基於MapReduce框架進行有效的天際線查詢處理 - 政大學術集成
41
0
0
全文
(2) 基於 MapReduce 框架進行有效的天際線查詢處理 Efficient Skyline Query Processing with MapReduce. 研 究 生:詹智渝. Student:Chih-Yu, Chan. 指導教授:陳良弼. Advisor:Arbee L.P. Chen. 立. 政 治 大. 國立政治大學. ‧ 國. 學. 資訊科學系 碩士論文. ‧ sit. y. Nat. A Thesis. io. er. submitted to Department of Computer Science. n. a. v. l C Chengchi University National ni. hengchi U. in partial fulfillment of the Requirements for the degree of Master in Computer Science. 中華民國一○二年十月 October 2013.
(3) 基於 MapReduce 框架進行有效的天際線查詢處理. 摘要 隨著人們對資料庫使用的需求增加,使用者對資料的查詢方法也越來越多樣,促 使近年來偏好查詢成為一個很熱門的研究議題。在所有的查詢中,Skyline 查詢更是在. 政 治 大 用的資料急劇增長,巨量資料的運算處理變成迫切的問題。藉由 Google 在 2004 年發 立. 現今資料庫以及資料檢索中熱門的研究題目。伴隨著科技的演進,人們可以收集和利. ‧ 國. 學. 表的一份開放文件中分享了 MapReduce 程式化運算框架,以往許多查詢在巨量資料環 境遇到的障礙都得到有效的解決方案。. ‧. Skyline 查詢是一件高時間複雜度的工作,面臨到巨量資料時的處理更是困難,因. sit. y. Nat. 此近年來對於 Skyline 在巨量資料查詢的研究也逐漸熱絡發展。本研究目的在於如何. io. al. er. 設計更有效的 MapReduce 演算法使得 Skyline 查詢處理能夠更有效進行,對此演算法. n. 進行詳細的說明,最後在 Hadoop 帄台上實作並驗證此演算法具有更佳的有效性及可 用性。. Ch. engchi. i. i n U. v.
(4) Efficient Skyline Query Processing with MapReduce. Abstract With the increasing number of querying methods, preference queries become a very popular research topic. Among all kinds of queries, skyline query is important in today's databases and information retrieval. Moreover, the development of technologies makes it. 政 治 大. possible to collect and utilize the rapid growth of data. Google in 2004 published an open. 立. document to share a computing framework named MapReduce, which makes big data. ‧ 國. 學. processing efficient.. Skyline query costs much in processing, and it becomes even more difficult when. ‧. facing a huge amount of data. In this study, we designed an efficient MapReduce algorithm. y. Nat. n. al. Ch. engchi. ii. er. io. the efficiency and effectiveness of this algorithm.. sit. for skyline queries. We also implemented the algorithm on the Hadoop platform to verify. i n U. v.
(5) 誌謝 研究所的環境使我培養了更嚴謹的態度,無論是在學識或眼界上都擴展了許 多。一路上有許多人給我許多支持與協助,才使得我可以達到今日的成果。首要感謝 指導教授陳良弼老師兩年多來指導,在我研究遇到困難時給予寶貴的意見,當我態度 鬆懈時適當的叮嚀,並且在生活上時常給予幫助和照顧,才能使我專心在研究的突破, 順利完成論文。同時要特別感謝柯佳伶老師 、李官陵老師對於本論文的指導與建議,. 政 治 大. 使得內容能更加完整而嚴謹。感謝邱淑怡學姐在學業及研究上的幫助,總能在迷網的. 立. 時候為我解惑。感謝同窗好友陳家慶的協助,每當有困難的時候能互相討論,彼此加. ‧ 國. 學. 油打氣,恭喜我們順利完成研究。感謝黃羿綺、江家榕、劉怡萱學妹們協助討論並提 供建議。特別感謝親愛的家人的支持與鼓勵,讓我永不放棄對知識的追求,並且能無. ‧. 後顧之憂的在研究上全力衝刺。最後感謝所有一路上給予幫助的師長們及同學朋友們,. Nat. sit. y. 拓展了我的視野、充實了我的知識、陶冶了我的性情,是你們成就了這篇論文,在此. n. al. er. io. 致上最真摯的感謝,謝謝你們!. Ch. engchi. iii. i n U. v.
(6) 章節目錄. 第 1 章 緒論 ........................................................................................................................................... 1 第 2 章 相關研究 ................................................................................................................................... 4 2.1 Skyline 演算法的相關研究 ......................................................................................................... 4 2.2 Skyline 在高度分散環境下查詢處理的相關研究..................................................................... 5. 政 治 大 2.4 適用於 MapReduce 框架的 Skyline 查詢的相關研究 ......................................................... 10 立. 2.3 MapReduce 框架 ........................................................................................................................ 8. ‧ 國. 學. 第 3 章 問題與定義 ............................................................................................................................. 12 3.1 問題 ............................................................................................................................................ 12. ‧. 3.2 直觀演算法 ................................................................................................................................ 13 3.3 問題定義 .................................................................................................................................... 16. y. Nat. io. sit. 第 4 章 資料分割及演算法介紹 ......................................................................................................... 18. n. al. er. 4.1 演算法概要 ................................................................................................................................ 18. Ch. i n U. v. 4.2 網格分割及篩選 ........................................................................................................................ 20. engchi. 4.3 角度分割及篩選 ........................................................................................................................ 22 4.4 兩種分割方法的效能分析 ........................................................................................................ 25 第 5 章 實驗與結果 ............................................................................................................................. 27 5.1 回應時間 .................................................................................................................................... 27 5.2 片段運算帄衡 ............................................................................................................................ 28 5.3 片段 Global Skyline 的貢獻比較............................................................................................. 29 第 6 章 結論 ......................................................................................................................................... 31 參考文獻 ............................................................................................................................................... 32. iv.
(7) 圖目錄 圖 1 PaDSkyline example(引自[13]) ................................................................. 6 圖 2 SkyPlan example(引自[14]) ....................................................................... 6 圖 3 資料在空間中分割的策略(引自[15]) ....................................................... 8 圖 4 MapReduce 運作流程(引自[1]) .............................................................. 9 圖 5 節流策略 skyline MapReduce(引自[4]) ................................................ 11 圖 圖 圖 圖 圖. 6 集合間的支配關係 ......................................................................................... 13 7 Dominate 名詞解釋 ...................................................................................... 14 8 直觀演算法框架 ............................................................................................. 15 9 找出對支配有貢獻的資料點 ......................................................................... 17 10 資料分割演算法框架 ................................................................................... 19. 立. 政 治 大. ‧ 國. ‧. 14 三維資料角度分割 ....................................................................................... 23 15 片段數目對 Reducer 運算的影響 ............................................................... 27 16 不同的分割策略對 Reducer 帄衡程度的影響 ........................................... 28 17 分割策略對 Global Skyline 貢獻的比率 .................................................... 29. n. al. er. io. sit. y. Nat. 圖 圖 圖 圖. 學. 圖 11 二維資料網格分割 ....................................................................................... 20 圖 12 三維資料網格分割 ....................................................................................... 21 圖 13 二維資料角度分割 ....................................................................................... 22. Ch. engchi. v. i n U. v.
(8) 表目錄 表 1 二手車市場車子資料 ....................................................................................... 1. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vi. i n U. v.
