Java網頁程式安全弱點驗證之測試案例產生工具 - 政大學術集成
116
0
0
全文
(2) Java 網頁程式安全弱點驗證之測試案例產生工具 Test Case Generation for Verifying Security Vulnerabilities in Java Web Applications. 研 究 生 : 黃于育. Student: Yu-Yu Huang. 指導教授 : 陳 恭. Advisor : Kung Chen. 國立政治大學 資訊科學系 碩士論文. A Thesis Submitted to Department of Computer Science National Chengchi University in partial fulfillment of Requirements for the degree of Master in Computer Science. 中華民國一百年七月 July 2011.
(3) Java 網頁程式安全弱點驗證之測試案例產生工具. 論文摘要. 近年來隨著網路的發達,網頁應用程式也跟著快速且普遍化地發展。 網頁應用程式快速盛行卻忽略程式設計時的安全性考量,進而成為網 路駭客的攻擊目標。因此,網頁應用程式的安全議題日益重要。目前 已有許多網頁應用程式安全弱點的相關研究,以程式分析的技術找出 弱點,主要分成靜態分析與動態分析兩大類。但無論是使用靜態或是 動態的分析方法,仍有其不完美的地方。其中靜態分析結果完備但會 產生過多弱點誤報;動態分析結果準確率高但會因為測試案例的不完 備而造成弱點的漏報。因此,本論文研究結合了動靜態分析,利用靜 態分析方法發展一套測試案例產生工具;再結合動態分析方法隨著測 試案例的執行來追蹤測試資料並作弱點的驗證,以達到沒有弱點漏報 的產生以及改善弱點誤報的目標。 本論文研究的重點集中在以靜態分析技術產生涵蓋目標程式中 所有可執行路徑的測試案例。我們應用測試案例產生常見的符號化執 行技巧,利用程式的路徑限制蒐集與解決來達成測試案例產生。實作 上我們利用跨程序性路徑分析找出目標程式中所有潛在弱點的路徑, 再以反向路徑限制蒐集將限制資訊完整蒐集;最後交給限制分析器解 限制並產生測試案例。接著利用剖面導向程式語言 AspectJ 的程式插 碼技術實現動態的汙染資料流分析,配合產生的測試案執行程式觸發 動態的汙染資料流分析並產生可信賴的弱點分析結果。. i.
(4) Test Case Generation for Verifying Security Vulnerabilities in Java Web Applications. Abstract. Due to the rapid development of the internet in recent years, web applications have become very popular and ubiquitous. However, developers may neglect the issues of security while designing a program so that web applications become the targets of attackers. Hence, the issue of web application vulnerabilities has become very crucial. There have been many research results of web application security vulnerabilities and many of them exploit the technique of program analysis to detect vulnerabilities. These analysis approaches can be can basically be categorized into dynamic analysis and static analysis. However, both of them still have their own problems to be improved. Specifically static analysis supports high coverage of vulnerabilities, but causes too many false positives. As for the dynamic analysis, although it produces high confident results, yet it may cause false negatives without complete test cases. In this thesis, we integrate both static analysis and dynamic analysis to achieve the objectives that no false negatives are produced and reduce false positives. We develop a test case generation tool by the static analysis approach and a program execution tool that dynamically track the execution of the target program with those test data to detect its vulnerabilities. Our test case generation tool first employs both intra- and inter-procedural analysis to cover all vulnerable paths in a program, and then apply the symbolic execution technique to collect all path constraints. With these collected constraints, we use a constraint solver to solve them and finally generate the test cases. As to the execution tool, it utilizes the instrumentation mechanism provided by the aspect-oriented programming language AspectJ to implement a dynamic taint analysis that tracks the flow of tainted data derived from those generated test cases. As a result, all vulnerable program paths will be detected by our tools. ii.
(5) 目錄 第一章. 導論................................................................................................................ 1. 1-1 研究之背景 .................................................................................................... 1 1-2 研究動機 ........................................................................................................ 2 1-3 研究目的 ......................................................................................................... 4 1-4 論文之章節架構 ............................................................................................ 5 第二章. 相關研究與背景技術.................................................................................... 6. 2-1 相關研究 ......................................................................................................... 6 2-1-1 靜態分析方法(Static Approach)......................................................... 6 2-1-2 動態分析方法( Dynamic Approach) .................................................. 8 2-1-3 混合式分析方法(Hybrid Approach) .................................................. 9 2-1-4 測試為基礎分析方法(Testing-based Approach).............................. 11 2-2 背景技術 ....................................................................................................... 18 2-2-1 常見網頁應用程式弱點介紹 ............................................................ 18 2-2-2 分析方法 ........................................................................................... 20 第三章. 系統架構...................................................................................................... 24. 3-1 系統設計考量與目標 ................................................................................... 24 3-2 系統架構概觀 ............................................................................................... 27 3-3 系統主要元件介紹 ....................................................................................... 30 第四章. 系統實作方法.............................................................................................. 33. 4-1 測試案例產生的實作(Test Case Generation) .............................................. 33 4-1-1 測試案例產生演算法(Algorithm for test case generation) .............. 33 4-1-2 跨程序性的路徑分析(Inter-Procedural Path Analysis) ................... 35 4-1-3 路徑限制解(Solving path constraints&Path constraint solution)..... 59 4-2 測試案例執行(Test Case Execution) ............................................................ 62 iii.
(6) 4-2-1 汙染資料流追蹤器(AspectJ Taint Tracker) ..................................... 63 4-2-2 程式執行器(Program Executor) ...................................................... 64 第五章. 實驗評估...................................................................................................... 67. 5-1 標竿程式介紹 .............................................................................................. 67 5-2 實驗結果 ...................................................................................................... 69 5-3 討論 .............................................................................................................. 70 第六章. 結論與未來研究方向.................................................................................. 72. 6-1 結論 .............................................................................................................. 72 6-2 未來研究方向 .............................................................................................. 73 參考文獻...................................................................................................................... 74 附錄.............................................................................................................................. 77. iv.
(7) 圖表目錄 Table 4.1 Analysis Results of Test Case Execution ..................................................... 65 Table 5.1 The description of intra-procedural micro benchmarks ............................... 67 Table 5.2 The description of inter-procedural micro benchmarks ............................... 68 Table 5.3 The experimental results of our system tool ................................................ 70 Figure 1.1 The Motivating Example .............................................................................. 3 Figure 1.1 The Motivating Example .............................................................................. 3 Figure 2.1WebSSARI System Architecture in [6] ......................................................... 6 Figure 2.2 Type Judgments in [6]. ................................................................................. 7 Figure 2.3 Judgment Rules in [6]................................................................................... 8 Figure 2.4 System Architecture of Hybrid Security Analyzer for Java Web Applications in [2]. .............................................................................................. 10 Figure 2.5 System architecture of WAVES in [5]. ....................................................... 11 Figure 2.6 An architecture diagram of testing framework in [8]. ................................ 12 Figure 2.7 SAFELI Framework in [3]. ........................................................................ 13 Figure 2.8 ARDILLA Framework in [7]. ..................................................................... 15 Figure 2.9 An Example for describing Tainted Dataflow Analysis ............................. 21 Figure 2.10 AOP pointcut and advice mechanism ....................................................... 23 Figure 3.1 A Java Servlet example for describing the design of the system ................ 25 Figure 3.2 Inter-procedural call out method idCheck of Java Servlet example........... 26 Figure 3.3 High-level Overview of Our System Architecture ..................................... 27 Figure 3.4 The basic idea of Symbolic Execution. ...................................................... 29 Figure 3.5 The Flow Chart of Our System Architecture .............................................. 30 Figure 4.1 Algorithm for Test Case Generation ........................................................... 34 Figure 4.2 Path Analysis and Constraints Collection depend on method .................... 36 v.
(8) Figure 4.3 The Demonstration of Call Graph .............................................................. 37 Figure 4.4 Control Flow Graph after preprocessing .................................................... 39 Figure 4.5 The Demonstration of Loop Statement Tagging ........................................ 40 Figure 4.6 Control Flow Graph of idCheck method after preprocessing .................... 41 Figure 4.7 Control Flow Graph of doGet method after preprocessing ........................ 41 Figure 4.8 The Simplified Control Flow Graph of Figure 4.6 ..................................... 42 Figure 4.9 All Paths found in Figure 4.8 ...................................................................... 43 Figure 4.10 The Simplified Control Flow Graph and all paths of Figure 4.7.............. 44 Figure 4.11 The Demonstration of Path-Specific SSA Transformation ....................... 46 Figure 4.12 The Key Rules of Linear Relationship Analysis in [16]........................... 48 Figure 4.13 The Demonstration of loop handling ........................................................ 49 Figure 4.14 Example of Nested Loop Handling .......................................................... 51 Figure 4.15 Intra Path constraints collection of idCheck method ................................ 54 Figure 4.16 Inter path constraints collection of Call out statement ............................. 56 Figure 4.17 Call out method path constraint Inlining .................................................. 57 Figure 4.18 Collected Path constraint after Inter Path constraint collection ............... 58 Figure 4.19 Jimple Constraint Grammar ..................................................................... 59 Figure 4.20 Kaluza Constraint Generation Rules ........................................................ 60 Figure 4.21 Kaluza Input Format Transformation ....................................................... 61 Figure 4. 22 The Architecture of AspectJ Taint Tracker .............................................. 63. vi.
