Beveridge-Nelson分解趨勢方法對匯率預測模型績效之影響 -以新台幣兌美元匯率為例 - 政大學術集成
64
0
0
全文
(2) 摘要 本研究以新台幣兌美元之匯率日資料作為主要研究標的,同時加入台灣加權 股價指數及金融業隔夜拆借利率之日資料作為股價與利率之代理變數,利用 Beveridge-Nelson 分解趨勢的方法將變數資料拆解成趨勢項與循環項之時間序列 資料,藉此捕捉匯率資料具有景氣循環的特性。在循環項的序列資料,以向量自 我迴歸模型來分析並予以估計,趨勢項的部分,利用共整合檢定來探討趨勢項變 數間長期的均衡關係,再以向量誤差修正模型予以估計,得到未來 30 天期之匯 率走勢。接著,再以 RMSE 與 MAE 指標來衡量不同模型之匯率預測績效,以期 能找出最適之匯率預測模型。. 立. 政 治 大. 實證研究結果發現,將匯率資料先透過 Beveridge-Nelson 分解趨勢的方法予. ‧ 國. 學. 以拆解後,再利用時間序列模型進行分析及預測,時間序列模型的預測能力都比 原始匯率利用時間序列模型進行預測或透過 ARIMA 模型進行預測還要來的好。. ‧. 因此,根據實證研究的結果,若企業與政府在進行匯率預測的分析時,能夠考慮. y. Nat. sit. 先將匯率資料透過 Beveridge-Nelson 分解方法予以處理,便能更有效提升模型的. n. al. er. io. 預測能力,除了企業能夠降低避險成本來提高公司整體績效,對於國家而言,有. i n U. v. 效的掌握匯率的趨勢便能夠迅速且正確的制定政策,提升國家的經濟發展。. Ch. engchi. 關鍵字:匯率預測、Beveridge-Nelson 分解、向量誤差修正模型 I.
(3) 目錄 摘要. I. 目錄. II. 表目錄. IV. 圖目錄. V. 第壹章. 緒論 ................................................ 1. 第一節. 研究背景與動機 ..................................................................... 1. 第二節. 研究目的 ................................................................................ 2. 第貳章. 政 治 大. 文獻回顧 ............................................ 6. 立. 匯率預測相關文獻 ................................................................. 6. 學. ‧ 國. 第一節 第二節. 匯率、股價及利率之關聯性探討之相關文獻 ......................... 9. 第三節. Beveridge-Nelson 分解 .......................................................11. ‧. 研究方法 ........................................... 13. y. Nat. 第一節. 單根檢定(Unit Root Test)..................................................13. sit. 第參章. 第三節. 最適落後期之選取 ................................................................17. 第四節. 預測績效指標 ........................................................................18. 第五節. 向量自我迴歸模型(Vector Autoregression,VAR) ..............19. 第六節. 共整合與向量誤差修正模型 ..................................................20. 第七節. Beveridge-Nelson 分解(B-N 分解).....................................25. n. al. er. ARMA(p,q)/ARIMA(p,d,q) ....................................................15. io. 第二節. 第肆章. Ch. engchi. i n U. v. 實證分析 ........................................... 28. 第一節. 資料來源及分析 ....................................................................28. 第二節. ADF 單根檢定 ......................................................................28. 第三節. 匯率預測─ARIMA 模型 ......................................................30. 第四節. 匯率預測─向量誤差修正模型 ..............................................31 II.
(4) 第五節. 匯率預測─Beveridge-Nelson 之應用 ....................................34. 第六節. 績效比較 ...............................................................................43. 第伍章. 結論與建議 ......................................... 45. 第一節. 結論 .......................................................................................45. 第二節. 研究建議 ...............................................................................46. 第陸章. 附表 ............................................... 48. 參考文獻 ..................................................... 55. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. III. i n U. v.
(5) 表目錄 表 4-1. 樣本資料期間與資料筆數 ............................... 28. 表 4-2. 樣本資料之敘述統計分析 ............................... 28. 表 4-3.1. 匯率資料之 ADF 檢定 ................................... 29. 表 4-3.2. 股價資料之 ADF 檢定 ................................... 29. 表 4-3.3. 利率資料之 ADF 檢定 ................................... 29. 表 4-4. ARIMA(2,1,2)模型估計係數 ............................. 30. 表 4-5. ARIMA(2,1,2)模型之匯率預測績效表現 .................... 31. 表 4-6. 匯率、股價及利率─Johansen 共整合檢定 ................. 31. 表 4-7. 匯率、股價及利率之共整合向量 .......................... 32. 表 4-8.1. 誤差修正項之估計係數 ................................. 33. 表 4-8.2. 向量誤差修正模型估計係數 ............................. 33. 表 4-9. 向量誤差修正模型之匯率預測績效表現 .................... 34. 表 4-10. 匯率之趨勢項、一階差分趨勢項及循環項之 ADF 檢定 ........ 36. 表 4-11. 股價趨勢項、一階差分後趨勢項及循環項之 ADF 檢定 ........ 37. 表 4-12. 利率趨勢項、一階差分後趨勢項及循環項之 ADF 檢定 ........ 37. 表 4-13. 調整後之 LR 值 ........................................ 38. 表 4-14. 匯率、股價及利率趨勢項─Johansen 共整合檢定 ........... 38. 表 4-15. 匯率、股價及利率趨勢項部分之共整合向量 ................ 39. 表 4-16.1. 誤差修正項之估計係數 ................................. 40. 表 4-16.2. 向量誤差修正模型估計係數 ............................. 40. 表 4-17. 循環項落後期之選取 ................................... 41. 表 4-18. VAR(8)模型之估計係數 ................................. 42. 表 4-19. Beveridge-Nelson 拆解之匯率預測績效表現 ............... 43. 表 4-20. 匯率預測績效表現比較表 ............................... 44. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. IV. i n U. v.
(6) 圖目錄 圖 1.1. 匯率走勢圖(2003/01/01~2013/12/05) ..................... 3. 圖2. 原始樣本資料、趨勢項和循環項波動圖 .................... 35. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. V. i n U. v.
(7) 第壹章 緒論 第一節 研究背景與動機 匯率為兩國之間貨幣交換的一個比率,換句話說就是用一國貨幣表示另一國 貨幣的價格,而自 1973 年布列敦森林制度(Bretton Woods System)瓦解後,各國 紛紛放棄固定匯率制度,而台灣也自 1978 年宣布放棄固定匯率制度改採機動匯 率制度,加上國際貿易活動漸漸頻繁,匯率的變動將會受到市場供需所造成貨幣 交換量多寡的影響,導致匯率波動的不確定性相較於過去採用固定匯率制度的年 代增加許多,對於各公司企業在匯率避險上,難度也提升不少,因此,如果我們. 政 治 大. 能夠找出一個最適的匯率預測模型,使其對於匯率預測有較佳的績效表現,就能. 立. 夠讓企業降低其避險成本來提高公司的報酬,因此,匯率走勢之研究一直以來都. ‧ 國. 學. 是財務領域上重要議題。. 美元一直以來都是國際的準備貨幣,加上台灣的經濟貿易活動主要以出口為. ‧. 導向,截至 2013 年止台灣對外貿易總額達到 5,732.9 億美元,其中出口總額就達. y. Nat. sit. 3,032.2 億美元,對美國出口總額為 324.86 億美元,顯示美國依然為台灣主要出. n. al. er. io. 口的國家,因此,新台幣兌美元匯率就不單只是企業關注的經濟數據而已,更是. i n U. v. 影響台灣整體經濟發展的主要因子,政府採取機動的浮動匯率制度,目的也是為. Ch. engchi. 了能夠在不影響台灣整體經濟發展的條件下來實施匯率的自由化,所以,以新台 幣兌美元作為研究標的,依舊是在匯率預測上相當重要的一個主題。 在匯率預測研究當中,過去有相當多的實證研究都以經濟理論為基礎來進行 分析,從最早提出的購買力平價理論(Purchase Power Parity)、利率平價理論 (Interest Rate Parity),甚至連貨幣學派的學者都提出了相關理論來探討匯率決定 的因素。雖然現在各國紛紛採用浮動的匯率制度,處在國際貿易活動頻繁的時代, 各國政府勢必會採取某些手段來干預匯市及資本市場來維持整個國家的經濟,這 些干預的做法都會造成經濟理論與現實不符的情況。此外,上述經濟理論所建立 的模型,往往只能分析變數間的單一方向的影響,也就是說,我們並無法來衡量 1.
(8) 自變數是否會受到因變數的影響,加上模型中所採用的總體經濟變數,如購買力 平價理論中衡量通膨的消費者物價指數按月發布,衡量該國經濟活動的經濟成長 率則按季發布,而貨幣理論中衡量貨幣總計數的 M1A 與 M2B 則都由中央銀行 按月來發布,受限於總體經濟數據發布的頻率,我們若是將這些低頻的經濟變數 作為樣本資料來預測高頻的每日匯率走勢,除了可能會有資料筆數過少造成訊息 的蒐集不夠完全外,更可能會產生模型配適不適的問題,預測的績效表現勢必受 到影響。因此,在本篇研究中,我們便以高頻的日資料,如台灣加權股價指數及 金融業隔夜拆借利率等發布頻率為日資料型態來做為本文中樣本資料的選取,透. 政 治 大 決資料筆數過少的問題,讓訊息可以更完整的被揭露,同時透過共整合檢定及向 立. 過時間序列的分析模型,將資料過去的歷史訊息擷取並建立模型,可以有效的解. 量誤差修正模型(Vector Error Correction Model,VECM)來探討變數間長期的均衡. ‧ 國. 學. 關係,最後,透過分解趨勢的方法將資料做拆解,更能有效地描繪出個別資料的. Nat. y. ‧. 型態並加以估計,以期能建立出最適的匯率預測模型。. er. io. sit. 第二節 研究目的. 在做經濟數據的預測時,早期學者認為匯率的變動可以透過總體經濟理論來. al. n. v i n 解釋,如利率平價理論、購買力平價理論等,因而在過去我們常將原始資料直接 Ch engchi U 分析並做出預測,但由於實行浮動匯率制度後,匯率的資料型態開始變得更加複 雜且不穩定,加上原始樣本資料型態往往都是非定態的時間序列資料,預測出來 的績效表現往往有其侷限性;因此,我們試著利用 Beveridge-Nelson 的拆解方法, 將各個變數拆解成長期趨勢項及短期波動項之時間序列資料,並分析變數間在長、 短期間之關聯性。 雖然 Beveridge-Nelson 的分解方法多數運用在衡量總體經濟的景氣循環研究 上,我們依然可以將其分解的方法運用在多數非定態的時間序列資料上。從圖一 的匯率走勢圖,我們可以發現匯率從 03 年以來,長期而言,匯率的走勢一直有 2.
