可提供語意搜尋之部分知識建構
王宗一 謝東成 陳慶龍 林群貿 國立成功大學 工程科學系 [email protected]摘要
近十年網路的發明帶動著資訊大量的 流通。由於許多知識已經數位化,故造成 資訊氾濫相關問題。因此,如何正確、有 效率的重複利用知識是目前重要的研究議 題。目前最常被用來尋找知識的工具為 Google 或 Yahoo 搜尋引擎,所依賴是輸入 關鍵字利用資訊檢索的技術獲取網頁相關 資訊,再由使用者自行閱讀並組織知識。 如果搜尋結果非常龐大,使用者必須花費 很多時間去瀏覽內容,以找尋所需的資 訊。有鑑於此,本研究將提出一套自動化 建構部份知識本體的方法以提供問答系統 的語意搜尋資料來源。其方法是將問句本 身的語意擴展,再從體育新聞內容中自動 建構所屬的部份知識本體,作為回覆答案 的資料集。經過實測所得數據顯示本研究 方法有顯著的效果。 關鍵詞:資訊檢索、知識本體、問答系統一、前言
目前知識本體建構必須依賴專家的參 與,如果可以自動化建構知識本體,將可 節省知識管理的人力,所建置的知識本體 也會因為減少人的介入而降低不必要的錯 誤。自動化建構的另一項優點就是知識本 體的結構較為彈性。人工建置類別架構可 能是依據當時的資料內容與屬性才能定 義,然而隨著時間的變化資訊內容可能也 跟著轉變,如果沿用先前制定的知識本體 架構,知識的表達可能就不符合實際狀況 而產生不符需求或錯誤。如果知識本體可 以隨著時間與資料內容的變化自動調整, 資料內容可以更正確的對應到合適的知識 類別,在問題的推論上也會更準確。對於 問答系統而言可以幫助使用者獲取知識, 為了達到此目的則必須結合人工智慧、自 然語言處理與資料檢索的技術,並正確的 辨識問題類型以回覆適合的答案,但目前 問答系統的效能還有很大的進步空間。 因 此 本 研 究 利 用 Formal Concept Analysis, FCA 方法建構部份知識本體,將 其整合在問答系統內,利用其概念的關聯 性找出正確的資訊給使用者,使問答系統 的效能提昇。本研究以網路電子媒體報導 體育新聞為題材,如 NBA 籃球新聞。利 用中文斷詞系統切割新聞詞句,處理後的 資料經過分析過濾,將有意義的詞彙儲 存,提供建構知識本體的素材。使用者對 問答系統輸入問題,系統分析問句並將問 題分類並擴展產生物件集與屬性集,利用 FCA 分析所形成的概念,初步建立階層關 係,再依據新聞內容標定關係的描述,由 此形成部份體育知識本體。問句的類型也 經過剖析、分類,再依據其問題類型與所 建構的部份體育知識本體回答使用者問題 的答案。 本研究後續架構如下:第二節說明相 關文獻探討。第三節說明本研究所提出之 系統架構,分別包含三個子系統即文件前 處 理 子 系 統 (Documents Preprocessing Subsystem)、詢問式知識本體建構子系統 (Query-based Ontology Construction Subsystem)以及語意問答子系統(Semantic Aware Question Answering Subsystem)。第 四節為本研究實驗結果部分。最後,第五 節則是本研究的結論部分。二、相關文獻探討
(一) 知識本體(Ontology) 知識本體源自哲學理論,其意義是有 系統的解釋存在的現象。主要探討存在現 象的一切現實事物的基本特徵。知識本體 定義了一個主題領域的構成詞彙,包含詞 彙間基本條件與關係,以及延伸詞彙所定 義的基本條件與關係的法則,是一種正規 化的(Formal)、明確的(Explicit)、概念化的 (Conceptualization)、可分享的(Share)描述 的邏輯理論[6] [7] 。 知識本體敘述是以名詞所代表真實存 在的實體或概念,而概念是知識的最小基 本單位或元素。這種具有抽象與具象的元 素,很適合表達資訊領域的知識,資訊技 術相關領域逐漸藉由知識本體的基本元 素:實體、概念及概念間的關係,作為描 述真實世界的知識模型[8] 。針對此一趨 勢,W3C 組織制定許多知識本體的相關表 示語言,例如 RDF、DAML+OIL、OWL… 等[4] 。透過這些語言可將知識本體當成 語意網的骨架,而知識本體提供人與系統 之間可分享的、可理解的與重複使用的溝 通平台[10] 。 描述知識本體的重要元素包括有:概 念(Class 或 Concept)、屬性(Attribute 或 Property)、實例(Instance)、關係(Relation)。 