1
考慮景氣循環趨勢應用資料探勘於企業財務危機之預測
Using data mining techniques with the trends of business cycle for financial crisis prediction 林裕晟 國立高雄大學資管系研究生 [email protected] 丁一賢 國立高雄大學資管系助理教授 [email protected] 摘要 在不同的景氣循環趨勢下,企業所面臨的財務危機通常不盡相同,當景氣復甦時, 企業因為過於樂觀市場上的需求,利用高財務槓桿策略進行操作,以致引發財務危機; 而當景氣反轉時,企業可能因存貨壓力,加上變現不易等,造成資金週轉不靈而演變為 財務危機。 本研究運用資料探勘技術,揭露企業發生財務危機之風險,目的是從不同的景氣循 環趨勢中,找出重要的財務比率,以提昇預測之準確率及變數之解釋能力。過去的研究 著重於預測的方法及變數的選擇,鮮少有學者,針對不同的景氣趨勢,提出資料分割的 方法。 實驗設計為兩部份,(1)利用資料探勘,在未考慮景氣循環趨勢下,檢視預測之能 力。(2)將景氣循環分為收縮及擴張趨勢,就財務報表的特性,將資料進行分割,評估 準確率是否能有效提昇? 本研究以台灣電子產業為樣本,樣本集為正常公司及財務危機各 115 家,選擇了 57 個變數。結果顯示:(1)加入景氣循環因素,準確率高於未加入景氣循環預測方法。 (2)資料分割的方法以財務危機發生日較佳。(3)景氣循環的基準日,其季的分割的解釋 能力較佳。最後本論文就所得之結果加以探討,以解釋不景氣循環趨勢下變數之差異。 關鍵字:景氣循環、財務危機、資料探勘
2 壹、 緒論 一、 研究動機 根據遠見雜誌及台灣經濟新報(TEJ)所做的研究中指出[9],台灣企業 1982 年至 2009 年 2 月,發生財務危機的上市櫃公司共有 152 家,至下市前的總資產合 計約 1.43 兆台幣,其中電子產業居多占整體家數 30%,共有 45 家,主要原因是台 灣電子產業占總體上市櫃家數一半以上,市值台幣約 12.5 兆元,對於台灣的經濟 成長占有舉足輕重的地位。 台灣電子業發展至今已趨於成熟,具有完整的上下游產業鏈,企業間彼此存在 著高度的合作及競爭關係,且產業同質性高,因此當產業間一家企業發生財務危機 時,很容易殃及到上下游的企業,造成連鎖效應,接連引發跳票、違約、破產事件 發生,而連帶影響到台灣整體的產業結構,銀行呆帳、投資人損失等,影響層面廣 泛,對於總體經濟而言會是一大傷害。 考量台灣電子產業之特性建構一套符合實務需求的預警系統,有其必要性。而 目前研究鮮少考慮到景氣循環因素的影響,本研究試圖找出在不同的景氣環境下, 發生財務危機的情況,若能在不同的趨勢中找到重要的財務比率便能提高其財務危 機之預測能力,在企業發生財務危機前提出警示,告知該企業在未來幾個月內具有 潛在的違約風險,相信此一系統的建立對於政府監理單位而言,能盡早發現問題, 並提出因應政策,對金融機構而言,可減少銀行呆帳之損失;就企業而言,了解公 司問題所在,調整公司之營運策略;就投資人而言,避免投資損失。 二、 研究目的 本研究的主要是建構一套台灣電子產業的財危機預警系統,首先考量台灣總體經濟 環境,利用經建會所發佈的景氣循環基準,將景氣分為收縮及擴張趨勢,在利用公開資 訊站所發佈的財務資訊中找出電子產業中每家企業的財務比率,最後在利用資料探勘技 術,從電子產業中,發掘企業發生財務危機重要變數,而本研究的主要目的有以下三點:
(一) 利用支援向量機之 SVM attribute 及主成份分析(Principal Components Analysis)進行特徵選擇。 (二) 利用 SVM、類神經網路等探勘技術,就景氣循環的趨勢,分別找出重要的財 務變數,以提高財務危機之預測準確度。 (三) 從挑選的選數中,實際進行預測,找出潛在問題之企業,減少投資人損失。 三、 論文架構 本研究共分為五個章節: (一) 緒論:說明研究的動機、目的及架構。 (二) 文獻探討:主要是說明研究的相關定義,包含了財務危機、信用評等、景氣 循環、財務及非財務比率相關議題進行定義,並就國內外的相關研究方法與 研究結果加以比較說明。 (三) 研究設計:首先確立研究資料集,再利用統計及人工智慧方法進行建模,並 加入總體經濟因素及特徵選擇的方法進行五次實驗,分別為實驗(一)至(五), 以找出最佳樣本分割之方法,進而提昇財務危機之預測能力。
3 (四) 實證與結果方析:就分割之資料集及選用的預測方法所得知結果加以解釋其 意涵。 (五) 結論與建議:包含了本研究的結論、建議及研究限制。 貳、 文獻探討:
一、
