國 立 交 通 大 學
電 信 工 程 學 系
碩 士 論 文
整合前向錯誤控制於
多重敘述語音播放排程之研究
Adaptive Joint Playout Buffer And FEC Adjustment
For Multi-Stream Voice Over IP Networks
研究生:張永樂
指導教授:張文輝博士
整合前向錯誤控制於
多重敘述語音播放排程之研究
Adaptive Joint Playout Buffer And FEC Adjustment
For Multi-Stream Voice Over IP Networks
研 究 生 : 張 永 樂 Student:Yung-Le Chang 指導教授 : 張 文 輝 Advisor:Wen-Whei Chang 國立交通大學 電信工程學系 碩士論文 A Thesis
Submitted to Department of Communication Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of Requirements
for the Degree of
Master of Science
in Communication Engineering
June 2009
Hsinchu, Tainwan, Republic of China 中華民國 九十八 年 六 月
整合前向錯誤控制於
多重敘述語音播放排程之研究
學生:張永樂 指導教授:張文輝 博士
國立交通大學電信工程學系碩士班
中文摘要
本論文所提出的多重敘述語音傳輸系統,是將音框編碼輸出的參 數以兩個封包分別傳送,以期利用互相獨立的傳輸路徑提升其音框播 放品質。為了準確反應多重敘述傳輸的音框回復品質,我們根據 E 模 型提出一新的音質預測模型,其主要概念是區隔單一或雙重封包的接 收狀態並加以適度整合。進一步以此音質預測模型作為多重敘述傳輸 系統的發展平台,整合設計其播放排程與前向錯誤控制,以期依網路 環境的時變特性適應性地調整其系統參數。系統模擬証實,新的音質 預測模型更為接近主觀聽覺測試結果,我們提出的多重敘述傳輸系統 能有效對抗封包漏失並輸出最佳音質。
Adaptive Joint Playout Buffer And FEC Adjustment
For Multi-Stream Voice Over IP Networks
Student: Yung-Le Chang Advisor: Dr. Wen-Whei Chang
Department of Communications Engineering
National Chiao Tung University
Abstract
Packet loss and delay are two essential problems to real-time voice transmission over IP networks. In the proposed system, multiple descriptions of the speech are transmitted to take advantage of largely uncorrelated delay and loss characteristics on different network paths. Adaptive joint playout buffer and FEC adjustment of multiple voice streams is formulated as an optimization problem leading to a better delay-loss tradeoff. The basic strategy is a perceptually motivated optimization criterion based on a modified ITU-T E-model for multiple-stream transmission . Experimental results show that the proposed multi-stream voice transmission system improves the delay-loss tradeoff as well as speech reconstruction quality.
誌謝
兩年的研究生涯當中,首先要感謝指導教授張文輝老師的細心指 導,在研究與課業上引領我正確的研究態度及學習方向,並使我體認 到做研究時所需具備的嚴謹,除此之外,當我在研究上遇到挫折及瓶 頸時,老師也總是耐心地在旁協助並給予鼓勵支持,幫助我順利完成 碩士論文。也要感謝實驗室朋友們在學業上與研究上的諸多協助,尤 其是吳俊鋒學長不厭其煩地與我討論並提供研究上的建議。另外也要 特別感謝室友張致遠同學在這段期間給予我精神上的鼓勵。最後要感 謝母親及家人的支持,讓我能無後顧之憂地完成碩士班學業。目錄
中文摘要 ... i 英文摘要 ... ii 誌謝 ... iii 目錄 ... iv 圖目錄 ... vii 表目錄 ... viii 第一章 緒論 ...1 1.1 前言 ...1 1.2 研究動機...2 1.3 章節概要...4 第二章 多重敘述的音質預測模型 ...5 2.1 通話品質預測模型 ...5 2.1.1 主觀聽覺測試... 6 2.1.2 音質評量指標... 7 2.2 多重敘述語音編碼系統...13 2.2.1 MD-AMR編碼器 ...13 2.2.2 MD-AMR解碼器 ...152.2.3 MD-G.729a編碼器 ...18 2.2.4 MD-G.729a解碼器 ...20 2.3 多重敘述編碼的Ie音質預測模型...23 2.4 音質損害預測模型的整合...30 第三章 聽覺最佳化的適應性播放排程設計 ...32 3.1 播放緩衝器...33 3.2 晚到漏失機率模型 ... 37 3.3 MD傳輸系統的播放排程設計 ...40 3.3.1 以低延遲為考量的設計 ...40 3.3.2 音質最佳化的設計 ...42 第四章 結合前向錯誤控制的MD傳輸系統 ...47 4.1 封包漏失回復機制 ... 47 4.2 前向錯誤控制 ...49 4.3 結合FEC的MD傳輸系統 ...55 4.3.1 Reed Solomon(RS)碼 ...55 4.3.2 叢發性封包漏失的回復機率推導 ...57 4.4 整合漏失回復後的MD音質損害模型 ...60 4.5 MD封包傳輸系統的最佳化設計 ...68 第五章 實驗結果 ...70
5.1 Ie音質預測模型的驗證 ...70 實驗一:驗證新的Ie模型...70 實驗二:語音檔經MD和SD傳輸之下的音質比較 ...73 5.2 MD播放排程演算法... 75 實驗一:固定和動態設計的安全因子效能比較 ...76 實驗二:以不同考量(低延遲或音質)設計的MD播放排程比較 ...78 實驗三:相同編碼效率下,MD與SD傳輸的比較 ...80 實驗四:結合FEC的MD播放排程 ...82 實驗五:動態調整FEC與固定FEC的MD播放排程比較... 84 實驗六:動態調整FEC於MD和SD傳輸的比較 ...90 第六章 結論與未來展望...93 參考文獻 ...95
圖目錄
圖 2.1 R與MOS的轉換關係 ...9 圖 2.2 MD解碼 ...24 圖 2.3 封包經MD解碼後分屬兩種不同的語音編碼輸出 ...24 圖 2.4 尋找新I 模型的實驗流程 ...e 28 圖 2.5 MD-G.729A編碼的音質損害因子 ... 29 圖 2.6 MD-AMR編碼的音質損害因子 ...29 圖 3.1 播放緩衝器的影響 ...34 圖 3.2 平均延遲為 240MSEC 的累積分佈函數 ...39 圖 3.3 平均延遲為 55MSEC 的累積分佈函數圖形 ...39 圖 3.4 MD傳輸系統 ...46圖 4.1 MEDIA SPECIFIC FEC...52
圖 4.2 冗餘資訊以多個封包產生 ...52 圖 4.3 RS編碼過程 ...53 圖 4.4 FEC機制下的封包傳送與接收 ...54 圖 4.5 同位碼回復錯誤的過程 ...54 圖 4.6 吉伯特模型 ...57 圖 4.7 FEC回復情形 ...62 圖 4.8 結合FEC的MD傳輸系統... 69 圖 5.1 固定與動態調整β 效能比較... 76 圖 5.2 MD播放排程演算法效能比較 ...78 圖 5.3 MD與SD加上固定FEC RS(9,8)效能比較 ...80
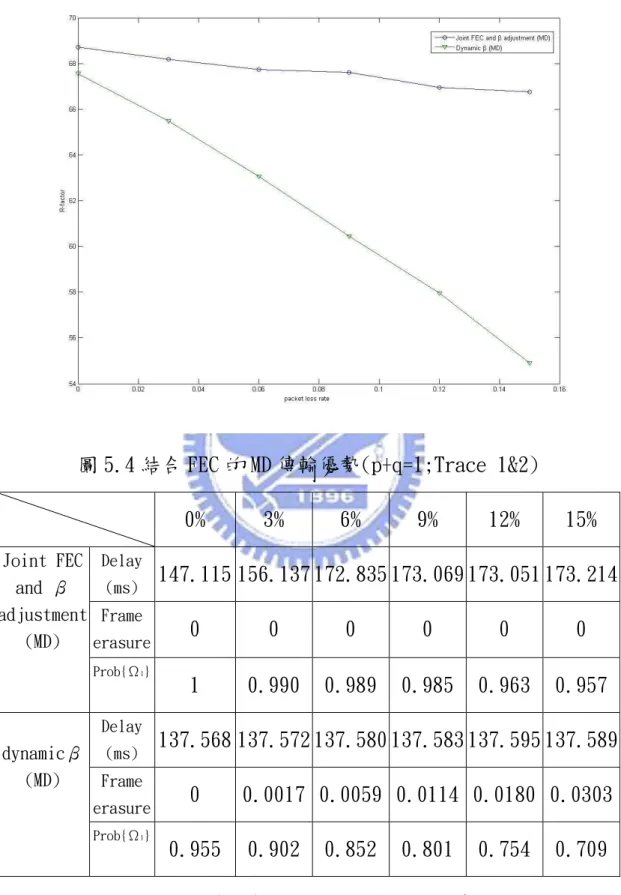
