P2P網路借貸平台違約風險分析-RapidMiner之應用
49
0
0
全文
(2)
(3) 誌謝 時光飛逝,研究所生涯即將結束,首先我要感謝我的指導教授-邢厂民老師, 在繁忙的時間中悉心地指導我,當我在研究上遇到瓶頸時,總會提出各種建議來 輔助我,相互討論想出最好的解決方式,在過程中讓我學習到解決問題的能力, 也因老師細心地教導與督促,本論文才能順利完成。也要感謝老師除了指導論文 外,經常與我分享各種經驗,讓我在未來道路上能做好充足的準備,勇往直前, 在此由衷感謝邢厂民老師。此外,也非常感謝論文口試委員-陳亭甫老師和邱信 瑜老師,在百忙之中撥空審閱論文,給予我許多建議,使論文更加完善。. 感謝研究所期間授課的老師們,在課程中教導我們許多知識及分享人生閱 歷;感謝同學們一路以來的陪伴,大家互相學習及督促,使我碩班生活不枯燥乏 味,願各位在未來的求職之路能一切順利,盡情地展翅高飛;感謝家人默默地為 我付出及苦心栽培,讓我在求學過程中沒有壓力地學習,如果沒有你們,也不會 有現在的我。. 最後再次由衷感謝老師、同學及家人們,我將帶著你們的期許,克服所有挑 戰,努力追求自己的夢想,有所成就後必定回饋於社會,祝福各位心想事成、萬 事如意。. 莊睿尤 謹誌于 國立屏東大學財務金融學系 碩士班 中華民國 109 年 6 月. I.
(4) 摘要 金融科技在近年來成為國際間最熱門的詞彙之一,其中又以 P2P 網路借貸 平台最為熱門。本研究採用美國最大 P2P 網路借貸平台-Lending Club 之歷史數 據進行分析及預測違約風險,研究使用 RapidMiner 資料探勘平台進行建模,採 用簡單貝氏、隨機森林及邏輯斯迴歸三種演算法進行分析。在研究流程中採用雙 層交叉驗證選擇最佳變數及參數,以求得更客觀與可信度更高之預測結果。實證 結果顯示三種演算法模型準確率皆接近 90%,其中隨機森林演算法為最高,達 92.66%。最後,本研究使用 2015 及 2017 年樣本外資料進行違約風險預測,其預 測準確率分別為 86.31%及 90.94%,研究模型選擇之最佳變數可提供貸款機構在 進行審核貸款時之參考。. 關鍵詞:P2P 借貸、違約風險、交叉驗證、資料探勘、RapidMiner. II.
(5) Abstract Fintech has become one of the most popular word in the world in recent years, among it, P2P online lending is one of the most well-known term. This study uses historical data from Lending Club, the largest P2P online lending platform in the United States, to analyze and predict borrower‘s default risk. The study uses the RapidMiner data mining platform for modeling, where Naïve Bayes, Random Forest and Logistic Regression algorithms are applied. In the research process, double-layer crossvalidation is used to select the best variables and parameters in order to obtain more objective and reliable prediction results. The empirical results show that the accuracy rate of the three algorithms are close to 90%, of which the Random Forest algorithm shows the highest rate of 92.66%. Finally, this study uses the trained model to predict the out-of-sample data in 2015 and 2017, with prediction accuracy rate of 86.31% and 90.94%, respectively. The variables selected by the model in this study can provide lending institutions valuable information when examing future loan applications.. Keywords:P2P Lending, Default Risk, Cross-validation, Data Mining, RapidMiner. III.
(6) 目錄 誌謝 ........................................................................................................................... I 摘要 .......................................................................................................................... II Abstract ................................................................................................................... III 目錄 ........................................................................................................................ IV 圖目錄 ......................................................................................................................V 表目錄 .................................................................................................................... VI 第一章 緒論............................................................................................................. 1 第一節 研究背景與動機.................................................................................. 1 第二節 研究目的 ............................................................................................. 3 第三節 研究架構 ............................................................................................. 4 第二章 文獻探討 ..................................................................................................... 5 第一節 P2P 網路借貸平台 .............................................................................. 5 第二節 影響 P2P 網路借貸違約因子之相關文獻 ......................................... 12 第三節 利用機器學習預測 P2P 網路借貸違約之相關研究 ......................... 13 第三章 研究方法 ................................................................................................... 16 第一節 RapidMiner 介紹 ............................................................................... 16 第二節 研究樣本說明及資料預處理 ............................................................ 17 第三節 變數優化選擇 ................................................................................... 20 第四節 參數最佳化 ....................................................................................... 21 第五節 演算法說明 ....................................................................................... 23 第四章 實證結果 ................................................................................................... 27 第一節 最佳變數與參數最佳化 .................................................................... 27 第二節 變數分析 ........................................................................................... 29 第三節 模型準確率、精確率及召回率......................................................... 32 第四節 模擬預測 ........................................................................................... 33 第五節 研究限制 ........................................................................................... 35 第五章 結論........................................................................................................... 36 參考文獻 ................................................................................................................ 38 IV.
(7) 圖目錄 圖1. 研究架構流程圖 ........................................................................................... 4. 圖2. 2017-2022 全球 P2P 借貸成交金額統計 ...................................................... 6. 圖3. Lending Club 網路借貸平台營運流程 ....................................................... 10. 圖4. 美國兩大 P2P 網路借貸平台之五年違約率................................................ 11. 圖5. Lending Club 五年投資報酬率 ................................................................... 12. 圖6. RapidMiner 介面介紹 ................................................................................. 17. 圖7. 第一層交叉驗證變數優化選擇之流程圖 ................................................... 20. 圖8. 第二層交叉驗證變數優化選擇之流程圖 ................................................... 21. 圖9. 第一層交叉驗證參數最佳化之流程圖....................................................... 22. 圖 10 第二層交叉驗證參數最佳化之流程圖....................................................... 22 圖 11 隨機森林演算流程 ..................................................................................... 25 圖 12 2015 年資料使用隨機森林模型之預測結果 .............................................. 34 圖 13 2015 年資料使用隨機森林模型預測結果之混淆矩陣............................... 34 圖 14 2017 年資料使用隨機森林模型之預測結果 .............................................. 34 圖 15 2017 年資料使用隨機森林模型預測結果之混淆矩陣............................... 34. V.
(8) 表目錄 表1. 重點國家 P2P 網路借貸平台彙整表 ............................................................ 5. 表2. 傳統銀行借貸與 P2P 網路借貸平台之比較................................................. 7. 表3. 知名 P2P 網路借貸平台營運模式 ................................................................ 9. 表4. 貸款狀態合併前後分布 .............................................................................. 18. 表5. 樣本變數說明 ............................................................................................. 18. 表6. 三種演算法雙層交叉驗證選擇之最佳變數及最佳參數 ............................ 28. 表7. 最佳變數與目標變數之相關係數 .............................................................. 29. 表8. 混淆矩陣分布 ............................................................................................. 32. 表9. 三種演算法單、雙層交叉驗證之模型準確率、精確率及召回率 ............ 33. VI.
(9) 第一章 緒論 第一節 研究背景與動機 金融科技(Financial technology,以下簡稱 Fintech)一詞在近年來成為國際間 最熱門的詞彙之一,引發全球金融市場廣泛的討論,Fintech 是將資訊科技技術 實現金融交易服務而形成的經濟產業,提供低成本、高效率及高價值的金融服務, 根據美國 CB Insights 2019 年 Q1 全球金融科技報告顯示,全球在 Fintech 領域的 投資規模迅速成長,2017 年投資金額為 183 億美元,2018 年高達 403 億美元, 年成長 220%。 在 Fintech 這 股 浪 潮 下 引 發 出 五 種替 代 性金 融 服 務 (Alternative Finance Services),替代性金融泛指在傳統金融體系之外所提供的金融管道與工具,分別 為:P2P 網路借貸平台(P2P Online Lending Platform)、群眾募資(Crowdfunding)、 第三方支付(Third-Party Payment)、虛擬貨幣(Virtual Currency)、智能機器理財顧 問(Robot Advisor)等,非傳統金融機構提供之金融服務。根據 Cambridge Centre for Alternative Finance (CCAF)報告顯示,替代性金融又以 P2P 網路借貸占比最 高,2018 年占比高達 81%,預估未來還會持續增長。 Fintech 裡又以「P2P 網路借貸平台」最為熱門,P2P 網路借貸平台是藉由「微 型借貸」、「共享經濟」與「群眾募資」結合而形成的一種新型替代性金融服務。 「微型借貸」主要幫助一般無法與銀行取得借貸的貧困者取得資金,最早由穆罕 默德·尤努斯(Muhammad Yunus)於 1976 年創立的孟加拉鄉村銀行(Grameen Bank,也稱為格萊抿銀行)為先驅,銀行向貧困者提供不需要抵押物的小額貸款, 除了借貸給貧困者外,還進一步提供房屋貸款及小企業資金週轉。隨後聯合國在 2005 年小額信貸年提出“普惠金融 (Financial Inclusion) ”一詞的概念,在一定 程度上顛覆主要為富人服務的傳統理念,使弱勢客戶也可得到平等享受金融服務 的權利。至今在許多國家中已成功地幫助人們擺脫貧困,亦助於社會及經濟發展。 在「共享經濟」體系下,人們可將所擁有的資源有償租借給他人,使閒置資 源獲得更有效地利用,從而使資源的整體利用效率變得更高。經濟學人 1.
