XML 文件的多值相依性與第四正規化
14
0
0
全文
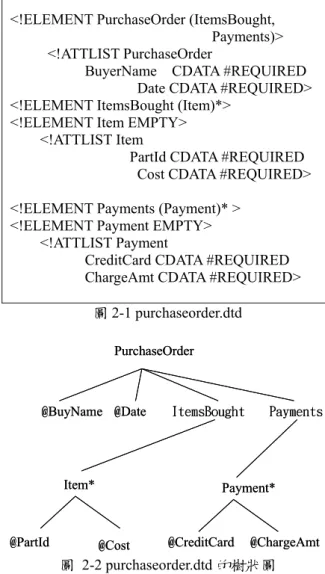
(2) 號 ε 表示元素型態是 EMPTY,S 表示#PCDATA。. 性(@)為終點,以符號表示的話,Epaths(D) = {p ∈ paths(D)|last(p) ∈ E},last(p)表示路徑 p 的終 點元素。一個 DTD 若有遞迴(recursive)的現象, 則 paths(D)將會是無限的。Leafpaths(D)表示所有 leaf path 所形成的集合, Leafpaths(D)={p ∈ paths(D)|last(p) ∉ E}。. 例子 2.1 若有一個描述購物訂單的 DTD,如圖 2-1 所示。某家商店用這個 DTD 用來標準化訂單的格 式。則 D=(E,A,P,R,r),E、A、P、R、r 分別說明如 下: E 是此 DTD 裡所有的元素型態(element type)集 合,E={PurchaseOrder,ItemsBought,Payments, Item,Payment}。 A 是 DTD 裡所有屬性集合,A= { @BuyerName,@Date,PartId,@Cost, @CreditCard , @ChargeAmt},P(ItemsBought)=Item*,P(Item)= ε, R(ItemsBought) = ε,R(Item)={@PartId ,@Cost},r 為樹根節點 PurchaseOrder。. 例子 2.2 在圖 2-2 purchaseorder.dtd 裡頭, PurchaseOrder.@Date 和 PurchaseOrder.ItemsBought.Item.@PartId 是 paths(D) 裡頭的其中兩個 path,且皆是 Leafpaths(D)裡的路 徑。PurchaseOrder.ItemsBought.Item 是 element path,屬於 Epaths(D)。 last(PurchaseOrder.ItemsBought.Item)=Item。 定義 2.3 (前序路徑,prefix path) 假如 p 是路徑 l1…ln ,q 是路徑 q1…qm,若 p 是 q 的 prefix path, 則記做 p ⊆ q,其中 n≦m,l1=q1,…,ln=qn,當 n=m 時,則 p=q。如果 p 是 q 的 prefix path,但是 p≠q,則稱 p 為嚴格的前序路徑(strict prefix path)。 令 q 是一個 path: q1…qm,定義函數 parent(q)= q1…qm-1,意即 parent 找出 q 的最大 strict prefix path。. <!ELEMENT PurchaseOrder (ItemsBought, Payments)> <!ATTLIST PurchaseOrder BuyerName CDATA #REQUIRED Date CDATA #REQUIRED> <!ELEMENT ItemsBought (Item)*> <!ELEMENT Item EMPTY> <!ATTLIST Item PartId CDATA #REQUIRED Cost CDATA #REQUIRED>. 例子 2.3 在圖 2-2 中,PurchaseOrder.ItemsBought 和 PurchaseOrder.ItemsBought.Item 都是 PurchaseOrder.ItemsBought.Item.@PartId 的 prefix path,parent(PurchaseOrder.ItemsBought.Item. @PartId)=PurchaseOrder.ItemsBought.Item。. <!ELEMENT Payments (Payment)* > <!ELEMENT Payment EMPTY> <!ATTLIST Payment CreditCard CDATA #REQUIRED ChargeAmt CDATA #REQUIRED>. 定義 2.4 (部分路徑,partial path) 假如 p 是路徑 li…ln,若有一路徑 q:l1…lm,其中 i≠1,n≦m,則 稱 p 是 q 的 partial path。. 圖 2-1 purchaseorder.dtd PurchaseOrder. 例子 2.4 圖 2-2 中,ItemsBought 和 @BuyName @Date. Item*. @PartId. ItemsBought. ItemsBought.Item.@PartId 都算是 PurchaseOrder.ItemsBought.Item.@PartId 的 partial path。. Payments. 定義 2.5 (路徑差集,path difference) 路徑差集是 一個函數,所謂路徑差集就是在給定兩個路徑 p1、 p2,找出在 p1 裡的最大 partial path,但 partial path 上的元素不可以是 p2 裡的元素,若有 2 個 path p1、 p2,則用 p1﹣p2 來表示 p1 跟 p2 的 path difference, 或以函式 difference(p1,p2)表示。. Payment*. @Cost. @CreditCard. @ChargeAmt. 圖 2-2 purchaseorder.dtd 的樹狀圖. 例子 2.5 difference(PurchaseOrder.ItemsBought.Item.@PartId, PurchaseOrder.ItemsBought)= Item.@PartId。 difference(PurchaseOrder.ItemsBought.Item.@PartId, PurchaseOrder.Payments.payment) = ItemsBought.Item.@PartId。. 定義 2.2 (路徑,path) DTD 上的 path 是一種路徑 的描述方式,在 D=(E,A,P,R,r)中,若有一節點到節 點的路徑 l1.….ln,則 li ∈ P(li-1),此處 i ∈ [2,n-1], 若是 i=1,則 l1 為 XML 樹的根節點。ln ∈ P(ln-1)或是 ln=@A,當然這時@A 會屬於 R(ln-1)。用 paths(D) 表示 D 上的所有 path 所形成的集合。Epaths(D)表 示所有元素路徑(element path)所形成的集合,也就 是 Epaths(D)裡的 paths 不可以是以字串(S)或是屬. 定義 2.6 (路徑交集,path intersection) 路徑交集 是一個函數,所謂路徑交集就是在給定兩個 path 2.
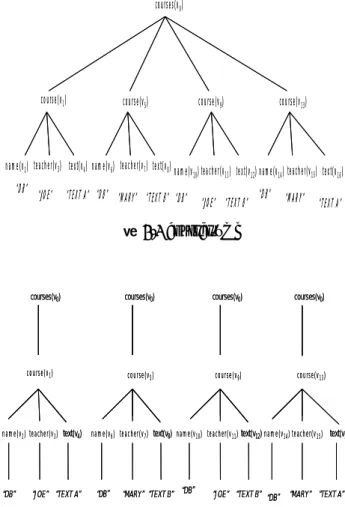
(3) ele(V1)={V2,V3},ele(V2)={1,3000}, att(V5,@CreditCard)=8342398432,root 是 V0 是 purchaseorder.xml 這個 XML 文件的根節點,如圖 2-4 所示。. 情形下,找出這兩個 path 最大的共同 prefix path。 若有 2 個路徑 p1、p2,則用 p1∩p2 來表示 p1 跟 p2 的 intersection,或以函式 intersection(p1,p2)表示。. 例子 2.6 intersection( PurchaseOrder.ItemsBought.Item.@PartId, PurchaseOrder.ItemsBought)= PurchaseOrder.ItemsBought。 intersection( PurchaseOrder.ItemsBought.Item.@PartId, PurchaseOrder.Payments.payment)= PurchaseOrder。. 定義 2.8 若有一個 DTD D=(E,A,P,R,r)和一個 XML tree T = (V,lab,ele,att,root),若有下面的情 形,則稱此 XML tree T 遵守 D。lab 是 V 對應到 E 的函數,att 是一個 partial function,任何屬於 V 集 合裡的 v 和屬於 A 集合的@l,att(v, @l)存在若且 為若 @l 屬於 R(lab(v))。lab(root)=r ,每一個在 V 集合裡的 v,如果 P(lab(v))=S,則 ele(v)=S。否則 ele(v)=[v1,…,vn],lab(v1),…,lab(vn)屬於 P(lab(v))。. 定義 2.7 (XML tree) 一個 XML tree T 為一棵樹, 用符號(V,lab,ele,att,root)來表示,其中 V 是有限的 點集合,lab 是一個函數:VÆEl,將 V 中的點(node) 對應到 E 中的元素。ele 是一個函數:VÆStr∪V*找 出 V 中的點的子節點。att 是一個 partial function:V×AttÆStr。root 是 T 的根節點。. 定義 2.9 (tree tuple) 給定一個 DTD D = (E, A, P, R, r), D 裡頭的每ㄧ個 tree tuple t 都是一個函數, t: paths(D) Æ Vert ∪ Str ∪ {⊥} 使得: 1.若 p ∈ EPaths(D),則 t(p) ∈ Vert ∪ {⊥}, 但 t(r) ≠⊥(NULL). 2.若 p ∈ paths(D) - EPaths(D),t(p) ∈ Str∪{⊥}. 3.若 t(p1) = t(p2) 而且 t(p1) ∈ Vert, 那麼 p1 會等於 p2. 4.若 t(p1)=⊥ 而且 p1 是 p2 的 prefix path, 那麼 t(p2)=⊥(NULL). 5.若{p ∈ paths(D) | t(p)≠⊥},則 p 會是一個有限 的路徑. 用 T(D)表示 D 上的所有的 tree tuple 所形成的集合。. <PurchaseOrder BuyerName=“Car Corporation” Date=“1 Jan 2000”> <ItemsBought> <Item PartId=“1” Cost= “3000” /> <Item PartId= 2” Cost=“6000” /> </ItemsBought> <Payments> <Payment CreditCard=“8342398432” ChargeAmt=“8000.00” /> <Payment CreditCard=“3474324934” ChargeAmt=“2000.00” /> </Payments> </PurchaseOrder>. 例子 2.8 若有一個 DTD D courses.dtd,如圖 3-1 所示。圖 3-2 courses.xml 是遵守 D 的 tree,在這個 tree 裡存在一個 tree tuple t,使得 t(courses) = v0 t(courses.course) = v1 t(courses.course.name) = v2 t(courses.course.teacher) = v3 t(courses.course.text) = v4 t(courses.course.name.S) =“DB” t(courses.course.teacher.S) =“JOE” t(courses.course.text.S) =“Text A”. 圖 2-3 purchaseorder.xml PurchaseOrder(V0). @BuyName. ItemsBought(V1). @Date. Payments(V4). Car Corporation 1 Jan 2000. courses v0. Item(V2). Item(V3). Payment(V5). course. Payment(V6). v1 name. @PartId @Cost @PartId 1. 3000. 2. teacher. @Cost @CreditCard @ChargeAmt @CreditCard @ChargeAmt 6000 8342398432 8000 3474324934 2000. v2. 圖 2-4 purchaseorder.xml 的樹狀圖. “DB”. v3. text v4. “JOE” “TEXT A”. 圖 2-5 tree tupple t 示意圖. 例子 2.7 圖 2-3 是一個遵守圖 2-1 purchaseorder.dtd 的 XML 文件, purchaseorder.xml 用(V,lab,ele,att,root)來表示: lab(V0)=PuchaseOrder,lab(V2)=Item,. 用圖 2-5 可以更清楚的明白 tree tuple t 的對應 關係,雖然某些 tree tuples 可能將 path 對應到空值 3.
