國立交通大學
土木工程學系
碩 士 論 文
應用類神經網路配合 ACI 規範
輔助卜作嵐混凝土配比設計
Application of neural networks and ACI
code in pozzolanic concrete mix design
研 究 生:沈錦鴻
指導教授:洪士林 博士
中華民國 一○二年六月
應用類神經網路配合 ACI 規範輔助卜作嵐混凝土配比設計
Application of Neural Networks and ACI code in pozzolanic
concrete mix design
研 究 生:沈錦鴻 Student:Chin-Hung Shen
指導教授:洪士林 Advisor:Dr. Shih-Lin Hung
國 立 交 通 大 學
土 木 工 程 系
碩 士 論 文
A ThesisSubmitted to Department of Civil Engineering College of Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master of Science
in
Civil Engineering
June 2013
Hsinchu, Taiwan, Republic of China
i
應用類神經網路配合 ACI 規範輔助卜作嵐混凝土配比設計
研究生:沈錦鴻 指導教授:洪士林 博士
國立交通大學土木工程學系碩士班
摘要
混凝土是土木營建工程中最被廣為運用之材料。混凝土本身為一變異
性很高之材料,其是由各種不同之材料所組成,每種材料之特性都不一樣,
目標需求所設計出的配比往往和實際有落差。而配比、製作及養護環境之
不同,皆會對混凝土之性質產生影響。其中又以配比對混凝土之影響最大,
再加上材料科技的進步,現行所用之混凝土已非傳統一般水泥混凝土,因
混凝土配比中皆添加了卜作嵐掺料及化學掺料,這使得混凝土性質更加難
以掌控。本研究之目的係建構一套電腦輔助混凝土配比系統。首先,先利
用由各文獻或實驗室中所蒐集到的資料來建構一個真實混凝土配比資料
庫;接著我們利用監都式學習的類神經網路來建立混凝土強度及坍度之預
測模型,並同時利用電腦程式配合 ACI 規範及設計流程來產生合理之混凝
土配比。預測模型經訓練及測試後,其所得之結果、準確性和效能皆屬不
錯。再以所建立好之預測模型來預測混凝土配比之強度和坍度性質,並將
此配比資料整合成一可用配比資料庫。隨後利用一試驗來驗証模型預測配
比之準確度,試驗結果顯示,實際值和預測值之誤差大多在合理範圍之內,
再次證明預測模型之準確性是可靠的。最後,利用歐式距離觀念、卜作嵐
取代率及材料成本三種方法來將配比加以分類,並建立一配比資料庫,使
其有如一混凝土配比之型錄,可提供使用者方便依其工區環境、材料使用
及成本考量來作選擇及使用。
關鍵字:類神經網路、預測模型、混凝土配比、分類、資料庫。
ii
Application of Neural Networks and ACI code in pozzolanic
concrete mix design
Student:Chin-Hung Shen Advisor:Dr. Shih-Lin Hung
Department of Civil Engineering
College of Engineering
National Chiao Tung University
Abstract
Concrete is the most widely used materials in civil engineering. Concrete is
a high variability of material owing to composed with a variety of different
materials. Since the mix proportioning of concrete are added pozzolanic and
chemical admixtures, it became more difficult to control the properties of
concrete. The purpose of this study is to establish a computer-aided system for
concrete mix design. First, actual data in reference or laboratory are collected
to establish a real mix proportioning of concrete database. A supervised neural
network (ANN) model is then employed to establish the prediction models of
strength and slump of concretes. Following, based on ACI code, a practical
database of mix proportioning of concrete is produced. For verifying the
correction of generated data, the strength and slump of concrete are yielded via
ANN prediction models. 12 different mix designs are also verified via cylinder
test in laboratory. Finally, a classification system is utilized to categorize data
into 360 clusters based on strength of concrete, pozzolanic admixtures
replacement rate, and materials costs. Simulation results reveal that based on
these grouped 360 clusters, the proposed concrete mix computer-aided design
system can provide engineering acceptable solutions (mix design) as users
acquiesced required strength of concrete, pozzolanic admixtures replacement
rate, and materials costs.
Keywords: Neural networks, Prediction model, Mix proportioning of concrete,
iii
誌謝
轉眼間研究所二年的生活即將結束,回想起當初決定暫時離開工作崗
位,重返學生生活的那一刻,感覺就好像是昨天剛發生的事一樣,如今我
已經要畢業了,真是時光飛逝。在這條路上,首先,最要感謝的是我的指
導教授洪士林老師,老師總在我研究出現瓶頸和迷惘時為我指點迷津,甚
至一直到口試前還教導我在簡報製作和上台報告方面的技巧,令學生我獲
益良多,在此先謝謝洪老師這二年來的指導和教誨。再來感謝黃炯憲老師、
林昌佑老師和詹君治學長於課餘時間撥冗參加學生的口試,並給予許多寶
貴的意見,使學生的論文能夠更為完整,在此也謝謝老師們的指導。
感謝詹君治學長這二年來,不論是在簡報製作、專業知識和口頭報告
上給予的指導,使我們在個人本質學能上又更精進了許多。感謝穎泰學長、
思伶學姐、孟軒學長、宣治學長、晟佑學長、俊佐學長、勇奇學長在課業
和論文方面給予的協助和建議,使我在面臨困難之時,也不會覺得無助。
感謝研究所同窗好友子陽、銘澤、奇霖、義洋、耀緯、明廉、冠龍、
湘銘、曉德、懿賢、立晨、俊閡、孟諺和伯熙在生活、課業、程式、實驗、
論文方面給予的協助,大家一起討論、嘻笑、打鬧、玩樂在一起的日子和
回憶,我想我這輩子都不會忘記。感謝學弟丁丁、智嵩、建文和允璿也在
我需要幫忙時,即時伸出援手,研究室有你們的加入,增添了不少歡樂。
有你們這群小老弟的相伴和互相扶持,即便碩士這條路再辛苦,也不會讓
我感到孤單,謝謝你們。
感謝五專同窗好友俊村、宗國、政富、盛清、室賢總在我論文卡關、
心情煩悶和需要幫忙時即時挺身而出,不論是在論文寫作、實驗幫忙、聽
我抱怨和解悶,感謝你們總在重要的關鍵時刻拉我一把、排解疑惑和情義
相挺,不論何時何地,只要我開口,你們總是說 yes,即便擔誤到你們的
假期,你們也都相挺到底、毫無怨言,我想這就是認識了快 20 年的同窗
iv
情誼吧,在此我想跟你們說聲謝謝,你們是我一生的摯友。
感謝英文小老師祺惠老是幫我翻譯看不懂的英文 paper,以及在英文
文法和語句用法方面的指導,有時候還指導我到凌晨一~二點,害妳睡眠
不足,對妳真的很不好意思,謝謝妳讓我的破英文又進步了。
感謝二技同學科呈、俊元,同梯的虹升,同事顥頲、士棋、致廷、國
霖、文鋒、鈞宇、斐津、金輝、冠名、佩諭、子慶、勝仁哥、小花姐、阿
峯姐、斐津、寶桂姐和滿滿姐三不五時的給我加油打氣和勉勵,謝謝你們。