(9) 第一章 導論 1-1 研究之背景 隨著網路的日漸發達,透過 World Wide Web 提供服務的需求增加,因此許多造 成網頁應用程式(Web Application)開發語言的盛行,例如 PHP、Perl、JSP&Servlet,、 ASP.NET、、、。而這些網頁應用程式開發語言能夠快速竄紅,是因為程式開發 者能夠快速且方便地設計網頁應用程式,但是大部分程式開發者都忽略了網頁應 用程式設計時的嚴謹性以及安全性。因此,網路駭客針對此弱點進行許多種類的 惡意攻擊來竊取私密資訊、或是癱瘓整個網站系統。根據 OWASP(Open Web Application Security Project) [13] 統計 2010 的網頁應用程式安全弱點的排行,前 三名弱點造成的原因都是因為程式開發者設計的網頁應用程式不夠嚴謹,所以 網 路資訊安全議題的探討不再只限於密碼的加密是否夠安全。如何完備地分析網頁 應用程式是否有潛藏的弱點在目前資訊安全領域已經是一個很重要的研究議 題。 根據 OWASP 的統計資料,目前最常見的攻擊型態都是屬於使用者輸入驗證 攻擊(Input Validation Attack) [18]。發生弱點的源頭來自於使用者輸入的資料,例 如注入缺失(Injection Flaw)像是常見的 SQL Injection;或是跨網站腳本攻擊 (Cross-site Scripting, XSS)。這些攻擊的發生,都是因為程式設計者沒有檢驗或過 濾掉使用者輸入的資料。惡意的攻擊者就利用這樣的弱點來竊取系統機密的資料 或是破壞整個網頁應用程式。目前已經有許多網頁應用程式安全的相關研究以及 自動化掃描弱點的工具。主要是應用汙染資料流分析(Taint Analysis)的概念,來 追蹤並分析程式的弱點,實作方法可分成靜態分析與動態分析方法兩大類。其他 1.
(10) 還有測試為基礎的方法,利用配對好的攻擊字串資料庫,配合測試案例執行來驗 證程式弱點。至於上述提到攻擊弱點的分類、汙染資料流分析和測試為基礎的方 法在本論文研究第二章的技術背景有更詳細的介紹。. 1-2 研究動機 使用程式分析概念來驗證網頁應用程式的安全弱點是目前資訊安全相關研究發 展的趨勢。大部分相關研究應用汙染資料流分析(Taint Analysis)的概念來分析弱 點。利用程式分析方法來追蹤汙染資料(Tainted Data)的流向,檢查是否到達程式 接收點,確定到達的話,則代表一個可能潛在的弱點。其中使用者輸入的資料就 代表汙染資料,而分析方法大致上可分為靜態分析和動態分析兩類。 靜態分析是在不實際執行程式源碼的情況下,對目標程式進行分析。靜態分 析的主要優點為沒有執行程式所產生的額外負擔以及有很高的程式涵蓋率(High Coverage)。由於靜態分析少了動態執行程式後才能得到的資訊,在對目標程式 進行弱點分析時,只要是 ”可能”的弱點要全部考慮進來。弱點分析結果較保守但 是完備,也因此會產生過多弱點誤報(False Positive)的分析結果。過多的誤報使 得程式開發者需要以人工或其他方法在進一步做弱點驗證去找出真正的弱點而 非誤報,此過程則是一項耗時間且容易出錯的工作。 動態分析則是實際地執行程式源碼,利用程式插碼技術(Instrumentation)或是 修改程式直譯器的方法達成汙染資料流分析。因為多了程式執行時的動態分析資 訊,動態分析能夠更精確地偵測出真正弱點(True Positive)。缺點在於程式執行時 缺乏完備的測試案例,無法涵蓋程式所有執行路徑,因此會有弱點漏報(False Negative)的問題產生。 Figure1.1 的程式範例說明靜態分析發生誤報與動態分析可能產生漏報的情 況。在程式片段第 2、6 行變數 name 和 id 是來自使用者輸入產生的 HTTP request, 為汙染資料的來源(Source)。而在第 5、7、14 行 writer.println(…)為程式接收點 (Sink)。根據汙染資料流分析的概念,弱點的定義是根據判斷程式接收點的資料 2.
(11) 是否從汙染資料來源所傳遞而來。 01 protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException { 02. String name = req.getParameter(“name”);. 03. PrintWriter writer = resp.getWriter();. 04. if(name.length() >= 5){. 05. writer.println(“Hello!” + name);. 06. // Source-1. // Sink-1. }else if(name.equals(“Admin”)){. 07. String id = req.getParameter(“id”);. // Source-2. 08. writer.println(name + id);. // Sink-2. 09. }else{. 10. LinkedList c1 = new LinkedList();. 11. c1.addLast(name);. 12. c1.addFirst(“123”);. 13. Object[] array = c1.toArray();. 14. List c2 = java.util.Arrays.asList(array);. 15. Writer.println(c2.get(0));. 16. // Sink-3. }. 17 }. Figure 1.1 The Motivating Example. 在此例子對靜態分析來說,會找出三個弱點,分別為第 5 行 Sink-1 的變數 name 來自第 2 行 Source-1、第 8 行 Sink-2 的變數 id 來自第 7 行 Source-2、第 15 行 Sink-3 來自第 2 行的 Source-1。但實際上靜態分析在此會產生兩個弱點誤報, 第一個誤報為 Source-2 到 Sink-2 的弱點,因為第 4 行的條件式包含了第 6 行的 條件式,此為一條程式永遠不會執行到的路徑。其中字串變數 name 長度大於等 於 5 也包含了 name.equals( “Admin”)的情況,所以可以知道第 7、8 行是永遠不 可能執行的程式碼,但是對靜態分析來說無法得知這樣的資訊所以造成誤報;第 二個誤報為 Source-1 到 Sink-3 的弱點,第 11 行鏈結串列 c1 將來自 Source-1 的 汙染資料 name 加到串列的最後,對靜態分析來說無法得知 addLast 函式內容, 因此將整個 c1 視為被汙染的。接著 c1 先轉換成陣列型態再轉換成串列並指派給 3.
(12) c2,因此,c2 也視為被汙染的。所以 Sink-3 的引數 c2.get(0)被當成弱點,但追 蹤程式碼可知 c2.get(0)實際的值為常數值”123”,不是弱點所在。在此造成誤報 的是因為缺少了動態的資訊。 對動態分析來說,由於追蹤汙染資料時多了動態執行程式的資訊。因此,能 夠判斷到達接收點的資料為常數值而非真正的弱點。在此程式有兩條可執行路徑, 代表動態分析需要兩組測試案例才進行完整的弱點分析。如果測試案例不完備無 法涵蓋所有可執行路徑就會有漏報發生的可能性。 所以就此程式範例來說,如果我們能夠利用測試案例產生技術,取得符合條 件式的測試資料來涵蓋程式的所有可執行路徑。在此就能夠產生符合 name 長度 大於等於 5 和小於 5 的兩組測試資料,並且刪掉 name.equals(“Admin”)這條不可 執行的路徑。再配合動態分析執行這些測試案例,分析這些可能潛在弱點的路徑, 就能夠達成既不會產生動態分析的漏報又能夠改善靜態分析的誤報問題。. 1-3 研究目的 本論文研究希望結合動靜態分析方法,利用彼此優點作互補。其中利用靜態分析 自動化地對要分析弱點的目標程式產生完備的測試案例,涵蓋目標程式中所有可 執行路徑以達成沒有弱點漏報的情況,並且自動化或半自動化地執行測試案例。 其中再以動態分析方法實現汙染資料流分析來達成弱點的驗證以及改善弱點誤 報的數量。 動態分析方法的優勢在於弱點判斷的準確性,但在實際執行程式時會面臨到 沒有測試案例可使用的問題。尤其面對目標程式包含許多不同執行路徑時,沒有 完備的測試案例會造成動態的污染資料流分析無從分析弱點。程式開發者可能需 要以手動的方式找出測試案例。因此,利用靜態分析方法去分析目標程式,產生 所有程式可執行路徑所屬的測試案例,能夠自動化地解決這個問題。並且保有動 態分析作弱點判斷的高準確率優勢。因此,首要目標為產生完備的測試案例,涵 蓋程式所有潛在弱點的可執行路徑。為了達成此目標,本論文研究希望利用測試 4.
(13) 案例產生常用的符號執行(Symbolic Execution)與限制解決(Constraint Solving)技 巧發展一套測試案例產生工具。 為了實現動態的汙染資料流分析,我們利用剖面導向程式語言 AspectJ 的程 式插碼技術,實現汙染資料流分析的部分是應用 Taint Tracker Aspect[2]。Taint Tracker Aspect 能夠確定汙染資料的流向,首先檢驗接收端的資料是來自不被信 任的來源端,再配合產生的測試案驅動程式執行;在動態執行可能潛在弱點的程 式路徑時,剖面導向程式語言隨著執行路徑驗證弱點,以達成自動化測試案例產 生以及自動化改善弱點誤報的目標。. 1-4 論文之章節架構 本論文接下來的章節架構如下分類 : 第二章為相關研究與本論文研究相關技術 的背景知識介紹。其中相關研究部分為目前概況的討論與優缺點比較,背景知識 部分為常見網頁應用程式的弱點種類、分析方法以及剖面導向技術的介紹。第三 章為本論文研究系統架構的概觀描述。包含系統設計考量的討論以及整個系統的 流程說明,其中對每個系統元件會作概觀的介紹。第四章為系統實作的細節,分 成測試案例產生與測試案例執行兩大部分。我們以一個程式範例貫穿此章節作為 輔助,對整個系統實作細節作清楚的描述。第五章展示最後實驗評估之成果及討 論,包含我們設計的標竿程式介紹和弱點分析結果的呈現。最後在第六章作本論 文研究的總結以及描述未來的研究方向。第七章為參考文獻。. 5.