(4) (null,⊥),例如 D = (E, A, P,R, r), E = {r, a, b}, A =ψ,P(r) = (a|b),P(a) =ε and P(b) =ε,paths(D)= {r, r.a, r.b},路徑 r.a 和路徑 r.b 不會同時出現,所 以一定會有 t(r.a)=null 或是 t(r.b)=null 的情形發 生。在這篇論文裡頭,我們只討論每一個 XML tree 都有抵達葉節點,並且不去考量 null 的情形。. 若圖 3.2 是一個遵守 courses.dtd 的文件,我們用 tree tuple 來表達圖 3-2 的文件。courses.xml 共由 4 個 不同的 tree tuple 組成,見圖 3-3。 courses(v0). 定義 2.10 (等價) 若存在兩個 XML tree T1、T2, 如果 tuplesD(T1)和 tuplesD(T2)隱含相同的訊息則稱 T1 和 T2 具有等價關係,以 T1≡T2 來表示。. course(v1). course(v5). course(v9). course(v13). 三、XML 文件的多值相依性 name(v2) teacher(v3) text(v4) name(v6) teacher(v7) text(v8) name(v ) teacher(v ) text(v ) name(v ) teacher(v ) text(v ) 11 15 10 12 14 16. 在這節裡,我們延伸文獻[3]所提出的 XML Functional Dependency(XFD)概念以及關聯式資料 的多值相依性(MVD),來定義一個新的 XML Multivalued Dependency (XMVD),並在第四節說 明如何利用 XML 的樹狀結構來達到減少資料重複 的目的,但卻不會失去 XMVD 的語意概念。在這 篇論文裡依舊使用 tree tuple 來定義 XML 上的 multivalued dependency 。. “DB”. “JOE”. “TEXT A” “DB” “MARY” “TEXT B” “DB”. “JOE” “TEXT B”. “DB”. “MARY”. “TEXT A”. 圖 3-2 courses.xml. courses(v0). 定義 3.1 (XML 多值相依性,XMVD) 在任何一個 DTD D 上,我們使用 tree tuple 來定義 XMVD,XML 多值相依性(XMVD)是指在 D 上具有 p1ÆÆp2 | p3 形式的一種相依性,這裡的 p1、p2、p3 是 paths(D) 裡有限的、非空的子集合,所有在 D 上的 XMVD 用 XMVDS(D)來表示。 任兩個在 T(D)裡的 tree tuple t1,t2 ,若 t1(p1)=t2(p1) 則會存在 t3, t4 在 tuplesD(T)裡,使得 t1(p1)=t2(p1)=t3(p1)=t4(p1) t3(p2)=t1(p2) t3(p3)=t2(p3) t4(p2)=t2(p2) t4(p3)=t1(p3). course(v1). name(v2) teacher(v3) text(v4). “DB”. “JOE” “TEXT A”. courses(v0). courses(v0). courses(v0). course(v5). course(v9). course(v13). name(v6) teacher(v7) text(v8) name(v10) teacher(v11) text(v12) name(v14) teacher(v15) text(v16). “DB”. “MARY” “TEXT B”. “DB”. “JOE” “TEXT B” “DB”. “MARY” “TEXT A”. 圖 3-3 四個不同的 tree tuple 示意圖 將 4 個 tree tuple 轉換成關聯式資料表的 4 個 tuple,如表 3-1 所示,觀察會得知 courses.xml 有 類似關聯式的多值相依性。意即由表 3-1 我們會知 道 courses.xml 滿足 XML 多值相依性(XMVD 1)。. 直覺來看,一個 XML multivalued dependency: p1ÆÆp2 | p3 是表達出 p1 跟 p2 的關係獨立於 p1 跟 p3 的關係。. 表 3-1 圖 3-3 對應的關聯式資料表. 例子 3.1 圖 3-1 courses.dtd 是描述學校課程資訊 的 dtd,若存在一個 XMVD: courses.course.name.SÆÆ courses.course.teacher.S | courses.course.text.S (XMVD 1). <!DOCTYPE courses [ <!ELEMENT courses(course*)> <!ELEMENT course(name,teacher,text)> <!ELEMENT name(#PCDATA)> <!ELEMENT teacher(#PCDATA)> <!ELEMENT text(#PCDATA)> ]>. t1. V0. V1. V2. V3. V4. DB. JOE. TEXT A. t2. V0. V5. V6. V7. V8. DB. MARY. TEXT B. t3. V0. V9. V10. V11 V12 DB. JOE. TEXT B. t4. V0. V13 V14. V15 V16 DB. MARY. TEXT A. 如同關聯式資料庫一般,並不是所有的多值相 依性都必須被消除,唯有那些會導致資料重複的 XMVD 才需被消除,那些會導致資料重複的 XMVD,我們稱它們為不規則的 XMVD (anomalous XMVDs)。另外必須定義出 trivial XMVD,好在正規化步驟裡略過 trivial XMVD,因 為 trivial XMVDs 總是存在於任何 DTD 裡。在 RDB. 圖 3-1 courses.dtd 4.
