國立臺灣大學公共衛生學院
流行病學與預防醫學研究所生物醫學統計組 碩士論文
Division of Biostatistics, Graduate Institute of Epidemiology and Preventive Medicine, College of Public Health
National Taiwan University Master Thesis
多階層 Rasch 模式於麻醉學筆試的應用
Hierarchical Rasch Model for Written Examinations in Anesthesiology
黃裕峰 Yu-Feng Huang
指導教授:陳秀熙 博士 Advisor: Hsiu-Hsi Chen, Ph.D.
中華民國 102 年 6 月
June, 2013
i
誌謝
這篇論文的完成,首先要感謝指導老師陳秀熙教授,在跟隨陳教授學習的這 段期間,充分感受到「師者,所以傳道、受業、解惑也」這句話的意義,不管是 對學術的熱情,對人生的智慧,總讓我如沐春風,帶來前進的力量;也要感謝張 光宜醫師,總是在我遇到問題時給予即時的回答與鼓勵,並且慷慨提供研究相關 的資源;還要感謝嚴明芳老師,在最後階段帶來關鍵而重要的協助;並謝謝同學 們在學業上的分享,以及同事們在工作上的協助,最後要感謝我的太太與家人的 包容與支持,讓我有機會一窺統計世界的堂奧。
ii
摘要
背景:生物醫學研究領域中,預測變項與反應變項之間經常是存在非線性的函數 呈現關係。其中一個典型的例子是利用羅吉斯迴歸(logistic regression)處理以二元 反應變項的資料,例如 Rasch 模式,根據概似函數理論而來的傳統 Rasch 模式需符 合局部獨立(local independence),或稱為條件獨立(conditional independence)的假設,
而且無法處理影響個人能力的共變量和階層的資料結構。因此如何對於 Rasch 模 式發展新的統計方式,來避免局部獨立假設,並考慮因共變量造成的異質性,或 是階層結構帶來的相關性影響,是值得關注研究的問題。
目的:我們提出非線性混合迴歸和貝氏多階層模式,來配適麻醉專科醫師甄審筆 試中的實際數據,以表現此兩種創新 Rasch 模式的合適性。並且比較此兩種方式 所得到的估計值與傳統最大概似法的差異。
研究材料與方法:首先在非線性混合迴歸的架構分析 Rasch 模式,將考生能力參 數(θ)視為服從常態分配的隨機效應,來估計考生能力(θ)與試題難度(β),再進一步 將此模式擴展為納入多階層的結構,包含來不同訓練醫院的考生和不同出題者的 試題;同理,並且對此問題發展貝氏多階層 Rasch 模式。所應用的資料來自參加 2007 至 2010 這四年測驗的考生,分別有 34 至 37 人,每一次筆試各有 100 道麻醉 學方面的題目,同時考慮個人與醫院或不同出題者的試題,以及年齡、性別等共 變量所帶來的多階層的資料結構,我們使用 SAS (Statistical Analysis System)統計軟 體中的 NLIN 和 NLMIXED 運算功能來估計 Rasch 模式中的參數;貝氏多階層 Rasch 模式是利用 WinBUGS 軟體來處理。
結果:我們的結果顯示使用最大概似法與非線性混合迴歸所得到關於考生能力(θ)
iii
與試題難度(β)的估計值與標準誤差非常接近。代表這份資料可能符合局部獨立的 假設。然而,使用貝氏多階層模式來配適資料時,會使標準誤差有擴大的情況。
結論:非線性混合迴歸模式與貝氏多階層 Rasch 模式提供了另一種較具有彈性的 估計參數方式,特別是對於多階層的資料結構,這項特性可藉由應用 Rasch 模式 分析麻醉學筆試資料來表現。
iv
Abstract
Background: The relationship between the predictors and the response in biomedical
field is often characterized by a non-linear function. One of classical examples is the application of the logistic regression model to dealing with the data on threshold-based response outcomes, such as the Rasch model. The conventional Rasch model based on likelihood-based theory requires the assumption of local independence (conditional independence) and cannot deal with covariate affecting ability and hierarchical data structure. It is therefore interesting to relax the assumption of local independence and consider the heterogeneity due to covariates or correlated property from hierarchical structure by developing new statistical methods for the Rasch model.
Aims: We proposed the nonlinear mixed and Bayesian hierarchical regression model to
fit the empirical data on the written test of board certification examination for anesthesiologists to demonstrate the feasibility of using the two innovative Rasch models. Estimates obtained from both methods were compared with the conventional maximum likelihood method.
Material and Methods: The Rasch model was first framed by a non-linear mixed
regression underpinning to analyze the examinee ability (θ) and item difficulty (β) by treating the parameters of θ as a random effect following a normal distribution. This non-linear mixed regression was further extended to accommodate the data with hierarchical structures on examinees from training hospitals and items developed by raters. We also developed Bayesian hierarchical Rasch model for the same purpose. The data used for applications are the numbers of examinees distributed from 34 to 37 in 4
v
consecutive years from 2007 to 2010. There were 100 questions related to
anesthesiology in each test. Hierarchical data structured on individuals and hospitals or items under raters and also covariates on age and gender were considered in our
illustration. We used Statistical Analysis System (SAS) to estimate the parameters of the Rasch model by using PROC NLIN and NLMIXED. WinBUGS software was used for Bayesian hierarchical Rasch model.
Results: Our results show the two sets of estimates (θ and β) and standard error from
maximum likelihood method were very close to those from non-linear mixed regression model. This suggests the data may obey the assumption of local independence. However, the standard errors were inflated when Bayesian hierarchical Rasch model was fitted to data.
Conclusion: The nonlinear mixed regression model and Bayesian hierarchical Rasch
model provides alternative ways of estimating parameters with flexibility, particularly for hierarchical data. The feasibility is demonstrated with the application of the Rasch model to written examinations in anesthesiology.
