在變動位元速率串流下之平順演算法
85
0
0
全文
(2) 在變動位元速率串流下之平順演算法 A Smoothing Algorithm in Variable Bit Rate Streaming. 研 究 生:謝明昇. Student:Ming-Sheng Hsieh. 指導教授:張文鐘 博士. Advisor:Dr. Wen-Thong Chang. 國立交通大學 電信工程學系碩士班 碩士論文. A Thesis Submitted to Department of Communication Engineering College of Electrical Engineering and Computer Science National Chiao Tung University In Partial Fulfillment of the Requirements for the Degree of Master of Science in Communication Engineering August 2004. Hsinchu, Taiwan, Republic of China. 中華民國九十三年八月.
(3) 在變動位元速率串流下之平順演算法 研究生:謝明昇. 指導教授:張文鐘. 博士. 國立交通大學電信工程學系碩士班. 中文摘要 隨著網路頻寬的增加與視訊壓縮技術的進步,藉由隨選視訊、即 時視訊轉播等服務,即時接收到高品質的視訊已慢慢變成可能而且可 接受。VBR constant quality 的視訊壓縮的方式可以得到較佳的品質, 不過也會造成資料流突衝(bursty)的特性,它會造網路服務較大的負 擔。這時我們就可利用平順演算法來改善這個問題,所謂平順簡單講 就是在減少資料流突衝變異情況。最佳平順演算法目的是達成速率整 體變異度最小,也就是整體速率標準差最小的一種平順演算法。本論 文首先針對此演算法的方法作介紹與探討,並將它用在實際的 video trace 上作模擬,觀察客戶端緩衝區大小與統計特性的關係,像是峰 值與標準差。根據模擬的結果再作討論與分析。其次我們引入每單位 時間傳送最小單位精確度為位元組的情況,針對所會遇到的問題作修 正,並用實際的 video trace 作模擬,最後並比較原本與修正過後表現 的差異,並探討其差異的原因。.
(4) A Smoothing Algorithm in Variable Bit Rate Streaming Student: Ming-Sheng Hsieh Advisor: Dr. Wen-Thong Chang. Institute of Communication Engineering National Chiao Tung University. Abstract With the increase of bandwidth and the progress in image compression, it has become acceptable to watch real-time high quality video through the network.. VBR compression can gain better quality but it introduces burstier traffic. This will cause a burden to the network service, making the bandwidth usage inefficient. Smoothing algorithm can deal with this problem; it can make the traffic less burstier. The optimal smoothing algorithm can optimizes the traffic in terms of the variance. In this thesis, first we introduce and analyze this algorithm; then we simulate it on real video traces, discussing the relation between buffer size and statistical data, such as peak frame size and variance. Second, we introduce the minimum unit(byte) in transmission rate to this algorithm and solve the problems it meets with. Then we simulate this algorithm on the same video trace and discuss its characteristics. Finally, we compare the original algorithm and the modified one..
(5) 誌. 謝. 研究所的生涯,已經要結束了。學習愈多才愈知自己的不足,更 明白要謙虛的道理以及終身學習的重要。 首先,我想要感謝我的指導教授張文鐘博士,以很開放的方式, 引領我進多媒體通訊的領域,並在論文裡面給我指導。還有感謝當天 的口試委員的范國清博士、余孝先博士、何文楨博士,謝謝你們當天 不吝惜提出您們的看法與指教,讓我的論文更臻完備。 其次,我要感謝我實驗室的伙伴承軒、政儒、承霈、旃偉、心賢, 大家一起砥礪打氣使研究的路不孤單;遠青、猪頭、小盧、趙爸、德 倫學長與孋雅學姐,碩一剛來,有你們親切的帶領和有經驗分享,讓 我們比較能進入狀況;學弟們,謝謝你們的幫忙、協助;室友們永隆、 明宗、震軒,謝謝你們常常和我分享生活點滴,生活上有照應。家庭 聯合會的伙伴,在我剛來新竹時人生地不熟的時候,給我人際上的支 援,讓我在這兩年課餘時還有機會接觸到其他東西,讓我有志願服務 的機會。玫伶,同鄉的好同學,謝謝妳不吝惜和我交流一些生活上的 意見。老猴,謝謝的來電,可以在研究之餘談比較輕鬆的話題。302 的全體伙伴,謝謝你們不經意捎來的問候,大學畢業後大家比較忙 了,比較少聯絡,但是每當覺得很難過或壓力很很大的時候,我常常 會想到你們,想到我們一起出遊的快樂時光,就更有力量前進。.
(6) 最後,我要感謝我的家人,爸爸、媽媽、姐姐、哥哥、弟弟,因 為你們在背後的支持,才可以讓我可以在研究上無後顧之憂;可愛 beer,讓枯躁日子增添趣味。感謝上天,也許這一切冥冥都有您的代 領,也願您看顧以上每一個關心我和我所關心的人。.
(7) 目. 錄. 中文摘要 英文摘要 誌謝 目錄 表目錄 圖目錄 第一章 緒論…………………………...……………………………………….……1 1.1 研究動機………………...…………………………………………….……1 1.2 論文架構………………...…………………………………………….……3 第二章 最佳平順演算法說明與分析………………………………..……………..4 2.1 傳輸架構……….…………………………………………..……………….5 2.2 傳輸排程上下限………………………………………….………………...6 2.2.1 傳輸下限……………………………………………………………...7 2.2.2 傳輸上限……………………………………………………………...8 2.3 可行的傳輸排程………..………………………………………………......9 2.4 最佳平順演算法 …………………………………………….…………...11 2.4.1 演算法說明………………………………………………………….12 2.5 總結 ……………………………….…………………………………….24 第三章 最佳平順演算法的模擬與討論………………..…………………………26 3.1 最佳平順演算法對 video trace 的模擬結果……………………………...27 3.2 最佳平順演算法對其他樣本 video trace 的模擬結果…………………...38 3.3 其他特性的比較…………………………………………………………..43 3.4 總結………………………………………………………………………..45 第四章 最佳平順演算法的延伸探討 ……………………………………………46 4.1 修正位元組精準度最佳平順演算法 …………………………………...46 4.1.1 原本最佳平順演算法的觀察……………………………………....46 4.1.2 位元組精準度………………………………………………………46 4.1.3 修正位元組精準度最佳平順算法…………………………………50 4.2 觀察 MBPOS 演算法標準差、峰值、速率改變次數之於緩衝區大小的 關係………………………………………………………….……………53 4.3 比較 MBPOS 與最佳平順演算法的差別……………………….............60 4.4 總結……………………………………………………………………….66 第五章 結論…………..……………………………………………………………67 參考文獻…………..…………………………………………………………………68 附錄一………………………………………………………………………………..70.
(8) 表. 目. 錄. 表 2.1 所用到的參數表……...…………………………………………….…………6 表 2.2 演算法文字說明步驟…………………….….................................................25 表 4.1 (a)OS 與 MBPOS 標準差詳細數值………………………………………….61 表 4.1 (b)OS 與 MBPOS 標準差的差值.……………………………………………61 表 4.1 (c)OS 與 MBPOS 峰值詳細數……………………………………………….63 表 4.1 (d)OS 與 MBPOS 峰值的差值………………………………………………. 63 表 4.1 (e)OS 與 MBPOS 速率改變次數詳細數值.…………………………………64 表 4.1 (f)OS 與 MBPOS 速率改變次數的差值……………………………………..65.
(9) 圖. 目. 錄. 圖 1.1 三種不同的平順演算法………………………………………………………3 圖 2.1 平順示意圖……………………………………………………………………5 圖 2.2 輸入的 video trace…………………………….……………………………….7 圖 2.3 傳輸下限 ……………………………………...…………………………….8 圖 2.4 傳輸上限 ……………………………………..……………………………..9 圖 2.5 傳輸上下限………………………………………..…………………………10 圖 2.6 不可行排程 ………………………...…………………………………...10 圖 2.7 可行排程 ...…………………………….…………………………………..11 圖 2.8 Optimal smoothing algorithm pseudo codes………………………………..12 圖 2.9 (a) ……………………………………………………………………………..13 圖 2.9 (b) ……………………………………………………………………………..14 圖 2.9 (c)(d) ………………………………………………………………………….15 圖 2.9 (e) ……………………………………………………………………………..16 圖 2.9 (f)……………………………………………………………………………...17 圖 2.9 (g) ……………………………….…………………..………………………...18 圖 2.9 (h)… …………………………………………………………………………..19 圖 2.9 (i)…. ……………..............................................................................................19 圖 2.9 (j)…. ……………..............................................................................................20 圖 2.9 (k)……………………………………………………………………………...21 圖 2.9 (l) ……………………………………………………………………………...22 圖 3.1 (a)……………………………………………………………………………...27 圖 3.1 (b)……………………………………………………………………………...29 圖 3.1 (c)……………………………………………………………………………...29 圖 3.1 (d)……………………………………………………………………………...30 圖 3.1 (e)……………………………………………………………………………...30 圖 3.2 (a) standard deviation versus buffer size……………………………………...31 圖 3.2 (b) peak frame size versus buffer size…………………………………………32 圖 3.2 (c) Normalized standard deviation versus buffer size…………………………33 圖 3.2 (d) Normalized peak frame size versus buffer size……………………………33 圖 3.3 variance and peak frame size versus buffer size(0~1024KB)………………...34 圖 3.4 (a)……………………………………………………………………………...35 圖 3.4 (b)……………………………………………………………………………...36 圖 3.4 (c)……………………………………………………………………………...38 圖 3.5 測試檔為 MTV 的結果…………………………………………………….....39 圖 3.6 測試檔為 football 的結果…………………………………………………….40.
