國 立 交 通 大 學
電信工程學系碩士班
碩士論文
基於聽覺感知模型的語音增強技術
Speech Enhancement Method based on Auditory
Perceptual Model
研 究 生:洪詠能 Student:
Yung-Neng
Hung
指導教授:冀泰石 博士 Advisor:
Dr.
Tai-Shih
Chi
基於聽覺感知模型的語音增強技術
Speech Enhancement Method based on Auditory
Perceptual Model
研 究 生:洪詠能 Student: Yung-Neng Hung
指導教授:冀泰石 博士 Advisor:
Dr. Tai-Shih Chi
國立交通大學
電信工程學系碩士班
碩士論文
A Thesis
Submitted to Department of Communication Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of
Master of Science
in
Communication Engineering
June 2008
Hsinchu, Taiwan, Republic of China
中 華 民 國 九 十 七 年 六 月
基於聽覺感知模型的語音增強技術
學生:洪詠能
指導教授:冀泰石 博士
國立交通大學電信工程學系碩士班
中文摘要
在早期的語音信號處理問題中,研究人員只從時域或頻域上觀察信號的特性 並予以處理,此種方式可以在高訊噪比的環境下,獲得極佳的效能。但隨著訊噪 比的降低,效能也急速的下降,而於實際應用中造成很大的影響。相較之下,人 類聽覺處理語音訊號,是在時域和頻域上同時執行的,並不會隨著環境的不同以 及訊噪比的改變,而受到太大的影響,即有著較佳的健全性。這也是在近年的語 音處理研究中,皆會加入人類對於聲音感知特性的原因。本論文中,我們使用一 已被提出的,模擬聲音沿著人耳到大腦傳輸路徑的聽覺感知模型,以此模型中頻 譜估計的初期階段來抽取語音特徵參數,並透過隱藏式馬可夫模型套件(HTK)來訓 練出連續數字串的語音辨認系統並測試此辨識器的效能。其後,以感知模型的時 域-頻域分析階段來壓抑噪音,達到語音增強的目的,並由辨識率的提昇來證實語 音增強的效果。Speech Enhancement Method based on Auditory
Perceptual Model
Student:
Yung-Neng
Hung Advisor:
Dr.
Tai-Shih
Chi
Department of Communication Engineering
National Chiao Tung University
Abstract
In earlier speech signal processing work, signal was observed and processed only on time or frequency domain. Such methods have excellent performance under high SNR environments, but poor performance with low SNR such that practical applications are limited. As a contrast, human hearing deals with sounds on both time and frequency domains such that it is not affected easily by different environments and SNR conditions, i.e., more robust. That is the main reason why perceptual properties are considered in recent speech researches. In this thesis, we investigate an auditory perceptual model in the speech enhancement application. The auditory model simulates the human hearing signal processing principles along the auditory pathway from the ear to the brain. First, the speech perceptual features are extracted from the spectrum estimation stage. A perceptual-feature based consecutive digit string recognizer is trained and evaluated by using Hidden Markov Model Toolkit (HTK). Secondly, we enhance speech signals by suppressing noise from the brain spectral-temporal analysis stage, and confirm its validity by the improvement of the recognition rate.
誌謝
在研究所的這兩年,我最想感謝的便是我的指導教授,冀泰石老師。老師從 我們一進來開始,便親自教導我們語音處理的概念及感知模型的使用,讓我們能 在短時間內快速的了解並應用人耳感知模型。而在開始模擬相關研究之後,也常 常與學生一同討論研究的方向及需要改進的地方,讓我學到許多的東西並且能更 多元的去觀察實驗結果。 再來要感謝實驗室的夥伙們,平時在課業上或實驗上的討論,使我能對感知 模型更加的了解而且也學到了更多關於語音處理的知識。雖然大家平時的興趣不 盡相同,但每個人都很好相處,實驗室的感覺讓我覺得有像家一樣的溫暖;目前 實驗室的規模並不是很大,但我相信將來在這股和諧的氣氛下,一定會不斷的壯 大起來的。 最後要感謝我的女友及父母,由於有你們的諒解和默默的支持,才能讓我專 心的完成學業,謝謝你們。目
錄
中文摘要
……… i
英文摘要………... ii
誌謝……… iii
目錄………
iv
表目錄……… vii
圖目錄………... viii
第一章 緒論………. 1
1.1 研究動機………..
1 1.2 研究方法………..
2 1.3 章節綱要………..
2第二章 聽覺感知模型及基本系統介紹………. 3
2.1 聽覺感知模型………
3 2.1.1 初期耳蝸階段的生理學現象……….
4 2.1.2 聽覺感知模型的初期耳蝸階段………..
6 2.1.3 聽覺感知模型的大腦聽覺階段……….
10 2.2 基本系統……….
132.2.1 語料庫
………..……….
13 2.2.2 訓練模式及語料設定………..………...
15 2.2.3 語音特徵擷取及模型設定………..………….
15 2.2.4 實驗結果……….………..………….
16第三章 語音特徵參數抽取………... 18
3.1 聽覺倒頻譜參數………
18 3.1.1 語音訊號前處理……….………..……
19 3.1.2 聽覺倒頻譜參數擷取……….………
20 3.1.3 聽覺倒頻譜參數的特性……….……….
20 3.2 英文連續數字串之辨識---使用聽覺倒頻譜參數……….
21 3.2.1 實驗設定……….……….………..……
21 3.2.2 實驗結果……….……….………..……
21第四章 以大腦聽覺階段為主之語音增強………25
4.1 大腦聽覺階段的統計特性………
25 4.1.1 高斯混合模型..……….……….………..……
26 4.1.2 聽覺頻譜圖在大腦聽覺階段的表現.……….……….……
26 4.1.3 高斯混合模型之參數設定與訓練模式..……….……….…
27 4.2 分散式語音辨識系統前級---AFE………...
29 4.2.1 分散式語音辨識系統..……….……….……….
304.2.2 辨識系統前級參數抽取---AFE
..……….………..
31 4.2.3 實驗設定………....……….………...
32 4.2.4 實驗結果……….……….………..
32 4.3 結合高斯混合模型的語音增強策略………....
34 4.3.1 以權重係數降低噪音能量..……….……….…………...
34 4.3.2 實驗設定及實驗結果…....……….……….…………...
36第五章 使用時域-頻域混合的調變濾波器的語音增強策略..39
5.1 聽覺頻譜圖上語音部分的重建………..
39 5.1.1 聽覺頻譜圖的重建..……….……….………
40 5.1.2 語音重建範圍的選擇..…….……….……….
