才生成出完整的資料。 資料好了,接下來就要選擇分析的方法。當然我們有考慮運用線性迴歸的方法建立模型 作出分析解釋,但資料的變數之間可能有強烈的關係,因此容易造成訊息混雜,配適出來模 型的參數估計不穩定的情況。最後我們決定運用主成份分析方法為資料中不同地區作排序, 利用R軟體中的Shiny套件製作資料互動視覺化的程式,讓使用者挑選想了解的變數和年份, 再利用視覺化方法呈現結果。 在製作Shiny資料互動視覺化的程式時也遇到不少問題,例如,資料的挑選匯入、程式 排版頁面、視覺化地圖的呈現等,幸好指導老師給與我們大量的幫助,大家同心合力最後得 以完成報告,可見團隊的合作十分重要,缺少任何一位隊員的合作也令報告崩解離散。
姓 名 唐秉宏 學 號 D0482135 社會責任認知與心得 進入大學以來,已經到了第四個年頭了,經過了大一的時的統計學,大二的統計計算、 抽樣調查、統計資料分析,還有大三的數理統計、回歸分析、統計預測方法,終於到了大四, 要迎接畢業前最後的大關卡--專題。 這次的專題從上個學期分組名單出來後,我就覺得組員都讓我挺安心的,不過在我們合 作要克服專題這個大關卡時,我們就先被第一步的決定主題這個問題給卡住了,雖然每個禮 拜都有出來討論過,也各自回去查詢各自有興趣的題目,但最後決定主題也是過了好幾週 了,而下一步的蒐集資料因為網站提供的資料很完整,沒有缺東缺西的,所以整理起來比較 方便,不過因為我們需要的是十年的資料,還是讓我們花了一些時間。 這次的專題主要是要R裡面的Shiny套件所製作,由於這個東西是所有組員們都沒有碰過 的,所以裡面的許多東西都是和組員慢慢摸索,才漸漸有了進展,而在這次,我和另外2個 組員是負責裡面的UI的部分,也就是界面的呈現,剛開始是完全不知道那些code到底是在寫 些什麼,經過一條又一條的改動與嘗試,才漸漸地能清楚知道每個指令代表什麼,不過也在 其中遇過了許多麻煩,像是拉條的位置一直無法放到想要的位置,顏色也無法改成自己想要 的顏色,常常為了幾條指令就試了好幾個小時,最後還沒有辦法解決,且常常為了一個括號 就會導致東西跑不出來,因此每條指令都需檢查再檢查。 最後終於我們做出了一個互動式介面,能夠讓使用者勾選在意的變數,就可以將複雜的 資料,經過統計運算,為台灣各個縣市做出排名,並在台灣地圖上顯示,讓他們能夠清楚的 知道哪些縣市的犯罪率比較低,更適合去居住。 在這次的專題中,我學習的到了團隊合作,其中經過了無數討論,有爭吵,也有歡笑, 甚至也曾考慮要不要換主題,最後還是排除萬難,大家一起同心協力做出了一個成果,也是 為了我們大學這四年做了一個紀念,不過在這次過程中也發現了許多自己還缺乏的部份,了 解到了學習之路還遙遙無期,我想這次的經驗,對於之後在職場上,和同事之間的溝通,也 一定都會有幫助的。
姓 名 徐昀靖 學 號 D0597309 社會責任認知與心得 起先想當初從會計系轉進來統計系也只是個莫名其妙的插曲,對統計的認知就只是數 學算算平均數,但後來才發現,統計其實遠比想像的還要複雜,資料蒐集要做整理,整理完 要選擇要用的統計方法,做完的分析又要能言之有物,每一步驟都需要合理的解釋,而在修 習數理統計學時,又發現有各式各樣的分配要去瞭解,甚至還需要學會用R來做統計計算, 學的東西很多,但必須要會把每個科目做結合來使用,這次的統計專題就是一個很好考驗自 己歷年來學習的成果。 此次統計專題我們利用R裡Shiny的套件和Leaflet來做視覺化的互動式網頁,一開始想到 要做網頁一方面是興奮,另一方面是懼怕自己的能力不夠,無法做出個結果,所以自己私下 多找了有關於Shiny和Leaflet這兩個套件的使用範例,看到網路上形形色色、各式各樣的範 例,其實心中甚是佩服,有可以做出密集度表現方式、區域表現方式…能提供我們來參考。 一路上的討論都挺順遂的進行,資料的彙整、程式語言的編碼、報告的文字敘述或口述報告 的流程,大家都提供了各種想法,即便反覆的修改與修改,都是為了呈現出更好的報告。即 使順遂,但難免會遇到困難的時候,在這裡由衷地感謝組員們的互相幫忙,在我想破腦也沒 有法子的時候,能夠伸出援手,拉我一把,讓我能夠面對問題並且解決它。 總的來說,學到最多的其實是團隊之間的溝通,平常修課都是在靠個人,成績好壞都是 自己取捨,付出的多相對獲得的多,但團隊的能力並不是把每個人的個人能力做加總,而是 讓每個人能發揮他最大的功用,來讓團隊達到最大的效用,其中最重要的因素就是溝通,我 是一個說話有時候心直口快的人,有時候當下沒顧慮太多就脫口,出口後才發現自己可能無 心傷害到別人,但感謝組員的海涵以及不棄嫌,真是有一群很棒的組員。 最後說說大學幾年來的心得,其實我從一開始就很清楚自己未來不會走會計相關或統 計相關的科目,但如果要說這幾年是白費的,我完全不這麼認為,畢竟我學到很多專業科目 上的學識,而若要真說未來想做什麼,改革教育是我的理想目標,我也正往這條道路上努力。