文件自動化摘要方法之研究及其在中文文件的應用
77
0
0
全文
(2) 文件自動化摘要方法之研究及其在中文文件的應用 研究生: 葉鎮源. 指導教授: 柯皓仁博士,楊維邦博士. 國立交通大學資訊科學研究所. 摘要 本論文提出了兩種新的文件摘要方法來摘錄原始文件中的重要語句。第一個 方法屬於以文件集為基礎的摘要技術(Corpus-based Approach),此方法基於統計 模型,利用特徵的分析來計算語句重要性。我們提出三個新的想法:1) 利用語 句位置重要性的分級以提高不同語句位置的重要性;2)利用詞彙相關程度(Word Co-occurrence)計算找出文件中的新詞,並將新詞加入關鍵詞重要性的計算,以 得到更精確的關鍵詞權重特徵值;3) 利用基因演算法訓練計算語句權重的 Score Function,以期了解訓練文件集的特性。第二個方法,我們結合潛在語意分析 (Latent Semantic Analysis)與主題相關地圖(Text Relationship Map)的概念,用來擷 取文件中的概念結構(Conceptual Structure)以期得到語意層面的分析。實驗中, 我們收集 100 篇新台灣週刊中關於政治類的文章,並將上述的兩種方法應用於中 文文件的摘要實驗上。效益評估結果顯示,我們所提的方法都有不錯的表現,在 壓縮比為 30%的情況下,平均來說,召回率分別為 52.0%及 45.6%。 關鍵字:中文文件摘要、以文件集為基礎的摘要技術、潛在語意分析、主題關係 地圖. II.
(3) 致謝 本論文的完成,首先感謝指導教授柯皓仁老師及楊維邦老師。他們的指導, 啟發我對於研究的興趣,並督導我學習研究的學問,更帶領我進入自然語言的研 究中。除了課業與研究的寶貴指點,生活與做人處事上,也給我不少的影響。 感謝實驗室的夥伴們,由於你們對我的關懷與照顧,讓我的研究生活變為一 種樂趣;並且感謝你們提供我寶貴的意見,讓我獲得許多新的想法。 謝謝圖書館計畫室的夥伴們在定期的報告討論時給我許多意見。另外,特別 感謝何佳欣及鄭怡君幫忙作實驗評估的部分,使得我論文得以順利的完成。 最後,感謝我親愛的家人與朋友們長久以來的支持與鼓勵,使我能專心致力 於研究,並得以順利完成學業。願以這篇論文與你們分享。. June 22, 2002. III.
(4) 目錄 英文摘要........................................................................................................................ I 中文摘要.......................................................................................................................II 致謝............................................................................................................................. III 目錄..............................................................................................................................IV 圖目錄..........................................................................................................................VI 表目錄........................................................................................................................ VII 方程式目錄...............................................................................................................VIII 第一章 第一節 第二節 第三節 第四節. 簡介................................................................................................................1. 第二章. 自動化資訊摘要........................................................................................1 研究動機....................................................................................................4 研究目的....................................................................................................5 論文架構....................................................................................................5. 第一節 第二節 第三節 第四節. 相關研究工作................................................................................................7. 第三章. 文件摘要相關研究....................................................................................7 以文件集為基礎的摘要技術..................................................................12 以主題關係地圖(Text Relationship Map)為基礎的摘要技術 ..............18 以語段模型(Discourse Model)為基礎的摘要技術 ...............................23. 第一節 第二節. 改良型語句權重摘要..................................................................................26. 第四章. 基本特徵值分析......................................................................................26 語句權重的計算與摘要生成..................................................................30. 第一節 第二節 第三節. 以潛在語意分析為基礎的語句摘要..........................................................34. 第五章. 潛在語意分析(Latent Semantic Analysis) ..............................................34 系統架構..................................................................................................39 語句分群與摘要生成..............................................................................41. 第一節 第二節 第三節 第四節. 實驗結果分析與評估..................................................................................46. 第六章. 實驗資料說明..........................................................................................46 評估方法..................................................................................................46 改良型語句權重摘要之效益評估..........................................................47 潛在語意分析語句摘要之可行性評估..................................................53 結論與未來研究方向..................................................................................59. IV.
(5) 第一節 第二節. 結論與討論..............................................................................................59 未來研究方向..........................................................................................60. 附錄一:實作系統展示..............................................................................................62 附錄二:範例文件......................................................................................................63 參考文獻......................................................................................................................67. V.
(6) 圖目錄 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 1:文件摘要系統架構概觀....................................................................................2 2:文件摘錄的範例................................................................................................8 3:相關研究工作..................................................................................................10 4:「以文件集為基礎的自動摘要技術」系統概觀............................................13 5:壓縮比對摘要系統正確率的影響..................................................................16 6:Text Relationship Map 的範例 ........................................................................19 7:Paragraph Relationship Map 與其對應的 Text Segmentation........................21 8:計算 Aggregate Similarity 的概念圖示 ..........................................................22 11:m-n 基因交配方法 ........................................................................................31 12:個體的基因組(M1,1, M1,2, M1,3 , M1,4, M1,5 )與其突變 ..................................32 13:Corpus-based 文件摘要生成演算法.............................................................32 14:LSA 工作原理示意圖 ...................................................................................35 15:LSA 文件摘要系統架構 ...............................................................................40 16:Word-by-Sentence 矩陣範例.........................................................................41 17:LSA 文件摘要生成演算法 ...........................................................................45 18:Modified Corpus-based Approach.................................................................62 19:LSA-based T.R.M. Approach.........................................................................62. VI.
(7) 表目錄 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格. 1:以文件集為基礎的摘要方法研究的比較..................................................17 2:Global Bushy Path, Depth- first Path 與 Segmented Bushy Path 的比較....22 3:Characteristics of Discourse Model Approach ............................................25 4:Lexical Chain 與 Co-reference Chain 的相異之處.....................................25 5:實驗文件集的統計特性..............................................................................46 6:考慮語句位置特徵時語句摘錄的召回率..................................................49 7:考慮正面關鍵詞特徵時語句摘錄的召回率..............................................49 8:考慮負面關鍵詞特徵時語句摘錄的召回率..............................................50 9:考慮與標題的相似度特徵時語句摘錄的召回率......................................50 10:考慮向心性特徵時語句摘錄的召回率....................................................51 11:利用詞彙相關程度所找到的部分新詞....................................................51 12:Original 與 Modified 的實驗數據比較(考慮所有的特徵)......................52 13:Original 與 Modified 的實驗數據比較(不考慮負面關鍵詞)..................52 14:利用基因演算法所得到的特徵權重組(不考慮負面關鍵詞) .................53 15:Modified 與 Modified+GA 的實驗數據比較(不考慮負面關鍵詞) ........53 16:以 LSA 與 Keyword 向量表示法來實作 Global Bushy Path 摘要方法的 比較......................................................................................................................54 表格 17:不同的維度約化比例對摘要結果的影響................................................55 表格 18:LSA-based T.R.M.及 Keyword-based T.R.M.得到的主題相關地圖.......57 表格 19:各種摘要方法的綜合比較........................................................................58. VII.
(8) 方程式目錄 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式. 1:給予 F1 , … ,Fk 個特徵,語句 s 屬於摘要的機率 ..................................14 2:化簡後語句 s 屬於摘要的條件機率 ......................................................14 3:當 s 屬於摘要的情形下,Fj 出現在摘要中的條件機率 ......................14 4:訓練文件集中,特徵 Fj 的分佈機率.....................................................14 5:訓練文件集中,摘要語句的分佈機率..................................................14 6:Si, Sj 相似度的計算方式 .........................................................................22 7:Si 的 Aggregate Similarity 的計算方式...................................................23 8:s 的語句位置特徵值 ...............................................................................27 9:A, B 關鍵詞的詞彙相關程度 .................................................................28 10:s 的正面關鍵詞特徵值 .........................................................................28 11:給予負面關鍵詞 Keyword i 的條件下,s 不屬於摘要的機率 ............28 12:s 的負面關鍵詞特徵值 .........................................................................29 13:s 與標題的相似度特徵值 .....................................................................29 14:s 的向心性特徵值 .................................................................................30 15:計算語句權重值的 Score Function ......................................................30 16:Kij 的計算公式.......................................................................................42 17:Wi 於 Si 中的相對頻率 f ij.......................................................................43 18:Wi 於 D 中的資訊分佈值 ......................................................................43 19:Wi 於 Sj 中的總體權重 Gi......................................................................43 20:Wi 於 Sj 中的權重 Lij..............................................................................44 21:自動摘要系統的精確率評估................................................................47 22:自動摘要系統的召回率評估................................................................47. VIII.
