國立臺灣大學法律學院法律學研究所 碩士論文
Graduate Institute of Law College of Law
National Taiwan University Master Thesis
法律資料分析的優化與應用:
以離婚後未成年子女親權酌定的裁判為素材
The Optimization and Application of Legal Analytics:
A Study on Child Custody Cases
姜晴文
Ching-Wen Chiang
指導教授:黃詩淳博士
Advisor: Sieh-Chuen Huang, Ph.D.
中華民國 108 年 10 月
October, 2019
i
口試委員會審定書
國立臺灣大學碩士學位論文
口試委員審定書
ii
誌謝
感謝黃詩淳老師,是您引領我進入實證裁判的統計與量化分析領域,帶著我 們把 Kevin D. Ashley 的那本深奧天書:Artificial Intelligence and Legal Analytics 研 讀一遍,過程是痛苦的,但收穫卻是滿滿的。
感謝吳從周老師和劉宏恩老師在百忙中願意撥冗擔任口試委員,並給予無價 的修正意見,讓我的論文能夠更臻完善,也讓我學習到如何以邏輯嚴密的架構呈 現研究內容。這次因為米塔颱風意外打亂口試計畫,特別謝謝老師們熱心幫我迅 速重定時間,讓我在這終身難忘的經歷中,順利完成口試。
感謝林仁光老師,老師是我大學時代的導師,論文寫作期間,教我引註的精 神和方法,帶著我釐清問題意識、推敲邏輯理路的罅漏。謝謝老師的支持和教導,
讓我得以通過研究所以來磨人的試煉。
感謝岡毅學長,學長就像是本活字典,在自然語言處理和類神經網路的測試 都提供了完整而深入的解答,讓我少走了許多冤枉路。
也感謝台灣師範大學東亞學系的邵軒磊老師。
感謝我的家人,媽媽、爸爸和姊姊,你們照顧我的衣食起居,每天和我分享 心情。
感謝貝珍,沒有你的陪伴和支持,我真不知要如何渡過這段艱辛歲月,此外 也感謝家綺、芝寰,還有斯婷、容萱、綉棋學姊和宜慶、旻諺學長的幫助,學習 的路上有你們,讓我不孤單。
感謝 Ashley 讓我跳出機器學習的領域,重新回到法律的本質,思考實證裁判 研究的定位,更發現了 i-like 這個新朋友。
最後感謝這 4,340 位孩子--3,272 個家庭,和 229 位法官。是你們的悲歡離 合和斟酌衡平,告訴了我法律精神背後活生生的人與事。
iii
中文摘要
夫妻離婚後,法院如何將具有高度不確定性之「子女最佳利益原則」,貫徹於 實際親權酌定個案中,往往是當事人激烈爭議的焦點。儘管有民法第 1055 條之 1 提供各項判斷方針,依然難以解決「子女最佳利益原則」判斷標準模糊不明之困 難。本研究統計民國 98 年 1 月 1 日起至 106 年 12 月 31 日止全台地方法院有關親 權酌定第一審的 2,775 件裁判,計未成年子女 4,340 人,計劃透過實證裁判的統計 與量化分析,以歸納法試圖尋繹出親權酌定在實務案件的實踐原則。
本研究之取樣係以司法院法學資料檢索系統為範圍,而法院設定裁判不公開 之作為並非隨機,此將影響研究取樣的隨機性,而成為本論文所有統計量化分析 與立論的最大限制。再者,本研究事實的認定以裁判書為準,採法官的觀點,不 作事實認定的工作,故而本論文預測模型的預設使用對象為法官、而非律師或當 事人,並無取代律師、法官的可能。第三,本研究僅以研究者一人間隔一段時間 重新編碼的方式改正失誤,防錯、偵錯、除錯的機制均不夠嚴謹。最後,目前裁 判書的編碼工作尚未找到可以避免觀察者錯誤效應的標準流程,可能會因此導致 預測模型準確率的高估。
本研究羅列了對數機率迴歸、決策樹、隨機森林、梯度型推進決策樹、類神 經網路等 5 種預測工具。發現它們預測裁判結果的準確率差別有限,皆可達 95.5%
以上,整體而言本研究的資料型態較適合使用梯度型推進決策樹。若使用本研究 建議的客製化流程,準確率可再提高,且預測的信度上升。為解決預測模型「解 釋性受限」的問題,本研究提出在預測模型之外另行建構論理模型的主張,根據 本研究的樣本完成樣式化論理模型--以親子意願交叉比對、輔以親職能力、現 住所等因素所建構的高維複合邏輯路徑模型。不管是整體樣本、或其他分眾樣本,
其解釋覆蓋率介於 96.93%-99.27%,已能成功擔當實證裁判研究的論理任務。
我們以前述 5 種客製化預測模型逐年滾動分析近五年的裁判資料,發現準確
iv
率維持在 97.25%-99.86%之間,可見這 5 種預測模型都具有預測全新未知樣本的能 力。雖然進一步科曼哈卡方檢定發現 103 年的資料因為無書狀母親的事件較多而 與其他年份的資料在分布上有顯著的不同,唯不影響本研究預測模型與論理模型 的表現。
本研究進一步分析與親權酌定相關的 28 種因素,發現當訴訟一方為外籍配偶、
或有一造未到庭且無書狀聲明陳述意見時,其對造都有較高的比率取得未成年子 女的親權。在地域的分布上,一造未到庭且無書狀聲明陳述意見的事件比較偏向 非六都地區。
子女年齡與親權歸屬有關聯性,分別在 0-2 歲、及 14-19 歲的兩極出現親權歸 母的高峰。本研究在論理模型的導引下,發現這是因為「幼兒從母」、「中兒唯父 有意」及「大兒擇母」三股不同力量共同作用的結果,而後兩者都與外籍母親有 關。至於其他因素,除子女的排行、父母教育程度與親權歸屬無關之外,主要照 顧者等另 18 個因素的組間比較都達顯著差異。我們利用對數機率迴歸,檢定出權 值較大的 9 個因素依序為:父母意願、子女意願、親職能力、父母品行、支持系 統、主要照顧者、現住所、經濟能力、對子女有不當行為。
本研究發現,社工的利用率高(95.36%)且 98.74%的親權建議與裁判結果相 同。而程序監理人、家事調查官則利用率低,分別為 1.32%、及 1.48%。程序監理 人 97.62%的建議與裁判結果相同,家事調查官則是 100%一致。
有關外籍配偶,本研究發現有著城鄉分布的差距:以台籍父母為基準,陸籍 配偶的分布偏向六都地區,而越印等其他籍則偏向非六都。個別因素分析結果,
不論陸籍或越印其他籍母親組,法官裁判標準其實是一致的--都是以父母及子 女的意願最具影響力。細部檢定發現,台籍、陸籍、越印等其他籍母親出庭有書 狀的比率出現由高而低的變化,她們取得親權的比率也是如此趨勢。即便有書狀 的外籍母親,其獲得親權的比率還是不如台籍。本研究藉由七維表格分析、樣式 化論理模型的樣本流檢定等數據,進一步分析發現外籍母親在親子意願、及主要
v
照顧者、現住所、支持系統都是有利父多於有利母,且達顯著差異,試圖說明為 何外籍母親取得親權的比率會低於台籍母親。
關鍵字:法律資料分析、親權酌定、預測模型、論理模型、幼兒從母原則、外籍 配偶
vi
英文摘要
Applying Artificial Intelligence on litigation prediction has developed for more than 40 years. A litigation predicting model can play a role of communicator, opening a window for us to look outside. The more accurate it is; the more people will embrace it.
Several models have been applied in the field of litigation prediction. Hu and Huang predicted the guardianship for the ward by regression; Huang and Shao operated models of decision tree and artificial neural network to analyze child custody in
divorcing cases. The results of their studies show surprising accuracy. In addition, some ensemble learning machines, such as random forests and gradient boost, also lead to widespread attentions.
However, the database in Huang and Shao's study was restricted to the parents with equal intention to fight for the custody only, just about one fourth of the whole child custody cases, whereas we need a comprehensive case bank, allowing us to rearrange data to find a better set for the the training of the predicting models. On the basis of the aforesaid database, we can also compare these predicting models to find a better one, and optimize their performance. Furthermore, there might be possibility to evolve a reasoning model from them, which can avoid the potential conflicts arising from the explaining limitation of the predicting models.
Absract
vii
We collected all the child custody cases from 2009 to 2017 and applied the predicting models as well as the statistical tests for analysis. We find when one of the parents is not a native, or when he or she did not appear in court, the counterpart would have a good chance to be awarded the custody. The families resided in the rural area tended to not appear in court.
The ages of the children are correlated with the custody. If they are younger than 2, or older than 14, their mothers would have a tendency to be entitled the custody. By the aid of a templated reasoning model, called "i-like", we find three phenomena
responsible: "the tender years doctrine", "the predominance of the father's intention of fighting for the custody when the child is a tween", and "the teenager's preference for mother". The latter two have something to do with the characteristic foreign spouses in Taiwan.