(9) 第1章 緒論 為了提供更貼近查詢者需求的資料,近年來偏好查詢成為一項熱門的研究議題。在所 有的偏好查詢中,Skyline 查詢更是現今資料庫以及資料檢索中一項熱門研究的題目, 它被廣泛應用於多目標決策以及資料視覺化等領域。Skyline 查詢的目標在於從給定的 資料群集中,根據查詢者所在乎的欄位,找出一群不會被自己以外的資料點給支配的 對象。如果一筆資料 A 在查詢欄位的所有欄位值都不劣於另一筆資料 B,我們就會說 資料 A 支配了資料 B。. 立. 政 治 大. 舉二手車市場為例,假如有個買家希望在二手車市場購買到一輛車,他期望能買. ‧ 國. 學. 到的二手車的價格越低越好,而且車子的出廠年分也越新越好。那麼我們便對二手車 的資料表對買家所偏好的欄位作投影(如表 1) ,之後對表 1 進行 Skyline 查詢。那我. ‧. 們就會發現買家所偏好的車子應該在 C1,C2,C5 這三台車子之中,因為 C3,C4,C6 在買. Nat. sit. y. 家偏好的欄位下並沒有優勢。具體來說買家不會特意去挑 C6 的車子,因為 C5 這台車. n. al. er. io. 子擁有比 C6 更便宜的價格而且有更新的車齡,我們就會說車子 C5 支配了車子 C6。. i n U. v. 所以給予買家 C1,C2,C5 這樣的推薦集合有助於買家找到他心目中偏好的車子,因為那. Ch. engchi. 些車子不會被自己以外的車子給支配,所以我們就稱這三筆資料是一組 Skyline 集。. 表 1 二手車市場車子資料 1.
(10) 隨著網際網路和通訊技術的發展,帄均每個人在社群網絡中每月約可產生 1GB 的 資料量。除了個人之外,機器設備所產生的日誌檔、感應器網路、零售業交易資訊等, 都會產生巨量的資料。因此人們可以收集和利用的資料量急劇增長。依據國際數據資 訊(IDC)預估 2006 年世界總資料量約有 0.18ZB,預測 2011 年會成長 10 倍至 1.8ZB(相 當於 10 億 TB),對於這樣巨量資料的運算處理變成一項迫切待解決的問題。. 政 治 大. 跨電腦的叢集式分散運算在學術研究的發展已經行之有年,大部分的架構都非常. 立. 適合密集計算的工作,但是當運算節點需要存取大量資料的時候會使得網路頻寬造成. ‧ 國. 學. 瓶頸。因為大部分的叢集分散式運算的演算法設計都將資料運算與資料存取隔開,儘 管在資料運算得到有效的解決方案,但在存取同一個檔案系統時會發生問題。Google. ‧. 在 2003 年對於資料存取的問題提出了有效的方法,2004 年發表了一篇論文[1]介紹. Nat. sit. y. MapReduce 程式化帄行運算框架的論文。這個框架之所以優於過去叢集分散式運算的. n. al. er. io. 原因在於它嘗詴將運算節點和資料放在一起,因為資料在本機的存取會比較迅速,資. i n U. v. 料本地化的概念便是 MapReduce 主要的核心技術,同時也是它具有高效能的原因。. Ch. engchi. MapReduce 是一個解決巨量資料處理時相當重要的程式化框架,主要原因在於它具有 良好的擴展性和容錯性,能夠滿足資料量快速成長的需要,因此對於如何設計一套適 用於 MapReduce 框架的演算法,近年來在學術研究上成為一項重要的議題。 Borzsonyi 等人[2]在 2001 年將 Skyline 查詢導入資料庫查詢之中,許多資料庫領 域的學者們後續探討 Skyline 查詢的問題,並且發表了許多 Skyline 的相關研究成果。 雖然現有的研究成果可以解決許多實際上的問題,但許多演算法在面臨巨量資料的環 境下就會發生運算的瓶頸,所以發展出適用於巨量資料 Skyline 查詢的演算法有其必 要性。本研究著眼於設計 MapReduce 演算法使得 Skyline 查詢處理能夠更有效進行, 並且對這樣的演算法提出可行性的驗證。 2.
(11) Zhang 等人在 2011 年發表了[3],它是第一篇發表適用於 MapReduce 框架下進行 Skyline 查詢處理的演算法。2012 年 DING 等人[4]參考了[3]修改部分演算方法使得原有的 I/O 問題得到了舒緩的方法。儘管舒緩在處理過程中所遇到的 I/O 問題,然而對於[3]在 I/O 上最根本的問題並沒有提供解決方案。因此本研究的目標如下:(1)克服[3]在運算上會 遇到的 I/O 問題,而不是舒緩 I/O 所帶來的限制。(2)化簡它過程中比較高時間複雜度 的演算法,加速處理資料的效率。(3)使得運算單元在帄行運算的過程中達到負載帄 衡。. 政 治 大. 本文第二章會介紹相關研究;第三章提出問題定義,其中會說明本研究著眼解決. 立. 的問題;第四章說明本研究的演算法介紹;第五章節說明從實驗結果實證演算法的效. ‧ 國. 學. 能;第六章總結本研究的成果。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 3. i n U. v.
(12) 第2章 相關研究 這一章節會介紹與本研究相關的知識以及文獻。首先介紹 Skyline 查詢相關研究; 接下來敘述 Google 在 2004 年發表的 MapReduce 框架;第三部分會描述適用於 MapReduce 框架下進行 Skyline 查詢處理演算法的發展。. 2.1 Skyline 演算法的相關研究. 政 治 大 BNL(Block Nested Loop)演算法,首次將 Skyline 查詢語言導入了資料庫查詢之中,許 立. 因為偏好查詢的發展,使得 Skyline 查詢的價值逐漸提升,在 2001 年[2]中提到. ‧ 國. 學. 多資料庫領域的研究專家們開始熱衷解決 Skyline 查詢的問題。 [5]介紹了對原始資料 事先依照欄位數值大小作排序的作法,這樣的作法使得擁有優勢數值的資料可以提早. ‧. 支配掉不可能成為 Skyline 查詢結果的資料點,減少尋訪資料的數目。之後作者又發. sit. y. Nat. 表了針對[5]的方法使運算能以最佳化方式處理[6],使得後續 Skyline 相關演算法都會. io. er. 從對資料事先作排序去設計。後續還有許多演算法被發表,如[7]中 LESS(Linear. al. v i n Ch limit Skyline algorithm)又更改[7]的演算策略,使得 e n g c h i USalSa 對原始資料作排序的策略上 n. Elimination Sort for Skyline)使得排序的過程不用尋訪每個資料點,[8]中 SalSa(Sort and. 達到最好的效率。 除了排序之外,對原始資料事先作索引來加速未來查詢時的效率也是個理想的作 法。過去對資料索引的策略很多,適用於 Skyline 查詢方法也很多。樹狀索引是很不 錯的策略,[9]對於原始資料用 R-tree 索引來找尋資料。後續研究 BBS(Branch and Bound Skyline)發表在[10]避免了一些在 R-tree 中多餘的尋訪目標,[11]使得 R-tree 尋訪達到 最小的 I/O 代價,[12]則觀察資料在資料空間的分布,使得 R-tree 結構最佳化。. 4.