41 5.2 使用調變濾波器的語音增強策略………...
42 5.2.1 以閾值決定聽覺頻譜圖上的噪音..……….……….……..
42 5.2.2 實驗設定及實驗結果…....……….……….…………...
44第六章 結論與未來展望………....47
6.1 結論……….………..
47 6.2 未來展望………...………..
48參考文獻……….………….49
表
目
錄
表 2-1 語音特徵參數(MFCC)抽取之參數設定
………...
16 表 2-2 英文連續數字串---語音特徵參數 MFCC 的辨識結果…………..
17 表 3-1 語音特徵參數(ACC)抽取之參數設定………...………...
21 表 3-2 英文連續數字串---語音特徵參數 MFCC 的辨識結果…………..
22 表 4-1 英文連續數字串---AFE+MFCC 的辨識結果………….………..
33 表 4-2 小量英文連續數字串---不同權重係數的辨識結果………
34 表 4-3 英文連續數字串---GMM+ACC 的辨識結果………….………..
36 表 5-1 英文連續數字串---經由調變濾波器+ACC 的辨識結果…………
44圖
目
錄
圖 2-1 基底膜在耳蝸中的分佈及對於不同頻率弦波的共振反應
………..
4 圖 2-2 基底膜上單一及多個合成行進波的示意圖………
5 圖 2-3 聽覺神經細胞的神經發射脈衝產生圖………...
6 圖 2-4 聽覺感知模型的初期耳蝸階段………...
7 圖 2-5 分析時期中濾波器組的振幅響應………...
8 圖 2-6 一段語音訊號的時域波形及對應之聽覺頻譜圖………...
9 圖 2-7 移動波紋刺激源………...
10 圖 2-8 大腦聽覺階段對於聽覺頻譜圖的分析………...
11 圖 2-9(a) 長時段男性語者乾淨語音的平均調變內容 (橫軸:rate;縱軸: scale)...
12 圖 2-9(b) 長時段男性語者訊噪比為 5 dB 語音的平均調變內容 (橫軸:rate; 縱軸:scale)………...
13 圖 2-10(a) 穩態噪音的聽覺頻譜圖表現………...
14 圖 2-10(b) 非穩態噪音的聽覺頻譜圖表現………...
14 圖 3-1 擷取聽覺倒頻譜參數前時域上的處理………...
19 圖 3-2 八種環境雜訊在兩種語音特徵參數下的比較………
23 圖 3-3 不同訊噪比在兩種語音特徵參數下的比較………...
24圖 4-1(a) 聽覺頻譜圖上不同時間-頻率點的調變內容 (橫軸:rate;縱軸: scale)
………...
26 圖 4-1(b) 聽覺頻譜圖在大腦聽覺階段的調變內容 (橫軸:rate;縱軸: scale)………...
27 圖 4-2(a) 乾淨語音在非語音高斯混合模型中的對數機率及分類結 果……….
28 圖 4-2(b) 訊噪比 10 dB 的語音在非語音高斯混合模型中的對數機率及分類結 果……….
29 圖 4-3 分散式語音辨認系統架構圖………...
30 圖 4-4 AFE 中降低雜訊的處理流程圖………...
32 圖 4-5(a) 訊噪比 10 dB 的語音經過 GMM 模型語音增強後的結果…………
35 圖 4-5(b) 訊噪比 5 dB 的語音經過 GMM 模型語音增強後的結果………….
35 圖 4-6 八種環境雜訊在 GMM 及 AFE 語音增強策略下的比較…………...
37 圖 4-7 不同訊噪比在 GMM 及 AFE 語音增強策略與基本線的比較……….
38 圖 5-1 經由不同的時域-頻域分析後重建出的聽覺頻譜圖………
40 圖 5-2 訊噪比 5 dB 的語音經由大腦聽覺階段重建出的語音聽覺頻譜圖..
41 圖 5-3(a) 訊噪比 10 dB 的語音經過調變濾波器語音增強後的結果……....
43 圖 5-3(b) 訊噪比 5 dB 的語音經過調變濾波器語音增強後的結果………..
43 圖 5-4 八種環境雜訊在調變濾波器及 AFE 語音增強策略下的比較…….
45 圖 5-5 不同訊噪比在調變濾波器及 AFE 語音增強策略與基本線的比較…
46第一章
緒論
1.1 研究動機
隨著科技技術的急速發展,電子產品可以處理的事情愈來愈多,範圍也愈來 愈廣,也為人類帶來甚多的便利。在輸入介面的部份,也隨著產品的輕薄短小, 想使其可以由傳統的鍵盤或按鍵輸入轉而讓電子產品接受聲音的訊號來執行命 令。但是在接收的過程中往往伴隨著週遭的噪音或通道的效應而使得產品反應的 表現不甚理想,此時,以語音強健技術來增進機器對於聲音的辨識率便是一個可 以改進效能的研究方向。 近年來亦隨著科技進步,而將人類在心理聲學及生理學上的研究發現(例如: 人耳對於聲音感知的特性),廣泛應用於電子產品上。MP3 編碼便是利用了人耳聽 覺的頻率及時域的遮蔽效應,大大降低了音訊的編碼容量。 如上所述,我們亦可以將人耳處理聲音的方式,應用到語音強健的方向上, 希望能讓機器達成像人一般,即使是在嘈雜的環境下,也能夠容易的將聲音辨認 出來。1.2 研究方法
本論文主要的研究方向在結合已提出的聽覺感知模型及連續數字串語料庫的 基礎上,建立數字串的辨認器。並使用語音在時域-頻域分析階段的統計特性及經 由時域-頻域混合的調變濾波器兩種方式,提昇在不同訊噪比及環境下的辨認率, 進而驗證此聽覺模型對於語音處理的健全性。1.3 章節綱要
第一章 導論:說明本篇論文的研究動機、研究方法及章節概要。 第二章 聽覺感知模型及基本系統介紹:介紹由生物實驗所建立起的聽覺感知模型 及整篇論文所使用到的語料庫和訓練工具,並做英文連續數字串辨認來當 做之後實驗的基準線。 第三章 語音特徵參數抽取:說明如何從聽覺模型中的頻譜估計階段所得到的聽覺 頻譜圖中,進行語音特徵參數的抽取;以此參數同樣做數字串的辨認實驗 並與基準線做比較。 第四章 高斯混合模型應用於語音增強:訓練乾淨語音在時域-頻域分析階段的高 斯混合模型並使用此模型來偵測並處理聽覺頻譜圖上的噪音部分。 第五章 使用時域-頻域混合的調變濾波器的語音增強策略:使用時域-頻域分析階 段的調變濾波器將乾淨的語音部分從聽覺頻譜圖上抽取出來。 第六章 結論與未來展望:總結本論文所提出的方法,並說明可改進的方向。第二章