描述知識本體的範例,如圖 1 所示。範例 所描述的概念 Car 下有包含有兩個子概念 (Subclass) 為 Two-wheel drive 以 及 Two-wheel,如果 Car 這個概念具有屬性: 引擎、方向盤、輪子…等,其子概念將繼 承父概念的所有屬性,也就是說子概念 Two-wheel drive 同樣也有概念 Car 的屬 性 : 引 擎 、 方 向 盤 、 輪 子… 等 。 概 念 Two-wheel drive 的實例為 Altis,實例將繼 承父概念所有的屬性,也可能具備與其他 實例不同的獨特屬性,以表現與其它實例 的差異性,例如:實例 Altis 與實例 Benz ML63AMG 皆有引擎、方向盤、輪子…等 屬性,但在內裝配備的屬性值上會大不相 同。概念與概念之間或概念與實例之間使 用關係描述來表現彼此的關聯性。例如實 例 Sailboat 與 概 念 Ship 存 有 關 係 instance_of,說明 Sailboat 是 Ship 的一個 實例。 Vehicle Two-wheel drive Four-wheel drive Benz ML63 AMG AltisSaiboat Endeavour Atlantis Shuttle Ship Car Class Instance Instance_of Kind_of 圖1 知識本體概念描述範例 (二) 正 規 概 念 分 析 (Formal Concept Analysis, FCA) 正 規 概 念 分 析 (Formal Concept Analysis, FCA)是一種理論方法,用於分析 辨識一組資料集合的概念結構[3] 。1982 年 Rudolf Wille 介紹推廣後,相關的研究 已迅速增加。FCA 的分析方法成功的應用 在各領域之中,例如:醫學、心理學、語 言資料庫…等。其原因在於它具有可以產 生視覺化內部結構圖表的能力。特別是用 於社會科學領域,處理不能被完全定量分 析的資料集合之研究。在資訊科學領域, FCA 使用的數學方格(Lattice)可應用在分 類系統上。依據他們的類別屬性建構階 層。以下說明正規概念分析之定義。 一個正規化的本文具備三個部份表示 為
G,M,I
。 G 與 M 分 別 為 集 合 , M G I 則表示 I 為 G 與 M 所形成二元 關係的集合。G 集合內的元素稱為物件 (Objects) , M 集 合 內 的 元 素 稱 為 屬 性 (Attributes)。一般表示(g,m)I 可以寫成gIm,表示為 Object g 存有 Attribute m 其
二元關係屬於集合 I 之一[3] 。對所有
G
A 且BM 時且 A 與 B 為有限集合 時,定義如下:
Im} ) ( | { ' g A g M m A Im} ) ( | { ' g B m G g B ' A 集合是所有物件 A 集合內所有的 屬性集合。 ' B 集合是所有包含屬性 B 集合 的物件集合。而本文
G,M,I
內的某一概 念(Concept)定義為(A, B),其中A 、G M B 、A' B、B' A。(A, B)的 A 稱 為範圍(Extent),B 稱為含義(Intent)。 除此之外,如果(A, B)是唯一的概念, ) , (A A' 的範圍為 A,若且唯若A'' A且 B B'' 。G 的概念子集合(A,A')是擁有集 合 A 所有範圍的一個獨特的概念,概念 ) , (B B' 亦同。如果本文內所有的概念集合 存 在 (A1,B1)與 (A2,B2) 這 兩 概 念 , 若 2 1 A A 則(A1,B1)(A2,B2)。 近一步的 說 , 因 為 '' 1 1 A A 且 2 '' 2 A A , 所 以 當 2 1 A A 時意味著 ' 2 ' 1 A A 也就是B1 。B2 2 1 2 1 2 2 1 1, ) ( , ) (A B A B A A B B三、系統架構
Question Answer Retrieval Agents Documents Preprocessing Subsystem Query-based Ontology Construction Subsystem Semantic Aware Question Answering SubsystemSports news website
