行政院國家科學委員會專題研究計畫 成果報告
以語料庫為本分析文本中的詞彙啟動與詞彙變化及其教學 應用
研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 97-2410-H-011-024-
執 行 期 間 : 97 年 08 月 01 日至 98 年 11 月 30 日 執 行 單 位 : 國立臺灣科技大學應用外語系
計 畫 主 持 人 : 王世平
計畫參與人員: 此計畫無其他參與人員:王世平
報 告 附 件 : 國外研究心得報告
出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢
中 華 民 國 99 年 02 月 26 日
Table of Contents 目錄 1. Introduction & aim 2. Literature review 3. Methodology
4. Results & Discussion
5. Self-evaluation (計畫成果自評) References (參考文獻)
行政院國家科學委員會專題研究計畫成果報告
國科會專題研究計畫成果報告
計畫編號:NSC 97-2410-H-011-024 執行期限:20080801~20091130
主持人:王世平 [email protected] 執行機構:台灣科技大學應外系
「以語料庫為本分析文本中的詞彙啟動與詞彙變化及其教學應用」
Lexical priming and variation in text and teaching: a corpus-based approach
Keywords: corpus, formulaic language, lexical priming, variation, and text analysis
報告內容
Shih-ping Wang(王世平)
Department of Applied English, Ming Chuan University [email protected]
1. Introduction & aim
The aim of this project is to apply a) the BNC as internal evidence for the quantitative analysis, the construction of web as corpus as the external evidence and the application of formulaic language at different language levels; b) text analysis will be used for qualitative analysis; c) conducting testing and questionnaires to evaluate students’ language proficiency and their association with their reading ability; d) students were exposed to authentic materials, via consciousness-raising activities for data-driven learning (Johns 1997: 101).
This project will integrate the relevant theories such as text analysis, lexical cohesion, lexical priming, language variation, creativity and socio-culture context to explore the major research question: Is students’proficiency of formulaic language related to English vocabulary and reading ability?
2. Literature review 2.1 Corpus & the BNC
The British National Corpus ((BNC; Aston & Burnard, 1998)) is a large corpus of modern English (over 100 million words; N= 100,106,008 words, derived from 4,124 texts), including both spoken (approximately 10%) and written (approximately 90%) data (Leech, Rayson, & Wilson, 2001: Introduction; Burnard, 2007). The BNC was made available by Oxford University Press (1991-1994). The BNC is relatively user-friendly and easily available on CD-ROM with the Sara-32 software package1 (Aston & Burnard, 1998). It is appropriate for the present research, which is orientated towards British English (see also
http://info.ox.ac.uk/bnc/what/ index.html).
The Corpus represents a wide range of modern British English. The written part (90%) includes a great variety of different genres such as extracts from newspapers, periodicals and journals for all ages and interests, academic books, popular fiction, school and university essays, among many others. The spoken part (10%) consists of a great deal of informal conversation, recorded by volunteers chosen from diverse ages, regions and social classes in a demographically balanced way, together with other spoken language collected in all types of different contexts, ranging from formal business and government meetings to radio shows and the like.
2.2 Lexical priming
Hoey argues how texts function crucially related to lexical cohesion (1991:
51-75). Lexis creates cohesion mainly through several kinds of repetition. But, later he develops the theory of lexical priming and claims that words are primed for certain uses and meanings in text, such as the phenomena of collocation, indicating how language is really organised. Hoey recognises that a stretch of sound may associate with meaning (sl- in ‘slippery slope’). A phonetic or phonological starting point allows priming to explain wordplay, rhyme, etc.
Carter and McCarthy (2004) propose thatcreativity is‘a capacity ofallpeople, but not a capacity of special people’. The concept of creativity with ‘novel, interpersonal and interactive’ attributes involves individual, social and cultural
1The online BNC is available from the websites http://sara.natcorp.ox.ac.uk/lookup.html and http://view.byu.edu/. See also the BNC Handbook (Aston & Burnard 1998).
contexts. Carter argues that ‘creativity is always contextually framed and conditioned…Socialand culturalcontextsplay asignificantpart as sites for creative language use’ (2004: 210). He also argues that there are two levels of ‘creative’ interactions (ibid:109).Thefirstoneismoreovert:‘presentationalusesoflanguage, open displays of metaphoric invention, punning, uses of idioms and departures from expected idiomatic formulations (pattern re-forming)’.The second level is less overt,
‘maybe even subconscious and subliminal parallelisms, echoes and related matchings… in implicitsymmetriesoffeeling (pattern forming)’.
