國 立 交 通 大 學
資訊科學與工程研究所
碩 士 論 文
部落格分群
Blog Clustering
研 究 生:陳佑州
指導教授:李嘉晃 教授
部落格分群
Blog Clustering
研 究 生:陳佑州
Student:You-Chou Chen
指導教授:李嘉晃
Advisor:Chia-Hoang Lee
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science Jun 2010
Hsinchu, Taiwan, Republic of China
部落格分群
學生 : 陳佑州 指導教授:李嘉晃 教授
國立交通大學資訊學院 資訊科學與工程研究所碩士班
摘要
網際網路能夠如此快速的發展成為現代人生活中不可或缺的一部分,搜尋引 擎的出現功不可沒,但是現今的搜尋技術幾乎都是以關鍵字來查找網頁,也就是 當使用者輸入關鍵字之後,搜尋引擎幫忙找出含有這個關鍵字的網頁。假設你是 一位部落格作者,擁有自己的部落格,搜尋引擎目前並無法根據你撰寫文章的主 題來自動找出你可能有興趣閱讀的部落格,因為目前搜尋引擎無法根據部落格的 特徵自動分群。因此,在本篇論文中,我們將研究如何將網路上的部落格根據其 主題分群,藉此找出有相同興趣的作者。我們提出利用部落格的標籤雲來代表部 落格的概念。標籤雲就是一個部落格中所有文章之標籤的集合,部落格上的標籤 是由人工所標記的,很適合用來代表一篇文章的概念或主題,所以本系統直接以 標籤雲來代表部落格而不是藉由分析每一篇文章來找出部落格的主題。得到部落 格的表示法後,就可以計算部落格與部落格之間的相似度,接著再使用不同的分 群演算法將部落格分群,比較其結果。根據實驗結果可知,我們幾乎可以很準確 的把相同主題的部落格分在同一個群中,這代表同一個群中之部落格的作者都有 著相同的興趣或喜好。Blog Clustering
Student:You-Chou Chen Advisor:Prof. Chia-Hoang Lee Department of Computer and Information Science
National Chiao Tung University
ABSTRACT
Discovering social interests from user's blog content or social tags is one of the interesting and challenging problems in social network research. We tackle this problem using blog clustering based on the tags of blogs. In blog representation, we employ the tags of a blog to represent the blogger's interests and discover user's common interests using blog clustering. In this paper, we propose two kinds of approaches to tackle this problem. In the first approach, we employ spectral clustering to cluster the blogs in the concept vector space. The construction of concept vector representation is similar to dimensionality reduction. First, we regard the Web as system corpus to measure the relevance of two tags based on the hits returned from the search engine. Second, a balanced hierarchical agglomerative clustering, which takes into account the size of the clusters, is proposed to aggregate the tags that are relevant. Finally, the original tag vector representation can be transformed into its corresponding concept vector representation. The experimental results show that the F1 value can be improved a lot as compared with the clustering in the tag vector space. In the second approach, we propose to employ multidimensional scaling technique to perform dimensionality reduction and then apply K-means clustering in the reduced coordinates. The experimental results show that our approaches can effectively cluster the blogs with similar interests and it can be applied to other social network clustering easily.
誌謝
誌謝
誌謝
誌謝
本論文可以順利完成,首先要感謝的就是我的指導教授李嘉晃教授。有了教 授的指引,我在研究的過程中才不會手足無措;也謝謝教授的耐心指導,讓我對 自然語言處理這個領域有更深的認識。我從教授的身上學到了做研究的方法,未 來將成為我工作上的助力。接著要感謝三位辛苦的口試委員,王勝德教授、張道 行教授與李漢銘教授,謝謝教授們的建議,讓本論文的內容可以更加完整。 再來要特別感謝我的學長,在我課業上有問題時,你們總是細心的指導我, 讓我獲益良多。還要謝謝同屆的同學們,紀孝承、鍾喻安與楊瑞敏。不管在研究 上或是課業上,我都從你們的身上學到很多東西;也因為有你們的陪伴,讓辛苦 的碩士生涯增添了許多歡樂。謝謝實驗室的學弟們,因為你們在實驗上的幫助, 讓我可以更快完成論文。謝謝交通大學提供一個這麼好的環境,讓我可以在這學 習且有所成長。 最後,謝謝我的家人,你們總是一直支持我、鼓勵我。謝謝所有幫助過我的 朋友們,我以此篇文章表達我誠摯的謝意。
目錄
目錄
目錄
目錄
第一章、緒論... 1 1.1 研究動機 ... 1 1.2 研究目的 ... 1 1.3 論文架構 ... 2 第二章、相關研究... 3 2.1 標籤雲(Tag Cloud) ... 3 2.2 Multidimensional Scaling(MDS) ... 4 2.3 Spectral Clustering ... 10 2.3.1 定義符號 ... 10 2.3.2 Laplacian matrix ... 11 2.3.3 RatioCut 與 Ncut ... 15 2.3.4 Spectral clustering 演算法 ... 21 第三章、系統設計... 23 3.1 概念 ... 23 3.2 系統架構 ... 23 3.3 收集部落格之標籤雲 ... 25 3.4 前置處理 ... 25 3.5 計算所有標籤之間的相似度 ... 25 3.6 將部落格以向量表示 ... 27 3.6.1 標籤分群 ... 29 3.6.2 產生部落格向量 ... 33 3.7 以座標表示部落格 ... 35 3.7.1 使用 Multidimensional scaling 產生標籤之座標 ... 36 3.7.2 計算部落格之座標 ... 36 3.8 分群 ... 37 3.9 分析結果 ... 37
第四章、實驗過程與結果討論... 39 4.1 實驗資料 ... 39 4.2 實驗步驟 ... 39 4.3 實驗結果 ... 39 4.4 實驗討論 ... 43 第五章、結論與展望... 44 5.1 研究總結 ... 44 5.2 未來研究 ... 44 參考文獻... 45
圖目錄
圖目錄
圖目錄
圖目錄
圖 2-1 Multidimensional Scaling 範例... 4 圖 2-2 賦予每一個節點座標 ... 8 圖 3-1 系統流程圖 ... 24 圖 3-2 標籤之分群結果 ... 28 圖 3-3 不同的分群結果 ... 30 圖 3-4 用新的相似度來挑選最相似的兩個群合併 ... 31 圖 3-5 任意選擇想要的群數 ... 34 圖 4-1 各種不同維度的向量使用 kmeans 分群之曲線圖 ... 40 圖 4-2 各種不同維度的向量使用演算法(a)分群之曲線圖 ... 41 圖 4-3 各種不同維度的向量使用演算法(b)分群之曲線圖 ... 42
表目錄
表目錄
表目錄
表目錄
表 3-1 標籤之間的相似度 ... 28 表 3-2 120 群,新的相似度計算方法... 32 表 3-3 120 群,舊的相似度計算方法... 32 表 3-4 使用新的相似度計算方法分群時,前五大群的標籤數 ... 33 表 3-5 使用舊的相似度計算方法分群時,前五大群的標籤數 ... 33 表 4-1 對 2447 維的部落格向量使用不同分群演算法之結果 ... 40 表 4-2 各種不同維度的向量使用 kmeans 分群的結果 ... 40 表 4-3 各種不同維度的向量使用演算法(a)分群的結果 ... 41 表 4-4 各種不同維度的向量使用演算法(b)分群的結果 ... 42 表 4-5 對部落格座標分群的結果... 43
第一章
第一章
第一章
第一章、
、
、
、緒論
緒論
緒論
緒論
1.1
1.1
1.1
1.1 研究動機
研究動機
研究動機
研究動機
網際網路能夠如此快速的發展成為現代人生活中不可或缺的一部分,搜尋引 擎的出現功不可沒,因為「網路」幾乎已經成為全世界最大的資料庫。由於網路 上的資料量實在過於龐大,且每天都在持續增加中,如果沒有一個方法能讓使用 者快速的找到所需的資料,使用者必定得花費大量的時間在搜尋上。但是現今的 搜尋技術都是以關鍵字來查找網頁,也就是當使用者輸入關鍵字之後,搜尋引擎 幫忙找出含有這個關鍵字的網頁。但是假設今天有一個部落格作者想找到與自己 興趣相同的其他作者時,使用搜尋引擎就顯得不太方便。因此本篇論文希望發展 一套系統,能夠找出哪些部落格所描述的主題是相似的,以減少使用者的搜尋時 間。
1.2
1.2
1.2
1.2 研究目的
研究目的
研究目的
研究目的