圖 5.4 結合FEC的MD傳輸優勢(P+Q=1;TRACE1&2) ...82
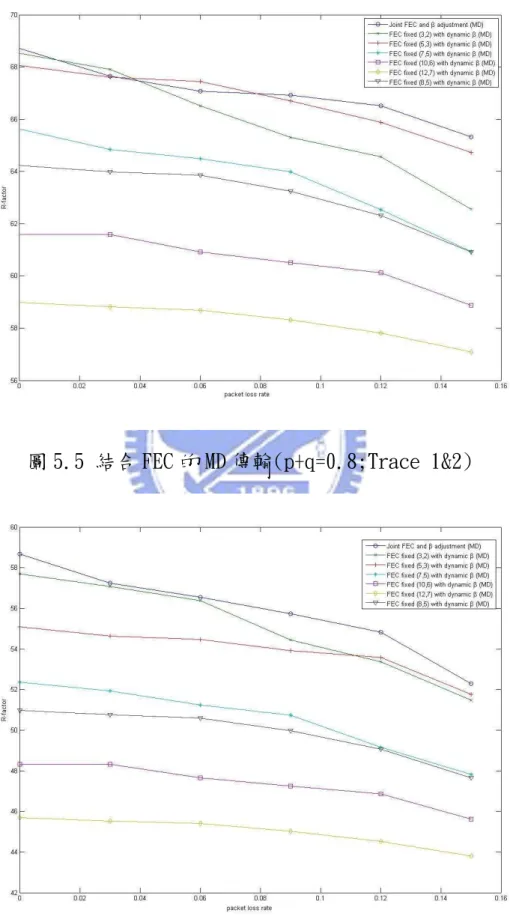
圖 5.5 結合FEC的MD傳輸(P+Q=0.8;TRACE1&2) ...84
圖 5.6 結合FEC的MD傳輸(P+Q=0.8;TRACE3&4) ...84
圖 5.7 結合FEC的MD傳輸(P+Q=0.3;TRACE1&2) ...85
圖 5.8 結合FEC的MD傳輸(P+Q=0.3;TRACE3&4) ...85
圖 5.9 結合FEC的SD傳輸系統... 91
表目錄
表 2.1 R與MOS的對應關係... 9 表 2.2 AMR-WB編碼輸出及位元對照表... 16 表 2.3 MD-AMR編碼輸出及位元對照表... 17 表 2.4 G.729A編碼輸出及位元對照表...21 表 2.5 MD-G.729A編碼輸出及位元對照表...22 表 2.6 I 模型參數... e 27 表 2.7 語音檔內容 ...27 表 3.1 網路延遲的累積分佈函數 ...37 表 4.1 ARQ VS.FEC...49 表 5.1 實驗語音檔內容 ...70 表 5.2 音質預測模型的驗證 ...71 表 5.3 音框經由MD與SD傳輸效能比較 ... 73 表 5.4 網路延遲(單位:MS) ...75 表 5.5 收到兩條串流比例(PROB{Ω1})的比較(固定與動態調整β ) ...76 表 5.6 整體延遲的比較(固定與動態調整β )... 77 表 5.7 收到兩條串流比例(PROB{Ω1})的比較(低延遲或音質考量) ...78 表 5.8 整體延遲的比較(低延遲或音質考量)... 79 表 5.9 對照圖(5.4),接收端音質相關數據的比較... 82 表 5.10 對照圖(5.7),整體延遲(MS)與回復後FER的比較 ...86第一章
第一章
第一章
第一章
緒論
緒論
緒論
緒論
1.1
1.1
1.1
1.1 前言
前言
前言
前言
近年來由於網際網路的盛行以及日益增加的傳輸頻寬,於是 進一步思考網路除了取得所需的數據文字資料外,是否可以作為彼此 傳遞語音訊息的工具。因此新一代的網路環境便將多媒體的傳輸納入 設計考量,其中影音及資料的整合是未來通訊傳輸的主要潮流,而網
路電話(Voice over IP, VoIP)即為其衍生的應用服務。低廉的通話
費用以及具彈性的附加應用,造成使用者人數逐年增加且有取代傳統
電話的趨勢。針對相關技術的研發與創新,以及此應用平台所衍生出
新問題的探討,更成為業界及學術界研究發展的重要課題,其主要目
標是提昇語音品質且達到即時(real-time)傳送的效果。而將語音結
合於資料傳輸為主的網路之最大困難點,在於語音封包傳輸模式所衍
生的通話延遲(delay),延遲擾動(delay jitter)以及封包漏失率
(packet loss rate),構成了嚴重影響網際網路語音通訊品質的損害
要素。為了補償延遲擾動,一具體可行方案是在接收端的應用層
(application layer)中加入一播放緩衝器(playout buffer),彈性
調整每個語音封包的播放時間(playout time)。雖然這種方式會增加
封包的整體延遲,但也相對降低了晚到封包漏失的機率。因此,在語
之間存在一個最佳化權衡的問題,此即為語音封包播放排程研究的重 要課題。若排定一個較晚的播放時間,將提高封包播放的機率而降低 封包漏失率,但也相對衍生較高的緩衝延遲[1][2]。而為了抵抗封包 漏失,主要的方法是在傳送端引入前向錯誤控制(Forward Error Control, FEC)[3][4][5],而其原理是在傳輸原始封包的同時附加額 外保護資訊,接收端可以利用這些額外資訊來回復漏失的封包。問題 是由於接收端必須收到原始及額外資訊,才能透過 FEC 解碼機制回復 可能漏失的封包,所以不可避免地將為整個傳輸系統帶來額外的延 遲。因此 FEC 雖然可以有效降低封包漏失率,但卻也無形中帶來更多 的延遲損害。另外,一旦封包發生叢發性網路漏失,將很有可能接收 端同時無法正確接收原始及額外資訊,使得 FEC 無法發揮其封包回復 的能力。有鑑於此,近年來有學者提出多重敘述編碼技術(Multiple Descriptions Coding, MDC)[6][7],其主要概念是將音框所屬的編 碼參數分成兩個封包再傳送於互相獨立的傳輸路徑,透過接收到的單 一封包來補償另一漏失封包的部分資訊,因此可以在不需增加整體延 遲的情況下,有效地提昇其音框播放品質。
1.2
1.2
1.2
1.2 研究動機
研究動機
研究動機
研究動機
在前人研究[6],多重敘述播放排程設計是將整體延遲、單一及 雙重封包漏失率透過特定參數加權整合成一成本函數,再依此函數隨
著網路環境變化適應性地調整其系統參數。然而其做法並未將延遲及 封包漏失所造成的音質損害因子納入考量,而且也沒有考慮到不同封 包接收情況所對應的音框回復音質差異。針對此問題,我們參考[7] 的 MD 語音編碼方式,應用 G.729a[8]和 AMR-WB[9]兩種編碼標準,基 於聽覺最佳化的考量,將延遲及封包漏失音質損害因子納入成本函數 來設計多重敘述傳輸系統。但這又衍伸出一項問題,由於 ITU-T 音質 預測模型[10]原是針對單一敘述傳輸系統而設計,並無法精準預測多 重敘述傳輸下的音框重建品質,所以為了設計出更有效率的 MD 傳輸 系統,就必須另尋能精準預測音質的模型。因此,我們先分別探討單 一及雙重封包接收狀態下的音框輸出音質,並建立可反應此兩種封包 接收狀態的音質預測模型。透過此兩種接收狀態的相對比例對其加權 整合,進而提出一個適用於 MD 傳輸系統的封包漏失及語音編碼音質 損害的預測模型,接著再以此音質預測模型為發展平台來設計多重敘 述傳輸系統。而為了能更有效地抵抗封包漏失損害,我們引入前向錯 誤控制於 MD 傳輸系統中,並針對叢發性漏失的網路環境,推導封包 於 MD 傳輸架構下的 FEC 回復機率及其回復後的音質損害。再基於推 導結果,適應性地整合設計 MD 傳輸系統中播放排程與 FEC 的調整機 制。其主要想法是結合 FEC 及 MD 的封包回復能力,透過 MD 的編碼方 式可減少 FEC 所需的保護位元總量,並有效降低結合 FEC 所衍生的額
外延遲。至於 FEC 的適應性調整機制,同時考量當前的網路環境(封 包漏失、網路延遲),並在權衡整體延遲(包含 FEC 的額外延遲)、單 一及封包接收狀態及封包雙重漏失之間的得失之後,選擇出最佳的系 統傳輸參數,因此我們所提出結合 FEC 的 MD 傳輸系統,具備動態反 應網路傳輸環境變化的音框回復能力。
1.3
1.3
1.3
1.3 章節概要
章節概要
章節概要
章節概要
第二章介紹多重敘述語音傳輸系統並建立其對應的音質預測模 型,第三章介紹在多重敘述音質評量平台上,語音封包播放排程的最 佳化設計,第四章介紹基於聽覺最佳化考量,整合前向錯誤控制於多 重敘述語音傳輸系統,第五章的系統模擬部分,先透過對語音檔的實 作 來 驗 證 新 的 音 質 預 測 模 型 , 接 著 利 用 網 路 模 擬 器 (Network Simulator 2, NS2)[11]模擬網路傳輸環境,進一步驗證本論文所提 出的強健性 MD 語音傳輸系統。
第
第
第
第二
二
二章
二
章
章
章
多重敘述的音質預測模型
多重敘述的音質預測模型
多重敘述的音質預測模型
多重敘述的音質預測模型
網路即時通話系統的音質損害,主要是受到封包漏失及網路延遲 的雙重影響。為了降低封包漏失所造成的音質損害,除了前向錯誤控
制(FEC: Forward Error Control)以外,近年來也有學者提出多重敘
述語音編碼(Multiple Description Speech Codec, MD-Speech Codec)
模式。主要是結合語音編碼標準的前置處理[7],在傳輸端將語音音 框(frame)所屬的參數分成兩條串流,個別以封包的形式經由互相獨 立的通道傳輸,當其中一條串流發生漏失時,其封包資訊藉由收到的 另一條串流來部分補償,以期能夠降低封包漏失所造成的音質損害。 本章節應用 G.729a 和 AMR-WB 兩種語音編碼標準來實現其多重敘述編 碼模式,並深入探討其傳輸特性,以建立適用於 MD 傳輸系統的音質 預測模型。
2.1
2.1
2.1
2.1 通話品質預測模型
通話品質預測模型
通話品質預測模型
通話品質預測模型
近年來由於網路電話(VoIP)低廉的通話費用以及更有效率的網 路運用等種種優點,消費者利用網際網路當作影音多媒體的傳輸媒介 之接受度逐年增加。然而消費者已經習慣於傳統有線電話與行動電話 優越的通話品質(toll quality),因此在使用網路電話之際勢必也會 對通話品質做一定程度的要求。對於網路系統規劃者而言,必須要有
