期末報告
以人工智慧與自然語言處理技術為基礎之數位人文資訊服務
:資訊檢索、時空分析、音譯詞彙、實體名詞辨識與社群計算
(第2年)
計 畫 類 別 : 整合型計畫
計 畫 編 號 : MOST 102-2420-H-004-054-MY2
執 行 期 間 : 103年08月01日至105年01月31日
執 行 單 位 : 國立政治大學資訊科學系
計 畫 主 持 人 : 劉昭麟
共 同 主 持 人 : 沈錳坤、蔡宗翰
計畫參與人員: 碩士班研究生-兼任助理人員:王睿揚
碩士班研究生-兼任助理人員:黃致凱
碩士班研究生-兼任助理人員:林書佑
碩士班研究生-兼任助理人員:吳俊鎧
碩士班研究生-兼任助理人員:林柏誠
碩士班研究生-兼任助理人員:羅國峯
碩士班研究生-兼任助理人員:林育增
博士班研究生-兼任助理人員:王昱鈞
報 告 附 件 : 移地研究心得報告
出席國際會議研究心得報告及發表論文
處 理 方 式 :
1.公開資訊:本計畫可公開查詢
2.「本研究」是否已有嚴重損及公共利益之發現:否
3.「本報告」是否建議提供政府單位施政參考:否
中 華 民 國 105 年 02 月 18 日
人文研究。從許多不同的角度分析人文領域的語料並且發表學術論
文。分析的語料包含全唐詩、中國地方志、新青年、清末立憲檔案
、清季外交史料、紅樓夢、西遊記、人民日報和台灣四大報的內容
。詳細情形請再參考結案報告全文。
中 文 關 鍵 詞 : 語言模型、機器學習、文本分析、全唐詩、中國地方志、新青年、
清末立憲檔案、清季外交史料、紅樓夢、西遊記、人民日報、客家
、硬頸
英 文 摘 要 :
英 文 關 鍵 詞 : language modeling, machine learning, textual analysis,
Complete Tang Poems, Difangzhi, La Jeunesse, Dream in the
Red Chamber, Journey to the West, Renmin Ribao, Hakka
Language
自然語言處理技術為基礎之數位人文資訊服務:資訊檢索、時空分析、音譯詞
彙、實體名詞辨識與社群計算
研究計畫編號:
MOST-102-2420-H-004-054-MY2
研究計畫執行期間:
2013 年 8 月 1 日到 2016 年 1 月 31 日
壹、前言
這一份研究計畫的結案報告主要是由劉昭麟撰寫。附件一是蔡宗翰教授部分的補充報告。
提出研究計畫書的當時,這是一份三年的研究規畫,實際上獲得補助的時間是兩年。之後因為
研究工作內容和人力的變化,經過核可、展延到
2016 年元月結束。
以一般研究計畫的成果來說,我想我可以說這一個研究計畫達成了合理的成果;特別因為這是
一個跨領域的研究計畫。在草擬計畫書的時候,並不是每一個參與教授都有合作的實際經驗,
雖然不是夠熟悉的友人是不會一起提案。
雖然我們達成了合理的成果,但是這並不意味著我們達成了最佳的成果。經過兩年多的努力,
我覺得、要為一個跨領域、跨校的研究計畫達成
“最佳”的結果是相當不容易的,需要許多條件
的配合。
貳、成果
附件二表列的是我們這一計畫所完成的幾項工作。
在這一附件中,我們把工作成果分成四大類別。首先一項是我們積極地支援
2015 年底在台灣
大學舉辦的第六屆數位典藏與數位人文國際學術研討會。
這一研討會是台灣大學項潔老師推動
多年的數位人文學術交流活動,積極地協助這一研討會的舉行對於國內數位人文研究的發展,
應該可以算是一項成果。
第二類是軟體工具的建立和開放。在
2013 年擬定計畫之時,原本希望把政治大學的中國近現
代思想及文學史專業數據庫的重新設計;雖然我們真正啟動了這一工作,但是這一件事情並沒
有真正地完成。
基於一些先前的準備工作和後來的積極加工,我們在
2013 年底就有一個新版系統的雛形,在
2013 年國內的人工智慧研討會中發表該系統 [DC3],同時持續改進該雛形,並且把所完成的系
統安裝在中國近現代思想及文學史專業數據庫的計畫辦公室中。
這一系統雖然能夠吸引一些政大的學者來使用,不過由於中國近現代思想及文學史專業數據庫
的內容並不對外開放,最終這一系統並不能對外開放,因此實際使用的族群非常有限,無法成
就有意義的氣候。
中,邀請沈老師加入,就是想要利用社會網路分析
(social network analysis,SNA)的技術,來分
析詞彙的關聯性。在沈老師的積極督促之下,研究生確實也建立了一個可用的基本系統。
跟我們所完成的數據庫新系統的雛形的情形類似,這一個詞彙社群網路分析的軟體的使用者並
不多。除了因為語料庫沒有開放之外,要讓參與計畫的人文專家真正了解
SNA 技術的用途和
限制,實際上並沒有想像中那樣容易。最後這一件工作的產出是,相關的老師和研究生在
2014
年第五屆數位典藏與數位人文研討會中發表了一篇論文
[IC7]。
基於先前的這一些經驗,我個人於
2015 年初把原先在研究群內部的軟體清理出來,包裝成一
些可以讓國內學者使用的軟體工具,放在網站「臺灣數位人文小小讚」
1上讓研究者免費下載。
透過當時國科會人文處數位人文推動計畫的清華大學祝平次教授的協助,我們在台灣大學、清
華大學、成功大學、中興大學,先後舉辦過四次的研習會,來推廣這一些公開軟體。從網路流
量統計數據來看,這一些軟體應該是發揮了一些推動數位人文研究和教學的效果。
第三項是在一些學術研討會分享我們研究群的研究經驗。
在
2014 和 2015 年我們各有兩次的機
會跟人文領域的學者分享數位人文的研究經驗。
2014 年的十月,我們首先在台北大學所主辦的「文學與資訊研討會」,報告了政大的數位人文
研究經驗。接著在十二月,在科技部人文與社會科學司中文學門的年度工作坊之中,我們又再
度介紹了政大團隊的研究工作。
在
2015 年,我們有兩次的機會在正式的學術研討會報告和分享我們的研究經驗。第一次是 2015
年九月在澳門大學所舉辦的
The Pacific Neighborhood Consortium 2015 Annual Conference and
Joint Meetings
2,第二次是
2015 年十一月在國家圖書館所主辦的全球視野下的漢學新藍海國際
研討會
3。
這兩個會議的舉辦地點雖然一個在國內一個在國外,實際上都有很多國外學者參加。國外有相
當多研究漢學的學者,他們的中文都相當地好,因此許多演講都還用中文來進行。
在這一些會議之中,我們報告的先前處理清代資料
(清末立憲檔案、清季外交史料)的資料,也
分享了四大小說中的紅樓夢、西遊記的有趣問題,更提到了我們處理近代白話文語料
(人民日
報、台灣四大報
)的經驗。同時我也可以談到我個人參與哈佛大學的中國歷代人物傳記資料庫
的開發工作中,處理以文言文撰寫的中國地方志的經驗。我們從不同的角度分析和需求出發,
展現了資訊科技協助人文研究的機會。
透過大會之後人文學者的回應和討論,我個人覺得這一類的會議,確實能夠吸引人文學者更加
注意到數位技術和工具的潛力。
1 「臺灣數位人文小小讚」網址:https://sites.google.com/site/taiwandigitalhumanities/ 2 The Pacific Neighborhood Consortium 2015 Annual Conference and Joint Meetings : http://www.pnclink.org/pnc2015/english/
量來說,我覺得或許可以算是已經達成不錯的成果。但是,數位人文領域不容易有傳統的期刊
論文的發表,不能算是沒有遺憾。我們目前所發表的工作成果,主要集中在
12 篇的國際學術
會議之中,其中比較多的是台灣大學所主辦的數位典藏與數位人文國際學術會議
[IC2, IC3, IC7,
