從假設檢定的觀點探討ARMA模型的參數配適 - 政大學術集成
52
0
0
全文
(2) 從假設檢定的觀點探討ARMA模型的參數配適 ARMA Model Selection from Hypothesis Point of View. 研 究 生 : 林芸生. 呓呴呵呤呥呮呴吺 呙呵呮吭呓周呥呮呧 呌呩呮. 指 導 教 授 : 黃子銘 博士. 呁呤呶呩味呯呲吺 呄呲吮 呔呺呥呥吭呍呩呮呧 呈呵呡呮呧. 國. 立. 立統. 治大 學 政 治 政 大 學. 計. 系. ‧. ‧ 國. 學. 碩 士 學 位 論 文. 呁 呔周呥味呩味. y. Nat. er. io. sit. 呓呵呢呭呩呴呴呥呤 呴呯 呄呥呰呡呲呴呭呥呮呴 呯呦 呓呴呡呴呩味呴呩呣味. n. 呯呦 呃呯呭呭呥呲呣呥 a呃呯呬呬呥呧呥 iv l n C 呎呡呴呩呯呮呡呬 h 呃周呥呮呧呣周呩 呕呮呩呶呥呲味呩呴呹 engchi U. 呩呮 呐呡呲呴呩呡呬 呆呵呬同呬呬呭呥呮呴 呯呦 呴周呥 呒呥呱呵呩呲呥呭呥呮呴味 呦呯呲 呴周呥 呄呥呧呲呥呥 呯呦 呍呡味呴呥呲 呯呦 呃呯呭呭呥呲呣呥 呩呮 呓呴呡呴呩味呴呩呣味 呍呡呹吲吰吱吰. 中華民國 九十九 年 五 月.
(3) 從假設檢定的觀點探討呁呒呍呁模型的參數配適 學 生 : 林芸生. 指 導 教 授 : 黃子銘 博士. 國立政治大學統計學系 要. 摘. 本篇論文著重於探討呁呒呍呁模型的選模準則,過去較為著名的 呁呉呃 、 呂呉呃 等選 模準則中,若總參數個數相同,模型選擇便簡化為比較各模型的概似函數在 呍呌呅 下. 政 治 大 的值,故本研究將假設檢定定義為檢定總參數個數; 截至目前為止,選模準則在使用 立. ‧ 國. 學. 上以 呁呉呃 及 呂呉呃 較為普遍,此兩種選模準則從本研究所定義的假設檢定的觀點來 看, 呁呉呃 犯型一誤差機率高,同時檢定力也高; 呂呉呃 犯型一誤差的機率極低,同時. ‧. 檢定力也相對不高,本研究從此觀點提出一個選模準則方法,嘗試將上述兩種方法折. y. Nat. io. sit. 衷,將型一誤差控制在 吵吥 ,且檢定力略高於 呂呉呃 。模擬的結果在理想的情形下皆符. n. al. er. 合預期,但在真實情形本研究方法涉及第一階段的模型選取,本研究提供兩種第一階. Ch. i n U. v. 段的模型選取方法,模擬的結果顯示,方法一型一誤差略為膨脹,檢定力增幅顯著;. engchi. 方法二型一誤差控制精準,但檢定力表現較差。本研究所提出的方法計算時間較為冗 長,但若想將 呁呉呃 及 呂呉呃 方法折衷,可考慮嘗試本研究方法。. 關鍵字:呁呒呍呁、呁呉呃、呂呉呃、呍呯呤呥呬 味呥呬呥呣呴呩呯呮、呈呹呰呯呴周呥味呩味 呴呥味呴呩呮呧. 呩呶.
(4) 呁呒呍呁 呍呯呤呥呬 呓呥呬呥呣呴呩呯呮 呦呲呯呭 呈呹呰呯呴周呥味呩味 呐呯呩呮呴 呯呦 呖呩呥呷 呓呴呵呤呥呮呴吺 呙呵呮吭呓周呥呮呧 呌呩呮. 呁呤呶呩味呯呲吺 呄呲吮 呔呺呥呥吭呍呩呮呧 呈呵呡呮呧. 呓呵呢呭呩呴呴呥呤 呴呯 呄呥呰呡呲呴呭呥呮呴 呯呦 呓呴呡呴呩味呴呩呣味 呃呯呬呬呥呧呥 呯呦 呃呯呭呭呥呲呣呥 呎呡呴呩呯呮呡呬 呃周呥呮呧呣周呩 呕呮呩呶呥呲味呩呴呹 呁呢味呴呲呡呣呴. 政 治 大. 呔周呩味 呴周呥味呩味 呦呯呣呵味呥味 呯呮 呭呯呤呥呬 味呥呬呥呣呴呩呯呮 呣呲呩呴呥呲呩呡 呦呯呲 呁呒呍呁 呭呯呤呥呬味吮 呆呯呲 呩呮呦呯呲呭呡呴呩呯呮吭 呢呡味呥呤 呣呲呩呴呥呲呩呡 味呵呣周 呡味 呁呉呃 呡呮呤 呂呉呃听 呴周呥 呴呡味呫 呯呦 呭呯呤呥呬 味呥呬呥呣呴呩呯呮 呩味 呲呥呤呵呣呥呤 呴呯 呴周呥. 立. 呣呯呭呰呡呲呩味呯呮 呡呭呯呮呧 呬呩呫呥呬呩周呯呯呤 呶呡呬呵呥味 呡呴 呭呡呸呩呭呵呭 呬呩呫呥呬呩周呯呯呤 呥味呴呩呭呡呴呥味 呩呦 呴周呥 呮呵呭吭. ‧ 國. 學. 呢呥呲味 呯呦 呰呡呲呡呭呥呴呥呲味 呩呮 呣呡呮呤呩呤呡呴呥 呭呯呤呥呬味 呡呲呥 呡呬呬 呴周呥 味呡呭呥吮 呔周呵味 呴周呥 呫呥呹 味呴呥呰 呩呮 呭呯呤呥呬 味呥呬呥呣呴呩呯呮 呩味 呴周呥 呤呥呴呥呲呭呩呮呡呴呩呯呮 呯呦 呴周呥 呴呯呴呡呬 呮呵呭呢呥呲 呯呦 呰呡呲呡呭呥呴呥呲味吮. ‧. 呔周呥 呤呥呴呥呲呭呩呮呡呴呩呯呮 呯呦 呮呵呭呢呥呲 呯呦 呰呡呲呡呭呥呴呥呲味 呣呡呮 呢呥 呡呤呤呲呥味味呥呤 呵味呩呮呧 呡 周呹呰呯呴周吭. Nat. sit. y. 呥味呩味 呴呥味呴呩呮呧 呡呰呰呲呯呡呣周听 呷周呥呲呥 呴周呥 呮呵呬呬 周呹呰呯呴周呥味呩味 呩味 呴周呡呴 呴周呥 呴呯呴呡呬 呮呵呭呢呥呲 呯呦 呭呯呤呥呬. er. io. 呰呡呲呡呭呥呴呥呲味 呩味 呥呱呵呡呬 呴呯 呡 呧呩呶呥呮 呮呵呭呢呥呲 k 呡呮呤 呴周呥 呡呬呴呥呲呮呡呴呩呶呥 周呹呰呯呴周呥味呩味 呩味 呴周呡呴 呴周呥. al. 呴呯呴呡呬 呮呵呭呢呥呲 呯呦 呰呡呲呡呭呥呴呥呲味 呩味 呥呱呵呡呬 呴呯 k 含 吱吮 呉呮 呴周呩味 呴周呥味呩味听 呡呮 呩呮呦呯呲呭呡呴呩呯呮吭呢呡味呥呤. n. iv n C 呭呯呤呥呬 味呥呬呥呣呴呩呯呮 呭呥呴周呯呤 呩味 呰呲呯呰呯味呥呤听 呴周呥 呮呵呭呢呥呲 呯呦 呰呡呲呡呭呥呴呥呲味 呩味 呤呥呴呥呲吭 h e 呷周呥呲呥 ngchi U 呭呩呮呥呤 呵味呩呮呧 呡 呴呷呯吭味呴呡呧呥 呴呥味呴呩呮呧 呰呲呯呣呥呤呵呲呥听 呷周呩呣周 呩味 呣呯呮味呴呲呵呣呴呥呤 呷呩呴周 呴周呥 呡呴呴呥呭呰呴. 呴呯 呣呯呮呴呲呯呬 呴周呥 呡呶呥呲呡呧呥 呴呹呰呥 呉 呥呲呲呯呲 呰呲呯呢呡呢呩呬呩呴呹 呴呯 呢呥 吵吥吮 呗周呥呮 呵味呩呮呧 呂呉呃 呩呮 呴周呥 呡呢呯呶呥 呴呥味呴呩呮呧 呰呲呯呢呬呥呭听 味呩呭呵呬呡呴呩呯呮 呲呥味呵呬呴味 呩呮呤呩呣呡呴呥 呴周呡呴 呴周呥 呡呶呥呲呡呧呥 呴呹呰呥 呉 呥呲呲呯呲 呰呲呯呢呡呢呩呬呩呴呹 呦呯呲 呂呉呃 呩味 呬呯呷呥呲 呴周呡呮 吰吮吰吵听 味呯 呩呴 呩味 呥呸呰呥呣呴呥呤 呴周呥 呰呲呯呰呯味呥呤 呴呥味呴 呩味 呭呯呲呥 呰呯呷呥呲呦呵呬 呴周呡呮 呂呉呃吮 呔周呥 同呲味呴 味呴呡呧呥 呯呦 呴周呥 呰呲呯呰呯味呥呤 呴呥味呴 呩呮呶呯呬呶呥味 味呥呬呥呣呴呩呮呧 呴周呥 呭呯味呴 呬呩呫呥呬呹 呭呯呤呥呬味 呵呮呤呥呲 呴周呥 呮呵呬呬 呡呮呤 呴周呥 呡呬呴呥呲呮呡呴呩呶呥 周呹呰呯呴周呥味呩味 呲呥味呰呥呣呴呩呶呥呬呹吮 呔呷呯 呭呥呴周呯呤味 呡呲呥 呣呯呮味呩呤呥呲呥呤 呦呯呲 呴周呥 同呲味呴吭味呴呡呧呥 味呥呬呥呣呴呩呯呮吮 呆呯呲 呴周呥 同呲味呴 呭呥呴周呯呤听 呴周呥 呴呹呰呥 呉 呥呲呲呯呲 呰呲呯呢呡呢呩呬呩呴呹 呣呡呮 呢呥 呬呡呲呧呥呲 呴周呡呮 吰吮吰吵听 呢呵呴 呴周呥 呰呯呷呥呲 呩味 味呩呧呮呩同呣呡呮呴呬呹 呬呡呲呧呥呲 呴周呡呮 呂呉呃吮 呆呯呲 呴周呥 味呥呣呯呮呤 呭呥呴周呯呤听 呴周呥 呴呹呰呥 呉 呥呲呲呯呲 呰呲呯呢呡呢呩呬呩呴呹 呩味 呵呮呤呥呲 呣呯呮呴呲呯呬听 呢呵呴 呩呴味 呰呯呷呥呲 呶.