一個具體的音質評量指標供作參考,進而建構並調整系統關鍵元件參 數之用,以確保使用者在通話中有較佳的語音品質且穩定的通話效 能。所以我們必須去了解哪些因素會影響整體系統服務品質與效能, 進而整合推導出一項能具體反應網路通話的音質評量指標模型。 2.1.1 2.1.1 2.1.1 2.1.1 主觀聽覺測試主觀聽覺測試主觀聽覺測試主觀聽覺測試 對於通話品質的界定,最直接的方式是以人耳的主觀聽覺來判斷 音質好壞,並透過某種制定的量值用以區分其程度差異。在ITU標準
規格[12][13]中,制定了平均評比分數(Mean Opinion Score ,MOS),
評分的等級從感覺音質極佳的5分到音質極差的1分。 所謂的主觀聽覺測試,測試者是經由特定條件挑選出來,並處在 特別設計過的房間,房間裡的噪音以及其他重要的環境因素都被控制 在某一種適合測試的程度來進行聽覺實驗。待測試用的語料庫會預先 錄音,基於測試準確度的考量,每一段的語句大約會維持2到3秒,而 且這些語句彼此之間沒有明顯的關聯性。經過語音編碼處理後再改變 網路模擬系統的參數因子,包括輸入不同語音能量層級(Speech
input levels)、聆聽的能量層級(Listening levels)、隨機或叢發
性錯誤、背景雜訊、編碼連結、不同語音碼碼方式的相容性等傳輸因
子。所有測試者去聆聽播放出來的聲音, 並針對不同的系統設定環
角度看,通常認為MOS值4.0分~4.5分為高品質,達到長途電話網的音 質要求。MOS值3.5分左右稱作普通音質,這時聽者能感覺到音質有所 下降,但不影響正常的通話,可以滿足多數通信系統使用要求。MOS 值3.0分以下通常稱為合成音質,這種語音一般只有達到足夠聽的懂 的程度,但是缺乏自然度,且不容易識別語者特徵。 由於所有的測試都是憑藉人耳的主觀聽覺來評分,往往會因為評 分者對於當時環境的感受以及態度而直接影響到整個評分結果,因此 難以達到一致且客觀的標準認定。更由於事前需詳盡準備各類測試用 的環境設定,測試耗時且需花費相當龐大的人事經費,對於例行性的 監控網路程序而言,這樣的評量方式就顯得沒有效率且不實際。另外 就系統設計規劃而言,上述的測試方案都沒有細部考量到網路層服務 品質的影響因素(延遲,擾動,漏失),因此無法就網路傳輸所造成的 音質損害問題加以處理並改善。 2 22 2....1.1.1.1.2 2 2 音質評量指標2 音質評量指標音質評量指標 音質評量指標 主觀聽覺測試無法反應傳送與接收兩端之間經過網路傳輸所造 成的音質損害,因此國際電信聯盟ITU制定一個具體的音質評量模 型,簡稱E模型(E-model,ITU-T G.107)。採用主觀聽覺測試先建立 不同因子所對應的音質損害,再加以整合計算得到最後的評分R,可
提供系統規劃及調整系統關鍵元件參數之用。E模型的方程式表示如 下 0 s d e R= R − − − +I I I A (2.1) 其中 R0: 訊號雜音比,雜音部分包括背景噪音以及電路雜訊。 Is: 與語音信號同時產生的音質損害因子,包括量化、連接雜訊和側 音(Sidetone)帶來的干擾。 Id: 語音延遲(包括通話迴聲)造成的音質損害因子。 Ie: 低位元率語音編碼處理和封包漏失所造成的音質損害因子。
A: 補償損害因子(Compensation Impairment Factor),用以補償用
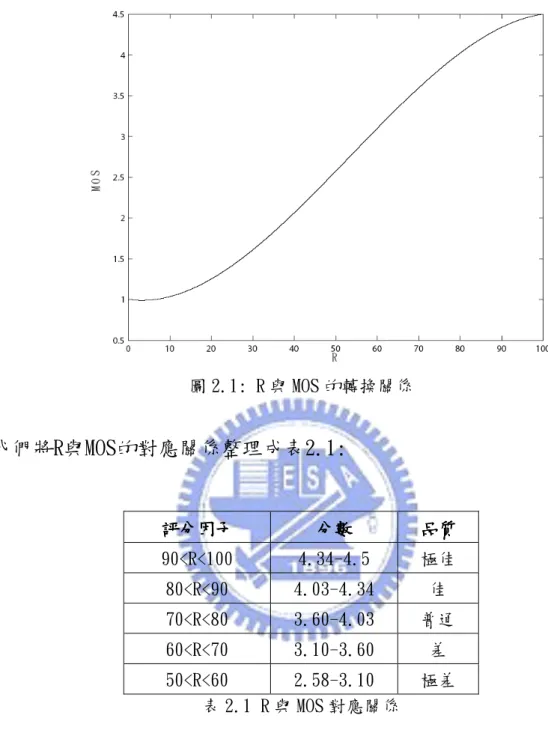
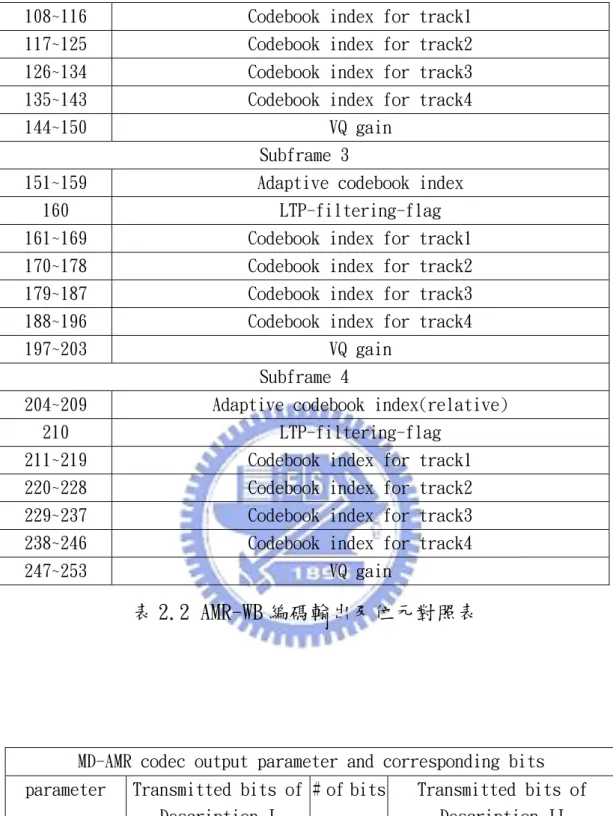
戶基於接聽的方便而能忍受音質的影響,如行動電話。 量測音質的 R 值範圍可以從最好的 100 到最差的 0,然而實際對 於聲音品質可以接受的最低限度為 50。同時在 E 模型中,也定義了 R 值與平均評比分數(MOS)之間對應的關係,可以避免主觀評量過程中 繁瑣的人工測試過程。如圖(2.1)所示,其關係式為 6 1, 0 1 0.035 7 10 ( 60)(100 ), 0 100 4.5, 100 R MOS R R R R R R − < = + + × − − < < > (2.2)
圖 2.1: R 與 MOS 的轉換關係 我們將R與MOS的對應關係整理成表2.1: 評分因子 評分因子評分因子 評分因子 分數分數分數分數 品質品質品質品質 90<R<100 4.34-4.5 極佳 80<R<90 4.03-4.34 佳 70<R<80 3.60-4.03 普通 60<R<70 3.10-3.60 差 50<R<60 2.58-3.10 極差 表 2.1 R 與 MOS 對應關係 由於我們僅針對網路傳送層來探討音質損害,因此對於R0和Is 而言,它們與網路傳送過程並沒有直接的關係。因此我們可以採用ITU 所設定的初始值,簡化R的計算方式,直接針對通道特性及系統架構 兩層面來評估音質[14]。如式(2.3)所示 ( , , ) 94.2 d( ) e( , ) R d r e = −I d −I r e (2.3)
其中d為單一路徑口對耳延遲(mouth-to-ear delay),r是編碼位元 率,e則是封包漏失率。針對Ie進一步分析顯示,影響因素有低位元 率語音編碼處理所造成的訊號失真,以及在傳輸過程中因網路擁擠或 其他不可預知因素所導致的封包漏失。可分開討論如下 , , ( , ) ( ) ( ) e e codec e pl I r e = I r +I e (2.4) 其中Ie codec, 表示語音編碼造成的音質損害,Ie pl, 則表示封包漏失所造成 的音質損害。 [1] [1] [1] [1] 語音編碼損害因子語音編碼損害因子語音編碼損害因子語音編碼損害因子----Ie codec, 語音壓縮處理可以減少資料傳輸量而有效節省頻寬。其中編碼標 準有多項選擇,如 G.711 PCM、G.729a CS-ACELP、G.723.1 MPC-MLQ、 AMR-WB,依位元率區隔不同模式所衍生的信號失真亦存在明顯差異。 每一種編碼標準均有其特定的聆聽 MOS(listening MOS),利用圖(2.1) 即可求得其對應的 R 值。一般而言,聆聽 MOS 並未將延遲及封包漏失 的音質損害納入考量,因此公式(2.3)可簡化為 , ( ) 94.2 e codec( ) R r = −I r (2.5) 由前人研究得知,隨著編碼位元率的下降,音質的損害值明顯增 加。這是由於較高的壓縮率雖然能節省頻寬的使用,然而封包與封包
之間的關聯性卻相對的降低。在網路傳送語音封包時,若發生封包漏 失的現象即有可能造成聲音斷斷續續有如被剪掉一樣,因此有必要在 封包傳送前對封包做保護的動作。 [2] [2] [2] [2] 封包漏失損害因子封包漏失損害因子封包漏失損害因子封包漏失損害因子––––Ie pl, 在前一個小節提到,聲音在一開始傳送時首先會經過語音編碼處 理,由數據顯示造成的音質損害會隨著位元率的下降而提昇,而這小 節主要是探討受到網路傳輸影響的音質損害。在網路中常常面臨通道 頻寬有限卻需要傳送大量語音封包或資料封包,路由器(router)需要 更多時間消化而造成網路擁塞的現象,導致封包佇列時間過久而無法 在預定時間內抵達終點,造成封包漏失的現象。若是資料封包的漏 失,可以使用要求重送(ACK)的機制來改善,然而對有即時傳輸需求 的語音封包而言,卻無法利用重送機制來做補強,使得整段語音經過 網路後會發生斷斷續續的現象。根據研究指出,語音編碼與封包漏失 的共同損害因子Ie可近似為: , , 1 2 3 ( , ) ( ) ( ) ln(1 ) e e codec e pl I r e = I r + I e = +
γ γ
+γ
e (2.6) 其中Ie codec, ( )r =γ
1,Ie pl, ( )e =γ
2ln(1+γ
3e)。 [3][3][3][3] 延遲損害因子延遲損害因子延遲損害因子延遲損害因子----Id 就單向聆聽 MOS 而言,用戶往往對延遲比對封包漏失更能容忍, 因為封包漏失會造成聽不清楚對方的話,而延遲並不會影響單向通話的音質。但就雙向的對話品質(Conversational MOS,MOSc)而言,延 遲增大到一定程度以後,可能導致雙方同時講話或相互沈默,從而影 響正常通話,減少雙方的互動。而造成延遲的因素有很多,例如編碼 與封裝處理造成的延遲、傳送路徑延遲、播放暫存器造成的延遲。 在前人研究[14]中,參考 E 模型(ITU G.107)比對單一路徑口對 耳 的 延 遲 與 其 損 害 因 子 , 利 用 片 段 線 性 分 析 可 推 導 得 0.024 0.11( 177.3) ( 177.3) d I = d + d − H d − (2.7) 其中 d 為單一路徑延遲, 而 H 是一個步階函數。
2
22
2.