(14) 第二章 相關研究與背景技術 2-1 相關研究 本論文研究在此章節將介紹相關研究的技術方法,以及優缺點的討論。在網頁應 用程式的安全性的領域中,已經有很多種方法用來偵測或是防止弱點,大致上可 以將這些方法分成四大類。分別是靜態分析方法(Static Analysis)、動態分析方法 (Dynamic Analysis)、混合式分析方法(Hybrid Analysis)、測試為基礎的分析方法 (Testing-based Approach)。 2-1-1 靜態分析方法(Static Approach). Figure 2.1WebSSARI System Architecture in [6]. Huang et al.[6] 這篇相關研究為首先提出將程式分析技術中靜態分析的概念應用 到網頁應用程式安全議題上,將網頁應用程式的弱點視為一個資料流. 6.
(15) (Information flow)的問題。從 Type System 和 TypeState 推演出的一個 Lattice-based 的靜態分析演算法,在配合上 Run-time 的防護,在偵測出是弱點的程式碼前加 入動態防護。是一個不需人為介入自動化的架構,如 Figure 2.1。 為了分析使用者輸入在整個程式中的傳遞細節,整個 Information Flow Model 的參與對象為 Variables、Sensitive Functions 和 Security Class。其中 Security Class 為資料信任程度的定義(eg. Tainted/Untainted),每個變數都要自己的 Security Class。在此使用一個 Type Environment Γ: X |-> T,作為變數和與他相關 security class 的配對函式,也就是說變數 X 的 security class 為 Γ(X);而這些 Security Class 會形成一個 Lattice。為了可以在編譯時間估算出執行時間的 Type Environment, 所以採用保守的估算。取 Lattice 的最小上限(Least Upper Bound),將變數的 security class 視為 Static Most Restrictive。舉例來說,Security Class 有 Tainted 和 Untainted 兩種類別,形成的 Lattice 為 Tainted – Untainted(偏序為左高又低)。假 設有一段程式碼 if(C) x = t1 ; else x = t2 ; exec(x) ;其中已知 t1 是 Tainted 而 t2 是 Untainted。在這情況下變數 x 的 Security Class 需要找 Static Most Restrictive,所 以 Γ(x) = Tainted ∪ Untainted = Tainted。由此可見靜態分析的缺點就是過於保守 而造成誤報。為了減少誤報,作者將 type 資訊加到 Security Class 中變成 Type-aware Security Class,而 Lattice 就變成大了。目前 Type 只分成 Int 和 String 兩種型態,因此 Lattice 擴大成為 Tainted String – Tainted Int – Untainted String – Untainted Int。在這樣的情況下,如果 Security Class 是 Tainted Int,因為在 PHP 中使用者輸入的資料型態都是 String 的型態,所以 Tainted Int 是可以被接受的。 在驗證 PHP 程式之前,先將程式解構成為規定的 Program Abstraction。接著 依照 Figure 3.2 Type Judgments 和 Figure 2.3 Judgment Rules 來追蹤變數的安全層 級以及檢查程式的正確性。. Figure 2.2 Type Judgments in [6]. 7.
(16) Figure 2.3 Judgment Rules in [6].. 2-1-2 動態分析方法( Dynamic Approach) Hidehiko Masuhara et al.[10] 的 研 究 在 剖 面 導 向 程 式 設 計 (Aspect-Oriented Programming , AOP) 提出 Data-flow Pointcut,可以用來解決網頁應用程式的安全 漏洞。Data-flow Pointcut 提供能夠用來定義來源端(Source)與接收端(Sink)的程式 切入點(Pointcut)語法。當符合某個定義的 Data-flow Pointcut,表示在某個程式接 收點(Sink Point)的引數是來自汙染來源端(Tainted Source),此時會觸發使用者定 義的建議(Advice)來處理汙染資料(Tainted Data)。 Anh Nguyen-Tuong et al.[12]替換掉 PHP 原本標準的直譯器(Interpreter),換成 作者修改過的直譯器,在字串資料型態加入一個紀錄汙染(Taint)資訊的額外值。 其中強調他們的方法是以一個字元為單位來進行資料的汙染追蹤,可以很精準的 追蹤汙染資料的流向,稱之為 Precise Tainting。由於網頁應用程式弱點造成的原 因不同,有了精準的汙染傳遞資訊,對於處理不同的弱點有很大的幫助。例如在 呼叫函式之前先檢查函式的引數是否被汙染。尤其安全性特別重要的函式,因此 避免了 PHP Injection。為了防止 SQL Injection,修改 PHP 函式中會傳送指令到資 料庫的 Query 函式。利用提供的污染資訊,來檢查資料是否包含特殊的 SQL token, 若有包含,在進資料庫前會做阻擋;對於 XSS 的防禦也是利用 Precise Tainting 8.
(17) 提供的資訊去辨認來自使用者輸入而且將要輸出的資料,將包含 script 語法的資 料過濾掉。 Vivek Haldar et al.[4] 提出在 Run-time 用標籤(tag)紀錄使用者輸入以及做標 籤追蹤,在 JVM(Java Virtual Machine)實作 Taint Propagation。利用 Javassist 對 Bytecode 作插碼(Instrumentation),不需要程式源碼,只需要 Bytecode 的 Java classfile。追蹤汙染資訊傳遞的過程在 java.lang.String class 中作插碼,但因 JVM 禁止 load-time 修改系統的 classes,所以要在 off-line 才能完成插碼。除了做汙染 標記,由於消毒函式(Santinization Function)存在的可能性,使原本汙染資料在消 毒過後變成乾淨的,所以插碼也要考慮還原乾淨資料的動作。 Wei Xu et al.[18] 利用 Source-to-Source Transformer 技巧,在 Bytecode 階段 作程式插碼去追蹤那些汙染資料。現在很多腳本語言(Scripting Languages)像是 PHP、Perl、Bash 都是直譯為基礎(Interpretation-based)的語言。因為這些語言的 直譯器都是由 C 語言撰寫的,因此,作者發展程式轉換器(Program Transformer) 用來轉換這些腳本語言的直譯器。這樣的技巧就可以套用到許多不同的語言上。 這篇文章對於汙染資訊傳遞提出較詳細的列舉,除了一般顯而易見的傳遞方法, 像是 Assignment、Function Call,還考慮像是 Indirect Data Propagation 及處理外 部函式的情形。 2-1-3 混合式分析方法(Hybrid Approach) Chiang S.-L.[2] 提出動態分析與靜態分析結合的弱點掃描工具。重點擺放在動態 程式分析技術,隨著程式執行期間進行 Java 網頁應用程式的分析,運用 Java 剖 面導向語言 AspectJ 的程式插碼技術實作汙染資料流分析。其中 利用 Taint Tracker Aspect 去追蹤記錄程式接收端的資料是否來自來源端,在動態執行檢驗時為了減 少漏報的情況,加入靜態分析 Online Analyzer。在程式執行遇到造成路徑分支的 條件式( Branch Condition)時,驅動靜態分析 Online Analyzer 以達成用靜態分析 輔助動態的方式偵測 Java 網頁應用程式的弱點。. 9.
(18) Figure 2.4 System Architecture of Hybrid Security Analyzer for Java Web Applications in [2].. Figure 2.4 為系統架構圖可分成三個重要的元件,Taint Tracker、Online Analyzer 和 Program Executor。首先是剖面導向程式 AspectJ 實作的 Taint Tracker Aspect 元件,利用剖面導向程式 pointcut and advice 機制的技術。應用 AspectJ 現存的 Pointcut 類型去實現[10]所提出的 Data-flow Pointcut,負責對程式源碼進 行插碼,追蹤程式中接收點使用的資料使否來自汙染資料來源;而 Program Executor 元件採用單元測試,以自訂的測試資料來驅動程式執行。在執行過程中 隨著執行的路徑 Taint Tracker 會做汙染資料流的傳遞記錄,將因為傳遞而被汙染 的資料記錄到 Taint Set 中。最後檢查在接收點使用的資料是否存在於 Taint Set, 是的話就為一個偵測到的弱點。但執行路徑中遇到條件判斷式會造成動態執行路 徑只能擇一執行,此時會驅動靜態分析的 Online Analyzer 元件,利用靜態分析保 守但高涵蓋率的優點來幫助分析漏掉的路徑。比起傳統的動態分析方法,此混合 式分析方法除了有動態分析判斷弱點準確性的優勢,又結合靜態分析改善動態分 析弱點漏報的可能性。. 10.
(19) 2-1-4 測試為基礎分析方法(Testing-based Approach) 2-1-4-1 黑箱測試 在網頁應用程式中如何做黑箱測試,主要利用測試的技術像是 Fault Injection 與 Runtime Monitoring 幫助網頁應用程式掃描出錯誤或是弱點。Fault Injection 的測 試概念是利用事先設計好的輸入資料,在黑箱測試過程中可以由這個特別的資料 來辨別在程式中經過了哪些地方,以提供可用的判別資訊。. Figure 2.5 System architecture of WAVES in [5].. Huang et al.[5] 實作一個自動化的黑箱測試架構 WAVES,如 Figure2.5 表示。 主要觀念是利用 Fault Injection 並且從回傳的結果觀察是否攻擊成功。整個 WAVES 的架構主要由 Complete Crawler、Injection Knowledge Manager(IKM)、 Self-learning Knowledge Base(KB)組成。整個測試可以分為三個步驟 : 一、尋找 Injection Points,二、產生測試案例,三、比對結果,若攻擊成功,則回報為安 全上的漏洞。 為了尋找適當 Injection Points,需要利用網頁爬蟲(Crawler)去抓取一個網頁 應用程式所有網頁。因為現在動態網頁非常普遍,所以作者提出一個 Complete 11.