(10) 圖 3.7 測試檔為 aladdin 的結………………………………………………………..40 圖 3.8 測試檔為 oprah 的結…………………………………………………………41 圖 3.9 ………………………………………………………………………………...42 圖 3.10 rate change times versus buffer size(不含原本未經平順的部分).………….43 圖 3.11 rate change times versus buffer size(含原本未經平順的部分)……………. 44 圖 4.1 (a)最佳平順演算法的結果…………………………………………………...47 圖 4.1 (b)位元組精確度最佳平順演算法的結……………………………………...48 圖 4.2 (a)問題 1 的情況……………………………………………………………...49 圖 4.2 (b)圖 4.2(a)的放大圖………………………………………………………….50 圖 4.3 (a)針對某 run 修正和原本的比較……………………………………………51 圖 4.3 (b)圖 4.3(a)的放大圖………………………………………………………….52 圖 4.3 (c)修正位元組精準平順算法的結果………………………………………...52 圖 4.4 (a)(b)…………………………………………………………………………. 54 圖 4.4 (c)(d)…………………………………………………………………………. 55 圖 4.5 (a)standard deviation versus buffer size……………………………………... 56 圖 4.5 (b)Normalized standard deviation versus buffer size…………………………57 圖 4.5 (c)Peak frame size versus buffer size………………………………………….57 圖 4.5 (d)Normalized peak frame size versus buffer size…………………………….58 圖 4.5 (e)Rate change times versus buffer size(不含未經平順的情形)……………..59 圖 4.5 (f)Rate change times versus buffer size(含未經平順的情形)………………..59 圖 4.6 (a)OS 與 MBPOS 標準差的比較圖………………………………………….60 圖 4.6 (b)OS 與 MBPOS 峰值的比較圖…………………………………………….62 圖 4.6 (c)OS 與 MBPOS 速率改變次數的比較圖………………………………….64 圖 b…………………………………………………………………………………..72.
(11) 第一章 緒論. 1.1 研究動機 隨著頻寬的增加與視訊壓縮技術的進步,要透過網路欣賞到高品 質的即時視訊服務,已不再是遙不可及的夢想。不過其實在傳送即時 視訊上是有許多地方要克服的,每個不同類型網路有不同的限制,更 何況每個使用者的資源也不同,原本網路規格適用性其實也不足,要 解決這樣的問題需要每個階層一起努力克服的。其中一個問題,VBR (變動位元速率) constant quality 的視訊壓縮方式雖然可以保有每個 畫面品質的一致,不過卻造成這個資料流有比較突衝(bursty)的特 性,資料量隨時間的變異度很大,這在網路服務供給面來說是一大負 擔。如果可以把它變成一個比較平緩的資料流,對整個網路的負擔應 該可以大為減輕。平順演算法就是在解決這樣問題的方法,利用客戶 端的緩衝區,用先導(work-ahead)的方式將部分資料傳到客戶端,有 了緩衝區的幫忙,就可以比較彈性調整傳輸排程,即可以讓整個資料 流較為平順。. 1.
(12) 平順演算法依不同的目標,有不同的運作方式,差異主要是在速 率增加和速率減少的情況區段選取原則的不同,像是 MCBA (minimum changes bandwidth allocation) [13]它是最小化速率改變次數,如圖 1.1(b),在速率增加或速率減少的情形都是以選取延伸愈長的區段為 目標,以達到速率改次數最小;MVBA(minimum variability) [1]最小 化整體速率的標準差,如圖 1.1(c),不管是速率增加或速率減少的情 況,都是以速率變異最小為目標,以達到整體整率標準差最小;CBA (critical bandwidth allocation) [12]最小化速率增加的次數,如圖 1.1(a), 雖然有速率增加和速率減少的情況,但是它只在最小化速率增加的次 數,在速率增加的情形採用和 MCBA 相同的選取方式,在速率減少 的情況,則是採用和 MVBA 相同的的選取方式,可以說是兩者的綜 合體。為了達成不同的目標,其選取原則也會有差異。本論文是對最 佳平順演算法作探討,它就是上面介紹的第二種平順演算法,主要是 在整體速率變異度作最佳化,最小化整體速率的標準差。最佳平順演 算法的運作方式以及其成效與分析,就是本論文的主要探討核心。. 2.
(13) (a). (b). (c). 圖 1.1 三種不同的平順演算法【註 1】. 1.2 論文架構 基本上論文的編排方式,第一章緒論,從研究動機與基本背景作 出發,第二章是平順演算法概念的介紹與最佳平順演算法的說明,第 三章則是在利用此演算法在真實 video trace 的模擬結果與分析,第四 章是架構在最小單位限制的修正演算法與其結果分析,並與原演算法 作比較,第五章則是結論。. 【註 1】圖 1.1 上圖代表速率減少的狀況,下圖代表速率增加的狀況。 3.
(14) 第二章 最佳平順演算法的說明與分析. CBR、variable quality 的視訊,對於網路服務供給面上來說,複 雜性相較起來單純,可是視訊品質在人眼感覺上並不夠好;VBR constant quality 的壓縮方式影像品質佳,由於它有資料量隨時間變異 性很大的特性,所以複雜度較高。以現今天數位視訊壓縮技術 MPEG 而言,短期的資料暴衝(burst)、資料變異,是由於 I、P、B frame 的 關係;長期則是由於 scene content 的不同。 針對像 VBR 這樣的資料,我們如果直接傳,對於整個網路服務 來說,會造成資源的浪費,網路的使用效能也不夠高。為了因應這個 問題,才有了 smoothing 技術的探討。smoothing 照字面來講,就是 使平順的意思,平順什麼呢?就是平順資料量,也是是使資料量的變 異度降低,在資料量負擔小一點的時間點多傳一點,資料量負擔大的 時間點少傳一點。最理想的狀況就是 CBR 情況,如圖 2.1(b),也就 是傳輸速率剛好為原本資料量總和取平均,都沒變就最平順,可是因 為有網路資源緩衝區大小、等待的時間的限制,造成傳輸上會受限, 所以大部分只能採取 piece-wise CBR 的方式才可行,以下均會對這些 4.
(15) 問題作探討。. I I B. B. B. B. P. I. I. B. B. B. B. P. 經過平順的資料流. 未經平順的資料流. 圖 2.1 平順示意圖(橫軸為時間,縱軸為資料量). 根據[1],經過最佳平順後,可以大大地使資料變動率降低,網 路資源的使用率可以大大的提升。以下就對最佳平順的架構與其原理 作一番探討。. 2.1 傳輸架構 用一般影像傳輸架構,伺服端(server)和用戶端(client)先建好連線 後,伺服端經由傳輸路徑將資料送至用戶端,用戶端利用其緩衝區大 小作為緩衝的要件。用戶端的緩衝區就是讓我們可以作平順(smoothing)的關鍵。藉由先導(work-ahead)將一部分視訊資料先送到客端的緩 衝區暫存,下個時刻的工作量就可減輕了,尤其當下個時刻資料量特 5.
(16) 別大的時候。其本上它的原理,就是資料量的分擔,儘可能的利用資 源。 由於針對的是視訊資料,因而有即時性的問題。伺服端傳輸的資 料量如果不及用戶端播放的資料量就會發生 underflow 的問題,接下 來的資料不夠播;伺服端傳輸量如果大於用戶端播放量和可暫存住的 量的和又會發生 overflow 的問題,會造成資料的遺失。所以由伺服端 傳至用戶端的資料必須介於這兩個限制之中,才算是有意義的排程。 如圖 2.2 所示。以下就對上下限作一番說明。. 2.2 傳輸排程上下限 N b. d (t ) D(t ) s (t ). S (t ) B (t ) L(t ). 為串流視訊資料的 frames 數。 客戶端的緩衝區大小 單位時間的播放量 播放的累積資料量 伺服端傳送給客戶端每單位時間的資料量 伺服端傳送給客客端累積資料量 客戶端所能接收的累積資料量上限 客戶端所需接收的累積資料量下限 表 2.1 所用到的參數表 6.
(17) 50 45 40. frame size(byte). 35 30 25 20 15 10 5 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.2 輸入的 video trace 【註 2】. 2.2.1 傳輸下限 S (t ) = s (1) + s (2) + ⋅⋅⋅ + S (t ) 為傳送到 t 時刻的傳送累積資料量, D(t ) = d (1) + d (2) + ⋅⋅⋅ + d (t ) 為到 t 時刻時的播放累積資料量。累積傳進來的資料. 至少要大於累積即將要播放的資料量,所以 S (t ) ≥ D(t ) ,故可得傳輸下 限: L(t ) = D(t ). (2.2-1). 如圖 2.2 就是原本的 video trace。利用 video trace 就可以建出一個下 限,圖 2.3。. 7.