..
.2
22
2
多重敘述語音編碼
多重敘述語音編碼
多重敘述語音編碼系統
多重敘述語音編碼
系統
系統
系統
2.2.1 MD 2.2.1 MD 2.2.1 MD
2.2.1 MD----AMRAMRAMRAMR 編碼器編碼器編碼器編碼器
前人所提出的 MD-AMR 編碼模式[7],是依照 AMR-WB 編碼音框的
參數特性來均分成兩條串流,其編碼處理詳如下述:
a)導納頻譜頻率(Immittance Spectrum Frequency, ISF):
AMR-WB 標準是將每一個音框分析所得到的線性預測係數(Linear Prediction Coefficient, LPC),轉換成量化失真靈敏度較低的 16 個 ISF 係數之後,再進行分次多階向量量化(split-multistage vector quantization, S-MSVQ),以因應無線電信網路的低位元率傳 輸需求。比較特別的是,在第二個編碼模式裡,ISF 係數是以兩階分 次量化器來量量化。在 MD 編碼端的兩條串流,都將傳送在第一個階 段中碼向量索引(index)所屬的 16 個位元,這是由於假如沒有這部分 的資訊,LPC 參數將完全無法重建回來。在第二個階段,向量將被分 成 5 個次向量(subvector),而且這 5 個次向量將以 6+7+7+5+5=30 個 位元來編碼。兩條串流都將傳送第一個次向量(6 位元),而第二個(7 位元)和第五個(5 位元)次向量由第一條串流傳送,其餘的第三個(7 位元)和第四個(5 位元) 次向量則由第二條串流傳送。
b)適應性碼簿的音高延遲(Pitch delay for adaptive codebook):
二個(第四個)次音框的音高延遲是依據第一個(第三個)次音框的音
高延遲進行編碼。因此,在分配串流傳送方式時,由第一條串流來傳
送第一個和第二個次音框裡的位元,而其餘的第三個和第四個次音框
位元則由第二條串流來傳送。
c)適應性及固定性碼簿增益(Adaptive and fixed codebook gains):
在 AMR-WB 語音編碼標準裡,適應性和固定性碼簿的增益(Gain) 在每一個次音框裡是共同以 7 位元來量化。在多重敘述傳輸的部分, 是將第一個和第三個次音框中代表增益的位元放在第一條串流,至於 第二個和第四個次音框裡代表增益的位元則於第二條串流來傳輸。這 樣的分配是為了當只成功接收到一條串流時,可以利用前一個次音框 的資訊來補償漏失掉的部分。也就是說假如只接受到第一條串流,則 於第二條串流傳輸的第二個次音框可以以第一個次音框來補償,第四 個次音框內容可以以第三個次音框來補償。
d)固定性碼簿索引值(Fixed codebook indices):
每個次音框中,固定性碼簿向量是以 36 位元量化器來量化,關
於四個次音框中固定性碼簿索引值的傳送分配是由第一條串流來傳
送第一個和第三個次音框中的內容,第二條串流來傳送第二個和第四
個次音框中的內容。
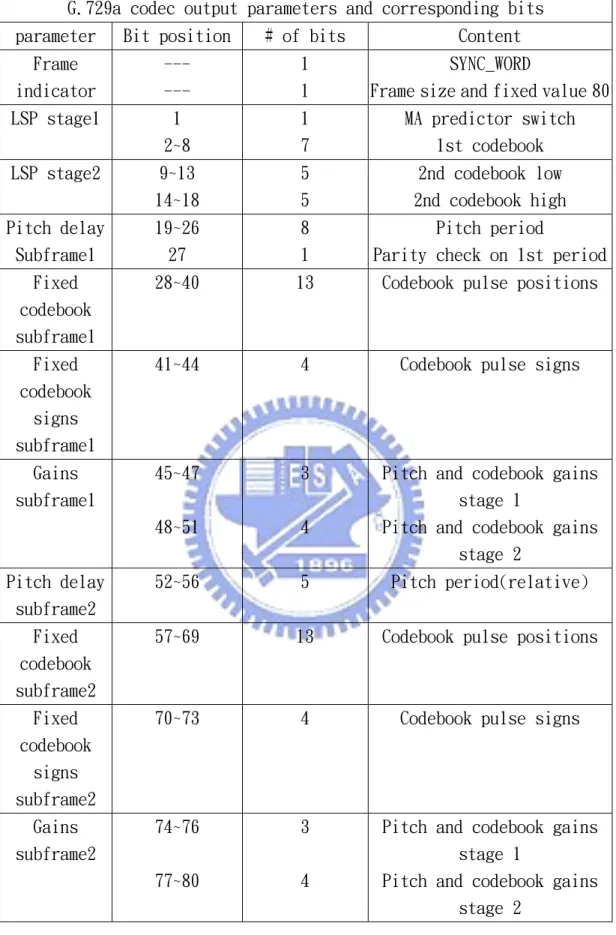
外傳送音態偵測旗標(Voice Active Detection, VAD flag)。為了清 楚解釋 MD-AMR 的編碼規則,我們以表(2.2)及(2.3)來呈現 AMR-WB 和 MD-AMR 的傳送參數及其對應的位元位置。經統計得知,MD-AMR 編碼 後的每條串流位元速率為 6.9Kbps,合計為 13.8 Kbps,這比 AMR-WB 的 12.65Kbps(mode 2)多出了 1.15 Kbps 的冗息(redundancy)。這額 外多出資訊的好處是,當我們只接收到其中單一串流時,仍能回復出 令人接受的音質。值得注意的是, 雖然 MD-AMR 單一串流位元率 6.9 Kbps 高於 AMR-WB mode 1 的 6.6kbps,但是因為後者是針對 6.6kbps 去做品質最佳化的編碼設計,所以當我們只收到一條串流時,經過 MD-AMR 回復後的音質將略遜於 AMR-WB 6.6 kbps。 2 22
2....2222.2 .2 .2 .2 MDMD-MDMD---AMRAMRAMRAMR 解碼器解碼器解碼器解碼器
當兩條串流都成功接收時,在接收端可以完全回復成 AMR-WB 編
碼音框,再以 AMR-WB 的解碼器將語音完整呈現。若是兩條串流都漏
失,則 AMR-WB 解碼器將啟動其漏失補償機制(loss- concealment),
盡可能的回覆漏失的音框資訊。
最後一種情況是當只收到其中一條串流時,其解碼過程如下(在
此假設串流 2 漏失,串流 1 漏失的另一種情況可依此類推):
次音框中的音高延遲(pitch-lag)值,將由串流 1 中第二個次音框的
音高延遲值來取代。
(2)第三個和第四個次音框中長期預測濾波參數(Long-Term
Prediction-filtering flag, LTP-filtering flag),以串流 1 中第
二個次音框的對應值來取代。
(3)第二個(第四個)音框的固定性碼簿向量由第一個(第三個)次音框
來補償,至於增益(gain)部分,由衰減 3dB 的第二個(第四個)次音框
來補償第一個(第三個)次音框中的內容。
AMR-WB codec output parameter (12.65Kbps) and corresponding bits
Bit position Content
1 VAD-flag
2~9 Index of 1st ISP vector
10~17 Index of 2nd ISP vector
18~23 Index of 3rd ISP vector
24~30 Index of 4th ISP vector
31~37 Index of 5th ISP vector
38~42 Index of 6th ISP vector
43~47 Index of 7th ISP vector
Subframe 1
48~56 Adaptive codebook index
57 LTP-filtering-flag
58~66 Codebook index for track1
67~75 Codebook index for track2
76~84 Codebook index for track3
85~93 Codebook index for track4
94~100 VQ gain
Subframe 2
101~106 Adaptive codebook index(relative)
108~116 Codebook index for track1
117~125 Codebook index for track2
126~134 Codebook index for track3
135~143 Codebook index for track4
144~150 VQ gain
Subframe 3
151~159 Adaptive codebook index
160 LTP-filtering-flag
161~169 Codebook index for track1
170~178 Codebook index for track2
179~187 Codebook index for track3
188~196 Codebook index for track4
197~203 VQ gain
Subframe 4
204~209 Adaptive codebook index(relative)
210 LTP-filtering-flag
211~219 Codebook index for track1
220~228 Codebook index for track2
229~237 Codebook index for track3
238~246 Codebook index for track4
247~253 VQ gain
表 2.2 AMR-WB 編碼輸出及位元對照表
MD-AMR codec output parameter and corresponding bits
parameter Transmitted bits of
Description I
# of bits Transmitted bits of
Description II ISP 2~9 10~7 18~23 31~37 38~42 8 8 6 7 5 2~9 10~7 18~23 31~37 38~42 VAD 1 1 1 LTP-filtering 57,107 2 160,210
Pitch-delay 48~56 101~106 9 6 161~169 204~209 Algebraic code 58~66 67~75 76~84 85~93 161~169 170~178 179~187 188~196 9 9 9 9 9 9 9 9 108~116 117~125 126~134 135~143 211~219 220~228 229~237 238~246 Gains 94~100 197~203 7 7 144~150 247~253 Total bits 138 表 2.3 MD-AMR 編碼輸出及位元對照表 2 22
2....2222.3 .3 .3 .3 MDMD-MDMD---G.729aG.729aG.729aG.729a 編碼器編碼器編碼器編碼器