(20) Crawler 裡面必須含有 Script Engine 來解讀動態網頁,才能將所有的網頁一網打 盡。得到網頁之後,需要 DOM parser 去解析網頁並找出所有的 HTML 的表單 (form) , 將使 用者輸 入的欄位 變 數全 部 抓 出來。 所 有欄位 變數 都會記錄在 Self-learning KB,這些變數就成為 Injection Point 的候選人。接著由 IKM 負責將 這些欄位變數填入適當的值以產生測試案例。為了讓特別設計的 Injection Pattern 能夠攻擊成功,Self-learning KB 除了儲存變數之外,也利用演算法去配對變數 對應的值,讓產生的測試案例能順利地跳過輸入驗證。最後觀察產生的結果來判 斷式攻擊成功或是失敗,黑箱測試的缺點在於有漏報的情況發生,為了減少漏報, 作者還提出 Negative Response Extraction 機制來降低漏報的發生。 Lin et al.[8]提出了一個自動化消毒(Sanitizing)系統來處理使用者的輸入,其 中測試架構如 Figure 2.6。此系統除了測試架構之外,還包含了應用層的 Security Gateway 來過濾使用者的輸入。有別於其他的系統[5]僅只偵測弱點的所在,卻沒. Figure 2.6 An architecture diagram of testing framework in [8]. 12.
(21) 有作自動化的修正。測試的概念類似,首先需要網頁爬蟲(Crawler)抓取網頁,分 析出欄位變數,產生測試案例。差別在執行測試案例之前須要先經過 Security Gateway 過濾再比對結果,若結果跟預期的不同表示過濾成功,代表修正了弱點, 若與預期相同,表示攻擊成功,則回報為弱點。 黑箱測試的好處在於不需要程式源碼即可做弱點的驗證或修正,而且自動化 過程能節省不必要的人為參與。但對黑箱測試來說,漏報問題成為最大的缺點, 因為缺少程式源碼的資訊,想要找到全面性的測試資料是很困難的。 2-1-4-2 白箱測試 X. Fu, et al.[3] 提出一個能偵測 SQL Injection 的工具 SAFELI,利用對 Java 網頁 應用程式進行 bytecode 插碼來實現符號化執行(Symbolic Execution),將真正的變 數型態轉換成符號化變數(Symbolic Variable)連同運算式一起轉換,以符號化執行 與路徑限制(Path Constraint)蒐集。再以自己開發的 String solver 解出限制並針對 特定 SQL 攻擊字串做偵測。Fugure 2.7 為 SAFELI 的系統架構,可分為三組主要 區塊進行討論。 第一組為 Java Symbolic Execution Engine (JavaSye),JavaSye 包含兩個重要 的模組 Java bytecode instrumentor 和 Symbolic execution Engine。其中 Java. Figure 2.7 SAFELI Framework in [3]. 13.
(22) bytecode instrumentor 利用工具 Javassist,對 Java bytecode 進行程式插碼。插碼主 要先將 Int、String 這些基本資料型態取代成符號化的資料型態,例如將 integer 型態轉換成符號化型態 IntExpr。接著蒐集路徑限制的部分,在 Java bytecode 遇 到條件判斷指令時,利用插碼技巧以隨機執行的方法讓分支的兩條路徑都有機會 被執行到,並在程式結束或遇到 exception 時記錄這條路徑的所有限制。架構圖 中可以看到 Bytecode instrumentor 會 產生插碼後 程式碼,再交給 Symbolic Execution Engine 執行達成上述蒐集路徑限制的目的。 第二組為 Library of Attack Pattern。資料庫蒐集特別設計的 SQL 攻擊範例, 每個攻擊範例由兩個 SQL syntax tree 組成,分別為攻擊前和後的 SQL syntax tree。 在符號化執行蒐集限制的階段同時也搜尋會送出 SQL query 的接收點函式,將此 標記為一個 Hotspot。當每找到一個 Hotspot 就會先隨機產生一組符合此 SQL query 且無害的對照範例,再與攻擊範例做比對。當此範例的 Syntax tree 和攻擊 範例的第一個 Syntax tree 相同,表示兩個 SQL 語法結構相同。因此,產生一組 方程式,由後面 Hybrid String Solver 去產生一組測試案例,使 SQL syntax tree 的 結構能夠在攻擊後符合攻擊範例的第二個 Syntax tree。則代表此為真正 SQL Injection 攻擊。 第三組為 Hybrid String Solver/ Test Case Replayer(APOGEE)。作者開發符合 自己系統架構的 Hybrid String Solver,能夠解跟整數相關的限制。主要是要解出 SQL 攻擊範例產生的方程式,進而產生 SQL 攻擊的滲透測試資料。Test Case Replayer 主要是為了達成自動化地執行測試案例。 從這篇相關研究,我們學習到符號化執行(Symbolic Execution)蒐集程式路徑 限制的概念,以及使用 SQL syntax tree 的概念做比對來判斷 SQL Injection 攻擊 類型。雖然屬於靜態的分析方法,但此工具仍需要執行插碼之後的 bytecode,利 用插碼的技術實現符號化執行。在尋找程式所有可執行路徑的方式採用忽略限制、 多次隨機執行,以達成涵蓋所有程式可執行路徑。此想法啟發我們,如果能夠改 用傳統靜態分析中資料流分析方法,幫助找出程式所有可能執行路徑,就可以有 14.
(23) 效的刪減根本不會執行到的路徑,以減少分析的額外負擔。 A. Kiezun, et al [7] 提出針對 PHP 網頁應用程式弱點檢測工具 ARDILLA,利 用污染傳遞(Taint propagation)去追蹤記錄輸入的測試案例是否流向程式接收端, 並將測試資料的值換成攻擊字串(Attack Pattern),確定攻擊成功後即產生攻擊字 串的滲透測試案例。Figure 2.8 為 ARDILLA 的系統架構圖,整個系統架構分成. 四個主要元件。. Figure 2.8 ARDILLA Framework in [7].. 第一個元件為 Input Generator。他們利用先前研究 Apollo[13]中開發的 Input Generator,以涵蓋充足的測試資料。目的是想要包含所有控制路徑(Control-Flow Path),畢竟測試一直以來的挑戰就是測試資料的完整性。在 ARDILLA 架構中的 Input Generator 是獨立出來的方便之後替換更好的 Input Generator。 第二個元件為 Executor/Taint Propagator。假設有了完整的測試資料可以涵蓋 所有檢測的執行路徑,接著應用 Taint Propagator 實現汙染資料流分析,追蹤那 些測試資料是否流向 Sensitive Sink。Sensitive sink 就是網頁應用程式會造成弱點 的所在,可能是輸出到 Html 網頁的函式或是要進入資料庫相關函式。Taint 15.
(24) Propagator 確定哪些使用者輸入的參數會流向 Sensitive Sink 後,Executor 會將這 些輸入的參數存放到 Taint set。也就是利用測試資料執行程式,並找出所有可能 潛在弱點之路徑的測試資料。 第三個元件為 Atack Generator/Checker。每個 Sensitive Sink 會有自己的 Taint Set,因為程式中可能不只一種 Sensitive Sink。接著由蒐集好 SQL Injection 和 XSS 的攻擊範例去取代那些在 Taint Set 中輸入的參數值。也就是將可能流向 Sensitive Sink 的測試資料改換成真正的攻擊範例,Attack Generator 就是負責產生替換過 後的攻擊測試案例,然後再由 Attack Checker 去判斷是否真的攻擊成功。 第四個元件為 Concrete+Symbolic Database。Concrete+Symbolic Database 是為了 處理 Second-order XSS 而提出的概念。所謂的 Second-order XSS 是使用者輸入包 含惡意 Script 語法的資料存入了資料庫之中。雖然不會直接對資料庫進行攻擊, 每當使用者從資料庫出資訊就會受到 XSS 的攻擊。比起一般的常見的 First-order XSS 造成的問題更為嚴重。所以藉由 Concrete+Symbolic Database 的技巧,先複 製一份真正的資料庫做為符號化資料庫(Symbolic database)。因此,就能在此資 料庫新增加一個欄位,用來追蹤汙染資料的資料結構。並改寫一些資料庫函式來 讓 Taint Propagator 在資料庫中也能做到汙染資料的傳遞。進而使工具可以精準 的偵測到更多種類型的攻擊手法。ARDILLA 能夠處理 SQL Injection、First-order XSS 和 Second-order XSS。 此研究採用 Apolle[1]的 Input Gnerator,就是使用 Concolic Testing 技巧來實 現測試案例的產生。其實就是結合實際執行(Concrete Execution)與符號化執行 (Symbolic Execution),採用一邊作實際程式測試的執行一邊執行符號化執行。概 念是先用一組隨機的測試資料開始,利用符號化執行即時地調整測試資料。每遇 到一個新限制沒有符合,實際執行會先暫時終止。此時符號化執行紀錄測試資料 不符合限制的情況,在下次實際執行之前就會將最後一個遇到的限制條件做否定 (negate)。並且將否定後限制調整到新的測試資料在往下執行,始採用深度優先 搜尋的演算法,將每條路徑都找出來。 16.
