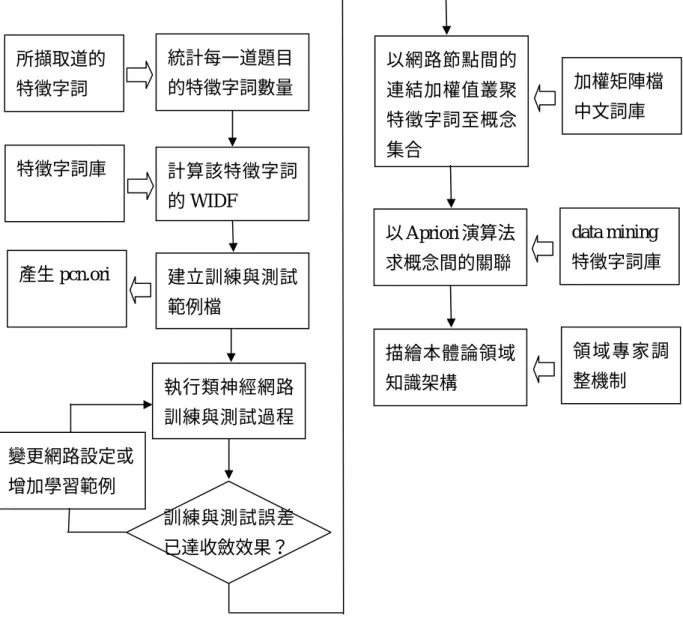
第四章 研究步驟及實驗結果
本研究以中華民國電腦教育發展協會所開發的 Word 文書處理系統認證 PreMOUS (MOCC 標準級)的試題為素材 (有關於 PreMOUS 的試題內容,請參考附錄 1)。而針對 系統的需求,規劃三大作業,字詞剖析作業、自動建構本體論作業及樣本試題分析作 業規劃系統架構如圖 4-1﹔
圖 4-1 題庫整體概念分析系統架構圖
z 字詞剖析工具:針對 PreMOUS 每一道試題,剖析出特徵特徵字詞,並將特徵特徵 字詞,存放於「特徵特徵字詞庫」的資料表中,並且記錄每一特徵字在每一道試 題的出現頻率 (Term Frequency) 。而每一道試題都有其對應的能力項目,也可以 由「特徵特徵字詞」資料表中透過加總聚合 (Aggregate) 運算,得到特徵字詞 t 在 各能力項目 a 的出現頻率 (Term Frequency)。
題庫整體概念分析系統
字 詞 剖 析 工 具 自 動 建 構 本 體 論 工 具 概 念 關 聯 分 析 工 具
z 自動建構本體論工具:當「特徵特徵字詞庫」完成之後,此一詞庫,在內容上已 經具備有 PreMOUS 試題特徵意義。接著採 WIDF 字詞權重函數當作倒傳遞類神經 網路的輸入來源值,執行倒傳遞演算法完成學習並調整概念節點間的連結權重閥 值後以程式自動描繪出 PreMOUS 領域的本體論知識架構。
z 概念關聯分析工具:為了解試題的能力項目分類之間的關係,藉由擷取各能力項
目分類的屬性與方法中的特徵字詞,以 Apriori 演算法求出其彼此間的信賴度,作
為題庫品質管控與供題庫學習者的學習參考。
第一節 系統資料結構及規劃
本詞庫採用 PreMOUS 作為建立「特徵特徵字詞庫」的素材。PreMOUS 每一道試 題內容都具有獨立的能力項目,詞庫的儲存系統應用檔案型資料庫系統 Access XP,有 二個資料表:
基礎字詞庫:中央研究院詞庫小組的中文詞庫轉置而成內含十萬筆中文詞庫資料。
z 能力項目:PreMOUS 共分為 24 種能力項目,為提供倒傳遞類神經網路學習 與資料表間的關聯,將由專家歸類的能力項目予以編碼,並儲存於「能力項 目」資料表中,格式如表 4-1 所示。
表 4-1 「能力項目」資料表格式
欄位名稱 資料格式 資料長度 能力項目碼 數字 2 Bytes
能力項目 文字 50 Bytes
24 組能力項目,分別使用 1~24 代表,以簡化運算的程序,並方便
作資料表間的關聯。其內容如圖 4-2 所示。
圖 4-2 「能力項目」資料表的內容
z 特徵特徵字詞庫:PreMOUS 的試題內容,經過剖析工具後,便可以得到該 試題的特徵字詞,及該特徵特徵字詞的出現頻率。資料表格式規劃如表 4-2 所示。
表 4-2 「特徵字詞庫」資料表格式
欄位名稱 資料格式 資料長度 編號 自動編號 4 Bytes 關鍵字 文字 50 Bytes
試題 文字 50 Bytes
出現頻率 數字 2 Bytes
詞性 文字 3 Bytes
資料表內容參考如圖 4-3 所示 (該圖編號為流水號,在分類上不具任何意義)。