2.3 Idioms
Idioms and binomials are types of fixed expressions (cf. 2.1.3). Fernando (1996: 40) argues that different ‘analysts will come up with somewhat different criteriaand differentidentifications’(cf.Grantand Bauer2004;Schmitt and Carter 2004: ch. 1). Moon (1998) argues that there are three criteria to distinguish multi-word items, together with a further criterion used in spoken English (see below):
Institutionalisation, i.e. ‘the degree to which a multi-word item is conventionalised in the language:doesitrecur?’.
Fixedness,i.e.‘the degreeto which amulti-word item is frozen as a sequence ofwords.Doesitinflect?’.
Non-compositionality,i.e.‘thedegreeto which amulti-word item cannot be interpreted on a word-by-word basis, but has a specialised unitary meaning’.
Phonological criterion,i.e.‘multi-word itemsoften form singletoneunits’.
Fixed expressions consist of different types, i.e. compounds (car park =
carpark = car-park), phrasal verbs (get up, go on), idioms (spill the beans), fixed phrases (of course), and prefabs (the fact is) (Moon 1997: 44-7).
2.4 Frequency and idioms
Frequency plays a role in corpus linguistics (cf. Sinclair 1991; Hunston 2002). It has been assumed to influence the word order of individual items in binomials.
However, the whole unit of formulaic sequences should be considered because lexical meaning is not concerned with single words only. What matters is that a different word order of formulaic sequences may lead to different meanings/use across both written and spoken modes, especially at the discourse level.
2.5 Summary for text analysis
The theories related to text analysis have some features such as ‘cohesion, coherence
and chain’in common. It is evident that Halliday and Hasan (1976) mainly use cohesive ties in text analysis. Hasan (1984) and Halliday and Hasan (1989) revise their previous theory and focus on cohesive harmony and chain interactions in texts.
Hoey (1991) applies lexical repetition and repetition link to text analysis. But, Hoey (2005) emphasises collocation and lexical priming, and reverses the roles of lexis and grammar which is an outcome of the lexical structure. Carter and McCarthy (2004) propose that creativity is a special feature of all people. It is interactive and contextual in a specific socio-cultural context, including pattern forming and pattern re-forming as the main levels of interactive creativity.
3. Methodology
The mixed methods design has been considered for the current study (Creswell 2003; Lazaraton 2002). A combination of quantitative and qualitative research was applied to ‘bring out the best of both approaches’(Dörnyei 2001: 242; Dörnyei 2007:
24-47), including the corpus design and construction for language analyses. As McCarthy, Matthiessen and Slade (2002: 70) propose, ‘broadly, corpus linguistics may be performed in two ways: quantitative and qualitative’. Corpus-based approaches first offer the texts and statistical facts (e.g. frequency, wordlist, collocations, etc.) for text analysis to do qualitative research, which in turn gives feedback to the corpus in order that each reinforces the other. The quantitative results provide text analysis with the statistical results to strengthen the analysis of the contexts of texts in the corpus.
3.1 Data types and data collection
The data for the current study consist of the British National Corpus (BNC) and SS database, constructed by the present author, as the ‘direct evidence’. The texts extracted from various websites, using the Google search engine, are used as the external or supplementary materials to the analysis of corpus-based research.
Additionally, all tokens were run through the Sara-32 search engine to search the frequency of occurrence in the BNC. A database was constructed to design questionnaires for the informant assessment, and the use of the Academic Word List (AWL, Coxhead 2000) for a vocabulary placement test.
3.2 Participants
The test-takers in Taiwan undertook the vocabulary test, idiom test and reading test conducted by the author. All completed the test in the classroom. Most were first year and second year students of English Departments from two local universities, 142 students in total.
3.3 Instruments and materials
The main instruments and analytical tools used in this study include the software suite Sara-32 for searching for frequency of occurrence and concordance evidence from the BNC, which is chosen because of its size, prominence and availability in current corpus-based work (Kennedy, 1998). AWL is used for a vocabulary test. The SPSS software suite presents descriptive statistical results and executes theoretical calculations for statistical significance or correlation (e.g., One-way ANOVA ,).
4. Results & Discussion
In general, this research suggests that students’word power and idiom ability can be enhanced to a great extent when corpus-based approaches and text analysis are integrated into language instruction.
4.2 Results of the application of vocabulary placement test: L, M, & H groups A placement test was administered for the classification of all test-takers. Table 1 indicates the categorizations of three groups, vocabulary, idiom and reading.
Table 1 Test results (N= 142)
Paired Samples Statistics
73.4859 142 20.6349 1.7316
77.4577 142 19.1284 1.6052
60.0141 142 11.3687 .9540
59.6479 142 12.1259 1.0176
45.9859 142 24.7272 2.0751
54.2958 142 22.9831 1.9287
VOCT1 VOCT2 Pair 1
IDT1 IDT2 Pair 2
READINGT READIN_A Pair 3
Mean N Std. Deviation Std. Error Mean
The design of the research indicates highly correlated for each other after the pre-test and post-test were conducted as shown below:
Table 2 Paired Samples Correlations
Type N Correlation Sig.