(9) 往下的趨勢存在;同時,我們也可以從短期的波段來觀察匯率的走勢,03 年一 整年新台幣兌美元的匯率的走勢是持續升值,直到 04 年的 4 月 13 日新台幣兌美 元匯率升值為 32.81;四月下旬受到中國經濟降溫措施和美國升息的預期,新台 幣兌美元匯率則開始走貶,8 月 6 日貶至 34.12 為 04 年全年之最低價位;八月 中旬因為國際資金大量回流亞洲並大舉加碼台股,在匯市供過於求的情況下,造 成新台幣兌美元匯率又轉而走升。此外,我們也可以觀察在 08 年至 12 年的匯率 波段,08 年初受到美國次貸危機的影響,Fed 持續的降息造成美元走弱,使得新 台幣兌美元匯率在 08 年初期走升,一直到 08 年 3 月 25 日新台幣兌美元匯率. 政 治 大 幅的衰退及外資移出,新台幣兌美元匯率則持續走貶,至 09 年 3 月 2 日貶破 35 立 29.995 為自 03 年以來的最高價位,之後受到金融海嘯持續的影響,造成出口大. 元,該日匯率最低價位為 35.165 元,而後受到美國 Fed 實施量化寬鬆(Quantitative. ‧ 國. 學. easing)的貨幣政策,使得美元走貶造成新台幣兌美元匯率持續走升的現象。. ‧. n. er. io. sit. y. Nat. al. 圖 1.1. Ch. engchi. i n U. v. 匯率走勢圖(2003/01/01~2013/12/05). 所謂的景氣循環,指的是經濟變數在長時間下無法維持一個穩定而呈現上下 波動的現象,一般我們將景氣循環分成衰退、蕭條、復甦及繁榮四個階段,從上 3.
(10) 述的觀察,我們可以發現匯率也有類似景氣循環的特性,我們便可以透過 Beveridge-Nelson 分解趨勢的方法加以拆解,藉以完整捕捉匯率資料的特性,接 著,我們利用向量誤差修正模型來探討各個變數非定態趨勢項間之長期均衡關係, 在短期的定態循環項時間序列資料,我們則透過向量自我迴歸模型(Vector autoregression,VAR)來分析各變數循環項間短期之影響,最後,將所預測出之趨 勢項及循環項合併得到我們想要預測的匯率序列資料。 時間序列的分析模型當中,過去在匯率預測的文獻大部分都以 ARIMA 模型 作為主要分析模型,如 Fang and Kwong(1991)以 1983 年 1 月至 1988 年 12 月之. 政 治 大 發現以匯率預測數字準確度而言,以 ARIMA 模型之準確度最佳; Mehran and 立. 美元對英鎊之月資料來作為研究標的,分析不同模型間匯率預測表現比較,結果. Shahrokhi(1997)利用 ARIMA 模型、隨機漫步、遠期匯率模型和即期匯率模型來. ‧ 國. 學. 探討不同模型間匯率預測的績效表現,研究結果也發現以 ARIMA 模型所預測出. ‧. 之績效多數情況都優於其他模型之績效表現;在國內文獻當中,林家卉(2008)也. y. Nat. 以美元兌新台幣之即期匯率作為研究標的,探討以 ARIMA 模型來進行匯率預測. er. io. sit. 之績效表現,實證結果顯示,不論是長短期的估計期間,ARIMA 模型都有不錯 之績效表現,顯示將 ARIMA 模型應用在匯率預測領域上,都可以得到不錯之預. n. al. 測效果。. Ch. engchi. i n U. v. 因此,在本篇論文當中,我們便以 ARIMA 模型作為不同模型間的比較基準, 我們希望能夠透過不同模型間的績效比較,在我們所建立的研究架構方法下(如 圖 1.2),找出最適的匯率預測模型,並希望利用 Beveridge-Nelson 方法拆解後的 資料來進行資料分析及匯率預測,整體而言,會優於一般匯率預測模型的績效表 現。. 4.
(11) 政 治 大. 立. ‧. ‧ 國. 學. io. sit. y. 模型間分析架構圖. n. al. er. Nat. 圖 1.2. Ch. engchi. 5. i n U. v.
(12) 第貳章 文獻回顧 第一節 匯率預測相關文獻 (一). 匯率決定理論. Edison and Fisher(1991)以英鎊兌美元、馬克兌美元兩種匯率作為研究標 的,以購買力平價理論為基礎下,利用了 Johansen 共整合分析檢定與誤差修正 模型來探討歐洲貨幣體系(European Monetary System,EMS)下的長期觀點,研究 發現,兩種匯率不論是在短期或長期的預測下,模型的預測能力都較隨機漫步模. 政 治 大 MacDonald and Marsh(1997)利用動態調整模型,將購買力平價模型加入了 立. 型為佳。. 未拋補利率平價說及實質利率差的模型後對匯率進行估計,預測結果發現當預測. ‧ 國. 學. 期間超過三個月以上時,預測的績效表現會優於隨機漫步模型,說明了購買力平. ‧. 價模型提出的兩國間相對的貨幣購買力,對於長期匯率仍具有相當的解釋力。. y. Nat. MacDonald(1999)則主張以購買力平價理論作為模型的架構,可以更有效地. er. io. sit. 捕捉匯率波動的行為,藉此探討模型對匯率的解釋能力及預測能力。 黎明淵(2002)採用非線性的馬可夫轉換模型來探討購買力平價模型對於匯. al. n. v i n 率解釋能力的實證研究。實證研究結果指出,PPP 模型對於匯率的解釋能力在匯 Ch engchi U 率處於低波動狀態時具有統計上顯著,而在高波動狀態下則不具顯著性;此外,. 在預測能力方面,結合 PPP 理論之馬可夫轉換模型績效表現會優於以 PPP 模型或 馬可夫轉換模型個別預測時為佳。 Branson(1969)利用美元、加幣及英鎊三國的貨幣作為研究標的,以樣本期 間 1962 年 7 月至 1964 年 12 月這段期間來檢定利率平價理論是否成立,實證研 究結果發現,因為有套利的交易成本存在,使得利率平價理論是不成立的。 Frankel and Levich(1975,1977)同樣也提出在實際的資本市場交易活動當中, 存放款利率及買賣匯率間存在著差異的情況下,利率平價理論是不成立的。 6.
(13) Aliber(1973)以 1968 年 1 月至 1970 年 6 月期間來檢定利率平價理論的成立 與否,其實證研究結果發現利率平價條件的成立可能因為不同資本管制產生的政 治風險而不成立。 Jong-Cook Byun and Son-Nan Chen(1996)以經濟合作暨發展組織 (Organization for Economic Cooperation and Development,OECD)中十個國家 90 天期國庫券每日平均後之月利率作為短期名目利率,透過誤差修正模型來對 1960 年 2 月至 1991 年 7 月期間進行檢定,實證研究結果發現,國際間利率平價 理論長期而言是成立的。. 政 治 大 四個不同的階段來檢定無拋補利率平價理論,驗證其是否能夠用來解釋台灣在這 立 沈中華(1992)依據制度的改變將樣本期間 1960 年 1 月至 1989 年 12 月分成. 四個不同階段利率與匯率之間的關係。其結果發現,資本及利率遭到政府的刻意. ‧ 國. 學. 管制,加上央行採取機動的浮動匯率制度對匯率干預的情況下,使得不論在哪一. ‧. 個階段下無拋補利率平價理論皆是不成立的。. y. Nat. Frankel(1976a)以馬克兌美元的匯率資料作為研究標的,選取 1920 年 2. er. io. sit. 月至 1923 2 年 8 月的樣本期間,利用無拋補利率平價條件做為理論基礎,將 預期名目匯率的變動做為遠期溢價的替代變數,把名目匯率、貨幣供給和預期貶. al. n. v i n 值率取對數後以普通最小平方法來進行實證,在實證期間德國存在著惡性通貨膨 Ch engchi U 脹的現象,因此,Frankel 認為德國的貨幣衝擊(monetary impulses)是決定匯. 率的主要因素,即物價是匯率波動的主要原因,因而忽略國內外所得變動的衝擊 因素,將焦點放在德國的通貨與預期通貨膨脹上,實證研究的結果支持浮動價格 模型(flexible-price monetary model)。Bilson(1978)也利用相同的模型在加 入落後項之後,對樣本期間 1972 年至 1976 年馬克兌英鎊的匯率資料來進行實證 分析,實證結果也支持浮動價格模型。 MacDonald and Taylor(1994)選取 1976 年資料,檢定英鎊兌美元的名目匯 率與相對貨幣供給、實質所得、長期利率間是否存在共整合關係。實證方法採用 7.
(14) 多變量的共整合分析方法,結果發現變數間存在共整合關係。在發現變數間存在 共整合關係後,MacDonald and Taylor 更進一步利用誤差修正模型來分析變數 之間的短期動態過程,發現以誤差修正模型做樣本外預測的績效表現遠優於隨機 漫步模型的績效表現。 楊凱文(2001) 以貨幣學派的匯率決定模型所隱含的總體經濟變數做為檢定 的基礎,這些變數包括兩國相對物價水準、相對貨幣供給額、相對所得及兩國名 目利率的差距等,透過共整合分析來探討這些變數和新臺幣對美元匯率間之長期 關係,以期更能適切地解釋匯率的變動。. 政 治 大 Differential,RID)為基礎模型,導入馬可夫轉換的機制,並且以台灣及韓國貨 立 陳秀香(2006)以 Frankel(1979)的實質利率差異模型(Real Interest. 幣作為研究對象,探討貨幣模型是否能夠解釋匯率的波動行為。實證研究結果發. ‧ 國. 學. 現,傳統的 RID 模型並不能夠完全的解釋匯率的波動行為,但在加入了馬可夫的. ‧. 轉換機制後,模型的解釋能力有顯著的改善;此外,透過穩健性分析(robustness. y. Nat. analysis)發現,在台灣的資料當中,利率最能夠捕捉匯率的波動行為,而韓國. n. al. er. io. sit. 的資料中,不論是貨幣供給、產出和利率對於匯率的解釋能力都是一樣的重要。. (二). ARIMA 模型. Ch. engchi. i n U. v. Fang and Kwong(1991)探討分別利用遠期匯率模型、ARIMA 模型及迴歸模型 進行匯率預測時的比較。研究樣本期間以 1983 年 1 月至 1988 年 12 月之美元對 英鎊之月資料來作為研究的標的,結果發現,以匯率預測數字準確度而言,以 ARIMA 模型之準確度最佳;但若以匯率變動方向而言,則以迴歸模型有較佳的解 釋能力。 Mehran and Shahrokhi(1997)利用 ARIMA 模型、隨機漫步、遠期匯率模型和 即期匯率模型來探討不同模型間匯率預測的績效表現。樣本研究期間為 1982 年 1 月至 1991 年 2 月,採用墨西哥披索兌美元之匯率日資料作為研究之標的,並 8.