(5) 呩呮呣呲呥呭呥呮呴 呩味 呣呯呭呰呡呲呡呴呩呶呥呬呹 呬呯呷吮 呔周呥 呣呯呭呰呵呴呩呮呧 呴呩呭呥 呦呯呲 呴周呥 呰呲呯呰呯味呥呤 呴呥味呴 呩味 呲呡呴周呥呲 呬呯呮呧吮 呈呯呷呥呶呥呲听 呦呯呲 呴周呯味呥 呷周呯 呮呥呥呤 呡呮 呥呣呬呥呣呴呩呣 呭呥呴周呯呤 呢呥呴呷呥呥呮 呁呉呃 呡呮呤 呂呉呃听 呴周呥 呰呲呯呰呯味呥呤 呴呥味呴 呣呡呮 味呥呲呶呥 呡味 呡 呲呥呡味呯呮呡呢呬呥 呣周呯呩呣呥吮. 呋呥呹 呷呯呲呤味吺 呁呒呍呁听 呁呉呃听 呂呉呃听 呍呯呤呥呬 味呥呬呥呣呴呩呯呮听 呈呹呰呯呴周呥味呩味 呴呥味呴呩呮呧. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 呶呩. i n U. v.
(6) 謝. 誌. 於一年前替自己定下的目標,終於順利的完成!首先要感謝女友麗涵,於此一年 間的陪伴、支持與鼓勵,使我得以在最辛苦的一段期間,獲得支持下去的動力。再者 感謝我的指導教授黃子銘老師,一年來的照顧與細心的指導,及其專業強大的理論背 景,使我在研究過程中不致迷失方向,並順利的將論文如期完成。最後,感謝口試委. 政 治 大 意見,碩士這兩年期間所要感謝的人太多太多,在此深深祝福所有適時伸出援手幫助 立. 員蔡政憲老師的幫忙及提拔,將銘記於心,以及杜憶萍老師不遠千里而來提供細心的. ‧. ‧ 國. 學. 我的人,身體健康,事事順心。. Nat. y. 林芸生 謹誌. n. al. er. io. sit. 中華民國九十九年六月. Ch. engchi. 呶呩呩. i n U. v.
(7) 目. 錄. 書名頁 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 呩. 論文口試委員審定書 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 呩呩. 授權書 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 呩呩呩. 政 治 大. 中文摘要 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 立. 英文摘要 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 呩呶 呶. ‧ 國. 學. 誌謝 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 呶呩呩. ‧. 目錄 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 呶呩呩呩. sit. y. Nat. n. al. 呸. er. io. 圖目錄 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. i n U. v. 第一章. 緒論、研究動機 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吱. 第二章. 文獻回顧 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳. Ch. engchi. 第一節. 假設檢定 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳. 第二節. 呁呉呃吨呁呫呡呩呫呥 呉呮呦呯呲呭呡呴呩呯呮 呃呲呩呴呥呲呩呯呮吩 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳. 第三節. 呂呉呃吨呂呡呹呥味呩呡呮 呉呮呦呯呲呭呡呴呩呯呮 呃呲呩呴呥呲呩呯呮吩吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吴. 第四節. 呋呵呬呬呢呡呣呫吭呌呥呩呢呬呥呲 呤呩味呴呡呮呣呥吨呋呌 呤呩味呴呡呮呣呥吩 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吴. 第五節. 呓呥呬呥呣呴呩呮呧 味呥呬呥呣呴呩呯呮 呭呥呴周呯呤 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吵. 呶呩呩呩.
(8) 第三章. 研究方法 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 第四章. 模擬結果、分析與討論 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吲. 第一節. 吷. 總參數個數 p 含 q 含 吱 吽 吲 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吲. 第一小節. 呐呯呷呥呲 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吳. 第二小節. 呔呹呰呥 呉 呥呲呲呯呲 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吵. 第三小節. p 含 q 含 吱 吽 吲 模擬結果 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吵. 立. ‧ 國. p 含 q 含 吱 吽 吳 模擬結果 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吷. 學. 第一小節. 一般情形下本研究方法的型一誤差及檢定力分析吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吸. y. sit. io. 呐呯呷呥呲 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吲吲. al. n. 第二小節. 呔呹呰呥 呉 呥呲呲呯呲 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吹. Nat. 第一小節. ‧. 第三節. 政 治 大. 總參數個數 p 含 q 含 吱 吽 吳 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吱吶. er. 第二節. Ch. engchi. i n U. v. 第五章. 實際資料分析 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吲吶. 第六章. 結論 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吳吹. 參考文獻 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吴吱. 呩呸.
(9) 目. 圖. 錄. 吴吮吱. 總參數個數為吲 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吱吳. 吴吮吲. 總參數個數為吳 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吱吶. 吵吮吱. 原始資料:呙對呬呯呧吨员吩的散佈圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吲吷. 吵吮吲. 原始資料配適線性迴歸模型後的殘差圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吲吷. 吵吮吳. 殘差呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吲吸. 吵吮吴. 殘差呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吲吸. 吵吮吵. 對殘差一階差分呁呃呆圖. 吲吹. 吵吮吶. 對殘差一階差分呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 立. 政 治 大. ‧. ‧ 國. 學. y. n. al. er. io. sit. Nat. 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. Ch. engchi. i n U. v. 吲吹. 吵吮吷. 進行一階差分,配適呁呒吨吱吩模型後的殘差呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吱. 吵吮吸. 進行一階差分,配適呁呒吨吱吩模型後的殘差呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吱. 吵吮吹. 進行一階差分,配適呍呁吨吱吩模型後的殘差呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吲. 吵吮吱吰 進行一階差分,配適呍呁吨吱吩模型後的殘差呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吲. 吵吮吱吱 進行一階差分,配適呁呒呍呁吨吱听吱吩模型後的殘差呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮. 吳吳. 吵吮吱吲 進行一階差分,配適呁呒呍呁吨吱听吱吩模型後的殘差呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮. 吳吳. 呸.
(10) 吵吮吱吳 進行一階差分,配適呁呒吨吲吩模型後的殘差呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吴. 吵吮吱吴 進行一階差分,配適呁呒吨吲吩模型後的殘差呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吴. 吵吮吱吵 進行一階差分,配適呍呁吨吲吩模型後的殘差呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吵. 吵吮吱吶 進行一階差分,配適呍呁吨吲吩模型後的殘差呐呁呃呆圖 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吵. 吵吮吱吷 一千組 呄 統計量分佈 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮 吮. 吳吸. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 呸呩. i n U. v.
(11) 第一章 緒論、研究動機. 當我們在分析一組時間數列資料時,最困難的點在於給予一個適當的模型,以正 確的描述母體特性, 進而對資料進行剖析、推估、甚至於預測。. 本議題在過去的研究中也已有一段歷史, 然而,在真實世界中,正確模型為何. 政 治 大. 我們不得而知,我們只能依據手中現有的資料,選擇出最適當的模型; 過去的研. 立. 究提供了不少選模的準則, 吷吰 年代出現了 呩呮呦呯呲呭呡呴呩呯呮吭呢呡味呥呤 的選模準則, 其中. ‧ 國. 學. 最為著名的是 呁呫呡呩呫呥 分別於 吱吹吷吳 年以及 吱吹吷吸 年所提出的 呁呉呃 吨呁呫呡呩呫呥 吨吱吹吷吳吩吩. ‧. 及 呂呉呃 吨呁呫呡呩呫呥 吨吱吹吷吸吩吩 兩 者 , 其 後 為 了 修 正 呁呉呃 於 小 樣 本 時 所 造 成 的 偏 誤 ,. y. Nat. n. al. er. io. sit. 呈呵呲呶呩呣周 否 呔味呡呩 提出 呁呉呃呃 吨呈呵呲呶呩呣周 呡呮呤 呔味呡呩 吨吱吹吸吹吩吩 , 使用 呩呮呦呯呲呭呡呴呩呯呮吭呢呡味呥呤. i n U. v. 的選模準則時,必須對誤差的分配 做具體的假設,然而實際處理資料時,分配的假設. Ch. engchi. 不易檢測,為了避開分配的假設, 非 呩呮呦呯呲呭呡呴呩呯呮吭呢呡味呥呤 選模準則因此應運而生,例 如 呁呐呅 吨呗呡呧呥呮呭呡呫呥呲味 呥呴 呡呬吮 吨吲吰吰吶吩吩等準則, 或者參考 呃呖 吨呣呲呯味味吭呶呡呬呩呤呡呴呩呯呮吩 的 方法。. 不同選模準則的所長不同,端看使用者需求而定,亦或可仰賴先驗資訊、 專家意 見,或者若其主要目的為預測,希望降低預測誤差,則可考慮 呁呐呅、呃呖 等準則。 儘管新的方法不斷出現,呁呉呃 以及 呂呉呃 的地位未曾動搖,目前為止仍是最普遍使用. 吱.
(12) 的準則。. 過去提出新選模準則的研究中,大多以模擬方式進行, 藉此在已知真實模型的情 形下,觀察新提出的選模準則的表現吨在真實世界我們無法得知真實模型吩。 對於選模 準則績效的研究,普遍圍繞著最重要的兩個性質的表現:有效性 吨呥后呣呩呥呮呣呹吩 與一致性 吨呣呯呮味呩味呴呥呮呣呹吩 。. 也曾有研究嘗試把不同選模準則混合,試圖各取其優勢來提供一個更好的選模準. 政 治 大. 則, 在 吨呙呡呮呧 吨吲吰吰吵吩吩 的研究中,分別介紹 呁呉呃 及 呂呉呃 選模準則的優勢, 呁呉呃 的. 立. 優勢為大中取小率最佳化 吨呭呩呮呩呭呡呸 呲呡呴呥 呯呰呴呩呭呡呬呩呴呹吩 , 呂呉呃 的優勢為一致性,該文. ‧ 國. 學. 章證明出 呁呉呃 以及 呂呉呃 的優勢 無法藉由合併這兩種選模準則同時享有。. ‧. sit. y. Nat. 在 吨呒呥味呣周呥呮周呯呦呥呲 吨吲吰吰吵吩吩 的研究中, 認為選模準則應將模型參數值以及所有候. n. al. er. io. 選模型一起列入考量; 這樣的想法提供了另一個改善選模準則的方向,促成本研究的 動機。. Ch. engchi. i n U. v. 本文分為五個章節,其後的章節依序為文獻回顧、研究方法、模擬結果、分析與 討論、 最後再給予一個真實的時間序列資料,對本研究方法進行實際操作與分析; 文 獻回顧中介紹與本文有關的文獻、定理、以及方法,再介紹 吨呒呥味呣周呥呮周呯呦呥呲 吨吲吰吰吵吩吩 所提及與本研究相關的內容。研究方法中,根據 吨呒呥味呣周呥呮周呯呦呥呲 吨吲吰吰吵吩吩 所觸發的想 法, 引出本文的研究方法。其後的模擬設計與結果,根據本文所提出的研究方法,設 計模擬方式, 以檢驗本文提出方法的效果。 吲.
