條件評估法中抗議性答覆之處理
吳珮瑛*
台灣大學農業經濟學系
鄭琬方
**台灣大學農業經濟學系
蘇明達
***中國技術學院企業管理系
關鍵詞:開放雙界二元選擇方式、雙檻式模型、標準 Tobit 模型、支出差異、願意 支付額度、國家公園 JEL 分類代號:Q26, D12, C24 * 聯繫作者:吳珮瑛,台灣大學農業經濟學系教授,106 台北市羅斯福路四段 1 號, 電話:(02) 3366-2663,傳真:(02) 2363-5995,Email: [email protected]。本 文承國科會補助(計畫編號:NSC 90-2415-H-002-024),謹誌謝忱。感謝二位 審查人的意見,使本文修正得更臻完善。 ** 台灣大學農業經濟學系研究助理。 *** 中國技術學院企業管理系助理教授。農業與經濟 (Agriculture and Economics), 32 (2004), 29-69 台大農業經濟學系出版
摘 要
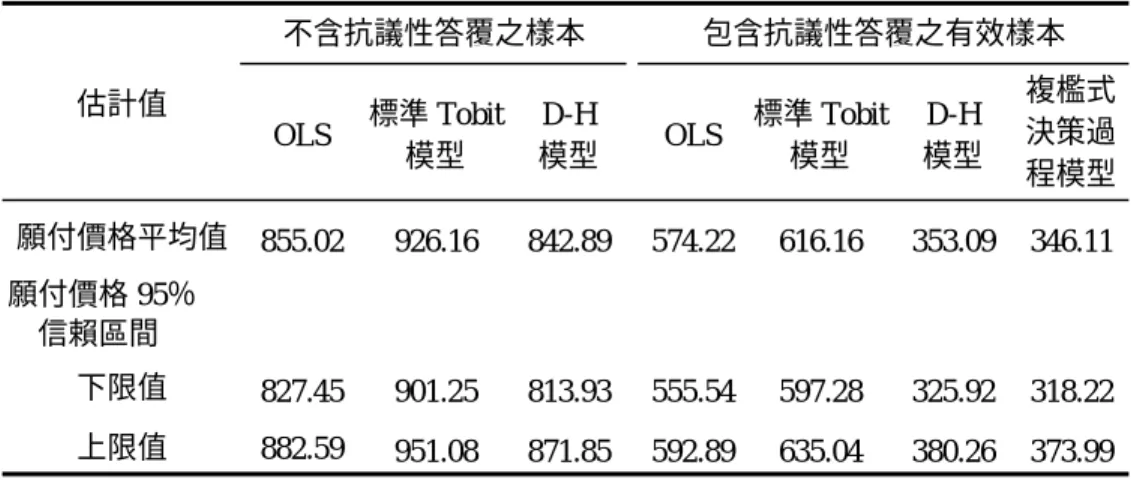
本研究所設計的「複檻式決策過程模型」(multiple-hurdle with decision process model),是一個可以分析有經過明顯的選擇過程而後顯示最後 支付金額的消費決策資料。由於此一模式對選擇決策過程的考量,同時 對零支付樣本觀察值的豐富解釋能力,因而得以處理條件評估法中的抗 議性答覆樣本。以支出差異詮釋利用開放雙界二元選擇誘導支付方式收 集到的資料,同時以墾丁國家公園資源經濟價值的調查資料進行實證檢 驗。 結果顯示,複檻式決策過程模型因納入明顯選擇決策過程,因此,雙檻 式模型(double-hurdle model)與標準 Tobit 模型具估計有效性,此外, 亦更能詳細判別與解釋抗議性樣本觀察值的社會經濟特徵屬性,對不同 決策過程之影響。同時,結果亦顯示雙檻式模型對零觀察值之解釋能力 明顯優於標準 Tobit 模型,而本研究所建構的複檻式決策過程模型,對 於分析具有大量零觀察值之抗議性答覆的樣本,則具有較雙檻式模型更 佳之解釋能力,同時,也更能有效估計、分析開放雙界二元選擇條件評 估方法收集來之資料。故而,以複檻式決策過程模型計算所得到平均每 戶每年願意支付 346 元,及其對應的平均值 95%信賴區間之上下限值, 應該是可信度相對較高的數值。
1. 前言
一般經由調查所獲得的家計消費支出資料,在假設受訪者不會顯示負值 支付額度的情況下,最小樣本觀察值均設限於零。因此,當所觀察到的消費 支出樣本中,有很高的比例為受限於零之觀察值時,樣本將明顯地不服從常 態分配,此時若沿用一般迴歸模型進行分析,勢必會引起估計結果之偏誤與 不一致性。因此,在消費支出調查之研究,針對有許多零觀察值樣本之處理 方式,多採用能夠分析受限資料(censored data)之受限應變數(limited dependent variables)模型,其中最被為廣泛使用的是 Tobit 模型(Tobin, 1958)。 Tobit 模型基本上是假設所有的受訪家計單位都願意參與消費,因此對 於零觀察值的解釋有兩種,一為真正的零支出與另一類非正值的消費支出, 亦即將所有的零觀察值均視為角解(corner solution)。然而,Cragg(1971) 認為零觀察值的由來,除了可能是角解之外,也有可能是受訪者對該財貨的 需求為零,也就是受訪者選擇不參與該消費行為。因此,Cragg(1971)乃 延伸 Tobit 模型,發展出雙檻式模型1 (double-hurdle model),簡稱為 D-H 模型。該模型認為一個消費決策是由「決定是否參與消費」與「決定支付多 少金額」兩個階段結合而來,唯有在兩個決定同時確立的情況下,才會構成 一個完整的消費支出決策。 進而,根據 Blackwell、Miniard 與 Engel(2001)對消費行為的定義認為, 消費行為是人們為獲取並使用財貨所直接參與的行為,包括在行為之前決定 此行為的種種決策程序。由此觀之,D-H 模型較 Tobit 模型更合乎消費者之1 過去對於 double-hurdle 模型之中文譯名,尚有複檻式模型(Chi, Luzar & Hill,
1999)與複欄式模型(陳麗婷,1996)。但是,對於 double-hurdle 模型之原文 名稱明顯有「雙」的意思,因此,將其翻譯成複檻式或複欄式之名稱,並無法確 切使該模型之欄數或是檻數(hurdles)一目了然。此外,為了使本研究後續所建 構的複檻式決策過程模型,能更貼切反應是一種比兩個檻數更多的模型,因此, 本研究乃將文獻上之「double-hurdle model」之中文名稱譯為「雙檻式模型」。
購買行為模式。事實上,許多文獻也已證實 D-H 模型較 Tobit 模型,對消費 行為結果的解釋更具一致性(Demoussis & Mihalopoulos,2001;Nichola, 1996;Jones,1992;Reynolds,1990)。
此 種 對 消 費 者 決 策 行 為 的 兩 階 段 解 釋 , 使 我 們 聯 想 到 條 件 評 估 法 (contingent valuation method,CVM)中,一些透過特定誘導支付方式收集 來 之 資 料 的 解 釋 與 分 析 。 其 中 , 開 放 雙 界 二 元 選 擇 ( double-bounded dichotomous choice with open-ended follow-up)模式是一種結合雙重二元選擇 與開放之詢問方式,使受訪者得以藉由經驗之累積或學習而反應出其心中的 願意支付(willingness to pay,WTP)或願意接受(willingness to accept,WTA) 額度,實證結果顯示,利用此種誘導支付方式估算所得到的 WTP,比只採用 二元選擇式之結果更具有效性(Wu & Su,2002)。
分析開放雙界二元選擇決策過程所獲得的 WTP 或 WTA 觀察值,一般多 直接採用受訪者最後所顯示的 WTP 或 WTA 做迴歸,其形式有如開放式條件 評估法的分析方式。然而在開放雙界二元選擇之決策過程中,事實上是牽涉 到兩種行為模式,也就是受訪者先決定是否選擇願意支付所給定之受訪金 額,之後再依其決定,回答最高的 WTP 或 WTA,倘若只利用一般迴歸式或 Tobit 模型分析最後所觀察到的 WTP 或 WTA,勢必忽略了受訪者在回答「決 定支付多少金額」前,對特定金額「決定是否參與消費」之選擇決定,也就 是視受訪者猶如在一開始即做了最後「決定支付多少金額」的決定。 而設計開放雙界二元選擇模式之原始出發點,即為藉由模仿一般消費購 物行為,由多重的選擇過程中提供受訪者較多訊息,以協助受訪者顯示出最 後的 WTP 或 WTA。因此,和 Blackwell、Miniard 與 Engel(2001)對消費 行為的解釋相同,亦即消費者何以會選擇購買特定財貨某些的數量,也就是 受訪者何以會於最後顯示特定的 WTP 或 WTA,其合理的決策過程應該由「決 定是否願意參與支付」與「決定支付多少金額」兩個階段所構成。而這種考 量階段式的決策過程,我們發現開放雙界二元選擇模式與 D-H 模型的概念不 謀而合。 D-H 模型除了與開放雙界二元選擇模式的概念不謀而合之外,由於 D-H 模型對於消費者最後所顯示的零支出之值有特別的處理,這又使我們進一步