(25) 在此我們學習到蒐集路徑上的限制及解決限制的方法,這樣的概念啟發我們 可以針對來源端到接收端路徑來產生測試案例。利用反推方式,從接收端開始解 決離接收端最近的限制,最後到達程式起始點。只要和使用者輸入的變數相關, 路徑限制在解決後就能產生測試案例。 P. Saxena, et al [15]提出了擴充迴圈的符號化執行(Loop-extended Symbolic Execution, LESE),能夠處理包含迴圈的程式。改善了目前符號化執行技巧受限 於 一 次 只 能 夠 抽 象 的 執 行 一 條 路 徑 的 限 制 , 稱 之 為 Single-Path Symbolic Execution(SPSE),也擴展了符號化執行對程式的涵蓋。LESE 引進一個新的迴圈 符號化變數 Trip Count(TC),程式中的每個迴圈都有屬於自己的迴圈符號化變數 TC,代表迴圈的實際執行次數。除了支援原本 SPSE 對資料相依性的處理,還應 用了其他分析來作迴圈相關變數(Loop-dependent variable)的辨別,並找出這些變 數值與迴圈執行次數的線性關係。其中迴圈相關變數代表受迴圈執行次數影響的 變數。 主要分成兩個步驟,第一個步驟為 Symbolic analysis of loop dependencies, 目的是找出迴圈相關變數值與迴圈執行次數之間的關聯性,主要根據一組 Linear relationship analysis 的規則來找出彼此的線性關係;第二個步驟為 Constraints linking the input grammar to loops,目的是找出迴圈符號化變數 TC 的值,其中說 明迴圈經常與使用者輸入的變數長度相關,因此利用一組定義的文法來描述使用 者輸入,並根據此文法取得輸入變數與 TC 值彼此的連結關係。舉例來說,假設 一個迴圈相關變數 i,在第一步驟後得到的值為 i = 1 + 1*TC,代表變數 i 的初始 值為 1 經過迴圈每回合會增加 1,其中迴圈執行次數為 TC。再經過第二步驟得 到 TC = length(UserInput),表示此迴圈執行次數就是使用者輸入的長度。 從此文獻我們學習到了符號化執行對於迴圈處理的概念,對測試案例產生來 說,迴圈的處理是一個需要面對的挑戰,因為迴圈可能產生回窮的路徑而造成分 析上的困難。因此,應用擴充迴圈的符號化執行能夠分析包含迴圈的程式,我們 17.
(26) 就能夠涵蓋更廣的程式,面對迴圈也能夠產生完備的測試案例。 測試為基礎的分析工具主要目標達成滲透案例測試,利用產生包含攻擊字串 的測試案例進行真正的攻擊模擬。告訴網頁程式設計開發者他們所開發的程式真 的有弱點,而且進一步說明是哪種類型的弱點。測試為基礎的分析工具在執行測 試案例的部分還能夠結合其他動態或混合式的分析方法來追蹤汙染資料流向,更 進一步幫助分析攻擊產生的結果比對。但沒有完備的測試案例產生,對測試方法 來說,即使驗證弱點的準確性很高卻會有遺漏,因此如何產生完備的測試案例是 一個重要的相關研究。. 2-2 背景技術 在此章節將會介紹本論文研究的基本背景知識與技術描述,可以分為兩大部分。 首先,我們會介紹常見的網頁應用程式弱點,並以資料庫注入(SQL Injection)和 跨網站腳本攻擊(XSS)這兩個最具代表性的例子說明。接著介紹相關的分析方法, 包含汙染資料流分析、測試案例產生以及剖面導向程式語言的技術。 2-2-1 常見網頁應用程式弱點介紹 下列為 2010 年 OWASP [13] 統計資料顯示前 10 名網頁應用程式的弱點,常見的 弱點都是與未經驗證的使用者輸入有關,以下將介紹前兩個最出名攻擊手法。 . A1: Injection. . A2: Cross-Site Scripting (XSS). . A3: Broken Authentication and Session Management. . A4: Insecure Direct Object References. . A5: Cross-Site Request Forgery (CSRF). . A6: Security Misconfiguration. . A7: Insecure Cryptographic Storage. . A8: Failure to Restrict URL Access. . A9: Insufficient Transport Layer Protection 18.
(27) . A10: Unvalidated Redirects and Forwards. 2-2-1-1 注入缺失(Injection Flaw) 在此最具代表性的注入缺失為資料庫注入(SQL Injection),以此為例做說明。SQL Injection 的發生在於不被信任的使用者輸入構成了 SQL 的指令,而惡意的輸入 會改變 SQL 指令的原來要做的工作。像是常見的竊取資料庫的機密資訊,或是 毀壞資料庫的內容,下面舉一個 PHP 建立的 SQL 指令。 $cmd = “SELECT COUNT(*)” FROM user WHERE name = ‘” . $name . “’ ; AND passwd = ‘ “ . $pwd . “’ ;. 其中 $name 和 $pwd 這兩個變數的值是由使用者所提供的。正常的 SQL 指 令會比對使用者的輸入是否符合,符合的話就會回傳 1 否則回傳 0。但今天惡 意的攻擊者在$name 和$pwd 的都輸入‘ OR 1 = 1,SQL 指令結果如下。 $cmd = “SELECT COUNT(*)” FROM user WHERE name = ‘’ OR 1 = 1 ; AND passwd = ‘’ OR 1 = 1 ;. 於是回傳結果為 1 ,攻擊者就成功的竊取所有資料庫的資訊。常見的 SQL Injection 攻擊方法還有像是輸入兩個 hyphen -- 符號,這在 SQL 語法中是作註解 用的,所以攻擊者就可以藉此達到成功的攻擊。 目前用來偵測 SQL Injection 的方法就是去辨別使用者的輸入是否包含有特 殊字元、或是含有 SQL 語法,再做過濾或阻擋的動作。 2-2-1-2 跨網站腳本攻擊(Cross-Site Scripting , XSS) 網頁通常有很多表單欄位處允許使用者輸入資料,再根據這些資料動態地產生新 的網頁。使用者輸入的表單資訊若沒有進一步檢查,就可能因為攻擊者利用惡意 的 script 當作輸入資料而造成 XSS 的發生。假設 <script>alert('Vulnerable')</script> 被當成使用者輸入的資料,沒有過濾的話就會自動地執行 script 語法。在此就會 造成網頁一直跳出”Vulnerable”的警告標示。 19.
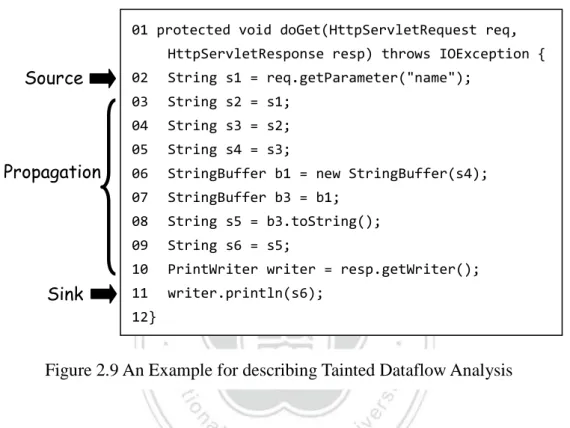
(28) 而 XSS 又可分為兩種形式,舉例來說,第一種 Stored XSS : 就是像是在留 言板或是論壇中輸入 script 的語法的惡意程式碼。如果 server 端沒有過濾過使用 者輸入的內容,就會直接執行攻擊者想要做的事;第二種,Reflected XSS : 在瀏 覽網站時(使用者 log-in 且 cookie 已經被記錄了),此時收到一封 mail(受到 attacker 破壞的 link),點開時會經過使用者將連結傳給伺服器,伺服器以為是使用者傳 入的訊息,而導向 attacker 的惡意網站。下列舉例說明 : http://www.trustedsite.com/searchdoc.cgi?file=<script> windows.open(“http://www.attacker.com/malicious_script.js”)</script>. 當不知情的使用者點下此 URL,就會執行攻擊者惡意的 script 語法,開啟一 個惡意的 JavaScript。XSS 的攻擊常造成不知情的使用者 Cookie 被竊取的狀況, 攻擊者就能假冒使用者然後直接登入成為合法使用者。 目前 XSS 的偵測方式是檢查使用者輸入是否含有<script>的 tag,或是利用 encoding 的方式,將字元‘<’ encode 成 ‘<’來避免惡意 scripting 的執行。 2-2-2 分析方法 2-2-2-1 汙染資料流分析(Taint Analysis) 網頁中需要使用者輸入的資料是目前造成網頁應用的安全出現漏洞的主要原因, 因此只要是使用者的輸入資料,都視為被汙染資料(Tainted Data )。接著如何紀錄 以及後續的追蹤汙染,就是所謂汙染資料流分析,簡單來說就是在整個網頁應用 程式中追蹤使用者輸入的資料。 Figure 2.9 為說明汙染資料流分析的程式範例。其中主要分成由三個主角, 一、程式來源端(Source),代表接收使用者輸入的函式。只要是從來源端來的使 用者輸入資料都視為被汙染(Tainted)。在此第 2 行 req.getParameter(“name”)就是 一個程式來源端;二、程式接收端(Sink),例如會輸出資料的函式(eg. println)或 是會進入資料庫的函式(eg. SQL query)。在第 11 行 writer.println(s6)為一個程式接 20.