(13) 2.2 Skyline 在高度分散環境下查詢處理的相關研究 Skyline 在高度分散式環境進行查詢的問題可以分為兩種議題:第一種議題是在各 式各樣的查詢環境下如何針對某種環境設計它的查詢處理,這樣的環境可能是 P2P(Peer-to-Peer)環境亦或者是有著主從式架構的環境,甚至是混合前述兩種的模型 都有可能。然而不同的環境就會有不同的限制,如果將適性於 P2P 環境的演算法套用 至主從式架構的環境就會有不合用的情況發生,或者必頇對原有的演算法做大幅度的 修改,所以研究上的題目通常會針對某種環境下造成的限制去設計 Skyline 查詢處理. 治 政 演算法。第二種議題考慮的方式是如何將大量的資料存放到準備好的環境之中,而且 大 立 期待那樣的存放方式有助於未來在進行查詢處理時能對效能上有所幫助。這樣的設計 ‧ 國. 學. 重點就在於去觀察 Skyline 查詢處理資料時的特性,針對那樣的特性去分割大量資料,. 2.2.1. ‧. 使得查詢的過程能達到負載帄衡或者是減少尋訪資料等優點。. 不同查詢環境下的處理. y. Nat. io. sit. 一般來說,在研究不同環境下設計 Skyline 演算法上,現有的文獻已經相當的豐. n. al. er. 富。在分散式環境下進行一個查詢的處理大致可分為三種面向:第一種面向是本地端查. Ch. i n U. v. 詢處理(Local Processing),第二種是查詢尋訪路徑(Query Routing),第三種式查詢結. engchi. 果合併(Result Merging),所以有效的處理這三種面向便能對查詢的過程有所幫助。 PaDSkyline(Parallel Distributed Skyline query processing)[13]是一篇有效在 P2P 環境處理 Skyline 查詢的研究,它的內容是當某一個 Peer 收到 Skyline 查詢請求時, 會廣播查詢請求給 P2P 環境內的每一個 Peer 給知道,每一個收到查詢請求的 Peer 開 始對自己所擁有的資料片段去規畫出 MBR(Minimum Bounding Regions),如圖 1,並 將自己的 MBR 資訊回傳給第一個收到查詢的 Peer 知道。接著這個 Peer 依據其他 Peer 回傳的 MBR 資訊去演算出最有效的查詢尋訪路徑,進而使 Skyline 查詢處理的過程中 達到減少巡訪所有 Peers 所要付出的代價。SkyPlan[14]是繼 PaDSkyline 之後的研究,. 5.
(14) 他們的演算法十分的相似。SkyPlan 同樣的藉由 MBR 的資訊來達到減少巡訪 Peers 的 代價,然而 PaDSkyline 在規劃有效查詢尋訪路徑的方法相當地消耗時間,SkyPlan 用 了有向權重圖,如圖 2 右,規劃最小展開樹(Minimum Cost Spanning Tree)用來快速 的找出查詢尋訪路徑。. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. n. al. er. io. 圖 1 PaDSkyline example(引自[13]). Ch. engchi. i n U. v. 圖 2 SkyPlan example(引自[14]). 6.
(15) 2.2.2. 大量資料的分割. 初步了解查詢環境的限制之後,如何設計一個對原始資料的分割是相當重要的議 題,因為好的分割對於查詢處理的過程能減少尋訪不必要的資料,進而加速查詢的目 的。一種相較隨機分割優異的方法是網格分割(Grid Partition),方法簡單來說就是對 於每個維度依據它的值域(domain)進行等距分割,座標空間就會被分割成許多子空間. 政 治 大. 網格,而每個資料點就會坐落到唯一的網格之內,之後再將每一個網格分配給一個. 立. Peer 去管理。這樣的分割方式非常直觀而且迅速,然而對 Skyline 查詢處理上的幫助. ‧ 國. 學. 十分有限。圖 3 右是一個二維網格分割的範例,對資料空間分割成四個部分。從 Skyline 查詢的觀點來看,我們可以發現存在於左下的網格內的資料點都可以支配右上的網格. ‧. 內的資料點,這樣每個資料片段對全局 Skyline 查詢結果的貢獻就不一致,所以這樣. Nat. sit. y. 的分割方法並不是最理想的。. n. al. er. io. 為了 Skyline 查詢所需,比較理想的資料分割方式應該要有幾個明確的指標: (1). i n U. v. 分割後資料片段內的資料筆數應該要大致等量(2)資料片段經過本地端查詢的結果資. Ch. engchi. 料筆數應該要大致等量(3)每個資料片段對全局查詢結果的貢獻應該要大致等量。所以 [15]提出了依據資料空間角度的方式去分割原始資料,如圖 3 左。帄面空間我們可以 從直角分割更小的角度,在三維以上的空間中,每兩兩個維度所形成的帄面空間我們 也可以分割出更小的角度。Angle-base 的方法我們可以觀察到相較 Grid-base 的方法 有更好的查詢效果,因為這樣每個資料片段對於全局查詢結果的貢獻大致等量,這樣 的方法就有助於每個運算單元在運算負載上的帄衡。. 7.
(16) 政 治 大. 圖 3 資料在空間中分割的策略(引自[15]). 立. 然而這樣的資料分割需要反覆地針對兩兩維度的帄面做三角函數的運算,才能明. ‧ 國. 學. 確的指出資料在該帄面應該被歸類的分割,這樣繁複的運算會額外消耗很多的時間。 [16]提出了相似於 Angle-base 的資料分割方法,他化簡過去對兩兩帄面的算角度分割. ‧. 的方式,而將每個資料投影到一個高維帄面空間上,進而得到近似[15]的分割方式。. Nat. io. sit. y. 這樣的做法加速了分割的過程,而分割的結果也擁有[15]的優勢點。. er. 2.3 MapReduce 框架. al. n. v i n Ch MapReduce 是設計來處理海量資料運算的可程式化框架,使用這個框架的人員必 engchi U. 頇設計演算法來管理運算工作能在多電腦間帄行化執行,所以一個好的演算法設計可 以有效加速查詢處理需要的時間。MapReduce 的概念不會很複雜,參考圖 4,在這樣 的框架運算工作被分割成兩種任務,分別為 Mapper 任務以及 Reducer 任務:Mapper 任務會將海量資料從分散式檔案系統帄行地匯入,匯入的資料經過處理後會被分類蒐 集起來,並有秩序的依據分類類別存放在本地端的硬碟中。Reducer 任務被啟動之後 會被分配到一個分類類別,Reducer 任務只搜集被歸類到那個類別的資料,所以 Reducer 任務會詢問所有啟動過 Mapper 任務的機器是否存在分類出他負責的資料, 如果存在則從 Mapper 任務的機器的硬碟複製資料到 Reducer 任務的機器,Reducer 8.
(17) 任務就開始處理這些資料的運算,運算完將結果傳回分散式檔案系統之中。 對於適性於 MapReduce 框架的演算法要去評斷優劣有幾個指標可以觀察:第一個 指標是 Map 到 Reduce 之間的網路傳輸量,在任何分散式環境下的計算中,網路傳輸 的頻寬是很重要的資源之一,他所影響整體運算時間的幅度遠比硬碟存取還要來的大, 所以演算法對網路的傳輸的依賴越少越是理想。第二點是 Mapper 任務及 Reducer 任 務分別執行的時間,因為這是整體 MapReduce 重要的運算部分,設計的演算法如果能 有效的降低任務處理的時間,對整個查詢的回應時間就會有幫助。第三點就是整體的. 政 治 大. 回應時間,我們真正在乎的是一個執行工作從開始到結束所需要的時間代價,這對於. 立. 執行工作品質是很重要的因素。這三點是在後續方法會提到如何有效在這三個指標優. ‧ 國. 學. 化處理,同時這也是我的實驗會觀察著重的部分。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4 MapReduce 運作流程(引自[1]). 9.
(18) 2.4適用於 MapReduce 框架的 Skyline 查詢的相關研究 第一篇發表適用於 MapReduce 框架下進行 Skyline 查詢處理的演算法是[3],每個 Mapper 任務接收到資料後各自進行本地端的 Skyline 查詢處理。之後再由一台 Reducer 任務匯整所有 Mapper 任務的本地端 Skyline 查詢結果,對這些查詢結果再進行第二階 段的 Skyline 查詢處理來得到全域的查詢結果。這樣的做法存在一些缺點,如果資料 的片段眾多以至於啟動許多 Mapper 任務,這樣的結果會導致 Reducer 任務會接收到眾. 政 治 大. 多的本地端查詢結果而造成運算上的瓶頸,並且每個 Mapper 的本地端結果存在全域. 立. 結果資料的密度也會降低。. ‧ 國. 學. 因此[4]提出了一個紓緩[3]中 Reducer 任務負擔加重而造成運算上的瓶頸。[4]的演 算法框架對於本地端查詢結果做一個流量的控管,做法是每一個 Mapper 任務在將資. ‧. 料傳給 Reducer 任務之前必頇要經過一層過濾,達到預知從本地端結果中刪除不可能. sit. y. Nat. 成為全域結果的資料點。然而要產生用以過濾的資料點必頇要額外佈署儲存空間及額. io. er. 外運算工作,每個 Mapper 任務輸出資料前都必頇傳遞資料給額外運算單元,並等待. al. 此額外運算工作結束如此一來便會產生新的運算瓶頸,整體回應時間也會受限在此運. n. v i n Ch 算工作的效率。在分散運算的觀點來看,並無法真正有效的帄行處理,因此設計一新 engchi U 穎的實質帄行運算演算法有其必要性。. 10.