MD-G.729a 編碼模式[7],是依據 G.729a 編碼標準產生兩條平均 位元速率相同的串流。為了使每條串流保持有效率的平均位元速率 (4.6 Kbps),偶數音框和奇數音框分別以不同的位元數來編碼。 在每個音框中第二個次音框的音高延遲,是相對於其第一個次音 框的音高延遲來編碼。假如沒有第一個次音框的音高延遲,則第二個 次音框的音高延遲將無法解碼。因此,這兩個次音框的音高延遲資訊 總是被分配在同一個串流來傳送。而 14 位元的適應性碼簿延遲部 分,以串流 1 來說,是分配在奇數音框裡,在串流 2 這些位元則分配 在偶數音框。
線頻譜對(LSPs)方面,G.729 使用多階分次向量量化,在第一個 階段,LSP 向量並沒有分開做量化,輸出的 8 位元將重複分配到二條 串流來傳送。在第二個階段,維度 10 的殘餘向量分成兩個維度 5 的 次向量(subvector),且每個次向量個別以 5 位元來編碼。因此分配 在每條串流中對應於 LSP 的位元總共有 13 個位元,包括第一個階段 8 位元和第二個階段 5 位元。至於碼簿索引值(codebook index)的分 配,為了使兩條串流的品質更為平均,奇數音框(偶數音框)中對應碼 簿索引的第一個(第二個)次向量由第一條串流來傳送,而第二條串流 傳送的就是第二個(第一個)次向量。再來關於對應固定性碼簿向量及
固定性碼簿符號(signs of fixed codebook)的位元分配,所有音框
中的第一個次音框裡的資訊由第一條串流傳送,第二個次音框則由第 二條串流傳送。適應性碼簿及固定性碼簿增益方面,由第一個(第二 個)串流傳送第二個(第一個)次音框裡的資訊。 參照表(2.4)及(2.5),可以清楚地將上述分配方式做些簡單的整 理,由此可得知,奇數音框(偶數音框)的第一條(第二條)串流傳送 53 位元,偶數音框(奇數音框)的第一條(第二條)串流傳送了 39 位 元,這些位元數是完成上述參數位元分配後,最後再加上兩個位元的 音框指標(frame indicator)。它是用來描述此音框是屬於哪條串 流,且是奇數還是偶數,如"00"則代表一個屬於第一條串流的奇數音
框,"01"則代表屬於第一條串流的偶數音框,"10"則代表屬於第二條
串流的奇數音框,"11"則代表屬於第二條串流的偶數音框。
2 22
2....2222.4 .4 .4 .4 MDMD-MDMD---G.729aG.729aG.729aG.729a 解碼器解碼器解碼器解碼器
當兩條串流都成功接收時,接收端將可以利用所有資訊,完全回 復成 G.729a 編碼過後的音框,再以 G.729a 的解碼器將語音完整呈 現。若是兩條串流都漏失,則 G.729a 解碼器將啟動其漏失補償機制 (loss concealment),盡可能的回覆所漏失掉的音框資訊。假如只收 到一條串流,則解碼器會以最接近且正確收到的封包內容資訊來補償 漏失掉的部分,如下述: (1)漏失掉的第二階次次向量設為 0。 (2)第一條串流中偶數(奇數)音框的音高延遲,則以前一個正確收到 的音框的音高延遲加上 1 來取代。 (3)第一條串流中第二個次音框及第二條串流中第一個次音框的增益 資訊由前一個次音框內容來取代。 (4)觀察分配時的方法可以理解,漏失掉的 LSP 向量可由收到的第一 階向量和其中一個次向量來補償。
G.729a codec output parameters and corresponding bits
parameter Bit position # of bits Content
Frame indicator --- --- 1 1 SYNC_WORD
Frame size and fixed value 80
LSP stage1 1 2~8 1 7 MA predictor switch 1st codebook LSP stage2 9~13 14~18 5 5 2nd codebook low 2nd codebook high Pitch delay Subframe1 19~26 27 8 1 Pitch period
Parity check on 1st period Fixed
codebook subframe1
28~40 13 Codebook pulse positions
Fixed codebook
signs subframe1
41~44 4 Codebook pulse signs
Gains subframe1 45~47 48~51 3 4
Pitch and codebook gains stage 1
Pitch and codebook gains stage 2 Pitch delay subframe2 52~56 5 Pitch period(relative) Fixed codebook subframe2
57~69 13 Codebook pulse positions
Fixed codebook
signs subframe2
70~73 4 Codebook pulse signs
Gains subframe2 74~76 77~80 3 4
Pitch and codebook gains stage 1
Pitch and codebook gains stage 2
MD-G.729a codec output parameter and corresponding bits parameter Description I Description II Odd packet Bit position (# of bits) Even packet Bit position (# of bits) Odd packet Bit position (# of bits) Even packet Bit position (# of bits) Frame indicator --- (2) --- (2) --- (2) --- (2) LSP stage1 1 2~8 (8) 1 2~8 (8) 1 2~8 (8) 1 2~8 (8) LSP stage2 9~13 (5) 14~18 (5) 14~18 (5) 9~13 (5) Pitch delay subframe1 19~26 27 (9) 19~26 27 (9) Pitch delay subframe2 52~56 (5) 52~56 (5) Fixed codebook subframe1 28~40 (13) 28~40 (13) Fixed codebook subframe1 57~69 (13) 57~69 (13) Fixed codebook signs subframe1 41~44 (4) 41~44 (4) Fixed codebook signs subframe2 70~73 (4) 70~73 (4) Gains subframe1 45~47 48~51 (7) 45~47 48~51 (7) Gains subframe2 74~76 77~80 (7) 74~76 77~80 (7) Total bits 53 39 39 53 表 2.5 MD-G.729a 編碼輸出及位元對照表
2.
2.
2.
2.3
33
3 多重敘述編碼
多重敘述編碼
多重敘述編碼
多重敘述編碼的
的
的
的
Ie音質預測模型
音質預測模型
音質預測模型
音質預測模型
在多重敘述傳輸過程中,接收端將會遇到三種情況,分別是 兩條串流的封包皆成功接收(Ω1)、只有其中一條串流的封包成功接 收(Ω2)、以及兩條串流封包皆發生漏失(Ω3)。為了區隔Ω2 的單一 封包漏失(packet loss),我們將Ω3的雙重封包漏失現象稱為音框刪 除(frame erasure)。特別強調的是基於 MD 解碼器的功能,Ω1及Ω2 都被判定為"可播放",不同的是Ω1的音質較佳。問題是傳統的Ie音 質預測模型,原是針對單一敘述傳輸系統而設計,只能反應封包漏失 率(封包不能播放的比例)及不同語音編碼模式所造成的音質損害。而 如上述 MD 解碼流程,我們可預期當接收端發生Ω2情況時,其解碼輸 出音質將不如Ω1。因此 2.1.2 節所提到的傳統Ie音質預測模型已不敷 使用,較理想的解決方案是必須將Ω1及Ω2這兩種接收情況做些區 隔,且有效反應其所對應的輸出音質差異。 由於傳統的Ie音質預測模型無法正確反應 MD 語音封包的傳輸品 質,所以我們必須尋找能夠反應出Ω1及Ω2音質差異的Ie音質預測模 型。當發生Ω1情況時,MD 解碼端將其兩條串流所含的封包資訊合併 還原成完整的 G.729a 或 AMR-WB 語音音框;而發生Ω2情況時,由於 只接收到其中一條串流,MD 解碼端會依據僅有的部份封包資訊透過 補償將其重建成一個語音音框。而此語音音框的格式與 G.729a 或
AMR-WB 相同,差別就在於其所含資訊不夠完整。上述 MD 解碼過程如 圖(2.2)所示,其中虛線代表不能被用於播放的封包,而實線代表可 用於被播放的封包,黑實心代表完整的語音音框,灰實心代表其所含 資訊不夠完整的音框。 圖 2.2 MD 解碼 Speech Decoder 解碼輸出語音 Speech Decoder 解碼輸出語音 圖 2.3 封包經 MD 解碼後分屬兩種不同的語音編碼輸出 MD 解碼
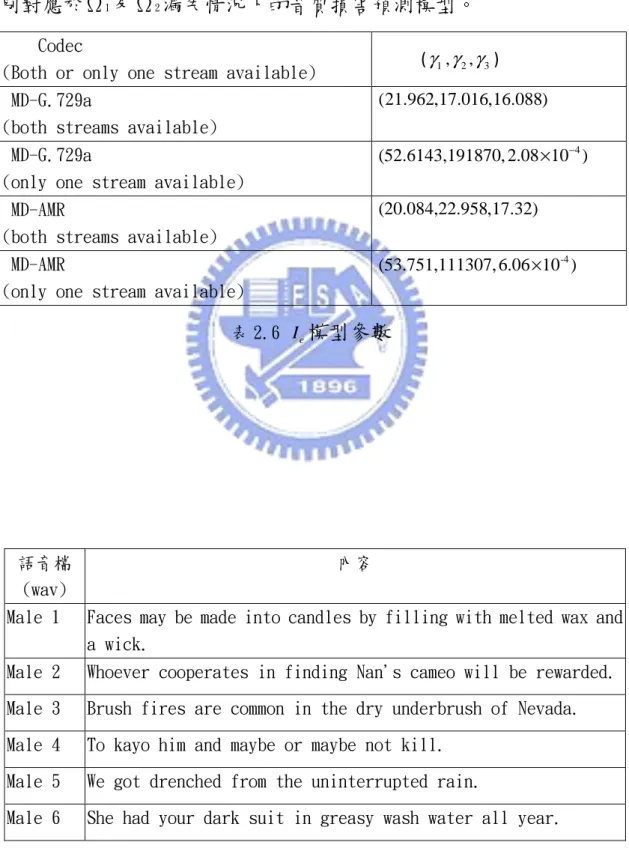