User Meaningful Term Database Query-based Partial Ontology 圖2 系統架構圖 圖 2 為本研究所提出的系統架構,分 成下列六個部分: 首先,新聞擷取器(Retrieval Agents) 將所擷取的新聞資料內容,儲存於系統 內,作為系統執行的資料來源。文件前處 理 子 系 統 (Documents Preprocessing Subsystem)負責處理原始新聞內容,包括 有兩個主要功能模組分別是詞彙分析模組 (Term Analysis Module)以及內文分析模組 (Context Analysis Module)。詞彙分析模組 切割原始新聞語句並標記詞性,濾出欲分 析的詞彙並將結果存放至有意義詞彙資料 庫(Meaningful Term Database);內文分析 模組則是分析新聞內容段落,並且輸出詞 彙同現矩陣(Co-occurrence Matrix)。有意 義詞彙資料庫紀錄文件前處理子系統產生 的有意義詞彙資料集,提供系統執行時可 以依照詞彙同現矩陣的紀錄,快速且有效 率取用有意義詞彙。 詢 問 式 知 識 本 體 建 構 子 系 統 (Query-based Ontology Construction Subsystem)是依據使用者輸入的問句,利 用正規概念分析方法建構詢問式之部份知 識本體(Query-based Partial Ontology),此 知識本體初步建構有階層性的概念結構, 再參照原始文章的語句描述,標記關係的 名稱以提供系統作為回答問題的資料集來 源。
語 意 問 答 子 系 統 (Semantic Aware Question Answering Subsystem)可分為三 個部份即分析問句、回覆問題答案與系統 評 估 。 問題 分 析模 組 (Question Analysis Module)的目的是將使用者所詢問的問題 進行切割、過濾出有意義的字詞並標記問 題類型。答案分析模組(Answer Analysis Module)的目的為分析問題的類型,取得詢 問式之部份知識本體的資料集做為回答問 題 的 資 料 來 源 。 最 後 , 後 端 評 估 模 組 (Evaluation Module)將相關的問答資訊皆 儲存於資料庫提供專家(Domain Experts) 檢視與驗證之用。 本研究主軸分別架構於三個子系統之 中,分別是:文件前處理子系統、詢問式 知識本體建構子系統以及語意問答子系 統,以下詳細說明每一個子系統的處理流 程。 (一) 文件前處理子系統 此子系統包括有詞彙分析模組與內文 分析模組,首先詞彙分析模組是將新聞擷
取器(Retrieval Agents)所取得的原始新聞 資料,利用中央研究院所開發的中文斷詞 系統 CKIP [12] 將新聞詞句切割為有意義 的詞彙集並標注該詞彙之詞性。再利用詞 彙 過 濾 器 (Term Filter) 篩 出 具 有 意 義 詞 彙,如下表 1 為本研究欲保留之具有意義 的詞彙集合。其主要目的在去除無意義的 虛詞,如:介詞、副詞、連接詞、助詞…, 並 將 結 果 儲 存 於 有 意 義 詞 彙 資 料 庫 (Meaningful Term Database)。
表 1 有意義詞組範例表 詞性標注 詞性描述 Na 普通名詞 (Common noun) Nb 專有名詞 (Proper noun) Nc 地方名詞 (Place noun) Nd 時間名詞 (Time noun) VA 動作不及物動詞
(Active intransitive verb)
VC 動作單賓動詞
(Active transitive verb)
VD 雙賓動詞
(Ditransitive verb)
VHC 狀態使動動詞
(Stative unaccusative verb)
VH 狀態不及物動詞
(Stative intransitive verb)
VJ 狀態單賓動詞
(Stative transitive verb) 經過詞彙分析模組初步處理新聞資料 後,內文分析模組將進行新聞資料內文分 析。根據前模組處理後可以產生兩個集 合 , 分 別 為 : 新 聞 文 件 集 合
n
i D D D D D 1, 2, 3,..., 與 詞 彙 過 濾 器 所 得有意義詞彙集合Tj
T1,T2,T3,...,Tm