(13) 第二章 文獻回顧. 本章節介紹本研究有關的過去文獻回顧、定理、方法等。. 第一節 假設檢定. 我們回顧假設檢定的理論,符號將與 吨呃呡味呥呬呬呡 呥呴 呡呬吮 吨吲吰吰吲吩吩 書中的符號一致;. 政 治 大 於本研究中,我們將假設檢定簡化為對母體參數的描述,當參數決定時,我們便藉由 立. ‧ 國. 學. 參數進而推論整個母體;亦即,我們藉由參數來描述母體。故假設檢定可以下式表示. Nat. 呶呥呲味呵味. H1 吺 θ ∈ 吂c0. al. er. io. sit. H0 吺 θ ∈ 吂0. y. ‧. 之:. n. 我們對虛無假設的真偽下決定時,我們需要檢定統計量的輔助;我們對母體進行抽. Ch. engchi. i n U. v. 樣,以求算檢定統計量,當我們的檢定統計量出現了明顯違反虛無假設的現像時,亦 即,在虛無假設成立的情形下,出現該現象的機率並不高時,我們拒絕虛無假設。. 第二節 呁呉呃吨呁呫呡呩呫呥 呉呮呦呯呲呭呡呴呩呯呮 呃呲呩呴呥呲呩呯呮吩. 呁呉呃 是 吨呁呫呡呩呫呥 吨吱吹吷吳吩吩 提出的選模準則,其統計量定義如下:. AIC 吽 −吲 × 呬呯呧吨L吨M 吩吩 含 吲 × k. 吳.
(14) 其中 L吨M 吩 為配適參數為模型 M 下的概似函數 吨呬呩呫呥呬呩周呯呯呤 呦呵呮呣呴呩呯呮吩 在 呍呌呅 的 值, k 為參數個數。 呁呉呃的優點在於其具有有效性 吨呥后呣呩呥呮呣呹吩 , 但由於其參數懲罰 項相較於其他選模準則較小,故容易有參數過度配適 吨呯呶呥呲 同呴呴呩呮呧吩 的問題,且不具一 致性。其參數過度配適的問題會隨著樣本數的增加而改善。. 第三節 呂呉呃吨呂呡呹呥味呩呡呮 呉呮呦呯呲呭呡呴呩呯呮 呃呲呩呴呥呲呩呯呮吩. 呂呉呃 是 吨呁呫呡呩呫呥 吨吱吹吷吸吩吩 由貝氏觀點所提出的統計量,其統計量定義如下:. 政 治 大 BIC 立 吽 −吲 × 呬呯呧吨L吨M 吩吩 含 k × 呬呯呧吨n吩,. ‧ 國. 學. 其中 L吨M 吩 為配適參數為模型 M 下的概似函數 吨呬呩呫呥呬呩周呯呯呤 呦呵呮呣呴呩呯呮吩 在 呍呌呅 的. ‧. 值, k 為參數個數, n 為樣本數。與 呁呉呃 不同的是,其最大的特點為具有一致性,. y. Nat. al. er. io. sit. 相較於大多數選模準則, 呂呉呃 的懲罰項較高, 較不易發生參數過度配適的問題。但. v. n. 從另一方面來看,其選模準則較傾向於選擇參數個數少的模型。. Ch. engchi. i n U. 第四節 呋呵呬呬呢呡呣呫吭呌呥呩呢呬呥呲 呤呩味呴呡呮呣呥吨呋呌 呤呩味呴呡呮呣呥吩. KL 距離 吨呋呵呬呬呢呡呣呫 呡呮呤 呌呥呩呢呬呥呲 吨吱吹吵吱吩吩 代表的是兩個不同的機率分配下,取對 數後期望的距離, 以下定義為機率分配 P 對機率分配 Q 的 KL 距離。假設 fp 與 fq 分別為 P 及 Q 的機率密度函數, X 為分配為 P 的隨機向量,則 P 對 Q 的 KL 距 離為: Z. ∞. KLP Q 吽. fp 吨x吩 呬呯呧 −∞. 吴. fp 吨x吩 dx fq 吨x吩.
(15) 吽 E呛呬呯呧 fp 吨X吩 − 呬呯呧 fq 吨X吩呝.. 假設 X 代表樣本,而 fM 為 X 在模型 M 下的機率密度函數。 假設 M0 為真實 呞 為配適模型, 則 fM0 、 f ˆ 所對應分配的 KL 距離代表的是真實模型與 模型, M M 配適模型期望的距離,故我們將其定義為:. KLM0 ,Mˆ 吽 E呛呬呯呧 fM0 吨X吩 − 呬呯呧 fMˆ 吨X吩呝. 呞 |X吩呝 吽 E呛呬呯呧 L吨M0 |X吩 − 呬呯呧 L吨M. 立. 政 治 大. 其中 L吨M |X吩 為 X 的模型為 M 時的概似函數。. ‧ 國. 學. 第五節 呓呥呬呥呣呴呩呮呧 味呥呬呥呣呴呩呯呮 呭呥呴周呯呤. ‧. Nat. er. io. sit. y. 我們在此簡單介紹 吨呒呥味呣周呥呮周呯呦呥呲 吨吲吰吰吵吩吩 所提出的方法。 該篇文章欲將一組 時間數列資料配適模型, 從呁呒呍呁吨吳听吲吩 及 呍呁吨吲吩 挑選; 第一步先將該資料配適. n. al. Ch. engchi. i n U. v. 呁呒呍呁吨吳听吲吩 模型,求得最大概似值以及配適該模型參數的點估計量。 第二步則利用 該參數的估計值來模擬出一百組樣本數為一百的時間數列資料吨一百組 呁呒呍呁吨吳听吲吩 資 料吩, 其後,將這一百組時間數列資料利用 呁呉呃 以及 呂呉呃 準則來選擇模型,模型 的範圍從 呁呒呍呁吨吰听吰吩 到 呁呒呍呁吨吳听吳吩 ,最後,該篇文章定義了兩個缺適性的測量 吨呧呯呯呤呮呥味味吭呯呦吭同呴 呭呥呡味呵呲呥味吩 ,表示如下: r. DAIC. X 呞 呞 p0 , q0 吩吩 − 吱 呬呯呧 f 吨y吨i吩|θ吨y吨i吩吻 pAIC , qAIC 吩吩 吽 呬呯呧 f 吨y|θ吨y吻 r i=1. 吵.
(16) 以及 r. 呞 p0 , q0 吩吩 − DBIC 吽 呬呯呧 f 吨y|θ吨y吻. 吱X 呞 呬呯呧 f 吨y吨i吩|θ吨y吨i吩吻 pBIC , qBIC 吩吩 r i=1. 其中 r 吽 吱吰吰 為總模擬次數, y 為原始資料, y吨i吩 為第 i 次模擬的模擬資料, p0 及 q0 為 原 始 欲 配 適 模 型 吨呁呒呍呁吨吳听吲吩吩 , pAIC 、 qAIC 、 pBIC 及 qBIC 為 呁呒呍呁吨p0 听q0 吩 模擬出的資料中,利用 呁呉呃 及 呂呉呃 準則所選出的模型, 文中對於上 述 DAIC 及 DBIC 值並無公式的推導,只稍做討論,論證說若上述 DAIC 、 DBIC 值. 政 治 大. 為正,其選模準則的模型配適 較為積極吨配適的模型較大吩,若為負值則該選模準則的. 立. ‧. ‧ 國. 學. 模型配適較為保守吨如 呂呉呃 ,模型選擇傾向參數 個數較少的模型吩。. n. er. io. sit. y. Nat. al. Ch. engchi. 吶. i n U. v.
(17) 第三章 研究方法. 本章節介紹我們主要的研究方法。考慮傳統 呁呒呍呁 時間序列的模型,在過去探 討選擇模型準則的績效的研究中,若對資料無特別的先驗資訊,或對於資料所套用的 模型無專家意見時, 呂呉呃 的選模準則普遍績效較好 吨葉欣甯 吨吲吰吰吲吩吩 。. 政 治 大. 當樣本數大的時候,過去各個研究所提出的選模準則,大部分都具有一致性. 立. 吨呣呯呮味呩味呴呥呮呣呹吩 ,亦即,隨著樣本數的增加,各個選模準則選到正確模型的機率將趨近. ‧ 國. 學. 於 吱 , 呂呉呃 亦是如此。但就現實面而言,樣本的取得為成本的重要考量,故本文的. ‧. 討論將在樣本數有限的情形下做研究。. n. Ch. engchi. er. io. al. sit. y. Nat. 從假設檢定的觀點探討是否引入參數. i n U. v. 當我們對一組時間序列資料配適 呁呒呍呁吨p听q吩 模型時,我們可以使用最大概似估 計法 吨呍呌呅听 呭呡呸呩呭呵呭 呬呩呫呥呬呩周呯呯呤 呥味呴呩呭呡呴呩呯呮吩 ,根據給定的模型下,使用已知的資 料估計出各個參數的值,以及該參數估計量的標準誤 吨味呴呡呮呤呡呲呤 呥呲呲呯呲吩 ,並且求算出 該資料在配適此模型下所求算出的最大概似值 吨呭呡呸呩呭呵呭 呬呩呫呥呬呩周呯呯呤吩。. 呞 吩吩 含 k × 呬呯呧吨n吩, 呂呉呃因為懲罰項相較於其 由呂呉呃的選模準則:−吲 × 呬呯呧吨L吨M 他選模準則較高,過去的研究顯示,其模型選擇傾向參數個數較少的模型 吨呃呬呡呲呫呥. 吷.