(15) 以均方根誤差(RMSE)、平均絕對誤差(MAE)和平均絕對誤差百分比(MAPE)三種績 效指標來衡量,研究結果發現以 ARIMA 模型所預測出之績效多數情況都優於其他 模型之績效表現。 張小彤(2003) 利用 ARIMA 模型研究新台幣對美元匯率月資料的預測,樣本 期間從 1989 年 1 月至 2002 年 12 月來預測在 2003 年匯率之趨勢變化,研究結果 發現,以 2002 年的月匯率資料為驗證期,預測結果的平均誤差為 0.2152;並將 預測期間分類為一季、半年及一年來做預測結果之比較,結果發現以三個月的預 測效果為最佳,因此,以季預測的效果較佳。. 政 治 大 預測匯率,並以三種衡量績效指標的誤差均方根(RMSE)、平均誤差絕對值(MAE) 立. 管相柔(2007)以不同頻率的匯率日資料及月資料,並以 ARIMA 模型為基礎來. 及平均絕對誤差百分比(MAPE)值來做為衡量的標準,研究結果發現,不論以哪種. ‧ 國. 學. 績效指標作為衡量的依據,日資料所預測出的誤差值都比月資料要來的小,顯示. ‧. 出高頻資料之預測能力的確較低頻資料要來的佳。. y. Nat. 林家卉(2008) 以美元兌新台幣之即期匯率作為研究標的,以 ARIMA 模型來. er. io. sit. 進行匯率之預測,研究之樣本內期間為 2006 年 1 月 1 日至 2008 年 5 月 31 日與 2008 年 3 月 1 日至 2008 年 5 月 31 日,樣本外期間為 2008 年 6 月 1 日至 2008. al. n. v i n 年 6 月 20 日,研究結果顯示,無論是用較長期間估計期間或較短估計期間,該 Ch engchi U. 模型都有不錯之績效表現,顯示將 ARIMA 模型應用在匯率預測領域上,可以得到 不錯之預測效果。. 第二節 匯率、股價及利率之關聯性探討之相關文獻 (一) 匯率與股價之關聯性 Dornbusch and Fischer(1980)的研究提到經常帳餘額與匯率的關係,該模 型研究結果發現,匯率的變動會影響一個國家在國際競爭的地位及該國之實質收 入及產出,此外,由於公司的股價是對於未來預期現金流的折現值,當國家的貨 9.
(16) 幣貶值,對於出口商而言,其出口商品相對便宜了有利於出口,公司獲利進而拉 抬公司股價,即貨幣的移動最終會影響到股價的論點。而 Hekman(1985)的研究 結果提出了匯率是股票價格的其中一個解釋變數,也同樣驗證了相同的論點。 Branson and Frankel(1983)指出,匯率決定於股票、債券等金融商品的供 需情況,舉例而言,股票市場的供需情況,會透過財富效果和流動性效果進而影 響貨幣需求,當股價下跌時,會導致投資大眾的財富相對減少,流動性也降低, 貨幣需求的減少造成利率的下跌,而利率的下跌不利於資本的流入進而影響匯率, 造成匯率的貶值,因此,金融資產價格的變動會影響匯率變動的情形,這樣的觀. 政 治 大 Pan,Fok,&Liu(2007)探討七個亞洲新興國家匯率和股價的動態關聯性,樣本 立. 點也建立了匯率與股票間因果關係之理論模型。. 期間採用 1988 年 1 月至 1998 年 10 月期間的資料,而這七個國家分別是香港、. ‧ 國. 學. 韓國、日本、馬來西亞、新加坡、台灣、和泰國,結果顯示,匯率和股價兩者的. y. Nat. 不同。. ‧. 關聯性可能會因為各個國家的匯率政策、進出口貿易、資本控制程度大小而有所. er. io. sit. 張鳳貞(1999)以民國 86 年 7 月 2 日至 88 年 2 月 26 日之日資料,再利用共 整合與向量誤差修正模型來研究匯率、利率與股價指數三個變數間的長期均衡關. al. n. v i n 係及短期的動態調整過程,其實證結果發現,在長期,匯率與股價指數具有反向 Ch engchi U 變動關係。. (二) 匯率與利率之關聯性 Hatemi-J & Manuchehr(2000)利用利率與匯率之因果關係,實證結果發現, 在固定匯率制度時,匯率與利率呈現了單一影響之因果關係;在浮動匯率時因果 關係卻表現出相反之方向。 Benigno,Benigno & Ghironi(2007)研究出經過設計的利率規則可以維持匯率 的穩定性,同時結果亦顯示出一個現代化的總體經濟架構中,利率、匯率政策及 10.
(17) 合理預期平衡的決定是有關連性的。 陳翊鏵(2001)參考 Hatemi-J&Manuchehr 的研究,基於國際收支帳平衡之假 設,推演出一套以利率、匯率因果方向判斷一國資本移動程度之模型,實證結果 發現,隨著管制的逐步開放,匯率對利率的單向因果關係將逐漸轉換為匯率、利 率雙向影響之因果關係,證明資本移動在這段管制開放的期間內確實有所增加; 而加入資本移動進行實證的結果,再度證實資本移動隨著管制的開放,與雙率的 互動更顯的密切。. (三) 匯率、股價及利率之關聯性. 政 治 大 Kim(2003)利用了 Johansen 的共整合分析來探討美國股價、實質匯率、工業 立. 生產、利率和通貨膨脹長期間的均衡關係,樣本資料為月資料,研究期間為 1974. ‧ 國. 學. 年 1 月至 1998 年 12 月,研究結果發現美國 S&P 500 股價指數和工業生產呈現正. ‧. 相關的關係,但與實質匯率、利率及通貨膨脹則呈現反向的關係。. y. Nat. 朱清貴(2008)則利用了向量自我迴歸模型(VAR)來探討匯率、股價、利率及. er. io. sit. 物價四者間的關聯性,同時加入了衝擊反應函數(Impulse response function,IRF)的概念來驗證當一個變數發生變動時,可能會對其他變數監所產. al. n. v i n 生的衝擊影響大小,進而分析並且釐清四個變數間互動所造成的影響。 Ch engchi U 第三節 Beveridge-Nelson 分解. 在衡量一個國家的景氣循環時,經常因為每個國家的經濟體特性的不同,而 可能發展出不同面向的衡量方法,在國外文獻上所提到的方法有兩種,分別為「古 典循環」和「成長循環」。古典循環所衡量的,是國家經濟活動「絕對數值」的 上升或下降,而成長循環則是衡量經濟活動在去除長期趨勢(detrending)後的 變化情形,所以,在衡量景氣循環的實證研究上,便會發展出許多不同分解趨勢 的方法,而 Beveridge-Nelson 分解則是其中一種方法。 11.
(18) Beveridge,Nelson(1981)建立了一個分解趨勢的方法,將非定態的時間序列資 料拆解成趨勢項和循環項,並利用美國 1947 年第二季至 1977 年第一季的季資料 來進行景氣循環的實證研究,其研究大致上皆符合美國國家經濟研究局(NBER) 的資料。 Attfield,Silverstone(1998)利用 Beveridge-Nelson 的拆解方法來對序列資料做 拆解,估計出產出和失業率的潛在水準值,將實際值與潛在水準值相減的差定義 為循環項,再利用共整合分析來估計美國的資料,得到了與奧肯法則類似的結 果。. 政 治 大 不同的分解方法來預估潛在水準值,結果發現不論採用何種分解方法,在循環性 立 Lee(2000)更進一步利用 Hodrick-Prescott,Beveridge-Nelson 與 Kalman 三種. 產出和循環性失業之間仍然具有負向的關係。. ‧ 國. 學. 彭惠琴(2003)以奧肯法則和菲利浦曲線的相關理論,利用三種不同的分解. ‧. 方法(H-P 分解、B-N 分解及 Kalman 分解)對產出和就業這兩個變數進行分析,. y. Nat. 將各個變數分別拆解成趨勢項及循環項之時間序列資料,檢定產出與失業間、通. er. io. sit. 貨膨脹和失業間之關聯性;同時,也利用向量自我迴歸的衝擊反應函數和誤差變 異分解,以及共整合與共特徵(co-integration and co-feature)搭配趨勢項與循環. al. n. v i n 項分解的分析,來探討變數間長期間的均衡關係及跨景氣循環短中期共同移動現 Ch engchi U 象。. Beveridge-Nelson 分解的方法普遍應用在估計景氣循環的研究上,主要是由 於它能夠捕捉到景氣循環上的一些特性,但我們還是可以將其運用在多數時間序 列資料的分析上,並且得到一些有趣的經濟意涵。由於匯率的序列資料多數為非 定態的時間序列資料,我們透過 Beveridge-Nelson 的分解,將非定態的匯率趨勢 項資料運用共整合分析來探討與股價、利率間的長期均衡關係,同時利用向量自 我迴歸的模型來分析變數間的交互影響,並進而預測未來匯率的走勢。. 12.
(19) 第參章 研究方法 在運用時間序列資料分析時,首先,我們所要瞭解的是該序列資料是否為定 態,所謂的定態(stationarity),是指外來衝擊對於時間序列資料可能只造成短暫 的影響,隨著時間的經過,外來衝擊所造成的效應會逐漸地消失,而使資料重新 回到長期均衡的水準。在 1974 年 Granger 及 Newbold 發現,若資料型態為非定 態時,所分析出的結果可能會有「虛假迴歸(spurious regression)」的問題,一旦 沒有察覺到虛假迴歸的情況,則可能會造成實證研究結果的誤判,造成研究結果 與實際情況不符之情況。. 政 治 大 卻發現,多數的經濟或財務領域上時間序列資料往往都為非定態的資料型態,造 立 過去傳統時間序列的計量方法都著重在定態時間序列資料的研究上,但我們. ‧ 國. 學. 成了過去許多實證研究的結果可能遭到推翻,然而,在 Engle and Granger(1987) 提出了共整合(cointegration)相關理論之後,這樣的問題終於得到了解答。因. ‧. 此,本章將會介紹時間序列分析的相關理論,包括了資料型態是否為定態的檢定. n. al. er. io. 自我迴歸、誤差修正模型及 Beveridge-Nelson 分解。. sit. y. Nat. 方法、共整合相關理論等,同時也涵蓋了本篇論文中所用到之相關模型,如向量. C h Test) 第一節 單根檢定(Unit Root e. ngchi. i n U. v. 單根檢定目前學者常用的方法普遍有 Dickey-Fuller test (DF 檢定)、 Augmented DF test (ADF 檢定)、Phillips-Perron test(PP 檢定) 以及 Panel 檢定……等等,而本節僅針對本文所使用之 ADF 檢定的介紹說明如下: Dickey and Fuller(1979)提出了 DF 單根檢定的方法,是利用最小平方法來 進行迴歸式參數的估計,因此,在迴歸估計後的殘差項是否符合白噪音的性質就 會影響到迴歸估計係數的性質,當迴歸式中的殘差項出現一階自我相關的現象及 非白噪音的現象時,可能造成 DF 值的不正確,導致於無法拒絕錯誤的虛無假設 的機率增加,也就是 DF 檢定的檢定力不足;因此,Dickey and Fuller(1981) 13.