圖 4-3 「特徵字詞庫」資料表內容
第二節 自動建構本體論處理過程
z 流程規劃
特徵字剖析處理,主要的目的在於作試題內容的斷句,進而取得各試題所內含的 特徵字詞。字詞剖析的層次上,以圖 4-4 為例,共有三個層次。
圖 4-4 字詞剖析樹 (Parse Tree)
中文是由幾個獨立的單字組成一個詞,而英文屬於拼音式的語言,其單字可能就 等於中文的一個詞,因此在斷詞的方法上,有極大的差異。如英文斷詞處理,只要以 空白或標點符號來分段,然後將代名詞 (如﹔I, He, She, There, Here….) 、介詞 (如﹔
of , in, on, at …) 及助動詞 (如﹔is, am, are, was, were….) 予以刪除,便可以留 下比較具有特徵意義的單字,作為特徵字詞。
在中文方面由於介詞、主詞或助動詞也可能是其他字詞的一部份。如: 「我的電腦」
取出獨立的二字詞 公
清除英數字
清除綴字 詞庫斷詞法
取出可於詞庫中 查詢到的字詞
剔除綴字後,擷取剩餘的 2~4 字詞
………..
abc…ABC….123….?/+-()…….
刪除
的 之 是 請 將 為…
刪除
在 Windows 軟體中,屬於一個特有的名詞,然而如果採用英文的斷詞法,則會造成
「我」、「的」兩的字被析離後,而只剩下「電腦」兩個字。這樣的斷詞方式,顯然會 讓字詞的分類屬性產生很大的差距。
因此為了可以完整的擷取具有意義的特徵字詞,規劃步驟及方法說明如下:
步驟一 將英數字刪除。由於使用的中文系統,因此將英文字視為較不具特徵 的部分予以刪除。英數字刪除後,若有兩個中文字相連,則可以視為 一個特徵字詞。
步驟二 採用適合中文的「詞庫式斷詞法」 ,先擷取試題中既有的特徵字詞。如 此可以避免介詞、助動詞及主詞夾雜在某個字詞中而造成斷詞後,特 徵意義消失的困擾。詞庫式斷詞法本身便需要一個豐富的「基礎詞 庫」 ,本實驗的「基礎詞庫」來源採用中央研究院詞庫小組訂定的十萬 筆中文詞庫。
步驟三 將綴字予以刪除。經詞庫式斷詞法之後,介詞、主詞及助動詞便可以 放心的刪除。
步驟四 刪除後所殘留的一些字詞可能有特徵意義。因此擷取二到四個連續排 列的中文字,捨棄獨立的中文字,並放入特徵特徵字詞庫。
經由上述的四個步驟之後,比較具有特徵性的字詞,已經擷取並放入特徵特 徵字詞庫,而該資料表也詳細紀錄某個特徵字出現於那道試題、出現的次數。
針對擷取特徵字詞的功能需求,系統規劃的流程圖,分別如圖 4-5 所示:
圖 4-5 擷取特徵字詞的處理流程
擷取完特徵字詞後,就已經完成建構本體論最底層的概念節點。但因往往整個 題庫內容往往超過上千個的特徵字詞,若單純將所有特徵字詞列出,並以 1 代表該對 應的字詞出現在某題中;以 0 代表該對應的字詞未出現在某題題目中,則訓練與測試 範例檔的輸入來源值數目將遠大於類神經網路所能負荷。故改採將每一道題目所包含 的特徵字詞換算成其在整個題庫中的 WIDF 數值,則其數量將大幅縮小至 50 以下。接
特徵字詞剖析
刪除英數字
詞庫斷詞法擷取 既有字詞
刪除介詞、主詞及 助動詞
擷取剩餘的二∼
四字詞 讀取檔案
指向下一筆資料 置入「關鍵字詞」庫
完成 No
Yes
自動剖析? 最後一筆?