1 VOCT1 & VOCT2 142 .868 .000
2 IDT1 & IDT2 142 .400 .000
3 READINGT & READIN_A 142 .541 .000
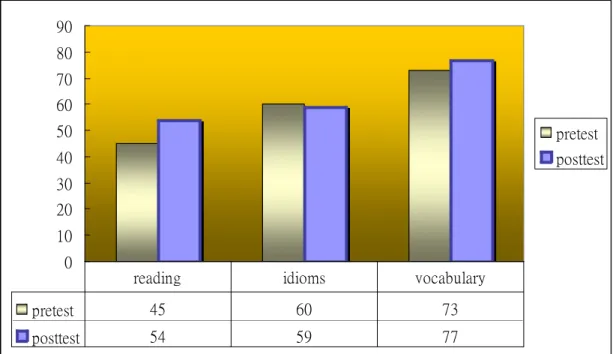
A further analysis indicates that the students improved in both vocabulary and reading comprehension, but not the idiom part (or formulaic language) as shown below:
0 10 20 30 40 50 60 70 80 90
pretest posttest
pretest 45 60 73
posttest 54 59 77
reading idioms vocabulary
Figure 1 The results of the experiments
A further paired samples test (or One-way ANOVA test) for the test was employed to confirm that the difference among the three groups was significant (F (2, 342)= 1291.692; *p< .01) except the idiom testing group.
Table 3 Paired samples test
Paired Samples Test
-3.9718 10.3355 .8673 -5.6865 -2.2572 -4.579 141 .000
.3662 12.8811 1.0810 -1.7708 2.5032 .339 141 .735
-8.3099 22.9081 1.9224 -12.1103 -4.5094 -4.323 141 .000
VOCT1 - VOCT2 Pair 1
IDT1 - IDT2 Pair 2
READINGT - READIN_A Pair 3
Mean Std. Deviation Std. Error
Mean Lower Upper
95% Confidence Interval of the
Difference Paired Differences
t df Sig. (2-tailed)
It is easier for students to improve in vocabulary and reading. However, idioms or formulaic language is the most difficult part to get better.
5. Self-evaluation (計畫成果自評)
I constructed an idiom database and proposed the importance of formulaic languages (or idioms) and text analysis in language teaching and learning. I have also investigated the effectiveness of integrating corpus-based approaches into a linguistics project concerning vocabulary and idiom growth of L2 learners. The finding is idioms or formulaic language is more difficult for students to improve. This is one of the
reasons why students cannot improve themselves in learning English. For further language studies and teaching, there are some aspects worthy of consideration. For instance, it is interesting to explore in-depth, lexical priming, idioms and individual lexical items in text.
References (參考文獻) SELECTED REFERENCES
Boers, F. and S. Lindstromberg 2005. Finding ways to make phrase-learning feasible: The mnemonic effect of alliteration, System 33: 225-238.
Carter, R. 1998. Vocabulary: Applied Linguistic Perspectives (2ndedtion). London:
Routledge.
Coxhead, A. 2000. ‘A new academicword list.’
TESOL Quarterly 34/2: 213-238.
Dörnyei, Z. 2003. Questionnaires in Second Language Research: Construction,
Administration, and Processing . Mahwah, NJ: Lawrence Erlbaum.
Fernando, C. 1996. Idioms and idiomaticity. Oxford: Oxford University Press.
Grant, L. 2005. Frequency of core idioms in the British National Corpus (BNC).
International Journal of Corpus Linguistics, 10(4): 429-451.
Hoey, M. 1991. Patterns of Lexis in Text. Oxford: Oxford University Press.
Lazaraton, A. 2002.‘Quantitativeand qualitativeapproachesto discourseanalysis.’
Annual Review of Applied Linguistics 22: 33-51.
Liu, D. 2003. The most frequently used spoken American English idioms: corpus analysis and its implications. TESOL Quarterly 37(4): 671-700.
McCarthy, M. 1990. Vocabulary. Oxford: Oxford University Press.
Moon, R. 1998a. Fixed Expressions and Idioms in English. Oxford: Oxford University Press.
Nation, P. 2001. Learning Vocabulary in Another Language. Cambridge: Cambridge University Press.
Nattinger, J. and J. DeCarrico. 1992. Lexical Phrases and Language Teaching.
Oxford: Oxford University Press.
Read, J. 2000. Assessing Vocabulary. Cambridge: Cambridge University Press.
Read, J. and Nation, P. 2004. Measurement of formulaic sequences. In N.