感謝 99HS2 班的同學懷萱、龍哥、嘉麟、馨誼、建智、銘軒、文祥的
關心和鼓勵,謝謝你們的噓寒問暖和帶我出遊放鬆心情,讓我在巨大的課
業壓力下,能獲得短暫的疏緩,也讓我有繼續努力下去的動力,謝謝你們。
感謝台科大材料實驗室、交大材料實驗室以及趙文成老師研究室裡的
學長和同學們於實驗方面提供的協助和支持,令本研究之實驗能順利進行
並如期完成,在此謝謝你們的幫忙和配合。
感謝弟弟錦蔚、妹妹怡均、小表妹怡蓓、表弟柏維和文哲以及親友們
的鼓勵和支持,在我心情不好的同時,還有你們陪我說話解悶,謝謝你們。
碩士班這條路上,一篇論文的完成要感謝的人真的很多,在此可能有
遺漏或無法一一提及,但對於幫助過我的人,我在此致上最深的謝意,也
感謝老天爺能讓我認識你們大家,沒有你們我想我可能走不到這裡,更不
會有這本論文的誕生,我很想說有你們真好,謝謝你們。
最後,將本論文獻給從小到大養育、愛護和關懷我的父母,因為你們
無私的奉獻、付出、栽培和支持,才使我能無後顧之憂專心致力於我的研
究上,沒有你們就不會有今天的我,謝謝你們這 30 年來的養育之恩,這
份恩情我將永懷於心,此生不忘。
沈錦鴻 謹誌
中華民國 102 年 6 月于國立交通大學
v
目錄
摘要 ... i
Abstract ... ii
誌謝 ... iii
目錄 ... v
表目錄 ... vii
圖目錄 ...xii
一、緒論 ... 1
1-1 背景 ... 1 1-2 研究動機 ... 2 1-3 研究目的 ... 4 1-4 論文研究架構 ... 4二、文獻回顧 ... 5
2-1 混凝土抗壓強度之預測 ... 5 2-2 混凝土坍度之預測 ... 12 2-3 混凝土利用電腦程式作最佳配比設計 ... 14三、研究方法 ... 18
3-1 類神經網路 ... 18 3-2 類神經網路模型之建立 ... 24 3-3 混凝土配比之產生 ... 25 3-4 配比之分類 ... 26 3-5 試驗計畫 ... 30 3-6 系統架構 ... 34四、結果分析與討論 ... 35
4-1 類神經網路強度模型之結果分析 ... 35 4-2 類神經網路坍度模型之分析 ... 35 4-3 預測模型參數敏感度之分析 ... 36vi 4-4 試驗結果分析 ... 39 4-5 配比分類結果 ... 40
五、結論與建議 ... 42
5-1 結論 ... 42 5-2 建議 ... 43參考文獻 ... 44
附錄 ... 52
vii
表目錄
表 1 類神經網路模型統計值 ... 52
表 2 文獻配比資料 ... 52
表 3 文獻配比資料出處 ... 67
表 4 類神經網路模式 ... 68
表 5 混凝土暴露卻冰鹽下對卜作嵐材料之限制量(ACI 318-95) ... 69
表 6 坍度與標稱最大粒徑所需單位用水量及含氣量 ... 69
表 7 單位體積混凝土中乾燥粗粒料所佔體積 ... 70
表 8 無試拌或試驗資料之最大容許水膠比 ... 70
表 9 特殊暴露環境下最大水膠比及最低抗壓強度限制 ... 71
表 10 各種構件混凝土施工之坍度建議值 ... 71
表 11 混凝土抵抗凍融環境之總含氣量規定 ... 72
表 12 混凝土暴露於含硫酸鹽溶液環境之限制 ... 72
表 13 材料上下限範圍 ... 73
表 14 卜作嵐取代率分類表 ... 73
表 15 單價表 ... 73
表 16 成本分類表 ... 73
表 17 水泥物理性質及化學成份 ... 74
表 18 飛灰之物理性質及化學成份 ... 75
viii
表 19 爐石粉之物理性質及化學成份 ... 75
表 20 粗、細骨材基本性質 ... 76
表 21 強塑劑之基本性質 ... 76
表 22 混凝土配比(kg/m
3) ... 76
表 23 強度模型測試結果表 ... 77
表 24 坍度模型測試結果表 ... 78
表 25 強度參數敏感度分析表 ... 78
表 26 坍度參數敏感度分析表 ... 78
表 27 配比試驗結果表 ... 79
表 28 坍度範圍表 ... 79
表 29 強度範圍表 ... 79
表 30 210kgf/cm
2配比分類表(成本≤2000 元) ... 80
表 31 280kgf/cm
2配比分類表(成本≤2000 元) ... 80
表 32 350kgf/cm
2配比分類表(成本≤2000 元) ... 81
表 33 420kgf/cm
2配比分類表(成本≤2000 元) ... 81
表 34 490kgf/cm
2配比分類表(成本≤2000 元) ... 83
表 35 560kgf/cm
2配比分類表(成本≤2000 元) ... 84
表 36 630kgf/cm
2配比分類表(成本≤2000 元) ... 84
表 37 700kgf/cm
2配比分類表(成本≤2000 元) ... 85
ix
表 38 770kgf/cm
2配比分類表(成本≤2000 元) ... 85
表 39 840kgf/cm
2配比分類表(成本≤2000 元) ... 86
表 40 210kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 86
表 41 280kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 86
表 42 350kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 87
表 43 420kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 87
表 44 490kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 88
表 45 560kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 89
表 46 630kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 90
表 47 700kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 90
表 48 770kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 91
表 49 840kgf/cm
2配比分類表(2000 元<成本≤2250 元) ... 91
表 50 210kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 92
表 51 280kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 92
表 52 350kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 92
表 53 420kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 93
表 54 490kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 93
表 55 560kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 94
表 56 630kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 95
x
表 57 700kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 96
表 58 770kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 96
表 59 840kgf/cm
2配比分類表(2250 元<成本≤2500 元) ... 97
表 60 210kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 97
表 61 280kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 97
表 62 350kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 98
表 63 420kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 98
表 64 490kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 99
表 65 560kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 99
表 66 630kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 100
表 67 700kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 100