財務危機定義: 財務危機,國內外學者並沒有其明確定義,財務危機的發生指企業尚未破產,但已 經無法履行債務責任等。Beaver (1966)認為發生巨額銀行透支、公司債無法履行、特別 股違約及宣告破產。Deakin (1972)債權人利益遭清算,且公司面臨倒閉,無力清償債務。 而本研究所認定之財務危機之企業,係以台灣經濟新報所認定之實質財務危機事件及準 財務危機[1],舉凡企業在公開市場上發佈之以下事件: (一) 實質財務危機事件:跳票擠兌、倒閉破產、繼續經營疑慮、重整、紓困、接 管、鉅額虧損、每股淨值低於 5 元、違反資訊揭露、財務吃緊停工、淨值為 負。 (二) 準財務危機事件:掏空挪用、暫停交易、董事長跳票、銀行緊縮、大虧、景 氣不佳停工、價值減損。二、
財務危機之預測模型 財務危機預測是風險管理的重要議題,過去學者常用統計方法進行財務預測,演變 至目前人工智慧的方式,另一方面,在變數的選擇,不僅考慮到財務比率,也加入了非 財務比率及總體經濟因素,進而提升財務危機企業之預測能力。 (一) 統計方法: 1960 年代 Beaver(1966)最早使用單變量區別分析(Univariate discriminant analysis)針對美國的企業進行財務危機預測,期間以 1954 至 1964 年失敗企業 79 家及成功企業 79 家為樣本,研究結果發現“現金流量/總負債”為最佳的衡量指標。 但影響企業失敗的原因眾多,採用單一變數解釋企業危機與否並不周全。 Altman(1968)利用多變量區別分析,利用 1964 至 1965 年破產及正常美國企業各 33 家為樣本,並選用了 22 個財務比率進行分析,發展出 Z-Score 模式,運用營運資 金/總資產、保留盈餘/總資產、稅前息前盈餘/總資產、股東權益市值/總負債及銷 貨收入/總資產所組成之財務比率對於財務危機之企業具良好之預測能力。 然而多變量區別分析仍有其限制,像是資料分配需符合常態分配之假設,因此 後續學者採用迴歸(Regression)及羅吉斯迴歸(Logistic Regression)解決非常態分配 之問題。 Ohlson(1980)曾以羅吉斯迴歸,採美國 1970 年至 1976 年間公司資料,進行公 司的破產預測,其此方法改善複迴歸模型估計落到 0,1 以下的缺點,而該模型對於 破產預測能力可高達 84%的正確性。 (二) 人工智慧 1990 年後電腦運算能力提昇,資料探勘的方法應用於企業財務危機之預測 上,相較於統計方法,人工智慧整體表現較佳,Odom and Sharda(1990); Coats and4
Fant (1993)利用過去 Altman 所建立的 Z-Score 模型,所採用的變數進行分析,雖然 兩篇採不同的研究數據,但分別將資料利用類神經網路(ANN)及多變量區別分析比 較,結果一致性認為類神經網路具較佳之分類結果。
Chaveesuk et al.(1997)探討倒傳遞類神經網路(Back-Propagation Neural
Network ; BNN)、徑向基網路(Radial Basis Function Networks)、學習向量量化網 路(Learning Vector Quantization)、複迴歸及 logistic 對美國公債進行評等能力分 析,其分析結果以倒傳遞神經網路的正確率最高。
洪智力,陳勁宏(2006)以期望機率為基礎的多專家模型,進行破產預測,其研 究的方法是利用決策樹、類神經網路及支援向量機(support vector machines),進行 集成學習運用在企業的破產預測上,研究結果證明,可整合個別分類器之優點,改 善多數決及加權多數決為基礎的分類器集成以提昇破產預測能力。
Min and Lee(2005)利用 SVM 進行財務危機之預測,研究發現,核函數參數的 轉換,影響預測的準確率,因此在研究結果發現(1)整體而言以 Poly kernel 的核函 數參數結果較好(2)相較於 MDA、Logistic Regression,實驗結果 SVM 預測能力較 高。Huang et al.(2004) 試圖利用資料探勘的方式找出美國及台灣之企業的在不同信 用等級中重要的財務變數,研究發現 SVM 相較於 BNN 具有較佳之分類能力。 由文獻中發現,人工智慧的分類方法是近幾年常見的財務危機預測工具,早期 多數學者較多採用單一分類器進行財務預測,而近幾年多分類的運用也較為常見, 但研究數據顯示多分類器其預測效果並沒有顯著提升,反倒是支援向量機具有其較 佳之預測能力。而在變數的選擇上 Altman(1968)所建的 Z-Score 經常被後續學者運 用於研究模型中,且具有顯著性的影響,因此本研究將 Z-Score 視為財務變數之一, 並且就 Tsai(2009)所建議之特徵選擇的方法,找出最適之特徵選擇之工具。
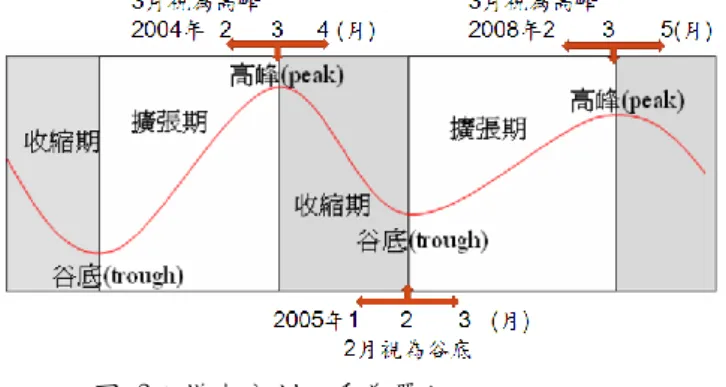
