國
立
交
通
大
學
統計學研究所
碩 士 論 文
一個有效且有力的檢定對於單邊製程規格的供應商選擇問題
An Effective and Powerful Test for One-sided Manufacturing Characteristic
in Supplier Selection Problem
研 究 生:莊育珊
指導教授:洪慧念 教授
一個有效且有力的檢定對於單邊製程規格的供應商選擇問題
An Effective and Powerful Test for One-sided Manufacturing Characteristic
in Supplier Selection Problem
研 究 生:莊育珊 Student:Yu-Shan Chuang
指導教授:洪慧念 Advisor:Hui-Nien Hung
國 立 交 通 大 學
統計學研究所
碩 士 論 文
A ThesisSubmitted to Institute of Statistics College of Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Statistics
June 2009
Hsinchu, Taiwan, Republic of China
學生:莊育珊
指導教授
:洪慧念
國立交通大學統計學研究所碩士班
摘
要
這篇論文主要考慮選擇供應商的問題,在兩家供應商中,以單邊規格為製程
能力標準選擇具有較高製程能力的廠商。本文一開始會先回顧三個針對此類問題
的方法,其中兩種為大樣本時的逼近方法,另一個則是由 Pearn et al. (2009)
所提出之精準方法,稱為 Division method。在此篇論文中,我們將提出一個新的
精準方法,在此稱為 Subtraction method。我們會以正確選取檢定力來比較這兩種
excat 方法。結果顯示,我們所提出的 Subtraction method 相較於 Division method
來看,具有較佳的檢定力。而為了實際上的應用,也提出了兩步驟(two-phase)
的選擇過程。且為使業界能方便的使用,一些計算上的結果也將以列表之方式呈
現。
An Effective and Powerful Test for One-sided Manufacturing Characteristic in
Supplier Selection Problem
Student:Yu-Shan Chuang
Advisors:Dr. Hui-Nien Hung
Dr.
------Dr.
------Institute of Statistics
National Chiao Tung University
ABSTRACT
In this paper, we consider the supplier selection problem, which deals with
comparing two one-sided processes and selecting a better one that has a higher
capability. We first review two existing approximation approaches, and an exact
approach proposed by Pearn et al. (2009) which we refer to as the Division
method. We then develop a new exact approach called the Subtraction method.
We compare the two exact methods on the selection power. The results show
that the proposed Subtraction method is indeed more powerful than the Division
method. A two-phase selecting procedure is developed for practical applications.
Some computational results are tabulated for practitioners’ conveniences.
誌
謝
畢業將至,回想起這些日子,除了在專業上更加精進之外,更獲得了許多
學業以外的知識。首先,感謝指導教授洪慧念教授在這段期間對於課業上
的指導,除此之外,對於生活上也提供了一些見解和關心,每當有疑惑,
和教授聊過後都能瞬間感到豁達許多。感謝口試委員對我論文的各方指導
與建議。也謝謝同學之間的互相打氣,這段期間得到了不少可貴的情誼,
我會好好珍惜。更謝謝家人在我學生生涯中,默默的支持與鼓勵,使得我
能無後顧之憂,一路走來直至順利完成碩士班學業。在此,將對於我的師
長、家人、好朋友以及同學,致上我最誠摯的謝意。
莊育珊 謹誌于
國立交通大學統計學研究所
中華民國九十八年六月
目
錄
中文提要
………
i
英文提要
………
ii
誌謝
………
iii
目錄
………
iv
表目錄
………
v
圖目錄
………
vi
一、
緒論………
1
二、
現有的選擇方法………
2
三、
提議的 Subtraction method………
3
四、
Subtraction method 的製程選取方法………
5
4.1
Phase I :選擇較佳製程………
5
4.2
Phase II:製程差異程度………
6
4.3
檢定力分析
8
五、
兩種精確方法之比較………
10
六、
實例………
14
六、
結論………
16
參考文獻
………
17
表目錄
表 1
某特定 C
I之下的 NCPPM
2
表 2
n
1= n
2= 30(10)200 和
α=0.05 之下,拒絕 C
PU2≤C
PU1的臨界
值………
6
表 3
α= 0.05 及某些 h 值之下,拒絕 C
PU2≤C
PU1+ h 的臨界值
7
表 4
在檢定力
1−β=0.9、0.95、0.975 和 0.99 之下,使用 Subtracion
(S)和 Division (D) methods 方法去區別 C
PU1和 C
PU2所需的
樣本大小………
13
表 5
在 C
PU1=1.250,C
PU2=1.450、1.550、1.650、1.660 和 1.670
之下,對於兩家分波多工器廠商的所做的決策………
16
表 6
在 C
PU1=1.250,C
PU2=1.680(0.01)1.740 之下,對於兩家分波
多工器廠商的所做的決策………
16
圖目錄
Figure 1
樣本數 n
1=n
2=30、50、100、150 和 200(圖中由下至上)
之下,W 的機率密度函數 ………
5
Figure 2
C
PU1=1.0、1.5 和 2.0 以及樣本數 n=30 之下的檢定力函數
9
Figure 3
在 C
PU1=1.00 及 n
1=n
2=30 下,兩種方法的檢定力曲線……
11
Figure 4
在 C
PU1=1.00 及 n
1=n
2=50 下,兩種方法的檢定力曲線……
11
Figure 5
在 C
PU1=1.00 及 n
1=n
2=100 下,兩種方法的檢定力曲線……
11
Figure 6
在 C
PU1=1.00 及 n
1=n
2=150 下,兩種方法的檢定力曲線……
11
Figure 7
在 C
PU1=1.33 及 n
1=n
2=30 下,兩種方法的檢定力曲線……
11
Figure 8
在 C
PU1=1.33 及 n
1=n
2=50 下,兩種方法的檢定力曲線……
11
Figure 9
在 C
PU1=1.33 及 n
1=n
2=100 下,兩種方法的檢定力曲線……
11
Figure 10
在 C
PU1=1.33 及 n
1=n
2=150 下,兩種方法的檢定力曲線……
11
Figure 11
在 C
PU1=1.67 及 n
1=n