First,Previous,Next,Last 的瀏覽動作
No
移動到指標所 指的試題 Yes
是否儲存?
著,將這些特徵字詞的字詞權重函數經過線性轉換函數將其換算成介於 0 到 1 之間的 實數,並將這些轉換後的實數當成類神經網路的輸入來源值。
再來,將所形成的訓練與測試範例檔輸入至倒傳遞類神經網路中,再以最陡坡降 演算法調整理論分類值與推論分類值之間的誤差至最小值,亦即使訓練誤差與測試誤 差均達到收斂效果。在這個過程中,介於輸出層與輸入層之間的隱藏層代表本體論架 構中介於類別與特徵字詞間的虛擬概念階層,其主要是用來表現底層的特徵字詞的交 互影響,如此做的好處是允許概念間可以有重疊的部分,而這些重疊的部分亦即代表 概念間的關聯。
當執行訓練過程時,因採競爭化學習,其目的是將同一層中的處理單元原始輸出
值所組成的向量中,選擇一個或若干個最強值的優勝單元,網路將只調整與優勝單元
相連的下層網路連結。在描繪本體論架構時,若只針對這些優勝單元做輸出,則可將
原本網狀拓僕的結構變更為類似樹狀拓僕結構。針對自動建構本體論領域知識架構的
功能需求,系統規劃的流程圖,分別如圖 4-6 所示:
圖 4-6 建構領域知識本體論架構的處理流程
第三節 自動建構實體論工具
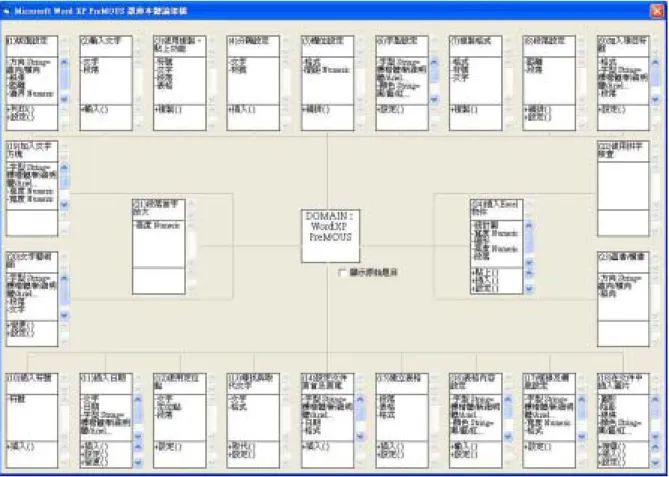
(一)擷取特徵字詞
經設計完成擷取 WordXP PreMOUS 特徵字詞工具程式如圖 4-7 所示,目的 是要自動擷取 PreMOUS 題目的特徵字詞,並自動產生倒傳遞類神經網路的學習 範例檔。程式介面包括題目瀏覽區、詞性與斷詞分析區、特徵字詞截取參數設 定區、特徵字詞統計區,並設有第一筆、上一筆、下一筆、最後一筆、隨機選 取學習範例、全部清除等六個按鈕與選取學習範例核取方塊。按鈕與核取方塊
統計每一道題目 的特徵字詞數量
計算該特徵字詞 的 WIDF
建立訓練與測試 範例檔
執行類神經網路 訓練與測試過程
訓練與測試誤差 已達收斂效果?