5 參、 研究設計: 本章主要可分為四小節,(一)說明台灣所採行之景氣循環為何、(二)選擇之樣本資 料、(三)說明本研究所採用之財務變數、(四)說明本研究所採用之人工智慧方法。 一、 景氣循環 景氣循環[2]代表的是國家總體經濟環境的波動,一個完整的景氣循環會歷經四個 不同的階段,擴張、收縮、衰退及復甦期。在景氣週期中,由谷底到達景氣的高峰稱為 擴張期,而收縮期則是由景氣的高峰到谷底稱之。台灣所採用的景氣循環為成長循環 (Growth Cycle),所採的用的基準循環數列為包含了 1.實質 GDP、2.工業生產指數、3. 實質製造業銷售值、4.指發零售及餐飲業營業額指數、5.非農業部門就業人數,五項總 體經濟指標所構成的基準數列。而景氣循環的基準日之認定,除了以上之基準循環數 列,亦將生產、消費、就業、貿易、交易等代表性數列做輔助判斷,最後再召集學者討 論,進行事後高峰及谷底之認定。 台灣從 1954 年至 2010 年止,歷經 11 次的完整循環,而第 12 次循環目前僅可以確 立 2005 年 2 月至 2008 年 3 月為擴張期,而至 2010 年 1 月景氣的谷底仍未定,其景氣 循環如表 1 所示。 表 1:台灣景氣循環基準日期 循環次序 谷底 高峰 谷底 第 1 循環 1954.11 1955.11 1956.09 第 2 循環 1956.09 1964.09 1966.01 第 3 循環 1966.01 1968.08 1969.01 第 4 循環 1969.01 1974.02 1975.02 第 5 循環 1975.02 1980.01 1983.02 第 6 循環 1983.02 1984.05 1985.08 第 7 循環 1985.08 1989.05 1990.08 第 8 循環 1990.08 1995.02 1996.03 第 9 循環 1996.03 1997.12 1998.12 第 10 循環 1998.12 2000.09 2001.09 第 11 循環 2001.09 2004.03 2005.02 第 12 循環 2005.02 2008.03 未定 資料來源:經建會 2009 年
6 本研究之基本假設認為,在不同景氣循環中,企業所面臨的財務危機不盡相同,因 此在研究設計的部份,將景氣循環分為擴張趨勢及收縮趨勢,其目的是藉由不同趨勢 中,找出重要的財務變數,以提升財務危機之預測能力。其資料來源取自台灣經濟新報 資料庫,以台灣電子產業之上市、上櫃、興櫃及公開發行之財務危機之企業為樣本,以 台灣電子產業為研究對象,主要是考量,(1)電子產業占台灣總體上市櫃家數一半以上、 (2)康峻維(2002)電子產業與非電子產業在財務特性上有顯著不同,因此應考量不同產業 所存在之財務特性,以提升財務危機之預測能力。 本研究根據台灣經濟新報所定義之實質財務危機事件及準財務危機事件,於 1992 年至 2009 年 1 月所發生財務危機之共有 115 家,並以證交所公佈之產業類別中,股票 代碼相近且市值最接近,以 1:1 比例的方式進行配對。 二、 財務變數 在參數的選擇上,本研究考量到電子產業之財務特性,因此將財務報表所獲得之財 務比率納入並加入 Z-Score 及 TCRI 參數,再以特徵選擇的方式,找出具有重要性之財 務變數,最後以分類器進行準確率實證研究。 三、 研究設計(一)~(五) 本研究以 Weka 3.5.5 軟體做為分類工具,研究設計可分為兩部份,在未加入景氣循 環及加入景氣循環的情況下、則考量景氣循環因素,是否能提升企業財危機之預測能力。 實驗設計(一)是未考慮景氣循環情況下,經由特徵選擇的方式進行預測,也是過去 學者較常採用的方式。而實驗設計(二)~(五)的部份則是考量景氣循環趨勢針對不同的 實驗環境進行設計,而樣本資料的分割會是本節論述的重點如圖所示。 圖 1:研究設計-實驗(一)~(五)
7 (一) 財務危機發生日及財報發佈日進行樣本分割: 財務危機日即企業發生財務危機之基準日,而財報發佈日即年報或者是半年之 公告之基準日。以博達為例,於 2004 年 6 月 15 宣佈重整,引發財務危機,此時 若以財務危機日為基準,則會視該樣本為何種景氣循環趨勢中?由於 2004 年 3 月 1 日至 2005 年 1 月 31 日為景氣循環之收縮期,因此,此例將博達視為收縮期之樣本 之一,如圖 2 所示。 陳瓊蓉(2008)過去的研究發現,當選用的財報越接近財務危機日時,其財務危 機預測準確率也就越高。然而現實生活中,永遠不知企業何時會引發財務危機,但 可以從財報發佈日進行財務危機預測,因此如果能將這些發生危機企業利用財報發 佈日期進行樣本分割,或許能找出重要的財務變數。