聽覺感知模型及基本系統介紹
在本章中,將先介紹 Neural Systems Laboratory [1] 所提出的模擬人類聽覺的 感知模型;而後介紹本篇論文所使用的語料庫及評估所提出語音強健技術效能之 隱藏式馬可夫模型套件(HTK) [2] 的設定。並以此套件做了英文連續數字串的基本 實驗。
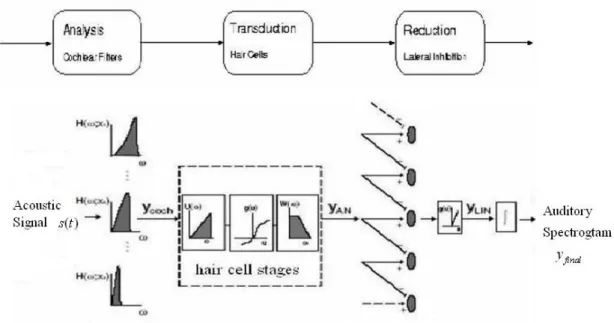
2.1 聽覺感知模型
由研究哺乳動物聽覺系統的生理實驗發現 [3]-[5],人類對於聲音處理沿著耳 朵經由中腦到大腦的聽覺路徑,基本上可以分為兩個階段: (1) 頻譜估計:這個部份是模擬經由聽覺處理的初期階段,從人耳接受聲音到中 腦的神經元傳輸,所觀察到的信號轉換結果。 (2) 時域-頻域分析:此部份是基於生理實驗在大腦皮質聽覺區(AI)的發現,模擬 大腦對於初期階段的結果所做的分析,此分析可以用一組時域-頻域混合的調 變濾波器來完成。 下面的小節將分別詳細介紹兩個階段的內容。2.1.1
初期耳蝸階段的生理學現象
當聲波由外耳接受,經過鼓膜,三小聽骨而抵達卵圓窗,這一階段主要的生 理功能是聲音由空氣壓力轉換成液體壓力及振幅的補償,使得聲音並不因為壓力 形態的轉換而有著太多能量的耗損,而影響後面神經元轉換聲音訊息的正確性。 而後聲音進入內耳,並由內耳中的耳蝸將訊息由波的型式轉換成神經衝動。 內耳是由耳蝸和幾個非關聽覺的結構組成。耳蝸由三個充滿淋巴液的空腔組 成,並由基底膜(Basilar membrane)橫跨而分成兩部分,基底膜是一個貫穿耳蝸底 部自頂部的膜狀結構。來自卵圓窗的液壓振動,在基底膜形成一個行進波(Traveling wave),行進波在基底膜的不同部位形成不同的共振幅度。自底部至頂部,基底膜 的橫向寬度遞增且彈性遞減。這兩個趨勢的綜合作用結果是共振頻率(亦稱為特性 頻率(Characteristic frequency)或最佳頻率(Best frequency))自底部至頂部的遞 減,即高頻的共振部位位於底部;低頻共振部位位於基底膜的頂部。基底膜共振 頻率的範圍約為 20-20000 Hz,即人類的正常聽覺頻率範圍。圖 2-1 簡單地表示 基底膜的結構及頻率特性。當不同頻率的聲音造成的行進波於基底膜上發生共振時,規則地分佈於基底 膜之上的毛髮細胞(Hair cells)便負責將液壓轉換成神經訊號,毛髮細胞可分為內毛 細胞和外毛細胞,主要的轉換是由內毛細胞所完成。內毛細胞是感受器細胞,與 若干個聽神經纖維形成突觸連接,以感受液壓的變化將機械振動轉化為與之相連 的聽神經纖維的動作電位。而外毛細胞一般認為與增強聽神經的高度頻率選擇 性、耳蝸的調節和自我保護機制有關。 一般來說,人耳接受到環境的聲音通常是以複雜的頻率所組成,因此,會在 基底膜上連續產生不同的行進波而造成鄰近位置的內毛細胞有著彼此壓抑的效 果,如圖 2-2 所示;此種微觀現象便是造成人耳的頻率遮蔽效應的原因。 圖 2-2:基底膜上單一及多個合成行進波的示意圖 在內毛細胞將聲音從壓力形式轉換成動作電位時,訊息便沿著聽神經繼續傳 遞上去。但由於神經元在連續發射動作電位後,需進入靜止電位讓神經細胞休息, 此結果導致神經發射速率(firing rate)並不能跟上較高頻的輸入信號,如圖 2-3 所 示。內毛細胞的最高神經發射速率大約是 4~5K Hz;而中腦的聽神經細胞,大約只 能到 1K Hz 的神經發射速率。
圖 2-3:聽覺神經細胞的神經發射脈衝產生圖
2.1.2
聽覺感知模型的初期耳蝸階段
聽覺感知模型的初期階段,便是模擬聲音訊息由波的型式,在耳蝸中被轉換 成神經脈衝並傳輸至中腦的部分,也就是對於聲音的頻譜估計。上節所描述的生 物 學 現 象 , 主 要 可 以 對 應 到 此 階 段 中 的 分 析 時 期 (analysis stage) 、 轉 導 時 期 (transduction stage)以及簡化時期(reduction stage),圖 2-4 表示此階段的組成並由 下列的數學式說明。
圖 2-4:聽覺感知模型的初期耳蝸階段 ( , ) ( ) ( ; ) coch t y t x =s t ∗ h t x (2-1) ( , ) ( ( , )) ( ) AN t coch t y t x = ∂g y t x ∗ w t (2-2) ( , ) max( ( , ), 0) LIN x AN y t x = ∂ y t x (2-3) μ τ ( , ) ( , ) ( ; ) final LIN t y t x =y t x ∗ t (2-4) 式 (2-1) 表示此階段的分析時期,模擬時域信號 ( )s t 在基底膜上發生共振的反 應。此式中的∗ 表示在時域上的褶積(convolution)而 ( , )t h x t 代表在x 上的脈衝響 應,x 表示的是距離耳蝸底部的距離,即基底膜上不同的共振頻率的位置。在此聽 覺模型中,耳蝸是以一濾波器組(filter bank)來模擬,此濾波器組中包含了 129 個不 同頻率解析度的濾波器,各個濾波器的中心頻率在對數頻率上呈現線性分佈的狀 態,並設計為在一個倍頻中分佈 24 個濾波器(24filters/octave),即此濾波器組可分 析約 5.3 個倍頻。但人類的正常聽覺頻率範圍可從 20 至 20000 Hz,是為 10 個倍頻, 因此濾波器組亦被設計為中心頻率可變,以因應不同的取樣頻率的輸入信號分 析。而各濾波器的頻寬與中心頻率符合下面的式子 / center f bandwidth=Q (2-5) Q 為一常數,其數值為 4,由此可知,隨著濾波器中心頻率的增加,濾波器的頻寬 亦會變寬,以一個取樣頻率 8K Hz 的信號為例,此濾波器組的振幅響應可由圖 2-5
