第二章 文獻探討
回顧國內外對於 SCP 問題的研究已經行之有年,由於 SCP 問題屬於 NP-hard,
因此對於問題大小較大的問題無法在合理的時間內求得最佳解。近年來,有關於SCP 的演算法概略可分為以下三種[12]:(1)線性規劃(Linear programming,LP)與相 關的鬆弛法(relaxation)、(2)啟發式演算法(Heuristic algorithm)、(3)最佳精 確演算法(Exact algorithm)。
現今有效率的最佳精確演算法大多基於分支界定法(Branch-and-Bound),如Balas 和Ho[1],Beasley [4],Fisher 和 Kedia [16],Beasley 和 Jörnsten [7],Nobili 和 Sassano [13],以及 Balas 和 Carrera [3]。其藉由求解 SCP 的 LP relaxation 的下限(lower bound)
來幫助搜尋,當問題大小較大時,所需的搜尋時間與空間非常大,若欲在合理可接受 的執行時間內得解,此法只適用於數百列與數千行以內的SCP 問題上。
為了有效率的求解,許多的研究者轉而使用各式的啟發式演算法來幫助解決SCP 問題。一般而言,啟發式演算法(Heuristic Algorithm)可分為兩大類:建構式啟發式演 算法(Constructive Algorithm)與改善式啟發式演算法(Improving Algorithm)。前者常見 的為貪婪法(Greedy Method)。後者常見的有禁制搜尋法(Tabu Search)、模擬退火法 (Simulated Annealing)、基因演算法(Genetic Algorithms)、拉格蘭茲啟發式演算法 (Lagrangian Heuristic Algorithms)等。貪婪式演算法在實際應用上執行時間非常短,但 通常都無法提供非常好的解,例如:Balas 和 Ho [1]以及 Balas 和 Carrera[3]。拉格蘭 茲啟發式演算法便是近年來用來求解SCP 的最有效率方法之一,相關的研究有 Balas 和Ho[1],由 Beasley[5]提出的改進方法,Fisher 和 Kedia [16],Balas 和 Carrera [3],
以及 Ceria,Nobili 和 Sassano[13]。拉格蘭茲啟發式演算法使用拉格蘭茲鬆弛法 (Lagrangian relaxation)與次梯度最佳化(subgradient optimization)並配合啟發式演算法 (heuristics) 來求解 SCP。Lorena 和 Lopes[20]提出一個基於 surrogate relaxation 的類似 方法來求解SCP。Wedelin [24]提出一個對於整數規劃具有 0-1 限制矩陣的一般化的 啟發式演算法來求解SCP。最近,Beasley 和 Chu [8]提出一有效率的基因演算法來求
解 SCP。啟發式演算法可以在短時間內求得 SCP 的近似解,但缺點是無法保證所得 之解為最佳解。
以下,我們分別對貪婪法、基因演算法、拉格蘭茲法以及二階段最佳化演算法如 何用來求解SCP 做詳細的介紹。
第一節 貪婪法
使用貪婪法解決SCP 之演算法如圖 2.1.1 所示。在一開始,U 為還未被覆蓋的列
(元素)所成的集合,初始U 為包含所有列的集合,此時 SCP 的解 S 是空的。然後 每次在所有的行中選擇一個相對選擇成本最低的行(集合)Jj (其cj UIβj 最小),
將Jj加入解 S 中並更新 U,重複上述動作直到所有的列都被覆蓋為止(U={}),這時 我們所得到解S 就是我們利用貪婪法所求得的一個可行解。然而使用貪婪法所得到的 解S 通常包含了一些冗餘行,也就是解 S 去掉這些冗餘行依舊是一個 SCP 可行解。
圖2.1.1 SCP 之貪婪演算法
以圖 2.1.2(a)的例子來說,目的在於選取部分集合能夠涵蓋所有的元素,而所選 Greedy_SCP( I, J ){