。 otherwise. , 0 , with occurs -co , 1 i j ij T D X (1) nm n n m m ij X X X X X X X X X M 2 1 2 22 21 1 12 11 (2) 利用公式(1)產生新聞文件與有意義 詞彙的同現陣列。其表示方式為公式(2)之 m n 矩陣。其中 n 表示文件的篇數,m 為 有意義詞彙的個數。此步驟所建立之同現 矩陣資訊將作為詢問式知識本體建構子系 統的二元關係矩陣產生器所取用。 (二) 語意問答子系統 語意問答系統處理使用者所輸入的問 句並依其問題的類型回覆答案。使用者輸 入的詢問句是由問題分析模組(Question Analysis Module) 處 理 , 答 案 分 析 模 組 (Answer Analysis Module)則是將答案結果 回覆給使用者。 表 2 問句樣式範例表 樣式類型 範例 WHEATHER 熱火隊教練是萊里嗎? (Nb + DE + Na + SHI + Nb + T ?) WHERE 騎士隊主場城市在哪裡? (Nb + DE + Na + Na + P + Ncd ?) WHICH_ONE 諾威茲基是哪隊的前鋒? (Nb + SHI + Nep + Nf + DE + Na ?) WHO 湖人隊的後衛是誰? (Nh + SHI + Nb + DE + Na?) WHOSE 請問歐尼爾暱稱是什麼? (VE + Nb + DE + Na + SHI + Nep ?) 首先問題分析模組部份,使用者的問 句先經由 CKIP 切割並標記詞性,再經由 詞彙過濾器篩出有意義的詞彙,藉由此步 驟系統能夠擷取出具有意義的辭彙傳送至 詢問式知識本體建構子系統中進行建構。 其後,則會標注問句焦點(Question Focus)標 籤 與 問 句 焦 點 描 述 (Question Focus Description)標籤[9] ,如標注<QF> Term A </QF>或<QFD> Term B </QFD>的標籤, 其目的在了解使用者所詢問的問題焦點, 例 如 , 使 用 者 詢 問 “誰 是 熱 火 隊 的 教 練?”,經由標注的結果為誰是<QFD>熱火 隊</QFD>的<QF>教練</QF>? 系統對問句類型的分析結果將是選取 答案的重要依據。對問句類型的辨識與解 析係依據事先收集的多種問句型式與內容 分析得來,經過所收集問句的訓練,歸納 整理出問句基本的樣式如表 2 所示。當使 用者輸入問句經過分析,如符合系統預設 的樣式類型,該問題將被標記為所符合的 問句類型。系統依符合的樣式類型標記 <QT VALUE=”XXXX”/>的標籤,標記後 的問句範例如表 3 所示。 表 3 問句類型標記 問句範例 註記標籤的問句 請問小牛隊 的教練是誰? 請 問 <QFD> 小 牛 隊 </QFD> 的 <QF> 教 練 </QF> 是 誰?<QT VALUE="WHO" /> 請問火箭隊 的主場在哪? 請 問 <QFD> 火 箭 隊 </QFD> 的 <QF> 主 場 </QF> 在 哪?<QT VALUE="WHERE" /> 請問姚明是 那一隊? 請問<QF>姚明</QF>是那一 隊 ?<QT VALUE="WHICH_ONE" /> 答案分析模組依據註記標籤決定問題 答案的範圍,並且從建置好的部份知識本 體之中搜尋適當的答案提供給使用者。圖 3 則是根據上面所提到的問題 “誰是熱火 隊的教練?”進行建構的部份體育知識本 體。此架構已具有階層結構與關係的描 述,可做為回答問題的依據。 教練 (18) 熱火隊 (41) 萊里 (8) 艾維強生 (3) 傑克森 (2) 喬丹 (2) 小牛隊 (22) 湖人隊 (13) 巫師隊 (19) 歐尼爾 (9) 韋德 (16) Direct relation Internal relation 9 2 2 3 8 8 9 8 2 1 1 1 1 4 2 1 圖3 部分體育知識本體之範例 由於詢問的問題類型不同,有時候產 生的部份體育知識本體之答案候選可能為 多個或無法直接從階層架構找出答案時, 必須挑選最合適的答案給予使用者。因 此,本研究在此部分將依據詞彙間共同出 現頻率,使用公式(3)計算資料集內與問題 有關的詞彙分數。其中 w 為一權重值,當 概念之間具有 Direct relation 時作為增加 權重的指標,其值為 0.7,相反則為 0.3。 最後,系統則挑選總分數最高者為答案提 供給使用者。 