(10) (Economist)雜誌在許多文章提起,P2P 網路借貸平台即是「共享經濟」的延伸模 式,透過網路平台作為借貸中間人,提供借款人與投資人更好的交易條件,幫助 借款人擺脫過去在傳統銀行借貸時,信用不良、資產負債表不佳、負擔高利率的 重擔。 「群眾募資」泛指透過網路平台將借款人與投資人連接,借款人展示資金需 求目標,以社會大眾的小額資金贊助,支持個人或組織完成目標或專案。而「群 眾募資」是 Jeff Howe(2006)提出“群眾外包”的概念延伸,群眾外包是指「將過 去由指定公司員工完成的工作,公開號召交由不固定的一大群人完成」 Howe(2009)。根據 IOSCO 研究報告將「群眾募資」分為四種類型,分別為捐贈、 回饋、借貸及股權模式,而其中借貸模式被定義為可以使用線上平台,將借款人 與投資人相互聯繫,提供無抵押貸款之借貸,這種借貸模式也是 P2P 網路借貸平 台發展的開端。 P2P 網路借貸平台是在網路平台上,個體對個體(Peer to Peer)的直接借貸行 為,而個體包含自然人與法人。借款人能以不同目的在平台上申請小額貸款,而 投資人可根據借款人的信用評分、貸款細節等資訊,選擇投資哪些貸款,且通常 這些貸款都是無抵押貸款。而 P2P 網路借貸平台即是扮演雙方的仲介角色,意味 著這些過程皆不經過金融機構,也能更快地完成借貸服務,且借款人能以低於銀 行利率來取得資金,投資人也能收到比金融機構更高的利息。 P2P 網路借貸平台相對銀行來說需要承擔較高的違約風險,P2P 網路借貸平 台獲利來源為收取借貸成交後之手續費,且不必承擔借款人的違約風險,因此違 約風險的承擔者為投資人。但也因 P2P 借貸逐年成長,平台開始提供一筆預備賠 償金,此筆金額用在借款人違約時,對投資人的補償,也因此機制,違約風險轉 由平台與投資人共同承擔,則評估借款人的信用風險並有效預防違約風險的發生 是至關重要的。 本研究使用美國最大 P2P 網路借貸平台-Lending Club 之歷史數據找出何種 因素會導致借款人違約風險增加,研究同時利用樣本外資料模擬預測違約風險。 而本研究有別於過去使用單層交叉驗證,採用 2018 年 RapidMiner 白皮書介紹之 雙層交叉驗證,使模型預測結果可信度更高。 2.
(11) 第二節 研究目的 基於以 上研究 動機, 本研 究將數 據集 事前 處理及 使用 簡 單貝氏 (Naïve Bayes)、隨機森林(Random Forest)及邏輯斯迴歸(Logistic Regression)三種演算法 訓練 Lending Club 之貸款資料,並引用 2018 年 RapidMiner 白皮書之雙層交叉驗 證找出影響貸款違約因素,研究同時利用樣本外資料模擬預測違約風險。本研究 目的可分為以下三點: 一、使用簡單貝氏、隨機森林及邏輯斯迴歸演算法進行雙層交叉驗證取得最佳變 數及參數。 二、利用上述三種演算法所訓練之模型進行樣本外資料模擬預測。 三、利用最佳模型建議之最佳變數,提供貸款機構在未來評估借款人申請貸款時 之參考,以求降低違約風險。. 3.
(12) 第三節 研究架構 本研究蒐集有關全球 Fintech 與 P2P 借貸的相關文獻,使用美國 P2P 網路借 貸平台-Lending Club 之歷史資料,在樣本確定之後,利用各演算法找尋最佳變數 及參數最佳化並建立模型預測借款人違約風險,最後提出研究結論。本研究架構 如圖 1 所示。. 研究背景與動機. 研究目的. 文獻探討. 資料預處理. 簡單貝氏. 隨機森林. 變數選擇. 邏輯斯迴歸. 參數最佳化. 實證結果. 結論 圖1 研究架構流程圖. 4.
(13) 第二章 文獻探討. 第一節 P2P 網路借貸平台 一、 P2P 網路借貸平台興起 P2P 網路借貸平台主要概念為透過網路平台,不透過金融機構,直接將資金 貸給借款人。而最早的 P2P 網路借貸平台-Zopa(Zone of Possible Agreement)於 2005 年在英國成立。隨後 2006 年美國成立 Prosper、Lending Club。接連世界各 國 P2P 網路借貸平台相繼問世,而台灣直到 2016 年才有 P2P 網路借貸平台的出 現。表 1 列出重點國家 P2P 網路借貸平台,也因國家法規、金融市場及資金供需 不同,而存在多種平台營運模式(曾俐雯 2017)。 表1 重點國家 P2P 網路借貸平台彙整表 國家 P2P 網路借貸平台 英國 Zopa、Funding Circle、Rate Setter 美國 Prosper、Lending Club、Sofi、Kiva 中國 拍拍貸、宜人貸、陸金所 台灣 LnB 信用市集、鄉民貸、TFE 台灣資金交易所 資料來源:曾例雯(2017)、本研究整理 起初英國會發展 P2P 網路借貸平台是受到當時英國被五家大型銀行壟斷整 個行業,這種壟斷性增加了個人與企業的貸款難度,其中包括:繁瑣的貸款程序、 貸款速度慢、貸款較難成功等問題,對各個借款人造成諸多不便,為此發展出 Zopa 網路借貸平台(王明俐 2018)。由於 2008 年爆發金融海嘯,全世界的金融體 系受到嚴重衝擊,許多國家銀行開始實施信用緊縮,造成許多借款人無法在傳統 銀行上取得資金,因此借款人紛紛轉向 P2P 網路借貸平台尋求資金挹注。根據 Statista 統計,2017 年 P2P 借貸成交金額為 728 億美元,2018 年為 789 億美元, 成長 8.4%,且預估 2022 年可高達 1000 億美元。圖 2 為 Statista 統計全球 P2P 借 貸成交金額(2020-2022 年為預估值)。. 5.
(14) 圖2 2017-2022 全球 P2P 借貸成交金額統計 資料來源:Statista(2019)、本研究繪製. 二、 傳統借貸與 P2P 借貸之比較 本研究整理出以下四點比較傳統銀行借貸與 P2P 網路借貸(曾俐雯 2017;王 志瑋 2018): 間接金融轉為直接金融:就傳統銀行來說,是將銀行存戶之存款貸放 出去,而存款人與借款人在借貸交易之往來對象皆是銀行,彼此並非 直接相對,故屬間接金融;P2P 網路借貸平台之借貸是由借貸平台媒 合,不透過金融機構,且彼此在知道對方資訊下,建立個人對個人的 債權與債務關係,屬於直接金融。 獲利來源不同:傳統銀行借貸的獲利來源為存款與貸款之間的利息 差,也就是銀行要求借款人以較高的貸款利率支付還款利息,並給予 存款人較低的存款利息,而從中獲利;P2P 網路借貸平台獲利來源即 是收取媒合成功後借貸金額一定比例之手續費。 借款人信用評估數據化:傳統銀行在評估借款人信用程度是根據政府 機構下的聯合徵信中心所提供的信用分數為依據,再加上借款人之職 業、收入等因素來評估;P2P 網路借貸平台則是透過大數據分析與機 器學習的方式來計算信用等級。 不為資金擔保風險轉高:傳統銀行資金充足且受到政府法規嚴格規 6.
(15) 範,所以銀行必須準備一定資金額度承擔借款人違約時的損失;P2P 網路借貸平台主要為雙方借貸媒合,因此大部分平台不提供違約擔 保,違約風險承受者為投資人。 綜合上述,表 2 彙整出傳統銀行借貸與 P2P 借貸之比較,分別為資金來源、 資金仲介方、金融方式、獲利來源、借款人信用評估及投資人風險。 表2 傳統銀行借貸與 P2P 網路借貸平台之比較 借貸管道. 傳統銀行借貸 P2P 網路借貸平台 比較項目 資金來源 銀行存戶 投資人 資金仲介方 金融機構 網路平台 金融方式 間接金融 直接金融 獲利來源 利息差 手續費 借款人信用評估 聯合徵信中心 大數據分析及機器學習 投資人風險 低 高 資料來源:曾俐雯(2017)、王志瑋(2018)、本研究整理. 三、 P2P 網路借貸平台經營優勢 P2P 網路借貸平台發展迅速是因跟傳統銀行相比之下,具有以下經營優勢 (Chen & Han 2012;王明俐 2018;王志瑋 2018): 進入門檻低:借貸雙方只需擁有良好信用,即使缺乏擔保品,也能獲 得資金,因此對於資金需求不高的個體更容易形成微型貸款。 身分安全驗證:P2P 網路借貸平台會透過公正的第三方或政府機關, 協助建置或蒐集借款人的徵信資料,提供投資人更多參考值及平台的 正確性。 跨越時間和空間限制:傳統銀行辦理借貸時需親自至實體分行辦理, 且實體分行皆有營業時間,而 P2P 網路借貸平台卻可在任何時間、任 何地點不受限制地透過網際網路完成借貸,這樣的便利非常符合現代 人的需求。 核貸速度快:傳統銀行借貸必須親自到實體分行辦理,且申請過程需 經過照會、審核、對保等複雜程序,核貸時間長達一至二週;相對 P2P. 7.
(16) 網路借貸平台透過網路申請借貸,流程方便、快速,核貸時間只需一 至二天,有效將貸款速度大幅縮短。 交易透明化:P2P 網路借貸平台會公告借款人之信用等級、資金用途、 貸款期限等資訊,也會公告投資人的風險偏好程度、要求報酬率等資 訊,雙方皆可在資訊充分揭露下進行借貸交易,減少資訊不對稱之情 形。 投資人風險分散:P2P 網路借貸平台的機制會將一位或一群借款人的 貸款資金分散給多個投資人投資,因此可以降低每位投資人的投資風 險。. 四、 P2P 網路借貸平台之營運模式 隨著 P2P 網路借貸平台興起,平台營運模式發展也會因各國法規有所不同, 本研究根據中央銀行報告將全球 P2P 網路借貸平台分類為五種營運模式,分別 如下(中央銀行 2018;趙毓馨 2015): 傳統模式:為最基本之營運模式,平台參與度最少,借款人於網路平 台申請貸款,平台核准貸款後將貸款資訊上架,隨後擔任媒合角色, 投資人則透過該平台尋找投資標的,將資金貸予借款人完成該契約, 也因為此機制,假設平台經營不善而倒閉,借貸雙方之間契約責任仍 不受影響。 公證模式:平台同樣為媒合雙方借貸之角色,與上者不同的是貸款成 立後,款項是由合作銀行進行撥貸,而後投資人將資金匯款至平台後, 平台再將債權轉讓予投資人或投資機構,代表銀行將貸款之違約風險 完全移轉至投資人身上。 保證收益模式:在此模式下,投資人將想投資之金額匯入平台,且投 資人設定報酬率,平台會自行幫投資人做出相對應金額的投資組合, 並保證一定的利率報酬。 資產負債表模式:借款人通過平台核貸後,平台會直接撥貸,並帳載 於自身的資產負債表內,而投資人將貸款匯入平台後,平台會透過轉 讓債權予投資人或投資機構,獲取所需資金。資產負債表模式與公證 8.