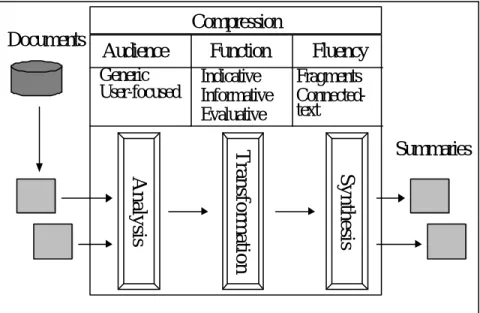
(9) 第一章. 簡介. 第一節 自動化資訊摘要 隨著電腦科技的進步與數位資訊技術的蓬勃發展,網際網路的存在儼然成為 現代人生活中不可或缺的重要角色,並且帶動了人類文明往新的資訊紀元推進。 拜科技之賜,大量的數位資訊在網路流通,網際網路無形中成為一個儲存各種資 訊的大型倉儲;資訊的傳播不再完全藉由傳統平面媒體,人們漸漸地習慣在網路 上找尋所要的資料,資訊的取得變成非常容易的事情。 隨手可得的資訊相對地也衍生許多問題,其中最大的問題是面對如此龐大的 資訊時,人們無法快速且有效地得到真正符合自己需求的資料。究其原因,乃是 因為大量的資訊使得搜尋及分辨是否為相關資訊的困難度大幅提昇。為了解決上 述問題,人們需要藉助外在工具以便於在短時間內理解所取得資料中隱含的意 義,迅速且正確地判斷真正符合自身需求的資料。 前述常用的工具主要分為兩大類:(1)搜尋引擎(Search Engine),(2)自動資訊 摘要(Automated Information Summarization)。[Gong01]對於上述二種工具做了以 下詮釋:搜尋引擎所扮演的角色是『資訊過濾器(Information Filter)』,它的功能 是分析使用者所下的檢索條件(Query),並從資料倉儲中篩選出與檢索條件相關 的資料;自動資訊摘要則是扮演『資訊監察者(Information Spotter) 』的角色,它 的功能是將相關的資訊作統整,幫助使用者在最短時間內得知資訊內容的意義。 自動資訊摘要是由電腦自動地從原始資料中精練出最重要資訊的過程。根據 原始資料的性質,自動資訊摘要大致上可分為以下三種: l. 文件摘要(Text Summarization)— 原始資料為純文字;. l. 多媒體摘要(Multimedia Summarization)— 原始資料為影音等多媒體;. 1.
(10) l. 複合性摘要(Hybrid Summarization)— 原始資料綜合了純文字與多媒體。. [Mani99]為文件摘要作了以下的定義: 文件摘要是從原始文件中精練出最重要資訊的過程;其結果為足以代表該 原始文件的精簡化版本,且可作為人們或其他資訊系統的判斷與決策依據。 Text summarization is the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks). 圖 1 是文件摘要系統架構與流程圖,自動化文件摘要的過程可分為三個階 段:首先是「分析原始文件(Analyze the input text)」與「選取重要特徵(Select salient features)」;接著將分析的結果轉換為系統內部的摘要表示法(Transform the input text into a summary representation);最後是評估內部摘要表示法的重要性,並挑 選候選的表示法來合成摘要的輸出格式(Synthesis an appropriate output form)。. Documents. Audience Generic User-focused. Compression Function Indicative Informative Evaluative. Fluency Fragments Connectedtext. Synthesis. Analysis. Transformation. Summaries. 圖 1:文件摘要系統架構概觀 [Mani99]. 2.
(11) 整個過程中有幾項重要的因素需要考慮,如使用者對於摘要內容的需求、摘 要內容的形式、 摘要內容的流暢程度、可閱讀性以及文件摘要間的壓縮比 (Compression Ratio)等等,都會影響所產出摘要結果的好壞 [Mani99]。 文件摘要的壓縮比是評估文件摘要系統優劣的重要指標之一,所謂的壓縮比 係指摘要文件長度與原始文件長度的比例。壓縮比愈低的話,產出的文件摘要愈 精練,但相對地也遺漏了愈多原始文件的資訊。相反地,壓縮比愈高,產出的文 件摘要愈冗長,雖然包含的資訊愈多,但是相對地也包含愈多不重要的資訊。一 般而言,壓縮比約在 1%— 30%左右,便可以提供足夠的資訊給使用者作為決策 判斷的依據 [Habn00] [Kupiec95] [Mani99]。 文 件 摘 要 系 統 最 後 所 產 生 的 摘 要 , 可 能 是 經 過 自 然 語 言 處 理 (Natural Language Processing, NLP)所潤飾過的文字(Connected-text),也可能是原始文件的 摘錄(Extract)— 即直接由原始文件中節錄出足以提供該文件提及之事實或資訊的 文句與段落片段(Fragments)。 文件摘要依其原始文件數量的多寡,可分為單文件摘要(Singular Document Summarization) [Aone99] [Edmundson68] [Hovy99] [Gong01] [Kim00] [Kupiec95] [Luhn59] [Myaeng99] [Salton97] [陳鈺瑾 00] 與多文件摘要(Multiple Documents Summarization) [黃聖傑 99] [翁鴻加 01] [蘇哲君 01]。單文件摘要把單篇文件的內 容精簡化與重點化,注重的是能否有效地刪減沒有必要的資訊,並留下真正能代 表文件內涵的資料;多文件摘要則是把多篇探討類似主題或事件的文件融合在一 起,除了刪減無用的資料外,尚需有效率地過濾重複在多篇文章中所出現的資訊。 根據文件摘要所要達到的目的,產出的摘要結果可 分為指示性摘要 (Indicative Summary) [Aone99] [Edmundson68] [Gong01] [Kim00] [Kupiec95] [Luhn59] [Myaeng99] [Salton97] [陳鈺瑾 00] [黃聖傑 99] [翁鴻加 01] [蘇哲君 01]、. 3.
(12) 資訊性摘要(Informative Summary) [Hovy99]與評論性摘要(Evaluative Summary) 三種。指示性摘要提供閱讀者足夠的資訊,使其能夠根據這些資訊判斷並決定是 否閱讀原始文件;資訊性摘要提供豐富的資訊內容,有時甚至可以取代原始文 件;評論性摘要以摘要形式對原始文件作評論,可提供閱讀者不同角度的論斷。. 依照讀者需求的不同,文件摘要的結果可分為一般性摘要(Generic Summary) [Aone99] [Edmundson68] [Gong01] [Hovy99] [Kim00] [Kupiec95] [Luhn59] [Myaeng99] [Salton97] [陳鈺瑾 00] [黃聖傑 99] [翁鴻加 01] [蘇哲君 01] 及特定使 用者導向(User-oriented Summary)的摘要等。前者針對較廣大的讀者群,摘要系 統所產生的摘要以寫作者的角度出發,期能提供一般性的摘要給所有讀者閱覽; 後者根據特定使用者的需求— 如使用者感興趣的主題或是使用者所下的檢索條 件— 所產生的專屬摘要。隨著資訊爆炸時代的來臨,如何針對使用者的特定需求 來產生摘要已經變得越來越重要。 由語言的角度來看 ,摘要可分為單語言摘要(Mono-lingual Summarization) [Aone99] [Edmundson68] [Gong01] [Hovy99]. [Kim00] [Kupiec95] [Luhn59]. [Myaeng99] [Salton97] [黃 聖 傑 99] [翁鴻加 01] 與多語言摘要 (Multi- lingual Summarization) [陳鈺瑾 00] [蘇哲君 01]。多語言摘要係指原始文件包含多國語 言。這類研究,最大困難在於多國語言間字詞的用法、語句的表達方式及字義間 了解與轉換所造成的語意模糊和誤解,若沒有領域知識(Domain Knowledge)與人 工適時的介入,可能導致產出的摘要與原文件所要表達的意思南轅北轍。. 第二節 研究動機 好的文件摘要必須滿足以下兩個條件: l. 文件摘要必須要在真正了解文件內容之後而產生;. l. 文件摘要必須涵蓋原始文件所要表達的意涵; 4.
(13) 為了滿足上述的兩個要求,我們認為較佳的文件摘要系統必須要能夠理解文 件的內容,並建構足以代表該原始文件意涵的知識模型,以便透過該知識模型來 生成最後的摘要結果。 過去文件摘要的技術主要都是著重於英文文件摘要方面的研究,有鑑於英文 文件與中文文件特性— 比如關鍵詞的斷詞、語句切割、特徵值計算方式等— 的不 同,如果要將英文文件摘要的方法套用到中文文件摘要上,勢必要有所修正。 本論文研究的動機便是希望針對中文文件與英文文件特性的不同,修改過去 文件摘要的技術應用於中文文件上,並提出一套知識模型來表達原始文件的意 義,最後我們將以該知識模型為基礎提出一個文件摘要的演算法,並將其應用於 中文文件。. 第三節 研究目的 綜合上述的說明,本論文主要的研究在於單文件的自動摘要產生,且所著重 的 是 如 何 產 生 具 指 示 性 、 一 般 性 與 單 文 件 的 摘 錄 (Indicative and generic single-document extract)。 本研究擬達到以下三個目標:首先,將英文文件摘要的技術移植到中文文件 摘要上;第二,採用潛在語意分析(Latent Semantic Analysis)來建構文件中內隱的 知識模型,並以此知識模型做為摘要生成的表示法;最後,針對上述兩個目標設 計適當的實驗,以比較過去文件摘要技術與本論文所提出方法間的差異性,並討 論潛在語意分析(Latent Semantic Analysis)模型應用在文件摘要上的可能性。. 第四節 論文架構. 5.
(14) 本論文共分為六章,第二章介紹自動化文件摘要的相關研究工作;第三章及 第四章分別描述我們提出的兩種自動摘要方法:(1)以文件集為基礎的改良型摘 要技術(Modified Corpus-based Approach),(2)以潛在語意分析(Latent Semantic Analysis)為知識模型的摘要技術(Proposed LSA-based Approach)。第五章說明系統 實作與實驗結果的分析討論,藉以驗證本論文所提研究方法的可行性。最後,第 六章是結論與未來可行的研究方向。. 6.