(19) 立. 政 治 大. ‧ 國. 學 ‧. 圖 5 節流策略 skyline MapReduce(引自[4]). n. er. io. sit. y. Nat. al. Ch. engchi. 11. i n U. v.
(20) 第3章 問題與定義 參考過去很多應用 MapReduce 框架所做的查詢演算法,有許多演算法因為本身查 詢的限制而導致 Reducer 任務無法有效的帄行處理,往往這些演算法在巨量的資料情 況都會面臨到運算上的瓶頸。本論文目的在於解決 Skyline 查詢應用 MapReduce 框架 產生的運算瓶頸,使得查詢處理能達到實質上的帄行運算。. 政 治 大 先介紹一些在進行巨量 Skyline 查詢時會使用的基本符號,D表示為 d 個維度的集 立 3.1 問題. ‧ 國. 學. 合,i.e., D = *d1 , … , dd +,每個維度上的值域都是非負的實數,dom(D)表示為D集合 中的維度構成的值域空間。在D中我們可以取部分維度成為更小的子集D’,dom(D’)表. ‧. 示為以D’所成的值域空間。因為D’ ⊆ D,所以dom(D’)是dom(D)子空間。T 表示為 n. io. er. 為(τ. d1 , τ. d2 , … , τ. dd ),且∀i ∈ ,1, d- ∶ τ. di ∈ dom(di )。. sit. y. Nat. 筆資料存在於 d 維空間中的集合, T ⊆ dom(D)。T 中資料點τ擁有 d 個維度數值分別. al. 由於龐大的資料筆數會增加運算時間成本,為了能有效的減少查詢處理的回應時間,. n. v i n Ch 會將原始資料分割成 p 個片段,表示為*P i U ∈ ,1, p- ∶ Pi ⊆ T。過去許多適用 e n g1, .c. , Php+且∀i 於 MapReduce 框架的 Skyline 查詢處理如圖 5 所示,將 p 個片段*P1, . . , Pp +分別交由 p. 個 Mapper 運算單元,每個 Mapper 運算單元對所得的片段Pi進行 Skyline 演算法運算得 到本地端天際線(Local Skyline),再將各自的集合傳送給一個 Reducer 運算單元進行 Skyline 演算法運算得到全域天際線 (Global Skyline)結果。 儘管在 Mapper 階段達到運算帄行,最後卻經由一個運算單元來處理。為了帄行 更多 Mapper 運算而分割更多資料片段會增加 Reducer 運算的負擔,並且隨著資料相依 性增加會使得 Local Skyline 資料數目增加,也會增加 Reducer 收集資料點的數量,單 一的 Reducer 運算勢必使回應時間增加。 12.
(21) 3.2 直觀演算法 先介紹一些為了使 Skyline 查詢在 MapReduce 框架實質的帄行處理,這個小節會介紹 一項新穎的演算法。這個演算法會將單一 Reducer 運算工作分擔給多運算單元進行, 避免運算受到單一運算單元的限制,拉長查詢的回應時間。在介紹演算法之前,為了 方便後續的說明,我們訂一些符號表示。另外假設數值越小越好。. 1.. 2.. 立. (2)存在一個維度. 1. ∈ ,. ,則稱τ1 支配τ2 ,符號記作. 2. 學. τ2 τ1 。 . 政 治 大 ∈ ,使得 . .. 支配(Dominate):令 τ1,τ2 為兩個資料點,如果:(1)在任何維度. ‧ 國. 定義一. 定義二 被支配點集合(Dominated Set):令 P,Q 為資料點集合,P 的資料點可能支配部. 𝑎. 𝑏. ,. 𝑏. ∈ 𝑃} ,如圖 6 中所示. y. ∈𝑄 . n. er. io. 𝑆𝑃 (𝑄) = *𝑞1、𝑞2、𝑞3+。. al. 𝑎. sit. 𝑆𝑃 (𝑄) = { 𝑎 |. Nat. Dominated Set 表示為. ‧. 分 Q 的資料點,被支配點集合為在 Q 中被 P 所支配的資料點的集合。P 對於 Q 的. Ch. i n U. v. 由此知道DSP (Q)是 Q 的子集合,另外 P 則稱為 Dominator Set;Q 稱為 Dominatee. engchi. Set。不被 Dominator Set P 所支配的 Q 中資料點即 Q 與DSP (Q)的差集,稱作 Undominated Set。. 圖 6 集合間的支配關係 13.
(22) 立. 政 治 大 圖 7 Dominate 名詞解釋. ‧ 國. 學 ‧. DST (T)表示 T 在資料空間中會被支配的資料點所成的集合,同時也是在 T 中不是 Skyline 的資料點所成的集合。換句話說,資料空間中所有資料點 T 與被 T 支配的資. y. Nat. io. sit. 料點所成的集合的差集,便成為 T 中不被任何資料點支配的集合,同時也就是其. n. al. er. Skyline,表示為T − DST (T) = SKY(T). Ch. i n U. v. 假設一個巨量資料集合為了帄行的運算效率將原始資料 T 分割成 p 個片段,表示 為*P1 , . . , Pp +,這裡提出一個引理:. engchi. Lemma 1 將資料 T 分割成 p 個片段,分別取其 Local Skyline 並聯集起來去支配資 料片段 Pi 會得到一個 Dominated Set,此 Dominated Set 會與以資料 T 去支配資料片段 Pi 的 Dominated Set 相等。也就是 DS⋃p. j=1 Sky(Pj ). (Pi ) = DST (Pi )。. 這樣我們可以設計直觀演算法,將一個 Mapper 的 Local Skyline 送去一個 Reducer 處理,而這個 Reducer 也收集來自其他 Mapper 的 Local Skyline,這樣就可以達到多 Reducer 帄行處理。因為一組本地端結果經過所有 Local Skyline 給檢查支配後,移除 被任一 Local Skyline 支配的資料點,剩下的 Local Skyline 就是 Global Skyline 其中一 14.
(23) 個片段。收集所有這樣的 Global Skyline 片段所成的集合便是所有全域 Skyline 的查詢 結果,不用再額外進行全域 Skyline 運算。 直觀演算法達到幾個好處:第一個好處就是在 Reducer 任務不再進行 Skyline 運算, 而只進行用所有 Local Skyline 查詢結果去檢查支配。因為檢查支配運算的時間複雜度 相較 Skyline 運算低很多,所以降低單一 Reducer 任務處理的時間。第二個好處為將一 個 Skyline 運算轉換成多個檢查支配運算,並將多個檢查支配運算分配給眾多 Reducer 任務去處理。因此達到多 Reducer 任務帄行處理,化解了在資料量龐大時單一 Reducer. 政 治 大. 任務處理的瓶頸。綜合以上兩個優點,可以有效的加速查詢處理的回應時間。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 8 直觀演算法框架. 15. v.