來表示。 圖 2-5:分析時期中濾波器組的振幅響應 式 (2-2) 表示此階段的轉導時期,模擬內毛細胞將感受到的液壓變化轉變成 電訊號的過程。此時期對於分析時期的輸出ycoch變化量的處理,是一種非線性的 振幅壓縮:先由一高頻濾波器來取出濾波器組輸出的變化量,類似液壓的變化, 接著經由 sigmoid 函數g u( )=1/(1+e−u),表示內毛細胞的轉換及保護作用,最後 以一 3 dB 頻寬為 4K Hz 的低頻濾波器來模擬內毛細胞的最高神經發射速率,此時 信號的變化量大於 4K Hz 的組成將被壓抑。 式 (2-3) 及式 (2-4) 表示最後的簡化時期。式 (2-3) 對應到鄰近內毛細胞會 有彼此壓抑的現象,即上一節所提到的人耳頻率遮蔽效應,此處只有簡單的以濾 波器組中鄰近一階濾波器的差分量串接半波整流器來模擬此現象,實際上人耳遮 蔽效應對於鄰近內毛細胞的壓抑範圍要較為廣大的。式 (2-4) 使用一時域上的積 分視窗μ τ( ; )t =e−t/τ ⋅u t( )來模擬電訊號由耳蝸傳遞到中腦後,中腦聽覺神經細胞
的神經發射速率,約 1K Hz。此處的τ 是時間常數(time constant)、u t( )是單位位階 函數(unit step function),時間常數一般是取 8ms 來因應 1K Hz 的發射速率,但是 在聽覺模型中,時間常數可以做 1ms 到 128ms 的調整以對應不同目的的使用。式 (2-3) 中的半波整流器及式 (2-4) 可以合併視為一波封檢測器(envelope detector)。 經由上述三個時期的轉換,最後輸出的時域-頻域表現,是對於噪音干擾以及 語音特性有著較為強健的估計頻譜圖,稱之為聽覺頻譜圖(auditory spectrogram) [6] , 以一取樣頻率 8K Hz,時間長度 1 秒的英文數字串(九-二-三)為例,其相對 應的聽覺頻譜圖可如圖 2-6 所示,此圖的頻率軸呈現對數的分佈方式。此階段輸 出的二維頻譜圖將再傳遞至大腦聽覺階段以便進一步的分析。 圖 2-6:一段語音訊號的時域波形及對應之聽覺頻譜圖
2.1.3
聽覺感知模型的大腦聽覺階段
對於聽覺感知模型的初期階段輸出的聽覺頻譜圖,大腦聽覺階段會給予進一 步的分析。此階段的頻譜圖分析可以用一組時域-頻域混合的調變濾波器來模擬。 此一多重解析度的分析有效地對於聽覺頻譜圖的局部頻寬及非對稱性做編碼。音 源之所有的音色及基頻的資訊皆可清楚地展示於此種分析結果內。 此階段的模擬是以生物的實驗為根據而得到。由上一節的結果可知,聽覺頻 譜圖是時域-頻域的共同表示式,也就是說,大腦皮質所接收的輸入訊號是有兩個 維度的,而研究中想要測得大腦皮質的反應。由信號處理的觀點來看,將大腦皮 質視為一系統,可以使用頻率響應分析來測試此系統的反應,即使用各種單一頻 率的波形來測試此系統對於各頻率的反應;又因為此系統的輸入是二維的,研究 中便設計出特定的時域-頻域組成訊號,稱之為移動波紋刺激源(moving ripple stimulus)。以圖 2-7 為例,其在時域上以 250 ms 為一個週期,此時域軸上的變化 率,定義為 rate(單位:Hz),圖中的 rate 是 4 Hz;而在對數頻率軸上,一個週期大 約包括了兩個倍頻,對數頻率上的變化率,定義為 scale(單位:cycle/octave),圖中 的 scale 為 0.5 cyc/octave。 圖 2-7:移動波紋刺激源生物實驗發現,對於不同的移動波紋刺激源,大腦皮質上的某個部分的聽覺 神經元會有特別強的反應,這表示不同聽覺神經元,是以不同的解析度,來處理 由中腦所傳遞上來的二維訊息,解析出輸入訊號中不同的時域-頻域特性;在模型 中,是將聽覺頻譜圖經過一群二維帶通調變濾波器而得到時域-頻域多重解析的分 析結果。因此,此階段的輸出結果是為一四維的表示,除了時間及對數頻率外, 還有上述定義的 rate 及 scale。除此之外,由於大腦中對於調頻(FM)的上昇或下降, 亦是由不同的神經元來做解析,模型中也定義了正的 rate,是對調頻的下降 (downward)有所反應;而負的 rate,則是對調頻的上昇(upward)有所反應,上述的 相關參數及特性可由圖 2-8 來表示。 圖 2-8:大腦聽覺階段對於聽覺頻譜圖的分析 圖中各解析結果的左上角小圖,稱之為時頻反應域(spectro-temporal response field, STRF ),即是模擬大腦皮質上的聽覺神經元;值得注意的是,由於個別神經 元反應函式有相當的重疊性,即對高變化率有反應的聽覺神經元亦會對低變化率 有些許的響應,而表現出高度的冗餘性。這種高度的冗餘性可使得原本顯著的語 音特性較不易被噪音完全破壞,進而加強語音之強健性。從圖中也可得知,神經
元函式對於調頻的下降反應較強,表示人類的語音中,大體上有著調頻變化為向 下的趨勢。 此階段的輸出結果,讓我們有更多的維度去觀察聲音訊號,因此聲音的特性 便更加容易地被分析出來,初步的結果顯示,語音以及噪音在經由聽覺模型時域-頻域調變分析後,於 rate、scale 兩個維度的分佈結果有顯著的不同。乾淨的語音 訊號在經過時域-頻域調變分析時,大部分的能量將出現在 rate 8 Hz 以及 scale 4 cycle/octave 以下,而白雜訊(white noise)的調變能量會出現在更高的 rate 及 scale, 分別如圖 2-9(a)、圖 2-9(b) 所示。因此,我們可以應用時域-頻域調變濾波的概念, 來增強語音訊號或語音品質的提昇。