When it comes to the other related facors, all but the rankings of the child and the education of the parents are related to custody decision with statistical evidence. The rankings of the factors determined by logistic regression are: the parent's intention, the child's preference, the parent's proficiency, the parent's conduct, the supporting system, the major caregiver, the child's present residence, the parent's economic status, and the happening of undue behavior to the child.
As for the foreign spouses, while comparing with the Taiwanese ones, the families
viii
having foreign spouses from mainland China were prone to reside in the urban area, whereas the families with ones from those other than mainland China tended to reside in the rural area. The possibility of being rewarded the custody for them both fell far behind the Taiwanese spouses. Possible reasons may be they had a tendency to not appear in court, and they had less competence in the factors of the major caregiver, the child's present residence, and the supporting system from the analysis of a 7-way table.
Applying "i-like" model on them, we could also deduce similar reasons closely relative to their nativity by its major factors.
Keywords: Legal Analytics, Child Custody, Predicting Model, Reasoning Model,
Tender Years Doctrine, Foreign Spouse
ix
目錄
口試委員會審定書 ... i
誌謝 ... ii
中文摘要 ... iii
英文摘要 ... vi
表目錄 ... xvi
圖目錄 ... xviii
第一章 緒論 ... 1
第一節 研究動機 ... 1
第二節 國內相關文獻的回顧 ... 3
第三節 研究目的 ... 7
第四節 研究架構 ... 8
第二章 裁判結果的預測模型與論理模型 ... 11
第一節 總論 ... 11
第一項 預測模型與論理模型 ... 12
第二項 電腦學得會裁判案件嗎? ... 13
第三項 不懂法律的機器如何論理? ... 17
第一款 一致性 ... 17
第二款 擬人化 ... 18
第三款 平衡性 ... 19
第二節 第一個自動化法律預測程式:誰離你最近? ... 20
第三節 對數機率迴歸 ... 21
第一項 對數機率迴歸的演算法 ... 22
第二項 用機率來呈現對數機率迴歸的結果 ... 26
第三項 利用對數機率迴歸為因素的重要性排序 ... 30
x
第一款 用決策樹決定因素的重要性 ... 31
第二款 用對數機率迴歸模型決定因素的重要性 ... 31
第四項 對數機率迴歸係數的求值 ... 31
第五項 對數機率迴歸的操作建議 ... 32
第六項 對數機率迴歸的係數失真與決策樹的維度收闔 ... 33
第一款 實例演練說明 ... 34
第二款 原因的探討 ... 38
第三款 因素的多元共線性(Multicolinearity) ... 40
第七項 利用主成份分析處理係數失真與維度收闔 ... 42
第一款 操作流程 ... 42
第二款 主成份分析的解釋性 ... 46
第三款 利用主成份分析處理高度多元共線的樣本 ... 47
第四節 決策樹、隨機森林與梯度型推進決策樹 ... 48
第一項 監督式機器學習簡介 ... 48
第二項 決策樹 ... 49
第一款 決策樹的演算法 ... 49
第二款 決策樹的解釋性與維度收闔 ... 51
第三項 隨機森林 ... 52
第一款 隨機森林的演算法 ... 52
第二款 隨機森林的商榷 ... 56
第四項 梯度型推進決策樹 ... 56
第一款 梯度型推進模型的原理 ... 56
第二款 梯度型推進決策樹的表現與解釋性 ... 58
第五節 類神經網路 ... 59
第一項 人類大腦的運作模式 ... 61
xi
第二項 模擬大腦運作的人造模型 ... 63
第三項 反向傳播類神經網路 ... 68
第四項 深度學習網路 ... 72
第五項 解讀反向傳播類神經網路的黑盒子 ... 74
第六項 反向傳播類神經網路的商榷 ... 77
第一款 電腦硬體的需求高 ... 77
第二款 對訓練樣本極度敏感 ... 77
第六節 以案件論述為基礎的預測模型 ... 79
第一項 以爭點為基礎的預測模型 ... 79
第一款 IBP 的演算法 ... 80
第二款 IBP 的實例演練 ... 82
第三款 IBP 的準確率評估 ... 83
第二項 採用基本價值的預測模型 ... 84
第七節 評價預測模型的方法 ... 85
第一項 驗證模型的方法 ... 85
第二項 驗證的指標 ... 87
第三項 兩模型間的比較 ... 88
第一款 κ 一致性係數 ... 88
第二款 ROC 曲線與 AUC 面積 ... 89
第三章 研究方法 ... 91
第一節 取樣 ... 91
第一項 取樣的方法 ... 91
第二項 取樣關鍵字的商榷 ... 91
第三項 只取第一審裁判的商榷 ... 92
第四項 取樣的限制 ... 94
xii
第五項 取樣之後的人工手動調整 ... 94
第二節 編碼 ... 96
第三節 依法官認定的事實編碼 ... 98
第一項 缺失值的處理 ... 99
第二項 資料的除錯 ... 99
第一款 人為的查核 ... 99
第二款 利用電腦的模板查核 ... 100
第四節 親權歸屬的定義 ... 101
第五節 外籍配偶的定義 ... 101
第六節 統計的方法 ... 102
第一項 組間平均值的定量分析 ... 102
第二項 定性分析 ... 102
第三項 統計軟體 ... 103
第七節 預測模型的優化 ... 103
第一項 客製樹(Customized tree, Cus-tree)... 104
第一款 優化的程序 ... 104
第二款 客製樹模型的應用 ... 107
第二項 客製對數機率迴歸及客製 XGBoost ... 111
第一款 訓練組樣本數的調校 ... 112
第二款 客製對數機率迴歸、客製 XGB 的操作程序與舉例 ... 112
第三項 類神經網路預測模型的優化 ... 113
第一款 獨熱類神經網路模型(one-hot ANN, oh-ANN) ... 113
第二款 類神經網路模型的隨機(附隨機森林) ... 116
第八節 樣式化論理模型(i-like) ... 118
第一項 i-like 的演算法 ... 118
xiii
第一款 四個基本價值的架構 ... 118
第二款 四個基本價值的複合邏輯架構 ... 119
第三款 i-like 的解釋覆蓋率 ... 121
第二項 以 i-like 來預測 ... 123
第三項 關於 i-like 的商榷 ... 125
第九節 演練以爭點為基礎的預測模型 ... 125
第四章 研究結果 ... 129
第一節 樣本資料的檢驗和預測 ... 129
第一項 逐年滾動式的客製樹模型 ... 129
第一款 106 年資料分析 ... 129
第二款 102-105 年資料的滾動分析 ... 130
第二項 其他預測模型的逐年滾動分析 ... 132
第一款 客製對數機率迴歸與客製 XGBoost ... 132
第二款 客製類神經網路與客製隨機森林 ... 132
第三項 近五年的資料有無變化? ... 132
第一款 三維表格的介紹 ... 132
第二款 無書狀的母親 ... 134
第三款 求助於 i-like ... 134
第二節 因素各論 ... 135