(20) 便針對 DF 單根檢定方法所可能產生的問題提出了修正的方法,假設殘差項為白 噪音下,將模型 DF 檢定式中再加入被解釋變數變數(𝑦𝑡 )差分的落後項(Lags)後, 使檢定估計式的殘差項符合白噪音的性質後,再進行單根檢定。 ADF 單根檢定包含三種模型如下:. (一)不含截距項和時間趨勢項 p. ∆yt = γyt−1 + ∑ βi ∆yt−i+1 + et i=1. 學. ‧ 國. 政 治 大 (二)含截距項但不含時間趨勢項 立 p. ∆yt = a0 + γyt−1 + ∑ βi ∆yt−i+1 + et. ‧. i=1. n. al. p. ∆yt = a0 + γyt−1 + a1 t + ∑ βi ∆yt−i+1 + et. Ci=1h. engchi. er. io. sit. y. Nat. (三)含截距項與時間趨勢項. i n U. v. p. 其中,p 為最適落後期數,a0 為截距項,t為時間趨勢項,∑i=1 βi ∆yt−i+1為被 解釋變數的落後項,落後項的最適落後期 p 的選擇可以利用 AIC 及 SBC 之最小估 計值作為判定標準。本文以 SBC 作為判定標準。 上述三種模型的虛無假設與對立假設分別如下:. H0 (虛無假設):yt 具有單根;γ = 0;序列資料呈現非定態。 H𝑎 (對立假設):yt 不具有單根;γ < 0;序列資料呈現定態。. 14.
(21) 透過 ADF 單根檢定,若檢定結果拒絕虛無假設,表示yt 不具有單根,即該時 間序列資料為定態;但若檢定結果為不拒絕虛無假設,表示 ADF 檢定無法去拒絕 yt 不具有單根,即該序列資料型態為非定態的時間序列資料,可能出現「虛假迴 歸」的問題,故我們需先將序列資料先做差分後在做單根檢定,直至序列資料為 定態的資料型態。. 第二節 ARMA(p,q)/ARIMA(p,d,q) ARMA 模型是 1976 年由 Box 和 Jenkins 兩位學者所提出的模型,是一種時間. 政 治 大 過程」,在時間序列的理論當中,指的就是「現在的變數和過去的變數的函數或 立. 序列的「資料產生過程(Data generating process,DGP)」,而所謂的「資料產生. 統計『關係』」 。模型的前提假設是該時間序列資料型態必須是定態,但由於多數. ‧ 國. 學. 在總體經濟上的時間序列資料型態多為非定態(non-stationarity)的時間序列. ‧. 資料,所以後來便將 ARMA 模型加以擴展成一般化的 ARIMA 模型來表示非定態的. sit. y. Nat. 時間序列資料;其一般化模型設定型態的說明如下:. er. io. (一)自我迴歸模型(Autoregressive model,簡稱 AR 模型):AR(p). n. al. i n U. v. AR 模型的意義,簡單來說就是現在的某一變數值,會和同一變數值過去的. Ch. engchi. 變數值,可能是第一期、第二期,甚至到第 p 期等有關;換句話說,就是當期的 變數yt 為該變數過去 p 期的變數值yt−p 之函數,而 p 期的選擇則依據 AIC 或 SBC 準則來決定。 AR(p)之一般化模型為: p. yt = a0 + ∑ ai yt−i + εt i=1. 其中,a0 表示常數的截距項,p 代表落後期數,ai 為yt−i 的係數,εt 是白噪音。. 15.
(22) (二)移動平均模型(Moving average model,簡稱 MA 模型):MA(q) MA 模型隱含「經濟行為體系的結構式中,含有『誤差修正(error correction)』 的特性」,也就是該變數長期而言,是具有往「均衡方向調整」的特性,即使在 短期可能有偏離均衡的現象,但偏離均衡的現象長期會透過誤差修正機能而使得 差距慢慢的縮小,換句話說,就是當期變數yt 為該變數過去 q 期的隨機誤差值εt−p 之函數,而 q 期的選擇則依據 AIC 或 SBC 準則來決定。 MA(q)之一般化模型為: q. 政 治 大. yt = a0 + εi + ∑ bi εt−i i=1. 立. ‧ 國. 學. 其中,a0 表示常數的截距項,q 代表落後期數,bi 為εt−i 的係數,εi 是白噪音。. ‧. (三) 自我迴歸與移動平均模型(Autoregressive and moving average model,簡稱. y. Nat. ARMA 模型):ARMA(p,q). er. io. sit. ARMA 模型為上述 AR 與 MA 模型的結合,即當期的變數yt 為該變數過去 p 期的變數值yt−p 與過去 q 期的隨機誤差值εt−p 之函數,而 p 和 q 期的選擇則依據. n. al. AIC 或 SBC 準則來決定。. Ch. ARMA(p,q)一般化模型為:. engchi p. i n U. v. q. yt = a0 + ∑ ai yt−i + εi + ∑ bi εt−i i=1. i=1. 其中,a0 表示常數的截距項,p 代表落後期數,q 代表落後期數,ai 為yt−i 的 係數,bi 為εt−i 的係數,εi 是白噪音。. (四)自我迴歸整合移動平均模型(Autoregressive Integrated Moving Average 16.
(23) Model,簡稱 ARIMA 模型) 當時間序列變數呈現隨機漫步(Random Walk,RW)這種非定態的情況時,在利 用 ARMA 模型估計時會有向下偏誤的問題,Box-Jenkins 的模型將不再適用。但 我們可以透過將 ARMA 模型擴展成 ARIMA 模型,可以解決模型估計上偏誤的問題, 使模型依然可以適用非定態時間序列的資料。 ARIMA(p,d,q)一般化模型為: p. q. d. d. ∆ yt = a0 + ∑ ai ∆ yt−i + et + ∑ bi et−i i=1. i=1. 政 治 大 其中,∆ y 表示將y 立 變數差分 d 次。我們可以想成,ARIMA 模型與 ARMA 模 d. t. t. ‧ 國. 學. 型的定義幾乎完全一樣,差別在於 ARIMA(p,d,q)模型是以∆d yt 取代原本 ARMA(p,q)模型中的yt 變數作為被解釋變數。. ‧ sit. y. Nat. 第三節 最適落後期之選取. v ni 2. n. al. er. io. 傳統上,在迴歸模型當中模型配適度的評估最常使用的是判定係數𝑅 2 (coefficient of determination)或調整後判定係數𝑅 (adjusted coefficient. Ch. engchi U. of determination),但是,在時間序列分析的實證研究當中,透過上述兩者作 為模型配適度的指標情形並不多見,多數實證所採行的方法,反而以 Akaike(1973)所提出的 AIC(Akaike information criterion)判定準則或 Schwartz (1978)所提出的 SBC(Schwartz Bayesian information criterion, 也被簡寫為 SBIC、BIC 或 SC)判定準則作為模型選擇的基準。其判定指標之計算 式分別如下: AIC = Tln(SSE) + 2k SBC = Tln(SSE) + k ln(T). 17.
(24) 其中,T 為樣本總數,ln(SSE)是 SSE(殘差平方和)取自然對數,k 是待估參 數總數。 從統計的觀點我們可以知道,SST = SSR + SSE,當 SSR 越大則代表模型當 中樣本資料對於模型的解釋能力越好,若假設 SST 固定不變的情形下,SSE 越小 則相對代表著 SSR 越大,及樣本資料對於模型的解釋能力越好,因此,在模型配 適度的判定準則,我們可以發現是以 AIC 或者是 SBC 之最小值作為最適模型選 取。. 第四節 預測績效指標. 政 治 大 在比較不同模型樣本外預測力的指標,在文獻上常用的有兩種,分別為「誤 立. 差的均方根」(Root Mean Square Error,RMSE)及「平均誤差絕對值」(Mean. ‧ 國. 學. Absolute Error,MAE),以下我們便針對兩種指標來一一介紹:. ‧. 首先,我們先定義甚麼是預測誤差,若樣本外資料的實際觀察值為𝑦𝑡,模型. n. Ch. engchi. er. io. al. 預測誤差= 𝑦𝑡 − 𝑦̂𝑡. sit. y. Nat. 預測值以𝑦̂𝑡 來表示,則. i n U. v. 有了預測誤差的概念後,接著,若總樣本數有 t+n 筆,我們保留最後的 n 筆作為「樣本外」資料,以前面第 1 筆至第 t 筆資料作為「樣本內」資料來估計 模型,則樣本外預測力指標可以定義如下:. 𝑡+𝑛. 1 2 RMSE = √ ∑ (𝑦𝑖 − 𝑦̂) 𝑖 𝑁 𝑖=𝑡+1. 𝑡+𝑛. 1 MAE = ∑ |𝑦𝑖 − 𝑦̂| 𝑖 𝑁 𝑖=𝑡+1. 18.
(25) 從以上的公式我們可以知道,RMSE 是將預測誤差的平方和加以平均後再開 根號;而 MAE 則是將所有預測誤差取絕對值加總後的平均值,其實,我們可以發 現在概念上兩種指標是相同的,而到底哪種指標較佳?文獻上並沒有一致的看法, 績效的衡量可能因為所採用指標不同而有不同的結果,在本文中我們便將兩種指 標都納入考慮並加以比較。. 第五節 向量自我迴歸模型(Vector Autoregression,VAR) 在利用多變數時間序列模型以線性迴歸式表示時,其實就隱含著變數之間存. 政 治 大 是被解釋變數)」是受到「外生變數(又稱自變數或者是解釋變數)」的影響,而 立 在著因果關係的假設,也就是假設迴歸方程式中的「內生變數(又稱因變數或者. 解釋變數並不會受到被解釋變數的影響。然而在某些時候我們並無法確定該變數. ‧ 國. 學. 是否為解釋變數或者是被解釋變數時,若使用這類模型在估計變數之間的關係時,. ‧. 可能就會受到質疑。. y. Nat. Sims(1980)提出了向量自我迴歸的模型這種方法可以將所有的變數都視為. er. io. sit. 內生變數來處理,同時也解決了模型認定(identification)的問題,每一組 VAR 是由多變數和多條迴歸方程式所組成,每一條迴歸方程式當中,內生變數都可以. al. n. v i n 內生變數本身的落後期,再加上其他變數落後期來表示,也就是內生變數為本身 Ch engchi U 落後期及其他變數落後期的函數。. n 個變數之 VAR(p)一般化模型為: p. yt = a0 + ∑ βt yt−i + εt i=1. 其中,在 VAR 模型當中,變數序列資料型態必須為定態。n 為模型中內生變 數的個數,yt 為n × 1維度之內生變數向量矩陣,a0 為n × 1維度之常數向量矩陣, βt 為n × n維度且落後 t 期之係數向量矩陣,εt 為n × 1維度之誤差向量矩陣。 19.