Schmitt (ed.), Formulaic sequences (pp. 23-35). Amsterdam: John Benjamins.
Schmitt, N. (ed.) 2004. Formulaic Sequences. Amsterdam/Philadelphia: John Benjamins Publishing Company.
Schmitt, N. 2000. Vocabulary in Language Teaching. Cambridge: Cambridge University Press.
Wang, S.P.. 2003b. ‘Corpus-based approaches to frequency and word association for
English vocabulary and multiword units.’Paper presented in BAAL 2003, UK:
University of Leeds.
Wang, S.P. 2004. ‘Word frequency, word order and word proficiency.’Paper presented at AAAL 2004, Portland, Oregon, USA, May 1-4, 2002.
Wang, S.P. and M. McCarthy 2004. ‘Corpus-based analysis and discourse analysis of fixed expressions: fixed, flexible or free formulation?’ Paper presented at
IVACS 2004, Belfast, Northern Ireland, UK, June 25-26, 2004.
Wang, S.P. 2005. ‘Corpus-based approaches and discourse analysis in relation to reduplication and repetition.’
Journal of Pragmatics 37(4): 505-540.
Wang, S.P. 2006. Corpus-based approaches and discourse analysis in relation to
sound symbolism, reduplication and fixed expressions. Unpublished PhD thesis,
University of Nottingham.Wray, A. 2002. Formulaic Language and the Lexicon. Cambridge: Cambridge University Press.
1
國科會專題研究計畫赴國外出差或研習心得報告一份 計畫編號:NSC 97-2410-H-011-024
執行期限:20080801~20091130 主持人:王世平
執行機構:台灣科技大學應外系
「以語料庫為本分析文本中的詞彙啟動與詞彙變化及其教學應用」
Lexical priming and variation in text and teaching: a corpus-based approach
問卷調查及研習心得報告
University of Newcastle (UK), 3 - 5 September 2009 Shih-ping Wang (王世平)
一、參加會議
2009 年 9 月飛往大不列顛主要依計劃做研究調查,並參加在 University of Newcastle 舉辦的「2009 英國應用語言學年會」(BAAL 2009, The British Association for Applied Linguistics, 3 - 5 September 舉行)。本會議所探討的研究領域相當的廣 泛,還包括 3 場 Plenary speeches:
Plenary speakers:
David Crystal (Bangor University)
Pauline Rea-Dickins (University of Bristol)
Bethan Benwell (University of Stirling) & Elizabeth Stokoe (Loughborough University)
BAAL 目的在於: 鼓勵語言「教學」專家彼此對話;鼓勵類似問題、不同領域、
語言之間的交流。BAAL2009 旨在強調提供一個學術探討與交流的環境給每一位 與會者,以助於探討語言「教」、「學」實際的應用與理論的發展,此外,大會 書卷獎(The 2009 BAAL Book Prize)得主為:
Wei, L. and M.G. Moyer (eds) (2008): The Blackwell Guide to Research Methods in Bilingualism and Multilingualism. Blackwell.
感謝國科會的經費補助,能有這次參加國際學術研討會議的寶貴機會。個人除了 在專業方面能向許多國際知名的學者專家執經請益以外,還可以有機會從高水準 的演講中學習。對於主辦單位熱切服務,感到由衷的敬佩。
2
我們的論文(R. Johanson, S. Wang)為〝When Sexy is No Longer Sexy: A Corpus Based Analysis of the Lexical Amelioration of a Loaded Term〞。我們的研究方法偏向 experimental,;另 外也盡最大可能到處傾聽別人的論文發表。發現幾個值得進一步研究的題目。這 是一次很好的機會能夠獲得這麼多相關的資訊,個人非常珍惜這次與會的寶貴經 驗,相信對於將來想要參與相關研究以及未來有機會參與這種國際會議有更進一 步的幫助。
三、結語
參加此類的研討會,可以印證自己的研究成果,獲得相關領域其國際上的最新研 究趨勢及發展,對於教學與研究皆具有十足的正面意義。在此,再次感謝國科會 給予筆者參與該會的補助。若能常和國外相關學者有較多和較深入的交流,不但 增強學習的層面,有助於培養更多專業的優秀人才,還能夠提昇將來國內學術領 域在國際上的知名度。此外,我們也應該多多舉辦國際性學術研討會,藉以使國 際上能進一步了解我國情況,提高我國之學術聲譽。
國科會專題研究計畫出席國際會議研究心得報告及發表之論文 計畫編號:NSC 97-2410-H-011-024
執行期限:20080801~20091130 主持人:王世平
執行機構:台灣科技大學應外系
建構雙語詞、成語和格式化語言的常用表及其教學應用 AAAL 2009, 21-24 March 2009
Shih-ping Wang (王世平) 心得報告
Corpus-based and word-focused tasks for vocabulary and formulaic language learning and teaching, paper presented at the AAAL 2009 Conference in Denver, Colorado, March 21-24.