第一項 城鄉差距:無書狀聲明陳述意見者 ... 136
第二項 年齡 ... 139
第一款 從親權歸屬看年齡:無母數分析 ... 139
第二款 年齡看親權歸屬:卡方檢定 ... 140
第三款 利用 i-like 協助分析 ... 142
第四款 父母子女意願交叉分析的立體九宮格 ... 147
xiv
第五款 利用 i-like 的樣本流分析 ... 149
第六款 外籍母親造成「中兒唯父有意」 ... 150
第七款 不同的離婚原因造成「大兒擇母」 ... 152
第三項 排行、子女數與子女性別 ... 158
第一款 子女的排行 ... 158
第二款 子女的人數 ... 159
第三款 子女的性別 ... 160
第四項 其他因素 ... 160
第五項 眾因素重要性的排行 ... 167
第六項 社工、程序監理人與家事調查官 ... 169
第三節 外籍母親專論 ... 170
第一項 城鄉差距與無書狀聲明陳述的比率 ... 170
第二項 與親權歸屬相關的因素 ... 173
第三項 親權歸屬 ... 178
第四項 子女年齡 ... 181
第五項 探討外籍母親的弱勢本質 ... 186
第一款 從各因素的分布來探討 ... 187
第二款 從多維表格來分析 ... 188
第三款 從 i-like 來分析 ... 192
第五章 研究結論與討論 ... 194
第一節 研究結論 ... 194
第一項 關於預測 ... 194
第二項 關於因素 ... 196
第三項 外籍母親 ... 197
第二節 延伸討論 ... 199
xv
第一項 法律在家庭價值變遷中扮演的角色 ... 199
第二項 實證裁判量化研究的主體 ... 201
第三項 人工智慧的限制 ... 202
參考文獻 ... 208
附錄一:對數機率迴歸係數的概似估計 ... 220
附錄二:主成份分析的本徵向量推導 ... 223
附錄三:XGBoost 的演算法 ... 225
附錄四:賦予上標的反向傳播類神經網路的偏微分推導 ... 230
xvi
表目錄
表 1 四個自變因素在不同狀態下親權歸母的機率與勝算比 ... 28
表 2 親權歸屬四因素各種組合的機率列表 ... 29
表 3 決策樹、客製樹、客製森林、XGBoost 的平均準確率比較 ... 54
表 4 最簡單的架構的輸出組合(左)及邏輯異或(XOR)的輸出組合(右) . 65 表 5 本研究選取之裁判的後續結果追蹤 ... 93
表 6 篩選裁判(排除不列入分析)的原因分布 ... 95
表 7 各因素欄位代碼中英文對照及欄位內容 ... 96
表 8 訓練組的抽樣比率(數量)對預測能力的影響 ... 105
表 9 106 年客製樹的母全體準確率 ... 110
表 10 106 年客製迴歸/客製 XGB 模型的母全體準確率 ... 113
表 11 106 年客製 oh-ANN 模型/客製隨機森林的母全體準確率 ... 117
表 12 i-like 與 ctree 在不同樣本的覆蓋率 ... 122
表 13 決策樹、客製樹、客製森林、客製 XGB、論理模型的準確率比較 ... 124
表 14 106 年資料在 IBP 找不到答案與非一致性答案的分布情形 ... 127
表 15 各種不同訓練資料下之逐年滾動客製樹的準確率比較 ... 131
表 16 各種客製預測模型與 i-like 的逐年滾動準確率 ... 132
表 17 無書狀聲明裁判的縣市分布情形 ... 136
表 18 無書狀聲明陳述之事件在六都與非六都地區的分布情形 ... 137
表 19 有無書狀聲明陳述者獲得親權的分布情形 ... 138
表 20 親權歸屬與子女年齡、子女人數的關係 ... 139
表 21 親權歸屬與子女的年齡(分齡) ... 141
表 22 不同子女年齡的意願分布 ... 144
表 23 不同子女年齡的父母意願 ... 145
xvii
表 24 各類不同樣本在 i-like 內部的流向 ... 149
表 25 不同離婚原因下的子女意願 ... 153
表 26 離婚原因依子女年齡的分布 ... 154
表 27 親權歸屬依子女年齡的分組 ... 157
表 28 親權歸屬依子女排行的分布 ... 158
表 29 親權歸屬與子女數的關聯(事件) ... 159
表 30 親權歸屬與子女數的關聯(人) ... 160
表 31 親權歸屬依子女性別的分布 ... 160
表 32 有關親權酌定的各項因素統計表 ... 161
表 33 親權歸屬與專業評估報告的關聯性 ... 169
表 34 外籍配偶事件的縣市分布情形 ... 171
表 35 外籍配偶事件在六都/非六都地區的分布情形 ... 172
表 36 陸籍母親組親權酌定的各項因素統計表 ... 173
表 37 越印其他組親權酌定的各項因素統計表 ... 174
表 38 台籍母親組親權酌定的各項因素統計表 ... 175
表 39 外籍配偶的親權歸屬分布 ... 178
表 40 台籍、陸籍、越印其他籍母親獲得親權的分布情形 ... 179
表 41 台籍、陸籍、越印其他籍母親孩子的年齡分布 ... 181
表 42 台籍、陸籍、越印其他籍母親孩子的意願分布 ... 183
表 43 台籍、陸籍、越印其他籍母親孩子的年齡及意願分布(全部) ... 184
表 44 台/陸/越印三組子女的年齡及意願分布(兩造均有書狀) ... 185
表 45 台/外籍母親在父母品行、子女意願的三維表格 ... 189
表 46 七維表格的進一步分析(Ⅰ) ... 190
表 47 七維表格的進一步分析(Ⅱ) ... 191
xviii
圖目錄
圖 1 訓練組不同抽樣比率的決策樹準確率分布 ... 18
圖 2 連續變項的事件發生機率分布 ... 22
圖 3 線性機率模型的圖示 ... 23
圖 4 對數線性函數的曲線圖 ... 24
圖 5 親權酌定四因素的迴歸報表: ... 27
圖 6 全體樣本的決策樹圖 ... 34
圖 7 整體樣本的對數機率迴歸報表 ... 35
圖 8 越印其他籍母親組的對數機率迴歸報表 ... 36
圖 9 越印等其他籍母親的決策樹圖 ... 37
圖 10 陸籍母親組的對數機率迴歸報表 ... 37
圖 11 陸籍母親組的決策樹圖 ... 38
圖 12 三組樣本的對數機率迴歸機率分布圖 ... 39
圖 13 演練三樣本的 VIF 指標 ... 41
圖 14 PCA 報表一隅:21 因素分析 ... 44
圖 15 PCA 的前 10 大主成份 ... 44
圖 16 利用四個主成份的決策樹(ctree)分析 ... 45
圖 17 利用四個主成份的線性迴歸 ... 45
圖 18 主成分分析 PC1 與 PC2 的各因素係數 ... 47
圖 19 經 PCA 投影後的決策樹及線性迴歸報表(陸籍母親組) ... 48
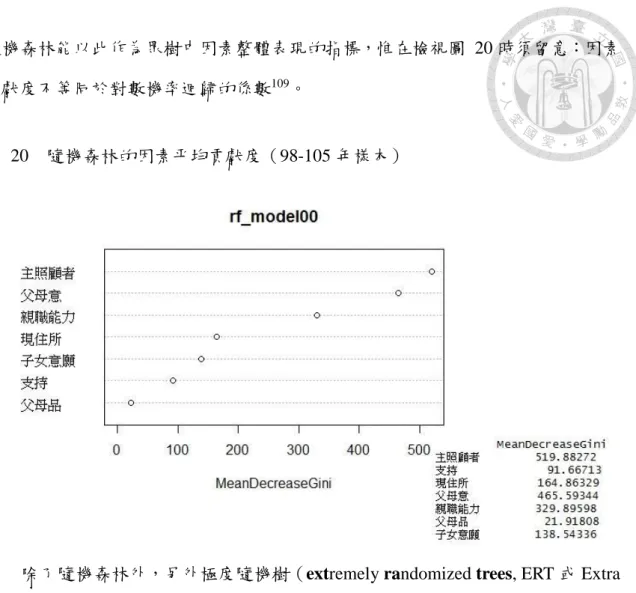
圖 20 隨機森林的因素平均貢獻度(98-105 年樣本) ... 55
圖 21 XGBoost(98-105 年樣本)因素的重要性 ... 59
圖 22 神經元結構與神經元間的連結示意圖 ... 62
圖 23 神經元運作模式圖 ... 64
xix
圖 24 二輸入、二處理神經元的處理架構 ... 66
圖 25 反向傳播類神經網路架構 ... 67
圖 26 反向傳播類神經網路的簡化架構 ... 69
圖 27 類神經網的代價函數 ... 73
圖 28 利用預訓數據尋找初始權值的落點 ... 74
圖 29 類神經網路模型的實際演練 ... 75
圖 30 類神經網路模型的係數報表 ... 76
圖 31 類神經網路模型準確率最高與最低的六名 ... 78
圖 32 one-hot ANN 隨機抽樣 100 次的預測準確率分布 ... 78
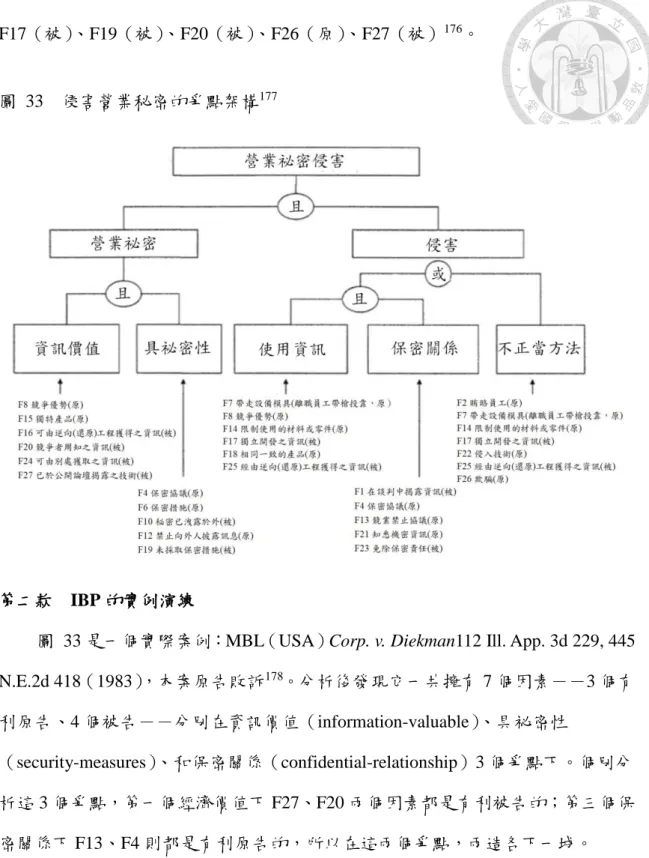
圖 33 侵害營業秘密的爭點架構 ... 82
圖 34 滾動式客製樹的準確率分布圖 ... 86
圖 35 不同預測模型的 ROC 曲線 ... 90
圖 36 千樹選秀的報表--106 年資料選樹 ... 108
圖 37 最高與最低五棵客製樹的準確率分布(106 年) ... 109
圖 38 驗證組與訓練組的準確率分布(106 年客製樹) ... 110
圖 39 內部/外部驗證組的準確率差的分布 ... 111
圖 40 獨熱類神經網模型的架構 ... 114
圖 41 獨熱類神經網模型的係數報表 ... 115
圖 42 i-like 的路徑邏輯 ... 121
圖 43 ctree 解釋全體樣本的邏輯路徑 ... 123
圖 44 IBP 預測結果的分布圖(106 年資料) ... 126
圖 45 客製樹滾動式預測最高最低五樹的準確率分布(102-105 年) ... 130
圖 46 無書狀聲明者的比率(法院別) ... 137
圖 47 不同親權歸屬的子女年齡及人數分布 ... 140
圖 48 親權歸屬依子女年齡的分布圖 ... 142
xx