vi
目錄
誌謝 ... i
摘要 ... ii
Abstract ... iv
目錄 ... vi
表格目錄 ... viii
圖目錄 ... ix
I 緒論 ... 1
I.1 研究背景 ... 1
I.2 研究目的 ... 2
II 文獻回顧 ... 4
II.1 非線性迴歸模式 (Non-linear Regression Model) ... 4
II.1.1 非線性迴歸模式例子 ... 5
II.1.2 非線性迴歸模式應用於羅吉斯迴歸的例子 ... 6
II.2 非線性混合效應模式 (Nonlinear mixed effects model) ... 8
II.3 試題反應理論 (Item Response Theory) ... 9
II.3.1 Rasch 模式 ... 10
II.3.2 Rasch 模式與非線性混合效應模式 ... 13
II.3.3 多階層試題反應理論模式 ... 14
II.4 Rasch 模式在麻醉學領域應用 ... 15
II.4.1 Rasch 模式於麻醉學測驗應用 ... 15
III 材料與方法 ... 18
III.1 資料來源 ... 18
III.1.1 資料變項 ... 18
III.2 Rasch 模式統計分析方法 ... 19 III.2.1 聯合最大概似參數估計 (Joint maximum likelihood parameter
vii
estimation) ... 19
III.2.2 非線性混合模式 ... 21
III.2.3 潛在變項 Rasch 迴歸模式 ... 23
III.2.4 貝氏多階層 Rasch 模式分析 ... 23
III.3 基本資料分析、事前處理及模式比較... 25
IV 結果 ... 27
IV.1 考生基本資料 ... 27
IV.2 非線性混合迴歸模式與聯合最大概似估計法比較 ... 27
IV.2.1 試題難度參數估計值與標準誤差 ... 27
IV.2.2 考生能力參數估計值與標準誤差 ... 28
IV.2.3 預測值與觀察值比較 ... 28
IV.2.4 非線性混合迴歸模式運算時間... 29
IV.3 多階層 Rasch 模式分析 ... 29
IV.3.1 潛在變項迴歸 ... 29
IV.3.2 醫院與考生階層的隨機截距模式 ... 29
IV.3.3 醫院與考生階層的隨機截距模式合併出題者訊息 ... 31
V 討論 ... 33
V.1 估計法比較 ... 33
V.2 多階層 Rasch 模式應用 ... 35
V.3 研究限制 ... 35
VI 結論 ... 36
表格 ... 37
圖 ... 46
參考文獻 ... 48
viii
表格目錄
表 II-1 甲蟲死亡數據 ... 7
表 II-2 非線性迴歸模式與廣義線性模式估計結果比較 ... 8
表 III-1 測驗結果的資料結構 ... 18
表 III-2 非線性混合效應模式應用資料格式 ... 22
表 IV-1 各年度考生的基本資料 ... 37
表 IV-2 2008 年所有試題前 10 項估計值比較... 38
表 IV-3 去除 2008 年全對題目後前 9 項試題估計值比較 ... 39
表 IV-4 2008 年某五位考生能力估計值(θ)比較 ... 39
表 IV-5 2008 年不同試題答對機率預測值與觀察值比較 ... 40
表 IV-6 2008 年某五位考生平均答對機率預測值與觀察值比較 ... 40
表 IV-7 對於 2008 年不同試題與積分條件的運算結果比較 ... 41
表 IV-8 考生年齡性別影響效果估計... 41
表 IV-9 各年度去除全對或全錯題目回答結果估計不同階層的標準誤差 ... 42
表 IV-10 以各年度難度十分位題目估計不同階層的標準誤差 ... 42
表 IV-11 各年度難度中間 30 題回答結果估計不同階層的標準誤差 ... 43
表 IV-12 2008 年度去除全對或全錯題目回答結果估計不同階層的標準誤差 ... 43
表 IV-13 去除 2008 年全對題目後前 9 項試題在非線性混合模式與貝氏方法含出題 者訊息模式之估計值 ... 44
表 IV-14 去除 2008 年全對題目後某五位考生在非線性混合模式與貝氏方法含出 題者訊息模式之估計值 ... 44
表 IV-15 去除 2008 年全對題目後前 9 項試題在非線性混合模式與貝氏方法含醫院 模式之估計值... 45
ix
圖目錄
圖 III-1 貝氏多階層 Rasch 模式處理考生、試題及訓練醫院對考試結果影響之 DAG 模式圖 ... 24 圖 III-2 貝氏多階層 Rasch 模式處理考生、試題、訓練醫院及出題者對考試結果影
響之 DAG 模式圖 ... 25 圖 V-1 2008 年度去除全對題目後不同階層標準誤差之模擬收斂情形 ... 46 圖 V-2 2008 年度去除全對題目後不同階層標準誤差之事後機率分佈 ... 47
1
I 緒論
I.1 研究背景
當進行生物醫學研究的統計模型分析過程中,若反應變數不是呈現常態分布 的連續性資料時,即無法依據一般線性迴歸模式中的線性關係假設,來描述預測 變數與反應變數之間的關係,例如在臨床麻醉學領域探討發生死亡或其他重大併 發症的有無,或者以是否超過某一門檻來判定疼痛發生的研究,都是屬於二元反 應變數,符合二項式分布(Binominal distribution)的資料型態,適合用羅吉斯迴歸 (logistic regression)的模型來估計預測變數的參數。
Nelder 與 Wedderburn (1972)首先所提出的廣義線性模式(Generalized linear model),將上述某些非常態資料分布納入在指數分布家族之中,透過概似函數所 建構理論而來的統計方式,可利用聯結函數g(μi)來建立解釋變數與反應變數期 望值之間的關係,並藉由 Newton-Raphson 方法來求出參數的最大概似估計值 (Maximal likelihood estimates)和變異數,根據指數家族所應用之統計模式,在統 計學上有良好性質的優勢;但是當反應變數和預測變數之間的聯結函數,無法使 用指數分布家族來評估時,使得預測變數與反應變數之間的概似函數關係相對複 雜,因而不易得到其一次和二次導函數,這種情形特別是在資料之間具有多層次 結構,造成資料相依性的情況下,經常容易發生。
除了廣義線性模式之外,對於兩種變數之間不屬於線性關係時,亦可利用非 線性迴歸模式(Non-linear regression model)來建構解釋變數與反應變數的關係,非 線性迴歸模式由於不需指定資料符合某種分布(SAS Institute & Publishing, 2011),
且代表期望值的函數可根據不同領域,如生物學或物理化學的理論來設定,所建 立的統計模型涵蓋範圍較廣,但也因此使得參數估計的過程較為複雜且較難獲得 最佳估計值。
因此,當一項研究所要觀察預測的結果是屬於二元變項時,除了常用的羅吉
2
斯迴歸模式之外,還可以透過非線性迴歸模式,來估計不同影響因子的迴歸係數 與變異數,例如要分析筆試測驗的回答是否正確的機率,是屬於一種二元反應變 項;在有關測驗分析的試題反應理論(Item response theory)領域中,Rasch 模式是 一種經常用來估計受試者能力與試題難度的解釋變數,影響答案對錯發生機率的 統計方式(Andrich, 1988; Bond & Fox, 2007)。