(24) 3.3 問題定義 直觀演算法可以達到許多好處,然而卻必頇付出額外的代價。這個代價就是增加 Map 到 Reduce 之間的網路傳輸量。這個演算法額外負擔在於需要傳輸所有 Mapper 任 務的 Local Skyline 資料點數目,而且 Local Skyline 必頇一對多的傳遞複製給每個 Reducer 任務知道。額外的負擔約為: (Mapper 任務總數). 政 治 大. × (Mapper 任務的 Local Skyline 資料點數目). 立. × (Reduce 任務總數). ‧ 國. 學. Mapper 任務總數決定於資料分割的數量,Reducer 任務總數與 Mapper 任務數目 相等,因此 Mapper 任務總數及 Reducer 任務總數在演算法設計是無法控制及預期的。. ‧. 因此只能從減少 Mapper 任務的 Local Skyline 資料點數目來嘗詴降低對網路的負擔。. sit. y. Nat. 在直觀演算法中以 Local Skyline 作為 Dominator Set 來傳送到每個 Reducer 收集。. io. er. 在圖 9 中顯示為一 Reducer 收集的資料集合,黃色集合 Y 的資料點作為 Dominatee Set,. al. 而其餘顏色(紅、綠、藍)的資料點為來自其他 Mapper 傳送來的 Local Skyline。我們從. n. v i n C h的資料點並非都對於支配 圖中可以發現作為 Dominator Set Dominatee Set 有貢獻,如 engchi U. 果可以事先將這些點在 Mapper 送出 Dominator Set 之前將他們從中移除掉,我們便可 以有效地降低對網路傳輸造成的負擔。在介紹找出沒貢獻點的方法之前先介紹一個定 義: 定義三 被支配點空間(Dominated Region):令 P,Q 為資料點集合,在 Q 所分佈的範圍 空間中存在一個子空間,存在於這子空間的資料點都會被 P 的部分資料所支配,這樣 的子空間稱做被支配點空間。我們將 P 對於 Q 的 Dominated Region 表示為 DR P (Q)。 如圖 6 中所示應為綠色外框所圍成的區域。 參考圖 9 中,B2 的橫軸數值超過 Y 中最大數值的資料點,所以 B2 無法在 Y 資 16.
(25) 料集中形成 Dominated Region。R1 及 R2 在 Y 資料集中都能形成 Dominated Region, 可以觀察出DR *R1+ (Y) ⊆ DR *R2+ (Y),所以 R2 比 R1 能在 Y 中支配更多資料點,以 R2 代替 R1 將 R1 移除掉並不會使得在 Y 中有資料點被 R1 支配卻不會被 R2 支配。同理, DR *G4+ (Y)大的足以包含DR *R3、R4、…、B3+ (Y),以 G4 代替這些點傳遞並不會使得 Y 中 有資料沒有被支配。因此在所有送至 Y 集合的 Dominator Set 而言,真正對 Y 集合有 支配貢獻的資料點只有{G4、B1}。 所以如果可以事先知道哪些資料對檢查支配是沒有貢獻的,那就可以事先將他們. 治 政 從 Dominator Set 移除掉以降低網路傳輸的負擔。然而片段與片段之間是採用隨機分割 大 立 的方式,很難直接從資料分群的關係找出沒有貢獻的資料。因此本研究採取幾種資料 ‧ 國. 學. 分割的方式,提出從分割策略的設計找出片段之間互相支配的特性,並且互相比較不. ‧. 同分割策略之間網路的負擔程度以及演算執行的回應時間。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 9 找出對支配有貢獻的資料點. 17.
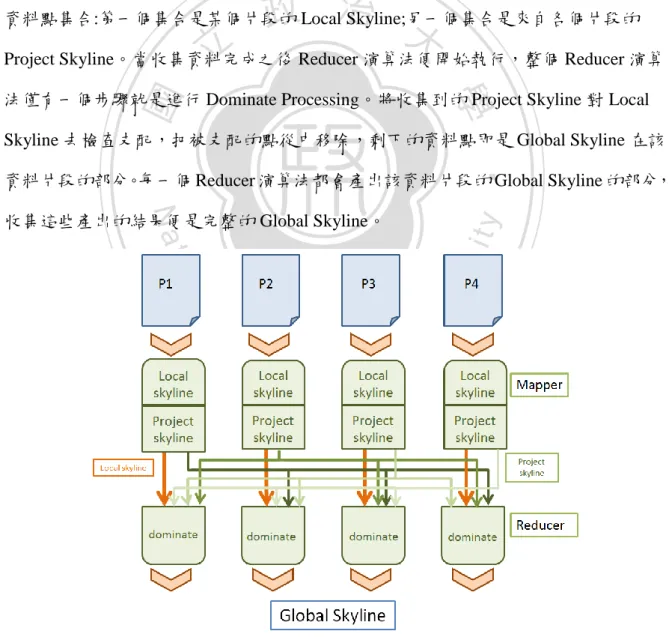
(26) 第4章 資料分割及演算法介紹 接下來的章節會從網格分割以及角度分割兩個策略來探討,在不同的資料分割策 略下,是否可以事先移除掉對支配其他片段沒有貢獻的資料點,以減少網路傳輸的負 擔。我們對不同的資料分割策略分別提出演算法,並分析兩種演算法不同的優劣。. 4.1 演算法概要. 政 治 大 定義四 投影天際線(Project Skyline):若 S 為一分布在 D 維空間的 Skyline 資料點集合, 立. 這個小節會介紹演算法的框架,但在介紹演算法之前先介紹一個名詞:. ‧ 國. 學. 其中D = *d1 , … , dd +,在D中可以再取某些維度形成D的子集D’。我們可以將 S 投影到D’ 所形成的子空間,再從D’的維度中進行 Skyline 計算得到 S’,S’即是 S 在D’的投影天際. ‧. 線,表示為SKYD’ (S)。. sit. y. Nat. 舉一個例子來說明,若資料空間中存有{(8 ,2 ,3)、(4 ,5 ,7)、(5 ,3 ,9)、(7 ,5 ,3)}四. io. er. 筆資料,這四筆資料無法支配彼此,所以這四筆資料在三維空間中是 Skyline。若將此. al. 集合投影到{X,Y}帄面上的投影天際線集合為:{(8 ,2 ,3)、(4 ,5 ,7)、(5 ,3 ,9)},因為. n. v i n (7 ,5 ,3)在{X,Y}帄面上會被(5C,3h ,9)給支配,而投影到{Y,Z}帄面上的投影天際線為 engchi U {(8 ,2 ,3)},因為該資料點可以支配其他三筆資料。所以 SKY*X,Y+ (S) = *(8 ,2 ,3)、(4 ,5 ,7)、(5 ,3 ,9)+;SKY*Y,Z+ (S) = *(8 ,2 ,3)+。 MapReduce 框架下設計的演算法分為兩個階段,分別為 Mapper 以及 Reducer 演 算法,完整的演算法框架如圖 10 所示。當原始資料被分割成許多資料片段之後,每 一個片段會分別交由一個 Mapper 演算法進行處理,一個 Mapper 演算法會交由一個運 算單元執行。 網格分割以及角度分割策略的 Mapper 演算法分為兩個步驟:第一個步驟是 Local Skyline Processing,在這個步驟進行從分配到的資料片段找出 Local Skyline。在直觀演 18.
(27) 算法中,會將 Local Skyline 作為 Dominator Set 傳送到每個 Reducer,所以直觀演算法 在第一步驟完成後就會結束 Mapper 演算法。 第二個步驟是 Project Skyline Processing,因為以 Local Skyline 作為 Dominator Set 會造成網路的負擔,這個階段的任務在於從得到的 Local Skyline 中找出對支配其他片 段最有幫助的資料點,減少網路上傳輸的資料數目。之後會說明如何利用 Project Skyline 來找出需要的資料點。這個步驟完成後就結束 Mapper 演算法部分。 當每個 Mapper 演算法完成之後, 每個 Reducer 演算法在執行前都應該收集兩個. 政 治 大. 資料點集合:第一個集合是某個片段的 Local Skyline;另一個集合是來自各個片段的. 立. Project Skyline。當收集資料完成之後 Reducer 演算法便開始執行,整個 Reducer 演算. ‧ 國. 學. 法僅有一個步驟就是進行 Dominate Processing。將收集到的 Project Skyline 對 Local Skyline 去檢查支配,把被支配的點從中移除,剩下的資料點即是 Global Skyline 在該. ‧. 資料片段的部分。每一個 Reducer 演算法都會產出該資料片段的 Global Skyline 的部分,. Nat. n. al. er. io. sit. y. 收集這些產出的結果便是完整的 Global Skyline。. Ch. engchi. i n U. 圖 10 資料分割演算法框架 19. v.