以網路節點間的 連結加權值叢聚 特徵字詞至概念 集合
以 Apriori 演算法 求概念間的關聯
加權矩陣檔 中文詞庫
描繪本體論領域 知識架構
所擷取道的 特徵字詞
data mining 特徵字詞庫 特徵字詞庫
產生 pcn.ori
領域專家調 整機制
變更網路設定或
增加學習範例
屬於人工操作的部份,如果要將畫面上顯示的題目納入學習範例檔中,則必須 核取「選取本題做為學習範例」的核取方塊。如果按下「隨機選取學習範例」
按鈕,則會在題庫中以隨機的方式自動選取題目並完成特徵字詞剖析及建立學 習範例檔的動作。而綴字可以在綴字定義中設定,系統會在清除綴字的流程上 判讀試題內容是否有綴字定義區的文字。如果有則該字元一律予以刪除。
圖 4-7 擷取 WordXP PreMOUS 特徵字詞工具
本研究除了要為題目進行認知技能的能力項目分類外,還要自動建構整個題庫的 領域知識本體論架構。而本體論中概念節點的屬性與方法則分別以名詞與動詞為主。
在中央研究院詞庫小組訂定的中文詞庫中,其詞性標籤與代表的意義如表 4-3 所示:
表 4-3 台灣中央研究院詞庫小組訂定的中文詞性標籤與其代表意義
編號 詞性標籤 代表意義
1 VA Intransitive verb (動作不及物動詞) 2 VB Single verb class (動作類及物動詞) 3 VC Single verb (動作及物動詞)
4 VD Two words verb (雙賓動詞) 5 VE Verb sentence (動作句賓動詞) 6 VF Name verb (動作謂賓動詞) 7 VG Classification verb (分類動詞)
8 VH Status Intransitive verb (狀態不及物動詞) 9 VI Status single verbs class (狀態類及物動詞) 10 VJ Status single verbs (狀態及物動詞)
11 VK Status single verbs (狀態句賓動詞) 12 VL Status name verb (狀態謂賓動詞) 13 A Adjective (非謂形容詞)
14 Na Common noun (普通名詞) 15 Nb Proper noun (專有名詞) 16 Nc Location noun (地方名詞) 17 Nd Time noun (時間名詞) 18 Ne Stable noun (定詞) 19 Nf Quantity noun (量詞) 20 Ng Direction noun (後置詞) 21 Nh Pronoun (代名詞)
22 Da Adverb, Quantity (數量副詞)
23 Dba Law Adverb (法相副詞)
24 Dbb,Dbc Evaluation Adverb (評斷副詞)
25 Dc Negate Adverb (否定副詞)
26 Dd Time Adverb (時間副詞) 27 Df Degree Adverb (程度副詞) 28 Dg Location Adverb (地方副詞) 29 Dh Method Adverb (方式副詞) 30 Di Symbol Adverb (標誌副詞) 31 Dj Interrogative Adverb (疑問副詞) 32 Dk Sentence Adverb (句副詞) 33 P Preposition (介詞)
34 Ca Side by side conjunction (對等連接詞) 35 Cb Correlation conjunction (關聯連接詞) 36 T Particle (語助詞)
37 I Interjection (感嘆詞)
(二)產生類神經網路訓練與測試範例
將各特徵字詞所對應的的 WIDF 值代入(3-4) 式,即
x x ef −
= + 1 ) 1
( ,將其值域轉換 為 0~1 之間,以當作類神經網路的輸入來源值。接著,利用產生神經網路訓練與測試 範例檔工具(如圖 4-7 所示)所產生的倒傳遞類神經網路學習範例檔格式如下:
0.25000000 0.10000000 0.12500000 0.00124069…1 0 0 0…
0.10000000 0.00694444 0.12500000 0.00124069…0 1 0 0…
0.10000000 0.00694444 0.00124069 0.12500000…0 0 1 0…
0.00252525 0.20000000 0.50000000 0.12500000…0 0 0 1…
各題目的輸入來源值 分類目的
每 列 代 表 一 題
圖4-8 產生神經網路訓練與測試範例檔工具
在實際的應用上,首先將資料分為訓練集及測試集兩部分,其中訓練資料為真正 網路訓練的資料樣本,代入網路系統依上述流程訓練類神經網路;其餘之測試資料則 用來驗證此網路模式是否具推廣性。如不能符合誤差要求,則更改網路架構重新訓練;
若合於誤差標準,則輸出網路。
因為類神經網路之精確度必須仰賴大量的資料範圍,愈多之訓練資料將愈能反應 出現實之情況,因此訓練集資料將會略多於測試集資料,但是類神經網路特點在於強 大之推廣性,推廣性之好壞取決於測試集之表現,所以測試集比例太小將不足以代表 推廣性之好壞。假設訓練集與測試集之比例為5:5,則可能因訓練資料太少不能代表 現實之情況而影響測試集之表現;假設訓練集與測試集之比例為9:1,則可能因測試 資料太少不能代表網路的推廣性是否較佳,因此訓練集資料與測試集資料折衷採用7:
3 之比例為較佳之選擇。
(三)網路訓練與測試過程達
將所產生的訓練與測試範例檔輸入至類神經應用軟體,接著進行變數統計與範例 取樣等前置處理如圖4-9、圖4-10所示與網路設定如圖4-11所示。
圖4-9 訓練與測試範例檔的變數統計前置作業
圖4-10 訓練與測試範例檔的範例取樣前置作業
圖4-11 倒傳遞網路設定
做完相關的設定之後,開始執行網路訓練與測試過程達到收斂後,執行網路回想 過程。其執行結果之訓練誤差與測試誤差收斂過程圖(convergence diagram)分別如圖 4-12與圖4-13所示。其中,可看出在1000個學習循環內,訓練誤差與測試誤差均可達 到非常好的收斂效果。
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 學習循環(x40)
訓練誤差
圖 4-12 訓練誤差收斂過程圖
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 學習循環(x40)
測試誤差
圖 4-13 測試誤差收斂過程圖
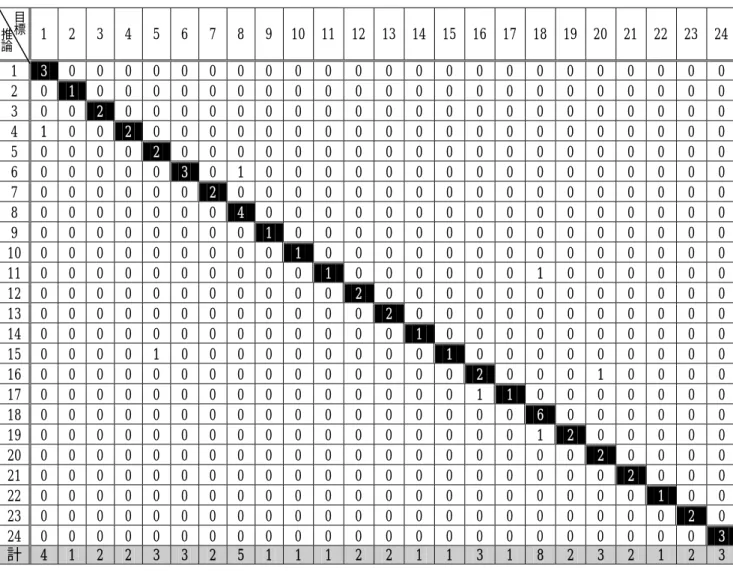
表 4-4 的混亂矩陣(confusion matrix)中每一縱行代表一種目標分類,每一橫列代 表一種推論分類,所以第 j 縱行第 i 橫列的元素值的代表意義為應當屬於第 j 種分類,
而被網路推論為第 i 種分類的範例數。如果混亂矩陣中對角線上的元素值越大,非對 角線上的元素值越小,則分類效果良好。
表 4-4 混亂矩陣
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 1 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 3 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 14 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 15 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 1 0 0 0 0 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 0 0 0 0 0 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 計 4 1 2 2 3 3 2 5 1 1 1 2 2 1 1 3 1 8 2 3 2 1 2 3