如圖 2 所示,博達在 2004 年 6 月 15 日前,也就是博達尚未發生財務危機以前,本研究會就財務報表的發佈日, 做為樣本分割之基準日,而年報的發佈日會在 2004 年的 3 月 1 日至 4 月 30 日之前, 此時財報的發佈日正好落入景氣循環的收縮趨勢之中,因此視博達為收縮期之樣 本。 (二) 以月及季做為樣本分割之單位 另一個景氣循環趨勢分割的方法,則是以月及季做為分割之單位,以月分割為 例:從 2004 年 3 月正好是景氣循環的高峰,接下來的幾個月景氣面臨反轉,至 2005 年 2 月來到谷底,此時以月為單位,找出在 2004 年 3 月 1 日至 2005 年 1 月 31 日 發生財務危機企業,並將該企業歸為收縮期之樣本,擴張期做法亦同,其做法如圖 3 表所示。 季的分割方法,如圖 4 所示,主要是考量到,企業財務危機或者是年報之發佈 正好落在景氣反轉之前一、兩個月,此時該如何認定樣本應歸類為何種景氣趨勢? 以圖表為例:如果在 2004 年 2 月 1 號公司面臨財務危機,若以月分割處理,則會 視為擴張期之樣本,但現實情況中在接下來的幾個月,景氣將面臨反轉,走向收縮 期,或許該公司引發財務危機與景氣反轉有關,因此若將該筆資料視會收縮期之樣 圖 2:樣本分割方法-財務危機發生日日及財報發佈日以博達為例
8 本,將有助於財務危機之預測,而季分割之方式將可改善上述之問題,所以本研究 以季為單位,將 2004 年第 1 季至 2005 年第一季視為該景氣循環之收縮期。 因此本研究利用上述之實驗設計獲得以下之資料集: 實驗設計(一):未考慮景氣循環,正常公司(115)、財務危機(115)。 實驗設計(二):考慮景氣循環,依財務危機日及月,擴張期(138)、收縮期(92)。 實驗設計(三):考慮景氣循環,依財務危機日及季,擴張期(140)、收縮期(90)。 實驗設計(四):考慮景氣循環,依財務發佈日及月,擴張期(170)、收縮期(60)。 實驗設計(五):考慮景氣循環,依財務發佈日及季,擴張期(166)、收縮期(64)。 肆、 實證與結果分析: 一、 特徵選擇: 首先針對分割完成之資料集進行特徵選擇(feature vector),本研究利用兩種方法 SVM Attribute (Guyon et al. 2002)及主成份分析,而 SVM Attribute 是將每一個財務變數 利用 SVM 分類器,所獲得的權重值開平方而得,並以排名的方式表示每個變數的重要 程度,因此本研究將 SVM Attribute 做為 SVM 特徵選擇之方法,並分別找出排名前 5、 10、15、20 及 25 重要之財務變數。另一個特徵選擇的方法是利用主成份分析,主成份 分析的主要目的是變數化簡,將相關性高的變數轉化成互相獨立之變數,並利用取得的 新變數,來解釋大部份的資料,而本研究根據(Min and Lee, 2005)特徵選擇的方式,將 累積變異數(variance covered)大於 0.3 及因素負荷量(factor loading)絕對值大於 0.2 做為
圖 4:樣本分割以月為單位 圖 3:樣本分割以季為單位
9 選擇變數的標準。
二、 比較 SVM、BNN 及 Logistic 預測之準確度:
本研究利用 k 疊交互驗證法(k-fold cross validation) 進行實證,其研究結果顯示如 表 2 所示,在未考慮景氣循環,正常公司 115 家、財務危機 115 家,利用 SVM Attribute 所選擇的 5 個財務變數利用 SVM 的核函數參數 Poly Kernel 平均,達 85.26%準確率, 相較於倒傳遞類神經網路的 79.85%及 Logistic Regression 的 80.19%具有較高之預測能 力。 表 2:實驗(一)未考慮景氣循環實證結果 表 3 為實驗設計二,在考慮景氣循環趨勢下,分別將景氣循環分為收縮及擴張趨 勢,以財務危機發生日及月做為樣本分割之基準,其獲得擴張期 138 家及收縮期 92 家, 其研究結果顯示在收縮趨勢下,其預測之準確率 SVM、BNN、Logistic 分別為 83.81%、 78.39%、80.19%,預測效果較未考慮景氣循環來得差,但在於擴張趨勢下,利用 SVM Attribute 所選擇的 15 個財務變數,其 SVM 預測能力為 87.84%。 