聯想到在 CVM 的調查中,往往會有許多零觀察值出現。一般將這些出現在 CVM 調查中的零觀察值,分為真正的零(real zero)觀察值與抗議性零(protest zero)觀察值。所謂抗議性的零觀察值是指,受訪者未對受訪議題顯示其心 中真正的 WTP 或 WTA,而並非該資源對該受訪者沒有效益。因此,對於有 抗議性答覆之零觀察值的 CVM 資料,慣例的處理方式是先將抗議性答覆樣 本刪除,再對剩下被視為合理觀察值之非抗議性答覆樣本進行分析。但刪除 大量抗議性樣本,不但將縮小原樣本規模,更有可能因為蓄意選擇非抗議性 樣本而產生抽樣偏差(sampling bias),故只分析所謂的合理觀察值對最後 估計結果將有高估的傾向。因而,近年來對於抗議性樣本的處理方式已逐漸 引起爭議(Eulàlia,2001;Jorgensen et al.,2000;Jorgensen & Syme,2000; Kotchen & Reiling,2000)。
由前述消費行為的角度來分析 CVM 調查中的零觀察值,所謂的抗議性 零觀察值,可能是來自受訪者決定不參與支付而產生的,也就是受訪者在「決 定是否願意參與支付」與「決定支付多少金額」之兩階段決策過程中,不論 該受訪者心中願意支付多少金額,即使其心中所決定願意支付金額為正值, 但因為某些因素而導致該受訪者決定不參與支出,因此我們所觀察到該受訪 者最後所做出的消費支出決策為零支出,於是產生了 CVM 調查中的抗議性 零觀察值。 由此觀之,以 CVM 調查得到包含抗議性樣本之資料即可視為受限資 料。因此,我們可以藉由 D-H 模型對零樣本觀察值豐富的解釋能力,將利用 開放雙界二元選擇模式之 CVM 調查資料,藉用 D-H 模型之兩階段消費決策 概念來分析。過去,Eulàlia(2001)曾採用開放單界二元選擇(single-bounded dichotomous choice with open-ended follow-up)模式,將包含抗議性樣本之 CVM 調查資料直接取用受訪者最後所顯示的 WTP 金額,以 Tobit 與 D-H 模 型進行比較分析。 雖然 Eulàlia(2001)已證實在採用開放單界二元選擇模式下之 CVM 調 查資料中,使用 D-H 模型會較 Tobit 模型對於消費行為更具一致性的解釋能 力。然而,對於這種結合選擇與開放的誘導支付模式,因為受訪者是透過明 顯的決策過程表示出其選擇行為,亦即受訪者是經過一個明顯的選擇詢問過
程才顯示出最後的結果,此與 D-H 模型只將消費者最後顯示出之結果,詮釋 為「決定是否參與消費」與「決定支付多少金額」兩種行為之合併是有所不 同的。故而,直接將 D-H 模型應用於此種有明顯選擇過程之開放雙界二元選 擇模式並不合理。 職是之故,本文將設計一個可以考量消費者明顯所顯示之選擇過程與最 後結果之多檻(hurdle)式模型,這是一個結合二次外顯的選擇與雙檻式支 出的三檻式決策模型,稱之為「複檻式決策過程模型」(multiple-hurdle with decision process model)。同時,本文將以支出差異來詮釋開放雙界二元選擇 模式下所得到的資料,同時將包含抗議性樣本資料,帶入本文所建構的複檻 式決策過程模型,以檢驗利用此一模型分析包含抗議性樣本資料,所得到的 結果將比利用標準 Tobit 及 D-H 模型,對消費行為有更合理的解釋。此外, 以支出差異為詮釋不僅更明確轉化了 Tobit、D-H 與複檻式決策過程模型架 構之基礎,同時也對 Eulàlia(2001)以效用差異為詮釋,然卻將實證模型設 定為支出差異的不一致進行修正。最後,本文亦將有無包含抗議性答覆兩組 樣本,分別帶入 OLS、標準 Tobit 與 D-H 模型中進行分析,以比較有無保留 抗議性答覆所造成各項估計結果之差異。
2. 以支出差異詮釋開放雙界二元選擇資料
開放雙界二元選擇詢價是一種結合開放式(open-ended)與雙界二元選 擇(double-bounded dichotomous choice)而來的誘導支付模式,對受訪者而 言,選擇式的答覆不僅較為簡易,此一模型不但擷取了雙界二元選擇誘導支 付方式較單界二元選擇有效率的優勢,又可避免受訪者在面對開放式時無從 填答之困擾(吳珮瑛、蘇明達,2001)。除此之外,過去的研究亦顯示,此 種選擇與開放混合的誘導支付方式,在係數估計結果與效益的估算上,比單 純選擇式的誘導支付方式更具有效性(Wu & Su,2002)。而開放雙界二元選擇的詢問方式是,提供第一階段的願付價值
A
i詢問受訪者i
是否願意參與 支付,接續以更高或更低之的金額 U iA
或 L iA
作為第二階段的詢問金額,最後,在第三階段時則誘導受訪者自行填寫一最適的願付價值
Y
i ,其決策過程 如圖 1 所示。 圖 1 受訪者顯示願意支付額度之決策過程 自從 Bishop 與 Heberlein(1979)首次應用封閉式二元選擇誘導支付方 式以來,對於如何解釋受訪者對這類誘導支付方式之答覆即引發了爭議。 Hanemann(1984)認為對於受訪者之選擇應賦予效用差異之解釋,亦即受訪 者是在比較不同狀況下的效用與滿足程度後所做的決定,其處理方式是以間 接效用函數之差做為反應函數;而 Cameron(1988)則認為應賦予支出差異 之解釋,也就是受訪者將問卷中所提供的金額與其心中之 WTP 或 WTA 相互 比較後所做的抉擇,其處理方式是以支出函數之差做為反應函數。 McConnell(1990)由理論與實證上證明並驗證,其實效用差異與支出 差異是互為對偶性的(duality),因此不論是由間接效用函數或支出函數的 形式來解釋受訪者之選擇,在所得邊際效用固定,且函數之隨機項為零之條 件下,理論上應可得到相同的結果。然而,一般而言,所得的邊際效用並不 i A $ L i A $ $AUi 不願意 願意 第一階段 第二階段 第三階段 不願意 願意 不願意 願意 (甲) (乙) (丙) (丁) $是固定的,而且函數的隨機項也不會為零,因此,兩種反應函數設定下所得 到的結果並不會相同,Wu 與 Hsieh(1996)乃確立了此兩種解釋在不同模型 與多種函數形式設定下估計結果之異同,該研究認為支出函數法較間接效用 函數法簡易、可行且結果也較完整。 而自 Hanemann、Loomis 與 Kanninen(1991)將單界二元選擇擴展為雙 界二元選擇後,仍以效用差異來解釋試受訪者面對兩次價格詢問的答覆,並 驗證雙界二元選擇比單界二元選擇之估計結果更具有效性;在 Cameron 與 Quiggin(1994)延續以支出差異做為受訪者決定的詮釋後,吳珮瑛與吳巽庚 (2001)則同時以效用差異與支出差異之詮釋,將受訪者兩次答覆所產生的 四種可能選擇納入實證估計中,以資料驗證由雙界二元選擇所獲得之估計結 果的效率性較單界選擇為佳,同時歸納出以支出差異做為詮釋較效用差異有 實證上的可行性、簡便性與一致性。 在環境惡化與資源受破壞的情形下,在特定的環境品質