(5) 裡,trivial MVD 是具有 AÆÆB 形式的多值相依 性,其中 A∪B=R 或是 B ⊆ A。要在 XML 裡定義 出 trivial XMVD 是更加複雜的一件事,已知 DTD D 和 XMVDs 集合 Σ ,在此 DTD 和 Σ 條件下衍生出 來的 XMVD 稱 ϕ,用(D, Σ ) ϕ 來表示,任何 遵守(D, Σ )的 XML 文件也會遵守 ϕ,所有被(D, Σ ) 衍生出的 XMVDs 用集合(D, Σ )+來表示,我們說 一個 XMVD ϕ 是 trivial 的意思是指(D,ψ) ϕ, 舉例說明:在 XML 文件裡若 p 屬於 Epaths(D),且 存在 p ′ 是 p 的前序路徑(prefix path)則 (D,ψ) pÆÆ p ′ 會存在。另外若 p、p@l 屬於 paths(D),則(D,ψ) pÆÆ p@l 會存在。. courses(v0). course(v1). name(v2). teachers(v3). texts(v6). “DB” teacher(v4) “JOE”. teacher(v5) “MARY”. text(v7) “TEXT A”. text(v8) “TEXT B”. 圖 4-2 newcourses.xml 包含重複的資訊. 四、XML 第四正規化 一個符合 XMVD 的 XML 文件可能會有什麼 樣的問題,一個遵守圖 3-1 courses.dtd 的 XML 文 件,並滿足(XMVD 1)的 XML 文件,如圖 3-2 所 示的 courses.xml。圖 3-2 courses.xml 被使用來儲存 學校裡授課的資訊,此文件儲存著每一門課程的名 稱以及可以教授此課程的老師,以及可以用來使用 的教材。假如我們要將 peter 老師加入 DB 可授課 老師行列裡,就會產生異常情形,因為 courses.dtd 的結構問題,我們必須要同時加入 2 筆資料才不會 因為加入 peter 老師而導致違背(XMVD 1)限制。同 樣的若是一位老師退休的話也勢必會有異常現 象,這也是因為要從 xml 文件裡刪除 2 筆資料,才 不會使文件違背 XMVD。 接下來看另一個例子,若是有一個遵守圖 4-1 dtd 的 XML 文件,並且滿足(XMVD 2)的 XML 文 件,如圖 4-2 newcourses.xml。在 newcourses.xml 裡,我們將 peter 老師加入 DB 的可授課老師行列 裡,就不會有異常情形,因為只需在 teachers 節點 下加入 peter 老師的訊息即可。若是一位老師退休 的話也不會有刪除異常的現象了。這是因為所刪除 和所加入的資料並不會導致 XML tree 違背 (XMVD 2)。. 觀察上述的兩個 XML 文件,我們可以輕易的 發現上面這兩個 XML 文件的目的是一樣的,所儲 存的資訊也是一樣的,都是為了存放學校課程資訊 而被設計的,也都各自遵循所該遵循的 DTD 和 XMVD,只是結果不同,其中一個會導致更新的異 常,而另外一個卻不會。經由上面例子的描述,我 們可以很容易的相信明白,當我們若要設計一份具 有 XMVD 語意的 XML 文件時,有可能會設計出 隱含有更新異常問題的文件或是無更新異常問題 的文件。當然我們會希望設計出的文件是沒有更新 異常且是盡量佔用較少儲存空間的文件。為了能更 進一步的說明接下來的內容,我們將一份遵循 XMVDs 的文件且此文件沒有更新異常現象,稱為 是滿足 4XNF 的文件。 根據先前的敘述,我們提出一個正式定義來描 述何謂是 4XNF 的文件。 定義 4.1 (XML 第四正規化, 4XNF) 若有一個 DTD D,存在一個 XMVD 及 XFD 的集合 Σ , ( D, Σ) 若是符合 XML 第四正規化 (4XNF) 若且為若每一個具有 S1ÆÆ S2 | S3 的形 式的 nontrivial XMVD ϕ ∈ ( D, Σ) +,其中 S1={q,x1.@x1,...,xm.@xm},S2={y.@l}, S3={z1.@z1,...,zn.@zn},m≧0,n≧1, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψ,for i≠j 且 任何(a,b) ∈ S2 ×S3,p=intersection(a,b),存在 S 1 Æ p ∈ ( D , Σ ) +。. <!DOCTYPE newcourses [ <!ELEMENT courses(course*)> <!ELEMENT course(name,teachers,texts)> <!ELEMENT name(#PCDATA)> <!ELEMENT teachers(teacher*)> <!ELEMENT teacher(#PCDATA)> <!ELEMENT texts(text*)> <!ELEMENT text(#PCDATA)> ]>. 4.2 有效的 XML 第四正規化演算法 接下來將解釋如何將任意一個滿足 DTD D、 相依性集合 Σ ,但不符合 4XNF 的文件,轉換成符 合第四正規化的文件。若 S1ÆÆ S2 | S3 ∈ ( D, Σ) + 是一個異常的 XMVD (anomalous XMVD),且 S2={y.@l},則稱 y.@l 是 anomalous path,用集合 AP ( D, Σ) 來表示 D 隱含的所有 anomalous path。 若針對 S1ÆÆ S2 | S3 這個 anomalous XMVD 做正 規化,則會得到新的 DTD D ′ ,新的相依性集合 Σ′ 。 我們假設所有的 DTD 都是非遞迴的 (non-recursive),所有的 anomalous XMVD 都是 S1ÆÆ S2 | S3 的形式,其中 S1={q,x1.@x1,...,xm.@xm},S2={y.@l},. 圖 4-1 newcourses.dtd courses.course.name.SÆÆ courses.course.teacher.teacher.S | courses.course.texts.text.S (XMVD 2). 5.
(6) S3={z1.@z1,...,zn.@zn},m≧0,n≧1, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψ,for i≠j 且 q ∈ EPaths(D)。最多只有一個 element path 在左 邊,這是因為若有兩個以上的 element path 發生在 左半部,那麼這個 XMVD 在語意表達上會相當的 不自然,然而即使真的存在這樣的情形,也可以輕 易的利用增加一個屬性@l 來轉變,例如將 {q, q ′ }∪SÆÆS2 | S3 縮減成 q ′ .@lÆ q ′ 和 {q, q ′ .@l}∪SÆÆ S2 | S3。此外我們假設並沒有以 S(#PCDATA)做為終點的路徑(path),這是因為在這 個演算法表達方法裡,p.S 可以用@ p 來表達。 我們依 XMVD 的形式,將演算法分成三種情 形,每一種情形適合某條件成立的 XMVD,依據 XMVD 的條件,使用其中之ㄧ來正規化 XML 文 件。. 和課程名稱的 dtd, 若此 dtd 具有(XMVD 3)這個 多值相依性的話,意思是說同一個系所開的任何課 程可以使用系所分配到的任何教室上課,若有一文 件符合此 DTD 且滿足(XMVD 3)如圖 4-5。圖 4-5 並不符合 4XNF,因為存在一個路徑 college.department.class_info,此路徑是 college.department.class_info.c_name.S 和 college.department.class_info.location.S 做 intersection 得來.且 college.department 無法決定(Æ) college.department.class_info,所以這樣的文件不符 合 4XNF。我們依據演算法,將它變成符合 4XNF 的文件如圖 4-6。我們在元素 department 底下建立 一個叫 class 的 element,並移動 c_name.S 到 class 底下,把 c_name.S 當成是 class 的的屬性,得到新 的 DTD,完成正規化。經正規化後的文件明顯的 少了會引起資料重複的(XMVD 3),而以不會引起 資料重複的 XMVD : college.department ÆÆ college.department.class.c_name.S | {college.department.class_info.location.S , college.department.@name}取代會引起異常的 (XMVD 3)。. (ㄧ) case 1: D=(E,A,P,R,r) 是一個 DTD,令 anomalous XMVD : S1ÆÆ S2 | S3 ,其中 S1={q,x1.@x1,...,xm.@xm},S2={y.@l}, S3={z1.@z1,...,zn.@zn},m≧0,n≧1 ,S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψ,for i≠j 且,q ∈ EPaths(D),若 qÆS1,要消除 anomalous XMVD,則在 q 底下建立一個新的點(element) τ, 移動屬性@l 到 τ 的屬性集合裡,使得屬性@l 為 τ 的屬性,生成新的 DTDD[y.@l:=q.τ.@l] ,如圖 4-3 所示。. <!DOCTYPE department [ <!ELEMENT college(department*)> <!ELEMENT department(class_inf*)> <!ATTLIST department name CDATA #REQUIRED > <!ELEMENT class_inf(c_name,location)> <!ELEMENT c_name(#PCDATA)> <!ELEMENT location(#PCDATA)> ]>. r q last(x1). x1 xm last(xm). z1. zn. y. last(z1) last(zn). last(q) last(y). ……. ……. 圖 4-4 department.dtd. τ @x1. @xm. @z1. @zn. @l. college.department ÆÆ college.department.class_info.c_name.S | {college.department.class_info.location.S , college.department.@name} (XMVD 3). @l. 圖 4-3 case 1:DTD 轉換示意圖. college. 令新生成的 DTD D[y.@l:=q.τ.@l]用 ( E ′, A, P ′, R ′, r ) 來表示, E ′ =E∪τ,且 1.如果 P(last(q))是一個 regular expression,則 P ′ (last(q))= (P(last(q)),τ*), P ′ (τ)= ε。 P ′ (e)=P(e) for each e∈ E-{last(q)}。 2. R ′ (τ)= @l, R ′ (last(y))= R(last(y))-{@l}, R ′ (e)= R(e) for each e ∈ E-{last(y) }。. department. department @name. @name. “CS”. “APM”. class_inf. 將 DTD 做轉換後,得到新的 DTD D ′ = D[y.@l:=q.τ.@l],由於轉換動作已經改變了 DTD 的結構,所以連帶的產生了新的相依性 ∑ ′ = ∑ [y.@l:=q.τ.@l], ∑ ′ 包含 ∑ 裡的所有的相 依性,但是將 y.@l 改為 q.τ.@l 。. class_inf. class_inf class_inf. class_inf. class_inf. class_inf. class_inf. location location location location c_name location c_name locationc_namelocationc_name location c_name c_name c_name c_name “A222” “S562” “A222” “S562” “EM” “D455” “D455” “D555” “D555” “DB” “DB” “MIS” “MIS” “LA” “EM” “LA”. 圖 4-5 department.xml 並不符合 4XNF. 例子 4.1 若是存在一個 DTD 如圖 4-4 department.dtd 是一個描述某學院的系所上課地點 6.