2=30 下,兩種方法的檢定力曲線……
12
Figure 12
在 C
PU1=1.67 及 n
1=n
2=50 下,兩種方法的檢定力曲線……
12
Figure 13
在 C
PU1=1.67 及 n
1=n
2=100 下,兩種方法的檢定力曲線……
12
Figure 14
在 C
PU1=1.67 及 n
1=n
2=150 下,兩種方法的檢定力曲線……
12
Figure 15
在 C
PU1=2.00 及 n
1=n
2=30 下,兩種方法的檢定力曲線……
12
Figure 16
在 C
PU1=2.00 及 n
1=n
2=50 下,兩種方法的檢定力曲線……
12
Figure 17
在 C
PU1=2.00 及 n
1=n
2=100 下,兩種方法的檢定力曲線……
12
Figure 18
在 C
PU1=2.00 及 n
1=n
2=150 下,兩種方法的檢定力曲線……
12
Figure 19
兩筆偏極化相依損失資料的直方………
15
一、 緒論
對於製造業以及服務業來說,為了量測現有的產品或服務的品質是否有能力 達到需求的標準內,製程能力指標(process capability indices)已經被廣泛地運
用。在製程能力指標中,常用的包含了Cp、CPU、C 、PL 、 以及 (Kane
(1986, Chan et al. (1988), Pearn et al. (1992))。這些製程能力指標用在產品 或者是服務品質上,主要是比較它們已先定義好的規格和它們實際上的品質特 性。這些指標的定義如下: pk C Cpm Cpmk , , , min{ , 6 3 3 3 p PU PL pk
USL LSL USL LSL USL LSL
C C C C }, 3 μ μ μ σ σ σ σ − − − − = = = = μ σ − 2 2 , min 2 2 , 2 6 ( ) 3 ( ) 3 ( ) pm pmk USL LSL USL LSL C C T T μ μ σ μ σ μ σ μ 2 T ⎧ ⎫ − ⎪ − − ⎪ = = ⎨ ⎬ + − ⎪⎩ + − + − ⎪⎭ 其中USL為規格上界,LSL為規格下界,μ為製程的平均值,σ 為製程的標準差, 以及T 為製程的目標值。而其中指標 、 、 以及 C 是用在雙邊規格的 製程上,而 p C Cpk Cpm pmk PU C 以及C 則適用在製程只有單邊規格的情況上。 PL 這些指標已被廣泛的應用在許多地方,其中包括了應用在工廠不良品控制 上,多重製程的性能分析圖(Pearn 和 Chen (1997), Pearn and Shu(2003a, 2003b) ),多重品質特性的製程性能分析(Bothe (1997), Wu and Pearn (2005)),選擇較佳的供應商(Chou(1994), Huang and Lee (1995), Pearn et
al. (2004), Pearn et al. (2009)),量測多重製造過程的製程能力(Bothe (1999), Pearn and Chang (1998)),判定整批貨接受與否的允收抽樣計畫 (Pearn and Wu (2006a, 2006b), Wu and Pearn (2008)),工具替換的最佳化(Pean and Hsu (2007), Pearn et al. (2006, 2007)),以及其他許多的應用上。Pearn 和 Kotz (2006) 對 於過去二十年來製程能力指標的發展,給了一個全面性的回顧。 少量的不良品 考慮具有單邊規格界線USL或LSL且為常態分佈的製程,其良率 Pr(X <USL)或者 Pr(X >LSL)可被改寫為如下: Pr( ) Pr( ) Pr( 3 ) (3 ) Pr( ) Pr( ) Pr( 3 ) (3 ) PU PU PL P X USL X USL Z C C X LSL L X LSL Z C C μ μ σ σ μ μ σ σ − − < = < = < = Φ − − > = < = > − = Φ 其中 Z 為服從標準常態分配的隨機變數, ( )Φ ⋅ 為標準常態分配的累積分佈函數。 為了便利起見,均將CPU或C 定義為PL CI。因此,對於一個在良好控制底下
的常態分配製程而言,每百萬的不良品個數(NCPPM)就可以精確地被計算為 NCPPM 6 。舉例來說,如果 10 [1 (3CI)] = × − Φ CI =1.00,則相對應的 NCPPM 為 1350;如果CI =1.25,則相對應的 NCPPM 為 88;如果CI =1.33,則相對應的 NCPPM 為 33;如果 ,則相對應的 NCPPM 為 6.8;如果 ,則 相對應的 NCPPM 為 3.4;如果 1.45 I C = CI =1.50 1.67 I C = ,則相對應的 NCPPM 為 0.27;以及如 果CI =2.00時,則相對應的 NCPPM 為 0.001。Table 1 將上述結果以表呈現。 Table 1. Corresponding NCPPM for some specific values of CI.
CI NCPPM 1.00 1349.898 1.25 88.417 1.33 33.037 1.45 6.807 1.50 3.398 1.67 0.272 2.00 0.001
二、 現有的選擇方法
對於選擇供應商的問題,Chou (1994)提出了一個概似比的近似方法。此 處考量兩間供應商,並適合以CPU為製程能力指標來衡量他們的製程能力。現有 的供應商稱為供應商 I,新的供應商為供應商 II,而它們的製程能力指標分別為 1 PU C 和CPU2。Chou 所提出的的方法可對假設檢定H0:CPU1≥CPU2和 1: PU1<CPU2 H C 做出決策。令CˆPU1 =(USL−x1)/ (3 )s1 和CˆPU2 =(USL−x2) / (3s2), 其中x1和x2分別為供應商 I 和供應商 II 的樣本平均數, 和 則為它們的樣本標 準差。若 1 s s2 1 ˆ ˆ 2 PU PU C <C 2 並同時滿足 2 時,將拒絕虛無假設 1 exp{ χ (1 2 < − − α) / 2} A 0: PU1≥CPU H C ,其中:{
2 2}
1 2 ˆ 2 ˆ 2 PU PU C aC aC = + + − ˆ 1ˆ 2 n PU C ⎡ ⎤ ⎢ ⎥ ⎣ ⎦ 2 / PU A a , 2 1(1 2 n 為兩家供應商分別抽取的樣本數,a=9 / (n n− ,以及1) χ − α)是自由度為 1 的卡方分配的第 (1 2 )− α 百分位數,而α 則為該檢定之顯著水準(不正確地將 判定為 0 PU2 H :C −CPU1≤0 CPU2−CPU1> 的機率)。在大樣本理論下,檢定統計0 量 A 為概似比函數(likelihood ratio statistic),他取自然對數後的大樣本分配會趨 近於自由度為 1 的卡方分配。在應用上,這個近似的方法要求兩家供應商具有相Hubele et al. (2005)利用 Nairy 以及 Rao (2003)提出的 Wald test 來修正 Chou (1994)的這個式子,並發展了一個可以檢定 家供應商是否均有一樣的 製程能力的近似方法。若令第 i 家供應商的製程能力指標為 k PUi C ,i , 則假設檢定為 {1, 2,..., }k ∈ 0: PU1 P 2 P H C =C U =L=C Uk以及H1: 至少有一對( , )i j 使得 PUi PUj C ≠C ,i ,其中 。值淂注意的是,此方法就不限制不同供 應商需要抽取的樣本數為相同了。 j ≠ i j, ∈{1,2,..., }k
The Division Method