(15) 第二章. 相關研究工作. 本章說明相關的研究工作。[Habn00]依照輔助資訊(Auxiliary Information)介 入的多寡將自動文件摘要技術分為兩大類,一類為 Knowledge-rich approaches, 例如[Mckeown95] [Barzilay97] [Aone99] [Azzam99] [Hovy99] [Silber00],這類的 論文著重於建構文件內容的表達模型;另一類則是 Knowledge-poor approaches, 例 如 [Luhn59] [Edmundson68] [Kupiec95] [Myaeng95] [Salton97] [Aone99] [Hovy99] [Lin99] [Kim00] [Gong01],這類論文討論直接評估文件中語句的重要 性。 本章首先介紹文件摘要的相關研究,接著分別介紹三種不同觀點的研究技 術:(1)以文件集為基礎的摘要方法(Corpus-based Approaches)、(2)以主題關係地 圖為基礎的摘要方法(Text Relationship Map-based Approaches)與(3)以語段模型為 基礎的摘要方法(Discourse-based Approaches)。. 第一節 文件摘要相關研究 自動化文件摘要的研究起源於 1950 年代。受限於過去電腦技術的不發達, 以及自然語言處理的高困難度,先前的研究方法僅僅著眼於計算文件中每個語句 所提供的資訊量多寡或是判斷每個語句的重要性;此外,亦研究如何根據語句的 重要性摘錄出足以代替原始文件的語句或段落,也就是所謂的語句(段落)摘錄1 (Sentence/Paragraph Extraction) [Aone99] [Gong01] [Kim00] [Kupiec95] [Myaeng99] [Salton97]。 圖 2 舉例說明語句摘錄的範例,圖中的陰影部分即是範例文件的摘錄結 果。摘錄類型的摘要作法是由原始文件計算每個語句的資訊量,並依照重要性的 不同賦予每個語句權重;接著考慮使用者的需求(如壓縮比),並依照語句權重挑 1. 以下所提的文件自動摘要 ,所指的皆是語句或段落的摘錄 。 7.
(16) 選出候選的重要語句;最後再經過語句的排序與重組後即可作為該原始文件的摘 錄。. 三月四日一大早約九點出頭 ,前總統夫人曾文惠在女兒李安妮與隨扈的護送下 ,出現在 台北地方法庭。在出發之前,前總統李登輝才對曾文惠表示了精神上的完全支持,但是她還是 抵擋不住硬吞下眼淚的那種心情。 台灣有史以來,第一次出現前第一夫人到法院出庭的情況 ,曾文惠臉上沒有面對群眾時 慣有的那種溫暖笑容,而是勉強擠出淺淺的笑,低著頭快速地進入法庭。只有在步出法庭時, 看到熱情的支持群眾,她才露出親切溫柔的笑臉。 許多人都還記得 ,當然,李登輝一家人也都深深地記得。兩年前總統大選後的那幾天, 許多「國民黨人士」包圍國民黨中央黨部,在民眾情緒激憤,要求李登輝下台的時候,謝啟大 在宣傳車上,對著底下的群眾喊著「曾文惠帶了八千五百萬美金逃到美國 」 。 接下來 ,前立委馮滬祥以及前僑務委員戴錡更召開記者會 ,提出洋洋灑灑的「證據」,公 開指稱曾文惠搭乘長榮航空,私運八千五百萬美元到美國,被美方拒絕入境,又緊急搭華航班 機運回美元,於是引來了所謂的「八千五百萬元美金運送風波 」 。 小女兒李安妮不甘曾文惠被如此惡意誹謗 ,建議曾文會自訴謝啟大等三人涉嫌誹謗 ,並 求償三億元賠償。但是,法官出身的謝啟大深闇司法,第一次出庭就採取反擊,反控曾文惠誣 告,也要求三億元賠償,並且要求曾文惠出庭,也使得曾文惠必須在三月四日出庭應訊。 當天,曾文惠進入台北地院的北大門時,離開庭時間還有約半個小時,她快速地走上樓 梯進入休息室,並準時出現在位於二樓的第七法庭。經過冗長的庭訊過程,從上午九點四十分 開庭到中午一點休息,曾文惠完全沒有發言。經過短暫的休息之後,曾文惠才站在法庭前接受 法官的詢問,否認運美金赴美。 在經過身體與精神的雙重煎熬之下,下午三點多,曾文惠終於承受不住心裡的委屈 ,趴 在桌上偷偷地落淚,並在李安妮的攙扶下暫時離開法庭。在庭訊的過程中,曾文惠也不禁用紙 張寫下她的心情, 「上帝創造人的眼淚是流下來的,我的眼淚卻是吞進去的」。 實際上 ,基於對司法的尊重 ,曾文惠與家人也完全不願意對這件官司發表談話 。而儘管 曾文惠的高中校友鄭玉麗,曾經在二○○○年三月二十二日下午打了通電話給她,並聊了將近 半個小時,但基於自己沒有舉證責任的原則之下,曾文惠也不願鄭玉麗出面作證。 對曾文惠而言,這場官司是一種捍衛自己尊嚴的官司 。看著老妻受到這麼大的委屈 ,李 登輝心底絕對是相當心疼的。 圖 2:文件摘錄的範例. 自動化文件摘要技術的發展. 2.1.1. 接下來介紹文件自動摘要技術的發展歷程。1950 年代到 1960 年代是文件摘 要研究的開始,這個時期的研究重點著重於文件類型(Document Genre)的分析, 例如:每一個段落的第一句話,通常都會直接點出接下來所要敘述的主題大綱; 或 是 語 句 中 出 現 某 些 常 用 的 提 示 片 語 (Cue Phrase)— “in summary”、 ”in 8.
(17) conclusion”— 等等,這些具有提示片語的語句通常是總結內容主題的說明,因此 也具有高重要性。 文件摘要初期的研究,絕大多數都以分析文件類型與寫作風格的方式,以達 到自動化摘要的目的。這類摘要技術的優點在於簡單容易,但這也是它最大的致 命傷:摘要的方法和文件的類型與風格息息相關,導致同一技術在不同類型文件 中的重複利用性不高。 1970 年代到 1980 年代初期,人工智慧的研究成果開始應用在文件自動摘 要。這個時期的研究,重點在於如何建構知識的表達模型,用以辨析文件內容的 主題與涵義,所使用的知識表達模型不外乎框架(Frame)及模板(Template)等。此 類方法係利用自然語言的處理技巧來辨認出文件內容中人物、地點以及時間等基 本要素(Entity),並將之套用在事先定義好的模板或框架以取代原始文件中的語 句,接著經由這些知識模型的推演來得知文件內容的主題並由模板來生成摘要。 此類技術的最大缺點在於模板的定義必須由專家進行,且因為模板的廣泛度 不夠,使得有限數量的模板影響到文件涵義辨析的不正確性,導致產出的摘要內 容在意義上的扭曲。. 資訊擷取(Information Retrieval, IR)研究的議題在於如何從一文件集(Corpus) 裡尋找與檢索條件有關聯的文件;若將資訊擷取的範圍縮小到單篇文件中,則文 件摘要可以定義成如何在單篇文件中擷取出與內容主題相關的重要語句。 資訊擷取的技術從 1990 年代初期起大量地應用在文件摘要上,因為資訊擷 取的分析著重於字層面(Word- Level)的分析,並未考慮到同義詞(Synonymy)與一 詞多義(Polysemy)的詞義辨析、字詞與片語(Phrase)的辨析以及如何衡量字詞與字 詞間的依屬(Term Dependency)程度等語意層面的分析,因而不能提供正確的摘要 資訊。 9.
(18) 除了上述幾種研究方法外,文件自動摘要的研究還有兩類不同的方法:以語 言學(Linguistic s)分析為主的摘要技術以及由認知心理學(Cognitive Psychology) 來理解文件的摘要技術。它們的發展時期分別是 1960 年代到 1970 年代,以及 1970 年代到 1980 年代左右。 相關研究工作. 2.1.2. 第一章中曾經提到,自動化文件摘要系統的第一階段是分析原始文件,並擷 取文件的特徵。究竟如何判斷所擷取特徵的重要性呢?[Habn00]根據詮釋知識 (Meta-Knowledge)在特徵擷取過程中參與的程度,將使用的方法歸為以下三類: l. Knowledge-poor Approaches: [Luhn59] [Edmundson68] [Kupiec95] [Myaeng95] [Salton97] [Aone99] [Hovy99] [Lin99] [Kim00] [Gong01]. l. Knowledge-rich Approaches: [Mckeown95] [Barzilay97] [Aone99] [Azzam99] [Hovy99] [Silber00]. l. Hybrid Approaches:[Aone99] [Hovy99]. 圖 3 中我們依年份及方法整理了這些相關的研究工作。. 圖 3:相關研究工作. Knowledge-poor approach 是一種通用性的方法,不會因為所處理資料的不同 而有所改變。其方法是擷取文件的實體特徵(Physical Features)作為分析的依據。 10.