本論文希望能分析出在網際網路上的許多部落格作者中,哪些作者有相同的 興趣,本論文假設若某兩篇部落格中的文章所描述的主題都相近,則這兩篇部落 格的作者有相同的興趣。 在自然語言處理的領域中,常常是用統計的方法來找出一些重要詞彙來當成 文章的標籤,當文章數量越多的時候,計算所花費的時間也會越多。由於許多部 落格作者在撰寫文章時都會替文章標上標籤,本系統將不考慮部落格中每篇文章 的內容,而直接以標籤雲裡的標籤來代表整個部落格,將所有部落格分群,然後 檢視是否同一個群內的部落格都描述相同的主題。根據最後的實驗結果顯示,系 統確實可以將大部份的部落格分到正確的群中,也間接表示以標籤雲來代表整個 部落格是非常合適的。
1.3
1.3
1.3
1.3 論文架構
論文架構
論文架構
論文架構
第一章:緒論,描述本論文之動機與目的。 第二章:相關研究,描述本論文會用到的演算法及技術原理。 第三章:系統設計,將系統的整體架構做一個完整的介紹。 第四章:實驗過程與結果討論,分析實驗結果。 第五章:結論與展望,將本論文做個總結並討論系統未來走向。
第二章
第二章
第二章
第二章、
、
、
、相關研究
相關研究
相關研究
相關研究
2.1
2.1
2.1
2.1
標籤雲
標籤雲
標籤雲(
標籤雲
((
(Tag Cloud
Tag Cloud
Tag Cloud)
Tag Cloud
))
)
標籤雲[1]主要的功能就是關鍵詞的視覺化描述,它是由許多用戶生成的標 籤聚集而成。通常標籤雲中的標籤按照字母的順序排列,而且每一個標籤都是一 個獨立的詞彙。標籤可以透過改變字體大小和顏色來表示不同的意義。大多數的 標籤本身就是一個超連結,可以直接指向與標籤相關聯的資訊。 標籤雲的其中一個普遍的應用就是應用在部落格中,部落格中通常有一區塊 用來容納部落格作者產生的標籤。每當部落格作者發表文章時,可以將文章與一 個或數個標籤連結,標籤雲中的每一個標籤就會根據與它連結的文章數的多寡而 呈現不同的字體大小。當部落格的閱讀者來訪時,可以根據標籤雲中每一個標籤 字面上的意義得知這個部落格所談論的主題。舉例來說:假設某一部落格上的標 籤雲裡的標籤有「comedy, DVD, review, …」,則可以推測這個部落格的內容可 能是關於電影或電視劇。每一個標籤的字體大小可以更進一步告訴閱讀者與這個 標籤連結的文章數的多寡。通常部落格中的標籤為超連結,閱讀者可以直接點擊 標籤閱讀與這個標籤相關的文章。所以標籤雲在部落格中所扮演的角色就像是書 中的目錄或是索引,通常人們可以根據目錄來找到所需的資訊,也可以根據目錄 大致上了解這本書的內容。
2
22
2.2
.2
.2
.2
Multidimensional Scaling(
Multidimensional Scaling(
Multidimensional Scaling(MDS
Multidimensional Scaling(
MDS
MDS
MDS)
))
)
先考慮下面這個例子: 圖 2-1 Multidimensional Scaling 範例 在許多應用中,常常可以得到如圖 2-1 這樣的圖形。每一個節點代表一個物 件,而每一個邊上的值代表物件之間的距離,距離可以代表相似度,距離越近代 表相似度越高,距離越遠代表相似度越低。而在某些應用中,可能需要更進一步 知道每一個節點的座標。Multidimensional scaling 就是用來賦予每一個節點 一個合適的座標,使得節點之間利用此座標計算出來的距離盡可能的接近原本節 點之間的距離。以下說明 Multidimensional scaling 的原理[2]: 假設 6 與 7 是兩個向量,則 6 與 7 之間的距離的平方為: 89:6, 7; = :6 − 7;>:6 − 7; = 6>6 + 7>7 − 2 × :6>7; (2.1) 假設矩陣 A 的行向量就是最後賦予每一個節點的座標: A = B xC yC x9 y9 zC z9 xD yD zDE 利用矩陣 A 可以求得 gram matrix F : 3 3 4 5 7.21 5 yC y9 yD yG
F = A>A = H I>I I>J J>I J>J I >K J>K K>I K>J K>KL (2.2) 接著再利用矩陣 F 求得矩陣 M : M = N × O>+ O × N>− 2 × F (2.3) = HI >I I>I J>J J>J I >I J>J K>K K>K K>KL + H I>I J>J I>I J>J K >K K>K I>I J>J K>KL − 2 × H I>I I>J J>I J>J I >K J>K K>I K>J K>KL = HI >I + I>I − 2 × :I>I; I>I + J>J − 2 × :I>J; J>J + I>I − 2 × :J>I; J>J + J>J − 2 × :J>J; I >I + K>K − 2 × :I>K; J>J + K>K − 2 × :J>K; K>K + I>I − 2 × :K>I; K>K + J>J − 2 × :K>J; K>K + K>K − 2 × :K>K;L (2.4) 其中, N 為 F 之對角線所形成之行向量BI >I J>J K>KE,O = B 1 1 1E。 根據(2.1)與(2.4)可知,矩陣 M 中的每一個元素 MPQ 代表節點 i 與節點 j 之 間之距離的平方。 經過以上的推導,可以看到從矩陣 A 求得矩陣 M 的過程。Multidimensional
scaling 的步驟恰好與上述相反,Multidimensional scaling 可以從已知的矩陣 M 來求得座標矩陣 A : 假設矩陣 M 為 n×n 的矩陣。首先,求一個向量 R , R 為一個 n×1 的向量, R 中所有元素皆為 1/n,所以可以得到下列結果: R>× O = 1 (2.5) 接下來,利用向量 R 可以求得矩陣 S : S = T − O × R> (2.6)
求出矩陣 S 後,利用矩陣 M 與矩陣 S 就可以求出矩陣 F : F = −C 9S × M × S> (2.7) (2.7)留到這一個小節的最後再證明。這裡繼續說明如何從矩陣 F 求得矩陣 A ,先假設矩陣 A 存在,且將矩陣 A 做 SVD 分解得到 A = UVW> ,根據(2.2)將 A = UVW>代入: F = :UVW>;>:UVW>; = WV>U>UVWX = WV>VWX = WYW> (2.8) = W√Y√YW> = [√YW>\>:√YW>; (2.9) (2.8)為矩陣 F 的 eigen-decomposition。Y = B λC ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ λ` E,其中 λC, λ9, … , λ`為矩陣 F 之 eigenvalue 且λC ≥ λ9 ≥ ⋯ ≥ λ` ≥ 0,因為矩陣 F
是 positive semi-definite,所以矩陣 F 的所有 eigenvalue 皆大於等於 0,矩
陣 W 之行向量 cP 為矩陣 F 相對於 λP 且長度為 1 之 eigenvector。根據(2.9)可
知,取 A = √YW> 就能得到矩陣 A ,但是當我們使用 Multidimensional scaling 來求得圖形中每一個節點的座標時,我們通常會更進一步地希望能將圖形畫出來 以利於觀察,所以通常都會將維度降至 1、2 或 3 維。在降低維度的同時,一定 會失去資訊,所以每次都刪去影響最小的部分,一直刪除到目標的維度為止。為 了達到這個目的,將矩陣 F 寫成另外一個形式: F = WYW> = λCcCcC>+ λ9c9c9>+ ⋯ + λ`c`c`> (2.10)
從觀察式子(2.10)發現,可以將矩陣 F 看成是很多矩陣組合而成,因為 λC ≥ λ9 ≥ ⋯ ≥ λ`,所以從後面的項開始刪除對矩陣 F 的影響最小。假設我 們希望最後要顯示的座標維度是 p,則取 A = Td×`√YW> 可以使得 ‖F − A>A‖ 最 小。 回到圖 2-1,可以求得矩陣 M 為: M = H 0 25.00 25.00 0 16.00 9.009.00 51.98 16.00 9.00 9.00 51.98 25.000 25.000 L 矩陣 S 如下: S = H 0.75 −0.25 −0.25 0.75 −0.25 −0.25−0.25 −0.25 −0.25 −0.25 −0.25 −0.25 −0.25 0.750.75 −0.25 L 利用矩陣 M 與矩陣 S 來計算矩陣 F : F = H 4 −4 −4 13 −44 −134 −4 4 4 −13 −4 134 −4 L 將矩陣 F 分解成 WYW> 可得: Y = H 29.035 0 0 4.957 0 0 0 0 0 0 0 0 0.004 00 0 L ,W = H 0.251 0.661 −0.661 0.251 −0.5 0.50.5 0.5 −0.251 −0.661 0.661 −0.251 −0.5 0.50.5 0.5 L 為了將yC~yG標示在平面上,所以取 T = n1 0 0 0 0 1 0 0o,則可計算 A : A = T × √Y × W = n1.353 −3.562 −1.353 3.5621.472 0.559 −1.472 −0.559o
計算出矩陣 A 之後, A 的行向量 IP 就是節點 yP 的座標,將yC~yG標示在圖 2-2: 圖 2-2 賦予每一個節點座標 從圖 2-2 中可以觀察到,在賦予節點yC~yG座標之後,每一個節點間的距離 幾乎與原本節點之間的關係一模一樣。 最後證明(2.7): 首先,從圖 2-2 中可以看到,若將此圖往任意方向平移一段距離,將獲得另 一組新的座標,而這組座標之間的距離與原本相同,所以說有無限多組解可以來 解決這個問題。為了固定一組解,可以限制此組解的中心點必須為原點,假設中 心點為原點可以得到以下式子: AR = p (2.11) 由(2.3)可以知道 M = NO>+ ON>− 2F ,將它代入 −C 9SMS> : −C 9SMS> = − C 9SNO>S>− C 9SON>S>+ SFS> (2.12) 2.99 2.99 4 5 7.21 5 y9= (-3.562,0.559) yD= (-1.353,-1.472) yG= (3.562,-0.559) yC= (1.353,1.472)
接下來證明 SNO>S> 與 SON>S> 皆為 p 矩陣: SNO>S> = SNO>:T − OR>;> = SNO>:T − RO>; = S:NO>− NO>RO>; (O>R = 1) = S:NO>− NO>; = S × p = p (2.13) 且 SON>S> = ::SON>;>;>S> = :NO>S>;>S> = p>S> = p × S> = p (2.14) 然後將SFS>展開: SFS> = :T − OR>;F:T − OR>; = F − FRO>− OR>F + OR>FRO> (2.15) 根據(2.2)可知 F = A>A ,再從(2.11)可知 AR = p,我們可以藉由(2.2)與 (2.11)來證明 FR 與 R>F 皆為 p 向量: FR = A>AR = A>p = p (2.16) 且
R>F = ::R>F;>;> = :F>R;> = :FR;> = p> (2.17) 從(2.15)、(2.16)、(2.17)可知: SFS> = F (2.18) 最後,從(2.12)、(2.13)、(2.14)與(2.18)得到:−C 9SMS> = F,得證。
2.