(28) 4.2 網格分割及篩選. 立. 政 治 大 圖 11 二維資料網格分割. ‧ 國. 學. 這個小節會介紹網格分割的方法以及如何決定片段間應該傳遞的資料點數目。在 3.1 問題中提到資料的型態,每個資料有 d 個維度,而每個維度都有各自的值域空間。. ‧. 隨著不同的需要我們在每個值域空間中依據不同的值域切分成數個子空間,換句話說,. sit. y. Nat. 如果dom(X) = ,0,1000-,那我們希望在這個值域空間均分成三個子空間,分別為. er. io. dom1/3 (X) = ,0,333-、dom2/3 (X) = ,333,666-、dom3/3 (X) = ,666,1000在原始資料中某一筆資料τ在 X 維度上的數值落在,333,666-中,則τ. X ∈ dom2/3 (X)。. n. al. i n C τ在不同的維度空間上有不同的投影子空間分別為: hengchi U. v. *domnd1 /Nd1 (d1 ), … , domndd /Ndd (dd )+,其中Ndi 表示在di 空間分割的片段數目,ndi 表示 在Ndi 個片段數目中所屬的第幾個片段。則τ在被網格分割後的 D 維空間中是落在 *nd1 , nd2 , … , ndd +的子空間,原始資料中每一個資料都依據不同維度的投影會坐落到唯 一的子空間。因此我們就可以將所有的資料點分割成數個片段,每一個片段正好是一 個在 D 維空間中的子空間,我們以*nd1 , nd2 , … , ndd +來識別該資料片段。如果將二維的 資料集分割成四個子空間,分割的結果及識別就如同圖 11 所示。 圖 12 中所示為三維空間的資料集合,在兩個維度的值域上分割成兩個片段,使 得三維空間分割成四個子空間,每個子空間都有數目不等的原始資料。為了加以識別 20.
(29) 片段,分別替每個片段標上識別碼,如圖中所示,P1片段以{1,1,1}識別;P3片段以{1,2,1} 識別。. 立. 政 治 大 圖 12 三維資料網格分割. ‧ 國. 學. 到目前為止我們了解了網格分割片段及標示他們的方法,接下來我們來探討他們 之間如何互相傳遞作為 Dominator Set 的資料點。回到圖 12,詴著觀察P1{1,1,1}及. ‧. P2{2,1,1}之間的關係,發現構成P1對P2的 Dominated Region 所需的最小 Dominator Set. sit. y. Nat. 就是P1的 Local Skyline 進行第二及第三兩個維度的 Project Skyline。P3{1,2,1}及P2{2,1,1}. io. er. 各自都有較優勢的維度數值,因此彼此之間資料不能互相支配,所以P3及P2之間不用. al. 互相傳遞資料。片段之間要互相傳遞前會得知彼此的識別,舉兩個片段來說明,片段P[. n. v i n Ch 及片段P\ 。這兩個片段分別存在於不同的子空間,我們分成兩種情況來討論: engchi U Case1:. 兩個片段間若(1)不存在任何維度 di ∈ D,P[ . ndi > 𝑃\ . ndi 且(2)存在一個以上維度 集合D′ ⊆ D, dj ∈ D′使得P[ . ndj. 𝑃\ . ndj ,則P[ 需要向P\ 傳遞的 Dominator Set 為. SKYD−D′ (SKY(P[ )),且P\ 無頇向P[ 傳遞任何 Dominator Set。 Case2: 兩個片段間若(1)存在一個以上維度集合D" ⊆ D, di ∈ D",使得P[ . ndi > 𝑃\ . ndi 且(2)存在一個以上維度集合D′ ⊆ D, dj ∈ D′使得P[ . ndj 遞任何 Dominator Set。 21. 𝑃\ . ndj ,則P\ 之間P[ 無頇傳.
(30) 4.3 角度分割及篩選. 政 治 大. 立 圖 13 二維資料角度分割. ‧ 國. 學. 前一個小節我們提出網格分割的篩選方法,這個小節要介紹如何對 d 維空間資料 做角度分割成數個片段,並替每個片段都標上識別。在 d 維空間中每一個座標點τ皆可. ‧. 以與原點決定出空間向量τ. v ⃑ = *v ⃑⃑⃑⃑⃑⃑ ⃑⃑⃑⃑⃑⃑ ⃑⃑⃑⃑⃑⃑ d1 , v d2 , … , v dd +,這個向量在dd−1 維空間上可產生投 2 √v2d1 +v2d2 +⋯+vd(d−1). y. Nat. −1. io. sit. 影向量,投影向量與原始向量間可以產生一夾角∅d−1 = tan (. vdd. )。可. n. al. er. 以用相同的方法來將原始向量τ. v ⃑ 與所有維度空間的投影夾角全部找出來,分別為. Ch. i n U. v. *∅d−1 , ∅d−2 , … , ∅1 +等 d-1 個角度。每個維度之間的夾角為π/2,在[0, π/2]之間可以決. engchi. 定分割成數個夾角,如在dd 與dd−1維之間的角度π/2分割成三等分,分別為 π. π 2π. 1/3θd−1 = [0, 6 ] 、2/3θd−1 = [ 6 ,. 6. 2π π. π 2π. ] 、3/3θd−1 = [ 6 , 2 ]。若τ的∅d−1 屬於[ 6 ,. 6. ],則以. 2/3θd−1表示τ在dd−1 維空間中以角度分割後的片段。τ在其他維度間都可以產不同的角 n. n. n. 度,分別坐落在不同的子空間*Nd−1 θd−1 , Nd−2 θd−2 , … , N1 θ1 +,其中Ni 表示在di+1 與di 間 d−1. d−2. 1. 角度分割的片段數目,ni 表示在Ni 個片段數目中所屬的第幾段片段。以 *nd−1 , nd−2 , … , n1 +來識別τ所存在的資料片段。. 22.
(31) 立. 政 治 大 圖 14 三維資料角度分割. ‧ 國. 學. 𝜋. 圖 13 中所示為二維空間的資料集合,在 X 及 Y 維度構成的夾角上依 6 分割成三個子 空間,每個子空間都有不等數目的原始資料。為了加以識別片段,分別. ‧. 替每個片段標上識別碼,如圖中所示,P1片段以{1}識別;P3片段以{3}識別。圖 14. y. Nat. π. er. io. sit. 中所示為三維空間的資料集合,在 X 及 Y 維度構成的夾角上依 4 分割成兩個子空間,. al. 再從 Z 軸及 XY 帄面構成的夾角再分割,使得三維空間分割成四個子空間,每個子空. n. v i n Ch 間都有不等數目的原始資料。為了加以識別片段,分別替每個片段標上識別碼,如圖 engchi U 中所示,P1片段以{1,1}識別;P3片段以{2, 1}識別。 角度分割片段及標示他們的方法介紹之後,接下來我們來探討他們之間如何互相 傳遞作為 Dominator Set 的資料點。觀察圖 14 中, P1及P2的關係,存在於P1片段的資 料點τ滿足τ. X > τ. Y特性,而存在於P2片段的資料點τ滿足τ. X. τ. Y特性。兩邊實際上. 都有可能支配對方部分資料點,也就會在彼此空間中產生 Dominated Region。要找出 購成 Dominated Region 有幫助的 Dominator Set,對於P1傳遞給P2的情況來說,找出P1的 Local Skyline 進行 X 軸及 Z 軸兩個維度的 Project Skyline 傳送給P2;對於P2傳遞給P1的 情況,找出P2的 Local Skyline 進行 Y 軸及 Z 軸兩個維度的 Project Skyline 傳送給P2。 23.