Pearn et al. (2009)提出了一個精確的方法去處理選擇供應商的問題,也就 是之前所提到的 Division method。這個假設檢定是考慮虛無假設 ,而對立假設為 。在 Division method 中並不 要求這兩個製程需有相同的樣本數。首先,令 0: PU2/ PU1 H C C ≤ 1 H1:CPU2/CPU1 >1 1 PU 和 C CPU2 別為供應商 I 和供應 商 II 的製程能力指標,n 和1 n2 分別為它們抽取的樣本個數。在此方法中採用 的檢定統計量為 分 則 2 ˆ ˆ 1 / PU PU R=C C ,其機率密度函數為:
(
)
(
)
1 1 2 2 2 1 1 2 2 2 1 2 2 1 2 1 2 2 1 1 2 2 2 2 1 2 1 2 1 1 2 2 2 1 2 1 9 ( ) 0 exp 2 1 1 1 2 9 exp 9( ) 2 2 + n PU PU R n n PU PU PU PU r n C n C u r u f r A I u u n n u n r n u n C n C u n n u n n u n C n C u n n u − ∞ + − −∞ ⎛ ⎞ ⎜ ⎟ ⎡ + ⎤ ⎛ ⎞ ⎝ ⎠ = ⎜ > ⎟ ⎢ ⎥ + ⎝ ⎠⎛ − ⎛ ⎞ ⎞ ⎢⎣ ⎥⎦ + ⎜ ⎜ ⎟ ⎟ ⎜ − ⎝ ⎠ ⎟ ⎝ ⎠ ⎧ ⎡ + ⎤ ⎪ ×⎨ + ⎢− + ⎥ ⎢ ⎥ ⎪ ⎣ ⎦ ⎩ + +∫
1 1 2 2 2 2 1 2 1 2 3( ) 1 2 , 9( ) PU PU n C n C u du n n u n n u π ⎡⎢ − Φ⎛⎜− + ⎞⎟⎤⎥⎫⎪ ⎬ ⎜ ⎟ + ⎢⎣ ⎝ + ⎠⎥⎦⎭⎪ 其中(
)
1 1 1 2 2 1 2 2 2 1 1 1 2 2 1 2 2 1 9 1 2 9 2 exp 1 1 1 2 2 2 2 n PU PU n n n n n A n n n n π − Γ⎛ + − ⎞ ⎜ ⎟ ⎛ − ⎞ , C n C ⎡ ⎤ ⎝ ⎠ = ⎜ ⎟ ⎢− + ⎥ − − − ⎛ ⎞ ⎛ ⎞ ⎣ ⎦ ⎝ ⎠ Γ⎜ ⎟ ⎜Γ ⎟ ⎝ ⎠ ⎝ ⎠ ( ) Φ ⋅ 為標準常態分配的累積密度函數, I 為指標函數,以及−∞ < < ∞ 。 rPearn et al. (2009)說明了 Division method 比起 Chou 的近似方法來,確實是 更為精準且檢定力更高的。
三、 提議的 Subtraction Method
在此節中,我們採用了不同的統計檢定量提出了一個新的精準方法,稱之為 Subtraction method。我們考慮了如下的假設檢定來比較兩個CPU值,其中虛無假 設為H0:CPU2 ≤CPU1,對立假設為H1:CPU2 >CP 1 1 0 PU C U (此假設檢定相當於 與 0: PU2 PU1 0 H C −C ≤ H1:CPU2− > )。在本文中,我們採取 為檢定統計量,當中 2 1 ˆ ˆ PU PU W =C −C ˆ ( ) / (3 ) PUi i C = USL−x si 的分配等同於( )
3 −1 1(3 i i n i PUi n t − n C ) , 其中 1(3 )是自由度為 i n i PUi t − n C ni− ,non-centrality 參數為31 的 non-central t 隨 機變數, 1、2。我們可以得到此檢定量有如下的機率密度函數: i PUi n C i= 1 1 2 1 1 1 1 ( ) ( ) ( ) ( , ) , W Y Y f w f y f w y dy B g w y dy w ∞ −∞ ∞ −∞ = + = × − ∞ < < ∞∫
∫
其中 1( ) Y f ⋅ 和 2( ) Y f ⋅ 分別為CˆPU1和CˆPU2的機率密度函數, 1 2 ( 1)/ 2 ( 1)/ 2 1 2 1 1 2 2 2 2 1 1 2 2 2 2 9 2 1 9 2 1 n n B n n n n n n π − π − = × ⎛ ⎞ ⎛ ⎞ − − ⎛ ⎞ ⎛ ⎞ Γ⎜ ⎟⎜ ⎟ Γ⎜ ⎟⎜ ⎟ − − ⎝ ⎠⎝ ⎠ ⎝ ⎠⎝ ⎠ , 2 1 1 1 1 2 1 1 1 1 1 2 1 1 0 9 ( ) ( , ) exp 2 n v n PU n v y C g w y v e dv ∞ − − − ⎡ − ⎤ = ⎢− ⎥ ⎣ ⎦∫
1 2 2 2 2 1 2 1 2 2 1 2 2 2 2 0 9 ( ( ) ) exp 2 n v n PU n v w y C v e dv ∞ − − − ⎡ + − ⎤ × ⎢− ⎥ ⎣ ⎦∫
。 和上節相同地,CPU1和CPU2分別代表供應商 I 和供應商 II 的製程能力指標,而 和 則分別為它們抽取的樣本個數。 1 n 2 n 我們將W的機率密度函數畫在 Figure 1,其中涵蓋了CPU1 = 1.0、1.5, 1.0、1.5,以及 30、50、100、150 和 200(在圖中是依序由底部往 上)。從 Figure 1 中,我們可以看出(1)越大的 2 PU C = n1 =n2 = 2 1 PU CPU C − 值, 的變 異數也就越大,(2) 的分配為單峰的,且幾乎對稱於 2 1 ˆ ˆ PU CPU = − 1 W C 2 W CPU −CPU ,就算在樣本 數小的情況下也是如此。CPU1 = 1.0, CPU2 = 1.0 CPU1 = 1.0, CPU2 = 1.5
CPU1 = 1.5, CPU2 = 1.0 CPU1 = 1.5, CPU2 = 1.5
Figure 1. Probability density function plots of W for sample sizes n1=n2=30, 50, 100, 150, 200(from bottom to top in plots).
四、 Subtraction Method 的製程選取方法
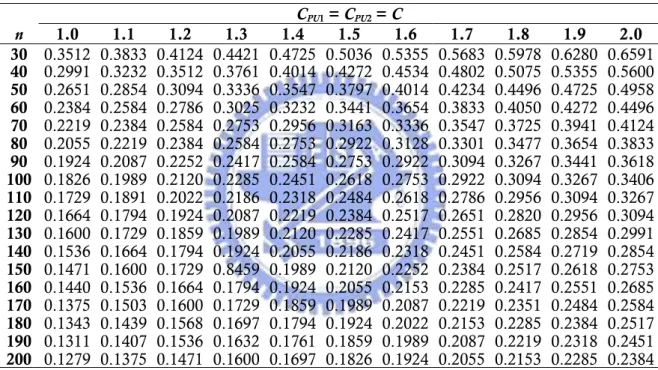
4.1 Phase I: 選擇較佳製程 假設在所有待選的製程當中,CPU值至少都要大於某個特定需求值 ,而現 行的供應商,在此稱供應商 I,也已經符合這樣的一個基本需求,亦即,C C 。 如果現在有一個新的供應商,供應商 II,宣稱它比現行的供應商 I 能提供更好的 品質,以此來爭取訂單。因此,新的供應商就必須在規定的信賴水準下,提供可 令人信服的資訊來證明它的宣稱為事實。為了去檢定新的供應商(供應商 II)所 提供的品質是否真的比現行的供應商 I 還好,我們在此考慮了如下的假設檢定: C 1 PU ≥ 0: PU2 P 1 H C ≤C U 和H1:CPU2 >CPU1,其等價於: 0: PU2 PU1 0 H C −C ≤ 1: PU2 PU1 0 H C −C > 。 在已有W的機率密度函數,以及顯著水準(不正確地將 判定 為 的最大機率)已給定之下,決策即可決定。此假設檢定的 決策為,若 ,則拒絕 。其中 為滿足以下條件的一個臨界 值: 0: PU2 PU1 0 H C −C ≤ 1 PU2 H :C −CPU1> PU W =C − 0 0 2 1 ˆ ˆ PU C ≥c H0 c00 0 2 1 1 2 1 Pr{W ≥c |H :CPU ≤CPU , ,n n , and }CPU ≥C ≤α C 為符合假設檢定的原理,我們找到在CPU2 =CPU1 = 這樣的條件下去計算,會得 到最大的臨界值c0。亦即: 0 2 1 1 2 Pr{W ≥c |CPU =CPU =C n n, , }= α 值得注意的是,我們的供應商選擇過程,可以被應用在兩家供應商樣本數不 相同的情況下,也就是 。而若想應用在規格為下界的情況下,也就是假設 檢定為 1 n ≠n 1 2 0: PL2 P H C ≤C L 以及H1:CPL2 >CPL1,只需將CPU以C 取代即可。Table 2 PL 列出了當CPU2 =CPU1=1.0(0.1)2.0,n1=n2 = =n 30(10)200,與顯著水準α =0.05的 情況下,所得到臨界值。
Table 2. Critical values for rejecting CPU2 ≤ CPU1 with n1 = n2 = 30(10)200 and α = 0.05.