(17) 模式差別在於公證模式是由銀行撥貸,資產負債表模式是由平台撥貸, 而兩者模式皆把貸款之違約風險轉嫁至投資人。 發票交易/應收帳款承購模式:中小企業可以透過平台出售未到期之 商業發票或是有(或無)追索權的應收帳款予投資人或投資機構承購, 以獲取營運資金。 國際間 P2P 網路借貸平台皆有各自的營運特色,各借款人皆有不同的資金 需求,各平台提供多元化貸款與借貸便利性,成功吸引不同類型客戶交易,以下 表 3 整理出國際知名 P2P 網路借貸平台之營運模式: 表3 知名 P2P 網路借貸平台營運模式 經營模式 借貸平台 (一)傳統模式 Zopa(英國) (二)公證模式 Lending Club(美國)、Prosper(美國) (三)保證收益模式 點融(中國大陸)、宜人貸(中國大陸) (四)資產負債表模式 SoFi(美國) (五)發票交易/應收帳款承購模式 Market Invoice(英國) 資料來源:中央銀行(2018)、本研究整理. 五、 Lending Club P2P 網路借貸平台介紹 Lending Club 簡介 Lending Club 成立於 2006 年 10 月,總部位於美國加利福尼亞州 舊金山,為全美最大 P2P 網路借貸平台,市佔率高達 75%,是第一家 於美國證券交易委員會(SEC)註冊並接受監管的 P2P 網路借貸平台 (陳賢澔 2016),且於 2014 年以發行價每股 15 美元發行上市於紐約證 券交易所(NYSE),成為當年最大的科技股 IPO。根據 Lending Club 統 計顯示,截至 2019 年 9 月底 Lending Club 已完成 429 萬筆借款,借 款金額高達 537 億,其中有 68.16%的借款人使用貸款資金對現有貸 款進行再融資或還清信用卡。 Lending Club 營運模式 Lending Club 營運模式採用公證模式,貸款將全部由銀行放貸, 其合作銀行為 WebBank,是一家於美國猶他州註冊設立的銀行。當借. 9.
(18) 款人在 Lending Club 上申請貸款後,Lending Club 會將貸款資訊放置 網站上以供投資人選擇,當借貸雙方撮合後 Lending Club 會將借款人 的借款資訊提供給 WebBank,由 WebBank 進行放貸,而後再將借款 債權以無追索權的方式平價轉讓給 Lending Club,最後投資人資金進 來後,Lending Club 在給予投資人受益憑證,以完成借貸手續(梅驊 2016),Lending Club 網路借貸平台營運流程如圖 3 所示。. 1.借款申請. 2.提供資金 Lending Club 3. 借 款 資 訊. 借款人. 4.銀行撥款. 5. 債 權 轉 移. 6.受益憑證 投資人. WebBank. 圖3 Lending Club 網路借貸平台營運流程 資料來源:梅驊(2016)、本研究繪製 Lending Club 信用評分 Lending Club 對於借款人的信用評分標準高,以降低違約率,借 款人申請貸款最低門檻必須符合以下三點(張小玫、周意庭 2016): 1. 信用分數 FICO(Fair Issac Corporation)須高於 660 分以上 2. 債務收入比須低於 40% 3. 至少提供 3 年以上之信用紀錄 通過審核後,Lending Club 會根據借款人提供的資訊、信用數據、 貸款期限和金額,套用至平台建置的評分標準,標準從 A1 到 G5 一 共 35 個評級,不同級別有不同的利率,利率從 A1 的 6.95%至 G5 的 35.89%。根據 Lending Club 統計,截至 2019 年 3 月底,Lending Club 借款人信用級別 A1 至 D5 占了全貸款 99%,且根據借款期間利率也 會有所變動,36 個月與 60 個月的借款期間平均利率分別為 11.50%和 14.35%,所有貸款平均利率為 12.74%。也因有如此嚴謹的審核機制, Lending Club 違約率相對同行來的低,以下圖 4 顯示美國兩大 P2P 網 10.
(19) 路借貸平台之五年違約率。 12.00% 10.96% 11.00% 10.00%. 9.13%. 9.32% 8.69%. 9.00% 8.00% 7.00%. 7.72%. 8.70%. 9.08% 8.56%. 7.14%. 7.65%. 6.00% 5.00% 2014年. 2015年. 2016年. Lending Club. 2017年. 2018年. Prosper. 圖4 美國兩大 P2P 網路借貸平台之五年違約率 資料來源:NSR invest(2019)、本研究繪製 Lending Club 借貸雙方參與方式及投資報酬率 借款人通過 Lending Club 信用評分審核後,即可在平台上刊登貸 款資訊,當借貸雙方媒合後,會與借款人收取一筆開辦費(Origination Fee),此筆費用為總費用 1-6%的一次性費用,該費用會基於借款人 的信用等級在收到貸款時收取(Lending Club 2019)。而投資人只要有 閒置資金時即可進入平台投資,Lending Club 的投資模式會將借款人 的一筆貸款分割成多個 Notes 並放入投資平台,透過與多個借款人等 級和期限相對應的 Notes 進行多樣化選擇,最終形成自身的投資組合, 而平台要求投資人的初始存款至少為 1,000 美元,帳戶入金後,每張 票據的最低投資額為 25 美元,最後淨收益為投資組合相對應的平均 利率減去損失和費用,費用為每期從借款人那裡回收本息的 1%,而 Lending Club 歷史投資報酬率為 4-7%,此投資模式與股票市場的相 關性較低,則投資人可使用此模式為新的投資替代方案(Lending Club 2019)。以下圖 5 顯示 Lending Club 五年投資報酬率。. 11.
(20) 8.00% 7.00%. 6.81%. 6.00% 5.16% 4.82%. 4.74%. 5.00%. 4.33% 4.00% 3.00% 2014年. 2015年. 2016年. 2017年. 2018年. 圖5 Lending Club 五年投資報酬率 資料來源:NSR invest(2019)、本研究繪製. 第二節 影響 P2P 網路借貸違約因子之相關文獻 過去有許多學者探討影響 P2P 網路借貸平台違約風險之因子,以貸款金額 方面來看,Li et al.(2011)研究借貸平台雙方交易是否成功原因有兩大關鍵決策, 發現借款人要求的貸款金額有重大影響,與貸款金額相比,利率的影響很小,表 示成交的貸款金額低,貸款利率較高。 以信用評分來看,Ghatge & Halkarnikar(2013)將機器學習模型與人工計算之 信用評分進行比較,發現機器學習具有統計學上的顯著預測優勢,因而將信用評 分定義為一種統計方法,可估算借款人的信用度及是否有違約的可能。Duarte et al.(2012)研究發現值得信賴的借款人融資成功的機率較高,且值得信賴的借款人 也具有很高的信用評分,使貸款違約率低。 以貸款期間來看,Dorfleitner & Oswald(2016)採用 Kiva 的小額貸款樣本研究 借款人還款行為,研究結果發現貸款規模、貸款期限和貸款還款寬限期會影響違 約的可能性。 而過去也有許多學者使用 Lending Club 提供的歷史數據找出影響違約的因 素,Emekter et al.(2015)探討 P2P 網路借貸的變數,評估借貸風險,發現信用等 級、債務所得比率、FICO 分數和循環額度影響借貸違約最為關鍵,信用等級較 12.
(21) 低和貸款期間較長的貸款,會有較高的違約率。Serrano-Cinca et al.(2015)探討利 率、信用評分與違約風險的關聯性,研究結果顯示借款人的貸款利率越高,違約 率就越高,將信用評分視為最佳的違約風險預測因子,研究也發現貸款目的、年 收入、當前房屋狀況、歷史信貸和債務皆會影響貸款違約的可能性。 Jin & Zhu(2015) 預測 P2P 網路借貸違約風險,發現貸款期間、年收入、貸款金額、債 務所得比率、信用等級和循環額度為貸款違約的決定因素。 除了上述,也有學者認為有許多其他外在因素會影響違約風險, Lin et al.(2009) 發現借款人的線上友誼(online friendships)是信用程度的信號。友誼增加 了融資成功的可能性,降低貸款的利率,也降低了事後違約率。Ramcharan & Crowe(2013)發現房價波動可能會對信貸產生重大影響,表明房價下跌的州的屋 主會承擔更高的利率且違約機率高,發現房屋的價格風險高,也會使 P2P 借貸的 違約風險高。. 第三節 利用機器學習預測 P2P 網路借貸違約之相關研究 過去有許多學者利用多種機器學習探討 P2P 網路借貸的違約風險,有些是 針對於貸款申請目的、信用評分、貸款期間等來研究,有些是利用機器學習來預 測違約風險,本節將探討簡單貝氏(Naïve Bayes)、隨機森林(Random Forest)、邏 輯斯迴歸(Logistic Regression)三種演算法之相關文獻。. 一、 簡單貝氏(Naïve Bayes) Vedala & Kumar(2012)認為一個簡單的分類器在現實單表數據(single table data)上表現良好,但在多關係(multi-relational)設置應用時,它的準確率會受“加 入”期間各個屬性的統計資料改變而影響。作者利用簡單貝氏演算法來比較預測 兩者借款人的違約率。實證結果顯示,通過多關係簡單貝氏演算法後,獲得較高 的準確率及更高的靈敏度(預測違約者的違約比例)。. 二、 隨機森林(Random Forest) Jin & Zhu(2015)使用 Lending Club 歷史數據,探討貸款及借款人的特徵,並. 13.
