中 國 醫 藥 大 學
碩士論文
編號:
IEH-1712
世界衛生組織生活品質問卷用於
自填模式與面訪模式之比較
Comparison of self-administration and
face-to-face interview modes on the
WHOQOL-BREF questionnaire
所別:環境醫學研究所
指導教授:梁文敏
學生:許雅琳
Hsu Ya-Lin
學號:
9465012
中
華
民
國
九
十
六
年
六
月
誌謝
本論文承蒙指導教授梁文敏老師於論文寫作期間的細心指導,並不時花 費時間進行討論與指導,才得以有今天的成果,梁老師在平時的討論中,有 如良師益友般的教導,不僅僅於論文的指導,在平常日常生活當中,也常常 提供她的經驗談,實讓我獲益良多。並且也要感謝中醫部陳建仲主任,不論 是對於研究執行經費以及人力的支持與指導,本研究收案才得以順利完成, 在此謹致本人最深及由衷的感謝。 在兩年的研究所的過程當中,特別感謝所上老師們的細心教導,另外, 研究期間,多虧了研究所兼辦公室同學泰進、懿諄學姐、宏偉學長以及哲瑋 學弟,在學業上互相學習,並在精神上彼此鼓勵與支持,另外,也要感謝在 健檢中心幫忙收案的雅慧、寧玹和小杜妹妹,多虧了你們辛苦的收案,這個 研究才得以順利完成。 最後,我要感謝背後支持我的好友以及家人,我的好友佳萱、麗杏姐、 淑玲姐,真的謝謝妳們的貼心關懷,我要感謝我最愛的父母、哥哥、弟弟和 政國,你們對我無限的支持和鼓勵,讓我沒有後顧之憂,並陪伴我一路走來, 謝謝! 雅琳 謹致於中國醫藥大學 民國六十九年六月摘要
研究目的: 世界衛生組織生活品質問卷(WHOQOL-BREF)原先設計用在自我填答 施測模式,但實際在臨床應用上,卻有許多限制,尤其在讀或寫不方便的族 群,有鑑於此,在臨床上就常常用面對面訪問的方式完成問卷,本研究即在 探究WHOQOL-BREF 實際用在自填模式或面訪模式上的差異。 方法: 本研究在中國醫藥大學附設醫院健檢門診收案,採取交叉研究設計,一 共收取212位自願參與者。自願者則先分派為先面訪或先自填兩組,隨後再 進行交叉自填或面訪。我們利用古典測驗理論(classic test theory, CTT)及項 目反應理論(item response theory, IRT),看WHOQOL-BREF在使用兩種施測 之心理特質及差異性,進而深入探討。 結果: 整體而言,不論施測模式的順序先後,WHOQOL-BREF 全部範疇的面 訪得分均高於自填得分。 比較兩組的再現性,結果顯示先面訪組內在等級相關係數 (ICC):0.71~0.8,較先自填組 ICC: (0.56~0.77)穩定。再區分年齡、性別來看 再現性,發現男性、年齡大於65 歲者其 ICC 指標較不穩定。不論 CTT 或 IRT 來看問卷各範疇內部一致性,WHOQOL-BREF 之生理、心理與環境範 疇信度均不錯,但在社會範疇之中,CTT 與 IRT 信度均較差,結果與 WHOQOL-BREF 其他相關文獻吻合。 項目反應理論的結果顯示:在兩種施測模式下,反向題”需要醫療應付 日常生活”、”負面感覺”和”疼痛會妨礙需要做的事”,不符合單一向度的假設,反向題會降低其單一向度指標。另外,在”性生活”對於老年人不符合單 一向度的假設。 不同的施測模式下,題目相對的難度順序亦不同,變化較顯著的題目 如:在反向題”負面感覺”男性在自填較面訪容易傾向有負面得分,女性則相 反;老年人在”接受自己的外表”,自填較面訪容易傾向有不滿意的感覺;而 在字面上較抽象的題目,需要訪員進一步解釋題意,也會造成受訪者對不同 施測模式之間的感受不同。 試題差別功能結果顯示在”身體疼痛會妨礙您所需要做的事”、”性生活” 和”方便得到資訊”則在不同性別上兩種模式均出現差別,這 3 題在不同施測 模式之間的特質呈現不穩定。 結論: WHOQOL-BREF用在面訪與自填兩種施測模式之下,面訪分數均高於 自填。施測模式的不同其測量結果隨人口特質不同亦有差異。比起古典測驗 理論,項目反應理論提供了另一種方式,讓我們進一步從試題層面看到兩種 施測模式的不同。
Abstract
Purpose:The Taiwan version of the WHOQOL-BREF has been designed mainly for using as a self-administered questionnaire inheriting difficulties in clinical application for subjects of limitated in reading or writing. The purpose of this study is to test the difference of the face-to-face interview mode and the self-completion mode of administration on the measurement of
WHOQOL-BREF.
Methods:
A crossover study was carried out on 212 volunteers from the center of health examination clinic at a teaching hospital in central Taiwan. We divided the sample into two groups, one group used self-completion first, followed by face-to-face interview, another group used face-to-face interview first and then followed by self-completion. The outcome was the difference in
WHOQOL-BREF profiles comparing clinical based self-administration with face-to-face interview by using the classical test theory (CTT) and item response theory (IRT).
Results:
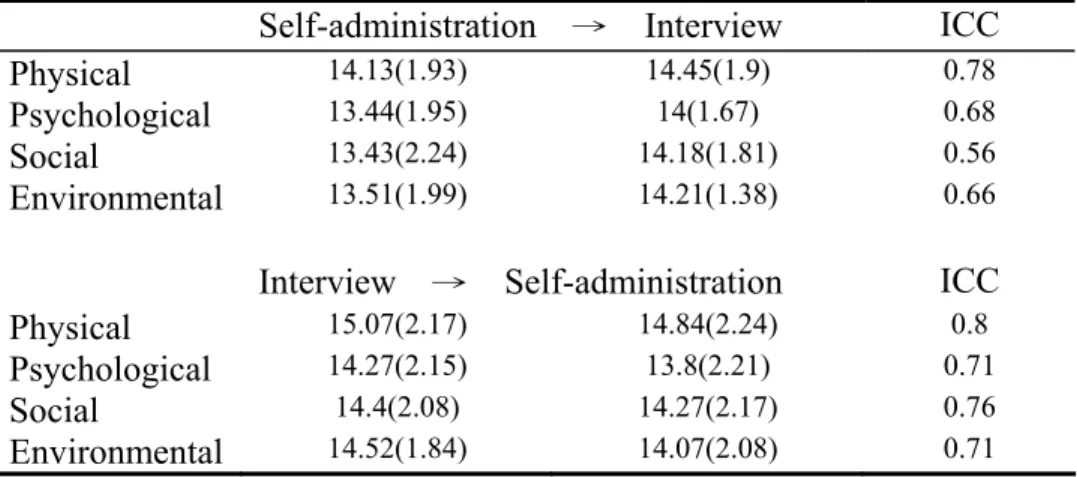
All domain scores were higher by interviews than by self-administration. The ICC indices in interview first group (0.71~0.8) were higher than those in self-administration first group (0.56~0.77). In addition, stratifying by age and gender, the reproducibility was lower for the elderly and males. Physical, psychological and environment domains demonstrated satisfactory reliability. However, the social relationships domain exhibited poor reliability.
Three items:“need medication", “negative feeling"and
sequence of item difficulty, for the item “negative feeling", males in the self-administration mode had lower scores than males in the interview mode; female had opposite result. For the item “accepting appearance", the elderly in the self-administration mode had lower scores than in the interview mode. For the items, of vague abstract in the wording requiring explaination at interview, the difference of scores between the two modes was more significant.
Significant differenential item functioning (DIF) presented in items ” pain and discomfort”, ” sexual activity” and ” opportunities”.
Conclusions:
The scores obtained from interview mode were generally higher than those by self-administration mode in WHOQOL-BREF. The patterns of compared between the two modes varied by age and gender. Compared with CTT, IRT offers a new way to show the pattern of psychological characteristic, which is more structured and detailed in the item level.