將混亂矩陣中的元素換算各類別的誤判率,即將相對的混亂矩陣元素代入(3-22) 式可求出各類別的誤判率。如表 4-5 所示:
表 4-5 由混亂矩陣中推算出各類別的誤判率
分類項目 誤判率
類別 1 25%
類別
20%
類別
30%
類別
40%
類別
533%
推論 目標
類別
60%
類別
70%
類別
820%
類別
90%
類別
100%
類別
110%
類別
120%
類別
130%
類別
140%
類別
150%
類別
1633%
類別
170%
類別
1825%
類別
190%
類別
2033%
類別
210%
類別
220%
類別
230%
類別
240%
(四)描繪本體論架構
本研究將類別視為最大的『虛擬概念』 ,在階層架構上來說,這些虛擬概念還是原
有『概念』的一部份,故虛擬概念亦具有與概念一般的屬性與方法,而且彼此間也可
能具有關聯性質。以程式自動描繪 PreMOUS 領域的知識架構之類別(最大虛擬概念)
圖 4-14 PreMOUS 領域知識架構的類別
圖 4-14 中每一類別的名稱乃以 PreMOUS 的命題專家群在規劃題庫內容時所訂定 的二十四項能力項目,並輔以一流水號表示。中間的方塊代表屬於該虛擬概念的相關 屬性,其中有些屬性有固定的資料型態,如 Numeric 或 String…等。且某些屬性的內 容值只允許在有限的項目中擇一設定,如「字型 String=標楷體/新細明體/Ariel... 」或
「方向 String=直向/橫向」等。最底下的方塊,為屬於該類別(能力項目)的題目主 要的操作方法,如「設定」 、 「複製」 、 「輸入」…等。
(五)顯示各能力項目間的關聯
以 Aprori 演算法計算其包含的屬性與方法的高頻特徵字詞集合的支持度與信心
值,以驗證類別(最大虛擬概念)間是否具有關聯性。接著再以
χ2(卡方考驗)來驗
證其關聯性是否達到顯著?在工具程式中輸入欲求關聯的類別,例如: 「表格內容設
定」 ,則可顯示與其具關聯的類別為「字型設定」與「建立表格」等兩項,如圖 4-15 所示。若勾選『顯示關聯性卡方考驗』 ,則會在標示關聯類別的同時,也顯示以 Aprori 演算法計算出的各關聯類別的
χ2考驗值,如圖 4-16 所示,其中「輸入文字」類別的
χ2考驗值為 2.116642 小於 3.841,未達顯著所以未標示關聯符號。
圖 4-15 類別(最大虛擬概念)間的關聯性
圖 4-16 與「表格內容設定」(類別 16)關聯的各類別
χ2考驗值
表 4-6 本研究所推論的 PreMOUS 類別之間的關聯性 類別(能力項目) 關聯類別
χ2考驗值
1 版面設定 X X
2 輸入文字 16 表格內容設定 0.89
3 使用複製、貼上功能 X X
4 分隔設定 X X
5 欄位設定 X X
9 加入項目符號 6.69 10 插入符號 1.09 11 插入日期 4.00 13 尋找與取代文字 5.71 14 設定文件頁首及頁尾 4.63 16 表格內容設定 6.43 17 框線及網底設定 6.57 19 加入文字方塊 2.94 6 字型設定
20 文字藝術師 4.16
7 複製格式 X X
8 段落設定 X X
9 加入項目符號 6 字型設定 6.69 10 插入符號 6 字型設定 1.09 11 插入日期 6 字型設定 4.00
12 使用定位點 X X
13 尋找與取代文字 6 字型設定 5.71
14 設定文件頁首及頁尾 6 字型設定 4.63
15 建立表格 16 表格內容設定 6.33
2 輸入文字 0.89 6 字型設定 6.43 16 表格內容設定
15 建立表格 6.33 17 框線及網底設定 6 字型設定 6.57
18 在文件中插入圖片 X X
19 加入文字方塊 6 字型設定 2.94 20 文字藝術師 6 字型設定 4.16