(7) r. college. @name. @name. “CS” class_inf class_inf class. x1. department. department. class. class_inf class_inf class. location location c_name c_name. “A222” “S562” “MIS”. “D455”. “D555” “EM”. @ x1. z1. zn. last(y). last(y). last(xm) last(y). ……... class. location location c_name c_name “DB”. xm. last(x1). “APM”. y. last(z1). @l. last(zn). …………….. @ xm. @ z1. @ zn. “LA”. r. 圖 4-6 department.xml 經正規化後的文件. y. (二) case 2: 令 D=(E,A,P,R,r) 是一個 DTD,若存在 anomalous XMVD: S1ÆÆ S2 | S3 ,其中 S1={q,x1.@x1,...,xm.@xm},S2 ={y.@l}, S3={z1.@z1,...,zn.@zn}, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψ,for i≠j, q ∈ EPaths(D),m≧1,n≧1,,若是同時具有以 下情形時: 1.任何(a,b) ∈ S2×S3,intersection(a,b)=y 2.若 S1 裡最長的路徑是 p, intersection(y,p)=parent(p) 在 y 底下建立兩個新的子節點(element) τ,τ ′ ,移 動@l 到 τ ′ 的屬性集合裡。原在 S3,以 y 為 root 的根節點的路徑,全部轉變成以 τ 為根節點。形成 成新的 DTD D[y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn]:= y.τ[(z1-y).@z1,…,(zn-y).@zn]]。 如圖 4-7 所示,用 ( E ′, A, P ′, R ′, r ) 來表示。. x1. last(y). xm. last(x1). last(xm). ………… @ x1 @ xm. τ′. τ last(zn-y). @l. last(z1-y). …….. @ z1. @ zn. 圖 4-7 case 2:DTD 轉換示意圖. 例子 4.2 圖 3-2 是遵守圖 3-1 courses.dtd 的 XML 文件,且具有多值相依性(XMVD 1)。因為圖 3-2 不是 4XNF 的文件,所以將文件轉換成圖 4-8 格式。 將(XMVD 1)視為 courses.course.@nameÆÆ courses.course.@teacher | courses.course.@text。 courses.course.@teacher∩courses.course. @text= courses.course。courses.course 是 S1 裡最長路徑 courses.course.@name 的 parent path,courses.course = parnet(courses.course.@name)。所以在 courses.course 底下建立兩個子點 teachers 和 texts, 移動 teacher.S 到 teachers 底下,移動 text.S 值到 texts 底下。會得到圖 4-8 的 xml tree。. E ′ =E ∪{τ, τ ′ },且 1. P ′ ( τ ′ )=ε, P ′ (τ)= P(last(y)), P ′ (last(y))= (τ*, τ ′ *), P ′ (e)=P(e) for e ∈ E-{ last(y)}。 2. R ′ ( τ ′ )=@l。 R ′ (τ)= R (last(y))-{@x1,...,@xm,@l}。 R ′ (last(y))= R(last(y))-{ @zn,...,@zn,@l }。 R ′ (e)=R(e)for each e ∈ E-{last(y)}。 ∑ ′ = ∑ [y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn]: = y.τ.[(z1-y).@z1,…,(zn-y).@zn]], ∑ ′ 包含 ∑ 裡的所 有的相依性,但是將 y.@l 改為 y. τ ′ .@l, zi.@zi 變成 y.τ.(zi-y).@zi,zi 變成 y.τ.(zi-y)。. courses. course. name. teachers. texts. texts. teacher. text. text. “MARY”. “text A”. teachers. “DB” teacher “JOE”. “text B”. 圖 4-8 courses.xml 經正規化後的文件 (三) case 3: 令 D=(E,A,P,R,r)是一個 DTD,若存在 7.
(8) anomalous XMVD: S1ÆÆ S2 | S3 ,其中 S1={q,x1.@x1,...,xm.@xm},S2 ={y.@l}, S3={z1.@z1,...,zn.@zn}, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψ,for i≠j, q ∈ EPaths(D),m≧1,n≧1,若 XMVD 不是上述 的兩種 case 狀況的話,則建立一個 element τ,使 τ 為 last(q)的子節點,並在 τ 底下建立 m+1 個子節點 τ1,…,τm, τ ′ 。分別移動屬性@x1,...,@xm 到 τ1,…,τm 的屬性集合裡,並且移動屬性@l 到 τ ′ 的 屬性集合,但是不將原本屬於 last(x1),…,last(xm) 的@x1,…,@xm 移除,這個步驟形成新的 DTD D[y@l:=q.τ[τ1@x1,… ,τm@xm , τ ′ .@l]],如圖 4-9 所 示。 r. @x1. 例子 4.3 若存一個遵守圖 4-10 course2.dtd 的 XML tree 稱 course2.xml,如圖 4-11 所示,且 course2.xml 滿足(XMVD 4). q last(q). x1 last(x1). 當使用這個 case 轉換時,被轉換的 anomalous XMVD 需要是 minimal 的,亦即我們不希望轉換 後,取代的 XMVD 還包含有 anomalous 元素。如 果沒有 anomalous XMVD : S ′ ÆÆxi.@ xi | Leafpaths(D)- S ′ -{xi.@ xi} ∈ (D, ∑ )+,其中 i ∈ [0,n]且 S ′ ⊂ {q,x0,…,xm,x0.@x0,...,xm.@xm }, | S ′ |≦n,則我們稱{q,x1.@x1,...,xm.@xm}ÆÆ x0.@ x0 | Leafpaths(D)-{q,x1.@x1,...,xm.@xm, x0.@ x0} 是 minimal anomalous XMVD。. xm. last(xm). y last(y). @xm @l. z1. last(z1) last(zn). @z1. <!DOCTYPE course2 [ <!ELEMENT courses(course*)> <!ATTLIST courses department CDATA #REQUIRED > <!ELEMENT course(name,teacher,text)> <!ELEMENT name(#PCDATA)> <!ELEMENT teacher(#PCDATA)> <!ELEMENT text(#PCDATA)> ]>. zn. @zn. τ. τ1…………. τm. τ′. @x1 … @xm. @l. 圖 4-10 course2.dtd courses.course.name.SÆÆ courses.course.teacher.S |{courses.course.text.S , courses.@department} (XMVD 4). 圖 4-9 case 3:DTD 轉換示意圖 DTD D[y@l:=q.τ[τ1.@x1,…. ,τm.@xm, τ ′ .@l]] 用 ( E ′, A, P ′, R ′, r ) 來表示。 E ′ =E ∪{τ, τ ′ ,τ1,…,τm} 1. 如果 P(last(q)) 是一個 regular expression,用 s 來表示這樣的 regular expression, 則 P ′ (last(q))=(s, τ*), P ′ (τ)= (τ1*,…,τn*, τ ′ *)。 P ′ (τi)= ε for each i ∈ [1,m]。 P ′ ( τ ′ )=ε。 P ′ (e)=P(e) for e ∈ E-{last(q)}。 2. R ′ (τ)=ε。 R ′ (τi)=@xi for each i∈ [1,m]。 R ′ ( τ ′ )=@l。 R ′ (e)=R(e)for each e ∈ E-{ last(y)}。 R ′ (last(y))=R(last(y))-{@l}。. 因為有存在一個 path 是 courses.course.teacher.S 和 courses.course.text.S 的對大 prefix path,這個最大 prefix path 是 courses.course,使得路徑 courses.course.name.S 無法決定 courses.course ,所 以 course2.xml 並不符合 4XNF。依據演算法,可 以將 course2.xml 轉會成符合 4XNF 的文件,見圖 4.12 在這裡 q 是 courses,在 courses 底下建立一個 子節點 info 用來存放 S1、S2 的資訊,在 info 底下 建立兩個子節點分別是 course_joint 和 teachers,移 動 name.S 到 course_joint 底下,移動 teacher.S 到 teachers 底下,注意我們不可刪除原本在 course 底 下的 name.S,因為這個值存在的目的是要做 joint 來還原訊息的。. ∑′ = ∑ [y@l:=q.τ[τ1.@x1,…,τm.@xm, τ ′ .@l]],由底下 (1)、(2)、(3)構成: (1) 所有在 ∑ 裡的相依性,將 y.@l 改為 q.τ. τ ′ .@l。 (2)如果 S1∪S2 ⊆ {q,x1,…,xm,x1.@x1,…,xm.@xm, y.@l}且 S3 ⊆ paths(D)- S1-S2, S1ÆÆS2| S3 ∈ (D, Σ )+,則將 xi 改為 q.τ.τi,xi.@xi 改為 q.τ.τi.@xi,y.@l 改為 q.τ. τ ′ .@l。 (3){q, q.τ.τ1.@x1,..., q.τ.τm.@xm}Æ q.τ 及{q.τ , q.τ.τi.@xi}Æ q.τ.τi。 8.