目
錄
第一章 緒論
……… 1 第一節 研究背景與研究動機……… 1 第二節 研究的重要性………... 4 第三節 研究目的……….. 4 第四節 研究問題與研究假設………... 5 第五節 名詞界定……… 6第二章 文獻查證
………... 7 第一節 WHOQOL-BREF……….. 7第二節 Patient Rrported Outcome 及相關測量準則……… 8
第三節 自我填答與面對面訪問管理模式……… 16 第四節 不同模式測量偏差的影響因素相關研究………… 20 第五節 項目反應理論看試題的心理特性的應用………… 30
第三章 研究方法
………... 33 第一節 研究設計……… 33 第二節 研究對象……… 34 第三節 研究工具的擬定……… 35 第四節 資料收集過程……… 36 第五節 資料統計與分析………... 37第四章 研究結果
………... 41 第一節 基本人口學變項之敘述統計……… 41 第二節 前後測的信度分析……… 43 第三節 組間兩種方式的比較(範疇分析)……… 48 第四節 項目反應理論分析結果………... 53第五章 討論
……….. 78第六章 結論與建議
……… 84 第一節 結論……….. 84 第二節 研究限制……….. 85 第三節 應用與建議……….. 86參考文獻
………... 87 附錄一 世界衛生組織生活品質問卷……… 93 附錄二 簡易心智狀態問卷調查表………. 95Table contents
Table 1. Taxonomy of PROs used in clinical trials……….. 10 Table 2. Demographic characteristic of self-administration first group and
interview first group………... 42
Table 3. Physician-diagnosed chronic condition distrubtion in self-administrated
first and face-to-face interview first………. 42
Table 4. Reproductivity of domain score among two measurements within each
group ……… 45 Table 5. Reproductivity of self-administration and interview in domain scores of
WHOQOL-BREF for each group stratified by gender, age, education and
disease status.……….. 47
Table 6. Cronbach’s alpha, mean score of each item and comparison between
self-administration first group and face-to-face interview first group…… 55 Table 7. Cronbach’s alpha, mean score of each item and comparison between
self-administration first group and face-to-face interview first group for
male………. 56
Table 8. Cronbach’s alpha, mean score of each item and comparison between self-administration first group and face-to-face interview first group for
female………... 57
Table 9. Cronbach’s alpha, mean score of each item and comparison between self-administration first group and face-to-face interview first group for
age < 65 years……….. 58
Table 10. Cronbach’s alpha, mean score of each item and comparison between self-administration first group and face-to-face interview first group for age
≧ 65 years……… 59
Table 11. Item difficulty, infit statistics, and personal separation reliability of each item among self-administration first group and face-to-face interview
first group (arranged by item difficulty within each domain) ……… 62 Table 12. Comparison of internal consistent reliability between CTT and IRT
among self-administration first group and face-to-face interview first
group……….. 63
Table 13. Item difficulty, infit statistics, and personal separation reliability of each item among self-administration first group and face-to-face interview first group for male (arranged by item difficulty within each domain)………. . 66 Table 14. Item difficulty, infit statistics, and personal separation reliability of each
item among self-administration first group and face-to-face interview first group for female (arranged by item difficulty within each domain).…… 70 Table 15. Item difficulty, infit statistics, and personal separation reliability of each
item among self-administration first group and face-to-face interview first group for age<65 years (arranged by item difficulty within each domain)age 40-64 years, according to the item order of the
WHOQOL-BREF ……….. 73
Table 16. Item difficulty, infit statistics, and personal separation reliability of each item among self-administration first group and face-to-face interview
Figure contents
Figure 1. The PRO Instrument Development and Modification Process…………... 13 Figure 2. Comparison of mean score of each domain in the WHOQOL-BREF
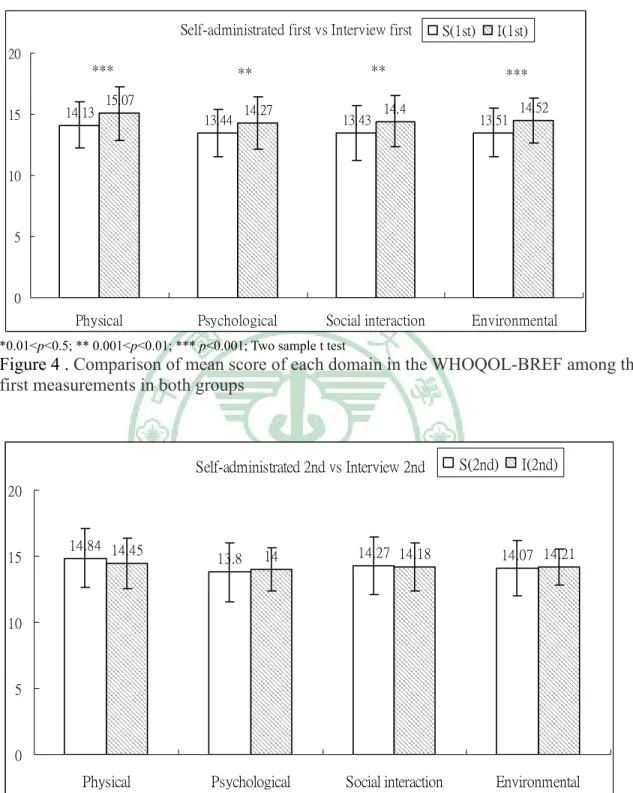
among two measurements in self-administrated first group……… 44 Figure 3. Comparison of mean score of each domain in the WHOQOL-BREF
among two measurements in face-to-face interview first group…………... 44 Figure 4. Comparison of mean score of each domain in the WHOQOL-BREF
among the first measurements in both groups……….... ……….. 50 Figure 5. Comparison of mean score of each domain in the WHOQOL-BREF
among the second measurements in both groups……….. 50 Figure 6. Comparison of mean score of each domain in the WHOQOL-BREF