IC8]。我們在國際間比較注重的 International Conference on Digital Humanities 會議中,連續在
2014[IC12]和 2015[IC6]年都有發表成果。鄭文惠老師和邱偉雲博士在 2014 年於歐洲漢學會議
分別發表了兩篇論文
[IC10, IC11]。我們也在適當的國際學術研討會發表成果,例如 PACLIC [IC4] 、
ASE 的 Social-Informatics 研討會[IC5]、CSCA 工作坊[IC9]、CoLTA [IC1]。另有一篇專書篇章論文
[BC1],和三篇國內學術會議的論文[DC1, DC2, DC3]。
我這一個計畫是一個大型整合計畫的一部分,在這一個數位人文跨領域計畫,一開始就沒有設
定自己明確的工作目標。我的工作目標只是協助人文領域的學者分析各該領域的文本資料。在
這一個目標之下,我想難保不會有學者認為我所處理的問題,不夠專注而過於雜亂。
從
2011 年初,當時的國科會人文司還沒有現在所講的數位人文計畫之前,我們就在政大用數
位技術分析中國近現在思想及文學史專業數據庫的文本資料。當時所分析的有不少是清代的資
料;有一些特別著重於金觀濤老師所主導的觀念史的研究
[IC5, IC9, IC10, IC11, IC12]。後來為了
吸引更多人文學者願意使用數位技術來做研究,我們嘗試以紅樓夢、西遊記
[IC9, DC2]、四書、
五經的分析比對來當作範例。
基於先前的一些推廣,
2013 年開始有申請數位人文計畫的機會之後,我開始協助當時政大國
關中心的陳至潔老師分析人民日報關於
“人權”的資料。再之後則有政大英語系賴惠玲老師所欲
分析的客家相關語料,這一批語料來自於國內四大報
(中時、聯合、自由、蘋果)中關於客家話“硬
頸
”的報導,研究的目的是關於“硬頸”的使用和語意的轉變 [IC1]。我們也曾經短暫地與台灣史
的學者合作,因此也分析過一些關於
228 事件的報導 [DC2]。
2015 年的一些研究,已經不再只是協助文史研究者觀察關鍵詞頻或者共現詞組的頻率而已。
我們開始應用稍微進階的文字分析工具,例如詞彙共現強度
(strength of collocation)和主題分析
(topic modeling)的工具[IC2]。
我們也同時開拓一些新的議題。在文學領域有《全唐詩》的內容分析
[IC3, IC4, DC1],在史學
文獻方面,則有與哈佛大學合作的中國地方志的資訊擷取工作
[IC6]。在這一些工作之中,除了
文本分析技術之外,我們還帶入了
language modeling 的技術。
本計畫的兩位共同主持人,在
DADH 2014 會議中,都發表了研究成果。沈錳坤老師協助了詞
彙關係網路的分析對於史學研究的貢獻
[IC7],蔡宗翰老師則偕同金觀濤老師探索《清季外交
史料》中的歷史事件的標記
[IC8]。
以上所述一些論文,有不少是陸續發表的系列工作,因此不需要全部都附在這一份結案報告之
中。有一些則是已經附在參加國際會議的報告之中,因此在這分報告的附件三。我們附上在
PACLIC 發表的《全唐詩》分析[IC4],還有兩位共同主持人在 DADH 2014 發表的論文 [IC7, IC8]。
作為數位人文專題計畫第一期參與者來說,我們的計畫要算是成功或者失敗呢?
我覺得這是一個介於成功與失敗之間的計畫。
從以上的報告,我覺得我們已經做了相當多的事情。透過過去兩年多的努力,我們發表了為數
不算少的研究成果;我們也在許多機會可以與國內學者分享研究成果;我們更將比較穩定的軟
體工具公開,與國內學者共享。
儘管如此,我們覺得我們有許多可以更多的期待。
以整合計畫裡面的人文和資訊學者的比例來說,資訊領域的學者本來有不錯的機會可以支援到
每一個子計畫。不過,在計畫執行過程中,並不是所有資訊學者和他們的學生,都願意真正投
入到數位人文的工作之中。
人文和資訊領域的學者的合作,需要很多耐心,慢慢培養互信和共識。這在國內或許也不是一
件簡單的事情。有一些時候,人文學者不見得能夠接受計算技術的現有限制,有一些時候計算
技術的細節確實也不容易讓人文學者真正理解。
有耐心、持續地合作,是跨領域研究的基本條件,之後才能培養出有深度的產出。這需要制度
和參與人員共同的體會和身體力行。
一、研究動機與目的
在古文獻考證與歷史語言學的研究上,古文獻中所出現之音譯詞對於研究當
時之文化交流與語言發音上具有極重要之研究價值。當時的文獻撰寫者,將外國
事物之名以當時的漢語發音進行轉譯並以漢字記錄下來,因此以漢字音譯的外國
音譯詞,是我們研究古文獻之時代的漢語發音與文化交流之重要媒介。中國自古
以來之官修史書與私撰文獻皆或多或少記載了許多域外的音譯詞,隨著文明演進
與交通方式的進步,漢文古文獻中所記載的音譯詞的來源亦逐步擴大,從東南亞、
南亞區域開始,及至中亞、西亞,甚而遠及歐洲與非洲大陸。南宋時期趙汝适所
編撰之《諸蕃志》一書,即詳細記載了當時宋人透過泉州商港頻繁的國際貿易中
所收集之關於海外諸國相關的資料與國名地名等音譯詞,如吉尼玆、弼琵囉等音
譯國名,其甚至記錄了遠及斯伽里野即現今義大利西西里島相關之記載。到了十
八、十九世紀清代晚期,由於當時西方列強與與中國政治經濟各方面的交流與脅
迫日益擴大,在中國內部造成了極欲瞭解西方諸國現勢與西洋文明的迫切需求,
也因此有許多學者開始翻譯或撰寫介紹西方國家與文物之著作,如魏源的《海國
圖志》與徐繼畲的《瀛寰志略》等書。於此時期,由於許多西方之國名、地名與
專有名詞等,對於當時的中國人來說仍屬全新之概念,因此尚未有固定之譯法,
而著書者則多依其當時之漢字語音嘗試自行音譯,而此類音譯詞多半與現今中文
所慣用之譯名多有出入,例如國名葡萄牙於《海國圖志》中譯為「布路亞」
,德
國則譯為「亞勒馬尼」等等。這些不同的音譯詞譯法,對於研究當時的文化接觸
與文明思想以及語言等各層面皆是十分重要且珍貴的研究資料。
然而此類漢文典籍卷秩浩瀚,要以人工方式於如此龐大之漢文史料內逐一審
視並收集音譯詞項目實為一煩耗人力之研究工作。因此若是能利用資訊技術於漢
文文獻中自動擷取辨識可能的音譯詞項目並以予以排序,將可大幅降低人力的消
耗,提供文史專家一個快速辨識音譯詞的工具,加速其研究之時程。故本計畫以
數位人文研究之角度出發,研發出一個針對漢文文獻之外來語音譯詞擷取方法,
自漢文文獻中抽取出可能的詞彙,進行過濾後再依其特性進行相關性的排序,產
生出音譯詞候選詞列表,以輔助文史學家與語言學家之研究。
本計畫所研發之音譯詞擷取方法之流程如圖
1 所示,其包含了詞彙抽取、候
選詞過濾、音譯詞排序三個主要模組,其各模組之方法詳述如下。
2.1
詞彙擷取
為了從漢文文獻之中擷取出重要的詞彙以建立候選詞集合,我們採用基於後
綴數組(suffix array)的方式(Manzini, 2004)
。利用將字串轉為後綴數組的方法,
擷取序列中的最長前綴字串作為候選詞。後綴數組是一種常見於生物資訊以及文
字探勘的方法,其為一種文本索引結構,紀錄一筆字串各種後綴形式的索引,利
用對所有字串中的字符編號,後綴數組可用來作序列化的處理。
後綴數組是一個用以有效地對於大量文本進行索引處理的方法,其基本的演
算概念如下。令一長度為 n 的字串 S,對每個存在於字串 S 的 n 個字符作 0 至 n-1
的索引,S[i]表示索引 i 的後綴字串,假定 S = “abracadabra”'在索引之後結果會如
下:
圖
1 音譯詞擷取方法流程
索引
0 1 2 3 4 5 6 7 8 9 10
該字串總共有 12 個後綴,依字典順序排序後產生下列的後綴字串,其中之
頻率為該後綴出現於所有後綴字串之前綴部分的次數:
排序過之後綴
後綴 S
頻率
a
S[10]
5
abra
S[7]
2
abracadabra
S[0]
1
adabra
S[5]
1
acadabra
S[3]
1
bra
S[8]
2
bracadabra