2.
2.
2.3
33
3
Spectral Clustering
Spectral Clustering
Spectral Clustering
Spectral Clustering
Spectral clustering 是一個分群演算法,它根據點與點之間的相似度將空 間上的一組點分群,使得同一個群內的點與點之間的相似度越高越好,不同群的 點與點之間的相似度則越低越好。這一節將簡單說明 spectral clustering 的 基本原理[3]。
2.3.1
2.3.1
2.3.1
2.3.1 定義符號
定義符號
定義符號
定義符號
假設有一無向圖(undirected graph) G = :V, E;,圖中每條邊(edge)上都有
權重(weight), V = svC, … , v`t 是點(vertex)所形成的集合,wPQ 為 vP 與 vQ 相連 的邊上的權重。其中, wPQ ≥ 0 且 wPQ = wQP ,若 wPQ = 0 代表 vP 與 vQ 之間無邊相 連。
定義weighted adjacency matrix u: u = :wPQ;P,QvC,…,`
G 中的每個點 vP ∈ V 的degree定義為: dP = x wPQ ` QvC 定義 degree matrix y : y = Bd⋮ ⋱C ⋯ 0⋮ 0 ⋯ d` E y 為對角矩陣且對角線上的值為 dC, … , d`。 假設有一 V 的子集 A ⊂ V,則 A 的補集(complement)標記為 A{ ,定義 indicator vector |} = :fC, … , f`;>∈ ℝ` 為: f fP = 1, if vP ∈ A P = 0, if vP ∈ A{
假設 A、B ⊂ V 且 A ∩ B = ∅ ,則定義 A、B 之間的 weight 為:
W:A, B; = x wPQ P∈},Q∈
2.3.2
2.3.2
2.3.2
2.3.2
Laplacian
Laplacian
Laplacian
Laplacian
matrix
matrix
matrix
matrix
Laplacian matrix 可以分為 unnormalized 與 normalized。首先說明 unnormalized Laplacian matrix,其定義為:
矩陣 具有下列性質: (1)對於所有的向量 | ∈ ℝ`,下列式子成立: |>| =1 2 x wPQ:fP− fQ;9 ` P,QvC 證明: |>| = |>y| − |>u| = x dPfP9− ` PvC x fPfQwPQ ` P,QvC =12 x dPfP9 ` PvC − 2 x fPfQwPQ ` P,QvC + x dQfQ9 ` QvC =12 x wPQ:fP− fQ;9 ` P,QvC
(2) 是 symmetric 且 positive semi-definite。
因為 y 與 u 皆為 symmetric,所以 也是 symmetric。且由(1)可知 為
semi-definite。
(3) 最小的 eigenvalue 為 0,且相對於 0 之 eigenvector 為 O。
證明: × O = :y − u; × O = y × O − u × O = Bd⋮C d` E − Bd⋮C d` E = p = 0 × O 由此可知,0 必為 之 eigenvalue。且因為 為 semi-definite,所以所有的 eigenvalue 皆大於等於 0,由此可知,0 為最小的 eigenvalue。
(4) 的所有 eigenvalue 皆為實數,且 0 = λC ≤ λ9 ≤ ⋯ ≤ λ`。
因為 是一個對稱矩陣,所以 之所有 eigenvalue 皆為實數,且由(3)可
知,0 為最小之 eigenvalue。
接下來說明 normalized graph Laplacian。normalized graph Laplacian 分為兩種,其定義分別為: = yC 9⁄ yC 9⁄ 與 = yC 矩陣 與 具有下列性質: (1) 對於所有的向量 | ∈ ℝ`,下列式子成立: |>| =1 2 x wPQ:dfPP−dfQQ;9 ` P,QvC 證明: |> | = |>yC 9⁄ yC 9⁄ | = [yC 9⁄ |\>[yC 9⁄ |\ =12 x wPQ: fP dP− fQ dQ; 9 ` P,QvC
(2) = λ ⟺ = λ,其中 = yC 9⁄ 。 證明: = λ ⇔ yC 9⁄ yC 9⁄ = λ ⇔ yC 9⁄ yC 9⁄ yC 9⁄ = λyC 9⁄ ⇔ :yC;:yC 9⁄ ; = λ:yC 9⁄ ; ⇔ = λ (3) = λ ⟺ = λy。 證明: = λ ⇔ yC = λ ⇔ yyC = λy ⇔ = λy (4) 與 是 positive semi-definite。 由(1)可知 為 semi-definite,接著根據(2)可知,若 λ 是 的 eigenvalue,則 λ 也是 的 eigenvalue,所以 的所有 eigenvalue 皆大
於等於 0,由此可知 為 semi-definite。
(5) 最小的 eigenvalue 為 0,且相對於 0 之 eigenvector 為 O。 最 小的 eigenvalue 為 0,且相對於 0 之 eigenvector 為 yC 9⁄ O。
因為 O = yCO = p = 0 × O 且 為 semi-definite,所以 0 為
之最小的 eigenvalue。由(2)與(4)可知,0 也是 最小的 eigenvalue 且
(6) 與 的所有 eigenvalue 皆為實數,且 0 = λC ≤ λ9 ≤ ⋯ ≤ λ`。 因為 為對稱矩陣,所以 之所有 eigenvalue 皆為實數,且由(5) 可知,0 為 最小之 eigenvalue。由(2)可知, 與 具有相同的 eigenvalue,所以 亦有此性質。
2.3.3
2.3.3
2.3.3
2.3.3
RatioCut
RatioCut
RatioCut 與
RatioCut
與
與
與 Ncut
Ncut
Ncut
Ncut
給定一 similarity graph G = :V, E; ,為了將所有點 V 分成任意 k 群,首 先定義 cut 如下: cut:AC, … A; =12 x W:Ad, Ad; dvC 其中,AC∪ … ∪ A= V 且 AC∩ … ∩ A= ∅。
spectral clustering 的目標就是找出一組分割(partition) AC, … , A,使
得 cut:AC, … , A; 為最小。但是在分群時,有時會希望分群完成之後每一個群內 點的數量都差不多,所以必須將群的大小也考慮進去,於是就有 RatioCut 與 Ncut 的出現。分別定義如下: RatioCut:AC, … , A; = xcut:Ad, Ad ; Ad dvC Ncut:AC, … , A; = xcut:Ad, Ad ; vol:Ad; dvC 其中,|A|代表A中點的數量,vol:A; = x dP P∈} 。 接下來就可以將重點放在如何找出 RatioCut 與 Ncut 的最小值上面。在這 一小節中,只說明 k = 2 之原理,因為 k 為任意值時,其原理與 k = 2 時是一樣 的。先說明 RatioCut:
根據之前的敘述,目標是要找出:
min}⊂RatioCut:A, A{;
首先定義向量 | = :fC, … , f`; ∈ ℝ`為: fP = |A{|/|A| , if vP ∈ A −|A|/|A{| , if vP ∈ A{ :2.19; 則 | 具有以下性質: (1) | ⊥ O 證明: | ⋅ O = x fP ` PvC = x £|A{||A| P∈} − x £|A||A{| P∈}{
= |A|£|A{||A| − |A{|£|A||A{| = 0
(2) ‖|‖ = √n 證明: ‖¤‖9 = x f P9 ` PvC
= |A||A{||A| + |A{| |A||A{| = |A{| + |A| = n
(3) |>| = |V| ⋅ RatioCut:A, A{; 證明: |>| =1 2 x wPQ[fP− fQ\9 ` P,QvC
=12 x wPQ£|A{||A| + £|A||A{|
9 P∈},Q∈}{
+12 x wPQ−£|A{||A| − £|A||A{|
9 P∈}{,Q∈}
= cut:A, A{; ¥|A{||A| +|A||A{| + 2¦