表 68 770kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 101
表 69 840kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 102
表 70 910kgf/cm
2配比分類表(2500 元<成本≤2750 元) ... 102
表 71 490kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 103
表 72 560kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 103
表 73 630kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 103
表 74 700kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 104
表 75 770kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 104
xi
表 76 840kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 104
表 77 910kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 105
表 78 980kgf/cm
2配比分類表(2750 元<成本≤3000 元) ... 106
表 79 700kgf/cm
2配比分類表(成本>3000 元) ... 106
表 80 770kgf/cm
2配比分類表(成本>3000 元) ... 106
表 81 840kgf/cm
2配比分類表(成本>3000 元) ... 107
表 82 910kgf/cm
2配比分類表(成本>3000 元) ... 107
表 83 980kgf/cm
2配比分類表(成本>3000 元) ... 108
xii
圖目錄
圖 1 研究流程圖 ... 109
圖 2 強度模型預測與實際值比較圖 ... 110
圖 3 坍度模型預測與實際值比較圖 ... 110
圖 4 真實系統和類神經網路之比較圖 ... 111
圖 5 監督式學習演算法流程 ... 111
圖 6 非監督式演算法流程 ... 111
圖 7 倒傳遞類神經網路架構圖 ... 112
圖 8 常用之活化函數型態圖 ... 113
圖 9 倒傳遞演算法流程圖 ... 114
圖 10 類神經網路模型建立流程 ... 115
圖 11 Convex hull 凸多邊形 ... 116
圖 12 普通卜作蘭混凝土配比設計流程 ... 117
圖 13 配比產生流程圖 ... 118
圖 14 二維平面歐式距離計算示意圖 ... 119
圖 15 爐石之分類 ... 119
圖 16 試驗流程圖 ... 120
圖 17 強制式拌合機 ... 121
圖 18 坍度模及搗棒 ... 121
xiii
圖 19 試體模具 ... 122
圖 20 試體養護槽 ... 122
圖 21 200 噸抗壓試驗機 ... 123
圖 22 新拌混凝土坍度施作 ... 123
圖 23 試體澆灌搗實施作 ... 124
圖 24 試體養護施作 ... 124
圖 25 試體蓋平施作 ... 125
圖 26 試體蓋平完成 ... 125
圖 27 混凝土抗壓試驗施作 ... 126
圖 28 系統架構圖 ... 127
圖 29 類神經網路強度模型基本設定圖 ... 128
圖 30 強度模型網路最佳驗證效能圖 ... 128
圖 31 強度模型網路訓練成果圖 ... 129
圖 32 強度模型測試結果圖 ... 129
圖 33 類神經網路坍度模型基本設定圖 ... 130
圖 34 坍度模型網路最佳驗證效能圖 ... 130
圖 35 坍度模型網路訓練成果圖 ... 131
圖 36 坍度模型測試結果圖 ... 131
圖 37 水-強度分析圖 ... 132
xiv
圖 38 水-強度敏感度分析圖 ... 132
圖 39 水泥-強度分析圖 ... 133
圖 40 水泥-強度敏感度分析 ... 133
圖 41 SP-強度分析圖 ... 134
圖 42 SP-強度敏感度分析圖 ... 134
圖 43 SP-坍度分析圖 ... 135
圖 44 SP-敏感度分析圖 ... 135
圖 45 預測值-實際值強度圖 ... 136
圖 46 實際-預測坍度圖 ... 136
圖 47 分類流程圖 ... 137
1
一、緒論
1-1 背景
混凝土是土木營建工程最被廣為運用的材料,目前混凝土配比設計品
質一般是參照中國國家標準 CNS 規範來控制。隨著建築物越蓋越高的情況
下,這使得傳統普通水泥混凝土已不符需求,為求在工程品質及成本均能
兼顧的考量下,許多專家學者或學術研究單位開始致力於研究發展具有較
高工作性、耐久性、安全性及經濟性之新型混凝土。
現代混凝土之組成成份裡,除了水、水泥、粗骨材、細骨材外,還另
外添加了如飛灰、爐石粉……等卜作嵐礦物掺料用來取代部分水泥用量或
填塞骨材間的間隙。這除了可減少水泥用量,使混凝土較為經濟外,尚可
降低水化熱、增加水密性、晚期強度及耐久性。而添加了如緩凝劑、強塑
劑(即高效能減水劑)……等化學掺料則是可以用來增加混凝土的工作性、
減少混凝土用水量。這使得混凝土在低水膠比下,仍保有高的工作性,除
降低發生泌水或析離等現象的機率,還可藉由自身的高流動性容易填充至
狹窄的鋼筋與模板間隙中,避免產生蜂窩或冷縫等混凝土澆置缺失,有助
於結構物品質強度的提升
﹝2﹞
。
混凝土是一種不確定性很高的材料,即便使用想同的配比設計,若材
料來源改變或生產過程溫濕度的改變,都可能造成混凝土強度與工作性之
變化。又其品質及特性之表現主要取決於其配比設計;再加上配比須依澆
置構造物之複雜度、施工人員本身技術和環境不同等因素來作考量及設計
﹝2﹞
,另配比之好壞將直接影響現場施工品質之良窳及成本之控制,故
配比設計於建物結構體工程品質、強度、耐久性及成本考量上,佔有著極
為重要的地位。
2
1-2 研究動機
在早期一般傳統的配比設計方面,主要以純水泥混凝土為主,其在品
質強度方面係以水灰比(W/C)來控制,水灰比(W/C)越低,亦即用水量越少、
水泥量越多,則混凝土強度就越高。
但殊不知在要求低水灰比、高強度設計的同時,因水泥用量之增加,
從而造成混凝土成本的提高,既不經濟、且不環保,更不符合現代提倡綠
建築、生態工法及永續經營的理念,另用水量的減少,亦導致混凝土工作
性變差、澆置不易、施工現場加水等導致混凝土泌水或析離等影響施工品
質之缺點產生,這使得傳統混凝土在設計的同時,無法兼顧施工時之強度
與工作性,故要如何使混凝土能於適當之環境或場所發揮其最大之性能及
經濟效益,則成為了工程師需要思索及探討的課題。
在為了使混凝土之強度、工作性、耐久性和經濟性等皆可兼顧的需求
下,而有了卜作嵐礦物掺料和化學掺料的加入。但由於添加了礦物掺料及
化學掺料後,將使得其配比設計較一般傳統混凝土要來得困難,因任一種
掺料加入的多寡,皆有可能使得混凝土不論在工作性、強度或其它性能方
面產生極大的變異性。配比設計一般都是先由傳統配比設計法配合工程師
的經驗和反覆的試拌後,視混凝土拌合後之情況,再作配比上適當之調整,
並經由統計分析後,才可獲得合理之配比,以達到最初所預期之效果。
在台灣地區,每一種混凝土經配比設計、拌合完成後,該試體皆需依
照中國國家標準 CNS1232 澆置並養護混凝土圓柱試體,並以 28 天混凝土
齡期試驗來測試其抗壓強度,而所設計之混凝土配比並不一定一次就能成
功達到所需之目標需求,再加上整個過程中最耗費的就是時間的等待,若
試驗所得之結果不如預期,則不僅費時,亦浪費掉許多寶貴的資源
﹝3﹞
。
為使混凝土能滿足、配合和適應當今各種環境之現況,故如何將混凝土配
比作一完整且準確之設計,應為現前最主要之考量。
3
有鑑於上述各種原因,在為求節省人力、時間和資源成本且希望以較
科學,而非以個人經驗判斷之方式來設計配比的情況下,開始有專家學者
利用各種方法或工具來建立混凝土預測模型,從早期以水灰比來預測試體
強度及利用統計學原理建立經驗公式,到後來運用電腦之運算能力並搭配
不同之演算法所建立出的預測模型,皆是為了使混凝土配比設計之品質及
其預測結果能夠更加準確。
過去也曾有利用電腦搭配其它方法來隨機產生混凝土配比之研究,如
呂夙修
﹝3﹞
於 2010 以 convex hull 之方法來界定配比之有效區域,並利
用電腦程式在有效區域範圍內產生各種配比,再以預測模型來預測配比之
強度和坍度。但此方法所得到之配比並不一定能符合規範之規定(如:卜
作嵐掺料取代率限制…等),而工程師亦可能無法以經驗或直覺來判斷該
配比是否合理,再加上其產生配比之方法較為耗時,倘若產生之配比不滿
足設計需求,則需重複上述動作,直到有合用之配比出現為止。這樣的方
式可能會有以下二種缺點的發生,第一,整個過程中所獲得之配比並不一
定皆符合設計規範的規定,第二,工程師可能要經過多次數或長時間的嘗
試後才能獲得合理之配比,此二點缺點可能會導致花費了很多的人力、時
間或資源後,仍無法獲得我們所需之配比。