S[1]
1
cadabra
S[4]
1
dabra
S[6]
1
ra
S[9]
2
racadabra
S[2]
1
上述後綴字串中頻率大於 1 者即為可能的候選詞,然而若該候選詞為其它候
選詞所包含,且其頻率未高於較長的候選詞,則該候選詞會被濾除。以上例,最
終我們可以得到“a”和“abra”二個候選詞。
2.2、候選詞過濾
藉由後綴數組方法,可以從漢文文獻中抓取出大量的可能候選詞,但亦含有
大量無用的雜訊詞,且其中可能多半皆非音譯詞。而這些大量之非音譯詞雜訊詞
彙將對於文史學家分析毫無幫助,且大幅影響辨識之正確率,因此我們設計過濾
的模組,用以濾除大部分無意義與顯非音譯詞的詞彙。在候選詞過濾上,我們混
合二種不同的作法,其一為規則式之候選詞過濾方法,另一則為利用其它漢文文
獻之差集過濾法。
2.2.1 規則式候選詞過濾方法
由實驗中進行觀察後綴數組方法所抽取出來的詞彙,並分析音譯詞之相關特
性後,我們設計如下數個過濾條件,依序將無用的詞彙濾除。
該過濾條件將抽取出來之詞彙中含有中英文標點符號的詞一律濾除,
如
, 。 : ; ! 「 」 ( ) 等符號。
b、漢文數字規則
該過濾條件為將抽取出來之詞彙中包含漢文數字組合之詞彙一律進行濾除,
漢文數字包含一至十,以及百千萬等進位單位,如「三十」
、
「凡五十年」等詞。
c、天干地支規則
該過濾條件為將抽取出之詞彙中同時包含天干與地支兩者組合之詞彙一律
進行濾除,例如「壬午年」
、
「庚申之變」等等。
d、帝王年號規則
該過濾條件為將抽取出之詞彙中包含該漢文文獻著作時期所屬之該朝代歷
代帝王年號之詞彙一律進行濾除,例如「康熙年間」
、
「道光初」等詞。
e、單位量詞與稱謂規則
該過濾條件為將抽取出之詞彙中含有常見之單位量詞與稱謂詞者之詞彙一
律予以濾除。所使用之單位量詞共有:日、年、月、次、斤、尺、姑、姊、姐、
哥、弟、妹、爺、分、時、天、歲、回、件、錢、位、更、人、洲、府、倍、代、
大、方、點、部、城、郡、麵。
f、漢文虛詞規則
該過濾條件為將抽取出之詞彙中含有漢文語法虛詞者之詞彙一律予以濾除。
所使用之漢文虛詞共有:之、乎、且、矣、邪、於、哉、相、遂、嗟、與、噫。
2.2.2 漢文文獻差集過濾方法
就算是一部講述西方諸國的漢文文獻,其內容之中語法功能性詞彙與非專有
名詞之一般詞彙仍然佔了大部分,故透過後綴數詞方法所抽取出之候選詞有相當
大的比例為該類詞彙。我們提出一個差集過濾方法,選擇與該漢文文獻時代相近
之其它非講述同類主題之著作,例如言情志怪小說等文學作品,這些作品其內容
中多含有常見的語法功能性詞彙與一般詞彙,而少有音譯詞之類的專有名詞。我
們以同樣參之(一)節之後綴數詞方法將這些漢文著作進行抽詞取得候選詞集合,
而後將原有文獻所抽取之候選詞集合減去非同類主題著作抽取出之候選詞集合
而取得其差集。其差集處理方法可定義如下:
其中{ Candidate
target}為目標漢文文獻經過後綴數組抽取方法抽取後並依前節規
則式過濾方法過濾後之候選詞集合,而{Book
i}則為與目標文獻非同類主題著作
經過後綴數組抽詞之候選詞集合,我們可以引入多部不同的著作進行差集以取得
更佳之過濾結果。而{Final_Candiate
target}即為目標漢文文獻之候選詞過濾的最終
結果。
2.3 音譯詞排序
透過前節之候選詞過濾方法後,已可大幅排除諸多顯非音譯詞之項目。然而
其餘之候選詞中,仍有許多非音譯詞之詞彙混雜其中尚需辨識。且對於文史研究
者來說,若能將音譯詞依其可能性予以排列產生一列表供其檢視,自可能性較高
者優先檢視,將能大幅節省其耗費時間並增進其效率。故我們針對該問題提出一
基於最大熵模型演算法(Maximum Entropy Modeling)之監督式學習方法(Berger et
al., 1996),用以進行音譯候選詞的辨識與排序。
2.3.1 最大熵模型演算法
最大熵模型演算法其理論之基本概念是為所有已知的因素建立模型,而把所
有未知的因素排除在外,也就是找出一個機率分布可滿足目前所有已知的事實,
而不考慮任何未知因素的影響。最大熵模型的一個最顯著的特點是其不要求需要
條件獨立的特徵,故可以相對任意地加入對最終分類有用的特徵,而不用顧及它
们之間的相互影響。此外,最大熵模型對各個類別輸出一相對較為客觀之機率值
結果,該機率之結果便可用於後續之排序使用。此外,最大熵模型在訓練時之效
率相對其它機器學習模型要高,故於音譯詞排序之模組中採用該演算法。
在我們要預測該候選詞是否為音譯詞時會涉及各種因素,假設 X 就是一個
由這些因素所構成之向量,而變數 y 的值則代表是否為音譯詞,故 p(y|X)就是該
候選詞是否屬於音譯詞之類別之機率。而這個機率則可以利用上述之最大熵模型
進行估算,最大熵模型要求 p(y|X)在滿足其一定約束之條件下,必須使如下定義
之熵取得最大值:
H(𝑝𝑝) = − � 𝑝𝑝(𝑦𝑦|𝑋𝑋) log 𝑝𝑝(𝑦𝑦|𝑋𝑋)
𝑋𝑋,𝑦𝑦而此處所種之一定約束之條件,實際上即指目前所有已知之事實,可以用以
𝑓𝑓
𝑖𝑖(𝑋𝑋, 𝑦𝑦) = �1, if (𝑋𝑋, 𝑦𝑦) satifies certain condition
0,
otherwise
, 𝑖𝑖 = 1, 2, 3, … , 𝑛𝑛
其中 f
i(X, y)可稱為最大熵模型之特徵,而 n 則為所有特徵之總數。這些特徵則描
述了向量 X 與最終屬於音譯詞與否之分類結果 y 之間的關係。我們可以得到最終
之機率結果為
𝑝𝑝
∗(𝑦𝑦|𝑋𝑋) =
1
𝑍𝑍(𝑋𝑋) exp �� 𝜆𝜆
𝑖𝑖 𝑖𝑖𝑓𝑓
𝑖𝑖(𝑋𝑋, 𝑦𝑦)
� ,
𝑍𝑍(𝑋𝑋) = � exp �� 𝜆𝜆
𝑖𝑖𝑓𝑓
𝑖𝑖(𝑋𝑋, 𝑦𝑦)
𝑖𝑖� ,
𝑦𝑦其中
λi
為每個特徵之權重,其權重值則由限制記憶體 BFGS 算法(limited-memory
BFGS)計算而得(Liu & Nocedal 1989),其為一擬牛頓(quasi-newton)演算法以迭代
方式增進調整對特徵權重之估計。該估計方法確保對於每一個特徵 fi,其估計出
之權重
λi
與其於訓練集中實驗觀察之期望值相同。
透過給定特徵與訓練語料,最大熵模型演算法便能自訓練語料之中找出符合
特徵條件之機率結果,並以此預測未知之 X 向量屬於結果 y 之機率值。針對音譯
詞排序之問題,我們設定結果 y 值有二種可能性,其一為 y=1 表示該詞屬於音譯
詞類別,另一為 y=-1 代表該詞不屬於音譯詞類別。最大熵模型分類方法將會同
時估算 p(y=1|X)與 p(y=-1|X)之機率,若 p(y=1|X) > p(y=-1|X)則將該詞分類為音譯
詞類別,若否則分類為非音譯詞類別。在音譯詞排序中,我們先將最大熵模型所
分類出屬於音譯詞類別者置於前,而分類出非屬於音譯詞類別者則置放於後。而
後該二類之中,分別再以最大熵模型所計算出之 p(y=1|X)即屬於音譯詞類別之機
率數值大小作為排序之依據,產生出最終之排序結果。
2.3.2 特徵選擇
在最大熵模型之特徵部分,我們針對音譯詞的特性,包含音譯詞漢字本身之
發音屬性、其於漢文文獻中出現之位置及前後漢字出現情況等,設計出適用於音
譯詞辨識分類之特徵,詳述如下。
a、後方詞彙
觀察漢文文獻,發現許多音譯詞於文獻中出現時,其後方緊鄰之漢字多有其
特定之樣版,特別是地名相關之音譯詞,後方所接之漢字常為「洲、國、海、教、
人」等,如「阿細亞洲」
、
「美裡哥國」
、
「亞德蘭的海」
、
「加特力教」
、
「佛蘭西人」
徵,其計算出該候選詞於原漢文文獻之中出現之時,後方曾有鄰接所整理出之漢
字詞彙之比例數值。
b、Accessor Variety
我們參考 Feng et al. (2004)所提出之 Accessor Variety 算法,用以估算該候選
詞於原本之漢文文獻中出現時其左右兩側共現之其它漢字之可能性。由於後綴數