(19) 所謂的實體特徵可以是關鍵詞(Keyword)、語句位於文件中的位置或是提示詞語 等等。這類方法通常是由資訊擷取的方法所衍生而來。 它的作法說明如下,首先分析文件中每個語句的特徵,並利用這些特徵作為 語句的表示法;接著考慮特徵的重要性賦予每個語句不同的權重值(亦即代表該 語句的資訊量或重要程度);最後將文件裡的所有語句依照權重值由大而小排 序,並挑選出權重值較高的數個語句成為原始文件的摘錄結果。 由上可知,利用實體特徵分析的方法,一般只著重於某些特定且較低層次的 特徵分析,並沒有考慮到較高層次的語意,如知識概念(Knowledge Concepts)的 分析。並且 Knowledge-poor 的方法用的是資訊擷取的技術,因此所擷取的特徵 僅僅是建構在統計模型上的分析結果,並無法真正涵蓋到文件內容的意義。. 為了彌補 Knowledge-poor 方法的缺陷,近年來關於文件自動摘要技術的研 究已逐漸朝向 Knowledge-rich 的方法發展。所謂 Knowledge-rich 的方法除了分析 文件結構與文件特徵之外,還加入領域知識(Domain Knowledge)輔助,以了解並 表現出文件中所隱藏的主題和概念(Concepts),進而達到語意層面(Semantic Level) 的摘要目的。. 此類方法引入額外的知識來分析文件的結構及其代表意義,以發掘出文件中 包含的基本要素(Text Entity)和各個基本要素間的關聯性,從而建立文件的知識 表示模型(Knowledge Representation Model),最後精簡此模型(亦即保留此模型中 具代表性的部分),並利用精簡過後的模型來擷取文件中的語句以達到摘要的目 的。. [Mani99]提出基本要素間的關聯性可能包含: l. 相似度(Similarity):例如語彙的重複性(Vocabulary Overlap);. l. 鄰近度(Proximity):二基本要素(如關鍵詞、人事時地物)在文件中的距 11.
(20) 離; l. 同時出現(Co-occurrence):基本要素是否在同一上下文(Context)中出現;. l. 語彙在詞典中的關係(Thesaural Relationship):如同義字(Synonym)、部 分關係(Part-of relationship)等;. l. 共同參照(Co-reference):參照到共同的要素或者超鏈結(Hyperlink);. l. 邏輯上的相關性:如同義 (Agreement)、 矛盾性(Contradiction)與一致 (Consistency)性等等;. 舉例來說,新聞文件中的基本要素不外乎就是『人』 、 『事』 、 『時』 、 『地』 、 『物』 五個要素所構成的,因此只要利用足夠的輔助知識,如人名的表格、地點的表格 或是語料辭典等等,便可以辨認出該新聞文件中所存在的事件關係的模型; 有了知識模型後,更可以藉由邏輯推理來找出其中的隱性知識,最後挑選重 要的知識概念用來當作文件中重要語句的擷取依據。然而此種方法最大的缺陷在 於必須藉由外在知識的分析,因此可能導致字詞、語句、段落或文件層面的語意 被誤解。. 第二節 以文件集為基礎的摘要技術 以文件集為基礎的摘要技術說明. 2.2.1. 不同類型的文件,因為寫作方式及用字用詞等特性的不同,最後所產生的摘 要形式也該有所差異;比如說科技論文與新聞文件的摘要在本質上就不會相同, 科技論文的摘要著重於簡介(Introduction)以及結論(Conclusion)的部分,而新聞文 件著重的是給閱讀者概觀性的敘述。然而,屬於同類型文件的摘要,就有可能具 有某些共通的特性。. 以文件集為基礎的自動摘要技術(Corpus-based Approaches)係利用機器學習 (Machine Learning),從已經具備摘要的同類型文件集中,探索出該類型文件摘要. 12.
(21) 所必備的共同特性,並應用這些共同特性於該類型文件之摘要的自動生成。圖 4 是「以文件集為基礎的自動摘要技術」之系統概觀圖。. Domain Knowledge Learning Algorithm. Feature Extractor Source. Vectors Rules Source Labeler. Rule Application. Summary Training Corpus. Machine-generated Summary. Test Corpus. Test Phase. Training Phase. 圖 4:「以文件集為基礎的自動摘要技術」系統概觀 [Kupiec95]. 以文件集為基礎的自動學習摘要技術的流程分為兩個階段:(1)訓練階段 (Training Phase),(2)測試階段(Test Phase)。在訓練階段中,輸入事先由人工標示 好摘要的訓練文件集(Training Corpus),具有學習能力的摘要系統會自動從每篇 訓練文件及其對應的摘要中擷取出具有代表性的特徵(Feature Extraction);接著參 考相關的領域知識,並選擇適當的學習演算法(Learning Algorithm)來產生相對應 的摘要規則(Rule)。 在測試階段中,則是輸入同類型但不屬於訓練文件集的測試文件集(Test Corpus),系統先根據學習得之摘要規則擷取出相關的特徵,並套用摘要規則產 生屬於該測試文件的摘要。至於評估摘要系統優劣的方法,主要是比較系統產生 的摘錄與人工標示的摘要間之準確率(Precision)和召回率(Recall)。 [Kupiec95]提出一個以貝式定理(Bayesian Rule)為基礎的 Corpus-Based 方法 來計算每個語句的權重值。假設語句 s 是測試文件中的任一個語句,F1 到 Fk 則 13.
(22) 是系統中用來衡量語句重要性的 k 個不同的特徵,那麼語句 s 屬於摘要的機率如 方程式 1: P(s ∈ S | F 1, F 2,..., Fk ) =. P (F 1, F 2,..., Fk | s ∈ S )P(s ∈ S ) P (F 1, F 2,..., Fk ). 方程式 1:給予 F1 , … ,Fk 個特徵 ,語句 s 屬於摘要的機率. 假設每個特徵都是獨立事件的話,則方程式 1 可化簡成方程式 2:. P(s ∈ S | F 1, F 2. ∏ ,..., F ) = k. k j =1. P (Fj | s ∈ S )P(s ∈ S ). ∏. k j =1. P( Fj ). 方程式 2:化簡後語句 s 屬於摘要的條件機率. P(s ∈ S ) 、 P( Fj | s ∈ S ) 、 P( Fj ) 是在訓練階段時由訓練文件集計算得知,其中 P(s ∈ S ) 代表訓練文件集中每個語句屬於摘要的機率,為一常數值;P( Fj | s ∈ S ) 代 表當語句 s 屬於摘要的情形時,Fj 出現在摘要中的條件機率; P( Fj ) 代表訓練文 件集中,特徵 Fj 的分佈機率。詳細的計算公式如方程式 3、方程式 4 和方程式 5: P( Fj | s ∈ S ) =. #(sentence in summary, and has feature Fj) #(sentence in summary). 方程式 3:當 s 屬於摘要的情形下,Fj 出現在摘要中的條件機率. P( Fj ) =. #(sentence in traini ng corpus, and has feature Fj) #(sentence in traini ng corpus) 方程式 4:訓練文件集中,特徵 Fj 的分佈機率. P(s ∈ S ) =. #(sentence in summary) #(sentence in traini ng corpus). 方程式 5:訓練文件集中,摘要語句的分佈機率. [Kupiec95]所實作的系統中,用來判斷語句重要性的特徵主要為下列幾項:. 14.
(23) l. 語句長度(Sentence Length). 語句的長度會影響到語句所涵蓋資訊量的多寡,較長的語句所包含的資 訊通常比較短的語句所含的資訊量來得豐富。他們認為語句的長度至少必須 要 5 個字才可能屬於摘要。 l. 提示片語(Fixed-Phrase). 文件中常用的提示片語,如”in summary”以及”in conclusion”等等,這些 片語往往會出現在介紹或總結主題敘述的語句中。他們認為文件中的語句如 果包含這些常用的提示性片語,那麼該語句便有極高的可能性是屬於摘要。 l. 段落位置(Paragraph). 他們將文件分為 paragraph- initial、paragraph-medial 以及 paragraph- final 等三個部分;並認為出現在 paragraph- initial 以及 paragraph- final 這兩個部份 的語句,通常都是帶出主題或是總結主題的語句,所以,落於這兩個部份的 語句具有較高的重要性。 l. 主題字詞(Thematic Words). 一篇文件中,如果某個關鍵字重複出現許多次,則這篇文件的主題極可 能與此關鍵字有關。他們認為擁有愈多出現頻率越高的關鍵詞的語句,愈有 可能是屬於文件的摘要中。 l. 大寫字詞(Uppercase Words). 他們認為文件中大寫 (Uppercase)的 字 詞或是特殊的專有名詞(Proper Nouns)具有較高的重要性,因此擁有愈多大寫字詞或專有名詞的語句便愈可 能屬於文件摘要。. 15.
(24) 這篇論文中有兩個很重要的結論: 1.. 雖然使用上述五個特徵當作語句重要性的計算依據,但是,實驗的結果 顯示,若只考慮 Paragraph、Fix-Phrase 以及 Sentence Length 的組合所得 到的結果最佳。. 2.. 文件摘要的壓縮比會影響到自動摘要系統結果的正確率。從圖 5 中可 知,當摘要系統所摘要出來的語句數目越多的話(代表壓縮比越高),所 得到的正確率就越高。. 圖 5:壓縮比對摘要系統正確率的影響 [Kupiec95]. 相關的研究成果比較. 2.2.2. [Kupiec95]提出一個以貝式定理為核心的自動摘要方法,之後的研究都以此 為中心而衍生,例如[Myaeng99]、[Aone99]與[Hovy99]。以下針對這幾篇論文的 不同之處加以詳述,這幾篇論文的重點比較則列於表格 1 中。. [Myaeng99]認為文件摘要必須考慮到文件內容的架構。他們認為具有代表性 的語句會出現在文件中 Introduction 及 Conclusion 這兩部分,且這兩個部分可進 一步分割成四個組成結構— background, main theme, explanation of the document structure 及 future work,屬於各個部分的語句其重要性會有所差異。實驗結果顯 示 Cue Word, Sentence Location及 Resemblance to Title 最能夠代表語句的重要性。 16.