因此,我們若能建立一套準確預估混凝土配比設計的機制與方法,並
提早預知混凝土配比之試驗結果,則不僅對成本控管、提供合適之配比及
品質提升等方面有所幫助外,亦可使大大節省人力、時間的浪費和地球資
源的損耗。
4
1-3 研究目的
本研究目的係希望先由國內外文獻中蒐集相關之混凝土配比,而後經
由類神經網路訓練學習並建立模型,並利用電腦程式配合混凝土 ACI 設計
規範(如:水膠比、各材料之上下限值、掺料取代率之限制……等)和流程
來分析並建立一準確性高且可用之混凝土配比資料庫,另再加上現場實驗
輔以佐證,藉此除可增加並補充原始配比資料庫中不足之數據外,亦可提
供更多種配比組合資料供使用者參考,並可依其工區或現場施工之環境條
件選擇合適之配比來使用。
1-4 論文研究架構
本研究論文架構大致上共分為五個章節,其章節名稱及內容概要介紹,
如下所述,而研究流程則如
圖 1
所示。
第一章為緒論,本章將說明本研究之背景、動機、目的及研究架構。
第二章為文獻回顧,本章將針對國內外人士已完成之相關研究作一簡要之
回顧、概述和介紹。
第三章為研究方法,本章主要將本研究所使用之系統工具、方法及其原理
和架構作一介紹和概述。
第四章為研究結果分析,本章為將研究中所獲得之結果作進一步之分析和
探討。
第五章為結論與建議,本章主要為對本研究所得到之結果作一總結,並對
本研究中尚不足之部分或未來可繼續研究之方向提出相關之建議。
5
二、文獻回顧
本章將針對近幾年來與本研究有關之國內外文獻作一簡單的回顧、敘
述和介紹,其中包含混凝土抗壓強度與坍度之預測,以及如何利用電腦程
式軟體來輔助混凝土作配比設計之發展史
﹝3﹞
。
2-1 混凝土抗壓強度之預測
混凝土之抗壓強度與用水量、水泥用量、膠結量、水灰比、水膠比、
骨材粒徑級配和掺料取代量有著密不可分的關係。設計者往往需藉由上述
條件,依指定規範來設計配比,並以設計強度作為依據,初步評估混凝土
強度是否可達目標需求,而在經由多次設計和實驗過程中,即有某些專家
學者便利用相關數據作迴歸分析,進而推導出與抗壓強度有關之預測式。
2-1-1 利用水灰比原理預測抗壓強度
Abrams
﹝6﹞
於 1918 年從大量實驗數據中,發現了混凝土行為與用水
量、骨材粒徑級配大小及水泥使用比例有著密切的關係,並發現用水量與
混凝土強度趨勢呈反比,而水泥用量則與混凝土強度趨勢呈正比現象,作
者以水灰比為依據,並利用數值分析迴歸出需要的參數來推導以下之經驗
公式,並用以預測混凝土之抗壓強度,公式如下:
S =
𝐴
𝐵
𝑥=
14000
8.2
𝑥(1)
(1)式中,S 為 28 天之抗壓強度;𝑥為水灰比(即 W/C);𝐴 和𝐵則為因應水
泥種類、空氣含量、齡期、養護條件、強度及隨其它影響條件而改變之實
驗參數。
Feret
﹝7﹞
於 1984 年認為中等強度之混凝土,其強度主要係由混凝
土本身水泥漿體之性質特性來控制,因而提出下式來預估強度:
6
f
′c = k (
𝐶
𝑐 + 𝑤 + 𝑎
)
2(2)
(2)式中,
f
′c為混凝土抗壓強度(MPa);k 為係數;𝐶為水泥重(kg/cm
3);
𝑐、𝑤
和𝑎則分別為水泥、水、空氣之絕對體積(m
3/m
3)。
在水灰比方面,前人已針對混凝土強度與水灰比(或灰水比)二者間之
關係,提出了許多預測式,以下即列出一般常用之預測式
﹝8﹞
:
1. ACI Code 建議關係式:
f
′c = −60 + 176 ×
𝑐
𝑤
(3)
(3)式中,f
′c為混凝土 28 天抗壓強度(kgf/cm
2),𝑐為水泥重,𝑤為水
重,
𝑐 𝑤則為灰水比(
𝑐 𝑤<1.6)。
2. 日本土木學會建議關係式:
f
′c = 215 ×
𝑐
𝑤
− 210 (4)
3. 美國墾務局建議關係式:
f
′c = 200 ×
𝑐
𝑤
− 100 (5)
(5)式中,
𝐶 𝑊之範圍介於 0.5~0.7 之間
4. Popovics(1990)建議關係式
﹝9﹞
:
log 𝑓′𝑐 = 4.43 − 0.972 ×
𝑤
𝑐
− 0.00111 × 𝑤 (𝑝𝑠𝑖) (6)
(6)式中,𝑤為用水量;單位為(
𝑦𝑑𝑙𝑏3)或(0.593
𝑚𝑘𝑔3)
除上述由水灰比或灰水比推導出之強度預測式外,另尚有一些專家學
者及相關文獻利用其它與混凝土強度有關之相關參數提出了不同的強度
預測式,其關係式如下所示:
1. 若 ACI 配比不考慮卜作嵐材料及含氣量時,則可以下式來預測混凝土
抗壓強度
﹝10﹞
:
7
f
′c =
𝐾
𝑔𝑆
𝑐[1 + 3.1 (
𝑊
𝐶 )]
2(7)
(7)式中,
𝐾
𝑔=3.5(骨材河川係數),
𝑆
𝑐=750.6kg/cm
2(水泥強度因數),
而
𝑊 𝐶為水灰比。
2. 上式若考量水泥強度因素、骨材形狀及堆積因素、卜作嵐材料因素拌
合及含氣量因素等,建立本土化 HPC 強度預測及評估公式,參考 Larrad
﹝11﹞
於 1987 年所提出之公式,重新修正實驗,獲得下列 HPC 材料配
比參數及強度推估公式:
f
′c =
𝐾
𝑔𝑅
𝑐[1 + 3.1
𝐶(1 + 𝐾
𝑊 + 𝐴
1+𝐾
2) + 𝑠𝑙]
2(8)
𝐾
1= 0.4
𝑓𝑎
𝐶
+ 3
𝑠𝑓
𝐶
(9)
𝐾
2= 0.2
𝑙𝑓
𝐶
(10)
上列(8)式、(9)式及(10)式為 1987 年 Larrad 所提出之經驗公式,式
中,𝑊為用水量,𝐴為含氣量之當量水量,𝐶為水泥量,𝑠𝑙為爐石量,
𝐾
1≦0.05;該值卜作嵐係數,𝑓𝑎為飛灰量,𝑠𝑓為矽灰量,𝐾
2≦0.07;
該值為填充料係數,𝑙𝑓為石粉量。
而經改良後所得之修正式如下所示:
f
′c =
𝐾
𝑎𝑆
𝑐[1 + 3.1
𝐶 + 0.4𝑓𝑎 + 𝑠𝑙]
𝑊 + 𝐴
2(11)
(11)式中,𝐾
𝑎為骨材係數;𝑆
𝑐為水泥強度因數;𝑊為用水量;𝐴為含
氣量(等值水之體積);𝐶為水泥量;𝑓𝑎為飛灰量;𝑠𝑙為爐石量。
潘坤勝
﹝12﹞
認為 Abrams 強度預測式之所以未臻完善的原因是由於
該式並未考慮如:水化程度、毛細孔隙等影響混凝土強度之重要因素,而
使得該式強度預測方面之準確性,仍尚有改善及加強之空間,故其於 2004
8
年時,利用試驗資料分別建立了水化程度與水灰比以及水化程度與毛細孔
隙間之關係式,並利用水灰比及毛細孔隙兩個參數來建立二者與混凝土強
度間之共同關係式,而後再以此模式驗證其它配比資料,建立以水灰比及
孔隙推導而得之普通水泥混凝土強度預測式,該式如下所示:
f
′c =
𝐴
𝐵
𝑤/𝑐+
𝐶
𝐷
𝑃𝑐(12)
(12)式中,為混凝土抗壓強度;
𝐴、𝐵、𝐶和𝐷均為常數;𝑤/𝑐為水灰比;𝑃𝑐為
MIP 試驗之毛細孔量(cc/g),其中𝑃𝑐之求法如下所示:
Pc = −0.25458 ln ( 𝛼) +
0.333849
0.30749
𝑤/𝑐− 0.6213 (13)
(13)式中,𝛼為水化程度;𝑤/𝑐為水灰比。
另在研究中提到除改善原本普通水泥混凝土之預測式外,亦針對了添加波
索蘭材料之混凝土推導出相關之預測式,該式主要以混凝土之材齡和強度
發展趨勢及波索蘭材料取代率作為推導依據,其預測式如下所示:
fc = a + b × log(材齡) + c × 材齡 + d × 材齡
2+ 𝑒 × 波索蘭取代率(14)
(14)式中,a、b、c、d、𝑒均為迴歸係數
最後結果顯示,該式於任何齡期上,其抗壓強度與齡期之 R
2值始終維持在
0.95~0.99,此表示二者間有著相當高之關聯性,亦即該式能夠有效並準
確地預測波索蘭混凝土之抗壓強度。
2-1-2 利用類神經網路預測抗壓強度
賴鴻成
﹝13﹞
於 1993 年利用類神經網路來預測混凝土之強度行為,
其類神經網路之輸入層係以兩種不同之參數模式來建立,第一種模式之輸
入參數為水灰比、水、水泥、細骨材、粗骨材和試體齡期等六個參數,而
第二種模式除了包含上述參數外,還增加了骨材最大粒徑作為輸入參數,
而在隱藏層部分皆設定為一層,隱藏層神經元之數量係以輸入層參數數量
9
之二倍加上一(即輸入層參數數量× 2 + 1),而輸出層參數則為混凝土抗
壓強度,研究中類神經網路之學習訓練方式係以改變輸入結點數目和變化
學習速率η二種方式作為控制因素,最終結果顯示,整體預測之均方誤差
為 4.14%相較於台泥公司的 30.39%和日本土木協會的 47.30%為低,故類
神經網路對於混凝土抗壓強度方面之預測精度是良好且可靠的。
陳堉照
﹝14﹞
於 2000 年利用非監督式模糊類神經網路
(Unsupervised Fuzzy Neural Network Reasoning Model, UFN)來建立混
凝土抗壓強度預測模型,其原理係先將過往解決過的相似案例全部集結為
一「案例資料庫」,再將新進之案例拿來和原有資料庫中之案例作相似度
的比對,進而從中找出相像或相關之案例,最後將這些相似案例的答案組
合成新案例之解答。研究中將非監督式模糊類神經網路(UFN)用來和監督
式類神經網路中的 BFGS 演算法以及傳統經驗公式預測法分別針對一般傳
統混凝土和高性能混凝土所建立之模型進行比較,並評估預測模型之效益,
由實際分析結果中顯示,UFN 推理模式用於一般傳統混凝土和高性能混凝
土之強度預測模式,其有著低於相對系統誤差 5%以下之良好精度,此一
結果亦證明了非監督式模糊類神經網路(UFN)對於處理關於資料複雜、龐
大以及高度非線性之混凝土強度預測問題同樣具有著相當好之解決能
力。
Ahmet Öztas et al.