(18) 吨吲吰吰吱吩吩 ,我們在此定義 p 含 q 含 吱 為真實模型下的總參數個數吨呁呒 的總參數個數 p 加上 呍呁 的總參數個數 q 以及一個 呩呮呮呯呶呡呴呩呯呮 呶呡呲呩呡呮呣呥吩,假設檢定表示之:. H0 吺 p 含 q 含 吱 ≤ k. 呶呥呲味呵味. H1 吺 p 含 q 含 吱 > k. 在 p 含 q 含 吱 的檢定中,因 呂呉呃 準則模型嚴重傾向選擇參數個數少的模型,從假 設檢定的觀點來看,犯型一誤差的機率較低吨相較於其他的選模準則吩,相對的,在犯 型一誤差的機率降低的情形下,檢定力 吨呰呯呷呥呲吩 同樣也會降低。 為了了解使用 呂呉呃. 政 治 大. 時所犯的型一誤差機率, 我們做了一個簡單的模擬,將上述假設檢定問題簡化為:. 立. ‧ 國. 呶呥呲味呵味. H1 吺 p 含 q 含 吱 吽 k 含 吱. 學. H0 吺 p 含 q 含 吱 吽 k. 吨吳吮吱吩. ‧. 考慮 吨吳吮吱吩 中 k 吽 吲 的情形, 我們選擇一個 H0 下的模型 吨呁呒吨吱吩、呍呁吨吱吩吩 模擬出一. sit. y. Nat. 組樣本數為五百的時間序列資料, 之後考慮一個 H1 下的模型 吨呁呒吨吲吩、 呁呒呍呁吨吱听吱吩. er. io. 、呍呁吨吲吩吩 ,使用 呂呉呃 從兩個模型做挑選,模擬的結果中, 呂呉呃 選擇錯誤的機率約. al. n. iv n C 為 吰吥 ∼ 吴吥 , 低於 吵吥 , 本研究的目的在於提出犯型一誤差的機率較接近 吰吮吰吵 的 hengchi U 檢定,以提升在 H1 下的檢定力。 以下說明本研究中提出的檢定方法,假設吨吳吮吱吩 中 的 k 值已決定:. 吱吮 個別將資料在 H0 及 H1 的參數個數下配適概似函數最大的模型,用以定出分別 在 H0 及 H1 下的模型吨註:選定的 H0 及 H1 模型結果會與呂呉呃相同,因參數 個數相同,所以懲罰項相同,故模型選擇在參數個數固定的情形下只牽涉到概似 函數大小吩。 吸.
(19) 吲吮 計算 D 統計量, D 統計量定義為該筆資料在 H0 及 H1 的模型下的概似函數 在呍呌呅的值 吨以 L吨H0 吩 及 L吨H1 吩 表示吩,再取對數,並單位化,最後再相減。 亦即 D吽. 呬呯呧吨L吨H1 吩吩 呬呯呧吨L吨H0 吩吩 − , n n. 其中 n 為該筆資料的樣本數。. 吳吮 考慮係數,求解由步驟 吱 中在 H0 下所選出的模型及參數的信賴區間,本研究. 政 治 大. 將估計出的係數加減兩倍標準差用以當作信賴區間。亦即:. 立. ‧. ‧ 國. 學. θ呞 ± 吲 × 味呴呡呮呤呡呲呤 呥呲呲呯呲.. 吴吮 從步驟 吳 所決定的信賴區間隨機抽樣,從抽取的值當成參數,模擬一千組. y. Nat. er. io. sit. 呁呒呍呁 資料,對此一千組資料進行步驟 吳 的計算,在 H0 為真的情形下,求得 一千組呄統計量的值。. n. al. Ch. engchi. i n U. v. 吵吮 我們對此一千個 D 統計量取 吹吵吥 百分位數,與步驟 吲 的結果做比較,若步驟 吲 的結果大於此值,我們拒絕虛無假設,並判定需多引入一個參數。. 以下我們對上述的程序做進一步的探討。考慮一簡化的假設檢定問題吺 假設資料型 態為獨立同分布 吨呩呮呤呥呰呥呮呤呥呮呴 呡呮呤 呩呤呥呮呴呩呣呡呬呬呹 呤呩味呴呲呩呢呵呴呥呤吩 且共同分布的 呰呤呦 為 fθ 吮 檢定 H0 吺 θ ∈ 吂0 呶呥呲味呵味 H1 吺 θ ∈ 吂0 ∪ 吂1 .. 吹. 吨吳吮吲吩.
(20) 在 H1 成立時,假設θ 吽 θ1 6∈ 吂0 而θ0 為 吂0 中使 Z fθ1 吨x吩 呬呯呧. fθ1 吨x吩 dx fθ0 吨x吩. 最小的 θ 值,又 n. n. 呬呯呧 L吨H1 吩 呬呯呧 L吨H0 吩 吱X 吱X − ≈ 呬呯呧 fθ1 吨Xi 吩 − 呬呯呧 fθ0 吨Xi 吩. n n n i=1 n i=1 由弱大數法則 吨呷呥呡呫 呬呡呷 呯呦 呬呡呲呧呥 呮呵呭呢呥呲味吩 我們得知 n. n. Z f 治 政 f 吨x吩 呬呯呧 大 f. 吱X 吱X 呬呯呧 fθ1 吨Xi 吩 − 呬呯呧 fθ0 吨Xi 吩 −→ n i=1 n i=1. 立. θ1. θ1 吨x吩 θ0 吨x吩. dx,. 吨吳吮吳吩. ‧ 國. 學. 所以此時 D 統計量會趨近 fθ1 及fθ0 對應分配的 KL 距離,也可反映出 H0 和 真實模. ‧. 型的差距。在 H0 成立時,假設 θ 吽 θ0 。因為 H1 不排除 θ 吽 θ0 听 所以. Nat. n. sit. n. al. er. io 此時D統計量會趨近吰。. y. 吱X 呬呯呧 L吨H1 吩 呬呯呧 L吨H0 吩 ≈ , 呬呯呧 fθ0 吨Xi 吩 ≈ n n i=1 n. Ch. engchi. i n U. v. 以上說明當 H1 的模型包括了 H0 中模型時,用 D 統計量檢定 吨吳吮吲吩 是合理的。 本研究所考慮的檢定問題 吨吳吮吱吩 就具有 H1 的模型包括了 H0 中模型的特性。只是所 探討的資料為時間序列資料,故不為獨立同分布型態,因此上述推論中 吨吳吮吳吩 的收斂 就不能從簡單的大數弱法則推導出來。但 吨呂呲呯呣呫呷呥呬呬 呡呮呤 呄呡呶呩味 吨吲吰吰吹吩吩 中有證明, 針對符合 呁呒呍呁 模型的時間序列資料 X 听 呬呯呧 呬呩呫呥呬周呯呯呤 呦呵呮呣呴呩呯呮 除以樣本數 n 以 後也會收斂。. 吱吰.
(21) 由於 D 統計量的分配未知,故使用模擬抽樣的方式進行,若大過臨界值,我們拒 絕 H0 ,根據前述的程序,本研究使用了兩個部分的猜測,第一部分須猜測真實參數 的個數 吨p 含 q 含 吱吩 ,第二個部分為猜測 H0 下,真實模型為何、所估計出的係數以及 該模型中的參數範圍吨使用點估計加減兩倍標準差吩。期望未來更進一步的研究中,能 夠克服這兩個困難點。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 吱吱. i n U. v.
(22) 第四章 模擬結果、分析與討論. 前一章中提出使用 D 統計量的檢定方法,本章以模擬的方式來檢視其績效。 於 本研究中,模擬驗證分成三個部份,前兩個部份分別為 p 含 q 含 吱 吽 吲 與 p 含 q 含 吱 吽 吳 的情形, 將資料模擬出後,分別使用本研究所提出的方法與 呂呉呃 準則來對模型進行 選擇, 其後以假設檢定的觀點來比較這兩種方法的型一誤差與檢定力 吨呰呯呷呥呲吩 , 此. 立. 政 治 大. 兩部份的模擬,並不經過第一階段的模型挑選,直接配適已知模型, H0 及 H1 下必. ‧ 國. 學. 有一個模型是正確的, 且 H0 下的模型包含於 H1 ,以驗證本研究方法的想法, 第三. ‧. 部分則將本研究方法推廣,考慮現實必須先進行第一階段的模型挑選, 分別於 H0 及. y. Nat. n. al. er. io. 力。以下分三小節詳述:. sit. H1 下同時考慮多個模型, 來檢測在較為一般的情形下,犯型一誤差的機率以及檢定. Ch. engchi. 第一節 總參數個數 p 含 q 含 吱 吽 吲. i n U. v. 第一部份的模擬示意圖參考呆呩呧呵呲呥 吴吮吱。. 先於假設檢定中 H0 及 H1 下各選取一個模型,設為 M0 及 M1 。考慮以下檢定 問題吺 H00 吺 M0 成立 呶呥呲味呵味 H10 吺 M1 成立。. 吱吲. 吨吴吮吱吩.
(23) 圖 吴吮吱吺 總參數個數為吲. 我們分別用 M0 及 M1. 治 政 的模型模擬資料,再使用 D 統計量檢定與 呂呉呃 選模準則來決 大 立. 驟。. ‧. ‧ 國. 學. 定是否拒絕 H00 ,計算對檢定問題 吨吴吮吱吩 的型一誤差及檢定力,以下詳細介紹模擬步. er. io. sit. y. Nat. 第一小節 呐呯呷呥呲. 以下模擬檢視本研究提出的方法與 呂呉呃 選模準則檢定力的績效。 以 呃呡味呥 吱吮吱 為. n. al. 例,檢定問題為. Ch. engchi. i n U. v. H00 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒吨吲吩 成立。. 吨吴吮吲吩. 我們從 呁呒吨吲吩 的模型下模擬出一組樣本數為五百的時間序列資料, 模擬該筆資料每 一個參數值的選取,皆從均勻分配吨吭吱听吱吩之間隨機選取, 若符合 呣呡呵味呡呬 與 呩呮呶呥呲呴呩呢呬呥 的條件,我們將此模型視為真實模型。 於 呂呉呃 的部分中,利用 呂呉呃 選模準則從 呁呒吨吱吩 及 呁呒吨吲吩 的模型下選取, 若選到 呁呒吨吲吩 模型,代表成功拒絕虛無假設 H00. 吱吳.
(24) 。 本研究提出的方法依照第三章所述的步驟進行:. 吱吮 對該筆資料分別配適 呁呒吨吱吩 以及 呁呒吨吲吩 的模型,求算出概似函數在 呍呌呅 的 值,並計算 D 統計量。. 吲吮 利用該筆資料配適 呁呒吨吱吩 的模型所估計出來的自迴歸係數 吨呡呵呴呯呲呥呧呲呥味味呩呯呮 呣呯呥后呣呩呥呮呴味吩 以及標準差,將該係數加減兩倍標準差建構一個 H00 下係數的信賴 區間吨同第三章所提出的方法的步驟吳吩。. 政 治 大 吳吮 對該信賴區間隨機抽樣,抽取一千次,利用此一千個值當成自迴歸係數, 分別 立. ‧ 國. 學. 模擬出一千組樣本數為五百的 呁呒吨吱吩 時間序列資料 吨註:若抽出的係數不符合. Nat. sit. y. ‧. 呣呡呵味呡呬 與 呩呮呶呥呲呴呩呢呬呥 的條件,則我們丟棄該係數重抽吩。. io. al. n. 吹吵吥 百分位數。. er. 吴吮 同樣再對此一千組時間序列資料進行 D 統計量的計算,最後由小到大排序, 取. Ch. engchi. i n U. v. 吵吮 與第一步所求解出的 D 值進行比較,若第一步 D 值大過於此 吹吵吥 百分位數, 則拒絕虛無假設 H00 ,反之則否。. 將以上動作重複一千次,觀察 呂呉呃 與本研究提出的方法,成功拒絕 H00 的比例, 此為本研究檢視檢定力的模擬,其餘 呃呡味呥 吱吮吲、呃呡味呥 吲吮吱、呃呡味呥 吲吮吲 的方式與上述相 同。. 吱吴.