(25) [Aone99]從解決資訊擷取的共通弊病來著手— 語句的斷詞切字好壞會影響 到摘要結果;亦即,文件中的特殊片語或是專有名詞,如果沒有正確地分辨的話, 很有可能會誤解文章的涵義。他們提出兩個原則來解決前述問題。第一,斷詞切 字時盡量將可能是片語的字詞結合在一起;第二,利用 NameTag 工具來擷取專 有名詞,並將具有相同意義的字詞視為相同,如”IBM”與”International Business Machines”在計算關鍵詞的權重時,這兩個字詞的出現頻率必須要同時考慮。. [Hovy99]集先前研究之大成,提出了一個重要的概念:摘要 (Summarization) = 主 題 辨 認 (Topic Identification)+ 概 念 融 合 (Concept Fusion)+ 摘 要 的 生 成 (Generation)。亦即,輸入文件先經過主題的辨認以擷取出文件內容中描述的主 題,接著將具有相同涵義的主題融合,最後再將這些主題所要表達的概念經過語 句重組(Sentence Planning)後產生新的摘要。. [Kupiec95]. [Myaeng99]. [Aone99]. [Hovy99]. Analysis Features. Improvement (Compared with [Kupiec95]). n Sentence Length n Cue Phrases n Paragraph n Thematic Words n Uppercase Words n Proper Nouns n Cue Words n Negative Words n Position n Theme Words n Centrality n Resemblance to Title. n A statistical model based on Bayes’ Rule. n Thematic Words n Sentence Length n Position n Paragraph. n To reshape the word unit n To acquire domain knowledge n To approximate text structure. n Thematic Structure Decomposition n Dempster-Shafer’s Combination Rule n Use “text component” as filter. No. of Training/ Testing Documents 187/1. 30/30. 100/100. Performance. Recall: 42%. The same number of sentences as in the corresponding manual summary.. 11-point average precision: 44%. 5 sentences regardless of the size of source document.. Recall: 56% Precision: 51.4%. n Propose a new idea: Summarizat ion = Topic Identification + Interpretation + Generation n A method combines robust NLP and symbolic knowledge by concept fusion. 表格 1:以文件集為基礎的摘要方法研究的比較. 17. Compression Rate.
(26) 綜合以上的說明,不難想像以文件集為基礎的摘要方法,它最大的問題在於 只考慮到低層次(Low-Level)的特徵分析而已,其他較高層次的特徵,如語意索 引(Semantic Index)、概念階層(Concept Hierarchy)等等語意層次的分析並沒有考 慮在內。也就是說,利用這種技術來建構自動摘要系統可能導致所產生的文件摘 要品質低劣,並且沒有辦法有效地涵蓋原始文件所要表達的意義。 以文件集為基礎的摘要技術延伸討論. 2.2.3. 以文件集為基礎的摘要技術還有一些其他的缺失,比如說 Anaphora Link 的 問題等等。所謂 Anaphora Link 指的是某個語句中出現代名詞用以取代先前所提 過的名詞個體,如『(1)王老先生有塊地。(2)他在這塊地上種了很多農作物。』 上述語句中的『他』便是 Anaphora Link;假若摘要系統挑選了(2)當摘要,如此 一來,第二句中的他便失去了原有的意義。為了解決這個問題,通常都是(1)(2) 兩句一起挑選當作摘要,以保留原本 Anaphora Link 所代表的意思。 除此之外,以文件集為基礎的摘要方法,仍需要注意到以下幾點:. 1.. 當套用到不同寫作格式的文件集時,摘要系統該如何自動且有效地學習 並發掘新的可利用特徵?. 2.. 當使用關鍵詞當作特徵時,摘要系統該運用何種技巧將關鍵詞層面 (Term- Level)的涵義提昇到概念層面(Concept-Level)的涵義。. 3.. 如何利用輔助的資源如概念階層等來辨認各個關鍵詞所代表的語意。. 第三節 以主題關係地圖(Text Relationship Map)為基礎的摘要技術 主題關係地圖(Text Relationship Map)由自動主題連結(Automatic Text Link) 的研究延伸而來的。自動主題連結原本用在建構文件集中文件間的關聯,作法上 將每篇文件以關鍵字詞的向量表示法表示,並計算所有文件兩兩間的相似度. 18.
(27) (Similarity);如果相似度大於系統內定的臨界值時,表示這兩篇文件具有相似的 連結關係(Semantic Related Link)。依此原則可以建構出所有文件間的關係地圖。. 17012. 11830. Links below 0.01 ignored 0.57. 0.54. 0.49. 0.50 17016. 22387— Thermonuclear Fusion 0.38 19199— Radioactive Fallout 17016— Nuclear Weapons 17012— Nuclear Energy 11830— Hydrogen Bomb 8907— Fission, Nuclear. 8907. 0.24. 0.23 0.33. 0.09. 19199. 22387. 圖 6:Text Relationship Map 的範例 [Salton97]. 舉例來說,圖 6 中編號 17012 及 17016 的文章,二者的相似程度約 0.57, 大於臨界值 0.01,所以存在連結關係;而 8907 與 22387 這兩篇文章的相似度則 因為低於臨界值,所以在 Text Relationship Map 中並沒有連結存在。具有連結的 文章,可說是具有關聯性。. [Salton97]將 Text Relationship Map 的概念應用在文件摘要的研究上,並提出 一個以段落(Paragraph)為摘錄單位的文件摘要系統。對於輸入的文件,以每個段 落為單位計算兩兩段落間的相似度,建構 Paragraph Relationship Map。他們認為 若某個段落與其他段落的連結數愈多,則代表該段落和整篇文章主題的相關性愈 高。根據這個想法,連結數目愈多的段落則愈重要。 至於根據 Paragraph Relationship Map 來產生摘要,作法上分為兩個步驟。第 一是判斷 Text Relationship Map 中每個段落的重要性;第二,根據 Text Relationship Map 中的連結數目來決定摘錄段落的先後順序。他們提出以下三種方法:. 1.. Global Bushy Path. 19.
(28) 首先定義 Text Relationship Map 上任一節點的 Bushiness 為該節點與其 他節點間的連結數目,擁有越多關聯連結的節點,表示該段落與其他段落的 寫作與用字方式相似,並且討論的主題也相似,因此,該段落視為討論文件 主題的段落。Global Bushy Path 乃是將段落依照原本出現在文件中的順序以 及其連結個數由大而小的排列結果。. 定義 Global Bushy Path 之後,只要從 Global Bushy Path 中挑選排名最前 面的 K 個段落(Top K),即可當作該文件的摘要。此方法所摘錄出來的段落 雖然涵蓋整篇文件所要表達的涵義,但是可能發生段落間語意不連續的問 題,導致摘要的可閱讀性(Readability)降低;也就是說,所挑選出來的摘要 中連續兩個段落雖然都是很重要的段落,但是所描述的事情可能截然不同。. 2.. Depth- first Path Depth- first Path 方法可避免 Global Bushy Path 的問題。首先選取一個節. 點— 可能是第一個節點或是具有最多連結的節點,接著每次選取在原始文件 中順序與該節點最接近且與該節點相似度最高的節點當作下一個節點,依此 原則選取出重要而且連續的段落以形成文件摘要。. 這個方法挑選重要段落的時候也一併考慮到原始文件中的段落順序與 關聯,因此可以避免類似 Global Bushy Path 的問題,同時使摘要的一致性 (Coherence)與可閱讀性提高。然而,其最大的問題在於摘要內容的一致性提 高,並不見得能夠涵蓋原始文件中所有主題與概念,原因乃是摘要的大小是 固定的,為了要使摘要內容的連貫性提高,勢必要選取重複敘述的段落,如 此便會造成篇幅的不足,而導致摘要內容的不完整。. 3.. Segmented Bushy Path. 20.
(29) 以上兩個方法共同的問題在於沒有考慮到文件的內容架構,舉例來說, 根據文件的起承轉合,文件的內容可分為幾個不同的結構,如 Introduction、 Main Them 以及 Conclusion 等等;如果套用上述的方法來挑選段落,很容易 忽略掉屬於不同結構,但是重要性同樣很高的段落,最後導致摘要內容的完 整性不足。Segmented Bush Path 可用來解決上述的問題。 Segmented Bushy Path 分為兩個步驟,第一個步驟是文件結構的切割 (Text Segmentation),也就是分析文件內容並將文件內容切割成幾個具有代 表的結構。Text Segmentation 利用 Paragraph Relationship Map 來分析文章的 結構,圖 7 的左半部很明顯地發現 Map 上幾個節點之連結數目近乎相同, 而形成可以分割的區段,其分割的結果如圖右半部,共分割成 5 個結構。. 圖 7:Paragraph Relationship Map 與其對應的 Text Segmentation [Salton97]. 接下來的工作便是針對每個 Segmentation 個別利用 Global Bushy Path 來選取重要的段落。為了保留每個 Segmentation 的涵義,每個 Segmentation 至少要挑選出一個段落納入最後的摘要。這樣做的好處是摘要可以涵蓋不同 的主題,並使其完整性提高。 最後總結上述方法。第一,Global Bushy Path 所產生摘要的一致性最差,原 因乃是挑選段落時沒有考慮到段落與段落間的連續性;第二,Depth- first Path 所. 21.
