國立臺灣大學理學院心理學研究所 博士論文
Graduate Institute of Psychology College of Science
National Taiwan University Doctoral Dissertation
診斷式的適讀性評估系統:
以小學文本探討四種模式的比較研究
Readability Diagnosis System: A Comparative Study of Four Models on Elementary School Textbook
曾昱翔 Yu-Hsiang Tseng
指導教授:胡志偉 博士 Advisor: Chih-Wei Hue, Ph.D.
中華民國 108 年 1 月
January 2019
致謝
「這是最好的時代,也是最壞的時代。」這句話應非評價,而是在講二 元,談對比;凸顯矛盾和掙扎,期待迸發的創意和擘畫可能是憧憬也可能是理 想的未來。
時間是寫作論文時最大的感觸。直觀上,時間永遠是研究過程中的稀缺資 源。撰寫論文時,一邊看著自己研究室桌上用鉛筆草擬的時間表,一邊掐算著 自己剩餘的時間。蒐集資料時,同時寄望著電子郵件的魚雁往返,又忖量著資 料蒐集時程。論文中牽涉的模型開發,我總想著有幾組模型需要嘗試,每組模 型約需要幾個小時。研究的過程,就是在跟時間打交道的過程。
時間不僅體現在各種具體的作業上,也在論文寫作本身。此處的時間無疑 是被抽象化的-論文陳述是根據文獻、實驗結果、實徵資料,有系統性地推出 結論。所有的作品、實驗程序,縱使有時態,在書寫時還是把所有發生的事情 凝結在時空中的一點,好像它們是如此地純粹必然。當它們發生之後,就像是 時間流裡的結晶,在剎那間被拍下最美的瞬間,於是淬鍊成時空中的翡翠,完 美地靜態呈現在幾萬字的文字晶格。
時間的痕跡也是形而上的。就如同心理學與語言學中,不斷反省著語言與 認知之間的關係,我好奇的是時間和語言的關係。在符號學三角形中,語言、
符號、指涉物的關係彼此密不可分,如果人們承認時間是這世界的一部份,很 難想像語言與概念要如何獨立於時間之外。語言心理學在這個脈絡下是特別 的,它處在語言與人類認知系統之間,它應該要有「時間感」。
我妄想探索這份「時間感」,卻花了很多時間。我在博士班的頭幾年在一系 列神經造影的研究計畫中,試圖從底層視覺尋找靈感。感謝當時的計畫主持人 陳建中教授和蔡紫薰醫師給我很重要的學習機會。底層視覺理論與方法的成
功,總是給我很大的希望。
在博士班期間,我有幸參與諸多重要的研究計畫,培養許多日後進行論文 研究的養分。在研究團隊中,有一位最重要的老師,也是這份論文的口試委員 呂菁菁老師。呂老師指引我一起完成很多研究工作、更拜訪世界各地。感謝呂 老師在那段時間以及最後論文階段中給予的莫大支持、協助、信任和鼓勵。
在博士班的最後幾年,我很高興參與謝舒凱老師的實驗室。感謝LOPERs 們在最後這段時期的支持鼓勵,他們讓我感受到語言研究的活力與生命力。更 感謝謝老師在計算語言學上給我的諸多指導和靈感,並擔任我的口試委員。更 重要的,是讓我相信我在意的並非完全孑然於世。
感謝我的口試委員宋曜廷教授,在每日繁忙公務纏身之餘,特地撥空指導 我的計畫書和論文。宋老師在適讀性研究上的專業學養和觀點,幫助我有更清 楚的研究方向,讓這份論文的內容更完整豐富。
感謝我的口試委員許聞廉研究員,在口試時提出很多深富經驗與智慧的評 語。許研究員的意見讓我感受到語言處理的深與廣,以及各種研究取向總有不 足之處。我作為後輩的研究者總是需在巨人肩上,才能找到前進的方向。
感謝我的指導教授,胡志偉老師。從大學部到博士班畢業,無數次的概念 發想、研究方向、設計、文章修改、報告呈現,過程中老師的學術素養令我深 感欽佩,更是感謝老師對我總是耐心且包容。如果大學時的我和現在相比,真 的有多那麼一點點學術色彩,那完全是老師的功勞。
感謝我的父母,我從碩士班到博士班一路走了十多年,若不是父母的相 信、尊重與支持,這一步是不可能的。也感謝我的新家人思瑩,同樣都在博士 生的道路上,她總是我不變的支持來源。
最後,感謝過去每個時刻的自己,以及那些存在與不存在的時間。在之 中,我多看到了些什麼,也多學到了些什麼。謹此誌謝,給未來的自己。
摘要
適讀性研究試圖透過分析文本的文字安排,以建立讀者閱讀時,文本易理 解程度的預測模式。有研究者根據適讀性模式納入的文本屬性,以及模式建構 的方式,將此類研究的發展分為三個時期。不同時期的研究在建構適讀性模式 時深受「計算預測」和「認知解釋」等兩種考量的影響。在早期的傳統公式 期,研究者希望從文本中找出一些屬性,然後以不同方法(如統計迴歸法)根 據這些屬性,建構預測文本適讀性的模型。受到文本分析工具的限制,這時期 納入適讀性模式的多是方便計算的文本表層屬性(如,文章中的難詞比例、文 句的長度等)。隨著認知心理學不斷深化研究者對於人類閱讀的了解,以及電腦 作為文本分析工具的出現,適讀性研究者參考閱讀理解的認知研究成果,在適 讀性模式中納入一些可能影響閱讀理解歷程的文本屬性;這個階段被稱做認知 理論期。當文本適讀性模式牽涉的文本屬性愈來愈多,且複雜時,一些比統計 迴歸模式更有效率的文本適讀性計算方式受到了研究者的重視;這個階段可被 稱做統計語言模式期。因為一些適讀性模式的計算複雜度超出一般使用者的理 解範疇,有研究者提出,這可能會影響他們接受適讀性預測模式的意願。本研 究的目的如下:(1)根據建構適讀性模式時,輸入資料的來源是否與適讀性文 獻相關(本文稱之輸入透明度),以及適讀性模式之參數透明度,區分出四種建 構適讀性模式的取徑。其中,低輸入透明度/高參數透明度的模式是一種新的文 本適讀性的預測取徑。本研究將實際建構這四種模式,並比較它們對文本適讀 性預測的有效性。(2)研究顯示,句法複雜度會影響讀者的文章閱讀,但因為 這個屬性不易被量化,所以之前的文本適讀性模式均未納入能直接反應句法複 雜度的屬性。本研究根據小學課本中的文本,建構各種語式的出現頻率常模,
然後據以找出兩個能反應句法複雜度的屬性,並探討能否將它們納入適讀性模
式中。(3)本研究針對一群現任小學教師,進行問卷調查及訪談,收集他們對 幾種適讀性模式之建構取向的看法。(4)本研究開發了一套診斷式適讀性系 統;該系統除了預測文本的適讀性外,還能為使用者提示哪些文本屬性影響文 本的適讀性。本研究亦透過問卷調查與訪談結果瞭解國小教師對此系統的看 法,調查結果顯示此系統可幫助教師理解及改變文章困難之處。
關鍵字:適讀性、文本屬性、輸入透明度、參數透明度、文本分析、
診斷式系統
Readability Diagnosis System: A Comparative Study of Four Models on Elementary School Textbook
Yu-Hsiang Tseng Abstract
Reading is an essential process through which people learn and communicate. In order to predict how comprehensible texts were for readers, readability studies identified text properties and build predicting models. Three genres of studies were differentiated in literatures basing on their text properties considered and modeling methods. In the genre of traditional methods, researchers used easily available text properties (e.g. percentage of difficult words, sentence length, etc.), and used models such as linear regression to predict readability. In the genre of cognitive science- inspired methods, readability studies started to incorporate theories from cognitive science and include more text properties relating to reading comprehension. Some of these properties could be extracted by computerized automatic text analysis tools. As models involved more and more properties, genre of statistical language modeling methods emerged. Researchers employed more elaborate models to predict
readability. However, other researchers argued these elaborate models were not easily understandable by average users, and therefore affected how users would adopt the predictions.
Purposes of current study were as follows: (1) four modeling approaches were differentiated by input transparency, which based on the relationship between model’s input data and readability literatures, and parameter transparency. Among them, a new modeling approach (i.e. the one with topic modeling) of low input and high parameter transparency was attempted to predict readability of text. This study implemented four
models and compared their performances on predicting readability. (2) Literatures showed that text properties related to syntactic complexities affected reading comprehension, but these properties are not easily computable and thus few
readability models directly incorporated them. This study built a frequency norm of phrasal patterns, based on which text properties were extracted to reflect syntactic complexities of phrases. These properties were then tested if they improved readability models. (3) In a survey study, we interviewed teachers in elementary schools, and collected their opinions on how willingly they were to adopt predicitons made by different readability modeling approaches. (4) A readability diagnosis system was developed. The system not only predicted readability but provided extra
information on the properties affecting readability. Survey studies on teachers showed the diagnosis system could help them understand text properties and edit text.