但是 Rasch 統計模式使用一般廣義線性模式,在概似函數理論下進行估計已 有專門處理統計軟體,如 Winsteps 等,依據資料所得到最大概似估計法來計算 試題的難度與受試者的能力(K. Y. Chang et al., 2010),然而這樣專業軟體所得到 之應用範圍,往往受限於研究者對於研究需求之必要性,其應用範圍較受限制,
但是這樣的估計方法通常需要用到局部獨立性(local independence)之假設來處理 同一受試者試題間之相依性,但如果局部獨立性假設違背時,傳統以最大概似法 通常不適用。
從統計學上的觀點而言,因為 Rasch 模式中反應變數與解釋變數的聯結函數 屬於非線性關係(Sheu, Chen, Su, & Wang, 2005),也可透過非線性迴歸模式的建 立,來估計函數中的不同變項所代表的參數,來適應多層次資料結構對資料相依 性所產生之影響,或來自不同族群的考生或是由不同出題者設計的題目所延伸之 多層次內容,也可考慮使用貝氏統計分析方法來處理多階層 Rasch 模式,這兩個 模式是本論文之主要重點。
I.2 研究目的
本論文的研究的主要目的,即是以民國 2007 至 2010 年間台灣麻醉專科醫師 筆試測驗資料為例,嘗試應用非線性迴歸的方式來對於 Rasch 模式的參數進行相 關統計分析與比較,可分為下列幾個項目:
(1) 分析並探討在非線性迴歸模式下,對於受試者能力以及試題難度的參數與變 異數估計值,與聯合最大概似估計法所得的結果之差異比較。
3
(2) 透過代表受試者特徵的共變量(covariates),將部分屬於隨機成份的潛在變項 以迴歸方式納入統計模型中,並觀察其分析結果。
(3) 嘗試將來自於不同受訓醫院的受試者,以及由不同出題者設計的題目,所組 成多階層的資料結構,透過非線性混合模式(Nonlinear mixed model)及貝氏多 階層 Rasch 模式進行應用分析。
4
II 文獻回顧
II.1 非線性迴歸模式 (Non-linear Regression Model)
非線性迴歸模式廣泛地應用在生物醫學的研究上,包括對於藥物從身體吸收 與代謝的藥物動力學模式(Cox & Ma, 1995),或是藥物劑量反應的特性與劑量選 擇的藥物效力學模式,非線性迴歸模式可由下列方程式( II-1 )呈現(Bates & Watts, 1988):
𝐘𝑛 = 𝑓(𝐱𝑛, 𝛉) + 𝐙𝑛 ( II-1 ) 其中隨機變數 Yn代表第 n 個案例的反應,f 是期望函數(Expectation function),
xn則是第 n 個案例的相關自變數向量,期望反應是參數 θ 的非線性函數,意思是 將期望函數對參數微分,至少有一個導函數與至少一個參數有關;不同於常見的 線性迴歸模式,如下列方程式(II-2)中所表示,期望反應函數 Xβ 對任一參數 β 微分的導函數與所有參數均無關;
𝐘 = 𝐗𝛃 + 𝐙 ( II-2 ) 模式中的迴歸係數β=(β1,β2,…,βp)T和預測(迴歸)變數所組成 n x p 的矩陣 X,
即稱為導函數矩陣(derivation matrix),決定了隨機變數 Y 所形成的向量中的確定 性部分(deterministic part),其中 X 可表示成下列矩陣:
𝐗 = [
𝑥11 𝑥12 𝑥13 𝑥21 𝑥22 𝑥23⋯𝑥1𝑝
𝑥2𝑝
⋮ ⋮ ⋮ ⋮ 𝑥𝑛1 𝑥𝑛2 𝑥𝑛3⋯ 𝑥𝑛𝑝
]
兩種模式中同樣含有代表隨機變數的向量 Z,並假設其符合常態分布,變異 數相等,平均值為 0,表示為下式:
E[Z] = 0 Var(Z) = E[ZZT] = σ2I
利用非線性迴歸模式可以使解釋變數與反應變數之間的關係具有很大彈性,
其參數θ 的估計是利用非線性最小平方法,從指定的起始值展開疊代的過程,因
5
此相較於線性模式或廣義性性模式,在統計軟體中,除了模式的指定外,還需要 額外的程式碼來指定尋找參數估計值的起始值;一般用來求得非線性最小平方估 計值的疊代過程中所使用的方法,包括 Gauss-Newton 法、Newton-Raphson 法和 Marquardt 法;這些方法利用最小誤差平方和(Sum of squared errors, SSE)對參數 微分後的導函數或導函數的近似值,來求出產生最小誤差平方和的參數值(SAS Institute & Publishing, 2011)。由於誤差平方和在不同範圍下,可能有超過一個的 最小值,因此疊代過程中所求出的值,會受到起始值的設定影響,我們可指定一 系列的參數起始值,但仍無法保證求到的是所有可能的最小值。對於非線性迴歸 模式中參數估計值的統計推論,如信賴區間的計算,通常是利用當樣本數增加所 得到的漸近性質(Asymptotic properties)來逼近後求出,在小樣本情況下,特別是 當參數的估計值遠離線性時,漸近的推論就可能產生問題,可透過再參數化讓參 數的特性接近於線性模式的估計值。
II.1.1 非線性迴歸模式例子
首先我們先以非線性迴歸的實際應用來舉例,在 Bates 與 Watts (1988) 所著 的書中,利用酵素動力學中的 Michaelis-Menten 模式,描述了酵素反應的起始速 率,經由下方公式(II-3)決定於基質濃度 x:
𝑓(𝑥, 𝛉) = θ1𝑥
θ2+ 𝑥 ( II-3 ) 將𝑓(𝑥, 𝛉)分別對 θ1與θ2微分後分別得到公式(II-4)與(II-5):
∂𝑓
∂θ1 = 𝑥
θ2+ 𝑥 ( II-4 )
∂𝑓
∂θ2 = −θ1𝑥
(θ2+ 𝑥)2 ( II-5 ) 由於兩導函數式均至少與一參數有關,因此 Michaelis-Menten 模式就可視為 一非線性函數關係。
在非線性迴歸模式中,經常是利用疊代的方式來求得最小平方估計值,以
6
Gauss-Newton 法為例,將期望函數經由線性逼近的過程,讓一開始對於參數 θ 的猜測值θ0,持續更接近最佳估計值,首先將期望函數 f(xn,θ)對於 θ0化為一次 泰勒展開式:
𝑓(𝐱𝒏, 𝛉) ≈ 𝑓(𝐱𝒏, 𝛉𝟎) + v𝑛1(θ1− θ10) + v𝑛2(θ2− θ20) + ⋯ + v𝑛𝑃(θP− θP0) 其中
v𝑛𝑝 = 𝜕𝑓(𝐱𝒏, 𝛉)
𝜕𝜃𝑝 | 𝑝 = 1,2, … , P 考慮所有 N 個案例後可表示為下式:
𝛈(𝛉) ≈ 𝛈(𝛉0) + 𝐕𝟎(𝛉 − 𝛉𝟎) ( II-6 ) 其中 V0是 N x P 的微分矩陣,其元素為[vnp],上(II-6)式相當於將殘差 z(θ)=y-η(θ),
藉由下列(II-7)式來逼近:
𝐳(𝛉) ≈ 𝐲 − [𝛈(𝛉0) + 𝐕𝟎𝛅] = 𝒛𝟎− 𝐕𝟎𝛅 ( II-7 ) 其中 z0=y-η(θ0),而 δ=θ-θ0,接著要計算δ0 (高斯增量,Gauss increment),來逼 近殘差平方和‖𝒛𝟎− 𝐕𝟎𝛅‖2的最小值,因此找到下一個點
𝛈̂1 = 𝛈(𝛉1) = 𝛈(𝛉𝟎+ 𝛅𝟎)
會比𝛈(𝛉0)更靠近 y,因此可以得到更佳的參數估計值 θ1=θ0+δ0,再經由計算 z1=y-η(θ1)來進行下一次疊代,持續至得到收斂為止。
上述 Gauss-Newton 疊代法的步驟可以從透過幾何的意義來說明:
(1) 利用泰勒展開式來求得 η(θ)在 η0=η(θ0)的近似值。
(2) 計算殘差向量 z0=y-η0
(3) 將殘差投影在正切平面(tangent plance)上來產生𝛈̂1
(4) 透過𝛈̂1在線性座標系統的映象,來找出增量δ0,並移動到𝛈(𝛉𝟎+ 𝛅𝟎)
II.1.2 非線性迴歸模式應用於羅吉斯迴歸的例子
在 Dobson 與 Barnett (2008) 關於廣義線性模式的著作第七章的內容裡,舉
7
了一個羅吉斯迴歸分析的案例,說明甲蟲暴露在不同濃度的二硫化碳氣體五小時 之後,死亡率的差別如表 2-1。
表 II-1 甲蟲死亡數據