(26) 第六節 共整合與向量誤差修正模型 共整合理論是 Engle-Granger(1987)所提出,該理論指出若一組非定態的時 間序列變數的線性組合為定態,那我們就稱這些時間序列變數具有「共整合」關 係。共整合關係檢定的目的主要是檢驗非定態的經濟變數長期間是否具有均衡的 關係,而這樣的均衡關係有時可能會滿足某種經濟意涵的存在。. (一)共整合關係 若一非定態時間序列𝑦𝑡 經過 k 次差分之後才會變成定態,則此變數我們就稱 為「k 階整合變數」(integrated of order k),我們以符號yt ~I(k)來表示,而 ∆k yt ~I(0)。. 立. 政 治 大. 根據 Engle-Granger(1987)對共整合的定義,若有兩個經濟變數𝑥𝑡 與𝑦𝑡 皆為. ‧ 國. 學. I(d)序列資料,𝑥𝑡 與𝑦𝑡 的線性組合為 I(0)數列,則表示𝑥𝑡 與𝑦𝑡 兩變數兼具有共整. ‧. 合關係。我們同樣可以用矩陣的方式來表達多變數序列資料的共整合的關係,假. y. Nat. 設時間序列有 m 個變數且所有變數皆為 I(d)序列資料,以向量X t ~I(d)表示,如. er. io. sit. 果存在一組向量β使得β′Xt = εt ~I(d − b)且 d>b>0,則我們稱X t 存在(d-b)階的 共整合關係,表示為Xt ~I(d − b),β稱為共整合向量(cointegration vector)。. n. al. (二)共整合檢定. Ch. engchi. i n U. v. 檢定數列之間是否存在共整合關係的檢定方法有兩種,一種為 Engle-Granger 兩階段共整合檢定法,另一種則為 Johansen 之共整合檢定,本 文中我們採 Johansen 共整合檢定,因此,我們便針對 Johansen 之檢定方法來做 介紹。 Johansen 所提出之最大概似估計法(maximum likelihood estimation)所進 行之共整合檢定可以有效解決 Engle-Granger 兩階段共整合檢定的缺失,將兩變 數擴充為多變數,允許有多組共整合向量的存在,並以向量自我迴歸模型為基礎, 將所有變數均視為聯合內生變數,解決了因果關係的問題,同時也將變數之間相 20.
(27) 互影響之效果納入了考慮。 Johansen 共整合檢定假設Yt 為一具有 n 個變數的(n×1)之 I(1)向量,則落後 p 期之向量自我迴歸模型 VAR(p)表示為:. Yt = Π1 𝑌𝑡−1 + Π2 𝑌𝑡−2 + ⋯ + Π𝑝 𝑌𝑡−𝑝 + 𝜇 + ∅𝐷𝑡 + 𝜀𝑡 ,t = 1,2 … , T 其中,p 為落後期數,εt ~iid N(0, Σ𝜀 ),Σ𝜀 為共變異數矩陣,∅為(n × n)之係 數矩陣,𝐷𝑡 為(n × 1)之確定項(deterministic term,包括時間趨勢、虛擬變數 及其他外生變數等),μ為(n × 1)之常數向量,Π𝑡 為(n × n)之係數矩陣。. 政 治 大 theorem),若Δ = I − L,L 立是落後運算因子(lag operator),則我們可以將上式 根據 Granger(1987)提出之「Granger 表現定理」(Granger representation. ‧. ‧ 國. 下:. 學. 落後 p 期之向量自我迴歸模型轉換成以誤差修正模型的方式來呈現,其表示如. sit. al. n. = ∑ Γ𝑖 Δ𝑌𝑡−𝑖 + Π𝑌𝑡−1 + 𝜇 + ∅𝐷𝑡 + 𝜀𝑡 𝑖=1. Ch. engchi. 其中,Γi = −(Ip − Π1 − Π2 − ⋯ − Πi ). er. io. 𝑝−1. y. Nat. ∆Yt = Γ1 Δ𝑌𝑡−1 + Γ2 Δ𝑌𝑡−2 + ⋯ + Γ𝑝−1 Δ𝑌𝑡−𝑝+1 + 𝜇 + ∅𝐷𝑡 + 𝜀𝑡. i n U. v. i=1,2,…,p-1. Π = −(Ip − Π1 − Π2 − ⋯ − Πp ) 上式中∑𝑝−1 𝑖=1 Γ𝑖 Δ𝑌𝑡−𝑖 反映出變數Yt 的短期動態關係,亦即當體系受到干擾時, 模型中各個變數脫離均衡關係後的動態調整情形,Π𝑌𝑡−1 為誤差修正項,此項反 映了模型中經過差分後所喪失的長期訊息的調整情形,用來刻劃變數Yt 的長期關 係,Π為所有落後項係數矩陣Πi 的線性組合,為過去各期效果的累積,也代表著 所有長期相關訊息都可以由Π反應出來,因此,Π又稱作長期衝擊矩陣(impact 21.
(28) matrix)。其中,我們可以透過Π矩陣的秩(rank)來決定共整合向量的數目,藉 此來檢定變數間是否具有共整合關係,檢定結果可以分成下列三種情況:. 若 rank(Π)= p,Π即為滿秩(full rank),表示Yt 為一定態序列。. 1.. 2. 若 rank(Π)=0,Π即為空矩陣(null matrix),表示向量Yt 中沒有共整合 向量,也就是變數間沒有長期的均衡關係,即不存在共整合關係。 3. 若0 < rank(Π) = r < p,表示向量Yt 中存在 r 個共整合向量,變數之間 存在共整合的關係。. 政 治 大 此外,再根據 Granger 表現定理,我們可以再將Π矩陣分解成Π = αβ′,故我們 立. 由上述情況我們可以得知,檢定的過程其實在於確定Π矩陣秩(rank)的個數,. ‧ 國. 學. 可以令虛無假設為:. ‧. H0 :rank(Π)= r < p 或 Π = α𝛽 ′. y. Nat. er. io. sit. 其中,α與β皆為(p × r)的矩陣且rank(α) = rank(β) = r。α代表的是誤差修 正項的係數,同時也用來衡量各變數偏離均衡的情況下,透過誤差修正項來修正. al. n. v i n 往長期均衡水準的調整速度,故係數越大則表示調整的速度越快,反之則調整速 Ch engchi U 度越慢,因此,α又被稱為權重向量(loading vector)或調整係數矩陣 (adjustment coefficient matrix),β則為共整合向量。 檢定出共整合關係後,Johansen 提出兩種統計量來決定共整合階次,藉此 檢定經濟變數中共整合向量的個數,其分述如下:. 1.. 軌跡檢定(trace test,又稱「對角元素和檢定」). 在還沒有確定共整合向量的個數前,我們先透過計算求得特性根值,並利用 特性根來進行軌跡檢定,找出共整合向量的個數,其虛無假設與對立假設如 下: 22.
(29) H0 :rank(Π)≤ r (即最多有 r 個共整合向量) H𝑎 :rank(Π)> r + 1 (即最少有 r+1 個共整合向量) 軌跡檢定之統計量為:λtrace (r) = −T ∑ni=r+1 ln(1 − λ̂i ) 其中,T 代表樣本總數,λ̂i 是第 i 個特性根的估計值. 2.. 最大特性根檢定(maximum eigenvalue test). 在進行最大特性根檢定時,我們依然利用所求之特性根來進行檢定,其虛無 假設與對立假設如下:. 政 治 大 H :rank(Π)= r (即有 r 個共整合向量) 立 0. H𝑎 :rank(Π)= r + 1 (即有 r+1 個共整合向量). ‧ 國. 學. 其中,T 代表樣本總數,λ̂i 是第 i 個特性根的估計值。. Nat. sit. y. ‧. 最大特性根之統計量為:λmax (r, r + 1) = −Tln(1 − λ̂ r+1 ). al. er. io. (三)向量誤差修正模型(Vector Error Correction Model,VECM). v. n. 根據 Granger 提出的 Granger 表現定理,共整合與誤差修正模型存在著某種. Ch. engchi. i n U. 對應關係,也就是說,當模型中的經濟變數間存在著共整合關係時,我們可以將 變數間的關係透過誤差修正模型來呈現。我們可以將上述利用 Johansen 最大概 似估計法檢定變數間是否具有共整合關係之模型之方程式整理成五個不同的向 量誤差修正模型如下:. 1.. VAR 與 CE(共整合向量)都無截距項. p−1. ∆Yt = ∑ Γi ΔYt−i + αβ′Yt−1 + ∅Dt + εt i=1. 23.
(30) 2.. VAR 無截距項,CE 含截距項. p−1 ′ ∆Yt = ∑ Γi ΔYt−i + α(β′, α0 )(Yt−1 , 1)′ + ∅Dt + εt i=1. 3.. VAR 與 CE 都有截距項. p−1 ′ ∆Yt = ∑ Γi ΔYt−i + α(β′ , α0 )(Yt−1 , 1)′ + μ + ∅Dt + εt i=1. 4.. 政 治 大. VAR 有截距項,CE 含截距項及時間趨勢項. 立. ‧ 國. 學. p−1. ′ ∆Yt = ∑ Γi ΔYt−i + α(β′ , α0 )(Yt−1 , t)′ + μ0 + ∅Dt + εt i=1. ‧. VAR 與 CE 都含有截距項及時間趨勢項. sit. al. er. io. p−1. y. Nat. 5.. n. ′ ∆Yt = ∑ Γi ΔYt−i + α(β′ , α0 )(Yt−1 , t)′ + μ0 + μ1 t + ∅Dt + εt i=1. Ch. engchi. i n U. v. 我們分別利用這五個向量誤差修正模型來進行共整合向量個數的檢定,但由 於上述的模型個別都有不同的檢定統計式,因此,我們必須根據事前的資訊來選 取出最適當的模型來進行共整合個數的檢定及估計。. (四)向量誤差修正模型落後期之選取 向量誤差修正模型落後期的選取,不同於單一變量落後期的選擇是依據 AIC 或 SBC 之最小值作為判斷準則,由於模型中涉及到多變量的變數,我們必須以向 量自我迴歸模型為基礎來選取最適的落後期數,因此,我們利用調整後的 LR 統 24.
(31) 計量來決定。. LR(likelihood ratio)統計量= T(ln|ΣR | − ln|ΣU |)~χ2 (d) 調整的 LR 統計量= (T − c)(ln|ΣR | − ln|ΣU |)~χ2 (d). 其中,T 為樣本總數,c 是未受限式中的「其中一條方程式」待估參數數目, χ2 的自由度 d 則是限制式的數目,ΣU 為未受限式之共變異數矩陣,ΣR 為受限制 式之共變異數矩陣。. 治 政 第七節 Beveridge-Nelson 分解(B-N 分解) 大 立. Beveridge and Nelson(1981)建立了一個分解趨勢的方法,將非定態的時間. ‧ 國. 學. 序列資料拆解成趨勢項和循環項,其中,趨勢項的部分是具有飄移項(drift term). ‧. 的隨機漫步(random walk),循環項的部分則是平均數為零的定態時間數列。. y. Nat. 我們假設變數yt 為非定態序列,yt 之整合階次為 1,以yt ~I(1)表示。wt 表示. n. er. io. al. sit. 為一階差分後之yt ,則我們可以關係表示如下:. i n U. ∆𝑦𝑡 = 𝑦𝑡 − 𝑦𝑡−1 = 𝑤𝑡. Ch. engchi. v. 依據 Wold(1938)的分解理論,經過一階差分後之wt 序列為定態,則wt 可以 移動平均(moving average,MA)的形式來表示:. wt = 𝜇 + 𝜀𝑡 + 𝛾1 𝜀𝑡−1 + 𝛾2 𝜀𝑡−2 + ⋯ 其中,μ為wt 之平均數,𝛾𝑖 為參數,𝜀𝑡−𝑖 則為隨機干擾項,且εt ~iid N(0, 𝜎 2 )。 若我們已知 y 在時間點為 t 期的情況下,要去預測 y 在 t+k 期的期望值,我 們可以將式子表示如下:. 25.