Keywords: readability, text properties, input transparency,
parameter transparency, text analysis, diagnosis system
目次
第一章 前言... 1
第一節 早期適讀性研究... 4
第二節 認知心理學取向的適讀性研究... 12
第三節 文本特徵與自然語言處理... 29
第四節 診斷式的適讀性系統... 39
第二章 研究一、文本屬性分析... 55
第一節 文本屬性的抽取與分析... 55
第二節 文本屬性與適讀年級迴歸分析... 68
第三章 研究二、四種取向建構之適讀性模式 的開發與比較... 77
第一節 研究方法... 77
第二節 結果與討論... 84
第四章 研究三、四種不同模式信任度比較... 95
第一節 研究方法... 95
第二節 結果與討論... 97
第五章 研究四、建立適讀性的診斷系統... 99
第一節 系統架構... 100
第二節 系統功能... 101
第三節 文本診斷與編輯... 106
第六章 研究五、評估診斷系統... 109
第一節 研究方法... 109
第二節 結果與討論... 111
第七章 綜合討論... 113
第八章 參考資料... 119
第九章 附錄... 135
第一節 語式常模... 135
第二節 文本屬性列表... 141
第三節 文本屬性與年級常模... 143
第四節 文本屬性的迴歸分析表... 147
表圖目次
表2.1 各模式在各文本類型中之迴歸分析結果 ... 73
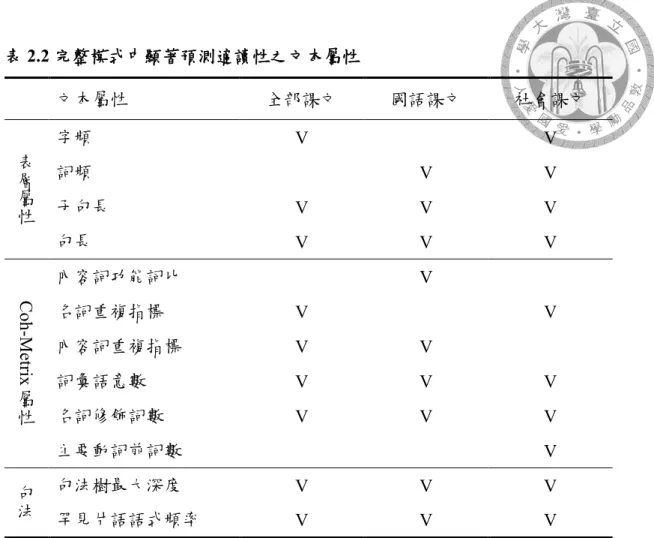
表2.2 完整模式中顯著預測適讀性之文本屬性 ... 75
表3.1 四種適讀性模式 ... 77
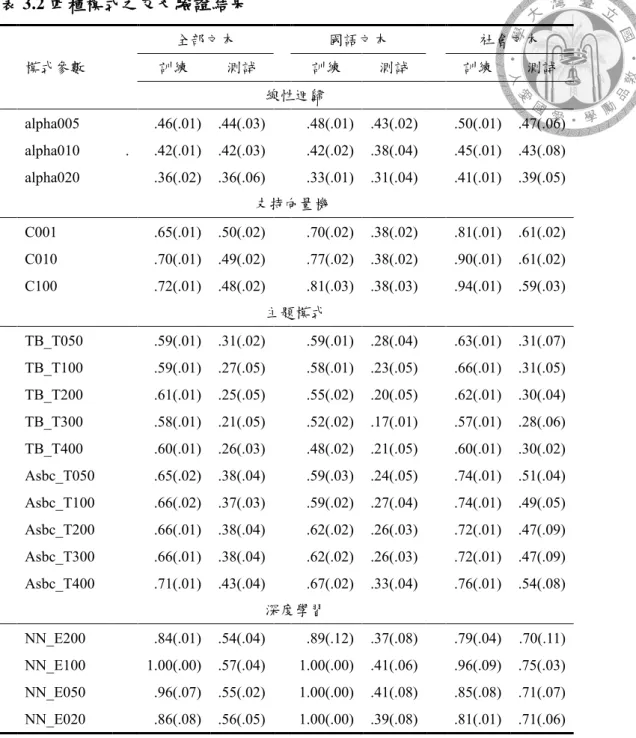
表3.2 四種模式之交叉驗證結果 ... 91
表3.3 各適讀性模式正確率 ... 92
表6.1 診斷式系統問卷之題目列表 ... 110
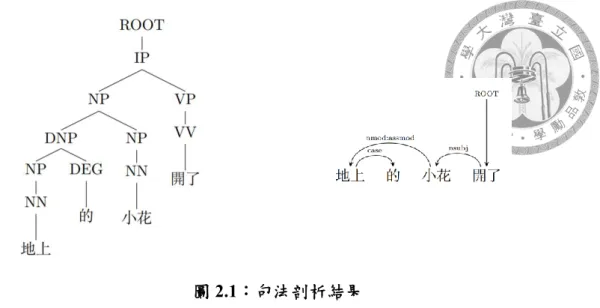
圖2.1 句法剖析結果 ... 62
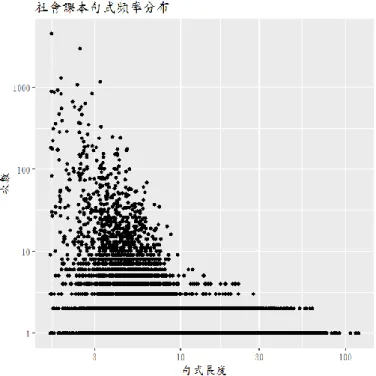
圖2.2 國語課本語式頻率與長度分布 ... 66
圖2.3 社會課本語式頻率與長度分布 ... 66
圖3.1 各模式在不同文本類型下預測之混淆矩陣 ... 92
圖3.2 各模式預測在不同文本類型下之相關矩陣 ... 93
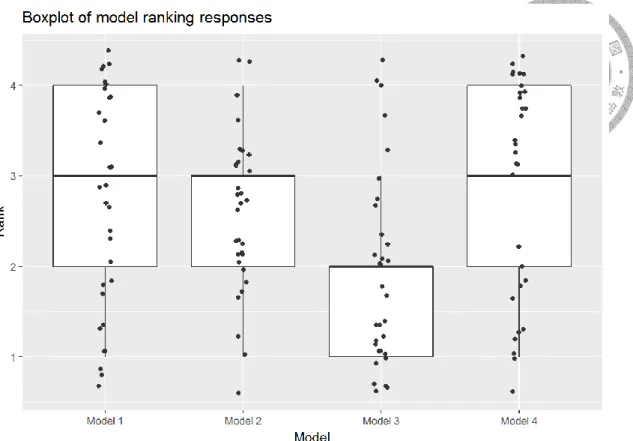
圖4.1 小學教師對四種不同模式願採用程度之排序 ... 98
圖5.1 診斷式系統架構 ... 101
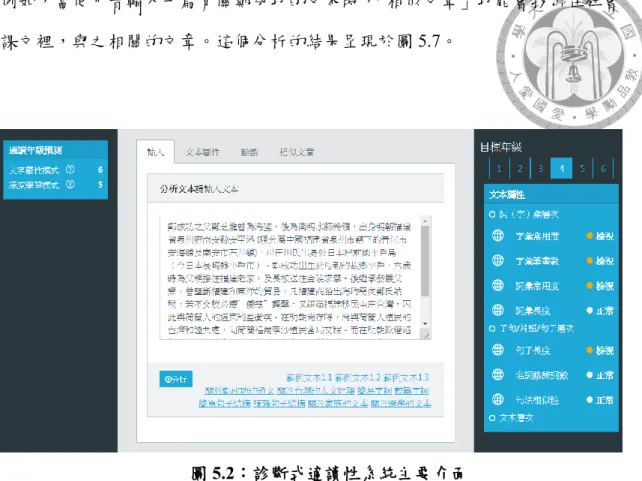
圖5.2 診斷式適讀性系統主要介面 ... 103
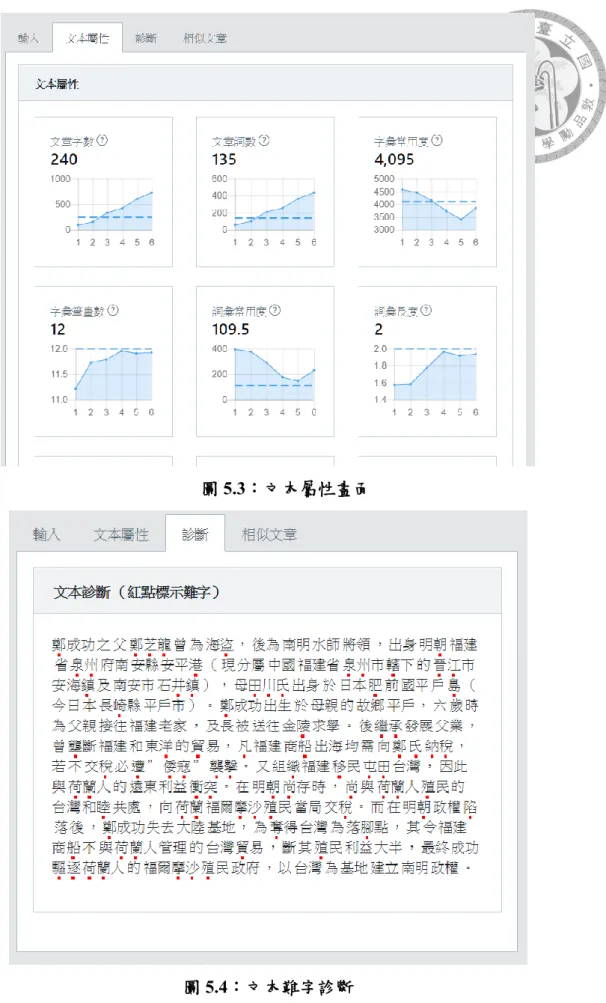
圖5.3 文本屬性畫面 ... 104
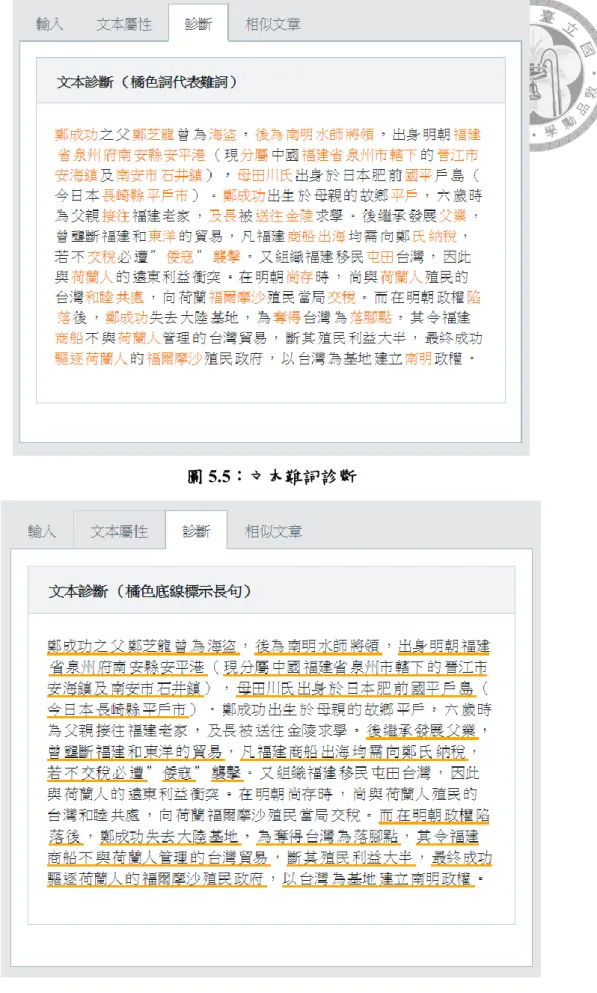
圖5.4 文本難字診斷 ... 104
圖5.5 文本難詞診斷 ... 105
圖5.6 文本難句診斷 ... 105
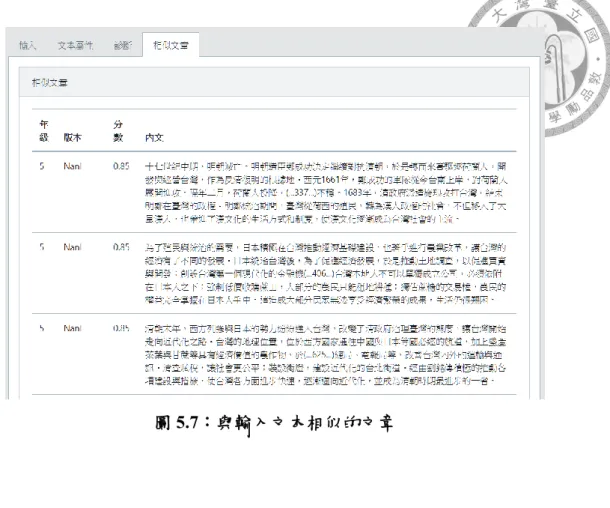
圖5.7 與輸入文本相似的文章 ... 106
圖5.8 文本診斷畫面 ... 107
第一章 前言
讀者藉由閱讀從文本中獲取其所承載訊息。透過分析文本,研究者能客觀 地理解讀者從文本中可能獲得的訊息,甚至如何獲取訊息。早在19 世紀末,一 位在大學教授英語文學的教師Sherman 就認為對文本客觀、科學地分析,有助 於學生欣賞、理解文學作品的精神,甚至更能讓學生具體的欣賞、批判文學作 品。在他的著作中,他區分出文學作品中的各個元素,例如每個小節(stanza)
的用字數、詞彙在朗誦時的力度等等,甚至以圖表的方式呈現這些資料,讓學 生理解詩歌所傳達的精神(Sherman, 1893)。
從Thorndike(1921)在 Teachers' Word Book 一書開創對文本適讀性
(readability;下文將以適讀性稱之)的研究,以及 Lively 與 Pressey(1923)
提出第一個適讀性研究至今,已將近百年。雖然這個領域的研究者大都承襲上 述Sherman 對文本進行客觀分析的想法,並用類似 Thorndike 根據文本的屬性 推算適讀性,但Benjamin(2012)還是根據適讀性模式的建構方法,以及模式 所用之文本屬性1的考量,將適讀性研究分成三個時期:(1)傳統公式期、(2)
認知理論期,以及(3)統計語言模式期。也就是說,適讀性研究在「計算預 測」(傳統公式時期和統計語言模型時期的主要考量)與「認知解釋」(認知理 論時期的主要考量)兩個因素上,漸漸的改進適讀性公式的建構方式。
在傳統公式期沒有電腦輔助文本分析,所以這時期的研究者大都找一些既 能預測文章難度(適讀性),又容易取得的文本屬性。往往,這些屬性都是和文
1 本研究以文本屬性(properties)代表在文本中,以人工或電腦自動抽取出的文本相關數 值(如音節數、字頻、句長、名詞比例、句法樹深度等數值)。這些文本屬性可用在傳統統計迴 歸模式中作為迴歸變項(variables),或在其他機器學習模式(如支持向量機)中作為特徵
(features)。在本研究中,部份模式是以文本屬性作為輸入,其他模式則直接以文本詞彙作為
章內容以及語法複雜度無關的文本表層屬性(如,文本中含有的「難詞」詞 數,句子的長度等)。例如Throndike 就建立一個教師詞彙表,提供一萬個英語 詞彙在一些讀物中的使用頻率。教師能夠以此作為工具,評斷一篇文章所包含 詞彙是否適合學生閱讀。在接下來的數十年間,眾多研究以詞彙難度做基礎,
發展出許多不同的適讀性模式,來預測文本的難度或適讀年級;其中以線性迴 歸模型建立模式的方式最被學界採用。
其後,受到認知心理學思潮的影響,「認知解釋」的想法逐漸萌芽,研究者 開始探討文本的適讀性與閱讀理解歷程間的關係,並企圖從文本中挖掘更多影 響閱讀理解歷程的文本屬性,並根據這些屬性建構適讀性模式。此時期就是認 知理論期。但是,因為這些屬性(如,一篇文章中的文字和內容之間的相關 性,以及句子的句法複雜性等)不易量化,所以鮮有研究能夠將閱讀的認知研 究結果真正落實於具體的適讀性模式中。近年,也就是Benjamin 所說的統計語 言模型期,結構與非結構化資料的快速累積,機器學習演算法迅速發展,研究 者開始應用許多分類器來分類文本。例如,從一些已經被標定年級或難度的文 本中,應用監督式學習讓電腦得以預測文本的適讀性。這個取向的研究讓適讀 性模式的建構者找到更多的屬性、更有效的演算法,建構出的預測模式能更準 確預測資料集裡的文本的適讀性。
雖然學者將適讀性研究的發展分為三個時期,但這並不意味著,一個時期 的出現就取代了上一個時期。事實上,即便在認知時期的應用研究中,傳統的 適讀性公式在近年仍然是重要的研究工具。例如,在一個探討因為車禍而民眾 傷亡的研究中,就發現造成幼童傷亡的一個重要原因是父母沒有正確的在車上 安裝幼兒椅(Wagner & Girasek, 2003),而造成他們沒有正確安裝的原因可能是