圖 49 依子女年齡分布的子女意願 ... 143
圖 50 依子女年齡分布的父母意願 ... 146
圖 51 親子意願依子女年齡的分布圖 ... 147
圖 52 台籍/外籍母親組父母意願依子女年齡的分布 ... 150
圖 53 父母的原生國籍依子女年齡的分布 ... 151
圖 54 不同離婚原因依子女年齡的分布 ... 155
圖 55 親權歸屬依子女年齡的分組分布 ... 157
圖 56 親權歸屬依子女排行的分布 ... 158
圖 57 親權歸屬依各相關因素的分布 ... 162
圖 58 最後九因素對數機率迴歸的細部數據分析報表 ... 168
圖 59 父母原生國籍的城鄉差距 ... 172
圖 60 台籍母親組最終八因素的對數機率迴歸報表 ... 176
圖 61 親權歸屬依父母意願的分布(台、陸、越印籍母親的組間比較) ... 177
圖 62 父母有無書狀、原生國籍與親權歸屬的交叉比對圖 ... 180
圖 63 子女年齡依母親原生國籍的分布 ... 182
圖 64 子女意願依母親原生國籍的分布 ... 183
圖 65 子女年齡依母親原生國籍的分布 ... 186
圖 66 母親的有無書狀對子女的意願的影響(台籍/陸籍/越印比較) ... 186
圖 67 三個與親權歸屬相關因素的分布(台籍、陸籍、越印組間比較) ... 187
圖 68 外籍母親在 i-like 的樣本流分布 ... 192
圖 69 XGBoost 的樹形例舉(Tree 2) ... 228
圖 70 反向傳播類神經網路的簡化架構 ... 231
1
第一章 緒論
第一節 研究動機
早在上世紀中葉,就已經有學者開始研究人工智慧(artificial intelligence)1, 企圖開發出能因應外界環境的變化進行記憶推理、並能與外界互動以達成任務目 標的機器2。透過 0 與 1 的演算法,模擬出人類的認知功能3。但時至今日,將近八 十年的歲月過去,擬真的人工智慧卻一直未能出現4。
早期的人工智慧著重在邏輯推理,以程式碼盡括所有相關的程序,演算出人 類智慧應有的反應。這種架構一開始就遇到瓶頸,因為它對軟體(程式的完備性)
及硬體(機器的運算能力)的要求都很高。起初是硬體跟不上需求5,但隨著機器
1 1956 年達特茅斯夏季會議中,來自各領域的學者廣泛地討論人工智慧研究,這被公認為人工智 慧革命之開端。PAMELA MCCORDUCK,MACHINES WHO THINKS:APERSONAL INQUIRY INTO THE HISTORY AND PROSPECTS OF ARTIFICIAL INTELLIGENCE111-36(2004).
2 See Lee Moran, 'He was always inventing, inventing, inventing': Father of artificial intelligence dies, MAILONLINE (Oct. 26, 2011), https://www.dailymail.co.uk/news/article-2053617/Professor-John- McCarthy-Father-artificial-intelligence-dies-aged-84.html.
3 這種機器的基礎概念最早由圖靈(Alan Mathison Turing)所提出,是為了解答德國數學泰斗希爾 伯特(David Hilbert)在 1928 年研討會所提出的「判定性的問題:以明確的方法至少在基本邏輯 的原則上能判定任何給定的命題(Entscheidungsproblem, decisive problem)」所構想的機械化程序,
後人稱之為圖靈機(Turing machine)。這部證明了判定性問題為無解的機器,依循演算法可以執行 任何可運算數(圖靈稱之為 computable number)的計算,且具通用機(universal computing machine)
的概念。See Alan Mathison Turing, On Computable Numbers, with an Application to the
Entscheidungsproblem, 42 PROC.LOND.MATH.SOC. 230, 231-3 (1936). 1938 年,德國工程師 Konrad Zuse 做出了採用二進位、可編寫程式的電腦 V1。See Raúl Rojas, Konrad Zuse's Legacy: The Architecture of the Z1 and Z3, 19 IEEEANN.HIST.COMPUT. 5, 5-6 (1997).
4 人工智慧的擬真程度是跨越電腦科學與哲學領域的討論議題,最早是圖靈在 1950 年提出的模仿 遊戲--圖靈測試(Turing test):當無法通過對談的內容分辨出人與機器的差別時,這部機器便可 視為具有智慧。See A. M. Turing, Computing Machinery and Intelligence, 59 MIND. 433, 433-4 (1950).
但 1980 年 John. R. Searle 從哲學的角度提出反思--中文房實驗(Chinese room experiment):即使 通過圖靈測試,也不代表產生智慧,只有程式的語法不能產生語言的意義。"they have only a syntax but no semantics." See John R. Searle, Minds, Brains, and Programs, 3 BEHAV.BRAIN SCI. 417, 420-2 (1980). 他同時提出強人工智慧(strong AI)與弱人工智慧(weak or cautious AI)的概念,前者不 只是一個非常有力(powerful)的工具,同時應還具有了解及認知的能力(to understand and have other cognitive states)。See Id. at 417.
5 當年圖靈寫的西洋棋程式,因為電腦無力執行,他只好自己用人腦操作程式與同事 Alick E.
Glennie 對奕。參見:Andrew Hodges(著),林鶯(譯)(2017),《艾倫.圖靈傳(下):特立獨行 的電腦之父》,頁 309-310,臺北市:時報文化。這局棋仍然保存在 chessgames 的網頁裡,CHESSGAMES, http://www.chessgames.com/perl/chessgame?gid=1356927 (last visited Oct. 28, 2019).
2
運算能力一日千里的發展,變成程式軟體無法面面俱到6。畢竟現實生活裡極少出 現百分之百確定的事實可以配合程式的邏輯7。
與程式演算幾乎同時發展的則是專家系統(Expert System),這是在發現電腦 的記憶及搜尋等能力,不論速度、或精確性都遠勝過人腦的特性後,必然會有的 發展8。它所著重的是知識庫的建構,與搜尋、比對、簡單邏輯判斷(if-then)之 後的結果輸出。
專家系統多扮演類似百科全書的角色,應用的領域有限9,潮流便轉向機器學 習(Machine Learning)。自 1980 年起研究者結合了統計學、經濟學、與數學的工 具10,研發出讓機器自我學習、改善的演算法,從而在許多領域找到了應用的機會,
完成人腦困難處理的、前無答案的任務11,成為目前人工智慧的主流。
機器學習的演算法可以從我們給它的資料中,利用統計學、數學的方法取得 其規律性,再利用該規律對未知資料進行分類、預測。其中往往會涉及一些無程 式可循的難度的推算,也可以用近似演算法來解決這個問題12。
然而,人們對於使用人工智慧預測裁結果始終還是抱持著疑慮。其實,預測 模型(Predicting Model)所扮演的只是一個促進溝通的角色,透過它好像開了一 扇窗,讓我們知道外面的世界--實務上大多數的案件是如何進行的。誰會拒絕 更加了解周遭的客觀局勢呢?有了它,一個持相同心證的法官可以更放心地撰寫 他的裁判書,不一致的法官也未必要改變見解,他反而會因此更充分地在裁判書 強化自己的論述,以理據服人:預測模型是一扇讓人家看出去的窗,而不是一道
6 這些軟硬體的限制讓這個時期的人工智慧又被戲稱為 toy problem,意指研究的都是些 toy domain。
Toy problem 一辭參見:劉靜怡(2018),〈人工智慧潛在倫理與法律議題鳥瞰與初步分析〉,劉靜怡
(主編),《人工智慧相關法律議題芻議》,頁 3,臺北:元照。
7 劉靜怡,前揭註 6,頁 3。
8 MCCORDUCK, supra note 1, at 327-35.
9 「人類的各種知識內容過於龐大,卻形成未能真正解決的障礙。」,參見劉靜怡,前揭註 6,頁 3。
10 MCCORDUCK, supra note 1, at 486-7.
11 有關機器學習最被接受的定義是由 Mitchell 所下的:"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E." TOM M.MITCHELL,MACHINE LEARNING2(1997).