= cut:A, A{; ¥|A| + |A{||A| +|A| + |A{||A{| ¦ = |V|:cut:A, A{;|A| +cut:A, A{;|A{| ;
= |V| ⋅ RatioCut:A, A{; 因為 |V| 為定值,所以找出 RatioCut:A, A{; 的最小值相當於找出 | 使得 |>| 的值為最小,因此可以將問題重新表示如下: min}⊂ |>| subject to | ⊥ O 且 f P 定義於:2.19;,‖|‖ = √n 但是這是一個 NP hard 的問題,沒有辦法有效率的被解決,所以將 | 放寬一些 限制,改成 fP ∈ ℝ 皆可,如此可以將問題簡化成: min |∈ℝ¨ |>| subject to | ⊥ O,‖|‖ = √n 由Rayleigh-Ritz theorem[4]可知: λC ≤| >| |>| ≤ λ` 且 | 若取 之 eigenvector 代入 |T| |T| 會得到相對應的 eigenvalue,所以取 相對於 λ 之 eigenvector 即可,但是前面敘述可知, 相對於 λ 之
eigenvector為 O ,但是因為 | 被限制要垂直於 O ,所以改取相對於 λ9 之
eigenvector。求得 | 後將 | 當成 indicator vector,就可以藉由 | 得到 A ,也
就是將 V 分成兩群: vvP ∈ A, if fP ≥ 0 P ∈ A{, if fP < 0 :2.20; 接下來說明如何求 Ncut 之最小值,其過程與求 RatioCut 之最小值非常類 似。首先定義向量 | = :fC, … , f`; ∈ ℝ`為: fP = ª ª £vol:A{; vol:A; , if vP ∈ A −£vol:A;vol:A{; , if vP ∈ A{ :2.21; 則可求得: (1):y|;>O = 0 證明: :y|;>O = BdC⋮fC d`f` E > × O = dCfC+ ⋯ + d`f` = «x dP P∈} ¬ £vol:A{;vol:A; − «x dP P∈}{ ¬ £vol:A;vol:A{; = vol:A;£vol:A{;vol:A; − vol:A{;£vol:A;vol:A{; = 0
(2)|>y| = vol:V; 證明: |>y| = x fP9d P ` PvC
= vol:A;vol:A{;vol:A; + vol:A{; vol:A;vol:A{; = vol:A{; + vol:A; = vol:V; (3)|>| = vol:V;Ncut:A, A{; 證明: |>| =1 2 x wPQ[fP− fQ\9 ` P,QvC
=12 x wPQ£vol:A{;vol:A; + £vol:A;vol:A{; 9 P∈},Q∈}{
+12 x wPQ−£vol:A{;vol:A; − £vol:A;vol:A{; 9 P∈}{,Q∈}
= cut:A, A{; ¥vol:A{;vol:A; +vol:A;vol:A{; + 2¦
= cut:A, A{; ¥vol:A; + vol:A{;vol:A; +vol:A; + vol:A{;vol:A{; ¦ = vol:V;:cut:A, A{;vol:A; +cut:A, A{;vol:A{; ;
= vol:V;Ncut:A, A{; 所以可以將問題表示如下: min}⊂ |>| subject to y | ⊥ O 且 f P 定義於:2.21;,|>y| = vol:V; 同樣可以將 | 放寬限制將問題變成: min
最後將 | = yC 9⁄ 代入: min
∈ℝ¨ >yC 9⁄ yC 9⁄ subject to ⊥ yC 9⁄ O,‖‖9 = vol:V;
其中, yC 9⁄ yC 9⁄ = ,且如前所述 相對於 λC 之 eigenvector 為 yC 9⁄ O,所以根據 Rayleigh-Ritz theorem,取 為
相對於 λ9 之
2.3.4 S
2.3.4 S
2.3.4 S
2.3.4 Sp
pp
pectral clustering
ectral clustering
ectral clustering 演算法
ectral clustering
演算法
演算法
演算法
這一小節將介紹兩個較有名的 spectral clustering 演算法。分別為 Shi and Malik 在 2000 年所提出的演算法[5],以下為其虛擬碼:
這個演算法非常的簡單,首先,必須先決定要將這些點分成多少群,標記為
k 。利用 Gaussian function 計算每兩點之間的相似度,建構出矩陣 u。。。。利用
矩陣 u 就可以計算 ,得到 之後就可以計算 之 eigenvalue 與
eigenvector。接著取前 k 小的 eigenvalue 所對應的 eigenvector ®C, … , ®
形成矩陣 ¯ ,其中,矩陣 ¯ = °®C … ®± 。。。。矩陣 ¯ 是一個 n×k 矩陣,我們用 矩陣 ¯ 的第i列來代表點 xP 的座標,因此我們可以賦予每個點一個新的座標,接 著對此新的座標執行 k-means 所得到的分群結果即為最後的分群結果。。。。
Spectral clustering according to Shi and Malik
Input: A set of point X = sxC, … x`t, number k of clusters to construct .
Output: Clusters AC, … , A with AP = s j | yQ∈ CP t .
1. Construct u and y, ³PQ = exp ´−µ¶· − ¶¸µ9⁄2¹9º if i ≠ j, and ³PP = 0. y is a diagonal matrix and yPP is the sum of u′s i-th row . 2. Compute = yC , , , , = y − u .
3. Compute the first k eigenvectors ®C, … , ® of .
4. Let ¯ ∈ ℝ`× be the matrix containing the vectors ®C, … , ® as columns .
5. For i = 1, … , n, let ½P ∈ ℝ be the vector corresponding to the i-th row of ¯ .
6. Cluster the point :½P;PvC,…,` in ℝ with the k-means algorithm into clusters CC, … , C .
Ng, Jordan, and Weiss 在 2002 年提出了另一個演算法[6],這個演算法 與 Shi and Malik 所提出的有些許不同,其虛擬碼如下:
這個演算法不同的地方在於,它將 換成 。且在計算完矩陣 ¯ 之後,
必須將矩陣 ¯ 的每一個列向量正規化成長度為1,形成矩陣 ¾ 。然後用矩陣 ¾ 的
第i列來代表點 xP 的座標,再利用 k-means 對這些座標分群。
Spectral clustering according to Ng, Jordan, and Weiss Input: A set of point X = sxC, … x`t, number k of clusters to construct .
Output: Clusters AC, … , A with AP = s j | yQ∈ CP t .
1. Construct u and y,uPQ = exp ´−µ¶· − ¶¸µ9⁄2¹9º if i ≠ j, and uPP = 0 .y is a diagonal matrix and yPP is the sum of u′s i-th row .
2. Compute .
3. Compute the first k eigenvectors ®C, … , ® of .
4. Let ¯ ∈ ℝ`× be the matrix containing the vectors ®C, … , ® as columns .
5. Form the matrix ¾ ∈ ℝ`× by normalizing the rows to norm 1 . 6. For i = 1, … , n, let ½P ∈ ℝ be the vector corresponding to the
i-th row of ¾ .