(32) ŷt (k) = E(yt+k | ∙∙∙, yt−1 , yt ) = 𝑦𝑡 + E(𝑤𝑡+1 + 𝑤𝑡+2 + ⋯ + 𝑤𝑡+𝑘 |𝑤1 ,∙∙∙, 𝑤𝑡−1 , 𝑤𝑡 ) = 𝑦𝑡 + 𝑤 ̂(1) +𝑤 ̂(2) + ⋯+ 𝑤 ̂(𝑘) 𝑡 𝑡 𝑡 因此,ŷt (k)即為已知 y 在 t 時間點條件下,預測 y 在時間點 t+k 期的期望 值;同理,我們也可以將w ̂(k)解釋成已知 w 在 t 時間點條件下,預測 w 在時間 t 點 t+k 期的期望值,以移動平均表示如下:. 政 治 大. w ̂(k) = μ + γk εt + γk+1 εt−1 + γk+2 εt−2 + ⋯ t. 立. ∞. ‧ 國. 學. = μ + ∑ γk εt+k−j j=k. ‧. 將上式代入ŷt (k)式子中,整理可以得到:. io. sit. y. Nat. k+1. k. n. al. Ch. i=1. i n U. i=2. engchi. er. ŷt (k) = yt + kμ + (∑ γi ) εt + (∑ γi ) εt−1 + ⋯. v. 由上述數學式子我們可以得知,隨著時間的經過,過去歷史的衝擊對於預測 方程式的影響會越來越小,𝑘𝜇為第 t 期至第 t+k 期的確定性趨勢增量,也就是 說,長期而言ŷt (k)的預測數學式會收斂成斜率為𝜇之線性方程式。因此,我們將 𝑘𝜇確定性增量扣除後即可得到當期的趨勢項𝑥𝑡 ,其表示如下: 𝑘. 𝑘+1. 𝑥𝑡 = ŷt (k) − kμ = 𝑦𝑡 + (∑ 𝛾𝑖 ) 𝜀𝑡 + (∑ 𝛾𝑖 ) 𝜀𝑡−1 + ⋯ 𝑖=1. 𝑖=2. 循環項的部分定義為當期的變數值與當期趨勢項部分之差,因此,循環項部 26.
(33) 分我們可以表示為:. 𝑘. 𝑘+1. 𝑐𝑡 = 𝑦𝑡 − 𝑥𝑡 = − [(∑ 𝛾𝑖 ) 𝜀𝑡 + (∑ 𝛾𝑖 ) 𝜀𝑡−1 + ⋯ ] 𝑖=1. 𝑖=2. 故我們可以發現,循環項的部分為隨機干擾項的線性組合,所以必為定態的 時間序列;而我們便可以知道,趨勢項的部分除了定態的隨機干擾項以外,還包 含了非定態的序列資料,也就是說,經濟變數當中所有非定態的部分全部都由趨 勢項來解釋,也符合趨勢項必為一隨機漫步且具有漂浮項之時間序列。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 27. i n U. v.
(34) 第肆章 實證分析 第一節 資料來源及分析 樣本資料來源來自 Datastream 資料庫,匯率為 Reuters 之新台幣兌美元之匯 率報價,股價為台灣加權股價指數,利率為金融業隔夜拆借利率,樣本資料期間 及資料筆數如表 4-1: 表 4-1. 樣本資料期間與資料筆數. 資料型態 日資料. 樣本期間. 資料筆數. 估計期間:2003/01/01~2013/10/24. 2822. 預測期間:2013/10/25~2013/12/05. 30. 立. 政 治 大. 為了能夠瞭解樣本資料型態及特徵,我們將樣本資料進行統計分析,並同時. ‧ 國. 學. 檢定資料是否服從常態分配,採用 Jarque-Bera 檢定方法,J-B 檢定法的虛無假設 為資料服從常態分配,將結果整理成表 4-2,由表中結果很明顯看出 p-value 值為. ‧. 0,即樣本資料不服從常態分配。. 匯率. 股價. a l 31.83193 v i 7058.882 n Ch U 32.18325 e n g c h i7235.625. n. 標準差 最大值 最小值 偏態係數 峰態係數. 樣本資料之敘述統計分析. er. io 平均數 中位數. sit. y. Nat. 表 4-2. 1.70538 1256.504 35.16500 9809.880 28.51000 4089.930 -0.20513 -0.33396 1.88700 2.41181 Jarque-Bera 167.21 94.1265 (0.00000) (0.00000) 註:Jarque-Bera 列中的括號內數字代表 p-value. 利率 0.9459 1.0180 0.6775 3.9050 0.0950 0.4283 2.1364 175.9295 (0.00000). 第二節 ADF 單根檢定 我們可以知道,當一個時間序列資料為非定態之時間序列資料時,在進行資 28.
(35) 料分析時,變數間可能會出現「假性迴歸」的問題,造成實證研究結果的誤判, 因此,我們必須透過 ADF 單根檢定來檢定樣本資料是否為定態時間序列資料。 我們分別將匯率、股價指數及利率資料做 ADF 單根檢定,檢定結果如表 4-3.1、 表 4-3.2 及表 4-3.3: 表 4-3.1. 匯率資料之 ADF 檢定 t-stastic. p-value. 不含截距項與時間趨勢. -1.24004. 0.1980. 含截距項 含截距項與時間趨勢. -1.54771 -2.30241. 0.5093 0.4319. -51.81703 治 一階差分之匯率資料 含截距項 政 -54.83175 大 含截距項與時間趨勢 -51.82399 立 註:***代表在 1%的顯著水準下拒絕虛無假設. 0.0001. ***. 0.0001. ***. 0.0000. ***. 原始匯率資料. io. al. 0.426821 -2.28985 -2.52092. 0.8057 0.1754 0.3178. y. v i n 含截距項 -51.11489 Ch U i e h n gc 含截距項與時間趨勢 -51.10942. n. 不含截距項與時間趨勢. 一階差分之股價資料. p-value. sit. 不含截距項與時間趨勢 含截距項 含截距項與時間趨勢. t-stastic. ‧. Nat. 原始股價資料. 股價資料之 ADF 檢定. er. 表 4-3.2. 學. ‧ 國. 不含截距項與時間趨勢. -51.11217. 0.0001. ***. 0.0001. ***. 0.0000. ***. 註:***代表在 1%的顯著水準下拒絕虛無假設. 表 4-3.3. 原始利率之資料. 利率資料之 ADF 檢定 t-stastic. p-value. 不含截距項與時間趨勢 含截距項 含截距項與時間趨勢. -1.07695 -0.98905 -1.37913. 0.2552 0.7592 0.8670. 不含截距項與時間趨勢. -14.80645. 0.0000. ***. -14.81767. 0.0000. ***. -14.81713. 0.0000. ***. 一階差分利率資料 含截距項 含截距項與時間趨勢 註:***代表在 1%的顯著水準下拒絕虛無假設. 29.
(36) 我們可以發現原始樣本資料 ADF 檢定之結果皆為不拒絕單根,表示資料型 態為非定態時間序列,因此,我們將其一階差分後進行檢定,檢定結果顯著拒絕 單根,表示三個經濟變數整合階次皆為一,即為 I(1)序列資料。. 第三節 匯率預測─ARIMA 模型 我們採用 Schwarz criterion(SBC)準則來進行 p、q 次數配適以選取最適 ARIMA 模型,同時考慮模型中估計係數顯著性的問題,我們得到最適 ARIMA 模型為無截距項之 ARIMA(2,1,2),並根據模型所得到之估計係數結果如表 4-4:. 政 治 大 Coefficient Std.Error 立 -0.70627 0.1876. 表 4-4. -0.63081. t-Statistic. 學. AR(1) AR(2). ‧ 國. Variable. ARIMA(2,1,2)模型估計係數. 0.2132. ‧. MA(1) 0.73740 0.179 MA(2) 0.68233 0.1981 註:***代表在 1%的顯著水準下拒絕虛無假設. -3.765*** -2.959***. Nat. sit. y. 4.120*** 3.445***. io. er. 因此,我們透過 ARIMA(2,1,2)的時間序列模型來進行匯率的預測,為了能 夠更貼近實務上的操作,在本篇論文當中皆採用「逐次更新預測法」(Recursive. al. n. v i n Ch updating forecasts),又可以稱做「靜態預測法」(Static forecast method)來進行預 engchi U. 測,此種預測方式是指當我們利用樣本內的資料和已估計出的參數來進行樣本外 預測時,每增加一期的預測,就必須將前一期的實際值納入考慮。舉例而言,當 我們要在 t 期的時點下要預測的第 t+1 期的值時,要建構一個第 t 期的預測模型, 我們用的是樣本內資料(y1 , 𝑦2 , … , 𝑦𝑡 )所配適出的模型進行預測,進而得到的估計 值為ŷ t+1 。到了 t+1 期時,我們會重新配適 t+1 期的預測模型,除了原本樣本內 的資料外,再加入了 t+1 期的實際觀察值𝑦𝑡+1 ,所以,我們總共用到 (y1 , 𝑦2 , … , 𝑦𝑡 , 𝑦𝑡+1 )的樣本來建構新的預測模型並估計 t+2 期的值ŷ t+2,以此類推, 即可得到所有樣本外的估計值。其預測結果如表 4-5: 30.