劑量, x (log10CS2mgl-1) 甲蟲數目 死亡數
1.6907 59 6
1.7242 60 13
1.7552 62 18
1.7842 56 28
1.8113 63 52
1.8369 59 53
1.8610 62 61
1.8839 60 60
由於不同組別的死亡率是以二項式分布呈現,在廣義線性模式中,可透過公 式( II-8 )中間的 logit 函數來聯結預測變數與反應變數之間的關係:
𝑔(𝜋) = log ( 𝜋
1 − 𝜋) = 𝛽0+ 𝛽1𝑥 ( II-8 ) 此案例中 x 代表不同組別甲蟲所接受二硫化碳的劑量,而 π 則是各組甲蟲的 死亡率,β0和β1兩個參數則分別為廣義線性模式中的截距與斜率,經過運算後 可將等式兩邊轉換成公式( II-9 ):
π= 𝑒𝛽0+𝛽1𝑥
1+𝑒𝛽0+𝛽1𝑥 ( II-9 ) 可發現預測變數與反應變數之間呈現非線性關係,因此我們可利用非線性迴 歸模式透過 SAS 軟體中的 PROC NLIN 運算功能,來估計參數 β0與β1,並與廣 義線性模式透過 PROC GENMOD 所得到的參數估計值與標準誤差作比較,結果
8
如下方表格 2-2 所示:
表 II-2 非線性迴歸模式與廣義線性模式估計結果比較
參數
非線性迴歸模式 廣義線性模式
估計值 標準誤差 信賴區間 估計值 標準誤差 信賴區間 β0 -60.69 7.42 -78.84 -42.54 -60.72 5.18 -70.87 -50.56 β1 34.17 4.17 23.96 44.37 34.27 2.91 28.56 39.98
從表 2-2 中可發現兩種模式所得到 β0與β1的參數估計值均相當接近,但是 在非線性迴歸模式中對於參數估計值的統計推論,如標準誤差和信賴區間的計算,
則明顯比廣義線性模式來得大,可能是由於此案例中的樣本數較少,因此在非線 性迴歸模式中,無法透過漸近的性質而得到趨近於線性的推論。
II.2 非線性混合效應模式 (Nonlinear mixed effects
model)
混合模式是用來分析群集性或相依性資料的統計工具(Verbeke &
Molenberghs, 2009),例如相同學校內的學生或是相同受試者重覆測量的結果,不 同單位間的異質性可以利用其參數服從某一種隨機分布的假設來計算,此潛在的 隨機變數即代表迴歸模式中的隨機效應,其他不隨著單位不同而改變的參數則代 表固定效應,當統計模式中同時具有隨機效應與固定效應的參數,且以非線性迴 歸的方式表達,如前一節公式( II-1 )中的期望函數𝑓(𝐱𝑛, 𝛉),即稱為非線性混合 效應模式(Davidian & Giltinan, 2003)。過去主要應用的範圍廣泛,包括藥物動力 學的研究中(Sheiner & Ludden, 1992),可用來描述不同受試者在接受不同劑量的 藥物後,體內藥物濃度隨著時間變化的個體差異與族群特性;另外也可以應用在 生物醫學以及環境科學等的研究,例如依據非線性模式,藉由血中的前列腺特異
9
性抗原指數(Prostate-specific antigen)隨著時間的改變,來預測前列腺癌的復發 (Pauler & Finkelstein, 2002);亦或是用非線性模式中的參數,來估計黑熊的年齡 與體型的關係(McRoberts, Brooks, & Rogers, 1998);另外也可以分析樹木在接受 密集培育後,生長速度的變化與培育方式、土壤型態、樹木種植密度等因素之間 非線性的關係(Fang & Bailey, 2001)。
這些研究中具有幾個共同的特性:(1)對於族群中的每一個體進行重覆觀察 測量,所得到在不同時間或情況下的反應;(2)不同個體之間對於不同情況的反 應有所差異;(3)可透過科學模式中的參數來描述不同個體之間的差異;參數估 計的結果可代表不同個體的特性所造成的現象,並用來分辨反應變數的差異是否 來自個體的因素,以及預測個體的表現。因此,非線性混合效應模式所建構預測 變數與反應變數的關係,可以將個體之間差異考慮在內。
基本的非線性混合效應模式通常可用下列兩階層的等式表示(Davidian &
Giltinan, 2003):
第一階:個體模式 𝑦𝑖𝑗 = 𝑓(𝑥𝑖𝑗, 𝛽𝑖) + 𝑒𝑖𝑗, 𝑗 = 1, … , 𝑛𝑖 ( II-10 ) 第二階:族群模式 𝛽𝑖 = 𝑑(𝛽, 𝜃𝑖) ( II-11 ) 在上式中,yij代表第 i 個受試者在第 j 次測量的反應,例如在測驗分析中,
第 i 個考生答對第 j 題的機率,f 代表個體層次的函數關係,受到與個體 i 有關參 數的( p x 1)向量 βi所影響;而 d 是 p 個維度的函數,決定於固定效應所代表參數 的( r x 1)向量 β,以及與個體 i 產生隨機效應所代表參數的(k x 1)向量 θi。 在公式(II-11)中的 θi通常代表族群中個體由於生物學的自然差異造成無法 解釋的變異,或是在測驗分析中考生能力的不同,通常假設θi~N(0,σ2),也就是 E(θi)=0,且 var (θi)= σ2,此時σ2就代表βi之中無法解釋差異的程度大小。
II.3 試題反應理論 (Item Response Theory)
試題反應理論是現代測驗理論的重心,特點是以機率的概念來建構統計模式,
10
來描述個人與試題的潛在變數和測驗反應間之關係(De Ayala, 2009),但並不著重 解釋個人對於試題產生特定反應的原因,而是利用個人的能力與試題的難度等所 要估計的潛在特徵,作為所觀察到反應值的預測因子。
試題反應理論主要包含兩項假設,第一項是單一面向假設(unidimensionality assumption),意思是對於測驗中試題的反應,只和單一連續性潛在個人變項(θ) 有關,例如該次測驗項目所要評量的能力。實際上,雖然單一面向假設可能會有 某種程度上的違背,但只要有主要影響測驗結果的變項,通常仍能對於資料足夠 有效力的解釋。
第二項假設是在固定個人潛在變數的情況下,對於某項試題的反應和其他試 題無關,稱做條件獨立(conditional independence) 或是局部獨立( local
independence),可以用下列方程式表示:
P(𝑌1, 𝑌2, … , 𝑌𝐽|𝜃) = P(𝑌1|𝜃)P(𝑌2|𝜃) … P(𝑌𝐽|𝜃) = ∏ P(𝑌𝑗|𝜃)
𝐽
𝑗=1
( II-12 )
上式中 θ 是模式中代表個人能力或其他特質的潛在變項,Yj是對第 j 項試題 的反應,P(𝑌𝑗|𝜃)是潛在變項為 θ 的受試者,對於第 j 項試題反應為 Yj的機率。
當滿足第一項的單一面向假設時,同時也表示一位受試者對於一項問題的反 應只決定於其潛在變項的數值,而和其對其他問題的反應無關,這也同時滿足了 條件獨立假設,所以這二項假設也被認為是同一件事。
II.3.1 Rasch 模式
對於試題結果為二元反應變項的測驗,Rasch 模式是試題反應理論中,經常 使用的心理計量方法(Andrich, 1988; Bond & Fox, 2007),透過基本的單參數羅吉 斯模式作為工具,建構固定單位(logit),客觀地測量並比較我們所感興趣的變項,
可用下列方程式來代表個人能力(θ)與試題難度(β)和回答正確的機率(p)之間的關 係:
11
P(𝑌𝑖𝑗=1|𝜃𝑖,𝛽𝑗)= exp(𝜃𝑖-𝛽𝑗)
1+exp(𝜃𝑖-𝛽𝑗) ( II-13 ) 或是轉換為羅吉斯(logistic)形式:
log 𝑝𝑖𝑗
1 − 𝑝𝑖𝑗 = 𝜃𝑖-𝛽𝑗 ( II-14 ) 上方(II-13)式中的 Yij是測驗結果中第 i 個受試者對於第 j 題的回答是否正確,
