國立高雄大學統計學研究所
碩士論文
A Generalized Nearly Isotonic Regression and its
Applications
廣義近乎保序迴歸及其應用
研究生: 方奕婷 撰
指導教授: 黃士峰 教授
3
致謝
時光飛逝、歲月如梭,轉眼間兩年的研究所生涯即將邁入尾聲,驀然回首 總有釋懷的感覺,感謝讓我有所蛻變的一切,也感謝我從未想過放棄。 首先感謝我的指導教授黃士峰老師,在論文撰寫期間給予的教導與督促, 當我迷惘時幫助我導正方向,讓我學習到對於研究的執著與態度。老師與學生 們的相處,亦師亦友,沒有距離,除了給予專業知識的指導,也告訴我們很多 面對困難的處理方式及人生的道理,謝謝您兩年的照顧。 其次,感謝論文口試委員王功亮老師、張志浩老師,細心的閱讀我的論文 初稿,並給予的寶貴意見與指正,讓此篇碩士論文更臻於完善,在此表示深摯 的謝忱。感謝在所上所有老師的教導與扶持,謝謝俞老師、湘伶老師、志浩老 師以及錕霖老師,謝謝你們用心的教學,讓我們的專業基礎更加紮實,也讓我 知道統計的學問有多寬廣,還有更多的知識要去追求。再來一定要特別感謝蘭 屏姐的關心及支持,永遠用最溫暖的笑容迎接我們,每次去工讀的時候就是我 最放鬆的時刻了,謝謝你,我們的心靈導師。 謝謝研究所的小夥伴們,多虧了你們讓我的研究生活如此多采多姿,永遠 充滿歡笑的 305、306 研究室,那些跑阿跑又下棋又戰爭的日子,那些熬夜寫程 式寫論文的日子,我永遠都不會忘記的,希望我們大家一切順利一起畢業,未 來一定要保持聯絡。 謝謝青梅竹馬們--湘玲、文祥、采榛,跟你們在一起總是能找到最純粹的 自己,謝謝你們在我身邊十幾年了從沒離開過。 謝謝堉綸這兩年的陪伴,你把我照顧的很好,謝謝你陪著我經歷這些大大 小小的事,每件事都會成為我的回憶,變成我的力量,也希望你陪著我繼續笑 著走下去。謝謝家人們,你們大家都是我最強大的後盾,不斷的支持我、鼓勵 我、安慰我,千言萬語說不盡,但我想你們都明白。 最後我想將此篇論文獻給我的爸媽,謝謝你們讓我在充滿愛與歡樂的環境 下成長,無條件的支持我所有的決定,從不給我任何壓力,讓我能夠無憂的學 習,我希望我能一直成為你們的驕傲,我愛你們。 方奕婷 撰 中華民國一○八年七月4
A Generalized Nearly Isotonic Regression
and its Applications
by
Fang, I Ting
Advisor
Huang, Shih Feng
Institute of Statistics
National University of Kaohsiung
Kaohsiung, Taiwan 811 R.O.C.
5
目錄
摘要 ... 8 Abstract ... 9 第一章 緒論 ... 10 1.1 研究動機及目的 ... 10 1.2 研究架構 ... 11 第二章 相關文獻探討... 13 2.1 保序迴歸 ... 13 2.2 近乎保序迴歸 ... 14 第三章 研究方法及流程 ... 16 第四章 方法應用 ... 19 4.1 降低風險值波動 ... 19 4.1.1 GARCH 模型估計風險值 ... 20 4.2 風險狀態及關聯分析 ... 24 4.2.1 風險狀態及關聯分析-實證結果 ... 28 第五章 討論與建議 ... 31 參考文獻 ... 32 附錄 ... 34 附錄 1 ... 34 表格目錄 ... 35 表 1. 超限數、Chrisoffersen(1998)測試的 p 值及VaR𝐺、NVaR1、NVaR2每 年平均之變動量、變動標準差與期望短缺。 ... 35 表1.(續) ... 36 表2. 由VaR𝐺、NVaR1及NVaR2估計量計算的每年平均 CR 值、變動量和 變動標準差。 ... 37 表3. Scaling factors ... 38 表4. 高低風險損失期望值列表,使用作用度(𝑙𝑖𝑓𝑡)最高時的百分 比組合作為最佳界線,來呈現各國相互估計列表,其中A1~A13 代表事件 A,依序為美國、澳洲、日本、韓國、馬來西亞、新加玻、香 港、印度、法國、德國、英國、巴西及加拿大,而B1~B13代表事件 B,國家排序與事件 A 相同,綠色區塊為自身估計值,白色區塊 為依時區的差一步當日預測,黃色區塊為差一步的跨日預測。 . 39 表4(續). ... 40 圖目錄 ... 41 圖1. S&P500 從 2006 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡 + 1(黑色實線)和 2007 年 1 月至 2017 年 12 月的VaR𝐺(紅6 色虛線)在(3)式中定義,移動窗口方法之窗口大小為 250 天,α = 0.01。 ... 41 圖2. S&P500 從 2006 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡 + 1(黑色實線)和 2007 年 1 月至 2017 年 12 月的VaR𝐺(紅 色虛線)在(3)式中定義,以及 2007 年 1 月至 2017 年 12 月的 NVaR1(藍色實線)在(6)式定義,移動窗口方法下窗口大小為 250 天,水平 α = 0.01。 ... 41 圖3. S&P500 從 2006 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡 + 1(黑色實線)和 2007 年 1 月至 2017 年 12 月的VaR𝐺(紅 色虛線)在(3)式中定義,以及 2007 年 1 月至 2017 年 12 月的 NVaR2(藍色實線)在(6)式定義,移動窗口方法下窗口大小為 250 天,水平 α = 0.01。 ... 42 圖4. S&P500 從 2007 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡 + 1(黑色實線)、VaR𝐺(紅色實線)與VaR𝐺的 CR(紅色虛 線)、NVaR1(藍色實線)與NVaR1的 CR(藍色虛線)及NVaR2 (綠色實線)與NVaR2的 CR(綠色虛線)。 ... 42 圖5. 2007-2017 年 S&P500 之各項指標比率𝐹𝑉(NVaR1)/ 𝐹𝑉(VaR𝐺) (黑色實線)、𝐹𝑉(NVaR2)/𝐹𝑉VaR𝐺(紅色實線)、 𝑠𝑡𝑑𝑅𝐶(NVaR1)/𝑠𝑡𝑑𝑅𝐶(VaR𝐺)(黑色虛線)以及𝑠𝑡𝑑𝑅𝐶(NVaR2)/ 𝑠𝑡𝑑𝑅𝐶(VaR𝐺) (紅色虛線)。 ... 43 圖6. 2007-2017 年 S&P500 的每年資本準備金各項指標之比較 𝐴𝑣𝑒(CR1)/𝐴𝑣𝑒(CR𝐺)(黑色實線)、𝐴𝑣𝑒(CR2)/𝐴𝑣𝑒CR𝐺(紅色實 線)、𝐹𝑉(CR1)/𝐹𝑉(CR𝐺)(黑色虛線)、𝐹𝑉(CR2)/𝐹𝑉CR𝐺(紅色虛 線)、𝑠𝑡𝑑𝑅𝐶(CR1)/𝑠𝑡𝑑𝑅𝐶(CR𝐺)(黑色點線)以及𝑠𝑡𝑑𝑅𝐶(CR2)/ 𝑠𝑡𝑑𝑅𝐶(CR𝐺)(紅色點線)。 ... 43 圖7. 2007-2017 年 13 個全球金融市場指數之比率(a) 𝐹𝑉(VaR)、 (b) 𝐹𝑉(CR)、(c) 𝑠𝑡𝑑𝑅𝐶(VaR)、(d) 𝑠𝑡𝑑𝑅𝐶(CR)、(e) ES 以及(f) 𝐴𝑣𝑒(CR)。 ... 44 圖8.GNIR 步驟流程圖 ... 45 圖9. 透過所配適的 GNIR 定義出 2005~2017 年巴西指數的風險 狀態序列,紅線表示為高風險時期,藍線表示為低風險時期。 . 46 圖10. 巴股當日(𝑡 + 1時間)判定為高風險狀態時的損失與前一日 (𝑡時間)的美股損失之高風險界線示意圖,取 0 為界線(灰色實線) 做網點收尋,藍色、紅色虛線分別為事件A 及事件 B 之下界限選取組 合,藍區、紅區分代表事件A、B 損失小於界線的區域。 ... 47 圖11. 2005~2017 年巴西每日指數關聯分析之風險狀態預測圖, 其中2005~2016 年做樣本內測試(In-sample-test),2017 年做樣本
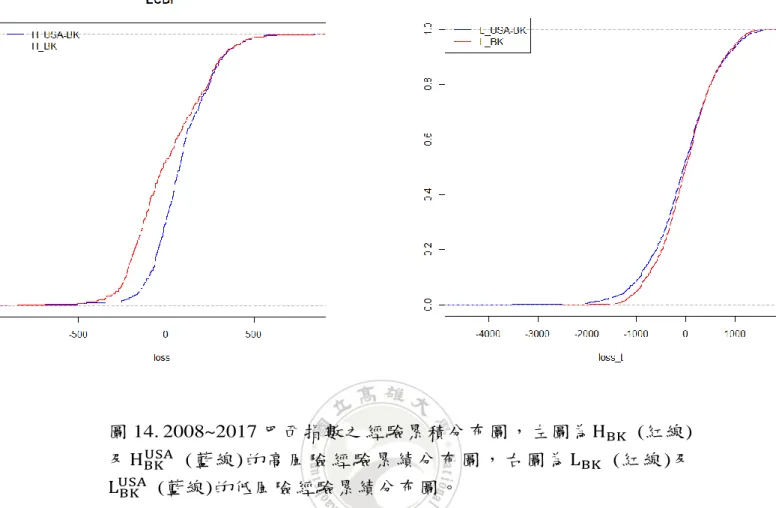
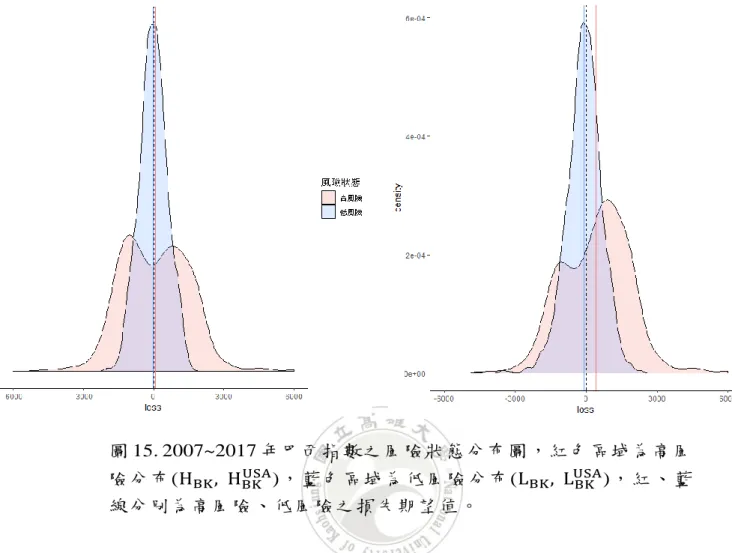
7 外測試(Out-of-sample-test)為估計結果,黑色實線為每日損失𝑃𝑡 − 𝑃𝑡 + 1,原始高低風險損失期望值為 79.6 及 -19.68 (分別為背景 顏色紅色、藍色),經由關聯分析後高低風險損失期望值為 97.78 及-24.95(分別為紅色、藍色實線)。 ... 48 圖12. 2007~2017 年的巴西每日指數關聯分析之風險狀態預測 圖,其中 2005~2007 年為移動窗口為 450 天(2 年),黑色實線為 每日損失𝑃𝑡 − 𝑃𝑡 + 1,原始高低風險損失期望值為 50.54 及 -0.44(分別為背景顏色紅色、藍色),經由關聯分析後高低風險損 失期望值為307.18 及-70.03(分別為紅色、藍色實線)。 ... 49 圖13. 2007~2017 年巴西指數之損失盒鬚圖,HBK、LBK為原始估 計的高、低風險狀態所對應之損失盒鬚圖;HBKUSA、LBKUSA為 加入美股關聯分析後,預測的高、低風險狀態所對應的損失盒鬚 圖。 ... 50 圖14. 2008~2017 巴西指數之經驗累積分布圖,左圖為HBK (紅 線)及HBKUSA (藍線)的高風險經驗累績分布圖,右圖為LBK (紅 線)及LBKUSA (藍線)的低風險經驗累績分布圖。 ... 51 圖15. 2007~2017 年巴西指數之風險狀態分布圖,紅色區域為高 風險分布(HBK, HBKUSA),藍色區域為低風險分布(LBK, LBKUSA),紅、藍線分別為高風險、低風險之損失期望值。 ... 52 圖16. 2007~2017 年各國關係網絡圖,其中箭頭方向代表被影響 之國家,線的顏色代表關聯性的高低,黑線代表影響性較高,灰 線代表影響性較低,線之間的長短代表關係的強弱,例:短黑線間 的關係較長黑線強。 ... 55 圖17. 對照圖 16 之各年網絡特徵折線圖,其中藍點線為各年之 網絡圖密度,代表該年國家間影響的密集程度,藍字為該年之網 絡中心,代表該年綜合影響他國最多的國家,紅點線及紅字為各 年最高出度密度,代表造成影響最大之國家,黑點線及黑字為各 年最高入度密度,代表被影響最多的國家,背景顏色為年度歷史 事件,藍背景為 2007~2010 年次貸危機,紅背景為歐債危機,黃 背景為全球股災,綠背景為英國脫歐事件。 ... 55