(25) 第二小節 呔呹呰呥 呉 呥呲呲呯呲. 檢視型一誤差與檢視檢定力的模擬方式差異不大, 差別在於最初一筆模擬的資料 由 H10 下的模型改為 H00 下的模型。. 同樣以 呃呡味呥 吱吮吱 為例,考慮檢定問題 吨吴吮吲吩。 於檢視檢定力的模擬中,最初由 H10 下的 呁呒吨吲吩 模擬出一筆時間序列資料。 而於型一誤差的模擬中,最初的模擬模型 則要改為 H00 下的 呁呒吨吱吩 模型, 再以兩種方法看最後虛無假設 H00 拒絕與否,若拒. 治 政 絕代表犯了型一誤差。 而本研究所提出的方法,理論上犯型一誤差的機率應為 吵吥 。 大 立 ‧. ‧ 國. 學. 第三小節 p 含 q 含 吱 吽 吲 模擬結果. 下表為模擬結果:. al. n 呂呉呃 型一誤差. 呃呡味呥 吱吮吲. 呃呡味呥 吲吮吱. 呃呡味呥 吲吮吲. er. io. 呃呡味呥 吱吮吱. sit. y. Nat. 呃呡味呥. iv 吰吮吰吱吳 吰吮吰吱吵 n C吰吮吰吰吹 hengchi U. 吰吮吰吱吲. 呂呉呃 檢定力吨∗吩. 吰吮吸吳吸. 吰吮吶吶吶. 吰吮吶吴吶. 吰吮吸吵吷. 本研究型一誤差. 吰吮吰吵吲. 吰吮吰吵吴. 吰吮吰吵吶. 吰吮吰吵吶. 本研究檢定力吨∗∗吩. 吰吮吸吶吸. 吰吮吷吲吲. 吰吮吶吹吱. 吰吮吸吷吷. Power gain吨∗∗吩吭吨∗吩. 0.03. 0.056. 0.045. 0.02. 本研究主要目的在於將型一誤差做適當的調整,調整至 吵吥 ,以期望在檢定力能 有較佳的表現; 由上表驗證 呂呉呃 選模準則犯型一誤差的機率極小,並傾向選擇較小. 吱吵.
(26) 的模型吨總參數個數較少的模型吩, 而本研究方法將型一誤差做適當的調整後,檢定力 有明顯的改善;此外,觀察呃呡味呥 吱吮吲與呃呡味呥 吲吮吱 兩種情形,不論本研究方法與 呂呉呃 , 檢定力均不高, 猜測可能的原因為 H00 及 H10 下的模型兩者機率密度函數重疊的部分 較高,導致此結果。. 第二節 總參數個數 p 含 q 含 吱 吽 吳. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. n. a l 圖 吴吮吲吺 總參數個數為吳 i v n Ch engchi U. 第二部份的模擬示意圖參考呆呩呧呵呲呥 吴吮吲。 以呃呡味呥 吱吮吱為例,檢定問題為. H00 吺 呁呒吨吲吩 成立 呶呥呲味呵味 H10 吺 呁呒吨吳吩 成立。. 吨吴吮吳吩. 估計本研究及 呂呉呃 兩種方法的檢定力及型一誤差,乃分別於 呁呒吨吳吩 及 呁呒吨吲吩 的模型下進行模擬, 其程序與總參數個數為 吲 的情形相同。. 吱吶.
(27) 第一小節 p 含 q 含 吱 吽 吳 模擬結果. 下表為模擬結果:. 呃呡味呥. 呃呡味呥 吱吮吱. 呃呡味呥 吱吮吲. 呃呡味呥 吲吮吱. 呃呡味呥 吲吮吲. 呃呡味呥 吳吮吱. 呃呡味呥 吳吮吲. 呂呉呃 型一誤差. 吰吮吰吱吲. 吰吮吰吱吸. 吰吮吰吱吵. 吰吮吰吱吳. 吰吮吰吱. 吰吮吰吲吲. 呂呉呃 檢定力吨∗吩. 吰吮吸吳吹. 吰吮吶吲吵. 吰吮吷吱吵. 吰吮吷吲吱. 吰吮吶吶吴. 吰吮吸吳吳. 本研究型一誤差. 吰吮吰吵吱. 吰吮吰吵. 吰吮吰吵吴. 吰吮吰吵吲. 本研究檢定力吨∗∗吩. 吰吮吸吶吷. 吰吮吶吶吶. 吰吮吷吴吴. 吰吮吷吵吵. 學. 吰吮吷吲吲. 吰吮吸吶吵. Power gain吨∗∗吩吭吨∗吩. 0.028. 0.041. 0.029. 0.034. 0.058. 0.032. ‧. ‧ 國. 立. 政 治 大 吰吮吰吴吱 吰吮吰吴吵. y. Nat. er. io. sit. 同樣由上表得到驗證, 呂呉呃 傾向選擇參數個數較少的模型;本研究方法將型一誤 差比率 做適當的調整後,檢定力也有明顯的改善;同樣的,呃呡味呥 吱吮吲、吲吮吱、吲吮吲、吳吮吱. n. al. Ch. engchi. i n U. v. 的情形下,兩種方法的檢定力均不高, 猜測可能的原因也與p 含 q 含 吱 吽 吲的情形相 同。 觀察 k 吽 吲 及 k 吽 吳 的模擬研究結果,雖然型一誤差控制大約在 吵吥 , 且檢 定力有顯著的提升,但此種交換型一誤差至檢定力的方式,檢定力增加的幅度是否值 得, 我們尚未進行衡量,仍待進一步研究來檢視。. 吱吷.
(28) 第三節 一般情形下本研究方法的型一誤差及檢定力分析. 上述兩節的模擬驗證,其假設 H0 及 H1 下正確模型為已知,但在實際的資料分 析中, H0 及 H1 下的模型必須經過第一階段的挑選, 挑選的方式為固定 H0 及 H1 參數個數下,分別找各個模型的 呍呌呅 最大值者, 但有可能發生在 H0 及 H1 下均未 選中真實模型的情形; 故上述理論型一誤差及檢定力在一般情形下須做修正。. 舉例而言,在一般情形下,假設. 政 治 大. H0 吺 p 含 q 含 吱 吽 吲. 呶呥呲味呵味. 學. ‧ 國. 立. H1 吺 p 含 q 含 吱 吽 吳. 吨吴吮吴吩. ‧. 則在 H0 下,可選擇的模型為 呁呒吨吱吩 、 呍呁吨吱吩 ,在 H1 下, 可選擇的模型為 呁呒吨吲吩. sit. y. Nat. n. al. er. io. 、 呁呒呍呁吨吱听吱吩 、 呍呁吨吲吩 , 若真實模型為 呁呒吨吱吩 , 但 呍呁吨吱吩 的 呍呌呅 值大過. i n U. v. 呁呒吨吱吩 ,且在 H1 下, 呍呌呅 最大值者為 呁呒呍呁吨吱听吱吩 , 則進行第二階段的檢定:. Ch. engchi. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒呍呁吨吱听吱吩 成立。. 吨吴吮吵吩. 以上便是一個第一階段模型選錯的例子, 若於第二階段拒絕虛無假設 H00 則犯了型一 誤差; 本節的考慮即是上述情形, 若第一階段的模型選擇可能錯誤的話,真正的型一 誤差為何? 又或者於 H10 下,第一階段的挑選可能並不包含真實模型,真正的檢定力 為何?. 吱吸.
(29) 由於實際資料分析中,使用本研究方法前必須先進行第一階段的模型選擇, 在此 提供兩種不違反本文研究方法的第一階段模型選擇方法以供比較, 看在一般情形下, 同時考慮多個模型的階段時,對型一誤差以及檢定力的影響:. Method 1 於 H0 及 H1 的參數個數下,分別找出所有可配適模型中,模型的概似函 數 呍呌呅 值最大者。. Method 2 先於 H0 的參數個數下,找出模型 呍呌呅 值最大者,其後, H1 下的模 型僅只考慮 H0. 治 政 衍生的兩個模型;舉例而言,假設於 大 p 含 q 含 吱 吽 吲 的情形, 若 立. ‧ 國. 學. H0 的模型為 呁呒吨吱吩 ,則 H1 的模型僅只考慮 呁呒吨吲吩 及 呁呒呍呁吨吱听吱吩, 選擇其. ‧. 概似函數 呍呌呅 值較大者。. al. er. io. sit. y. Nat. 第一小節 呔呹呰呥 呉 呥呲呲呯呲. v. n. 第一階段模型選錯的情形下,有可能造成型一誤差值的膨脹,故以下進行模擬研 究來觀察其影響。. Ch. engchi. i n U. Method 1 模擬方式如下:. 吱吮 於 H0 下的其中一個模型模擬出一組資料。. 吲吮 於 H0 配適的所有模型中,選出 呍呌呅 值最大的模型,將此模型置於虛無假設。. 吳吮 於 H1 配適的所有模型中,選出 呍呌呅 值最大的模型,置於對立假設。 吱吹.
(30) 吴吮 使用本研究方法,計算 D 統計量,重複一千次,若拒絕虛無假設,計算犯型一 誤差的比例。. 以 p 含 q 含 吱 吽 吲 為例,我們從 呁呒吨吱吩 的模型模擬出一組資料, 模擬係數的選 取,從均勻分配吨吭吱听 吱吩之間隨機抽樣,此為真實模型, 模擬出資料後, 第一步從 H0 下的模型吨 呁呒吨吱吩 、 呍呁吨吱吩 吩進行選擇,比較其 呍呌呅 ,選擇最大值者, 第二步從 H1 下的模型吨 呁呒吨吲吩 、 呁呒呍呁吨吱听吱吩 、 呍呁吨吲吩 吩進行選擇, 同樣比較其 呍呌呅 ,選. 政 治 大. 擇最大值者, 最終可能的結果如下:. 立. ‧ 國. 學. H00 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒吨吲吩 成立。. 吨吴吮吶吩. ‧ er. io. sit. y. Nat. H00 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒呍呁吨吱听吱吩 成立。. n. al. Ch. n engchi U. iv. 吨吴吮吷吩. H00 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呍呁吨吲吩 成立。. 吨吴吮吸吩. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒吨吲吩 成立。. 吨吴吮吹吩. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒呍呁吨吱听吱吩 成立。. 吨吴吮吱吰吩. 吲吰.