表 3:實驗(二)考慮景氣循環以財務危機日及月分割實證結果 (二)考慮景氣循環 收縮趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVM Attribute SVM-POLY(5) 80.43 82.60 84.78 84.78 84.78 85.86 83.69 82.60 84.78 83.81 PCA>0.2 BNN 79.34 81.52 78.26 77.17 79.34 78.26 78.26 77.17 77.17 78.39 Simple Logistic 79.34 80.43 80.43 76.08 80.43 83.69 82.60 81.52 77.17 80.19 考慮景氣循環 擴張趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVM Attribute SVM-POLY(15) 84.78 87.68 89.85 86.23 89.13 88.40 88.40 89.85 86.23 87.84 PCA>0.2 BNN 80.43 88.40 84.78 83.33 84.05 86.23 83.33 86.23 83.33 84.96 Simple Logistic 78.26 86.23 84.78 80.43 84.05 84.05 86.23 85.50 81.88 83.49 (一)未考慮景氣循環 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVM Attribute SVM-POLY(5) 84.34 86.52 84.34 85.65 85.21 84.78 85.21 85.65 85.65 85.26 SMO-POLY(10) 83.47 84.78 84.34 83.47 84.78 83.47 83.91 84.34 83.91 84.05 SMO-POLY(15) 82.60 83.47 84.34 83.47 83.91 83.04 83.04 83.91 83.04 83.42 SMO-POLY(20) 82.17 83.91 83.91 82.17 83.04 83.91 83.04 85.21 83.04 83.38 SMO-POLY(25) 81.73 81.73 82.60 83.04 81.73 83.04 81.73 83.47 83.04 82.46 PCA>0.2 BNN 81.30 79.13 81.30 79.56 79.13 80.00 79.13 77.80 81.30 79.85 Simple Logistic 79.13 78.69 80.86 80.43 80.00 80.00 80.86 80.00 81.73 80.19 PCA=Principal Components Analysis
10 表 4 在考慮景氣循環趨勢下,依財務危機發生日,並以季為樣本分割之方法,其樣 本在擴張期間為 140 家及收縮期間 90 家,而實證結果顯示,在收縮趨勢中 SVM Attribute 所選取之 20 個財務變數,並利用 SVM 進行預測其平均準確率達 85.55%;而在擴張趨 勢中以 SVM Attribute 所選取之 10 個財務變數,以 SVM 進行預測其準確率平均達 87.69 %,整體而言,不管是在收縮趨勢或者是擴張趨勢下,其預測之準確度較未考慮景氣循 環下,可獲得較高之預測能力。 表 5 為實驗設計四之實證結果,在考慮景氣循環,依財務發佈日及月做為樣本分 割,分別獲得擴張趨勢及收縮趨勢各 170 及 60 個樣本,其研究結果顯示在收縮趨勢下 利用 SVM Attribute 進行特徵選擇, SVM 平均之預測能力達 88.33%,但於擴張趨勢 其預測能力較未考慮景氣循環下,最高僅 SVM 的 82.15%。表 6 為實驗設計五之研究 結果,在考慮景氣循環,依財務發佈日及季做為樣本分割,並分割為擴張期 166 家及收 縮期 64 家,其實證結果顯示,在收縮趨勢下以 SVM 進行財務危機預測,準確率達 88.02%,而在擴張趨勢下其預測準確率以 SVM 較佳平均 84.06%。 表 4:實驗(三)考慮景氣循環以財務危機日及季分割實證結果 表 5:實驗(四)考慮景氣循環以財報發佈日及月分割實證結果 (三)考慮景氣循環 收縮趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVM Attribute SVM-POLY(5) 83.33 84.44 84.44 87.77 84.44 85.55 85.55 87.77 86.66 85.55 PCA>0.2 BNN 78.88 83.33 82.22 81.11 81.11 81.11 82.22 83.33 80.00 81.80 Simple Logistic 77.77 82.22 81.11 80.00 80.00 80.00 82.22 81.11 84.44 80.99 考慮景氣循環 擴張趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVM Attribute SVM-POLY(10) 85.70 89.28 87.85 86.42 88.57 87.85 87.85 88.57 87.14 87.69 PCA>0.2 BNN 81.42 82.85 80.71 81.42 82.14 80.71 82.85 82.85 79.28 81.60 Simple Logistic 82.85 78.57 80.71 80.00 77.85 77.85 79.28 82.14 81.42 80.07