Q
之下,假設受 訪者i
之效用水準欲維持在U
i,又如果其所得為y
i,個人之性別、年齡與教 育程度等所有其他社經變數組成之向量為X ,則受訪者ii
之效用函數可表示 為Ui(
Q,yi;Xi)
。若該資源當前的水準為 0Q
,遭受破壞後的水準降為Q
−, 則當資源品質為 0Q
時,受訪者之效用水準為U
i,其支出為 0 iE
;當品質降低 為Q
−時,受訪者欲維持U
i效用水準之支出水準為E
i−,則 0 iE
與E
i−可分別設 定為(
)
[
0 0]
0 0 0 ; , , i i i i i i y Q U Q y X E = − +ε (1)(
)
[
− −]
− − − = + i i i i i i y Q U Q y X E , , 0; ε (2) (1)與(2)兩式中的y
i0()
⋅
及()
⋅
− iy
表示可以確定的部分,而 0 iε
與ε
i−為隨機誤 差項,假設兩者是互為獨立且期望值為零之機率密度函數(probability density function)。受訪者根據其在(1)與(2)式中,兩種不同狀況下所得到之效用水 準來決定是否願意支付受訪金額。在兩種不同環境品質水準 0Q
與Q
−相較之 下,為維持效用水準於U
i,則其支出水準之差,就相當於受訪者i
心中的願 付金額Y
i*,即* 0 i i i
E
Y
E
−−
=
(3) 換言之,受訪者最高願意支付 * iY
以避免該環境資源惡化。假設受訪者在 選擇式的支付模式中面對一給定的受訪金額A ,並被要求決定是否接受支付i 該金額以避免品質降低至Q
−。若受訪者同意接受支付該金額,則必然是因 為此一金額A
i小於或等於受訪者維持其效用於Ui(
Q−,yi0;Xi)
時,其心中最 高之 WTP 金額Y
i*,即當 i i iE
A
E
−−
0≥
(4) 也就是當()
i i()
i i iy
A
y
−⋅
+
ε
−−
0⋅
−
ε
0≥
(5) 在(5)的情況下,受訪者將回答「願意」支付A
i金額;反之,當受訪金額A
i 大於其心中最高之 WTP 金額 * iY
時,則該受訪者將回答「不願意」。經過第 一階段的詢問後,接續詢問受訪者是否願意接受一個比A
i更高的受訪金額 U iA
或一個比A
i更低的受訪金額 L iA
。 Cameron 與 Quiggin(1994)認為受訪者心中之 WTP 額度會因為第二階 段受訪金額之出現而有所調整,亦即他們認為受訪者在第二階段面對受訪金 額 U iA
或 L iA
時,與之對照或比較的並不是該受訪者心中原來之 WTP。但事 實上,受訪者是否會因為面對第二次受訪金額而調整其心中之 WTP 並不重 要,因為受訪者在經過兩次的選擇後,最後所顯示的結果必定分別屬於由 L iA
、A
i與 U iA
四個金額所形成的四種組合中的一種,而此四種選擇組合已考 慮了第一階段與第二階段之所有訊息,所以其最後所顯示的結果,即是受訪 者在接受一連串訊息後之經驗累積的一個反應(Wu & Su,2002)。因此,我們假設受訪者
i
認定其心中之 WTP 金額 * iY
並不會因為第二個 金額的出現而有所改變,即受訪者將仍把其在第二階段所面對的受訪金額 U iA
或 L iA
,與其心中之 WTP 金額 * iY
進行比較對照。此時,若受訪者回答「不 願 意 」 接 受 支 付 第 二 階 段 所 提 供 之 受 訪 金 額 , 則 必 定 是 因 為 U i iA
Y
*<
或 L i iA
Y
*<
。相對的,若受訪者回答「願意」接受支付第二階段所提供之受訪金額,必然是因為 U i i
A
Y
*>
或 L i iA
Y
*>
。 開放雙界二元選擇模式,即在經過第一階段與第二階段的詢問過程後, 受訪者對於其心中的 WTP 額度將會有較清楚的輪廓,因此進而要求受訪者 於第三階段自行填答其最高之 WTP 金額 * iY
,而此一金額即為經由開放雙界 二元選擇模式所誘導出的最高願意支付額度。如果進一步假設Y
i*是受一系列 變數X
之影響,即受訪者i
心中的 WTP 金額 * iY
之數值大小是由β
X
i加上隨 機誤差項ε
i所決定,則可表示為 i i iX
Y
*=
β +
ε
(6) (6)式中β
X
i=
y
i−()
⋅
−
y
i0()
⋅
且 0 i i iε
ε
ε
=
−−
,其中β
為待估計係數。若欲分 析各種解釋變數X
i,對受訪者最後所顯現之 WTP 額度 * iY
的影響,一般多直 接取用受訪者於第三階段所回答的 * iY
做分析,此種做法則有如對開放式條件 評估資料之分析。此時,因將受訪者的願意支付額度 * iY
之下限值設於零,故 一般多採用可以分析受限資料之受限應變數模型來進行分析,其中 Tobit 模 型是最廣為應用的受限應變數模型。3. 複檻式決策過程模型之建構
3.1 標準 Tobit 模型
Tobin(1958)觀察到在家計單位的消費支出調查中,由於受限觀察值 的影響,特別是在耐久財的消費支出調查方面,大多數的家計單位在特定的 時間內,對於汽車或冰箱等主要的家用耐久財之消費通常都是零支出,因此 常會出現大量的零觀察值,而這種現象破壞了線性(linearity)的假設,以 致於最小平方法並不適用於這類資料。 在分析受限應變數與其他解釋變數間的關係時,對於受限觀察值有特殊 的處理方式。在此種關係下,解釋變數也許只是被用來說明受限反應機率與 非受限反應機率之大小。自 1958 到 1970 年,Tobit 模型很少用於經濟實證,直至 1970 年後才大量出現。因為由 Tobit 模型變化而來之其他模型與估計方 法太多,且相似的概似函數會引伸出類似的估計方式,也就是兩個看似很不 相同的模型,其實是同一類型的。Amemiya(1984)曾歸納文獻中之研究發 現,百分之九十五應用 Tobit 模型之經濟實證,依據概似函數型態的不同可 區分為五種類型。因此,由 Tobin(1958)所創造之最原始的 Tobit 模型,就 被稱之為標準 Tobit 模型(standard Tobit model)。
標準 Tobit 模型早期多用於耐久財之消費分析,近年來應用的領域則欲 趨廣泛,如 Moore et al.(2000)估計哥倫比亞河流域鮭魚生產者剩餘,Duquette (1999)估計租稅補貼的價格彈性。此外,也有許多環境資源財貨之研究採 用標準 Tobit 模型,如 Pruckner(1995)用於衡量奧地利的農業景觀;Boyle et al.(1996)衡量美國獵麋許可證的價值;Alvarez-Farizo et al.(1999)分 析英 國 蘇格 蘭 地 區因 劃 定 環境 敏 感 地區 之 非市 場 效 益; 吳 珮 瑛與 蘇 明 達 (2001)則用於評估墾丁國家公園的資源經濟價值等。 在開放雙界二元選擇的 CVM 調查資料中,也往往會出現許多零觀察 值,但這些受限於零的觀察值,並不一定表示該受訪者心中的 WTP 為零, 也就是受訪者在圖 1 第三階段中所填寫的 WTP 金額 * i