以上面的問題為例,本研究必須計算 出總分數為最高者作為提供使用者答案。 因此,熱火隊出現的句子共有 41 句;教練 出現的句子共有 18 句;熱火隊與萊里共同 出現的句子共有 8 句;教練與萊里共同出 現的句子有 8 句。因兩兩概念之間具有 Direct relation 故 w 為 0.7,再利用公式(3) 可計算出 Score(熱火隊, 萊里)=0.137 與 Score(教練, 萊里)=0.311 為最高值,因此 系統將挑選萊里作為答案提供給使用者。 w Term Term Term Score x y x 出現的句子個數 共同出現的句子個數 與 (3) (三) 詢問式知識本體建構子系統 此系統主要目的是依據使用者所詢問 的 問 題 建 構 一 詢 問 式 之 部 分 知 識 本 體 (Query-based Partial Ontology)。因此依據
語意問答系統的問題分析模組所取得的有 意義片段描述和文件前處理子系統的同現 矩陣與有意義詞彙資料庫的資料集,送到 此子系統中進行建構部份知識本體的步 驟。 此 子 系 統 使 用 Formal Concept Analysis 方法,藉由概念所包含的物件集 與屬性集來決定概念之間隱含的關係或屬 性的階層[2] [5] [11] 。其建構步驟如下: Step1: 產生二元關係矩陣與概念集 以符號
O,A,X
表示有物件集合 O 與 屬性集合 A 存在二元關係集合 X,換言之 即X OA。物件集合 O 的產生是由問 題分析模組所找出的問題焦點與問題焦點 描述的重要詞彙,從該重要詞彙的所屬的 文件集合中所有的描述語句的集合即為物 件集合 O。而 A 為該文件描述語句集合中 所有屬於有意義的詞彙的集合。 要產生一個概念集合 C,假設 S 為物 件 O 的部份集合,Q 為屬性 A 的部份集 合,則S 且O QA。該物件 S 集合的 所有屬性值為: ] ) , ( : | { ) (S aA oS a o X 而其包含 Q 屬性集合的所有物件集合 為: ] ) , ( : | { ) (Q oO aQ a o X 而概念則是一組(S,Q)所組成。換言 之即一組有意義的詞彙(屬性)與一組擴展 衍 生 的 文 章 描 述 語 句 ( 物 件 ) 其 關 係 為 ) (S Q 且S (Q)[11] [1] 。此步驟是取 得文件前處理子系統產生之同現矩陣有關 物件的資料與有意義詞彙資料庫內的資料 集,再依據其矩陣的描述比對資料庫內的 有意義矩陣的關聯性,產生具有物件集 合、屬性集合與物件與屬性二元關係的資 料結構。並且依照該資料結構生成一組概 念集合。 Step2: 建立所有的概念的階層關係 在產生概念集合後,概念之間的關係 就可以被建立。假設某概念(A0,B0)為概 念(A1,B1)的子概念(Sub-concept)之一,可 表 示 為 (A0,B0)(A1,B1) 。 換 句 話 說 ) , ( 0 0 0 A B c 為c1 (A1,B1)的子概念[5] 。 在概念階層上給定兩個元素(I1,J1) 與(I2,J2),他們的下確界(Infimum)定義為 )) ( , ( ) , ( ) , (I1 J1 I2 J2 I1 I2 I1 I2 而 上 確 界 (Supremum) 定 義 為 ) ), ( ( ) , ( ) , (I1 J1 I2 J2 J1 J2 J1 J2 所有的概念階層關係的建構皆由上確 界與下確界來決定[1] 。此步驟決定概念 間的階層關係,利用上述定義決定每個概 念是否具有父概念或子概念。概念間產生 關聯性後,將提供系統尋找或判斷答案之 用。另一方面也會搜尋文章內容的描述, 標記該階層關係適合的屬性值。 Step3: 建立概念間之內部關係 概念之間除了繼承的關係外,可能也 存有部份交集的關係。部份交集可以說明 兩概念間存有某種程度的相似性。藉此步 驟彌補 FCA 方法無法呈現概念間部份交 集,藉由此步驟找出概念間內部的關係 [11] 。 假 設 有 兩 個 概 念c0 (A0,B0) 與 ) , ( 1 1 1 A B c , 使 Setx 且 Sety , 當 0 BSetx 、Sety B1且Setx Sety,則概
念c 與0 c 之間存有內部的關係。系統會依1 據上述原則決定概念間是否存在共同的屬 性集合,存有該屬性集合表示存有內部關 係,並且逐一搜尋新聞內容找尋適合標注 內部關係的屬性值。 經過上述建構步驟與流程,此子系統 將 建 構 出 詢 問 式 之 部 份 知 識 本 體 (Query-based Partial Ontology),提供語意 問答系統的答案分析模組做為回覆問題的 答案來源。
