國立臺灣大學管理學院會計學研究所 碩士論文
Department of Accounting College of Management
National Taiwan University Master Thesis
利用深度學習預測審計失敗--以台灣為例
Predict Audit Failure Using Deep Learning Algorithm—
Take Taiwan as Example
徐佳揚 Hsu, Chia-Yang
指導教授:吳琮璠 博士 Advisor: Chung-Fern Wu, Ph.D.
中華民國 110 年 1 月
January 2021
第一章 口試委員會審定書
中文摘要
利用台灣上市、櫃公司財務報表重編作為審計失敗的指標,並依照 Fully Connected Feedforward Network 架構架設深度學習模型,用以預測可能發生審計失 敗的查核案件,並利用半監督式學習與 Voting 等方式強化預測效果。與對照組邏 輯斯回歸模型相比,預測能力顯著提升。
程式碼: https://github.com/R07722005/Audit_Failure_Prediction 關鍵字:會計師、審計失敗、深度學習、機器學習
英文摘要
Used financial statement restatements of Taiwanese lised companies as indicator of audit failure, and built a Deep learning models based on Fully Connected Feedforward Network framework to predict audit failure, then used semi-supervised learning and Noting methods to improve prediction outcome. The predictive ability was signigicantly improved compared with the logistic regression model of the control group.
Code: https://github.com/R07722005/Audit_Failure_Prediction
Keywords: Auditor, Audit Failure, Deep Learning, Machine Learning
感謝詞
感謝林鈺澄、卓訓輔、黃亭硯、張哲瑋、王思源、王智生與沈家睿,沒有你 們我肯定沒有辦法完成這篇論文。感謝家人一路上的陪伴,也紀念我在天上的家 人。
Nobody exists on purpose, nobody belongs anywhere, everybody's gonna die.
Come watch TV.
–Morty Smith
目錄
口試委員會審定書 ... I 中文摘要 ... III 英文摘要 ... IV 感謝詞 ... V 圖目錄 ... IX 表目錄 ... X
第一章 緒論 ... 1
第一節 研究背景與動機 ... 1
第二節 研究目的 ... 2
第三節 研究架構 ... 3
第二章 文獻回顧 ... 4
第一節 審計失敗 ... 4
第二節 審計失敗的傳染效果 ... 5
第三節 裁決性應計數 ... 6
一、 Johns Model ... 6
二、 Modified Johns Model ... 7
三、 加入ROA 的 Modified Johns Model ... 7
第三章 深度學習 ... 8
第一節 名稱的由來 ... 8
第二節 Activation Function ... 9
第三節 深度學習架構 ... 10
一、 Input layer ... 11
二、 Hidden layer ... 11
三、 Output layer ... 11
四、 Fully Connected Feedforward Network ... 12
第四節 Loss Function ... 13
第五節 Gradient Descent ... 14
第六節 Backpropagation ... 15
第七節 小結 ... 17
第四章 研究方法 ... 18
第一節 資料整理 ... 18
一、 審計失敗 ... 18
二、 裁決性應計數 ... 19
三、 審計失敗傳染效果 ... 20
四、 整理結果 ... 21
第二節 模型架構 ... 22
第三節 訓練模型 ... 24
一、 資料清洗 ... 25
二、 訓練資料抽選 ... 25
三、 半監督式學習 ... 26
四、 訓練過程 ... 28
五、 Voting ... 30
第五章 研究結果 ... 32
第一節 實驗組 ... 32
第二節 對照組 ... 32
第三節 實驗組與對照組比較 ... 35
第四節 模組的優點與缺點 ... 37
第六章 結論 ... 38
第一節 研究結論 ... 38
第二節 研究建議 ... 38
參考資料 ... 39
附錄 ... 41
Confusion Matrix ... 41
Zmijewski (1984) index ... 42
其他參數 ... 43
圖目錄
Fig. 2-1 財務報表編制至申報流程 ... 5
Fig. 3-1 Sigmoid Function ... 9
Fig. 3-2 ReLU Function ... 9
Fig. 3-3 轉換前的資料 ... 10
Fig. 3-4 轉換後的資料 ... 10
Fig. 3-5 Fully Connected Feedforward Network... 12
Fig. 3-6 Loss 值分布圖,上層為 Cross Entropy,下層為平方差公式 ... 14
Fig. 4-1 深度模型架構 ... 24
Fig. 4-2 抽選並創造平衡資料集(取自於 ufoym 的 Github, 2020) ... 26
Fig. 4-3 未使用 Pseudo-label 第 20 Epoch 時測試資料的混淆矩陣 ... 28
Fig. 4-4 使用 Pseudo-label 後第 49 組模組第 20 Epoch 時測試資料的混淆矩陣 .. 28
Fig. 4-5 1 號模型 0 至 19 Epoch 的 Loss 值、訓練資料正確率與測試資料正確率 ... 29
Fig. 4-6 0 號模型至 49 號模型在測試資量上的表現 ... 30
Fig. 4-7 25 號模型至 49 號模型 Voting 結果 ... 31
Fig. 4-8 25 號模型至 49 號模型經由不同投票門檻產生的預測表現 ... 31
Fig. 5-1 深度學習模型實驗結果 ... 32
Fig. 5-2 對照組 Logit Regression Result ... 34
Fig. 5-3 對照組 ROC curve ... 35
Fig. 5-4 實驗組與對照組的 Precision-Recall Plot ... 36
Fig. 5-5 對照組預測結果(閥值為 0.009) ... 37
表目錄
Tabel 1 審計失敗所使用的重編原因 ... 18
Tabel 2 審計失敗傳染效果應變數 ... 20
Tabel 3 訓練資料與測試資料 ... 21
Tabel 4 實驗設備與軟體 ... 24
Tabel 5 對照組使用的自變數及應變數 ... 33
Tabel 6 模組的優缺點 ... 37
Tabel 7 Confusion Matrix ... 41
Tabel 8 其他參數 ... 43
第二章 緒論
第一節 研究背景與動機
2001 年 10 月安隆案爆發之後1,投資大眾對會計師查核簽證產生疑問,認為 會計師自律組織並不能發揮效益,出具適當查核報表。於是美國通過著名的沙賓法 案(Sarbanes Oxley Act) , 並 成 立 公 開 公 司 會 計 監 督 委 員 會 ( Public Company Accounting Oversight Board,PCAOB),以法律形式制定審計準則,並要求會計師 遵守。
財務報表錯誤與舞弊一直是社會矚目的焦點,台灣也曾出現過多起財報舞弊 案例,如博達、力霸案等,而會計師需要針對錯誤或有舞弊的財務報表表示適當的 意見以警示投資人,使投資人能夠判斷其投資風險,基於這種信任關係才能促進更 多的投資,活絡整體經濟。然而會計師可能因為諸多原因而導致出具無適當的查核 意見,造成投資人誤判而損失,這就是審計失敗。台灣上市、櫃財務報表取得會計 師查核意見之後,需要將財務報表申報至主管機關審核,但由於台灣上市、櫃公司 數量龐大,主管機關僅能以抽查的方式審查,這使得主管機關每年要投入大量人力 卻無法涵蓋所有須審查的公司。因此若有能夠預測審計失敗的模型,能縮小需審查 的範圍,主管機關便能更精準地抽查財務報表,有效減少審計失敗發生,並改善金 融環境,促進整體經濟。國、內外對審計失敗的研究已相當廣泛,舉凡審計品質、
會計師與事務所間的傳染效果、會計師是否輪調等問題皆有論文發表,然而真正預 測審計失敗的模型卻不多,且多半使用回歸模型,精準度並不高。在此篇論文中以 已被分析的審計失敗因子並利用深度學習模型來強化預測效果,訓練出能夠更精 準預測可能產生審計失敗的查核案件,作為主管機關選擇審查目標時的依據。
1 陳怡均. 2008. 簡介美國PCAOB 對於公開公司會計師之監理. 金融監督管理委員會 2008 [cited October 16 2008]. Available from
https://www.fsc.gov.tw/fckdowndoc?file=/%E5%AF%A6%E5%8B%99%E6%96%B0%E7%9F%A5%20 (1).pdf&flag=doc.