(30) 產生摘要一致性最好,對於內容的全盤涵蓋程度(Comprehension)最差,原因乃是 因為所挑選到的段落集中於某幾個主題;第三,Segmented Bushy Path 的方法所 產生的摘要考慮到文章內容的結構,因此對於內容的全盤涵蓋程度最好。表格 2 中整理上述三個方法的特性。. Global bushy path Segmented bushy path. Depth-first path. Importance of initial paragraph Usually starts with important early paragraph May lose important first paragraph because of need to include material from other segments Starts with important first paragraph. Coherence/comprehensiveness Not coherent because adjacent paragraphs may be unrelated Not coherent but more comprehensive than global central path Not comprehensive but more coherent than central paths, may be specialized to important subtopic. 表格 2:Global Bushy Path, Depth-first Path 與 Segmented Bushy Path 的比較 [Salton97]. 相對於[Salton97]只考慮到 Text Relationship Map 上每個節點的連結個數, [Kim00]認為若將每個連結的權重(語句的相似度 )納入考慮,可產生更好的摘 要,因此,他們提出一個以 Aggregate Similarity 計算每個語句重要性的方法。. 圖 8:計算 Aggregate Similarity 的概念圖示 [Kim00]. 圖 8 是 Aggregate Similarity 的概念圖示。圖中的每個節點代表的是文件中 某個語句的關鍵詞向量表示法,每個連結代表兩個語句間的相似度,任兩個語句 的相似度即是計算相對應向量間的內積值,詳細的計算方法如方程式 6: n. sim (i, j ) = ∑ si, k * sj, k k =1. 方程式 6:S i , S j 相似度的計算方式 22.
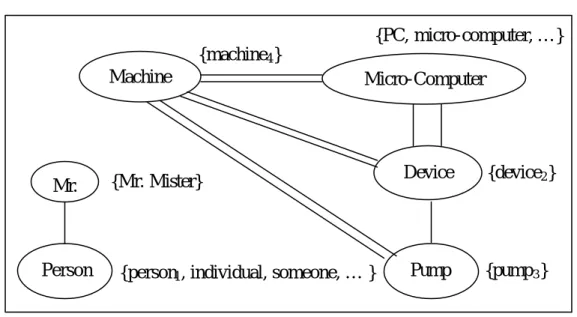
(31) 其中 n 表示出現在整份文件中相異的名詞個數,Si 可以(si,1, si,2 , … , si,n)表示, si,k 是名詞 Nk 在語句 Si 中出現的頻率。Si 的 Aggregate Similarity 的計算方式如方 程式 7: n. asim (i ) = ∑ sim (i , j ) j =1 j ≠i. 方程式 7:S i 的 Aggregate Similarity 的計算方式 [Kim00]. 對於某個節點而言,Aggregate Similarity 為此節點與其他節點之相似性的總 和。計算每個語句的 Aggregate Similarity 的好處在於除了考慮到每個節點的連結 個數,更考慮到每個連結的權重值。因此,Aggregate Similarity 的結果理論上會 比 Global Bushy Path 的結果來得好。. 第四節 以語段模型(Discourse Model)為基礎的摘要技術 認知心理學假設文件的作者在進行寫作的過程時,乃是由他本身所認知的概 念空間(Conceptual Space)中去定義某個用詞的涵義,接著再組合這些定義好的詞 句而成為一篇文章。當讀者閱讀文件的時候,他所作的事情便是試著去重組並建 構當初該文件的作者所認知的概念空間,藉此得到相同語意的理解與認知。. [Barzilay97]以此想法為基礎,他們認為文件中所描述的概念,其實是由擁 有該概念意義的所有字詞組成的結果;於是他們提出語意鏈結(Lexical Chains)的 想法。所謂 Lexical Chains 即是一篇文章中相同意義的字詞所組成的集合,每個 Lexical Chain 代表這篇文件所要描述的一個概念,也就是對於這篇文件的一個認 知;基於 Lexical Chains 所得到的摘要最能涵蓋該文件所要表達的意義。 作法上,首先將文件中的名詞詞彙都擷取出來,接著藉由 WordNet [24]來判 斷每個字詞所代表的意義,並將具有相同詞義的字詞串接起來變成了 Lexical. 23.
(32) Chains。美中不足的是,藉助 WordNet 的分析來建構字詞間的相似關係,可能因 為其中某個字詞的意義辨認錯誤而導致產生錯誤的 Lexical Chain;如此一來,所 得到的認知模型便可能偏離原文所要表達的意思。. 圖 10 是圖 9 原始文件之 Lexical Chain 的視覺化示意圖。圖中清楚地看到 Mr.與 person被歸在同一個 Lexical Chain 中,這個 Lexical Chain 所表達的便是『人』 這個概念;而 Machine,Micro-computer,Device 以及 Pump 則被歸屬於另外一 個 Lexical Chain 中,這個 Lexical Chain 所要表達的是『機器』這個概念。我們 可以發現,Lexical Chain 的確可以反映出文件中的知識概念。. Mr. Kenny is the person that invented an anesthetic machine which uses micro-computers to control the rate at which an anesthetic is pumped into the blood. Such machines are nothing new. But his device uses two micro-computers to achieve much closer monitoring of the pump feeding the anesthetic into the patient. 圖 9:原始文件範例. {PC, micro-computer, … } {machine4 } Machine. Mr.. Person. Micro-Computer. {Mr. Mister}. {person1 , individual, someone, … }. Device. {device2 }. Pump. {pump 3 }. 圖 10:語意鏈結的視覺化示意圖. [Azzam99]認為直接辨析文件內涵的一致性(Text Cohesion)可以更正確地認 知文件。文件內涵依照[Halliday76]的定義可以由辨認下列四種關係來得到:(1). 24.
(33) 相 互 參 照 (Co-reference) 、 (2) 取 代 與 省 略 (Substitution and Ellipsis)、 (3)關 聯 (Conjunction)以及(4)語詞相關(Lexical Cohesion)。. [Azzam99]利用相互參照的關係來建構文件的認知模型。其中相互參照用來 描述文件中所提及的基本要素間的關係,其與語詞相關最大的不同點在於它不像 語詞相關必須藉由輔助的詮釋知識來建構關係,而是直接分析文件中的基本要素 來達到建立關係的目的。此方法最大的缺點是計算複雜度太高,且必須要人工的 介入才能正確地辨認出文件中基本要素間的關係。 表格 3 說明 [Barzilay97]與[Azzam99]方法的特性;表格 4 則比較 Lexical 與 Co-reference Chain 的差異性。. [Barzilay97]. [Azzam99]. Representation Model Lexical Chain. Co-reference Chain. Performance. Comments. Recall: 64% Precision: 47%. The results indicate the strong potential of lexical chains as a knowledge source for sentence extraction. The novelty is to combine the idea of a document extract based on co-reference chains with the idea of chains of related expressions serving to indicate sentences for inclusion in a generic summary.. Recall: 30% Precision: 65%. 表格 3:Characteristics of Discourse Model Approach. Differences. Lexical Chains n Easy to compute n Not rely on full text processing n Not always convey real “aboutness” of a text because of being indicated by an external resource. Co-reference Chain n Require more complex techniques n Need to understand the meaning of texts n Hard to recognize relationships among objects correctly. 表格 4:Lexical Chain 與 Co -reference Chain 的相異之處. 總結以上描述,以外在知識輔助的方法所建構的知識模型並不能保證真正能 夠包含文件中所敘述的意思,原因乃是一詞多義與同義詞等語意混淆的現象,導 致了字詞的意義沒有辦法正確地被定義。此外,使用自然語言處理的技術來分析 文件,如果沒有人工的適時介入,便無法正確地建立基本要素關係的模型。. 25.
(34) 第三章. 改良型語句權重摘要. 過去以文件集為基礎的摘要技術主要應用於英文文件,若將英文摘要的研究 成果應用在中文文件上,必須針對中英文的差異性加以修正,其中最大的差異在 於中文斷詞比英文更容易影響到摘要結果的好壞;另外,針對過去方法的弱點, 我們亦提出幾點改進:第一,針對每個語句位置的不同,我們賦予不同的權重以 加強語句位置的重要性;第二利用詞彙相關程度(Word Co-occurrence)建構新字 詞,並加入關鍵詞權重的計算;第三,利用基因演算法(Genetic Algorithm)得知 每個特徵的重要性。. 第一節 基本特徵值分析 先前提及以文件集為基礎的摘要技術,主要透過特徵來評估每個語句的重要 性,本節說明我們所考慮的幾項特徵,分別為語句位置(Position)、正面關鍵詞 (Positive Keyword) 、 負 面 關 鍵 詞 (Negative Keyword) 、 與 標 題 的 相 似 度 (Resemblance to the Title)以及向心性(Centrality),以下逐一說明。 1.. 語句位置(Position) 從文件內容結構的角度來看,文件中重要的語句通常出現於某幾個特定. 的位置;舉例來說,每一段落的第一句常常會點出該段落的主題,因此,它 的重要性會比同段落中其他位置的語句還要高。 此外,即使是同樣屬於摘要的語句,我們認為他們的重要性也會因為位 在文件中不同位置而有所不同;亦即,語句位置的特徵值不只是屬於或不屬 於摘要的機率差別而已,每個位置都應賦予其不同的重要性。 為了加強語句位置的重要性,當人工挑選摘要語句的同時,我們也賦予 每個屬於摘要的語句一個權重值;因此,概念上計算位置的特徵值,便相當 26.