組方法之抽詞方式並不考慮所抽取出之候選詞是否為實際有意義之詞組,許多抽
取出之候選詞多為音譯詞之子字串之一部分,例如透過後綴數組方法可能同時抽
取出「英吉」與「英吉利」兩候選詞,如我們分析漢文文獻中「英吉」與「英吉
利」之出現時其左右出現之漢字種類,可發現「英吉」右方共現之漢字絕大部分
都為「利」字,故文獻中候選詞兩側共現之不相同之漢字數量多寡將對於判斷音
譯詞與否具有其重要性。對於一字串 s,其 Accessor Variety (AV)數值定義如下:
𝐴𝐴𝐴𝐴(𝑠𝑠) = min{𝐿𝐿
𝑎𝑎𝑎𝑎(𝑠𝑠), 𝑅𝑅
𝑎𝑎𝑎𝑎(𝑠𝑠)}
其中 L
av(s)為 left accessor variety,其定義為在語料中含有字串 s 之句子中,
字串 s 第一個字元左側之所共現之不同的漢字字元個數;而 Rav(s)為 right accessor
variety,其定義為在語料中含有字串 s 之句子中,字串 s 最後一個字元右側之所
共現之不同的漢字字元個數。若 s 出現在句首或句末,則其左側或右側並無漢字
字元,於此情形下,空字元亦當作一種特殊之漢字計入 Lav(s)或 Rav(s)之中。然而
每個候選詞於文獻之中出現之次數各不相同,故仍再須依照候選詞出現之次數進
行正規化,最終之特徵值定義為:
𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹
𝑎𝑎𝑎𝑎(𝑠𝑠) = log
𝐶𝐶𝐶𝐶𝐹𝐹𝑛𝑛𝐹𝐹(𝑠𝑠)
𝐴𝐴𝐴𝐴(𝑠𝑠)
其中 Count(s)為字串 s 於文獻中出現之次數。
c、漢字發音相似度
於十八、十九世紀之古漢文文獻中對於外國事物所採行的漢字音譯詞多與現
代習用者不同,然其仍多與現代之譯詞來自同樣的外語詞彙之音譯。例如在《海
國圖志》一書中,
「敘利亞」一詞譯為「西里亞」
,
「亞歷山大」譯為「阿勒山德
里」等。雖其音譯所使用之漢字與現代習用者差異甚大,然其漢字之發音仍具有
相當高之一致性。因此,候選詞之漢字發音序列與現代之音譯詞之間發音之相似
程度亦是辨別是否為音譯詞一重要之依據。
為計算語音之相似度,我們採用 ALINE 演算法(Kondrak, 2003)。ALINE
演算法以字串編輯距離演算法為基礎,來計算二個發音符號串列的相似度。演算
算後則輸出二字串的語音相似度之值。該演算法具有三種字串編輯動作:skip、
substitute、expand。skip 為跳過該位置的音素,substitute 為將該位置的音素置換
為另一音素,而 expand 則是將該位置的音素一次置換為二個音素。由於漢語外
來語音譯的特性,有時會將尾音省略或輔音連綴(consonant cluster)中其中一個
輔音省略,因此需考量 expand 的動作。演算法中的δ
skip, δsub, δexp
為進行 skip、
substitute 和 expand 動作的評價函數(scoring function)
。
由於語音在歷史的演變上仍有其傾向與差異,例如齒齦塞音 [t]變為硬顎塞
擦音[tɕ]是語言中常見的現象,然而齒齦塞音[t]變為聲門擦音[h]相較之下就相當
罕見,因此[t]→[tɕ]的相似度應較[t]→[h]要高。因此在設計評價函數時必須考量
實際的語音特徵,如發聲部位、發聲方式、有聲或無聲等。表 1 為詳細的評價函
演算法
1: 基於字串編輯距離的語音相似度演算法
S[0, 0] ← 0
n ← |x|
m ← |y|
for i = 1 to n do
S[i, 0] ← S[i – 1, 0] + δ(a
i, -)
end for
for j = 1 to m do
S[0, j] ← S[0, j - 1] + δ(-, b
j)
end for
for i = 1 to n do
for j = 1 to m do
+ − − + − − + − − + − + − ← − − 0 ) , ( ] 1 , 2 [ ) , ( ] 2 , 1 [ ) , ( ] 1 , 1 [ ) ( ] 1 , [ ) ( ] , 1 [ max ] , [ 1 1 j i i exp j j i exp j i sub j skip i skip y x x j i S y y x j i S y x j i S y j i S x j i S j i Sδ
δ
δ
δ
δ
end for
end for
return S[n, m]
Csub = 35、Cexp = 45、Cvwl = 10。每個音素的語音特徵以一組特徵向量表示,而函
式 diff(p, q, f)表示音素 p 與音素 q 於語音特徵 f 間的差異數值。
用以比較二個母音之間的語音特徵集合 R
V為:Syllabic(音節性)
、Nasal(鼻
音)
、Retroflex(捲舌)、High(舌頭高度)、Back(舌頭前後)、Round(圓唇)。
而比較二子音或母音子音間的語音特徵集合 R
C為:Syllabic(音節性)、Manner
(發聲方式)
、Voice(有聲)
、Nasal(鼻音)
、Retroflex(捲舌)
、Lateral(流音)、
Aspirated(送氣)
、Place(發聲部位)。
每個特徵的值介於[0.0, 1.0]區間,其中 Place(發聲位置)
、Manner(發聲方
式)
、High(舌頭高度)
、Back(舌頭前後)為多值特徵,其對應之值如表 2 所示。
而其餘的特徵僅有 0.0 與 1.0 二種值。而 salience(f)函式則用以決定不同的語音特
徵之間的權重,例如語音的發聲部位對於估算相似度的重要性高於是否有送氣,
故 Place 的 salience 較 Aspirated 為高。各個語音特徵的 salience 數值列於表 3 之
中。
經由演算法 1 之計算之後,其中陣列 S[i,j], 0≦i≦n, 0≦j≦m 中最大值即為
該二語音符號串列的相似值。然而其值會隨著比較之二字串的長度而增加,故需
將其正規化至[0, 1]的區間之中。我們以下列之公式進行正規化以求出最終之二
語音符號串列的相似值。令
𝐴𝐴𝐴𝐴𝑖𝑖𝐴𝐴𝑛𝑛𝐴𝐴𝐴𝐴𝐶𝐶𝐹𝐹𝐹𝐹(𝑥𝑥, 𝑦𝑦) = max
0≤𝑖𝑖≤𝑛𝑛,0≤𝑗𝑗≤𝑚𝑚𝐴𝐴[𝑖𝑖, 𝑗𝑗],則二語音
串列 x 與 y 之間的語音相似度為:
𝐴𝐴𝑖𝑖𝑆𝑆𝑖𝑖𝐴𝐴𝐹𝐹𝐹𝐹𝑖𝑖𝐹𝐹𝑦𝑦(𝑥𝑥, 𝑦𝑦) =
𝐴𝐴𝐴𝐴𝑖𝑖𝐴𝐴𝑛𝑛𝐴𝐴𝐴𝐴𝐶𝐶𝐹𝐹𝐹𝐹(𝑥𝑥, 𝑦𝑦)
𝐴𝐴𝐴𝐴𝑖𝑖𝐴𝐴𝑛𝑛𝐴𝐴𝐴𝐴𝐶𝐶𝐹𝐹𝐹𝐹(𝑞𝑞, 𝑞𝑞)
表
1: 評價函數
skip skip(p)=C δ ) ( ) ( ) , ( ) , (p q Csub p q V p V q sub = −δ
− −δ
)) ( ), ( max( ) ( ) , ( ) , (p q1q2 Cexp p q1 V p V q1 V q2 exp = −δ − − δwhere
= otherwise consonant a is if 0 ) ( vwl C p p V其中
q 為 x 與 y 字串中長度較長者。
Feature name
Phonological term
Numerical value
Place 發聲部位
[bilabial]雙唇音
1.0
[labiodentals]唇齒音
0.95
[dental]齒音
0.9
[alveolar]齒齦音
0.85
[retroflex]捲舌音
0.8
[palate-alveolar]齒槽硬顎音
0.75
[palatal]硬顎音
0.7
[velar]軟顎音
0.6
[uvular]小舌音
0.5
[pharyngeal]喉音
0.3
[glottal]聲門音
0.1
Manner 發聲方式
[stop]塞音
1.0
[affricate]塞擦音
0.9
[fricative]擦音