8
廣義近乎保序迴歸及其應用
指導教授 : 黃士峰 博士 國立高雄大學應用數學系 學生 : 方奕婷 國立高雄大學統計學研究所 摘要本研究提出一個廣義近乎保序迴歸(Generalized Nearly Isotonic Regression,簡 記為 GNIR)的無母數統計方法以描述資料的動態,GNIR 具有自我調整以捕捉 資料大趨勢時而向上、時而向下的能力。本研究亦提出 GNIR 方法的演算法, 並證明其收斂性。在數值研究方面,我們採用2006 年至 2017 年間全球 13 個金 融市場的每日風險值(Value-at-Risk,簡記為 VaR )序列進行實證分析,數值 結果顯示 GNIR 不僅可以有效地捕捉 VaR 序列的變動趨勢,也能透過所配適的 GNIR 定義出每一個市場的風險狀態序列,接著運用關聯規則建立 13 個金融市 場間的關聯性,實證結果發現應用金融市場間的關聯性可提升對未來市場風險 狀態的預測準確度。 關鍵詞: 關聯規則、近乎保序迴歸、風險值
9
A Generalized Nearly Isotonic Regression
and its Applications
Advisor: Shih-Feng Huang Department of Applied Mathematics
National University of Kaohsiung Student: I-Ting Fang
Institute of Statistics National University of Kaohsiung
Abstract
This study proposes a non-parametric approach, called Generalized Nearly Isotonic Regression (GNIR), to describe the dynamics of data. The GNIR is capable of depicting the up/down fluctuation of data automatically. An algorithm for the GNIR is proposed and its convergence property is derived. The daily Value-at-Risk (VaR) of 13 global financial markets during 2006-2017 are employed for our empirical study. The numerical results reveal that the GNIR is capable of depicting the dynamics of VaR sequences well. In addition, the sequence of risk status for each market is defined by the fitted GNIR and predict the risk status for the 13 markets. Furthermore, we use the association rules to establish the associations among the risk status of the 13 financial markets. The empirical results show that applying the associations among financial markets is capable of improving the accuracy in predicting market risk status.
10
第一章 緒論
1.1 研究動機及目的 隨著經濟全球化的快速發展及激烈的競爭,經濟變動受到其他國家市場和 政策的影響也因為全球化而變得格外引人注目。對於現代化國家而言,金融市 場震盪所帶來的作用巨大無比,而各國金融市場經常因許多因素處於動盪多變 的環境之中,面對變化莫測的影響,金融市場的趨勢變動漸成為投資人所關注 的重要指標。 本研究主要針對財務資料提出一個可以良好描述趨勢變動的無母數統計方 法,除了能夠捕捉財務資料大趨勢時而向上、時而向下的能力,甚至呈現短期 的細微變化,使得投資人能夠完整的觀察出未來金融趨勢,除此之外,對於任 何擁有時間性之資料,此統計方法皆能描繪。研究金融市場趨勢的文獻在近年 來亦呈現大幅度成長,Brown (1980)利用金融資產的每日價格(如商品,貨幣和 股票)的時間序列定義了一套新的統計模型觀察價格趨勢的變動,在歷經 2008 年的金融海嘯後,許多學者亦投入研究關於金融危機前後的各國市場指數趨勢 等…,顯見此一領域所受的重視。 近年來,風險值(Value-at-Risk,簡記為 VaR)的概念已經廣為國際金 融監理機構和多數金融機構使用,它能明確掌握投資部位風險,並能將所有投 資部位做總和考量,且易於以統計的概念加以檢定。而一個良好的模型所估計 的風險值應該能夠反應投資部位的真實損益,唯有合理預測風險值之模型才具 有 實 用 性 (Brown, 1980; Hendricks, 1996) , 若 VaR 模 型 通 過 了 回 溯 測 試 (backtesting),則被認為是準確的,若 VaR 模型無法通過回測,將會自動拒絕 (Basel Committee, 1996)。傳統上,可以通過時間序列模型配適標的資產收益並 計算損失的相應分位數來獲得 VaR,例如 GARCH 模型(Bollerslev, 1986; Nelson, 1990; Tsay, 2010 及其中參考文獻)。在此,我們將 GARCH 模型計算出的 VaR 稱 作VaR𝐺,並參考 Barlow et al. (1972) 保序迴歸 (Isotonic Regression, IR)及11
Tibshirani et al. (2011) 提出的近乎保序迴歸 (Nearly Isotonic Regression, NIR) 之 模 型 , 加 以 推 廣 提 出 廣 義 近 乎 保 序 迴 歸 (Generalized Nearly Isotonic Regression, GNIR) 的無母數統計方法,且通過回溯測試,確認其方法之實用 性。 在實證研究中,我們採用 2006 年至 2017 年間全球 13 個金融市場 (澳 洲-- AORD、印度--BSESN、巴西--BVSP、英國--FCHI、法國--FTSE、德國-- GDAXI、美國--GSPC、加拿大--GSPTSE、香港--HSI、馬來西亞--KLSE、南韓--KS11、新加玻--STI、日本--N225 ) 的每日風險值進行分析探討,並定義各國 的風險狀態,利用關聯分析討論各國彼此間的趨勢發展所造成的影響。 故本論文之研究目的分例如下: 1. 提出有助於觀察財務資料之預測趨勢的無母數統計方法。 2. 定義各國間的風險狀態並建立關聯分析。 1.2 研究架構 本研究的架構共分為五章,將先探討研究動機及目的,進行保序迴歸、近似保 序迴歸的文獻探討,再介紹我們提出的方法及流程,以及證明其收斂性,接著 對全球 13 個金融市場指數進行實證研究分析,最後做出結論與建議。 第一章 緒論 本章敘述本研究的研究動機及研究目的,為此研究方法的最初想法,及希望此 研究方法對於觀察財務資料的分析有所貢獻。 第二章 文獻回顧 本章回顧 (1)保序迴歸、(2)近似保序迴歸,作為本研究的研究基礎,並且介紹 過去文獻對於資料的研究方法。 第三章 研究方法及流程
12 本章闡述我們提出的研究方法,敘述其理論推導程序及選取參數的方法步驟, 以及決定參數之作法,最後證明其收斂性。 第四章 實證研究 本章採用 2006~2017 年之 13 個國家市場指數的真實數據,其中 2006 年為建模 資料,使用方法 GNIR 進行實證研究及分析: (1)估計風險值並與不同估計方法進 行比較、(2)運用 GNIR 之參數預測風險狀態,並使用關聯分析加強預測準確度。 第五章 討論與建議 本章為本研究定下結論,並提出本未來的研究建議,以供日後相關領域研究者 的參考。
13
第二章 相關文獻探討