一、參加會議
2009 三月飛越太平洋,參加在 Denver (Colorado)舉辦的「2009 美國應用語言學 年會」(the American Association of Applied Linguistics ( AAAL), 21 - 24 March, 2009 舉行)。本會議所探討的研究領域相當的廣泛 ;AAAL 提供一個學術探討 與交流的環境給每一位與會者,以助於探討實際的應用與理論的發展,這些探討 的主題涵蓋層面包含 English teaching, theoretical linguistics, applied linguistics, experimental and descriptive linguistics。包括六場 Plenary speeches:
Lyle Bachman, University of California, University of California, Los Angeles Toward an 'activist' Applied Linguistics
Ellen Bialystok, York University Interactions of language processing and cognitive control in bilingualism
Guy Cook, The Open University Sweet talking: Food, language, and democracy
Graham Crookes, University of Hawai'I The relevance of SL critical pedagogy
Rod Ellis, University of Auckland
Second Language Acquisition: Theory, research and language pedagogy
Heidi Hamilton, Georgetown University Life as a linguist among clinicians:
Learnings from cross-disciplinary collaborations
各場主講者都能將將理論與實際發揮得凌漓盡致,整體而言這次的學術研討會相 當圓滿成功。
二、與會心得
能有這次參加國際學術研討會議的寶貴機會,主要感謝國科會的經費補助。個人 除了在專業方面能向許多國際知名的學者專家執經請益以外,還可以有機會從高 水準的演講中學習。對於主辦單位主要承辦者熱切服務,感到由衷的敬佩。 筆 者的論文〝Corpus-based and word-focused tasks for vocabulary and formulaic language learning and teaching〞是在第二天發表。筆者的研究方法偏向量化;報 告完後,引起迴響,也回答一些問題。在答辯中,幸好可以圓滿達成任務,另外 也盡最大可能到處傾聽別人的論文發表。發現幾個值得進一步研究的題目。
這是一次很好的機會能夠獲得這麼多相關的資訊,個人非常珍惜這次與會的寶貴 經驗。相信對於將來想要參與相關研究以及未來有機會參與這種國際會議有更進 一步的幫助。
三、結語
參加此類的研討會,可以印證自己的研究成果,獲得相關領域其國際上的最新研 究趨勢及發展,對於教學與研究皆具有十足的正面意義,在此,再次感謝國科會 給予筆者參與該會的補助。其實,對於國內各大學院校的學術水準,除了硬體設 備方面的完善,更重要的是能多多獎勵出國參加學術會議,一方面可以增加視野 與國際觀,再者也藉以獲取與國外學術單位的學者們交換寶貴的經驗。若能這樣 和國外相關學者有較多和較深入的交流,不但增強學習的層面,有助於培養更多 專業的優秀人才,還能夠提昇將來國內學術領域在國際上的知名度,筆者此行面 見一群大師級人物即是一例。此外,我們也應該多多舉辦國際性學術研討會,藉 以使國際上能進一步了解我國情況,提高我國之學術聲譽。
NSC project: Constructing wordlists of the commonly used binomials, idioms and formulaic languages for English teaching and learning
AAAL2008: Text analysis and text types: sound, form, meaning, and use Shih-ping Wang
Department of Applied Foreign Languages, NTUST
This paper is concerned with word usage in texts, which explores how sound repetition and sound symbolism interact with lexical items in terms of form, meaning, and use (Tannen 1989). A database was constructed for the current study, including 90,000 words and 4,000 sound symbolism tokens. This research then integrates corpus-based analysis and textual analysis in relation to word usage at different language levels (Halliday and Hasan 1989; Carter and McCarthy 2004, Hoey 2005). A combination of quantitative and qualitative analyses (Dörnyei 2001) is employed to support the statistical results and language use in texts. The findings with some specific features indicate that sound may interact with lexical items in texts, by choice or by chance, whcih can be classified into some typical text types, e.g., the musicality, metaphor, socio-cultural factors, typographic errors, phonological and lexical priming, language creativity, and the like.
This paper explores how repetition and sound symbolism interact with lexical items in texts, integrating corpus-based analysis and textual analysis in relation to word usages at different language levels. The findings show some typical text types with features, e.g., the musicality, metaphor, phonological priming etc.