第二節 研究目的
以往的審計失敗相關論文多半是討論哪些因子會增加審計失敗出現的機率,
而預測審計失敗多半是使用線性回歸或邏輯斯回歸,準確性並不高。本次研究將訓 練一組深度學習模型用以預測審計失敗,並以提升預測準確率為目標,預測下一年 中的可能產生的審計失敗,幫助主管機關選擇要抽查的財務報表時能夠縮小抽查 的範圍。
本次研究以Python 中的 Pytorch 套件為核心,以 Fully Connected Feedforward Network 架構設計深度學習模型,並加入半監督式學習與 Voting 等技術強化預測 結果。模型的自變數來自台灣經濟新報TEJ+中現有的資料,與過往已被分析的審 計失敗因子,為了創造資料取得容易、訓練容易的深度學習模型,且成果超越其他 預測模型。
總以上所述,本研究將以以下幾個目標訓練模型:
(一) 使用台灣經濟新報 TEJ+中現有的資料與過往已被分析的審計失敗因子 (二) 以 Fully Connected Feedforward Network 架構設計深度學習模型
(三) 預測結果的正確率、Sensitivity、Precision 要比邏輯斯回歸模型更高
第三節 研究架構
研究動機與目的
文獻回顧
審計失敗的傳染 效果文獻
裁決性應計數 審計失敗文獻 文獻
介紹深度學習
訓練模型
實驗結果分析 與對照組
研究結論與建議
第三章 文獻回顧
第一節 審計失敗
依照吳琮璠教授 (2001)2在審計學中對審計失敗的定義,審計失敗指:「查核人 員未依照一般公認審計準則執行查核工作,出具不當的查核報告。」需要注意審計 失敗並非企業失敗,企業失敗指企業因為內在或外在的因素而倒閉或重整2,企業 失敗並不直接導致審計失敗。在查核時會計師應「盡專業上應有之注意,蒐集足夠 及適切的查核證據,出具適當意見」2,當企業失敗產生時,若會計師依照其專業 出具適當查核意見,則不能稱之為審計失敗。證券交易法中亦規定3若公司公開說 明書有虛偽或隱匿之情事,會計師對善意第三人所受之損失負連帶賠償責任,但會 計師若如能證明已經合理調查,並有正當理由確信其簽證或意見為真實者則免責。
由此可見審計失敗著重於是否出具適當的報告,而非企業本身營利狀況的好壞。
台灣財務報表發布需要經過三個步驟,由公司編製,經過會計師查核,再申報 主管機關審查。證券交易法第 14 條規定:「財務報告應經董事長、經理人及會計主 管簽名或蓋章,並出具財務報告內容無虛偽或隱匿之聲明。」其表示財務報表的編 製階段,需要公司潔身自愛,讓財務報表內容無虛偽或隱匿之情事,再經過會計查 核。而依照證券交易法第 32 條規定,會計師需要近專業上應有之注意查核財務報 表,並對財務報表出具適當意見。最後財務報表經查核後申報主管機關審查,依證 券交易法施行細則第 6 條規定,未依有關法令編製而應予更正者,應照主管機關 所定期限自行更正,且依證券交易法第 39 條規定,若發行人申報之財務報表發現 有不符合法令規定之事項,得以命令糾正、限期改善並處罰。由上述可知若財務報 表有虛偽或隱匿,經查核後申報審查,主管機關有權利要求公司重編,且公司與會 計師都要受處罰,只有在會計師依照專業之注意出具適當之意見時才能免罰。換句
2 吳琮璠教授. 2001. 審計學--新觀念與本土化. 台北市: 吳琮璠教授. 頁 76
3 證交法 32 條
話說,除因會計原則改變、會計個體變更造成的財務報表重編,或有會計師能證明 自己已盡專業上應有之注意的狀況外,財務報表重編可以當成審計失敗的指標。並 可運用財務報表重編當作應變數來訓練模型並用以預測審計失敗。
Fig. 2-1 財務報表編制至申報流程
第二節 審計失敗的傳染效果
審計失敗的傳染效果係指若一件審計失敗發生時,與其有一定關聯性的審計 案件的審計品質也會下降,造成發生審計品質的可能性升高。在Li et al. (2015) 4 的研究中,傳染效果分為垂直傳染與水平傳染,並又以會計師或會計師事務所的傳 染效果做區分。垂直傳染效果指會計師或事務所曾經發生過審計失敗,接下來數年 間該會計師或事務所所執行的查核案件審計品質也會下降,出現審計失敗的可能 性較其他查核案件更高。而水平傳染效果指會計師或事務所發生過審計失敗的年 度,當年同會計師或事務所所執行的查核案件審計品質也會下降,出現審計失敗的 可能性較同年度其他查核案件更高。
4 Li, L., B. Qi, G. Tian, and G. Zhang. 2015. The Contagion Effect of Low-Quality Audits along Individual Auditors. Available at SSRN 2478348.
Li et al. (2015)4 分析中國證券監督管理委員會(CSRC)與中國註冊會計師協會 (CICPA)中有關於會計師相關的資料,發現不論會計師層級或事務所層級皆出現水平 及垂直傳染。會計師與事務所層級的垂直傳染約會影響四年,若一件查核案件其執行 查核的會計師或事務所若在前四年間出現審計失敗,則該案件出現審計失敗的可能性 提升。而會計師與事務所層級的水平傳染則是讓當年度該會計師或事務所執行的其他 查核案件出現審計失敗的可能性提高。
第三節 裁決性應計數
在會計上應計基礎較現金基礎使用廣泛5,應計基礎能讓管理階層更容易地將 公司內部的資訊向外界透露,然而管理階層也能透過激進的盈餘管理讓財務報表 失真,進而造成財報使用者做出錯誤判斷。裁決性應計數(Discretionary Accrual)是 衡量盈餘管理的指標,藉由過去一定年間自己的財務資訊或同年間同產業其他公 司的財務資訊計算該公司今年度應有的應計數,而偏離預測應計數的數字為裁決 性應計數,代表管理階層盈餘管理的程度。裁決性應計數與審計品質有一定的關連 性5,而依據DeAngelo (1981) 6對審計品質的定義為會計師發現並報導財報舞弊與 錯誤的能力,這顯出審計品質與審計失敗有關,審計失敗就是低審計品質的表現,
會計師無法發現財報舞弊與錯誤導致出不適當之查核意見。由此推論裁決性應計 數與審計失敗有所關連。
一、 Johns Model
Jones (1991)7 Model 最初的目的是要測試那些公司藉由降低營收來爭取補助 款。論文中將總應計數定義為非現金營運資金變動,去除總折舊費用所獲得的值。
5 Krishnan, G. V. 2003. Audit quality and the pricing of discretionary accruals. Auditing: A journal of practice & theory 22 (1):109-126.
6 DeAngelo, L. E. 1981. Auditor size and audit quality. Journal of accounting and economics 3 (3):183- 199.
7 Jones, J. J. 1991. Earnings management during import relief investigations. Journal of accounting research 29 (2):193-228.
模型利用不動產、廠房與設備、收入年變動、常數項,並將各項皆除去年總資產來 模擬一間公司正常的應計數。不動產廠房與設備是為了控制非裁決性折舊費用,收 入年變動則是要控制經濟環境對公司的影響。依照模型計算出該年度正常應計數 後,與總應計數之差額極為裁決性應計數。
二、 Modified Johns Model
Dechow et al. (1995) 8認為單純使用Johns Model 單純使用收入無法完整詮釋 正常的應計數,應將收入年變動減除應收帳款年變動。未修正前的Johns Model 認 為收入是無法被管理階層藉由盈餘管理更改其數值,而Modified Johns Model 則認 為所有賒銷都有盈餘管理的可能,這是因為相較於現金銷貨,管理階層能更輕易地 藉由賒銷的收入任列執行盈餘管理,因此收入變動需減除應收帳款變動。
三、 加入 ROA 的 Modified Johns Model
Kothari et al. (2005) 9認為於眾多偵知裁決性應計數的方法之中,由Dechow, P.
et al 所提出的 Modified Johns Model 解釋能力最高, 為了要減少因忽略公司大小 而造成的變異數不一致的問題,S.P. Kothari et al.增加 ROA 項來控制此問題。這也 是本次實驗中會使用的裁決性應計數,其公式詳見公式(4.1)
8 Dechow, P. M., R. G. Sloan, and A. P. Sweeney. 1995. Detecting earnings management. Accounting review:193-225.
9 Kothari, S. P., A. J. Leone, and C. E. Wasley. 2005. Performance matched discretionary accrual measures. Journal of accounting and economics 39 (1):163-197.