過去對於近似序列的問題已有許多文獻提出解決的方法,在本章中我們簡 要地探討其中常見的無母數統計方法--保序迴歸(isotonic regression, 簡記 IR, Barlow et al. 1972),經研究推導,保序迴歸可以藉由 PAVA 演算法(pool adjacent violators algorithm, Barlow et al. 1972)在簡易的計算中求解,然而保序迴歸卻無法 描述數據間小趨勢下降的問題,因此本章同時探討近乎保序迴歸(nearly isotonic regression, 簡記 NIR, Tibshirani et al. 2011),此統計方法大幅的改善問題並良好 的描繪出數據中的小趨勢,且加以修正 PAVA 演算法,使得演算速度獲得大幅 提升。 2.1 保序迴歸 保序迴歸為一種無母數的迴歸模型,適用於非遞減函數之數據。保序迴歸 的基本想法為: 給定任意有限的𝑦1, … , 𝑦𝑛,以及單調序列𝛽1, … , 𝛽𝑛,訓練一個模 型來最小化以下的方程式,並滿足條件𝛽𝑚𝑖𝑛 = 𝛽1 ≤ ⋯ ≤ 𝛽𝑛 = 𝛽𝑚𝑎𝑥 ∑(𝑦𝑖 − 𝛽𝑖)² 𝑛 𝑖=1 這個問題在形式上可以寫成(1)式 𝛽̂𝑖𝑠𝑜 =argmin 𝛽∈𝑅𝑛 ∑𝑛𝑖=1(𝑦𝑖− 𝛽𝑖)² subject to 𝛽1 ≤···≤ 𝛽𝑛. (1) 在這整個過程中假設的“單調”皆代表單調非遞減,對於單調非遞增亦存在類似 的問題陳述。而 Barlow et al. (1972)發現(1)式的解可以透過 PAVA 演算法求得, 以下簡述 PAVA 演算法的步驟,首先須從最左邊的端點𝑦1開始,接著向右進行 移動直到遇到違反項(相鄰點非遞增),然後使用與向左相鄰點的平均來替代這 一對的數據值,以此類推直到最右邊的端點𝑦𝑛以達成單調性,而相鄰違規演算
14
法的計算速度為O(𝑛) (Grotzinger and Witzgall 1984) ,而此模型的好處為其不假 設任何形式的目標函數,如線性。
在早期也有很多關於保序迴歸的參考文獻(Ayer et al. 1955; Brunk 1955; Bartholomew 1959a, 1959b; Miles 1959)。De Leeuw et al. (2009) 發表的論文亦很 好地描述了這個問題的由來和計算方法。Luss et al. (2010)也提出了一種遞移分 區的算法,該算法產生一個不平滑的保序序列,最後產生標準的保序迴歸。 2.2 近乎保序迴歸 近乎保序迴歸同樣是一個無母數的迴歸模型,但考慮的問題比保序迴歸更 加複雜一些,適用於主趨勢向上但小趨勢向下的數據。其運用近乎保序函數逼 近數據,制定一個凸優化的問題,首先給定數據序列 𝑦𝑡, 𝑡 = 1, … , 𝑇,通過(2) 式求解得到近乎單調遞增的近似數據 𝜷̂𝜆 = argmin𝜷∈𝑅𝑇1 2∑ (𝑦𝑡− 𝛽𝑡) 2 𝑇 𝑡=1 + 𝜆 ∑𝑇−1𝑡=1(𝛽𝑡− 𝛽𝑡+1)+, (2) 其中𝜷 = (𝛽1, … , 𝛽𝑇)⊤,𝑥+表示𝑥的正部分,此假設數據為等間隔的網格測量, 若非等間隔測量,則(2)式中的懲罰項需改為 𝜆 ∑(𝛽𝑖 − 𝛽𝑖+1)+ 𝑥𝑖+1− 𝑥𝑖 𝑛−1 𝑖=1 而(2)式是固定𝜆 ≥ 0的凸優化問題,右邊第二項為懲罰項,它將會懲罰違反 單調性的相鄰對,即𝛽𝑡 > 𝛽𝑡+1。當λ = 0 時,𝛽𝑡 > 𝛽𝑡+1; 當λ → ∞時,(2)式會 簡化成 Barlow et al. (1972)所提出的標準保序迴歸問題。而 Tibshirani et al. (2011) 透過修改 PAVA 演算法來解決(2)式,修改的 PAVA 算法不需要從數據的左端開 始進行運算,而是判斷最需要連接的相鄰點進行合併,且修改後的方法將運算 速度縮減至O(𝑇𝑙𝑜𝑔𝑇),亦提出引理 1.支持其理論。
引理 1 (Tibshirani et al. 2011).取任意 λ 皆可使兩相鄰點之解滿足𝛽̂𝜆,𝑖 = 𝛽̂𝜆,𝑖+1,且
15
但實際上,(2)式主要是用於描述當數據的主要趨勢隨著局部遞減的部分而增加 的無母數方法。然而,若數據中同時存在上下主趨勢時,使用(2)式求解將會把 所有遞減數據視為懲罰項,造成模型偏離,無法良好的描述數據,為了解決此 問題,我們提出一個新統計方法,稱作廣義近乎保序迴歸(generalized nearly isotonic regression, 簡記 GNIR)。
16
第三章 研究方法及流程
在第二章提到的近乎保序迴歸雖良好的改善了數據中小趨勢下降的問題, 但若數據的主趨勢亦為下降時,近乎保序迴歸將無法將其趨勢描繪,而+實際資 料大多同時存在上下主趨勢,因此我們提出一個新的無母數統計方法,稱作廣 義近乎保序迴歸(generalized nearly isotonic regression, GNIR)用以解決當數據之主 趨勢時而向上及時而向下的問題。我們提出以下 GNIR 準則: 𝜷̂𝜆1,𝜆2 = argmin𝜷∈𝑅𝑇 1 2∑ (𝑦𝑡− 𝛽𝑡) 2 𝑇 𝑡=1 +𝜆1∑𝑇−1(𝛽𝑡− 𝛽𝑡+1)+ 𝑡=1 + 𝜆2∑𝑇−1𝑡=1(𝛽𝑡+1− 𝛽𝑡)+, (3) 其中(3)式右側的第 1 個懲罰項,𝜆1∑𝑇−1(𝛽𝑡− 𝛽𝑡+1)+ 𝑡=1 用於懲罰相鄰對,如(2)式 中違反單調增加的性質,而第二個懲罰項,𝜆2∑𝑇−1𝑡=1(𝛽𝑡+1 − 𝛽𝑡)+,是為了處理遞 減的部分。另外,懲罰參數𝜆1和𝜆2可通過交叉驗證等來確定。此外,對於任何 固定的𝜆1和𝜆2,可以通過擴展 Tibshirani et al. (2011)的算法來有效地解決(3)式。 首先,我們將(3)式分開寫成(4)式及(5)式 𝑓1(𝜷|𝜅1) =1 2∑ (𝑦𝑡− 𝛽𝑡) 2 𝑇 𝑡=1 + 𝜅1∑𝑇−1𝑡=1(𝛽𝑡− 𝛽𝑡+1)+ (4) 及 𝑓2(𝜷|𝜅2) =1 2∑ (𝑦𝑡− 𝛽𝑡) 2 𝑇 𝑡=1 + 𝜅2∑𝑇−1𝑡=1(𝛽𝑡+1− 𝛽𝑡)+, (5) 其中 𝜅1 ≥ 0且 𝜅2 ≥ 0。而分別在(4)和(5)中定義的問題𝑓1(𝜷) 和𝑓2(𝜷)皆擁有凸 性質並且使得 𝜷̂𝜅1 = 𝑎𝑟𝑔𝑚𝑖𝑛 𝜷 𝑓1(𝜷|𝜅1) 𝑎𝑛𝑑 𝜷̂𝜅2 = 𝑎𝑟𝑔𝑚𝑖𝑛 𝜷 𝑓2(𝜷|𝜅2) (6) 為最佳解,此解可以經由 Tibshirani et al. (2011)的算法獲得,如(6)所示,而𝜅1和 𝜅2可以通過交叉驗證、Mallow’s CP 準則、AIC 或 BIC 等方法挑選,在此研究中 應用回溯測試(backtesting)選取。此外,對於任何0 ≤ 𝑐 ≤ 1,可將(3)的優化問 題之目標函數重寫為
17 𝑓(𝜷|𝑐, 𝜆1, 𝜆2) = 𝑐𝑓1(𝜷|𝜅1) + (1 − 𝑐)𝑓2(𝜷|𝜅2), (7) 其中𝜆1 = 𝑐𝜅1和 𝜆2 = (1 − 𝑐)𝜅2。此時,𝑓(𝜷|𝑐, 𝜆1, 𝜆2) 仍然是凸函數,並且存在 0 ≤ 𝑘𝑐 ≤ 1 如下式 𝜷̂𝜆1,𝜆2 = 𝑎𝑟𝑔𝑚𝑖𝑛 𝜷∈𝑅𝑇 𝑓(𝜷|𝑐, 𝜆1, 𝜆2) = 𝑘𝑐𝜷 ̂𝜅 1 + (1 − 𝑘𝑐)𝜷̂𝜅2. (8) 因此,(3)式的期望最佳解可以表示為具有參數𝑘𝑐的𝜷𝜅1、𝜷κ2的加權平均值,其 取決於(7)式中的加權參數 c。 最後通過(6)、(8),我們有效地得到了 GNIR 準則(3)的解。而我們將此方 法應用於財務資料,接下來,將說明如何基於(3)式去計算一步預測的 NVaR 之 過程細節。令 t 為當前時間,NVaR̂ 𝑡+1則表示一步預測(𝑡 + 1時間)的 VaR 所對應 的估計量。 1. 假設我們有一筆每日風險指數之歷史數據,記做VaR𝑖𝐺, 𝑖 = 𝑡 − 𝑠, … , 𝑡, 並獲 得一步預測的VaR𝑡+1𝐺 , 其中𝑡 > 𝑠 > 0,而 s 為窗口大小(window size)。接
著將應用於{VaR𝐺𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1},並挑選(4)式中的懲罰項𝜅 1,使 得𝛽̂𝜅1每年的超限數小於等於 6,這邊的𝛽̂𝜅1可以藉由(4)式求得,而超限數的 限制是參考回溯測試模型(Kupiec, 1995)。特別是,如果𝜅̂1不存在超限數 6, 我們將超限數替換為 7 並再次選擇𝜅1以此類推…,最後將得到的𝛽̂𝜅1表示為 NVaR̃ 𝑖 , 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1。 2. 我 們再將第二個 回 溯測試 (Christoffersen, 1998) 應用於步驟 1 中獲得的 {NVaR̃ 𝑖 , 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1}。如果測試的 p 值大於 0.01,則NVaR𝑢𝑡+1 =
NVaR̃ 𝑡+1;若 p 值小於 0.01,則使用NVaR𝑡+1𝑢 = 𝛾NVaR̃
𝑡+1來做調整,
其中比例γ 從 1.001,1.002 依次選擇...直到{NVaR𝑢𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1}
18 3. 將 GNIR 應用於 {−VaR𝐺𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1} 並重複步驟 1 和 2,這相 當於求解(5)式。用 {−VaR𝐺𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1}表示獲得{−NVaR𝑑𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1}的估計值。 4. 通過(7)和(8)任意給定 c,我們可得出 NVaR̂ 𝑡+1 = 𝑘𝑐NVaR𝑢𝑡+1+ (1 − 𝑘 𝑐)NVaR𝑑𝑡+1. (9) 直觀的來說,NIR 的準則(2)式主要是找到觀察值的近乎非遞減之估計。當 觀察值遞減時,NIR 對遞減部分的估計波動較小。而這也是在步驟 2 中得到的 NVaR𝑢能夠及時反映市場風險,並同時減少VaR𝐺遞減部分波動的主要原因。另 一方面,我們還需要減少VaR𝐺遞增部分的波動。因此,我們建議使用NVaR𝑑來 處理步驟 3 中遞增的部分。然而在步驟 4 中,我們考慮(7)式中參數 c 的兩種設 置。第一個使用加權平均值來估計NVaR̂ 𝑡+1,使得 𝑐 = ∑ (VaR𝑖+1𝐺 −VaR𝑖𝐺) + 𝑡 𝑖=𝑡−𝑠+1 ∑𝑡𝑖=𝑡−𝑠+1|VaR𝑖+1𝐺 −VaR𝑖𝐺| , (10) 此為增加的幅度與前 s 步(s-steps)的VaR𝐺之絕對波動比率。而所提出的(10)式 中,c 的選擇能夠反映VaR𝐺序列的主要趨勢。例如,若VaR𝐺的主要趨勢為增加