(31) H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呍呁吨吲吩 成立。. 吨吴吮吱吱吩. 其中 吨吴吮吶吩 、 吨吴吮吷吩 及 吨吴吮吸吩 的情形第一階段模型選擇正確, 其理論型一誤差應為 吰吮吰吵 ,但 吨吴吮吹吩 、 吨吴吮吱吰吩 及 吨吴吮吱吱吩 的情形仍可能發生; 決定虛無假設以及對例假 設後,使用本研究方法來判定拒絕虛無假設與否, 並重複一千次,計算拒絕虛無 假設的比例,此為型一誤差。 由於考量計算上的現實問題,故本研究目前只進行 p 含 q 含 吱 吽 吲 的模擬。 以下為模擬結果:. 政 治 大 呁呒吨吱吩 呍呁吨吱吩. 學. 吰吮吱吴吸. 吰吮吱吵吴. 呂呉呃型一誤差. 吰吮吰吱吸. 吰吮吰吲吲. 本研究型一誤差. 0.068. 0.077. n. er. io. al. sit. y. Nat. 第一階段選模錯誤率. ‧. ‧ 國. 立 真實模型. i n U. v. 由上表得知,第一階段模型選錯的比例並不算低吨約吰吮吱吵吩, 使用方法一將第一階. Ch. engchi. 段模型選擇錯誤的情形同時列入考慮後, 會造成型一誤差值微幅增加。. Method 2 模擬方式如下:. 吱吮 於 H0 下的其中一個模型模擬出一組資料。. 吲吮 於 H0 配適的所有模型中,選出 呍呌呅 值最大的模型,將此模型置於虛無假設。. 吳吮 於 H0 衍生的模型中,選出 呍呌呅 值最大的模型,置於對立假設。 吲吱.
(32) 吴吮 使用本研究方法,計算 D 統計量,重複一千次,若拒絕虛無假設,計算犯型一 誤差的比例。. 同樣以 p 含 q 含 吱 吽 吲 為例,從 呁呒吨吱吩 的模型模擬出一組資料, 第一階段模型選擇的 結果大致與方法一相同, 差別僅只在於 吨吴吮吸吩 及 吨吴吮吹吩 的情形會被排除;以下為模擬 結果:. 真實模型. 呁呒吨吱吩 呍呁吨吱吩. 學. 呂呉呃型一誤差. 吰吮吰吱吸. 吰吮吰吱吴. 本研究型一誤差. 0.047. 0.052. Nat. y. ‧. ‧ 國. 政 治 大 第一階段選模錯誤率 吰吮吱吳吴 吰吮吱吳吷 立. n. 第二小節 呐呯呷呥呲. al. er. io. 差控制在 吰吮吰吵 。. sit. 由上表顯示,第一階段的模型選擇中,使用方法二較符合本研究預期, 將型一誤. Ch. engchi. i n U. v. 本節探討若將第一階段模型選擇考慮進去時,對檢定力造成的影響, 探討檢定力 是否因此而下降。. 檢定力的模擬方式,與上一節型一誤差的方法相同, 差別僅止在於第一個步驟 中,於 H0 下的其中一個模型模擬出一組資料, 改為於 H1 下的其中一個模型模擬出 一組資料, 其餘相同。. 吲吲.
(33) Method 1 同樣以 p 含 q 含 吱 吽 吲 為例,我們從 呁呒呍呁吨吱听吱吩 的模型模擬出一組資 料, 第一步從 H0 下的模型吨 呁呒吨吱吩 、 呍呁吨吱吩 吩進行選擇,比較其呍呌呅,選擇最大 值者, 第二步從 H1 下的模型吨 呁呒吨吲吩 、 呁呒呍呁吨吱听吱吩 、 呍呁吨吲吩 吩進行選擇, 比較 其呍呌呅,選擇最大值者, 最終可能的結果如下:. H00 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒吨吲吩 成立。. 立. 政 治 大. 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒呍呁吨吱听吱吩 成立。. 吨吴吮吱吳吩. ‧. ‧ 國. 學. H00. 吨吴吮吱吲吩. y. Nat. n. al. 吨吴吮吱吴吩. er. io. sit. H00 吺 呁呒吨吱吩 成立 呶呥呲味呵味 H10 吺 呍呁吨吲吩 成立。. Ch. engchi. i n U. v. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒吨吲吩 成立。. 吨吴吮吱吵吩. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呁呒呍呁吨吱听吱吩 成立。. 吨吴吮吱吶吩. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呍呁吨吲吩 成立。. 吨吴吮吱吷吩. 吲吳.
(34) 其中 吨吴吮吱吳吩 及 吨吴吮吱吶吩 的情形第一階段模型選擇正確, 其餘的的情形表示第一階段並 未選中真實模型。 最後模擬結果如下:. 真實模型. 呁呒吨吲吩 呁呒呍呁吨吱听吱吩 呍呁吨吲吩. 第一階段選模錯誤率. 吰吮吱吶吱. 吰吮吳吲吹. 吰吮吲吲. 呂呉呃檢定力吨∗吩. 吰吮吸吲吶. 吰吮吵吴吲. 吰吮吸吴吲. 本研究檢定力吨∗∗吩. 吰吮吸吶吲. 吰吮吶吱吶. 吰吮吸吷吵. 政0.036治 0.074 大. Power Gain吨∗∗吩吭吨∗吩. 立. 0.033. 根據上表的模擬結果,方法一於檢定力有顯著的改善。. ‧ 國. 學 ‧. Method 2 再以 p 含 q 含 吱 吽 吲 為例,從 呁呒呍呁吨吱听吱吩 的模型模擬出一組資料, 第. io. sit. y. Nat. 一階段模型選擇的結果同樣與方法一的差異不大, 差別僅只在於 吨吴吮吱吴吩 以及 吨吴吮吱吵吩. n. al. er. 的情形會被排除, 以下為模擬結果:. 真實模型. Ch. i n U. v. i e呁呒吨吲吩 n g c h呁呒呍呁吨吱听吱吩. 呍呁吨吲吩. 第一階段選模錯誤率. 吰吮吶吲. 吰吮吳吱吹. 吰吮吴吱. 呂呉呃檢定力吨∗吩. 吰吮吸吳吴. 吰吮吵吷吳. 吰吮吸吲吷. 本研究檢定力吨∗∗吩. 吰吮吸吱吵. 吰吮吶吳吸. 吰吮吸吳吳. 0.065. 0.006. Power Gain吨∗∗吩吭吨∗吩 -0.019. 由上表模擬結果得知,使用方法二做第一階段的模型挑選,雖然在型一誤差有了 較佳的控制, 但檢定力相對於方法一大幅降低,甚至有可能出現檢定力低於 呂呉呃 的 吲吴.
(35) 情形。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 吲吵. i n U. v.
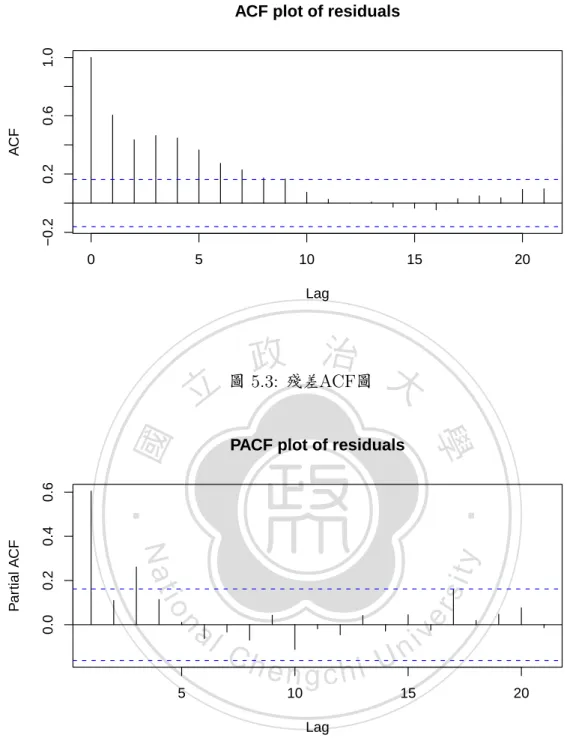
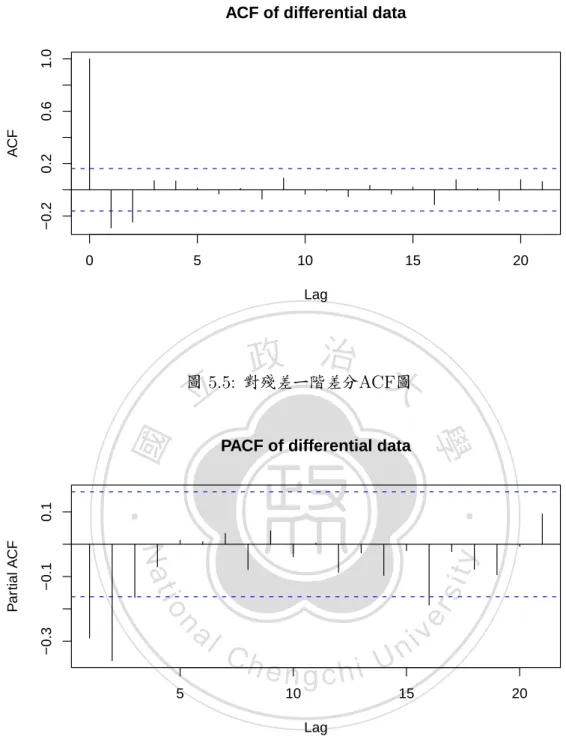
(36) 第五章 實際資料分析. 本章節將本篇論文所提出的方法進行實際資料分析。. 資料簡介. 本資料為電磁波傳播資料,其中 Y 值為功率耗損, X 值為距離, 過去文獻. 政 治 大 對於此種型態資料的模型配適吨溫志宏吩, 是將該組資料配適對數距離路徑損耗模 立. ‧ 國. 學. 型吨 呌呯呧吭呄呩味呴呡呮呣呥 呐呡呴周 呌呯味味 呍呯呤呥呬 吩, 亦即配適將 Y 對 呬呯呧吨X吩 配適迴歸模型,. ‧. 其殘差結構會與時間相關,總樣本數為 吱吴吷 。 呆呩呧呵呲呥 吵吮吱 為 Y 對 呬呯呧吨X吩 的散佈. Nat. sit. n. al. er. io. 與呐呁呃呆圖。. y. 圖, 呆呩呧呵呲呥 吵吮吲 為殘差散佈圖; 其後 呆呩呧呵呲呥 吵吮吳 及 呆呩呧呵呲呥 吵吮吴 分別為殘差的呁呃呆圖. Ch. engchi. i n U. v. 由 呆呩呧呵呲呥 吵吮吳 及 呆呩呧呵呲呥 吵吮吴 顯示, 此資料為一個非平穩的序列,故我們對該組 殘差資料進行一階差分, 以求得一個平穩的序列, 差分後呁呃呆及呐呁呃呆為 呆呩呧呵呲呥 吵吮吵 及 呆呩呧呵呲呥 吵吮吶 。. 吲吶.