(9) [z1.@z1,...,zn.@zn] := y.τ[(z1-y).@z1,…,(zn-y).@zn]] (3.4) Go to step(1) (4) Else there is a minimal anomalous XMVD: S1ÆÆ S2 | S3 where S1={q,x1.@x1,...,xm.@xm},S2 ={y.@l}, S3={z1.@z1,...,zn.@zn},m≧1,n≧1, S1∪S2∪S3=Leafpaths(D)∪q, Si∩Sj=ψ for i≠j , q ∈ EPaths(D),then. courses. @department “CS” course. teacher text name. name “DB”. “JOE”. course. course. teacher. text. name teacher. “TEXT A” “DB” “MARY” “TEXT B” “DB”. course. name teacher. text. (4.1) Create fresh element types τ, τ ′ ,τ1,…,τm (4.2) D:=D[y@l:=q.τ[τ1@x1,….,τm@xm, τ ′ .@l]] (4.3) Σ := Σ [y@l:=q.τ[τ1@x1,…,τm@xm, τ ′ .@l]] (4.4) Go to step(1). text. “DB” “MARY” “TEXT A”. “JOE” “TEXT B”. 圖 4-11 course2.xml courses. 圖 4-13 4XNF 重組演算法 @department “CS”. 由於 XML 查詢語言尚未標準化,所以文獻[3] 採用函數對應的方式來證明正規化的不失真,這裡 我們延續文獻的方法來證明我們的演算法是不失 真的重組 ,所謂不失真重組是指文件經正規化重組動作後, 資訊能完整被保留,資訊不會因為正規化動作而有 遺失。 換句話說,就是正規化前的文件上訊息,可由正規 化後的文件中取得。如果有一個函數 f 存在,如圖 4-14,使得 D ′ 裡的 paths 能對應到 D 裡頭的 paths ,每個遵守 ( D, ∑) 的 xml tree T,若存在一個 xml tree T ′ 遵守 ( D ′, ∑ ′) 使得 D、 D ′ 上的 paths 皆滿 足函數 f,我們稱 ( D ′, ∑ ′) 是不失真的重組結果。. info inf. course. course course_joint. name “DB”. Text name “TEXT A” “DB”. teachers. teachers. Text “TEXT B” name “DB”. teacher “JOE”. teacher “MARY”. 圖 4-12 course2.xml 經正規化後的文件 綜合以上 3 種 case,我們將 XML 第四正規化演算 法整理成如圖 4-13 所示。 (1) If ( D, Σ) is in 4XNF then return ( D, Σ) , otherwise go to step (2). (2) If there is an anomalous xmvd S1ÆÆS2 | S2 where S1={q,x1.@x1,...,xm.@xm},S2={y.@l}, S3={z1.@z1,...,zn.@zn},m≧0,n≧1, S1∪S2∪S3=Leafpaths(D)∪q, Si∩Sj=ψ for i≠j , q ∈ EPaths(D),若 qÆS1,then: (2.1) Create a fresh element type τ (2.2) D := D[y.@l:=q.τ.@l] (2.3) Σ := Σ [y.@l:=q.τ.@l] (2.4) Go to step(1) (3) Else if there is an anomalous xmvd S1ÆÆ S2 | S3 where S1={q,x1.@x1,...,xm.@xm},S2={y.@l}, S3={z1.@z1,...,zn.@zn},m≧1,n≧1, S1∪S2∪S3=Leafpaths(D)∪q, Si∩Sj=ψ for i≠j , q ∈ EPaths(D), ∀ (a,b) ∈ S2×S3, intersection(a,b)=y, intersection(y,p)=parent(p) ,where p is the longest path in S1,then (3.1) Create fresh element types τ , τ ′ (3.2) D:=D[y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn] := y.τ[(z1-y).@z1,…,(zn-y).@zn]] (3.3) Σ := Σ [y@l:=y. τ ′ .@l ,. paths(D). paths ( D ′ ) f. 圖 4-14 f (paths( D ′ ))=paths(D) 上述的 3 種轉換 cases,我們進一步證明每一 個 case 都是不失真的重組,意即轉換後的文件並 不會有資訊內容的遺失。詳細證明,請參閱附錄或 [1]。 定義 4.2 : 假設 D 是一個 DTD, Σ 是 D 上的相依 性集合,若 S1ÆÆ S2 | S3 是 Σ 裡的一個 anomalous XMVD,針對 S1ÆÆ S2 | S3 做正規化所得到 ( D ′, Σ ′),若是存在一個函數 f 可以將 D ′ 裡的 path 對應到 D 裡的 path,使得每一個 T 遵守 ( D, Σ) 會 存在一個 T ′ 遵守 ( D ′, Σ ′) 使得 T ≡ f T ′ ,我們稱 ( D ′, Σ ′) 是 ( D, Σ) 的不失真重組,用 ( D, Σ) ≤ lossless ( D ′, Σ ′) 表示。. 9.
(10) 定理 4.1 ( D, Σ) 經由我們所提出的正規化演算法 轉變成 ( D ′, Σ ′) ,每一個 case 都是不失真的重組: ( D, Σ) ≤ lossless ( D ′, Σ ′) 。. 不同時存在時。. 經每一步驟的轉換,我們可以證明轉換後的 XML 文件上的不規則路徑會小於轉換之前。詳細 證明,請參閱附錄或[1]。. XMVDs that are also XFDs S1ÆÆS2|S3 and S1ÆS2. 定理 4.2 假設 D 是一個 DTD, Σ 是 D 上的相依 性集合,若 S1ÆÆ S2 | S3 是 Σ 裡的一個 anomalous XMVD,針對 S1ÆÆ S2 | S3 做正規化所得到 ( D ′ , Σ ′ ),會有|AP( D ′ , Σ ′ )|<|AP(D, Σ )| 的性質。. 皆有可能違背4XNF S1ÆÆS2|S3 and not S1ÆS2. 圖 4-16 狹義的的 XFD、XMVD 關係圖. 定理 4.3 4XNF 重組演算法動作終止時,亦即 Σ 中 已無需正規化的 anomalous XMVD 時,則此時的 (D, Σ )是 4XNF 形式。. 圖 3-2 course.xml 和圖 4-2 newcourses.xml 同樣都具 有 S1ÆÆ S2 | S3 形式的多值相依性且皆無 S1Æ S2 形式的相依性,其中 course.xml 違背 4XNF,但 newcourses.xml 符合 4XNF,可得知 S1ÆÆ S2 | S3 會不會導致 XML 文件違背 4XNF 跟是否具有 S1Æ S2 形式的相依性無關。見圖 4.17 DBLP.xml, DBLP.xml 若滿足功能相依性: DBLP.conf.issueÆDBLP.conf.issue.article.@year, 則此 tree 同時也會滿足多值相依性: DBLP.conf.issueÆÆDBLP.conf.issue.article.@year | Leafpaths(D)- {DBLP.conf.issue, DBLP.conf.issue.article.@year},但是 DBLP.xml 並 不符合 4XNF。會有以上異於 RDB 理論的結果, 是因為 XML 第四正規化符合條件並不是由 S1Æ S2 來決定。. 4.3 4XNF 與 XFD、XMVD 的關聯性 在 RDB 的 MVD 理論裡,並不是所有 MVD 都是 危險的,若存在一個 MVD: XÆÆY 而同時具有 FD : XÆY 的話,此 MVD 並不會導致文件違反 4NF,trivial MVDs 也不違反 4NF,真正在 RDB 裡 做第四正規化必須消除的 MVD 是所謂 true MVDs,true MVD 是具有 XÆÆY 形式的多值相依 性,但是 X Y,見圖 4-15,灰色的外圈所包含 的多值相依性是必須被消除的。 True MVDs. DBLP(v0). MVDs that are also FDs. Trivial ‘s MVDs. 違反4NF的MVDs. conf(v2) title(v1). XÆÆY and XÆY. issue(v3). conf ... issue(v10). “ICDT” article(v4). XÆÆY and not XÆY. article(v7). article(v11). 圖 4-15 RDB 理論的 FD、MVD 與 4NF 的關係圖 author(v5) title(v6) @year. 文獻[3]所提到需正規化的功能相依性是具有 S1ÆS2 形式的 nontrivial XFD,其中 S1={q,x1.@x1,...,xm.@xm},S2 ={y.@l},m≧0,本 篇論文所定義需正規化的多值相依性是具有 S1ÆÆ S2 | S3 形式的 nontrivial XMVD,其中 S1={q,x1.@x1,...,xm.@xm},S2 ={y.@l}, S3={z1.@z1,...,zn.@zn},n≧0,j≧1, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψfor i≠j, q ∈ EPaths(D)。在 XML tree 裡,若是 XFD: {q,x1.@x1,...,xm.@xm}Æ{y.@l}存在, m≧0,那麼 S1ÆÆ S2 | S3 形式的多值相依性也會存在,其中 S1={q,x1.@x1,...,xm.@xm},S2={y.@l}, S3={z1.@z1,...,zn.@zn},m≧0,n≧1, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψfor i≠j, q ∈ EPaths(D)。見圖 4-16,不同於 RDB 裡的相依 性關係,會使 XML 文件違背 4XNF 的 XMVD 可 能發生在相依性 S1ÆÆS2 | S3 與 S1ÆS2 同時存在或. “Dong”. “. . .”. “1999”. author(v8) title(v9) @year author(v12) title(v ) @year 13 “2001” “Jarke” “. . .” “1999” “carter” “. . .”. 圖 4-17 DBLP.xml 最後我們說明 XNF 跟 4XNF 的關係,我們知 道 RDB 中的 4NF schema 同時也是符合 BCNF,同 樣的情形也會發生在 XML 上,每一個符合 4XNF 的 XML 文件也會符合 XNF。以下面說明這樣的事 實,如果說存在某個 DTD D 不符合 XNF 的話,則 存在某個 XFD S1Æy.@l ∈ ( D, Σ) +,但 S1Æy ∉ ( D, Σ) +,因為 S1Æy.@l ∈ ( D, Σ) +會導出 XMVD S1ÆÆy.@l | Leafpaths(D)- S1-{y.@l},path k 是 y.@l 和集合 Leafpaths(D)- S1-{y.@l}裡任何 path 做 intersection 得來,k 一定會是 y.@l 的 strict prefix path,所以當 k=y 時,存在 S1Æk ∉ ( D, Σ) +, 使得 D 不符合 4XNF。換言之,一個 XML 文件若 10.