﹝15﹞
前於 2006 年提出高強度混凝土係為一無
法以一般組成成份、拌合、放置和養護方式即可達到滿足特殊性能及均勻
性要求之混凝土,且其為一高度複雜之材料,故要建立預測其行為之模型
是一件不容易的事。研究中將利用類神經網路的適用性來預測高性能混凝
土之行為,並從文獻上收集了 187 組高強度混凝土之配比供類神經網路訓
練學習和測試之用,研究中之類神經網路以水膠比、用水量、細骨材比例、
飛灰用量、輸氣劑量、強塑劑量及矽灰取代量等七種變數作為輸入參數,
10
隱藏層設為二層;第一層有五個節點;第二層則有三個節點,輸出參數為
抗壓強度及坍度,學習演算法則是使用調整共軛梯度法(scaled
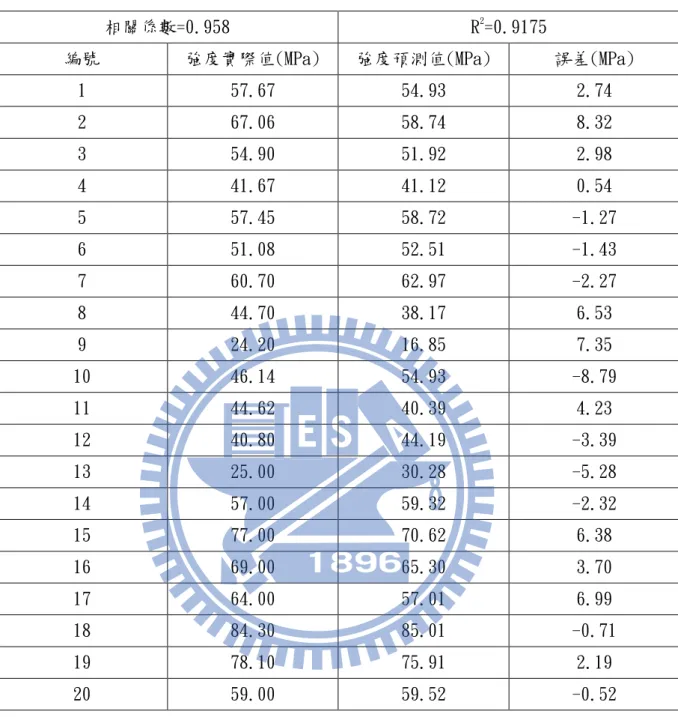
conjugate gradients algorithm),最後結果如
圖 2、圖 3
及
表 1
所示,
其強度模型之 R
2值為 99.93%、坍度模型之 R
2值為 99.34%,由此可見,類
神經網路於預測高強度混凝土之抗壓強度及坍度是一個可行且極具潛力
的工具。
Cahit et al.
﹝16﹞
於 2009 年利用三種不同之水灰比(W/C 等於 0.3、
0.4、0.5),三種不同之水泥用量(300、400、450kg/m
3),以及四種不同
之爐石取代率(20%、40%、60%、80%),一共製作了 225 個混凝土試體,並
測試其齡期為 3、7、28、90 及 360 之抗壓強度,將所測得之試驗數據交
由類神經網路作訓練、測試及建模,其以水泥、爐石、水、高效能減水劑、
骨材和試體齡期等六個輸入參數及抗壓強度一個輸出參數來建立模型,另
研究結果顯示出 Levenberg–Marquardt (LM)為該研究之最佳演算法,而
其實際強度和預測強度所得之 R
2值介於 0.92 至 0.96 之間,此一結果表示
類神經網路於預測爐石混凝土之抗壓強度上已有相當高之準確性。
Marek
﹝17﹞
於 2010 提出了三種方法來建立類神經網路預測混凝土
強度模型,這三種方法分別為驗證集法(validation set),最大邊界似然
法(maximum marginal likelihood)和貝葉斯法(full Bayesian approach),
藉由比較這三種方法之優缺點及差異性來選擇最佳模型,研究中提到以貝
葉斯法(full Bayesian approach)搭配蒙地卡羅(Monte Carlo)隨機抽樣
法所得之預測模型是最好的,其原理係基於貝葉斯推理而得,在此法中所
有參數皆被視為隨機變量,其預測原理是集合所有空間上之參數和超參數,
並使用其近似技術來解析較為複雜之問題,貝葉斯方程式推導如下所示:
𝑝(𝑤| 𝛼 ) =
𝑝( |𝑤 )𝑝(𝑤|𝛼)
11
𝑝( |𝑤 ) = ∏ 𝑝(
𝑛|𝑤 ) = ∏(2𝜋𝜎
2)
−12 𝑁 𝑛=1 𝑁 𝑛=1exp [−
{
𝑛− 𝑦(𝑥
𝑛; 𝑤)}
22𝜎
2] (16)
p( |𝛼 ) = ∫ 𝑝( |𝑤 )𝑝(𝑤|𝛼)𝑑𝑤 (17)
𝑝(
𝑁+1|𝑥
𝑁+1𝛼 ) = ∫ 𝑝(
𝑁+1|𝑥
𝑁+1𝑤 )𝑝(𝑤| 𝛼 )𝑑𝑤 (18)
𝑝(𝑤 𝛼 | ) =
𝑝( |𝑤 )𝑝(𝑤|𝛼)𝑝(𝛼)𝑝( )
𝑝( )
(19)
𝑝(
𝑁+1|𝑥
𝑁+1) = ∫ 𝑝(
𝑁+1|𝑋
𝑁+1𝑤 )𝑝(𝑤 𝛼 | )𝑑𝑤𝑑𝛼𝑑 (20)
(15)式中之𝑝(𝑤|𝛼)為先驗分佈之過量權重, =
1。
(16)式和(17)式中之𝑝( |𝑤 )為近似然函數,其係由式(16)推導而得。
(17)式中的p( |𝛼 )為正規化因子,其可表示為超參數。
(18)式中,𝛼和 皆假設為已知之超參數。
(20)式為貝葉斯預測方程式最終之推導結果。
而研究中亦於過程中配合實驗加以佐證,最後結果顯示,相較於驗證集法
(validation set)及最大邊界似然法(maximum marginal likelihood),
貝葉斯法(full Bayesian approach)應用於類神經網路作學習和預測混凝
土之抗壓強度是可在不需要手動選擇最終模型架構和超參數之情況下,即
可獲得最精確之預測值。
Mucteba et al.