Y
若為零,則該零觀察 值可能為真的零,也可能是抗議性零。標準 Tobit 模型對於這些零觀察值都 予以角解之解釋,即標準 Tobit 模型將所有的受訪者都視為對該環境資源財 貨有需求,並假設受訪者i
心中願意支付 * iY
以避免該環境資源惡化,其函數 形式與(6)式相同。假設受訪樣本數共有 n 個,誤差項ε
i的平均值為零,變異 數為σ
2 ,並符合獨立常態分配,亦即)
,
0
(
~
σ
2ε
iN
i = 1,…,n (7) 當Y
i*大於零時,受訪者i
所回答的願付價值Y
iT會等於其心中的願付價 值 * iY
,即我們可以觀察到該受訪者心中的實際願付 WTP;倘若受訪者i
心中 的願付價值 * iY
小於或等於零,則受訪者i
所回答的願付價值 T iY
,將全部表示 為最小的金額下限值零,也就是我們所得到的零觀察值,可能為真正的零, 也有可能為心中實際願付金額為負值的零觀察值,即0
0
0
* * *
≤
>
=
i i i T iY
Y
Y
Y
當
當
(8) 在(8)式之設定下,當受訪者i
回答的願付價值 T iY
大於零時,其樣本的機率密度函數(probability density function)可表示為
(
)
(
)
−
=
>
>
σ
β
φ
σ
X
Y
Y
Y
f
Y
ob
T i i T i T i T i1
0
0
Pr
(9) (9)式中φ
i為標準常態的機率密度函數。而當觀察值受限於零時,其連續隨機變數(continuous random variable)之函數形式並不屬於機率密度函數,因此 零 觀 察 值 之 機 率 分 配 應 視 為 累 積 分 配 函 數 ( cumulative distribution function)。即當受訪者
i
回答的願付價值 T iY
等於零時,其心中之願付價值 * iY
可能為零也可能小於零,則樣本機率函數可表示為(
)
(
)
Φ
−
=
≤
=
=
σ
β
i i i T iX
Y
ob
Y
ob
0
Pr
0
1
Pr
* (10) (10)式中Φ
i為標準常態的累積分配函數。利用(9)與(10)兩個機率函數,可以 導出標準 Tobit 模型的概似函數為∏
∏
> =
−
⋅
Φ
−
=
0 01
1
T i T i Y i T i i Y i iX
Y
X
L
σ
β
φ
σ
σ
β
(11) 在 CVM 調查資料之分析中,對於樣本觀察值慣例的處理方式是,先將 抗議性零觀察值一律從總樣本中刪除,再將其餘不含抗議性答覆之樣本帶入 標準 Tobit 模型中進行分析。但是,在將所有抗議性樣本刪除的同時,勢必 也將心中實際願付金額為負值之抗議性零觀察值也一起刪除了。因此,刪除 大量的抗議性零觀察值,可能會造成抽樣偏差,而使平均效益值有高估之疑 慮。為了要避免抽樣偏差問題之產生,應將 CVM 調查所獲得的全部觀察值 一律帶入標準 Tobit 模型中分析。進而,為計算以標準 Tobit 模型估計而來的 WTP 之平均效益點估計值,是以每個觀察點預測所得之願付價值而後求其平均,做為平均效益的點估計量,算式如(12)式。至於平均效益區間估計值之 計算方式,如(13)式所示
( )
( )
n
Y
E
Y
E
n i i∑
==
1 * * (12)( )
[ ]
N
S
t
Y
E
Y
E
CI
2 2 * * 1−α=
(
)
±
α (13) 式中S
為所有樣本點預測願付價格的標準差。 標準 Tobit 模型只是數種可以用來模擬消費行為的受限應變數迴歸模型 中的一種,此後,多種 Tobit 模型則被發展與修改,且應用於各種不同的問 題。當消費為非正值時,標準 Tobit 模型將此種觀察值假設為零支出,也就 是應變數在零時一律被視為角解。而其他依據標準 Tobit 模型所發展出的受 限應變數模型,與標準 Tobit 模型最大的差異是,後來的受限應變數模型放 寬了對 零觀 察值 的解 釋。 這些 改良自 標準 Tobit 模 型之 雙變 數決 策模 型 (bivariate decision models)的基本特性是,這些模型模擬合理的消費行為, 認為零觀察值之發生是一個決定不參與支出決策下的產物,此種解釋放寬了 標準 Tobit 模型中視零需求與角解是相等的假設。在這種允許零觀察值可能 來自零需求或角解的情況下,Cragg(1971)所發展出的 D-H 模型是最常被 應用的。 儘管過去的實證顯示,標準 Tobit 模型對家計基本消費行為之假設可能 是錯誤的,但是過去許多文獻仍是應用標準 Tobit 模型來進行分析,而忽略 了其他可以更合理解釋消費行為之迴歸模型。而且標準 Tobit 模型對於零觀 察值之解釋極其有限,因此選擇能對零觀察值有進一步解釋,且較標準 Tobit 模型符合實際消費行為模式的 D-H 模型,方得以分析有大量零觀察值之 CVM 調查資料。3.2 標準雙檻式模型
3.2.1 完整消費支出決策過程
Cragg(1971)認為家計單位也許渴望購買一些財貨,但基於某些因素, 如尋找、訊息與運輸成本等,而打消了購買該財貨的念頭。例如 Andrew 與 Yen(2000)分析豬肉之消費,認為某些受訪者可能是因為宗教信仰、素食 主義或健康理由而決定不消費豬肉,並不一定是因為該受訪者買不起豬肉; 但也有可能是該受訪者有意願要消費豬肉,卻因為沒有錢或市場上缺貨而買 不成豬肉,亦即想買而買不到或是買不到預期的數量。換言之,零支出對於 這些消費者而言並不可以完全被解釋為角解,也就是我們不可以假設相對價 格與所得的大幅度變動,會促使對該項商品沒有需求之受訪者去購買。 因此,Cragg(1971)在 Tobit 模型中引入一個賦有彈性之決定參數,並 將此改良後的模型稱之為雙檻式模型。Gao、Wailes 與 Cramer(1995)指出, 雙檻式模型其實就是將 Tobit 模型一般化(generalize)。為與後來所衍生出 的各種一般化雙檻式模型(generalized double-hurdle model)有所區分,一般 多 將 Cragg( 1971) 所 創 造 之 D-H 模 型 稱 為 標 準 雙 檻 式 模 型 ( standard double-hurdle model)或互為獨立之雙檻式模型(double-hurdle model with independence),Burton,Dorsett 與 Young(1996)則將此稱為互為獨立之 標準雙檻式模型(standard double-hurdle model with independence)。