「安裝手冊」撰寫的太難。研究者以適讀性公式計算安裝手冊的適讀年級,發 現其適讀性多在10 年級以上。所以研究者建議,廠商應該重新撰寫安裝手冊,
降低其適讀年級。
用適讀性公式改變文本的難度,以幫助讀者對文本的閱讀理解,一直是適 讀性研究很重要的應用目的之一。Klare(1976)就回顧了 36 個以適讀性公式 改變文本難度的研究。但是,在這些研究中,僅有19 個研究顯示適讀性公式在 改變難度上有正面幫助,另外17 個研究卻未發現正面效果。Klare 認為,那些 未能發現正面效果的研究,一部分是因為情境因素(如讀者的動機、作業設計 等),另一部份則是和研究者如何改變文章難度有關。他認為改變文章難度時,
不僅要考慮適讀性公式有用到的屬性(例如詞彙難度和句長),也應該考慮功能 詞彙的比例、詞的具體性、語式(如主動被動)、句子的複雜度等屬性。只是,
或許侷限於當時客觀條件的限制,當時的研究無法用方便有效的方式從文本中 提取出這些文本屬性,所以這類的考量難以實際落實到適讀性模式。近年來,
統計語言模式期雖提供更多更準確的適讀性預測方法,但其模式的預測方式不 能直接讓使用者瞭解文章難度,或者幫助使用者編輯文章難度。
本研究的目的即希望(1)比較幾種適讀性模式的建構取向在文本適讀性的 預測表現,也希望(2)透過實際開發一套診斷式系統,該系統除了預測文本適 讀性外,亦能指出是哪些文本屬性,影響這篇文本的適讀性。本研究期待此診 斷式系統的設計能讓使用者(如,教師)因為適讀性模式可幫助他們理解文章 難度,甚至編輯文章難度,進而提升他們接受適讀性模式之計算結果的意願。
文本適讀性研究在20 世紀初就開始蓬勃發展。為呈現適讀性研究豐富的研 究脈絡,本論文在此章第一節首先回顧1920-1960 年時期的早期適讀性研究。
其次,第二節將討論受認知心理學的閱讀研究影響的文本一致性指標。第三節 將探討自然語言處理如何幫助適讀性研究者自動地抽取文本屬性。當自然語言 處理自動地抽取出文本屬性,研究者面臨的挑戰是如何整合這些屬性並做出預 測,所以第四節將討論各種不同的預測模式之間的取向,以及這些取向如何影 響到輸入及參數透明度。
在接下來的論文中,研究者根據(一)適讀性模式的輸入資料與文本難度
(適讀性)之間的關係,區分出「輸入透明度」。例如,在適讀性文獻中指出
「文本包含低頻字的比率」該屬性是與文本難度相關的,所以使用該類屬性為 輸入資料的模式,具備較高的輸入透明度;相反地,有些模式以詞彙序列作為 模式輸入,這在傳統公式期與認知理論期的文獻中未提及,故其輸入透明度較 低。(二)根據適讀性預測模式中的參數與文本適讀的關係,區分出「參數透明 度」。例如,以迴歸模式預測適讀性時,其係數的意義是各文本屬性之線性組合 的權重,此參數與適讀性的關係是較清楚的,故其參數透明度較高。此研究按 照高(低)輸入及高(低)參數透明度,區分出四類適讀性模式的建構取向。
本研究將實際的建構出這四類的適讀性模式,然後比較它們預測文本適讀性的 準確度。
為了探討一般人對適讀性模式的看法,本研究以小學教師為對象,採用問 卷和訪談的方式收集小學教師使對上述四種適讀性模式的信任度以及他們在教 學中的實際使用文本適讀性的可能性。最後,本研究將呈現一個能整合研究結 果的診斷式適讀性系統。
第一節 早期適讀性研究
壹、適讀性公式的發展
在一篇回顧整理早期適讀性研究的文章中,Klare(1976)指出,當時的適 讀性模式的建構流程如下;(一)找出幾個語言(文本)屬性。(二)選取多篇 內容不同的文本,然後計算這些屬性與這些文本適讀性指標間的相關。文本適 讀性指標可以用學生閱讀文本後,理解測驗或記憶測驗的得分,或其它的客觀 指標。(三)選取相關最高的屬性,並根據這些屬性建構文本適讀性的模式。常 用的建構方法是運用統計迴歸法建構一條適讀性公式。(四)選取另一批文本,
驗證適讀性模式對文本適讀性指標的預測效度。
也就是說,傳統公式期的研究者認為,一篇文章的難度能夠透過幾個與文 本有關的屬性計算出來。從現在的眼光看,這些屬性都是一些文章的「表層」
特徵,如詞彙難度或句長等。例如,Fry(1977)的做法是,隨機在一篇文本中 選取一段100 字的章節,然後根據其中所含音節數及句數推算該篇文章的適讀 年級。他設計了一個由「音節數」和「句數」兩個屬性為向度的「適讀性圖」, 使用者只要按圖索驥,便可以得知一篇文章的適讀年級了(見DuBay, 2014)。
也有研究者則利用一些文本屬性為預測變項,經過線性迴歸分析,即可以一條 公式的形式,計算出一篇文章的適讀性。在當時,這種作法也引來許多批評。
因為適讀性公式只是透過文本屬性來「預測」閱讀時的難易程度,並無法「測 量」閱讀時讀者和文本之間的關係。但是,透過公式計算文本適讀性的方法,
比找教師或作者主觀認定文本的難度,適讀性公式顯然具備較高的效度,所以 這些研究的結果在當時的教育、軍事、商業等領域受到廣泛的重視與應用
(Klare, 1963)。甚至,在多年後的今天,一些適讀性公式仍普遍被用來評估兒 童讀物的適讀性,甚至一些商用的文書處理軟體裡(例如,微軟文書處理軟體 Word)會內建適讀性的公式(如,Word 即內建 Flesch 適讀性公式)。
根據Klare(1976),文章難度的客觀校標是建構適讀性模式的重要依據。
因為在模式開發期,研究者需要找到一組難易不等的文章,然後藉著分析這些 文章的文本屬性,找出哪些屬性能夠預測文章的難度。當適讀性模式建構出來 以後,研究者又需要找出另一組難易不等的文章,來檢驗適讀性模式的預測效 度。早期的適讀性研究的文章難度校標,多使用讀者在閱讀理解測驗、記憶測 驗,或是填空測驗的表現(Klare, 1974)。例如,McCall-Crabbs 標準閱讀測驗
(McCall-Crabbs Standard Test Lessons in Reading)(McCall & Crabbs, 1961)的 作法是,收集多篇文章,根據文章的行文及內容設計一些選擇題,然後請程度 不等的讀者(如不同年級的學生)閱讀文章並作答。根據讀者閱讀一篇文章
後,對測驗題目的答題表現,研究者可以推斷這篇文章適合哪個年級的學生閱 讀。例如,閱讀一篇文章後,三年級學生平均能答對一半以上的題目,這篇文 章的適讀性是三年級。也就是說,這是利用讀者在測驗題目上的表現,評估一 篇文章的難易程度;這在當時是很常用的文章難度效標。
另外,將文章設計為填充測驗(cloze test)也是一種測驗文章難度的方 法。在填空測驗中,一篇文章有某些字或詞被設定為空格(如,每5 個字/詞,
就有一個被掩蓋),讀者的作業是猜測,並填入空格中的字。為了控制被掩蓋之 字在句子中的位置對讀者答題的影響,研究者可以設計不同的填空測驗的版 本;例如,在一個「逢五刪一」的測驗中,研究者至可以設計5 個不同的版 本;版本A 將第 1、6、11…詞為空格;版本 B 為第 2、7、12 詞為空格,以此 類推。Bormuth(1969)做了一個大規模的適讀性研究。他用讀者對文章填充測 驗的表現作為文章適讀性的客觀效標。在研究中,Bormuth 選了 330 篇長度約 100 詞的文章,文章中每 5 個詞,留空一詞;每篇文章依據空格位置,設計出 5 個版本。研究參與者是2,600 位 4 到 12 年級的學童;Bormuth 用參與者在填充 測驗上的表現,估計這300 篇文章的難度。在諸多評量文章難度指標的方法 中,填充測驗似乎是較為適讀性研究之研究者青睞的方法。例如,Miller