0.8
[approximant]通音
0.6
[high vowel]高母音
0.4
[mid vowel]中母音
0.2
[low vowel]低母音
0.0
High 舌頭高低
[high]高
1.0
[mid]中
0.5
[low]低
0.0
Back 舌頭前後
[front]前
1.0
[central]中
0.5
[back]後
0.0
我們自國家教育研究院學術名詞資訊網
1中收集外國譯名共 61,121 個作為音
譯詞發音資料集,針對每一個候選詞,我們取將候選詞之漢字發音序列與資料集
內之所有譯詞之漢字先行轉換為漢語拼音後,依據漢語拼音再轉換為國際音標字
母(International Phonetic Alphabet, IPA)序列,利用 ALINE 演算法計算發音序列之
相似度,取其與資料集中譯詞字串編輯距離最小者作為該候選詞之特徵值。
d、非音譯詞語言模型
在漢語的構詞中,音譯詞與非音譯詞構詞所使用的漢字有相當程度的差異,
一般非音譯詞所使用的漢字,其漢字之間多有一定的語意關連,然音譯詞所使用
的漢字則僅單純表音,與漢字本身的語意無關。由此觀察,音譯詞與非音譯詞的
漢字組合具有相當之差異,音譯詞的漢字詞組之結合多半不會在一般的詞彙之中
出現,因此是一個用以分辨是否為音譯詞之有用特徵。
我們採用二元分詞語言模型(Bi-gram Language Model)用以估算漢字詞組結
合之機率,語言模型可針對一連續之字元串列 w
1, w
2, …, w
n,給定其機率 P(w
1,
w
2, …, wn),其定義如下:
𝑃𝑃(𝑤𝑤
1, 𝑤𝑤
2, … , 𝑤𝑤
𝑛𝑛) = 𝑃𝑃(𝑤𝑤
1)𝑃𝑃(𝑤𝑤
2|𝑤𝑤
1)𝑃𝑃(𝑤𝑤
3|𝑤𝑤
1, 𝑤𝑤
2) … 𝑃𝑃(𝑤𝑤
𝑛𝑛|𝑤𝑤
1, 𝑤𝑤
2, … , 𝑤𝑤
𝑛𝑛−1)
= � 𝑃𝑃(𝑤𝑤
𝑖𝑖|𝑤𝑤
1, 𝑤𝑤
2, … , 𝑤𝑤
𝑖𝑖−1)
𝑛𝑛 𝑖𝑖=1為了計算上的可行性,我們可假設每個字元出現之機率僅與其前一個字元有
關,此即二元分詞假設,因此,我們可以將上述之公式改寫如下:
𝑃𝑃(𝑤𝑤
1, 𝑤𝑤
2, … , 𝑤𝑤
𝑛𝑛) = � 𝑃𝑃(𝑤𝑤
𝑖𝑖|𝑤𝑤
1, 𝑤𝑤
2, … , 𝑤𝑤
𝑖𝑖−1)
𝑛𝑛 𝑖𝑖=1≈ � 𝑃𝑃(𝑤𝑤
𝑖𝑖|𝑤𝑤
𝑖𝑖−1)
𝑛𝑛 𝑖𝑖=1為建立非音譯語言模型,本計畫採用類似於前述音譯詞過濾方法中之漢文文
1 http://terms.nict.gov.tw/download_list.php?folder_id=118
Syllabic 5
Place
40
Voice
10
Nasal
10
Lateral 10
Aspirated 5
High
5
Back
5
Manner 50
Retroflex 10
Round 5
練出非音譯詞兩元分詞語言模型。而後每一個音譯詞候選詞皆以該兩元分詞語言
模型計算其漢字詞組之機率,作為最大熵模型之特徵值。
上述之音譯詞之數種特徵,其特徵數值將直接作為最大熵模型的訓練資料,
我們採用 Maximum Entropy Modeling Toolkit for Python and C++工具
2進行最大
熵模型之訓練,採用限制記憶體 BFGS 算法(limited-memory BFGS)計算特徵值之
權重,其在訓練時之迭代次數之上限設為 300 次。
三、實驗數據與分析
3.1 實驗資料集
在實驗資料集的收集上,我們主要採用十九世紀之古典漢文文獻《海國圖志》
一書作為驗證之實驗資料集。
《海國國志》最先為清代道光時期之名臣林則徐擔
任欽差大臣時,命手下之士翻譯英國人慕瑞所編著之《世界地理大全》一書,集
結成《四洲志》
,但未及出版。鴉片戰爭後,林則徐被貶至新疆,其書稿則全部
交給其好友魏源接手。魏源以此書稿為基礎,兼收更多資料後,彙集成《海國圖
志》一書,原書原為五十卷,而後增補為一百卷,其內文總字數超過八十八萬字,
包括地圖七十五幅與各種技藝圖式與天文圖。
《海國圖志》是中國近代第一部全
面有系統性介紹世界歷史地理與介紹各國情況之巨著,包含世界各國地理位置介
紹、歷史沿革、政治制度、物產、宗教、風俗民情,與彙集之國外情報資料等。
《海國圖志》於中國之外,更對日本之明治維新產生重要之影響,實為東亞近代
史上重要之漢文文獻,且其介紹世界各國之內容亦含有大量之音譯詞彙,為驗證
音譯詞擷取方法十分合適的實驗資料。
另外,為驗證本計畫所提出之方法於不同漢文文獻上應用之有效性,我們另
以一部同時代之地理方志著作《小方壺齋輿地叢鈔再補編》第十二帙《四洲志》
作為另一獨立之測試資料集,以驗證本計畫提出之方法確可應用於不同的語料
上。
2 http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html
在評估實驗之結果上,我們採用在資訊檢索領域中常使用之召回率(Recall)
與平均準確率(Average Precision)二種評估方法。為滿足文史學家研究之要求,在
擷取音譯詞上希望能盡量找出可能之音譯詞而減少漏失,故召回率是一重要之指
標。此外,若能利用資訊技術將確實是音譯詞者盡量優先列出以有效減少人力檢
查之耗費對於文史研究有極大之效益,故準確率為十分重要之評估指標。在音譯
候選詞的過濾上,我們以召回率來評估過濾方法濾除詞彙時對於音譯詞的影響。
為計算召回率需要有其標準答案,目前已有先前文史學者所整理出 6,605 個海國
圖志之音譯詞列表。由於我們採用之後綴數組抽詞方法為比較文句內容中具重覆
出現的部分以擷取出可能的候選詞,故詞彙必須於文獻中出現二次以上者方能被
後綴數詞方法擷取出,即詞彙能被擷取出所需之最小支持度為頻率需大為 1 者。
而前人所整理出之海國圖志之音譯詞列表中於海國圖志全文中出現二次以上者
共 2,115 個,故我們以此二千餘個標準答案做為召回率評估之標準答案用以計算
召回率數值。
在音譯詞排序部分,我們則以準確率來評估最終排序結果之好壞。為了驗證
我們提出之方法可否有效率找到前人未整理出之音譯詞,在得到最終之排序結果
後,仍需以人工方式進行檢視確認,因有許多音譯詞仍未記錄於前人整理之資料
之中。故我們以人工檢視音譯詞排序結果,為考量標注之人力成本,採用前 500
平均準確率(Average Precision@500)作為評估方法。在平均準確率的正確答案標
注上,我們以人工檢視系統最終抽取排序出之候選詞項目,如該候選詞項目包含
完整之音譯詞,或為音譯詞之二個字以上之子字串者即標注為正確之候選詞項目。
因對輔助文史學者研究來說,能找出確為音譯詞之項目並對回文獻原文後即能確
認音譯詞與否,故若能找出音譯詞之部分子串仍有其效益,故採用該答案標註準
則。
此外,本研究之目的在於希望能提供文史學家一個有效節省其研究時間之工
具,因此使用該工具與否對於自漢文文獻中檢閱音譯詞所費之時間成本亦十分重
要。為評估時間成本,我們以「第
n 個音譯詞位置」作為評估方法,其為自排序
結果的第一個項目起,第
n 個正確的音譯詞出現在排序結果的第幾順位,意即若
要找出
n 個音譯詞,從第一個項目開始看起,要看過多少個候選詞後才能找出 n
個音譯詞。
「第
n 個音譯詞位置」之評估方法之目的期能找出完整且正確之音譯
詞,故在候選詞為音譯詞與否的標註判定上採用較嚴格的標準。以人工檢視最終
之音譯候選詞排序結果,如該候選詞為完整之音譯詞,或是完整之音譯詞與其常
見之後綴字如「國、洲、河、海」等則判定為正確之音譯詞,因其為有意義之詞
彙,而其餘則判定為不正確。舉例來說,若一音譯詞為「伯爾西亞」
,則候選詞
「伯爾西亞」與「伯爾西亞國」則判定為正確詞,而「伯爾西」
、「至伯爾西亞」
等詞則判定為不正確,以此來計算最後之第 n 個音譯詞之位置。
3.3 實驗結果
3.3.1 候選詞過濾方法