(11) 不符合 XNF,那麼此文件也不可能是是 4XNF 的 文件。見圖 4-18 表示 XNF 和 4XNF 的關係以及 XFD 和 XMVD 的關係,XFDs 導出 XNF,XMVDs 導出 4XNF。. XFDs. XMVDs. 好的組合方式來節省節點是未來可以努力的 方向。 二、目前 XML 文件設計有多議題,但將 RDB 正 規化過程觀點搬移到 XML 文件上探討,目前 只探討到 XNF (相當 RDB 的 BCNF),另一個 是 4XNF(相當於 RDB 的 4NF)。是否有更進一 步正規化的可能是可討論的。XML 文件上是 否需要有合併相依性(join dependency)語意的 constraints 存在,若是需要的,那麼如何重新 組合樹狀結構來使文件符合相當於 RDB 中的 PJNF 是可以努力的方向。 三、系統的實際上應用:以下有幾點是必須的 1.一個免費的 XML 原生型資料庫(這部份有 很多的 open source)。 2.利用本文導出的結論以及文獻的 XNF 能幫 助我們設計 XML 正規化的機器,下列為機器 大致功能: (1)已知的第四正規化語意,以及已知的 DTD、XML 文件,若文件不符合正規化,將 它調整成正規化文件(XNF,4XNF)。 (2)未知 DTD 、未知 XML 文件,在設計之初, 根據我們需要的語意,配合我們的結論直接設 計好的 DTD 文件格式,直接效益是空間的大 幅減少,更新無異常。. 4XNF. XNF. 4-18 XFDs、XMVDs、4XNF、XNF 關係圖. 五、結論與未來展望 這一篇論文裡,我們延續了文獻[3]提到的 XFD 及 正規化方法來更進一步定義 XML 的多值相依性, 並且提出 XML tree 上的第四正規化定義,最後提 出ㄧ個有效的演算法來縮減資料重複的文件。 XML 不同於關聯式資料表的結構,雖然無法像關 聯式資料表正規化一般來將 XML 文件切割為兩個 以上的獨立 tree,但是我們卻可以藉由樹狀結構重 組來做到類似的結果,XML 的文件結構是樹狀的 結構,嚴格來說,在 XML 文件上的正規化動作是 一種樹狀結構的重新組合,在不失去資料的前題 下,我們可以任意組合 DTD 樹狀結構,以獲得能 保留原來訊息且更無資料重複特性的新生樹狀結 構。不過為了使演算法的效率較好,並不是任意的 組合樹狀圖,而是要儘量在不變動樹狀結構情形 下,轉換成新的結構。我們證明若是有一個 anomalous XMVD 會使資料違背 4XNF,經由正規 化後,這一個 anomalous XMVD 將會不存在,且 正規化後的文件會比正規化前擁有較少的 anomalous path。此外我們把焦點鎖在 non- trivial XMVD,而不是 trivial XMVD,是因為 trivial XMVD 是永遠發生在任何 DTD 上的,難以在 trivial XMVD 探討資訊重複,同此情形發生在 RDB 的正 規化一般。. 六、參考文獻 [1] 林穎聰,”XML 文件的多值相依性與第四正規 化”,中興大學資訊科學研究所,碩士論文, 2005. [2] S. Abiteboul, P. Buneman, and D. Suciu. Data on the Web. Morgan Kaufmann, San Francisco, CA, 2000. [3] M. Arenas and L. Libkin. A Normal Form for XML Documents. ACM Transactions on Databases Systems (TODS),29(1): pp.195 -232, 2004. [4] P. Buneman, W. Fan, J. Simeon, and S. Weinstein. Constraints for semi-structured data and XML. SIGMOD Record, 30(1): pp.47-54, 2001. [5] P. Buneman, S. Davidson, W. Fan, and C. Hara. Reasoning about keys for xml.In International Worksshop on Database Programming Languages, 2001. [6] M. W. Vincent and J. Liu, Multivalued dependencies and a 4NF for XML, in ‘CAiSE 2003’ : pp.14–29. [7] M. W. Vincent , J. Liu . and C. Liu., Strong functional dependencies and their application to normal forms in XML, ACM Transactions on Database Systems 29(3): pp.445–462, 2004 [8] Extensible Markup Language. http://www.w3.org/TR/REC-xml. [9] W3C and XML. http://www.w3c.org/xml [10] HTML 4.01 Specification. http://www.w3.org/TR/REC-html40/. 在研究的過程中,我們發現有許多未來足供發 展的空間。我們將未來可以改進及研究之方向以下 三點說明: 一、我們提出 4XNF 重組演算法除了可以避開異常 的更新外,最直接的效益就是減少原生型 XML 文件的複雜分支(NODE 減少,語意不變) 更省空間,當然也是有可能有更好的方法來節 省空間,這是未來可研究的。我們節省空間的 觀點是以"樹狀"結構的觀點出發(這是直覺的 觀點)。有可能在節省空間方面,可跳脫"樹狀" 的觀點去研究,例如實體儲存媒體觀點,有否 存在一種特別技術能利用少量的儲存資訊還 原大量資訊,而沒失真問題。此外 XML 正規 化演算法是在不失去資訊意含內容下重組樹 狀結構,但是重組的選擇並不唯一,是否有更 11.
(12) (1)若存在 S1∪PÆÆ q. τ .@l | S3-P ∈ ( D ′, Σ ′) +是 一個 nontrivial xmvd,令 P ⊂ S3,k 是 q. τ .@l 和 S3-P 集合裡任何 path 的路徑交集 (k=intersection(q. τ .@l ,b),where b ∈ S3-P),因為 S1Æq,且 qÆk (trivial fd),所以 S1Æk,並得 S1∪PÆk,因此 q. τ .@l ∉ AP(D ′, Σ ′) 。 (2)另外若 S1-QÆÆ q. τ .@l | S3∪Q ∈ ( D ′, Σ ′) +是 一個 nontrivial xmvd,令 Q ⊂ S1,若 q. τ .@l 是 anomalous path,則存在 k 是 q. τ .@l 和 S3∪Q 集合裡某 path 的路徑交集 (k=intersection(q. τ .@l ,b), where b ∈ S3∪Q),使 得 S1-QÆk ∉ ( D ′, Σ' ) +,因為 S1Æq,qÆk(trivial fd),所以 S1Æk,且因假設 S1-QÆk ∉ ( D ′, Σ' ) +, 可知必定 QÆk,S3∪QÆk。存在一個 XML tree T′ (D′, Σ ′) , S1-QÆk ∉ ( D ′, Σ' ) +和 S3∪QÆk ∈ ( D ′, Σ' ) 的條件同時存在,會使 T ' 不滿足 S1-QÆÆ q. τ .@l | S3∪Q,這造成了矛 盾,故這種型情下 q. τ .@l ∉ AP(D ′, Σ ′) 。 (3)若 S3ÆÆq. τ .@l | S1 ∈ ( D ′, Σ ′) +是 anomalous xmvd,存在 k 是 q. τ .@l 和 S1 集 合裡某個 path 的路徑交集(k=intersection(q. τ .@l ,b),where b ∈ S1),且 S3Æk ∉ ( D ′, Σ ′) +,因為 S1Æq, qÆk(trivial fd),所以 S1Æk。S3Æk ∉ ( D ′, Σ ′) + 以及 S1Æk ∈ ( D ′, Σ ′) +同時存在會與 S3ÆÆq. τ .@l | S1 ∈ ( D ′, Σ ′) +矛盾,故 S3ÆÆq. τ .@l | S1 ∈ ( D ′, Σ ′) +不是 anomalous xmvd,q. τ .@l ∉ AP(D ′, Σ ′) 。 (4)已知(1) S1∪PÆÆ q. τ .@l | S3-P 不是 anomalous xmvd,P ⊂ S3,同(3)證法,可證 S3-PÆÆ q. τ .@l | S1∪P 也不是 anomalous xmvd, q. τ .@l ∉ AP(D ′, Σ ′) 。 (5)已知(2) S1-QÆÆ q. τ .@l | S3∪Q 不是 anomalous xmvd,Q ⊂ S1,同(3)證法,可證 S3∪QÆÆ q. τ .@l | S1-Q 也不是 anomalous xmvd,q. τ .@l ∉ AP(D ′, Σ ′) 。. 附錄 定理 4.1:. ( D, ∑) 經由我們所提出的正規化演算法轉變成 ( D ′, ∑ ′) ,則 ( D, ∑) ≤ lossless ( D ′, ∑ ′) 。 