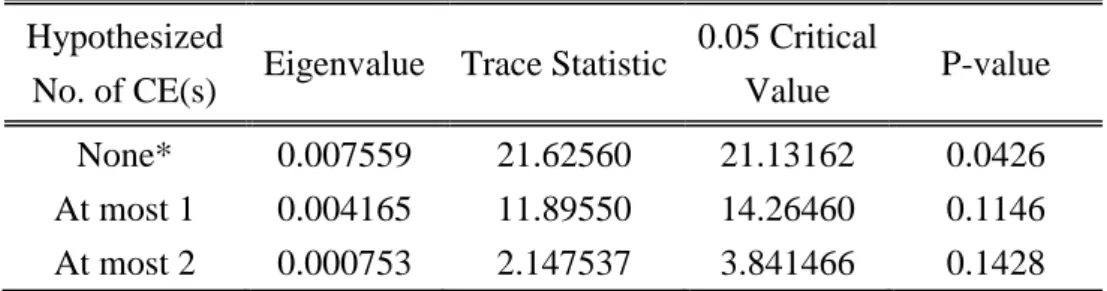
(37) 表 4-5 日期. ARIMA(2,1,2)模型之匯率預測績效表現. 原始匯率. 預測匯率. 預測誤差. 2013/12/5 29.59250 29.59090 0.00160 註:***代表在 1%的顯著水準下拒絕虛無假設 30 天期之新台幣兌美元匯率預測結果見附表 1. 累加 RMSE. 累加 MAE. 0.03161. 0.02339. 第四節 匯率預測─向量誤差修正模型 為了能夠比較是否運用 Beveridge-Nelson 拆解的分解趨勢方法對於匯率預測 的績效是否較佳,我們首先以沒有經過 Beveridge-Nelson 拆解的原始樣本匯率資 料,加入股價及利率兩個變數後以共整合檢定來探討變數間的關係,再透過向量. 政 治 大 我們從第二節的 ADF 立單根檢定結果發現,不論是原始的匯率資料,或者是. 誤差修正模型來進行匯率的預測。. ‧ 國. 學. 股價、利率資料,皆為 I(1)序列。因此,我們便可以利用共整合分析來探討三個 變數間的長期均衡關係,本文我們採用 Johansen 共整合檢定程序來檢定匯率、. ‧. al. n. Hypothesized No. of CE(s). Eigenvalue Trace Statistic. Ch. None*. 0.007559. At most 1 At most 2. 0.004165 0.000753. e35.66864 ngchi 14.04304 2.147537. sit. Unrestricted Cointegration Rank Test(Trace). io. A.. 匯率、股價及利率─Johansen 共整合檢定. er. Nat. 表 4-6. y. 利率及股價三個變數間的共整合關係,其檢定結果如下表 4-6:. v. 0.05 Critical Value. P-value. 29.79707. 0.0094. 15.49471 3.841466. 0.0818 0.1428. i n U. Trace test indicates 1 cointegrating eqn(s) at the 0.05 level * denotes rejection of the hypothesis at the 0.05 level. 31.
(38) B.. Unrestricted Cointegration Rank Test(Maximum Eigenvalue). Hypothesized No. of CE(s). Eigenvalue Trace Statistic. None* At most 1 At most 2. 0.007559 0.004165 0.000753. 21.62560 11.89550 2.147537. 0.05 Critical Value. P-value. 21.13162 14.26460 3.841466. 0.0426 0.1146 0.1428. Max-eigenvalue test indicates 1 cointegrating eqn(s) at the 0.05 level * denotes rejection of the hypothesis at the 0.05 level 從檢定結果,我們可以發現不論是以軌跡檢定或最大特性根檢定,變數間皆 存在一組共整合關係,再從表 4-7 的共整合向量我們可以得到得到匯率、股價及 利率之共整合關係為:. 表 4-7. 學. ‧ 國. 立. 政 治 大 E=1.56508R-0.00131S. 匯率、股價及利率之共整合向量. 1 Cointegrating Equation(s):. Log likelihood. -8664.996. ‧. Normalized cointegrating coefficients(standard error in parentheses) E R 1.000000 -1.565080 (0.43723). n. er. io. sit. y. Nat. al. S 0.00131 (0.00024). i n U. v. 我們可以知道,當變數間存在著共整合關係時,隱含著這些經濟變數長期會. Ch. engchi. 達到一個均衡關係,儘管短期而言,變數之間可能存在偏離均衡關係的現象,隨 著時間的經過,誤差修正機能(error correction mechanism)會讓這些變數往均衡方 向調整,使其滿足經濟意義的均衡。因此,我們可以從變數間的共整合關係發現: (1)匯率的變動與利率呈現同向關係:符合利率平價理論的經濟意涵,也就是 當一個國家利率相對處於較高水準時,會吸引國外資金的大量流入,進而 造成當期該國幣值的升值,相對地將預期未來該國匯率會呈現貶值的走勢, 因此,匯率與利率呈現同向的關係。 (2)匯率的變動與股價指數呈現反向關係:股價跟匯率的關係,通常有兩派說 法,其中一個觀點是說明股價的變動會影響匯率,當股票市場處於活絡的 32.
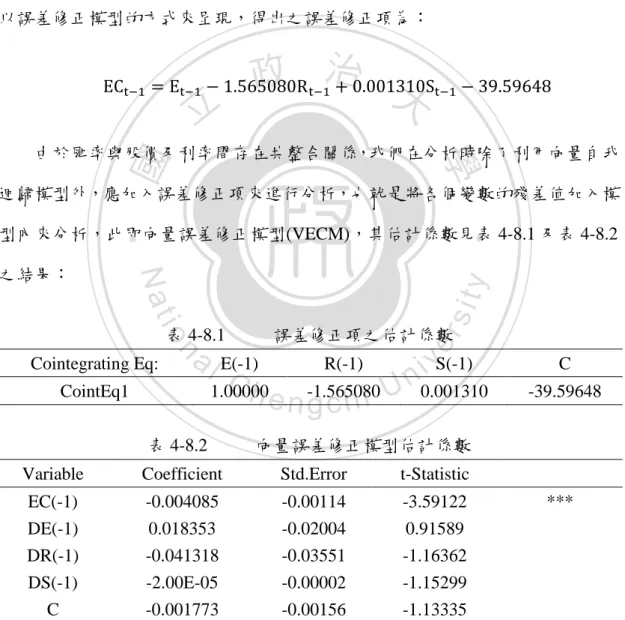
(39) 狀態下,不論是在人民的財富或者整體資本市場的流動性都相對較佳,貨 幣需求增加的情況下,利率上升,進而影響匯率的變化造成匯率升值,造 成匯率與股價指數呈現反向的關係。 (3)利率與股價指數呈現反向關係:我們可以解讀為當資本市場中利率相對處 於較高水準時,代表債市活動較為活絡,投資人也傾向將資金從股市中移 出去投入在高報酬率的債市,而使利率與股價指數呈現反向的現象。 我們可以將上述的共整合關係,我們可以根據 Granger 表現定理將其轉換成 以誤差修正模型的方式來呈現,得出之誤差修正項為:. 政 治 大. ECt−1 = Et−1 − 1.565080R t−1 + 0.001310St−1 − 39.59648. 立. ‧ 國. 學. 由於匯率與股價及利率間存在共整合關係,我們在分析時除了利用向量自我 迴歸模型外,應加入誤差修正項來進行分析,也就是將各個變數的殘差值加入模. ‧. 型內來分析,此即向量誤差修正模型(VECM),其估計係數見表 4-8.1 及表 4-8.2. CointEq1. a l E(-1) vS(-1) R(-1) i n C h -1.565080 U 0.001310 1.00000 engchi. n. Cointegrating Eq:. 表 4-8.2 Variable. 誤差修正項之估計係數. er. io. 表 4-8.1. sit. y. Nat. 之結果:. Coefficient. C -39.59648. 向量誤差修正模型估計係數 Std.Error. EC(-1) -0.004085 -0.00114 DE(-1) 0.018353 -0.02004 DR(-1) -0.041318 -0.03551 DS(-1) -2.00E-05 -0.00002 C -0.001773 -0.00156 註:***代表在 1%的顯著水準下拒絕虛無假設. 33. t-Statistic -3.59122 0.91589 -1.16362 -1.15299 -1.13335. ***.
(40) 由表 13,我們便可以得到匯率項之 VECM 為 ∆Et = −0.004085ECt−1 − 0.018353∆𝐸𝑡−1 − 0.00002∆St−1 − 0.041318∆R t−1 − 0.001773. 我們可以從表 13 發現,雖然在估計的係數在衡量短期關係的部份皆不顯著, 但是在衡量長期均衡關係的誤差修正項係數的部分卻相當顯著,代表著匯率在長 期仍然會滿足經濟意義的均衡,其意涵為匯率項當期的變動,短期也許不會受到 前一期的利率和股價指數變動的影響,但長期來說,卻會受到匯率、股價及利率 共整合均衡關係的影響,並且以 0.4065%的負向調整來達到均衡。. 政 治 大 透過上述之向量誤差修正模型,我們便可以對原始匯率進行預測,並透過 立. ‧ 國. 學. RMSE 與 MAE 之績效指標來衡量其預測績效,其最後一日預測結果如表 4-9:. 預測誤差. Nat. 2013/12/5 29.59250 29.58283 0.00967 註:***代表在 1%的顯著水準下拒絕虛無假設 30 天期之新台幣兌美元匯率預測結果見附表 2. io. n. al. 累加 RMSE. 累加 MAE. 0.03116. 0.02350. y. 預測匯率. sit. 原始匯率. er. 日期. 向量誤差修正模型之匯率預測績效表現. ‧. 表 4-9. i n C 第五節 匯率預測─Beveridge-Nelson h e n g c之應用 hi U. v. (一)Beveridge-Nelson 分解之匯率預測 將樣本資料做 Beveridge-Nelson 分解後,得到兩項時間序列資料分別為循環 項(cycle)和趨勢項(trend)之序列資料,資料之相關波動圖比較,整理如圖 2。從 圖 2 我們其實可以概略知道在匯率的循環項部分可能為定態,而趨勢項則為非定 態序列。. 34.
(41) 原始樣本資料、趨勢項和循環項波動圖. 圖2. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 因此,我們分別對匯率之趨勢項、一階差分趨勢項及循環項作 ADF 檢定, 檢定序列資料是否具有單根,也就是序列資料是否為定態,其檢定結果如表 4-10:. 35.
(42) 表 4-10. 匯率之趨勢項、一階差分趨勢項及循環項之 ADF 檢定 t-stastic. p-value. 不含截距項與時間趨勢 含截距項 含截距項與時間趨勢. -0.95651 -1.84043 -2.92145. 0.3028 0.3611 0.1557. 不含截距項與時間趨勢 匯率趨勢項之一階差分 含截距項 含截距項與時間趨勢. -53.1520 -53.1554 -53.1462. 0.0001 0.0001 0.0000. *** *** ***. -10.44057 0.0000 -10.43753 0.0000 -10.43463 0.0000. *** *** ***. 匯率之趨勢項. 不含截距項與時間趨勢 含截距項 含截距項與時間趨勢. 匯率之循環項. 政 治 大. 註:***代表在 1%的顯著水準下拒絕虛無假設. 立. 從表 4-10 我們可以發現,趨勢項序列資料為非定態,而一階差分後之趨勢. ‧ 國. 學. 項及循環項資料為定態資料,因此,我們將定態的循環項序列資料採向量自我迴. ‧. 歸模型(VAR)來處理,非定態的趨勢項序列資料我們則採共整合分析。. sit. y. Nat. (二)股價及利率之 ADF 檢定. n. al. ADF 檢定,其檢定結果如表 4-11、表 4-12:. Ch. engchi. 36. er. io. 我們同樣對股價及利率做 Beveridge-Nelson 拆解,並對其趨勢項及循環項做. i n U. v.