表 4 顯示經由後綴數詞抽詞方法擷取出音譯候選詞後,經過第參之二節音譯
詞過濾方法前後,候選詞之數量與召回率之數據。在漢文文獻差集過濾部分,我
們共使用了五部漢文小說作品,分別為《鏡花緣》
、
《紅樓夢》
、
《聊齋誌異》
、
《老
殘遊記》與《隋唐演義》
。由於後綴數組方法僅能抽取出於文獻中出現頻率大於
1 的詞彙,故詞彙所需之最小支持度為詞的頻率需大於 1 者。由實驗結果可知,
後綴數組方法抽取出超過 20 萬個候選詞,在經過我們的過濾方法,其有效篩檢
僅剩下五萬七千餘詞,大幅減少近 72%之錯誤候選詞,然而其召回率僅略下降
7.34%,此結果說明了我們的過濾方法是相當有效的。
分析標準答案中之詞彙遭候選詞過濾方法過度濾除之情形,主要可歸納為如
下數種情形。其一是部分音譯詞所使用的漢字包含數字,因此漢字數字之過濾規
則會過度濾除這類包含數字之音譯詞,例如「巴三」
、
「馬六甲」
、
「六坤」等詞。
數字之詞彙由於佔了非音譯候選詞相當部分之比例,對於濾除相當有效,然對於
此類包含單一數字之音譯詞則需再設計分辨之規則。其二情形為有一小部分國名
音譯詞,由於其與中土交流甚早,已是中國相關故事傳說中可能出現之故事背景,
因此在漢文文獻差集過濾時雖然所選之其它文獻皆為傳統小說,但其仍可能含有
這類之音譯詞,而使得進行差集運算時被濾除。此類音譯詞有「波斯」與「暹羅」
候選詞數量
召回率
後綴數組抽詞結果
202,890
83.88%
經規則式過濾後
75,449
(-62.81%) 79.57%
(-4.31%)
經漢文文獻差集過濾後
57,024
(-71.89%) 76.54%
(-7.34%)
等詞,但此類音譯詞多已被一般人所熟知,故在擷取出漢文文獻音譯詞之研究上
之其重要性較不那麼高。其三為文史學家所整理之二千餘詞之答案中,有小部分
並非實際之音譯詞彙,例如「天方」
、
「大東洋海」
(即今之太平洋)等詞,此類
詞彙於規則式過濾方法中會被濾除。由於此類詞彙並非實際音譯詞,故將之濾除
亦並無不妥。
3.3.2 候選詞排序方法
在候選詞之排序方法上,由於我們採用基於最大熵模型之監督式機器學習方
法,因此需先有一訓練集用以訓練出最大熵模型分類器,而後再以該訓練出之模
型進行音譯候選詞的分類及排序。在訓練集的建置上,我們將《海國圖志》全書
100 卷中,隨機選出其中 20 卷作為訓練集來源,其餘諸卷則用於測試集。我們
以後綴數組方法於訓練集內容與測試集內容抽詞並進行候選詞過濾,分別得到音
譯候選詞項目。在訓練集所擷取出之候選詞,檢視是否有出現於前人所整理之二
千餘詞之音譯詞列表中,若符合者則標示其標籤為“+1”,若否則標示為“-1”。而
後選出所有標籤為“+1”者,共 384 個候選詞,並自標籤為“-1”者中隨機選出 717
個候選詞組成一用於最大熵模型之訓練集,共 1,101 個候選詞項目,其標注為“+1”
與“-1”項目之比例為 1:2。
為了說明音譯詞排序之必要性,在利用後綴數組抽詞方法與音譯詞過濾後之
候選詞項目後,首先計算這些候選詞中之為音譯詞者之比例。如其比例不高,即
大部分皆非音譯詞的話,則說明了將候選詞進行排序選擇為十分必要之工作。因
抽詞結果之候選詞高達數萬個難以用人工全部進行檢視,因此我們採用隨機抽樣
的方式,共抽取 30 次,每次抽取其中 250 個候選詞,計算其中為音譯詞者之比
例後進行平均而得到取樣結果。取樣結果之數據為:30 次之平均中實際為音譯
詞者佔候選詞總數之比例為 3.44%,其統計標準差為 0.01327。從取樣結果之數
據顯見大多數皆非音譯詞,故進行音譯詞排序是十分必要之工作。
表 5 是候選詞排序方法於《海國圖志》資料集之實驗結果數據,其中 Baseline
為用以進行對照之基準組,其排序之方法為依據後綴數組抽出之詞的詞頻高低,
前 500 準確率
第 20 個音譯詞位置 第 30 個音譯詞位置
Baseline
45.82%
197
347
Our method
96.14%
41
71
詞頻高者排於前,而得到最終之排序結果。由實驗結果可知我們的候選詞排序方
法與基準方法相對照其準確率大幅提升,並有相當好的效果,此證明我們的候選
詞排序方法對於選擇較可能之音譯詞相當有效且有極大之助益。可以見到前 500
準確率之實驗結果顯示我們的方法可有效找出相當數量之音譯詞,而在節省查找
音譯詞之時間成本評估上,我們的方法僅需看過 71 個候選詞後就能找出 30 個音
譯詞,而基準方法則需看到 347 個候選詞才能找出 30 個音譯詞,顯示我們的方
法可大幅節省近 4/5 的查閱之時間成本,對於文史學家之研究應有相當之幫助。
表 6 為候選詞排序方法於《四洲志》測試資料集中之實驗結果,由實驗結果
亦可知我們的候選詞排序方法在不同的語料上對於選擇較可能之音譯詞仍然相
當有效且有極大之助益。我們的方法僅需看過 47 個候選詞後就能找出 30 個音譯
詞,顯見我們的排序方法能夠將大部分的音譯詞排至列表前端,可有效節省文史
學家查閱之時間耗費。
透過本計畫所發展之基於最大熵模型之候選詞排序方法,能有效找出許多如
「波爾多黎各」
、
「西爾加西亞」
、
「戈攬彌阿」
、
「迦濕彌羅」
、
「義斯巴尼亞」等不
存在於前人所整理之音譯詞,顯見音譯候選詞排序方法對於擷取出音譯詞相當有
效。然由於後綴數詞之抽詞方法僅考慮字元連續之組合,而未考慮詞之邊界,因
此其所抽取出之帶有音譯詞之詞彙其前後有時會帶有其它字元。然而本研究之主
要目的在於提供文史學家從漢文文獻中有效找出可能的音譯詞以大幅節省其研
究時間,雖然以資訊方法要辨識音譯詞邊界並不容易,然而對於人來說要辨識音
譯詞之邊界並非難事,因此只要能找出含有正確音譯詞之候選詞,並將正確的音
譯詞排序為前,提供文史學者檢視,研究者很快就能判斷並辨識出其中之音譯詞,
從而達到輔助人文學科研究之目的。
四、計畫成果與結語
在古文獻與歷史語言學研究上,古文獻中之音譯詞對於研究文化交流與語言
發音上具有相當重要之研究價值。在漢文古文獻中,針對域外諸國之人事物與新
概念皆以音譯詞的方式進行翻譯。然而漢文文獻卷秩浩繁,為協助文史學家深入
前 500 準確率
第 20 個音譯詞位置 第 30 個音譯詞位置
Our method
58.60%
27
47
與音譯詞排序三個模組。在詞彙抽取上,我們採用後綴數組抽詞方法對於整部漢
文文獻擷取出可能的詞彙。在候選詞過濾的方法上,包含規則式過濾與其它漢文
文獻差集過濾二種方式,先將後綴數組抽出之候選詞以觀察所得之規則式方法刪
除顯非音譯詞者,而後再以同時期之數部傳統文學文獻進行後綴數組抽詞,將其
抽詞結果與原文獻之抽詞結果進行差集運算,藉以過濾更多非音譯詞之詞彙。在
音譯詞排序上,採用基於最大熵模型之監督式機器學習方法,以候選詞於文獻原
文語句中出現之特性作為特徵,進行候選詞的分類排序,以篩選較具研究價值之
音譯詞。我們以十九世紀介紹域外諸國之漢文文獻《海國圖志》與《四洲志》兩
書作為實驗資料,以前人所整理之海國圖志音譯詞列表來評估實驗結果,我們方
法可大幅減少 72%錯誤之候選詞,且其召回率仍可達到 76.54%,此說明我們的
過濾方法相當有效且對於召回率之影響並不大。在候選詞之排序上,我們的方法
已可達到 96.14%之準確率,可篩選出較可能之音譯詞,從而輔助文史學者之研
究,以節省其於浩繁文獻中之查找時間。我們將後續將本方法整合開發成一完善
之工具提供文史學者使用,並於未來持續改善增進方法之效能,以擴大資訊技術
於文史領域之應用。
參考文獻
Berger, A. L., Pietra, V. J., Della and Pietra, Stephen A. D. A maximum entropy
approach to natural language processing. Computational linguistics, 22, 1: 39-71.