(1974)發現,填充測驗具備較能完整涵蓋文章難度的優點,而且以填充測驗 的分數作為適讀性公式的效標,也能得到較好的預測效果。又如在第一個使用 填充測驗作為驗證適讀性公式校標的研究中,Coleman(1965)發現,適讀性 公式的預測與填充測驗的結果之間的相關最高可達 .91;比以 McCall-Crabbs 分 數作為效標,得到的相關高(Szalay, 1965)。
根據Klare(1976),尋找與文本難度相關的屬性是建構適讀性模式的另一 個重要步驟。在適讀性研究發展的初期,研究者認為文章中的「詞彙負荷」
(vocabulary burden)是造成文章難度的重要因素。例如 Lively 與 Pressley
(1923)認為國中的科學教科書充滿艱澀的技術性詞彙,使得學生難以學習。
於是他們的適讀性計算每1000 個詞中不同的詞彙數量,以及在這些詞中,不在 Throndike 詞表裡的詞數。他們發現用這個簡單的屬性,可以和 700 本書的難度 達到0.80 的相關(Dubay, 2004)。適讀性和「難詞」有關的想法,影響到後續 的適讀性公式研發。例如:Lorge(1939)提出的適讀性公式可用來篩選 3-12 年級的適讀文本(Klare, 1974),該公式中用了三個屬性:
X1(年級程度) = 0.06 x 平均句長(詞數)+
0.10 x 每 100 詞中的平均介系詞片語數 +
0.10 x 難詞數(不在 Dale 詞表中的不同詞數)+
1.99 (常數項)
以McCall-Crabbs 測驗做驗證此適讀性公式時,得到頗高的相關。
Lorge 公式裡的難詞定義來自於 Dale 的 769 詞詞表。該詞表是 Dale
(1931)根據 Throndike 詞表改編而來。Dale 和 Chall(1948)再次修訂該詞 表,列出3000 個簡單詞,並提出 Dale-Chall 公式;此公式與 McCall-Crabbs 測 驗分數的相關達0.70。Dale-Chall 公式如下:
Xc50(年級程度) = 0.1579 x 難詞數(不在 Dale 詞表中的不同詞數)+
0.0496 x 平均句長(詞數) + 3.6365 (常數項)
然而,有些研究者認為,應有其他更基本的詞彙屬性可描述詞彙難度。例 如Flesch(1943)認為詞彙的抽象性和詞彙的難度有很重要的關係,而他的公 式中就用詞綴(affix)個數當作衡量詞彙抽象性的指標,他的公式如下:
年級程度 = 0.1338 x 平均句長(詞數)
+ 0.0645 x 綴詞個數 - 0.0659 x 個人指涉個數 - 0.7502 (常數項)
公式中的「個人指涉詞」指的是(在英文中)人名、代名詞(如he、
she)、人感興趣的詞(如,man、woman、child、boy、girl 等)。該公式也同樣 使用McCall-Crabbs 測驗做驗證,並得到高相關。
在當時,由於沒有其他工具的輔助,一篇文章的適讀性完全需要人工計 算。在上述的公式中,計算詞綴個數需要一個個詞檢查,讓該公式的實用性大 幅降低,同時,也因為計算個人指涉的定義較為模糊,於是Flesch(1948)提 出一個新的「閱讀簡易度公式」(reading ease)。該公式同時也是微軟文書處理 軟體(Word)到目前為止仍提供的適讀性公式:
Reading Ease = 206.835 - 0.846 x 每 100 詞中的音節數 - 1.015 x 平均句長(詞數)
如同Flesch 在 1943 年公式中的詞綴數,Flesch 認為音節數也是可代表詞抽 象度的指標。Farr、Jenkins 和 Paterson(1951)考慮到計算音節數需要公式使 用者知道音節規則,他們發現若只使用單音節詞的個數來替代音節數,也可以 達到同樣的預測效果。Farr 等的公式與 Flesch 的公式相關高達 0.93-0.95。他們 提出的新閱讀簡易度公式是:
New Reading Ease Index = 1.599 x 每 100 詞中的單音節詞數
− 1.015 x 平均句長(詞數) − 31.517
Gunning 的 Fog Index 也同樣用音節數來衡量難詞(Gunning, 1952)。他提 出用三個以上音節的詞數用來當作「難詞」的指標。McLaughlin(1969)則認 為計算平均句長需要較多時間,於是他提出更容易計算且準確率更高的SMOG 適讀性,SMOG 只用到多音節詞數(三個以上的音節),和句數。這兩個適讀 性公式是:
Gunning's Fox grade level = 0.4 x (平均句長 + 三或多音節詞數比例)
SMOG = 1.0430 ⋅ √多音節詞彙數 × 30
句數+ 3.1291
由於適讀性公式的發展動機與應用場域的關係,讓適讀性公式容易使用一 直是適讀性研究的趨勢(Klare, 1974)。例如,Danielson 與 Bryan(1963)首次 嘗試讓電腦計算適讀性公式所需要的屬性。Danielson 與 Bryan 公式含有詞長和 句長等兩個屬性,但為了讓電腦容易計算,他們改用「字母」(character)作為 計算單位:
DB Score = 131.059 − 10.364 × 空格間含有的平均字母數
−0.194 × 一個句子含有的平均字母數
為了讓適讀性公式更能廣泛應用,FORCAST 閱讀等級(RGL)公式僅包 含一個屬性(Caylor, Sticht, Fox, & Ford, 1973);這個屬性是,每 150 個詞中,
含有幾個單音節詞。該公式如下:
FORCAST RGL= 20 −單音節詞數
因為FORCAST 的方便性,美國軍方曾經使用它來評估文本的適讀性。
另一種增加適讀性公式易用程度的方法是Fry(1977)的適讀性圖。該適 讀性圖的x 軸代表每 100 個詞的音節數,y 軸則是每句的詞數。讀者只要依照 x 軸和y 軸的數值比對圖形,即可得到適讀性結果。該適讀性圖在 1980 年代間受 到非常廣泛的應用(Klare, 1988),其效度和其它適讀性公式的結果也非常相似
(Klare, 1963)。
過去的中文適讀性研究中也曾試圖以詞彙、字數等屬性預測中文文章適讀 性。例如陳世敏(1972)就用句子的平均字數和難字的多寡來預測中文文章的 適讀年級,Yang(1970)則藉常用詞彙數目、字彙的平均筆畫數以及含有主詞 及述詞的句數。荊溪昱(1995)以句子長度、課文長度、常用字比例為預測屬 性,預測國立編譯館版本的國小及國中教科書的年級。胡志偉、方文熙及李美 綾(1994)參考 Klare(1976)的適讀性模式建構流程,先以文章難度排序作 業、詞填充測驗,以及字填充作業評估21 篇短文(文章長度約 200 到 400 字)
的難度。其次以這三種不同測驗結果為效標,用多元迴歸的方法從23 個文本屬 性中,篩選少數幾個屬性,建構適讀性公式。研究發現,「文本包含的長子句數 目」這個屬性就可以解釋排序作業55.14%的變異量;「長子句數」和「高頻詞 數」可解釋詞填空作業48.89%的變異量。
貳、傳統適讀性公式的批評
前文臚列的數條適讀性公式,只是適讀性文獻的一小部份。DuBay
(2004)指出,在 1980 年代時,研究者已經提出超過 200 條的適讀性公式。雖 然研究結果豐碩,但這些適讀性公式卻接受到來自兩個層面的批評:(1)適讀 性公式僅能「反應」文章難度,但無法「創造」出適合閱讀的文章;(2)這些