(四)考慮景氣循環 收縮趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVMAttribute SVM-POLY(5) 86.66 88.33 88.33 88.33 90.00 88.33 88.33 88.33 88.33 88.33 PCA>0.2 BNN 71.66 76.66 73.33 75.00 76.66 73.33 75.00 71.66 76.66 74.79 Simple Logistic 73.33 71.66 71.66 76.66 70.00 76.66 76.66 71.66 75.00 73.70 考慮景氣循環 擴張趨勢 Classification accuracy(%)’
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVMAttribute SVM-POLY(20) 80.58 82.35 82.94 81.17 82.94 82.35 82.35 82.35 82.35 82.15 PCA>0.2 BNN 71.66 76.66 73.33 75.00 76.66 73.33 75.00 71.66 76.66 74.79 Simple Logistic 73.33 71.66 71.66 76.66 70.00 76.66 76.66 71.66 75.00 73.70
11 表 6:實驗(五)考慮景氣循環以財報發佈日及季分割實證結果 整體而言,SVM 相較於 BNN 及 Logistic,其預測之準確率最高。在未考慮景氣循 環下 SVM Attribute 所選出前五個財務變數,利用 SVM 進行財務危機預測平均可達 85.26。而經由實驗設計(三)利用財務危機發生日及考量景氣快速反轉以季為樣本分割之 方法,其實證結果顯示在收縮趨勢及擴張趨勢分別獲得 85.55%及 87.84%,準確率較未 考慮景氣循環之情況下高。 實驗(三)所挑選之重要財務變數如表 7 所示,包含了收縮趨勢 5 個財務變數及 10 個擴 張趨勢之財務變數,由研究結果發現,在未考慮景氣循環趨勢下及實驗設計(三)之擴張 及收縮趨勢三者情況下,TCRI 信用評等、負債比率及稅前純益/實收資本,皆為企業財 務危機發生之重要財務變數;另對照財務比率的五大類別,在收縮趨勢中,包含二大類: 資本結構(負債比率)及獲利能力(稅前純益/實收資本、每股盈餘、營業毛利成長率); 而在擴張趨勢中,包含三大類別:財務結構(淨值 /總資產、負債比率、折舊性固定資 產成長率)、經營能力(每股淨值、應收帳款 週轉率)及獲利能力指標(現金股利率、 稅前純益/實收資本、營業利益率、營收成長率)。由收縮趨勢之財務比率發現,期間 所發生財務危機之企業,其原因較為單純,大多因長期獲利能力不佳及高負債比率導 致。而在擴張趨勢中發生財務危機之面向較為廣泛,會因為公司缺乏經營能力、財務結 構及獲利能力不佳而引發財務危機。 (五)考慮景氣循環 收縮趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVMAttribute SVM-POLY(5) 89.06 84.37 89.06 87.50 89.06 87.50 89.06 89.06 87.50 88.02 PCA>0.2 BNN 78.12 75.00 73.43 75.00 76.56 82.81 79.68 76.56 79.68 77.34 Simple Logistic 78.12 76.56 73.40 84.37 79.68 84.37 81.25 78.12 76.56 79.16 考慮景氣循環 擴張趨勢 Classification accuracy(%)
特徵選擇 Model 2st fold 3st fold 4st fold 5st fold 6st fold 7st fold 8st fold 9st fold 10st fold Average SVMAttribute SVM-POLY(10) 83.13 82.53 83.13 83.73 84.33 84.33 84.93 84.93 85.54 84.06 PCA>0.2