Feng, H.
, Chen, K., Deng, X. and Zheng, W. (2004). Accessor variety criteria for
Chinese word extraction.
Computational Linguistics, 30, 1: 75-93.
Goldberg, Y. and Elhadad, M. (2008). Identification of transliterated foreign words in
Hebrew script. Computational Linguistics and Intelligent Text Processing.
Kondrak, G. (2003). Phonetic alignment and similarity. Computers and the
Humanities, 37: 273-291.
Kuo, J-S., Li, H., and Yang, Y-K. (2007). A Phonetic Similarity Model for Automatic
Extraction of Transliteration Pairs. ACM Trans. Asian Language Information
challenges in applying language technologies to historical studies in Chinese.
International Journal of Computational Linguistics and Chinese Language Processing,
16, 1-2: 27
‒ 46.
Liu, D. C., and Nocedal, J. (1989). On the limited memory BFGS method for large
scale optimization. Mathematical Programming, 45: 503–528.
Manzini, G., & Ferragina, P. (2004). Engineering a lightweight suffix array
construction algorithm. Algorithmica, 40: 33-50.
Oh, J., and Choi, K. (2003). A statistical model for Automatic Extraction of Korean
Transliterated Foreign words. International Journal of Computer Processing of
Oriental Languages, 16, 1: 41-62.
Sherif, T., and Kondrak, G. (2007). Bootstrapping a stochastic transducer for
Arabic-English transliteration extraction. In proceedings of Annual
附件二:成果清單
1 協辦第六屆數位典藏與數位人文國際學術研討會
2 軟體設計
中國近現代思想與文學史專業數據庫查詢與分析系統雛形
(孫瑋;劉昭麟指導)
詞彙社會網路的分析雛形
(陳柏聿;沈錳坤指導)
「臺灣數位人文小小讚」
(劉昭麟)
3 邀請演講
全球視野下的漢學新藍海國際研討會邀請演講:
Textual analysis of complete Tang
poems for discoveries and applications: A computational perspective
(20/November/2015)
The Pacific Neighborhood Consortium 2015 Annual Conference and Joint Meetings 邀請
演講:
Some Applications of Textual Analysis for Historical, Political, Linguistic, and Literary
Studies in Chinese (27/September/2015)
科技部人文及社會科學研究發展司中文學門「從人文到數位人文」學術研習營
(5-6/December/2014)
第七屆文學與資訊學術研討會專題演講
(31/October/2014)
4 論文發表
專書篇章
[BC1] 王昱鈞、呂翊瑄、蔡宗翰、劉青峰、金觀濤及劉昭麟。漢文文獻之外來語音譯詞擷取方
法
(Transliteration Extraction Methods for 19th Century Chinese Literature),數位人文研究
與技藝 (數位人文研究叢書),項潔編,121‒137。臺灣大學出版中心,臺灣,April 2014。
(中文內容)
國際學術會議
[IC1] Huei-Ling Lai (賴惠玲), Shao-Chun Hsu (徐韶君), and Chao-Lin Liu. Hakka symbolic code
<nganggiang stiff neck>: An analysis of its innovative development in Taiwan newspapers,
presented at International Conference on Corpus Linguistics and Technology Advancement
2015 (CoLTA 2015). Hong Kong, China, 16-18 December 2015.
[IC2] Wen-Huei Cheng (鄭文惠), Wei-Yun Chiu (邱偉雲), Chao-Lin Liu, and Shu-Yu Lin (林書佑). 概
念關係的數位人文研究:以《新青年》中的「世界」觀念為考察核心
, Proceedings of the Sixth
International Conference of Digital Archives and Digital Humanities (DADH'15), 305‒342 Taipei,
Taiwan, 30 November-2 December 2015. (in Chinese)
情感現象學與色彩政治學:中唐詩歌白色抒情系譜的數位人文研究
, Proceedings of the
Sixth International Conference of Digital Archives and Digital Humanities (DADH'15), 481‒522.
Taipei, Taiwan, 30 November-2 December 2015. (in Chinese)
[IC4] Chao-Lin Liu, Hongsu Wang (王宏甦), Chu-Ting Hsu (許筑婷), Wen-Huei Cheng (鄭文惠), and
Wei-Yun Chiu (邱偉雲). Color aesthetics and social networks in complete Tang poems:
Explorations and discoveries, Proceedings of the Twenty-Ninth Pacific Asia Conference on
Language, Information and Computation (PACLIC 29), 132‒141. Shanghai, China, 30 October-1
November 2015. (Chinese version appeared in ROCLING XXVII)
[IC5] Chao-Lin Liu, Guantao Jin (金觀濤), Hongsu Wang (王宏甦), Qingfeng Liu (劉青峰), Wen-Huei
Cheng (鄭文惠), Wei-Yun Chiu (邱偉雲), Richard Tzong-Han Tsai (蔡宗翰), and Yu-Chun Wang
(王昱鈞). Textual analysis for studying Chinese historical documents and literary novels,
Proceedings of the ASE International Conferences on BigData & SocialInformatics 2015, article
30. Kaohsiung, Taiwan, 7-9 October 2015.
[IC6] Peter K. Bol, Chao-Lin Liu, and Hongsu Wang (王宏甦). Mining and discovering biographical
information in Difangzhi with a language-model-based approach, Proceedings of the 2015
International Conference on Digital Humanities (DH 2015). Parramatta, New South Wales,
Australia, 29 June-3 July 2015.
[IC7] Guan-tao Jin(金觀濤), Wei-Yun Chiu(邱偉雲), Yin-yee Leong(梁穎誼), Po-yu Chen(陳柏聿),
Man-kwan Shan(沈錳坤), Qin-feng Liu(劉青峰). The alternation of idea groups on New Youth
(Xin Qingnian): A new digital humanity approach (觀念群變化的數位人文研究-以《新青年》
為例
). Proceedings of the Fifth International Conference of Digital Archives and Digital
Humanities (DADH'14), 333‒358. Taipei, Taiwan, 1-2 December 2014. (in Chinese)
[IC8] Yu-chun Wang(王昱鈞), Wei-yun Chiu(邱偉雲), Chun-kau Wu(吳俊鎧), Yi-hsuan Lu (呂翊瑄),
Richard Tzong-han Tsai (蔡宗翰), Guan-tao Jin(金觀濤). Historical event mention identification
method based on the context: Focusing on the “Qing Diplomatic Historical Data” (基於人時地
物脈絡之漢文歷史事件描述辨識方法-以清季外交史料為例
), Proceedings of the Fifth
International Conference of Digital Archives and Digital Humanities (DADH'14), 527‒531. Taipei,
Taiwan, 1-2 December 2014. (in Chinese)
[IC9] Chao-Lin Liu, Guantao Jin(金觀濤), Peter K. Bol, Qingfeng Liu(劉青峰), Wen-Huei Cheng (鄭文
惠
), Wei-Yun Chiu(邱偉雲), Richard Tzong-Han Tsai(蔡宗翰), and Yu-Chun Wang(王昱鈞).
Some examples of text analysis for studying Chinese history and literature, presented at the
CSAC Workshop 2014. Osaka, Japan, 21-22 November 2014.
[IC10] Wen-huei Cheng(鄭文惠), Wei-Yun Chiu(邱偉雲), and Chao-Lin Liu. Ideas, events, and
actions: The digital humanity study of the concept of "guojia"(國家) formation in modern
China, presented in the 20th Biennial Conference of the EACS (European Association of Chinese
Studies, 歐洲漢學學會) 2014, University of Minho (Braga) and the University of Coimbra
(Coimbra), Portugal, 22-26 July 2014.
Ideas, events, and actions: The digital humanity study of the concept of "Zhuquan"(主權)
formation in modern China, presented in the 20th Biennial Conference of the EACS (European
Association of Chinese Studies, 歐洲漢學學會) 2014, University of Minho (Braga) and the
University of Coimbra (Coimbra), Portugal, 22-26 July 2014.