圖 2-9(b):長時段男性語者訊噪比為 5 dB 語音的平均調變內容 (橫軸:rate;縱軸: scale)
2.2 基本系統
在本節中,介紹所使用之語料庫,辨認器的訓練流程,相關的設定及架構, 並以此語料庫進行一組英文連續數字串的辨認實驗。2.2.1
語料庫
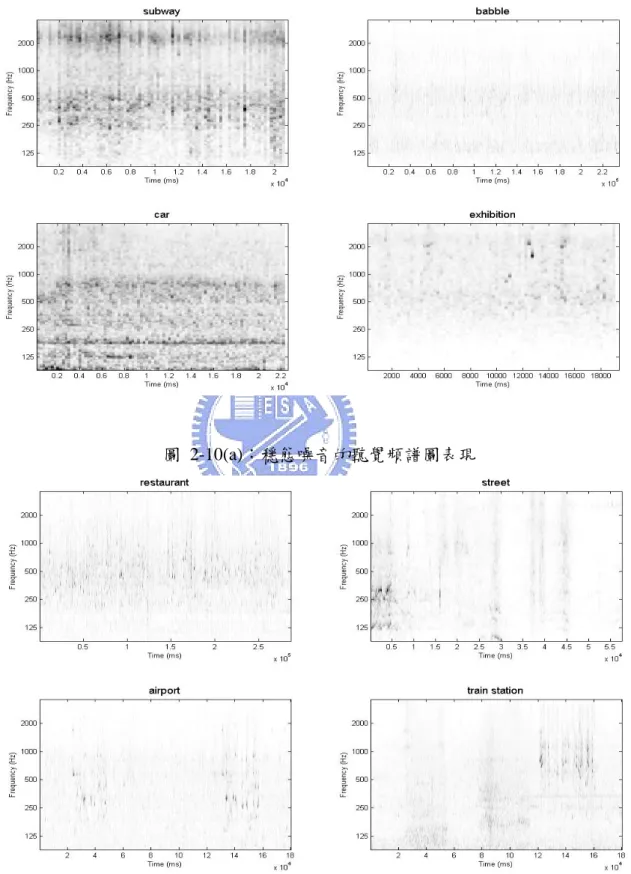
在 本 論 文 實 驗 中 所 使 用 的 語 料 庫 , 是 由 歐 洲 電 信 標 準 協 會 (European Telecommunication Standards Institute, ETSI)所發行的一套有包括雜訊的英文連續 數字串語料庫,AURORA-2 [7] 。其語料皆存為取樣頻率為 8K Hz,16 bit 的 PCM 檔案。其中雜訊包括八種由現實環境中取樣的真實加成性噪音源,包括了地下鐵、 人聲、汽車、展覽會館、餐廳、街道、機場、火車站,前面四種為 A 組,後四種 為 B 組,各噪音源並依不同的訊噪比各自加入乾淨的語音內,訊噪比從-5 dB~20 dB ,每 5 dB 為一個間隔。 A 組為穩態 (Stationary) 雜訊,而 B 組為非穩態任一時間的頻譜幾乎相同;而非穩態雜訊在聽覺頻譜圖上的表現,則隨著不同的 時間點,頻譜特性的變動很大。
圖 2-10(a):穩態噪音的聽覺頻譜圖表現
2.2.2
訓練模式及語料設定
在語料庫中,標示了一套訓練隱藏式馬可夫模型(Hidden Markov Model, HMM) 語音辨識器的流程,詳細流程及結果可參照 [8] 。此模型的產生也可分為只用乾 淨語料訓練,稱為乾淨語料訓練;或是用加入不同環境雜訊、以及不同的訊噪比 的語料做訓練,稱之為複合語料訓練。在本論文中,只使用了乾淨語料訓練的訓 練模式。由於本論文目的在驗證語音強健技術,因此訓練的模式也可由語料是否 經過同樣的語音強健技術而分為匹配訓練(Match condition)及不匹配訓練 (Mismatch condition),本論文中採用匹配的訓練方式,即是將訓練及測試的語料皆 以語音強健技術做處理。 在乾淨語料的訓練中,語料是由男性與女性各 55 人所錄製,共 8440 句的乾 淨連續數字串語音所組成;而測試的語料,則是由和訓練語料不同的男性與女性 各 52 人所錄製的語音,在每種真實噪音源皆有 1001 句,並依不同的訊噪比將噪 音源加入,故共有 8 種噪音源乘上 7 種聲噪比共有 56 組的測試語料情境,每一組 皆分別計算辨識結果。
2.2.3
語音特徵擷取及模型設定
本節實驗所使用的語音特徵參數是 12 維梅爾倒頻譜參數(Mel Frequency Cepstral Coefficients, MFCC),以及一維和二維的變化量,共 36 維特徵向量。表 2-1 列出特徵參數抽取過程中各項參數設定。 在模型的基本設定中,每個數字模型(1~9 及 zero 和 oh)皆由一個由左到右 (left-to-right)形式的連續密度隱藏式馬可夫模型(Continuous Density Hidden Markov Model, CDHMM)來表示,其中包含 16 個狀態(在 HTK 內為 18 個狀態,包含最前 面及最後面兩個虛擬狀態),每個狀態含有 3 個混合高斯數(Mixtures)。除了數字模 型外,還有兩個模型-靜音模型(Silence model)及停頓模型(Short-pause model),是用 來描述語音信號中靜音部份:靜音模型包括 3 個狀態,用來表示語句開始和結束時的靜音;停頓模型是用來描述字與字中間的短暫停止,設定為 1 個狀態,並與 靜音模型的中間狀態合併(Tying),此兩個模型的每個狀態皆含有 6 個混合高斯數。
表 2-1:語音特徵參數(MFCC)抽取之參數設定 取樣頻率(Sampling rate) 8K Hz 音框長度(Frame window size) 25 ms 音框位移量(Frame window shift) 10 ms 預強調的轉移函數(Pre-emphasis) 1−0.97z−1
梅爾濾波器組(Mel-frequency filter bank) 23 個
語音特徵向量(Speech feature vector) 36 維(12-MFCCs、一次及二 次動態係數)
2.2.4
實驗結果
由 HTK 套件所訓練出來的辨識器做辨識,錯誤的部分可以分為以下三種: (1) D:刪除錯誤,deletion error,為正確解中有而未辨識出的音節。
(2) S:替代錯誤,substitution error,為辨識錯誤的音節。
(3) I:插入錯誤 insertion error,為正確解中沒有卻辨識出的音節。
而辨識結果可以分為下面兩種,本論文中是以 Accuracy Rate 來當做辨識結 果,它將以上的三種錯誤皆考慮入內,其中 N 為正確解中總音節數。 Correct Rate = (N −D−S)÷N×100% Accuracy Rate = (N −D− −S I)÷N×100% 表 2-2 列出乾淨語料訓練模式在八種噪音源下的辨識結果。其中各種雜訊下 的平均辨識率是依照 AURORA-2 中平均辨識率的計算方式,只取訊噪比 20 dB 到 0 dB 做平均。