(22) 使用隨機森林進行建模,與以往不同的是把違約預測分類為三類,更可以幫助投 資人關注這些問題貸款。該研究比較五種資料探勘模型績效,分別為兩個神經網 絡(RBF 和 MPL)、兩個決策樹(CRT 和 CHAID)和一個支持向量機模型,實 驗結果顯示,支持向量機(SVM)模型達到了最佳性能,但改善幅度很小。最後使 用預測變數調查 10 項最造成違約風險的決定因素,分別為貸款期限、年收入、 貸款金額、債務所得比率、信用評分和循環額度。 Vinod-Kumar et al.(2016)利用 Lending Club 2013-2015 年的歷史數據,使用整 合機器學習演算法(Ensemble Machine Learning Algorithms)和預處理技術來分析 及預測貸款信用風險,機器學習演算法皆是基於樹的 決策樹、隨機森林及 bagging,研究結果顯示決策樹雖有最高的準確率,高達 97.1%,但隨機森林的精 確率為 88.5%,比決策樹高 7.2%。這表示隨機森林預測模型可以更好辨識違約 情況,而決策樹則在尋找優良信用方面更加強大。 Pan & Zhou(2019)提出一種基於隨機森林和可視圖模型的 P2P 借貸信用風險 評估新方法,解決 P2P 借貸不完善及風險高的問題。實驗總共收集 100 組數據並 依照級別從大到小分為五種不同級別的樣本做驗證,實驗結果準確率高達 98.63 %,證明提出的新方法在評估 P2P 借貸的信用風險方面是有效的。 Malekipirbazari & Aksakalli(2015)提出一種基於隨機森林的分類方法來預測 借款人的狀況。使用 Lending Club 2012 年 1 月至 2014 年 9 月的歷史數據,比較 四種不同的機器學習方法,包括隨機森林、近鄰(K-NN)、支持向量機(SVM)、邏 輯斯迴歸,研究結果顯示,隨機森林的準確率最高,為 78.0%,且擁有最高的 AUC 及最低的 RMSE。而後將隨機森林模型與 FICO 分數和 Lending Club 信用評分進 行比較,最後結果顯示三者的接受度(acceptance rates)皆相同,但隨機森林違約率 為最低,因此認為隨機森林為最佳分類器。 Ye et al.(2018)提出了一種利用基因演算法對利潤分數進行優化的隨機森林 演算法(Random Forest optimized by genetic algorithm with profit score, RFoGAPS), 其研究方法先進行參數調整及優化隨機森林。參數調整主要是確定隨機森林的最 佳參數。在使用基因演算法進行隨機森林優化,以優化參數優化隨機森林中決策 樹的組合,並在考慮實際收益、潛在收益及損失的情況下最大化利潤分數。研究 14.
(23) 結果顯示,利潤分數可以更好地評估 P2P 借貸中貸方利潤的貸款評估模型績效, 且利用 RFoGAPS 可為貸方帶來更高的利潤,並且報酬更高。. 三、 邏輯斯迴歸(Logistic Regression) Dong et al.(2010)提出一種具有隨機係數(Random Coefficients)的邏輯斯迴歸 模型,用於構建信用評分卡。認為有許多新技術(例如支持向量機)模型預測準確 率高,但結果的可解釋性存在許多問題。實驗結果顯示,所提出的模型可以在不 犧牲理想變數(desirable features)的前提下,提高具有隨機係數的邏輯斯迴歸預測 準確率。 Guo et al.(2016)設計基於實例的信用風險評估模型,該模型具有評估每筆貸 款收益和風險的能力,可使投資人優化投資決策。認為預測貸款違約率的眾多模 型中,邏輯斯迴歸是文獻中使用最廣泛的模型。利用邏輯斯迴歸來預測兩個數據 集(Lending Club 和 Prosper 兩平台的歷史數據)中每筆貸款的違約率,實證結果顯 示該模型具有比其他演算法有更好的績效。 Sutrisno & Halim(2017) 使用邏輯斯迴歸和下山單純形法(Nelder-Mead)優化 AUC(曲線下面積)來優化信用評分模型,發現經過優化 AUC 後的模型擁有較 高的 AUC,但 KS-Score 較低。儘管得分較低,還是與原先處於同一類別。即使 優化後的模型表現更好,但該模型仍具有很大的誤差。模型預測結果召回率 (recall)僅有 18.06%,表示可能違約的申請人裡只有 18.06%機率是真實違約,這 代表模型在未違約的狀況下拒絕了分數低於閾值的所有申請人中的 81.94%,銀 行可能會損失許多潛在收入,但可利用深度分析降低風險。 Tsai et al.(2014)嚴格區分具有潛在違約風險的貸款,並將其優化。在相同風 險水平下,模型成果希望減少貸款違約風險並超過 Lending Club 的投資報酬率。 使用修正邏輯斯迴歸、支持向量機、簡單貝氏、隨機森林四種演算法做比較,實 證結果顯示邏輯斯迴歸的績效優於其他三種演算法,提高精確率(Precision)的秘 訣是增加否定因素的影響因子,這樣可以產生更高的精確率,但也相對會降低召 回率(Recall)及準確率(Accuracy)。. 15.
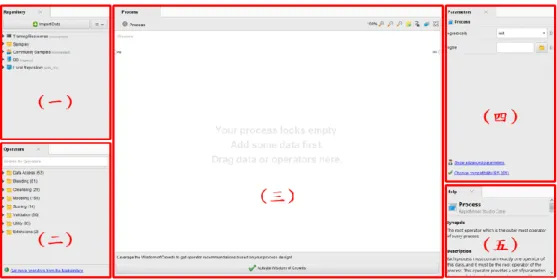
(24) 第三章 研究方法. 第一節 RapidMiner 介紹 RapidMiner 於 2001 年 由 德 國 多 特 蒙 德 技 術 大 學 人 工 智 能 部 門 Ralf Klinkenberg、Ingo Mierswa 和 Simon Fischer 三位學者開發,最初名稱為 YALE (Yet Another Learning Environment)。RapidMiner 經 KDnuggets 調查被評為 2019 年最受歡迎的分析/資料科學/機器學習工具第二名,僅次於 Python。該軟體提供 數據載入和轉換、資料預處理、機器學習、視覺化建模及評估和預測分析等。用 於商業、研究、教育、培訓和應用開發。 RapidMiner 是一個無須編寫程式碼的資料分析工具,僅需將資料載入並拖移 資料與運算式將其連接口連結即可,RapidMiner 涵蓋 1500 多個運算式,擁有豐 富的數據挖掘分析及演算功能。RapidMiner 介面操作相當簡易,如圖 6,介面大 致分為五個區塊,分別為: 一、資料庫(Repository):可將資料數據、模型及績效結果儲存於此,可儲存在本 機(Local Repository)或雲端(Cloud Repository),且此資料庫包含 RapidMiner 所提供的範本(Sample),可利用此數據進行練習。 二、運算式(Operators):內涵多種運算式及機器學習模型,可將運算式拖移至流 程介面進行運算。 三、流程介面(Process):將所有樣本數據及運算式拖移至此,運用其端口進行連 接,即可進行資料分析及預測等工作。 四、參數(Parameters):各運算式的參數設定,操作者可透過更改參數值,將資料 進行更精確之分析,獲得更好的績效。 五、幫助(Help):RapidMiner 提供各運算式的基本介紹、應用及參數設定說明, 其中也包含運算式的例題介紹,讓操作者可以快速了解運算式之用法。. 16.
(25) 圖6 RapidMiner 介面介紹. 第二節 研究樣本說明及資料預處理 本研究使用美國最大 P2P 網路借貸平台-Lending Club 2016 年借貸數據做為 研究樣本來源,樣本取自數據建模及分析平台-Kaggle 之公開資料(https://www. kaggle.com/wendykan/lending-club-loan-data),本樣本包含了借款人貸款相關資 訊、還款現況等 145 個變數,434,387 個觀測值。 將其中 loan_status(貸款狀態)設為目標變數,貸款狀態分為 Current(當前)、 Fully paid(全額付清)、Charged Off(轉呆帳)、In Grace Period(寬限期內)、Late (1630 days)(遲繳 16 天到 30 天)、Late (31-120 days)(遲繳 31 天到 120 天)及 Default(違 約)七種狀態,本研究將貸款狀態變更為雙元變數,Current(當前)及 Fully paid(全 額付清)視為正常還款(false),而其餘貸款狀態則視為廣義的違約(true)。如表 4 所 示。 表 4 顯示合併後觀察值,貸款是否違約之數量及比例,其中違約貸款有 73,873 筆,占 17.0%,而非違約貸款共有 359,596 筆,占 83.0%,屬於不平衡資料 (imbalanced dataset),不平衡資料可能高估預測準確率(Accuracy)及降低模型之召 回率(Recall),因此本研究以創造權重(Generate Weight (Stratification))的方式,改 善對資料不平衡的問題。. 17.
(26) 表4 貸款狀態合併前後分布 貸款狀態 Current Fully paid Charged Off Late (31-120 days) Late (16-30 days) In Grace Period Default. 觀察值 207,810 151,786 66,090 4983 773 2015 12. 比例 47.9% 35.0% 15.2% 1.1% 0.2% 0.5% 0.0%. 合併後觀測值 false true. 觀察值 359,596 73,873. 比例 83.0% 17.0%. 而剩餘 144 個變數設為解釋變數,首先將遺失值大於 80%之變數刪除,再將 剩餘遺失之觀察值予以剔除,而後將資料做初步整理,例如將就業年數變數更改 為數值型態、無銀行卡違約之客戶變數設為 0 等,最後為降低線性重合問題,本 研究將相關性高於 0.7 之變數予以剔除。經資料預處理後剩餘 64 個變數及 433,469 個觀察值。表 5 列出經資料預處理後之變數及相關說明。 表5 樣本變數說明 變數名稱 acc_now_delinq acc_open_past_24mths addr_state all_util annual_inc application_type chargeoff_within_12_mths collections_12_mths_ex_med debt_settlement_flag delinq_2yrs delinq_amnt disbursement_method dti earliest_cr_line emp_length grade hardship_flag home_ownership initial_list_status. 變數說明 借款人現在欠款的帳戶數量。 過去 24 個月內開立的帳戶數量。 借款人提供之州別。 所有交易信貸限額餘額。 自行報告之年收入。 貸款是單獨申請或兩個共同借款人聯合申請。 12 個月內的銷帳次數。 除醫療欠款外 12 個月內的欠款數量。 借款人是否曾有被債務清算。 過去兩年借款人信用檔案中逾期 30 天以上的拖 欠紀錄。 借款人拖欠帳戶以逾期數量。 借款人收取貸款的方法。 債務所得比率。總債務償還總額(不包括房貸和 LC 貸款)除以月收入之比率。 借款人最早信貸額度開始的月份。 目前職位就業年數。 Lending Club(LC)貸款等級。 借款人是否處於困難計劃中。 房屋持有狀態。 是否為初始貸款。 18.