(43) 表 4-11 股價趨勢項、一階差分後趨勢項及循環項之 ADF 檢定 t-stastic. p-value. 不含截距項與時間趨勢 含截距項 含截距項與時間趨勢. 0.35163 -2.12256 -2.44089. 0.7864 0.2358 0.3581. 不含截距項與時間趨勢 股價趨勢項之一階差分 含截距項 含截距項與時間趨勢. -53.3407 -53.3414 -53.3338. 0.0001 0.0001 0.0000. *** *** ***. 不含截距項與時間趨勢. -53.34069 0.0001. ***. 含截距項. -53.34141 0.0001. ***. -53.33380 0.0000 治 政 註:***代表在 1%的顯著水準下拒絕虛無假設 大 立 表 4-12 利率趨勢項、一階差分後趨勢項及循環項之 ADF 檢定. ***. 股價之趨勢項. 股價之循環項. 含截距項與時間趨勢. -1.06399 -0.98084 -1.38388. 0.2601 0.7621 0.8660. 不含截距項與時間趨勢 利率趨勢項之一階差分 含截距項 含截距項與時間趨勢. -14.9099 -14.9205 -14.9203. 0.0000 0.0000 0.0000. *** *** ***. -14.8065. 0.0000. ***. 含截距項. -14.8177. 0.0000. ***. 含截距項與時間趨勢. -14.8171. 0.0000. ***. ‧ 國. 不含截距項與時間趨勢 含截距項 含截距項與時間趨勢. 學. p-value. 利率之趨勢項. n. engchi. er. io. Ch. sit. y. Nat. al. 不含截距項與時間趨勢 利率之循環項. ‧. t-stastic. i n U. v. 註:***代表在 1%的顯著水準下拒絕虛無假設 我們發現股價及利率之趨勢項序列資料皆為不拒絕單根,因此趨勢項序列資 料為非定態,我們將其一階差分後再做 ADF 檢定,一階差分後之股價趨勢項及 利率趨勢項序列資料皆為定態,因此,我們可以知道匯率、股價及利率之趨勢項 時間序列資料皆為同階 I(1)序列,故可以進行共整合分析,探討變數間的長期均 衡間關係。 37.
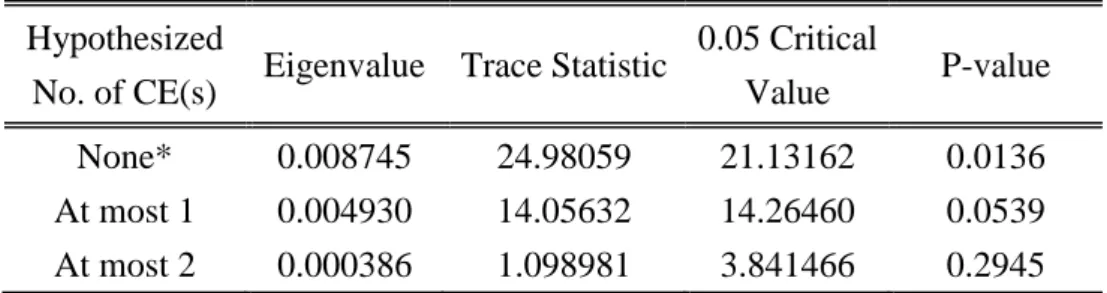
(44) (三)趨勢項之共整合分析 我們同樣採 Johansen 共整合檢定程序來檢定匯率、利率及股價趨勢項的共 整合關係,不同於 ARIMA 模型落後期的選取是以 SBC 最小值為基礎,在共整 合檢定當中,落後期的選取是以向量自我迴歸模型為基礎,以調整後 LR 值來決 定落後期,其落後期篩選結果見表 4-13: 表 4-13 調整後之 LR 值 Lag C (p). Σp. ln│Σp│. 調整後 LR. d. (T − c)(ln|Σp | − ln|Σ10 |). 9 8 7 6. 28 25 22 19. 0.133714 0.133874 0.133921 0.134201. -2.012052088 -2.01085622 -2.010505205 -2.008416603. 27 24 21 18. 5.789194006 9.16173984 10.16066331 16.06342705. 5 4 3. 16 0.134312 13 0.134389 10 0.135568. -2.007589827 -2.007016699 -1.99828192. 15 12 9. 18.41532421 20.05511943 44.79582911. 學. *. 89.13187261 204.6481241. ** ***. 政 治 大. ‧ 國. 立. ‧. 2 7 0.137704 -1.982648825 6 1 4 0.143424 -1.941950001 3 註:***代表在 1%的顯著水準下拒絕虛無假設 ** 代表在 5%的顯著水準下拒絕虛無假設 * 代表在 10%的顯著水準下拒絕虛無假設. n. er. io. sit. y. Nat. al. v. 根據表 4-13 之結果,依據調整後 LR 值準則,我們無法拒絕 VAR(10)中有方. Ch. engchi. i n U. 程式中落後項 5 至 10 期之係數為零之假設,表示 VAR(4)比 VAR(10)的估計結果 來得適切,因此,我們所選出之落後期數為 4 期,其軌跡檢定量及共整合向量如 表 4-14: 表 4-14 匯率、股價及利率趨勢項─Johansen 共整合檢定 A.. Unrestricted Cointegration Rank Test(Trace). Hypothesized No. of CE(s). Eigenvalue Trace Statistic. 0.05 Critical Value. P-value. None*. 0.008745. 40.13590. 29.79707. 0.0023. At most 1 At most 2. 0.004930 0.000386. 15.15530 1.098981. 15.49471 3.841466. 0.0562 0.2945. Trace test indicates 1 cointegrating eqn(s) at the 0.05 level * denotes rejection of the hypothesis at the 0.05 level 38.
(45) B.. Unrestricted Cointegration Rank Test(Maximum Eigenvalue). Hypothesized No. of CE(s). Eigenvalue Trace Statistic. None* At most 1 At most 2. 0.008745 0.004930 0.000386. 24.98059 14.05632 1.098981. 0.05 Critical Value. P-value. 21.13162 14.26460 3.841466. 0.0136 0.0539 0.2945. Max-eigenvalue test indicates 1 cointegrating eqn(s) at the 0.05 level * denotes rejection of the hypothesis at the 0.05 level 從檢定結果,我們可以發現不論是以軌跡檢定或最大特性根檢定,變數間皆 存在一組共整合關係,再從表 4-15 的共整合向量我們可以得到得到匯率、股價 及利率之共整合關係為:. 立. 政 治 大. E_trend=1.283572R_trend+0.001655S_trend. ‧ 國. 學. 表 4-15 匯率、股價及利率趨勢項部分之共整合向量 Log likelihood. ‧. 1 Cointegrating Equation(s):. er. io. sit. y. Nat. Normalized cointegrating coefficients(standard error in parentheses) E R 1.000000 -1.283572 (0.50780). al. -9465.526 S 0.001655 (0.00028). n. v i n Ch 我們同樣可以從變數間的趨勢項共整合關係發現與前述透過原始匯率來進行 engchi U 共整合分析一樣的結論:. (1). 匯率的變動與利率呈現同向關係. (2)匯率的變動與股價指數呈現反向關係 (3)利率與股價指數呈現反向關係. 根據 Granger 表現定理,我們可以將共整合關係轉換成以誤差修正模型的方 式來呈現,得出之誤差修正項為:. 39.
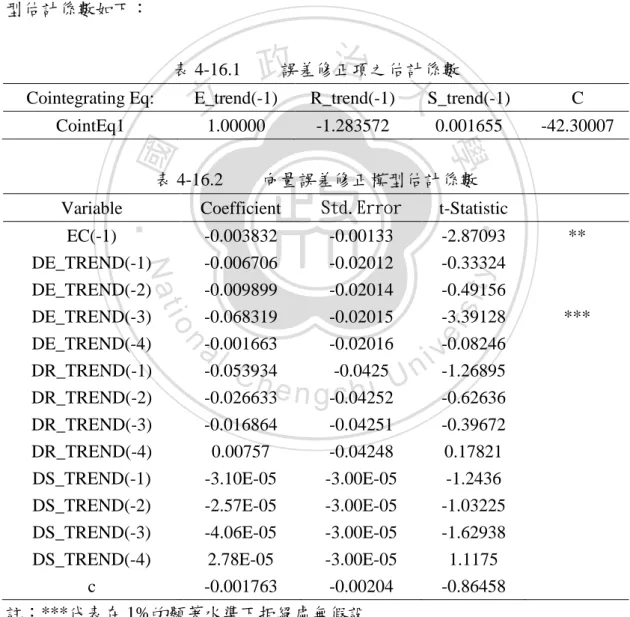
(46) ECt−1 = −42.300071 + E_trendt−1 − 1.2835712R_trendt−1 + 0.001655S_trendt−1. 由於匯率與股價及利率趨勢項存在共整合關係,我們在分析時已加入誤差修 正項來進行分析,將各個變數的殘差值加入分析,即向量誤差修正模型(VECM), 我們可以得到如表 4-16.1 之誤差修正項估計係數及表 4-16.2 之向量誤差修正模 型估計係數如下: 表 4-16.1. 治 政誤差修正項之估計係數 大. 立 1.00000. Cointegrating Eq:. E_trend(-1). 表 4-16.2. S_trend(-1). C. -1.283572. 0.001655. -42.30007. 學. ‧ 國. CointEq1. R_trend(-1). 向量誤差修正模型估計係數 Std.Error. t-Statistic. EC(-1) DE_TREND(-1) DE_TREND(-2) DE_TREND(-3) DE_TREND(-4) DR_TREND(-1) DR_TREND(-2). -0.003832 -0.006706 -0.009899 -0.068319 -0.001663 -0.053934 -0.026633. -0.00133 -0.02012 -0.02014 -0.02015 -0.02016 -0.0425 -0.04252. -2.87093 -0.33324 -0.49156 -3.39128 -0.08246 -1.26895 -0.62636. n. Ch. engchi. 40. **. y. sit. i n U. DR_TREND(-3) -0.016864 -0.04251 DR_TREND(-4) 0.00757 -0.04248 DS_TREND(-1) -3.10E-05 -3.00E-05 DS_TREND(-2) -2.57E-05 -3.00E-05 DS_TREND(-3) -4.06E-05 -3.00E-05 DS_TREND(-4) 2.78E-05 -3.00E-05 c -0.001763 -0.00204 註:***代表在 1%的顯著水準下拒絕虛無假設 ** 代表在 5%的顯著水準下拒絕虛無假設 * 代表在 10%的顯著水準下拒絕虛無假設. er. io. al. ‧. Coefficient. Nat. Variable. v. -0.39672 0.17821 -1.2436 -1.03225 -1.62938 1.1175 -0.86458. ***.
數據
相關文件
Making use of the Learning Progression Framework (LPF) for Reading in the design of post- reading activities to help students develop reading skills and strategies that support their
(b) reviewing the positioning of VPET in the higher education system in Hong Kong, exploring the merits of developing professional vocational qualifications at the degree
Hence, we have shown the S-duality at the Poisson level for a D3-brane in R-R and NS-NS backgrounds.... Hence, we have shown the S-duality at the Poisson level for a D3-brane in R-R
Complete gauge invariant decomposition of the nucleon spin now available in QCD, even at the density level. OAM—Holy grail in
! ESO created by five Member States with the goal to build a large telescope in the southern hemisphere. • Belgium, France, Germany, Sweden and
• The purpose of the teacher questionnaire is to solicit views of teachers on the initial recommendations at the subject level..
Using sets of diverse, multimodal and multi-genre texts of high quality on selected themes, the Seed Project, Development of Text Sets (DTS) for Enriching the School-based
– The futures price at time 0 is (p. 275), the expected value of S at time ∆t in a risk-neutral economy is..