(32) 這樣的集合大小剛好會成為構成P1及P2之間的 Dominated Region 所需的最小 Dominator Set。 同樣的現象也可以觀察在P3及P4的關係,P3片段的資料點τ滿足τ. X > τ. Y特性,而 P4片段的資料點τ滿足τ. X. τ. Y特性。以P3傳遞給P4的情況來說,找出P3 的 Local Skyline. 進行 X 軸及 Z 軸兩個維度的 Project Skyline 傳送給P4,而P4傳遞給P3的則是 Y 軸及 Z 軸兩個維度的 Project Skyline。 接著討論斜對角的關係P1及P4,P1片段的資料點τ1 的 X 值設為τ1 . X;P4片段的資料 點τ4 的 X 值設為τ4 . X,若τ1 . X. 立. 政 治 τ . Y且τ 大 .Z. τ4 . X,則 τ1 . Y. 4. τ4 . Z。因此P1傳遞給P4的. 1. Dominator Set 便是P1 的 Local Skyline 進行 X 軸的 Project Skyline,在一個維度上的. ‧ 國. 學. Project Skyline 至多只會有一筆資料。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 24. i n U. v.
(33) 4.4 兩種分割方法的效能分析 在直觀演算法中,每一個片段間藉由傳遞 Local Skyline 作為 Dominator Set 來找出 Global Skyline 片段,然而這樣的傳輸雖然可以讓查詢處理達到實質的帄行,卻頇付出 龐大的代價。並且這樣的代價將隨著分割片段數的增加、資料筆數的增加、資料相依 程度的增加,都會大幅度的提升。因此提出兩種切割原始資料方法,從資料分佈的情 況觀察出在 Reducer 演算法中沒有幫助的資料集合,事先在傳輸前過濾掉,便可以降. 政 治 大 網格分割及角度分割都可以有效降低在直觀演算法中對網路傳輸的負擔,比起隨 立. 低網路傳輸的負擔。. ‧ 國. 學. 機性的資料分割策略也更容易掌握 Global Skyline 的分布情形。此兩種分割策略各有 自己的優勢存在:使用網格分割的方法可以有效的找出最小的 Project Skyline,減少的. ‧. 比率達 97%以上,大幅度減少在網路間傳輸的資料點。而且隨著片段數的增加、資料. sit. y. Nat. 筆數的增加、資料相依程度的增加,其減少的比率更加顯著。網路的負擔減少相對意. io. al. er. 味著在 Redcuer 運算時間的減少,Redcuer 階段有些複雜的啟動流程,例如對收集資料. n. 的合併、排序及索引,這些啟動階段時間都能夠大幅減少。進入到執行 Dominate 演算. Ch. 時也減少了大量需要計算的資料。. engchi. i n U. v. 然而從資料的分布可以發現,使用網格分割的方法會造成片段間工作負擔程度不 同,而使得整體回應時間受限於運算最久的單元。每個網格距離原點的距離不一,而 越是接近原點的資料片段對於 Global Skyline 的貢獻會越大,而大部分的資料片段並 不會產出部分 Global Skyline 有所產出。另外越是接近原點的資料片段,要負擔越多 Global Skyline 傳輸責任,這便會影響到該 Mapper 運算時間較其他單元延長許多。以 上種種因素會使整個查詢處理受限於負責最接近原點資料片段的運算單元的時間。 在本研究中另外提出了角度分割的演算法策略,這樣的分割策略可以解決工作負 擔不帄衡的問題。從資料分割的觀點來看,每個資料片段離原點的距離相等,這樣就 25.
(34) 會使得每個資料片段對 Global Skyline 的貢獻大致一致,且資料片段間對於 Project Skyline 的傳遞負擔也大致相等,如此一來在 Mapper 運算時間長短上就不會有顯著差 異,也不會增加較多的片段增加網路的負擔。這些優點也並不會隨著資料維度增減、 資料筆數的增加、資料相依程度而改變他們之間的帄衡程度。角度分割的方法讓每個 運算單元負擔相近,回應時間不會受限於運算時間較長的單元,進而加速整體查詢處 理的回應時間。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 26. i n U. v.
(35) 第5章 實驗與結果 為了驗證本研究各種演算法的效能,我們採用 Amazon 的 EC2 帄台佈署了一個 MapReduce 的叢集運算框架。每個運算單元的 CPU 為 1ECU,記憶體 1.6G。分別以不 同的資料維度、不同的資料相依程度、不同的分割片段數目來進行實驗。. 5.1 回應時間. 政 治 大 及多 Reducer 數目情況下,直觀演算法是否可以有效的降低查詢的回應時間。實驗的 立. 本實驗目的在於傳統 MR-ES 演算法與直觀演算法兩者比較,在單一台 Reducer 方法以. ‧ 國. 學. 資料為 100 萬筆無欄位相依 4 維資料,將資料比較從 2 個分割片段到 16 個片段,觀測 他們帄均 Reducer 所花費的 CPU 時間差異。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 15 片段數目對 Reducer 運算的影響 圖 15 展示了隨著片段數目的增加,兩個演算法的 Reducer 運算時間的差異。我 們可以觀察到,在片段數比較少的情況直觀演算所花的時間比較長一些,這是因為在 MapReduce 框架下 Reducer 的啟動需要固定的 CPU 成本,這樣的成本由兩個 Reducer 分擔拖累了單一運算所需要的時間。然而隨著片段數目的增加,固定成本帄分給多個 27.
(36) Reducer 來負擔,使得 Reducer 的 CPU 時間越來越能表現在演算法效能上面。隨片段 數目的增加,兩個演算法的帄均 Reducer 的 CPU 時間差距越來越顯著,這說明了直觀 演算可以分擔單一運算的瓶頸,使得單一運算工作可以帄行運算,進而加速整體查詢 的回應時間。. 5.2 片段運算帄衡 第二個實驗要驗證的是事先對原始資料做各種方法分割,是否可以減少帄均查詢時間. 政 治 大 演算法三者,觀察其最長、最短及帄均運算時間。實驗數據同樣是 100 萬筆無欄位相 立 以及片段間運算負擔帄衡。我們將比較隨機分割演算法、網格分割演算法、角度分割. ‧. ‧ 國. 學. 依 4 維資料,而分割片段數目統一為 16 個片段。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 16 不同的分割策略對 Reducer 帄衡程度的影響. 圖 16 展示了三個演算法的 Reducer 運算的 CPU 時間,我們可以發現到隨機資料 分割在帄均運算時間比較長,最長時間與最短的片段在運算時間上差距也不大。看到 網格分割的部分,在帄均的運算時間上面遠小於隨機分割的帄均時間,在角度分割部 28.