(27) inq_fi inq_last_12m inq_last_6mths int_rate issue_d last_credit_pull_d last_pymnt_amnt last_pymnt_d loan_amnt max_bal_bc mo_sin_old_rev_tl_op mo_sin_rcnt_rev_tl_op mo_sin_rcnt_tl mort_acc mths_since_recent_bc_dlq num_accts_ever_120_pd num_actv_bc_tl num_bc_tl num_il_tl num_tl_90g_dpd_24m open_acc open_acc_6m open_act_il open_il_12m open_rv_12m out_prncp pct_tl_nvr_dlq policy_code pub_rec pub_rec_bankruptcies purpose pymnt_plan recoveries revol_bal revol_util sub_grade term tot_coll_amt tot_cur_bal. 個人財務被查詢次數。 過去 12 個月的信用查詢次數。 借款人 6 個月內信用被查詢之次數。 貸款利率。 貸款獲得資金的月份。 Lending Club 最近一個月查詢信用狀況的時間。 上次收到的付款金額。 上次收到付款的日期。 借款人申請的貸款金額。 所有循環帳戶上的最大當前餘額。 最早的循環帳戶開始以來的幾個月。 最近的循環帳戶開始以來的幾個月。 最近開戶以來的幾個月。 抵押帳戶數量。 最近一次銀行卡違約以來的幾個月。 逾期 120 天或以上的帳戶數量。 當前有效的銀行卡帳戶數。 銀行卡帳戶數量。 分期付款帳戶數量。 過去 24 個月內逾期 90 天或以上的帳戶數量。 借款人信用檔案中的未結信用額度。 過去 6 個月未結清帳戶數量。 當前有效的分期付款交易數量。 過去 12 個月內開設的分期付款帳戶數量。 過去 12 個月內開設的循環交易帳戶數量。 剩餘未償還本金總額。 從未拖欠的交易百分比。 產品是否公開。 詆毀信用數量。 公共記錄破產次數。 貸款目的。 是否已為貸款實施還款計劃。 總回收費用。 貸款帳戶循環使用餘額。 貸款帳戶循環使用率。 LC 貸款等級之次分(subgrade)。 貸款期間。 欠款總額。 所有帳戶的當前總餘額。 19.
(28) total_bal_il total_bc_limit total_cu_tl total_rec_int total_rec_late_fee verification_status. 所有分期付款帳戶的當前總餘額。 總銀行卡最高信用/信用額度。 融資交易數量。 至今收到的利息。 至今收到的滯納金。 年收入是否經過 LC 驗證。. 第三節 變數優化選擇 變數優化選擇(Optimize Selection)採用 2018 年 RapidMiner 白皮書,使用雙 層交叉驗證(Cross-validation),透過基因演算法(Genetic Algorithm)篩選出數據集 中的最佳變數,利用雙層交叉驗證進行模型評估,可使模型預測準確率更高。 第一層交叉驗證變數優化選擇:將數據集之 90%資料隨機抽取 90% (即原始 數據的 81%)資料,以演算法進行訓練(如圖 7 以簡單貝氏演算法作為範例),再將 剩餘資料集做測試,重複 10 次(假設 K=10),找出第一層交叉驗證選擇之最佳變 數。. 圖7 第一層交叉驗證變數優化選擇之流程圖. 20.
(29) 第二層交叉驗證變數優化選擇:將第一層變數優化選擇結果,利用權重選擇 的方式於原始資料中選擇最佳變數進行演算法之訓練,每訓練一次就將訓練結果 在測試集做測試 (測試集為原始數據集剩餘之 10%資料,依照權重選擇與訓練集 相同之變數),重複以上第二層交叉驗證 10 次後,找出最終最佳變數,相關流程 如圖 8 所示。. 圖8 第二層交叉驗證變數優化選擇之流程圖. 第四節 參數最佳化 參數最佳化(Optimize Parameters)同樣採用 2018 年 RapidMiner 白皮書,透過 雙層交叉驗證(Cross-validation)更改參數值並使用指定參數來測量測試誤差的變 化,為數據集找到所選參數的最佳值。雙層交叉驗證在訓練集使用參數最佳化並 利用演算法進行訓練,使模型可求得更高之準確率。 第一層交叉驗證參數最佳化:將數據集之 90%資料隨機抽取 90% (即原始數 據的 81%)資料,以演算法進行訓練(如圖 9 以簡單貝氏演算法作為範例),再將剩 餘資料集做測試,重複 10 次(假設 K=10),因而產生第一層交叉驗證之最佳參數 值結果。. 21.
(30) 圖9 第一層交叉驗證參數最佳化之流程圖 第二層交叉驗證參數最佳化:將第一層參數最佳化結果,利用設定參數運算 式把最佳值進行演算法之訓練,每訓練一次就將訓練結果在測試集做測試 (測試 集為原始數據集剩餘之 10%資料),重複以上第二層交叉驗證 10 次後,將結果平 均即可找出最終參數之最佳值,如圖 10 所示。. 圖10 第二層交叉驗證參數最佳化之流程圖. 22.
(31) 第五節 演算法說明 一、 簡單貝氏(Naïve Bayes) 簡單貝氏又稱為簡單貝葉斯或獨立貝葉斯,它被廣泛用於文字分類及資料探 勘。簡單貝氏可以簡單、快速、準確計算每個樣本的機率,適合處理大量數據, 是一種機率分類器,可利用特徵條件來計算該樣本的機率屬於何種類別,即使特 徵條件互相依賴,但在簡單貝氏下仍是獨立考慮的。 簡單貝氏是基於貝氏定理的統計分類技術。在介紹貝氏定理前要先了解條件 機率,P(A|B)表示在 B 已經發生的前提之下,A 發生的機率,其公式為:. P(A|B) =. Ρ(Α ∩ Β) Ρ(Β). (1). 在平常生活中很常遇到 P(A|B)發生的情況,但很難計算出 P(B|A),像是我們 知道貸款在延遲付款(P(B))發生的情況之下,可以容易計算違約(P(A))的機率,但 假如現在已知貸款已違約(P(A)),會較難計算出延遲付款(P(B))的機率為多少,因 此就可使用貝氏定理計算,其公式為:. P(Β|Α) =. Ρ(Α|Β)Ρ(Β) Ρ(Α). (2). 繼上述例子,可能影響貸款違約因子不只有一項變數,因此可將公式改寫為:. P(Β1 |Α) =. Ρ(Α|Β1 )Ρ(Β1 ) ∑𝑖 Ρ(Α|Β𝑖 )Ρ(Β𝑖 ). (3). 而簡單貝氏是從貝氏定理轉化而成的,假設有一數據集 X 有 i 個解釋變數, Y 為目標變數(Yes or No),而後測試觀察 X 的 i 個解釋變數,Y 的預測值為何。 簡單貝氏有一假設為解釋變數皆互相獨立,彼此互不影響,因此可以推導出以下 公式: 𝑛. P(X|Y𝑗 ) = Ρ(X1 , X2 , … , X𝑖 |Y𝑗 ) = ∏ Ρ(Χ𝑖 |Y𝑗 ) 𝑖=1. 23. (4).
(32) 再將公式(4)套用至貝氏定理公式(3),即可得出簡單貝氏模型,公式如下:. Ρ(Y𝑗 |Χ) =. Ρ(Y𝑗 ) ∏𝑛𝑖=1 Ρ(Χ𝑖 |Y𝑗 ) ∑𝑘𝑘=1[ Ρ(Y𝑗 ) ∏𝑛𝑖=1 Ρ(Χ 𝑖 |Y𝑗 )]. (5). 最後將數據集帶入模型後利用最大後驗機率(MAP)找出最有可能之值,並 考慮到公式(5)的分母值為一樣,因此忽略分母,其最終公式如下: 𝑛. Y = 𝑎𝑟𝑔𝑚𝑎𝑥Ρ(Y𝑗 ) ∏ Ρ(Χ𝑖 |Y𝑗 ). (6). 𝑖=1. 假如使用簡單貝氏模型有機會出現零機率問題,預測出來是 0。後驗機率為 0,會使模型無法預估,因此可使用拉普拉斯變換(Laplace Transform)做修正,將 每一分類增加一個數值,且不會對機率產生影響,即可解決此問題。. 二、 隨機森林(Random Forest) 隨機森林是由 Leo Breiman(2001)所提出,是一種基於決策樹(Decision Tree) 的集合型學習演算法,加入隨機分配的訓練資料,可為數據的隨機子集生成多個 決策樹,有效提高預測的穩健性與準確性,也因隨機性的抽取,相較決策樹更不 容易出現過度擬合(over-fitting),也能夠處理高維度(feature)的資料,且資料集無 需規範,能處理各種型態之資料。 隨機森林演算法的運算過程簡單來說是利用 Bagging (Bootstrap Aggregating) 演算法及決策樹(Decision Tree)演算法結合而形成的,首先 Bagging 演算法每一 輪透過 bootstrap 的方式來得到不同的資料,給定訓練集Χ = 𝑥1 , … , 𝑥𝑛 和目標Y = 𝑦1 , … , 𝑦𝑛 ,以隨機抽取且會放回的方式取得數個樣本,最後把抽取的訓練資料集 合成一個資料集,再利用分類和迴歸樹(Classification and Regression Tree,簡稱 CART)建立一棵樹,而抽取 N 個樣本就會形成 N 棵樹,最後再將 N 棵樹集合在 一起並公平的投票或平均得到最後的結果。圖 11 顯示隨機森林的演算流程。. 24.