表 2-2:英文連續數字串---語音特徵參數 MFCC 的辨識結果 乾淨語料訓練模式 A 組 訊噪比 (dB) 地下鐵 人聲 汽車 展覽會館 乾淨 98.40% 98.31% 98.21% 98.58% 20 95.36% 93.89% 96.54% 95.40% 15 89.50% 89.42% 89.53% 88.21% 10 68.47% 75.94% 64.87% 64.64% 5 38.04% 49.94% 31.37% 32.43% 0 22.38% 23.85% 19.06% 18.76% -5 16.73% 11.79% 11.75% 11.23% 平均值(20 dB~0 dB) 62.75% 66.61% 60.27% 59.89% B 組 訊噪比 (dB) 餐廳 街道 機場 火車站 八組噪音 源平均值 乾淨 98.40% 98.31% 98.21% 98.58% 98.38% 20 93.71% 95.83% 94.78% 94.82% 95.04% 15 89.28% 88.57% 90.84% 89.23% 89.32% 10 77.65% 67.44% 78.65% 72.69% 71.29% 5 51.83% 39.81% 52.16% 41.16% 42.09% 0 25.33% 22.85% 28.63% 22.68% 22.94% -5 11.79% 13.12% 14.58% 12.71% 12.96% 平均值(20 dB~0 dB) 67.56% 62.90% 69.01% 64.12% 64.14% 由實驗結果,我們可以發現,當訊噪比由 20 dB 降到 10 dB 時,辨識率大致 是以線性的趨勢下降;但當訊噪比由 10 dB 再向下降的時候,辨識率也會大幅的 下降,如各訊噪比的平均值,於表 2-2 中所示。我們以此結果來當做後續實驗的對 照基本線。
第三章
語音特徵參數抽取
從上一章的實驗結果中,我們可以知道在有雜訊的環境下,辨認率會隨著訊 噪比的降低而下降;尤其在訊噪比 10 dB 以下時,雜訊對於辨識率的影響更為嚴 動。在本章中,介紹如何從聽覺模型的初期耳蝸階段所產生的聽覺頻譜圖中,擷 取語音特徵參數,聽覺倒頻譜參數(Auditory Cepstral Coefficients, ACC),並以此參 數訓練語音辨識器且進行英文連續數字串的辨認。最後以此辨認結果,與上章 MFCC 參數所做的辨認實驗結果做比較,得到其對於訊噪比以及不同環境雜訊的 健全性。
3.1 聽覺倒頻譜參數
在本節中,介紹如何從聽覺頻譜圖上,擷取語音特徵參數,稱之為聽覺倒頻 譜參數,以及相關的擷取設定。3.1.1
語音訊號前處理
在信號進行處理之前,我們先將所有的語音訊號先經過正規化,即扣除其平 均值並除上其標準差,使整段訊號成為平均值零,且變異數為 1 的常態分佈,經 由簡單的測試,正規化的方式對於 ACC 的辨識率並不會造成影響,其原因是我們 於辨識實驗中並未使用能代表聽覺頻譜 DC 值的參數。 在處理數位信號時,通常會考慮到信號的時變特性,因此一次只取一小段來 處理。在分段處理語音信號時,時間過長或過短皆不好,本節中是以和擷取 MFCC 同樣的 25 ms 音框長度及 10 ms 音框位移量。由於初期耳蝸階段的設定中,在輸出 聽覺頻譜圖之前,會先做一次減少取樣(down-sampling)的動作,以降低資料量,因 此,我們將此減少取樣週期設定為 25 ms,即可以得到 25 ms 為一個音框單位,而 10 ms 為音框位移量的聽覺頻譜圖,如同圖 3-1 所示。 圖 3-1:擷取聽覺倒頻譜參數前時域上的處理3.1.2
聽覺倒頻譜參數擷取
由於聽覺頻譜圖的產生,是由濾波器組中鄰近一階濾波器的差分量並串接波 封檢測器的輸出,因此可視為一種能量的分佈;我們可以直接在上一小節所得到 輸出中的每個音框內取對數,而不會造成問題。再來,將取過對數的音框,以下 列的離散餘弦轉換,便可得到 ACC 參數。π
12
cos( (
0.5))
N i j ji
C
m
j
N
=N
=
∑
−
(3-1) 上式的 N 表示在聽覺頻譜圖上的對數頻率軸的維度,為 128;雖然在上一章 有提到,聽覺感知模型中的耳蝸濾波器組中包含了 129 個不同解析度的濾波器, 但是在簡化時期,取出了濾波器間的差分量,因此只有 128 個維度。而m 便是一j 個音框中,對數頻率軸上 128 維的輸出取對數後的值。而C 即為輸出的聽語倒頻i 譜參數。3.1.3
聽覺倒頻譜參數的特性
由聽覺頻譜圖所擷取出來的語音特徵參數 ACC,具有以下的特性: (1) 低頻多取,高頻少取:以取樣頻率 8K Hz 的語音信號為例,在 1K Hz 以下的 頻率便用了 84 個濾波器來做處理;而在 1K 到 4K Hz 的部份只用了 45 個濾 波器來進行處理。 (2) 在一個倍頻中提供了更多解析度:由於聽覺感知模型設計為一個倍頻中分佈 24 個濾波器,因此可以更容易地將音高及共振峰的資訊從語音信號中抓出來。 (3) 考慮了時域及頻域上的遮蔽效應:如同上一章對於模型的描述,ACC 亦包含 了此特性在內。3.2 英文連續數字串之辨識---使用聽
覺倒頻譜參數
3.2.1
實驗設定
本節中所使用的語料庫為 AURORA-2;實驗的訓練模式為乾淨語料訓練,訓 練的流程完全與上一章的實驗相同。 在參數抽取的設定是使用 12 維的聽覺倒頻譜參數,以及一維和二維的變化 量,共 36 維特徵向量。表 3-1 列出特徵參數抽取過程中各項參數設定。而在聲學 模型的基本設定中,也與上一章的實驗相同。 表 3-1:語音特徵參數(ACC)抽取之參數設定 取樣頻率(Sampling rate) 8K Hz 音框長度(Frame window size) 25 ms 音框位移量(Frame window shift) 10 ms 預強調的轉移函數(Pre-emphasis) 無 濾波器組(Cochlear filter bank) 129 個語音特徵向量(Speech feature vector) 36 維(12-ACCs、一次及二次 動態係數)
3.2.2
實驗結果
以聽覺倒頻譜參數來做英文連續數字串的實驗,其實驗的結果如表 3-2 所示 。