(18) 250. 200. size. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.3 傳輸下限. 2.2.2 傳輸上限 傳送累積的資料量扣除播放累積的資料量必須小於緩衝區量,意 即 S (t ) − D(t − 1) ≤ b 所以 S (t ) ≤ D(t − 1) + b ;又累積傳送量不能大於全部播 放累積播放量,所以 S (t ) ≤ D( N ) 。故我們可以推出傳輸上限: B (t ) = min( D(t − 1) + b, D( N )). (2.2-2). 利用 video trace 和緩衝區大小,即可建立一個上限。如圖 2.4。. 8.
(19) 250. 200. size. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.4 傳輸上限. 2.3 可行的傳輸排程 由上已知傳輸的下限就是 L(t ) ( D(t ) ),上限就是 B(t ) ,上下限一起 看,如圖 2.5 所示。只要是符合 D(t ) ≤ S (t ) ≤ B(t ) 的傳輸排程,也就是 介於上下限之間的排程,就是所謂可行的排程,如圖 2.7 所示;不符 合的就稱為不可行排程,如圖 2.6 所示。(像圖 2.6 這個情況下,CBR 就不可行。) 9.
(20) 250. 200. size. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 14. 16. 18. 20. 圖 2.5 傳輸上下限. 250. 200. size. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 圖 2.6 不可行排程(infeasible schedules). 10.
(21) 250. 200. size. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.7 可行排程(feasible schedule). 2.4 最佳平順演算法(Optimal Smoothing Algorithm)[1] 要符合以上在上下限之間的條件就是可行,一般情況通常有很多 組可能。哪一組才是最佳的呢?根據[1]它提出一種演算法,達到了 所謂最佳,它的最佳是在 rate variability 上,也就是整體速率變異度 最小的一種平順方式,在數學統計上也就是以整體傳輸速率標準差最 小為目標,它的演算法如下所示。其證明主要是利用蓋理論(Majorization theory)[14],我們在附錄一有節錄證明,是引自[1],詳細的證明 請參考[1][14][15]。 11.
(22) 2.4.1 演算法說明 因為 CBR 是最平順的,但是整個都採 CBR 不可行,所以我們採 用 piecewise CBR 的方式,也就是由許多段 CBR 所組成的排程(schedule)。選取的方式是以可以延伸最長的片段為主,延到不能再延時,例 如碰到 underflow 或 overflow 的時候,再從那一點作轉折。轉折點都 剛好在碰到上下限的地方。其演算法的 pseudo-code[1]如圖 2.8 所示, 輸入為 video trace 和緩衝區大小,輸出為最佳化排程(optimal schedule)。 P R O C E D U R E F in d _ o p tim a l_ s c h e d u le ( d ( t ), b ) ts = 0 , te = 1, q = 0 c m a x = b , t B = 1, c m in = d (1) tD = 1 d o{ te ' = te + 1 D ( te ') − ( D ( ts ) + q ) if ( c m a x < ) te ' − ts { o u tp u t _ s e g m e n t ( t B − ts , c m a x ) ts = t B , te = t B + 1, q = B ( t B ) − D ( t B ). } e ls e if ( c m in >. B ( te ') − ( D ( ts ) + q ) || te ' = = n ) te ' − ts. { o u tp u t _ s e g m e n t ( t D − ts , c m in ) ts = t D , te = t D + 1, q = 0 } e ls e { te = te ' } } w h ile ( ts < = N ) END PROCEDURE. 圖 2.8 Optimal smoothing algorithm pseudo-codes[1]. 12.
(23) 詳細的運作方式以下文字配合圖來作說明:. 1、 假設建立好原本的上下限,如圖 2.9(a)。. 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(a) 【註 3】. 2、由時間點 1 至 2 的一個單位時間間隔,我們可以決定初始的最大 速率 cmax=(B(2)-B(1))/(2-1)=B(2)-B(1),最小傳輸速率 cmin= (D(2)- D(1))/(2-1)=D(2)-D(1)。cmax、cmin 分別代表圖中上下兩條 斜線段的斜率,也就是在這個時間間隔內所容許的最大傳輸速率 與最小傳輸速率,如圖 2.9(b)。. 13.
(24) 300. 250. 200. 此線段的斜. size. 率為 cmax 150. 100. 50. 0. 此線段的斜率為 cmin. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(b). 3、起始點相同,延伸到下一時刻,也就是由時間點 1 到 3 的兩單位 時間間隔,從起始到這個時間間隔結束點滿足需求的最大平均速 率與最小平均速率,為 cmax’與 cmin’,如圖 2.9(c)。(cmax’、cmin’ 只是用來作為判斷,並不一定可行。cmax’=(B(3)-B(1))/(3-1)= (B(3)- B(1))/2,cmin’=(D(3)-D(1)) /(3-1)= cmin’=(D(3)-D(1)) /2。). 14.
(25) 300. 250. size. 200. 150. cmax’. 100. cmin’. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 18. 20. 圖 2.9(c). 4、比較 cmax、cmin 與 cmax’、cmin’,如圖 2.9(d)。 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 圖 2.9(d) 15. 14. 16.
(26) 5、因為 cmin 大於 cmax’,case2 的情況,這意味著如果繼續用這個 時刻最小的速率去傳到下個時刻還是會 overflow,所以有必要作 速率的改變。可是這個區段有很多選擇,要選擇哪一個速率呢? 就是因為下個時刻速率變慢,而我們的目標是使變動率最小,又 這個時刻的速率最接近下一個時刻的速率的線段就是 cmin,所以 我們便選擇 cmin 為這個區段的速率。決定好的線段,如圖 2.9(e)。. 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 圖 2.9(e). 16. 14. 16. 18. 20.
(27) 6、由這個線段的結束當下一個線段的起始,也就是以時間點 2 為起 始點,由時間點 2 至時間點 3 的區間,我們又可得到初始的 cmax、 cmin,如圖 2.9(f)。. 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(f). 7、由相同的起始點,延伸到下一個時刻,也就是時間點 2 至時間點 4 的兩個時間間隔,與之前方法相同,我們可以得到 cmax’和 cmin’,如圖 2.9(g)。. 17.
(28) 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(g). 8、不在 case1、case2 的情況下,cmax’和 cmin’和原本的 cmax 和 cmin 比較可得新的 cmax、cmin。假如 cmax’小於等於 cmax 的話,就 取 cmax’為 cmax;cmin’大於等於 cmin 的話,就取 cmin’為 cmin, 否則的話,維持不變。得到時刻到這個時刻可行的 cmax、cmin, 如圖 2.9(h)。這個步驟即是在決定這個區間內可行的最大、最小 速率。. 9、由相同的起始點延伸到再下一個時刻,同上的方式,可以得到 cmax’ 和 cmin’,如圖 2.9(i)。. 18.
(29) 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 14. 16. 18. 20. 圖 2.9(h). 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 圖 2.9(i). 19.
(30) 10、比較 cmax’、cmin’與 cmax、cmin,如圖 2.9(j)。 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(j). 11、因為 cmax 小於 cmin’,為 case 1 的情況,這意味著如果繼續用 這個時刻最大的速率去傳到下個時刻還是會 underflow,所以有 必要作速率的改變。可是這個區段有很多選擇,要選擇哪一個速 率呢?因為下個時刻速率變快,而我們的目標是使變動率最小, 同 case1 的選取原則,又這個時刻的速率最接近下一個時刻的速 率的線段就是 cmax,所以我們便選擇 cmax 為這個區段的速率。 圖 2.9(k)。. 20.
(31) 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(k). 12、重覆相同的步驟,最後就可以得到我們要的結果。最後一個 run 因為 cmax 和 cmin 相同,所以我們就選擇 cmin。如此就可以得 到完整的平順排程,如圖 2.9(l)。. 21.
(32) 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 2.9(l). 針對 underflow 和 overflow 的情況,以下再作詳述: 1、case 1 的情況 (再下去會發生 underflow 的情況):cmin’ × (t+d)指的 是下個時間至少所需累積的下限資料量。cmax × (t+d)指的是繼續用 這樣速率所能累積的資料量。因為 cmin’ × (t+d)>cmax × (t+d),所以 繼續用 cmax 這樣速率傳輸是不可行的,資料量不夠,會造成 underflow,所以在 t 點時就要作速率增加,才有辦法滿足其需求。 (d 指的是時刻差) 2、case 2 的情況 (再下去會發生 overflow 的情況): 同理 cmin × (t+d) > cmax’ × (t+d)表示用最小速率傳都會 overflow 了,所以在 t 時間就 必需作速率的減少,才不會在 t+d 時間點造成 overflow。. 22.
(33) 這個演算的基本原則就是儘量延長 constant bit rate 區段的長度, 直到說碰到 case 1、case 2 種情形不得作改變才改變,改變點也就是 速轉折點,我們就稱為 critical point。所謂不得不作改變的情況就是 以同樣的速度再傳下去會造成 overflow 或是 underflow 的情形。在會 造成 overflow 的情況,我們就需要讓速度下降,同理,在會造成 underflow 的情況下,我們就要讓速度上升。當時如果是會造成 overflow, 就選擇 cmin,因為這樣的速率差異才比較小;當時如果是 underflow 的情況,就選擇 cmax,同樣也是希望跟之後速率的差異可以比較小。 簡言之,這個演算法基本就是在 constraint 下,利用 cmax 和 cmin 與 cmax’和 cmin’來當作判斷的準則。線段速率的決定在兩個情形, 一是 cmin>cmax’,一是 cmax<cmin’,一個選取 cmin,一個選取 cmax, 選取的準則就是選則讓 rate 變化最小的那一個。 這個演算法的特性,經我們的觀察可作下面陳述:一、區段延伸 愈長愈好,直到遇到需改變的地方,如 underflow 或 overflow 才作轉 折,決定區段。二、遇到需改變的地方,才決定原本的區段,區段選 擇是以速率差異最小為原則,若是遇到 overflow,也就是需要速率下 降的時候,我們會選擇 cmin;遇到 underflow,也就是需要速率上升 的時候,我們會選 cmax,因為這樣才會使前後的速率差異最小。三、 區段轉折點都在邊緣,雖然區段愈長愈好,可是區段端點需在邊緣,. 23.