CPU1 = CPU2 = C n 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0 30 0.3512 0.3833 0.4124 0.4421 0.4725 0.5036 0.5355 0.5683 0.5978 0.6280 0.6591 40 0.2991 0.3232 0.3512 0.3761 0.4014 0.4272 0.4534 0.4802 0.5075 0.5355 0.5600 50 0.2651 0.2854 0.3094 0.3336 0.3547 0.3797 0.4014 0.4234 0.4496 0.4725 0.4958 60 0.2384 0.2584 0.2786 0.3025 0.3232 0.3441 0.3654 0.3833 0.4050 0.4272 0.4496 70 0.2219 0.2384 0.2584 0.2753 0.2956 0.3163 0.3336 0.3547 0.3725 0.3941 0.4124 80 0.2055 0.2219 0.2384 0.2584 0.2753 0.2922 0.3128 0.3301 0.3477 0.3654 0.3833 90 0.1924 0.2087 0.2252 0.2417 0.2584 0.2753 0.2922 0.3094 0.3267 0.3441 0.3618 100 0.1826 0.1989 0.2120 0.2285 0.2451 0.2618 0.2753 0.2922 0.3094 0.3267 0.3406 110 0.1729 0.1891 0.2022 0.2186 0.2318 0.2484 0.2618 0.2786 0.2956 0.3094 0.3267 120 0.1664 0.1794 0.1924 0.2087 0.2219 0.2384 0.2517 0.2651 0.2820 0.2956 0.3094 130 0.1600 0.1729 0.1859 0.1989 0.2120 0.2285 0.2417 0.2551 0.2685 0.2854 0.2991 140 0.1536 0.1664 0.1794 0.1924 0.2055 0.2186 0.2318 0.2451 0.2584 0.2719 0.2854 150 0.1471 0.1600 0.1729 0.8459 0.1989 0.2120 0.2252 0.2384 0.2517 0.2618 0.2753 160 0.1440 0.1536 0.1664 0.1794 0.1924 0.2055 0.2153 0.2285 0.2417 0.2551 0.2685 170 0.1375 0.1503 0.1600 0.1729 0.1859 0.1989 0.2087 0.2219 0.2351 0.2484 0.2584 180 0.1343 0.1439 0.1568 0.1697 0.1794 0.1924 0.2022 0.2153 0.2285 0.2384 0.2517 190 0.1311 0.1407 0.1536 0.1632 0.1761 0.1859 0.1989 0.2087 0.2219 0.2318 0.2451 200 0.1279 0.1375 0.1471 0.1600 0.1697 0.1826 0.1924 0.2055 0.2153 0.2285 0.2384 4.2 Phase II: 製程差異程度 在供應商選擇問題的 Phase I 中,供應商選擇的決策會僅僅依據比較兩個CPU 的值,而沒有進一步地去探討這兩個值之間的差異程度。在實務上,因為更換新 的供應商去取代現有的,會必須要付出一些代價,例如成本上的增加。所以為了 考量這額外多出的成本,顧客可能會只有在新的供應商比現有的供應商顯著更 好,且好過一定的程度時,亦即CPU2−CPU1大於某個特定的值 ,才會考慮 真的以新的供應商更換現有的供應商。因此,我們的方法,在這種需求之下,可 以用來使用在以下的假設檢定: 0 h> 0: PU2 PU1 H C ≤C + h , 1: PU2 PU1 H C >C +h
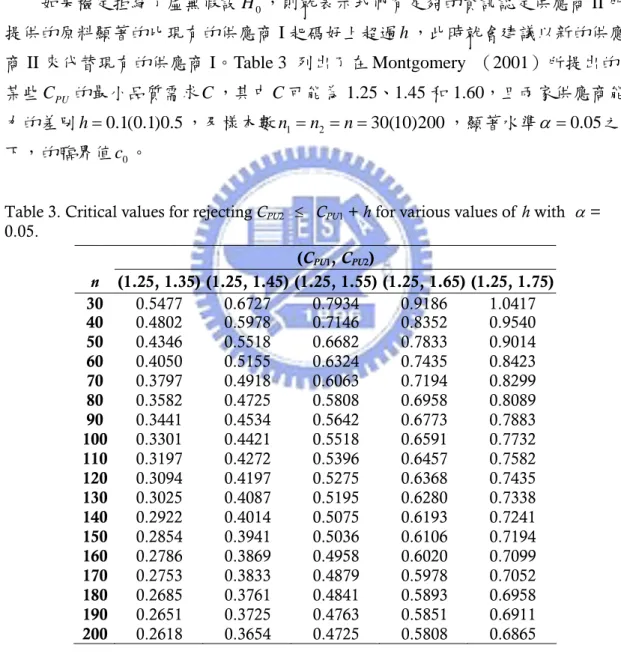
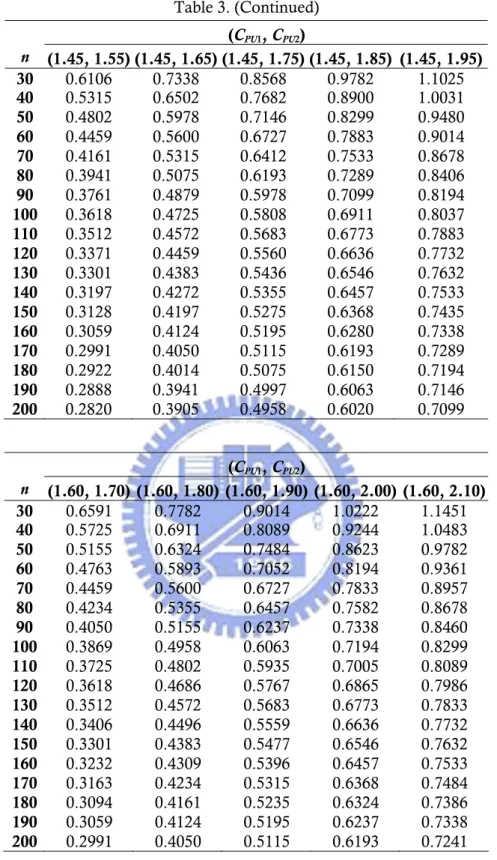
這裡所得到的決策規則和 Phase I 是很相似的。當 大於等於 某個臨界值 時,拒絕虛無假設 並接受 ,其中 滿足如下之條 件: 2 ˆ ˆ PU PU W =C −C 1+h c0 1 0 c H0 CPL2 >CPL 0 0 2 1 1 2 1 Pr{W ≥c |H :CPU ≤CPU +h n n, , , and }CPU ≥C ≤α ) 。 對於所有的 ,為符合假設檢定的原理,我們找到在 且 這樣的條件下去計算,會得到最大的臨界值 。因此,我們可以用 下列的機率等式來計算臨界值 : 1 2 (CPU ,CPU h + 1 PU C =C 2 PU C =C c0 0 c 0 1 2 1 2 Pr{W ≥c |CPU =C C, PU = +C h n n, , }= 。 α 如果檢定拒絕了虛無假設 ,則就表示我們有足夠的資訊認定供應商 II 所 提供的原料顯著的比現有的供應商 I 起碼好上超過h,此時就會建議以新的供應 商 II 來代替現有的供應商 I。Table 3 列出了在 Montgomery (2001)所提出的 某些 0 H PU C 的最小品質需求 ,其中 可能為 1.25、1.45 和 1.60,且兩家供應商能 力的差別 ,及樣本數 C C 0.1(0.1)0.5 h= n1=n2 = =n 30(10)200,顯著水準α =0.05之 下,的臨界值c0。
Table 3. Critical values for rejecting CPU2 ≤ CPU1 + h for various values of h with α=