(29) 收端;三、傳遞過程(Propagation),負責紀錄程式中間汙染資料流的傳遞過程。 例如資料流動的過程可能經過函式的操作或是 Assignment 動作而造成汙染的傳 遞。如第 2 行來自來源端的汙染資料 assign 給變數 s1,因此變數 s1 被傳遞成為 汙染資料,第 3 行汙染資料 s1 又傳遞給 s2,以此類推。. 01 protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException {. Source. Propagation. Sink. 02. String s1 = req.getParameter("name");. 03. String s2 = s1;. 04. String s3 = s2;. 05. String s4 = s3;. 06. StringBuffer b1 = new StringBuffer(s4);. 07. StringBuffer b3 = b1;. 08. String s5 = b3.toString();. 09. String s6 = s5;. 10. PrintWriter writer = resp.getWriter();. 11. writer.println(s6);. 12}. Figure 2.9 An Example for describing Tainted Dataflow Analysis. 程式接收端如果包含汙染資料,在輸出到網頁或是進入資料庫內部後,可能 造成網頁應用程式被攻擊或是被竊取資訊。因此,對汙染資料流分析來說,當程 式接收端的資料是被汙染的,代表來源端的汙染資料在經傳遞後到達了接收端。 在此範例中第 11 行接收端的引數變數 s6 為汙染資料,因為變數 s6 是從來源端 的汙染資料所傳遞而來,將此定義為一個網頁應用程式安全弱點。而弱點定義的 精確度跟對程式汙染傳遞分析的能力有關,如果能夠精確判斷傳遞過程,就能做 越精確的弱點定義。目前汙染資料流分析可以分成靜態分析方法[6]與動態分析 方法[4]、[18]兩種類別,無論是靜態或動態在判斷弱點的準確度部分以及涵蓋率 各有其優缺點。. 21.
(30) 2-2-2-2 測試為基礎的分析方法 在目前測試方法中,廣泛用來做網頁應用程式弱點驗證為滲透測試方法。產生惡 意的攻擊測試案例,封裝成 Http Request 傳送到網頁應用程式。策是案例攻擊成 功代表造成真正的弱點,就會造成像是整個網頁應用程式癱瘓。測試方法基本上 分成測試案例產生與測試案例執行兩部分,能夠做到自動化產生測試案例並執行 作弱點驗證。但對測試為基礎的方法來說,困難點在於當測試案例產生不夠完整 時,就無法保證測試出程式中所有潛在的弱點。 由於本論文研究與測試案例產生有關,是屬於測試為基礎的方法中白箱測試 的方法。白箱測試擁有程式源碼的資訊,可以利用靜態分析技術找出程式中所有 可執行路徑。再利用自動化產生測試案例的技巧符號化執行(Symbolic Execution), 將程式路徑上真的變數都替換成符號化變數(Symbolic Variable)。以抽象執行取代 實際執行程式的概念蒐集路徑上的限制(Constraint),在配合限制解決(Constraint Solving)解出限制,自動地產生測試案例。 在此說明利用靜態分析產生測試案例所需的背景知識。靜態分析原本為程式 分析中的一種技巧,常見於編譯器用來作程式的優化,在不需要執行程式的前提 下分析程式碼進而取得需要的資訊。其中資料流分析是靜態分析中使用到很重要 分析概念,要做資料流分析我們需要知道程式的邏輯順序。因此,靜態分析以控 制流程圖(Control Flow Graph, CFG)來記錄整個程式中路徑分支的關係。其中控 制流程圖中的節點代表一個基本分析區塊(Basic Block),例如以一個程式語句 (Statement)為單位,節點跟節點之間就代表執行的路徑。根據控制流程圖資訊輔 助,我們能夠藉此對程式進行資料流分析。 控制流程圖是以函式為單位,所以只是分析函式內部控制流程圖,稱為程序 內的分析(Intraprocedural Analysis)。隨著想要得到的資訊不同,分析進行的方向 又可分為 Forward 分析和 Backward 分析。假設我們想要知道在某個程式進入點 的變數是否已經被定義過,我們需要靠 Forward 分析。反之我們想要知道此變數 在未來是否會被重新定義,我們則需要 Backward 分析。至於函式跟函式之間的 22.
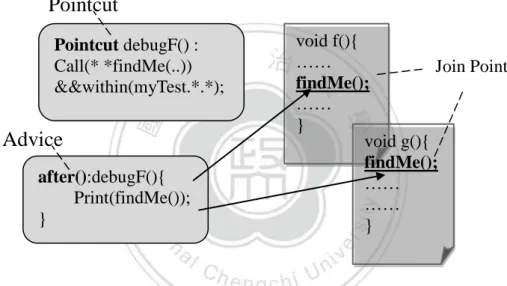
(31) 資 料 流 分 析 , 我 們 需 要 程 式 呼 叫 圖 (Call Graph) 的 輔 助 以 達 成 跨 程 序 分 析 (Interprocedural Analysis)。有了這些概念後,對於測試案例產生,我們需要利用 資料流分析來找出路徑,才能再進一步的分析無論是程序內部的路徑或是跨程序 的路徑,並進行路徑限制蒐集與解決。 2-2-2-3 剖面導向程式設計(Aspect-Oriented Programming) 剖面導向程式設計是專門處理橫跨性關注(Crosscutting concerns)議題的技術。在 網路應用安全研究中,使用者輸入的資料來源以及接收點在網頁應用程式中可能 分散在各處,要追蹤他們之間的關係其實就屬於一種橫跨性關注的應用。. Pointcut void f(){ …… Join Point findMe(); …… } void g(){ findMe(); …… …… }. Pointcut debugF() : Call(* *findMe(..)) &&within(myTest.*.*);. Advice after():debugF(){ Print(findMe()); }. Figure 2.10 AOP pointcut and advice mechanism. 剖面導向程式設計中最重要的機制就是 Pointcut and Advice 機制,我們利用 Figure 2.10 的例子說明剖面導向程式的 pointcut and advice 機制。其中 pointcut 是用來描述程式中橫跨性關注的所在,在此描述為在 myTest class 下所有呼叫 findMe()的程式所在點(Join Point)。advice 則是當找到符合 pointcut 的程式所在點 就執行我們想要做的事。pointcut and advice 機制在此例子首先找到符合 debugF pointcut 所有的 findMe()函式,由於 advice 是 after 的類型,所以將會在執行呼叫 findMe()之後再去執行 Print 的動作。. 23.
(32) 第三章 系統架構 此章節主要描述本論文系統架構設計原因,接著是系統架構概觀的描述以及系統 架構內部主要系統元件負責處理的工作。首先從一個 Java 網頁應用程式範例點 出整個系統設計的考量與目標,並去討論我們需要設計什麼樣的系統架構以達成 我們的目標。再分別針對測試案例產生與測試案例執行的設計考量進行討論,先 以一個概觀的角度來描述系統所有元件設計的因果關係,接著在第四章會再說明 實作的細節。. 3-1 系統設計考量與目標 為了清楚地描述本論文系統設計的考量與目標,我們特別設計一個 Java 網頁應 用程式的範例 Figure 3.1 為 Java Servlet 程式。從此範例中首先描述本論文研究想 要達成的目標,接著帶出我們系統設計的考量。 從第一章的研究動機與目的可知本論文研究希望藉由產生完備的測試案例, 並配合動態的污染資料流分析,同時改善動態分析的弱點漏報以及靜態分析的弱 點誤報。為了產生趨近完備的測試案例,從 Figure 3.1 的程式範例會指出我們在 測試案例產生的階段需要面對哪些問題與考量。為了進一步減少弱點誤報的情形, 在此我們會說明為何需要在測試案例執行階段加入動態剖面導向程式語言,來幫 助作程式弱點的驗證。 首先從 Figure 3.1 可以看到程式有三個危險的程式接收點(Sink),分別在第 9、 12、19 行。其中注意第 12 行的程式接收點,根據程式邏輯我們可以知道程式不 可能執行到這個接收點。原因在於第 11 行的條件式(Branch Condition)永遠不會 成立,因為與第 6 行的條件判斷式相互矛盾。當字串變數 name 長度大於等於 5 24.
(33) 也就包含 name.equals(”Admin”)的情況。但對靜態分析來說,會將此也視為一個 弱點所在。在此我們想要強調的是,採用測試案例產生的方法,我們可以確認到 達此接收點的程式路徑是不可執行的。因此,改善對於靜態分析來說會產生誤報 的情況。 01 protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException { 02. String name = req.getParameter("name");. // Source 1. 03. String id = req.getParameter("id");. // Source 2. 04. PrintWriter writer = resp.getWriter();. 05. int sum;. 06. if (name.length() >= 5) {. 07. id = idCheck(id);. 08. if (id.length() >= 5) {. 09. writer.println(id);. 10. // Sink point 1. }. 11. } else if (name.equals("Admin")) {. 12. writer.println(name + id);. 13. // Sink point 2. } else {. 14. sum = 2;. 15. for (int i = 0; i < id.length(); i++) {. 16. sum++;. 17. }. 18. if (sum > 15) {. 19. writer.println(name + id);. 20 21. // Sink point 3. } }. Figure 3.1 A Java Servlet example for describing the design of the system. 產生測試案例一定會面臨的挑戰就是測試案例產生的完備性,也就是程式路徑涵 蓋率(Coverage)的問題。要是產生的測試案例不夠完備就會造成弱點漏報的發生, 比起誤報,弱點的漏報是更具危險性的。因此,測試案例產生的目標是要產生完 備的測試案例來保證不會有弱點漏報的情況發生。下面會說明要達成路徑涵蓋率 的目標,需要哪些考量。. 25.