前述嚴謹而優美的定義試譯如下:一個能因經驗 E 而在任務 T 改善效能 P 的電腦程式。
12 類神經網路(Artificial Neural Network, ANN)與對數機率迴歸(Logistic Regression, LR)的迭代 演算法都運用了這裡所謂的近似演算法。
3
不讓人家走出去的框。有了它,律師可以在分析案情時,從眾多因素中,找到影 響案情的重要關鍵,有效擬定訴訟的攻防策略。各專業領域,因為它而工作更有 效率、經驗更容易傳承。以目前資訊科技的進展,尚不致出現機器取代人類的情 形。
既然是一個溝通的促進者,愈能傳真、預測得愈準,法律專業人員會愈願意 使用它,這也是本研究努力的方向之一。然而預測得準,未必論理得好;如果只 有答案而理據有間,不只是一種缺憾,也容易滋生誤解。所以本研究也將嘗試為 親權酌定建構其論理模型。
論及預測模型,我們有諸多選項:對數機率迴歸模型、決策樹(Decision Tree, DT)、隨機森林(Random Forests of Decision Trees,RFDT)、梯度型推動決策樹
(Gradient Boost Decision Tree, GBDT)、類神經網路、以爭點為基礎的預測模型
(Issue Based Predictor, IBP),每一種預測工具都有特色,也有其特別合適的資料 型態。究竟何種模型最適合我們親權酌定樣本的「體質」?它們需要資料型態作 如何的調整優化?這些都需要實際的演練來檢驗。
其實實證裁判研究並不是非要動用人工智慧的這些模型不可,各種統計學分 析檢定的工具,如 t 檢定、卡方檢定等,如果運用得當,同樣可以解決一些懸而未 決的問題。親權酌定領域裡一些有趣的議題,比如「幼兒從母」的原則是否仍舊 存在?台籍外籍配偶究竟有何不同?這些都是只要資料建置完整,就可以藉著各 種統計學的工具給予全體而客觀的描述和推論,也將是本研究在解決方法論的議 題之後,隨即著手研究的問題。
第二節 國內相關文獻的回顧
親權係保護教養子女的權利義務關係,專為子女的利益而存在13。民國 85 年
13 陳棋炎、黃宗樂、郭振恭(2018),《民法親屬新論》,修訂十四版,頁 336,臺北:三民;高鳳 仙(2018),《親屬法理論與實務》,十八版,頁 346,臺北:五南。
4
修正前之舊民法對兩願、判決離婚分別規定14,雖亦允許夫妻另行約定或法院得為 其子女之利益而介入酌定,然原則上及實務上仍由夫取得子女的監護權;現行法 刪除舊法第 1051 條、修正 1055 條、增訂 1055-1 條,改採「子女最佳利益原則」
為離婚後未成年子女親權歸屬決定的標準15。由父權優先原則演變為子女最佳利益 原則,不僅係為貫徹性別平等,更展現親權內涵由支配轉向保護、由父母本位轉 為子女本位的變化16。
早期的父權優先原則,係將未成年子女視為父親的附屬,而承認父親對子女 有絕對的權利17。隨著女性地位提升、兒童勞動力失去經濟誘因,美國法院逐漸放 棄父權優先原則,而認為應由對離婚原因較無過失之一方擔任親權人18,此無過失 優先原則仍以父母本位的角度關注未成年子女的親權議題。亦有採幼年原則
(tender years doctrine,又稱幼兒從母原則),認為除非有證據顯示母親不適任,否 則即由母親行使對幼童的親權,此原則雖從子女的福祉利益出發,但對母性天職 的分工預設仍未擺脫父權色彩19。
近年聯合國兒童權利公約所揭示之「未成年子女最佳利益」原則已成為各國 法院公權力介入親子關係領域的最高準則,該原則強調未成年人的主體性和其利
14 民國 85 年修正前之民法 1051 條規定:「兩願離婚後,關於子女之監護(此監護即是親權:參見 陳棋炎、黃宗樂、郭振恭,前揭註 13,頁 211),由夫任之。但另有約定者,從其約定。」修正前 民法第 1055 條規定:「判決離婚者,關於子女之監護,適用第一千零五十一條之規定。但法院得為 其子女之利益,酌定監護人。」
15 鄭麗燕(2009),〈離婚案件監護權(親權)調查相關法律案例解析〉,《社區發展季刊》,128 期,
頁 100;吳從周、徐慧怡(2010),〈親屬法與人事訴訟程序結合教學專題研究:第四講.親權之行 使、假處分與子女交付〉,《月旦法學教室》,87 期,頁 47-48;林秀雄(2013),《親屬法講義》,三 版,頁 202-204,臺北:元照;戴炎輝、戴東雄、戴瑀如(2014),《親屬法》,頁 284-292、302-303,
臺北:自刊;吳明軒(2016),〈關於夫妻兩願離婚後未成年子女之監護〉,徐慧怡(等著),《離婚 專題研究》,頁 273-274,臺北:元照;陳棋炎等,前揭註 13,頁 210-212、216-220;高鳳仙,前 揭註 13,頁 168-171。
16 林秀雄,前揭註 15,頁 320-321;戴炎輝、戴東雄、戴瑀如,前揭註 15,頁 445、462;高鳳仙,
前揭註 13,頁 346。
17 劉宏恩(1997),〈夫妻離婚後「子女最佳利益」之酌定〉,《軍法專刊》,43 卷 12 期,頁 33。
18 李立如(1994),《兒童保護行政之研究一實現兒童最佳利益》,頁 95,台灣大學法律學研究所碩 士論文;雷文玫(1999),〈以「子女最佳利益」之名:離婚後父母對未成年子女權利義務行使與負 擔之研究〉,《台大法學論叢》,28 卷 3 期,頁 274-275。
19 李立如(2010),〈論離婚後父母對未成年子女權利義務之行使負擔:美國法上子女最佳利益原 則的發展與努力方向〉,《歐美研究》,40 卷 3 期,頁 782。
5
益保護的優先性20,為我國現行法所明文採納的離婚後未成年子女親權酌定標準。
然而,未成年子女最佳利益原則屬不確定法律概念,這些具體因素涉及「大量屬 於心理面、社會面的事實與預測」21;而爭取親權又往往是離婚夫妻激烈訟爭的焦 點,是以如何於個案具體判斷子女之最佳利益,極易衍生爭議22。雖有民法第 1055 條之 1 各判斷標準之出現,仍無法完全解決「子女最佳利益」判斷標準模糊不明 的困難23。學者或致力於列出較為具體明確的衍生標準、導入新的檢核準則24;但 因「子女最佳利益」本質上就涉及對於過去、現在、未來諸多因素的判斷、考量 和預期,每一個「原則」或「審酌因素」其實都只是拼圖的一片25,且在實際個案 中諸原則間也常會出現彼此矛盾的情況,讓當事人欠缺預測可能性。
既然法理上「通案適用」的「單一標準」難以追索,何不試著轉換角度,改 由實證研究理解子女最佳利益原則在實務事件之實踐26?學者有認為「司法實務逐 漸摸索形成了自成一套的婚姻論述,而反過來成為學說上,學者們補充不確定法
20 馬憶南(2009),〈父母與未成年子女的法律關係一從父母權利本位到子女權利本位〉,《月旦民 商法雜誌》,25 期,頁 58-60;劉宏恩(2014),〈離婚後子女監護案件「子女最佳利益原則」的再 檢視--試評析 2013 年 12 月修正之民法 1055 條之 1 規定〉,《月旦法學雜誌》,234 期,頁 193-194;
鄧學仁(2016),〈離婚後子女親權酌定之問題與對策〉,徐慧怡(等著),《離婚專題研究》,頁 230,
臺北:元照。
21 劉宏恩(1996),《心理學取向之法律研究:以住宅搜索、子女監護及婚姻暴力問題為例》,國立 臺灣大學法律學研究所碩士論文,頁 105。
22 劉宏恩,前揭註 20,頁 196;雷文玫,前揭註 18,頁 297-308;鄭諺霓(2015),《離婚後未成年 子女親權酌定之實證研究》,國立臺灣大學法律學院法律學研究所碩士論文,頁 21-24。
23 李立如,前揭註 18,頁 107-110;李立如(2012),〈親屬法變革與法院功能之轉型〉,《台大法學 論叢》,41 卷 4 期,頁 1660-1663。該規定被批為「看似具體實則抽象,狀似合理卻有盲點」,見鄧 學仁,前揭註 20,頁 229。
24 鄧學仁,前揭註 20,頁 236-239、242-243,列出繼續性原則、嬰幼兒母親優先原則、子女意思 尊重原則、父母適性比較衡量原則、手足同親原則、主要照顧者原則和友善父母原則,作為酌定親 權之原則,並建議導入「子女照顧史」之觀念,參酌主要照顧者、繼續性原則及善意父母原則三項 檢核基準以解決酌定親權之問題。