過 去 雙 檻 式 模 型 多 應 用 於 市 場 財 貨 消 費 方 面 之 研 究 , 如 Reynolds (1990)分析新鮮蔬菜的消費、Jones(1992)分析煙草的消費、Yen 與 Huang (1996)分析鰭魚之家計需求、陳麗婷(1996)分析有機蔬菜願付價值與消 費決策、Yen 與 Jones(1997)則用於分析乳酪的消費。近年來,亦漸應用 於非市場財貨方面之研究,如 Lee 與 Kim(1999)分析老人的旅遊相關支出 模式、Eulàlia(2001)分析當日往返之外科手術的價值。 Cragg(1971)所建立的雙檻式模型是標準 Tobit 模型之延伸,該模型的 主要估計步驟為先使用 Probit 模型估計參與支出的機率,再應用標準 Tobit 模型中的受限迴歸分析來估計支出水準(Blundell & Meghir,1987)。因為 Cragg(1971)認為觀察到的資料雖具有受限性質,但資料的受限條件並非 如標準 Tobit 模型只是根據「決定支出多少金額」之應變數值 * i
Y
,應同時還 依據另一個影響支出決策之「決定是否參與支出」應變數D
i來設限。 也就是一個消費決策是由「決定是否參與消費」與「決定支付多少金額」兩個步驟結合而來,唯有在兩個決定同時確立的情況下,才會構成一個完整 的消費支出決策,如圖 2 所示。當受訪者被詢問其所願意支付之金額時,該 受訪者心中之願付金額
Y
i*可能為正值,亦有可能為負值或等於零之值;當 * iY
小於或等於零時,不論該受訪者願不願意參與支出,其所回答之願付金額 D iY
必為受限於零之觀察值;同理,即使Y
i*大於零,除非該受訪者決定願意 參與支出,否則我們將無法觀察到其心中真正的願付金額 * iY
。 $ ________ 不願意 願意D
i= 0D
i= 1Y
i*≤
0Y
i*> 0Y
i*≤
0Y
i*> 0Y
iD= 0Y
iD= 0Y
iD= 0Y
iD=Y
i* 圖 2 完整消費支出決策之形成 由此可知,受訪者「決定是否參與支出」與「決定支出多少金額」應為 兩個不同的行為,因此,D-H 模型乃設立兩個方程式以代表完整之消費決策 行 為 , 其 中 之 一 是 用 來 決 定 是 否 參 與 支 出 之 參 與 方 程 式 ( participation function ) , 另 一 個 則 用 來 決 定 支 出 多 少 金 額 之 支 出 方 程 式 ( expenditure function)。3.2.2 標準雙檻式決策資料之分析
假設D
i為「決定是否參與支付」之虛擬變數,當D
i等於 1 時表示願意 參與支付,α
為待估測的參數係數,Z
i為影響參與決定之解釋變數,υ
i為常 態獨立分配之誤差項,其他變數之假設與標準 Tobit 模型相同。假設誤差項i
υ
的平均值為零,變異數為 1,且符合獨立常態分配。在兩個檻(hurdle) 的誤差項彼此是獨立的假設下,此種決策模式可以兩條行為方程式表示為( )
0
,
1
~ N
Z
D
i=
α +
iυ
iυ
i(
)
i
n
N
X
Y
i*=
β
i+
ε
iε
i~
0
,
σ
2=
1
,...,
(14) (14)式中之第一個檻,即為前述之參與方程式,第二檻則為支出方程式, 只有當受訪者i
之參與變數D
i等於 1,且心中的願付價值Y
i*大於零時,該受 訪者回答之願付價值 D iY
將等於其心中實際 WTP 金額 * iY
;而在其他情況下, 無論受訪者i
心中真正的願付價值 * iY
是正或負值,我們觀察到的願付價值 D iY
均為零,即0
0
1
* *
=
>
=
其他情況
且
當
i i i D iY
D
Y
Y
(15) 結合(14)式與(15)式,將可產生四種消費決策組合,如表 1 所示。 表 1 兩種決定下所組成之各種消費決策 決定支出多少金額 決定是否參與支付 支出0
*>
iY
不支出0
*≤
iY
願意1
=
iD
D iY
=Y
i*> 0Y
iD= 0 不願意0
=
iD
D iY
= 0Y
iD= 0 資料來源:本研究整理。 利用(14)式與(15)之決策模型設定,當受訪者i
回答的願付價值 D iY
大於 零時,其樣本的機率函數可表示為(
=
)
(
>
)
>
=
Φ
( )
−
σ
β
φ
σ
α
i D i i i i D i D i D i iX
Y
Z
Y
Y
f
Y
ob
D
ob
1
Pr
0
(
|
0
)
1
Pr
(16) 當受訪者i
回答的願付價值 D iY
等於零時,其樣本機率函數表示成(
)
( )
Φ
Φ
−
=
=
σ
β
α
i i i i D iX
Z
Y
ob
0
1
Pr
(17) 利用(16)式與(17)式兩個機率函數,可以導出 D-H 模型的概似函數為( )
∏
( )
∏
> =
−
Φ
⋅
Φ
Φ
−
=
0 01
1
D i D i Y i D i i i i Y i i i iX
Y
Z
X
Z
L
σ
β
φ
σ
α
σ
β
α
(18) 此時,受訪者願付價值之平均值與區間估計值的計算方式,與標準 Tobit 模 型所採用的計算方式相同,如(12)式與(13)式所示。 在標準 Tobit 模型中是以相同的應變數,來解釋是否參與支出及支出多 少之決策,而在 D-H 模型則允許不同組的解釋變數分別存在於,「決定是否 參與消費」與「決定支付多少金額」兩個步驟的決策當中。同時,由於 D-H 模型允許不同的解釋變數影響兩個步驟之決定,如此也將能更顯現相同的變 數對於「是否參與支出」及「支出多少金額」兩個決策步驟,在變動方向、 影響程度與顯著性上之差異。 綜合上述可知,D-H 模型有兩個優於標準 Tobit 模型的特點,一是標準 Tobit 模型只由一組變數來解釋參與(participation)與支出之決定,也就是 決定「是否參與支出」與「要支出多少」乃合併於一個步驟。此種作法迫使 每一個解釋變數之參數都以相同的符號和大小,同時衡量參與及支出的決 定。而 D-H 模型則允許藉由不同之變數分別影響參與及支出之決定。第二個 特點是,標準 Tobit 模型假設所有的零觀察值都是角解,而 D-H 模型則允許 零觀察值可以同時有角解及非參與(non-participation)的理由存在,即放寬 了標準 Tobit 模型中角解等於零需求之假設。 至於,經由兩次明顯選擇之詢問,進而,再由受訪者以開放方式填答最 高願意支付或是最低願意接受額度的開放雙界二元選擇之模式,與 D-H 模型 將受訪者最後顯示出之結果詮釋為「決定是否參與消費」與「決定支付多少金額」兩種行為之合併乃有所不同。因此,為合理分析開放雙界二元選擇模 式之樣本資料,即同時考量消費者明顯所呈現出來之選擇過程與最後顯示的 支出結果,以下將建構一個結合雙檻式選擇與雙檻式支出的複檻式決策過程 模型。
3.3 複檻式決策過程模型
3.3.1 考慮雙界二元選擇過程之完整支出決策模式
雖然 D-H 模型相對於標準 Tobit 模型已有較佳的解釋效果,然而,在分 為三個階段的開放式雙界二元選擇誘導支付模式下,受訪者明顯地是先經過 二個階段的選擇過程,繼而才進入能夠顯示最高 WTP 之開放誘導支付階段。 此時,標準 Tobit 模型與 D-H 模型均只能針對最後開放誘導支付過程中,所 得到的 WTP 觀察值 M iY