第四章 深度學習
第一節 名稱的由來
1958 年10由Frank Rosenblatt 提出名為 Perceptron 的想法,這個演算法類似於 線性分類模型,在訓練資料可被線性函數區分時,Perceptron 可以保證在有限的步 驟中將此線性函數找出來。然而這個方法卻在 1962 年時遭到 Marvin Minsksy 抨 擊,他認為Perceptron 只能在有限的情況下才能運作,不能廣泛地被運用。這也導 致Perceptron 的研究熱潮迅速平息,直到 1980 年代中期才又被人提起。
1980 年代中期11,Multilayer Perceptron 的這個方法被提出,雖然叫做 Multilayer Perceptron,但這個演算法其實不是指很多的 Perceptron 接在一起,而是改用很多 層的Logistic Model 連接12。這個演算法又被人稱作Neural Network,也就是大家 現在常使用的「神經網路」一詞。這是因為當時的學者們想要利用 Multilayer Perceptron 來尋找生物神經系統的數學表示法。這時的 Multilayer Perceptron 已與 2015 年以後使用的深度學習演算法沒有太大的差別。
在1986 時由 Rumelhart et al. (1986)提出 Back-propagation 演算法 13,這個演 算法能夠重複調整神經網路中各單元中的權重,讓神經網路的輸出向量與目標向 量殘差值降到最低。然而當時卻發現如果神經網路的隱藏層超過三層 11,就無法 訓練出好的結果。於是在1989 年左右,多數學者認為一層的隱藏層就足夠模擬各 種函數14,於是Multilayer Perceptron 的聲量又再次下跌。
10.Bishop, C. M. 2006. Pattern recognition and machine learning: springer. (pp.193-194)
11 李宏毅. 2016d. ML Lecture 6: Brief Introduction of Deep Learning. YouTube.
https://www.youtube.com/watch?v=Dr-WRlEFefw. (4:19-10:59)
12 Bishop, C. M. 2006. Pattern recognition and machine learning: springer. (pp.226)
13 Rumelhart, D. E., G. E. Hinton, and R. J. Williams. 1986. Learning representations by back- propagating errors. nature 323 (6088):533-536.
14 Nielsen, M. CHAPTER 4 A visual proof that neural nets can compute any function 2019 [cited.
Available from http://neuralnetworksanddeeplearning.com/chap4.
在1999 年後,隨著 GPU 的發展,訓練多層以上的隱藏層成為可能,於是學者 們就將Multilayer Perceptron 重新命名為 Deep Learning,也就是現在常聽到的「深 度學習」,回到眾人的面前。而在 2006 年 Hinton et al. (2006)提出使用 Restricted Boltzmann machines(RBM)來訓練深度學習的各項權重的初始值 15 ,由於其結構 複雜吸引各研究者的目光,讓 Deep Learning 重新受到重視,甚至有人認為使用 Restricted Boltzmann machines(RBM)才算是 Deep Learning,而未使用則是屬於 1980 年代的 Multilayer Perceptron。但隨著更多研究投入,便發現不需要 Restricted Boltzmann machines(RBM)也能訓練 Deep Learning 模型,於是 Deep Learning 與 Multilayer Perceptron(Neural Network)成為同一種演算法但不同名稱,換句話說「深 度學習」與「神經網絡」屬於同一種演算法,兩個名稱常被交互使用,為了避免困 惑先在此述明。
第二節 Activation Function
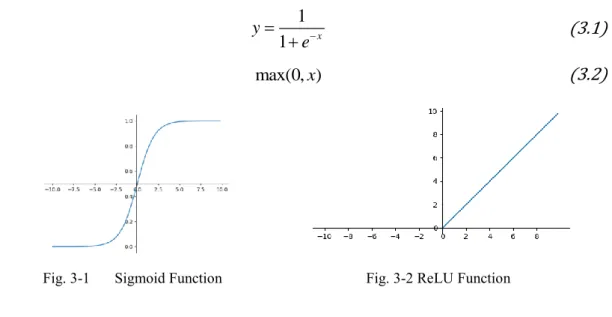
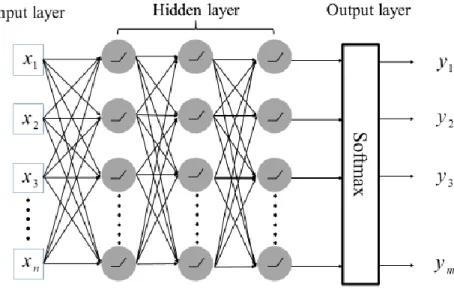
Activation function 是深度學習中最基本的單位,可以想像它是神經網路中的 一個節點(node),執行最簡單的非線性轉換。Activation function 有許多種,常見的 有Sigmoid(3.1)、Rectified Linear Unit (ReLU)(3.2)等。
1 1 x y e
(3.1)
max(0, )x (3.2)
Fig. 3-1 Sigmoid Function Fig. 3-2 ReLU Function
15 Hinton, G. E., S. Osindero, and Y.-W. Teh. 2006. A fast learning algorithm for deep belief nets. Neural computation 18 (7):1527-1554.
Activation function 可以產生相當於邏輯運算子的效果,而且串接越多效果越 強。舉一個例子,如附圖Fig. 3-3,有四的點,分別為(0,0)、(1,0)、(0,1)、(1,1)。如 果要將(0,0)與(1,1)分為一類,(1,0)與(0,1)分為另一類,會發現若單純使用線性函數 會無法進行分類。但若將各點經過下面兩組ReLU 轉換(3.3)(3.4),就會發現利用一 次函數區分成為可能16。
max(0, 0.5* )
w x y (3.3)
max(0, 0.9 )
z xy (3.4) 經轉換後的四個點分別為(0,0)、(0.5,0.1)、(1,0)、(0,1),如附圖 Fig. 3-4,可以 輕易的被一次函數區分。若使用多個Activation function 則能更有效地轉換資料,
幫助分類。
Fig. 3-3 轉換前的資料 Fig. 3-4 轉換後的資料
第三節 深度學習架構
深度學習的架構可以任意改變,以應對各種需求,在這篇論文中會使用最基礎 的Fully Connected Feedforward Network 架構17。深度學及模型可以想像成一個巨
16 李宏毅. 2016g. ML Lecture 11: Why Deep? YouTube.
https://www.youtube.com/watch?v=XsC9byQkUH8. (36:14-39:08)
17 ———. 2016d. ML Lecture 6: Brief Introduction of Deep Learning. YouTube.
https://www.youtube.com/watch?v=Dr-WRlEFefw. (16:58-18:48)
型的函數,和一般的函數一樣,將一向量輸入函數後能夠轉換成另一向量。此模型 由一層Input Layer、一層 Output Layer 以及任意數量 Hidden Layer 組成。
一、 Input layer
Input layer 並不是真的「一層」,而是單純指要輸入方程式的向量 17。換句話 說,就是指所有要使用的自變數,在Fully Connected Feedforward Network 的架構 下,每一個自變數都會輸入到下一層的所有節點(node)中,下一層的每個節點都會 使用Input layer 中每一個自變數。
二、 Hidden layer
Hidden layer 是 Input layer 輸出的對象,可以任意決定要有多少層,每層由任 意數量的Activation function 組成,作為 Hidden layer 的節點(node) 17。每一層的節 點不用相同,每層使用的 Activation function 也不用相同。如第一層是五千個 Sigmoid function,第二層可以接三千個 ReLU function。從 Input layer 得到自變數 後,每個節點會產出一個值,這些值會當作新的自變數輸入到下一層的 Hidden Layer 之中。如同 Input layer,在 Fully Connected Feedforward Network 的架構下,
每一個節點產生的值都會輸入到下一層的所有節點中,下一層的每個節點都會使 用上一層Hidden layer 中每一個產出的數值。最後一層的 Hidden Layer 會將值輸出 到Output layer。
三、 Output layer
Output layer 是一個分類器18,就像在Activation Function 章節提到的例子,原 資料經過非線性轉換後被一次方程式分類。對比到深度學習, input layer 是未經 轉換的資料,經過hidden layer 非線性轉換後,將資料點轉換成容易被分類的型態,
或可稱為找到資料的特徵(Feature),再利用 Output layer 把資料分類成多個種類,
但相較於一次方程式,Output layer 會使用能夠一次區分多種類類別的函數。常在
18 Ibid. (27:24-28:30)
分類時被使用的函數為Softmax function(3.5)。Sigmoid function 的主要目的直覺上 從hidden layer 中的資料壓縮到 0 至 1 之間18,並算出一筆資料被分到各個類別的 後驗機率(Posterior probability) 19,其中擁有最大值後驗機率的類別就是該筆資料 被預測出來的類別。
1
( )
i
j
z
i K
Z j
z e
e
(3.5)四、 Fully Connected Feedforward Network
這是指一種最常見的連接各Layer 的方法20,每一個節點產出的資料都會輸出 到下一層的所有節點中,而每一個節點也會使用上一層所有節點產出的資料,這就 是Fully Connected,如附圖 Fig. 3-5 21。Feedforward 則是指資料從 Input Layer 傳遞 到 Hidden Layer 在傳 遞到 Output Layer, 呈現順向的結 構。 Fully Connected Feedforward Network 只是最基礎的深度學習架構,還有許多別的架構如 DANN、
Residual Net 等。
Fig. 3-5 Fully Connected Feedforward Network21
19 Bishop, C. M. 2006. Pattern recognition and machine learning: springer. (pp.209-210)
20李宏毅. 2016d. ML Lecture 6: Brief Introduction of Deep Learning. YouTube.