﹝18﹞
於 2011 年利用了一種一般混凝土和六種 SCC
混凝土共七種配比設計製作了七組試體牆,其於每組試體牆上取 24 個點
來做吸水率、單位重和試體鑽心試抗壓試驗,並以每組配比之水泥、飛灰、
石灰粉、大理石粉、砂、粗骨材 I、粗骨材 II、高效能減水劑、吸水率及
單位重等十個參數作為類神經網路之輸入參數,隱藏層數量設定為兩層,
其節點數分別為十四個和十個,而輸出參數則為抗壓強度,再以倒傳遞類
神經網路(Back-Propagation-Networks)搭配(Fletcher–Powell
12
conjugate gradient)共軛梯度法和(Levenberg–Marquardt)二種演算法
來預測鑽心試體抗壓強度,於研究結果顯示,由(Fletcher–Powell
conjugate gradient)共軛梯度法所得之預測結果較好,也證明了類神經
網路可用來準確預測 SCC 混凝土鑽心試體之抗壓強度。
2-2 混凝土坍度之預測
在混凝土壓送、拌合或澆置的過程中,工作性佔有著極為重要的地位,
工地現場常為提高工作度而發生任意加水之現象,此舉除會提高混凝土之
水灰比且降低混凝土本身強度外,尚有可能使混凝土產生析離或造成表面
泌水等不良之現象,故工作性之好壞除了直接影響混凝土施工之難易度外,
還進而控制施工品質之良窳,且會間接影響混凝土相關成本之支出及硬固
後是否產生蜂窩、冷縫等澆置不良的情況發生,而在配比中控制工作性之
主要因子即為用水量、減水劑或強塑劑等化學掺料,又現今混凝土配比中
皆含有各式各樣的掺料,使得工作性變化更為多樣,傳統之迴歸分析已無
法準確地分析、評估、預測並建構新拌混凝土工作性之模型,故已有許多
專家學者開始利用各種方法來預估混凝土之工作性,期望能使混凝土品質
達到一定的水準,以下就以最近國內外的文獻作一簡單之回顧和介紹。
柯泰至
﹝19﹞
於 2001 年認為若採以拌合實驗(mixture experiments)
之理念來作為混凝土工作度模型實驗之設計方法,並在實驗設計階段選擇
以單體形心設計作為實驗因子之控制方法來設計和進行相關實驗時,可較
有效率地來建構高性能混凝土之工作度模型。研究中於實驗階段係經由限
制各材料成份及比例上下限,以作為實驗施作之合理範圍,實驗雖經上述
各過程作合理化之篩選,但仍有多組配比因用水量或強塑劑(SP)用量調配
不當;亦或材料比例限制偏異,造成其初始結果所得之工作度不如預期,
且有較為偏低之現象,故其將原始設計中之用水量及強塑劑用量作適度的
13
調整,才改善上述工作度不良之情況。而後其分別以一階、二階迴歸分析
及類神經網路三種方法建立工作度模型並分析比較三種方法之優劣,而我
們從分析結果中發現水及強塑劑(SP)的用量對於工作性有著很大的影響,
這顯示三者間之相互關係是密不可分的,同時亦發現了強塑劑(SP)和工作
度間的關係是非線性的。最後經由驗證結果顯示,三種方法就整體評估而
言,類神經網路仍為建構工作性模型之最佳工具。
葉怡成
﹝20﹞
於 2005 年以導入篩選問題之實驗方法,來獲得精確的
實驗數據,並利用類神經網路建構更精準的工作性模型。其研究過程主要
分為五個階段,首先,第一階段是利用單體形心設計之實驗方法取得實驗
數據,在實驗設計之過程中,故依規範和經驗公式對材料用量之上下限及
各成份間之比例作一定的限制,此為使混凝土設計配比更加合理且可行。
第二階段:將初始實驗之數據結果利用類神經網路來建構模型,其輸入變
數為水、水泥、爐石、粗骨材、細骨材、飛灰、爐石及強塑劑等 7 項參數,
輸出變數則為坍流度。第三階段:以建構好之坍流度模型對原本設計之實
驗配比進行坍流度之預測,將誤差偏差較大之數據篩選出來,並針對該筆
數據重覆進行實驗,除確保實驗數據無誤外,亦可使實驗數據更為可靠。
第四階段:以修正後之實驗數據再利用類神經網路建構新的模型。第五階
段:評估初始及修正數據二模型間之差異及影響,經比較過後,修正過後
之模型不論是在判定係數或均方根誤差方面皆較初始模型要來得好,由此
可見,研究中所提出之方法確實對提升模型之準確性有著極高的助益。另
研究中亦用相同之實驗數據比較類神經網路和二階迴歸分析二種方法何
者所建立之預測模型較佳,結果顯示,類神經網路遠比二階迴歸分析所建
立之模型來得精確。
14
2-3 混凝土利用電腦程式作最佳配比設計
當電腦可準確地建立混凝土預測模型時,便有專家學者開始想利用電
腦程式來設計配比,一來是希望藉由電腦高運算之效能來減少設計過程中
之錯誤,二來則希望能夠由電腦直接得知配比之設計資料(即強度或工作
性),以便評估該配比是否適用於當地現場之環境狀況,藉此除可減少混
凝土試拌的次數,還能避免材料的浪費和 28 天試體養護之等待期,以下
則就國內外一些相關的文獻作一簡單之回顧和簡介。
陳怡成
﹝21﹞
於 2001 年以材料成本和配比須同時滿足強度限制、工
作度限制、各成份上下限限制、各成份間比例限制、絕對體積限制等五個
條件,以作為高性能混凝土最佳化設計之目標。因強度與工作度二者為研
究成敗之關鍵,又兩者雖是材料成份之函數,但此函數確是個未知數,而
類神經網路又是解決非線性問題之最佳利器,因此研究過程中,利用類神
經網路來建立強度及工作度模型,以增加模型之準確性,最後搭配以類神
經網路為基礎之品質設計軟體 CAFÉ(Computer-Aided Formula
Engineering)作為設計系統,以配合不同設計需求,用來產生不同之混凝
土配比,最後經實驗驗證結果顯示,CAFÉ 軟體雖於強度和工作度預測方
面,多呈低估傾向居多,且有些許工作度需求較高之配比經實驗後,會有
泌水及析離之現象發生,此一現象可依現場狀況,調整用水量或強塑劑(SP)
用量,即可改善之。但就整體而言,各實驗誤差之均方根尚在合理範圍內,
且配比本身與混凝土設計規範及過往經驗法則相符合,故證明利用本軟體
來作高性能混凝土最佳化配比設計,仍為一可用途徑。
Tao Ji et al.
﹝22﹞
於 2006 年提出傳統之混凝土配比設計法皆由膠
結料之漿體量來推算粗細骨材之用量,作者認為使用傳統設計法將導致混
凝土成分中之水和水泥用量過多;粗細骨材粒料用量減少,而所設計出來
之混凝土既不經濟、耐久性也較為不足,其亦提出傳統混凝土設計法本身
15
即建立於過往之經驗公式及表格上,又因每一材料本身即存在著不確定因
子,使得每項經傳統設計法所設計出之配比皆要經過大量之試誤過程,方
可使用,此舉將造成很多人力、資源和時間上之浪費。故作者於研究中將
提出由骨材體積量及最小膠結漿體量之觀念來作混凝土配比設計,其所使
用主要參數有標稱水灰比、當量水灰比、平均漿體厚度、飛灰膠體比及細
骨材體積比等五個參數,再配合類神經網路及 Modified Tourfar's 模型
來作配比設計。在強度模型之建立方面,其係以細骨材體積比、平均漿體
厚度、飛灰-膠體比及當量水灰比作為輸入參數;而輸出參數則為強度,
另坍度模型之輸入參數則為細骨材體積比、平均漿體厚度、飛灰-膠體比、
標稱水灰比;輸出參數則為坍度,其中,強度模型及坍度模型可用於反推
算當量水灰比及平均漿體厚度,其反推算之過程,僅需將強度和坍度值設
定為模型之輸入參數,而欲求解設為輸出參數即可,本法之主要流程第一
步為需先假設標稱水灰比及細骨材体積比;第二步為計算平均漿體厚度、
細骨材體積比及混凝土配比總漿體體積所對應之骨材單位體積(V
, p),若所
計算出之細骨材體積比和原本假設的值相等,則第三步繼續計算當量水灰
比及標稱水灰比;若否則重回第一步,最後所計算出之標稱水灰比要和當
初假設之量相同,則該水灰比即為所求,而作者認為利用此法所設計出之
混凝土配比要比它法來得經濟且耐久性較高。
Bang Yeon Lee et. al.