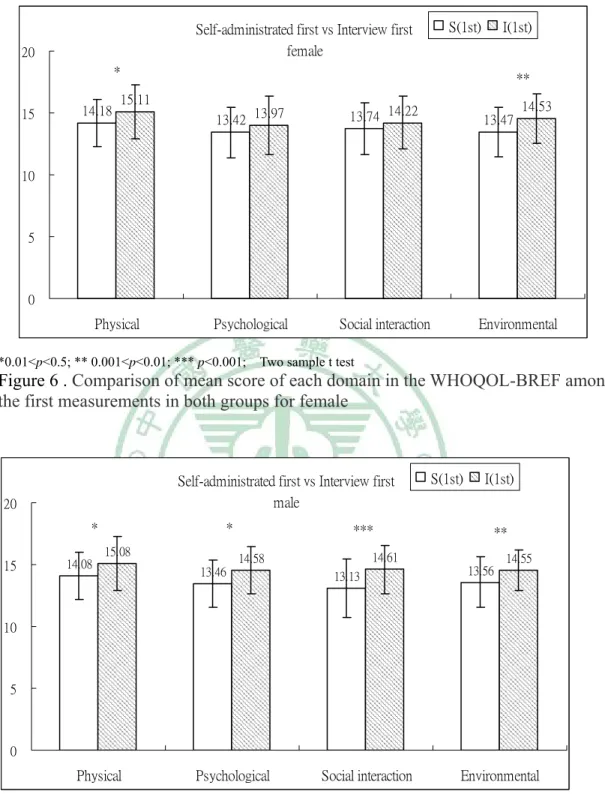
among the first measurements in both groups for female………. 51 Figure 7. Comparison of mean score of each domain in the WHOQOL-BREF
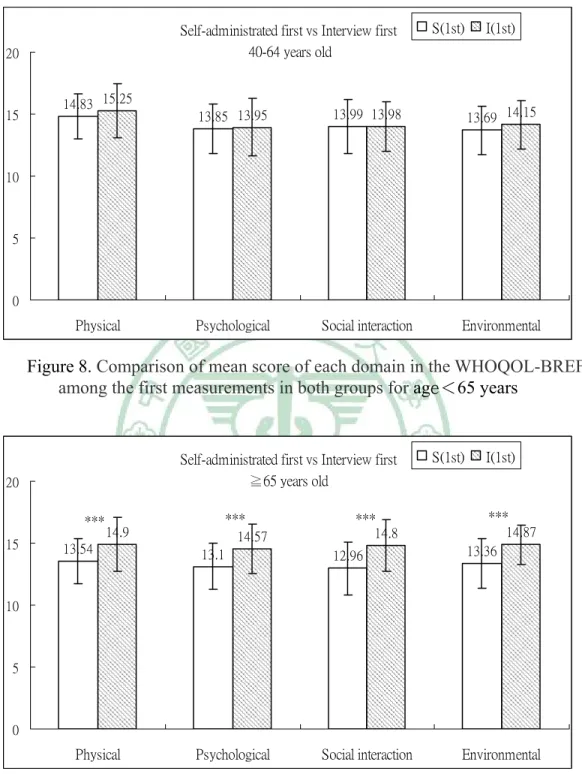
among the first measurements in both groups for male………. 51 Figure 8. Comparison of mean score of each domain in the WHOQOL-BREF
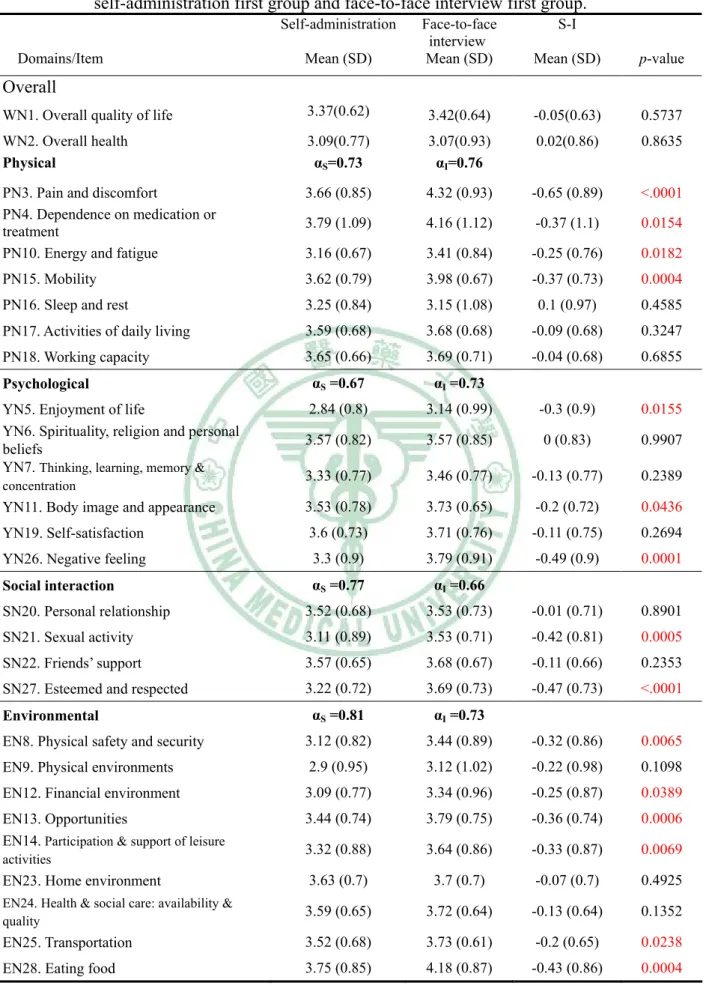
among the first measurements in both groups for age<65 years……… 52 Figure 9. Comparison of mean score of each domain in the WHOQOL-BREF
among the first measurements in both groups for age≧65 years………. 52 Figure 10. DIF analysis among the mode of self-administration first and the mode
of face-to-face interview first in each domain of WHOQOL-BREF…… 63 Figure 11. DIF analysis among the mode of self-administration first and the mode
of face-to-face interview first in each domain of WHOQOL-BREF for
male……….. ………….. ………….. ………….. ………. 67
Figure 12. DIF analysis among the mode of self-administration first and the mode of face-to-face interview first in each domain of WHOQOL-BREF for
female……….. ………….. ……….. ………….. ……… 71
Figure 13. DIF analysis among the mode of self-administration first and the mode of face-to-face interview first in each domain of WHOQOL-BREF for
female age 40-65 years………….. ………….. ……… 74
Figure 14. DIF analysis among the mode of self-administration first and the mode of face-to-face interview first in each domain of WHOQOL-BREF for
第一章
緒論
第一節
研究背景與研究動機
面訪(face-to-face Interview)方式與自我填答(self-administration)方式是 資料收集的兩種主要實施模式(two main common modes of administration of data collections),針對問卷調查,面訪又可稱為訪談式問卷調查法,自我填 答方式則稱為自我填答式問卷調查法。兩者的主要區分可從資料收集過程的 管理模式來看,訪談式問卷調查法主要由訪談者來實施問卷的填寫,而自我 管理式問卷調查法則主要由受訪者來實施問卷的填寫1。 面訪是訪問調查者透過口頭交談等模式向被訪問者了解所要的訊息,是 一種最古老、最普遍的資料收集方法,其特點在於整個訪談過程是訪問者與 被訪問者互相影響、互相作用的過程,訪談者可以創造和諧的調查氣氛,可 以獲得較高的應答率,但相對地其結果可能會受到訪談者個人特質、雙方互 動的過程等之影響,而影響到測量的品質,其誤差尤其對於測量心理感受的 題目特別的敏感,此外面訪花費的人力、物力、財力較大,也比較費時1。 自我填答(self-administration)方式因由受訪者自己填答問卷,則相對能 避免上述所提及的面訪方式所具有的缺點,但由於少了彼此的互動,其缺點 是應答率(分為問卷的回收及答題的完整性)降低、尤其是問卷的完整性部 份,此外針對不識字的老人、視力狀況不佳者、疾病患者等,因缺少了彼此 的互動及關心,造成問卷施測不易實施。故許多生活品質問卷,在資料搜集 的管理模式上,原則上均建議採用自我填答方式,而針對不易採用自我填答 方式者,則採用面訪或由代理人代為回答2-4,有關代理人所可能產生的誤差 討論常見於文獻5-9。 根據世界衛生組織將生活品質定義為『個人在所生活的文化價值體系中
的感受程度,這種感受程度與個人目標、期望、標準、及關心等方面有關。』。 世界衛生組織(World Health Organization, WHO)於 1991 年開始,結合了 15 個國家發展了一份與健康相關生活品質問卷,定名為「世界衛生組織生 活品質問卷(WHOQOL-100)」10,11。台灣於1997 年由姚開屏等人向世界衛 生組織取得授權,組成台灣版生活品質問卷發展小組,將WHOQOL-100 原 始問卷翻譯為本國文字,並按其規定先做問卷量尺的發展,進行台灣版生活 品質問卷的研究與發展12。世界衛生組織生活品質問卷簡明版 (WHOQOL-BREF)的問卷題目是由 WHOQOL-100 的 24 個層面中各選出一 個題目,並將這24 題簡明版題目分成四個主要的範疇:生理健康範疇 (physical health domain,包含原先的生理及獨立程度範疇)、心理範疇 (psychological domain,包含原先的心理及心靈/宗教/個人信念範疇)、社會 關係範疇(social relationships domain)以及環境範疇(environmental
domain),也從一般性評量中挑選出兩個題目分別為與「整體生活品質」與 「一般健康」相關的題目各一題,並且亦提供2 題針對不同文化特質的本土 性題目,此問卷共有28 題。 WHOQOL-BREF原先本設計為自我填答(self-administration)方式請患者 自行填答問卷,但在實際執行上,尤其是老年人,自我填答的方式不容易執 行,其限制在於視力老化、問卷字太小、看不懂題目或時間短促拒絕填答, 故針對此族群,多以面訪方式來進行資料的搜集。在過去的經驗談中,面訪 方式可能造成系統性偏差(systematic error),但兩種測量方式所得到的結果 差異有多大,所見探討並不多。甚至,有鑑於此,在香港更直接發展 WHOQOL-BREF的面訪版本,用以對策13。而現今在大多數的關於此類研究 中,通常直接用面訪方式,或限制研究對象為識字者而採用自我填答方式,
義,鮮少有深入探討,若有也僅止於問卷範疇而非問卷試題。
本研究針對WHOQOL-BREF採取面訪以及自填模式,使用古典測量理 論以及項目反應理論分析其差異性,不僅僅從範疇觀點,更微觀至試題層面 進行探討。
第二節
研究的重要性
1. 可 使 研 究 者 更 瞭 解 世 界 衛 生 組 織 生 活 品 質 簡 明 版 問 卷 (WHOQOL-BREF)用於自填模式與面訪模式上的差異,臨床實際使用時 之選擇參考。 2.透過瞭解施測模式所造成差別,對可能造成的偏差,加以調節,對臨 床實際應用合併模式的整合提出可能的解決的方案,以提昇測量品質。第三節
研究目的
本研究目的為探究 WHOQOL-BREF 採用自填模式與面訪模式間的差 異 , 兼 用 古 典 測 驗 理 論 與 項 目 反 應 理 論 的 Rasch 模 式 分 析 探 討 WHOQOL-BREF 在兩收樣模式下之心理特性差異。 古典測驗理論: 1. 世界衛生組織生活品質簡明版問卷(WHOQOL-BREF)在不同施測模 式下,各範疇與各試題平均值、標準差與檢定值。 2. 內在等級相關係數指標(ICC)看同一個人在同時間點用不同施測模式 上的再現性。 項目反應理論: 1. 各範疇試題是否符合單一向度(unidimensionality)的假設。 2. 各範疇試題困難度(item difficulty)在不同施測模式上有何不同。 3. 再各範疇試題看試題差別功能(differential item functioning)。第四節
研究問題與研究假設
研究問題 (1)同一個人自填與面訪的組內範疇得分是否有差異? (2)同一個人自填與面訪的範疇再測信度是否良好? (3)在不同人口特質分層(性別、年齡)下,自填與面訪模式之再測信 度是否良好? (4) 在同一時間點上自填與面訪範疇得分差異? (5) 同一時間點上,在不同人口特質分層(性別、年齡)下,自填與面 訪 (組間)範疇和試題得分差異? (6) 使用項目反應理論看各範疇是否符合單一向度的假設。 (7) 使用項目反應理論看自填與面訪的心理計量特質? (8) 自填與面訪模式下的試題差別功能(DIF)情形。 (9) 在特定人口族群下不同模式的試題差別功能(DIF)情形。 研究假設 (1) 使用自填與面訪施測模式在問卷結果中,各範疇得分相同。 (2) 不同人口特質使用自填與面訪施測模式得分相同 (3) 針對使用自填與面訪其各試題在量尺上的刻度(item calibration)(或 難度)相同。 (4) 在不同的人口特質下,自填與面訪各試題在量尺上的刻度(item calibration)(或難度)相同。 (5) 自填與面訪並不會顯示試題差別功能(DIF)情形。第五節