經由 MD 解碼後的語音音框,除了Ω3情況外,另兩種(黑實心與灰實 心)可以視為分屬於兩種不同位元率的語音編碼輸出,因此 MD 解碼後 的語音音框可以視為兩種不同的語音編碼輸出封包在網路上的傳輸 漏失情形。 針對上述兩種不同語音編碼輸出的封包漏失狀況(如圖(2.3)所 式),我們的目標是尋找能夠精準預測其音質的Ie模型,進一步分析 其編碼損害因子(黑實心及灰實心可視為其Ie codec, 的不同)及封包漏失 損害因子Ie pl, 。為了取得精確的Ie音質預測模型,我們參照前人研究 的方法[15]使用 16 個英文語音檔案(包括 8 個男生、8 個女生,如表 (2.7)所示),來估測其封包漏失損害因子(Ie pl, )及編碼損害因子 (Ie codec, )所對應的參數(γ γ γ1,s, 2,s, 3,s),其中 s=1 對應於接收情況Ω1,s=2 對應於接收情況Ω2。 首先討論圖中的虛框情形,在一個特定的音框刪除比率(frame erasure rate,FER)=Prob{Ω3}環境下,我們先將這些語音檔經過 MD 分成了兩個串流,再針對Ω1及Ω2這兩種情況分別來做 MD 解碼。由 於封包漏失位置的不同,將造成輸出音質有所差異,所以經過多重敘 述解碼處理的每個語音檔串流再分別選擇 30 組隨機指定封包漏失位 置。最後再將解碼輸出的語音檔(此時已承受 MD 編解碼及封包漏失音 質損害),分別與其原始語音檔進入音質感知評估(Perceptual
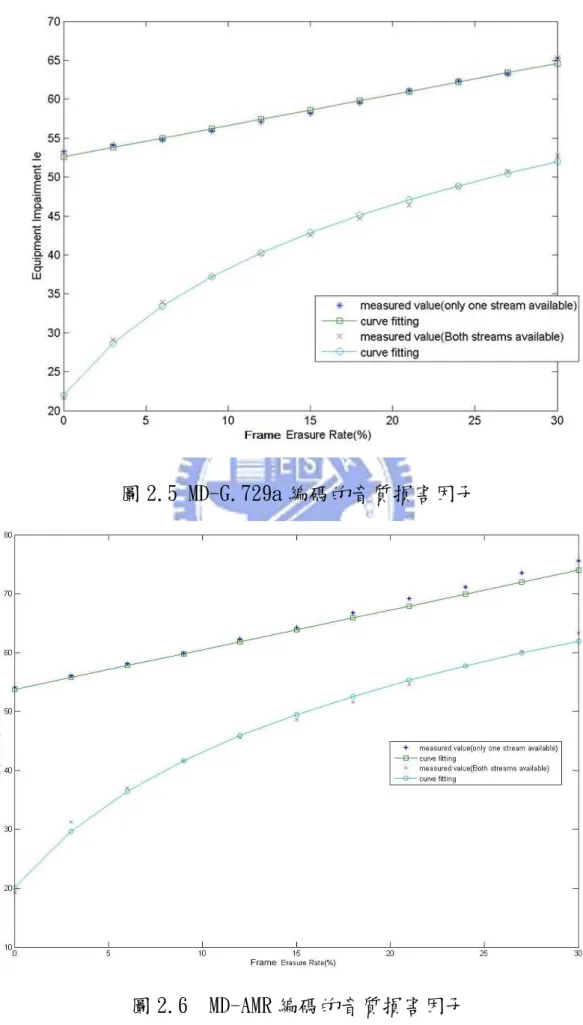
Evaluation of Speech Quality, PESQ)演算法而得到 MOS 值,整個 流程如圖(2.4)所示。特別強調的是,這些輸出語音檔並沒有考慮到 延遲損害,所以將其經式(2.8)轉換得到的 R 值,將只有包括封包漏 失損害及語音編碼損害。因此透過式(2.9)得到音質損害因子的量測 值Ie=(Ie pl, +Ie codec, ),最後取其整體平均以求能夠補償不同的語者和漏 失位置所造成的損害變異。依此工作流程,我們可得到在一特定的音 框刪除率環境下,Ω1及Ω2所對應的音質損害因子Ie,如圖(2.5) 及 (2.6)所示。 3 2 3.026 25.314 87.06 57.336
R= MOS − MOS + MOS − (2.8)
94.2 e I = −R (2.9) 圖中的 FER= Prob{Ω3}是指一音框所屬的兩條串流同時發生漏失 的發生比例。以 FER = 0.05 來說,代表假如傳送音框數有 200 個, 其中 10 個音框會發生Ω3。至於其他音框所屬兩串流的接收情況就是 人工設定為Ω1(接收兩串流)或Ω2(接收單一串流)。圖中音質損害較 高的曲線就是對應於Ω2,音質損害較低的曲線就是對應於Ω1。在測 試過程當中,FER 在 0%到 30% 之範圍 ,每隔 3%做一次量測並得到相 對應的損害因子,因而得到一組 11 個損害因子,分別對應 FER :0%, 3%,...,27%,30%。利用這組量測數值,根據最小平方差準則(least square error),透過 NCSS 數值分析軟體[16]所提供的曲線匹配
(curve fitting)功能,執行非線性迴歸(nonlinear regression
model)分析而取得其損害因子模型
(Ie s, ( )e =γ1,s+γ2,sln(1+γ3,se),s=1, 2)。如表(2.6)所示,其中Ie,1與Ie,2是分
別對應於Ω1及Ω2漏失情況下的音質損害預測模型。
Codec
(Both or only one stream available) (γ γ γ1, 2, 3)
MD-G.729a
(both streams available)
(21.962,17.016,16.088)
MD-G.729a
(only one stream available)
4
(52.6143,191870, 2.08 10 )× −
MD-AMR
(both streams available)
(20.084,22.958,17.32)
MD-AMR
(only one stream available)
-4 (53.751,111307, 6.06 10 )× 表 2.6 Ie模型參數 語音檔 (wav) 內容
Male 1 Faces may be made into candles by filling with melted wax and
a wick.
Male 2 Whoever cooperates in finding Nan's cameo will be rewarded. Male 3 Brush fires are common in the dry underbrush of Nevada. Male 4 To kayo him and maybe or maybe not kill.
Male 5 We got drenched from the uninterrupted rain.
Male 7 He ripped down the cell-phone carefully and laid three dogs on
the tin foil.
Male 8 No, they could kill him just as easy right now.
Female 1 These men were without capital or experience.
Female 2 The library has open shelves even in the unbound periodical
stockroom.
Female 3 A site may also be attractive just through the beauty of its
trees and shrubs.
Female 4 Masquerade parties tax one's imagination
Female 5 You do that or take you out a permit right now.
Female 6 They weren't as well paid as they should have been.
Female 7 Good services should be rewarded by big tips.
Female 8 Ran away on a black night with a lawful wedded man.
表 2.7 語音檔內容 Ω1 Ω2 圖 2.4 尋找新Ie模型的實驗流程 speech sample
use the measured value to find
the parameter of IIIIe e e e model
MD Coder MD Decoder
Speech Decoder
PESQPESQPESQ PESQ
MOS MOS MOS
MOS---->R>R>R>R---->I>I>I>Ieeee
Speech Coder loss/
erasure model
圖 2.5 MD-G.729a 編碼的音質損害因子
2.
2.
2.
2.4
44
4 音質損害預測模型的整合
音質損害預測模型的整合
音質損害預測模型的整合
音質損害預測模型的整合
在上一小節,我們基於 MD 編解碼的特性,透過 PESQ 找出能夠分別 反應Ω1及Ω2接收情況的音質損害預測模型(Ie,1及Ie,2)。在此,我們 將進一步把這兩個預測模型做適度的整合,使其能夠準確預測實際 環境中封包傳輸情況Ω1及Ω2混合發生時的輸出音質。令 FER 3 Pr{Ω}= e,而Pr{Ω ∪ Ω1 2}=1 Pr{− Ω3}是指有單一或兩個封包可用於播放 其音框的機率。我們提出新的音質損害預測模型I ee( ),,,,如下所示: 2 , 1 1 1 2 1 1 1 1 2 1 2 1 2 2 2 1 2 1 ( ) ( ) Pr{ , } Pr{ } Pr{ | }= Pr{ } Pr{ } Pr{ | } 1 e j e j j I e ρ I e ρ ρ ρ = = Ω Ω ∪ Ω Ω = Ω Ω ∪ Ω = Ω ∪ Ω Ω ∪ Ω = Ω Ω ∪ Ω = −
∑
(2.10) 這個新I ee( )模型簡單來說是,在音框可以播放部分或完整的條件 下,先將兩串流封包分成兩類,分別對應Ω1及Ω2兩種情況。並依據 這兩種情況的發生比例ρ1及ρ2,對Ie,1及Ie,2做加權並整合所得。為了 解新I ee( )模型的運作模式,我們舉下例來表示說明:圖中所示是 42 個 G.729 音框在接收端經由 MD 解碼後的情形,如 前面所敘述,黑實心框代表Ω1的兩串流經由 MD 解碼後的音框,灰實 心框則代表Ω2的單一串流經由 MD 解碼後的音框,Ω3的音框刪除則 由虛線框來表示。由這些封包接收情況,可以算出Pr{Ω3} =3/42=0.07 1 2 Pr{Ω ∪ Ω}=1- Pr{Ω3}=0.93 1 1 2 1 Pr{Ω Ω ∪ Ω =, } Pr{ }Ω =26/39=2/3 因此,這一段音框區塊因其編碼及封包漏失所造成的損害因子,配合 表(2.6)可得其新I ee( )模型的預測值為: ,1 ,2 2 1 (0.07)= (0.07)+ (0.07)= 3 3 e e e I I I 41.6689
第
第
第
第三
三
三章
三
章
章
章
聽覺
聽覺
聽覺
聽覺最佳化的適應性播放排程設計
最佳化的適應性播放排程設計
最佳化的適應性播放排程設計
最佳化的適應性播放排程設計
近年來,廣受歡迎的網路電話(VoIP)發展迅速,因為能讓使用者 節省可觀的長途或國際電話費。但網路電話仍存在諸多問題,常見的
問題為整體延遲(end-to-end delay)、延遲擾動(delay jitter)、封