﹝23﹞
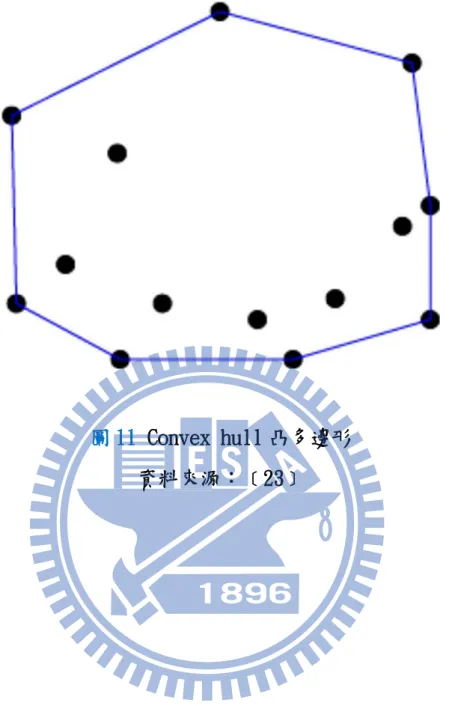
於 2009 年時認為類神經網路對於有限
資料庫區域面積外之預測模型,其所產生錯誤預測結果之機率較大,倘若
要解決此問題,除非以類神經網路之所有輸入變數之範圍來作為此資料庫
所函蓋的區域,但因混凝土本身之輸入變數居多,且要建立此一資料庫是
件非常費時、且成本昂貴的一件事,故作者提出了以數學方法中之 convex
hull 演算法來界定資料庫之有效區域範圍,藉此除可縮小搜尋範圍外,
尚可確保資料庫中所留下之數據具有一定的精度和準確性,並於研究中結
16
合了基因演算法,使其在分類過程中,亦能創造出新的解決方案,如此一
來,便可防止解答落入局部最佳解,而能更精準的評估及預測有效區域內
材料之最佳配比設計。
呂夙修
﹝3﹞
前於 2010 年利用凸殼演算法(Convex hull)來定義各材
料之有效區域及範圍,其原理係將所有資料點散佈在 X-Y 二維座標中,首
先先將各散佈於最外圍之資料點連接成一個凸多邊形,並定義在此凸多邊
形內之資料點稱為有效資料,而落於凸多邊形外之資料點,則視為無效資
料,而後再將電腦程式隨機產生之配比資料以此方法交由凸殼演算法
(Convex hull)之凸多邊形來判定該資料是否為有效資料,以確立配比資
料之有效性。待有效資料確定後,接著將配比資料交由已建立好之類神經
網路強度及坍度預測模型來預測該配比之強度及坍度,為了因應使用者須
在不同環境條件下有著不同的需求,研究中再利用 K-Means 演算法來分析、
分類混凝土配比資料庫中之有效配比,其以強度分別為 25MPa、32.5MPa、
40MPa、47.5MPa、55MPa,坍度則均為 25 公分,共分成五類作為設計目標
值,當資料庫中有符合前述五大類之相關配比,K-Means 演算法便會將其
選擇出來並放入有效資料庫內,以供使用者作選擇及使用。
Mohammad
﹝24﹞
於 2012 年提出了以類神經網路作高性能混凝土最佳
配比設計,其是針對需求強度、需求坍度、需要之流變性能(材料之降伏
應力和塑性黏度)、各材料重量範圍、成份比例、絕對體積等以上參數作
一定之限制,並於實驗中發現飛灰、爐石粉及矽灰等三種卜作嵐掺料之取
代量對於材料之降伏應力、塑性黏度和抗壓強度有一定之影響,研究中還
發現到在固定水膠比之情況下,以矽灰取代部分水泥會降低混凝土之工作
性,但可於混凝土中掺入飛灰來彌補不足之工作性。於強度方面,除了發
現當矽灰取代量為 7%至 12%有著較佳之強度外,也從飛灰、爐石粉和矽灰
間之相互關係中找出了可作為合理抗壓強度預測之條件,最後以類神經網
17
路預測材料本身之降伏應力及塑性黏度,並將所得之預測值和實際值繪製
成圖,結果顯示,二者有著很好的關聯性,此表示類神經網路已可提供一
些適當的指示來選擇混凝土材料之配比,以減少試驗配比之失敗及材料的
浪費。
Joo-Ha Lee et. al.
﹝25﹞
於 2012 年提出了以和諧搜尋演算法
(Harmony search algorithm)來作為高性能混凝土配比設計之工具,和諧搜
尋演算法的設計概念是從音樂執行的過程中搜尋一個較好且完美的和諧
而來的。在研究中總共搜集了 189 組配比來進行測試,其中以 181 組配比
試驗結果來建立強度及工作性之多元迴規模型,而多元線性迴歸方程式如
下所示:
f
′c = 𝑎
+ 𝑎
1𝑊
𝑐+ 𝑎
2𝑊
+ 𝑎
𝑊
+ 𝑎
𝑊
𝑤+ 𝑎
𝑊
+ 𝑎
𝑊
+ 𝑎
𝑊
(21)
l p =
+
1𝑊
𝑐+
2𝑊
+
𝑊
+
𝑊
𝑤+
𝑊
+
𝑊
+
𝑊
(22)
(21)式及(22)式中,f
′c表示強度(MPa),
l p
表示坍度(mm),𝑊
𝑐為水泥
重,𝑊
為飛灰重,𝑊
為矽灰重,𝑊
𝑤為水重,𝑊
為強塑劑重,𝑊
為細
骨材重,𝑊
為粗骨材重,𝑎
和
為迴歸係數。
最後再以和諧搜尋演算法應用適應性函數(fitness functions)來獲得混
凝土配比之最佳解,在求取配比最佳解的過程中,需適當的加入一些條件
限制,例如:定義各材料重量和參數比例之合理範圍,如:水泥重、水膠
比…等,此除可用來提高預測精度,且會加快最佳化之過程,而後將其餘
8 組配比用來和類神經網路及基因演算法所獲得之結果作一比較,並驗證
之,結果顯示,使用和聲搜尋演算法所得之配比設計亦有不錯之成效,由
此可見,利用和聲搜尋演算法來作混凝土最佳配比設計也是個不錯的方
法。
18
三、研究方法
本章節將介紹本研究所使用之方法理論、概念和架構以及試驗計畫和
流程,在方法理論方面以介紹類神經網路之基本原理和架構,以及其如何
配合 ACI 配比設計規範設計出適當且合理之配比為主,另於試驗計畫方面,
則以介紹整個試驗流程及過程中所使用之材料、機具為主。
3-1 類神經網路
人類的大腦是由數以計數的神經元所組成
﹝27﹞
,當其接收外來的資
訊,而神經元被該輸入資訊所激發時,會產生一串脈衝列延著軸索傳遞,
脈衝列的速率是由輸入信號的強弱和突觸強度所決定,而我們人就是透過
這個複雜的神經網路系統脈絡來學習、判斷和辨識。
電腦是現今社會上的主流,其擁有強大的運算能力及處理複雜問題的
技術,所以我們希望電腦能夠擁有和人腦一樣的學習及辨識能力來幫助我
們處理專業領域上一些非線性、複雜且棘手之問題,故許多學專家學者開
始研究如何使電腦也能試著模擬像人腦一樣架構之神經網路脈絡系統,我
們將該系統稱之為類神經網路系統
﹝3﹞
。
類神經網路是一種基於腦與神經系統研究所啟發的資訊處理技術
﹝4﹞
,其是由許多非線性的運算單元(稱做神經元 Neuron)和位於這些運
算單元間的眾多連結所組成的,而這些運算單元通常是以平行且分散的方
式來進行運算
﹝27﹞
,並用以模仿生物神經網路之能力,故亦可視為一種
模仿生物神經網路的資訊處理計算系統
﹝28﹞
,它是利用一組範例(即系
統輸入與輸出所組成的資料)來建立系統模型(輸入與輸出間之關係),有
了這樣之系統模型後,便可利用此系統來推估、預測、決策及診斷
﹝4﹞
,
大腦與類神經網路系統上之不同,可由
圖 4
來表示。
19
在本系統中,包含軟、硬體方面,皆使用了大量且簡單之神經元來模
仿生物神經網路系統,這些運算單元(神經元)其通常係由外界環境或其它
神經元來獲取相關資訊
﹝29﹞
,並從人類專家解決問題的實際案例中來做
學習,再藉由系統本身之非線性函數作轉換,且能對大量資料作有效的分
析、處理、運算及應用,綜合以上敘述,類神經網路的運作模式,就有如
人類的大腦一般,可透過樣本或資料之訓練,進而展現出學習、回想、歸
納推演之能力,而其在處理形式配套、分類、函數近似、最佳化及資料聚
類等方面皆有不錯的成效
﹝27﹞
。
3-1-1 類神經網路之特性
﹝28,29﹞
1. 具有平行處理之特性。
2. 具有高度容錯的特性(fault tolerance)。
3. 具有結合式記憶的特性(Associative Memory)。
4. 具有解決最佳化問題之能力(Optimization)。