(33) 圖11 隨機森林演算流程 Bagging 演算法透過 bootstrap 來形成資料集時,原始的樣本中會有一部分樣 本不會被採集到,這些資料被稱為 OOB(Out-Of-Bag)誤差,OOB 的計算公式如 下: 1 𝑁 (1 − ) = 𝑁. 1 𝑁 ( 𝑁 − 1). 𝑁. =. 1 1 (1 + 𝑁 − 1). 𝑁. ≈. 1 𝑒. (7). 上述公式簡化後大約會有 0.368 的 OOB 值,可以利用 OOB 資料來估計樹的 泛化誤差(Generalization error)及計算單項變數的重要性,也可以利用交叉驗證 (Cross-validation)的方式驗證抽出樣本的好壞。. 三、 邏輯斯迴歸(Logistic Regression) 邏輯斯迴歸最早是由 Ohlson(1980)運用於財務危機預測,邏輯斯迴歸又稱為 邏輯迴歸或對數機率迴歸,是一種對數機率模型(Logit Model),屬於多變量分析 之一,最常用於二元分類問題,判斷某個問題是 1 還是 0 或用於預測在不同解釋 25.
(34) 變數下,發生某種情況的機率大小。邏輯斯迴歸執行速度非常快,也可避免線性 迴歸(Linear Regression)模型中預測機率可能出現大於 1 或小於 0 的問題,線性回 歸是用來預測一個或多個連續的值,利用最小平方法對一個或多個自變數和因變 數之間關係進行建模的一種迴歸分析;而羅吉斯迴歸利用最大概似法(MLE)進行 預測類別型變數。 由於邏輯斯迴歸基於線性模型,利用 sigmoid 函數將 X 映射至(0,1)之間,其 公式為:. F( X ) =. 𝑒𝑋 1 + 𝑒𝑋. (8). 假設數據集的選擇變數為(X1 , X2 , … , Xn ),目標變數 Y 為二項式變數時,事 件成功(Y=1)的機率如下:. Ρ(Y = 1|X) =. 𝑒 𝛽0 +𝛽1 𝑋1 +⋯+𝛽𝑛 𝑋𝑛 1 + 𝑒 𝛽0 +𝛽1 𝑋1 +⋯+𝛽𝑛 𝑋𝑛. (9). 則事件失敗(Y=0)的機率為:. Ρ(Y = 0|X) = 1 − Ρ(Y = 0|X) =. 1 1+. 𝑒 𝛽0 +𝛽1 𝑋1 +⋯+𝛽𝑛𝑋𝑛. (10). 將勝率(ODDS)取自然對數為對數勝率,公式如下:. ln. Ρ(Y = 1|X) = 𝛽0 + 𝛽1 𝑋1 + ⋯ + 𝛽𝑛 𝑋𝑛 1 − Ρ(Y = 1|X). (11). 最後使用最大概似法(MLE)求迴歸係數,其對數概似函數為: 𝑛 𝑦. L(𝛽0 , 𝛽1 ) = ∏ P𝑖 𝑖 (1 − P𝑖 )1−𝑦𝑖 𝑖=1. 26. (12).
(35) 第四章 實證結果. 第一節 最佳變數與參數最佳化 本研究使用 P2P 網路借貸平台-Lending Club 之借款人資訊,此資料包含借 款人個人資訊、個人信用狀況及貸款後之貸款資訊,原始資料共有 2,260,517 筆 觀察值及 145 個變數,經資料預處理後,本研究採用 2016 年 433,469 筆觀察值 及 64 個變數進行分析。 本研究將資料進行三種演算法雙層交叉驗證變數選擇,由於數據及變數過 多,為減少模型執行時間,本研究設定 K 為 3。結果顯示,簡單貝氏利用拉普拉 斯平滑(Laplace Smoothing),最終選出 30 個變數;隨機森林採用 10 棵決策樹、 深度 5 及以獲利比(Gain ratio),在不採用修枝(apply pruning)與事前修枝(apply prepruning)情況下,最終選出 28 個變數;邏輯斯迴歸採用原始設定(default setting) 之參數,包含標準化(standardize)、截距項(add intercept)與刪除線性列(remove collinear columns),最終選出 32 個變數(表 6)。 參數最佳化可增加模型預測準確率,本研究同樣採用 K 為 3 的雙層交叉驗 證進行參數最佳化。由於各演算法所涵蓋參數眾多,最佳化之參數也有所差異, 故本研究皆採用變數選擇之參數進行篩選。表 6 顯示各演算法進行雙層交叉驗證 參數最佳化結果。簡單貝氏最佳參數為 Laplace_correction=true;隨機森林最佳參 數為 Number_of_trees: 10、Criterion: gain_ratio、Maximal_depth: 0、Apply_ pruning: false 、 Apply_prepruning: false ; 邏 輯 斯 迴 歸 最 佳 參 數 為 Solver: IRLSM 、 Reproducible: false、Use_ regularization: false。. 27.
(36) 表6 三種演算法雙層交叉驗證選擇之最佳變數及最佳參數 簡單貝氏 (Naïve Bayes). 最佳 變數. 隨機森林 (Random Forest). 邏輯斯迴歸 (Logistic Regression). 1.home_ownership. 1.loan_amnt. 1.term. 2.annual_inc. 2.term. 2.sub_grade. 3.verification_status. 3.home_ownership. 3.home_ownership. 4.issue_d. 4.issue_d. 4.annual_inc. 5.loan_status. 5.loan_status. 5.verification_status. 6.purpose. 6.pymnt_plan. 6.issue_d. 7.addr_state. 7.purpose. 7.loan_status. 8.dti. 8.dti. 8.purpose. 9.delinq_2yrs. 9.delinq_2yrs. 9.addr_state. 10.inq_last_6mths. 10.open_acc. 10.dti. 11.revol_bal. 11.last_pymnt_d. 11.delinq_2yrs. 12.revol_util. 12.last_pymnt_amnt. 12.inq_last_6mths. 13.total_rec_late_fee. 13.last_credit_pull_d. 13.pub_rec. 14.last_pymnt_d. 14.collections_12_mths_ex_m. 14.revol_bal. 15.last_pymnt_amnt. ed. 15.revol_util. 16.last_credit_pull_d. 15.open_act_il. 16.total_rec_late_fee. 17.collections_12_mths_ex_m. 16.total_bal_il. 17.last_pymnt_d. ed. 17.all_util. 18.last_pymnt_amnt. 18.tot_coll_amt. 18.inq_fi. 19.last_credit_pull_d. 19.open_act_il. 19.acc_open_past_24mths. 20.collections_12_mths_ex_m. 20.total_bal_il. 20.chargeoff_within_12_mths. ed. 21.max_bal_bc. 21.delinq_amnt. 21.tot_coll_amt. 22.inq_fi. 22.mo_sin_old_rev_tl_op. 22.open_act_il. 23.acc_open_past_24mths. 23.mo_sin_rcnt_rev_tl_op. 23.total_bal_il. 24.mo_sin_old_rev_tl_op. 24.mths_since_recent_bc_dlq. 24.max_bal_bc. 25.num_accts_ever_120_pd. 25.num_accts_ever_120_pd. 25.inq_fi. 26.num_actv_bc_tl. 26.num_il_tl. 26.mo_sin_old_rev_tl_op. 27.num_il_tl. 27.pub_rec_bankruptcies. 27.num_accts_ever_120_pd. 28.num_tl_90g_dpd_24m. 28.disbursement_method. 28.num_actv_bc_tl. 29.disbursement_method. 29.num_il_tl. 30.debt_settlement_flag. 30.num_tl_90g_dpd_24m 31.disbursement_method 32.debt_settlement_flag. 1.Laplace_correction: true. 最佳 參數. 1.Number_of_trees: 10. 1.Solver: IRLSM. 2.Criterion: gain_ratio. 2.Reproducible: false. 3.Maximal_depth: 0. 3.Use_regularization: false. 4.Apply_pruning: false 5.Apply_prepruning: false. 28.
(37) 第二節 變數分析 本研究採用 Lending Club 貸款資料,檢視 2016 年開始貸款者在 2016 至 2019 年(2 月)間之還款狀況,評估借款人申請貸款時提供之相關資料,是否可預測該 借款人未來有違約的可能。本研究採用三種演算法雙層交叉驗證選擇結果,選定 至少被兩種演算法涵蓋之最佳變數,檢視其與目標變數間之正負相關性。 為計算相關性,本研究將目標變數以外之所有類別型態變數轉換為以 0 與 1 組成之虛擬變數(dummy variable),並將日期型態變數轉換為以月為單位之期間 (epoch)。轉換後變數共計 49 個,表 7 顯示各變數與目標變數間之相關係數。 表7 最佳變數與目標變數之相關係數 Attributes. loan_status. Attributes. debt_settlement_flag = Y. 0.354. purpose = renewable_energy. 0.001. total_rec_late_fee. 0.145. tot_coll_amt. 0.001. acc_open_past_24mths. 0.117. home_ownership = OWN. 0.000. inq_last_6mths. 0.081. home_ownership = ANY. 0.000. term = 60 months. 0.076. purpose = wedding. -0.001. dti. 0.075. purpose = vacation. -0.002. verification_status = Verified. 0.074. purpose = other. -0.003. home_ownership = RENT. 0.066. purpose = major_purchase. -0.006. inq_fi. 0.064. purpose = car. -0.013. revol_util. 0.037. purpose = home_improvement. -0.019. purpose = debt_consolidation. 0.034. disbursement_method = Cash. -0.027. num_actv_bc_tl. 0.030. issue_d. -0.029. disbursement_method = DirectPay. 0.027. purpose = credit_card. -0.030. purpose = small_business. 0.021. revol_bal. -0.031. num_il_tl. 0.018. annual_inc. -0.037. delinq_2yrs. 0.014. max_bal_bc. -0.052. collections_12_mths_ex_med. 0.013. mo_sin_old_rev_tl_op. -0.057. open_act_il. 0.013. home_ownership = MORTGAGE. -0.064. num_accts_ever_120_pd. 0.011. term = 36 months. -0.076. num_tl_90g_dpd_24m. 0.009. verification_status = Not Verified. -0.079. total_bal_il. 0.008. last_credit_pull_d. -0.218. purpose = house. 0.007. last_pymnt_amnt. -0.249. purpose = moving. 0.005. last_pymnt_d. -0.284. verification_status = Source Verified. 0.004. debt_settlement_flag = N. -0.354. purpose = medical. 0.002. 29. loan_status.