NSC project: Constructing wordlists of the commonly used binomials, idioms and formulaic languages for English teaching and learning
AAAL2008: Text analysis and text types: sound, form, meaning, and use Shih-ping Wang
Department of Applied Foreign Languages, NTUST
This paper is concerned with word usage in texts, which explores how sound repetition and sound symbolism interact with lexical items in terms of form, meaning, and use (Tannen 1989). A database was constructed for the current study, including 90,000 words and 4,000 sound symbolism tokens. This research then integrates corpus-based analysis and textual analysis in relation to word usage at different language levels (Halliday and Hasan 1989; Carter and McCarthy 2004, Hoey 2005). A combination of quantitative and qualitative analyses (Dörnyei 2001) is employed to support the statistical results and language use in texts. The findings with some specific features indicate that sound may interact with lexical items in texts, by choice or by chance, whcih can be classified into some typical text types, e.g., the musicality, metaphor, socio-cultural factors, typographic errors, phonological and lexical priming, language creativity, and the like.
Keywords: corpus-based approaches, text analysis, sound patterns, 4-components
1 Introduction
This paper aims to explore how sound repetition and sound symbolism in English interact with lexical items exhibiting various sound patterns and word usage in texts, e.g., the onset /h/ and the rhyming /-ustle/ in ‘Lifewasterribly hectic in the city, she thought, all hustle and bustle’. A combination of corpus-based approaches and text analysis is designed to underpin the statistical results in terms of the integrated four-component framework, i.e., ‘sound, form, meaning and use’
.
The cohesive or lexical chains are incorporated into the analytical framework to link language components and demonstrate what they have to do with sound repetition and word usage (Halliday and Hasan 1989; Carter and McCarthy 2004). Furthermore, lexical priming, language creativity and socio-cultural contexts play a significant part in supporting the analysis of lexical items in texts (Hoey 2005; Carter 2004).This paper will scrutinize how sounds, sound symbolism and repetition interact with word usage from the phonological, the lexical to the text level, in accordance with the major research questions below:
●What evidence is there that the textual environment may influence or be influenced by ‘sound, form, meaning and use’?
●How are sound symbolism and repetition actually used in real texts?
●What do sound patterns contribute to their texts?
●Put simply, what types and features do they exhibit in texts?
2 Literature review
2.1 Repetition and text analysis
Repetition or reduplication has long been explored in spoken and written texts (Wang 2005a). Sapir (1921: 79-80) argues that ‘nothing is more natural than reduplication’.Halliday and Matthiessen (2004: 571) highlight that ‘themostdirect form oflexicalcohesion istherepetition ofalexicalitem’.Repetition is also at the heartof‘how aparticulardiscourseiscreated’and ‘how discourseitselfiscreated’
(Tannen 1989: 3). Repetition takes the form of a recurrent sound to become phonological, syntactic, and cohesive (McCarthy and Carter 1994). It may create a parallelism, suggesting a connection of meaning through an echo of form, and may also be a sound parallelism such as rhyme and other sound effects of verse in texts (Cook 1989).
2.2 Application of repetition and SS
Repetition and SS are routinely employed in many areas. Yip (2000) views
‘reduplication as the most grammaticalized end of a continuum from ‘song,verse, language games, onomatopoeia, mimetics, reduplication with an iconic residue, to non-iconicreduplication’. It has also been suggested elsewhere (Wang 2005a) that symbolic reduplication is commonly used in different genres such as baby talk, children’ssongs,lyrics,poetry,and prayer(Tannen 1989), language games, tongue twisters, comics and cartoons (Hinton et al. 1994), icons, advertisements, brand-naming, political slogans (Goddard 1998), headlines for any message or newspaper (Beard 2000), political and ideological rhetoric (Carter et al. 2001), and names and place names (Hoey 2005).
For instance, a typical tongue twister case in relation to sC-cluster exhibits vivid sound reduplication in terms of onset-repetition, nuclei repetition, assonance repetition and rhyming (Jakobson and Waugh 1979). Figure 1 elaborates the interactions of repetitions between onsets (/sk-/~/st-/) and codas (/-nk/ ~/-mp/), i.e., the interaction between SS and sound repetition.
2.3 SS in language teaching and learning
It is commonly accepted that alliteration and rhyming patterns are helpful for language learning (Boers and Lindstromberg 2005; Wang 2005a). Consider the examples with high frequency in the BNC in Table 1. The onomatopoeic words can be straightforwardly perceived in terms of sound-meaning association for L2 learners (Jespersen 1922/64). All tokens can be readily perceived and possibly memorized immediately, e.g., ‘bang’and ‘babble’(see Wang 2005b for details of teaching SS).
The task in Table 2 below encourages language learners to identify
onomatopoeic words. It is a comical poem with 41 words (‘When Carly Eats Spaghetti’), including 12 underlined onomatopoeic words (29.2% SS words). The rhyming patterns in this task are useful for instructional and mnemonic motivation:
/-p+s/ (e.g., ‘chomps, slurps’); /-CCle + s/ (e.g., ‘gobbles, gurgles’); /-ing/ (e.g.,
‘slapping, smacking’); others (e.g., /i/-rhyming: Carly, spaghetti; and direct imitation air sound: whoosh).