名詞界定
傳統測量理論:又稱為古典測量理論或真實分數模式(true score model), 這個理論是假設任何觀察的測驗分數是由真實分數及隨機誤差兩個成 分組成的,亦即觀察分數=真實分數+隨機誤差(X=T+E)。 項目反應理論:在心理計量理論中是較近期發展的一套理論,故又稱為現代 測量理論。它是因應古典測量理論的一些限制,而發展出的一系列家族 模式,可方便評估模式與資料間之適合度,並常用在教育及心理學上的 評估上。項目反應理論主要的假設為一個人對於一個特定的題目答對 (期待)機率為人的能力與一個或以上的題目參數的聯合函數。 Rasch 分析:為項目反應理論中的一種。
試題差別功能(Differential item functioning):用於決定在不同族群的受測者 中測量值是否準確地測量相同的概念。
第二章
文獻查證
第一節
世界衛生組織生活品質問卷簡明版(WHOQOL-BREF)
本研究使用的健康相關生活品質(health-related quality of life, HRQOL) 問卷,為台灣版世界衛生組織生活品質問卷簡明版(WHOQOL-BREF),其問 卷是一個一般性的生活品質測量工具,包含生理、心理、環境與健康等四個 向度,具備發展良好之信效度指標14,版權屬於世界衛生組織及世界衛生組 織生活品質問卷台灣版研究小組所有15。 世界衛生組織生活品質計畫於1991 年開始,其目標就是為了發展一份 國際化且跨文化間可以比較的生活品質量表。世界衛生組織集合15 國 20 個中心共同發展出WHOQOL-100 問卷,其內容一共可分為六大範疇
(domains),再細分成24 個層面(facets);包括:生理範疇(physical domain)、 心理範疇(psychological domain)、獨立程度(level of independence)、社會 關係(social relationship)、環境(environment)、心靈/宗教/個人信念 (spirituality/ religion/ personal beliefs)16。後來又發展出簡明版問卷
(WHOQOL-BREF);使獨立程度併入生理範疇,宗教併入心理範疇,各層 面一個問題而成。 而WHOQOL 台灣版問卷發展小組也依照 WHOQOL 研究總部的規定, 除了WHOQOL-BREF 的 26 個題目外,還加上了「飲食」及「面子」等兩 個本土性層面的題目,同時也出版了一本「台灣簡明版世界衛生組織生活品 質問卷之發展及使用手冊」15供使用者參考。
第二節
PRO (patient reported outcome)及相關測量準則
本研究為測量WHOQOL-BREF使用兩種施測模式之間的反應差異,問 卷的施測方法一直是研究中的重要環節,影響問卷測量的準確性。 在過去,健康相關以及生活品質問卷的建構、評估問卷未予以標準化, 學界充斥著信效度參差不齊的問卷,因此,如何得到一個信效度皆佳的評估 結果,日益漸形重要,其中包括適當的評估工具、如何使用這些工具,完整 詳細的規範是亟需建立的。有鑑於此,美國食品與藥品管理局FDA(Food and Drug Administration ) 於2006年2月2日為此提出準則初稿,希望能夠讓醫療界有遵循的標準,包括 過去所通稱的「生活品質量表」、「健康生活品質量表」,未來在醫療界都將 統一以PRO(患者報告資料:Patient Reported Outcomes)方式稱呼。
「Patient-Reported Outcome Measures: Use in Medical Product
Development to Support Labeling Claims」17乃因應醫療產業發展而生,其內 容包含了引言、背景、PRO的管理觀點、如何評估PRO工具、研究設計與資 料分析。 PRO意指「直接」由病人方面所測得到的健康狀況方面的測量,而非經 過醫生或其他人解釋所得的結果。臨床研究中,PROs工具(PRO instrument) 可以用來測量對於介入一個或多個層面的病人的健康狀況稱之為PRO概 念,其概念可分為三種:1.純症狀(purely symptomatic),例如:單純的頭痛 反應;2.較複雜的概念(more complex concepts),例如:實行一些日常生活的 能力;3.極端複雜的概念(extremely complex concepts ),如本研究所測量的 健康相關生活品質。
為什麼醫學相關發展要使用PRO? 1.經常某部分療效只有病人自己知道,例如醫生使用疼痛的藥物治療, 要知道病人本身疼痛的強度以及痛苦的減輕有否,答案都在病人本身的感 受。 2.病人對療效所提供獨一無二的觀點:PRO可以測量得知病人在他們的 治療過程中所想要、期望與最重要的是什麼?要得知病人心中所期待與感覺 是非常重要的,例如:對於有氣喘相關症狀的病人,他在臨床上真正有意義 的改善應該是在於病人本身因該疾病所帶來給病人本身的衝擊減輕,而不是 單單只看肺功能值的改善。 3.正規的評估比起不正規的訪問較為可信:一個結構化的問卷,可以將 測量誤差降到最小,並確保其一致性。可以自我填答而完成的問卷,比起經 由臨床醫生或其他人來填寫完成來得好,舉例說明,自我填答完成問卷直接 反應了病人對於治療之後的反應,沒有第三者的介入觀察再報告,所以相較 於一般的觀察報告的測量值更加可信;因為觀察者與觀察者間會有誤差,除 非透過規模更大更完整的觀察者(訪員)訓練,才能降低此誤差。 但另一方面來說,PRO也可能因測量工具(問卷)使患者難以理解與填 寫,而影響其問卷效度;但儘管如此,如能擁有發展良好且適切效度的PRO 工具,它所評估的結果,是可以和專家認定的結果相吻合,所以,這也是PRO 在醫學研究中特別適合使用的因素。
(二)PRO的分類(A Taxonomy of PRO Instruments):
PRO 工具所測量的概念非常廣泛,由單一症狀(例如疼痛程度或頻率) 到整體的狀況,例如憂鬱,以及較特殊的症狀以及衝擊,像是活動力、以及 治療的感覺…等都可以被測量,所以進一步來看,PRO的概念可以是一般普 遍性的,也可以是特殊的。
有些屬性較特殊的PRO 工具會去影響到與其結合的研究,像是療效之類。
PRO 的屬性及其特性如下:
Table 1: Taxonomy of PROs Used in Clinical Trials 17
屬性 型態 欲使用的測量Intended use of the measure • 定義研究族群 • 評估效益 • 評估不良事件( Adverse events ) 測量概念 Concepts measured • 整體健康狀況 • 病徵或疾病的症狀 • 官能狀況,例如生理、心理或社會的狀況 • 自覺健康狀況(Health perceptions) • 療效滿意度或治療的偏好 • 療效評估 試題數 Number of items • 單一題一個概念 • 多題一個概念 • 多題多個層面一個概念 預期測量的族群或狀況 Intended measurement population or condition • 一般狀況 • 特殊狀況 • 族群的特殊狀況 資料收集的模式
Mode of data collection
• 訪員面訪 • 自填式
• 電腦自填或電腦輔助自填式 時間與頻率
Timing and frequency of administration • 當事件發生 • 研究中定期 • 療程的開始與結束 計分方式 Types of scores
• 某一個概念的程度(e.g., pain severity)
• 索引(Index):單個得分結合了多個相關方面或獨立 的概念 • 概況(Profile):多個分數多個相關層面 • 一系列(Battery):多個分數多個概念 • 混和的(Composite):合併索引、概況或一系列的 題目或概念的權重 Weighting of items or concepts • 所有試題和層面(Domains)權重相等 • 試題權重不同 • 層面權重不同 計分法 Response options
•視覺化量表(Visual analog scale ;VAS) •定錨分類量尺(Anchored categorized VAS) •李克特尺度量尺(Likert scale)
•等級評價量尺(Rating scale) •狀況紀錄表(Event log) •繪畫量尺(Pictorial scale) •清單(Checklist)
(三)評估PRO 工具
一份能適切測量的PRO 工具必須仰賴其發展過程及證明其測量特性。 所以在研究初始期間,新的PRO 工具可以被繼續發展或者當研究者認為其 工具不合用、不適切時則繼續修改。下列有五個部分(A-E)分別說明 PRO 評 估發展過程:A-概念架構與應用的發展(Development of the Conceptual Framework and Identification of the Intended Application);B-發展 PRO 工具 (Creation of the PRO Instrument) ;C-評估測量屬性(Assessment of
Measurement Properties) ;D-修正現有問卷(Modification of an Existing