0.05. (CPU1, CPU2) n (1.25, 1.35) (1.25, 1.45) (1.25, 1.55) (1.25, 1.65) (1.25, 1.75) 30 0.5477 0.6727 0.7934 0.9186 1.0417 40 0.4802 0.5978 0.7146 0.8352 0.9540 50 0.4346 0.5518 0.6682 0.7833 0.9014 60 0.4050 0.5155 0.6324 0.7435 0.8423 70 0.3797 0.4918 0.6063 0.7194 0.8299 80 0.3582 0.4725 0.5808 0.6958 0.8089 90 0.3441 0.4534 0.5642 0.6773 0.7883 100 0.3301 0.4421 0.5518 0.6591 0.7732 110 0.3197 0.4272 0.5396 0.6457 0.7582 120 0.3094 0.4197 0.5275 0.6368 0.7435 130 0.3025 0.4087 0.5195 0.6280 0.7338 140 0.2922 0.4014 0.5075 0.6193 0.7241 150 0.2854 0.3941 0.5036 0.6106 0.7194 160 0.2786 0.3869 0.4958 0.6020 0.7099 170 0.2753 0.3833 0.4879 0.5978 0.7052 180 0.2685 0.3761 0.4841 0.5893 0.6958 190 0.2651 0.3725 0.4763 0.5851 0.6911 200 0.2618 0.3654 0.4725 0.5808 0.6865
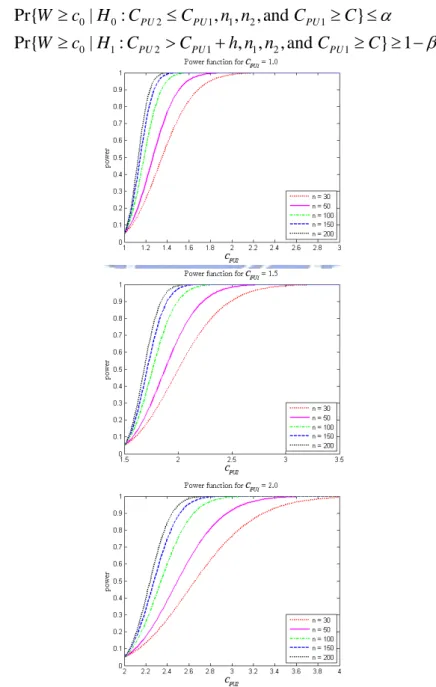
Table 3. (Continued) (CPU1, CPU2) n (1.45, 1.55) (1.45, 1.65) (1.45, 1.75) (1.45, 1.85) (1.45, 1.95) 30 0.6106 0.7338 0.8568 0.9782 1.1025 40 0.5315 0.6502 0.7682 0.8900 1.0031 50 0.4802 0.5978 0.7146 0.8299 0.9480 60 0.4459 0.5600 0.6727 0.7883 0.9014 70 0.4161 0.5315 0.6412 0.7533 0.8678 80 0.3941 0.5075 0.6193 0.7289 0.8406 90 0.3761 0.4879 0.5978 0.7099 0.8194 100 0.3618 0.4725 0.5808 0.6911 0.8037 110 0.3512 0.4572 0.5683 0.6773 0.7883 120 0.3371 0.4459 0.5560 0.6636 0.7732 130 0.3301 0.4383 0.5436 0.6546 0.7632 140 0.3197 0.4272 0.5355 0.6457 0.7533 150 0.3128 0.4197 0.5275 0.6368 0.7435 160 0.3059 0.4124 0.5195 0.6280 0.7338 170 0.2991 0.4050 0.5115 0.6193 0.7289 180 0.2922 0.4014 0.5075 0.6150 0.7194 190 0.2888 0.3941 0.4997 0.6063 0.7146 200 0.2820 0.3905 0.4958 0.6020 0.7099 (CPU1, CPU2) n (1.60, 1.70) (1.60, 1.80) (1.60, 1.90) (1.60, 2.00) (1.60, 2.10) 30 0.6591 0.7782 0.9014 1.0222 1.1451 40 0.5725 0.6911 0.8089 0.9244 1.0483 50 0.5155 0.6324 0.7484 0.8623 0.9782 60 0.4763 0.5893 0.7052 0.8194 0.9361 70 0.4459 0.5600 0.6727 0.7833 0.8957 80 0.4234 0.5355 0.6457 0.7582 0.8678 90 0.4050 0.5155 0.6237 0.7338 0.8460 100 0.3869 0.4958 0.6063 0.7194 0.8299 110 0.3725 0.4802 0.5935 0.7005 0.8089 120 0.3618 0.4686 0.5767 0.6865 0.7986 130 0.3512 0.4572 0.5683 0.6773 0.7833 140 0.3406 0.4496 0.5559 0.6636 0.7732 150 0.3301 0.4383 0.5477 0.6546 0.7632 160 0.3232 0.4309 0.5396 0.6457 0.7533 170 0.3163 0.4234 0.5315 0.6368 0.7484 180 0.3094 0.4161 0.5235 0.6324 0.7386 190 0.3059 0.4124 0.5195 0.6237 0.7338 200 0.2991 0.4050 0.5115 0.6193 0.7241 4.3 檢定力分析 在 Phases I 和 II 中,選擇供應商的過程是先給定α 風險,也就是不正確地將 判定為 的機率,並沒有考慮到 0 H H1 β風險(型二誤差),不正確地將H 判1 定為H0 率,亦即在新的供應商確實有較佳的製程能力之下,判定為沒有比較佳的機 率,這樣會對於新的供應商相對地不利。一旦樣本數和 的機 α 風險固定後,檢定力
1−β就可以被計算出了。Figure 2 畫了在CPU1 = 1.0、1.5、2.0 之下,不同的 2 PU C (CPU2從CPU1至CPU1+2),以及樣本數n1 =n2 = =n 30、50、100、150、200, α =0.05 之下的檢定力。從圖中我們可以看出樣本數越大,檢定力就越大,因此, β風險就會越小。 β 為了降低 風險以及同時維持所需水準的α 風險,我們可以增加樣本數。藉 由計算在某個特定CPU2值之下的檢定力,我們可以得到在某個指定的檢定力以 及α 風險下,所需要的最小樣本數。所需的樣本個數可用下列的兩個機率不等式 去求得: 0 0 0 1 | : | : H H C 2 1 2 1 , 1 PU PU PU PU W c C C W c C C 1 2 1 2 , , a , , , n n h n n 1 1 nd } and } PU PU C C C Pr{ Pr{ α β ≥ ≤ ≥ ≤ ≥ > + ≥ ≥ −
Figure 2. Power curves for CPU1=1.0,
1.5, and 2.0, with sample sizes n=30, 50, 100, 150, 200.