5. 聯想速度快、網路架構容易調整。
3-1-2 類神經網路之優點
﹝4﹞
1. 可建構非線性之模型,且模型準確度高。
2. 可表達輸入變數間的交互作用,且模型準確度高。
3. 可接受邏輯、數值、有序分類、無序分類變數作輸入,適應性強。
4. 可用於函數映射、數列預測、樣本分類等問題。
5. 模型建構能力強。
20
3-1-3 類神經網路之缺點
﹝4﹞
1. 易因中間變數(即隱藏層)數目的多寡而影響學習速率及優化。
2. 因其加權值和門檻值可調整,故易發生過度學習之現象,而產生
較大之誤差。
3-1-4 類神經網路之類型
類神經網路之類型若依其學習方式來分的話,可分為監督式學習和非
監督式學習二種,以下即針對二種學習方式之原理分別作介紹:
1. 監督式學習
﹝27,30﹞
從問題領域中取得所需學習之範例,必須包含有輸入變數資料及
輸出變數資料,透過範例之學習以迭代方式不斷修正神經網路中的權
值,在修正的過程中,使網路從中取得輸入變數與輸出變數間之對應
規則,再以此規則應用於新案例之推論(只有輸入值,輸出值則以推
論方式取得)
,將輸出儘量符合預期結果,在每個訓練例子給予神經網
路輸入值與期望輸出值,不斷監督神經網路,並不斷修正權值,直至
神經網路輸出值與期望輸出值之間的誤差小於一定之臨界值或權值不
再改變為止,有如老師指導學生對問題做正確的回答。其演算法之流
程如
圖 5
所示。
2. 非監督式學習
﹝27,30﹞
從問題領域中取得所需之學習範例,此法之特點為在訓練過程中,
只需要提供輸入變數值,但不需提供輸出變數值,網路會依輸入資料
本身之特性自行調整學習權重,亦即表示不需要誤差訊息去改善類神
經網路之輸出值,而僅需透過範例學習就能夠自行找出資料中的那些
特徵是重要的或是可忽略之潛在規則,再將資料作“群聚”
21
(clustering)之處理,最後將這個聚類規則應用於新的案例分析,如
此便可以判斷其類別。其演算法之流程如
圖 6
所示。
本研究係利用監督式學習中之倒傳遞神經網路(Back-propagation
network, BPN)來建立混凝土強度預測模型及坍度預測模型,倒傳遞神經
網路為一前向式架構之類神經網路,因其有著簡易操作學習和預測準確率
高之特性,故其目前為類神經網路學習模式中最具代表性,且應用最為普
遍之模式。
3-1-5 倒傳遞類神經網路(Back-propagation network, BPN)
倒傳遞類神經網路於 1986 年由 Rumelhart 等人所提出,也使得網路
架構為多層感知器之構想得以實現
﹝27﹞
。在網路學習之過程中,其目的
即為修正網路連結上的加權值,令網路誤差能夠達到最小值,使得網路模
擬預測之輸出值能趨近原本之目標輸出值,故其基本原理係利用最陡坡降
法(Gradient Steepest Descent Method)之觀念將誤差函數予以最小化
﹝4﹞
,透過它可以將資料的輸入與輸出值間的映射問題變成一個非現性
的最佳化問題,而後再利用網路運算逐步修正參數,最後經由迭代運算後
得到更精確的解答
﹝27﹞
。
倒傳遞類神經網路之學習精度高、回想速度快、輸出值可為連續值,
能處理複雜的樣本識別與高度非線性的函數合成問題,其適用範圍非常廣
泛,如樣本識別、分類問題、函數模擬、預測、系統控制、雜訊過濾、資
料壓縮等,可說是一種應用普遍之類神經網路
﹝27﹞
。
1. 網路架構
﹝4,27﹞
倒傳遞神經網路之整體架構如
圖 7
所示,共有輸入層、隱藏層、輸出
層,各層之功能及設定如下所述:
22
(1) 輸入層:
用來表現輸入值的量,其個數之多寡,視問題大小、型式來決定。
(2) 隱藏層:
用以表現處理單元間之交互影響,其神經元個數並無定量,通常
須以試誤法來決定最佳數目,而層數則依問題複雜程度來決定。
(3) 輸出層:
用來表示輸出值的量,其個數之多寡,視問題大小、型式來決定。
網路中各層間之神經元係靠相關權重來連結,輸入層中之輸入值傳至
隱藏層後,經過加權及活化函數轉換完成後,得一輸出值,再將此輸出值
傳至輸出層
﹝2﹞
。常用之活化函數則如(23)式所示,而函數之型態則如
圖 8
所示。
f(x) =
1
1 + 𝑒
−𝛼𝑥(23)
2. 網路演算法
倒傳遞網路演算法之學習過程是由正向及負向傳播所組成,整個過程
中係透過修正各神經元之權重和偏權值來降低誤差,希望能使誤差函數 E
在容許範圍內並達到最小值,最後再利用最陡坡降法來搜尋 E 之最佳解
﹝27﹞
。以下則就權重與偏權值之修正公式及誤差函數 E 之定義做一介紹,
另網路演算法之程序流程如
圖 9
所示。
(1) 權重與偏權值修正公式:
𝑦
𝑗𝑛= 𝑓 (∑ 𝑤
𝑗𝑦
𝑛−1) = 𝑓(𝑛𝑒
𝑗𝑛) (24)
𝑛𝑒
𝑗𝑛= ∑ 𝑤
𝑗 𝑛𝑦
𝑛−1+
𝑗𝑛(25)
23
(24)式中,𝑦
𝑗𝑛為第 n 層之輸出值,f 為活化函數,𝑛𝑒
𝑗𝑛為第 n-1
層輸出值之權重累積值。
(25)式中,𝑤
𝑗 𝑛為第 n 層第 j 個神經元與第 n-1 層第 i 個神經元
之連結權重,
𝑗𝑛為第 n 層第 j 個神經元之偏權值。
(2) 誤差函數 E 的定義:
E =
1
2
∑(𝑑
𝑘− 𝑦
𝑘)
2 𝑘(26)
(26)式中,𝑑
𝑘為第 k 個神經元之目標輸出值,𝑦
𝑘為輸出層第 k
個神經元之網路輸出值。
24
3-2 類神經網路模型之建立
本研究需利用類神經網路來建立一強度模型及一坍度模型,兩模型皆
由監督式學習之倒傳遞神經網路來建立,建立模型所使用之真實配比數據
由各文獻中來取得,一共蒐集了 482 筆數據,該數據之內容及出處請詳見
表 2
及
表 3
所示。
在強度模型建立方面,首先由各文獻中所蒐集到的 482 筆混凝土配比
數據,利用其中的 462 組數據讓類神經網路作學習、訓練之用,另 20 組
數據則作為測試之用,本網路之輸入參數為水、水泥、細骨材、粗骨材、
飛灰、爐石粉及高效能減水劑(SP)等 7 種,隱藏層設定為 1 層;其結點數
量則以試誤法來決定最佳個數,而輸出參數則為混凝土 28 天抗壓強度。
在坍度模型方面,由各文獻中所蒐集到的 482 筆數據中,擁有坍度數
據之配比共有 295 組,利用其中 285 組數據讓類神經網路作學習、訓練之
用,另 10 組數據則作為測試之用,本網路之輸入參數及隱藏層之設定方
法皆與強度模型相同,唯獨輸出參數改為混凝土之坍度。
類神經網路模型架構如
表 4
所示,所有訓練及測試數據皆需經由正規
化程序之處理,而所有資料經正規化後之數值必須介於 0~1 之間,正規化
公式如(27)式所示。
正規化之數值
=
𝐴
− 𝐴
𝑚 𝑛𝐴
𝑚𝑎𝑥− 𝐴
𝑚 𝑛(27)
(27)式中,𝐴
為該材料之值,𝐴
𝑚 𝑛為該材料之最小值,𝐴
𝑚𝑎𝑥為該材料之
最大值。
類神經網路模型建立之步驟如下所述,整體流程如
圖 10
所示。
1. 首先由各文獻中蒐集真實之混凝土配比資料。
2. 將所蒐集到的資料先作正規化之處理。
3. 設定類神經網路模型之基本參數(如輸入值、隱藏層數、隱藏層節點數、
輸出值、演算法…等)。
25