25 劉宏恩,前揭註 20,頁 207。「事實的真相或許是:每一個『原則』或『審酌因素』其實分別都 只是拼圖的一片,而且對於每一個不同的個案和不同的孩子,我們最後要拼出來的可能還是不相同 的完整圖案。由於每個未成年子女的成長背景、生活環境、人格發展需求、他與父母之間的互動關 係都有所不同,他們的『最佳利益』也經常因此迥異,所以,『通案適用』的『單一標準』似乎難 以存在。」
26 學者主張,應透過往復辯論及實證研究逐漸深化、具體化不確定法律概念內涵和實踐機制,雷 文玫,前揭註 18,頁 297-308。相關實證研究請見劉宏恩(2011),〈「子女最佳利益原則」在台灣 法院離婚後子女監護案件中之實踐--法律與社會研究(Law and Society Research)之觀點〉,《軍 法專刊》,57 卷 1 期,頁 93-104。
6
律概念之解釋的依據。27」既稱其為「自成一套」,則自有「一套之理」。單一個案 的裁判書固無由呈現「親權酌定之本質」,倘能經完整而全面的實證研究28,則未 必不能歸納其理;而與一般非隨機採樣之案例評析有不同之風貌。本此,本研究 計劃透過「實證判決的統計與量化分析」29,以歸納法試圖尋繹出親權酌定在實務 裁判的實踐原則。
有關台灣親權酌定所有因素的完整實證研究,可參見民國 104 年鄭諺霓的碩 士論文--《離婚後未成年子女親權酌定之實證研究》30,該論文(以下簡稱鄭文)
以民國 101 年至 103 年 540 件均有意願的台籍父母爭取親權事件為素材,將可能 影響法院酌定未成年子女權利義務歸屬的所有因素,以統計分析的工具研究其個 別的影響程度。鄭文發現:裁判監護類型以單獨親權為主;母親任親權人或主要 照顧者的比例遠高於父親;未成年子女的意願影響甚大,而年齡則否;主要照顧 者、同住者任親權人的比例較高,而父母之經濟狀況則否;及社工報告為法院非 常重要之參考資料。
兩年後,胡珮琪進行影響法院選定親屬或非親屬監護人、及影響法院選定複 數監護人因素的實證研究31,該研究雖非親權領域,但其分別利用線性迴歸(Linear Regression)及對數機率迴歸檢定相關因素之關聯度32,發現「受監護人是否有近 親屬」、「聲請人或家屬是否推薦近親屬擔任監護人」、及「法院是否考量親屬年事 已高」等 3 個因素與法院選定親屬為監護人正相關;至於「法院是否考量近親屬
27 郭書琴(2007),〈逃家的妻子,缺席的被告?--外籍配偶與身分法之法律文化初探〉,《中正 大學法學集刊》,20 期,頁 30。
28 此處所稱之「完整」,係指所有相關因素之完整研究;所謂「全面」,係指以符合隨機抽樣原理 針對整體族群所作之全面抽樣。尤其後者乃實證研究與傳統案例評析的不同處。
29 引號名詞見於:吳從周(2017),〈序言〉,吳從周(等合著),《違約金酌減之裁判分析》,增訂 三版,頁序章,臺北:元照。該名詞完整地涵括了關於裁判的統計、人工智慧、與分析,非常切中 本研究 Artificial Intelligence and Legal Analytics 的題旨。
30 鄭諺霓,前揭註 22。
31 胡珮琪(2017),《我國成年監護制度之實證研究》,國立臺灣大學法律學院法律學科技整合法律 學研究所碩士論文。
32 按理說類別變項的樣本最好採對數機率迴歸模型,但胡文的研究樣本分布過於極端,導致迴歸 係數失控,無法判讀,不得不改用線性迴歸。見胡珮琪,前揭註 31,頁 125-133。(有關迴歸係數 失控的議題,另請參見本論文第二章 第三節 第五項 )
7
居住地理位置就近性」則為負相關,傾向選定非親屬擔任監護人。
民國 107 年,學者黃詩淳等根據鄭文相同時段的裁判資料33,以其 22 項因素 為基礎,調整編碼方式及意義34,建構了親權酌定的決策樹及類神經網路預測模型,
整體準確率分別超過 94%35/98%36,並認為子女主要照顧者、子女意願、親子互 動為最主要的影響因素,開啟了預測親權歸屬的時代。
距離鄭文蒐集裁判之民國 103 年,至今又過去五年,對於預測模型在實務上 的應用,又累積了一些疑問:
-當預測的樣本從有書狀均有意願的台籍父母擴大到全體事件時,模型的準 確率是否還能維持?
-五年後的今天,裁判的資料有否偏移?預測模型是否還能適用?
-若以全新未知的非內部驗證資料檢測,預測模型的表現如何?
-預測模型的高準確率,有無過度擬合(overfitting)的問題37?
-預測模型所植基的原理是一般法律人生疏的專業,要如何相信「黑盒子」
所給的答案?
本研究承襲鄭文及黃詩淳等論文,進行實證裁判研究的操作演練,統計 98 年 至 106 年的裁判。一方面讓相關議題的統計數據得能延續呈現,一方面針對其未 經深究的議題作預測工具、及統計領域的分析,試圖提出上述問題的答案。
第三節 研究目的
實證裁判的統計與量化分析是新興的法學研究方法,它應用了傳統統計量化 分析的檢定方法以及人工智慧的技術,藉由資訊科技的輔助,處理過去無法處理、
33 黃詩淳、邵軒磊(2018),〈酌定子女親權之重要因素:以決策樹方法分析相關裁判〉,《國立臺 灣大學法學論叢》,47 卷 1 期,頁 306-322。
34 黃詩淳等,前揭註 33,頁 313-316。
35 黃詩淳等,前揭註 33,頁 323-325。
36 黃詩淳、邵軒磊(2017),〈運用機器學習預測法院裁判:法資訊學之實踐〉,《月旦法學雜誌》,
270 期,頁 86。
37 一個預測模型在內部資料準確率很高,但遇到外部未知的樣本時卻表現走樣,謂之過度擬合。
8
或是雖能處理但效率不佳的工作,比如大量資料的輸入、處理、分析檢定,從而 探尋法學領域中與共相有關的事實與規律。
本研究目的為釐清統計與量化分析方法在法學研究的角色與定位,以供未來 相關研究參考,其細目如下:
-研究對數機率迴歸、決策樹、隨機森林、梯度型推動決策樹、類神經網路、
以爭點為基礎的預測模型等 6 種常用的預測模型,介紹其演算法
(algorithm),並實地演練本研究建構的親權酌定九年資料庫,比較其表現,
並進而研發彼等優化的操作程序,使其更適合法律領域的資料型態。
-本於上項研究的成果,建構親權酌定的論理模型(Reasoning Model)。
-結合上述論理模型與相關統計檢定工具,以本研究之九年數據為素材,從 資料庫的建構、資料欄位的處理、各種變項分析比對,實地演練實證裁判 研究的各種程序,進而解決親權酌定領域若干懸而未決的問題。
第四節 研究架構
本研究共分六章,以下將就各章節的內容說明如下:
第一章 緒論
依序說明本研究的動機與目的。
第二章 裁判結果的預測模型與論理模型
簡介現行常用的預測模型:對數機率迴歸、決策樹、隨機森林、梯度型推動 決策樹、類神經網路、以爭點為基礎的預測模型等 6 種預測方法。特別著重在演 算法與設計概念,使其成為第三章優化研究方法的理論基礎。
本章有兩個特點:
-以親權酌定的九年資料庫為例舉說明,使其親切而容易了解。
-側重討論各種預測模型的限制,特別是預測模型的解釋性問題,並以此推 論出論理模型的需求與規格。
9
第三章 研究方法
詳述本研究的研究方法,從取樣、編碼、事實認定的原則、缺失值的處理、
研究標的的定義、統計檢定的方法、各種預測模型的優化方法,最後提出樣式化 論理模型(IBP-like Reasoning Model, i-like)的架構與演算法。
第四章 研究結果
第四章以第三章所介紹的各種方法為工具、探索第三章所建構的親權酌定九 年資料庫,取得了以下研究成果:
-以第三章介紹的優化方法,結合 5 種預測模型,進行 102-106 年五年間親 權歸屬的逐年滾動預測。發現若經客製優化的程序,預測模型的準確率都 能比原始模型增加 1%以上,且各客製預測工具的準確率差異有限,都能 勝任全新外部樣本的預測工作,沒有過度擬合的問題。
-發現 102-106 年的資料除 103 年外並無顯著變化,且對預測模型及論理模 型 i-like 的功能發揮並無影響,確認法官裁判的標準是一致的。
-結合論理模型 i-like 與統計學檢定工具,發現子女的年齡與親權歸屬有關,
「幼兒從母」的原則依舊存在。
-結合論理模型 i-like 與統計學檢定工具,針對外籍配偶的弱勢議題,進行 全方位的探討,認為外籍配偶在爭取親權時,雖未受到司法不公平的對待,