四、實驗結果
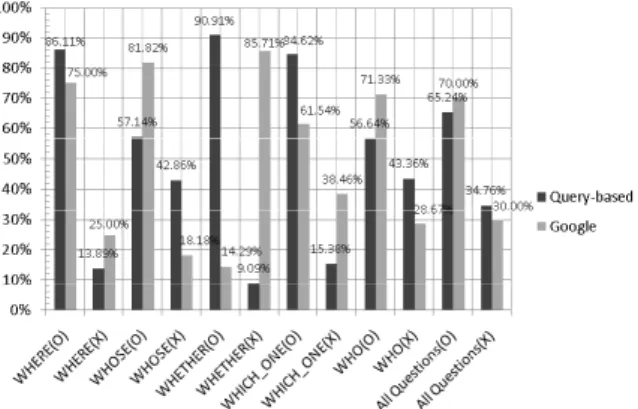
本研究是以 FCA 方法建構詢問式之 部 份 知 識 本 體 (Query-based Partial Ontology)以提供語意搜尋使用。故實作一 套問答系統並以體育新聞文件作為實驗素 材,其使用者操作介面如圖 4 所示。並且 進行兩種類型的實驗測試,其目的在驗證本系統的準確率與實用性。分別是實驗 一:比較本研究所實作的問答系統與關鍵 字搜尋引擎所得答案之準確率。實驗二: 使用本研究方法,將素材改為其他類型的 體育新聞並測試其答題準確率。 圖 4 使用者操作介面 (一) 實驗一 首先,新聞擷取器從聯合新聞網[13] 中擷取美國職業籃球相關新聞總共 180 篇 作為實驗素材,其資料如表 4 所示。表 5 為辭彙分析模組處理 180 篇新聞文件後之 詞彙結果,其中相異詞彙數量表示為該詞 性不同詞彙的各數。 表 4 文件與詞彙數量表 文件 數量 句子 數量 詞彙過濾 前之數量 詞彙過濾 後之數量 Total 180 1,728 66,296 25,493 表 5 中文自然語言處理分析之詞類統計 詞性 詞性 標注 詞彙數量 相異詞彙 數量 Na 8,127 2,286 Nb 5,084 331 Nc 766 144 名詞 Nd 1,271 93 VA 1,492 350 VC 3,679 775 VHC 208 45 動詞 VH 3,376 837 VJ 1,204 188 VD 286 37 總數 25,493 5,086 實驗環境設定 本測試之問題是從網路使用者對本研 究感興趣的問題與網路論壇所收集的常見 問題集來做為實驗材料,共 5 種題型、210 個問句,題型與問句統計如表 6 所示。 表 6 問題集的題型、說明與例句 問題類型 例句 數量 WHERE 湖人隊的主場是 哪一個城市? 36 WHETHER 歐尼爾是中鋒 嗎? 11 WHOSE 賈奈特的外號是 什麼? 7 WHICH_ONE 詹姆斯是哪個球 隊的呢? 13 WHO 姚明的教練是 誰? 143 合計 210 實驗評估方法 實驗方法是將所收集的問句分別輸入 至系統處理,個別將其處理的結果紀錄下 來,交由該領域專家評估判斷其答案的正 確性,再統計回答問題的準確率,所使用 的評估準確率的公式(3)如下所示。評估本 實驗之答題準確性由熟悉該體育知識背景 的專家擔任。 輸入實驗問題的總題數 正確回答問題的總題數 ) (Precision 準確率 (3) 為了驗證本系統的準確率以及實用 性,因此比較本研究所實作的問答系統和 關鍵字搜尋引擎所的得答案之準確率。其 搜尋引擎使用目前最深受歡迎的關鍵字搜
尋引擎 Google 擁有 80 億個網址索引 [14] ,將所收集的問題集分別輸入本研究 之問答系統與 Google 搜尋引擎,本實驗設 定 Google 搜尋模式為一般全域搜尋模 式,全域搜尋模式可以搜尋世界所有網站 的文件資料,指定搜尋字體為繁體中文, 輸入的例句如:小牛隊的教練是誰?,範例 其結果如圖 5 所示。由於 Google 搜尋引擎 每次提供搜尋結果的片段資料為 10 筆,因 此搜尋結果的 10 筆資料片段如果包含問 題答案任一項,即視為正確回答問題,如 果答案不出現在該次 10 筆片段資料內,則 視為錯誤的答案內容。檢視 Google 資料片 段正確性之專家評估介面如圖 6 所示。藉 此評估相同問句於兩種不同系統之準確 率。 圖 5 Google 檢視回傳之 10 筆 Snippet 內容 圖 6 使用 Google 查詢問句後的資料片段 實驗結果 表 7 則為本研究所提出方法之實驗結 果,其準確率為 65.24%。表 8 則為使用 Google 查詢後的 Snippet 資料,驗證其準 確率為 70%。 