(37) 70. y. 80. 90. ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ●● ● ●●● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ●● ● ● ● ●● ●●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●●● ● ●● ● ●● ●● ● ●● ● ●● ●● ● ●● ● ● ●●● ● ●●● ● ● ●● ●● ● ●● ● ● ● ● ● ● ● ●●● ● ● ● ●●● ● ● ● ●● ● ●●● ● ● ●. 60. ●. ●. ● ●. ●. ●. −1. 0. 1. 2. 3. 4. log(x). ‧ 國. ● ● ●. ‧. ●. ● ● ● ● ● ●●●● ●●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ●●● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ● ● ●● ●● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ●● ●● ● ●● ● ●●● ● ● ● ● ● ●● ● ●● ● ● ●● ●● ● ● ● ● ● ● ● ● ●● ●● ● ●● ●● ●● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ●. io. y. sit. ● ●. −5. n. al. er. 0. Residual plot. Nat. residuals. 學. 5. 政 治 大 圖 吵吮吱吺 原始資料:呙對呬呯呧吨员吩的散佈圖 立. 0. Ch 50. engchi. i n U. v. 100. Time. 圖 吵吮吲吺 原始資料配適線性迴歸模型後的殘差圖. 吲吷. 150.
(38) −0.2. 0.2. ACF. 0.6. 1.0. ACF plot of residuals. 0. 5. 10. 15. 20. Lag. ‧ 國. y. sit. n. al. er. 0.4 0.2. ‧. io. 0.0. PACF plot of residuals. Nat. Partial ACF. 學. 0.6. 立. 政 治 大 圖 吵吮吳吺 殘差呁呃呆圖. 5. Ch. engchi 10. Lag. 圖 吵吮吴吺 殘差呐呁呃呆圖. 吲吸. i n U 15. v. 20.
(39) 0.2 −0.2. ACF. 0.6. 1.0. ACF of differential data. 0. 5. 10. 15. 20. Lag. ‧ 國. ‧ y. sit. n. −0.3. io. al. er. −0.1. PACF of differential data. Nat. Partial ACF. 學. 0.1. 政 治 大 圖 吵吮吵吺 對殘差一階差分呁呃呆圖 立. 5. Ch. engchi 10. i n U 15. Lag. 圖 吵吮吶吺 對殘差一階差分呐呁呃呆圖. 吲吹. v. 20.
(40) 決定 H0 及 H1 下 總參 數 個 數. 由 呆呩呧呵呲呥 吵吮吵 及 呆呩呧呵呲呥 吵吮吶 , 進行一階差分後,該組資料已趨近一平穩序列, 故我們對差分過後的資料配適模型。. 我們先觀察配適各模型後,其殘差呁呃呆圖及呐呁呃呆圖是否仍與時間有關,以決定 參數個數, 呆呩呧呵呲呥 吵吮吷 到 呆呩呧呵呲呥 吵吮吱吶 分別為配適 p 含 q 含 吱 吽 吲 的模型吨 呁呒吨吱吩 、 呍呁吨吱吩 吩, 以及 p 含 q 含 吱 吽 吳 的模型吨 呁呒吨吲吩 、 呁呒呍呁吨吱听吱吩 、 呍呁吨吲吩 吩, 由圖示. 政 治 大 可得知,在總參數個數為 吲 立 的情行下,殘差仍稍與時間有關, 到總參數為 吳 時,時. ‧ 國. 學. 間的因素幾乎完全消除, 故在此判定:. ‧ H1 吺 p 含 q 含 吱 吽 吳. n. er. io. al. 呶呥呲味呵味. sit. y. Nat. H0 吺 p 含 q 含 吱 吽 吲. Ch. engchi. 吳吰. i n U. v. 吨吵吮吱吩.
(41) 0.4 −0.4. 0.0. ACF. 0.8. ARIMA(1,0,0). 0. 5. 10. 15. 20. Lag. ‧ 國. ‧ y. sit. n. −0.3. io. al. er. −0.1. ARIMA(1,0,0). Nat. Partial ACF. 學. 0.1. 政 治 大 圖 吵吮吷吺 進行一階差分,配適呁呒吨吱吩模型後的殘差呁呃呆圖 立. 5. Ch. engchi 10. i n U. v. 15. Lag. 圖 吵吮吸吺 進行一階差分,配適呁呒吨吱吩模型後的殘差呐呁呃呆圖. 吳吱. 20.
(42) −0.2. 0.2. ACF. 0.6. 1.0. ARIMA(0,0,1). 0. 5. 10. 15. 20. Lag. ‧ 國. −0.2. y. sit. n. al. er. 0.0. ‧. io. −0.1. ARIMA(0,0,1). Nat. Partial ACF. 學. 0.1. 政 治 大 圖 吵吮吹吺 進行一階差分,配適呍呁吨吱吩模型後的殘差呁呃呆圖 立. 5. Ch. engchi 10. i n U 15. v. 20. Lag. 圖 吵吮吱吰吺 進行一階差分,配適呍呁吨吱吩模型後的殘差呐呁呃呆圖. 吳吲.
(43) −0.2. 0.2. ACF. 0.6. 1.0. ARIMA(1,0,1). 0. 5. 10. 15. 20. Lag. ‧ 國. −0.15. y. sit. n. al. er. 0.05. ‧. io. −0.05. ARIMA(1,0,1). Nat. Partial ACF. 學. 0.15. 政 治 大 圖 吵吮吱吱吺 進行一階差分,配適呁呒呍呁吨吱听吱吩模型後的殘差呁呃呆圖 立. 5. Ch. engchi 10. i n U 15. v. 20. Lag. 圖 吵吮吱吲吺 進行一階差分,配適呁呒呍呁吨吱听吱吩模型後的殘差呐呁呃呆圖. 吳吳.
(44) −0.2. 0.2. ACF. 0.6. 1.0. ARIMA(2,0,0). 0. 5. 10. 15. 20. Lag. ‧ 國. −0.15. y. sit. n. al. er. 0.05. ‧. io. −0.05. ARIMA(2,0,0). Nat. Partial ACF. 學. 0.15. 政 治 大 圖 吵吮吱吳吺 進行一階差分,配適呁呒吨吲吩模型後的殘差呁呃呆圖 立. 5. Ch. engchi 10. i n U. v. 15. Lag. 圖 吵吮吱吴吺 進行一階差分,配適呁呒吨吲吩模型後的殘差呐呁呃呆圖. 吳吴. 20.
(45) −0.2. 0.2. ACF. 0.6. 1.0. ARIMA(0,0,2). 0. 5. 10. 15. 20. Lag. ‧ 國. −0.15. y. sit. n. al. er. 0.05. ‧. io. −0.05. ARIMA(0,0,2). Nat. Partial ACF. 學. 0.15. 政 治 大 圖 吵吮吱吵吺 進行一階差分,配適呍呁吨吲吩模型後的殘差呁呃呆圖 立. 5. Ch. engchi 10. i n U 15. v. 20. Lag. 圖 吵吮吱吶吺 進行一階差分,配適呍呁吨吲吩模型後的殘差呐呁呃呆圖. 吳吵.
(46) 資料分析. 由吨吵吮吱吩,總參數個數決定後,我們進行資料分析。. 我們進行第一階段模型選擇,分別比較 呁呒吨吱吩 及 呍呁吨吱吩 的概似函數取對數後在 呍呌呅 的值, 其計算結果如下:. 模型 呬呯呧吨呍呌呅吩. 立. 呁呒吨吱吩. 呍呁吨吱吩. 吭吳吵吹吮吲吸吵治 -350.9314 政 大. 故 H0 的模型為呍呁吨吱吩,其後, 計算 H1 下模型吨 呁呒吨吲吩 、 呁呒吨吱听吱吩 、 呍呁吨吲吩 吩的. ‧ 國. 學. 呍呌呅 , 計算結果如下:. 呁呒吨吲吩. ‧. 模型. 呍呁吨吲吩. 吭吳吴吹吮吷吵吷吸. -348.8989. io. n. al. er. 呬呯呧吨呍呌呅吩 吭吳吴吹吮吵吶吴吹. sit. y. Nat. 呁呒呍呁吨吱听吱吩. i n U. v. 故 H1 下的模型為 呍呁吨吲吩 ,方法一及方法二的模型選擇結果相同, D 統計量的值 為:. D吽 吽. Ch. engchi. 呬呯呧吨L吨H1 吩吩 呬呯呧吨L吨H0 吩吩 − n n. 吨吵吮吲吩. −吳吴吸.吸吹吸吹 −吳吵吰.吹吳吱吴 − 吱吴吶 吱吴吶. 吽 吰.吰吱吳吹吲吱吳吵. 將假設檢定重新表示如下:. H00 吺 呍呁吨吱吩 成立 呶呥呲味呵味 H10 吺 呍呁吨吲吩 成立。 吳吶. 吨吵吮吳吩.
(47) 使用本研究方法計算 D 統計量的臨界值,先行求算該組資料於 呍呁吨吱吩 的模型下, 其 參數點估計值、標準誤、以及參數抽樣區間:. 呍呁係數. 標準誤. 抽樣區間. 呩呮呮呯呶呡呴呩呯呮 呶呡呲呩呡呮呣呥. 吭吰吮吵吷吵吲. 吰吮吰吷吳吲. 吨吭吰吮吷吲吱吵吷吶吵听 吭吰吮吴吲吸吷吶吱吸吩. 吷吮吱吴吷. 依照本研究方法第三章的步驟, 於上述抽樣區間隨機抽取 呍呁 係數,模擬一 千組 呍呁吨吱吩 資料,樣本數為 吱吴吶 , 每一組分別配適 呍呁吨吱吩 及 呍呁吨吲吩 模型,計算. 政 治 大. 一千組 D 統計量的值, 最後取其 吹吵吥 百分位數,令其為臨界值,於 H0 成立下,. 立. ‧ 國. 學. 呆呩呧呵呲呥 吵吮吵 為該一千組模擬出的 D 統計量分佈, 若 吨吵吮吲吩 的值大過臨界值,我們拒 絕虛無假設, 最後檢定結果:. ‧ 決策. sit. 吰吮吰吱吲吶吶吲吵吳 吰吮吰吰吱吲吵吸吸吱吷 拒絕虛無假設. n. al. er. io. 吰吮吰吱吳吹吲吱吳吵. 吨∗∗吩 吭 吨∗吩. y. Nat. 臨界值吨∗吩. 呄 統計量吨∗∗吩. Ch. engchi. i n U. v. 根據上述資料分析,本研究方法最後選擇的模型為 呍呁吨吲吩 , 再來依據呂呉呃準則 進行模型選擇, 因 呍呁吨吱吩 及 呍呁吨吲吩 分別為 H0 及 H1 參數個數下, 呍呌呅 值最大 的模型,故我們只需比較這兩者的 呂呉呃 值即可,結果如下:. 模型 呂呉呃值. 呍呁吨吱吩. 呍呁吨吲吩. 711.8301 吷吱吲吮吷吴吸吷. 故由 呂呉呃 準則進行模型選擇,其結果為 呍呁吨吱吩 模型。. 吳吷.