(或減少),則 c 偏向 1(或 0)。最後,將 NVaR 定義為NVaR𝑢𝑖和NVaR𝑖𝑑的加權平
均,以跟隨整體趨勢並同時減少VaR𝐺的波動。另一種方式是設置 c = 0.5 來估計
NVaR̂ 𝑡+1,即為 NVaR𝑢𝑡 + 1、NVaR 𝑡 + 1
𝑑 的 未加權平 均值。這 裡,我們 分別用
19
第四章 方法應用
此章節採用 2006 年 1 月至 2017 年 12 月間全球 13 個金融市場的每日風險 值進行實證分析,再透過所配適的 GNIR 定義出每一個市場的風險狀態序列, 並依此建立13 個市場的每月風險狀態之關聯分析。 4.1 降低風險值波動 風險值(VaR)是評估市場風險的常用衡量,其意義為在特定期間及特定 機率下,持有單一資產或資產的投資組合,因市場上經濟變數之變動,預期該 組合可能產生的最大損失。根據 Basel Committee (2006),具有大量交易活動的 銀行需要留出一定數量的資金來彌補潛在的投資組合損失。該市場風險資本的 規模是根據銀行的一天(或 10 天)期限 VaR 估計值計算得出的,置信水平為 99 %。如果VaR 模型通過了回溯測試,並且將 VaR 模型的最近 250 個每日預測損 失與實際損失進行比較,則認為 VaR 模型是準確的。如果 VaR 模型不能通過回 溯測試,它將被自動拒絕 (Basel Committee 1996)。 傳統上,可以通過時間序列模型(例如,GARCH 模型)估計標的資產報酬和 計算損失分佈的相應分位數來獲得 VaR 估計量。理論上,如果採用適當的時間 序列模型,VaR𝐺估計量是準確的並且對市場風險具有及時反應,但它通常具有 強烈波動,這導致相關資本要求的頻繁變化。實際上,由於經營風險,價格波 動和再平衡成本,管理層不喜歡過於頻繁地改變資本水平。為了應對這種情 況,許多銀行採用臨時程序來平穩風險預測。例如,銀行可以每三個月更新一 次資產的共變異矩陣,或者設置每日風險限額的上限(Danielsson 2002)。然而, 前一種方法不能及時反映市場風險,後一種方法在發生特別大的風險值時無法 有效預警。為解決這些問題並在準確性、及時反應和穩定性間取得平衡,本研 究將提出的 GNIR 應用於 GARCH 模型估計風險值之預測過程以構建新的 VaR 估計,由NVaR 表示。20
4.1.1 GARCH 模型估計風險值
許多實證研究結果表明,金融市場中的標的資產通常有自相關、條件異質
性、波動性、不對稱性和厚尾分佈。為了描述上述特徵,GARCH 型模型廣泛 用於經濟學、統計學和金融學(參考 Bollerslev, 1986; Nelson, 1990; Tsay, 2010 及其中的參考文獻)。而 GARCH 模型在期權定價和投資組合選擇方面也 引起了很多關注(Duan, 1995; Harris and Mazibas, 2013; Huang and Guo, 2014; Huang and Tsai, 2015; Huang and Ciou, 2018; Huang and Lin, 2018 和 其中的參考文獻)。
對於估計風險值,使用 t 分布之下的 GARCH 模型(記為 GARCH-t)配適比 常 態 分 布 之 下 的 GARCH 模 型 更 加 合 適 ( Danielsson 和 Morimoto , 2000; Danielsson,2002)。因此,本研究採用以下的 GARCH 模型來描述股票報酬的 動態: { 𝑟𝑡 = 𝜇𝑡+ 𝑎𝑡 𝑎𝑡 = 𝜎𝑡𝜀𝑡, 𝜀𝑡 √𝑣−2 𝑣 𝑡(𝑣) 𝜎𝑡2 = 𝑔𝑡(𝑎𝑠, 𝜎𝑠; 𝜽, 𝑠 ≤ 𝑡 − 1) (11) 其中𝑟𝑡 = log (𝑃𝑡/𝑃𝑡−1)為𝑡時間的每日報酬,𝑃𝑡是每日股價,𝜇𝑡是𝑟𝑡的條 件期望值(𝑣 > 0),𝑔𝑡是𝑎𝑠及𝜎𝑠在固定參數𝜽下的函數(𝑠 ≤ 𝑡 − 1)。另外,令 𝜇𝑡和𝑔𝑡為ℱ𝑡−1的可測函數,其中ℱ𝑡−1是在時間𝑡 − 1獲得的資訊。模型(11) 包 括 GARCH(p, q) 模 型 (Bollerslev, 1986) 由 𝑔𝑡(𝑎𝑠, 𝜎𝑠; 𝑠 ≤ 𝑡 − 1) = 𝛼0+ ∑ 𝛼𝑖𝑎𝑡−𝑖2 + ∑ 𝛽 𝑖𝜎𝑡−𝑖2 𝑞 𝑖=1 𝑝 𝑖=1 獲得,以及 EGARCH 模型(Nelson,1990)。 此 外,ARMA 模型也可以在模型(11)的條件期望值𝜇𝑡中獲得。 將GARCH-t 模型配適的報酬 𝑟𝑖, 𝑖 = 1, … , 𝑡 之後,可以得到在ℱ𝑡為條 件下的𝑟𝑡+1,其𝛼-分位數(0 < 𝛼 < 1) 近似於下式 𝑞𝑟 𝑡+1|ℱ𝑡 (𝛼) = 𝜇̂𝑡+1+ √𝑣̂−2 𝑣̂ 𝑡𝑣̂,𝛼𝜎̂𝑡+1 (12)
21 其中𝜎̂𝑡+12 = 𝑔 𝑡(𝑎̂𝑠, 𝜎̂𝑠; 𝜽̂, 𝑠 ≤ 𝑡 − 1)和𝑡𝑣̂,α是𝑡(𝑣̂)分佈的𝛼 -分位數。在實際 資料中,𝛼通常設定為 0.01 或 0.05。此外,由於我們考慮每日報酬,因此 𝑟𝑡的平均值接近 0,造成(12)中定義的𝑞𝑟 𝑡+1|ℱ𝑡 (𝛼) 對於小𝛼是負的。 因此, 給定ℱ𝑡的時間𝑡 + 1的條件 VaR 可以通過估計 VaR𝐺𝑡+1= 𝑃𝑡× {1 − exp (𝑞𝑟 𝑡+1|ℱ𝑡 (𝛼) )} (13) 其 表 示從 時間 𝑡 到𝑡 + 1的水平𝛼 的估計損失。在該研究中,通過使用 (13)獲得的估計的 VaR 過程被稱為VaR𝐺。 例如,觀察2006 年 1 月至 2017 年 12 月標準普爾 500 指數的每日指數,並 由AR(1)-GARCH(1,1)模型描述,該模型是(11)的一個特例,在移動窗 口方法下,窗口大小為 250 天。圖 1 顯示了上述時間段內的每日損失𝑃𝑡− 𝑃𝑡+1以及(13)中定義的相關VaR𝐺序列,為了評估VaR𝐺估計的表現,我們 計算了11 年中每一年的每日損失超過每日VaR𝐺的數字,即5, 5, 4, 8, 6, 3, 2, 6, 7, 2 和 4 個。這些超限數量皆小於 10,符合巴塞爾協議中,每 250 天 的超限數上限值,但我們同樣採用 Kupiec(1995)提出的測試統計數據來 驗證年度VaR𝐺的準確性。根據Kupiec(1995)一年(約 250 天)的超限數 量的臨界值在 6 到 7 之間。結果顯示,VaR𝐺在這些年中具有可接受的性 質。由於 VaR 可以被視為單邊區間預測,我們採用 Christoffersen(1998) 提 出 的 區 間 預 測 之 覆 蓋 和 獨 立 性 聯 合 測 試 來 評 估 VaR𝐺的 特 性 。 Christoffersen(1998)對VaR𝐺進行了 11 年的 p 值顯示在表 1 中,表 1 中
VaR𝐺一樣通過Christoffersen(1998)的測試,大多數的年份之 p-value 顯著
性水平為0.01。
VaR𝐺的另一個特點是波動頻繁,這導致市場風險資本經常變化,對交易者
和財務管理來說不是一個好的財產。在巴塞爾協議中,根據內部模型方法 計算的一般市場風險的資本要求由下式定義
22 max {VaR𝑡, 𝑘 60∑ VaR𝑡−𝑖 59 𝑖=0 } + 𝐶, (14) 其中VaR𝑡表示在時間t 的估計 VaR,𝐶是常數,k 是表 3 中定義的比例因子 (Hendricks 和 Hirtle,1997)。通常,VaR𝑡是基於ℱ𝑡在𝛼 = 0.01之下,10 天 的 VaR 估計,並且應用在實際中近似於√10 × VaR𝐺𝑡+1。簡單來說,我們只 需計算其值 𝐶𝑅𝑡 = max {VaR𝑡+1𝐺 , 𝑘 60∑ VaR𝑡−𝑖+1 𝐺 59 𝑖=0 } (15) 基於本研究中的日常 VaR。 從(14)開始,𝐶𝑅𝑡大致上取決於 VaR 的估 計。如果VaR 波動較大,則需要更頻繁地調整相應的資本要求。 如圖 1 所 示,VaR𝐺過程具有強烈的波動。為了減少波動性,我們將此應用過程應用
於GNIR 上,如第三章之步驟方法,得出NVaR1和NVaR2。
4.1.2 降低風險值波動-實證結果(GSPC) 觀察研究提出的NVaR1和NVaR2的表現,實證研究採用2006 年 1 月至 2017 年12 月的澳洲、印度、巴西、英國、法國、德國、美國、加拿大、香港、馬來 西亞、南韓、新加玻、日本等 13 個全球市場每日指數。使用移動窗口法,由 2006 年開始建模,窗口大小為 250 天,因此計算 2007 - 2017 年每年 VaR 的年變 動量、年平均變動標準差及年期望短缺以比較它們的波動,以及呈現 2007 - 2017 年期間VaR𝐺、NVaR1和NVaR2的回溯測試結果。而回溯測試過程是通過將
VaR 估計的最後 250 個每日預測損失與實際損失進行比較來進行的。然後通過 計算每年的超限數來評估 VaR 模型。如前所述,Kupiec(1995)建議的一年 (約250 天)的超限數應小於 7,這限制比表 3 中的紅色區域更嚴格。我們還呈 現了 Christoffersen(1998)測試的 p 值,以評估 VaR 的準確性。此外,計算從 不同 VaR 估計量獲得的 CR 年平均值、年變動量和年平均變動標準差,以比較 它們的特性。
23 一階變動量(First-order variation):
𝐹𝑉 = ∑|VaR𝑡 − VaR𝑡−1|
𝑛
𝑡=1