BNN 78.31 77.71 79.51 81.32 77.71 77.10 77.71 77.10 78.31 78.31 Simple Logistic 79.51 76.50 80.12 81.92 81.32 82.53 81.92 82.53 81.92 80.92
12 表格 7:實驗(一)及實驗(三)之財務變數 實驗(一)未考慮景氣循環 實驗(三)收縮趨勢 實驗(三)擴張趨勢 TCRI 信用評等 TCRI 信用評等 淨值 /總資產 負債比率 負債比率 每股淨值 稅前純益/實收資本 稅前純益/實收資本 現金股利率 現金股利率 每股盈餘 負債比率 淨值成長率 營業毛利成長率 TCRI 信用評等 折舊性固定資產成長率 應收帳款週轉率 稅前純益/實收資本 營業利益率 營收成長率 伍、 結論與建議 本研究之基本假設認為,在不同的景氣循環趨勢下,企業所面臨的財務危機不盡相 同,因此如果能有效找出不同景氣趨勢下,企業發生財務危機之重要財務變數,便能提 升財務危機之預測能力。根據經建會所發佈之景氣循環,做為景氣收縮期及擴張期之區 分標準,共設計了四種樣本資料之分割方法,並與未考慮景氣循環下進行比較,其研究 結果顯示,支援向量機及映射函數選擇 polynomial kernel 能有效能提升財務危機之預測 能力其準確率較 BNN 及 Logistic 佳。 實證結果顯示,以實驗(三)其財務危機之預測能力較佳,該實驗設計採用財務危 機發生日做樣本分割,並以季做為之單位,其意涵是將景氣快速反轉之情況列入考慮, 找出不同趨勢下之重要財務變數,再利用 SVM Attribute 方法進行特徵選擇,分別在收 縮趨勢中找出重要的 5 個財務變數及擴張趨勢中 10 個財務變數,由實證研究中發現, 收縮趨勢及擴張趨勢之財務危機預測準確率達 85.55%及 87.69%,較未考慮景氣循環的 85.26%表現佳。因此本研究利用景氣循環趨勢找出合適之樣本分割之方法,其研究結 果顯示,能有效提升財務危機之預測能力。 在後續研究部份,本研究在財務變數的選擇上,目前僅採用財務比率,對於非財務 比率並未善加利用,因此後續研究可加入非財務比率進行研究。而在特徵選擇僅利用 SVM Attribute 及主成份分析,而特徵選擇的方法眾多,後續可多方嘗試之。
13 陸、 參考文獻: 1. 台灣經濟新報,上網日期:2009 年 8 月 1 日,取自 http://www.tej.com.tw/webtej/doc/wind1.htm。 2. 行政院經濟建設委員會,上網日期:2009 年 8 月 1 日,取自 http://www.cepd.gov.tw。 3. 洪智力,陳勁宏,2006,「期望機率為基礎的多專家破產預測模型」,北商學術論壇 -資訊管理與實務研討會。 4. 洪德生,2007,「信用評等對公司治理的重要性」,經濟日報,10 月 14 日。 5. 財訊出版社編,2007 「台灣電子產業新版圖」,財訊出版社。 6. 康峻維,2002,「初次公開發行後資本結構之實證研究分析--以台灣地區電子業與 非電子業上市公司為例」,國立清華大學經濟學系研究所碩士論文。 7. 張大成,2003,「違約機率與信用評分模型」,台灣金融財務季刊,4 卷 1 期:19-37。 8. 陳妙真,2004,華銀引用 TCRI 信用評等簡介,華南金控,第 20 期:11-18。 9. 陳瓊蓉,林俊男,2008,「臺灣上市櫃公司財務危機預警模型之研究—景氣收縮期 與擴張期之比較」,臺灣銀行季刊,59 卷 4 期:281-300 10. 彭杏珠,2009,「一兆台幣的一堂課」,遠見雜誌,3 月,132-137。
11. Altman, E. "Financial ratios, discriminant analysis and the prediction of corporate
bankruptcy," The Journal of Finance, vol. 23, 1968, pp. 589-609.
12. Beaver, W.H. "Financial ratios as predictors of failures," Journal of Accounting Research,
vol. 4, 1966, pp. 71-102.
13. Chaveesuk, R., C. Srivaree-Ratana, and Smith, A. "Alternative Neural Network
Approach to Corporate Bond Rating," Journal of Engineering Valuation and Cost Analysis,vol. 2(2) , 1997, pp.117-131.