所觀察到二元的隨機反應變數,P(Yij=1)或 pij代表答對的機率,P(Yij=0)或(1-pij) 代表答錯的機率,受到θi和βj的影響,βj是第 j 題難度的參數,θi代表第 i 個受 試者能力的潛在隨機變數,可以假設是來自同一個服從常態分配且彼此獨立的樣 本,也就是受試者參數代表的是混合模式中的隨機效應,試題參數則代表的是固 定效應。
由於 Rasch 模式中存在有條件獨立性的假設,也就是說在考慮 θi所代表的能 力後,同一受試者(即省略 i)對於不同題目的答對的機率P(𝑌𝑗|𝜃, β)彼此獨立,因 此在 Rasch 模式中同一受試者的聯合機率(joint probability)就可以表示為:
P(𝑌1, 𝑌2, … , 𝑌𝐽|𝜃,β) = P(𝑌1|𝜃, β)P(𝑌2|𝜃, β) … P(𝑌𝐽|𝜃, β)
= ∏ P(𝑌𝑗|𝜃, 𝛽) = ∏ P(𝑌𝑗|𝜃, 𝛽)𝑌𝑗[1 − P(𝑌𝑗|𝜃, 𝛽)]1−𝑌𝑗
𝐽
𝑗=1 𝐽
𝑗=1
接著利用觀察到反應值 yj取代隨機變數 Yj,可得到下方(II-15)式之概似函數 (likelihood function):
L(𝑦1, 𝑦2, … , 𝑦𝐽|𝜃,β) = ∏ P(𝑦𝑗|𝜃, 𝛽)𝑦𝑗[1 − P(𝑦𝑗|𝜃, 𝛽)]1−𝑦𝑗
𝐽
𝑗=1
( II-15 )
透過代表 Rasch 模式的公式(II-13)式,可將(II-15)式轉換為下列(II-16)式:
∏ P(𝑦𝑗|𝜃, 𝛽)𝑦𝑗[1 − P(𝑦𝑗|𝜃, 𝛽)]1−𝑦𝑗
𝐽
𝑗=1
= ∏ { exp(𝜃-𝛽𝑗) 1+exp(𝜃-𝛽𝑗)}
𝑦𝑗
{ 1
1+exp(𝜃-𝛽𝑗)}
(1−𝑦𝑗) 𝐽
𝑗=1
( II-16 )
12
為了簡化估計的過程,可以進一步將前述之概似函數取自然對數轉換,得到 對數概似函數(log likelihood function)如下:
𝑙𝑛𝐿(y|𝜃,β) = ∑[𝑦𝑗ln𝑃𝑗+ (1 − 𝑦𝑗)ln (1 − 𝑃𝑗)]
𝐽
𝑗=1
( II-17 )
之後再對參數θ,β 微分所得到的一次與二次導函數,利用 Newton-Raphson 逼近的方法,求取最大概似估計值。
關於參數估計值θ̂的變異數可透過下式來表示(De Ayala, 2009):
𝜎2(𝜃̂|θ) = 1
−𝐸 [ 𝜕𝜕𝜃22𝑙𝑛𝐿]= 1
∑ [𝑃𝑗′]2 𝑃𝑗(1 − 𝑃𝑗)
𝐽 j=1
( II-18 )
上式中的σ 代表估計值的標準誤差,E 代表期望值,𝑃𝑗′為模式中的一次導函 數,由於在 Rasch 模式中的𝑃𝑗′ = 𝑃𝑗(1 − 𝑃𝑗),因此上式可簡化成下式:
𝜎2(𝜃̂|θ) = 1
∑ [𝑝𝐽j=1 𝑗(1 − 𝑝𝑗)] ( II-19 ) 由於σ 的大小會影響我們對於參數估計的信賴區間範圍,當標準誤差越小,
信賴區間越窄時,可以視為我們對於參數估計的訊息越多,因此測驗量尺所提供 的整體訊息(I(θ)),可以用上方二式的倒數來表示為下式:
I(θ) = −𝐸 [ 𝜕2
𝜕𝜃2𝑙𝑛𝐿] = 1
𝜎2(θ)= ∑ [𝑝𝑗′]2 𝑝𝑗(1 − 𝑝𝑗)
𝐽
j=1
( II-20 )
而個別試題對於整體訊息貢獻的試題訊息,則可表示為 Ij(θ)如下:
Ij(θ) = [𝑝𝑗′]2
𝑝𝑗(1 − 𝑝𝑗) ( II-21 ) 上式在 Rasch 模式中可簡化如下:
Ij(θ) = 𝑝𝑗(1 − 𝑝𝑗) ( II-22 ) 由於𝑝𝑗(1 − 𝑝𝑗)在 pj=(1-pj),也就是 pj=0.5 時有最大值 0.25,由(II-13)或(II-14) 式可知,此時的𝜃̂ = 𝛽̂,因此可以了解在難度最接近考生能力的試題時可以提供 最多訊息。
13
另外,由於方程式等號右邊的解釋變數與左邊的反應變數之間,所依靠的聯 結函數為包含隨機效應的非線性關係,因此可用上一節所說明的非線性混合效應 模式來估計其參數。
II.3.2 Rasch 模式與非線性混合效應模式
從統計觀點而言,試題反應理論模式把受試者的能力或潛在特質視為服從某 一種分布的隨機變數,而試題的特性(例如難度)屬於固定效應,同時利用非線 性的函數,聯結反應變數與參數之間的關係,因此可視為是非線性混合模式的一 個集合(Sheu et al., 2005)。
Agresti (2000) 曾探討隨機效應模式對於類別性資料在社會科學上的各項應 用,包括重覆測量的二元性或序列性反應等,其中有使用試題反應理論模式中的 Rasch 模式作為混合羅吉斯模式的舉例。Rijmen 等人(2003)更進一步闡述如何將 常見試題反應理論模式,架構在非線性混合模式的概念之下,解釋二元變項的混 合羅吉斯模式,以及多元性資料的不同模式中,反應變數中羅吉斯(logit)表示方 式的差異,另外也將此架構至其他衍生的模式,最後並討論統計推論及軟體程式 的應用。
過去要進行試題反應理論分析時,需針對不同模式利用特定套裝軟體,參數 估計方式與操作界面均不同,造成使用者的不便,Sheu 等人(2005)以實際資料說 明如何使用常用統計軟體 Statistical Analysis System(SAS)中的 PROC NLMIXED 指令來估計試題反應理論的參數, 包括利用單參數羅吉斯模式(Rasch 模式),
分析 150 人回答有關平面幾何學的 9 道選擇題結果的二元性資料,還有應用三參 數羅吉斯模式,分析美國國防部在 1980 年對 776 位 16-23 歲的青年所作算術能 力調查結果;另外,作者使用一份關於 245 人回答 24 項關於死刑的敘述意見調 查的多元性反應結果為例,分別利用等級反應模式(graded response model)、評定 量表模式(rating scale model)(Andrich, 1978)、部份計分模式(partial credit
14
model)(Masters, 1982)分析並比較其結果;對於名義性反應資料,作者以名義性 類別模式(nominal categories model)(Darrell Bock, 1972)分析一份生活滿意度調查;
最後並利用合適度的統計檢定值,來說明模式估算期望值與實際值的差異。
此外,Smits 等人(2003)比較以 SAS 的 PROC NLMIXED 指令與 MIRID CML 軟體對於 Rasch 模式資料分析結果的差異,發現對於試題參數的估計值相近,但 受試者參數的估計卻有不同,應該是由於兩者對於受試者的假設不同,雖然使用 SAS 計算的速度慢了許多,但較具有彈性。
II.3.3 多階層試題反應理論模式
傳統上,如 Rasch 模式等試題反應理論的模式中,不同題目的測量值是以受 試者個人為單位來估計;然而,數據資料可能來自不同的族群單位,例如不同學 校的學生或是不同城鎮地區的居民,因此相同族群的受試者對於試題的反應就可 能彼此相關,此時代表隨機效應的潛在個人參數θi,也就無法滿足來自某一種個 人之間相互獨立分布的假設,除了個人階層之外,還多出族群階層的影響,因此 屬於多階層的試題反應理論模式。
一般而言,有兩種方式來評估多階層模式中的族群效應,首先,當我們對於 學校或是其他族群單位(例如:地區、性別),所產生的特定影響有興趣時,可以 將個人的的族群單位屬性視為共變量來編碼,進行潛在變項迴歸(latent
regression),此種方式能讓每個族群單位產生個別的固定效應參數。
或者可以將不同的學校或族群單位視為一個隨機樣本,如同在評估受試者的 隨機效應時,來分析學校或族群單位的隨機效應,這種方式形成所謂的多階層試 題反應理論模式(Multilevel IRT models)(Kamata, 2001; Maier, 2001)。在只有單一 個隨機效應的截距所產生的 Rasch 模式的情況,並假設所有階層的隨機效應服從 常態分配時,可得到下列方程式:
15
P(𝑌𝑖𝑗𝑘=1|𝜃𝑖k,𝛽𝑗)= exp(𝜃𝑖𝑘-𝛽𝑗)
1+exp(𝜃𝑖𝑘-𝛽𝑗) ( II-23 ) 其中θik~N(ϑ𝑘,𝜎s2), ϑ𝑘~N(0,𝜎ℎ2),θik代表在包含在第 k 個族群單位中的第 i 個受試者的隨機效應截距,ϑ𝑘代表第 k 個族群單位的隨機效應;因此對於單一族 群單位內潛在能力的聯合分布(joint distribution),會呈現平均值是 0,變異數是 𝜎s2+𝜎ℎ2,共變異數是𝜈2的多變量常態分布。
II.4 Rasch 模式在麻醉學領域應用
如前所述,Rasch 模式是試題反應理論中,利用單參數模式來作為測驗分析 的一種的心理計量方法(Andrich, 1988; Bond & Fox, 2007),在醫學領域上的應用 範圍不斷擴展,但在麻醉學方面仍然少見,可分為測驗試題的分析(K. Y. Chang et al., 2010; Yang, Tsou, Chen, Chan, & Chang, 2011)與疼痛測量工具的發展與評估 (Amtmann et al., 2010; Revicki et al., 2009; Varni et al., 2010)兩大類,分別敘述如 下:
II.4.1 Rasch 模式於麻醉學測驗應用
關於 Rasch 模式在麻醉學測驗應用的三項研究分別包括經食道超音波測驗 (Aronson et al., 2002),醫學生麻醉學期末考(Yang et al., 2011)以及麻醉專科醫師 考試(K. Y. Chang et al., 2010)。Chang 等人將麻醉專科筆試結果,利用 Rasch 模式 將試題難度與考生能力用相同尺度測量,並且評估題目的合適度,同時也檢驗出 題者設定的難度與 Rasch 模式分析的一致性,並且模擬去除極度困難及容易的題 目後,對於測驗結果信度(reliability)的影響。在 100 道題目當中,所有考生全部 都答對的共有 17 題,另外有一題因為配適度不佳而排除分析,題目與考生的信 度指數(Reliability index)分別是 0.87 與 0.71,考生的平均能力比試題的平均難度 高出 1.28 個 logit 單位,表示考生平均可以答對 78%的題目,試題難度從-2.43 到 4.25,代表在平均考生能力情況下,被答對的機率分別從 98%到 5%不等。
16
進一步的 Rasch 分析顯示有 60 道題目的難度低於能力最差的考生,有 7 道 題目的難度高於能力最好的考生,其他 32 道題目的難度分布在所有考生的範圍 中,由於難度與考生能力範圍相符的題目提供最多訊息,將極容易和極困難的題 目去除並不會明顯影響考生能力的估計值。此外,單因子變異數分析(One-way ANOVA)顯示不同出題者的題目難度有明顯差異,出題者自訂的題目難度和 Rasch 分析結果的一致性不高,加權 Kappa 統計檢定值為 0.23。
Yang 等人對於醫學生在麻醉學期末測驗的結果以 Rasch 模式分析(Yang et al., 2011),評估考生能力、題目難度以及測驗的信度,並且評估題目的配適度,將 配適度不佳的考生與題目排除後,測驗的信度指數只有 0.63,利用
Spearman-Brown 預測公式計算,在相同試題品質的情況下,增加試題數目到 70 題,測驗信度指數才能達到 0.7,若是題目增為兩倍時的測驗信度指數為 0.77,
若要信度指數要達到 0.8,此測驗的題目至少需增為 120 題。
相對而言,Aronson 等人並未針對測驗題目進行試題分析,而僅是在研究方 法中提到 Rasch 分析法,在其他專科考試方面,Garibaldi 等人研究利用 Rasch 分 析將內科考生的能力轉換成標準化的分數,並和受訓期間的測驗分數作比較 (Garibaldi, Subhiyah, Moore, & Waxman, 2002),但一樣沒有注重在試題分析上,
此外,O’Neil 等人使用 Rasch 模式來重新分析美國護士執照考試結果,來決定新 的通過標準(O'Neill, Marks, & Reynolds, 2005)。
除了麻醉學測驗之外,Chang 等人(2011)也曾使用 Rasch 模式來分析影響產 婦對於減痛分娩態度的因素,利用原本以多屬性效用分析理論(Multiattribute Utility)模式所建構的問卷資料(K.-Y. Chang, Chan, Chang, Yang, & Chen, 2008),將 產婦對於 20 項題目的測量結果重新分類,使得分成十等級的多面向反應,濃縮 簡化為四等級的單一面向反應,在排除配適模式程度不佳的產婦及題目後,估計 出每一位產婦對於減態分娩態度的分數,以及各項題目影響程度的參數,不同等 級反應之間的閾值。在 167 位問卷填答完成的產婦中,有 3 位產婦及 11 項題目
17
因配適度不佳而被排除,兩種版本的問卷信度指數分別為 0.68 和 0.74,彼此之 間的相關係數是 0.89,ROC (Receiver Operating Characteristics)曲線下的面積分別 是 0.80 和 0.81,因此透過 Rasch 模式分析可了解簡化版本問卷的內容,沒有明 顯改變其信度和效度。
18
III 材料與方法
III.1 資料來源
台灣麻醉專科醫師考試每年舉行一次,參加者為在專科醫師訓練醫院完成四 年住院醫師訓練,並達到相關規定者,分為筆試和口試兩階段,第一階段筆試通 過後方能參加第二階段口試,筆試題目由八位資深麻醉醫師所組成的委員會,每 位出題委員分別根據指定教科書的不同章節內容出 12 道試題,並經過所有成員 審核討論後,刪去不適合的題目,再由近年考題所組的題庫中補充,組成共有 100 道題目的考卷,所有題目都是從五個選項中選出最合適一項的選擇題,每答 對一題可得一分,答錯不倒扣,因此每一位考生對於每一題的回答都可視為一個 二元反應變項,資料格式如下表 3-1,考試時間共有二小時,及格標準為 60 分,
本研究的資料來源是取自民國 2007 至 2010 年此項筆試的測驗結果。
表 III-1 測驗結果的資料結構
試題
受 試 者
1 2 … J … 99 100
1 Y1,1 Y1,2 … Y1,j … Y1,99 Y1,100
2 Y2,1 Y2,2 … Y2,j … Y2,99 Y2,100
: : : : : : : :
i Yi,1 Yi,2 … Yi,j … Yi,99 Yi,100
: : : : : : :
n Yn,1 Yn,2 … Yn,j … Yn,99 Yn,100
Yi,j=1 代表回答正確,Yi,j=0 代表回答錯誤 (每一年試題皆為 100 題)
III.1.1 資料變項
19
在此麻醉專科醫師筆試的研究過程中,資料收集與分析的相關變項可分為 下列幾類:
(1) 潛在解釋變項(latent variables):考生關於麻醉學的能力(θi)與試題的難度(βj) (2) 反應變項(response variable):考生對於試題的回答是否正確(Yij),為二元變
項。
(3) 共變量:考生的特徵的部分包括年齡、性別、訓練醫院,試題的部分包括年 份、出題者。
由於在 Rasch 模式中,對於試題的反應是包括在每一位考生之下,因此本身 就具有階層的特性,再加上可依據考生的訓練醫院來分為不同的族群,或是其他 共變量形成多階層的統計模式,來評估不同因素對於考生作答結果的影響。
III.2 Rasch 模式統計分析方法
III.2.1 聯合最大概似參數估計 (Joint maximum likelihood parameter estimation)