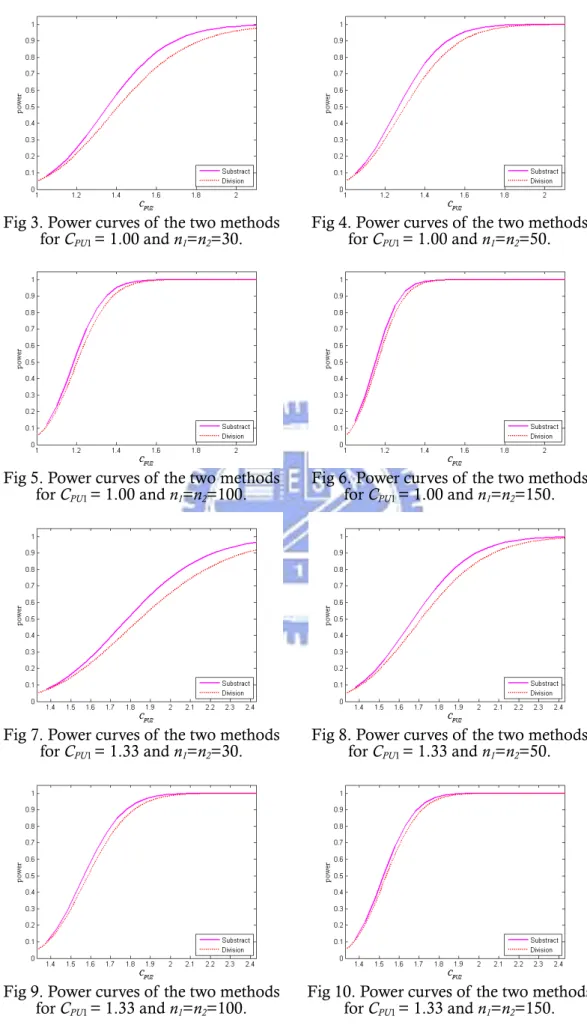
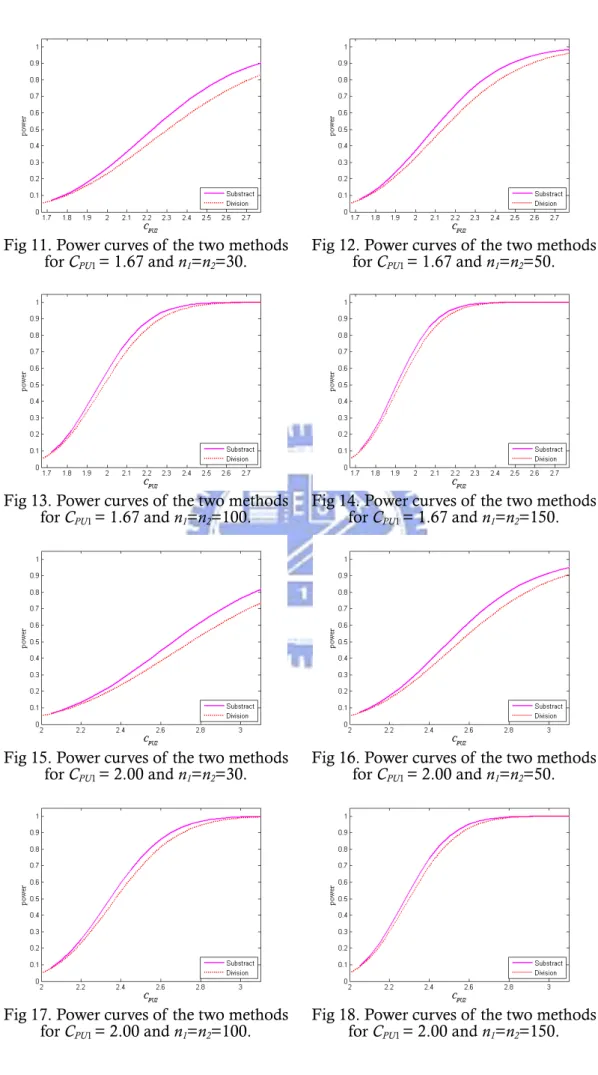
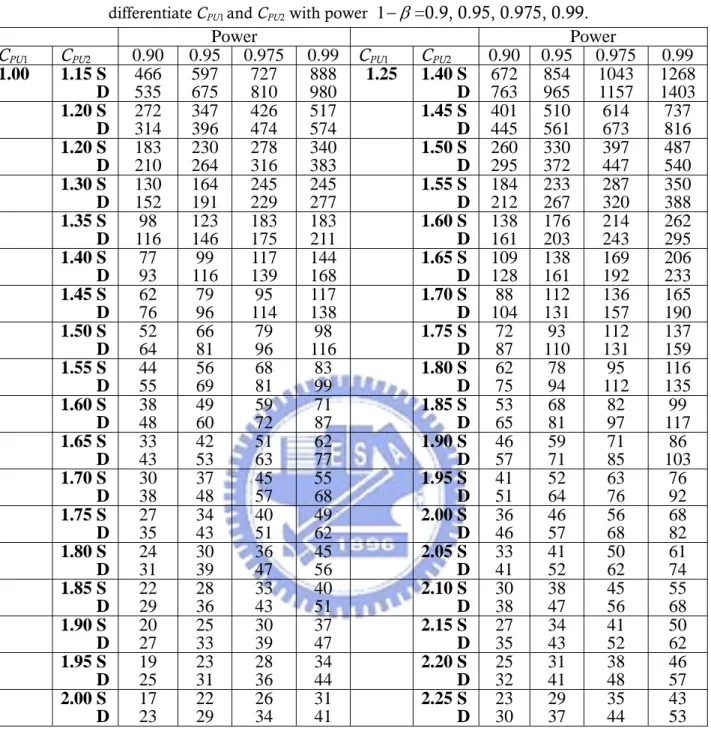
五、 兩種正確方法之比較
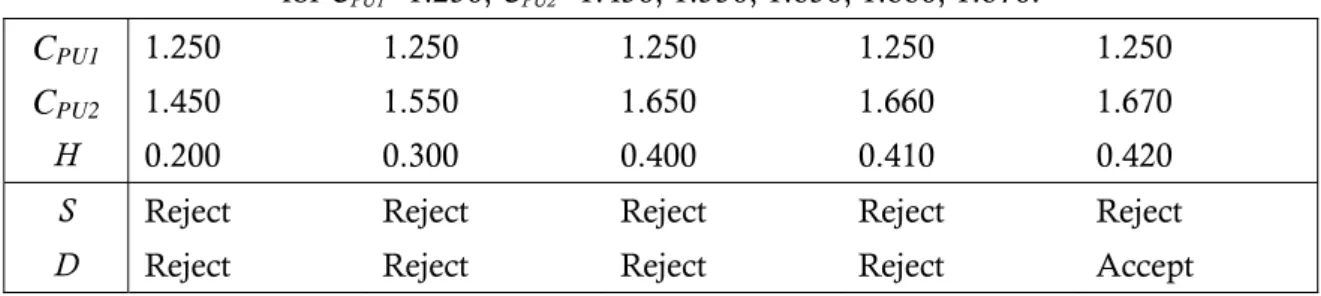
Pearn et al. (2009)以檢定統計量R=CˆPU2/CˆPU 1提出了一個選擇供應商問題 的正確方法。在一樣的顯著水準之下,我們透過檢定力函數,亦即正確拒絕虛無 假設的機率,來比較和評估他們的方法與本文之方法。Figure 3-6、7-10、11-14 以及 15-18 分別列出了CPU1 =1.00、1.33、1.67、2.00 對於CPU2(CPU2從CPU1至 ),樣本數 30、50、100、150 之下,Subtraction method(以 1 1 PU C + n1=n2 =n= − 線表示)和 Division method(以---線表示)的檢定力曲線。從這些圖中可以看出, 以W =CˆPU2−CˆPU1為檢定統計量的檢定力,明顯比使用R=CˆPU2/CˆPU 1的檢定力還 要好,因為在列出的這些所有情況中,Subtraction method 的檢定力曲線顯然是 始終高於 Division method 的。不幸地是,由於他們的機率密度函數都非常地複 雜,所以我們無法以理論去提供證明這樣的結果。接著,我們從所需的樣本數大小來比較 Subtraction method 和 Division method 間的差異性。計算的結果列表在 Table 4。在 Table 4,型一誤差α 被設定為 0.05, 而檢定力則給定為 0.90、0.95、0.975、0.99,CPU1=1.00、1.25、1.45、1.60,差 異程度 。舉例來說,若最小的製程能力需求為 1.25, 並指定 2 1 0.15(0.05)1.00 PU PU C −C = α 風險為 0.05,β風險也為 0.05(亦即撿定力為 0.95),期望的差異程度 2 1 PU C −CPU 為 0.3,則若以 Subtraction method 來做檢定,兩間供應商所需要的樣 本數至少為 233,而已 Division method 來做,則需要樣本數為 267,比 233 還要 來得多。從 Table 4 當中不難發現,在一樣的條件之下(α 風險、β風險、CPU1以
及CPU2−CPU1),以 Subtraction method 所得到的所需樣本個數均少於 Division method。
Fig 3. Power curves of the two methods for CPU1 = 1.00 and n1=n2=30.
Fig 4. Power curves of the two methods for CPU1 = 1.00 and n1=n2=50.