https://www.youtube.com/watch?v=Dr-WRlEFefw. (12:50-18:46)
21 Ibid. (28:19)
第四節 Loss Function
有深度學習的模組後,還需要一個用來評價模組好壞的方法22。此時就需 要使用 Loss Function。Loss Function 依照模組預測出來的結果與真實資料互 相比對後算出一個分數,這個分數(Loss)越低就代表預測的結果與真實資料越 接近,代表模組較為優良,反之分數(Loss)高就代表模組並不完善。在做分類 時常會使用Cross Entropy23當作Loss Function 24。會使用Cross Entropy 而不 是常見的平方差公式主要是因為Cross Entropy 在模組預測與真實資料相差很 大時,Cross Entropy 能在被微分後擁有較大的斜率25,有利於訓練,而平方差 公式在同樣情況下則呈現平緩,不利於訓練,可參考 Fig. 3-6。此外 Loss Function 必須能被微分,才能夠利用 Gradient Descent 的方法找出最符合真實 狀況的模組。此外依據狀況不同,也可以改用其他的Loss Function 或打造自 己的Loss Function。
, ,
1
- ln( )
M
o c o c
c
y p
(3.6)M = 類別數
y = 真實資料屬於某個 class p = 模組輸出的數字
22 李宏毅. 2016g. ML Lecture 11: Why Deep? YouTube.
https://www.youtube.com/watch?v=XsC9byQkUH8. (9:35-18:58)
23 ML-Glossary. Loss Functions 2017 [cited. Available from https://ml- cheatsheet.readthedocs.io/en/latest/loss_functions.html.
24李宏毅. 2017a. ML Lecture 5: Logistic Regression. YouTube.
https://www.youtube.com/watch?v=hSXFuypLukA. (3:53-14:56)
25 Glorot, X., and Y. Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. Paper read at Proceedings of the thirteenth international conference on artificial intelligence and statistics.
Fig. 3-6 Loss 值分布圖,上層為 Cross Entropy,下層為平方差公式 25
第五節 Gradient Descent
想像模型中每一個權重(weight)都代表空間中的一軸26,把所有權重帶入 Loss Function 中形成一個高低起伏不斷的大空間,如 Fig. 3-6 中所描繪,波浪上的每一 點都是一組權重算出來的 Loss,而最好的模組擁有最低的 Loss,也就是整個波浪 中最低點的位置。若要算出全部權重組合的 Loss 會消耗過多的資源,於是使用 Gradient Descent 來找出答案。
想像在Loss 組成的波浪中隨機抽選一個點,朝著該點斜率的反方向走一小步,
再從下一點的斜率反方向再走一小步,漸漸地朝向最低點邁進,最後會抵達斜率為 0 的最低點。而要得到此斜率需要把 Loss Function 對每一個權重做偏微分,得到的 值組成一個向量就叫做梯度(Gradient),可用符號∇表示。而為了要求得最低值,需 要將原本的權重減去Gradient,才會朝最低值前進。但直接減去 Gradient 可能會離
26 . 李宏毅. 2016a. ML Lecture 1: Regression - Case Study. YouTube.
https://www.youtube.com/watch?v=fegAeph9UaA. (18:59-38:14)
原先的點差距太遠而非像最低點前進,於是在減 Gradient 時會乘上一個數來限制 Gradient 的步伐長度,這個數稱之為 Learning Rate,可用符號 η 表示。以上步驟可 用公式(3.7)27表示。
( 1) ( ) ( )
( )
T T T
w w Loss w (3.7) 除了最基礎的Gradient Descent 外,他還有許多變形,如一次只使用一筆資料 的Stochastic Gradient Descent 28、能夠處理各不同散佈的自變數的Adagrad,結合 Adagrad 並加入動量概念的 Adam 29,也是本論文中所使用的方法。
第六節 Backpropagation
在Deep Learning model 中30,要完成一次的權重更新,需要幫每一個節點(node) 中每一個權重都算一次偏微分,其計算量過度龐大,用普通的微分方法算Gradient 十分困難,所以要使用Backpropagation 來計算 Gradient。換句話說 Backpropagation 並不是指一種獨立於Gradient Descent 外的演算法,而是指 Backpropagation 就是計 算Gradient Descent 的手段。
在開始介紹Backpropagation 前, 先定義五個式子,式子(3.8)表示資料輸入到 一個節點時經過各權重加權的結果,式子(3.9)代表把加權的結果輸入到 Activation Function 之中。式子(3.10)代表 Output Layer 要使用的 Softmax Function。式子(3.11) 代表要使用Cross Entropy 來當作 Loss Function,且代表使用單一一個 Training Data 所計算的Loss。式子(3.12)代表所有 Training data 算出來的 Loss 加總的結果。
1 n
i i i
z w x b
(3.8)
27 Bishop, C. M. 2006. Pattern recognition and machine learning: springer. (pp.239-240)
28 李宏毅. 2016c. ML Lecture 3-1: Gradient Descent. YouTube.
https://www.youtube.com/watch?v=yKKNr-QKz2Q.
29 ———. 2016f. ML Lecture 9-1: Tips for Training DNN. YouTube. (35:50-54:46)
30 ———. 2016e. ML Lecture 7: Backpropagation. YouTube.
https://www.youtube.com/watch?v=ibJpTrp5mcE.
( ) max(0, )
a z z (3.9)
1
( )
i
j
z
i K
Z j
z e
e
(3.10)1
C( ) =- ln( )
M
i i
i
y z
(3.11)1
Loss( ) =- ( )
S i i
C
(3.12)若要計算每個權重的偏微分,則需要對Loss Function 做偏微分,於是有式子 (3.13)。
1
( ) ( )
s i i
Loss C
w w
(3.13)於是我們可以利用分開計算各個Training Data 的 Cross Entropy 來計算整體的 Loss,
並藉由微分連鎖律,我們擁有以下的式子(3.14):
C z C
w w z
(3.14)
w 對 z 做偏微分很容易計算,就是與該權重相乘的自變數 x(或是從上一層節點傳 來的變數)。而 z 對 C 的偏微分則可以藉由微分連鎖律拆成以下式子(3.15):
C a C
z z a
(3.15)
z 對 a 的偏微分一樣容易計算,z 對 ReLU 的微分值在小於 0 時為 0,大於等於 0 時則為1。而 z 對 C 的偏微分利用微分連鎖律分成以下式子(3.16)31:
1 i p
i i
C z C
a a z
(3.16) 由於a 對 C 的影響在於 a 會作為下一層節點的自變數而被帶入下一層的 z 進而一 算到C,所以 a 對 C 的偏微分可以看成 a 對下一層所有節點的 z 做偏微分((3.16)中
31 Hoskiss. 2020. [機器學習] Backpropagation with Softmax / Cross Entropy 2019 [cited December 2 2020]. Available from https://medium.com/hoskiss-stand/backpropagation-with-softmax-cross-entropy- d60983b7b245.