相對變化的標準差(The standard deviation of relative change -- RC):
𝑠𝑡𝑑𝑅𝐶 = { 1 𝑛 − 1∑(𝜂𝑡 − 𝜂̅ ) 2 𝑛 𝑡=1 } 0.5 ,
令𝜂𝑡 = (VaR𝑡− VaR𝑡−1)/VaR𝑡−1 and 𝜂̅ =1
𝑛∑ 𝜂𝑡
𝑛 𝑡=1
我們以 S&P500 指數為例來說明我們的研究,數值結果如表 1 及表 2 所示,我
們得出以下結論:
1. 在大多數的情況下,VaR𝐺、NVaR1和NVaR2的每年超限數均小於 10 且大部
份小於 7。由於 p 值不顯著,每年的VaR𝐺、NVaR1和NVaR2大多情況下都通
過了 Chrisoffersen(1998)的測試。因此,VaR𝐺、NVaR1和NVaR2之估計在
回測中具有良好的特性。
2. 圖 5 顯 示 了 S&P500 指 數 在 2007-2017 的 各 項 指 標 值 : 𝐹𝑉(NVaR1)/
𝐹𝑉(VaRG)、𝐹𝑉(NVaR2)/𝐹𝑉(VaR𝐺)、 𝑠𝑡𝑑
𝑅𝐶(NVaR1)/𝑠𝑡𝑑𝑅𝐶(VaR𝐺) 以 及
𝑠𝑡𝑑𝑅𝐶(NVaR2)/𝑠𝑡𝑑
𝑅𝐶(VaR𝐺)。NVaR1和NVaR2的平均變動量(FV)和平均變
動標準差(𝑠𝑡𝑑𝑅𝐶)皆小於VaR𝐺的平均變動量和平均變動標準差。 因此,兩
次測量都表現出,所提出的NVaR1和NVaR2確實顯著降低了VaR𝐺的波動。
從表 1 可以看出,NVaR2在變動量和變動標準差方面表現最佳。然而,我 們還進一步展示了 風險值估計的期望短缺 (ES),此為一致性風險度 (Acerbi、Tasche, 2002),在此表現中NVaR1具有最小的平均期望短缺。 3. 圖 6 顯示了 2007-2017 年 S&P500 的每年資本準備金各項指標之 比 率 𝐴𝑣𝑒(CR1)/𝐴𝑣𝑒(CR𝐺) 、 𝐴𝑣𝑒(CR2)/𝐴𝑣𝑒(CR𝐺) 、 𝐹𝑉(CR1)/ 𝐹𝑉(CR𝐺) 、 𝐹𝑉(CR2)/𝐹𝑉(CR𝐺) 、 𝑠𝑡𝑑 𝑅𝐶(CR1)/𝑠𝑡𝑑𝑅𝐶(CR𝐺) 以 及 𝑠𝑡𝑑𝑅𝐶(CR2)/𝑠𝑡𝑑 𝑅𝐶(CR𝐺) , 其 中 𝐴𝑣𝑒(CR𝑖),𝑖 = 1,2 ,G , 表 示 從
24
NVaR1、NVaR2和VaR𝐺獲得的平均資本準備金(CR)。VaR𝐺,NVaR1和
NVaR2的資本準備金(CR)年平均值是可比較的。 然而,從NVaR1和
NVaR2計算的資本準備金的年平均動量(FV)和年平均變動標準差
(𝑠𝑡𝑑𝑅𝐶 )小於與VaR𝐺計算的資本準備金年平均動量和年平均變動標
準差。這些現象表明NVaR1和NVaR2具有比VaR𝐺更穩定的資本準備
金,且具有與VaR𝐺相當的資本準備金。
4.2 風險狀態及關聯分析
前一節已描述了VaR𝐺、NVaR1及NVaR2之間的比較,而在運用GNIR 模型估
計NVaR1及NVaR2的過程中,定義了三個參數 c、𝜆 1、𝜆2,其中 c 代表的是趨勢 的權重,而𝜆1及𝜆2分別為上下趨勢之懲罰係數。此章節首先藉由各國每日風險 指數之歷史數據以及其參數的代表意義建立出每一個市場的風險狀態( risk status, 簡記 RS),並估計其隔日的風險狀態。接下來,透過關聯分析建立各金 融市場間存在的關聯性,以反映全球經濟互相牽引的現象,並提升各金融市場 風險狀態預測的準確度,以下將詳細說明。 我們考慮兩種時間長度來建立模型,第一種使用 2005~2016 年作為建模資 料,對 2017 年的資料做風險狀態預測,另一種使用移動窗口的方法,移動窗口 為450 天(一年資料約為 225 日,採用 2 年,簡記 N 時間),此以移動窗口法作為 細節範例,令𝑡為當前時間,RŜ𝑡+1則表示提前一步預測時間𝑡 + 1時 RS 所對應的 估計量,RŜ∗ 𝑡+1為使用關聯分析預測之估計量。 移動窗口的方法預測隔日之風險狀態,步驟如下: 1. 原始預測(方法一): I. GNIR 模 型 估 計 之 每 日 風 險 指 數 並 無 分 級, 透 過 肘 部 法 則 (Elbow method)尋找分群最佳數目後,藉由模型中的每日變數𝑐𝑡、λ1𝑡、λ2𝑡、
25
VaR𝑡以及losst的變動量 ,使 用 K-平均演算法(K-Means)使其分成兩 群,決定VaR𝑡+1時RŜ𝑡+1 為高風險或低風險兩種類別(-1, 1) ,如圖9。 II. 接著分別觀察 2007~2017 年間,當狀態為高風險、低風險時之損失期 望值,以其作為原始觀測結果。 2. 加入關聯規則及網絡分析(方法二): I. 建立兩兩金融市場間的關聯性。首先定義低風險之損失上界與高風險 之損失下界,以建立 A、B 國之高風險定義下界為例,找出 A 國過去 𝑁天之狀態為高風險時,當日(𝑡 + 1時間)損失卻為負值(代表當日實際 為收益)的個數,定義為事件 A,而 B 國在前一日(t 時間) 損失卻為負 值的個數,定義為事件B,將事件 A、B 的數值經由網格收尋,選取其 大於負值 10%的界線開始依次增加,每次增加10%直到100% (數值 0),接著取兩事件界限之交集,運用在關聯規則中的作用度(𝐿𝑖𝑓𝑡)作為 選 取 標 準 ( 𝐿𝑖𝑓𝑡 = 𝑃(A|B) − 𝑃(A) > 0 ), 總 共 有 10 × 10 種 選 取 組 合,取作用度最高的組合作為最佳界線,以此代表高風險的損失下 界,圖 9 為選取界線之示意圖(藍色虛線、紅色虛線為其界限選取組 合,藍區、紅區分別代表事件 A、B 損失小於界線的區域)。當損失 (loss)大於低風險之上界,代表當日雖為低風險但損失卻達到一定程度 以上;當損失小於高風險下界,代表當日雖為高風險但收益卻達到一 定程度以上,而低風險的損失上界定義亦如此。 II. 因時區關係導致各金融市場收盤時間有所不同,因此我們將 13 個市場 估計之歷史每日風險指數按時區建立關聯性,分別依序為澳洲、日 本、韓國、馬來西亞、新加玻、香港、印度、法國、德國、英國、巴 西、加拿大及美國,接著定義各國間的關係,進而估計RŜ∗ 𝑡+1。
26 以下藉由建立美國與巴西股市下跌的關聯性作為例子,按照時區若觀 察目標 為 巴西 的風險狀態(RŜ𝑡+1BK )則要使用前一日的美國風險狀態 (RŜ𝑡USA)來建立彼此間的關聯性: 事件A: 定義在一段歷史時間(𝑁)內,當巴西股市在高風險(RSBK = −1) 時,卻為收益(損失<高風險下界)的次數 𝑃(A) =巴西股市為高風險狀態時,當日巴西股市損失為負之次數 𝑁 事件 B: 定義在一段歷史時間(𝑁)內,距離巴西股市為高風險時,最近 的美國股市為收益(損失<高風險下界)的次數 𝑃(B) =巴西股市高風險狀態時,前一日美股損失為負之次數 𝑁 支持度(𝑆𝑢𝑝𝑝𝑜𝑟𝑡): 定義在一段歷史時間(𝑁)內,事件 A、B 同時發生的 機率 𝑆𝑢𝑝𝑝𝑜𝑟𝑡 = 𝑃(A ∩ B) > 0.1 可信度(𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒): 定義為在事件 B 發生的條件下事件 A、B 同時發 生的機率 𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 =𝑆𝑢𝑝𝑝𝑜𝑟𝑡 𝑃(B) > 0.65 作用度(𝐿𝑖𝑓𝑡): 檢定其兩者在統計意義上並不獨立,確立兩者擁有關聯 𝐿𝑖𝑓𝑡 =𝑃(A|B) 𝑃(𝐴) > 1 若滿足以上三種條件,我們將視兩個市場在𝑁時間內有關聯性;若不 滿足其中任一項,則視此兩市場在𝑁時間內無關聯。 III. 當兩市場間確立有關聯性時,其觀察目標之風險狀態(RŜ∗ 𝑡+1 BK )則參考前 一日美股的損失作為估計 ∶ 藉由方法一估計出目標之風險狀態為高風
27 險(RŜ𝑡+1BK = −1 ),但前一日美股為收益 (loss < 0 )並且收益小於高風險 狀態之損失下界,則目標之風險狀態估計為RŜ∗ 𝑡+1 BK = 1;反之,當股 市上漲時採用手法亦相同。 IV. 觀察 2007~2017 年間,使用關聯分析後的風險狀態分類,當狀態為高 風險、低風險時之損失期望值,作為使用關聯分析後的觀測結果,因 目前我們只研究兩兩國家間的關聯性,為更清楚觀察全局以及是否有 多國影響單一國家或單一國家影響多國等特性,將關聯分析的結果以 每年作網絡圖視覺化呈現,進而解釋其網絡的特徵,本研究取用網絡 密度及網絡中心作為觀察指標,而網絡密度(degree centrality, 以𝐶𝐷表 示)即用於觀察網絡圖中節點間互相連邊的密集程度,於此表示該年金 融市場互相牽引程度強弱,定義之算式如下: 𝐶𝐷 = 2𝐿 𝑁(𝑁 − 1) 其中𝑁為節點總數,此為國家總數量 13 個,𝐿為連線的數目,此代表 國 家 與 國 家 連 線 的 總 數 目 , 而 網 絡 密 度 又 可 分 成 出 度 密 度(out- degree,此以𝐷𝑜𝑢𝑡表示)及入度密度(in-degree, 此以𝐷𝑖𝑛表示) ,定義之 算式分別如下: 𝐷𝑜𝑢𝑡 = 𝐿𝑜𝑢𝑡 𝑁 − 1, 𝐷𝑖𝑛 = 𝐿𝑖𝑛 𝑁 − 1 其中出度密度在此代表對他國影響的程度強弱,入度密度表示被他國 影響的程度強弱,而網絡中間中心性( betweenness centrality, 以𝐶𝐵表 示 )定義為以經過某個節點的最短路徑數目來刻畫節點重要性的指 標,而網絡中間中心性之定義算式如下: 𝐶𝐵 = 𝐿 𝑁 − 1
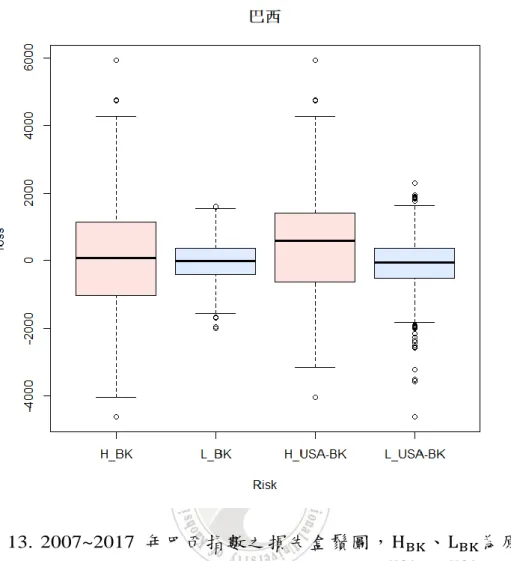