做分析,卻忽略了受訪者在前面兩個階段所做的選擇 決策過程。 以下所建構的一個具有三檻之完整支出決策模式,是結合代表開放雙界 二元選擇模式中兩個階段的明顯選擇過程,後續稱之為外顯選擇過程,加上 以 D-H 模式解釋最後開放填答結果的第二與第三階段決策過程之兩個檻,而 形成共有三個決策檻數之行為模式,因此,我們稱之為「複檻式決策過程模 型」。此一模型的整個決定支出決策如圖 3 所示,其中外顯選擇過程即是在 開放式雙界二元選擇模式中,經過兩次雙界二元選擇的詢問過程後,受訪者 對於特定金額選擇,所呈現出的明顯選擇組合結果,同時,受訪者也因為此 一過程而使其最後的 WTP 有比較清楚的輪廓。進而,經由 D-H 模型中「決 定是否參與支出」與「決定支出多少金額」的第二與第三階段決策過程,受 訪者因而得以回答一 WTP 金額 M iY
。3.3.2 複檻式決策過程資料之分析
假設C
1i是代表受訪者i
面對外顯選擇階段之第一次詢問金額A
i時,選擇 是否願意參與支付之虛擬變數; 2 iC
表示第二次詢問金額為一低於或高於A
i 之額度時,選擇是否願意參與支付之虛擬變數;D
i 則為開放階段受訪者i
決 定是否參與支付之虛擬變數,也就是相當於 D-H 模型中決定是否參與支出之 第一個檻。 在複檻式決策模型中,觀察值為零之情況,只有在圖 3 中(甲)的情形下 才有可能發生,但在 (甲)的情形下也有可能觀察到正值,而其他 (乙)、(丙)與(丁)三種情況,其觀察值必為大於零之正值。對於在最後開放過程所填答 的金額為正值者,如果是來自第一次選擇決策過程,回答「願意」接受,即 1 i
C
=1 的受訪者,則不論第二次之選擇是「願意」或是「不願意」,即不論 是 2 iC
=1 或是C
i2=0 的受訪者,由於此二種情況發生機率之和必為 1,因此, 可以合併列於(19)式中的第一種情形。而其他各種選擇與最後支付金額組合 的情形,亦一併列於(19)式之中。 開放支出過程 不願意 願意D
i = 0D
i = 1Y
i*≤
0 * iY
> 0Y
i*≤
0 * iY
> 0 M iY
= 0Y
iM= 0 M iY
= 0Y
iM= * iY
圖 3 三個階段之複檻式決策過程 i A $ L i A $ $AUi 不願意0
1=
iC
願意1
1=
iC
外顯選擇過程 不願意0
2=
iC
不願意0
2=
iC
(甲) (乙) (丙) (丁) $ 願意1
2=
iC
願意1
2=
iC
≤
=
=
=
≤
=
=
=
>
=
=
=
>
=
=
=
>
=
=
>
=
=
0
0
0
0
0
1
0
0
0
0
0
0
0
0
1
0
0
0
1
0
0
1
* 2 i 1 * 2 i 1 * 2 1 * 2 i 1 * 2 1 * 1 * i i i i i i i i i i i i i i i i i i i M iY
D
C
C
Y
D
C
C
Y
D
C
C
Y
D
C
C
Y
C
C
Y
C
Y
Y
且
且
且
或
;
且
且
且
或
;
且
且
且
當
且
且
且
或
;
且
且
或
;
且
當
(19) 由於 1 iC
與 2 iC
均表示外顯選擇過程中,受訪者i
是否參與支付之虛擬變 數,經過此一明顯的選擇過程,最後一併顯現於各種不同的選擇組合上,因 此待估計係數以r
代表,如果影響兩階段之選擇組合的解釋變數向量均相 同,令其為W
i,而u
i則表示平均值為零,變異數為 1 之常態獨立分配的誤 差項。至於其他變數之假設則與 D-H 模型相同,在各個階段之誤差項彼此獨 立的假設下,所有的估計式可以表示如下各式( )
0
,
1
~
2
1
,
j
,
u
N
u
rW
C
ij=
i+
i=
i( )
0
,
1
~
N
Z
D
i=
α +
iυ
iυ
i(
2)
*,
0
~
ε
σ
ε
β
X
N
Y
i=
i+
i i (20) 經由(19)式與(20)式之決策模型設定,當受訪者i
回答的願付價值 M iY
大 於零時,其樣本的機率函數可表示為2 2 本文的重點在於納入分析抗議性的答覆,因此,並未對兩個階段的「外顯選擇過 程」的相關性有所考慮,如此,對於後續分析抗議性答覆樣本的模型建構是無關 的。然而,感謝審查人之一的提醒,認為考慮兩個階段之「外顯選擇過程」互有 相關的情形,對於結果可能是有影響的,未來研究將可針對此而有更完整的模型 建構。(
) (
) (
)
(
) (
)
(
) (
)
(
) (
) (
)
(
) (
)
(
) (
)
[
]
−
×
Φ
−
Φ
−
−
=
>
>
=
=
=
+
>
>
=
=
+
>
>
=
σ
β
φ
σ
i M i i i i M i M i M i i i i M i M i M i i i M i M i M i iX
Y
Y
Y
f
Y
ob
D
ob
C
ob
C
ob
Y
Y
f
Y
ob
C
ob
C
ob
Y
Y
f
Y
ob
C
ob
1
1
1
1
0
|
0
Pr
1
Pr
0
Pr
0
Pr
0
|
0
Pr
1
Pr
0
Pr
0
|
0
Pr
1
Pr
2 2 1 2 1 2 1 1 (21) 式中
Φ
1i=
Φ
( )
rW
i,
Φ
2i=
Φ
( )
α
Z
i 。當受訪者i
回答的願付價值 M iY
等於零 時,其樣本機率函數表示成(
)
(
) (
) (
) (
)
(
) (
)
(
) (
)
(
) (
)
[
i i]
i i i i i i i i i M iY
ob
D
ob
Y
ob
D
ob
Y
ob
D
ob
C
ob
C
ob
Y
ob
Φ
Φ
−
Φ
−
−
−
=
≤
=
≤
=
>
=
=
=
=
=
2 2 1 * * * 2 11
1
1
1
0
Pr
0
Pr
0
Pr
1
Pr
0
Pr
0
Pr
0
Pr
0
Pr
0
Pr
+
+
(22) 式中
。
Φ
=
Φ
σ
β
i i iX
利用(21)式與(22)式兩個機率函數,可以導出複檻式決 策過程模型的概似函數為(
) (
)
[
]
(
) (
)
[
]
{
}
∏
∏
= >Φ
Φ
−
Φ
−
−
−
×
−
×
Φ
−
Φ
−
−
=
0 2 2 1 0 2 2 11
1
1
1
1
1
1
1
M i M i Y i i i Y i M i i i iX
Y
L
σ
β
φ
σ
(23) 同樣的,願付價值之平均值與區間估計值的計算方式,與標準 Tobit 模型 及 D-H 模型所採用(12)式和(13)式相同,(21)與(22)式的推導過程如附錄所 示。4. 資料來源與變數選擇
4.1 資料來源說明