的p 代表下一層所擁有的節點數),乘上下一層的所有 z 對 C 做偏微分。而計算 a 對下一層所有節點的 z 的偏微分很簡單,就是節點連結到下一層所有節點的權重 w。而 z 對 C 的偏微分則又會回到式子(3.15),這樣不斷的連鎖後,會達到 Output Layer,而 Output Layer 的微分式如下: (3.17):
C a C
z z a
(3.17)
以上的式子中z 對 a 的偏微分依然是權重 w,但 a 對 C 的微分經過 Softmax Function 簡化後會變為以下的式子(3.18) 31:
i i
C z y
a
(3.18)
a 對 C 的偏微分精簡化後為經過 Softmax 計算後的 z 減去真實資料的分類 y。於是 Output Layer 的 Gradient 被計算出來,依據微分連鎖率可算出上一層所有節點的 Gradient,一路算回最上層的節點。這樣從 Output Layer 向後算的動作我們稱之為 Backpropagation。
第七節 小結
這一章介紹Deep Learning model 的組成架構,如何利用 Loss Function 評估模 型的,以及如何利用Backpropagation 實作 Gradient Descent。幸運的是以上這些方 法都已經預先寫再python 的 PyTorch 套件之中,利用 PyTorch 套件能夠直接使用 以上的各項功能來架構與計算Deep Learning model,讓訓練模型的進入門檻降低。
第五章 研究方法
本次研究是利用台灣經濟新報TEJ+的資料,並訓練一組深度學習模型來預測 下一年可能發生審計失敗的查核案件,本章節介紹所使用的應變數、自變數、模型 架構與訓練方法。
第一節 資料整理
使用的資料皆是從台灣經濟新報TEJ+中取得,使用上市加上櫃,非金電(不含 TDR)加電子產業(不含 TDR)範圍中的資料。從 TEJ 審計品質分析資料庫向下的任 期及經驗、客戶重要性、產業專家以及IFRS 以合併為主簡表(單季)-全產業向下的 資產負債表、損益表、權益變動表、現金流量表中全部欄位另加上裁決應計數、會 計師與會計師事務所垂直與水平傳染效果作為本次使用的自變數。並以 TEJ 審計 品質分析資料庫向下的重編彙整資料庫中重編原因欄位為轉投資相關、會計估計 及評價、損益期間歸屬、虛增(漏列)交易、所得稅及租賃會計、重大重分類/CPA 更 新意見的資料作為應變數。期間為2006 年至 2019 年,包含季報與年報。
一、 審計失敗
審計失敗是本次研究所要預測的目標,並使用財務報表重編來代表審計失敗。
在台灣經濟新報 TEJ+中 TEJ 審計品質資料庫的衡量變數-重新彙整資料庫中,提 供各年度所有財務報表重編的資料與其發生原因。由於審計失敗代表會計師出具 不適當的查核意見而產生重編,而非因會計原則變動而產生重編,因此重編原因為 會計原則變動的重編案件從應變數中剔除。所使用的重編原因如Tabel 1 所示:
Tabel 1 審計失敗所使用的重編原因
重編大類別代碼 重編原因大類別 01 轉投資相關 02 會計估計及評價 03 損益期間歸屬 04 虛增(漏列)交易
05 所得稅及租賃會計
07 重大重分類/CPA 更新意見
二、 裁決性應計數
裁決性應計數為模型的自變數之一。Kothari et al. (2005)在其論文中提到32
33Dechow et al. (1995)所提出的 modified-Jones model 是最能夠詮釋裁決性應計數的 模型,而此模型與原本的Jones model 差別在於添加應收帳款年度變動作為盈餘操 作的變數之一。而Kothari et al.則在公式中加入常數項(α)與資產報酬率(ROA),這 是為了減少因忽略公司大小而造成的變異數不一致的問題。其公式如(4.1)
0 1 2 3
1 1 1 1 1
TAit 1 it it it it
it
it it it it it
REV AR PPE ROA
Asset Asset Asset Asset Asset
(4.1) 變數如下:
1. 總應計數(𝑇𝐴𝑖𝑡 ) = (流動資產年度變動-現金與約當現金年度變動-流動負 債年度變動+一年內到期長期負債年度變動-折舊-攤銷)/去年度資產總額 2. 資產(𝐴𝑠𝑠𝑒𝑡𝑖𝑡−1) = 去年度資產總額
3. 營業收入變動(∆𝑅𝐸𝑉𝑖𝑡) = 今年度營業收入淨額-去年度營業收入淨額 4. 應收帳款變動(∆𝐴𝑅𝑖𝑡) = 今年度應收帳款-去年度應收帳款
5. 不動產、廠房與設備(𝑃𝑃𝐸𝑖𝑡) = 今年度不動產、廠房與設備 6. 資產報酬率(𝑅𝑂𝐴𝑖𝑡) = 此處使用稅後息前的今年度資產報酬率 7. 常數項(α)
為了不減少訓練資料,計算公式的係數時採用當年度同產業的資料作回歸。依 照資料中的報表的年、月以及台灣證券交易所 TSE 產業代碼將資料分群,並對各 群中的資料分別做線性回歸並用其參數預測各筆資料應有的總應計數,再以各資
32 S.P. Kothari, Andrew J. Leone, Charles E. Wasley. (2005). Performance matched discretionary accrual measures. Journal of Accounting and Economics,39(1), 163-197.
33 蔡孟瑾. (2015). 審計失敗之傳染效果-以台灣為例. 臺灣大學會計學研究所學位論文, 1-48.
料真實的總預計數減去預計的總預計數得到裁決性應計數。
三、 審計失敗傳染效果
審計失敗傳染效果為模型的自變數之一。依照Li et al. (2015)4的研究,審計失 敗的傳染效果可分為垂直傳染與水平傳染,並又可區分為會計師層級與事務所層 級。在訓練模型時利用虛擬變數(dummy variable)來表符合被傳染的條件。水平傳 染為了要模擬真實預測時無法取得當年度審計失敗資料的狀況,而設為若前一年 同會計師或事務所執行的查核案件出現審計失敗,則本年度查核案件的被傳染可 能設為1。垂直傳染則分為五年內曾經發生審計失敗與以往曾經發生審計失敗,又 向下細分為是同公司的查核案件與不限同公司查核案件兩種。所有變數如 Tabel 2 所示:
Tabel 2 審計失敗傳染效果應變數
變數 定義
會計師水平傳染 若查核案件的執行會計師在去年執行的查核案件中出 現審計失敗,標示為1
事務所水平傳染 若查核案件的執行事務所在去年執行的查核案件中出 現審計失敗,標示為1
會計師垂直傳染不 同公司(無年限)
若查核案件的執行會計師在過去執行的查核案件中出 現審計失敗,標示為1
會計師垂直傳染同 公司(無年限)
若查核案件的執行會計師在過去執行的同公司查核案 件中出現審計失敗,標示為1
會計師垂直傳染五 年內不同公司
若查核案件的執行會計師在過去五年內執行的查核案 件中出現審計失敗,標示為1
會計師垂直傳染五 年內同公司
若查核案件的執行會計師在過去五年內執行的同公司 查核案件中出現審計失敗,標示為1
事務所垂直傳染不 同公司(無限年)
若查核案件的執行事務所在過去執行的查核案件中出 現審計失敗,標示為1
事務所垂直傳染同 公司(無限年)
若查核案件的執行事務所在過去執行的同公司查核案 件中出現審計失敗,標示為1
事務所垂直傳染五 年內不同公司
若查核案件的執行事務所在過去五年內執行的查核案 件中出現審計失敗,標示為1
事務所垂直傳染五 年內同公司
若查核案件的執行事務所在過去五年內執行的同公司 查核案件中出現審計失敗,標示為1
四、 整理結果
其他未經特殊處理的自變數於附錄中說明。除了當年度的資料外,每一筆查核 案件都會使用前二年內所有應變數,來達到時間序列的效果。最終每筆查核案件都 擁有5,679 個自變數與 1 個審計失敗應變數。使用上市加上櫃,非金電(不含 TDR) 加電子產業(不含 TDR)範圍中的資料。訓練資料年度從 2007 年至 2018 年,測試資 料則為2019 年的資料,詳細如 Tabel 3 所示:
Tabel 3 訓練資料與測試資料
訓練資料 測試資料
資料量 67,176 6,708
年度 2007~2018 2019
資料範圍 上市+上櫃,非金電(不含
TDR)+ 電 子 產 業 ( 不 含 TDR)
上市+上櫃,非金電(不含 TDR)+ 電 子 產 業 ( 不 含 TDR)
自變數維度 5,679 5,679
應變數(審計失敗)維度 1 1
審計失敗為1 的資料量 665 27
審計失敗為0 的資料量 66,511 6,681
第二節 模型架構
模型的架構由三種元件組成,ReLU、Drop Out 與 Batch Normalization 組成。
1. ReLU
ReLU 如第三章所述,其公式可參考(3.2),由一整排的 ReLU 組成的 Hidden Layer。選擇 ReLU 而非 Sigmoid 的原因在於它結構簡單微分容易,計算速 度快且較不易產生梯度消失(Gradient Vanishing)的問題 34。
2. Dropout
Dropout 擁有減低過度擬合(Overfitting)的效果35,在這次實驗中過度擬合是 十分嚴重的問題。Dropout 的作法是在每次更新參數時把模型中一部份的 節點拿掉,只訓練剩下的節點,讓模型變得更窄。這會使模型在訓練資料 上的表現降低,但由於每次都更換模型的形狀,可想像成是訓練大量不同 的模型,再將模型的結果平均,讓原本因為變異程度過大而使模型在測試 資料上表現不佳,降低其變異程度而讓預測結果能夠更為精準。
3. Batch Normalization
Batch 是指在訓練時不會一次把所有資料都投入,而會將資料切成需多小 組,依序投入,這能夠大幅降低訓練所需的時間。Batch Normalization 是使 用Batch 訓練時,將 Hidden Layer 執行一次標準化,這能夠有效處理 Internal Covariates Shifting 的問題,並可使用較大的 Learning Rate 來加快訓練速 度。此外也能防止梯度消失(Gradient Vanishing)、防止過度擬合(Over Fitting) 的效果。
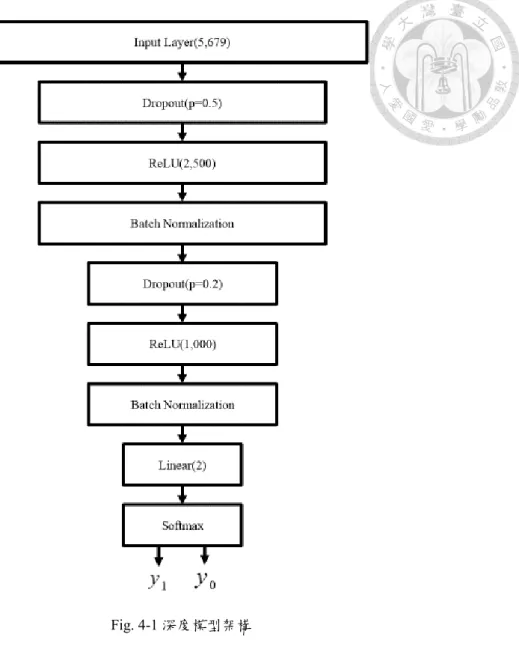
本次的模型如 Fig. 4-1 所示,Input Layer 有 5,679 維度的應變數,下一層是
34 李宏毅. 2016f. ML Lecture 9-1: Tips for Training DNN. YouTube. (17:08-23:46)
35 Ibid.(1:10:29-1:26:02)
2,500 個節點的 ReLU 層,訓練時會隨機 Dropout 百分之五十的節點進行訓練,並 執行一次 Batch Normalization,下一層為 1,000 個節點的 ReLU 層訓練時會隨機 Dropout 百分之二十的節點進行訓練,並執行一次 Batch Normalization。下一層為 兩個節點的Linear,並將資料送入 Softmax,最後輸出預測的審計失敗結果,1 代 表預測該筆查核案件會出現審計失敗,0 代表預測該筆查核案件不會出現審計失敗。
可以從模型看出此架構並不是非常深,這是因為實驗時發現若使用非常深的 模型會導致過度擬合的問題,在訓練資料上可以達到非常高的正確率,但在測試資 料中的正確率卻不高,因此加入Dropout 並使用較淺的模型減低過度擬合。各隱藏 層要使用的節點數並沒有硬性規定,可以依當時狀況或隨喜好更改,但最後一層 Linear Layer 需要使用與應變數要分成的類別數一樣,如審計失敗分成發生與未發 生兩類,所以使用兩個節點。另外需要注意使用 Pytorch 時,Softmax Function 會 包含在Loss Function 中,在架構模型時不要加入 Softmax Function 避免重複計算,
圖中僅為示意用途。
Fig. 4-1 深度模型架構
第三節 訓練模型
模型使用Python 中的 Pytorch 套件架構,並依照第三章所述,使用 Cross Entropy 為Loss Function,並使用 Adam 作為計算 Gradient Descent 的演算法,一次訓練 50 組模型,每組模型經過 20 個 Epoch 的訓練(使用全部訓練資料訓練一次為 1 個 Epoch)。本次實驗所使用的設備如 Tabel 4 所示:
Tabel 4 實驗設備與軟體
硬體/軟體 規格/版本
Python 3.6.8 Pytorch(Python 套件) 1.6.0 scikit-learn(Python 套件) 0.23.2.
作業系統 Windows10
CPU Intel Core i5-9600K CPU @ 3.70GHz RAM XPG SPECTRIX D41 DDR4 3200 8G*2 GPU NVIDIA GeForce GTX 1660
主機板 Gigabyte Z390 AORUS MASTER-CF 記憶體 ADATA SX8200PNP (SSD)
一、 資料清洗
在進行訓練前,需要將資料整理成可訓練的狀態。首先將類別類型的資料改以 虛擬變數(dummy variable)表示,經處理的應變數有:簽證意見類型、繼續經營假 設是否有疑慮、是否為大型事務所、會計師1、會計師 2、事務所代碼、產業名稱。
接著將非以虛擬變數表示的自變數標準化,標準化在訓練深度學習時十分重要,可 以增加訓練的效率,因為標準化能讓各自變數對模型的影響拉近,當計算梯度時,
參數會依Loss Function 法線向量反向更迭,若各自變數對模型的影響相近,法線 向量的反向會指向Loss 的最低點,讓訓練更準確快速 36。最後將資料中所有空值 都用 0 替代,這是為了要保持訓練的資料數量,且在真實預測的狀況億筆資料很 難擁有所有必需的應變數,因此補0 較直接刪除該資料更為合理。
二、 訓練資料抽選
從Tabel 3 中可以觀察到資料集有很嚴重的資料不平等(Imbalance Dataset)的問 題,出現審計失敗的查核案件在訓練資料中僅有665 筆,僅占訓練資料 0.99%。這
36 李宏毅(2016, October 7). ML Lecture 3-1: Gradient Descent: Tips for Training DNN (36:57-42:26).
Retrieved December 15, 2020, from https://www.youtube.com/watch?v=yKKNr-QKz2Q
樣的資料筆會使模型在訓練時僅針對非審計失敗的資料更新參數,隨然這能讓整 體模型的正確率達到最高,但卻無法得到預測出審計失敗的效果,因為模型會將所 有測試資料預測為非審計失敗,因此需要新的一組平衡的資料集才能更好的訓練。
製造平衡資料集的方法十分直觀,將發生審計失敗的資料複製到跟非審計失敗的 資料一樣多,但這會讓資料集過於龐大,訓練時間太長而難以訓練。於是我使用 ufoym (2020)所提供的 Imbalanced Dataset Sampler 37,這個方法能夠隨機抽選一 定數量的非審計失敗的訓練資料,並複製相同數量的審計失敗資料並將兩者混合 在一起,創造平衡的資料集。新的訓練資料為15,000 筆非審計失敗與 15,000 筆審 計失敗,並會隨著訓練新的模組改變其組成。
Fig. 4-2 抽選並創造平衡資料集(取自於 ufoym 的 Github, 2020)37
三、 半監督式學習
如果僅依靠第三章所述之監督式學習,預測效果仍人沒有預期中的高,在測試 資料的 27 筆審計失敗中,依靠監督式學習僅能預測出 23 筆審計失敗,佔總體審
37 ufoym. 2020. Imbalanced Dataset Sampler, October 9 2020 [cited December 15 2020]. Available from https://github.com/ufoym/imbalanced-dataset-sampler.