表 7 使用詢問式之部分知識本體之結果 題型 正確性 題數 準確率 % Correct 31 86.11% WHERE Wrong 5 13.89% Correct 4 57.14% WHOSE Wrong 3 42.86% Correct 10 90.91% WHETHER Wrong 1 9.09% Correct 11 84.62% WHICH_ONE Wrong 2 15.38% Correct 81 56.64% WHO Wrong 62 43.36% Correct 137 65.24% Total Wrong 73 34.76% 表 8 使用 Google 查詢問句之結果 題型 正確性 題數 準確率 % Correct 27 75% WHERE Wrong 9 25% Correct 1 14.28% WHOSE Wrong 6 85.71% Correct 9 81.82% WHETHER Wrong 2 18.18% Correct 8 61.54% WHICH_ONE Wrong 5 38.46% Correct 102 71.33% WHO Wrong 41 28.67% Correct 142 70% Total Wrong 68 30%
圖 7 使用詢問式之部份知識本體與 Google 搜尋引擎之準確率比較 由實驗結果可以觀察到本研究之問答 系 統 的 實 驗 準 確 率 65.24% 與 Google Search 使用 Key Word 尋找問題答案的準 確率 70%約略相近,如圖 7 所示。不過在 本實驗設定下,當使用者利用 Google 找尋 答案是必須檢閱 10 筆網頁部份資料,再確 認是否有答案在其中,此實驗 210 個問句 的 搜 尋 結 果 總 計 有 2,100 筆 資 料 、 共 228,804 個字,對於使用者來說瀏覽大量資 料是很沈重的負擔。在準確率相近的情況 下,使用本研究之問答系統直接提供一個 或一段答案的描述是比較有效率。 (二) 實驗二 圖 8 實驗二之專家檢視畫面 實驗二則是針對不同新聞題材進行比 較 , 其 文 章 內 容 取 自 中 華 職 棒 大 聯 盟 (Chinese Professional Baseball League, CPBL)新聞共 50 篇進行實驗。其實驗步驟 如同實驗一,開放使用者輸入問題測試, 系統將紀錄所有可處理之問題與系統答覆 之答案,提供專家檢視驗證如圖 8 所示。 實驗結果 系統收集有效問句 116 個,經由專家 檢視驗證其資料之正確性,其表 9 為實驗 之準確率結果。 表 9 實驗二之查詢問句結果 題型 正確性 題數 準確率 % Correct 3 50 WHERE Wrong 3 50 Correct 4 44.44 WHOSE Wrong 5 55.56 Correct 14 72.97 WHETHER Wrong 2 27.03 Correct 5 45.45 WHICH_ONE Wrong 6 54.55 Correct 54 68.97 WHO Wrong 20 31.03 Correct 80 68.97 Total Wrong 36 31.03 從此實驗中可發現,由於所收錄的文 件數量較少,因此是非問句題型的答題準 確率較高,反應 FCA 方法使用於小範圍文 件時,其建構屬性之間的階層關係較明 顯,對於是非問句題型的分析判斷較有 利。球員相關資訊題型的答題準確率較低 的原因可能是文件量未達規模,導致此部 份判斷的資訊不足。整體上,系統答題準 確率可達六成以上,可說明本研究對於問 答系統上之實用性。
五、結論
本研究運用正規概念分析方法將無結 構性的文字敘述轉成可被使用的知識,並且將文章內容自動的建構成具組織性、階 層性的資料集,使資料可被使用。並且實 作一問答系統,此系統內包含文件前處理 子系統,負責處理原始資料使之成為可被 使用的資料集。詢問式知識本體建構子系 統則建構知識本體,提供語意問答子系統 回答問題的資料集。語意問答子系統則對 問題進行剖析、問題焦點與描述的萃取、 辨識問題的類型,最後提供使用者答案。 本研究方法相對於搜尋引擎所提供大量、 冗餘而無結構性的資料而言,較能夠節省 使用者彙整資料的時間,初步達到智慧型 網路的願景,並經過實際測試,其回答問 題之準確率驗證具有可用性。
六、致謝
本 研 究 承 蒙 國 科 會 計 畫 NSC95-2221-E-006-158-MY3 經費部分補 助,特此感謝。七、參考文獻
[1] F. Buchli,“Detecting Software Patterns
using FormalConceptAnalysis,” in der Philosophisch-naturwissenschaftlichen Fakult¨: University of Bern, 2003.