Instrument) ;E-發展特定族群的 PRO 工具(Development of PRO Instruments for Specific Populations) 17
PRO 工具的發展及修改是非現性的一連串的多樣過程事件,有可能同 時間發生,並且不斷的重複。這個反覆的過程則是一個「循環與對話(wheel and spokes)」的圖示(如圖一所示),i 為「定義其概念架構的概念與發展」, 這個過程對病人來說很重要,決定了欲研究的族群和適用性,所以是假設其 相關都在概念之中;ii 為「問卷設計」,涵蓋產生試題、選擇收樣模式、回 答選項、問卷的編排、預測試的過程;iii 為「測試其問卷測量特性,其特 性包含得分的信度、效度和偵測改變的能力,在這部分當中,也評估收樣方 式和回答者的負擔,是否有需要增減或者反向題目,得分範圍的定義,也將 定版問卷的版面、計分規則、過程;iv 為「修改問卷」的部分,修改測量的 概念、研究的族群、研究的適用性或採樣方式。17
(四)研究設計
研究設計主要集中於對PRO 獨特性的問題,PRO 指引將其分成六個部 分(A-F) 17:
A. 一般研究擬定事項General Protocol Considerations
如果PRO測量的目標是支援所需,我們建議測量PRO概念需要具體的將 研究清楚說明:(1) 盲性與隨機分派(Blinding and Randomization);(2) 臨床 試驗的品質控管(Clinical Trial Quality Control);(3) 防止資料缺失的試驗設 計(Designing the Trial to Avoid Data Missing Due to Withdrawal From
Exposure)。 B. 測量的頻率(Frequency of Measurements) PRO評估的頻率取決於疾病自然發生史以及治療的性質,且應該符合其 已被證明的測量特性,並且計畫用以資料分析。 C. 研究持續期間(Duration of Study) 研究開始到結束所需要的時間是很重要的評估點,其中要去考慮疾病或 狀況的改善時間。一般來說,PRO所評估的時效應比預期測量效性時間長。 在對一種會日漸嚴重的疾病研究中,PRO的概念著重在於持續追蹤偵測其效 性,而非一時的改變。
D.多終點(Endpoints)的設計考慮(Design Considerations for Multiple Endpoints)
PRO 的測量終點(endpoint)是根據病人本身的症狀以及能力而評估的, 症狀的改善不必然代表功能以及心理狀態的改善;FDA 建議研究計畫應定 義其測量終點及準則,以供後續統計分析及結果解釋
E. 規劃結果的解釋(Planning for Study Interpretation)
FDA建議研究者要規劃如何將研究發現做最好的詮釋:詳盡的解釋研究 計畫發現。
F. 使用電子式PRO的注意事項(Specific Concerns When Using Electronic PRO Instruments)
電子式的PRO比起過去紙筆填寫的PRO來的容易、簡單,且更受回答者 喜愛。但也因為其特性,FDA也建議研究者使用有關電子式問卷注意事項17。
第三節 自我填答與面對面訪問管理模式
本研究特別將自填與面訪一併探討的原因在於,常常在臨床問卷使用 上,遇到病人無法自填,而由訪員面對面訪問完成問卷,究竟會造成什麼誤 差? 一般而言,雖然面對面訪問的資料收集方式,比起自填或郵寄方式,受 訪者較為喜歡18,19,但是它的花費比起其他方式來說卻較多4,18,20,21,僅管如 此,也有研究指出,在有規劃的郵寄問卷或電話訪問條件下,其回收率以及 信度也是可以和面訪比擬的18,20,21。 自填模式(self-administration)Ann Bowling將自填模式(self-administration modes)分為三類: (a)將問卷 郵寄至受測者,請受測者自行填答(PAPI)後回寄;或是直接將問卷傳遞給受 測者自填,填寫完畢後交回; (b)電子化、電腦化輔助自填; (c)電話自動語音 系統(ACASI) 22。 自我填答(self-completion)方式因由受訪者自己填答問卷,則相對能避免 上述所提及的面訪方式所具有的缺點,但由於少了彼此的互動,其缺點是應 答率(分為問卷的回收及答題的完整性)降低、尤其是問卷的完整性部份,此 外針對不識字的老人、視力狀況不佳者、疾病患者等,因缺少了彼此的互動 及關心,造成問卷施測不易實施。故許多生活品質問卷,在資料搜集的管理 模式上,原則上均建議採用自我填答方式,而針對不易採用自我填答方式 者,則採用面訪或由代理人填寫。
若問卷內容並非敏感或具威脅性的問題,自填與面訪管理模式所得到的 結果應該相差不遠,但是如果問卷內容是較敏感或具威脅性的,則自填方式 可能較面訪方式來的好。22
面訪模式(face-to-face interview)
Ann Bowling將(1)訪問模式分為三類:(a)描述:由訪員面對面訪問, 傳統的筆與紙書寫問卷(paper and pencil interview (PAPI); (b) 描述:由訪員 面對面訪問,利用電子化(個人電腦(pc)或手提電腦(CAPI))輔助訪問; (c) 描 述:由訪員訪問,打電話給受測者訪問訪問或使用問卷或電腦22。 面對面訪問則是指訪員將設計好的問卷及相關資料,以口述問卷內容的 方式當面向受訪者進行訪問。而面對面訪問與其他訪問類型最大的不同在於 訪員與受訪者之間的互動模式,訪員可以親自與受訪者實地接觸,受訪者可 以看到訪原本人。面訪期間,訪員的表現與受訪者的反應將決定訪問的成 敗,經由這樣的互動情境,完成問卷調查的工作。而面訪的優點在於訪問資 料的取得較為可信客觀、訪問內容可以深入而追根究底、時間較為寬裕、回 收率高且缺失填答者少,故樣本代表性較佳。 但在面訪的缺點有:(1)花費較昂貴。(2)面訪當中也有可能產生偏差 (bias):1. 社會期待性(social desirability) ;2. 訪視員偏差(interviewer distortion):訪視員有可能不經意的會扭曲受訪者的回答,一般而言,訪員 在訪視過程若過於主觀,而視對象而定,不去問較困難的問題、或是讓受訪 者有不舒服的感覺、不仔細聆聽受訪者的回答或是造成引導式偏差,都是在 訪員訓練要注意的。 3. 受訪者偏差(false respondents):訪視過程,受訪者 是否真能瞭解問題的意思,而做出正確的回應,若無,則造成隨機性偏差。
另外,決定進行面訪時,訪員的訓練對於面訪相當的重要,也是避免面 訪過程中可能會發生的誤差的關鍵。 訪員的訓練過程,有以下重點22: (1)對整個研究清楚的描述:訪視原不僅僅只是要做訪視工作,對於研 究目的及背景也需能夠瞭解,如此一來,訪員才能知道為何要做訪視工作, 也知道訪視工作對於此研究的重要性。 (2)知道誰是研究贊助者:這是訪視員與受訪者的權利,知道為誰工作 與誰在做此研究也是很重要的一環,他們有權利知道。 (3)對於此研究有足夠的教導:雖然我們可能沒有足夠的時間將研究方 法與問卷架構過程清楚教導說明,但我們還是儘可要讓訪視員知道並且重視 研究方法及研究目的,另外,對於問卷本身的結構以及問卷背後的意義,也 需要讓訪視員清楚。 (4)清楚解釋抽樣過程的邏輯和過程:訪視員可能不是很能夠瞭解「抽 樣」的重要性,所以研究者需將整個邏輯和過程解釋給訪視員知道。 (5)解釋受訪員可能會造成的誤差:訪視員必須要知道,他們可能不經 意的會造成結果的偏差,所以他們必須要知道可能會造成問題的所在原因。 特別是在研究較敏感的議題上,例如政治立場或道德相關議題,人們有較強 的信念,而造成結果的偏斜,這都是要避免的。 (6) 帶領訪員模擬情境:由研究者直接對訪視員演練,將同意書和問卷 正式問過,可以讓訪視員直接清楚明白工作。 (7) 教導受訪者篩選過程須知:受訪者是否為研究所需的受測者、是否 有符合研究規定、或為研究限制之對象,避免耗時費力。 (8) 訪員實際演練:研究者盡可能的安排幾次演練,讓訪員練習,從中
可以發現訪問中可能會發現的困難,進一步去討論,藉此訪員可以在真正去 訪視前更能熟練。 (9) 管理:為了確保研究資料的品質,研究者的管理是必要的,研究者 可以抽選部分資料,再行確認,或是建立訪問後的追蹤機制,都可以確保資 料品質。 (10) 解釋研究進度表:訪員必須知道,未在預定時間完成進度會對研 究造成影響的重要性,所以讓訪員清楚研究進度也是訓練訪員的一環節22。
第四節
不同模式測量偏差的影響因素相關研究
接下來,我們針對問卷施測時,可能產生的各種偏差討論。Ann Bowling22 對於各種採樣方式,提出各種的非測量誤差與測量偏差。非測量誤差的產 生,是由於研究設計上、抽樣和抽樣架構、受測者的不回應和試題漏答;測 量偏差是發生在研究工具上和資料收集的過程所產生的。不管在哪一種收樣 模式當中,都可能避免不了這兩種誤差的產生。 非測量誤差(Non-measurement error)1. 收樣的範圍(coverage for sampling)