14. Coats,P.K. and Fant, L.F. "Recognizing financial distress patterns using a neural network
tool," Financial Management, vol. 22, 1993, pp. 142-155.
15. Cristiamini,N. Shawe-Taylor, J. An Introduction to Support Vector Machines,
Cambridge university press, Cambridge, England, 2000.
16. Deakin, E.B. "A discriminant analysis of predictors of business failure," Journal of
Accounting Research, vol. 10, 1972, pp. 167-179.
17. Gehrke,J. Ramakrishnan,R. W.Y. Loh, BOAT-optimistic decision tree construction, in:
Proceedings ACM SIGMOD International Conference Management of Data, Philadel- phia, 1999, pp. 169-180.
18. Guyon,I. Weston, J. Barnhill, S. Vapnik V. "Gene selection for cancer classification
using support vector machines" Machine Learning., 2002, 46:pp.389-422.
19. Huang, Z. Chen, H. and Hsu,-J. Chen, W.-H. Wu, S. " Credit rating analysis with support
vector machines and neural networks: a market comparative study," Decision Support Systems, vol. 37, 2004, pp. 543-558.
20. Merkevicius E, Girdzijauskas S. "A Hybrid SOM-Altman Model for Bankruptcy
14
21. Min, J.H. and Lee, Y.C. "Bankruptcy prediction using support vector machine with
optimal choice of kernel function parameters. Expert Systems with," Applications, vol. 28, 2005, pp. 603-614.
22. Odom, M. and Sharda, R. "A neural network model for bankruptcy prediction," In
Proceedings of international joint conference, 1990, pp. 163-168.
23. Ohlson, J. "Financial ratios and the probabilistic prediction of bankruptcy," Journal of
Accounting Research, vol. 18, 1980, pp.109-131.
24. Orgler ,Y.E. "A Credit Scoring Model for Commercial Loans, " Journal of Money, Credit,
and Banking.,1970, pp.435-445.
25. Tsai, C. "Feature selection in bankruptcy prediction," European Journal Of Operational
Research, vol. 22, 2009, pp. 120-127.
26. Varetto Franco, “Genetic algorithms applications in the analysis of insolvency risk”,
Journal of Banking & Finance, vol. 22, 1998, pp. 1421-1439.
27. Werbos, P. J.. Beyond Regression: New Tools for Prediction and Analysis in the