公式使用文本的表層屬性預測適讀性,而文本表層屬性無法反應閱讀時的深層 認知機制。(Benjamin, 2012; Bormuth, 1966; Davison & Kantor, 1982)。
關於第一項批評,研究者確實發現,適讀性公式難以讓作者靠著適讀性公 式「寫出」一篇好文章。甚至當作者刻意「順著」適讀性公式的評估結果寫 作,反而會寫出不易閱讀的文章(Schriver, 2000)。這個批評的確影響到適讀性 的應用層面,但Klare(1976)認為適讀性公式的目的是預測適讀性,而不是因 果性的提出修正建議,所以他區分兩種適讀性的研究取向;其中一種是產生可 讀的文章,另一種是預測可讀的文章。前者適讀性公式中使用的文本屬性必須 是有因果關係的,且必須透過實驗法驗證其有效性;但後者才真正是適讀性公 式的研究目的。適讀性公式應該是用作為一種大規模的「過濾工具」
(screening),它使用到許多指標性的文本屬性來預測適讀性,並透過相關法來 確認其預測的有效性。
第二項批評則來自於適讀性公式使用之屬性的本質。由於適讀性公式是預 測性的文本篩檢工具,所以其包含的各種屬性,無論其本質為何,只要能夠幫 助適讀性公式提升它對文本客觀效標的預測效度,且容易計算,就是適讀性公 式會使用的屬性。有些研究者則質疑,適讀性公式常用的音節數、句子長度等 屬性,難以關連到真正適讀性所聲稱要測量的閱讀難度。亦即,適讀性所使用 的文本屬性缺乏表面效度(Schriver, 2000)。
另外,也有研究者質疑,適讀性研究常用的文本難度效標不夠精確。
Stevens(1980)指出,McCall-Crabbs 的標準閱讀測驗並不夠嚴謹。Kintsch 與 和 Vipond(1979)質疑填空測驗的分數反映的可能是文句中的訊息重複性
(redundancy),而不是閱讀難度。
這些對於適讀性公式的批評,反映研究者對適讀性模式的省思。尤其,對 適讀性公式所使用之屬性的本質的討論,更反映研究者在建構適讀性模式時,
不單只考量「預測」,也加入了「認知」的考量。傳統的適讀性公式就像是以
「頭髮長度測量性別」。它們的確取得某種程度上的正確率,但只考慮到文章中 的表層訊息,難以真正描繪讀者閱讀背後的心理歷程(Miller & Kintsch,
1980)。隨著當時認知心理學的發展,適讀性研究者開始注意「認知」因素,試 圖讓適讀性研究更能呼應認知心理學中的閱讀理論。
第二節 認知心理學取向的適讀性研究
認知理論期的適讀性研究反映了當時認知心理學的蓬勃發展,促使適讀性 研究在「計算預測」,在適讀性模式中反應人類閱讀的認知歷程。認知心理學在 1950-1960 年代萌芽,並在隨後的數十年間蓬勃發展。它與過去行為主義心理學 最大的不同,在於研究者不僅研究行為,更研究行為背後的心理機制。在閱讀 研究中,除了過去操弄文本的表層文字屬性(如字體大小、排版等)外,認知 心理學者進一步探討人們閱讀時,所牽涉的心理機制。例如,一篇文本含有的 語言層次,以及處理各語言層次的訊息時牽涉的心理歷程。
閱讀是讀者藉由視覺管道從文本中獲取訊息,並理解文本意義的歷程
(Rayner, Pollatsek, Ashby, & Clifton, 2012)。這個定義涵蓋了許多與閱讀歷程有 關的研究。例如,研究字詞辨識歷程的研究者探討人們如何從接受視覺刺激
(詞或是字)到從刺激中取得字形、字音和字義的歷程。他們在實驗中將字
(或詞)單獨呈現或呈現在語境脈絡中,然後操弄其各種與刺激字或語境脈絡 相關的屬性,最後通過參與者對刺激字的反應推論字彙辨識的心理機制。對句 子結構或句法與語義互動感興趣的研究者則會操弄句子的句法特徵及語義特 徵,並以句子(sentence)作為刺激材料,然後從參與者對句子的反應推測人們 閱讀句子時的心理機制。這些研究提供適讀性研究豐富的理論基礎,亦即讀者 在閱讀時如何理解一篇文章;以及哪些文本屬性,可能會影響讀者的閱讀理解 歷程。
壹、文本的心理表徵
有關閱讀理解歷程的理論頗多,本文將引用其中一個已經將部分想法實際 落實於適讀性模式的理論(Graesser, Singer, & Trabasso, 1994; Kintsch, 1988)。
因為這個理論的一個目的是建立一個能夠處理語言的人工智慧系統,所以它的 部分看法不一定被所有的語言研究者接受(如McKoon & Radcliff,1992)。根 據Kintsch 的理論,閱讀時,讀者會在文本中主動的搜尋訊息,以便他們建立 文本內容的心理表徵。該表徵需具備「一致性」(coherence),亦即每個元素
(字詞、子句、句子)間都必須彼此連結,成為一個協調的組織,且不同句子 所形成的組織,也需要相互整合成更高層次的組織,最後,這些組織將被抽象 為文章的主旨、綱要等。這樣的心理表徵就是讀者對文章的理解。當讀者能夠 成功理解一篇文本時,讀者就能進行與文本內容相關的推論,也能根據文本提 出問題,例如指出文本內容的邏輯錯誤、矛盾或缺漏等。同時,讀者也能正確 回答關於文本的問題,也能精準地摘要出文本的訊息(Graesser et al., 1994)。
讀者對文本建立的心理表徵包含5 個層次:(1)淺層編碼(surface code);
(2)文本表徵(textbase);(3)心智或情境模式(mental/situational model);
(4)文本類別與修辭結構(genre and rhetorical structure);(5)語用及溝通目 的(pragmatic communication)(Graesser, McNamara, & Kulikowich, 2011;
Graesser, Millis, & Zwaan, 1997)。讀者需有足夠的認知資源和對語言及世界的背 景知識,才能成功建立上述的心理表徵。以淺層編碼的訊息為例,該層次的訊 息包含表層語言編碼的辨識及剖析,包括文字的視覺訊息,聲音訊息,音節、
詞素、詞綴、時態(tense)和型態(aspect)。同時也包含詞彙的詞類和語法結 構(如名詞、動詞片語)等。在英文的研究也指出,初級的文字編碼階段的確 會影響之後的閱讀歷程(Rayner, 1998)。讀者的心理辭典中是否包含足夠的詞 彙數量,也會影響讀者的閱讀理解程度(Perfetti, 2007)。例如,初次接觸中文
的讀者,很可能無法理解中文的書寫系統、發音、詞彙、文法規則,則他很可 能無法建立初級的表層編碼,可能亦難以繼續建立更高層次的文本訊息。
第二層次是文本表徵。在文獻中,文本內容常以命題(propositions)的形 式表達(Graesser et al., 1997; Kintsch & Dijk, 1978)。「命題」在概念上是指涉到 外在(真實或想像)世界的狀態、事件或動作,且該指涉具有真假值(truth value)。在文本表徵裡的命題具備一個述詞(predicate),以及一或多個論元
(arguments)。述詞在命題中常是句子的主要動詞、形容詞或連接詞,而論元 則可能是名詞或其他的命題。例如以下取自Graesser 等人(1997)的例子:
A mushy, brown peach is lifted from the garbage and placed on the table to pinken.