表 3-2:英文連續數字串---語音特徵參數 ACC 的辨識結果 乾淨語料訓練模式 A 組 訊噪比 (dB) 地下鐵 人聲 汽車 展覽會館 乾淨 98.80% 98.46% 98.48% 98.86% 20 97.67% 93.53% 96.84% 96.98% 15 95.46% 90.90% 94.48% 94.94% 10 88.55% 83.49% 84.70% 87.75% 5 66.84% 66.02% 55.47% 61.71% 0 29.60% 31.89% 23.74% 28.57% -5 16.83% 12.94% 11.39% 14.84% 平均值(20 dB~0 dB) 75.62% 73.17% 71.05% 73.99% B 組 訊噪比 (dB) 餐廳 街道 機場 火車站 八組噪音 源平均值 乾淨 98.80% 98.46% 98.48% 98.86% 98.65% 20 92.48% 96.83% 94.57% 96.24% 95.64% 15 89.78% 94.86% 92.60% 93.74% 93.35% 10 83.70% 86.55% 84.70% 85.37% 85.60% 5 66.20% 61.67% 65.76% 62.08% 63.22% 0 34.36% 30.08% 34.24% 27.46% 29.99% -5 13.36% 15.63% 14.88% 12.19% 14.01% 平均值(20 dB~0 dB) 73.30% 74.00% 74.37% 72.98% 73.56% 由實驗結果中,可以發現: (1) 對於每一種噪音源,以 ACC 語音特徵參數所做的平均辨識結果皆可達到 70% 以上的辨認率。 (2) 在汽車及火車站的辨識結果為八種噪音源中最不好的,可能是由於在此兩種 噪音源中的低頻聲音較多,而 ACC 參數會將聲音低頻的部分清楚的抓取出 來,而影響到辨識的結果。 (3) 在訊噪比從 20 dB 降到 5 dB 時,辨識率尚有 60%以上,而到了 5 dB 以下時, 辨識率才有嚴重的下降情形發生。
在與上章中 MFCC 所做的實驗結果比較,可以得知: (1) 在八種噪音源的環境下,以 ACC 語音特徵參數所做的辨識結果皆較 MFCC 的辨識結果有所提昇,如圖 3-2 所示。但是在人聲、餐廳、機場提昇的部分 卻較少,原因是在此三種環境下,人聲的噪音皆容易被誤判成”oh”,而產生 了插入錯誤,進而影響了 Accuracy Rate 的結果。 (2) 在各種噪音下,MFCC 的辨識率結果可從 59.89%到 69.01%,而 ACC 的辨識 率結果是從 71.05%到 75.62%,標準差較低,由此可見 ACC 的辨識率並不會 因為不同的噪音源而受到太大的影響,即較有健全性。 (3) MFCC 在 10 dB 以上,辨識率大略呈線性下降,而從 10 dB 下降至 5 dB 時, 辨識率下降了約 30%;而此辨識率大幅下降的情形在 ACC 中到了 5 dB 以下 時才開始發生,如圖 3-3 所示,表示 ACC 對不同訊噪比下的健全性。 (4) 在訊噪比為-5 dB 的情形下,由於噪音源的能量已大於語音,故在 MFCC 及 ACC 兩者的辨識率表現並無太大的差異。 圖 3-2:八種環境雜訊在兩種語音特徵參數下的比較
第四章
以大腦聽覺階段為主之語音增強
在上一章中,實驗結果證實了從聽覺感知模型的初期耳蝸階段輸出所擷取的 語音特徵參數對於不同的環境噪音以及不同的訊噪比有著較佳的健全性。在本章 中,以統計的方式,結合聽覺頻譜圖在感知模型中的大腦聽覺階段的表現,訓練 出乾淨語音中靜音部分的高斯混合模型,來偵測並處理聽覺頻譜圖上的噪音部 分,達到語音增強的效果。其後,介紹歐洲電信標準協會所制訂的分散式語音辨 認架構中的辨識前級參數抽取,AFE(Advanced Front-End),其中使用了維納濾波 器(Wiener filter)來降低語音雜訊。最後,比較兩者之語音增強的效果。4.1 大腦聽覺階段的統計特性
在本節中,介紹聽覺頻譜圖在大腦聽覺階段的表現,以此來訓練高斯混合模 型(Gaussian Mixture Model, GMM),並以訓練出來的模型偵測出聽覺頻譜圖上的噪 音部分並予以處理。4.1.1
高斯混合模型
高斯混合模型是單一高斯機率密度函數的延伸,包含多個高斯機率分佈,由 於其能夠平滑地近似任意形狀的密度分佈,因此近年來常被用在語音與語者辨 識。模型中的參數包括平均值向量(mean vector),相關變異數矩陣(covariance matrix) 以及混合數權重(mixture weight)。本論文中以一語音套件:VOICEBOX [9] ,來訓 練高斯混合模型並以訓練出來的模型來計算輸入資料的對數機率。
4.1.2
聽覺頻譜圖在大腦聽覺階段的表現
由第二章對大腦聽覺階段的介紹,此階段的輸出結果為四維,包括了時間、 對數頻率外,還有rate及scale。我們可以視為,在聽覺頻譜圖上固定的時間及對數 頻率,都可以有一組相對應的rate及scale,如同圖 4-1(a) 所示。 圖 4-1(a):聽覺頻譜圖上不同時間-頻率點的調變內容 (橫軸:rate;縱軸: scale)當我們將同一段語音經由聽覺感知模型得到的四維結果在時間及對數頻率上 取平均,便可以得到此段語音在rate及scale上的表現,如同圖 4-1(b) 所示。由這 兩張圖發現,rate-scale的分佈圖並不完全相同,即表示在聽覺頻譜圖上不同點 rate-scale的表現仍和長時段的表現有所差異,因此我們可以以高斯混合模型來近似 這些不同rate-scale表現所形成的分佈。本章之基本觀念即是以語音及噪音在大腦聽 覺階段之統計表徵不盡相同,進而壓抑噪音而達到語音強化之目標。 圖 4-1(b):聽覺頻譜圖在大腦聽覺階段的調變內容 (橫軸:rate;縱軸:scale)