(35) 於計算某位置出現於摘要的期望權重。在實作上,對於位置的權重總共分為 6 個等級,分別為 0 到 5;其中 0 代表不屬於摘要,1 到 5 則表示該語句屬 於摘要,且其重要性的強度 1 最弱,而 5 最強。 對於測試文件中的某個語句 s 來說,它的位置特徵值計算方式如方程式 8:. ScorePosition( s ) = P(s ∈ S | Positioni ) ×. Average weight of Position i 5.0. where s comes from Positioni 方程式 8:s 的語句位置特徵值. 2.. 正面關鍵詞(Positive Keyword) 資訊擷取(Information Retrieval)認為一份文件可由其含有的關鍵詞所組. 成的向量來表示;同樣地,對於每個語句而言,也可由其含有的關鍵詞向量 來表示。基於這個想法,我們認為假若某個語句擁有越多重要的關鍵詞,那 麼該語句便越可能屬於摘要。所謂的正面關鍵詞指的是常出現在摘要語句中 的關鍵字詞。. 考慮到中文的斷詞切字的困難程度,中文斷詞的正確與否會影響到關鍵 詞出現在摘要語句的機率值;針對利用字典(Dictionary)作中文斷詞的缺點— 新 字 詞 無 法 辨 認 出 來 , 我 們 應 用 詞 彙 相 關 程 度 (Word Co-occurrence) [Kowalski97]的技術來尋找文件中出現的新詞,並將找到的新詞加入計算以 得到更正確的機率值。. 假設 A, B, C 是三個關鍵詞組,且 C 是由 A, B 所組成的(亦即,C 為新詞), freqa 表示 A 出現在文件集中的頻率,freqb 表示 B 出現在文件集中的頻率,. 27.
(36) freqc 則表示 C 出現在文件集中的頻率,則 A, B 兩關鍵詞間的詞彙相關程度 計算公式如方程式 9: WC ( A, B) =. freqc freqa * freqb. 方程式 9:A, B 關鍵詞的詞彙相關程度 [Kowalski97]. 當 WC (A, B)的值大於某個臨界值時,我們認為 C 是具有意義的新詞,因而 以 C 這個新詞來取代 A, B。 對 於 測 試 文 件 中 某 個 語 句 s 而 言 , 假 若 它 是 由 Keyword1 , Keyword2 , … ,Keywordn 所組成的,它的正面關鍵詞特徵值的計算方式如方程 式 10: ScorePositiveKeyword (s ) =. ∑ c ⋅ P( s ∈ S | Keyword ) k. k. k =1 , 2 ,..., n. where ck is the no. of Keywordk in s. 方程式 10:s 的正面關鍵詞特徵值. 3.. 負面關鍵詞(Negative Keyword) 相對於正面關鍵詞而言,在文件集中常出現但不屬於摘要中的關鍵詞,. 我們稱作負面關鍵詞。考慮這個特徵的原因,主要是希望將負面的關鍵詞特 性也一併考慮,以期能夠得到更正確的結果。對於某個負面關鍵詞 Keywordi 而言,擁有 Keywordi 的語句 s 不屬於摘要的機率,計算方式如方程式 11: P(s ∉ S | Keywordi ) =. P( Keywordi | s ∉ S )P(s ∉ S ) P( Keywordi). 方程式 11:給予負面關鍵詞 Keyword i 的條件下,s 不屬於摘要的機率. 28.
(37) 對 於 測 試 文 件 中 某 個 語 句 s 而 言 , 假 若 它 是 由 Keyword1 , Keyword2 , … ,Keywordn 所組成的,它的負面關鍵詞特徵值的計算方式如方程 式 12: ScoreNegativeKeyword (s ) =. ∑c. k. k =1, 2 ,..., n. ⋅ P(s ∉ S | Keywordk ). where ck is the no. of Keywordk in s. 方程式 12:s 的負面關鍵詞特徵值. 4.. 與標題的相似度(Resemblance to the Title) 這個特徵主要考慮每個語句與文件標題的相似程度。一般來說,標題通. 常可以代表文件中所要描述的主題,因此,假若文件中的語句包含越多標題 中所出現的詞彙,則該語句與文件主題的相關程度便會越高。 對於測試文件中的某個語句 s 來說,與標題相似度的特徵值的計算方式 如方程式 13:. ScoreResemblance to Title(s ) =. keywords in s I keywords in the title keywords in s U keywords in the title. 方程式 13:s 與標題的相似度特徵值. 5.. 向心性(Centrality) 文件中的語句如果越能代表該文件所要表達的意思的話,那麼該語句的. 重要性便會越高,這就是所謂向心性的概念。計算某個語句的向心性即是計 算語句的向量表示法與整份文件扣除該語句的向量表示法兩者間的相似 度。具有最大向心性的語句越能代表該文件的中心(Centroid ),換句話說, 便是最具代表性的語句。. 29.
(38) 對於測試文件中的某個語句 s 而言,向心性特徵值計算方式如方程式 14:. ScoreCentrality(s ) =. keywords in s I keywords in other sentences keywords in s U keywords in other sentences. 方程式 14:s 的向心性 特徵值. 第二節 語句權重的計算與摘要生成 第一節中說明如何從訓練文件集(Training Corpus)中計算單一語句每個特徵 值。在本節中我們介紹如何將單一語句的所有特徵值結合以得到該語句的真正權 重值。 首先就每個特徵來討論,我們認為每個特徵的重要程度有所不同。針對這 點,我們假設語句位置(Position)的權重是 w1,正面關鍵詞(Positive Keyword)的權 重 是 w2 , 負 面 關 鍵 詞 (Negative Keyword) 的 權 重 是 w3 , 與 標 題 的 相 似 度 (Resemblance to the Title)的權重是 w4,而向心性(Centrality)的權重是 w5,最後設 計了如方程式 15 的 Score Function 來計算每個語句的權重值。 對於測試文件中的某個語句 s 而言,它的整體權重值的計算方式如方程式 15: ScoreOverall(s ) = w1 ⋅ Score Position(s ) + w2 ⋅ ScorePositiveKeyword (s ) − w3 ⋅ ScoreNegativeKeyword (s ) + w4 ⋅ ScoreResemblance to the Title(s ) + w5 ⋅ ScoreCentrality(s ) 方程式 15:計算語句權重值的 Score Function. 其中 w1 , w2 , w3 , w4 , w5 的數值大小,我們利用基因演算法(Genetic Algorithm)來訓 練以得到適合該訓練文件集的最佳 Score Function。. 30.
(39) 訓練 Score Function 的做法,我們將每組 w1 , w2 , w3 , w4 , w5 視為基因組 (genome)。每次產生 1000 個個體(Element)當作一個世代(Generation),接著計算 每個個體對於該訓練文件集的摘要正確率— 以召回率(Recall)為參考標準,並保 留摘要召回率最高的 10 個個體當作下一世代的母體;每一個世代評估完後,依 照保留下來的 10 個個體來交配產生下一個世代的部分個體,並隨機產生其他個 體以補足每個世代的個體數目。個體交配的時候,我們以下面兩個原則來產生下 一世代的個體。. 1.. 以圖 11 為例。E1, E2 分別代表母代的基因組,產生下一世代的時候, 將 E1 的基因組(M1,1, M1,2 )與 E2 的基因組(M2,3, M2,4 , M2,5)組合成為 E3, 將 E2 的基因組(M2,1, M2,2)與 E1 的基因組(M1,3, M1,4, M1,5)組合成為 E4, 這樣的交配方法我們將之稱為”2-3 基因交換”。依照這個原則,我們實 作了 1-4, 2-3, 3-2, 4-1 四種交配的方法。. 圖 11: m-n 基因交配方法. 2.. 為了增加基因的突變能力,以圖 12 為例,以隨機的方式保留下 E1 中 的 M1,2 , M1,4 , M1,5 作為 E2 的基因(每次所保留的基因不同),另外,E2 中的 M1,1 與 M1,3 則由系統隨機產生,便可以保留下部分優良的基因, 以增加世代的突變能力。. 31.
(40) 圖 12:個體的基因組(M1,1 , M 1,2 , M 1,3 , M1,4 , M 1,5 )與其突變. 利用基因演算法的訓練方式,我們可以找到一組最適合該訓練文件集的特徵 權重值。這樣的作法乃是因為對於不同的訓練文件集,很難有效地找到最適合的 特徵權重值,然而,套用基因演算法的方式可以幫助找到一組適當的解,做為系 統設計者調整系統好壞的依據。 值得一提的是,我們將基因演算法套用於訓練文件集上,因此對於測試文件 集(Test Corpus )並不能保證所得到的權重值組也能得到相同的好結果。但是,假 如測試文件集與訓練文件集的性質非常接近的話,此方法的結果與實際上真正適 合該測試文件集的權重值組所計算出來的正確率並不會相差太多。 生成文件摘要的部份,以一篇測試文件而言,首先根據方程式 15 計算每個 語句的整體權重值,當成是每個語句的分數(Score),接著依據語句的分數將文件 中的語句依分數由大至小的方式作排名(Ranking),最後將 Top N 個語句擷取出來 當作該文件的摘要結果。綜合上述,我們將此摘要的方法加以整理於圖 13。 Corpus-based 文件摘要生成演算法 1. 2 3 4. 針對測試文件中的每個語句依下列步驟計算它的權重值。 1.1 利用方程式 8、方程式 10、方程式 12、方程式 13、方程式 14 計算每個特徵值的大小。 1.2 利用方程式 15 計算該語句的整體權重大小。 將文件中的所有語句,依照語句的分數由大排到小形成一份語句重要 性排名清單(Sentence Importance List)。 根據壓縮比(Compression Rate)計算欲摘要的語句個數 N。 從語句重要性排名清單中挑選出前面的 N 個語句即為該文件的摘要。. 圖 13: Corpus-based 文件摘要生成演算法 32.