所有的方法都需要最新的收樣訊息和在抽樣前將訊息傳達給受測者知 道,以確保涵蓋目標族群的完整性和其可能帶來的偏差形式。在屬於訪問和 郵寄性質的研究中,相當依賴完整和最新的郵寄資料,若資料不完整或沒有 及時更新,可能會造成選樣上的偏差。 電話訪問的研究中通常是隨機選號而播出的,因為在我們的電話簿中並 沒有列出號碼使用者的姓名。但這也因電話的回答與否的限制而造成選樣偏 差。 電子式的研究則限制受測者需要有個人電腦,電腦必須有網際網路功能 和個人電子信箱,這就造成了我們選樣的偏差,因為沒有上述配備的人無法 做電子式研究。而這些爭議在方法學的書籍上通常會有解決辦法而這些爭議 在方法學的書籍上通常會有解決辦法23。 2. 回應率(response rates) 在比較不同的收樣方式所造成的回應率在方法學的研究中都有比較,而 在大多數的研究中,指出在郵寄研究中特別容易造成回應率偏低24。 對於不回應的主要原因包含回應者不願意參與研究,研究者沒有辦法聯
繫到回應者(例如:做電訪時回應者剛好不在家)和受測者溝通能力上的障 礙(例如:閱讀與寫字的能力、認知退化)。進一步探討,受測者不回應受 到收樣模式的不同而影響(例如:如果受測者在寫字有困難時,顯然的在郵 寄問卷的方式上是行不通的)。 在研究當中如果回應率低的話,尤當不回應族群與回應族群之間,他們 具有不同的特徵的時候,潛藏著很大的危險,因為很有可能影響研究的信 度,造成研究的偏差,減弱了其研究結果的外推性;即使資料的品質在獲得 的過程中是好的,有偏差的樣本族群較難以去預估我們真的想知道的目標族 群。 同時也有不少的文獻報告關於不回應與回應的報告,在那些文獻當中, 探討回應者與不回應之間造成的不協調性與不確定性25,26。面對面訪問研究 比起郵寄問卷自填,長期以來被認為有較高回應率的。一個友善親切的訪 員,是可以促進受訪者回答,進而增加回應率的。 但在1990年代之前,也有文獻探討特別指出,在郵寄問卷自填模式當 中,能給予受訪者最少兩次的提醒填寫,其回應率幾乎可以達到與面訪時相 同(85%)26-28。 但在近十年,幾乎所有的方法其回應率都在降低29。有許多的研究都報 告過其在電訪、面訪和郵寄問卷時回應率的差異30。Sykes and Collins31在1980 年在英國時曾做過大樣本的研究:有兩個關於社會態度、一個生活形態的研 究,都直接比較電訪和面訪的回應率。 電訪的回應率大致上都比面訪低。也有研究指出,在自填郵寄問卷的方 式,其回應率和完成率高於在醫院分給病人自填32。 不同的收樣方式用不同的順序施測,回應率也會不同。Harris 33嘗試針 對住院病人隨機郵寄問卷,並隨後電訪完成其無回應者,比較先用電訪,在
隨後郵寄問卷完成無回應者,報告指出,先電訪者其回應率與答題率均高於 先郵寄問卷者。
3. 試題回答率(item response rates)
有較多的報告指出:郵寄較於面訪或郵寄較於電訪34,其試題的缺答率均 較來的高33。 De Leeuw35與 Zouwen的後設分析結果也發現,因為進行面訪訪員面對 回答者的時候,相對可以給予回答者些刺激,並且訪員也可以掌控當時的情 況,進而增加受測者的試題回答率。 另外,電子、電腦或電話自動語音系統問卷因程式設計防止跳題回答的 關係,所以也較不會有試題缺答的現象,但是這個方法並沒有辦法預防填答 者中途結束不填寫的現象。 即使這樣,所有的收樣管理模式都沒有辦法避免填答者中途不填寫而離 開,雖然這樣的情況,相對於面訪時比較少會發生,但是仍然是避免不了的。 尤在電訪、電子式或自動語音系統36其過程太過冗長以致於中斷受訪者 正在做的事,這種情況就特別容易發生。 另外,電子式的回答率仍然高於傳統用紙筆填寫問卷的試題回答率。 Johnson37在英國所做的關於性行為的研究中指出,關於電子式自填問卷 比起紙筆自填問卷,電子式的回答率來的較紙筆填寫問卷的方法高。 Tourangeau38也支持電子式的填答較傳統紙筆的填答有較高的試題回應 率這個結論。 測量誤差(Measurement error)
1. 社會環境以及偏見的影響(the social setting and bias)
對不同的受測者、文化差異、社會階層、不同的語言,都具有相同的意義, 並且對於這些造成的影響,可以合理化的解釋。 在實際資料收集的過程當中,也會受到問卷和回答者交互作用 (interaction)的影響,甚至電訪或面訪中,也會受到訪員的影響。 這樣的交互作用不管在訪問或是自行填寫,其實是很自然卻也不可避免 的。所以在不同的管理模式之下所造成的資料結果呈現的差異,我們是可以 預先假設並盡量避免的。雖然不是所有的研究調查者都可以去發現其回答者 在回應上的差別,但是理論上,我們知道各種管理模式差別的所在之後,在 臨床實際應用上就可以合併使用的。Tourangeau39等人認為,對於所採取的 模式(包括在訪問在內),對於其所可能造成的偏差,加以調節,也可以掌 握到問題的狀況和維持資料的品質22,40-43。 關於填寫問卷的步調和填寫問題因順序而產生的效應,如何控制與處理 22? 1. 利用電腦或其他自填問卷的方式會比起面訪更能將填寫時間的步調 放慢,因而給予回應者更多的時間思考,因此產生的回應更具準確性。 2. 面訪的優點在於問問題時,訪員可以控制、掌握問題的次序及步調。 3.電 子式和自動語音系統訪問方法的流程設計,為防止跳題回答的情況,程式設 計上通常填寫一題完畢後,下一題才會出現,但也因如此,填答者無法檢查 剛才填寫過的答案是否正確與否。 4.紙本的自填問卷因為沒有像訪員/程式 控制問卷的填答,所以填答者可以瀏覽過整份問卷,調整他們的回答。
2. 社會期待性偏差(Social desirability bias)
面對面訪問過程當中,人與人之間的互動產生社會相互作用,導致回答 者在回答問題時,考慮社會規範與社會期待,導致社會期待性偏差(回答者 的回答為符合社會期待的回答),社會期待性的回答會使研究問題的結果高
估,同時也會低估反社會性的行為,不論是社會期待性的回答或是反社會性 的回答,都屬於社會期待性偏差。 為了降低社會期待性偏差所產生的問題,除了保證資料的機密性和匿名 之外,(雖然敏感的題目會引起受訪者的防備心進而降低其答覆率)44;對於 關於有可能造成社會期待性的題目,我們可以檢查所回應的答案有沒有違反 事實、有技巧性的間接詢問問題。 對於後者這樣的一個技巧,回答者將被紀錄在一對的題目,一題是較敏 感的題目,另一題則不是,而答題時則隨機先回答其中一個問題,再將另一 題完成,整個過程當中,訪員是看不到其回答的結果。 為了要能推斷其反應是否會造成社會期待的影響,我們必須要知道其反 (非)社會期待所回答的另一個來源族群的分佈,要一個真實且隨機的過程 需要篩選過題目,並且再從其中抽樣比對45。 比起自填(例如郵寄自填),回應者通常在面訪和電訪時,在於回答中 表現出更多的正面與社會期待性的回答38,46,47,甚至於面訪時的環境也會影 響造成偏差(contextual effects) 40,48。 因此,評估帶有正面性的健康狀態、健康相關生活品質議題時,都是帶 有社會期望的行為與活動的內容,在評估反社會期待性行為時(例如抽煙), 採取面訪法或電話訪談時比起自填法,更容易低估了其反社會性的結果 19,20,40,48-52。 所以敏感的健康相關問題在面訪或電訪中是較容易被低估的(例如前列 腺疾病、泌尿道症狀)53,54。 但是也有小部分相關研究報告指出55-60,採用隨機抽樣的方式進行面訪 法與自填法,其結果並無異。 61
究設計用於有聲電子輔助訪問(audio-CASI)和面對面訪談兩種方法,隨後再 進行交換方法。他們的報告指出,收樣模式的不同並未造成其效應。但這份 文獻也指出,採取相同的模式比起不同的模式35,48,61,其結果上的差異會來 的較少,這結果建議需特別注意在混用模式的研究設計上(例如先以面訪為 基準,再郵寄追蹤)。也有其他非隨機化的研究報告也指出,電訪與面訪進 行選票和酗酒的相關議題,其結果並無差異62,63。 再者,Leeuw 35的後設分析結果發現,有小部分的差異在於電訪和面對 面訪談中,而造成社會期待性偏差。 但是Evans64卻指出不一樣的看法,交替採用面對面訪談和電化訪問於 同一組人,發現年齡大於60歲者在電訪中更易顯的焦慮或憂鬱。 Fouladi65也比較自填模式中的紙筆自填和電子式自填,問卷中的情感功 能和少部分的回應有發現到差異處。 類似的情況也在不同的自填研究中(電子郵件、郵寄、直接分派給病人 填寫)報告中,發現對於健康相關的滿意度與評估的研究,其結果並無明顯 差異32,66。 以上的研究結果並非全部一致,讓人不禁聯想到非實驗設計所帶來的效 應影響。對於回答形式所造成的差異可能歸因於選擇性偏差和回應偏差,或 者是兩群人真實存在著不同造成67。 3. 默許偏差(Acquiescence bias) 任何訪問的過程中,回答正向的回應,比起自填的狀況,要來的多出許 多,這可能起因於回答多次的「是」或者是默許偏差:從文化基礎與他人同 意一致的趨勢,因感覺填答「同意」比較填答「不同意」來的容易。 雖然這樣的情形,也有可能也有可能出現在自填模式當中,但是這樣的 情況比起訪談法還是較來的少,在古典心理學試驗中有證據顯示在自填問卷
當中因「容易」,而潛在造成其偏差,因回應者有傾向選擇最靠近問題的選 項。 通常我們會嘗試的去將其回答選項轉向以供受測者回答(例如:從強烈 的同意-強烈不同意轉成由從強烈的不同意-強烈同意)68,因在古典實驗 classic experiments證據顯示,在不同的模式中,其回答產生「yes」的情形 是不一致的。Nicholaas62指出尤在面訪及電訪的方法,證據發現比起其他的 方法,更容易產生默許偏差。 De Leeuw35的後設分析中並沒有發現在郵寄、電訪和面訪的情況之中有 其差異,但在De Leeuw更早期比較電訪與面訪研究中,後設分析中結果發 現了默認偏差的證據,其中較多許多模擬兩可(回答「不知道」或沒有回答) 和許多極端的回應出現在電訪當中。 4. 訪員偏差(Interviewer bias) 訪員的存在會讓回應者分心。如果在訪問的情況下產生過多的社會期待 性偏差的答案,這有可能是因為訪員所造成的23,69。 除此外,訪員可以在他們的能力可及之下,盡可能的維持中立的聲調、 形象,使用此法可以幫助回應者回想、以及記錄其回應。仔細的訪員訓練和 定期監督管理也可以降低訪員偏差,使用訪員間信度分析(inter-rater relability)可以檢測是否有訪員偏差的存在。而自填模式則沒有訪員偏差。 5. 選擇回應的次序 (Response-choice order: primacy and recency effects)