1. S={};//solution
2. U = I; //U is a set of the rows that cannot be covered by S 3. While U≠{} {
4. Choose a column Jj with minimal score cj UIβj ,Jj∉S;
5. S=S+{Jj}; //add Jj into S
6. U=U-βj; //remove the rows that Jj could cover from U 7. }
8. Return S }
素貢獻選擇成本函數來計算Jj的分數σ{Jj}=cj /U∩βj 來幫助求解,其中U∩βj 為 能夠被 Jj涵蓋而未被目前之部分解 S 所涵蓋的元素數,cj/U ∩βj 表示若是要用 Jj
來涵蓋可被Jj涵蓋而未被目前之部分解S 所涵蓋的元素的話,這些元素平均每個會增 加多少的總選擇成本。當U ∩βj 為0 時,表示 Jj並無法增加覆蓋的元素數量,我們 便假設Jj的分數σ{j}為無限大,因此我們便不會去選擇 Jj。在一開始我們的解為空集 合,所有的元素都未被覆蓋U={1,2,3,4,5,6,7,8,9,10,11,12},J1的選擇成本c1為1,可 被J1涵蓋而未被目前之部分解S 所涵蓋的元素數量為6,因此 J1的分數σ{J1}=1/6。
此時所有集合的分數為 σ{J1,J2,J3,J4,J5,J6}={1/6,1/4,1/4,1/5,1/4,1/2}。由於我們要使總 選擇成本最小,所以我們選分數最小的集合J1加入解S 中,我們可以由圖 2.1.3(a)看 出元素{1,2,3,4,5,6}已經被目前之部分解 S 所涵蓋(灰色的列),這個時候 U=
{7,8,9,10,11,12}。步驟 2:我們再來計算 σ{J2,J3,J4,J5,J6}={1/2,1/2,1/3,1/2,1/2},1/3 是 所有分數中最小的,所以我們選J4加入S 中,由圖 2.1.3(b)看出元素{1,2,3,4,5,6,7,8,11}
已經被涵蓋,此時U={9,10,12}。步驟 3:再計算 σ{J2,J3,J5,J6}={1/1,1/1,1/2,1/1},選 分數最低之 J5 加入 S 中,由圖 2.1.3(c)可知 U={10}。步驟 4:計算 σ{J2,J3,J6}=
{1/0,1/1,1/1},J3與J6的分數相同,此時任意選一集合,假設選到 J3加入 S 中。這個 時候,所有的元素都被S 涵蓋了且 U={},因此 S={J1,J3,J4,J5}成為了一個可行解,
這個解S 並不是此例之最佳解,此例之最佳解為{J3,J4,J5}。
1 ● ●
2 ● ●
3 ● ●
4 ● ●
5 ● ● ●
6 ● ● ●
7 ● ●
8 ● ●
9 ● ●
10 ● ●
11 ● ●
12 ●
J4 J5 J6 集合
元素 J1 J2 J3
(a) (b)
圖2.1.2 (a)一個簡單的 SCP 例子 (b)0-1 矩陣表示法
1 ●
2 ●
3 ●
4 ●
5 ● ●
6 ● ●
7 ● ●
8 ● ●
9 ● ●
10 ● ●
11 ● ●
12 ●
集合
元素 J2 J3 J4 J5 J6
1 ●
2
3 ●
4 ●
5 ●
6 ● ●
7 ●
8 ●
9 ● ●
10 ● ●
11 ●
12 ●
J6 集合
元素 J2 J3 J5
1 ●
2 3
4 ●
5 ●
6 ●
7 ●
8 ●
9 ●
10 ● ●
11 ●
12 集合
元素 J2 J3 J6
(a) (b) (c) 圖2.1.3 圖 2.1.2 中 SCP 例子之求解過程中,元素被涵蓋的情形
(a) 步驟 1 (b)步驟 2 (c)步驟 3
第二節 基因演算法
John Von Neumann 在 1960 年代提出一個自我複製(self-producting)的理論,
John-Holland 延續其觀念並加入達爾文之「物競天擇」與「適者生存,不適者淘汰」