28 在此取該年平均影響最多的國家作為網絡中心。最後以指標帶來的資 訊作為網絡關係的觀測結果。 4.2.1 風險狀態及關聯分析-實證結果 研究結果指出,單獨使用金融市場各自對隔天進行風險狀態估計,與經過 關聯分析後估計的風險狀態相比較,明顯地發現,若兩國間確定有關聯,使用 他國股市提前一步的風險狀態可以良好的輔助預測各國股市風險狀態,以致高 低風險的損失期望值更為準確。 使用不同時間長度建立模型,也會使國家彼此間的相關性有許多影響,若 透過較長時間建模,將可能因年限過長無法及時反映國家彼此間的相關性,而 使用移動窗口法較能依照短期趨勢反映當時的相關性且預測結果較佳,但當國 家間確定有相關性時,這兩種方法都能有效的輔助預測。而對於不同百分比制 定出的高低風險之下上界線,也會建立不同強度的相關性,比例越低表示標準 越嚴格,本研究依照關聯規則選取作用性最大,作為此國家相關性最強的比例 作為界線的取用依據,也可以使用其他規則做選取。 我們展示 13 個金融市場在 2007~2017 年間彼此關聯性的研究結果,如表 4, 因目前我們只研究兩兩國家間的關聯性,為更清楚觀察全局以及是否有多國影 響單一國家或單一國家影響多國等特性,將關聯分析的結果以每年作網絡圖視 覺化呈現,如圖 16,以檢視國家間在每年的影響程度,最後我們得出以下結 論: 1. 使用關聯分析後,若有關聯性將明顯的增加高風險及低風險分類狀態的準 確度,使得高低風險的損失期望值更加明顯,此以美股預測巴股為範例, 參考圖 10、圖 11。 2. 同時經由威爾寇克遜檢定(Wilcoxon test)來檢定方法一及方法二的高低風險 狀態是否有差異,亦透過柯史檢定(KS test)來檢定這兩種方法的定義的風險
29 狀態分布。此以美國與巴西指數作為檢定的成果例子,我們定義巴西原始 高、低風險狀態(方法一),簡記HBK、LBK;而由美國估計巴西高低風險狀 態(方法二),簡記HBKUSA、L BK USA,檢定結果顯示,H BK、LBK的差異並不明 顯,但 HBKUSA、L BK USA有顯著的差異,其p 值 < 0.001,並呈現盒鬚圖於圖 11;而風險狀態在關聯分析前後的差異於高風險狀態(HBK、HBKUSA)是顯著 的,其p 值 < 0.001,爾後呈現其經驗累績分布圖於圖 12 及分布圖 13,可 觀察出HBKUSA有往右移的現象,代表使用關聯分析後的確能夠使高風險狀 態的捕捉更加精確。雖然方法一及方法二的低風險狀態檢定並沒有顯著差 異,但由圖 13 可看出,藍線依然又往左偏移的現象,表示使用關聯分析後 仍有捕捉到更多低風險的狀態。 3. 可從表中發現某些國家跟漲不跟跌、跟跌不跟漲或跟漲亦跟跌,以美國輔 助預測他國為例,觀察出德國、英國、巴西及加拿大與美國的關係較為強 烈,屬於跟漲亦跟跌的國家,而 Kasa(1992)亦提出這些市場之間存在共 同的隨機趨勢。 4. 由網絡圖,如圖 16,亦可看出,當發生國際重大事件時各國之間將會互相 牽引,例如 : 2007~2008 年美國次級房貸風暴對全球經濟產生影響,由網 絡關係圖可看出影響較大的為歐美地區(黑線),因歐洲是全球最大的 CDO 產品市場,英、法、德皆受到美股的影響,雖新興市場及亞洲各國金融業 連結美國次級房貸不高,但龐大的基金贖回潮,亦使亞洲股市受到一些波 及。而次級房貸風暴造成全球股市巨幅波動,借入日圓買入高風險資產之 利差交易(carry trade)倉位出現平倉潮,日圓因而受到支撐上漲,這也良好 的解釋了網絡圖中美國與日本關係緊密的部分。2010~2011 年爆發歐債危 機,主要可看出歐盟國家互相牽引之外,香港與英國間因多年的殖民時 代,也依然有密不可分的關係。
30 5. 有趣的是,圖 17 中網絡密度及中心除了隨著時間變動之外,在 2015 年發生 的全球股災中可以看出主要影響國落在東亞地區,被影響國家為歐美區域 之國家,各報導也指出因為主要受到美國後 QE(量化寬鬆)時代、中國大陸 經濟趨緩等利空因素環環相扣,而引爆威力驚人的全球股災,由亞洲地區 首當其衝,接著才影響至歐股,此與本研究中計算出的網絡中心結果相 符。而在近年來的網絡中心都落在新加坡,新加坡為亞洲最依賴貿易的國 家,因隨中國需求復甦,帶動新加坡出口與經濟,進而與全球經濟貿易互 相牽引,但研究資料中未納入中國股市,反而將此現象反映在新加坡股市 中。
31
第五章 討論與建議
風險值(Value at risk, 簡記 VaR)根據國際清算銀行(Bank for International Settlements,簡稱 BIS)於 1996 年所發布巴塞爾修正案中,明訂將市場風險的計 算以風險值作為衡量的指標。風險值也被廣泛運用在資本適足率的計算、企業 內部之風險管控,或是資產配置等…參考依據,隨著風險值在市場上越來越重 要,各種估計方法也漸漸發展。本研究最大的貢獻即為提出一個新的無母數估 計方法GNIR,除了能夠結合傳統的風險值估計方法,亦能適應真實數據,並通 過回溯測試,使估計出的風險值有一定的準確度同時擁有平穩性,比原始估計 的風險值更加符合現今市場需求,進而衍生出估計市場的發展趨勢及風險狀 態。 本研究目前採用傳統 GARCH 模型估計之風險值結合 GNIR 估計,仍可更 換原始估計模型,依照需求挑選適當的原始模型,以達到研究最大效益,此方 法也可嘗試隨著挑選𝜆的手法運用在其他時間序列的資料上。此外採用所配適的 GNIR 定義出每一個市場的風險狀態序列,並同時使用關聯分析加強輔助預測, 而因目前本研究在關聯性的建模上僅對市場彼此間進行分析,若與某些國家無 關聯性時即不能加強預測,後續研究將針對這方面再進行加強。然而此研究亦 無決定該由特定國家作為預測國,但實際上這個問題也可透過關聯規則來解 決。 在研究過程中我們加入了網絡圖以方便觀察並對特徵分析,仍發現有許多 資訊可加以研究,例如是否可由網絡圖看出“跟漲不跟跌”或“跟跌不跟漲”的國 家,未來也可朝向多國對單一國家或多國對多國進行分析預測研究,甚至運用 網絡模型及特徵預測下一步的全球金融市場網絡圖,將此問題持續深入研究。
32
參考文獻
[1] Acerbi, C. and Tasche, D. (2002). On the coherence of expected shortfall.
Journal of Banking and Finance 26, 1487–1503.
[2] Ayer, M., Brunk, H. D., Ewing, G. M., Reid, W. T., and Silverman, E. (1955).
An empirical distribution function for sampling with incomplete information. The Annals of Mathematical Statistics, 641-647.
[3] Bartholomew, D. J. (1959a). A test of homogeneity for ordered
alternatives. Biometrika, 46, 36-48.
[4] Bartholomew, D. J. (1959b). A test of homogeneity for ordered alternatives.
II. Biometrika, 46, 328-335.
[5] Brunk, H. D. (1955). Maximum likelihood estimates of monotone
parameters. The Annals of Mathematical Statistics, 607-616.
[6] Barlow, R. E., Bartholomew, D., Bremner, J. M. and Brunk, H. D. (1972).
Statistical Inference under Order Restrictions: The Theory and Application of Isotonic Regression. Wiley: New York.
[7] Basel Committee of Banking Supervision (1996). Supervisory Framework
For The Use of “Backtesting” in Conjunction With The Internal Models Approach to Market Risk Capital Requirements. Available at www.bis.org.
[8] Basel Committee of Banking Supervision (2006). International
Convergence of Capital Measurement and Capital Standards-A Revised Framework, Comprehensive Version. Available at www.bis.org.
[9] Beder, T. S. (1995). VAR: Seductive but dangerous. Financial Analysts
Journal, 51, 12-24.
[10] Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. J. Econometrics 31, 307–327.
[11] Brown, S. J., and Warner, J. B. (1980). Measuring security price performance. Journal of Financial Economics, 8, 205-258.
[12] Campbell, S. D. (2006). A review of backtesting and backtesting procedures. J. Risk 9, 1.