然而現行社會整體的資源分配和體系運作不利他們取得親權。
第五章 研究結論與討論
第五章除摘要說明本研究的問題意識、研究發現與結論之外,並進一步由研 究結果省思「子女之最佳利益」精神。我們在研究過程也深切感受到:各種分析 檢定預測的方法都只是工具,運用工具的是人,問題意識與法律的專業才是法律 研究的主體。
本章同時探討研究方法中編碼者的主觀偏差對於研究結果的影響,因而推測 文本探勘、特別是類似圖片辨識自動擷取特徵(feature extraction)並進而分類的
10
深度學習模型將會是未來的趨勢。機器學習模型不是沒有侷限,尤其在法律領域 的應用,與大數據的概念總有一些扞格不入的稜角,其中分際的拿捏都需要法律 人三思。
11
第二章 裁判結果的預測模型與論理模型
第一節 總論
律師每天執業的工作內容與解釋案情、預測裁判結果息息相關,能否利用電 腦程式協助這些工作、乃至於如何讓電腦學會研判案情及模擬裁判,是一個饒富 研究意義的領域。人的心智活動究竟如何運作、心證如何形成,混沌難明,屬於 心理學的專業領域。但若要將解釋的工作交給電腦,那便屬於統計與量化分析的 領域,必須依機器語言的邏輯來進行。
傳統法律研究裡「案例分析」領域,研究的標的是每個案件的「別相」,透過 一些經典的、獨特的案件分析,探究法學概念和理論。實證裁判的統計與量化分 析所關注的焦點則為所有同類型案件的「共相」--「實證研究關注大範圍及總 體的現象,而非個案,此與傳統的裁判評釋有不同關懷38。」
想要利用電腦處理眾多同類型案件的共相,首先須將相關因素(factors)和結 果數位化並建構成資料庫39,才能利用程式建構模型,再以這些模型進行分析與裁 判結果預測的工作。預測模型可以分成兩大類型:以案件為本的模型(Case-Based Reasoning, CBR)、及機器學習演算法的模型(Machine Learning Algorithm, ML)40, 本章將依上述分類個別介紹相關的預測模型。
上述兩個類型,從方法論來看:前者著重在案件的比較和預測的解釋,並未 脫離傳統案件評析的舊路,基本上還是由人來決定分類的方式,並主導預測工作 的進行,電腦只是從旁協助比對資料庫、匯整報表。後者則把資料庫完全交給電 腦,由程式決定如何分類,最後依電腦分類的結果或計算的機率來預測41。就預測 結果的解釋能力來說,前者因為和主流的法學研究和實務的作法相通,也最容易
38 黃詩淳等,前揭註 33,頁 332。
39 本論文所稱之因素係指案件中可以被數位化成資料庫的一個欄位的現實特徵。
40 KEVIN D.ASHLEY,ARTIFICIAL INTELLIGENCE AND LEGAL ANALYTICS:NEW TOOLS FOR LAW PRACTICE INTHE DIGITAL AGE107(2017).
41 有關各個模型的演算法詳見本章第三至第六節及附錄一至四。
12
說明它預測的來龍去脈,至於後者的解釋能力則議題複雜,非一言可以說明清楚。
第一項 預測模型與論理模型
於此本論文提出論理模型的構想:預測模型專心追求預測裁判結果的準確率,
只要能夠準確預測,無法提供解釋的模型也不會被摒除在外42;論理模型則不同,
雖然不至於完全不顧及解釋覆蓋率43,但它之所以存在的理由就是對裁判的結果、
心證的形成提出論理。對論理模型而言,能否提出具有普遍性、一貫性,具溝通 說服能力的原則架構更顯重要。
人們看到模型預測的結果,不可能不問原因;法庭的攻防也不可能一句「大 數據說我的當事人該贏」就交代過去。如何在案件的核心因素擬定戰略?哪些因 素才是核心到足以改變法官的心證?這些都是論理模型的價值所在。
論理模型的解釋覆蓋率和預測模型的準確率其實是等價的指標,所以兩模型 間的界線模糊。通常它們可以相互流用,特別是論理模型,若要使用論理模型來 預測結果,幾乎不受限制。但此處還是要強調它們的目的不同,建構兩種模型的 演算法也因其不同目的,而有不同的倚重。預測神準的未必緊貼邏輯44,反倒是論 理完整的非得預測穩健不可。例如班上兩位同學,一個總是考 97 分、另一則是 93 分。請教他們功課,97 分的那位說的沒人聽得懂,拿起他的算式來看總是越看越 怪,比如「銅板連丟兩次,出現兩人頭、兩拾圓、一人頭一拾圓的機率各佔 1/3」
45;93 分的同學則計算過程完整、邏輯親切易懂。平時大家都圍著 93 分的同學討 論問題,但考試的時候,每個人都想坐在 97 分的旁邊;這兩個類型都為我們所需 要。
42 機器學習裡的隨機森林、梯度型推動決策樹、類神經網路都是解釋門檻較高的「黑盒子」。
43 解釋覆蓋率(explaining coverage)的定義為該論理模型正確解釋的樣本數除以整體樣本數的比 率。捨卻解釋覆蓋率,我們無從客觀評判論理模型的好壞。
44 畢竟人的行為不只是邏輯,預測模型即令迴歸、決策樹都會出現法律邏輯無法解釋的分類原則。
45 這其實是量子力學的一道名題,玻色和愛因斯坦從這個假設出發,推導出玻色.愛因斯坦凝態 的理論,奠定原子雷射的基礎。1921 年玻色也就因為這道 1/3 的式子,論文遭編輯退稿,只好求 助於愛因斯坦。參見石明豐,《台大探索講座第九期:沒人懂的量子力學》〈玻色子--「看不出來 不一樣」真的不一樣〉,https://www.youtube.com/watch?v=MfgizxbxQec&index=6&list=PLvWQohj H8rwgWa1QF0Duq99sKCecQ2s0Q&t=0s(最後瀏覽日:2019/10/28)。
13
既然兩種模型是可以互通的,又何必要區分為二呢?這是因為機器學習在預 測裁判結果的領域雖然才初試啼聲,但已隱隱和傳統法學的研究方法發生磨合的 問題。常有論者因為混淆了預測模型和論理模型的定位,引發錯誤的解讀並滋生 誤會。所以我們必須一開始就釐清兩者的角色,這個新興的研究領域才能有長遠 的發展。
第二項 電腦學得會裁判案件嗎?
Kevin D. Ashley 在他 Artificial Intelligence and Legal Analytics 的書裡,以英國 國籍法(British Nationality Act, BNA)為例,說明「教」電腦學習法律是如何的艱 辛(notoriously difficult)46。如果我們設身處地去模擬法官的心智運作,所謂的「心 證」、「情理之平」,似乎是交織著邏輯與直覺、理性與感性的混沌體,這涉及心理 學的專業領域,本論文只能嘗試推想。法官心裡真的有因素的存在:父母的意願、
子女的意願、親職能力、現住所、主要照顧者等即便是角色最不起眼的照顧計畫,
都不能說法官不會考慮。但這種在人心裡考慮的因素,和數位化後在電腦程式裡 運作的因素是截然不同的東西。
電腦裡的模型,是一個層次分明、架構謹嚴的邏輯自洽體。對數機率迴歸是 二維的架構,所有的因素都放在同一個平面來互動調整係數47。相形之下,決策樹 可容許的維度就比較高,每個節點因素都撐出一個維度的架構。至於類神經網路,
維度不高但維度切換間的交互作用更複雜。他們都是理路清晰、可以重現,未必 能夠論理(reasoning),但絕對可以自我解釋(explaining itself)的邏輯結構體。
在人的心裡,眾因素的圖像卻非如此:它根本沒有維度可言,就像一個尚未 定義的拓樸空間48。勉強比方:就像是一個個的冰山在情緒與直覺的感性大海裡載
46 ASHLEY, supra note 40, at 47-56.
47 在法的邏輯分析架構中,一個因素可以開出一個維度(dimension),本研究有關維度的概念,在 Kevin D. Ashley 博士論文的 HYPO 架構也有類似的論述。See, e.g.,KEVIN D.ASHLEY, MODELING LEGAL ARGUMENTS:REASONING WITH CASES AND HYPOTHETICALS108 (1990); Kevin D. Ashley, Reasoning with Cases and Hypotheticals in HYPO, 34 INT. J MAN-MACH. STUD753, 763 (1991).