的演化理論,在1970 年代發展出簡單基因演算法(simple genetic algorithm, SGA), 為 現今基因演算法之基本雛形。
基因演算法在搜尋時同時考慮搜尋空間中的多個點,能夠有效率的得到近似最佳 解,同時藉由其系統化的突變機制能夠有效的避免在搜尋中陷入局部最佳的情況,提 高找到最佳解的機會。在基因演算法之演化過程中依循著物競天擇與適者生存的定 律,族群中較為適應環境的個體具有較高的生存以及繁衍機率,較不適應環境的個體 則容易被淘汰。這表示在下一世代中,較適應環境個體的基因將會以存在於自己以及 所繁衍的後代中的方式,越來越散佈在族群中。依照此方式,族群中的個體在經過代 代繁衍過程之後,較適應環境個體的基因片段將會廣布於族群之中,使得整個族群越 來越適應環境。
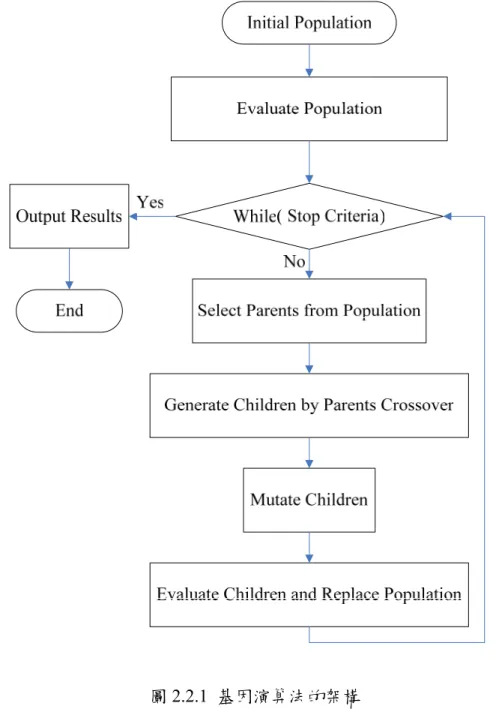
基 因 演 算 法 在 一 開 始 會 產 生 一 包 含 許 多 個 體(individual) 的 初 始 族 群 (initial population),並對此族群中的個體施以基因操作來模擬繁衍(crossover)、基因突變 (mutation)以及物競天擇(selection and replacement)等生物過程。所要解的問題中的一 個可能解答在經過適當的編碼(coding)之後成為族群中的一個個體,我們根據所欲達 到的目標設計一個適應函數(fitness function),來給予族群中的每一個個體一個適應性 評估值,藉以代表該個體在環境中的適應程度,也就是一個個體所表示的解滿足所欲 求解問題的程度。具有較高適應度的那些個體,有較高的機會與其它高適應度的個體 交換基因片段來繁衍後代。繁衍(crossover)是由族群中挑選兩個個體,藉由基因片段 的交換來產生後代,因此新產生的後代個體(新解)會具有其父母的某些特性。突變常 在繁衍之後用來改變個體中的一些基因,藉以在搜尋時提供一隨機搜尋(random search)以跳脫局部最佳的機制。經由繁衍所產生的後代,可以完全取代原來的族群(一 代取代一代法, generational replacement),或者只取代較不適應環境的個體(穩定狀
態取代法, steady-state replacement)。經由不斷重複這個評估適應性-選擇-繁衍的 過程,我們能得到越來越好的解答。基因演算法的基本架構如圖2.2.1 所示:
圖2.2.1 基因演算法的架構
Beasley 和 Chu 在[8]中提出了一個用來解決 SCP 問題的基因演算法(BeCh GA),
其如圖2.2.2 所示。
圖2.2.2 BeCh GA 之演算法
在此,一個體之適應函數值為該個體所形成之解的總成本,由於我們的目的在於 尋找最小成本的解,因此在最後的族群中適應函數值最小者,即為我們所要找的最佳 解了。
BeCh GA 法最重要的就是其設計一種適性的融合交換法(fusion crossover)作為 交配運算子,以及變動式的突變程序。融合交換法是改變自常用的均勻交換法
(uniform crossover),雖然一樣都是以一對父母只產生一個子代,但均勻交換法中 子代的任一基因來自父或母的機率是均等的,而融合交換法任一基因的機率是與其父 母的分數成反比,也就是有較高的機率來自父母中較好的解(分數較低者)。讓 fp1與fp2
分別為父母P1、P2的適應函數值,P1[i]與 P2[i]分別為父母 P1、P2第i 個基因值,其子 代C 的第 i 個基因 C[i], i=1,…, n 產生之規則如下:
BeCh_GA(SCP, M){
1. Selite =Uim=1αi,5 ; // elite set
2. Generate N solutions as the initial population randomly, t=0;// t records the number of solutions generated by GA crossover operator.