(38) 本研究將借款人提供之資料分為個人資訊及信用紀錄兩類分析如下:. 一、 個人資訊變數分析 表 7 中貸款期間(term)為 60 個月與貸款違約(loan_status)呈現正相關(0.076), 反之,期間為 36 個月呈現負相關(-0.076),與 Dorfleitner & Oswald(2016)結果一 致,貸款期間愈長借款人違約風險愈大。而借款人年收入(annual_inc)愈高,貸款 違約風險愈低(相關係數為-0.037),另外,借款人自行報告之年收入是否經過驗證 (verification_status),結果發現有經過驗證之年收入(verification_status=Verified、 verification_status =Source Verified)皆呈現正相關(0.074、0.004),反之,無經過驗 證之年收入(verification_status=Not Verified)呈現負相關(-0.079),與預期不符,這 或許反映貸款機構進行貸款審核時,對於風險較高之借款人才進行驗證,該類風 險較高者之違約風險自然較高。 借 款 人 申 請 貸 款 目 的 (purpose) 各 演 算 法 皆 有 選 出 , 其 中 債 務 整 合 (debt_consolidation)與小型企業貸款(small_business)與貸款違約之間有較高的正 相關(0.034、0.021),而信用卡(credit_card)與房屋裝潢(home_improvement)則有負 相關(-0.03、-0.019)。其中債務整合或屬再融資,表示借款人利用所貸款之資金進 行其他債務還款,實質上只是將債務移轉至 Lending Club,但還款狀況可能不佳。 而小型企業貸款資金用途廣,本身風險較高,與預期相符。另外,借款人將所貸 款之資金繳付信用卡則違約風險較低,根據 Financial Advisory 統計,美國信用卡 循環利率平均為 6.9%至 23.9%,而 Lending Club 貸款利率平均為 12.74%,客戶 可有效降低利息支出。最後將貸款資金運用在房屋裝潢未來有較低之違約風險, 或許反映有房屋資產者,會違約風險的可能性相對較低。. 二、 個人信用紀錄之變數分析 表 7 顯示借款人 曾有債務清算(debt_settlement_flag=Y) 呈現最高正相關 (0.354),反之,無債務清算者(debt_settlement_flag=N)呈現負相關(-0.354),表示 借款人只要有被債務清算之紀錄,貸款違約風險可能極高。另一變數為借款人每 月總債務償還金額(不包括房貸及 Lending Club 貸款)除以月收入之比率(dti)呈現 正相關(0.075),借款人每月償還金額愈接近月收入時,償債能力愈低,而導致違 30.
(39) 約風險上升,顯示每月償還金額占所得比過多之借款人較不適合再提供貸款。 此外,借款人之房屋持有狀況為租賃(home_ownership=RENT)呈現正相關 (0.066) , 表 示 無 資 產 之 借 款 人 違 約 風 險 高 , 而 房 屋 持 有 狀 況 為 抵 押 貸 款 (home_ownership= MORTGAGE)呈現負相關(-0.064),雖然借款人有抵押房屋貸 款,但意味其已有一定的信用條件,因此貸款違約風險較低。 而借款人在過去 24 個月開戶次數(acc_open_past_24mths)、6 個月內信用被 查詢之次數(inq_last_6mths)、個人財務被查詢次數(inq_fi)過多,違約機率將會提 高(相關係數為 0.117、0.081、0.064),表示借款人在短時間內開立太多帳戶可能 會有洗錢的疑慮,又或者借款人可能在其他多個管道進行申貸 (當借款人進行貸 款申請時被婉拒,在短時間內又重複申請,表示資金需求迫切),因而違約風險會 相對較高,與預期結果相符。 最後,借款人之貸款帳戶循環使用率(revol_util)愈高、貸款帳戶循環使用餘 額(revol_bal)愈低,且所有循環帳戶中積欠的最大餘額(max_bal_bc)愈低及最早開 立循環帳戶的時間(mo_sin_old_rev_tl_op)愈早,貸款違約風險高(相關係數為 0.037、-0.031、-0.052、-0.057),表示借款人已有高度循環使用之其他貸款,可能 無法再負擔多餘之貸款,貸款機構可考慮不再放貸給該類借款人,進而降低貸款 違約風險。 另外值得一提的是在表 7 中也顯示貸款發生後的相關資訊,顯示距離上次繳 款時間(last_pymnt_d)愈近以及償付之金額(last_pymnt_amnt)愈多,借款人愈不會 違 約 ( 相 關 係 數 為 -0.254 、 -0.249) , 反 之 , 借 款 人 延 遲 付 款 且 產 生 滯 納 金 (total_rec_late_fee)愈多,貸款違約風險就愈大(相關係數為 0.145),這與常理相符。 最後,表 7 顯示 Lending Club 最近一個月查詢信用狀況的時間(last_credit_pull_d) 愈近,違約風險會降低(相關係數為-0.218),由於此變數樣本相當不平衡(絕大部 分在 2019 年 1 月被查詢),本研究不予分析。 綜合上述,本研究研究結果顯示貸款期間、年收入、貸款目的、是否曾有債 務清算、債務所得比率、房屋持有狀況、過去 24 個月開戶次數、6 個月內信用被 查詢次數、貸款帳戶循環使用率、貸款帳戶循環使用餘額、循環帳戶中積欠的最 31.
(40) 大餘額、最早開立循環帳戶時間及個人財務被查詢次數為影響貸款違約主要變 數,而過去也有許多學者同樣使用 Lending Club 數據尋找影響違約的因素,雖然 過去研究多僅對部分變數進行分析,但結果與本研究仍有一定相同處,例如, Emekter et al.(2015)發現信用等級、債務所得比率、FICO 分數和循環額度影響借 貸違約最為關鍵;而 Jin & Zhu(2015)則發現貸款期間、年收入、貸款金額、債務 所得比率、信用等級和循環額度為貸款違約的決定因素。. 第三節 模型準確率、精確率及召回率 模 型 準 確 率 (Accuracy) 為 樣 本 進 行 各 演 算 法 後 之 準 確 度 , 計 算 公 式 為 (TP+TN)/(TP+TN+FP+FN);模型精確率(Precision)為抓出可能違約的客戶中,為 真正違約的客戶比重,計算公式為 TP/(TP+FP);模型召回率(Recall)為抓出違約 客戶中正確抓出的比重,計算公式為 TP/(TP+FN);F1-score 為測量準確性的標準 之一,利用精確率與召回率的調和平均數進行衡量,計算公式為 (2*Precision*Recall)/(Precision+Recall)。表 8 顯示混淆矩陣(Confusion Matrix)。 表8 混淆矩陣 預測違約. 預測非違約. 實際違約. True Positives (TP). False Negatives (FN). 實際非違約. False Positives (FP). True Negatives (TN). 表 9 顯示三種驗算法利用雙(單)層交叉驗證之變數選擇及參數最佳化後模型 準確率、精確率及召回率,無論使用雙(單)層交叉驗證,各演算法都有相當高且 數值相近的準確率,其中隨機森林準確率 92.66%(94.71%)為最高。利用雙層交叉 驗證之變數選擇及參數最佳化後,模型準確率雖比單層交叉驗證低,與預期相符, 以雙層交叉驗證的方式選擇變數及參數最佳化可擁有可信度更高之預測結果。而 本研究參考 Ye et al.(2018)使用參數最佳化,研究結果顯示此方法可以改善模型 預測準確率。 由於隨機森林與邏輯斯迴歸兩種演算法無法利用權重處理資料不平衡問題, 本研究因此採用閥值(threshold)調整方式處理該兩種演算法資料不平衡問題,以 32.
(41) 避免高估準確率。表 9 顯示三種演算法的精確率、召回率與調和平均值(F1-score) 皆接近 90%,其中隨機森林的表現最佳,表示此模型最能夠準確的找出可能違約 的客戶。 表9 三種演算法單、雙層交叉驗證之模型準確率、精確率及召回率 簡單貝氏. 隨機森林. 邏輯斯迴歸. 準確率. 86.51%. 92.66%. 91.16%. 精確率. 84.05%. 93.09%. 93.54%. 召回率. 90.12%. 92.16%. 88.41%. F1-score. 86.98%. 92.62%. 90.90%. 準確率. 89.59%. 94.71%. 92.02%. 精確率. 86.88%. 98.49%. 94.45%. 召回率. 93.27%. 90.82%. 89.28%. F1-score. 89.96%. 94.50%. 91.79%. 雙層交叉驗證. 單層交叉驗證. 第四節 模擬預測 本節利用預測準確率最高之隨機森林模型,分別針對 2015 及 2017 年貸款資 料進行違約風險之模擬預測。圖 12 顯示 2015 年部分模擬預測結果,資料共 21,340 筆,當可信度(confidence(yes))大於閥值(threshold=0.25)時,預測結果(prediction (loan_status))會顯示為 true,反之,則會顯示為 false。圖 13 顯示 2015 年模擬預 測結果之混淆矩陣,整體預測準確率為 86.31%,且精確率與召回率與模型預測 結果相近(80.26%、96.33%)。圖 14 顯示 2017 年部分模擬預測結果,資料共 442,009 筆,同樣使用 threshold 為 0.25 之閥值進行預測。圖 15 顯示 2017 年模擬預測結 果之混淆矩陣,整體預測準確率為 90.94%,且精確率與召回率也達 96.82%、 84.65%,由於 2017 年貸款資料至 2019 年 2 月貸款時間較短,貸款違約之筆數相 對較低,可能高估其準確率,但模型還是有一定之參考價值,因此可供貸款機構 作為預測違約風險之參考標準。. 33.