證明:. [1]case1:. 假設使用第一種轉換方法將 ( D, ∑) 轉換成 ( D ′, ∑ ′) , D ′ = D[y.@l:=q.τ.@l],[y.@l:=q.τ.@l], S1ÆÆ S2 | S3 是一個不規則的 XMVD 。在這個例 子裡,我們可以定義出一個函式 f,將 paths( D ′ ) 裡的 path 對應回 paths(D)裡的 path,f 定義如下: f(q.τ)=y,f(q.τ.@l)=y@l,令其他在 paths( D ′ )裡的 path 為 p ′ ,則 f( p ′ )= p ′ 。. [2] case2:. 假設使用第二種轉換方法將 ( D, ∑) 轉換成 ( D ′, ∑ ′) , D ′ = D[y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn]:= y.τ[(z1-y).@z1,… ,(zn-y).@zn]] ∑' = ∑ [y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn]:= y.τ[(z1-y).@z1,… ,(zn-y).@zn]]。 定義的函數 f : f(y. τ ′ )= y,f(y. τ ′ .@l)= y.@l , f(y.τ)=y,f(y.τ.(zi-y))=zi,f(y.τ.(zi-y).@zi)=zi.@zi , f(y.τ.p)= y.p ,p 是任一路徑 zi-y 裡的任一 prefix path,i ∈ [1,n],其他在 paths( D ′ )裡的 path 為 p ′ , f( p ′ )= p ′ 。. [3]case 3:. 假設使用第三種轉換方法將 ( D, ∑) 轉換成 ( D ′, ∑ ′) , D ′ =D[y.@l:=q.τ[τ1.@x1,….,τm.@xm, τ ′ .@l]], ∑' = ∑ [ y.@l:=q.τ[τ1.@x1,….,τm.@xm, τ ′ .@l]]。定 義的函數 f : f(q.τ)= x1∩x2∩... ∩xm∩y, f(q.τ.τi.@xi)=xi.@xi,f(q.τ.τi)=xi,f(q.τ. τ ′ .@l)= y.@l,f(q.τ. τ ′ )= y,其他在 paths( D ′ )裡的 path 為 p ′ , f( p ′ )= p ′ 。. 其次我們證明|AP( D ′ , ∑ ′ )|≦|AP(D, ∑ )|: 假設 S1∪S2 ⊆ paths( D ′ )-{q. τ .@l},由 Σ ′ 定義得 知 若 ( D, Σ ) S1ÆÆS2 | Leafpaths(D)- S1-S2 則 ( D ′, Σ ′) S1ÆÆS2 | Leafpaths( D ′ )-S1-S2. 定理 4.2 證明:. 分別證明 4XNF 重組演算法三種 case. 假設 ( D, Σ) S1ÆÆS2 | Leafpaths(D)- S1-S2,則 存在一個 XML tree T ( D, Σ) ,但是 T S1ÆÆS2 | Leafpaths(D)- S1-S2,定義一個 XML tree T′ (D′, Σ ′) 然而 T ′ S1ÆÆS2 | Leafpaths( D ′ )-S1-S2,因此 ( D ′, Σ ′) S1ÆÆS2 | Leafpaths( D ′ )-S1-S2 以上得證|AP( D ′ , ∑ ′ )|≦|AP(D, ∑ )|,但我們知道 y.@l ∈ AP(D, ∑ )且 y.@l 和 q. τ .@l ∉ AP(D ′, Σ ′) ,所以總結|AP( D ′ , ∑ ′ )|<|AP(D, ∑ )|。. [1]Case 1:. 若是 D 是一個 DTD, ∑ 是 D 上的相依性集 合,若是 S1ÆÆ S2 | S3 是 ∑ 裡的一個 anomalous XMVD,其中 S1={q,x1.@x1,...,xm.@xm}, S2 ={y.@l},S3={z1.@z1,...,zn.@zn},m≧0,n≧1, S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψfor i≠j,, q ∈ EPaths(D), qÆS1,對 S1ÆÆ S2 | S3 正規化後, D ′ =D[y.@l:=q.τ.@l], ∑ ′ = ∑ [y.@l:=q.τ.@l],會 有|AP( D ′ , ∑ ′ )|<|AP(D, ∑ )|的性質。 □. [2]Case 2:. 證明: 若針對 anomalous xmvd:S1ÆÆy.@l | S3 做 正規化,得到新的 xmvd: S1ÆÆq. τ .@l | S3,原本 的 anomalous path 是 y.@l 經正規化後此 path 變成 q. τ .@l,首先證明 q. τ .@l 不會是 anomalous path (q. τ .@l ∉ AP(D ′, Σ ′) )。我們分 5 種情形討論。. 若是 D 是一個 DTD, ∑ 是 D 上的相依性集 合,若是 S1ÆÆ S2 | S3 是 ∑ 裡的一個 anomalous XMVD,其中 S1={q,x1.@x1,...,xm.@xm}, S2 ={y.@l},S3={z1.@z1,...,zn.@zn},m≧1,n≧1, q ∈ EPaths(D),若是具有以下情形時: 12.
(13) 1. 任何(a,b) ∈ S2×S3,intersection(a,b)=y 2. 若 S1 裡最長的路徑是 p, intersection(y,p)=parent(p) 在 y 底下建立兩個新的子節點(element)τ, τ ′ ,移 動@l 到 τ ′ 的屬性集合裡。原在 S3,以 y 為 root 的根節點的路徑,全部轉變成以 τ 為根節點。經正 規化後 D ′ = D[y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn] := y.τ[(z1-y).@z1,… ,(zn-y).@zn]], ∑ ′ = ∑ [y@l:=y. τ ′ .@l , [z1.@z1,...,zn.@zn] := y.τ[(z1-y).@z1,… ,(zn-y).@zn]],會有 |AP( D ′ , ∑ ′ )|<|AP(D, ∑ )|的性質。 □. y.τ(zi-y)@zi,zi 變成 y.τ.(zi-y)。假設 S1∪S2 ⊆ paths(D)-{y.@l}, 若 ( D, Σ ) S1ÆÆS2 |Leafpaths(D)-S1-S2, 則 ( D ′, Σ ′) S 1′ ÆÆS 2′ | Leafpaths( D ′ )-S 1′ ′ S 2 ,此處 S 1′ 、S 2′ 是由 S1、S2 轉變而來(y.@l 變成 y. τ ′ .@l,zi.@zi 變成 y.τ.(zi-y).@zi,zi 變成 y.τ.(zi-y))。 假設 ( D, Σ) S1ÆÆS2 | Leafpaths(D)-S1-S2,則 存在一個 XML tree T ( D, Σ) 但是 T S1ÆÆS2 | Leafpaths(D)-S1-S2,定義一個 XML tree T′ (D′, Σ ′) , ′ 然而 T S 1′ ÆÆS 2′ | Leafpaths( D ′ )-S 1′ S 2′ , 因此 ( D ′, Σ ′) S 1′ ÆÆS 2′ | Leafpaths( D ′ )-S 1′ ′ S2 。 以上得證|AP( D ′ , ∑ ′ )|≦|AP(D, ∑ )|,我們知道 y.@l ∈ AP(D, ∑ ),但是 y.@l 和 y. τ ′ .@l ∉ AP(D′, Σ ′) ,所以總結 |AP( D ′ , ∑ ′ )|<|AP(D, ∑ )|。. 證明: 若針對 anomalous xmvd:S1ÆÆy.@l | S3 做 正規化,得到新的 xmvd: S1ÆÆy. τ ′ .@l | S 3′,S 3′ 是 S3 裡的 paths 依據 D ′ 轉換,原本的 anomalous path 是 y.@l 經正規化後 此 path 變成 y. τ ′ .@l,首先證明 y. τ ′ .@l 不會是 anomalous path (y. τ ′ .@l ∉ AP(D ′, Σ ′) )。 分 5 種情形討論。 (1) 若存在 S1∪PÆÆ y. τ ′ .@l | S 3′ -P ∈ ( D ′, Σ ′) + 是一個 nontrivial xmvd,令 P ⊂ S 3′ ,k 是 y. τ ′ .@l 和 S 3′ -P 集合裡任何 path 的路徑交集 (k=intersection(y. τ ′ .@l ,b),where b ∈ S 3′ -P), 因為 S1Æy,且 yÆk (trivial fd),所以 S1Æk, 並得知 S1∪PÆk,因此 y. τ ′ .@l ∉ AP(D ′, Σ ′)。 (2)另外若 S1-QÆÆ y. τ ′ .@l | S 3′ ∪Q ∈ ( D ′, Σ ′) + 是一個 nontrivial xmvd,Q ⊂ S1,k 是 y. τ ′ .@l 和 S 3′ ∪Q 集合裡某 path 的路徑交集 (k=intersection(y. τ ′ .