[IC12] Wen-huei Cheng(鄭文惠), Jui-sung Yang(楊瑞松), Wei-Yun Chiu(邱偉雲), Chao-Lin Liu,
Guan-tao Jin(金觀濤), and Qing-feng Liu(劉青峰). Ideas, events and actions: The digital
humanity study of the concept formation in modern China, Proceedings of the 2014
International Conference on Digital Humanities (DH 2014). Lausanne, Switzerland, 8-12 July
2014.
國內學術會議
[DC1] 劉昭麟、張淳甯、許筑婷、鄭文惠、王宏甦及邱偉雲。《全唐詩》的分析、探勘與應用
-風格、對仗、社會網路與對聯,
第廿七屆自然語言與語音處理研討會論文集
(ROCLING
XXVII),43‒57。臺灣,新竹,2015 年 10 月 1-2 日。(中文內容) (英文版本出版於 PACLIC
29)
[DC2] 黃植琨、黃致凱、林書佑、陳聖傑、陳建良及劉昭麟。數位技術於文史資料分析的應用:
《西遊記》與
228,2013 年全國計算機會議論文集(自然語言處理與語音處理領域)
(NCS'13)。臺灣,臺中,2013 年 12 月 13-14 日。(中文內容)
[DC3] 孫暐及劉昭麟。數位技術於文史資料分析的輔助環境,第十八屆人工智慧與應用學術研
討會論文集
(TAAI'13),系統展示,357‒358。臺灣,台北,2013 年 12 月 6-8 日。(中文
內容
)
附件三:論文著作
Chao-Lin Liu, Hongsu Wang (王宏甦), Chu-Ting Hsu (許筑婷), Wen-Huei Cheng (鄭文惠), and
Wei-Yun Chiu (邱偉雲). Color aesthetics and social networks in complete Tang poems: Explorations
and discoveries, Proceedings of the Twenty-Ninth Pacific Asia Conference on Language, Information
and Computation (PACLIC 29), 132‒141. Shanghai, China, 30 October-1 November 2015. (Chinese
version appeared in ROCLING XXVII)
Color Aesthetics and Social Networks in Complete Tang Poems:
Explorations and Discoveries
Chao-Lin Liu† Hongsu Wang‡ Wen-Huei Cheng∮ Chu-Ting Hsu§ Wei-Yun Chiu!
†§
Department of Computer Science, National Chengchi University, Taiwan
‡
Institute for Quantitative Social Science, Harvard University, USA
∮!
Department of Chinese Literature, National Chengchi University, Taiwan
†
Graduate Institute of Linguistics, National Chengchi University, Taiwan
{†chaolin,§104753021,∮whcheng}@nccu.edu.tw, ‡[email protected], ǂ[email protected]
Abstract
1The Complete Tang Poems (CTP) is the most important source to study Tang poems. We look into CTP with computational tools from specific linguistic perspectives, including distributional semantics and collocational analysis. From such quantitative viewpoints, we compare the usage of “wind” and “moon” in the poems of Li Bai2 (李白) and Du Fu (杜甫). Colors in poems function like sounds in movies, and play a crucial role in the im-ageries of poems. Thus, words for colors are studied, and “白” (bai2, white) is the main focus because it is the most frequent color in CTP. We also explore some cases of using colored words in antithesis(對仗)3 pairs that were central for fostering the imageries of the poems. CTP also contains useful historical information, and we extract person names in CTP to study the social networks of the Tang poets. Such information can then be inte-grated with the China Biographical Database of Harvard University.
1
Introduction
Complete Tang Poems (CTP) is the single most
important collection for studying Tang poems from the literary and linguistic perspectives (Fang et al., 2009; Lee and Wong, 2012). CTP
1 A majority of the contents of this paper was also published in Chinese in (Liu et al., 2015).
2
Romanized Chinese names are in the order of surname and first name, following the request of a reviewer.
3 “Antithesis” is not a perfect translation of “對仗” (dui4 zhang4). Roughly speaking, “對仗” refers to constrained collocations, and requires two terms to have opposite relationships in pronunciations, but does not demand the terms to be opposite in meanings. In English, “antithesis” carries a rather obvious demand for two referred terms to be opposite in meanings.
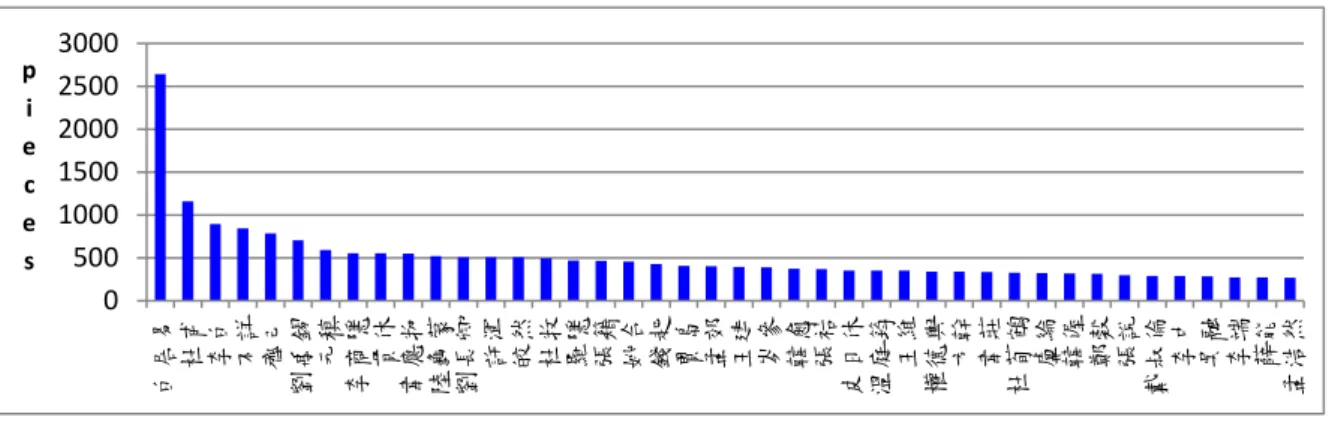
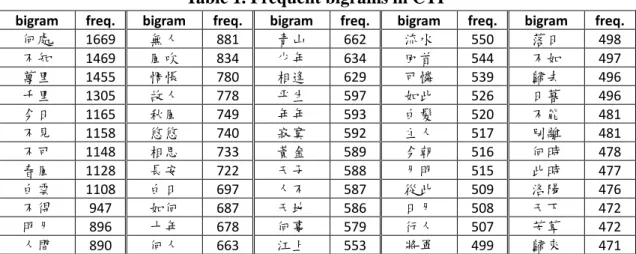
was officially compiled during the Kangxi years of the Qing dynasty, and includes more than 40,000 poems, totaling more than 3 million characters, that were authored by more than 2000 poets. Employing linguistic theories and computational tools, we analyze the contents of CTP for a wide variety of explorations.
Lo and her colleagues pioneered to handle texts of Chinese classical poetry with computer software (Lo et al., 1997). Hu and Yu (2001) achieved a better environment and demonstrated its functions with a temporal analysis of selected Chinese unigrams, i.e., 愁(chou2), 苦(ku3), 恨 (hen4), 悲(bei1), 哀(ai1), and 憂(you1). Jiang (2003) employed tools for information retrieval to find and study selected poems of Li Bai and Du Fu that mentioned “wind” and “moon”. Huang (2004) analyzed the ontology in Su Shi’s (蘇軾) poems based on 300 Tang Poems, and Chang et al. (2005) continued this line of work. Lo then built a more complete taxonomy for Tang poems (Lo, 2008; Fang et al., 2009).
Lee conduct part-of-speech analysis of CTP (Lee, 2012) and dependency trees (Lee and Kong, 2012). They also explored the roles of a variety of named entities, e.g., seasons, direc-tions, and colors, in CTP (Lee and Wong, 2012), and used their analysis of CTP for teaching computational linguistics (Lee et al., 2013).
CTP can serve as the bases of other innova-tive applications. Zhao and his colleagues have created a website4 for suggesting couplets, which was accomplished partially based on their analysis of the CTP (Jiang and Zhou 2008; Zhou et al., 2009). Voigt and Jarafsky (2013) consid-ered CTP when they compared ancient and modern verses of China and Taiwan.
Our work is special in that we analyze the contents of CTP from some linguistic perspectives, including collocational analysis and distributional
4 http://couplet.msra.cn/ of Microsoft Research Asia
132
29th Pacific Asia Conference on Language, Information and Computation: Posters, pages 132 - 141 Shanghai, China, October 30 - November 1, 2015