如前 II.3.1 節所述,Rasch 模式可表示為下列方程式:
P(𝑌𝑖𝑗=1|𝜃𝑖,𝛽𝑗)= exp(𝜃𝑖-𝛽𝑗)
1+exp(𝜃𝑖-𝛽𝑗) ( III-1 ) 由於 Rasch 模式中存在有局部獨立性(local independence)的假設,也就是說 對第 i 個受試者在考慮 θi所代表的能力後,同一受試者(即省略 i)對於不同題目的 答對的機率P(𝑌𝑗|𝜃, β)彼此獨立且服從二項分布,因此在 Rasch 模式中同一位受試 者的聯合機率(joint probability)就可以表示為:
P(𝑌1, 𝑌2, … , 𝑌𝐽|𝜃,β) = P(𝑌1|𝜃, β)P(𝑌2|𝜃, β) … P(𝑌𝐽|𝜃, β)
= ∏ P(𝑌𝑗|𝜃, 𝛽) = ∏ P(𝑌𝑗|𝜃, 𝛽)𝑌𝑗[1 − P(𝑌𝑗|𝜃, 𝛽)]1−𝑌𝑗
𝐽
𝑗=1 𝐽
𝑗=1
20
接著利用觀察到反應值 yj取代隨機變數 Yj,可得到下方(III-2)式之概似函數 (likelihood function):
L(𝑦1, 𝑦2, … , 𝑦𝐽|𝜃,β) = ∏ P(𝑦𝑗|𝜃, 𝛽)𝑦𝑗[1 − P(𝑦𝑗|𝜃, 𝛽)]1−𝑦𝑗
𝐽
𝑗=1
( III-2 )
透過代表 Rasch 模式的公式(III-1)式,可將(III-2)式轉換為下列(III-3)式:
∏ P(𝑦𝑗|𝜃, 𝛽)𝑦𝑗[1 − P(𝑦𝑗|𝜃, 𝛽)]1−𝑦𝑗
𝐽
𝑗=1
= ∏ { exp(𝜃-𝛽𝑗) 1+exp(𝜃-𝛽𝑗)}
𝑦𝑗
{ 1
1+exp(𝜃-𝛽𝑗)}
(1−𝑦𝑗) 𝐽
𝑗=1
( III-3 )
為了簡化估計的過程,可以進一步將前述之概似函數取自然對數轉換,得到 對數概似函數(log likelihood function)如下:
𝑙𝑛𝐿(y|𝜃,β) = ∑[𝑦𝑗ln𝑃𝑗+ (1 − 𝑦𝑗)ln (1 − 𝑃𝑗)]
𝐽
𝑗=1
( III-4 )
之後再對參數θ,β 微分所得到的一次與二次導函數,利用 Newton-Raphson 逼近的方法,求取最大概似估計值。
以上(III-2)式與(III-4)式中的概似函數皆是在固定受試者潛在參數 θ 下的條 件機率,當我們要求得同時考慮不同受試者與試題的聯合概似函數時,可以將 (III-2)式乘上 N 個受試者的情況,得到下方(III-5)式:
L = ∏ ∏ P(𝑦𝑖𝑗|𝜃𝑖, 𝛽𝑗)𝑦𝑖𝑗[1 − P(𝑦𝑖𝑗|𝜃𝑖, 𝛽𝑗)]1−𝑦𝑖𝑗
𝐽
𝑗=1 𝑁
𝑖=1
( III-5 )
同理,因計算簡便所需,將(III-5)式經自然對數轉換後,可得到相對應之聯 合對數概似函數(joint log likelihood functioin)如下方(III-6)式:
𝑙𝑛𝐿 = ∑ ∑[𝑦𝑖𝑗ln𝑃𝑖𝑗+ (1 − 𝑦𝑖𝑗) ln(1 − 𝑃𝑖𝑗)]
𝐽
𝑗=1 𝑁
𝑖=1
( III-6 )
21
在求得聯合最大概似估計值的過程包含一系列的步驟與階段,第一步首先利 用假設已知的臨時個人參數值來估計試題參數,由於不同試題的參數估計之間彼 此獨立,因此一次估計一項試題;第二步接著以第一步所得到已知的試題參數估 計值來推算個人參數值,同理,每位受試者的估計過程彼此獨立;完成第二步所 得到的個人估計值會改善第一步中所使用的臨時個人參數值,因此可以重覆第一 步來得到更準確的試題估計值,再繼續重覆第二步,這樣的過程持續進行到參數 的估計值收斂為止。
另外,由於在 Rasch 模式中,等號右邊的解釋變數與左邊的反應變數之間所 依靠的聯結函數,為包含隨機效應的非線性關係,因此可用下一小節所說明的非 線性混合效應模式來估計其參數。
III.2.2 非線性混合模式
在非線性混合模式的參數估計過程中,我們透過 Statistical Analysis System (SAS)統計軟體中的 NLMIXED 運算功能(SAS Institute & Publishing, 2011),利用 邊際概似函數(Marginal likelihood)的方式,透過上節的(III-3)式,可得到指定概 似函數如下方( III-7 )式所示:
∏ [∫ ∏ { exp(𝜃𝑖-𝛽𝑗) 1+exp(𝜃𝑖-𝛽𝑗)}
𝑦𝑖𝑗
{ 1
1+exp(𝜃𝑖-𝛽𝑗)}
(1−𝑦𝑖𝑗) 𝑘
𝜃 𝑗=1
𝜙(𝜃) 𝑑𝜃]
𝑛
i=1
( III-7 )
也就是將觀察資料的邊際密度函數視為參數的函數,接著以高斯積分 (Gaussian-Hermite quadrature)的數值積分方式,將受試者反應的聯合機率函數 (joint probability function)對於受試者分布(隨機效應)作積分處理,再利用一次和 二次導函數得到題目參數的估計值,再透過已知的題目參數去得到受試者參數。
上述(3-5)式中的 yij就是第 i 個受試者對第 j 題的反應變數,βj是第 j 題難度 的參數,θi代表第 i 個受試者的能力參數,θ~N(0, σ2),φ(θ)是變異數為 σ2常態分
22
布的機率密度函數,σ2代表考生彼此之間能力的變異大小。
在使用 NLMIXED 運算方式時,需要先把資料中每一橫列所代表一位受試 者對於所有題目的反應,透過對題目虛擬變項的設定,轉換成每一列為一位受試 者對單一題目的反應,因此資料中原先如表格 3-1 是 N 位考生(列) X 100 題(行) 的資料,經過轉換後會成為 100 x N (列) X 101 (行)的格式(如表 3-2)。
表 III-2 非線性混合效應模式應用資料格式
受試者 試題 反應
1 2 3 4 … 98 99 100
1 1 0 0 0 … 0 0 0 Y1,1
1 0 1 0 0 … 0 0 0 Y1,2
1 0 0 1 0 … 0 0 0 Y1,3
… …
1 0 0 0 0 … 0 1 0 Y1,99
1 0 0 0 0 … 0 0 1 Y1,100
2 1 0 0 0 … 0 0 0 Y2,1
… …
N 0 0 0 0 … 1 0 0 YN,98
N 0 0 0 0 … 0 1 0 YN,99
N 0 0 0 0 … 0 0 1 YN,100
Yi,j=1 代表回答正確,Yi,j=0 代表回答錯誤
在轉換資料格式完成,並依照上述(III-5)式在程式中建立概似函數,定義反 應變數與解釋變數的關係後,接著需要指定運算過程中所使用高斯積分法的積分 點(quadrature points)數目,過去文獻建議應逐次增加積分點數目,直到參數估計
23
值穩定(Sheu et al., 2005),較多的積分點會增加運算時間,但對於參數估計值的 影響是個複雜的問題,與模式的結構和資料的型態有關(Lesaffre & Spiessens, 2001),因此我們嘗試利用不同的積分點,來比較在參數估計值穩定的情況下,
對於參數標準誤差與運算時間的實際影響。
III.2.3 潛在變項 Rasch 迴歸模式
當我們要估計受試者的基本資料特性影響潛在個人參數θi的程度時,可對於 ( III-1 )式中的潛在變數 θi建立下列迴歸模式:
θi = 𝐱′iγ + 𝜀𝑛 ( III-8 ) 其中 xi代表第 i 個受試者共變數的向量,γ 係數是 x 每改變一單位,相對應 θ 改變的量,而誤差項𝜀𝑛~N(0, 𝜎𝜀2),其變異數𝜎𝜀2代表排除共變數影響後,受試 者能力的變異數,也就是模式中隨機效應的部分,在受試者之中以常態分布存在,
因此納入潛在變項迴歸的 Rasch 模式中,固定效應就同時包含受試者和試題所代 表的影響;相對來說,此時的θi會是一群常態分布的混合,而不再是原本沒有潛 在變項迴歸的情況下,呈現常態分布的隨機效應。
III.2.4 貝氏多階層 Rasch 模式分析