7. Cluster the point :½P;PvC,…,` in ℝ with the k-means algorithm into clusters CC, … , C .
第三章
第三章
第三章
第三章、
、
、
、系統設計
系統設計
系統設計
系統設計
3.1
3.1
3.1
3.1 概念
概念
概念
概念
在本篇論文中,假設若兩個部落格裡的文章其描述的主題都相近,則猜測部 落格的作者有相同的興趣。本論文利用一個部落格的標籤雲來代表整個部落格, 這樣的做法各有其優缺點。優點是可以避免處理大量的文章資料,通常在自然語 言處理中利用計算每一個詞的頻率來找出重要的詞彙,這個方法必須統計所有文 章中每一個詞出現的次數,這樣的做法需要花費較多的時間。而標籤雲裡的標籤 是作者在撰寫文章之後標記在文章上,可以視為文章之概念或標題,也因為它是 由人工所產生,所以更具代表性也更精確。但是,其缺點也是因為它是由人工自 由產生,所以造成在描述相同之概念時卻有可能使用不同的詞彙。舉例來說:兩 個部落格的主題可能都是關於旅遊,大部分部落格文章都是關於出遊的遊記或是 旅遊景點的介紹,但是這兩個部落格的標籤雲中卻可能完全沒有重複的標籤;假 設這兩個部落格都沒有重複的標籤,在這個情況下,如果以兩個部落格的標籤重 複的程度來代表它們之間的相似程度,則這兩個都是以旅遊為主題的部落格相似 度將為零,因此,本論文將針對該問題提出適當的演算法以克服這個困難,然後 再嘗試各種不同的分群演算法,試著找出相同主題的部落格。
3.2
3.2
3.2
3.2 系統架構
系統架構
系統架構
系統架構
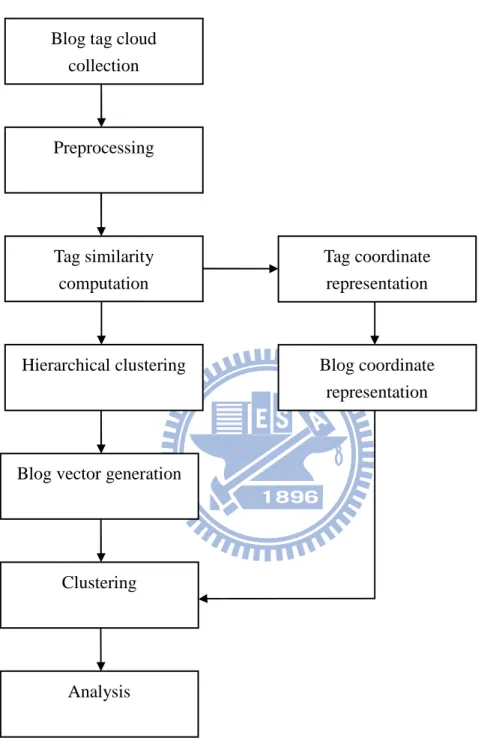
本系統分成幾個步驟來完成:首先,收集部落格之標籤雲,接著將收集來的 標籤做前置處理,在這個步驟中將刪除一些不合適的標籤。本論文提出,利用搜 尋引擎的幫助來計算標籤與標籤之間的相似度。在獲得相似度之後,本論文使用 兩個不同的方式來表示部落格。最後,分別使用不同的分群法來將這些部落格分 群,然後觀察是否在相同群中的部落格都討論相同的主題,來判斷分群結果的好 壞。圖 3-1 為系統流程圖。
圖 3-1 系統流程圖
Blog tag cloud collection
Preprocessing
Tag similarity computation
Hierarchical clustering
Blog vector generation
Clustering Tag coordinate representation Blog coordinate representation Analysis
3.3
3.3
3.3
3.3 收集部落格之標籤雲
收集部落格之標籤雲
收集部落格之標籤雲
收集部落格之標籤雲
本論文在網路上收集了 150 個英文部落格的標籤雲,這些部落格所討論的主 題分別是電影(movie)、旅遊(travel)與健康(health),每一個類別各包含 50 個部落格,而這三個類別的部落格所包含的標籤加起來總共有 2447 個。在這些 標籤中,有 2068 個標籤只出現一次,只有 379 個標籤重複出現 2 次以上,大約 佔所有標籤的 15%,從這個數據可以證明使用者自訂的標籤重複率確實非常的低。 在這邊要特別註明的是,系統在執行分群時不會知道每一個部落格的類別,類別 的資訊只用在分析分群結果的好壞。
3.4
3.4
3.4
3.4 前置處理
前置處理
前置處理
前置處理
由於每一個標籤都是由部落格作者自由產生,沒有任何限制,所以有些標籤 可能無法達到描述部落格主題的功能或是對分群可能沒有任何幫助,必須將這一 類的標籤給刪除。舉例來說:在電影的部落格中,許多作者會使用「2008, 2009, 2010, …」這樣的標籤來描述電影上映的年份,但是任何主題的部落格都可以含 有這一類的標籤,且標籤本身不含任何語意,所以這一類的標籤將被濾掉。接著, 只包含單一個字母的標籤也被過濾掉,因為單一字母標籤無法提供足夠資訊。另 外,大於三個詞(word)所組成的標籤也被去除,因為根據實驗結果,過長的標籤 與其他標籤的相似度很容易是零,它無法表現出「與某標籤較像」或是「與某標 籤較不像」這樣的訊息。
3.5
3.5
3.5
3.5 計算所有標籤
計算所有標籤
計算所有標籤
計算所有標籤之
之
之間的相似度
之
間的相似度
間的相似度
間的相似度
每當在搜尋引擎輸入一個關鍵字之後,搜尋引擎就會找到含有這個關鍵字的 網頁並回傳給使用者,這就是搜尋引擎的基本運作原理。本論文使用搜尋引擎 Altavista[7]來幫助計算相似度,假設要計算「標籤 1」與「標籤 2」之相似度
標籤 1 NEAR 標籤 2
則搜尋引擎會搜尋所有符合以下條件的網頁:
1.網頁同時包含「標籤 1」與「標籤 2」。
2.「標籤 1」與「標籤 2」在網頁上出現的位置相差在 10 個句子以內。
在 Peter D. Turney[8]的論文中,他使用 NEAR 運算子來計算 PMI。同時,搜尋 引擎也會回傳符合以上條件之網頁的數目,將搜尋引擎搜尋到的網頁數目標記 為: hits(標籤 1,標籤 2) 得到 hit 數之後,兩個標籤之相似度就定義為: Similarity(標籤 1,標籤 2) = log(hits(標籤 1,標籤 2)) 相似度不直接使用 hit 數而要取 log 的原因是因為目前網際網路上的網頁數 量實在過於龐大,取 log 可以讓這個值縮小,方便之後的計算。 這樣的相似度計算方式可以將它理解成「若兩個標籤一起出現的次數越頻繁, 則它們的相似度越高」;這樣的相似度非常適合用在這裡,因為在描述一個主題 時,一定會有常用於該主題的詞彙,只要撰寫該主題的文章時,這些詞彙就會常 常一起出現。舉例來說,可以試著計算「王建民」與 「伸卡球」和「王建民」 與「籃網」之間的相似度,分別為: Similarity(王建民, 伸卡球) = 4.99 Similarity(王建民, 籃網) = 2.46 從這個例子中可以看到,如果有一個部落格 A 包含「王建民」這個標籤,而另外 兩個部落格 B 與 C 分別包含「伸卡球」與「籃網」這兩個標籤,則系統會因為標
籤之間的相似度認為部落格 A 與 B 較相似,事實上,因為「王建民」與 「伸卡 球」常常在「棒球」這個主題下出現,所以它們計算出來的相似度也較高。
3.6
3.6
3.6
3.6 將部落格以向量表示
將部落格以向量表示
將部落格以向量表示
將部落格以向量表示
要將部落格表示成向量,首先就是要決定向量的維度,其中最簡單的方式就 是每一個標籤都代表一個維度。假設所有的標籤總共有 n 個,則每一個部落格就 可以表示為一個 n 維的向量。若一個部落格中包含某個標籤,則其向量表示法中 代表該標籤之維度的值就是 1,否則就是 0。這個方式雖然非常的簡單也非常的 直覺,但是並不適合用在這裡,原因就如前述,標籤是由人工自由產生,且重複 率非常的低。舉例來說:假設所有標籤的集合為{action, animation, comedy, fantasy, airlines, hotels},且有三個部落格 A、B 與 C,A 與 B 所描述的主題 都是電影而 C 所描述的主題是旅遊,其中,部落格 A 包含標籤{action,
animation},部落格 B 包含標籤{comedy, fantasy},部落格 C 包含標籤{airlines, hotels},則部落格 A,B 與 C 可以用此向量表示法表示如下:
A = (1, 1, 0, 0, 0, 0) B = (0, 0, 1, 1, 0, 0) C = (0, 0, 0, 0, 1, 1)
若使用上述表示法,不管使用 distance 或是使用 cosine similarity 來計 算部落格之間的相似度時,部落格 A 跟 B 的相似度與部落格 A 跟 C 的相似度都是 一樣的,所以在這種表示法下,沒有辦法顯示出部落格 A 與 B 是比較相近的。所 以必須用另一種能顯示部落格之間相似度的表示法。以上述例子來說,首先計算 每兩個標籤之間的相似度並將結果紀錄在表 3-1:
action animation action -- animation comedy fantasy airline hotels 觀察表 3-1之後可以發現 之間的相似度明顯較高而後兩個標籤 這與前四個標籤所描述之主題是 吻合,所以根據這個結果 向量,也就是將向量表示為 度分成數群,讓相似度高的標籤 一個主題的標籤相似度較高 內的標籤都在描述相近的主題 群演算法我們將在3.6.1
animation comedy fantasy airline
7.89 7.9 7.48 5.92 -- 7.98 7.09 5.24 -- 7.44 4.85 -- 4.62 --表 3-1 標籤之間的相似度