Fig 5. Power curves of the two methods for CPU1 = 1.00 and n1=n2=100.
Fig 6. Power curves of the two methods for CPU1 = 1.00 and n1=n2=150.
Fig 7. Power curves of the two methods for CPU1 = 1.33 and n1=n2=30.
Fig 8. Power curves of the two methods for CPU1 = 1.33 and n1=n2=50.
Fig 9. Power curves of the two methods for CPU1 = 1.33 and n1=n2=100.
Fig 10. Power curves of the two methods for CPU1 = 1.33 and n1=n2=150.
Fig 11. Power curves of the two methods for CPU1 = 1.67 and n1=n2=30.
Fig 12. Power curves of the two methods for CPU1 = 1.67 and n1=n2=50.
Fig 13. Power curves of the two methods for CPU1 = 1.67 and n1=n2=100.
Fig 14. Power curves of the two methods for CPU1 = 1.67 and n1=n2=150.
Fig 15. Power curves of the two methods for CPU1 = 2.00 and n1=n2=30.
Fig 16. Power curves of the two methods for CPU1 = 2.00 and n1=n2=50.
Fig 17. Power curves of the two methods for CPU1 = 2.00 and n1=n2=100.
Fig 18. Power curves of the two methods for CPU1 = 2.00 and n1=n2=150.
Table 4. Sample size required for the Subtracion (S) and the Division (D) methods to differentiate CPU1 and CPU2 with power 1− =0.9, 0.95, 0.975, 0.99. β
Power Power
CPU1 CPU2 0.90 0.95 0.975 0.99 CPU1 CPU2 0.90 0.95 0.975 0.99
1.00 1.15 S D 466 535 597 675 727 810 888 980 1.25 1.40 S D 672 763 854 965 1043 1157 1268 1403 1.20 S D 272 314 347 396 426 474 517 574 1.45 S D 401 445 510 561 614 673 737 816 1.20 S D 183 210 230 264 278 316 340 383 1.50 S D 260 295 330 372 397 447 487 540 1.30 S D 130 152 164 191 245 229 245 277 1.55 S D 184 212 233 267 287 320 350 388 1.35 S D 98 116 123 146 183 175 183 211 1.60 S D 138 161 176 203 214 243 262 295 1.40 S D 77 93 99 116 117 139 144 168 1.65 S D 109 128 138 161 169 192 206 233 1.45 S D 62 76 79 96 95 114 117 138 1.70 S D 88 104 112 131 136 157 165 190 1.50 S D 52 64 66 81 79 96 98 116 1.75 S D 72 87 93 110 112 131 137 159 1.55 S D 44 55 56 69 68 81 83 99 1.80 S D 62 75 78 94 95 112 116 135 1.60 S D 38 48 49 60 59 72 71 87 1.85 S D 53 65 68 81 82 97 99 117 1.65 S D 33 43 42 53 51 63 62 77 1.90 S D 46 57 59 71 71 85 86 103 1.70 S D 30 38 37 48 45 57 55 68 1.95 S D 41 51 52 64 63 76 76 92 1.75 S D 27 35 34 43 40 51 49 62 2.00 S D 36 46 46 57 56 68 68 82 1.80 S D 24 31 30 39 36 47 45 56 2.05 S D 33 41 41 52 50 62 61 74 1.85 S D 22 29 28 36 33 43 40 51 2.10 S D 30 38 38 47 45 56 55 68 1.90 S D 20 27 25 33 30 39 37 47 2.15 S D 27 35 34 43 41 52 50 62 1.95 S D 19 25 23 31 28 36 34 44 2.20 S D 25 32 31 41 38 48 46 57 2.00 S D 17 23 22 29 26 34 31 41 2.25 S D 23 30 29 37 35 44 43 53
Table 4.(Continued)
Power Power
CPU1 CPU2 0.90 0.95 0.975 0.99 CPU1 CPU2 0.90 0.95 0.975 0.99
1.45 1.60 S D 869 983 1099 1242 1335 1488 1639 1805 1.60 1.75 S D 1034 1167 1368 1475 1594 1768 1947 2145 1.65 S D 519 570 658 719 788 862 945 1046 1.80 S D 615 674 781 852 933 1021 1123 1238 1.70 S D 331 376 422 474 516 569 622 690 1.85 S D 394 444 501 560 618 672 740 815 1.75 S D 236 269 302 339 382 407 445 493 1.90 S D 282 317 360 400 432 479 528 581 1.80 S D 178 204 227 257 276 308 333 373 1.95 S D 212 239 271 302 325 362 394 438 1.85 S D 138 161 178 203 213 243 262 294 2.00 S D 165 189 211 238 252 285 308 345 1.90 S D 112 131 142 165 172 197 211 239 2.05 S D 132 153 170 193 205 231 250 280 1.95 S D 93 109 118 137 142 164 174 199 2.10 S D 109 127 139 160 169 192 205 232 2.00 S D 78 93 100 117 120 140 147 169 2.15 S D 92 108 117 136 142 163 174 197 2.05 S D 67 80 85 101 103 121 127 146 2.20 S D 79 93 100 117 122 140 148 170 2.10 S D 58 71 74 88 89 106 110 128 2.25 S D 68 82 87 103 105 123 128 148 2.15 S D 51 63 65 78 79 94 96 113 2.30 S D 60 72 76 91 92 109 113 131 2.20 S D 45 56 58 70 70 84 85 101 2.35 S D 53 65 68 81 82 97 100 117 2.25 S D 41 51 52 63 63 76 77 91 2.40 S D 48 58 61 73 73 87 90 106 2.30 S D 37 46 47 58 56 69 69 83 2.45 S D 43 53 55 66 66 79 81 96 2.35 S D 33 43 43 53 51 63 63 76 2.50 S D 39 48 49 61 60 72 73 87 2.40 S D 31 40 39 49 47 58 57 70 2.55 S D 36 45 45 56 55 67 67 80 2.45 S D 28 37 36 45 43 54 53 65 2.60 S D 33 41 42 52 50 62 62 74
六、 實例
為了說明我們所提出的 Subtraction method 的高效性,我們考慮了在 Pearn et
al.(2009)中提供的分波多工器(Wavelength Division Multiplexer, WDM)例子。這例
子是說有一家公司想要引進分波多工器產品,而此產品希望偏極化相依損失 (Polarization Dependent Loss, PDL)能夠越小越好。而對於偏極化相依損失這個品
質特性的最低要求為 。對於兩家供應商均先做 Kolmogorov-Simirnov 的常態分配檢定,以確認這兩家供應商的資料是否為常態分配,結果此兩家所得 到的 p-value 均大於 0.15。Figure 19 畫了這兩家供應商提供的資料的直方圖。 1 1.25 PU C =
Figure 19. Histograms of the two PDL data (Pearn et al.(2009)) 為了判定供應商 II 對於分波多工器產品是否比供應商 I 提供較好的製程能 力,我們執行的這樣的假設檢定,H0:CPU2 ≤CPU1以及H1:CPU2 >CPU1。對於偏 極化相依損失方面的資料,我們得到這兩家供應商的樣本平均數和樣本標準差, 估計值如下: 1 2 1 2 0.06079, 0.05018 0.00495, 0.00486 x x s s = = = = 若以 0.08 為規格上界,可得到CˆPU1 =1.2936、 。則對於我們 算出檢定統計 2 ˆ 2.04527 PU C = 2 ˆ PU PU W =C −C 2 / ˆ 1 1 PU CPU 所提出的 Subtraction method,可計 量 1=0.75167; 而對於 Division method 則可計算出檢定統計量R=Cˆ 計 算臨界值,我們以 C 程式來處理這樣複雜的計算。程式首先輸入兩家供應商的 製程能力指標值 1 ˆ .58107 = 。為了 PU C 、CPU2,以及所對應的樣本數n 、1 n ,和顯著水準2 α (當 2 1 PU PU C ≤C 為真之下,錯誤地拒絕CPU2 ≤CPU1的風險),而後便輸出臨界值。我 、n2 100 們以n1 =105 = 、CPU2 =CPU1 =1.25(CPU的最小能力需求)以及α =0.05 之下去 程式 Su 和 ision method 分別得到臨 0.2211 和 1.1924。因為檢定統計量W 0.75167
跑 C ,對於 btraction method Div 界值為
= >0.2211,R=1.58107>1.1924, 因此,在95%的信心水準之下,我們認為供應商 II 的確更勝於供應商 I。 差異程度的量測 家供應商在製程能力上的差異程度,我們執行了這樣的假設檢 為了研究這兩 定 , H0:CPL2 ≤CPL1+ 和h H1:CPL2 >CPL1+ 。 我 們 以h n1=105 、 n2 =100 、 1 PU C = 1.25 (CPU 的 最 小 能 力 需 求 )、CPU2 =1.25+ ,h 0. 和 49 及 0.05 其 中 h= 2(0.1)0.4 0.41(0.01)0. ,以 α = 之下去跑 C 同的h, 臨
定的結果 Table 5 和 Table 6。結果顯示如果使用 Division
程式,依照不 可得到不同的
method,我們只能下結論說供應商 II 的製造能力比供應商 I 好上 0.41,亦即 2 1 0.41 PL PL C >C + 。但如果我們是使用 Subtraction method,則可下結論說供應商 應商 I 好上 0.48,亦即CPL2 >CPL1+0.48。 II 的製造能力比供 T CPU1 1.250
able 5. Decisions of test pliers
1.250 ing the two WDM sup
for CPU1=1.250, CPU2=1.450, 1.550, 1.650, 1.660, 1.670.