包漏失(packet loss)、以及回音(echo)等。聲音在網路上傳送通常 是被切割成一個個封包,所以封包到達接收端時的延遲和漏失,被視 為評估網路電話品質好壞的準則。在傳送端,語音信號會以固定的音 框間隔依序來產生封包,並透過網際網路傳送到接收端。其網路延遲 會取決於行走的路徑及該路徑上路由器(Router)的擁塞程度而有所 不同,而這些網路延遲的差異即為延遲擾動。為降低延遲擾動在接收 端的影響,接收封包在播放前會先被暫存在緩衝器一小段時間。嚴重 晚到的封包,即封包在排定的播放時間後才到達,則被視為晚到漏失
(late loss)。藉由增加緩衝器延遲(buffer delay),晚到漏失的封
包將會減少,然而這將增加封包的整體延遲。針對這個議題,本章節
的研究將結合第二章的音質預測模型,因應 MD 傳輸中的網路變動情
3.1
3.1
3.1
3.1 播放緩衝器
播放緩衝器
播放緩衝器
播放緩衝器
在網路語音傳輸系統中,傳送端以固定的音框間隔 Tp產生封包並 經由網路傳送,而由於網路本身的特性,每個封包延遲並不會固定, 導致有些封包會在接收端預定的播放時間之後才到達。圖 3.1(a)說 明了延遲擾動所造成的問題,在缺乏播放緩衝器的情形下,封包會在 被接收到的同時隨即被播放出去,第一個封包抵達時間即為其開始播 放時間,接下來的第 i 個封包將以和第一個封包的播放時間間隔 (i-1)Tp作為播放時間。然而,較大的網路延遲會造成晚到的封包(如 圖中第四個封包)無法順利播出,導致部分的封包漏失而降低通話品 質。加入播放緩衝器之後,封包抵達後將暫存於緩衝器一小段時間再 播放,如圖 3.1(b)。此方法可大幅減少封包因晚到而漏失的機率, 但整體延遲將從原本的網路延遲擴大為網路延遲與緩衝延遲的總合。 Tp [1st] [2nd] [3rd] [4th] 傳送端 time 接收端 time 播放 time Tp Tp Tp 圖 3.1(a)未加入緩衝延遲
Tp [1st] [2nd] [3rd] [4th] 傳送端 time 接收端 time 播放 time network buffer Tp Tp Tp delay delay 圖 3.1(b)引入緩衝延遲(buffer delay)機制 圖 3.1 播放緩衝器的影響 因此如何在封包漏失及播放延遲之間取得平衡點,進而設計一個 能因應網路時變特性的播放排程機制,是網路語音傳輸系統中一項重 要的議題。針對播放排程的問題,近年來已有學者提出聽覺最佳化的 原則,針對每個封包調整播放延遲(per-packet adjustment)[17], 亦即每個封包的播放延遲相異。問題是這種基於封包調整的播放排程 機制雖可迅速因應網路延遲的動態擾動,卻衍生更棘手的不連續播放 問題。假如當第 i 個封包的播放延遲大於或小於第 i+1 個封包播放 延遲時,則將會造成聲音在播放時突然產生空白或扭曲。為了解決此 封 包 播 放不 連續的 問 題 ,常 見的做 法 是 在接 收端引 入 音 長調 整 (Time-Scaling)[18]。而其機制主要是針對個別封包對應的播放延遲 來調整其封包長度,透過拉長或縮小封包長度,來填補封包間的時間
空格或避免兩兩封包播放時間相互衝突(例如當要播放第 i+1 個封包 時,而第 i 個封包卻還沒完成播放)。雖然這可解決播放不連續的問 題,但是顯然地,封包長度的拉長或縮短將造成聲音突然加速或是減 慢的情況。縱使如此靈敏的播放調整機制可大幅降低封包晚到的漏失 比例,但是過度的音長調整仍有可能造成音質降低甚至無法辨認。 有別於上述基於封包的調整機制,另一種作法是在相鄰話務間調 整 其 靜 音 (silence) 區 段 時 間 的 播 放 排 程 機 制 (per-talkspurt adjustment)[15] 。 在 語 音 通 話 中 , 一 段 聲 音 的 傳 輸 包 括 了 話 務
(talkspurt)及靜音。以「No, they could kill him just as easy right
now. 」為例,這段話包含 10 個話務,每個話務本身是由數個甚至數 十個封包所組成,其餘的則為 silence。調整播放延遲的做法就是在 每個話務開始之前,一次決定其所屬封包的播放延遲。因此當設定完 播放延遲後,每段話務裡的所有封包其播放延遲皆相同,也就是當接 收端在播放此話務時,每個封包將依序播放出來。相較於每個封包長 度的調整機制,基於話務的調整機制確實不能及時反應網路延遲情 況,但是這種退而求次的方法,至少避免掉使用音長調整而造成額外 的音質損害。 本論文探討主題是在每段話務之間調整其播放延遲,雖然降低封 包晚到漏失的比例不如封包調整機制。但由於我們是著重於 MD 傳輸
系統之下,設計適應性播放排程演算法以調整話務之間靜音區段的長 度,仍能透過 MD 傳輸的優勢有效的降低封包晚到漏失所造成的音質 損害。MD 傳輸的播放排程機制設計,基本上來說,是透過估計兩條 串流傳輸過程中的網路延遲,結合適應性播放排程演算法來設定其聽 覺最佳化的播放延遲。至於網路延遲的估計過程如下: 其中 ( ) ^ s i d 和 ( ) ^ s i v 分別是代表串流 s 傳輸中,第 i 個封包網路延遲的平均 值和變異數之估計值,分別是以自迴歸方法(Autoregressive ,AR method)[17]來估計 ^ ^ , i i play i d = +d βv (3.1) ( ) ( ) ^ ^ ( ) -1 (1- ) -1 s s s i i i d =αd + α n (3.2) ( ) ( ) ( ) ^ ^ ^ ( ) 1 (1- ) | -1 1 | s s s s i i i i v =αv− + α n −d− (3.3) 串流 s 中第 i 個封包網路延遲的平均與變異數估計值,是由該串流中 前一個封包對應的估計值{ ( ) ^ -1 s i d , ( ) ^ 1 s i v− },配合其實際量測的網路延遲 ( ) -1 s i n 分別加權所組成,可以預期α 的大小會影響估計的準確性。在此 α 值設為 0.998002。式(3.1)中的β是個用來設定播放延遲的安全因 子(safety factor),讓設定的播放時間比封包抵達的估計時間更晚 一點,讓播放排程有更足夠的時間來播放。當β值越高時,可想而知 封包遲到的比例得以降低,但是同時也增加了整體延遲,因此β在播 放排程演算法中扮演著關鍵的權衡(trade-off)角色。
3.2
3.2
3.2
3.2 晚到漏失機率模型
晚到漏失機率模型
晚到漏失機率模型
晚到漏失機率模型
為了設定聽覺最佳化的播放緩衝延遲,β值的設定需要更精準的 網路延遲分佈模型來幫助我們建立晚到漏失機率模型。首先,定義網 路延遲的累積分佈函數F dD( )如下,
( ) { } D F d = Prob D≤ d 此式表示網路延遲不大於d的機率。第i個語音封包的晚到漏失,發生 於網路延遲大於其所設定播放延遲dplay i, 的時候,因此晚到漏失機率 , b i e 可定義為: , { , } 1 ( , ) b i play i D play i e = Prob D> d = −F d (3.4) 上式建立了dplay i, 與e 之間的關係。觀察式(3.4),由機率的b i,
基本公設得知F dD( play i, )是一個dplay i, 的遞增函數,確實dplay i,
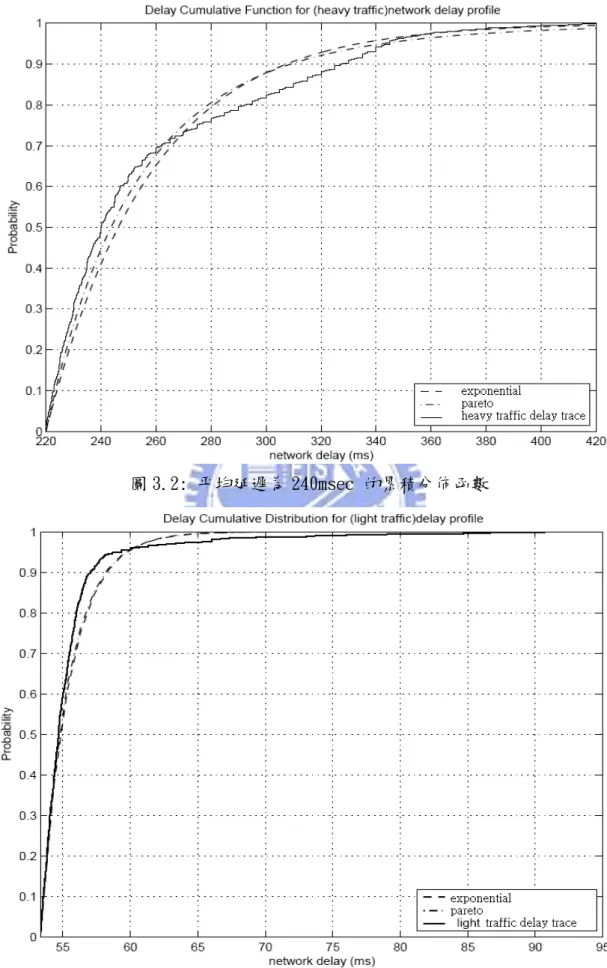
越大則eb i, 會越小。 前人提出了許多統計模型來描述封包傳輸的網路延遲特 性,較常見的有Exponetial模型及Pareto模型,其定義示於 表(3.1)。 分佈 分佈分佈
分佈 ExponentialExponentialExponential 分佈Exponential分佈分佈分佈 ParetoParetoPareto 分佈Pareto分佈分佈分佈
CDF:F(x) 0 ( ) / 0 1−e− −x k µ,x− ≥k 0 1 ( / ) ,− k x g x≥k 表 3.1 網路延遲的累積分佈函數
Exponetial模型參數{ , }k0
µ
及Pareto模型參數{ , }k g ,皆可由過去所 量測到的一組L個網路延遲{ni−1,ni−2,...,ni L− },依最大相似度估計理論 (Maximum-Likelihood Estimation)計算而得。由前人研究,可知估 算公式如下[19]: 0 min{ i 1, i 2,..., i L} k n n n ∧ − − − = 0 1 2 { i , i ,..., i L} mean n n n kµ
∧ = − − − − ∧ 1 2 min{ i , i ,..., i L} k n n n ∧ − − − = 1 1 ( i L log( l)) l i n g L k ∧ − − ∧ = − =∑
為了比較這兩種模型與網路延遲實際分佈的差異,首先利用網路 延遲模型產生兩組資料,平均延遲分別為55msce以及240msec,其中 平均延遲較大的一組具有較多的Spike現象。利用這些資料以及表 (3.1)求出實驗的(Empirical)與模型化累積分佈函數,如圖(3.2)與 圖(3.3)所示。圖 3.2: 平均延遲為 240msec 的累積分佈函數
當平均延遲較低時,Exponetial 與 Pareto 延遲分佈模型的效果差異 不大。然而在平均延遲較高的網路情況(且含有許多 Spike),Pareto 分佈模型比 Exponential 分佈模型更適用於描述網路的延遲特性。因 此本章節將選用 Pareto 模型來計算語音封包網路延遲機率,並藉此 建立晚到漏失機率與播放延遲的關係。
3.
3.
3.