3. Do_untill(t=M){
4. Choose two individual P1 and P2 from the population using binary tournament selection;
5. Combine P1 and P2 to form a solution C using fusion crossover operator;
6. Mutate k (determined by variable mutation schedule) randomly selected columns in C;
7. Apply a heuristic operator to make C feasible and remove redundant columns in C;
8. If(C is not identical to any one of the solutions in the population){
9. t=t+1;
10. Replace a randomly chosen individual with steady-state replacement by C;
11. } 12. }
13. Output the best solution which is the individual in the population with the lowest cost;
}
(i) 若 P1[i]=P2[i],則 C[i]=P1[i]
(ii) 若 P1[i] ≠ P2[i],則
(a) 有p= fp2/( fp1+ fp2)的機率使得 C[i]=P1[i]
(b) 有 1-p 的機率使得 C[i]=P2[i]
交配運算子好壞的判別標準可以由所產生的子代產生的重複率來比較,依實驗數 據來看,融合交換法優於單點交換法(圖 3.4.1)與兩點交換法(圖 3.4.2),但稍劣於均勻 交換法(圖 3.4.3)。
另外,BeCh GA 法設計了一個不與原始的 GA 一樣使用固定突變率的變動式突 變率,其突變基因數依GA 的收斂情形而改變。其理由在於一開始交配程序主要在於 搜尋產生不錯的解,此時突變率小可以避免打亂尋找好的解。當基因演算法所得的解 漸趨收斂,光靠 crossover 已經不能夠有效的產生好的解時,表示此時可能陷入了局 部最佳的情形,就需要突變的機制來幫助其跳脫局部最佳解的窘境。BeCh GA 法之 突變基因數
Mutate_gene_number
⎥⎥
⎥
⎤
⎢⎢
⎢
⎡
−
−
= +
) / ) ( 4 exp(
1 g c f
f
m m t m
m (式 2.1)
其中 t 為已產生的子代數目,mf為最終穩定的突變率,mc為當突變率為 mf/2 時所產 生的子代數目,mg為t=mc時的梯度。由圖2.2.3 可以清楚的看出,突變的基因數在一 開始為0,當 GA 所得到最好的解漸趨收斂時,突變的基因數開始上升到所設定的數 目為止,以免突變的基因數過多反而影響產生好的解。關於BeCh GA 法中突變的參 數,都是經由實驗觀察對於一SCP 問題的收斂過程而設定的。其中 mc為先使用沒有 突變運算子的 GA 先求解一次該 SCP 問題,藉由觀察所得到的解大約在產生多少子 代之後漸趨收斂,將mc的值設為漸趨收斂時所產生的子代個數,在圖2.2.3 中 mc的 值大約等於80。經由實驗觀察,在”OR-Library”中的各類問題的收斂速度大多相同,
圖2.2.3 GA 收斂與突變率的關係
第三節 拉格蘭茲法
Caprara, Fischetti 和 Toth[11]所提出之 CFT 演算法為目前用來解決 SCP 問題中最 有效率的演算法之一,其使用的方法是基於二元資訊(dual information)結合模型(式 1.1)-(式 1.3)的 Lagrangian relaxation。對於所有 Lagrangian multiplier 的向量u∈R+m結 合限制式(式 1.2),Lagrangian subproblem 可以寫成:
∑ ∑
∈ ∈
+
=
J
j i I
i j
j u x u
c u
L( ) min ( ) (式 2.2)
Subject to } 1 , 0
∈{
xj , j∈ (式 2.3) J 其中cj(u)=cj −∑i∈βjui 是對於行 j∈ 的 Lagrangian cost。很明顯的,(式 2.2)-(式 2.3)J 的最佳解可由下列規則得到:若 cj(u)<0 則 xj(u)=1,cj(u)>0 則 xj(u)=0,cj(u)=0 則 xj(u)={0,1}。(式 2.2)-(式 2.3)的 Lagrangian dual problem 由尋找一個 Lagrangian multiplier vector u*∈Rm所組成,而此u*會使下限(Lower bound, L(u))最大化。然而求
產生子代個數
GA 之收斂情形 突變基因數×10
平均適應函數值與突變基因數