3 Methodology: integrating quantitative and qualitative studies
The mixed methods design has been considered for the current study (Creswell 2003; Lazaraton 2002). A combination of quantitative and qualitative research was applied to ‘bring out the best of both approaches’(Dörnyei 2001: 242; Dörnyei 2007:
24-47), including the corpus design and construction for language analyses.
3.1 Data types and SS database (quantitative)
The data for the current study consist of the British National Corpus (BNC) and SS database, constructed by the present Wang, as the ‘direct evidence’. The texts extracted from various websites, using the Google search engine, are used as the external or supplementary materials to the analysis of corpus-based research.
3.1.2 Construction of the SS-database, wordlists and analytical tools
The database of SS comprises 15 major categories of tokens, including
‘reduplication,onomatopoeia(directimitation),speech organ,feeling/emotion,nature, movement, spreading, bloat/prick, clank, R/broken, Sc/st-, Tr-(1-2), diminutive, CC-le and animal’.The format, content and annotation for each token consist of lexical items, parts of speech, example sentences, English synonyms with their Chinese translations, analysis tip and code number. For instance, the coding number of
‘plunge’is‘8.2.1’.Thefirst8 represents Category 8 (‘to drop or throw’category). The second 2 represents the 2nd sub-type in ‘drop orthrow’category. The last number indicates where it (= plunge) is within this sub-category. Table 3 illustrates samples extracted or found from the BNC or websites (Wang 2005b).
The analytical tools included the built-in Sara-32 in the BNC (mainly for the calculation of frequency of tokens and their concordances), and the Wordsmith 4.0 used for the analyses of frequency, collocations and type/token ratio (TTR), etc.
3.1.3 Procedure for SS-database construction (quantitative)
The initial step was to collect data, do the frequency searching, and then create the wordlist according to the above SS classification. The wordlist with a different
codenumber(indicating ‘semantictype’and thefrequency in theBNC foreach token) was presented. Put simply, the basic procedure is a simple search of each token for its frequency. The next step was to select the top 100 tokens for the creation of wordlist.
Example texts can then be searched and extracted from the BNC or websites for the relevant analysis in terms of a 4-component framework (i.e., sound, form, meaning and use found in any natural language).
3.2 Qualitative analysis
3.2.1 Modified sound shift rules and word usage
Traditionally, Grimm’sLaw is used to elucidate the sound correspondences and to reconstruct the systematic relationships between Germanic and Indo-European languages (Hock 1986). It has long been used in historical linguistics to explain sound change at the lexical level. It is also applied to synchronic linguistics such as lexical analysis (e.g., labial ~ lip; dental ~ teeth). However, its applications can be expanded, modified and used more flexibly in text to explain word usage, which was explored in current studies.
This research developed the application of sound shift in depth from the phonetic level to the textual level.Thefunction ofGrimm’sLaw was adapted to some extent to show that sound shift may involve word usage beyond the lexical level. Some sound changesoccurdueto ‘assimilation,afundamentally physiologicalprocessofeaseof articulation’(Fromkinet al. 2003: 536-7).Thiseaseprincipleimplies‘thetendency of speakers to adjust their pronunciation to make it easier or more efficient, to move the articulators’(ibid.: 581). Sound shift therefore is considered a factor interacting with word choices in texts partly because of this principle.
The consonants for various sound shifts can be categorized into three larger groups to account for how sound shifts may involve word usage in texts. This modified categorisation is slightly different from the traditional classification, based on seven places of articulation (Fromkin et al.: ch. 6). For each group, there are two extra upper layers employed to illuminate sound shifts in a broader way. Group 1 dominates two labial places of articulation (Bilabial and Labial-dental [1] & [2]), Group 2, dental and alveolar ([3] & [4]); Group 3 includes palatal, velar and glottal places ([5], [6] & [7]) (see Table 4 below).
The grouping above can be used to explain three major rules in relation to sound shift. Rule 1 deals with the alternation of the labial and labial-dental group (Group 1).
For instance, the onset /p/ in the root pair ‘-pod/-ped’underwent sound change and became /f/ in foot/feet. Therefore, a person walking on foot is called a pedestrian (feet + -ian (‘person walker pedestrian’). Rule 2 is concerned with the dental-alveolar
group (Group 2) such as the alternations between /t/ and /θ
/ in ‘
dental ~ teeth’. Rule 3 is mainly related to the palatal-velar part of the mouth (Group 3), e.g., the alternation of /t∫/ ~ /k/ in ‘child ~ kid’.3.2.2 Sound change, misapprehensions and word usage
Contrary to the ease principle or sound shifts above, there are other forces causing sound change, which may prove stronger than the ease theory (Jespersen 1922/64: 262). Fromkin et al. (2003) argue that speech errors (or slips of the tongue) show phonological rules in action, which may influence word usage such as “That queer old dean’instead of ‘That dear old queen’(ibid.: 316).