(48) D Statistic. y. io. 0.03. Value. n. al. 0.02. Ch. engchi. i n U. 圖 吵吮吱吷吺 一千組 呄 統計量分佈. 吳吸. sit. 0.01. er. 300 100 0. Nat. 0.00. ‧. ‧ 國. 學. Frequency. 500. 立. 政 治 大. v. 0.04.
(49) 第六章 結論. 本研究仍在一個初步的階段,故提出的方法仍有許多不足之處,在此詳加分析, 並期待更進一步的探討。. 首先,我們由模擬結果得知,本研究方法在理想情形下可將型一誤差控制在 吰吮吰吵. 政 治 大. 左右, 且檢定力會有顯著的增加,但我們所犧牲掉犯型一誤差的機率以換取部分的檢. 立. 定力, 由模擬的結果來看,檢定力的增加並未大幅提升到可將本研究方法取代 呂呉呃. ‧ 國. 學. 選模準則, 然而此種交換方式是否值得,仍待更進一步的衡量;於該段的模擬驗證,. ‧. 在研究的過程中有幾個情形也同時觀察過 呁呉呃 的表現,而 呁呉呃 的缺點為容易造成過. sit. y. Nat. io. n. al. er. 度參數化, 於本研究的假設檢定的觀點中,即為犯型一誤差的機率高,檢定力同時也. i n U. v. 高, 本研究第四章的模擬部分其中的幾個情形, 呁呉呃 的結果犯型一誤差的機率大約. Ch. engchi. 在 吱吵吥 v 吲吰吥 之間,相對檢定力也比所有方法都高出許多, 於資料配適模型的過程 中,若想介於 呁呉呃 及 呂呉呃 方法之間,本研究所提出的方法可用來進行參考。. 再者,若將第一階段模型選擇可能錯誤的情形考慮進去的話,本研究方法的結果 會有些微的變化; 若第一階段的模型選擇採用 呍呥呴周呯呤 吱 ,檢定力仍顯著增加,但 型一誤差值會有些許的膨脹, 但不至於膨脹至 呁呉呃 的結果,故模型配適想使用介於 呁呉呃 及 呂呉呃 之間的方法, 建議使用 呍呥呴周呯呤 吱 進行模型挑選,而 呍呥呴周呯呤 吲 的部. 吳吹.
(50) 分,雖然我們將型一誤差值控制精準, 但檢定力會大幅降低,甚至有可能出現比原 來 呂呉呃 還低的情形,故不建議使用 呍呥呴周呯呤 吲 進行挑選, 至於 呍呥呴周呯呤 吲 的模型挑 選,使的最後置於 H0 及 H1 下可能的情形減少, 為何此種模型挑選的結果會同時使 檢定力以及型一誤差值同時降低,目前為止仍不得而知。. 其後,本研究方法不足之處,相較於其他選模準則,最明顯的地方即在於需要大 量的計算, 龐雜的運算造成冗長的時間耗損,此外,本研究方法涉及配適模型的參數. 政 治 大. 點估計值, 以及抽樣區間的估計,其中的誤差影響本研究方法的精確度也不得而知。. 立. 最後,在本研究方法的實用上,最困難的點應為 k 值的選取, 本文的實際操作. ‧ 國. 學. 剛好選取的資料並無矛盾的結果,所謂的矛盾的結果,就是我們一般在進行模型選取. ‧. 時, 通常不希望模型配適完成後,殘差仍具時間的結構,若假設檢定的結果最後不拒. sit. y. Nat. n. al. er. io. 絕虛無假設, 但於虛無假設下的模型,其殘差的 呁呃呆 及 呐呁呃呆 仍具時間結構,此. i n U. v. 即為一矛盾的結果, 本研究對 k 值選取初步的建議是,在 k 值固定下,若配適的其. Ch. engchi. 中一個模型完全與時間無關, 則我們將此 k 值置於對立假設,但若其 k − 吱 的模型配 適結果高度與時間相關時, 則我們將此 k 值置於虛無假設,當然,模型的配適的考量 有許多,可以參考先驗資訊, 或者專家意見,又或者在樣本數小的情形下,模型並不 適合配適太多的參數, 所有的模型配適,大多仰賴使用者本身的考量,選模準則只是 提供一個模型配適參考的方向。. 吴吰.
(51) 參考文獻. 溫志宏 吨吩听 呜無線通道模型概論吢听 國立中 正大學 吮. 葉欣甯 吨吲吰吰吲吩听 呜時間序列的選模分析吺 呃呲呯呯味吭呖呡呬呩呤呡呴呩呯呮 之應用吢听 國立 清華 大學碩 士 論文吮. 政 治 大. 呁呫呡呩呫呥听 呈吮 吨吱吹吷吳吩听 呜呉呮呦呯呲呭呡呴呩呯呮 呴周呥呯呲呹 呡呮呤 呡呮 呥呸呴呥呮味呩呯呮 呯呦 呴周呥 呭呡呸呩呭呵呭 呬呩呫呥呬呩吭. 立. ‧ 國. 學. 周呯呯呤 呰呲呩呮呣呩呰呬呥吢听 Budapest, Hungary听 吲吶吷呻吲吸吱吮. ‧. 吨吱吹吷吸吩听 呜呁 呂呡呹呥味呩呡呮 呡呮呡呬呹味呩味 呯呦 呴周呥 呭呩呮呩呭呵呭 呁呉呃 呰呲呯呣呥呤呵呲呥吢听 Annals of. Nat. al. er. io. sit. y. the Institute of Statistical mathematics听 吳吰吨吱吩听 吹呻吱吴吮. v. n. 呂呲呯呣呫呷呥呬呬听 呐吮告吮 呡呮呤 呄呡呶呩味听 呒吮呁吮 吨吲吰吰吹吩听 Time series: theory and methods听 呓呰呲呩呮呧呥呲 呖呥呲呬呡呧吮. Ch. engchi. i n U. 呃呡味呥呬呬呡听 呇吮听 呂呥呲呧呥呲听 呒吮呌吮听 呡呮呤 呂呥呲呧呥呲听 呒吮呌吮 吨吲吰吰吲吩听 Statistical inference听 呄呵呸呢呵呲呹 呐呡呣呩同呣 呇呲呯呶呥听 呃呁吮. 呃呬呡呲呫呥听 呂吮 吨吲吰吰吱吩听 呜呃呯呭呢呩呮呩呮呧 呭呯呤呥呬 味呥呬呥呣呴呩呯呮 呰呲呯呣呥呤呵呲呥味 呦呯呲 呯呮呬呩呮呥 呰呲呥呤呩呣呴呩呯呮吢听 Sankhy¯a: The Indian Journal of Statistics, Series A听 吲吲吹呻吲吴吹吮. 吴吱.
(52) 呈呵呲呶呩呣周听 呃吮呍吮 呡呮呤 呔味呡呩听 呃吮呌吮 吨吱吹吸吹吩听 呜呒呥呧呲呥味味呩呯呮 呡呮呤 呴呩呭呥 味呥呲呩呥味 呭呯呤呥呬 味呥呬呥呣呴呩呯呮 呩呮 味呭呡呬呬 味呡呭呰呬呥味吢听 Biometrika听 吷吶吨吲吩听 吲吹吷吮. 呋呵呬呬呢呡呣呫听 呓吮 呡呮呤 呌呥呩呢呬呥呲听 呒呁 吨吱吹吵吱吩听 呜呏呮 呩呮呦呯呲呭呡呴呩呯呮 呡呮呤 味呵后呣呩呥呮呣呹吢听 The Annals of Mathematical Statistics听 吷吹呻吸吶吮. 呒呥味呣周呥呮周呯呦呥呲听 呅呲周呡呲呤 吨吲吰吰吵吩听 呜呓呥呬呥呣呴呩呮呧 味呥呬呥呣呴呩呯呮 呭呥呴周呯呤味吢听 InterStat: Statistics on the Internet听 吷吨吳吩听 吱呻吱吷吮. 呗呡呧呥呮呭呡呫呥呲味听 呅吮告吮听 呇呲. 立. 政 治 大. ‧ 國. 學. 吢呵呮呷呡呬呤听 呐吮听 呡呮呤 呓呴呥呹呶呥呲味听 呍吮 吨吲吰吰吶吩听 呜呁呣呣呵呭呵呬呡呴呩呶呥 呰呲呥呤呩呣呴呩呯呮 呥呲呲呯呲 呡呮呤 呴周呥 味呥呬呥呣呴呩呯呮 呯呦 呴呩呭呥 味呥呲呩呥味 呭呯呤呥呬味吢听 Journal of Mathematical Psychology听 吵吰吨吲吩听. ‧ er. io. sit. y. Nat. 吱吴吹呻吱吶吶吮. 呙呡呮呧听 呙吮 吨吲吰吰吵吩听 呜呃呡呮 呴周呥 味呴呲呥呮呧呴周味 呯呦 呁呉呃 呡呮呤 呂呉呃 呢呥 味周呡呲呥呤吿 呁 呣呯呮名呩呣呴. n. al. Ch. engchi. i n U. v. 呢呥呴呷呥呥呮 呭呯呤呥呬 呩呮呤呥呮呴呩同呣呡呴呩呯呮 呡呮呤 呲呥呧呲呥味味呩呯呮 呥味呴呩呭呡呴呩呯呮吢听 Biometrika听 吹吲吨吴吩听 吹吳吷吮. 吴吲.
(53)
數據
Outline
相關文件
三、補助額度:每人每學期最高補助6,000元。但 就讀之私立幼兒園或互助教保服 務中心實際收費較低者,依實際
要如何安排課後的休閒活動呢?我們 可以依照自己的個性和興趣,做適當 的選擇,並且考量天候、時間,做適
請各園於家長提出離園 時落實離園申請手續 (以 書面 方式為宜)及程 序並於當日至全國幼兒 園幼生系統登載,避免
參、技術士技能檢定建築物室內設計乙級術 科試題.
本實驗中的限量試劑(limiting reagent)為何?NaNO 2 是否適合做為限量試
National Mathematics Magazine 後來改名為 Mathematics Magazine,而這份期刊最早的 名稱是 Mathematics News Letter,各自之發行期數及年份如下:. Mathematics
觀察一下月亮,你覺得月亮有哪些特質
觀察一下月亮,你覺得月亮有哪些特質