[13] Chrisoffersen, P. F. (1998). Evaluating interval forecasts. International
Economic Review 4, 841-862.
[14] Grotzinger, S. J., and Witzgall, C. (1984). Projections onto order simplexes. Applied mathematics and Optimization, 12, 247-270.
[15] Hendricks, D. and Hirtle, B. (1997). Bank capital requirements for market risk: The internal models approach. Federal Reserve Bank of
33
[16] Kasa, K. (1992). Common stochastic trends in international stock markets. Journal of Monetary Economics, 29, 95-124.
[17] Kupiec, P. (1995). Techniques for Verifying the Accuracy of Risk Measurement Models. Journal of Derivatives 3, 73–84.
[18] Luss, R., Rosset, S., and Shahar, M. (2010). Decomposing isotonic regression for efficiently solving large problems. In Advances in Neural
Information Processing Systems, 1513-1521.
[19] Mair, P., Hornik, K., & de Leeuw, J. (2009). Isotone optimization in R: pool-adjacent-violators algorithm (PAVA) and active set methods. Journal of
Statistical Software, 32, 1-24.
[20] Nelson, D. B. (1990). Stationarity and persistence in the GARCH(l,l) model. Econometric Theory 6, 318–334.
[21] Tibshirani, R. J., Hoefling, H. and Tibshirani, R. (2011). Nearly-isotonic regression. Technometrics 53, 54-61.
[22] Tsay, R. S. (2010). Analysis of Financial Time Series. John Wiley & Sons: New Jersey.
34
附錄
附錄 1 證明 𝑦̂𝑖𝑠𝑜 = 𝑎𝑟𝑔𝑚𝑖𝑛 𝑦̂∈𝑅𝑛 1 2∑ (𝑦𝑖 − 𝑦̂𝑖)² 𝑛 𝑖=1 + 𝜆1∑𝑛−1𝑖=1(𝑦̂𝑖 − 𝑦̂𝑖+1)+𝜆2∑𝑛−1𝑖=1(𝑦̂𝑖+1− 𝑦̂𝑖)+ 具有凸性質。The Hessian ∇2𝑓(𝑥) is a symmetric 𝑛 × 𝑛 matrix whose entries are the second-order partial derivatives of 𝑓 at 𝑥 :
[𝛻2𝑓(𝑥)]𝑖𝑗 = 𝜕2𝑓(𝑥)
𝜕𝑥𝑖𝜕𝑥𝑗 , for i , j = 1, ..., n
2nd-order conditions: For a twice differentiable f with
f is convex if and only if
∇2𝑓(𝑥) ≥ 0 for all x ∈ dom(𝑓) According to the definition of convex :
𝑓(𝑦̂) =1 2∑(𝑦𝑖 − 𝑦̂𝑖)² 𝑛 𝑖=1 + 𝜆1∑(𝑦̂𝑖 − 𝑦̂𝑖+1)+ 𝑛−1 𝑖=1 + 𝜆2∑(𝑦̂𝑖+1− 𝑦̂𝑖)+ 𝑛−1 𝑖=1 1. If 𝑦̂𝑖 − 𝑦̂𝑖+1> 0 𝜕𝑓 𝜕𝛽𝑖 = − ∑ (𝑦𝑖 − 𝑦̂𝑖 ) 𝑛 𝑖=1 + 𝜆1+0 𝜕𝑓 𝜕𝛽𝑖𝜕𝛽𝑗 = 1 ≥ 0 2. If 𝑦̂𝑖 − 𝑦̂𝑖+1< 0 𝜕𝑓 𝜕𝛽𝑖 = − ∑ (𝑦𝑖 − 𝑦̂𝑖 ) 𝑛 𝑖=1 + 0 + 𝜆2 𝜕𝑓 𝜕𝛽𝑖𝜕𝛽𝑗 = 1 ≥ 0 證明凸性質 𝑓 is a convex function.
35
表格目錄
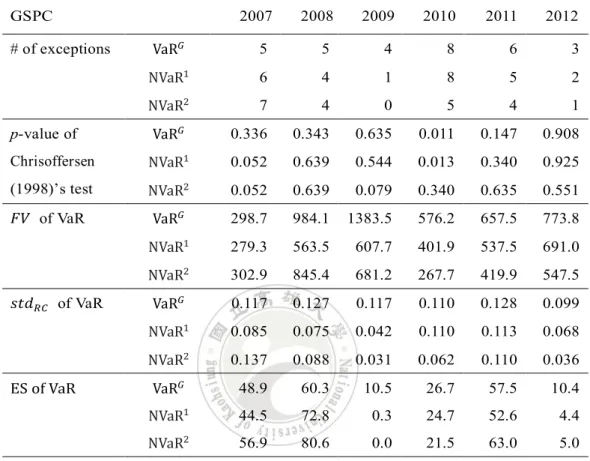
表 1. 超限數、Chrisoffersen(1998)測試的 p 值及VaR𝐺、NVaR1、NVaR2每年平均
之變動量、變動標準差與期望短缺。 GSPC 2007 2008 2009 2010 2011 2012 # of exceptions VaR𝐺 5 5 4 8 6 3 NVaR1 6 4 1 8 5 2 NVaR2 7 4 0 5 4 1 p-value of Chrisoffersen (1998)’s test VaR𝐺 0.336 0.343 0.635 0.011 0.147 0.908 NVaR1 0.052 0.639 0.544 0.013 0.340 0.925 NVaR2 0.052 0.639 0.079 0.340 0.635 0.551 𝐹𝑉 of VaR VaR𝐺 298.7 984.1 1383.5 576.2 657.5 773.8 NVaR1 279.3 563.5 607.7 401.9 537.5 691.0 NVaR2 302.9 845.4 681.2 267.7 419.9 547.5 𝑠𝑡𝑑𝑅𝐶 of VaR VaR𝐺 0.117 0.127 0.117 0.110 0.128 0.099 NVaR1 0.085 0.075 0.042 0.110 0.113 0.068 NVaR2 0.137 0.088 0.031 0.062 0.110 0.036 ES of VaR VaR𝐺 48.9 60.3 10.5 26.7 57.5 10.4 NVaR1 44.5 72.8 0.3 24.7 52.6 4.4 NVaR2 56.9 80.6 0.0 21.5 63.0 5.0
36 表 1.(續) GSPC 2013 2014 2015 2016 2017 Ave. # of exceptions VaR𝐺 2 6 7 2 4 4.7 NVaR1 2 6 3 2 3 3.8 NVaR2 2 6 3 2 2 3.3 p-value of Chrisoffersen (1998)’s test VaR𝐺 0.921 0.147 0.001 0.921 0.627 NVaR1 0.921 0.147 0.062 0.921 0.908 NVaR2 0.921 0.147 0.062 0.921 0.925 𝐹𝑉 of VaR VaR𝐺 389.5 573.8 1051.0 1270.0 832.4 799.2 NVaR1 278.8 294.3 607.2 644.0 423.8 484.5 NVaR2 175.5 255.7 592.3 636.1 373.3 463.4 𝑠𝑡𝑑𝑅𝐶 of VaR VaR𝐺 0.112 0.114 0.188 0.216 0.140 0.134 NVaR1 0.048 0.082 0.110 0.079 0.082 0.081 NVaR2 0.039 0.078 0.118 0.075 0.075 0.075 ES of VaR VaR𝐺 12.1 42.2 52.4 66.8 27.1 37.7 NVaR1 13.1 41.2 35.9 63.0 19.7 33.8 NVaR2 14.5 44.1 47.5 55.6 19.2 37.1
37
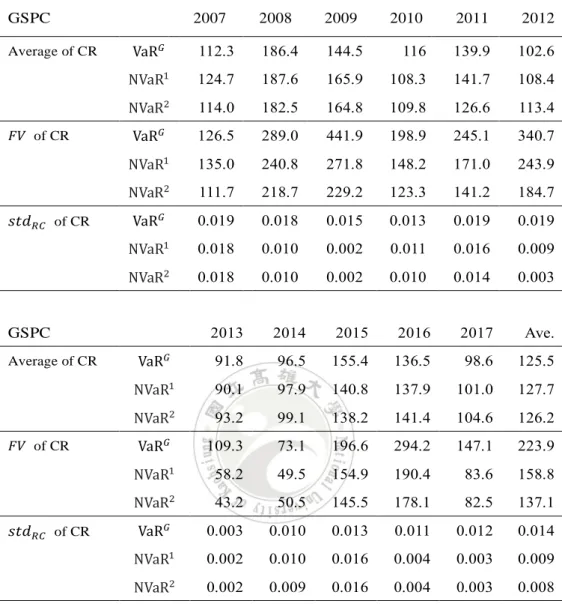
表2. 由VaR𝐺、NVaR1及NVaR2估計量計算的每年平均 CR 值、變動量和變動 標準差。 GSPC 2007 2008 2009 2010 2011 2012 Average of CR VaR𝐺 112.3 186.4 144.5 116 139.9 102.6 NVaR1 124.7 187.6 165.9 108.3 141.7 108.4 NVaR2 114.0 182.5 164.8 109.8 126.6 113.4 𝐹𝑉 of CR VaR𝐺 126.5 289.0 441.9 198.9 245.1 340.7 NVaR1 135.0 240.8 271.8 148.2 171.0 243.9 NVaR2 111.7 218.7 229.2 123.3 141.2 184.7 𝑠𝑡𝑑𝑅𝐶 of CR VaR𝐺 0.019 0.018 0.015 0.013 0.019 0.019 NVaR1 0.018 0.010 0.002 0.011 0.016 0.009 NVaR2 0.018 0.010 0.002 0.010 0.014 0.003 GSPC 2013 2014 2015 2016 2017 Ave. Average of CR VaR𝐺 91.8 96.5 155.4 136.5 98.6 125.5 NVaR1 90.1 97.9 140.8 137.9 101.0 127.7 NVaR2 93.2 99.1 138.2 141.4 104.6 126.2 𝐹𝑉 of CR VaR𝐺 109.3 73.1 196.6 294.2 147.1 223.9 NVaR1 58.2 49.5 154.9 190.4 83.6 158.8 NVaR2 43.2 50.5 145.5 178.1 82.5 137.1 𝑠𝑡𝑑𝑅𝐶 of CR VaR𝐺 0.003 0.010 0.013 0.011 0.012 0.014 NVaR1 0.002 0.010 0.016 0.004 0.003 0.009 NVaR2 0.002 0.009 0.016 0.004 0.003 0.008
38
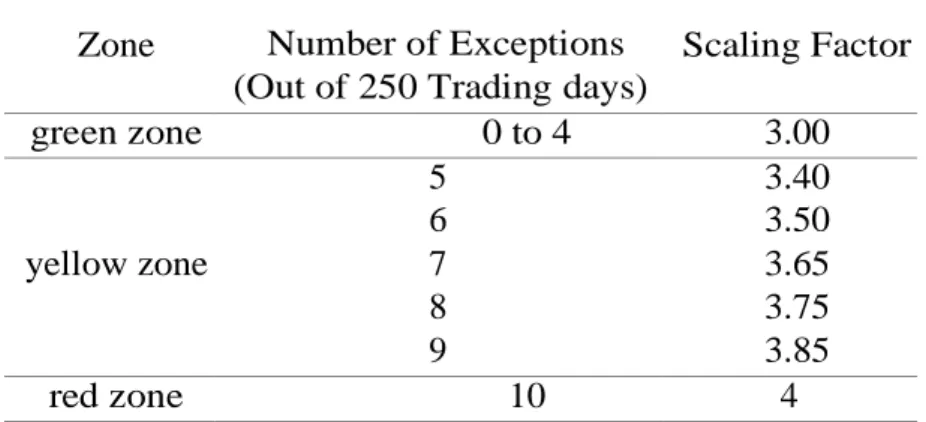
表3. Scaling factors Zone Number of Exceptions