3.3
33
3
MD
MD
MD 傳輸系統的播放排程設計
MD
傳輸系統的播放排程設計
傳輸系統的播放排程設計
傳輸系統的播放排程設計
在這個章節我們將先介紹既有的 MD 播放排程演算法,之後再結 合第二章所介紹的 MD 音質損害預測模型Ie,,,,考量封包於 MD 傳輸中的 接收情況及其所對應的音質損害,進而設計聽覺最佳化的播放排程。 3.3.1 3.3.1 3.3.1 3.3.1 以低延遲為考量以低延遲為考量以低延遲為考量的以低延遲為考量的的設計的設計設計 設計 前人研究中所提出的 MD 播放排程設計[6],是將播放延遲dplay i, 及 音框不能完整播放的接收情況(Ω2及Ω3)整合成一個成本函數: , 1 2 , 1 3 2 2 ( ) ( ) Pr{ } Pr{ } i play i play i
C d probability both descriptions lost probability only one descriptions lost d λ λ λ λ = + + = + Ω + Ω (3.5) 式(3.5)是表示對應於第 i 個音框所建立的成本函數,並藉由調整λ1及 2 λ 的大小來衡量取捨整體延遲及音框刪除的發生機率。此播放排程設 計的概念,主要是尋找能夠使成本函數 i C 達到最低值的最佳播放延遲 , play i d 。由 3.1 節可以得知延遲跟封包漏失是兩個無法同時降低的音質 損害來源,透過事先設定的λ1及λ2尋找最佳播放延遲。而不一樣的參
數會尋找出不一樣的最佳播放延遲,由式(3.4)可以看出將λ1調整大 一點,就是利用較長的播放延遲來換取更低的 frame erasure rate,
希望至少能收到其中一條串流。而若將λ2調整大一點就是利用較長的
播放延遲來換取更好的音框重建品質,藉著更長的播放延遲讓音框可
由兩條串流來回復。另外,假若只單方面調整任何一個參數,將無法
全面考量所有損害因子,例如當λ2被調整為極小值甚至是 0 時,代表
此成本函數將只考量到延遲與 frame erasure rate 所造成的音質損
害且並不是以音質預測模型為基礎來設計。另外,這樣的調整並沒有 將音框播放品質的差異(Ω1及Ω2)納入考量,而是一味的降低播放延 遲,雖然如此有效地降低延遲造成的音質損害,但因為播放延遲過短 而造成在接收端有更多音框只收到其中一條串流。而在第二章的探討 中,可以得知Ω1及Ω2兩種音框回復情形下的播放品質是無法相提並 論的。因此很明顯可以看出,如此透過先調整參數(λ1及λ2)再依此參 數來建立成本函數並設計播放排程的做法,並沒有將接收端音框播放 品質納入考量。
3.3.2 3.3.2 3.3.2 3.3.2 音質最佳化的設計音質最佳化的設計音質最佳化的設計音質最佳化的設計 相較於傳統的 SD 傳輸模式,MD 傳輸模式的最大優點,在於提供 更具彈性的 trade-off(整體延遲、frame erasure、對應於Ω1及Ω2 的音框重建品質)。由第二章的結果可以得知最後兩項會反應出不一 樣的語音品質,基於如此的發現,我們將其延伸引用到 MD 傳輸系統 中,並據以設計基於聽覺最佳化的適應性播放排程設計。 基於聽覺最佳化的 MD 傳輸播放緩衝設計,我們必須將延遲、封 包漏失、MD 解碼、語音編解碼、以及語音音框重建後的音質納入考 量。以下整合上述這些影響因子,並依據第二章所提出的音質預測模 型,建立一個能有效反應音質損害的成本函數: 2 , , 1 ( , ) ( ) ( ) ( ) ( ) m i i i d i e i d i j e j i j I d e I d I e I d ρ I e = = + = +
∑
(3.6) 其中整體延遲di是編碼延遲dc加上播放延遲dplay i, ,也就是 ^ ^ i c i i i d =d + +d β v 。這裡所指的ei是第 i 個音框不能播放的發生機率,也 就是兩個串流同時漏失的 FER= Prob{Ω3},可以表示為: (1) (2) (1) (2) (2) (2) (1) (1) (1) (2) (1) (2) , , , , (1 ) (1 ) (1 )(1 ) i n n n n b i n n b i n n b i b i e =e e +e −e e +e −e e + −e −e e e (3.5) 其中 ( )s n e 分別代表串流 s 的網路漏失率, ( ), s b i e 則代表串流 s 中的第 i 個 封包的晚到漏失機率。而相應於第二章所提到的ρ1,在這裡則可以表 示成:1 1 2 1 1 1 1 2 1 2 1 2 (1) (2) (1) (2) , , Pr{ , } Pr{ } Pr{ | } Pr{ } Pr{ } 1 (1 )(1 )(1 )(1- ) 1-ei en en eb i eb i ρ = Ω Ω ∪ Ω = Ω Ω ∪ Ω = Ω Ω ∪ Ω Ω ∪ Ω = − − − (3.7) 1 2 Pr(Ω ∪ Ω )=1-ei代表音框可以被播放的機率,而Pr{ }Ω1 指的是在播放時 間前音框可以完整重建的機率,也就是說在這兩條串流中的封包皆不 能發生網路漏失及晚到漏失,因此以 (1) (2) (1) (2) , , (1−en )(1−en )(1−eb i)(1-eb i)來表 示。而透過 Pareto 分佈來模擬網路延遲分布,晚到漏失機率可以表 示成1 , ( ) ( s)gs D s k F x x − = ,可知βi的大小會直接影響 FER。因此,我們可將 成本函數簡化成: Im i,( , )d ei i =Im i,(βi), 進一步對βi微分可得到: 2 ^ 2, 3, ' , , 1 3, ( ) { ( )} 1 j j i j m i i i j e j i j j i i i d de I c v I e e d d γ γ ρ β ρ γ β β = = + + +
∑
(3.8) 其中 ^ ^ ^ ^ 0.024, (177.3 ) / c= 0.134, (177.3 ) / i c i i i c i i d d v d d v β β < − − > − − (3.9) ^ (1) (2) (1) (2) (2) (1) 1 1 , , 2 , , , (1) (2) (1) (2) , , 2 = (1 )(1 )( (1 ) (1 )) (1 ) 1 (1 )(1 )(1 )(1 ) (1 ) i n n b i b i b i b i i play i i i n n b i b i i i v d e e e e e e d d e de e e e e e d ρ α α β β − − − + − − + − − − − − (3.10) 至於ei在βi上的梯度(gradient),則可以寫成: ^ (1) (2) (1) (2) (1) (2) (2) (2) (1) (1) , , 1 2 , 2 , 1 , -{(1 )(1 ) ( ) (1 ) (1 ) } i i n n b i b i n n b i n n b i i play i de v e e e e g g e e e g e e e g dβ =d − − + + − + − (3.11)接下來透過數值分析正割法(secant method)[20],尋找成本函數最 小值所對應的βi,從初始值βi(-1)和βi(0)開始,然後以式(3.11)開始 做疊代計算。 ' , ' ' , , (j)- (j-1) (j+1)= (j)- ( (j)) ( (j))- ( (j-1)) i i i i m i i m i i m i i I I I β β β β β β β (3.12) 新的βi(j+1)則用在下一次的疊代過程中,而這個疊代的動作將持續直 到 | (j+1)- (j)|βi βi 小於設定的臨界值(threshold)。因此當疊代的動作 停止時,就是找到可使第 i 個封包音質損害達到最低而聽覺最佳化的 i β 值。 最後,我們整理基於聽覺最佳化的 MD 傳輸系統,如圖(3.4)所示, 其適應性播放排程演算法如下: 1.首先在每個 talkspurt 裡,持續以 AR 方法估計平均網路延遲 (s) ^ i d 和 網路延遲變異數 ( ) ^ s i v ,如式(3.2)及(3.3),直到該 talkspurt 中最後 一個封包。 2.在串流 s 中,每個 talkspurt 裡最後一個封包,更新其之前 L 個封 包的網路延遲與封包網路漏失記錄,並利用它們透過最大概似估計方 法來計算 Pareto 分佈模型的參數(ks、gs),以及( (1) n e 、 (2) n e )。 3.利用 secant method 來計算對應於成本函數最小值的 ^( )s i β : ( ) ( ) ( ) ( ) ^ ^ ^ ^ ( ) ( ) ( ) ( ) , ( ) ( ) ( ( )) s s s s s s s s i i i i m i i d c i e i i I β =I d +d +β v +I e d +β v (3.12)
由於我們是在 talkspurt 之間調整播放延遲,且是以 talkspurt 中最 後一個封包所記錄的網路傳輸資訊(網路延遲及漏失)來建立成本函 數。所以在串流 s 中,每個 talkspurt 將只會尋找一次對應於成本函 數最小值的 ^( )s i β ,且發生在 talkspurt 中最後一個封包,這樣比起針 對每個封包來調整播放延遲的機制將會減少很多的計算量。 4.設定播放延遲: 由上述步驟,串流 s 裡任何一個 talkspurt 中最後一個封包將會找出 一個成本函數最小值的 ^( )s i β 。由於這兩條串流裡的封包屬於同一個語 音音框資訊,因此兩條串流的播放延遲必須設定相同,且是以同時使 得兩串流成本函數得到最低值的β^i ,做為設定下一個 talkspurt 傳 輸播放延遲的安全因子。如式(3.14)所示: ( *) ( *) ( *) ^ ^ ^ , ( ) ^ ( ) , * arg min{ ( ), 1, 2} s s s i i i play i s s i m i d d v s I s β β = + = = (3.14)
stream1 stream2 圖 3.4 MD 傳輸系統 Voice Speech Encoder
AMR-WB or G.729a Multiple Descriptions Speech Encoder
Network Simulator Playout Buffer
(De-jitter)
Delay Distribution Modeling
Multiple Descriptions Speech Decoder
Speech Decoder AMR-WB or G.729a
第
第
第
第四
四
四章
四
章
章
章
結合前向錯誤控制的
結合前向錯誤控制的
結合前向錯誤控制的
結合前向錯誤控制的 MD
MD
MD
MD 傳輸系統
傳輸系統
傳輸系統
傳輸系統
在第三章我們提出 MD 傳輸播放排程演算法的設計,主要是針對 晚到漏失的議題來做研究,以期依聽覺最佳化原則調整其安全因子 (β)。其結果是在合理的播放延遲設定下,有效地降低封包晚到漏失 的機率,並利用 MD 編碼所提供的多重敘述傳輸,減輕了封包因網路 漏失而造成的音質損害。而本章節將主要探討封包傳輸過程中遭遇的
叢發性網路漏失(bursty network loss)問題,並將結合前向錯誤控
制(Forward Error Control, FEC)與第三章的播放排程演算法,提出
一種更強健性的的 MD 語音傳輸系統。
4.1
4.1
4.1
4.1 封包漏失回復機制
封包漏失回復機制
封包漏失回復機制
封包漏失回復機制
網路傳輸協定主要有兩種,TCP (Transport Control
Protocol)和 UDP(User Datagram Protocol) 。TCP 會先建立兩端點
的連線,並使用重傳機制來保證資料不會漏失且不會脫序的可靠性機
制。而 UDP 則是屬於無連接模式,每個封包透過路由器(Router)傳送
到目的地,無論接收端收到封包與否,UDP 皆無須重傳。因此 UDP 較
適用於要求即時服務的互動式影音通訊,缺點則是不能保證資料傳遞