以下採用一份來自吳珮瑛與蘇明達(2001)調查墾丁國家公園經濟效益 評估問卷的資料,分析及驗證前述各模型之可行性。墾丁國家公園之環境資 源豐富,不但是國內唯一一座擁有海域的國家公園,其地形變化多端且富有 多樣性的景觀資源,可謂最佳之地形學戶外自然教室。在如此得天獨厚的地 理環境下,孕育了墾丁國家公園在地形景觀、動植物生態、海洋生態與人文 史蹟等各方面資源的豐富性與獨特性。然而,由於核三廠的溫水排放、餐飲 服務業之污水排放、沿岸地區土地的不當開發、大量遊客的遊憩活動與非法 的動漁獵行為等,均使得墾丁國家公園之環境資源遭受持續不斷的污染及破 壞。 因此,瞭解維護墾丁國家公園環境資源之經濟效益的大小,乃成為國家 公園管理當局的要務之一。該調查資料是以 CVM 評估墾丁國家公園之經濟 資源效益,該問卷除了有受訪者對國內六座國家公園的使用概況,尚包括了 受訪者對墾丁國家公園的一般印象、使用情形及受訪者的個人屬性資料。而 問 卷 之 第 二 部 分 即 是 以 開 放 雙 界 二 元 選 擇 誘 導 支 付 模 式 由 受 訪 者 提 供 WTP,即受訪者在被告知為避免破壞與污染繼續發生,而使國家公園內之資 源消失殆盡,以支付「資源維護費」所代表的 WTP,來顯示其對公園內現有 資源之評價。 此外,對於回答不願意支付任何資源維護費者,則進一步瞭解其不願意 的原因,並依據所答覆的理由判別出墾丁國家公園的資源對該受訪者是否有 價值可言。倘若墾丁國家公園的資源對該受訪者而言並非沒有價值,但該受 訪者回答之願意支付資源維護費為零時,則將此樣本觀察值視為抗議性樣 本。本文乃取用該問卷調查台灣本島各縣市居民這一部份的 800 個樣本觀察 值,此一樣本經過檢查後發現其中有 245 個抗議性答覆、52 個答覆「無法確 定」與 2 個極端值(outlier)答覆,其餘的 501 個觀察值我們稱之為不含抗議性答覆之樣本。 為避免產生估計偏誤,對於有抗議性觀察值存在的 CVM 資料,慣例的 處理方式乃將抗議性答覆由整體樣本中刪除,再對剩下的不含抗議性答覆樣 本資料進行分析。因此,吳珮瑛與蘇明達(2001)亦採取如此的做法處理該 研究之訪問調查資料,將所選取的 800 個樣本觀察值,刪除其中 245 個抗議 性答覆、52 個答覆「無法確定」之樣本與 2 個極端值答覆後,可供該研究分 析之樣本觀察值共 501 個,即上述之不含抗議性答覆樣本,再將此 501 個觀 察值帶入標準 Tobit 模型中進行分析。而在這 501 個不含抗議性答覆的觀察 值中,我們發現總共只有 16 個觀察值最後顯示墾丁的資源對其價值為零。 然而,標準 Tobit 與 D-H 模型是專門針對樣本中有大量零觀察值所設計 的模型。倘若樣本中只有極少數的零觀察值,則僅需將此樣本資料帶入一般 迴歸式即可。但如果加入 245 個支付額度為零的抗議性答覆,由於標準 Tobit 模型對於大量零觀察值的處理還不夠周全,因此,倘若仍採用標準 Tobit 模 型進行這種包括大量零觀察值之資料分析,其結果勢必不具有效性。也因 此,過去利用標準 Tobit 模型分析有大量零觀察值之 CVM 樣本資料,都先 將大量的抗議性零觀察值刪除以避免估計偏誤。除此之外,Eulàlia(2001) 雖然也嘗試以更具估計有效性之 D-H 模型,來進行有大量抗議性零觀察值之 CVM 樣本資料分析,但是 Eulàlia(2001)忽略了 CMV 中誘導支付方式之選 擇過程。因此,本文所設計的複檻式決策過程模型,應是能分析利用開放式 雙界二元選擇誘導支付方式,同時,能處理含有大量抗議性零資料的理想模 式。 而為了確認本文所建構的複檻式決策過程模型,是一個相對較佳的消費 決策行為模式,我們乃將所獲得的樣本資料分為兩組,其中一組則依傳統上 分析 CVM 調查資料之處理方式,將抗議性答覆樣本刪除,僅分析不含抗議 性答覆觀察值的部分,即上述的 501 個不含抗議性答覆樣本,並將此 501 個 觀察值分別帶入 OLS、標準 Tobit 與 D-H 模型中進行分析。而另一組則保留 抗議性答覆於總樣本觀察值中,也就是將總樣本數扣除 52 個回答「無法確 定」之觀察值及 2 個極端值答覆後,亦將此 746 個觀察值分別帶入 OLS、標 準 Tobit 與 D-H 模式,同時亦採用本文所建構的複檻式決策過程模型進行分
析,將結果與前述只分析 501 個觀察值之 OLS、標準 Tobit 及 D-H 模型進行 比對。由於包含抗議性答覆的這一組樣本,是本文所建構之複檻式決策過程 模型所欲分析的樣本,因此,將此 746 個觀察值樣本稱為有效樣本,為了與 不包含抗議性答覆之樣本相對應,亦將其稱之為包含抗議性答覆之有效樣 本。
4.2 變數選擇與定義
在吳珮瑛與蘇明達(2001)進行墾丁國家公園整體資源經濟效益之評估 研究中,自變數的選擇除了受訪者對墾丁國家公園和其他五座國家公園之使 用狀況之外,亦選擇了一些受訪者個人的特徵變數,即受訪者個人之社會經 濟變數。該研究所採用變數之定義及其平均值如表 2 所示。由於 D-H 模型是 一種可同時涵蓋兩種隨機過程的決策模型,即允許影響「決定是否願意參與 支付」與「決定支付多少金額」這兩類決策因子是不相同的(Burton,Dorsett & Young,1996;Eulàlia,2001)。由此可知,D-H 模型與標準 Tobit 模型最 大的差異是,標準 Tobit 模型只用一組變數同時影響「決定是否願意參與支 付」與「決定支付多少金額」之決策,亦即標準 Tobit 模型僅允許支出方程 式之存在,而 D-H 模型則允許不同組的變數分別影響參與及支出兩種決策。 為比較有無刪除抗議性觀察值之樣本資料分析結果,本文將 501 個不含 抗議性答覆樣本觀察值與包含抗議性答覆之 746 個有效觀察值樣本分別帶入 Tobit 模型中進行估計。在此兩組不同的樣本下,Tobit 模型中的支出方程式 均採用相同的自變數。進而,為比較 Tobit 模型與 D-H 模型之估計有效性, 亦將此兩組不同的樣本分別帶入 D-H 模型中進行估計。其中,D-H 模型中的 支出方程式將採用與 Tobit 模型之參與方程式相同的變數,以與 Tobit 模型之 估計結果有所對照比較,而參與方程式則依不含抗議性答覆樣本與有效樣本 兩組不同樣本,分別採用不同的變數。 要處理涵蓋 245 個抗議性答覆的有效樣本,如果認定影響抗議性受訪者 不願回答其心中願付金額的關鍵因素,是源自於外顯的選擇過程,與開放過 程中的「參與」,則外顯選擇之方程式所包含的變數,及開放過程的參與方 程式是相同的。然而,此二者與開放過程中的支出方程式的變數則可以不同,以凸顯影響抗議性答覆屬性之特質(Eulàlia,2001)。而由吳珮瑛與蘇 明達(2001)的研究中,對抗議性答覆樣本與不含抗議性答覆樣本特質差異 之比較得知,抗議性答覆樣本與不含抗議性答覆樣本在部分的特徵上確實有 差異,而這些有顯著差異之特徵變數,如果是影響抗議性受訪者不願回答其 心中真正願付金額的主要變數,在此乃將這些變數,選取做為外顯選擇及開 放過程之參與方程式中的自變數。 而影響抗議性答覆的主要特性為,五年內平均去過其他五座國家公園的 總次數(Subfre)較低、男性比例(Sex)較高、年齡(Age)較高、教育總 年數(Edu)較低、軍公教者比例(Oc1)較低、農漁業者比例(Oc2)較高、 年總所得(Income)較低、曾經對環保組織捐過款的比例(Green2)較低, 而其他特徵變數之平均值並無顯著不同。