(34) 如果較長但端點不在邊緣,在這樣的選取原則下並不會留下來。處理 的流程一開始決定初始的 cmax、cmin,延伸到下個時間點得到 cmax’ 和 cmin’,兩者比較,在沒遇到轉折的狀況,判斷準則如演算法說明 步驟 8,可行且愈長的會留下,然後再繼續下探,不過有時因下探的 的幾個 cmax’或 cmin’可能均不可行,所以 cmax’與 cmin’與原本的 cmax、cmin 可能不一定只差一個時間間隔,像圖 2.9(f)~(k),決定下 來的區段可能已是向後下探測試很多區段才決定出來的結果;之後由 決定好的區段的終點再當初始點,中間一些剛剛有測試過的地方,要 再重新作測試,所以這會造成運算量的增加。如果我們沒有區段端點 需在上下限邊緣的限制,區段可以延伸比較長,所以中間需重覆測試 比較短,計算量較少,可是這便不會達成最佳排程。換句話說,我們 達到最佳排程的代價就是付出較大的計算量。整個演算法其實可以用 文字歸納為幾個步驟,如表 2.2 所示。. 2.5 總結. 進行最佳平順(optimal smoothing)的流程在此作一個總整理,首 先根據緩衝區(buffer)和 playback video trace,依照 2.2-1、2.2-2 兩式 子建立上下限。接著在上下限的限制之下,利用演算法找到最平順的. 24.
(35) 一個結果。最佳平順演算法指的是在 rate variance 下的最佳化,也就 是這個排程的標準差必會小於等於其他排程的標準差。 這個演算法主要是針對 stored video 作探討,對於時況(live)影像 傳播和倒轉、快轉的問題並沒包含。針對此,有一篇是針對此篇再作 延伸至 on-line smoothing 的問題[3],另一篇是針對 buffer size 不定, 並且考慮到倒轉、快轉問題的提出的快速演算法[5]。. 1、 由起始點決定一開始的 cmax 與 cmin。 2、 從相同的起始點,延伸到下一個時刻,在這個間隔內得到 cmax'與 cmin'。 3、 比較 1、2 得到的值。 (1)假如 cmin 大於 cmax' 為 case2 的情況,決定區段, 此區段速率為 cmin。由這區段的結束當起始,回到 1。 (2)假如 cmax 小於 cmin',為 case 1 的情況,決定區段, 此區段速率為 cmax。由這區段的結束當起始,回到 1。 (3)其他情況,不決定區段,而是回到 1。 (決定目前 cmax 和 cmin 的值:cmax'和 cmin'和 原本的 cmax 和 cmin 比較可得新的 cmax、cmin。 假如 cmax'小於等於 cmax 的話,就取 cmax'為 cmax;cmin'大於等於 cmin 的話,就取 cmin'為 cmin,否則的話,維持不變。). 表 2.2 演算法文字說明步驟. 【註 2】此情況為 startup 為 1 個 frame time 的情況。 【註 3】為了說明方便,刻意將 constraint 選成會發生所有情況都的的例子。 25.
(36) 第三章 最佳平順演算法的模擬與討論. 經由上一章的介紹,對於最佳平順演算法的基本原理、方法應該 有些了解了。本章就進一步來分析最佳平順演算法實際帶來的效果有 多大。我們首先會針對單一實際的 video trace,作模擬與分析。但是 如果只針對一個視訊,普遍性不足,所以我們再會針對幾個不一樣的 video trace 來作相同的分析,看其效益是否相同;依據這些結果,我 們可以看其統計特性的關係 e.g. 緩衝區大小和標準差、峰值的關係。 通常我們在評量一個平順演算法的好壞,通常是利用它的標準差 (variance)和峰值(peak rate)的值來作評估。標準差愈小,代表整個排 程的變異度愈小,平順度愈大;標準差愈大,代表整個排程的變異度 愈大,平順度愈小。峰值愈小,代表所需預留的最大頻寬愈小。我們 以下主要探討的是標準差與 標值和緩衝區大小的關係。除此,我們 有還探討了另一個特性,也就是速率變動次數和緩衝區大小的關係。. 26.
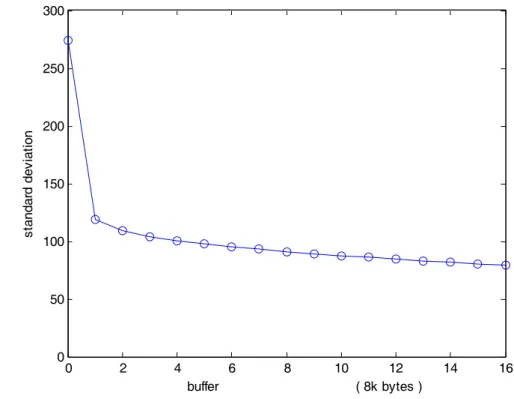
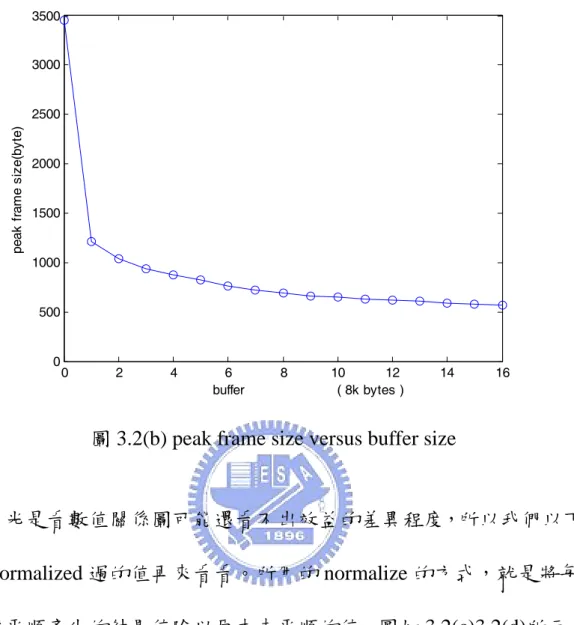
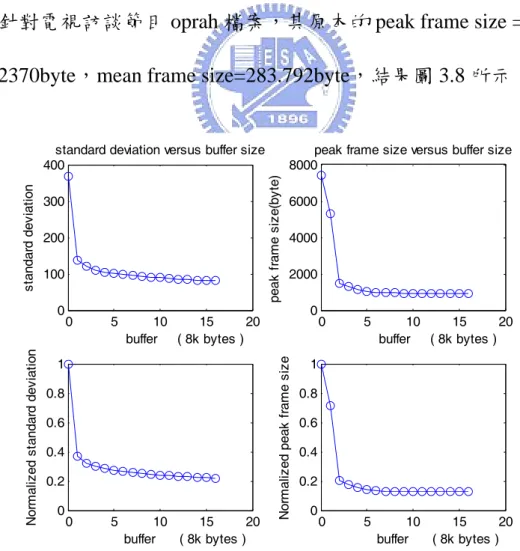
(37) 3.1. 最佳平順演算法針對 video trace 的模擬結果 測試 video 為經 MPEG4 壓縮產生的 video trace file,測試檔來源. 於[11],檔名 terminator1。它的統計資料為 mean frame size=325.6381 byte,peak frame size=3455 byte,variance = 274.2755,video trace 如 圖 3.1 所示。可以看出其變異程度相當大。. 圖 3.1(a). 以下分別就不同緩衝區大小,來看其結果: 1、以 startup delay =0.5s, buffer=8KB 情況去作 smoothing,8K 相當是 約是原本 mean frame size 的 25 倍,大約可以一次裝 25 個 frame, 27.
(38) 容許延遲大概是 0.8sec。以這樣的緩衝區去作模擬,得到結果如 圖 3.1(b)。其 peak frame size 變為 1210.1byte, variance 變為 118.4318。. 2、以 startup delay =0.5s, buffer=64KB 情況去作 smoothing,64K 相當 是約是原本 mean frame size 的 202 倍,大約可以一次裝 202 個 frame,容許延遲大概是 6.7sec。以這樣的緩衝區去跑得到結果如 圖 3.1(c)。其 peak frame size 變為 690.5363byte, variance 變為 91.0084。. 3、以 startup delay =0.5s, buffer=128KB 情況去作 smoothing,128K 相 當是約是原本 mean frame size 的 402 倍,大約可以一次裝 403 個 frame,容許延遲大概是 13.4sec。得到結果如圖 3.1(d)。其 peak frame size 變為 568.4664byte, variance 變為 79.1860。. 4、以 startup delay =0.5s, buffer=1024KB 情況去作 smoothing,1024K 相當是約是原本 mean frame size 的 3226 倍,大約可以一次裝 3226 個 frame,容許延遲大概是 1min 48sec。以這樣緩衝區去跑,得到 結果如圖 3.1(e)。peak frame size 變為 375.7135byte, variance 變為 34.4548。. 28.