計失敗的85%。為了提升預測能力而使用半監督式學習。半監督式學習的概念為,
先訓練一組模型後,利用模型先預測一次測試資料的結果,並依照特定方法來評斷 這次預測結果的好壞,再將結果重新修正原先的模型,讓模型在測試資料上的表現 越來越好。需要注意不能直接使用測試資料的答案,以免模型直接把答案背起來。
本次實驗使用Information Entropy Loss 與 Pseudo-label 兩種方法。
(一) Information Entropy Loss
Information Entropy Loss38的概念為當測試資料被預測時,模型會提供一筆 查核案件是屬於審計失敗或非審計失敗的機率,而這兩個機率差距很大,
代表模型對預測的結果很有把握,若機率十分接近則代表模型不能確定要 將資料分成哪類。我們需要鼓勵模型產出有把握的答案而減少不確定性的 答案,能夠藉由修改Loss Function 來達到這個效果。在公式(4.2)中,若各 類別的機率相差越大(k 表示有幾種類別,ym代表是某個類別的機率),結果 會越接近 0,而機率相近時則會大於 0。將這個結果加到原本的 Cross Entropy Loss Function ( ( , ))C y y ,並乘上調整值來調整測試資料對整體 Loss 的影響,我將設為0.05,公式如(4.3)。將 Loss Function(4.3)微分可 得到Gradient 來調整參數,在此使用 bravotty (2020)39 於 Github 所提供的 微分公式。需要注意Cross Entropy 使用訓練資料,Information Entropy Loss 則只使用測試資料。
1
E(y)=- ln( )
k
m m
m
y y
(4.2)( , ) ( )
r u
r r u
x x
Loss
C y y
E y (4.3)
38 李宏毅. 2016g. ML Lecture 11: Why Deep? YouTube.
https://www.youtube.com/watch?v=XsC9byQkUH8. (25:52-30:41)
39 bravotty. 2020. Information-entropy-loss-pytorch, March 31 2020 [cited December 15 2020]. Available from https://github.com/bravotty/Information-entropy-loss-pytorch/blob/master/entropy_loss_pytorch.py.
(二) Pseudo-label
Pseudo-label 是更為直覺的方法40,使用模型預測測試資料後,將模型認為 是審計失敗的測試資料與訓練資料合併後再重新抽選成新的訓練資料訓 練,共執行49 次,產生 50 組模組。這個方法能夠讓模型更熟悉測試資料 而提高準確率。
Fig. 4-3 為未使用 Pseudo-label 的 0 號模型,可以看出在測試資料的 27 筆審計 失敗中僅能預測出 21 筆,而此模型認為是審計失敗的查核案件共有 1,847 筆 (21+1,826),這些資料會被併入訓練資料中訓練下一組模型。而 Fig. 4-4 則是第 50 組模型,經過49 次合併訓練資料,可以看見在 27 筆審計失敗中已可預測出 26 筆,
可抓出96%的審計失敗。
Fig. 4-3 未使用 Pseudo-label 第 20 Epoch 時測試資料的混淆矩陣
Fig. 4-4 使用 Pseudo-label 後第 49 組模組第 20 Epoch 時測試資料的混淆矩陣
四、 訓練過程
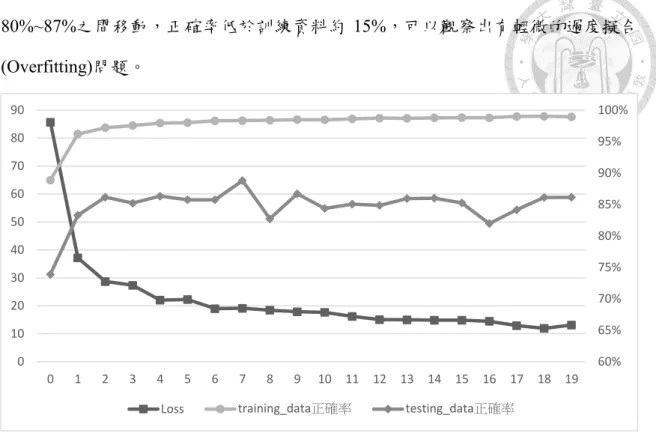
如第三章所述,在訓練時藉由Gradient Descent 尋找 Loss 的最小值,Gradient Descent 使用 Adam 演算法,Loss Function 使用(4.3)。以 1 號模型模型為例,Fig.
4-5 中 Loss 值從第一個 Epoch 的 85.7 下降到第二十個 Epoch 的 13.1,而模型在訓 練資料上的正確率從 88.8%上升至 98.8%,表現良好,然而在測試資料上卻在
40 李宏毅. 2016h. ML Lecture 12: Semi-supervised. YouTube.
https://www.youtube.com/watch?v=fX_guE7JNnY. (18:54-25:42)
80%~87%之間移動,正確率低於訓練資料約 15%,可以觀察出有輕微的過度擬合 (Overfitting)問題。
Fig. 4-5 1 號模型 0 至 19 Epoch 的 Loss 值、訓練資料正確率與測試資料正確率
若觀察角度改成50 組模型在測試資料上的表現(皆為第 19 個 Epoch),如 Fig.
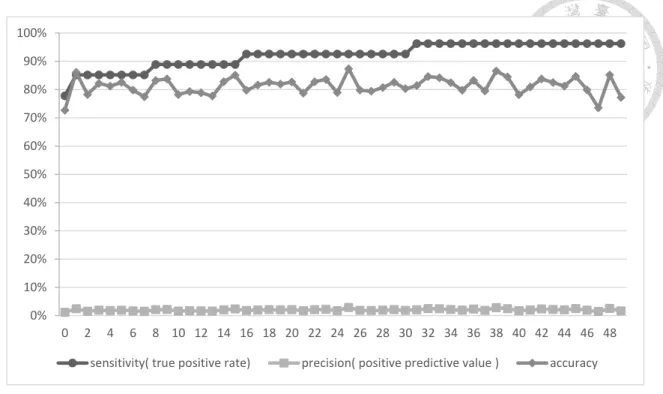
4-6 0 號模型至 49 號模型在測試資量上的表現,可以觀察到模型的正確率在 80%
附近浮動,然而 Sensitivity 卻隨著模組數不斷上升,從 77.8%上升至 96.3%,
Sensitivity 亦稱為 True Posituve Rate,代表有多少真正的審計失敗能夠被模型預測 出來。在0 號模組中,模型可從測試資料 27 筆審計失敗中預測出 24 筆,而到了 49 號模組,模型則可預測出 26 筆,幾乎全部都能預測出來,這是因為使用 Pseudo- label 讓模型更能夠熟悉測試資料的原因。另一方面,可從圖中觀察到模型的 Precision(positive predictive value)並不高,僅從 1.13%上升至 1.67%,這代表在 49 號模組所預測的審計失敗(1,553 筆)中,僅有 26 筆資料是真正的審計失敗,1,527 筆資料都是誤報,也使得模型的使用價值不高。
60%
65%
70%
75%
80%
85%
90%
95%
100%
0 10 20 30 40 50 60 70 80 90
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Loss training_data正確率 testing_data正確率
Fig. 4-6 0 號模型至 49 號模型在測試資量上的表現
五、 Voting
Precision 低落的原因為變異程度太高,使用大型模型時需要特別注意這個問 題 41,雖然模型能夠非常精準的找出目標值,也就是指Bias 很小,如 27 筆審計失 敗可以抓出26 筆,但結果會非常分散,雖然能抓出目標,但也會產生大量的誤報,
這時候就可以使用Voting 的技巧42。Voting 十分直觀,複數模型的情況下,將每個 模型所產生的答案進行投票,看所有模型對同一筆資料的預測結果,票數較多的結 果則認為是答案。舉例來說,若我將最後 24 組模型(因為 Sensitivity 較高)進行投 票,設定 24 組模型中有 24 組認為意見查核案件是審計失敗的時候,才將其認定 為審計失敗,結果如Fig. 4-7。可以看見 Precision 從原先的 1.67%提升至 20.16%,
每5 筆預測結果中就有一筆是真的審計失敗,且 Sensitivity 仍可保持在 92.59%,
27 筆審計失敗能抓出其中 25 筆。Voting 的原理在於利用交叉比對,剔除變異數產
41 ———. 2016b. ML Lecture 2: Where does the error come from? . YouTube.
https://www.youtube.com/watch?v=D_S6y0Jm6dQ.(20:49-22:51)
42 ———. 2017b. ML Lecture 22: Ensemble. YouTube.