48 顏厥安(2018),〈人之苦難,機器恩典必看顧安慰〉,劉靜怡(主編),《人工智慧相關法律議題 芻議》,頁 55,臺北:元照。該文以「墨闇碑」(monolith)作為心靈的象徵(symbol):「個別心靈
14
浮載沉,法官就是那艘在海上航行的船,要順著這些冰山走出自己的航線。有的 冰山非常大,那是父母和子女的意願;有的略小一點是親職能力,至於子女人數、
照顧計畫這些冰山就小很多;這大小的威力也非絕對,有時一個直覺大浪過來,
撞上小冰山也可能翻船。如果要說毫無邏輯可言,那些冰山的大小難道不是很明 顯的邏輯?可若真要排序、寫出條件判斷程式:如果這樣就轉彎、如果那樣就排 闥而去,往往又有困難,許多需要依具體個案微調的權衡是難以用數字去定義的。
即令寫得出因素間的條件判斷,較之電腦程式,在人的認知,其邏輯方面的 嚴密自洽程度也是截然不同的等級要求。一組在人腦裡相處融洽的原則規範,要 是一條條依樣寫成程式輸入電腦,鮮有一次轉譯成功。必須經過專家多次修正調 整(reformulation),釐清模糊空間。這就是 BNA 的故事:會讓程式停擺的條件組 合,那些邏輯不夠嚴密、甚至矛盾互斥的概念,都能在人腦「情理之平」的大海 中和平共處49,配合著直覺與本能靈光一閃的運作,作出裁判。整個思考過程平順 到連大腦的主人都自認為是一個「邏輯嚴謹」的人。
至於電腦,就是順著程式條件判斷、迴圈的邏輯路徑運作,它無法收納存在
「潛在矛盾」的規範。但如果我們徹底掃蕩邏輯不夠嚴密的模糊空間,讓它完全 按著理性運算、絕對邏輯,建構出人腦的「情理之平」來,其邏輯路徑又將蕪蔓 龐雜到無法架構。因此大多數由一道道程式所建構的模型(如 BNA),是用來輔助 企業建置法律遵循程序以避免訴訟,而非為法庭攻防所設計。
這樣的故事,是否代表機器該就此束手?倘若人類如此安於現狀,視困境為 當然,恐怕也不會有阿爾法圍棋(AlphaGo)的橫空出世了。機器學習預測模型也 是類似的情形:既然電腦無法直接學習法條涵攝50,那就另闢蹊徑,改從結果倒推
的運作,永遠是闇黑不明的。不但其他人的心靈是不透明的,我們永遠無法感知他者心靈。我們自 己心靈的運作,也是晦暗不明的。即便我們可以意識到我們自己的意識(此即自我意識),可以意 識到概念與推論、思考,然而永遠有一層最深層的運作,是無法自我知悉掌握的。」與本論文所描 述的混沌拓樸,可以相參。
49 王泰升(2017),《台灣法律史概論》,五版,頁 44-46,臺北:元照;王泰升(2018),〈再訪臺 灣的調解制度:對傳統的現代化轉譯〉,《臺灣史研究》,25 卷 1 期,頁 104。
50 這或許就是我們在第一章 第一節 討論過的「現實生活裡極少出現百分之百確定的事實可以 配合程式的邏輯」,對於規則驅動(rule driven)模型所造成的限制。
15
--利用電腦擅長的計數(counting)領域,以層次分明、架構謹嚴的邏輯高維複 合體模擬結果,此即所謂的監督式(supervised)學習。不僅法官的理性邏輯,甚 至連「直覺之浪」和「靈感之光」也能一概被模擬,於是在這個領域取得了突破 性的發展。
既然已經知道一邊是沒有維度定義的渾沌拓樸、一邊是高維度的邏輯空間,
所以這個模擬絕對不會是全等,甚至也稱不上詮釋,而是一種映射(mapping)。
決策樹算是解釋門檻最低的預測模型,訓練好的樹形可以將它轉譯成條件判斷的 程式語言。但如果我們認真拿著這一道道的程式按圖索驥:法官是因為這個因素 然後走左邊,又因為那個因素轉右邊,這就買櫝還珠了。因為預測模型是要連法 官的直覺、靈光一閃都要一齊模擬的,如果決策樹和法官理性邏輯的部分一樣,
意謂著它將沒有顧及非理性的層面,恐怕就得在直覺之海裡翻船。
難道預測模型就不需要論理了嗎?其實只要從制高點鳥瞰,把論理模型和預 測模型分流,很多紛爭都可以在各自的定位上各安其位。決策樹上的節點因素、
對數機率迴歸裡的大係數因素,我們可以認定是重要的因素;但這是否等同於論 理的全貌,則須嚴謹審慎。其中因素的銜接若有與專業邏輯解說不通的理路,很 可能就是預測模型中「用數學模擬直覺追求準確」的部分,不能以此為病。苟不 饜足於此,就該努力去尋找那位平易近人的 93 分同學--論理模型。
我們的研究是以群體的共相為對象,有些共相在個案的身上找得到,比如一 群都是 15 歲的孩子,這個 15 歲既是整體的一個因素,同時在每個孩子的身上也 都找得到。但更多的共相,是我們在個案的身上無從求索的,例如平均值、標準 差、勝算、卡方值等,這些我們慣常使用的統計參數幾乎都屬於後者。例如有群 人的平均年齡 12 歲,對其中一個 15 歲的孩子而言,一旦他離開該群體,12 歲這 個數值對他就不具意義,這就是共相不存在於個案。
共相存不存在於個案身上常會引發問題,特別是當我們想要知道的是「單一 法官的心證」的時候。例如:當我們在研究外籍母親的親權歸屬時,決策樹分類
16
裡一個 15 歲的小孩,同組成員的年齡分布恰與裁判結果相關,所以年齡就成了節 點因素。可當研究議題改成「對子女的不當行為與親權歸屬」,他和另一群小孩共 組一個年齡分布與裁判結果全無關聯的次群體,此時年齡就變得不「重要」了。
從制高點來看,不會覺得這種變化有何問題:不同的分類、不同的次眾,自 然就該有不同的共相、不同的分析結果,從統計的數學次元來看,這是再順理成 章也不過的事了。但我們回到現實的次元,法官開庭審酌親權的當下,他就是一 個 15 歲的孩子,在法官的心證裡 15 歲這個因素自有他的某種重要程度,不可能 擺盪,也和研究議題所選擇的分眾無關。
我們不認為這種「擺盪」是個問題,共相原就是變動不居的概念。現實世界 和統計世界,本屬不同的次元空間,兩者有交集也有差集51,才能激蕩出智慧的火 花。法官判案(別相)時不必理會我們將如何歸類這個孩子,正如決策樹在開出 或收闔年齡這個維度(共相)時,也無法觸及法官的心證,這就是純粹數學的領 域,數字與邏輯到哪裡,操作就到哪裡。
我們不是說預測模型就不需要對外解釋,這樣太不食人間煙火了,而且當手 上沒有論理模型時,也不能不用預測模型來說明因素的重要性。只是當我們就著 預測模型做出解釋時,須知這只是在解釋它何以如此預測,至於這個解釋是否等 同專業領域的論理,嚴謹的求證絕不可免。
預測模型所模擬的是整體案件的裁判結果52,而非單一法官的邏輯和直覺。模 型能夠告訴我們:根據蒐集的樣本,類似的案件的大多數結果會是什麼?至於它 是如何模擬成功的,我們可以從數學去了解它的原理、解釋它的演算法,但絕不 會有人就此認為法官是用數學判案。
可能有人會為不能從決策樹看法官如何判案而失望,就像總有人會想要從 AlphaGo 的程式碼裡面學點棋路。圍棋以它恒河沙數般的變數組合,力抗機器語言
51 AB 兩集合,同屬於 A 與 B 的部分為 AB 之交集(A∩B),屬於 B 且不屬於 A/屬於 A 且不屬 於 B 的部分,為差集(記為 B-A/A-B),三者之合為 AB 之聯集(A∪B)。
52 論理模型也是模擬的一種,所謂的「大多數法官的裁判原則/邏輯」和統計學的平均值、母全 體一樣,都是僅存於概念次元的東西。