(39) 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 8. 10. 12 4. x 10. 圖 3.1(b). 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 圖 3.1(c). 29. 8. 10. 12 4. x 10.
(40) 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 8. 10. 12 4. x 10. 圖 3.1(d). 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 圖 3.1(e). 30. 8. 10. 12 4. x 10.
(41) 以眼睛直觀的來看,也可以明顯看出平順程度有大大的增加,由 數據來看標準差(variance)也確實隨緩衝區大小的增加而減小,峰值 (peak rate)也是有隨緩衝區大小的增大而減小的趨勢(peak rate = peak frame size × 30)。不過光是數據分別看,可能還看不清其差異度有多 大,整合在一起關係圖可能更看的出其差別:標準差和緩衝區大小 間、峰值和緩衝區大小間關係圖如圖 3.2(a)、3.2(b)所示。 300. standard deviation. 250. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. buffer. 10. 12 ( 8k bytes ). 14. 圖 3.2(a) standard deviation versus buffer size. 31. 16.
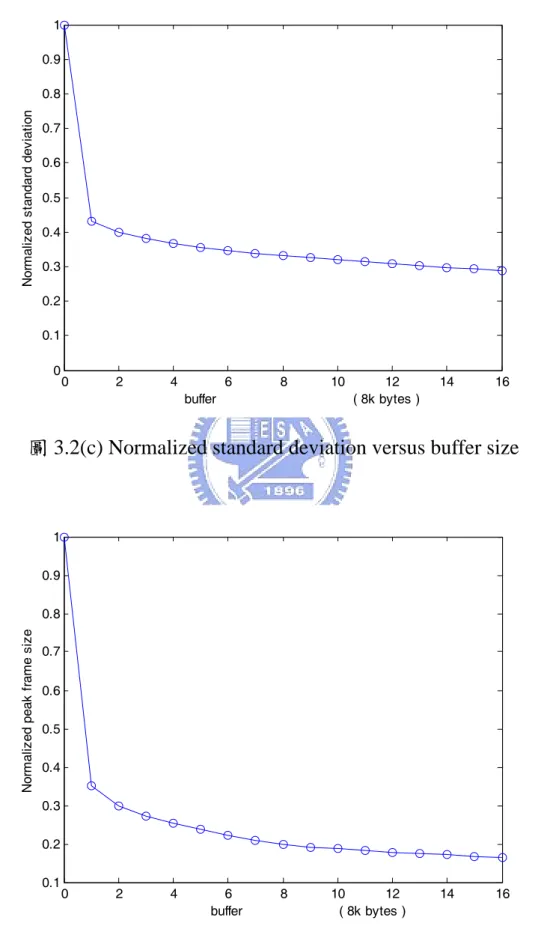
(42) 3500. 3000. peak frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 16. 圖 3.2(b) peak frame size versus buffer size. 光是看數值關係圖可能還看不出效益的差異程度,所以我們以下 用 normalized 過的值再來看看。所用的 normalize 的方式,就是將每 個經平順產生的結果值除以原本未平順的值。圖如 3.2(c)3.2(d)所示。. 32.
(43) 1 0.9. Normalized standard deviation. 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0. 0. 2. 4. 6. 8. buffer. 10. 12 ( 8k bytes ). 14. 16. 圖 3.2(c) Normalized standard deviation versus buffer size. 1 0.9. Normalized peak frame size. 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 16. 圖 3.2(d) Normalized peak frame size versus buffer size 33.
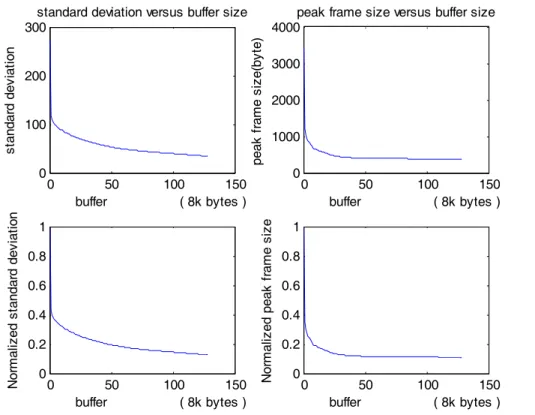
(44) 由圖 3.2(c)看出只用了 16KB 的緩衝區大小就可以將標準差降低 67%;由圖 3.2(d)看出只用了 16KB 的緩衝區大小就可以將峰值降低 80%。效益其實相當大,用一點點的緩衝區(16KB 相當可以存這樣的 video trace 50 張 frame)就可以使得原本的值降到很低。 由於以上緩衝區大小只測到 128kbyte,我們將它延深至 1024k byte 可能更看的出全面的效果。如圖 3.3 所示。. Normalized standard deviation. peak frame size(byte). 200. 100. 0. 0. 50 buffer. 0.8 0.6 0.4 0.2 0. 50 buffer. 3000 2000 1000 0. 100 150 ( 8k bytes ). 1. 0. peak frame size versus buffer size 4000. 100 150 ( 8k bytes ). Normalized peak frame size. standard deviation. standard deviation versus buffer size 300. 0. 50 buffer. 100 150 ( 8k bytes ). 0. 50 buffer. 100 150 ( 8k bytes ). 1 0.8 0.6 0.4 0.2 0. 圖 3.3 variance and peak rate versus buffer size(0~1024KB). 34.
(45) 因為個演算法本來就是在標準差上作上的最佳化,每一段都儘量 延伸,當緩衝區愈大的時候,可以選擇的區間愈大,可以選到一個延 伸更遠不轉折的線段的可能性也愈大,而且它在轉折的選擇上也是選 取使速率改變最小的線段,所以標準差會隨著緩衝區增大而漸減。不 過對峰值而言,光是可以延伸愈遠不變,並不表示 rate 就一定比較 小,不過因為緩衝區愈大,轉折愈少,需要一下子 rate 爬升的機會也 會減少,rate 變小的機率也比較大,但這似乎不也意味峰值也必然因 此減少。有關峰值隨緩衝區變大而變小的原因,詳細說明如下。. accumulative data. frame index. 圖 3.4(a). [5]中有證明 buffer size 大的轉折點是 buffer size 小的轉折點的子 集,所以我們可以作以下的假設。圖 3.4(a)虛線部分為原本排程的某 兩兩個區段,如果我們將 buffer size 加大到轉折點不見變一個區段。 如實線所示,明顯可以看出後來的區段 peak rate 較小。因為原本的. 35.
(46) 區段雖有兩個,但是一個斜率雖小,另一個卻大,那個大的就已經超 過原本的 peak rate 了。 如果兩個區段不準,我們看更多區段的情況,圖 3.4(b)如果原本 buffer size 小的時候 schedule 如下圖的虛線,buffer size 大之後的是實 線,明顯也看出原本的 peak rate 較大。雖然最後的累積量是一樣,可 是平緩上升的方式,peak rate 會比較小。想要全部都用比較小的 rate 要累積相同的量根本就不可能,只要一段變小一點,另一段就要變大 一點,那個變大的部分就會超過平順之後的 peak rate。(這次重疊的 轉折點有三點). accumulative data. frame index. 圖 3.4(b). 圖 3.4(c)是每單位時間傳送的資料量,不是累積的資料量,虛線 是 buffer size 小的時候最佳平順的結果,實線是 buffer size 大的時候 最佳平順的結果。雖然累積的量相同,不過原本 buffer size 小的時候. 36.
(47) peak rate 比較大,由這樣的示意圖也可以看出。 所以 buffer size 愈大,peak rate 愈小也是正確的結果。只是 buffer size 大到一個程度再加大,peak rate 改變的幅度會愈來愈小,後來會 趨近理想值,也就是整個 video trace 的 mean rate。 以簡單的數學式子也可以說明:假設有四個區段 t1、t 2 、t 3 、t 4 速率不同分別是 r1 、 r 2 、 r 3 、 r 4 我們藉由增大 buffer size,大到讓原 本的轉折點消失,得到一個新的區段,其值速率為 r 。因為用原本四 區段和後來單區段增加的累積資料量相同。所以 r 為四個區段 t1、t 2 、 t 3 、 t 4 的 weighted 平均速率,我們可以到下面的式子:. r = (r1× t1 + r 2 × t 2 + r 3 × t 3 + r 4 × t 4) /(t1 + t 2 + t 3 + t 4) r × (t1 + t 2 + t 3 + t 4) = r1× t1 + r 2 × t 2 + r 3 × t 3 + r 4 × t 4 t1× (r - r1) + t 2 × (r - r 2) + t 3 × (r - r 3) + t 4 × (r - r 4) = 0. r1 、 r 2 、 r 3 、 r 4 同時有大於、小於或是同時有大於、小於、等於 r 的. 狀況上式才成立。所以可以推得: r < max(r1, r 2, r 3, r 4). (3.1-1). ( r = r1 = r 2 = r 3 = r 4 也會使上式成立,不過 r = r1 = r 2 = r 3 = r 4 代表是同一 區段,它跟原本的假設不符) 每個部分的 peak rate 都變小了,整體 peak rate 當然也變小。. 37.