收樣模式中有關回應選擇所造成的偏差目前已經被報告研究。
回應者在訪談中聆聽問題後,如能在心中已有答案,並且他們能夠由他 們自行決定其選擇這是最理想。但其實這是有難度的任務,尤其是在電訪中 因看不到對方,而使得訪問過程中感到倉促而特別有時間壓力,Knauper70 報告指出電訪時間在一個問題的問與答的完成不超出1分鐘。
造成偏差的原因在於,當問卷試題呈現視覺化時(例如自填問卷),回 答者傾向於勾選他眼前第一個出現的選項,這個就是primacy effects。會發 生這種情況的原因在於回答者選擇選項的慣性,當他看到第一個選項,而如 果這個選項也是他所同意的話,他就會去選擇第一個選項,而不會在進一步 去看其他的選項。 再者,當問題的呈現是呈口語化的情況時(例如面對面訪問或電話訪問 時),回應者則會傾向於回答剛剛訪員所提供的最後唸出的選項(因為最先 想到的),並且最後一個選項他們也同意的。這個情況我們可以說是「最近 的效應」導致46,71-73。 這樣的情況也有研究證據見於電訪比較面訪的情況下,受測者在電訪中 更容易選擇較極端的答案,例如「非常滿意」相對於「極滿意」,他們則選 擇訪員最後念出的「極滿意」62,73。 有大樣本的研究在後設分析中(meta-analysis)發現,在年齡大於65歲以 上的老人70,74,有顯著的「最近的效應」發生,有可能是因為認知程度隨著 老化影響所導致75。 其他的研究報告也顯示,老年人和年輕人的回答會因研究問卷的特徵影 響而導致差異76。 6. 回憶效應 (Recall effects) 回應者在答題時需要時間回想相關的訊息,所以,管理模式的不同也會 造成影響。 在視覺化的紙本自填問卷當中,當回應者對於問題有所疑惑時,訪員可 以立即協助回應者,客觀描述問題,誘使回應者回想相關訊息,而後自行判 斷填答問題,相反的,在自行填寫模式當中,因沒有訪員立即協助,所以填 寫問卷時若有疑惑時,回應者可能用其他的方式來填答問卷23,但在這過
程,我們是無法確定回應者是真的回想到我們要問的概念。
在自填模式當中,由回應者自行判斷關於問題的相關訊息,和哪一個是 最好的回應,並不一定是指同一件事。
然而在非實驗研究設計中結果指出20,其採樣模式的不同,的確會造成 回應者在回想時的不一致20,77。
7.言語的長度 (Length of verbal response)
電話訪問的時間比起面訪所需的溝通時間,因情境較倉促的關係,所以 需要更短的時間來完成問卷35,電訪法比起面訪法,問題的開始與回答的結 束,都較為簡短31。 De Leeuw35認為在面訪當中比起電訪會得到更多的訊息,原因可能是因 為電訪法中只有言語的交流往返,互動較少,導致回應者回答問題更加快 速,而完成問題的時間則較少許多,所以,在面訪當中,是較可以接受較長 時間的過程。 8. 敏感的問題 (Sensitive information) 問卷採取自填模式比起面對面訪問和電訪,更可以增加回答者對於回答 敏感題目的意願。而為了削弱其社會期待性效應,匿名的方式多用在郵寄問 卷研究當中,因過去有報告指出,對於較敏感的健康和行為相關議題,其敏 感議題的回答是容易高估其正向行為的4,39,78,79。 因此,首要需要能知道何種是較敏感的訊息和察覺偏差的方法是很重要 的,這其中和降低社會期待性的方法有些雷同,所以,最好一開始就能夠降 低其潛在的偏差78。 敏感的題目最好是用較客觀的方式來問,自填法是大多研究在用的80。 其中較好的自填法通常是用電子聽力自填系統或電腦輔助自填系統,因
37,39,46,81 由於文獻中並沒有確定在這些模式當中他們的差異與敏感問題的效度 22。也有一些研究報告顯示,他們在比較電訪和面訪之間,電訪較能誘使回 應者更坦白的回答31,82。 但Groves83報告顯示比起電訪,個人的面對面訪談更能夠讓回應者更有 意願回答關於競爭、收入或者禁藥使用的問題。 但Smith84 和Tourangeau39他們的觀點卻與這個結果不符。 9. 回應者的喜好 (Respondent preferences) 在過去,回應者的偏好效應仍未知的時候,就有研究結果報告回應者喜 好面訪甚於電訪62,67,而喜好電子式自填甚於紙筆自填84。 在國外,電子式問卷的填答上,對於年齡65歲以上的老人85的接受度也 是很高的。
第五節
項目反應理論看試題的心理特性的應用
項目反應理論(item response theory, IRT)乃因應過去古典測量理論 (classical test theory, CTT)的限制而發展出來86-88。過去CTT的缺點在於(i)無 法將受測者表現特徵和題目的表現特徵分開看,受測者的能力就是等於題目 的得分,而在IRT之中,題目參數與潛在能力間是獨立的。(ii)過去我們知道, 同一個人,做不同份難度不一的問題,得分當然可能有所不同,表面上的得 分看似程度有差異,但實際上都是同一個人的程度,而在CTT無法解決因問 卷不同,而造成表面上程度的差異,IRT模式的表現是從觀察題目反應層級, 而不是從測驗分數反應(加總後的分數)的層級,(iii)經由IRT所提供的訊息 可以用來評估每一個題目對於所測量概念的貢獻,(iv)可用在偵測不同次族 群(subgroups)間的試題差別功能(differential item functioning, DIF)或題 目偏差,(v)可用來產生簡短,複本及特定形式的問卷,並且(vi)儘管研究對 象回答不同的問卷也可以將研究對象的分數等化(equating)89。 IRT分析可以提供的檢驗量表的心理特性和量表的品質,IRT提供一個 數學的基礎來代替傳統的方法,將量表的序位資料轉換為等距資料,並且提 供有關這些資料是否有達到測量被接受的指標。 這樣的分析可以提供量表的訊息量有:這個活動力是否適配這個潛在特 性?訪員如何使用這個量表?這一系列的活動(試題)是否可以定義在這個 潛在特性之中 所以項目反應理論不僅提供一個數學的基礎來代替傳統的方法,並且當 其他非心理學者努力地將他們的研究概念化成可操作的測量時,他們可以很 容易地了解,但是實證調查需要有一個明確的理論架構作為基礎並據以檢驗 找出適當模式整合,而不是任意找一個進階的模式來處理就可以了40,因應
以上的優點項目反應理論現在已被廣泛地用在主觀的健康測量上90。
Wang 等利用多向度 Rasch 模式調整 WHOQOL-BREF 各範疇的相關性分 析台灣國民健康局之國民健康調查資料庫,來評估建構效度並且改善問卷的 信度及估計的精確度91。DIF 分析被用來評估模式-資料的適合度,在不同 性別及年齡分層間題目難度是否會有顯著的不同,當不同分群中題目難度的 估計值最大差距大於0.5 時表示有 DIF91。 本研究,使用項目反應理論中的試題困難度來看不同收樣模式間的試題 困難度表現與適配度指標,另外,我們也用試題差別功能分析看不同收樣模 式的造成同一族群差異的心理特質。 在過去,也有研究做過問卷跨文化時,比較其心理特性差異,其中就使 用Rasch分析中的DIF功能,比較兩組在同一族群的人,使用荷蘭板和英文版 的差異92。 近年來,有相當多的研究報告使用IRT 的方式來測試跨文化的問卷試 題,不在拘泥在問卷傳統信、效度的特質,而是將試題等化,各個題目擁有 不同的困難度,以往古典測驗理論是沒有辦法將試題區別開來。 即使對什麼樣的DIF 的定義才較適當?也有很多爭辯存在。目前有個 關於測驗公平性問題的看法認為:「在某個試題上,如果多數族群和少數族 群的平均表現有所不同的話,該試題便顯示出具有DIF 的現象。」其實, 這種看法也有個缺失,那就是未考慮其他影響變項的可能性,如:原本這兩 個族群的能力就有所不同,因此才導致他們在某個試題(或某份測驗)上表 現不同。 目前,比較被心理計量學者所接受的DIF 的定義為:「來自不同族群, 但能力相同的個人,如果在答對某個試題上的機率有所不同的話,則該試題 便顯現出DIF 的現象。」有了這項定義,試題反應理論(IRT)很自然的提供
一個研究DIF 的架構,因為試題特徵函數正可以說明答對某個試題的機率, 是與受試者的潛在能力和試題的潛在特徵有某種關聯存在。因此,DIF 的定 義可以被寫成下列的操作型定義:「某個試題特徵函數如果對不同的族群而 言都不相同的話,則該試題便顯現出DIF;反之,如果跨越不同族群的試題 特徵函數都相同的話,則該試題便不具有DIF。」本文即談論試題反應理論 對診斷試題偏差(或說試題DIF)的各種方法,並舉例說明它的用法。 許多的跨文化研究更應用項目反應理論來看其相等性。Roorda將英文版 的Western Ontario and McMaster Universities osteoarthritis index (WOMAC) 問卷翻譯成荷蘭版後,除了用傳統方法看其信效度外,也使用項目反應理論 看其跨文化轉譯後的問卷,看荷蘭版試題的適合度指標是否仍符合原版問卷 單一向度的假設,並進一步再比較英文版與荷蘭版的DIF情形,來檢查在不 同的語言對同一族群,題目的重要性是否有顯著不同92。 現今DIF功能大多用在跨文化的量表研究比較相等性當中,鮮少用DIF 功能來看收樣管理模式之間的差異,在過去,多用傳統理論(cronbach alpha, internal consistent reliability , factor analysis),未曾有過用探討心理特質的項 目反應理論來比較收樣模式間的差異。