21 段落首字放大 X X
22 使用拼字檢查 X X
23 直書/橫書 X X
24 插入 Excel 物件 X X
由表 4-6 中可整理出 PreMOUS 類別之間的關聯性無向圖,如圖 4-17 所示。因 Apriori 演算法與
χ2考驗均為無方向性,所以所類別間的關聯也沒有方向性,故圖 4-17 中類別節點之間的線段沒有箭頭。若類別之間有關聯,則兩類別節點之間須有線段直 接連結,或類別節點之間須構成封閉迴路。
圖 4-17 PreMOUS 類別之間的關聯性無向圖 6
14
17 11
9
13
16 20
15
念關聯度,將領域知識概念之間的關聯性,如表 4-6 的結果加以整理後得到圖 4-17 的
PreMOUS 類別之間的關聯性無向圖。其中類別 6 與多項類別有直接關聯。亦即,教導
者或學習者在剛接觸 PreMOUS 的測驗領域時,可從類別 6 的字型設定開始教授或學
習,然後再往外擴展至其相關的類別。茲將研究結果描繪如圖 4-18 中。
Domain knowledge PreMOUS WordXP
(1)版面設定 -方向 String=
直向/橫向 -紙張 -距離
-邊界 Numeric +列印( ) +設定( )
(2)輸入文字
-文字 -段落 +輸入( ) (3)使用複
製、貼上功能 -符號
-文字 -段落 -表格 +插入( )
(4)分隔設定
-文字 -符號 +插入( )
(5)欄位設定
-格式
-間距 Numeric +編排( )
(6)字型設定 -字型 String=標楷 體/新細明體 /Ariel...
-顏色 String=黑/藍 /紅...
-文字 -格式
-間距 Numeric +列印( ) +設定( )
(7)複製格式
-格式 -符號 -文字 +複製( )
(8)段落設定 -距離 -段落 +編排( ) (9)加入項目符號
-格式
-字型 String=標楷 體/新細明體 /Ariel...
-段落 -符號 +設定( )
(10)插入符號
-符號 +插入( ) (11)插入日期
-文字 -日期 -字型 String=標楷 體/新細明體 /Ariel...
-格式 +插入( ) +設定( ) +變更( )
(12)使用定 位點 -文字 -定位點 -段落 +設定( ) (13)尋找與
取代文字 -文字 -格式 +取代( ) +設定( )
(14)設定文件頁 首及頁尾 -字型 String=標 楷體/新細明體 /Ariel...
-日期 -格式
-頁碼 Numeric -文字
+插入( ) (15)建立表 格
-段落 -表格 -格式 +插入( ) +設定( )
(16)表格內容設 定
-字型 String=
標楷體/新細明 體/Ariel...
-顏色 String=
黑/藍/紅...
-欄位
-寬度 Numeric -格式
-表格 +輸入( ) +設定( ) (17)框線及網底
設定
-字型 String=標 楷體/新細明體 /Ariel...
-寬度 Numeric -格式
-表格
-顏色 String=黑 /藍/紅...
+設定( )
(20)文字藝術師
-字型 String=標 楷體/新細明體 /Ariel...
-段落 -文字 +變更( ) +設定( ) (19)加入文字方塊
-字型 String=標 楷體/新細明體 /Ariel...
-高度 Numeric -寬度 Numeric -文字
-段落
(18)在文件中插 入圖片
-圖形 -陰影 -線條
-顏色 String=黑 /藍/紅...
-文字
-寬度 Numeric -段落
-格式 +搜尋( ) +插入( ) +設定( )
(23)直書/橫 書
-方向 String=直向/
橫向
(24)插入 Excel 物件 -統計圖 -寬度 Numeric -圖形 -高度 Numeric -段落 +貼上( ) +插入( ) +設定( ) (21)段落首
字放大 -高度 Numeric (22)使用拼
字檢查