(48) bytes/frame. frame index. 圖 3.4(c) 如果我們在某一時間隔想讓那時間間隔裡的峰值變小,我們就可 以調大緩衝區,大到讓一些轉折點消失,那部分的排程變會比較平 順。如果可以將彈性調整緩衝區的機制加到排程內,便可以讓整個排 程的可適性更大,資源利用也更有效率。利用這個理論,同理也可以 推出整體速率標準差會隨緩衝區愈大而愈來愈小。. 3.2 最佳順滑演算法針對其他樣本 video trace 的模擬 結果 單對某一個影片檔也許普遍度不夠,所以我們再針對幾個不同的 video trace 作平順,看其是否有相似的結果。每個樣本模擬時均設定 startup delay 為 0.5s。測試檔來源同樣於[11]。 38.
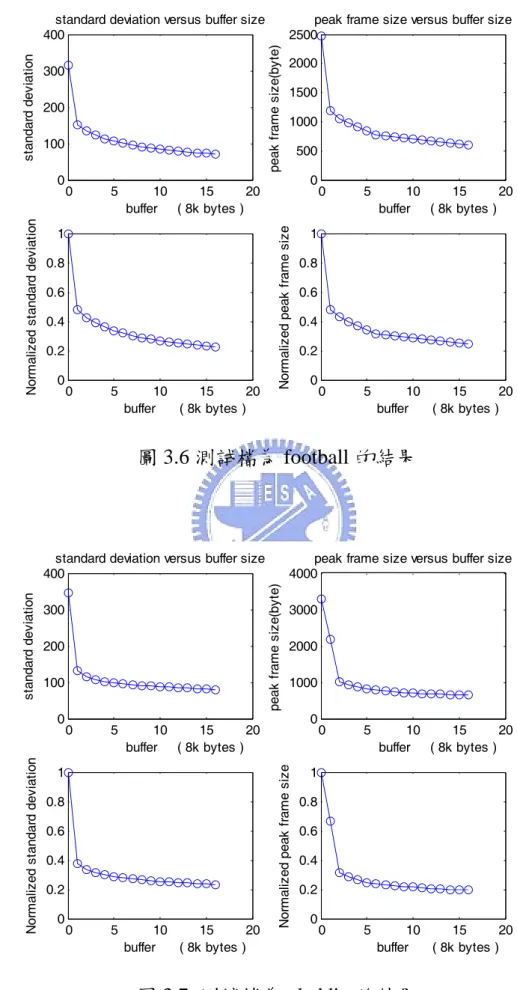
(49) 1、針對音樂錄影帶 MTV 檔案,其原本的 peak frame size=7430byte, mean frame size=349.728byte,結果如圖 3.5 所示。. 2、針對美式足球賽 football 檔案,其原本的 peak frame size = 2475byte mean frame size=355.762byte,結果圖 3.6 所示。. 3、針對卡通 aladdin 檔案,其原本的 peak frame size=3291byte, mean frame size=378.181byte,結果圖 3.7 所示。. 4、針對電視訪談節目 oprah 檔案,其原本的 peak frame size = 2370byte,mean frame size=283.792byte,結果圖 3.8 所示。. Normalized standard deviation. peak frame size(byte). 300 200 100 0. 0. 5. 0.8 0.6 0.4 0.2 0. 5. 6000 4000 2000 0. 10 15 20 buffer ( 8k bytes ). 1. 0. peak frame size versus buffer size 8000. 10 15 20 buffer ( 8k bytes ). Normalized peak frame size. standard deviation. standard deviation versus buffer size 400. 0. 5. 10 15 20 buffer ( 8k bytes ). 0. 5. 10 15 20 buffer ( 8k bytes ). 1 0.8 0.6 0.4 0.2 0. 圖 3.5 測試檔為 MTV 的結果 39.
(50) Normalized standard deviation. peak frame size(byte). 300 200 100 0. 0. 5. 0.8 0.6 0.4 0.2 0. 5. 2000 1500 1000 500 0. 10 15 20 buffer ( 8k bytes ). 1. 0. peak frame size versus buffer size 2500. 10 15 20 buffer ( 8k bytes ). Normalized peak frame size. standard deviation. standard deviation versus buffer size 400. 0. 5. 10 15 20 buffer ( 8k bytes ). 0. 5. 10 15 20 buffer ( 8k bytes ). 1 0.8 0.6 0.4 0.2 0. 圖 3.6 測試檔為 football 的結果. Normalized standard deviation. peak frame size(byte). 300 200 100 0. 0. 5. 0.8 0.6 0.4 0.2 0. 5. 3000 2000 1000 0. 10 15 20 buffer ( 8k bytes ). 1. 0. peak frame size versus buffer size 4000. 10 15 20 buffer ( 8k bytes ). Normalized peak frame size. standard deviation. standard deviation versus buffer size 400. 0. 5. 10 15 20 buffer ( 8k bytes ). 0. 5. 10 15 20 buffer ( 8k bytes ). 1 0.8 0.6 0.4 0.2 0. 圖 3.7 測試檔為 aladdin 的結果. 40.
(51) Normalized standard deviation. peak frame size(byte). 200. 100. 0. 0. 5. 0.8 0.6 0.4 0.2 0. 5. 2000 1500 1000. 10 15 20 buffer ( 8k bytes ). 500 0. 10 15 20 buffer ( 8k bytes ). 1. 0. peak frame size versus buffer size 2500. Normalized peak frame size. standard deviation. standard deviation versus buffer size 300. 0. 5. 10 15 20 buffer ( 8k bytes ). 0. 5. 10 15 20 buffer ( 8k bytes ). 1 0.8 0.6 0.4 0.2 0. 圖 3.8 測試檔為 oprah 的結果. 測試樣本含蓋電影、美式足球、訪談節目、卡通、音樂錄影帶等 各類型的動態影像檔。經由觀察,雖然因為測試樣本統計統性的不 同,造成同樣的緩衝區大小下降幅度的比例有差,不過我們可以看出 變動趨勢相當一致,同樣都是相當程度的隨緩衝區大小愈大,標準 差、峰值愈小的趨勢。所以最佳平順演算法是有普遍適用性的。 其次,我們觀察峰值與緩衝區大小的關係圖,發現到其實蠻相近 於 y=min(1/x+b,1)這個式子(b 為一個 constant offset)。我們設 b=0.1 可 得圖 3.9。. 41.
(52) 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0. 0. 10. 20. 30. 40. 50. 60. 70. 圖 3.9 總之,我們如果如道了峰值與緩衝區大小的關係,這對我們在資 源利用上會更有效率。不管是伺服端給用戶端通知,根據頻寬,要客 戶端端先預留適宜的緩衝區大小(緩衝區大小未知的情況)或者是緩 衝區大小已知,我們就可以約略估出所需的頻寬,好讓網路資源配置 的裝置可以更好管理。. 42.
(53) 3.3 其他特性的比較-速率改變次數 不過光利用 variance 來看它的平順度的衡量標準,並不一定足 夠,因為 variance 只能反映出變動幅度的大小,並不能反映出變動的 頻率。 平順的排程,除了變動幅度小之外,變動頻率小看起來才真的平 順。由平順過後的圖直觀來看是可以看出不僅變動幅度小,變動的頻 率也較低,由數值看來也是如此。圖 3.10 是速率改變次數和緩衝區 大小的關係。(所使用的測試檔也是 terminator1) rate change times versus buffer size 1400. 1200. rate change times. 1000. 800. 600. 400. 200. 0. 0. 2. 4. 6. 8 10 buffer ( 8k bytes ). 12. 14. 16. 圖 3.10 rate change times versus buffer(不含原本未經平順的部分). 43.
(54) 4. 12. rate change times versus buffer size. x 10. rate change times. 10. 8. 6. 4. 2. 0. 0. 2. 4. 6. 8 10 buffer ( 8k bytes ). 12. 14. 16. 圖 3.11 rate change times versus buffer(含原本未經平順的部分). 我們看一下緩衝區為 16kbyte 的情況,它的速率變動次只有 652, 原本的 frame 總數是 108000。這相當於說平均一個區段有 166 個 frame,這表示平均一個區段是維持 5.5sec。 因為緩衝區大小變大,所以可以找到最長不間斷的機率就大,線 段就可以儘量延伸不轉折,故 rate change 次數會比較少,但這樣的說 法雖然合理,但似乎還少了點證實,我們如果再利用[5]的證明,buffer size 大的轉折點是 buffer size 小的轉折點的子集,很明顯就可以證實 這樣的結果。 原本未經平順每個 frame size 幾乎均不同,所以 rate change 次數 近似它的 frame 個數,圖 3.11 就是將未經平順的部分考慮進去,不過 44.
(55) 因為差異懸殊,不容易看出不同緩衝區大小間的差異程度,所以我們 不考慮未經平順的部分再來看,如圖 3.10,就比較可以看出比較細微 的差異。. 3.4 總結 經由以上的模擬結果,我們可以知道最佳平順演算法對各類型的 VBR 視訊資料均有普遍的適用性。資料的峰值會隨著緩衝區的變大 而變小,標準差也是會隨著緩衝區的增大而變小。所以如果想要有比 較好的平順的表現,是需要客戶端緩衝區資源的配合才能達成。不過 光看標準差的大小有一個缺點,因為標準差的大小只能反映變動幅度 的大小,並沒法看出變動頻率的大小,所謂平順應該不只看標準差還 要看它的變動次數。比較佳的平順除了標準差變小之外,變動次數也 要變小。我們看了所跑的結果,隨著緩衝區大小的增大,速率改變次 數也遞減。有了這些關係式後,我們也許就可以利用它來作應用,像 是依據峰值和緩衝區大小的關係,我們便可根據我們現有的頻寬限制 來決定說客戶端需要預留多少緩衝區量,才能讓讓傳輸可行。. 45.