因此,包含抗議性有效樣本中的外 顯選擇及開放過程之參與方程式的自變數,我們將只選取在 1%之顯著水準 下,不含抗議性答覆樣本與抗議性答覆樣本平均數顯著不同之特徵變數。依 此,被篩選出的變數共有五個,分別為受訪者過去五年內平均去過墾丁之外 其他國家公園的總次數(Subfre)、性別(Sex)、年齡(Age)、教育程度 (Edu)以及是否曾經對環保團體捐過款(Green2)。 由 於 不 含 抗 議 性 答 覆 樣 本 即 為 已 刪 除 大 量 抗 議 性 零 觀 察 值 之 樣 本 資 料,因此在不含抗議性答覆樣本下開放過程之參與方程式,其自變數的選取 與前述包含抗議性答覆有效樣本中,外顯選擇及開放過程參與方程式並不相 同。我們選取了三個自變數,其中年齡(Age)與教育程度(Edu)是過去許 多文獻中常採用的社經變數,而受訪者過去五年內平均去過墾丁之外其他國 家公園的總次數(Subfre),則可顯示受訪者對參與國家公園之使用的狀況。 至 於 開 放 過 程 之 支 出 方 程 式 自 變 數 的 選 擇 , 則 沿 用 吳 珮 瑛 與 蘇 明 達 (2001)估計墾丁國家公園資源經濟效益時選擇之自變數,做為本文各種不 同模型之開放過程支出方程式的自變數。同時,為矯正 Eulàlia(2001)對解 釋變數的不當選擇,此處以支出差異為詮釋的開放過程支出方程式,則不包 含受訪者所面對的各種受訪金額。 表 2 估計模型使用之變數及其定義、平均值與標準差
不含抗議性 答覆樣本 (樣本數=501) 含抗議性答覆 之有效樣本 (樣本數=746) 變數符號 (單位) 平均值 (標準差) 平均值 (標準差) 變數定義 Fre (次) 2.287 (6.920) 2.378 (7.698) 受訪者 5 年內曾經去過墾丁國家 公園的總次數。 Subfre (次) 2.856 (6.529) 2.348 (6.241) 受訪者 5 年內平均去過其他五座 國家公園的總次數。 Sex 0.525 (0.500) 0.563 (0.496) 虛擬變數,1 表示男性,0 表示女 性。 Age (年) 37.996 (11.123) 39.694 (12.009) 受訪者年齡。 Family (人) 4.399 (1.589) 4.426 (1.737) 與 受 訪 者 共 同 生 活 的 家 庭 人 口 數。 Edu (年) 13.273 (3.075) 12.907 (3.287) 受訪者受教育總年數。 Oc1 0.166 (0.372) 0.147 (0.355) 虛擬變數,1 表示職業別為軍公教 者,0 表示其他職業別。 Oc2 0.022 (0.147) 0.036 (0.187) 虛擬變數,1 表示職業別為農漁業 者,0 表示其他職業別。 Oc3 0.068 (0.252) 0.067 (0.250) 虛擬變數,1 表示職業別為自由業 者,0 表示其他職業別。 Income (萬元) 100.709 (66.407) 95.838 (71.496) 受訪者 1999 年包括薪水、利息與 年終獎金等之總所得。 Green1 0.064 (0.245) 0.071 (0.257) 虛擬變數,1 表示受訪者曾經當過 環境保育組織之會員或義工,0 表示沒有。 Green2 0.222 (0.416) 0.173 (0.378) 虛擬變數,1 表示受訪者曾經對環 境保育組織捐過款,0 表示沒 有。 WTP (元) 855.020 (896.640) 574.216 (837.273) 受訪者所回答之願付價值。 資料來源:本研究整理。
4.3 估計模型之設立與估計方法
確定了分析的樣本與變數後,為完成前述七種模型之估計,還必須確立 估計(11)、(18)與(23)三式中β
X
i、α
Z
i與rW
i 之函數形式,在此選擇以線型 函數型式做為實證分析之用。因此,在前述所選定的變數下,開放過程支出 方程式之估計函數型式可表示為(24)式 i i i i i i i i i i i i iGreen
Green
Income
Oc
Oc
Oc
Edu
Family
Age
Sex
Sufre
Fre
Y
2
1
3
2
1
12 11 10 9 8 7 6 5 4 3 2 1 0 *
×
+
×
+
×
+
×
+
×
+
×
+
×
+
×
+
×
+
×
+
×
+
×
+
=
β
β
β
β
β
β
β
β
β
β
β
β
β
(24) 而不論是 D-H 模型或是複檻式決策模型於開放階段之參與方程式,則是在解 釋當受訪者於開放過程中之參與情形,因此估計函數設定為相同形式,如(25) 式所示 i i i i ii
Subfre
Sex
Age
Edu
Green
D
=
α
0+
α
1×
+
α
2×
+
α
3×
+
α
4×
+
α
5×
2
(25) 但在不含抗議性答覆樣本之 D-H 模型中,並未涵蓋抗議性答覆樣本,因此受 訪者之參與情形並不明顯,特別是當解釋變數又是虛擬變數時,因此將性別 (Sex)與是否曾經對環保團體捐過款(Green2)等變數予以剔除。至於複 檻式決策過程於外顯選擇階段之參與方程式,則是在解釋受訪者面對二元選 擇誘導支付方式時之參與情形,估計函數之設定如(26)式所示2
1
,
2
5 4 3 21
Subfre
r
Sex
r
Age
r
Edu
r
Green
j
,
r
C
i i i i i j i=
×
+
×
+
×
+
×
+
×
=
(26) 在(24)、(25)與(26)所設定的函數形式下,為了以最大概似法估計前述的 (11)、(18)與(23)各函數,我們採用 LIMDEP(Greene,1998)計量軟體寫出 估計所需的最大概似函數式。由於 LIMDEP 計量軟體中已內建了標準 Tobit 模型之指令,因此有關標準 Tobit 模型估計的部分乃直接使用該指令,而其 他的模型則是由自行設定之概似函數式以最大概似法進行估計。由於,所有最大概似函數式均為非線型,因此必須給予各估計參數一數值做為估計的起 始值。而利用最大概似法進行估計時,起始值常是決定能否獲得估計結果的 關鍵。由於 D-H 模型是標準 Tobit 模型之延伸,且 Cragg(1971)建立 D-H 模型的主要步驟為先使用 Probit 模型估計參與支出的機率,再應用標準 Tobit 模型中的受限迴歸分析來估計支出水準。因此,我們發現以標準 Tobit 模型 所獲得的係數估計值,做 D-H 模型中支出方程式之起始值,最能有效估計出 參數之估計值。 而 D-H 模型中開放過程之參與方程式起始值的給定,則分別以 Logit 與 Probit 模型所獲得之係數估計值做為起始值。至於複檻式決策過程模型,其 起始值的給定除了 D-H 模型所獲得的係數估計值之外,模型中其餘代表外顯 決策過程之參與方程式,則以 Probit 模型所獲得的係數估計值做為起始值。 此外,對於非線型概似函數式之估計,函數之逼近方式、反覆收斂次數與收 斂準則等,都會影響函數能否收斂而獲得估計結果之因素,在不同的反覆收 斂次數、函數逼近方式與收斂準則之多方嘗試後,完成了各模型的估計。