https://www.youtube.com/watch?v=tH9FH1DH5n0. (4:56-18:54) 0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 sensitivity( true positive rate) precision( positive predictive value ) accuracy
生的誤報,而只將重複出現的審計失敗的結果保留下來,同 Fig. 4-8 25 號模型至 49 號模型經由不同投票門檻產生的預測表現中可以觀察到,若將投票的門檻從 1 票就通過調到 24 票才通過,正確率與 Precision 都逐漸提高,並指犧牲 3.7%的 Sensitivity,表示這個模組對真實審計案件的掌握度高,只需利用重複比對來除去 誤報就能提升準確度。Voting 的好處在於只要模型夠多就能夠增加 Precision,若持 續訓練出更多的模組還可以達到比 20.16%更高的數值,缺點在於十分耗費時間,
50 組模型花費約 36 小時訓練,若要縮短時間則需要更好的演算法或價格更高的設 備。
Fig. 4-7 25 號模型至 49 號模型 Voting 結果
Fig. 4-8 25 號模型至 49 號模型經由不同投票門檻產生的預測表現 0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 sensitivity precision accuracy
第六章 研究結果
經由第四章所陳述的訓練方法訓練出一組能預測審計失敗的模型,為了比較 此模型的優劣,以Cristina De Fuentes & Rubén Porcuna43所提出的邏輯斯回歸作為 對照組,比較兩者間在預測審計失敗時所表現的正確率、Sensitivity 與 Precision。
此實驗使用資料範圍為 TEJ 資料庫中上是與上櫃公司,非金電加上電子產業並排 除TDR 的公司,2007 年至 2018 年為訓練資料,2019 年則為測試資料。
第一節 實驗組
實驗組是使用Pytorch 架構的 Fully Connected Feedforward Network,其架構請 參閱Fig. 4-1,並使用半監督式學習與 Voting 的方式強化其預測的精準度,Fig. 5-1 為模組於2019 年資料上的表現。模組正確率為 98.49%,Sensitivity 達到 92.59%,
27 筆審計失敗中成功找出 25 筆,Precision 則為 20.16%,124 筆預測為審計失敗的 案件當中僅有25 筆為真實審計失敗。
Fig. 5-1 深度學習模型實驗結果
第二節 對照組
De Fuentes and Porcuna (2019)43依 據 西 班 牙 會 計 與 審 計 學 會(Instituto de Contabilidad y Auditoría de Cuentas1 ,ICAC)所提供 2002 至 2013 年的資料,分析審 計失敗發生的原因並預測其發生,以解決歐盟中有關是否應該限制會計師任期的 爭議。研究中發現,當企業正經歷財務困境、會計師對正向盈餘管理過於寬容以及
43 De Fuentes, C., and R. Porcuna. 2019. Predicting audit failure: evidence from auditing enforcement releases. Spanish Journal of Finance and Accounting/Revista Española de Financiación y Contabilidad 48 (3):274-305.
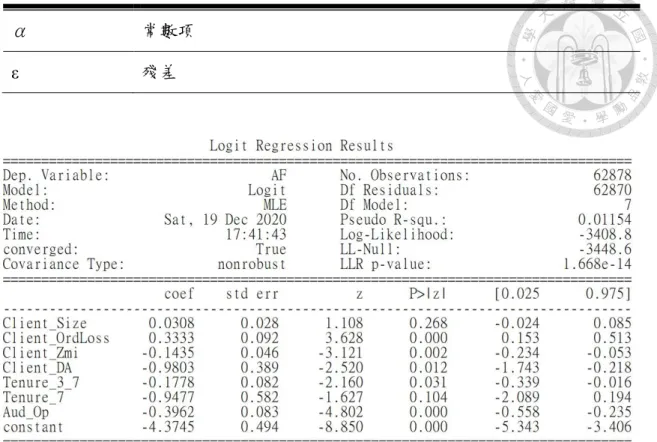
以個人身分而非事務所查核皆會增加審計失敗發生的可能性,此外若查核規模大 於事務所本身的公司時,審計失敗發生的可能性降低,而會計師任期與發生可能性 呈正向關係,但此現象僅存在於個人(非事務所)查核案件。其公式如(5.1),自變數 與應變數如Tabel 5,使用 Logistic Regression,其結果如 Fig. 5-2。
1 2 1
3 4 5
6 7 8
Pr( 1) _ _
_ _ _
_ 3 _ 7 _ 7 _
it it
it it it
it it it it
AF Client Size Client OrdLoss Client Zmi Client DA Aud Type
Tenure Tenure Aud Op
(5.1)44
Tabel 5 對照組使用的自變數及應變數
自變數/應變數 意義
AF 1 代表法定會計師於 t 年度的財報遭到懲罰,0 則相反
Client_Size 客戶總資產取自然對數
Client_OrdLoss 1 代表公司於 t-1 年度有虧損
Client_Zmi 利用probit's distribution function 求出的 Zmijewski 指數 45
Client_DA 裁決性應計數,在此使用未加絕對值得應計數
Aud_Type 1 代表受罰的是事務所,0 代表受罰的是獨立會計師,由於會計
師法規定台灣會計師都必須加入或設立事務所46,因此這項並不 使用。
Tenure_3_7 1 代表會計師任期介於 3 年至 7 年之間,使用主查會計師的任
期
Tenure_7 1 代表會計師任期大於 7 年,使用主查會計師的任期
Aud_Op 1 代表查核意見為無保留意見,0 則為其他
44 使用 Tabel 6 的公式
45 Zmijewski, M. E. 1984. Methodological issues related to the estimation of financial distress prediction models. Journal of accounting research:59-82.
46 會計師法第 8 條:領有會計師證書者,應設立或加入會計師事務所
α 常數項
ε 殘差
Fig. 5-2 對照組 Logit Regression Result
從 Fig. 5-2 中可以發現自變數中 Client_OrdLoss、Client_Zmi、Client_DA、
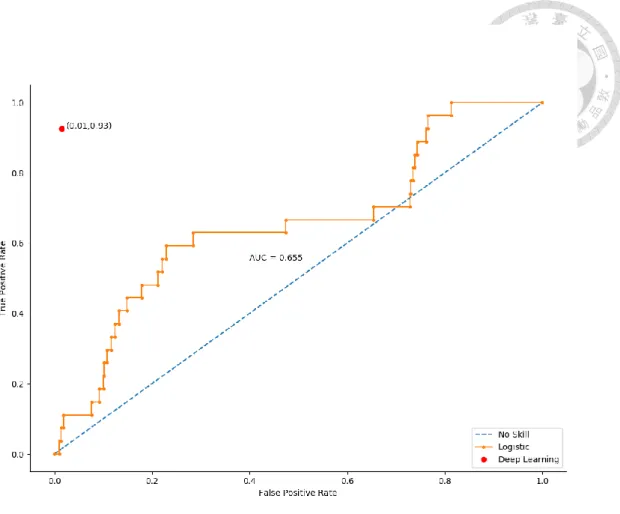
Tenure_3_7、Aud_Op 皆為顯著,可以觀察出以台灣的查核案件來說當企業經歷財 務困境、企業信用風險、裁決性應計數、會計師的任期及查核意見皆會影響讓審計 失敗出現的可能性。然而這個模型的解釋能力並不高,Pseudo R-square 僅有 0.00154,
而此模型於Receiver Operating Characteristic curve(ROC)上的表現也不佳,曲線下 的面積(AUC)僅有 0.655,曲線甚至在特定區段還比未使用模型還要低。此外從 Fig.
5-3 中可見,若將深度學習模組在測試資量上的表現繪於圖上,可發現表現遠好於 對照組,向畫面左上角靠近(由於深度學習模型並不是單純使用閥值進行預測,因 此難以繪製ROC curve,僅能存在一個點)。
Fig. 5-3 對照組 ROC curve
第三節 實驗組與對照組比較
比較兩組模型需要使用Precision-Recall Plot(PR Plot)。Precision-Recall Plot 以 Precision 與 Recall 作為兩軸,Recall 就是 Sensitivity,又稱為 True Positive Rate,
其計算方法為真實答案為1 之中,成功預測為 1 的比例,如 2019 真實發生審計失 敗中被模組成功預測的比例。而Precision 又可稱為 Positive Predictive Value,代表 預測為1 的資料,真實答案為 1 的比例,如模組對 2019 年審計失敗的預測當中,
真實為審計失敗的查核案件所佔的比例。當我們處理二元分類的問題,且資料分部 非常不平均時(Imbalanced Datasets),我們能夠從 Precision-Recall Plot 中得到比 Receiver Operating Characteristic curve 更多的資訊47。
47 Saito, T., and M. Rehmsmeier. 2015. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PloS one 10 (3):e0118432.