前文所述的兩種分析方法,對於隨機效應部份均限制只能估計個人的單一層 次,但在影響考試結果的研究中,除了考生本人的能力與試題的難易度需要考慮 之外,我們也有興趣凌駕於考生之上的因素,例如訓練醫院的不同,可能意味者 存在某種潛在因素會影響考生,進而造成同一訓練醫院訓練出來的考生能力其實 為相關的資料。因此,我們利用 Direct Acyclic Graphic (DAG) Model 建構貝氏多 階層 Rasch 模式,並且以 Markov Chain Monte Carlo 方法進行估計,在捨棄初始 階段的 10000 次重覆抽樣的樣本後,利用之後 20000 次重覆抽樣的樣本得到感興
24
趣變項之事後機率分佈(Posterior Distribution),並依據事後機率分佈報導其點估 計及區間估計結果。
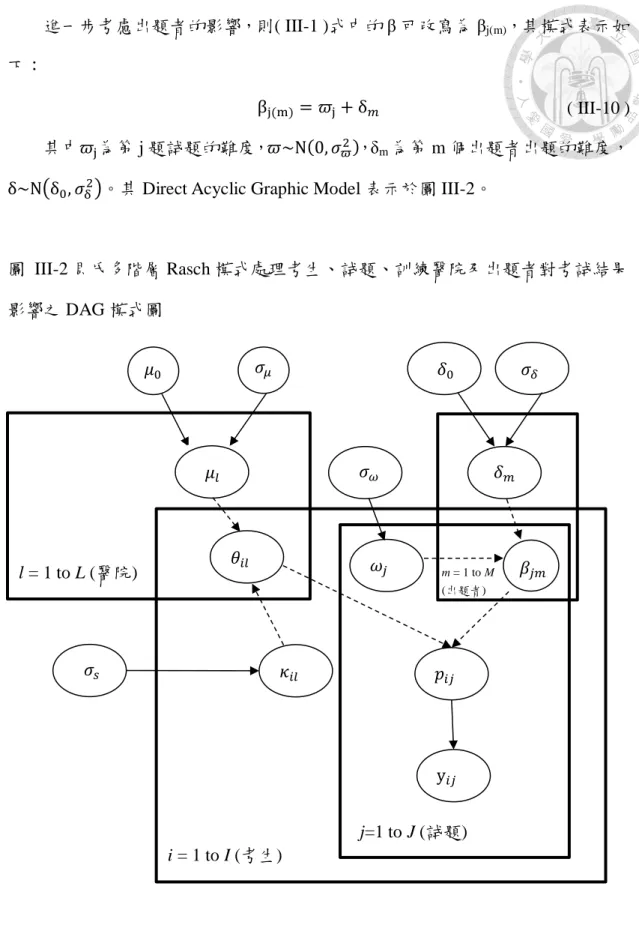
在此,可對於( III-1)式中的潛在變數 θ 變成 θi(l),並建立下列迴歸模式:
θ𝑖𝑙 = 𝜅𝑖𝑙 + μ𝑙 ( III-9 ) 其中κi為第 i 個受試者的能力,𝜅~N(0, 𝜎𝑠2),μl為第 l 家訓練醫院代表的潛在 變因,μ~N(𝜇0, 𝜎𝜇2)。其 Direct Acyclic Graphic Model 表示於圖 III-1。
圖 III-1 貝氏多階層 Rasch 模式處理考生、試題及訓練醫院對考試結果影響之 DAG 模式圖
y𝑖𝑗 𝑝𝑖𝑗
𝛽𝑗 𝜃𝑖𝑙
j=1 to J (試題) i = 1 to I (考生)
l = 1 to L (醫院)
𝜅𝑖𝑙 𝜎𝑠
𝜇𝑙
𝜎𝜇 𝜇0
25
進一步考慮出題者的影響,則( III-1 )式中的 β 可改寫為 βj(m),其模式表示如 下:
βj(m) = 𝜛j+ δ𝑚 ( III-10 ) 其中𝜛j為第 j 題試題的難度,𝜛~N(0, 𝜎𝜛2),δm為第 m 個出題者出題的難度,
δ~N(δ0, 𝜎δ2)。其 Direct Acyclic Graphic Model 表示於圖 III-2。
圖 III-2 貝氏多階層 Rasch 模式處理考生、試題、訓練醫院及出題者對考試結果 影響之 DAG 模式圖
III.3 基本資料分析、事前處理及模式比較
𝜇0
𝜔𝑗
y𝑖𝑗 𝑝𝑖𝑗
𝛽𝑗𝑚 𝜃𝑖𝑙
j=1 to J (試題) i = 1 to I (考生)
l = 1 to L (醫院)
𝜅𝑖𝑙 𝜎𝑠
𝜇𝑙
𝜎𝜇
m = 1 to M (出題者)
𝜎𝜔 𝛿𝑚
𝛿0 𝜎𝛿
26
在考生基本特性與測驗結果中,對於連續性變項如年齡、原始總分等,我們 使用變異數分析(analysis of variance, ANOVA)來比較不同年度的差異,而類別變 項如性別等,則使用卡方檢定來比較。
由於 Rasch 模式對於試題難度的估計值並沒有固定單位,只是相對於個人能 力的差別,因此若是全對或全錯的題目,會出現估計的範圍過大而不穩定的情況,
因此可以事先移除全對或全錯的題目再來估計,或是部分軟體會設定參數估計值 的範圍,如-3 到+3 之間。
根據先前 II.3.1 節中有關參數標準誤差估計的敘述,難度最接近考生能力的 程度的題目能夠提供最多的訊息,因此我們在比較不同試題數目對於參數估計的 影響時,首先選擇最靠近考生平均能力的 30 項題目;另外為了考慮不同能力的 考生,也將試題難度估計排序後,再取位置在十分位的題目來進行估計。
對於不同的貝氏模式比較時,本論文則使用貝氏 DIC(Deviance Information Criterion)準則來進行模式比較。
本論文中的非線性迴歸模式與一般敘述性統計以 SAS 統計軟體(9.3 版)分析,
聯合最大概似估計法是利用 Winsteps 統計軟體(3.6.6 版)進行處理,貝氏統計分析 經由 WinBUGS 統計軟體(1.4.3 版)來運算。
27
IV 結果
IV.1 考生基本資料
在此份專科醫師甄審測驗研究資料之中,2009 年度參加考試者有 34 位麻醉 科住院醫師,分別來自 14 家不同醫院,為四年當中人數最少的一次,最多的一 年 2008 年有 37 位來自 16 家醫院的考生,各年度人數相差不超過 3 位,四年累 計加總共有 22 家不同訓練醫院的 143 人次,但由於 2010 年有 3 位考生是重考,
因此實際上考生總數為 140 人;各年度受試者平均年齡分別從 31.6 至 32.3 歲,
分布範圍從 28 到 51 歲,男性比例分別占 63.9%至 69.4%,四年合計平均年齡 31.6 歲,男性比例為 65.7%,關於年齡和男女比例等各年度考生基本資料的變異,透 過 ANOVA 及 Chi-square 檢定的 p 值分別為 0.87 及 0.96,皆未達統計上顯著差 別,但其平均原始成績總分卻從 2008 年最高的 78.7 分到 2009 年最低的 60.3,
ANOVA 檢定的 p 值<0.001,若根據考生基本資料假設其平均能力差異不大,則 其平均分數可能來自試題的難易度,詳細資料如表 IV-1。
IV.2 非線性混合迴歸模式與聯合最大概似估計法比較
IV.2.1 試題難度參數估計值與標準誤差
首先我們以非線性混合迴歸模式,對於 2008 年試題難度參數的估計值與標 準誤差,以及透過最大概似法所得到結果的比較,在此估計過程中將將參數估計 值平均設為 0,因此我們將非線性混合迴歸模式中代表考生能力的隨機效應平均 值設定為最大概似法所估計得到的 1.71,以便兩者比較;將前十題的難度估計值 由大到小排列如表 IV-2,結果可發現雖然計算方式不同,兩者對於試題參數的排 序均完全相同(Spearman 排序相關係數 ρ=1),除了其中所有考生均答對的第一題 估計值(𝛽̂)呈現明顯不同外,其餘題目差異均小於 0.1,雖然差距隨估計值有些1 微增加,另外標準差也幾乎一樣。由於考生全對或全錯的題目對於模式中的參數
28
估計無法提供訊息,因此去除後應不影響對於試題難度與考生能力相對差距的分 析。
表 IV-3 為去除 2008 年 11 題全對題目,前 9 項題目難度估計值比較結果,
兩者除了排序相同之外,相較於最大概似法而言,非線性混合模式所得到的估計 值分布有往平均值集中的趨勢,對於難度在兩端的題目相差的絕對值較大,但整 體而言並未有顯著差異,其他年度的分析結果也呈現類似情形,沒有另外列出。
IV.2.2 考生能力參數估計值與標準誤差
表 IV-4 呈現 2008 年兩種統計方式對於編號 7 至 11 號的五位考生能力估計 值比較,透過由大到小依序排列,可發現非線性混合模式所得到的估計值,有類 似表 4.3 所觀察到,往平均值集中的趨勢,另外,其對於考生能力估計值的標準 誤差,相較於最大概似法來得小,可能由於非線性混合模式在估計受試者參數的 過程中,是利用指定參數屬於常態分布的方式,因此得到的估計值較為集中。
IV.2.3 預測值與觀察值比較
表 IV-5 利用表 IV-2 所得到的試題估計值中,其難易度分別落在不同範圍的 6 項題目,透過兩種模式所預測被所有受試者答對的機率,以及實際觀察結果的 比較,例如要預測第 9 題所被答對的機率,就是代入所有考生平均能力參數 1.71 與該題難度參數 2.62 得到 29% ( = 𝑒(1.71−2.62)
1+𝑒(1.71−2.62)× 100%),同理其他 5 題的難度參
數都小於考生平均能力,因此預測答對的機率均大於 50%,從比較結果中發現在 不同難度的試題中,兩種模式所得到的預測值都和觀察值相差不超過 2%,均可 得到很好的預測效果。
表 IV-6 比較表 IV-4 中的五位考生對於所有試題平均答對機率預測值與觀察 值,其中能力最高的 8 號考生其參數估計值為 2.55,代入平均試題難度參數 0