第三章
研究方法
第一節
研究設計
本研究為一橫斷式研究,採用交叉設計並便利取樣,將受測者分成兩 組,第一組先自填WHOQOL-BREF,而後過 10 分鐘再由訪員面訪 WHOQOL-BREF,則算是完成;第二組先由訪員面對面訪問 WHOQOL-BREF,而後過 10 分鐘再由受測者自填 WHOQOL-BREF,兩組 在填寫WHOQOL-BREF 之前,都會由訪員測驗簡易心智功能問卷(short portable mental state questionnaire; SPMSQ),符合標準後再納入研中,訪視 期間一併記錄受訪者基本資料以及過去病史,以便研究未來分析,本研究架 構如下: 資料來源:中國醫藥大學附設醫院中老年健檢 門診。徵得同意後,並且SPMSQ(簡易心智功 能問卷)測驗通過後,分派至各組。 先自填組n=106 自行填寫WHOQOL-BREF 先面訪組n=106 由訪員面對面訪問 WHOQOL-BREF 自行填寫WHOQOL-BREF 由訪員面對面訪問 WHOQOL-BREF 統計分析、書面資料整合、論文撰寫 10 分 鐘 後第二節
研究對象
本研究對象為中國醫藥大學附設醫院健檢門診之成年人與老年人。健檢 門診為中央健保局健保給付的項目,並又分為兩個部分,一是成年人健康檢 查,接受服務對象為四十歲以上至未滿六十五歲,每三年給付乙次,六十五 歲以上,每年給付乙次,二是老人健檢,接受服務對象則需設籍台中市(住 滿6個月)並年齡需滿70歲(民國21年12月31日以前出生者),方可參加。對象 為參與本研究的所有成年人與老年人均有加入全民健康保險。因此,本研究 之基本資料與個人病史資料均與健康檢查登記資料同步。 本研究收案其間為2006年三月至2007年四月,篩選年齡為40 歲以上之 對象,收案個數一共為212位,男性108 名及女性104 名。而研究期間,如 因不識字、視力模糊、聽力減弱…等因素無法完成兩份問卷者,或填寫 SPMSQ錯誤達兩題以上,以及不同意參與本研究者,均不納入本研究中。 在研究過程中,一共有三位訪員,訪員訓練時間長達3天,並訓練其問 卷問題台語口語問法的標準,使其過程盡其可能標準化。第三節
研究工具的擬定
本研究使用SPMSQ (Short Portable Mental Status Questionaire) 及 WHOQOL-BREF 臺灣簡明版,2000 版問卷進行施測,分別介紹如下:
(一) SPMSQ (Short Portable Mental Status Questionaire)。由Pfeiffer93,94發 展,簡便的評估認知功能,本研究用以測量老人認知狀況是否正常。此問卷 共10 題,內包含定向力、個人史、最近記憶及計算力,答錯2題以上則視為 異常93,95。 (二) WHOQOL-BREF台灣簡明版 「世界衛生組織生活品質–簡明版問卷:台灣版」WHOQOL-BREF台灣 版問卷15共由28題目所組成,其中有2題是屬於測量整體生活品質及ㄧ般健 康的題目。其餘26題主要分為四個範疇: 生理健康範疇(physical health domain)、心理範疇(psychological domain)、社會關係範疇(social relationships domain)以及環境範疇(environment domain),而在問卷計分方面,問卷中 所有題目皆是採用五點式量尺計分。本研究在分析及結果的呈現上,所有反 向題目皆經轉向,分數愈高,代表患者的生活品質愈好。範疇分數的計算為 範疇中所有題目的平均值乘上4,範疇的得分範圍為4~20分96。
第四節
資料收集過程
針對健檢中年、老年人,徵求其同意後填寫同意書,先由訪員以面對面 訪談的方式進行SPMSQ再分派到先自填組或先面訪組。先自填組則先完成 WHOQOL-BREF自填式問卷,再由訪員進行面對面訪談的方式進行 WHOQOL-BREF 的施測。先面訪組則反之。第五節
資料統計與分析
以Excel將資料建檔,並以SAS 8.2版統計分析軟體進行資料分析,以雙 樣本t檢定先自填組與先面訪組比較。然而,對於敏感議題相關的研究,最 好要有一正式評估代表性的樣本需要考量到人口基本變項(例如年齡、性 別)。過去對於一些較敏感的議題,我們在對性別、年齡分層評估其關係97。 由古典測驗理論的結果觀察到面訪範疇得分與自填平均得分的差異,再 細切至看單題平均值的差異。再用項目反應理論分析其試題,看在兩種管理 模式間的試題難度順序是否有差異,分別去看兩種模式在試題之中的感受性 差異。 內在等級相關係數分析指標 所以我們將在考量收案的人口基本變項,進行內在等級相關係數 (intraclass correlation coefficient, ICC)分析指標,進而評估組間每個範疇的 再現性(reproducibility)98,進行面訪與自填問卷結果之比較。 本研究採用SPSS10.0 英文版來分析組內相關係數 ICC 用再評估再現性 99,ICC 透過把同一測量個體的不同的等級的變化性和在全部等級和全部主 題的總變動程度以評價其可信度。 ICC 的原理公式如下: ICC coefficient:ρ
= 2 2 2 e s sσ
σ
σ
+
σe 2:組內變異量
σs 2:組間變異量
σs 2 +σe 2:組內變異量+組間變異量=總變異量
內在等級相關係數則根據Shrout &Fleiss100, ICC 值小於 0.4 則代表低度 再現性(poor reproducibility), ICC 值介於 0.4~0.7 則代表中等再現性(fair to good reproducibility), ICC 值介於 0.7~1 則代表再現性非常好(excellent reproducibility)101。
項目反應理論看不同管理模式下之心理特質
以 IRT 的 Rasch 系列模式中的 Partial credit model 來分析範疇及題目的 心理計量特質。分析項目包括:(1)以適合度指標(infit statistic)來檢驗各範疇 單一向度的假設。(2)IRT 的信度評估,受測者潛在特質的信度指標與傳統的 測量信度的Cronbach’s alpha 相同,用以比較其內在一致性。(3)題目難度的 測定值來檢驗題目難度的範圍及順序。(4)以試題差別功能 (differential item functioning, DIF)分析來檢驗性別及年齡間題目難度的順序是否相同。 (1)以適合度指標來檢驗各範疇單一向度的假設 一個範疇中的所有題目應該是要同一個方向或概念。例如,我們如果想 要測量生理健康,這個範疇的題目就不應該包含測量心理的題目。假如一個 範疇中包含許多不同概念的題目,所得分數的解釋將是困難的。在Rasch 分 析中,題目若缺少單一向度會反應在適合度檢定(misfit statistic),即當同 一範疇的題目間所測量的並非同一個概念時,misfit statistic 指標將會大於判 別標準,本研究中評估單一向度採用infit 統計量,並以 1.4 作為判別標準, 大於此值則代表此題在此範疇不符合單一向度的假設。
(2)IRT 的信度評估
Person separation reliability 是真實的變異數與獲得的誤差的比值。當誤 差愈小,這個比值就愈大。 數值的範圍為 0~1 並且結果解釋同 Cronbach’s alpha。係數為 0.7(可接 受),係數為0.8(良好),係數為 0.9(極好)。 (3)以題目難度的測定值來檢驗題目難度的範圍及順序 利用 Rasch 模式將人能力及題目難度放在同一個尺度上。當 logit 愈大, 表示題目愈難;logit 愈小,表示愈簡單。題目難度範圍愈廣愈好,並且要 準確的估計不同能力下的人需要有均勻分佈的題目難度,即盡量減少在測量 尺度上題目分佈的間隔(gap)及重疊性(redundancy)。在評估範疇中的題 目有無間隔時,我們是利用題目分佈的圖示來看每個範疇中兩個題目的間距 若大於一個logit,即表示有間隔存在。判別一組題目間難度的重疊性時, 可利用範疇平均難度(β))的2 個題目測量值的標準誤(2 standard error of measurement)。分別將兩種管理模式先依題目的難度排序,比較兩種管理模 式間的難度順序差異,若是難度順序有差異,則表示受測者填答試題時在這 兩種管理模式的感受性不同。 (4) 試題差別功能的評估 試題差別功能(DIF)主要對於不同管理模式間的估計值,來檢查在不 同的族群間題目是否有顯著不同的重要性。藉由比較兩個或以上樣本的題目 特質,評估DIF 所要呈現的是題目難度是否具有不變性。這個評估過程中, 需要分開估計每一個樣本的題目難度,並且以不同樣本題目的測量值來畫散 佈圖。在本分析中我們要比較自填及面訪是否有DIF 存在。 以本研究為例,要評估WHOQOL-BREF 的題目難度會不會因為管理模 式的不同而不同。所以需要以管理模式分群分別估計在自填與在面訪的題目
難度。以自填及面訪題目難度畫散佈圖,若是題目的難度具有的不變性,此 兩組人相對的難度估計值將會落在散佈圖中的45 度角附近。本研究中用 0.5-logit 作為評估的標準102以 45 度角的對角線往上下平移 0.5-logit,若是 兩組人相對的難度估計值落在此範圍外,就表示此題目有DIF。