PROP 1: lift (AGENT = X, OBJECT = peach, SOURCE = from garbage) PROP 2: brown (OBJECT = peach)
PROP 3: mushy (OBJECT = peach)
PROP 4: place (AGENT = X, OBJECT = peach, LOCATION = on table) PROP 5: pinken (OBJECT = peach)
PROP 6: [in order] to (PROP 4, PROP 5) PROP 7: and (PROP 1, PROP 4)
從上述例子可發現文本表徵和表層編碼不必然是相同的。例如,peach 和 table 在命題中都是以同樣的形式表達,並未區分在句子中一個是不定指(用不 定冠詞a),一個是定指(用定冠詞 the)。同時,命題形式僅表徵句子的意義訊 息,故已去除原本文句中的被動語態。
文本表徵中的命題形式很可能是斷裂的,讀者需透過各種推論歷程建立文 本的「微觀結構」(microstructure),該結構將文本中的命題連成一個完整的網 絡。讀者在短期記憶中透過各種策略來推論命題與命題之間的關係,例如命題 的論元重複(例如上述的PROP 2 和 PROP 32 都和 PEACH 有關)、代名詞指
涉、概念重複,或連接詞等,都能幫助讀者建立文本的微觀結構。讀者閱讀完 一個段落後,進一步從文本表徵中抽取出巨觀結構(macrostructure)。巨觀結構 是讀者透過直觀推理(heuristic),例如藉由長期記憶裡儲存的世界知識來推 論,或應用各種文本線索(因果、時間順序、並列等等)來產生命題間的連 結,最後經過刪除、概化等歷程,建立較高層次的篇章主題(theme)或綱要
(gist)(Kintsch & Dijk, 1978; van Dijk & Kintsch, 1983)。Graesser 等人
(1994)曾列舉 13 種在閱讀敘述文體時,讀者用來建立微觀、或巨觀結構的推 論類型,除了和語言符號相關的線索外,也包含因果關係、目的、主題、工具 目的、敘事狀態等。過去實驗也發現,讀者在閱讀的當下,便建立其所讀文句 的意義。例如Long、Golding 及 Graesser(1992)在實驗中讓讀者每讀完一句 話,就出現一個測試詞彙,參與者要猜測該詞彙是該句話的上位或下位
(superordinate/subordinate)目的。讀者看到測試詞彙後需盡快唸出它。實驗者 測量參與者唸出詞彙的念名時間。實驗結果發現,讀者對上位目的詞彙的念名 時間顯著低於下位詞彙和控制組,顯示讀者在閱讀句子時,便理解句子的意 義,並根據句子意義進行關於上位目的推論。
微觀結構和巨觀結構都涉及文本內容以及讀者的長期記憶訊息,這反應閱 讀時的心理表徵,並非只有單純的文本表徵。這些在閱讀過程中所牽涉的各項 訊息,都整合在讀者對文本的情境模式(situation model)裡。情境模式是一個 來自文本的新訊息,與讀者舊有的長期記憶間訊息整合的過程。讀者在閱讀時 在情境模式中建立命題與命題之間的共同指涉或推論關係,讓文本的命題結構 與讀者自己的背景知識形成一致性的知識網絡。此心理表徵在過去文獻中曾被 稱為可能世界(possible worlds)、篇章模式(discourse models)(van Dijk, 1976)、參照網絡(reference nets)(Habel, 1982)或心智模式(Johnson-Laird, 1980)。過去實驗也指出,讀者對於文本的記憶是讀者建立出的情境模式,而不 是淺層文字本身(Garnham, 1987)。讀者從文本中學習新知時,亦是透過舊有
知識的情境模式,並藉由文本的新資訊逐步更新原有訊息。
文章的淺層編碼、文本表徵和情境模式在文獻中有許多實徵研究的支持。
例如,在過去研究中,研究者要求參與者閱讀一篇文章,之後需對四種不同的 測試句做再認作業(recognition),再認的材料是:(1)文章中的原始句子;
(2)由原句改寫句子;(3)由原文中合理推論出的句子;(4)一個錯誤的句 子。研究者以相減法探討不同層次表徵的效果,亦即(1)減去(2)可以得到 表層編碼的訊息;(2)減去(3)透露的是文本表徵訊息;(3)減去(4)則代 表情境模式的表徵。實驗結果發現,淺層編碼訊息隨著時間間隔快速衰退,但 愈高層的情境模式則衰退得最慢,文本表徵則居中(Kintsch, Welsch,
Schmalhofer, & Zimny, 1990)。更有趣的是,研究也發現當讀者認為閱讀的文章 是文學作品時,表層編碼的表徵較強(衰退得較慢),而當讀者認為文章是新聞 報導時,情境模式的表徵則較強(Zwaan & Radvansky, 1998)。這同時呼應了文 章類別在理解文本時的效果。
研究發現,當文本中出現為違背語用原則的訊息時,會使讀者閱讀理解的 時間變長,而且容易出現理解上的錯誤。例如,Graesser 等人(1997)指出,
作者會透過語用訊息和讀者溝通。在寫作時,作者會用與讀者共享的知識寫文 章;當作者提出新的訊息時,會善用篇章線索。例如,以英文寫作的作者會將 舊的訊息放在主語位置的名詞片語中,而新的訊息通常放在動詞片語中。作者 也善用篇章結構以提示重點訊息,比如將重要的訊息放在每段的第一行。另 外,Graesser 等人(1997)也延伸 Grice(1975)在溝通中的合作原則(Grice’s axiom),認為作者應在情境模式之下提出真實的陳述,同時所有句子都應該和 前文相關,文章彼此之間不應互相矛盾抵觸。過去研究發現,一般讀者很難意 識到作者的語用線索,尤其是閱讀含有不熟悉議題的說明文持,即便文章中的 語用線索有衝突,讀者還是會認為自己已經理解文章了,而忽略文章中的矛盾 訊息(Glenberg & Epstein, 1987)。
上述五個層次的文本表徵,在實際閱讀文章時,是互相依存的。雖然讀者 若在建立底層表徵時受到阻礙,可能會影響高層次表徵的處理。例如,當一位 無法辨識中文字的讀者閱讀一篇中文的操作手冊時,他可能在第一層的文字編 碼層次就已受阻,亦無法建立文本表徵甚至情境模式等。然而,高層次的表徵 仍有可能透過其他線索的協助,完成該層次的訊息處理。舉例而言,兩位同系 的大學部同學共同合作一篇課堂報告。一位同學閱讀過初稿後,雖然他能夠理 解整篇報告的內容(因為他們共享相同學系的背景知識),但仍然覺得報告的行 文不清楚,例如文中缺少轉折語、連接詞等標示文章結構的用語。在這個例子 中,即便文本表徵中沒有提供足夠的線索給讀者,但讀者心中的背景知識(長 期記憶)還是能建立情境模式。甚至,讀者可以用情境模式的訊息幫助填補文 本表徵缺漏的訊息。
然而,也有些文本層次間的訊息是不能互相補足的。例如,在Graesser 等 人(2011)曾舉的例子中,兩人為了組裝一套新的視聽器材,而試圖閱讀一本 說明書。他們有正常的閱讀能力,所以在淺層文字編碼和文本表徵的層次都能 正常處理。他們甚至也都完全理解說明書的溝通目的(教使用者如何組裝)和 文類修辭結構(說明書是說明文類),但他們就是無法弄清楚到底哪一個線材要 接哪個設備(情境模式的訊息)。在這個例子中,這兩個人的淺層和文本表徵訊 息無法幫助他們建立情境模式,上層的文類和語用層級的訊息也無助於情境模 式的建立。這個例子反應出有些問題只能透過額外的背景知識,才能幫忙補足
(rectified or repaired)情境模式的缺陷(misalignment or misfire)。
貳、讀者如何建立一致性的心理表徵
當讀者「理解」一篇文本時,他能建立出一致性的心理表徵。讀者藉由該 表徵能處理與文本相關的問題,例如,回憶文本內容、對文本進行摘要、重述
(paraphrase)文本內容,以及回答與文本內容有關的問題等等。「建構整合理 論」描述了讀者如何建立出一致的文本表徵。該理論於1980 年代提出,但在 2016 年的「促進國際閱讀素養研究」(PIRLS)的閱讀架構仍深受「建構整合理 論」的影響(Mullis & Martin, 2015)。根據建構整合理論,讀者不但能從下而 上,彈性地從文本建構出各種訊息;同時也能用過去的知識和記憶,從上而下 地將建構出的訊息,整合進過去的經驗架構中(Kintsch, 1988)。該理論的建構 過程分為四個階段:(1)從語言內容建立命題結構;(2)從背景知識提取與文 本相關的知識;(3)從文本中推論出其他命題;(4)對命題間的關係設定權 重。上述四階段僅是建立初步的粗略文本表徵,所以裡面可能包含不一致的心 理表徵,或甚至與文本無關的訊息。整合階段的目的是要強化與文本脈絡相關 的訊息,並抑制與脈絡無關的訊息。在建構整合理論中,整合階段的歷程是一 次又一次的激發循環(cycle)(Miller & Kintsch, 1980)。每一次的循環都以前一 次的循環作為基礎,每一個命題節點都具備自己的激發強度,並用命題與命題 間的連結權重傳播激發能量。如果某次循環失敗,亦即有些命題節點無法整合 進網絡,則新的命題節點會再從長期記憶中提取出來,並再嘗試一次整合循 環。此整合階段將一直持續到所有節點的激發強度穩定為止。