解(式 2.2)-(式 2.3)相當於要求解max{∑i∈Mui :∑i∈Ijui ≤cj,ui ≥0,j∈J, i∈βj},亦 為對於此Lagrangian 問題的一個最佳解[15]。換句話說,藉由解一個線性規劃來計算 一個最佳乘數向量(multiplier vector)對於大問題來說是相當耗時的。因此通常會使用 相對應於所給的 u 得到的子梯度向量s(u)∈Rm在短時間內來尋找接近最佳乘數向 量,s(u)定義為:
. ,
) ( 1
)
(u x u i M
s
j i
j
i = −∑ ∈
∈
α
(式 2.4)
此方法會產生一連串的非負Lagrangian 乘數向量 u0, u1,….,u0為任意定義的。至於對 於k≧1 的 uk的定義,一個可能的選擇[17]使用下列的簡單更新公式:
I i for u
s u L u UB
u k
k k
i k
i+ = + − ,0} ∈
) (
) max{ ( 2
1 λ , (式 2.5)
其中UB 是此 SCP 目前所求得解的上限;λ 是預先給定的 Lagrangian 法在每次更新乘 數向量u 時調整量的倍率,用來控制 u 之改變量的大小。
對於接近最佳拉格蘭茲乘數向量 ui,拉格蘭茲成本 cj(u)對於選擇行 j 所的整體 效用提供可靠的資訊。基於這個特性,[11]使用拉格蘭茲成本對每個j∈J 來計算一個 分數σj,根據他們在最佳解中的可能性來對這些行來做排序。這些分數會被輸入一 個啟發式的程序中,該程序使用貪婪的方式找到一個有希望是個好的SCP 解。
第四節 二階段最佳化演算法
在最近的研究中,本人的指導教授林順喜博士與陳善泰學長提出了一新穎之近似
尋找可能的部分解;而exploitation階段是要選擇一個方法讓一個部分解成為最好的完 整解。此演算法有兩個參數需要設定,一個是分支係數k,一個是探索深度係數d,利 用此二參數決定TPOA之搜尋樹的探索搜尋空間。
TPOA 之搜尋樹的架構可以分為兩種(圖 2.4.1),TPOA+(k,d)樹的分支係數為常 數,而TPOA*(k,d)樹的分支係數則層層遞減。由圖 2.4.1(a)中我們可以看出 TPOA+(k,d) 樹所探索解的個數為kd個;而 TPOA*(k,d)樹因為採用了模擬退火的觀念,其探索解 的個數為kd×d!/dd,遠比kd還要小。假設TPOA 樹的樹高為h,TPOA+(k,d)所探索的 節點數為O(kd ×(h−d))=O(h),即在給定 k 跟 d 的情況下,TPOA+(k,d)所需的搜尋 時間只與樹高(問題大小)h 有關且為線性關係,並且可以獲得不錯的結果;此外 TPOA*(k,d)之探索節點數也可以在線性時間完成。因此這兩種 TPOA 樹的架構,皆 較一般的展開樹之以指數成長的探索節點數小的多。
接下來的問題就是如何依照現有的部分解來選擇k 個可能的下一個元素,這個問 題可以用有效率的分群方法來解決。TPOA 使用了雜湊碰撞群(hashing collision group, HCG)的概念,將可能會造成相同的解的元素放在同一群中,也就是 hashing 值相同的 元素會被歸在同一群中。由圖 2.4.2 可以看出 HCG 和等價類別之間在搜尋空間中的 關係,HCG 的重要特性包括了:
z 對於在相同 HCG 中的兩個元素,他們非常可能是等價的。而兩個等價的元 素,他們一定在同一個HCG 之中。
z 給定一個雜湊函數,它能有效率的得到 k 個最好的 HCGs。
z 在不失一般性的情況下,在一個 HCG 中的任一個元素可代表該 HCG。
k
k k
Exploration Phase
Exploitation Phase d
h-d
k
Exploration Phase
Exploitation Phase
d
h-d
⎣k(d−1)/d⎦
⎣k /d⎦
⎣k(d−1)/d⎦
⎣k /d⎦
(a) (b)
圖2.4.1 TPOA 的兩種不同搜尋架構:(a) TPOA+(k,d)樹 (b) TPOA*(k,d)樹
圖2.4.2 雜湊碰撞群之示意圖
一個SCP 問題,包含了一有限元素集合I,一個 J={J1,…Jn},其中 Jj為I 中元素 之子集合,I 中的所有元素都至少在 J 中的一個集合中出現。在這裡假設 J 中的每一 個集合的成本都相同,我們的目的就是要由J 中找出一些集合可以涵蓋所有 I 中的元
函數值之集合會被歸類在同一HCG 中,U 為由目前所得之部分解所無法覆蓋的元素 所成的集合。每次選擇雜湊函數值最小的集合加入目前的部分解中,直到所有的元素 都被解中的集合所覆蓋為止。由圖2.4.3(b)可求得最小成本涵蓋子集為{J3,J4,J5}。
在圖2.4.3(b)中,我們用*標在一集合上,用以表示該集合所在的 HCG 含有數個 集合,而以該集合代表其所在之 HCG。舉例來說,在第一階段選擇 J4之後,J1和 J5
的分數均為1/4,在此時我們選擇 J1*
用來代表其所在的HCG。
在這個簡單的例子中,我們可以看到 TPOA+(2,2)在只搜尋四個解的情況下就找 到了最佳解,這是只使用一般的貪婪法所難以達到的結果。
(a) (b)
圖2.4.3 (a)一個簡單 SCP 例子 (b)TPOA+(2,2)找到此例子的一個最佳解{J3,J4,J5}