(56) 第四章 最佳平順演算法的延伸探討. 經過第三章的模擬結果之後,對於最佳平順演算法的效益應該有 更進一步的了解了。此章想就此最佳平順演算法可能可以改進的地方 或會遇到的問題再作進一步的探討。這就需要再從原本的演算法觀 察。. 4.1 修正位元組精準度最佳演算法 4.1.1 原本運作方法的觀察 觀察原本演算法的情況,它的轉折點都是在 upper bound 或 lower bound 上,整個演算法是在假設理想狀態下,也就是傳輸速率可以在 非整數的狀態下,如此可以達到最佳平順。不過在一般的情況下,每 單位時間傳的值是非最小單位整數倍並不是非常合理。所以有必要將 此演算法作一下修正,讓它可以運用在一般的環境下。. 4.1.2 位元組精準度(byte-precision) 在原本的演算法加上 byte-precision 的機制,也就是每單位時刻. 46.
(57) 傳送的最小單位是 byte 的整數倍,情況會如何呢?原本的在理想狀 態的演算法結果如 4.1(a)所示,加了 byte-precision 的機制為 4.1(b), byte-precision 的機制是將原本轉折在 lower bound 的區段,若不為整 數,作無條件進入;原本轉折在 upper bound 的區段,若不為整數, 作無條件捨去。觀察原圖 4.1(a)在轉折點確實就是在 upper bound 和 lower bound,不過在作完 byte-precision 的情況下,轉折點就不再停 在 upper bound 或 lower bound 上,反之,可能是 upper bound 下一點 的地方,或是 lower bound 上面一點的地方。兩者的輸入皆相同。 b=68,原本的 peak 為 49,variance 為 15.3379,d=[46 12 13 49 6 7 5 16 5 44 18 17 5 5 4 2 3 1 5]。 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 圖 4.1(a) 最佳順滑演算法的結果. 47. 18. 20.
(58) 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 20. 圖 4.1(b)位元組精確度最佳順滑算法的結果【註 4】. 兩個圖的結果分別是 4.1(a)的 peak 為 46,variance 為 11.0746; 4.1(b)的 peak 為 46,variance 為 11.2870。我們觀察到兩者的 critical points,除了剛開始外,中間有兩點不同原本可行的選擇後的情況變 為不可行。比較其數值,peak rate 相同,variance 是 BPOS(Byte-precision Optimal Smoothing)的方式比較大一點。兩個都是在同一限制下的可 行排程,不過原本最佳平順的標準差比較小,雖然不能直接證明最佳 平順演算法標準差最佳的特性,不過可以作為一個例子。 不過如果光取是在最佳平順演算法加上位元組精準度的方式它 可行性不算非常佳,就算是在 upper bound、lower bound 正常的情況, 還是有可能會遇到一些問題。以下就將所可能會遇到的問題列出來: 48.
(59) 1、cmax 無條件捨去有可能發生小於 lower bound 造成 underflow,所 以不可行了。2、cmin 無條件進位造成大於 upper bound 造成 overflow 所以不可行。3、final run 的 rate 取了一個非整數的 rate。 問題一的情況舉例如下,這個區段的原本的傳輸速率 14.7143 非 整數,這個總共有 7 個單位時間,一般是無條件捨棄用 14 來傳,不 過整個 run 其累積資料 14*7=98 在 lower bound (其值=101)下,如此會 產生 underflow 的狀況。. 300. 250. size. 200. 造成 underflow 的狀況,因為 cmax 無條件捨 去取整之後有 可能會低於下 限。. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 圖 4.2(a) 問題 1 的情形. 49. 14. 16. 18. 20.
(60) 280 260 240. size. 220 200 180. 發生 underflow. 160 140 7. 8. 9. 10. 11 12 frame index. 13. 14. 15. 16. 圖 4.2(b) 圖 4.2(a)的放大圖. 4.1.3 修正位元組精準度最佳平順演算法(MBPOS) 針對這種情況我們提出一種修正的方式,在遇到這種情況的時候 讓這個 run 變成兩個 run 以次數來換取可行性,前半段的 run 還是採 用和原本 run 速率相同來傳,而把剩餘的資料留在後半段的 run。(事 實上後半 run 的長度只留一個單位時間)。 以圖 4.2(a)發生的問題而為例,總共有 7 個單位時間,我們在前 6 個單位時間還是用 14 的速率來傳,最後一單位時間再 101-14*6= 17 來傳,圖 4.3(a)(b)。如此就至少可以達到那點的最低值,至於為什麼. 50.
(61) 選 cmin 呢?主要還是希望它的變異可以比較小,因為原本就是速率 不夠不情況發生 underflow,cmin 是最接近的值差異最小,所以我們 便取 cmin。同理如果是在速率大於 upper bound 的情況,也是用類似 的處理方式,只不過它最後一個單位時間的速率是選 cmax,因為原 本就是 overflow 的關係,所以選 cmax 是最接近的,這樣變異度最小。 在 final run 的情況也是用相似的方法來解決。經過修正演算法跑出來 結果如圖 4.3(c)所示。. 300. 250. size. 200. 150. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 圖 4.3(a) 針對某 run 修正和原本的比較. 51. 18. 20.
(62) 260. 修正之後 的. 240. size. 220 200. 未修正之 前的. 180 160 140 7. 8. 9. 10. 11 12 frame index. 13. 14. 15. 16. 圖 4.3(b) 圖 4.3(a)的放大圖 300. 250. size. 200. 150. 這兩處是原本 不可行,經過 修正變可行的 地方. 100. 50. 0. 0. 2. 4. 6. 8. 10 12 frame index. 14. 16. 18. 圖 4.3(c) 修正位元精準平順演算法的結果. 52. 20.
(63) 原本演算法只要是 upper bound 與 lower bound 沒有交錯,就一定 可以找到一組最佳的排程。不過在加入 byte-precision 的情況下,如 果還是直接用原本最佳平順的方式,有可能會發生不可行的狀況。針 對 byte-precision 的情況,原本的演算法需作一修正以達到可行的方 法。只追求最佳化但是有可能不可行,如果不可行,就算可以達到最 佳情況也沒有用。可行的優先順序還是優於最佳,先求可行,再看有 沒有辦法最佳化。. 4.2 觀察 MBPOS 演算法標準差、峰值、速率改變次 數之於緩衝區大小的關係 使用測試的資料和第三章第一節相同。 1、 當 buffer=8k byte 得到結果 variance=118.61,peak frame size=1211byte,如圖 4.4(a)。 2、當 buffer=64kbyte 得到結果 variance=91.348,peak frame size=691byte,如圖 4.4(b)。 3、當 buffer=128kbyte 得到結果 variance=79.535,peak frame size=569,如圖 4.4(c)。 4、當 buffer=1024kbyte 得到結果 variance=34.832,peak frame size=376,如圖 4.4(d)。 53.
(64) 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 8. 10. 12 4. x 10. 圖 4.4(a). 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 圖 4.4(b). 54. 8. 10. 12 4. x 10.
(65) 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 8. 10. 12 4. x 10. 圖 4.4(c) 3500. 3000. frame size(byte). 2500. 2000. 1500. 1000. 500. 0. 0. 2. 4. 6 frame index. 圖 4.4(d). 55. 8. 10. 12 4. x 10.
(66) 像第三章一樣我們觀察標準差之於緩衝區大小,峰值之於緩衝區 大小的關係圖。. 一、 標準差之於緩衝區大小 300. standard deviation. 250. 200. 150. 100. 50. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 圖 4.5(a) standard deviation versus buffer size. 56. 16.
(67) 1. Normalized standard deviation. 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 16. 圖 4.5(b) Normalized standard deviation versus buffer size. 二、峰值之於緩衝區大小 3500. peak frame size(byte). 3000. 2500. 2000. 1500. 1000. 500. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 圖 4.5(c) peak frame size versus buffer size. 57. 16.
(68) 1 0.9. Normalized peak frame size. 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 16. 圖 4.5(d) Normalized peak frame size versus buffer size. Normalized standard deviation. peak frame size(byte). 250 200 150 100 50. 0. 5. 0.8 0.6 0.4. 0. 5. 3000 2000 1000 0. 10 15 20 buffer ( 8k bytes ). 1. 0.2. peak frame size versus buffer size 4000. 10 15 20 buffer ( 8k bytes ). Normalized peak frame size. standard deviation. standard deviation versus buffer size 300. 58. 0. 5. 10 15 20 buffer ( 8k bytes ). 0. 5. 10 15 20 buffer ( 8k bytes ). 1 0.8 0.6 0.4 0.2 0.