(42) 圖12 2015 年資料使用隨機森林模型之預測結果. 圖13 2015 年資料使用隨機森林模型預測結果之混淆矩陣. 圖14 2017 年資料使用隨機森林模型之預測結果. 圖15 2017 年資料使用隨機森林模型預測結果之混淆矩陣 34.
(43) 第五節 研究限制 本研究檢視 2016 年開始貸款者在 2016 至 2019 年(2 月)間之還款狀況,由於 絕大部分貸款期間(36 或 60 個月)尚未結束,將無法完整判斷該筆貸款之違約狀 態。建議未來使用此數據進行分析時,如可能可以採用貸款之完整期間,使模型 分析更加穩健,而本研究將貸款狀態為遲繳(Late)或在寬限期內(In Grace Period) 之顧客算為違約狀態,實際上此貸款尚未成為呆帳或違約,建議未來研究可將此 類型客戶予以剃除。此外,模型中各運算式參數之類別相當多,如何選擇那些參 數進行最佳化,可能會對預測準確率有所影響。最後,本研究建立模型時,使用 包括貸款發生前與發生後借款人全部的資訊,但由於貸款機構在審查時並無借款 人借款發生後的資訊,這可能會造成誤判,建議未來研究可僅使用貸款發生前之 借款人資訊評估模型,使貸款機構可在不高估準確率情況下決定是否放貸。. 35.
(44) 第五章 結論. 金融科技在近年來成為國際間最熱門的詞彙之一,其中又以 P2P 網際借貸 平台最為熱門。P2P 網路借貸平台是藉由「微型借貸」、「共享經濟」與「群眾 募資」結合而形成的一種新型替代性金融服務。而 P2P 網路借貸平台即是扮演雙 方的仲介角色,意味著這些過程皆不經過金融機構,也相對銀行來說需要承擔較 高的違約風險。因此本研究嘗試使用美國最大 P2P 網路借貸平台-Lending Club 之 歷史數據進行分析,並使用 RapidMiner 資料探勘平台進行建模,採用簡單貝氏、 隨機森林及邏輯斯迴歸三種演算法預測違約風險,有別於過去研究,在過程中加 入雙層交叉驗證之變數選擇及參數最佳化等,以求得更客觀之預測結果。 研究結果顯示使用雙層交叉驗證進行變數選擇及參數最佳化之模型準確率 比單層交叉驗證低,此與預期相符,使用雙層交叉驗證可以使模型不高估準確率, 擁有更客觀之預測結果。其中隨機森林的準確率為最高,達 92.66%。而各演算 法使用雙層交叉驗證變數選擇之結果不盡相同,本研究將同時出現在兩種演算法 以上之變數與目標變數進行相關性分析,從而提供以下建議,供貸款機構進行貸 款審核時之參考。 1.. 本研究以 Lending Club 來看,借款人選擇較短之貸款期間(36 個月)為佳,但 同時也需注意到借款人之年收入狀況。. 2.. 借款人申請貸款之目的為債務整合與小型企業貸款將有高違約風險,貸款機 構在進行審核時必須多加留意。而申請目的為信用卡與房屋裝潢有較低的違 約風險,貸款機構可多放貸給該類型之借款人。. 3.. 當借款人曾有債務清算之紀錄,貸款違約風險相當高,建議貸款機構在進行 信用評估時,可將借款人是否有債務清算紀錄納入主要衡量標準。. 4.. 當借款人每月償還金額愈接近月收入時,償債能力愈低,而導致違約風險上 升,表示每月償還金額占所得比過高之借款人較不適合再提供貸款。. 36.
(45) 5.. 房屋持有狀況為租賃之借款人違約風險高,表示無房屋資產之客戶須更謹慎 地審核,而持有狀況為抵押房屋貸款時,意味其已有一定的信用條件,因此 貸款違約風險較低。. 6.. 借款人在過去 24 個月內開太多帳戶及被查詢信用狀況次數太多,違約機率 相對較高。表示借款人在短時間內開立太多帳戶可能會有洗錢的疑慮,又或 借款人在短時間內申請貸款太多次(可能反映個人信用狀況不佳才多次遭拒 絕),貸款機構對該類貸款者需多加留意。. 7.. 借款人之貸款帳戶循環使用率愈高及及循環使用餘額愈低時,皆有較高之違 約風險。表示借款人已有高度循環使用之其他貸款,可能無法再負擔多餘之 貸款,貸款機構可考慮不再放貸給該類借款人,進而降低貸款違約風險。 最後本研究使用模型準確率最高之隨機森林模型,針對 2015 及 2017 年資料. 進行違約風險之模擬預測,預測準確率達 86.31%及 90.94%,其結果可提供貸款 機構在審核貸款時之參考。. 37.
(46) 參考文獻. 一、 中文文獻 王志瑋(2018)。銀行業因應網路借貸發展的策略之個案研究(未出版之碩士論 文)。國立臺灣科技大學,臺北市。 王明俐(2018) 。台灣 P2P 網路借貸影響因素之探討(未出版之碩士論文) 。淡江 大學,新北市。 梅驊(2016)。全球 P2P 網路借貸現況與台灣發展趨勢探討(未出版之碩士論 文)。國立臺灣科技大學,臺北市。 曾俐雯(2017)。P2P lending 貸款特性對違約機率之影響─以 Zopa 為例(未出 版之碩士論文)。國立臺灣大學,臺北市。 趙毓馨(2015)。群眾募資法制之研究- 以 P2P 借貸及股權模式群眾募資平台為 中心(未出版之碩士論文)。國立政治大學,臺北市。. 二、 外文文獻 Chen, D., & Han, C. (2012). A Comparative Study of online P2P Lending in the USA and China. Journal of Internet Banking and Commerce, 17(2), 1-15. Dong, G., Lai, K. K., & Yen, J. (2010). Credit scorecard based on logistic regression with random coefficients. Procedia Computer Science, 1(1), 2463-2468. Dorfleitner, G., & Oswald, E. M. (2016). Repayment behavior in peer-to-peer microfinancing: Empirical evidence from Kiva. Review of Financial Economics, 30, 45-59. Duarte, J., Siegel, S., & Young, L. (2012). Trust and Credit: The Role of Appearance in Peer-to-peer Lending. The Review of Financial Studies, 25(8), 2455-2484. Emekter, R., Tu, Y., Jirasakuldech, B., & Lu, M. (2015). Evaluating credit risk and loan performance in online Peer-to-Peer (P2P) lending. Applied Economics, 47(1), 5470. Ghatge, A. R., & Halkarnikar, P. P. (2013). Ensemble Neural Network Strategy for Predicting Credit Default Evaluation. International Journal of Engineering and 38.
(47) Innovative Technology, 2(7), 223-225. Guo, Y., Zhou, W., Luo, C., Liu, C., & Xiong, H. (2016). Instance-based credit risk assessment for investment decisions in P2P lending. European Journal of Operational Research, 249(2), 417-426. Jin, Y., & Zhu, Y. (2015). A Data-Driven Approach to Predict Default Risk of Loan for Online Peer-to-Peer (P2P) Lending. 2015 Fifth International Conference on Communication Systems and Network Technologies, 609-613. Li, S., Qiu, J., Lin, Z., & Qiu, J. (2011). Do borrowers make homogeneous decisions in online P2P lending market? An empirical study of PPDai in China. International Conference on Service Systems and Service Management, 11, 1-6. Lin, M., Prabhala, N., & Viswanathan, S. (2009). Judging Borrowers by the Company They Keep: Friendship Networks and Information Asymmetry in Online Peer-toPeer Lending. Management Science, 59(1), 15-35. Malekipirbazari, M., & Aksakalli, V. (2015). Risk assessment in social lending via random forests. Expert Systems with Applications, 42(10), 4621-4631. Pan, S., & Zhou, S. (2019). Evaluation Research of Credit Risk on P2P Lending based on Random Forest and Visual Graph Model. Journal of Visual Communication and Image Representation. Ramcharan, R., & Crowe, C. (2013). The Impact of House Prices on Consumer Credit: Evidence from an Internet Bank. Journal of Money, Credit and Banking, 45(6), 1085-1115 Serrano-Cinca, C., Gutiérrez-Nieto, B., & López-Palacios, L. (2015). Determinants of Default in P2P Lending. PloS one, 10(10). Sutrisno, H., & Halim, S. (2017). Credit Scoring Refinement Using Optimized Logistic Regression. 2017 International Conference on Soft Computing, Intelligent System and Information Technology, 26-31. Tsai, K., Ramiah, S., & Singh, S. (2014). Peer Lending Risk Predictor. Vedala, R., & Kumar, B. R. (2012). An application of Naive Bayes classification for credit scoring in e-lending platform. 2012 International Conference on Data Science & Engineering, 81-84. Vinod-Kumer, L., Natarajan, S., Keerthana, S., Chinmayi, K. M., & Lakshmi, N. (2016). Credit Risk Analysis in Peer-to-Peer Lending System. 2016 IEEE International Conference on Knowledge Engineering and Applications, 193-196. Ye, X., Dong, L. A., & Ma, D. (2018). Loan evaluation in P2P lending based on Random 39.
數據

相關文件
This study first uses the nine indicators of current domestic green architecture to examine those items needed to be considered in the air force base.. Then this study,
In this study, we took some elementary schools located in Taichung city as samples to analyze the quality properties of academic administration services from the perspective
Through the enforcement of information security management, policies, and regulations, this study uses RBAC (Role-Based Access Control) as the model to focus on different
This study uses data envelopment analysis to investigate the main technology develop- ment evaluation models adopted by Asian (Taiwan, Japan, Korea, Singapore, and Mainland
The purpose of this study is to analyze the status of the emerging fraudulent crime and to conduct a survey research through empirical questionnaires, based on
In this study, teaching evaluation were designed to collect performance data from the experimental group of students learning with the “satellite image-assisted teaching
Therefore, this study uses Mainland Chian tourist as survey respondent to explore the relationships among store expertise, shopping satisfaction and share of wallet.. The study
Therefore, this study aims to analyze a manufacturer's competitiveness from the viewpoints of cold chain equipment manufacturers through a case the with five forces