之後可以發現前四個標籤{action, animation, comedy, fantasy} 較高而後兩個標籤{airlines, hotels}之間的相似度也較高 這與前四個標籤所描述之主題是「電影」與後兩個標籤所描述的主題是 根據這個結果,本論文嘗試以每個維度來代表不同的「 將向量表示為(主題 1, 主題 2, …)。因此,可以將 讓相似度高的標籤聚集在一起,因為根據前面討論的結果 一個主題的標籤相似度較高,所以在分群完成之後可以合理的假設 內的標籤都在描述相近的主題。若將上述例子中的標籤根據相似度 3.6.1討論),可以到如圖 3-2 之結果。 圖 3-2 標籤之分群結果 airline hotels 5.92 7.08 5.24 5.45 4.85 6.4 4.62 7.18 7.21 --
{action, animation, comedy, fantasy} 之間的相似度也較高, 與後兩個標籤所描述的主題是「旅遊」 「主題」來表示 可以將標籤依照相似 因為根據前面討論的結果,描述同 在分群完成之後可以合理的假設,同一個群集 根據相似度分成兩群(分
由圖 3-2 可知,第一群為{action, animation, comedy, fantasy}且第二群 為{airlines, hotels},我們將向量表示法稍微做一點修改,改成以每一個群集 代表一個維度,也就是每一個主題代表一個維度,則部落格 A、B 與 C 的向量表 示法就變成: A = (2,0) B = (2,0) C = (0,2) 如此一來,若以此向量表示法來計算部落格之間的相似度,可以得到部落格 A 與 B 較像而部落格 A 與 C 較不像的結果,這樣就能正確的表達出部落格 A 與部落 格 B 有可能在描述較相似的主題,而部落格 C 是在描述另一個主題。3.6.1 節將 描述標籤分群的詳細步驟。
3.6.1
3.6.1
3.6.1
3.6.1 標籤分群
標籤分群
標籤分群
標籤分群
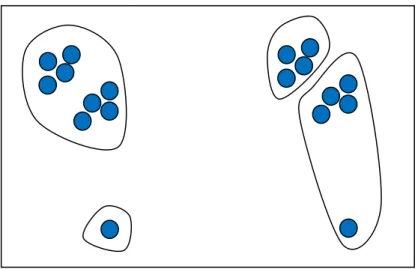
為了找出哪些標籤可能是代表相同的主題,本論文使用 Hierarchical clustering[9]來建立標籤的階層關係。一開始每一個標籤都是一個獨立的群, 之後開始每次合併相似度最高的兩個群,一直到剩下一個群為止。 在計算群與群之間的相似度時,主要有三種方法,分別是 Single linkage、 Complete linkage 與 Average linkage。本論文使用的是 Average linkage, Average linkage 的優點是較其他方法精確,缺點是計算起來較費時。但是在實 際分群的過程中,很容易碰到群與群的數目不平均的情況,考慮圖 3-3 之情況:
圖 3-3 不同的分群結果 如圖 3-3 左邊的分群結果,因為有一個標籤與其他所有標籤的相似度都很低, 所以很容易造成該標籤自成一群而其他所有的標籤形成一個大群,這並不是執行 分群演算法時想要看到的結果。較理想的分群結果應該是如圖 3-3 右邊的分群結 果,每一個群中的標籤數量較平均,也較符合分群的目的。為了解決這個問題, 必須在合併兩個群時考慮是否會造成標籤數目過多之情形,所以要將合併之後的 群之標籤數量當成一個參數去調整群與群間的相似度,基本的想法是根據兩個群 合併之後的標籤數量來降低這兩個群之間的相似度,若兩個群合併之後的標籤數 目越多,則這兩個群的相似度降低越多,此時系統就會選擇其他兩個群來合併。 因此將計算相似度的公式稍微調整為:
Similarity[gP, gQ\ = Original Similarity:gP, gQ; × :N − :size:gPN; + size:gQ;;;À
其中,Original Similarity:gP, gQ;是原本使用 Average linkage 所計算出來的相似
度,N是所有標籤的數量,size:g;代表標記為 g 這個群中的標籤數量,而 f 為一
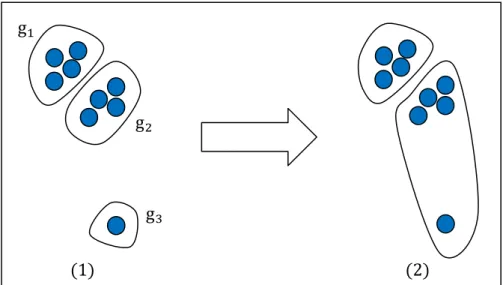
個參數,可以視最後的分群情況來調整,它代表兩個群合併之後的標籤數量對兩 個群之間的相似度的影響程度。圖 3-4 為用新的相似度來挑選最相似的兩個群合 併之情形:
圖 3-4 用新的相似度來挑選最相似的兩個群合併 圖 3-4 的(1)中有三個群,分別為 gC、g9 與 gD。如果使用 Average linkage 來計算群與群之間的相似度時,相似度分別為 sC9、sCD 與 s9D,其中sPQ代表 gP 與 gQ 之間的相似度且 sC9 > s9D> sCD,但是由於 gC 與 g9 合併之後的群包含八個標籤 而 g9 與 gD 合併之後只有五個標籤,假設合併後的標籤數量調整相似度之後造成 adjust:s9D; > ÂÃÄÅÆÇ:sC9;,其中,adjust:sPQ;就是 gP 與 gQ 經過調整之後的相似度, 所以系統最後選擇合併 g9 與 gD ,合併之後的結果如圖 3-4 的(2)。 為了證實新的相似度計算方式確實有用,我們以實際的資料分別使用舊的相 似度計算方式與新的相似度計算方式來比較: 首先,先觀察使用新的相似度計算方式將所有標籤分為 120 群時的分群狀況, 表 3-2 列出前五大的群所包含之標籤之內容。舉例來說:最大的群共有 775 個標 籤,其中 69 個標籤曾出現在電影類的部落格中,655 個標籤曾出現在旅遊類的 部落格中,67 個標籤曾出現在健康類的部落格中,6 個標籤同時出現在電影與旅 遊類,10 個標籤同時出現在旅遊與健康類。藉由表 3-2 可以發現,第一大的群 中有 84.5%都是旅遊類的標籤,第二大的群有 84.6%都是電影類的標籤,而第三 大的群則有 94.3%都是健康類的標籤。 g9 gC gD :1; :2;
標籤數 標籤數 標籤數
標籤數 MMMMovieovieovieovie TravelTTTravelravelravel HHHHealthealthealthealth M&TM&TM&TM&T M&H M&HM&HM&H T&HT&HT&HT&H M&T&HM&T&HM&T&HM&T&H 775 775775 775 69 655 67 6 0 10 0 546 546546 546 462 56 46 12 5 5 4 470 470470 470 14 26 443 0 0 13 0 455 455455 455 103 196 203 16 9 29 7 12 12 12 12 0 0 12 0 0 0 0 表 3-2 120 群,新的相似度計算方法 接下來觀察使用舊的相似度計算方式將所有標籤分成 120 群之分群狀況,表 3-3 列出前五大的群所包含之標籤之內容。我們可以看到,第一群就包含了 2236 個標籤,佔了所有標籤的 91.4%,其中 28.9%的標籤曾出現在電影類中,41.5% 的標籤曾出現在旅遊類中,33.8%的標籤曾出現在健康類中。第二大的群只包含 了 12 個標籤,剩下的群則包含更少標籤。 標籤數 標籤數 標籤數
標籤數 MMMM TTT T HHHH M&TM&T M&TM&T M&HM&H M&HM&H T&H T&HT&HT&H M&T&HM&T&HM&T&HM&T&H 2236 2236 2236 2236 647 928 755 34 14 57 11 12 12 12 12 0 0 12 0 0 0 0 10 10 10 10 10 0 0 0 0 0 0 9 99 9 9 0 0 0 0 0 0 7 77 7 0 0 7 0 0 0 0 表 3-3 120 群,舊的相似度計算方法 藉由觀察 120 群之情形可以發現,新的相似度計算方式可以將所有的標籤分 成較平均的群,且每個群中的標籤大部分都來自同一類的部落格。而使用舊的相 似度計算方式,大部分的標籤都落在同一個群中,且這個群中每個類別都大約佔 三分之一,也就是沒辦法將不同類別的標籤分開。
表 3-4、3-5 為分別使用這兩種相似度計算方法將所有標籤分為 250、500 與 1000 群之情形,並記錄了前五大群的標籤數。藉由這裡的分析可以證明,不 管分成多少群,新的相似度計算方法確實可以使每個群的大小較平均。 群數 群數 群數 群數 1111 2222 3 333 4444 5555 250 250 250 250 415 358 348 332 259 500 500 500 500 237 189 188 142 140 1000 1000 1000 1000 72 68 65 64 58 表 3-4 使用新的相似度計算方法分群時,前五大群的標籤數 群數 群數 群數 群數 1111 2222 3 333 4444 5555 250 250 250 250 1980 14 10 10 7 500 500 500 500 1434 86 19 18 16 1000 1000 1000 1000 718 42 39 32 29 表 3-5 使用舊的相似度計算方法分群時,前五大群的標籤數
3.6.2
3.6.2
3.6.2
3.6.2 產生部落格向量
產生部落格向量
產生部落格向量
產生部落格向量