(34) 01. public String idCheck(String s) {. 02. if (s.matches("[A-Z][^a-z]+")) {. 03. return s;. 04. } else {. 05. String[] array = new String[]{s,"00000"};. 06. return array[1];. 07 08. } }. Figure 3.2 Inter-procedural call out method idCheck of Java Servlet example. 首先從程式範例中第 7~9 行可以看到一個跨程序的外部呼叫函式 (Inter-procedural call out method) idCheck,Figure 3.2 為函式 idCheck 的程式碼。 可以看到函式 idCheck 回傳值會影響變數 id 的值,而變數 id 又會影響第 8 行條 件式的成立與否。條件式成立就會到達第 9 行的程式接收點,所以跨程序的路徑 分析(Inter-procedural path analysis)是測試案例產生一定要處理的問題。加上程式 幾乎都有呼叫外部函式的情況,所以這是首要考量的路徑涵蓋問題。接著我們看 程式範例第 14~19 行,可以看到變數 sum 會受迴圈影響而改變最後的變數值。 其中變數 sum 會影響第 18 行條件式的成立與否,也就會影響路徑是否會到達接 收點而形成一個弱點。所以另外一個要考量的路徑涵蓋率問題就是迴圈的路徑處 理問題。尤其在不知道迴圈會執行幾次的情況下,迴圈可能會對程式的路徑帶來 無限種的可能,對於迴圈處理的細節與討論在後面的章節會再進一步說明。 說明完測試案例產生的設計考量與目標之後,接著是測試案例執行的部分。 在產生完備的測試案例之後,我們知道每一組測試案例都代表著一條潛在弱點的 可執行路徑,但是這些路徑中可能還潛藏一些誤報的可能性。我們先看 Figure 3.1 的第 9 行的第一個程式接收點,到達此接收點跟變數 id 的長度有關,變數 id 會 受外部呼叫函式 idCheck 的影響。接著從 Figure 3.2 看到函式 idCheck 分成兩條 路徑,第一條路徑在符合第 2 行條件式下回傳變數 s 值;而第二條路徑在第 5 行 陣列 array 會分別在 array[0]和 array[1]存入變數 s 與常數值”00000”,第 6 行回傳 26.
(35) array[1]為常數值”00000”。回顧 Figure 3.1 中第 7 行 id 變數的值,上述兩條路徑 回傳值的結果都會使 id 變數長度符合第 8 行的條件式而到達程式接收點,但只 有第一條路徑會造成潛在弱點。因為第二條路徑經過的陣列初始化後,靜態分析 只知道汙染資料變數 s 會被加入陣列中,而將整個陣列視為被污染。無法辨認 array[1]為常數值”00000”,實際上不會造成弱點發生,是一種誤報的情況。 而在測試案例執行的目標就是希望進一步利用弱點判斷的準確性改善弱點 誤報。我們利用剖面導向程式語言 AspectJ 對目標程式作插碼來實現動態汙染資 料流分析,以達成改善誤報的目標。以上就是本論文系統設計想要達成的目標以 及考量,後面會開始作系統架構概觀的描述與系統元件的設計概念。. 3-2 系統架構概觀 本論文研究的系統架構是結合靜態分析和動態測試以及剖面導向程式語言 (Aspect-Oriented Programming Language, AOP Language)達成弱點的驗證。利用靜 態分析方法自動化地產生完備的測試案例;在動態測試的階段結合剖面導向程式 語言 AspectJ 實作的汙染資料流分析,配合測試案例的執行,去追蹤測試資料的 流向、驗證此測試案例所執行的路徑是否含有潛在的弱點。並改善誤報、回報程 式潛在弱點的所在。 Test Case Generator. Java Web Program. Test Cases. Test Case Executor. Analysis Result Figure 3.3 High-level Overview of Our System Architecture 27.
(36) 整個系統採用動靜態分析互補的概念設計,藉由靜態分析來達成程式路徑涵 蓋率的優點,自動化的分析出程式所有包含潛在弱點的可執行路徑,以保證不會 有弱點漏報的情形發生。再藉由半自動化動態測試方法,結合剖面導向程式語言 AspectJ 的插碼技術。隨著實際執行測試案例追蹤測試資料的流向,以達到動態 分析方法判斷弱點準確性高的優點,進一步改善弱點誤報。Figure 3.3 為我們系 統架構的概觀圖,從圖中我們可以清楚地看到整個系統架構分成兩個主要元件, 測試案例產生器(Test Case Generator )與測試案例執行器(Test Case Executor)。測 試案例產生器負責自動化產生完備的測試案例來涵蓋程式所有可執行路徑;測試 案例執行器則負責自動化地執行測試案例並產生最後弱點分析結果。 本論文研究重點擺在於如何產生完備的測試案例,測試案例執行中使用剖面 導向程式語言 AspectJ 來實現汙染資料流追蹤分析的部分,是參考本實驗室江尚 倫同學的論文[2]。利用他的混合式 Java 網頁應用程式分析工具中的污染資料追 蹤器(AspectJ Taint Tracker)。 Figure 3.5 為我們整個系統架構的流程圖,可以更清楚看到測試案例產生與 測試案例執行的過程中還有哪些更細部的元件。這些元件都扮演很重要的角色以 達成上一節中提到的系統考量與目標,在下面的元件介紹會再概述每個元件所負 責的工作為何。 測試案例產生的部分,我們使用白箱測試(White-box Testing)的方法。其中符 號化執行(Symbolic Execution)技巧在許多相關研究中被用來實現測試案例的產 生,符號化執行的基本概念就是執行程式時,利用符號化變數(Symbolic Variable) 來取代變數真正的值。不是不用執行程式而是執行不用到真正值,是一種抽象的 執行。Figure 3.4 展示整個符號化執行的基本概念,首先使用符號化變數來取代 真正的變數值。範例程式第 1 行變數 y 的值為使用者輸入,因此我們將它替換成 符號變數 s,因此變數 x 的值也符號化變成 s+3,這就是符號化執行的主要想法。 接著看用圖形呈現函式的控制流程圖(Control Flow Graph),我們可以清楚地 看到此範例程式包含兩條控制路徑(Control Path),每條控制路徑上都有路徑條件 28.
(37) (Path Condition),當符合 x > 0 的路徑條件時就會執行控制路徑 1,而符號化執行 的目的就是探索程式中所有控制路徑,每條控制路徑上的變數在作符號化後,會 隨著路徑條件蒐集的過程將路徑條件中的變數作符號化取代,我們將這些路徑條 件稱之為路徑限制(Path Constraints)。 在蒐集完整的路徑限制之後,路徑限制的表達式也會替換成符號化的樣式。 在 Figure 3.4 的下方框格中,可以看到最後路徑 1 與路徑 2 輸出的路徑限制。接 著經由路徑限制分析器來解這些蒐集好的路徑限制,就能知道使用者輸入在哪些 值域範圍內能執行哪一條路徑,因此,找到限制解就代表產生了一組測試案例能 夠執行經過此路徑。 01 y = input(); 02 x = y + 3; 03 04 if (x > 0){ 05 // do something 1 06 } 07 else{ 08 // do something 2 09 }. y = input(); x = y + 3; x>0 True. False. Control Path 2. Control Path 1. Path 1 : x > 0 => y+3 > 0 => s+3>0 Path 2 : x <= 0 => y+3 <=0 => s+3<=0 Figure 3.4 The basic idea of Symbolic Execution.. 以控制路徑 1 為例,蒐集到的路徑條件 x > 0 先被取代成 y+3 > 0,再換成 成符號化變數 s+3>0。我們可以得知路徑限制解為 s > -3,也就是當使用者的輸 入值大於-3 時,因此 我們就可以產生一組測試案例如 y = -2,讓程式執行路徑 1。 以此類推路徑 2 就可以產生測試案例如 y = -3。 有了符號化執行來產生測試案例的概念之後,我們知道測試案例產生的完備 性取決於路徑限制蒐集的完整性。所以本論文研究的重點就集中在要如何才能蒐 集完整的路徑限制,回顧上一節在測試案例產生的考量部分,提到程式可執行路 29.
(38) 徑涵蓋率的問題。其中提到程式中一定會出現的外部函式呼叫和迴圈都會影響路 徑限制蒐集的完整性問題,所以在遇到跨程序的外部呼叫函式和迴圈時,如何蒐 集完整的路徑限制就是本論文研究的分析重點,稱之為跨程序的路徑分析。其中 用到許多程式分析或是靜態分析的技巧,在之後實作的章節會再詳細說明。. 3-3 系統主要元件介紹 Figure 3.5 為本論文系統架構的流程圖,圖中包含兩個主要流程,分別為測試案 例的產生與測試案例的執行。系統架構的輸入為 Java 網頁應用程式,首先是測 試案例產生的流程,我們根據目標程式的入口函式(Entry Method),開始進行測 試 案 例 的 產 生 。 其 中 可 以 看 到 三 個 主 要 的 元 件 分 別 為 函 式 排 序 器 (Method Sequencer)、路徑限制蒐集器(Path Constraint Collector)和路徑限制分析器(Path Constraint Solver)。. Java Web Program Test Case Execution. Test Case Generation Method Sequencer. AspectJ Taint Tracker Instrumented Java Web Program. Program Executor. Method Sequence *[All methods in back order]. Path Constraint Solver * [All path constraints]. Test Cases. Path Finder and Constraint Collector. Paths and Constraints. Analysis Result. Figure 3.5 The Flow Chart of Our System Architecture 30.