Miller 和 Kintsch(1980)曾嘗試用 InterLisp 模擬整合階段的運算歷程,並 和參與者實際閱讀的閱讀時間、命題回憶數做比較。他們的「微觀結構一致性 模式」(microstructure coherence program, MCP)試圖模擬讀者在理解時,連結 命題單元以及擷取長期記憶的歷程。該模式具有3 個記憶區塊,其中輸入緩衝 區(input buffer)負責儲存目前正在處理的命題單位,如果該命題單位和工作 記憶(working memory graph)中的文本表徵共享概念(或論元),則該命題就 被納入工作記憶的文本表徵中。但如果輸入緩衝區的命題單位無法用上述方法 連結進工作記憶的文本表徵,則該模式會嘗試在長期記憶(LTM)中搜尋能幫 助連結的命題單元。長期記憶裡會儲存所有在文本中曾出現過,但已不在工作
記憶中的命題單元。如果長期記憶搜尋仍然無法接起輸入緩衝區的命題單元和 工作記憶的文本表徵,則此模式就判斷該文本產生主題轉移(topic shift)。工作 記憶裡的文本表徵就轉入長期記憶,輸入緩衝區的命題單元則進入工作記憶當 作新文本表徵的根節點。
雖然MCP 模式並沒有用到複雜的演算法,但模式的推論數和長期記憶搜 尋數和閱讀時間有顯著正相關,推論數則和回憶表現有顯著負相關。Miller 與 Kintsch(1980)認為,MCP 模式只模擬了部分的閱讀的歷程。如果要進一步貼 近真實的閱讀歷程,則應該要再加入語義剖析器,讓文本能自動轉成命題結構
(在MCP 裡,命題結構是由研究者手動輸入);另外也應有建立巨觀結構的演 算法。
「建構整合模式」和MCP 模式都試圖提供一套認知虛擬機器(cognitive virtual machine)(Pylyshyn, 1984),試圖用形式化的方法描述人類閱讀的認知歷 程。然而,建構整合模式的確提供一套解釋模式,讓研究者瞭解某一文本屬性
(例如文本中的連接詞)可能會如何影響讀者的理解(連接詞如何影響一致 性),但是由於這個理論相當複雜,所以它難以用實驗法探討讀者閱讀一篇文章 後,會引發哪些心理歷程。一篇「困難」的文章之所以困難可能牽涉到各種因 素,例如某個命題無法連結進文本表徵,進而引發長期記憶搜尋,甚至因為工 作記憶的限制而無法儲存文本表徵,使得讀者要啟動眼動機制再回視
(saccade)前一段文字等等。或者,研究者也無從得知讀者的長期記憶中,是 否擁有連結命題所需要的背景知識,若一次的長期記憶搜尋失敗,之後又將引 發其他的理解機制。閱讀所引發的複雜認知歷程,可能難以從認知虛擬機器的 角度,判斷讀者是否真的從文本中建立出一致性的心理表徵。
參、文本一致性指標和 Coh-Metrix
讀者對文本的心理表徵是否有一致性(coherence)是內在的抽象構念,難 以直接測量。但是「文本」是否提供足夠的一致線索(cohesive devices),讓文 章本身是一致的(cohesion),則是可從文本屬性計算而得的2。Coh-Metrix 即採 取此取向,找出一些會影響讀者對文本建立各層心理表徵的文本屬性,並以之 作為指標,描述一篇文章是否容易被讀者理解。
Coh-Metrix 希望對文本做多層次的難度和一致性評估,並瞭解在不同層次 間的難度和一致性會如何彼此互動及限制,並藉此發展多層次的閱讀理解模 式。過去實驗也發現高文本一致性(cohesion)的文章會幫助低背景知識的讀者 閱讀。有趣的是,這個實驗也同時發現,低文本一致性的文章反而有助於讀者 主動搜尋背景知識,進而幫助閱讀理解(McNamara, Kintsch, Songer, & Kintsch, 1996)。這些研究顯示文本的一致性的確對於閱讀理解有重要關係。
McNamara、Ozuru 及 Floyd(2011)的研究也得到類似地結果。他們直接 操弄文本的一致性程度對四年級學生閱讀的影響。研究中使用2 篇記敘文、2 篇說明文作為閱讀材料,並以Coh-Metrix 指標來操弄文本一致性,例如把代名 詞換成名詞片語、加入可以增加概念指涉性的詞彙,加上句子連接詞等等,以 增加文本的一致性;當然,反向操作則會減低文本一致性。研究以根據文本內 容設計的選擇題測量讀者對文本的理解程度,結果發現高一致性的文本能增加 學童對記敘文的理解程度。他們也發現和McNamara 等人(1996)類似地結 果,亦即當學童對於文章的背景知識高時,閱讀低一致性文本反而有更好的閱
2 心理表徵一致性(coherence)、文本一致性(cohesion)、以及一致性屬性(cohesive devices)是彼此相關聯的概念,但這三者在中文翻譯時不易區分。本研究實際操作並計算一致 性屬性,並作為預測文章適讀性的屬性之一;該屬性會影響文本的一致性,並進而影響讀者閱 讀時建立之心理表徵一致性。
讀理解表現。
Coh-Metrix 1.0(Graesser, McNamara, Louwerse, & Cai, 2004)分析超過 200 個文本指標,這些指標分成13 類,包括詞彙訊息、詞頻訊息、詞類標記、詞彙 密度、邏輯詞彙、連接詞、詞類詞例比、多義詞與上位詞、句法複雜度、適讀 性公式、共同指涉一致性、因果一致性和LSA 語意訊息。由於 Coh-Metrix 指 標相當豐富,Graesser 等人(2011)為凸顯指標與指標在真實文本間的關係,
故選擇53 個指標分析 TASA 的 37,520 篇文章,並用主因子分析法(PCA)得 到8 個主要因子;這些因子共可解釋 67.3%的變異量。他將這八個主要因子分 別對應到五個文本層次,與讀者在閱讀時建立的文本心理表徵相當類似
(Graesser et al., 2011),分別是詞彙、語法、文本、情境模式與文章類型。
一、詞彙層次指標
詞彙層次指標包含詞頻、詞類、熟悉度、具體性、習得年紀(age of acquisition, AOA)等。研究顯示,這些屬性都會影響讀者對語文材料的處理時 間與理解程度(Perfetti, 2007)。對閱讀初學者而言,口語化的詞彙較適合他們 閱讀者;但對精熟的讀者,文本中含有較複雜的詞彙可能更能引起他們的閱讀 興趣。在過去研究中,詞彙的使用頻率是最穩定地影響閱讀的屬性。研究者可 以透過大型語料庫(例如,Coh-Metrix 使用的 CELEX 語料庫)計算詞彙頻 率,並將此詞彙頻率用來估計讀者對其熟悉程度。
詞彙可區分為實詞(名詞、動詞、形容詞、副詞等)和功能詞(介系詞、
冠詞、代名詞等),Coh-Metrix 計算不同詞類在文本中所佔的比例,因為過去研 究發現實詞和虛詞在文章中扮演不同的角色,均可能影響閱讀理解。例如,在 眼動研究發現,讀者對實詞的凝視時間高於虛詞(柯華葳、陳明蕾、廖家寧,
2005;Rayner & Duffy, 1986)。然而,功能詞在文本理解中擔負非常重要的角 色,例如代名詞負責提示讀者前後文句之間的關係,有助於提醒讀者連結文本 中地不同命題單元。同樣地,連接詞詞類也是建立文本一致性時很重要的線
索,例如因果詞(因為、所以)、時間詞(然後,之後,之間)、邏輯關係(如 果、因此)、並列(同時、而且)和轉折(然而、但是)等等,這些詞彙也是讀 者建立情境模式的線索。
Coh-Metrix 也藉助 WordNet(Fellbaum, 1998)描述英文詞彙的語意內容
(semantic content)。WordNet 在 Coh-Metrix 裡提供三項關於詞彙意義的訊息。
(一)多義詞:一個詞彙在WordNet 的詞義數(sense)愈多,代表一個詞彙愈 多義。過去文獻指出,多義詞在閱讀時會造成閱讀速度變慢,對初學者的影響 尤其深遠(Gernsbacher & Faust, 1991)。(二)具體性:WordNet 不僅列出詞彙 的意義,也描述每個詞義之間的上下位關係(hypernym/hyponym)。例如,座 椅(seat)在 WordNet 中作為名詞時,有 9 個詞義(sense),其中一個詞義是
「用來坐的家具」(furniture that is designed for sitting on),其上位詞義
(hypernym)是家具(furniture)3。家具的上位詞(及這個詞的上位詞,以此 類推)依序是裝潢(furnishings)、工具(instrumentality)、人造物(artifact)、
物件(object)、物體(entity)。一個詞彙的上位詞數可代表其具體性(上位詞 愈多則該詞彙愈具體);(三)因果性:Coh-Metrix 也使用 WordNet 的詞彙訊息 來定義因果性動詞(causal verb,如 kill 等),這些動詞是在情境模式中,讀者 用來理解事件發生順序和因果關係的線索(Zwaan & Radvansky, 1998)。
二、句法層次指標
句法(syntactic)層次指標包含句子的複雜度以及句子與句子間的句法相似 度。有些句子具有很簡單的句法形式,例如單純的主動賓(SVO)形式(he went to school;我吃飯),但有些句子較長,鑲嵌許多的關係子句,且加上修飾 片語等等。例如在(Graesser & Mcnamara, 2011)的例子:
At anytime during the last 12 months, were you or any member of your
3 WordNet 的上下位關係是詞義與詞義(sense)間的關係,而非詞條(lemma)間的關 係。此處僅是上下位關係的舉例說明,故不額外區分詞條以及其所包含的詞義。
household enrolled in or receiving benefits from free or reduced price meals at school through the Federal School Lunch program or the Federal School Breakfast program?