@l ,b), where b ∈ S 3′ ∪Q),若 y. τ ′ .@l 是 anomalous path, 則 S1-PÆk ∉ ( D ′, Σ' ) +,因為 S1Æy,yÆk(trivial fd),所以 S1Æk,且因 S1-PÆk ∉ ( D ′, Σ' ) +,可 知必定 PÆk,S 3′ ∪PÆk。存在一個 XML tree T′ (D′, Σ ′) ,因為 S1-QÆk ∉ ( D ′, Σ' ) +同 時 S 3′ ∪QÆk 也存在的事實會使 T ' 不滿足 S1-QÆÆ y. τ ′ .@l | S 3′ ∪Q,這造成了矛盾, 故這種型情下,y. τ ′ .@l ∉ AP(D ′, Σ ′) 。 (3) 假設 S 3′ ÆÆy. τ ′ .@l | S1 ∈ ( D ′, Σ ′) +是 anomalous xmvd,若 S3ÆÆq. τ .@l | S1 ∈ ( D ′, Σ ′) +是 anomalous xmvd,存在 k 是 y. τ ′ .@l 和 S1 集合裡某個 path 的路徑交集 (k=intersection(y. τ ′ .@l ,b),where b ∈ S1),且 S 3′ Æk ∉ ( D ′, Σ ′) +,因為 S1Æy,yÆk(trivial fd),所以 S1Æk。S 3′ Æk ∉ ( D ′, Σ ′) +以及 S1Æk ∈ ( D ′, Σ ′) +同時存在會與 S 3′ ÆÆ y. τ ′ .@l | S1 ∈ ( D ′, Σ ′) +矛盾,故 S 3′ ÆÆ y. τ ′ .@l | S1 ∈ ( D ′, Σ ′) +不是 anomalous xmvd, y. τ ′ .@l ∉ AP(D ′, Σ ′) 。 (4) 同理可證 S 3′ -P ÆÆ y. τ ′ .@l | S1∪P ∈ ( D ′, Σ ′) +不是 anomalous xmvd where P ⊂ S 3′ ,y. τ ′ .@l ∉ AP(D ′, Σ ′) (5) 同理可證 S 3′ ∪Q ÆÆ y. τ ′ .@l |S1-Q ∈ ( D ′, Σ ′) +不是 anomalous xmvd where Q ⊂ S1,y. τ ′ .@l ∉ AP(D ′, Σ ′) 其次我們證明|AP( D ′ , ∑ ′ )|≦|AP(D, ∑ )|: 由 Σ ′ 定義可得知, ∑ ′ 包含所有在 ∑ 中的相依 性,但 ∑ 中的 y@l 變成 y. τ ′ .@l,zi.@zi 變成. [3]Case 3:. 若是 D 是一個 DTD, ∑ 是 D 上的相依性集合,若 S1ÆÆ S2 | S3 是 ∑ 裡的一個 minimal anomalous XMVD,其中 S1={q,x1.@x1,...,xm.@xm}, S2={y.@l},S3={z1.@z1,...,zn.@zn},m≧1,n≧1, S1,S2,S3 ⊂ paths(D), S1∪S2∪S3=Leafpaths(D)∪q,Si∩Sj=ψfor i≠j, q ∈ EPaths(D),經正規化後 D ′ =D[y.@l:=q.τ[τ1.@x1,…. ,τm.@xm, τ ′ .@l]], ∑ ′ = ∑ [y.@l:=q.τ[τ1.@x1,…. ,τm.@xm, τ ′ .@l]],會 有|AP( D ′ , ∑ ′ )|<|AP(D, ∑ )|的性質。 □ 證明: 首先證明 q.τ.τi.@xi 不會是 anomalous path,其中 i ∈ [1,m],若存在一個 xmvd: S ′ ÆÆq.τ.τi.@xi | Leafpaths( D ′ )- S ′ -{q.τ.τi.@xi} 屬於 ( D′, Σ ′) +, S ′ ⊂ paths(D),令 k 是 q.τ.τi.@xi 和 Leafpaths( D ′ )- S ′ -{q.τ.τi@xi}集合裡任何 path 的路徑交集(k=intersection(q.τ.τi.@xi ,b), where b ∈ Leafpaths( D ′ )- S ′ -{q.τ.τi.@xi},令 S ′ =S1∪S2 ,where (1) S1∩({q, q.τ. τ ′ .@l}∪{ q.τ.τj | j ∈ [1,m]}∪ {q.τ.τj.@xj | j ∈ [1,m] and j≠i})= φ (2) S2 ⊆ {q, q.τ. τ ′ .@l}∪{ q.τ.τj| j ∈ [1,m]}∪ {q.τ.τj.@xj | j ∈ [1,m] and j≠i}。 根據 Σ ′ 的定義以及{q,x1.@x1,...,xm.@xm}ÆÆy.@l | {z1.@z1,...,zn.@zn}是 minimal,其中 m≧1,n≧1 。 下面三個的其中之ㄧ是成立的: (1) S2ÆÆ q.τ.τi.@xi 不是 anomalous XMVD (2){q, q.τ.τ1.@x1,..., q.τ.τm.@xm, q.τ. τ ′ .@l}= S2∪{q.τ.τi.@xi} (3){q.τ.τi, q.τ.τ1.@x1,..., q.τ.τm.@xm, q.τ. τ ′ .@l} =S2∪{q.τ.τi.@xi} 在(1)裡,q.τ.τi.@xi ∉ AP ( D ′, Σ ′) 。 在(2)(3)裡,因為{q, q.τ.τ1.@x1,..., q.τ.τm.@xm}Æ q.τ,所以 S2∪{q.τ.τi.@xi}Æ q.τ,q.τÆk (trivial fd),得到 S2∪{q.τ.τi.@xi}Æk。 13.
(14) 若是 q.τ.τi.@xi 不是 anomalous path 的話 則 S1∪S2Æk 要存在,只要能証 S2Æk 存在即可。 假設 q.τ.τi.@xiÆk ∈ ( D ′, Σ ′) +,存在一個 XML tree T′ (D′, Σ ′) ,t1,t2 ∈ T (D ′) , t1(q.τ.τi.@xi)=t2(q.τ.τi.@xi)則 t1(k)=t2(k),因為在 Σ ′ 不含 q.τ.τi.@xi Æ S ′ ,所以令 t1( S ′ )≠t2( S ′ ),此會 與 S ′ ÆÆ q.τ.τi.@xi |leafpaths( D ′ )- S ′ -{q.τ.τi.@xi } 矛盾,故 q.τ.τi.@xi Æk ∉ ( D ′, Σ ′) +。 因已證明 S2∪{ q.τ.τi.@xi }Æk,且 q.τ.τi.@xi Æk ∉ ( D ′, Σ ′) +,所以 S2Æk ∈ ( D ′, Σ ′) +, S1∪S2Æk ∈ ( D ′, Σ ′) +,得證 q.τ.τi.@xi ∉ AP ( D ′, Σ ′) 利用類似證法可得證 q.τ. τ ′ .@l ∉ AP ( D ′, Σ ′) 其次我們證明|AP( D ′ , ∑ ′ )|≦|AP(D, ∑ )|: S3∪S4 ⊆ paths(D)-{y.@l} 由 Σ ′ 定義得知: 若 ( D, Σ ) S3ÆÆS4 | Leafpaths(D)-S3-S4 則 ( D ′, Σ ′) S3ÆÆS4 | Leafpaths( D ′ )-S3-S4 假設 ( D, Σ) S3ÆÆS4 | Leafpaths(D)-S3-S4,則 存在一個 XML tree T ( D, Σ) 但是 T S3ÆÆS4 | Leafpaths(D)-S3-S4,定義一個 XML tree T′ (D′, Σ ′) 然而 ′ T S3ÆÆS4 | Leafpaths( D ′ )-S3-S4, 因此 ( D ′, Σ ′) S3ÆÆS4 | Leafpaths( D ′ )-S3-S4 ′ 以上得證|AP( D , ∑ ′ )|≦|AP(D, ∑ )|,但我們知道 y.@l ∈ AP(D, ∑ )且 y.@l ∉ AP(D′, Σ ′),所以總結 |AP( D ′ , ∑ ′ )|<|AP(D, ∑ )|。. 14.
(15)
數據

相關文件
Chebyshev 多項式由 Chebyshev 於 1854 年提出, 它在數值分析上有重要的地位 [11], 本文的目的是介紹 Chebyshev 多項式及線性二階遞迴序列之行列式。 在第二節中, 我們先介
甲方為未成年人時,應具備甲方法定代理人同意書及其年齡證明文
Honolulu: University of Hawaii Press, 1986),討論中國佛教諸宗的禪學貢 獻。一九八七年,這位學者還編成一部會議論文集《頓與漸:中國思想裡的覺悟之路》 (Sudden and
校本文化 文化 文化及 文化 及 及文學課程 及 文學課程 文學課程整體規畫 文學課程 整體規畫 整體規畫 整體規畫. 一年級 二年級 三年級
(1999) Resiliency in Action) ,我們 對組員在強化活動中有高 的期望,期望他們能為學校 作出貢獻,同時亦希望藉此
宋代文化的繁榮與當時人們從文化角度吸收佛教的養分,應用
利用電腦來安排與整合多種媒體,可產生 利用電腦來 更多樣化的作品。如某一段背景配樂在影 片中的哪個時間點開始播放、新聞播報中 子母畫面的相對位置、文字字幕出現在畫
RMI,及 DCOM 這些以專屬 binary 格式傳送資料所不及之處,那 就是對程式語言、作業平台的獨立性--由於是純文字 XML 格 式,