Ohala (1990: 226) suggests that the listener as the source of sound change can be one of the factors for word usage (see also Blevins 2004). The reasons are various partially because of ‘the “innocent”misapprehensions about the interpretation of the speech signal’. Likewise, ‘the transmission of scribalerrors in the copying of manuscripts’(i.e., ‘slips of the pen’) or typographic errors may cause different word usage in contexts. Indeed, the analogy between speech errors and transcription errors is also made in Ohala’s discussion of sound change (ibid.: 216). In other words, typographic errors may occur due to the transcription mistake by chance or by choice, which may lead to different word usage and possibly become a kind of lexical priming or language creativity. It is useful to analyze texts and lexical cohesion in the light of their research.
3.2.3 Lexical cohesion
The primary work on English cohesion may be that of Halliday and Hasan (1976). Cohesion refersto ‘relationsofmeaning thatexistwithin thetext,and that defineitasatext’(ibid.: 4). Cohesion links a string of sentences to form a text, presenting a system to analyse cohesive relationships within a text. The organisation of text is made up of cohesive ties. One of cohesive ties occurring in text is lexical cohesion with two common attributes, reiteration and collocation. Reiteration involves the repetition of a lexical items and the use of the same word, synonym or a general term. Indeed, reiteration or relexicalization (see glimpse) chains can create lexical chains in text and across different language levels.
Hasan (1984) and Halliday and Hasan (1989: 70ff) extended their theory later and included theconceptofcohesiveharmony,referring to ‘chain interactionswithin text’.Chain interaction can be identified only ‘when two ormoremembersofachain stand in an identicalfunctionalrelation to two ormoremembersofanotherchain’
(ibid.: 212). For instance, the chain interaction occurs for the lexical items ‘girl, boy
and daddy stroke dog’and ‘girl, boy and daddy feed dog’. Each of these chains is constructed on a semantic principle, creating unity among its own members.
In other words, chain interaction is the crucial factor for coherence.
3.2.4 Lexical priming, creativity and socio-cultural context
Hoey argues how texts function crucially related to lexical cohesion (1991:
51-75). Lexis creates cohesion mainly through several kinds of repetition. But, later he develops the theory of lexical priming and claims that words are primed for certain uses and meanings, such as the phenomena of collocation, indicating how language is really organized (ibid.: 2005). Hoey recognizes that a stretch of sound may associate with meaning (e.g., /sl-/ in ‘slippery slope’). A phonetic or phonological starting point allows priming to explain wordplay, rhyme, etc.
Carter and McCarthy (2004) propose thatcreativity is‘a capacity ofallpeople, but not a capacity of special people’. The concept of creativity with ‘novel, interpersonal and interactive’ attributes involves individual, social and cultural contexts. Carter argues that ‘creativity is always contextually framed and conditioned…Socialand culturalcontexts play a significant part as sites for creative language use’ (2004: 210). He also argues that there are two levels of ‘creative’ interactions (ibid.:109).Thefirstoneismoreovert:‘presentationalusesoflanguage, open displays of metaphoric invention, punning, uses of idioms and departures from expected idiomatic formulations (pattern re-forming)’.The second level is less overt,
‘maybe even subconscious and subliminal parallelisms, echoes and related matchings… in implicitsymmetriesoffeeling (pattern forming)’.
Indeed, creativity may occur at different language levels and in a socio-cultural context. The above features together with repetition help us to perceive word usage in text as exemplified in the subsequent sections.
3.2.5 Summary and procedure for text analysis (qualitative)
The theories related to text analysis have some features such as ‘cohesion, coherence and chain’in common. It is evident that Halliday and Hasan (1976) mainly use cohesive ties in text analysis. Hasan (1984) and Halliday and Hasan (1989) revise their previous theory and focus on cohesive harmony and chain interactions in texts.
Hoey (1991) applies lexical repetition and repetition link to text analysis. But, Hoey (2005) emphasizes collocation and lexical priming, and reverses the roles of lexis and grammar which is an outcome of the lexical structure. Carter and McCarthy (2004) propose that creativity is a special feature of all people. It is interactive and contextual in a specific socio-cultural context, including pattern forming and pattern re-forming as the main levels of interactive creativity.
Concerning the analytical procedure for text analysis in terms of lexical cohesion, there are some prerequisites to bear in mind: First of all, I will scan