這段話有很長的名詞片語和修飾語;讀者需閱讀多個詞後才能遇到主要動 詞(enrolled),造成較大的工作記憶負擔;句子中也有許多個邏輯連接詞(and, or)等。根據過去的研究指出,複雜的句法會讓讀者增加建立文本表徵時的工 作記憶負擔(Perfetti, Landi, & Oakhill, 2005)。Coh-Metrix 首先透過詞類標記器 和句法剖析器幫助賦予每個句子句法樹(syntax tree)結構。並以句長、名詞片 語的修飾詞數、主要動詞前的詞數來評估句法複雜度。同時,Coh-Metrix 也計 算句子的句法相似度,其計算方法是根據句法樹的訊息,以兩句句法樹中相同 的節點數做為分子,除以兩句中所有的節點數減去相同節點數,並以此比例作 為兩句句法的相似度分數。過去研究指出,當文本中的句子共享類似地句法結 構時,有助於讀者的閱讀理解(Crossley, Greenfield, & McNamara, 2008)
以句法樹上的結構屬性來操作句法複雜度並不是唯一種操作句法複雜度的 想法。句法樹的結構複雜度,背後的想法與詞彙與規則的處理機制取向較一致
(Pinker & Ullman, 2002)。該取向假設一組儲存詞彙知識的心理辭典,以及另 一組抽象的形式(文法)規則,這些規則可用於合併、組合、轉換心理辭典的 詞彙,這些文本中的語句需要應用較多的規則,則這個句子則較「複雜」。然 而,這種看待句法複雜度的想法並非唯一的理論取徑。另一群研究者則認為語 言使用是動態的(Arnon & Snider, 2010):讀者如何表徵、處理語言受到經驗、
日常使用的影響。較常使用的語言單位會纏固(entrench)進讀者的記憶表徵,
亦即文法規則的表徵不是靜態的,而是透過語言使用不斷形塑改變。各種語言 粒度(granularity)的出現頻率則是不同語言單位在真實語言環境下的使用記 錄。這些模式被統稱為「突顯模式」(emergentist models),如語言使用取徑的 文法理論(Langacker, 1987)、連結論的語言理論(Rumelhart & McClelland, 1986)、組塊模式(Bransford & Franks, 1971)、或語言知識的事例模式
(exemplar models)(Gaul & Yu, 2006)。
過去的研究也的確發現,各種不同粒度的語言單位之出現頻率的確都會影 響閱讀時的心理歷程。例如,在詞彙再認作業中,除了詞彙出現頻率(即詞頻 效果)會影響作業表現外(Rayner & Duffy, 1986),多詞彙單位(multi-word phrases)的出現頻率(Arnon & Snider, 2010; Hsieh et al., 2017),甚至詞彙在句 子中句法中的關係,例如詞彙在特定語法結構裡的頻率(Garnsey, Pearlmutter, Myers & Lotocky, 1997)、詞彙與特定論元的共現性(Trueswell, Tanehaus, &
Gaurnsey, 1994)、整體的句法結構(Janssen & Barber, 2012)等都會影響讀者的 表現。這些研究暗示,文本各階層的頻率訊息都會影響到讀者閱讀理解時的處 理歷程(Diessel, 2007)。在適讀性研究中,大粒度(比詞彙單位大)之語言單 位的出現頻率也是較少包括在文本屬性中的。
三、文本層次指標
文本層次指標脫離詞彙與句法等語言層次的屬性,進一步衡量與文本內容 有關的工具。在這個層次中,讀者的目的是建立內容相關的一致性的文本表 徵,Coh-Metrix 即衡量文本間是否具備足夠的指涉(reference)線索,讓讀者 可以連接文本中不同的命題。
Coh-Metrix 從三個面向衡量指涉線索。第一是共同指涉(co-reference)指 標。此項指標是評估文本中有多少的重複詞彙,可以幫助讀者建立命題連結。
Coh-Metrix 有不同的方式定義詞彙重複度,例如當兩個句子彼此間有一個名詞 是相同的,則這一對名詞則被定義為名詞重複。若兩個句子的兩個名詞的詞幹
(stem)相同(例如 table/tables),則他們是論元重複。若兩個句子中,有一個 句子的名詞(如,work)和另一個句子中任意詞類的詞(如,working)重複,
則定義為詞幹重複。
另一種衡量文本指涉的方法,則是考量文章中的詞彙豐富度,亦即文本中 用到多少不同的詞彙:如果文章中用到愈多不同的詞彙,讀者就愈難從單純地
詞彙重複找到連結命題的線索。Coh-Metrix 是以詞類/詞例的比(type-token ratio)來計算詞彙豐富度,當該比例愈高,代表文章中用了愈多不同的詞彙,
讀者需要花費較多的心力將不同的詞彙整合進文本表徵。
第三個衡量文本表徵的則是用語意空間來計算概念的重複度。Coh-Metrix 使用潛在語意分析(latent semantic analysis, LSA)(Landauer & Dumais, 1997)
從原始語料建構出語意空間,並以此代表讀者的世界知識。在LSA 的模式中,
每個詞彙都可以以一個多維向量代表,向量與向量之間的相似度則代表兩個詞 彙的連結程度。過去研究亦指出,以LSA 計算的詞彙連結度和人類參與者的自 由聯想反應有顯著相關(Landauer & Dumais, 1997)。Coh-Metrix 藉著不同詞彙 在語意空間中的向量相似度,當作不同詞彙間的概念重複度。Coh-Metrix 也以 句子作為單位,計算相鄰兩個句子間的概念重複度,或是文本中的特定句子與 之前所有句子(given-new)的概念相似度(McCarthy et al., 2012)。
四、情境模式指標
情境模式指標衡量文本是否有足夠的線索,讓讀者建立出文本所要敘述的 事件或說明的內容。Zwaan 和 Radvansky(1998)將情境模式分成五個面向:
因果、目標、時間、空間和主角。若這五個面向中任意一個元素在文本中的關 係不連貫,讀者所建立的情境模式將會受到阻礙。此時,則需要文本提供額外 的連接詞、轉折語、副詞或其他線索,來幫助讀者察覺到訊息的不連貫,並幫 助讀者連結前後文的訊息(Rapp, van den Broek, McMaster, Kendeou, & Espin, 2007)。Coh-Metrix 將這些幫助建立情境模式的文本線索稱為助詞(particles),
並將他們分為因果、意向和時間三類。例如,因果連接詞(因為、使得),時間 副詞(之前、之後)、意向詞(為了,才能)等等。Coh-Metrix 除了計算這些助 詞出現的次數,同時也計算這些助詞(如因果性助詞because)和相關目標動詞
(例如因果性動詞,move)出現的比例,藉此評量文本在情境模式層次上提供 的因果線索。
五、文本類型指標
文本類型指標試圖評估不同文本類型對於閱讀理解的影響。過去研究發 現,即便內容領域相同、詞彙熟悉度相同,記敘文還是比論說文容易被讀者理 解(Graesser & McNamara, 2011)。讀者若能對不同類型的文章應用不同的閱讀 技巧,則可增加其對文章的理解程度(Meyer et al., 2010)。然而,一篇文章是 記敘文或說明文,不僅在概念上並無一個清楚明確的劃界,在文本中也難以找 到一組可操作的屬性來代表文本的類型。所以,這部份屬性雖然重要,但仍屬 於需專業人力判斷及提供標記的領域。故文本類型並不是目前Coh-Metrix 能自 動產生指標的範圍。不過,在Graesser 等人(2011)的主因子分析法中,仍發 現有些表層的屬性可能與文章類型有關,例如動詞個數、代名詞個數、內容詞 數目、熟悉度、負面詞彙等。
McNamara, Graesser, McCarthy 和 Cai(2014)整合 Graesser 等人(2011)
提出的主因子,然後再整理出一些其它的文本屬性,提出Coh-Metrix 3.0 版。
此版本的Coh-Metrix 共包含 106 項指標,共 11 個類別;這些類別分別是描述 性、主因子分數、指涉一致性、潛在語意分析、詞彙多樣性、連接詞數、情境 模式、句法複雜度、句法樣式複雜度、詞彙訊息以及適讀性公式。其中主因子 分數即來自於Graesser 等人(2011)提出的 8 項主因子,他們分別對應到讀者 閱讀時所建立不同層次的心理表徵,包括「詞彙豐富度因子」對應到詞彙層 次、「句法簡單性因子」對應到句法層次、「指涉一致性因子」對應到文本表徵 層次、「因果關係因子」、「動詞因子」、「邏輯因子」、「時間順序因子」對應到情 境模式層次,以及「敘事因子」對應到文本類型層次。這8 項因子共解釋 67.3%的變異量,其中前 5 項主要因子(敘事性、句法簡單性、詞彙具體性、指 涉一致性和因果一致性)已佔據54%的變異量。這個結果顯示雖然 Coh-Metrix 有100 多個文本屬性,但背後有簡單的結構,有助於研究者用文本一致性的理 論工具來分析文本,瞭解讀者閱讀時的心理歷程,甚至文本的適讀性。
肆、適讀性與文本一致性指標
Coh-Metrix 雖然臚列多項文本指標,但其本身並未定義哪些指標和文本適 讀性有關。McNamara 等人(2014)認為,Coh-Metrix 的眾多指標適合以多向 度的方式,以多個角度同時評量文本在閱讀時可能造成的困難。而且,Coh- Metrix 也能夠補足單向度的適讀性指標在衡量文本適讀性所造成的問題。例 如,傳統的適讀性模式偏重於詞彙等文本表層屬性來決定文本的適讀性,這些 模式未真正在屬性上考量到讀者在閱讀時所經歷的複雜認知歷程。其次,閱讀 時,讀者會同時受到很多因素的影響,而傳統單一向度的適讀性模式難以考量 到各種文本一致性屬性,以及敘述、說明文類等因素。最後,對實際教學者而 言,他們需要的是知道學生在閱讀文本時遇到哪些困難,以及如何幫助學生提 升閱讀表現(Connor, Morrison, Fishman, Schatschneider, & Underwood, 2007)。
亦即,理想的適讀性評量應該是診斷的過程,而這些訊息難以從單向度的適讀 性公式獲得。
文獻中也的確指出Coh-Metrix 有助於預測文章的適讀性。Dufty、
Graesser、Louwerse 及 McNamara(2006)即進行了 Coh-Merix 和文章適讀性的 效度研究。他們蒐集了311 篇讀物,每本讀物都有出版社依適讀性公式及專家 評定所設定的適讀年級。該研究以這些讀物的適讀年級為效標,結果發現適讀 年級與Flesch-Kincaid Grade level 的相關是 0.77,和 LSA 一致性(句子與文 本)的相關是-0.53。若以適讀性公式和一致性屬性兩者共同預測適讀年級時,
其判定係數為0.68。此結果顯示,對文本難度的預測,Coh-Metrix 所測量的文 本屬性比LSA 好。雖然加入一致性屬性後,略微減低適讀性公式的效度,但因 為一致性屬性具有理論上的意義,所以整體而言,這個取向的適讀性研究是有 意義的。Nelson、Perfetti、D. Liben 及 M. Liben(2012)的研究也得到相似的結 果。他們發現Coh-Metrix 的因子分數和文章的適讀年級以及學生的閱讀表現有