(41) 總結來說,我們以[Kupiec95]為本,提出了三項改進的方法:. 1.. 引入權重的概念應用在語句位置的重要性計算上,以期得到更正確的語 句位置特徵值的計算。. 2.. 根據中文斷詞切字的問題,利用詞彙相關程度的技術來找到文件集中的 新詞,以期能夠改進與關鍵詞相關的特徵值(正面關鍵詞、負面關鍵詞、 與標題的相似度及向心性)的計算結果。. 3.. 使用基因演算法來訓練 Score Function 中的 w1 , w2 , w3 , w4 以及 w5,以期 能夠提供系統設計者調整 Score Function 的依據。. 33.
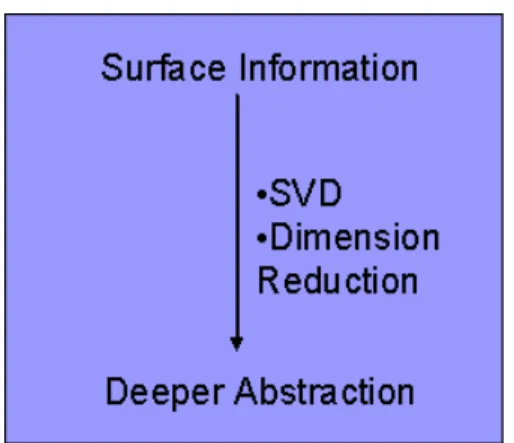
(42) 第四章. 以潛在語意分析為基礎的語句摘要. 受到資訊擷取中潛在語意分析(Latent Semantic Analysis, LSA)與潛在語意索 引(Latent Semantic Indexing, LSI)研究成果的影響,我們認為 LSA 可以正確地描 述文件中字詞、語句與文件意義的整體關聯性;因此,本論文將 LSA 應用在自 動摘要的研究上,並提出一套以 LSA 為知識核心的摘要方法。 本章中,首先介紹何謂 LSA 及其工作原理,接著說明本論文所提的以 LSA 為基礎的語句摘要技術的系統架構,最後描述我們的方法與相關討論。. 第一節 潛在語意分析(Latent Semantic Analysis) LSA 工作原理. 4.1.1. [Landauer98]認為 LSA 除可作為文件的知識表示(Knowledge Representation) 外,並可用來推演隱性的知識關聯;此外,LSA 的知識模型與知識推演過程接 近於人腦用來理解文件知識的推演與認知機制模型。. LSA是以數學統計為基礎的知識模型,其運作方式跟類神經網路(Neural Net) 的極為相似,不同的是類神經網路以權重的傳遞與回饋來修正本身的學習,LSA 則 以 奇 異 值 分 解 (Singular Value Decomposition, SVD) 與 維 度 約 化 (Dimension Reduction)為核心作為邏輯推演的方式。 LSA 的應用非常廣泛,主要集中在資訊擷取、同義詞建構、字詞與文句的 相關性判斷標準、文件品質優劣的判別標準及文件理解與預測等各方面的研究。. LSA 的工作原理如圖 14 所示:利用 SVD 及維度約化將輸入的知識模型抽 象化,整個過程除可以將隱含的語意顯現出來外,更能將原本輸入的知識模型提 升到較高層次的語意層面。. 34.
(43) 圖 14: LSA 工作原理示意圖. 實 際 運 作 的 過 程 中 , 首 先 將 文 件 集 (Corpus)中 所 有 文 件 的 Context 2 用 Word-by-Context 矩陣 M 來表示,矩陣中的每個元素即是某關鍵詞在某 Context 中的重要性或出現頻率。接著,將矩陣 M 經過 SVD 分解轉換得成新的矩陣乘積 LSUT,亦即 M=LSUT,其中 S 代表語意空間(Semantic Space),L 代表關鍵詞在此 語意空間中的表示法,UT 則代表 Context 在此語意空間中的表示法。LSA 利用維 度約化可更精確地描述語意空間的維度,並重建矩陣 M∼M’=L’S’U’T,更明確地 探究出 Word-Word、Word-Context 或 Context-Context 間的關聯性。 總結上述說明:. 1.. LSA 假設經過 SVD 後所得到的對角線矩陣(即上述中的 S 與 S’)所代表 的意義是整份文件的語意空間。所謂的語意空間就是文件中每個字詞的 定義空間,也就是說,每個字詞可以透過這個語意空間的定位來得到真 正代表的意思。. 2.. 為了要將語意空間的真正維度定義出來,LSA 需要經過維度約化來重 建最後的 Word-by-Sentence 矩陣。. 3.. M 經過 SVD 分解與維度約化後重建得到的新矩陣 M’中,S’代表語意空 間,此語意空間比 S 可以更正確地定義且描述關鍵詞與 Context 所代表. 2. 所謂 Context 可視需求定義為 Sentence, Paragraph, Chapter, 或 Document 的層面來考量 。 35.
(44) 的意義。 4.. 相較於使用外在資源以達到文件模型建構的方法,LSA 提供直接的分 析方式,更精確地建構文件的知識模型,且避免使用輔助知識可能發生 的語意混淆的問題。. 5.. LSA 與 資 訊 擷 取 的 不 同 在 於 LSA 可 以 涵 蓋 字 詞 間 關 聯 程 度 (Co-occurrence),更可藉由維度約化將原 Context 中潛在的語意表現出 來。. 6.. LSA 具有知識推演的能力,如果將最原始矩陣中的任一個數值改變後, 其結果會影響到最後重建的矩陣,且影響的範圍不只是原先經過改變的 數值,更可能影響到矩陣中的其他數值。 LSA 實例說明. 4.1.2. 接下來,我們以實例說明 LSA 的運作方式 [Landauer98]。這個例子中共包 含 9 個 Context,分別為 c1、c2、c3、c4、c5、m1、m2、m3 與 m4,其中 c1 至 c5 是 Human-Computer Interface 領域的相關文件標題,而 m1 至 m4 則來自於 Mathematical Graph Theory 領域的相關文件標題。 Exampl of text data: Titles of Some Technical Memos [Human-Computer Interface] c1: Human machine interface for ABC computer applications c2: A survey of user opinion of computer system response time c3: The EPS user interface management system c4: System and human system engineering testing of EPS c5: Relation of user perceived response time to error measurement [Mathematical Graph Theory] m1: The generation of random, binary, ordered trees m2: The intersection graph of paths in trees m3: Graph minors IV: Widths of trees and well-quasi-ordering m4: Graph minors: A survey 36.
(45) 我們挑選至少出現兩次的關鍵詞來建構 Word-by-Title 的矩陣{X},{X}中的每 一列(Row)代表在兩個或兩個以上的 Context 中出現過的關鍵詞 ,而每一行 (Column)則代表一個 Context ;此外, {X}中每個元素代表特定關鍵詞在特定 Context 中出現的次數。{X}經過 SVD 分解後得到三個矩陣,分別為{W},{S}以及 {P}T。其中{X}即是先前所說的 M,另外{W}、{S}與{P}T 分別為前面所說的的 L、 S 與 UT。. {X’}則是維度約化過程中取維度(Dimension)為 2,亦即取{W}、{S}與{P}的前 二 Column( 相 當 於 把 其 他 Column 的 值 均 設 為 0) 後 所 重 建 回 來 的 矩 陣 — {X’}={W’}{S’}{P’}T({W’}, {S’}, {P’}為將{W}, {S}, {P}取前二 Column 值,其餘 Column 值設為 0 的結果)。 human interface computer user system {X } = response time EPS survey trees graph minors. c1 c2 c3 c4 c5 m1 m2 m3 m4 1 0 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 1 2 0 0 0 0 0 0 1 0 0 1 0 0 0 0 = {W }{S }{P}T 0 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 1 1 . 37.
數據

![圖 6:Text Relationship Map 的範例 [Salton97]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8506883.185585/27.894.181.705.230.484/圖6TextRelationshipMap的範例Salton97.webp)
![圖 7:Paragraph Relationship Map 與其對應的 Text Segmentation [Salton97]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8506883.185585/29.894.179.713.556.792/圖7ParagraphRelationshipMap與其對應的TextSegmentationSalton97.webp)
+7
![圖 8:計算 Aggregate Similarity 的概念圖示 [Kim00]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8506883.185585/30.894.132.756.288.450/圖8計算AggregateSimilarity的概念圖示Kim.webp)


相關文件
另外,語文科高中的寫作活動也很多元化,題材亦很生活化,有助提高學生對創作 的興趣。 (高中語文寫作題目舉隅,見附件三 附件三 附件三。 附件三 。 。) 。 ) ) ).. 附件三
本書立足中華文化大背景,較為深入系統地分析研究了回族傳統法文化的形成基礎、發展歷
Segmented Bushy Path 分為兩個步驟,第一個步驟是文件結構的切割 (Text Segmentation),也就是分析文件內容並將文件內容切割成幾個具有代 表的結構。Text Segmentation
當兒童以自由叙述形式披露事件後,如 內容的資料不足,調查員可用開放式問 題澄清事件的時、地、人、性質及發生 經過.. 呢件事係點發 生,幾時發生
• Flash 的打散(Break Apart)功能,可以將群組 物件、點陣圖、文字物件,以及元件轉換成填色
• 本章動畫的主角是各個英文字母文字物件,由 於 Flash 提供了文字物件打散 (Break Apart) 及分散至圖層 (Distribute to Layer)
俄國的學者從 1957 年開始研究整理這些文獻,直到八十年代公布 於世的有五十件,之後整理出 488 件,然後拼合成 375 個序號,到
Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval pp.298-306.. Automatic Classification Using Supervised