[2] P. du Boucher-Ryan, and D. Bridge, “Collaborative Recommending using Formal Concept Analysis,” Knowledge-Based Systems, vol. 19, pp. 309-315, 2006.
[3] B. A. Davey, and H. A. Priestley,
Introduction to Lattices and Order, Cambridge University Press, pp. 65-84, 2002.
[4] D. Fensel, F. van Harmelen, I. Horrocks, D. L. McGuinness, and P. F. Patel-Schneider, “OIL: an ontology infrastructure for the Semantic Web,” Intelligent Systems, vol. 16, pp. 38-45, 2001.
[5] A. Formica, “Ontology-based concept
similarity in FormalConceptAnalysis,” Information Sciences, vol. 176, pp. 2624-2641, 2006.
[6] T.R.Gruber,“A Translation approach
to portable ontology specifications,” Knowledge Acquisition, vol. 5, pp. 199-220, 1993.
[7] R. Neches, R. Fikes, T. Finin, T. Gruber,
R. Patil, T. Senator, and W. R. Swartout, “Enabling technology for knowledge sharing,” Ai Magazine, vol. 12,pp. 36-56, 1991.
[8] N. F. Noy, and D. L. McGuinness, “Ontology development 101: A guide to creating your first ontology,” Stanford Medical Informatics Technical Report SMI-2001-0880, 2001.
[9] C. W. Shih, C. W. Lee, M.-Y. Day, T. H. Tsai, T. J. Jiang, C. W. Wu, C. L. Sung, Y. R. Chen, S. H. Wu, and W. L. Hsu, “ASQA: Academia Sinica Question Answering System for NTCIR-5 CLQA,”Proc. of NTCIR-5 Workshop, Tokyo, Japan, pp. 202-208, 2005.
[10] B. Swartout, R. Patil, K. Knight, T. Russ,
K. Knight, and Tom Russ, “Toward Distributed Use of Large-Scale Ontologies,” In Symposium on Ontological Engineering of AAAI Stanford, California, 1997.
[11] S. S. Weng, H. J. Tsai, S. C. Liu, and C. H. Hsu, “Ontology construction for information classification,” Expert Systems with Applications, vol. 31, pp. 1-12, 2006.
[12] Chinese Knowledge Information Processing Group, “CKIP AutoTag,” Academic sinica, 1998.
[13] http://udn.com/NEWS/main.html. [14] http://www.google.com/intl/zh-TW/why