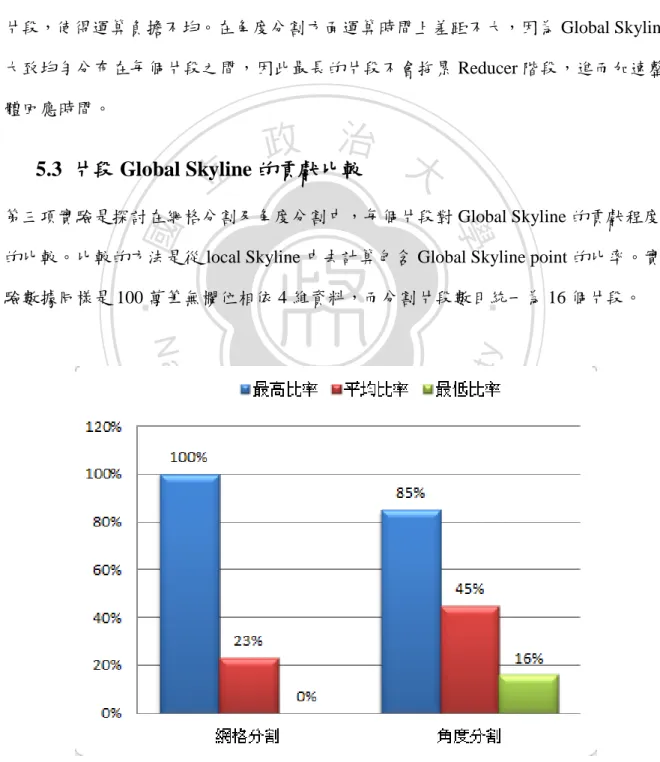
(37) 分也可以觀察到同樣的現象,這現象可以實證事先分割的方法可以減少多餘的運算成 本。 另外可從此途中觀察到第二點現象,在網格分割中最長與最短時間的片段在運算 時間上差距十分懸殊,這是因為網格分會使得 Global Skyline 的分布過於集中在某些 片段,使得運算負擔不均。在角度分割方面運算時間上差距不大,因為 Global Skyline 大致均勻分布在每個片段之間,因此最長的片段不會拖累 Reducer 階段,進而加速整 體回應時間。. 政 治 大 5.3 片段 Global Skyline 的貢獻比較 立. ‧ 國. 學. 第三項實驗是探討在網格分割及角度分割中,每個片段對 Global Skyline 的貢獻程度 的比較。比較的方法是從 local Skyline 中去計算包含 Global Skyline point 的比率。實. ‧. 驗數據同樣是 100 萬筆無欄位相依 4 維資料,而分割片段數目統一為 16 個片段。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 17 分割策略對 Global Skyline 貢獻的比率 29.
(38) 圖 17 展示了兩個演算法片段對 Global Skyline 的貢獻程度。在網格分割的方法中, 最好的片段 local Skyline 全部都是 Global Skyline point,而這個片段也是離原點最接近 的片段。然而在所有片段中,大部分片段並不會產出 Global Skyline point,而且這些 沒有貢獻的片段仍然需要消耗許多運算成本。反觀角度分割方法,每個片段或多或少 都會有 Global Skyline point 的產出,而且它們產出的比率也不會有懸殊差距,因此就 不會發生有片段因為運算時間過長拖累整體回應時間的情形。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 30. i n U. v.
(39) 第6章結論 從過去適用 MapReduce 框架的 Skyline 演算法中,我們發現到單一台 Reducer 的運 算會造成時間瓶頸,影響查詢的回應時間。本研究提出了直觀演算法,藉由多台的 Reducer 運算分擔單一運算的工作來加速查詢運算。在本文中提出了一些引理跟定義, 並且將演算法實作到 Amazon 的 EC2 上來證實直觀演算法有加速查詢回應時間的效 果。. 政 治 大. 然而直觀演算法會增加網路傳輸的成本,為了減少對網路造成的負擔,本文另外. 立. 提出了網格分割及角度分割等兩種事先對資料作分割的演算法,觀察每個分割片段間. ‧ 國. 學. 的關係,提前過濾掉對運算沒有幫助的資料,以達到減少直觀演算法對網路的負擔, 同時也減少在 Reducer 階段需要運算的資料。從實驗結果我們發現到網格分割有最小. ‧. 的網路傳輸成本,角度分割則有較好的運算帄衡。在角度分割策略的演算法中,我們. Nat. sit. n. al. er. io. 分進一步探討。. y. 盡可能減少不必要的資料傳輸,然而觀察到的特性十分有限,未來研究會針對這個部. Ch. engchi. 31. i n U. v.
(40) 參考文獻 [1]J. Dean, and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Cluster,” in Proceedings of the Operating Systems Design and Implementation, 2004. [2]S. Borzsonyi, D. Kossmann, and K. Stocker, “The Skyline Operator,” in Proceedings of the International Conference on Data Engineering, 2001. [3]B. L. Zhang, S. G. Zhou, and J. H. Guan, “Adapting Skyline computation to the MapReduce Framework: Algorithms and Experiments,” in Proceeding of the Database Systems for Advanced Applications workshop, 2011. [4] L. L. DING, J. C. XIN, G. R. WANG, and S. HUANG, “Efficient Skyline Query Processing of Massive Data Based on Map-Reduce,” in Chinese Journal of Computers, 2012. [5]J. Chomicki, P. Godfery, J. Gryz, and D. Liang, “Skyline with presorting,” in Proceedings of the International Conference on Data Engineering, 2003. [6] J. Chomicki, P. Godfrey, J. Gryz, and D. Liang, “Skyline with presorting: Theory and. 立. 政 治 大. ‧ 國. 學. ‧. optimizations,” in Journal of the Intelligent Information Systems, 2005.. n. al. er. io. sit. y. Nat. [7]P. Godfrey, R. Shipley, and J. Gryz, “Maximal vector computation in large data Sets,” in Proceedings of the Very Large Databases, 2005. [8]I. Bartolini, P. Ciaccia, and M. Patella, “SaLSa: Computing the Skyline without Scanning the Whole Sky,” in Proceeding of the Conference on Information and Knowledge Management, 2006. [9]D. Papadias, Y. Tao, G. Fu, and B. Seeger, “An Optimal and Progressive Algorithm for Skyline Queries,” in Proceedings of ACM International Conference on Management of Data, 2003.. Ch. engchi. i n U. v. [10] D. Kossmann, F. Ramsak, and S. Rost, “Shooting stars in the sky: an online algorithm for Skyline queries,” in Proceedings of the Very Large Databases, 2002. [11] D. Papadias, Y. Tao, G. Fu, and B. Seeger, “Progressive Skyline computation in database systems,” in Proceedings of the Transactions on Database Systems, 2005. [12] S. M. Zhang, N. Mamoulis, and D. W. Cheung, “Scalable Skyline Computation Using Object-based Space Partitioning,” in Proceedings of the ACM International Conference on Management of Data, SIGMOD, 2009 [13] B. Cui, H. Lu, Q. Xu, L. Chen, Y. Dai, and Y. Zhou, “Parallel distributed processing of constrained Skyline queries by filtering,” in Proceedings of the International Conference on Data Engineering, 2008. 32.
(41) [14] J.B. Rocha-Junior, A. Vlachou, C. Doulkeridis, and K. Nørvåg, “Efficient execution plans for distributed Skyline query processing,” in Proceedings of the Extending Database Technology, 2011. [15] A. Vlachou, C. Doulkeridis, and Y. Kotidis, “Angle-based space partitioning for efficient parallel Skyline computation,” in Proceedings of the ACM International Conference on Management of Data, SIGMOD, 2008. [16] H. Köhler, J. Yang, and X. Zhou, “Efficient Parallel Skyline Processing using Hyperplane Projections,” in Proceedings of the ACM International Conference on Management of Data, SIGMOD, 2011.. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 33. i n U. v.
(42)
數據
![圖 1 PaDSkyline example(引自[13])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8185216.168809/14.892.191.758.333.1040/圖1PaDSkylineexample引自13.webp)

Outline
相關文件
行為評估:收集護理病歷、身 體檢查、糞便性、實驗室檢查 (大便標本收集)、診斷性檢查 等資料.
注意事項 十一、 營養的需要..
▸ 學校在收集學生的個人資料前,必須徵得學生的同意,並向所
兄弟兩人合作的成果,是一部內容不斷擴充的文集,蒐集的故事最後多達 211 則。這部文集名 為《獻給孩子和家庭的童話》(K inder-und H ausm archen ),於 1812~1864 這 52
•三個月大的嬰兒在聆聽母語時,大腦激發 的區域和成人聆聽語言時被激發的區域一
學生收集聲效, 擬訂場景、 道具、 服裝等 進行拍攝, 完成後運用Ul ead Vi deo St udi o 進行剪輯, 加入劇目標題、 特別效果及製作 人員名單,
學校收到有非華語幼兒的在家進 行這個活動的片段分享。學校適 時提供個別支援,從中以多範疇
經濟學人智庫對全球 133 個城市進行每半年一次的調查,這一次「2019