在標籤分群一節中,使用 Hierarchical clustering 這個分群演算法的其中 一個重要原因就是當階層關係建構完成之後,可以根據需求任意的選擇想要的群 數,由以下討論可知,若能任意選擇群數就代表可以任意決定向量的維度,如圖 3-5:
圖 3-5 任意選擇想要的群數
在圖 3-5 中假設標籤的集合為{A, B, C, D, E},根據相似度建構完階層關 係之後,可以任意選擇分成 2 群:{{A, B, C, D}, {E, F}}、3 群:{{ A, B, C, D }, {E}, {F}}或 4 群:{{A, B}, {C, D}, {E}, {F}},甚至更多。
所以在決定群的數目 È 之後,就可以根據標籤分群所產生的階層關係將所 有的標籤分成 È 群,如此一來,同一個群內的標籤可以將它們視為都在描述相 同的主題,所以共有 È 個主題。 本論文將每一個部落格都表示成一個 È 維的向量,假設標籤有 n 個,由上 面的敘述可知, È 的值可以是 1 到 n 之間的任何一個值,也就是說,可以任意 決定向量的維度。本論文以一個群代表一個維度,每一個維度的值代表部落格的 標籤裡屬於代表該維度之群的個數。舉例來說:假設某一個部落格所包含的標籤 為{A, C, F},若採用圖 3-5 的分群結果,取È = 3的情況下,此部落格之向量 表示法為(2, 0, 1)。若取È = 4,則此部落格之向量表示法為(1, 1, 0, 1)。 在獲得每一個部落格的向量之後,最後一個步驟就是將向量正規化。要做正 規化的原因是因為每一個部落格的標籤數量都不相同,為了避免「標籤數量」這 個因素影響最後分群的結果,所以要將向量正規化成長度為 1。舉例來說:有兩 個相同主題的部落格 A 與 B,它們各包含 5 個標籤與 100 個標籤,分別為: A B C D E F 2 群 3 群 4 群
saC, a9, … , aÉt 與 sbC, b9, … , bCÊÊt 且這些標籤都不相同,而另一個不同主題的部落格 C 包含 5 個標籤: scC, c9, … , cÉt 假設在標籤分群的步驟中,系統將所有標籤分成三群分別為: gC = s… , aC, a9, … , aÉ, … , bC, b9, … , bCÊÊ, … t g9 = s… , cC, c9, … , cÉ, … t gD = s… … t 可以看到部落格 A 與 B 的 105 個標籤都很「正確」的被分到了第一個群中,而部 落格 C 的標籤被分到了第二個群中,所以部落格 A、B 與 C 的向量表示法分別為 A=(5, 0, 0)、B=(100, 0, 0)與 C=(0, 5, 0)。如果接下來在計算部落格之間的 相似度時是使用「距離」來代表部落格之間的相似度時,距離越近代表相似度越 高,距離越遠代表相似度越低,則部落格 A 與 B 的距離為 95,部落格 A 與 C 的 距離大約為 7,因此系統認為部落格 A 與 C 的主題較相近,這與事實不符。因此, 為了降低這種因為標籤數量而導致系統誤判的情況,所以需要加入正規化這個步 驟。以上述例子來說,經過正規化後 A=(1, 0, 0)、B=(1, 0, 0)、C=(0, 1, 0), 可以很清楚的看到,若同樣以距離來代表相似度時,部落格 A 與 B 為較相似的主 題。因此,這個正規化後的向量就是最終部落格的向量表示法。
3.7
3.7
3.7
3.7 以座標表示部落格
以座標表示部落格
以座標表示部落格
以座標表示部落格
另一個表示部落格的方法,就是為每一個部落格計算一個合適的座標。所謂 合適的座標代表座標之間的距離可以反映出部落格之間的相似程度。
3.7.1
3.7.1
3.7.1
3.7.1 使用
使用
使用
使用 Multidimensional scaling
Multidimensional scaling
Multidimensional scaling 產生
Multidimensional scaling
產生標籤
產生
產生
標籤
標籤
標籤之座標
之座標
之座標
之座標
在計算完所有標籤與標籤之間的相似度後,就可以使用 Multidimensional scaling 去賦予每一個標籤一個合適的座標。但是這裡有一點要特別注意,因為 在本論文所使用的相似度計算方法中,數值越小代表相似度越低,數值越大代表 相似度越高。但 Multidimensional scaling 對相似度的定義剛好是相反的,因 為在 Multidimensional scaling 中輸入的是節點與節點之間的距離,直覺上, 越相似的標籤被賦予的座標應該要越接近,所以距離越小代表相似度越高,而距 離越大代表相似度越低。因此在這個步驟中要做的事情就是將相似度轉換成距離, 相似度越高要轉換成越小的距離,反之,相似度越低則要轉換成越大的距離。本 論文提出下列公式將相似度轉換成距離:
distance:tC, t9; = :Max Similarity + 1; − Similarity:tC, t9;
其中,Max Similarity 是指所有標籤中,相似度最高的兩個標籤的相似度。Max Similarity + 1 的原因是避免讓相似度最高的兩個標籤距離是 0,因為只有「完 全相同」的兩個標籤距離才是 0,經過這個公式的轉換,就可以將相似度轉換成 距離。
3.7.2
3.7.2
3.7.2
3.7.2 計算
計算
計算
計算部落格之座標
部落格之座標
部落格之座標
部落格之座標
在獲得每一個標籤的座標之後,就可以利用標籤的座標去計算部落格的座標。 如果利用 Multidimensional scaling 產生之標籤座標的維度是三維,則部落格 之座標的維度也是三維。假設有一部落格有 n 個標籤,其標籤的座標分別為: :xC, yC, zC;、:x9, y9, z9;、 … 、:x`, y`, z`;
則部落格之座標 :x, y, z; 就是這些標籤之座標的中心點,其計算方法為: x =xC+ x9 + ⋯ + xn ` y = yC+ y9+ ⋯ + yn D z =zC+ z9+ ⋯ + zn D 經過計算所得之座標 :x, y, z; 即為代表部落格之座標。
3.8
3.8
3.8
3.8 分群
分群
分群
分群
將標籤表示成向量或者座標之後,就可以利用現有的分群法來將標籤分群。 本論文將使用 kmeans 與 spectral clustering 來測試是否能將不同主題的部落 格分開。
若使用 spectral clustering 時,會需要計算所有部落格之間的相似度,通 常在使用 spectral clustering 時都是用 Gaussian similarity function 來計 算所有點與點之間的相似度,其定義為: Similarity[xP, xQ\ = exp :−µxP− xQµ 9 2σ9 ;
3.9
3.9
3.9
3.9 分析結果
分析結果
分析結果
分析結果
本論文採用 F1 cluster evaluation measure[10]來評估最後分群結果的好 壞。當系統在收集資料時共收集了三個主題的部落格,分別是電影、旅遊與健康 類。系統在執行分群演算法時,並不會知道每一個部落格所屬的類別,它只會根 據部落格與部落格之間的相似度將所有的部落格分成三群,然後再將分群的結果 與真實的類別比較。比較兩個部落格有下列四種可能:
2.False Positives(FP):系統將兩個部落格分在同一群,但是這兩個部落格是不 同主題。 3.True Negatives(TN):系統將兩個部落格分在不同群,而這兩個部落格也是不 同主題。 4.False Negatives(FN):系統將兩個部落格分在不同群,但這兩個部落格是同 一個主題。 因此,就可以計算 precision、recall 與 F1,分別定義如下: precision =TP + FPTP recall =TP + FNTP
第四章
第四章
第四章
第四章、
、
、
、實驗
實驗
實驗
實驗過程與結果討論
過程與結果討論
過程與結果討論
過程與結果討論
4.1
4.1
4.1
4.1 實驗
實驗
實驗
實驗資料
資料
資料
資料
本論文之實驗資料為網路上收集的150個英文部落格之標籤雲,這些部落格 所討論的主題分別是電影、旅遊與健康類,每一個類別都包含50個部落格,而這 三個類別的部落格所包含的標籤加起來總共有2447 個。本論文將使用類別的資 訊當成最後分群結果的答案。
4.2
4.2
4.2
4.2 實驗步驟
實驗步驟
實驗步驟
實驗步驟
本論文將實驗分成數個部分。首先,測試不使用 hierarchical clustering 將相似度高的標籤合併,直接使用 2447 個維度來表示部落格向量,將結果紀錄 在表 4-1。接下來測試使用 hierarchical clustering 將相似度高的標籤合併的 結果,我們分別使用六個不同的維度來表示部落格,並用三種不同的分群演算法 將部落格分群,將結果紀錄在表 4-2、4-3 與 4-4。最後,將使用 Multidimensional scaling 計算出來的部落格座標也使用 kmeans 與 spectral clustering 等分群 演算法分群,並將結果紀錄在表 4-5。