(39) 從圖中的流程來做說明,第一個函式排序器主要負責產生待處理函式的正確 順序,目的是為了處理跨程序的外部函式呼叫問題。因為一個程式的入口函式內 部可能還有其他呼叫外部函式存在,以甚麼樣的順序安排這些外部函式、應該先 處理或是後處理,都會影響後續路徑限制蒐集的完備性。因此,函式排序器的工 作就是負責排序好正確的函式順序,接著按照此順序將函式一個一個取出來交給 下一個路徑限制蒐集器,對函式進行完整的路徑限制蒐集。一直到所有的函式都 蒐集完成後,最後就可以得到我們目標程式的完整路徑限制。接著再將這些路徑 限制交給路徑限制分析器去解,解出來的限制代表所有可執行路徑的測試案例。 在產生測試案例之後,我們進入第二個流程測試案例的執行,其中可以看到 兩個主要的元件。分別為汙染資料流追蹤器(AspectJ Taint Tracker)和程式執行器 (Program Executor)。首先我們的污染資料流追蹤器會對我們的目標 Java 網頁應 用程式進行程式插碼達成動態汙染資料流分析,目的是要追蹤資料的流向以驗證 弱點的所在。經過剖面導向程式語言 AspectJ 的編譯器的編譯後產生插碼過後的 程式碼,接著再交給程式執行器去自動化執行程式並產生最後的弱點分析結果。. 以下分別對系統架構流程圖的系統元件再作進一步的介紹。 . 函式排序器(Method Sequencer) 上述描述系統架構流程中,已經提到函式排序器負責的工作與目的,實際上. 函式排序器有兩個步驟。第一是先建立程式呼叫圖(Call Graph),找出跨程序的函 式和函式之間彼此的呼叫關係。接著第二步驟再根據建立好的呼叫圖,以及根據 呼叫的關係來產生最後的函式順序以提供給路徑限制蒐集器作分析。 . 路徑尋找器與限制蒐集器(Path Finder and Constraint Collector) 因為我們使用 SOOT[16]Java 優化工具進行程式分析,路徑限制蒐集器實際. 上是分析 SOOT 提供的函式控制流程圖(Control Flow Graph)。重點在於先找出函 式中所有正確的路徑,其中包含迴圈路徑的處理,由於迴圈可能造成函式的路徑 有無限的可能,因此我們參考迴圈分析相關研究[9]和[15]的概念,將迴圈主要分 31.
(40) 成兩條路徑。一條是有經過迴圈內部的路徑,另一條則是沒有經過迴圈內部的路 徑,諸多實作的細節與考量在論文的第四章會有詳細的說明。除了迴圈路徑的處 理之外,路徑限制蒐集器主要的工作分成兩個。其一為上述提到的如何找出函式 中所有需要被進一步分析的路徑,尤其是含有潛在弱點的路徑。其二為如何從找 到的路徑去做完整的路徑限制的蒐集,以產生完備的測試案例。整體來說,重點 在於如何執行跨程序的路徑分析與路徑限制蒐集。路徑限制蒐集器是本論文研究 的重點所在,在此我們只以概觀的角度描述路徑限制蒐集器所負責的工作。 . 路徑限制分析器(Path Constraint Solver) 路徑限制 分析器 在本 論文研究是利用現成的限制分析器 Kaluza String. Solver[14]。此分析器能夠解字串、布林代數和基本整數常數的算術運算,因為 網頁應用程式的汙染來源都來自字串的型態的使用者輸入,所以利用此分析器恰 好符合我們產生測試案例的需求。 . 汙染資料流追蹤器(AspectJ Taint Tracker) 污染資料流追蹤器實際上指的是剖面導向程式語言中的一組完整作資料流. 追蹤分析的剖面(aspect)。剖面導向程式語言是以一種對程式插碼的概念,以達 成程式在動態執行階段,能夠利用 Runtime 資訊再多做一些額外的處理,所以這 個剖面的內容就是想要額外的在程式執行過程中也同時做資料流追蹤,再配合測 試案例的執行追蹤弱點的所在。 . 程式執行器(Program Executor) 因為本論文研究的測試程式是 Java Servlet 程式,我們選擇在網頁為基礎測. 的試架構(Web-based Architecture)下作測試案例的執行。因此我們需要一個能夠 執行程式的伺服器,其中專門處理的 Java 網頁應用程式的伺服器就是 tomcat, 我們將測試案例封裝成 HTTP URL 形式來自動化的執行,並針對每組測試案例 產生最後的弱點分析結果。. 32.
(41) 第四章 系統實作方法 此章節主要在描述本論文系統架構實作的細節,重點擺在測試案例產生的部分。 其中會先以一個測試案例產生的演算法勾勒出測試案例產生的完整流程,在了解 系統的流程之後,為了能夠清楚地了解我們實作方法的細節,我們會將實作的內 容分成跨程序的路徑分析與反向路徑限制蒐集兩部分做說明,其中會以第三章提 出的程式範例,隨著實作的步驟做結果的展示來幫助說明。而在測試案例執行的 部分我們會說明我們套用哪些方法來做自動化的測試以及如何利用剖面導向程 式語言 AspectJ 作汙染資料流分析的實作細節。. 4-1 測試案例產生的實作(Test Case Generation) 我們是利用 SOOT[16](A Java Optimization Framework)來對目標程式做靜態分析 以 產 生 測 試案 例 ,在此 我 們 的 分析 是 建立在 SOOT 提 供 的一種 中 繼 表 示 (Intermediate Representation, IR ) Jimple code 上面。Jimple code 是一種三地址碼 (3-address code),內建有以函式為單位的控制流程圖(Control Flow Graph, CFG), 我們測試案例產生的實作都是從對函式的控制流程圖做分析開始的,在後面我們 會說明如何藉由程序內的函式控制流程圖來達成整個跨程序的路徑分析。 4-1-1 測試案例產生演算法(Algorithm for test case generation) Figure 4.1 為我們測試案例產生的演算法,其中給定的輸入為目標程式以及目標 程式的入口函式,最後的輸出為分析過後產生的測試案例。因為整個路徑限制蒐 集是跨程序的,所以首先需要由入口函式的控制流程圖來建立程式的呼叫圖(Call Graph),而對呼叫圖的每個函式都給予一個唯一的函式 ID,這是為了避免路徑 限制命名衝突的問題。然後根據呼叫圖,我們以反向呼叫順序(Backward Calling 33.
(42) Input : Program P, EntryMethod EM Output : Test cases for vulnerable paths in P //each method contains : (1) cfg: control flow graph // (2) id: an unique method id /* Method Sequencer: 1. construct the call graph 2. determine the method sequence from the call graph */ callgraph := constructCallGraph( EM.cfg); methodSequence := [m | m ϵ callgraph in backward calling order]; /* Path Constraint Collector: 1. path identification and analysis 2. backward path constraint collecting */ Foreach m in methodSequence do // path identification and analysis m.cfg’ := cfgPreprocessing(m.cfg ); //do loop, sink, call out stmt tagging m.cfg’’ := LoopPathHandling(m.cfg’); //do Trip Count Information tagging //discover all paths from control flow graph in Depth-First Search pathSet := PathFiltering(m.cfg’’); //locate vulnerable path ssaPathSet := SSATransformation(pathSet); //transform path to SSA form //backward path constraint collection //pc : path constraint, pcSet : path constraint set, pcTable : path constraint table Foreach p in ssaPathSet do pc := BackwardPathConstraintCollection(p); put pc. into. pcSet;. End pcTable[m.id] := pcSet End /* Path Constraint Solver */ pcSet := pcTable [EM.id] ; Foreach pc in pcSet do TestCase := PathConstraintsSolving(pc); put TestCase in. TestSuite. End Figure 4.1 Algorithm for Test Case Generation. 34.
數據

![Figure 2.1WebSSARI System Architecture in [6]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8277806.173013/14.892.136.644.502.955/figure-webssari-system-architecture-in.webp)
![Figure 2.3 Judgment Rules in [6].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8277806.173013/16.892.159.738.120.800/figure-judgment-rules-in.webp)
![Figure 2.4 為系統架構圖可分成三個重要的元件,Taint Tracker、Online Analyzer 和 Program Executor。首先是剖面導向程式 AspectJ 實作的 Taint Tracker Aspect 元件,利用剖面導向程式 pointcut and advice 機制的技術。應用 AspectJ 現存的 Pointcut 類型去實現[10]所提出的 Data-flow Pointcut,負責對程式源碼進 行插碼,追蹤程式中接收點使用的資料使否來自汙染資料來源;](https://thumb-ap.123doks.com/thumbv2/9libinfo/8277806.173013/18.892.144.752.117.446/Figure件利面導向程機制技術應用現存類型去實提出Pointcut負責對程式源碼進.webp)
+7
![Figure 2.6 An architecture diagram of testing framework in [8].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8277806.173013/20.892.137.755.484.1090/figure-architecture-diagram-testing-framework.webp)
![Figure 2.8 ARDILLA Framework in [7].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8277806.173013/23.892.223.688.374.749/figure-ardilla-framework-in.webp)


相關文件
(一)體能測驗:研習人員體能測驗,男女生3,000公尺徒手跑步,成績計算
在撰寫網頁應用程式 HTML 的語法當中,以下何者錯誤?(A)<a>是用來製作超連結的標記(Tag) (B)HREF 是一個在<a>與</a>中指定其他
二、應檢人員須攜帶附有照片足資證明身分之國民身分證、護照、全民健康保險卡或駕駛執 照之身分證明文件、准考證、術科測試通知單及規定之自備工具應檢,請於 7
主席身份證明 校監書面 確認 會議紀錄 校訊、學 校網頁資 料等 校友校董 教育條例 40 AP.
教育局網頁 www.edb.gov.hk > 課程發展 > 課程範疇 > 全方位學習. 與津貼有關的重要資訊 會通過聯遞系統 Communication and Delivery
本彙集輯錄了多篇學校經驗分享的文章,闡述「管理與組織」範疇的各項全校 參與訓育及輔導工作模式的重點,請參閱教統局網頁,索引: 本局向學生及家 長提供的服務 >
(網站主頁 > 課程發展 > 學習領域 > 藝術教育 > 教學資源 >視覺藝術
第三十九條 術科測試應 檢人進入術科測試試場 時,應出示准考證、術 科測試通知單、身分證 明文件及自備工具接受 監評人員檢查,未規定