(Out of 250 Trading days) Days) Scaling Factor green zone 0 to 4 3.00 5 3.40 6 3.50 yellow zone 7 3.65 8 3.75 9 3.85 red zone 10 4
39 t+1 表 4. 高低風險損失期望值列表,使用作用度(𝑙𝑖𝑓𝑡)最高時的百分比組 合作為最佳界線,來呈現各國相互估計列表,其中A1~A13代表事件 A,依序為美國、澳洲、日本、韓國、馬來西亞、新加玻、香港、印度、法 國、德國、英國、巴西及加拿大,而B1~B13代表事件 B,國家排序與事件 A 相同,綠色區塊為自身估計值,白色區塊為依時區的差一步當日預 測,黃色區塊為差一步的跨日預測。 高風險損失期望值 t A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 B1 0.26 6.18 4.59 1.65 0.16 2.24 -13.79 -2.08 9.15 14.69 9.05 307.18 68.64 B2 0.26 5.34 24.95 6.11 1.33 12.84 80.24 5.57 10.26 10.45 13.61 62.19 18.34 B3 0.42 5.34 4.59 11.79 2.89 15.98 151.91 21.11 11.02 9.67 3.72 48.53 9.76 B4 0.13 5.71 4.59 1.35 4.05 15.89 148.81 16.62 11.84 9.38 8.68 58.14 15.24 B5 0.26 5.51 4.59 1.14 0.19 14.95 164.55 24.73 7.26 8.14 7.96 47.24 15.29 B6 0.26 5.28 4.59 1.49 0.13 1.93 191.02 89.20 30.56 12.89 17.70 59.99 14.14 B7 0.26 5.34 4.59 1.31 0.17 1.94 -12.98 64.42 12.08 11.60 11.83 48.43 11.22 B8 0.26 5.46 4.59 1.54 0.19 1.87 0.07 -0.84 23.12 14.22 15.26 84.98 12.10 B9 0.26 5.34 4.59 1.93 0.26 2.90 -4.63 1.79 3.81 78.62 49.27 321.28 57.00 B10 0.26 5.82 4.59 2.05 0.33 2.65 2.27 4.56 5.14 9.22 48.24 283.26 40.42 B11 0.26 5.88 4.59 2.15 0.26 2.46 15.76 0.24 3.65 9.23 2.19 302.50 61.22 B12 0.43 5.51 4.89 2.38 0.58 2.18 39.08 6.09 3.53 8.47 1.94 50.54 85.74 B13 0.28 5.37 5.77 2.32 0.80 2.15 16.73 4.12 3.62 8.77 2.19 49.66 7.83
40 t+1 表4(續). 低風險損失期望值 t A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 B1 -0.73 -1.19 -3.37 -0.71 -0.54 -0.30 -0.06 -3.90 -1.83 -4.51 -2.77 -70.03 -21.10 B2 -0.87 -1.05 -17.88 -1.36 -1.07 -2.55 -21.74 -7.23 -1.31 -3.19 -2.07 -4.27 -5.68 B3 -0.70 -1.05 -3.37 -5.23 -1.58 -3.82 -48.72 -12.61 -1.50 -3.07 -0.35 0.82 -3.40 B4 -0.79 -1.12 -3.37 -0.69 -1.74 -4.06 -75.74 -11.19 -1.39 -2.94 -1.08 -2.72 -5.03 B5 -0.72 -1.09 -3.37 -0.64 -0.57 -3.11 -47.05 -13.79 -0.69 -2.32 -0.85 1.54 -4.94 B6 -0.72 -1.03 -3.37 -0.70 -0.52 -0.17 -101.57 -53.83 -4.16 -3.97 -2.91 -3.75 -4.70 B7 -0.69 -1.05 -3.37 -0.66 -0.53 -0.17 -0.33 -44.24 -1.62 -3.58 -1.76 1.06 -4.02 B8 -0.69 -1.07 -3.37 -0.71 -0.57 -0.15 -14.59 -4.58 -3.45 -4.33 -2.32 -11.98 -4.20 B9 -0.73 -1.05 -3.37 -0.78 -0.56 -0.47 -2.90 -5.84 0.19 -56.97 -37.34 -75.88 -13.18 B10 -0.73 -1.15 -3.37 -0.80 -0.65 -0.40 -4.74 -6.92 -0.15 -2.94 -34.40 -74.86 -11.78 B11 -0.74 -1.15 -3.37 -0.82 -0.53 -0.35 -7.55 -5.10 0.26 -2.96 -0.79 -66.03 -17.82 B12 -0.83 -1.10 -3.46 -0.85 -0.76 -0.29 -12.18 -7.73 0.33 -2.60 -0.89 -0.44 -22.99 B13 -0.77 -1.01 -3.91 -0.84 -0.81 -0.23 -7.71 -6.87 0.27 -2.74 -0.79 -0.22 -3.20
41
圖目錄
圖 1. S&P500 從 2006 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡+1 (黑色實線)和 2007 年 1 月至 2017 年 12 月的VaR𝐺(紅色虛線) 在(3)式中定義,移動窗口方法之窗口大小為 250 天,α = 0.01。 圖 2. S&P500 從 2006 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡+1 (黑色實線)和 2007 年 1 月至 2017 年 12 月的VaR𝐺(紅色虛線) 在(3)式中定義,以及 2007 年 1 月至 2017 年 12 月的NVaR1(藍 色實線)在(6)式定義,移動窗口方法下窗口大小為 250 天,水 平 α = 0.01。42 圖 3. S&P500 從 2006 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡+1 (黑色實線)和 2007 年 1 月至 2017 年 12 月的VaR𝐺(紅色虛線) 在(3)式中定義,以及 2007 年 1 月至 2017 年 12 月的NVaR2(藍 色實線)在(6)式定義,移動窗口方法下窗口大小為 250 天,水 平 α = 0.01。 圖 4. S&P500 從 2007 年 1 月至 2017 年 12 月的每日損失𝑃𝑡 − 𝑃𝑡+1 (黑色實線)、VaR𝐺(紅色實線)與VaR𝐺的 CR(紅色虛線)、
NVaR1(藍色實線)與NVaR1的 CR(藍色虛線)及NVaR2(綠色
43
圖 5. 2007-2017 年 S&P500 之各項指標比率𝐹𝑉(NVaR1)/𝐹𝑉(VaR𝐺)
(黑色實線)、𝐹𝑉(NVaR2)/𝐹𝑉(VaR𝐺)(紅色實線)、𝑠𝑡𝑑
𝑅𝐶(NVaR1)/
𝑠𝑡𝑑𝑅𝐶(VaR𝐺)(黑色虛線)以及𝑠𝑡𝑑𝑅𝐶(NVaR2)/𝑠𝑡𝑑𝑅𝐶(VaR𝐺) (紅色虛
線)。 圖 6. 2007-2017 年 S&P500 的每年資本準備金各項指標之比較 𝐴𝑣𝑒(CR1)/𝐴𝑣𝑒(CR𝐺) ( 黑 色 實 線 ) 、 𝐴𝑣𝑒(CR2)/𝐴𝑣𝑒(CR𝐺) ( 紅 色 實 線)、 𝐹𝑉(CR1)/𝐹𝑉(CR𝐺)(黑色虛線 )、𝐹𝑉(CR2)/𝐹𝑉(CR𝐺)(紅色虛 線 ) 、 𝑠𝑡𝑑𝑅𝐶(CR1)/𝑠𝑡𝑑𝑅𝐶(CR𝐺) ( 黑 色 點 線 ) 以 及 𝑠𝑡𝑑𝑅𝐶(CR2)/ 𝑠𝑡𝑑𝑅𝐶(CR𝐺)(紅色點線)。
44
圖 7. 2007-2017 年 13 個全球金融市場指數之比率(a) 𝐹𝑉(VaR)、 (b) 𝐹𝑉(CR) 、 (c) 𝑠𝑡𝑑𝑅𝐶(VaR) 、 (d) 𝑠𝑡𝑑𝑅𝐶(CR) 、 (e) ES 以 及 (f) 𝐴𝑣𝑒(CR)。
45 圖 8.GNIR 步驟流程圖 每日風險指數之歷史數據 VaR𝑖𝐺, 𝑖 = 𝑡 − 𝑠, … , 𝑡, t > s > 0 獲得一步預測的VaR𝐺𝑡+1 NVaR𝑖𝑢, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1 −NVaR𝑖𝑑, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1 透過時間序列模型 通過(7)任意給定 c 通過超限數檢定 挑選(5)式中的懲罰項𝜅1 −NVaR̃ 𝑑𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1 −VaR𝑖𝐺, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1 VaR𝑖𝐺, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1 挑選(4)式中的懲罰項𝜅1 NVaR̃𝑢𝑖, 𝑖 = 𝑡 − 𝑠 + 1, … , 𝑡 + 1 GNIR GNIR 通過超限數檢定 通過 p 值檢定 𝑁𝑉𝑎𝑅̂ 𝑡+1⬚ = 𝑘𝑐𝑁𝑉𝑎𝑅𝑡+1𝑢 + (1 − 𝑘𝑐)𝑁𝑉𝑎𝑅𝑡+1𝑑 通過(8)任意給定 c 通過 p 值檢定 合併
46
圖 9. 透過所配適的 GNIR 定義出 2005~2017 年巴西指數的風險狀 態序列,紅線表示為高風險時期,藍線表示為低風險時期。
47 圖 10. 巴股當日(𝑡 + 1時間)判定為高風險狀態時的損失與前一日 (𝑡時間)的美股損失之高風險界線示意圖,取 0 為界線(灰色實線) 做網點收尋,藍色、紅色虛線分別為事件 A 及事件 B 之下界限選取組 合,藍區、紅區分代表事件 A、B 損失小於界線的區域。 Event A Event B