4.3
4.3
4.3
4.3 實驗結果
實驗結果
實驗結果
實驗結果
在本表4-2中,(a)代表spectral clustering according to Ng, Jordan, and Weiss,(b)代表 spectral clustering according to Shi and Malik。
演算法 演算法演算法
演算法 precisionprecision precisionprecision recall recallrecallrecall F1F1F1F1 kmean kmeankmean kmeanssss 0.366 0.671 0.474 (a) (a) (a) (a) 0.497 0.710 0.585 (b) (b) (b) (b) 0.479 0.749 0.584 表 4-1 對 2447 維的部落格向量使用不同分群演算法之結果 維度 維度維度
維度 precisionprecision precisionprecision recall recallrecallrecall F1F1F1F1 250 250 250 250 0.769 0.805 0.787 120 120 120 120 0.817 0.831 0.824 60 6060 60 0.791 0.807 0.799 30 3030 30 0.545 0.692 0.610 10 1010 10 0.553 0.683 0.611 3 33 3 0.329 1.000 0.495 表 4-2 各種不同維度的向量使用 kmeans 分群的結果 圖 4-1 各種不同維度的向量使用 kmeans 分群之曲線圖 0 0.2 0.4 0.6 0.8 1 1.2 2447 250 120 60 30 10 3 pricision recall F1
維度 維度維度
維度 precisionprecision precisionprecision recall recallrecallrecall F1F1F1F1 250 250 250 250 0.796 0.824 0.810 120 120 120 120 0.829 0.841 0.835 60 6060 60 0.791 0.807 0.799 30 3030 30 0.564 0.642 0.600 10 1010 10 0.560 0.624 0.591 3 33 3 0.329 1.000 0.495 表 4-3 各種不同維度的向量使用演算法(a)分群的結果 圖 4-2 各種不同維度的向量使用演算法(a)分群之曲線圖 0 0.2 0.4 0.6 0.8 1 1.2 2447 250 120 60 30 10 3 pricision recall F1
維度 維度維度
維度 precisionprecision precisionprecision recall recallrecallrecall F1F1F1F1 250 250 250 250 0.771 0.807 0.789 120 120 120 120 0.829 0.841 0.835 60 6060 60 0.791 0.807 0.799 30 3030 30 0.564 0.642 0.600 10 1010 10 0.560 0.624 0.591 3 33 3 0.329 1.000 0.495 表 4-4 各種不同維度的向量使用演算法(b)分群的結果 圖 4-3 各種不同維度的向量使用演算法(b)分群之曲線圖 0 0.2 0.4 0.6 0.8 1 1.2 2447 250 120 60 30 10 3 pricision recall F1
演算法 演算法演算法
演算法 preprecisionpreprecisioncision cision recall recallrecallrecall F1F1F1F1 kmeans kmeanskmeans kmeans 0.870 0.874 0.872 (a) (a) (a) (a) 0.857 0.86 0.859 (b) (b) (b) (b) 0.870 0.873 0.871 表 4-5 對部落格座標分群的結果
4.4
4.4
4.4
4.4 實驗討論
實驗討論
實驗討論
實驗討論
從第一個實驗中可以觀察到,如果將部落格向量設定為每一個標籤都代表一 個維度,也就是2447 維,不管使用哪一種分群演算法,其precision、recall 與F1的值都非常的低。之後使用hierarchical clustering將相似度高的標籤合 併之後,其precision、recall與F1的值就會漸漸上升。部落格向量維度大約在 120維時效果最好,120大約是所有標籤數2447的5%。當維度漸漸縮小時,效果就 越來越差。效果變差的原因是因為,系統中會存在某些標籤與其他所有的標籤相 似度都很低,甚至都是0。在分群的過程中,這些標籤會一直保持自己一群的狀 態,此時系統就會選擇合併不同主題的標籤。當有不同主題的標籤被合併成為一 群時,產生的部落格向量對於分辨這兩個主題的能力就會降低。最後形成 precision與F1的值隨著維度降低的結果。而recall最後會升高的原因是因為在 維度是3時,系統將所有的部落格都分到了同一群,導致FN的值為0,所以recall 的值為1。當我們使用座標來表示部落格時,並不會有上述問題,所以能得到較 好的效果。
第五章
第五章
第五章
第五章、
、
、
、結論與展望
結論與展望
結論與展望
結論與展望
5.1
5.1
5.1
5.1 研究總結
研究總結
研究總結
研究總結
根據實驗結果可以發現,雖然只使用標籤雲來代表部落格,但是系統可以把 90%的部落格分配到正確的群中,這代表用標籤雲來代表部落格是非常適合的。 雖然本論文使用三個主題的部落格進行實驗,但是因為本系統可以準確的指出哪 些部落格是相似的,所以未來在應用時,是不限定任何主題或是類別的,只要給 定一個部落格,系統就能找出與它相似的部落格並回傳給使用者。
5.2
5.2
5.2
5.2 未來研究
未來研究
未來研究
未來研究
雖然現在網路上有非常多的部落格,但是並不是每一個部落格作者都有替每 一篇部落格文章標記標籤的習慣,未來可以研究如何替一個部落格自動產生標籤 雲,如此一來,系統可以根據自動產生的標籤雲在網路上搜尋類似的部落格,如 此可以提供使用者更多的選擇。
參考文獻
參考文獻
參考文獻
參考文獻
[1] tag cloud, http://en.wikipedia.org/wiki/Tag_cloud
[2] Hervé Abdi, Metric Multidimensional Scaling(MDS):Analyzing Distance Matrices.
[3] Ulrike von Luxburg, A Tutorial on Spectral Clustering. [4] Rayleigh-Ritz theorem,
http://myyn.org/m/article/rayleigh-ritz-theorem/ [5] Shi,J. and Malik,J., Normalized cuts and image
segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, pp.888-905, 2000.
[6] Ng,A.,Jordan,M.,and Weiss,Y., On spectral clustering:analysis and an algorithm. In Neural Information Processing Systems 14, pp.849-856, 2002.
[7] Altavista, http://www.altavista.com/
[8] Peter D. Turney, Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews . Proceedings of the
40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, pp.417-424, 2002.
[9] Hierarchical clustering,
http://www.resample.com/xlminer/help/HClst/HClst_intro.htm [10] Daniel Ramage, Paul Heymann, Christopher D.Manning, and Hector
Garcia-Molina, Clustering the Tagged Web. In Second ACM