1.250 1.250 1.250
CPU2 1.450 1.550 1.650 1.660 1.670
H 0.200 0.300 0.400 0.410 0.420
S Reject Reject Reject Reject Reject
D Reject Reject Reject Reject Accept Table 6. Decisions of test pliers
CPU1 1.250 1.250 1.250 1.250
ing the two WDM sup for CPU1=1.250, CPU2=1.680(0.01)1.740
1.250 1.250 1.250
CPU2 1.680 1.690 1.700 1.710 1.720 1.730 1.740
h 0.430 0.440 0.450 0.460 0.470 0.480 0.490
S Reject Reject Reject Reject Reject Reject Accept
D Accept Accept Accept Accept Accept Accept Accept
、 結論
七
PU C 和CPL 對於穩定且擁有單邊規格界線的常態分配製程,製程能力指標 在 。在 論 ,因為替換上的高成本考量,通常只有在新供應商的製程表現顯著elength Division Multiplexer, WDM) 這
製造業中已被廣泛地使用,這個指標將製程能力給予適當之量化標準 本 文
中,我們考慮了選擇兩家供應商的問題,此處的供應商具有單邊的製程。我們提 出了一個新的正確方法解決是否選取新供應商的問題。而我們所提出的方法,在 此稱為 Subtraction method,和現有的 Division method 相較,也的確提供了較佳 的檢定力。 在實務上 比現有的供應商好到超越某種程度以上,在此定義為h>0,才願意以新的供應 商替換現有的供應商。本論文提出的 Subtraction meth 可以用來檢定相對應 的假設檢定,H0:CPU2 ≤CPU1+ 和h H :CPU2 >CPU1+ 。在應用上,我們考慮分h 波多工器 (Wav 個例子,若使用現有的 Division method,則供應商 II 勝過供應商 I 的程度約為 0.41。而若使用這裡所建 議的 Subtraction method,則供應商 II 勝過供應商 I 的程度約為 0.48,而非 0.41。 od, 1
參 考 文 獻
1. Bothe, D.R. (1997). A capability study for an entire product. ASQC Quality ultiple process streams. Quality d Spiring F.A. (1988). A new measure of process rocess capability ng the largest capability index from
. (1986). Process capability indices. Journal of Quality Technology, 18, . S. and Rao, K. A. (2003). Test of coefficients of variation of normal
H., Abdelaziz, B. and Esma, S. G. (2005). A wald test for comparing index analysis: a case timal tool replacement for processes with
, Hsu, Y. C. and Wu, C. W. (2006). Tool replacement for production
, Hsu, Y. C. and Shiau, H. J. J. (2007). Tool replacement policy for
Y.C. (2009). Supplier selection for one-sided
d Kotz, S. (2006). Encyclopedia and Handbook of Process . L. (1992). Distributional and inferential
Congress Transactions, Nashville, 46, 172-178.
2. Bothe, D. R. (1999). A capability index for m
Engineering, 11(4), 613-618.
3. Chan, L. K., Cheng, S. W. an
capability: Cpm. Journal of Quality Technology, 20(3), 162-175.
4. Chou, Y. M. (1994). Selecting a better supplier by testing p indices. Quality Engineering, 6(3), 427-438.
5. Huang, D. Y. and Lee, R. F. (1995). Selecti
several quality control processes. Journal of Statistical Planning and Inference, 46, 335-346.
6. Kane, V.E 41-52. 7. Nairy, K
populations. Communications in Statistics Simulation and Computation, 32, 641-661.
8. Norma, F.
multiple capability indices. Journal of Quality Technology, 37(4), 304-307. 9. Pearn, W. L. and Chang, C. S. (1998). An implementation of the precision
for contaminated processes. Quality Engineering, 11(1), 101-110. 10. Pearn, W. L. and Chen, K. S. (1997). Multi-process performance
study. Quality Engineering, 10(1), 1-8. 11. Pearn, W. L. and Hsu, Y. C. (2007). Op
low fraction defective. European Journal of Operational Research, 180(3), 1116-1129.
12. Pearn, W. L.
with low fraction defective. International Journal of Production Research, 44(12), 2313-2326.
13. Pearn, W. L.
one-sided processes with low fraction defective. Journal of the Operational
Research Society, 58(8), 1075-1083.
14. Pearn, W.L., Hung, H.N. and Cheng,
process with unequal sample sizes. European Journal Operational Research, 195(2), 381-393.
15. Pearn, W. L. an
Capability Indices. World Scientific.
16. Pearn, W. L. Kotz, S., Johnson, N
properties of the process accuracy and process precision indices. Journal of
7. Pearn, W. L. and Shu, M.H. (2003a). Manufacturing capability control for
er confidence bounds with sample size
ing plans with PPM fraction
W. (2006b). Critical acceptance values and sample sizes
r supplier selection
. (2005). Measuring manufacturing capability for
ariable sampling plan based on Cpmk for
1
multiple power distribution switch processes based on modified Cpk MPPAC.
Microelectronics Reliability, 43, 963-975.
18. Pearn, W. L. and Shu, M.H. (2003b). Low
information for Cpm with application to production yield assurance. International
Journal of Production Research, 41(15), 3581-3599.
19. Pearn, W. L. and Wu, C. W. (2006a). Variables sampl
of defectives and process loss consideration. Journal of Operational Research
Society, 57(4), 450-459.
20. Pearn, W. L. and Wu, C.
of a nes variables sampling plan for very low fraction of defectives. OMEGA,
International Journal of Management Science, 34(1), 90-101.
21. Pearn, W. L., Wu, C. W. and Lin, H. C. (2004). A procedure fo
based on Cpm applied to STN-LCD processes. International Journal of Production
Research, 42(13), 2719-2734.
22. Wu, C. W. and Pearn, W. L
couplers and wavelength division multiplexers. International Journal of Advanced
Manufacturing Technology, 25, 533-541.
23. Wu, C. W. and Pearn, W. L. (2008). A v
product acceptance determination with low PPM defectives. European Journal of