(69) 三、速率改變次數之於緩衝區大小 rate change times versus buffer size 1200. 1000. rate change times. 800. 600. 400. 200. 0. 0. 2. 4. 6. 8 10 buffer ( 8k bytes ). 12. 14. 16. 圖 4.5(e) rate change times versus buffer size (不含未經平順的部分) 4. 12. rate change times versus buffer size. x 10. rate change times. 10. 8. 6. 4. 2. 0. 0. 2. 4. 6. 8 10 buffer ( 8k bytes ). 12. 14. 16. 圖 4.5(f) rate change times versus buffer size(含未經平順的部分). 59.
(70) 觀察幾個衡量的數據,我們發現 MBPOS 不論是在標準差、峰值 及速率改變次數的表現趨勢幾乎和原本的最佳平順演算法(Optimal Smoothing Algorithm)結果雷同,不過實際差別有多少,並看不太出 來,我們下節就有針對兩者細部的比較作探討。. 4.3 比較 MBPOS 與最佳平順演算法(OS)的差別 本想針對標準差、峰值及速率改變次數比較 MBPOS 與 OS 的差 異情形作比較及探討。. 一、標準差 首先我們針對標準差,觀查圖 4.6(a)可能還看不出實際的情況,只 能看出它們非常接近。我們可以由數值來比較,表 4.1(a)(b)。 300 OS MBPOS. standard deviation. 250. 200. 150. 100. 50. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 圖 4.6(a) OS 與 MPOS 標準差的比較圖 60. 14. 16.
(71) buffer size(KB). 8. 16. 24. 32. 40. 48. 56. 64. OS. 118.4 318. 109.5 624. 104.3 506. 100.6 735. 97.72 24. 95.18 68. 92.98 41. 91.00 84. MBPOS. 118.6 132. 109.7 632. 104.5 867. 100.9 357. 97.99 57. 95.47 42. 93.29 00. 91.34 85. buffer size(KB). 72. 80. 88. 96. 104. 112. 120. 128. OS. 89.20 24. 87.53 86. 85.97 72. 84.49 86. 83.09 10. 81.73 82. 80.43 81. 79.18 60. MBPOS. 89.55 00. 87.85 67. 86.26 31. 84.81 66. 83.46 53. 82.10 48. 80.76 49. 79.53 55. 表 4.1(a) OS 與 MBPOS 標準差詳細數值 buffer size(KB). 8. 16. 24. 32. 40. 48. 56. 64. difference. -0.18 13. -0.20 08. -0.23 61. -0.26 23. -0.27 32. -0.28 74. -0.30 60. -0.34 01. buffer size(KB). 72. 80. 88. 96. 104. 112. 120. 128. difference. -0.34 76. -0.31 82. -0.28 59. -0.31 80. -0.37 43. -0.36 66. -0.32 68. -0.34 94. 表 4.1(b) OS 與 MBPOS 標準差的差值. 經由觀察的結果,標準差雖非常接近,不過 OS 還是比 MBPOS 些微小一點。因為原本的最佳平順演算法中,標準差已經是理論最 佳化了。所以之後和它有稍微不一樣作法的,比它大也是很正常的 結果。不過因為這個演算法一樣是採取最小差異速率的選取原則, 所以標準差只有些微差異也是很正常的結果。 61.
(72) 二、峰值 觀察圖 4.6(b),峰值的差異也是幾乎不大,除了在 120KB 的時候 有一個明顯的差別,其他的差異並不大。同樣可用數值來比較,表 4.1(c)(d)。. 3500 OS MBPOS 3000. peak frame size. 2500. 2000. 1500. 1000. 500. 0. 2. 4. 6 buffer. 8. 10 12 ( 8k bytes ). 14. 16. 圖 4.6(b) OS 與 MBPOS 峰值的比較圖. buffer size(KB). 8. 16. 24. 32. 40. 48. 56. 64. OS. 1210. 1. 1035. 1. 938.3. 880. 822.7. 766.3. 723.6. 690.5. MBPOS. 1211. 1036. 939. 881. 824. 768. 725. 691. 62.
(73) buffer size(KB). 72. 80. 88. 96. 104. 112. 120. 128. OS. 662.3. 647.1. 631.9. 617.4. 605.2. 593. 580.7. 568.5. MBPOS. 663. 648. 632. 618. 606. 594. 615. 569. 表 4.1(c) OS 與 MBPOS 峰值詳細數值 buffer size(KB). 8. 16. 24. 32. 40. 48. 56. 64. difference. -0.86 84. -0.88 00. -0.65 63. -1.04 20. -1.32 87. -1.71 92. -1.43 15. -0.46 37. buffer size(KB). 72. 80. 88. 96. 104. 112. 120. 128. difference. -0.73 33. -0.90 37. -0.07 41. -0.55 31. -0.79 82. -1.04 33. -34.2 885. -0.53 36. 表 4.1(d) OS 與 MBPOS 峰值的差值. 經由觀察的結果,峰值雖非常接近,不過 OS 還是比 MBPOS 些微小一點。因為原本的最佳平順演算法中,峰值已經是理論最佳 化了。所以之後和它有稍微不一樣作法的,比它大也是很正常的結 果。雖然還是有愈來愈小的趨趨,但因為 MBPOS 已經不是理論上 最佳了,所以不適用[5]所推論的式子,故 buffer size 愈大,peak frame size 愈小的結論在此不成立,故才會有 120Kbyte 中 peak frame size 反而沒有變更小的結果發生。. 63.
(74) 三、速率改變次數 如圖 4.6(c)所示,圖上可以很明顯看出,MBPOS 的速率改變次 數均比 OS 小一個比例。觀察數值同樣可以明顯看出,表 4.1(e)(f)。 rate change times versus buffer size. 1400. OS MBPOS 1200. rate change times. 1000. 800. 600. 400. 200. 0. 0. 2. 4. 6. 8 buffer. 10 ( 8k bytes ). 12. 14. 16. 圖 4.6(c) OS 與 MBPOS 速率改變次數比較圖 buffer size(KB). 8. 16. 24. 32. 40. 48. 56. 64. OS. 1256. 652. 441. 340. 282. 247. 210. 195. MBPOS. 1040. 489. 318. 230. 194. 165. 140. 131. buffer size(KB). 72. 80. 88. 96. 104. 112. 120. 128. OS. 181. 166. 158. 148. 139. 132. 129. 128. MBPOS. 121. 109. 107. 103. 90. 82. 85. 81. 表 4.1(e) OS 與 MBPOS 速率改變次數詳細的數值 64.
(75) buffer size(KB). 8. 16. 24. 32. 40. 48. 56. 64. difference. 216. 163. 123. 110. 88. 82. 70. 64. buffer size(KB). 72. 80. 88. 96. 104. 112. 120. 128. difference. 60. 57. 51. 45. 49. 50. 44. 47. 表 4.1(f) OS 與 MBPOS 速率改變次數詳細的差值. 由數值觀察的結果,我們可以看到 MBPOS 比原本 OS 明顯速率 改變次數減低了。因為 OS 均是在邊緣作下個線段的起始點,當然可 以選擇的範圍比較小,所以要延更長的比例也比較小;但是 MBPOS 並不在邊緣,而是離一個距離才是起始點,這樣一來,反而讓它的選 擇範圍變大;雖然我們是用增加速率改變次數來增加它的可行性,但 在一般緩衝區大小夠大的情況,遇到 4.1 節所討論遇到那種不可行的 情況的機會其實不多,影響有限,故 MBPOS 速率改變次數會下降。 因為 OS 本來就是以標準差最小化為目標,不是以改變次數最小為目 標,所以可能會用較多的改變次數來達成標準差最小。有的平順演算 法是在最小化速率改變次數[13],它達成速率改變次數最小,不過可 能會犧牲一些標準差。標準差與速率變動次數似乎存在著 trade-off 的關係。. 65.
(76) 4.4 總結 由以上模擬結果,MBPOS 與最佳平順的結果相比是增加了些微的 標準差與峰值,但速率改變次數顯著的減少。MBPOS 可以說是 OS 修正在更實際狀況的版本,它失掉一些原本理想的特性,不過相對可 適性更大。以後如果遇到不同的最小單位限制的問題,也可以用類似 的方式解決。. 【註 4】這個限制下產生的結果剛好是特例,剛好沒發生問題,最後一個區段也 剛好是整數。. 66.
數據
![圖 2.8 Optimal smoothing algorithm pseudo-codes[1]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8384324.178353/22.892.273.649.547.1083/圖-optimal-smoothing-algorithm-pseudo-codes.webp)

+7


Outline
相關文件
➢
。當時人們發現的引擎在啟動後,機器會去尋找適合
還有一些寫卷,我們只能確認其大概書寫區域,無法將其系於
我們稱 RW 平面為相位平面 (phase plane) ,而相位平面上 的軌跡,則稱為相位軌跡 (phase trajectories) 。. 因此一個相位軌跡便是 (R,W)
觀念學習一 速率公式的變化 對應能力指標. 6-n-08
影格速率(Frame Rate )是指 Flash 動畫每 秒鐘播放的影格數,預設是 12 fps(frame per second),也就是每秒播放 12
香港是一個充滿活力的城市,各種事物總是在不斷改變,我們的人口狀況也是 一樣。根據香港特區政府統計處 2003 年進行的住戶統計調查結果顯示,香港
Motion 動畫的頭尾影格中只能有一個 Symbol 或是群組物件、文字物件;換 言之,任一動畫須獨佔一個圖層。.. Motion