4.1.3
高斯混合模型之參數設定與訓練模式
由於乾淨語音在經過時域-頻域調變分析時,大部分的能量將出現在rate 8 Hz 以及scale 4 cycle/octave 以下;又由 [10] 得知,大腦所能跟上的時變率中與人聲 產生較有相關的是在32 Hz以下。因此我們在rate方面,取了2、4、8、16及32 Hz, 而在scale方面,取了0.5、1、2、4、8 cycle/octave,暫不考慮正負rate,故在聽覺 頻譜圖上,一個固定的時間及對數頻率上,便對應了一組25維的能量向量,我們 以這些資料,並取8個高斯混合數,來訓練出高斯混合模型。在訓練的方式上,考慮語音和噪音特性在經過時域-頻域調變分析後的多變 性,因此我們採用乾淨語音的非語音部分在大腦聽覺階段的調變內容來訓練高斯 混合模式;當有一新的能量向量,將其代入已訓練出的模型中以計算其對數機率, 當得到的機率小於某閾值,即判斷其不屬於該群,反之,機率大於某閾值,可能 是非語音部分,我們將以此模型所分類出的語音及非語音部分進行處理。圖 4-2(a)、圖 4-2(b) 表示一新的聽覺頻譜圖在已訓練的模型中所計算出的對數機 率,由圖可發現,語音及非語音可以對數機率將其分類出來,如圖中的最下方所 示,白色部分為語音的範圍,而黑色部為非語音的範圍。經由小量語料的測試, 在此處及之後的實驗中我們取-7當做閾值。 圖 4-2(a):乾淨語音在非語音高斯混合模型中的對數機率及分類結果
圖 4-2(b):訊噪比10 dB的語音在非語音高斯混合模型中的對數機率及分類結果
4.2 分散式語音辨認系統前級---AFE
在本節中,介紹分散式語音辨認系統,並使用其加入降低噪音的辨識系統前 級所抽取的語音參數做辨識的實驗,並將其結果來當做本章與下一章所提出的語 音強健策略結果的比較對象。4.2.1
分散式語音辨識系統
分散式語音辨認系統的想法來自於:想要應用在行動裝置上可以使用語音輸 入更多更複雜的指令,但又礙於行動裝置的計算能力以及記憶體的不足。因此分 散式語音辨認系統的架構分為,在行動裝置也就是辨識系統的前級(DSR front-end) 來接收語音輸入,並從中抽取語音特徵參數,經過壓縮、編碼,再由通道傳送至 伺服器也就是辨識系統的後級(DSR back-end)進行解碼以及辨識,本論文中所採用 的語音辨識前級為歐洲電信標準協會編號 202 050 v1.1.3(ETSI ES 202 050 v1.1.3) [11] 之前級的標準,圖 4-3 為此分散式語音辨識系統之架構圖。 圖 4-3:分散式語音辨識系統架構圖4.2.2
辨識系統前級參數抽取---AFE
當使用者在使用行動裝置時,周圍通常都會有噪音的干擾,而影響了語音參 數的抽取。為了因應此情形,分散式語音辨識系統的前級會先加入一降低噪音 (Noise reduction)的處理。 圖 4-4 顯示 AFE 中降低雜訊的方塊圖,其處理雜訊的方式是使用一個二階 式的維納濾波器(Wiener filter),它是由兩個串聯的維納濾波器所組成,它們的輸入 和輸出波形都是時域的聲音信號。第一個濾波器中,輸入的是未經處理包括雜訊 的原始聲音信號,輸出的是經過初步處理的波形信號,此濾波器中包含了語音偵 測(Voice activity detection, VAD)的技術;第二個濾波器,將第一個濾波器的輸 出信號當做輸入,並假設此輸入所餘下的加成性雜訊可以用白雜訊(white noise) 來近似,而輸出便是消去大部分雜訊的語音信號。兩個濾波器皆隨著各個音框內 不同的訊雜比和雜訊特性來設計:首先做頻譜估計(Spectrum estimation),並依照不 同頻率的訊噪比,求出線性頻率上維納濾波器的係數,再將其通過梅爾濾波器組 (Mel filter-bank)而得到與聽覺系統較相關的梅爾維納濾波器係數,再將此係數做梅 爾反離散餘弦轉換(Mel -warped Inverse Discrete Cosine Transformation, Mel-warped IDCT), 得到在時域上的脈衝響應(Impulse response),最後將目前音框中的波形信 號通過此響應以得到輸出的波形信號。在第二個濾波器輸出之前,會執行偏移補 償(Offset compensation)以移除輸出波形中的直流偏移量(DC offset)。圖 4-4:AFE 中降低雜訊的處理
4.2.3
實驗設定
在 AFE 中的降低噪音的部分,會以 VAD 標示非語音的音框,在傳送至後端之 前可將被標示為非語音的音框捨棄不傳輸,除了可降低網路傳輸的負載外,也可 增進辨識率。由於在本論文中,只採用系統前級的語音擷取,著重在其降低噪音 的部分,故不使用 VAD 來捨棄非語音音框。 本實驗所採用的語料庫為 AURORA-2,在參數抽取方面,亦跟前面抽取語音 參數的設定完全相同,使用 12 維 MFCC,以及一維和二維的變化量,共 36 維。 乾淨的語料亦經過 AFE 的降低噪音的處理,即為匹配的模型訓練方式。4.2.4
實驗結果
以 AFE 及 MFCC 來做英文連續數字串的實驗,其實驗的結果如表 4-1 所示。表 4-1:英文連續數字串---AFE+MFCC 的辨識結果 乾淨語料匹配訓練模式 A 組 訊噪比 (dB) 地下鐵 人聲 汽車 展覽會館 乾淨 98.56% 98.16% 98.36% 98.33% 20 96.07% 93.17% 97.17% 96.79% 15 93.80% 90.93% 96.03% 94.08% 10 86.46% 84.10% 91.14% 86.79% 5 70.62% 69.47% 75.57% 68.81% 0 41.20% 40.60% 40.86% 37.80% -5 22.04% 17.90% 18.58% 17.86% 平均值(20 dB~0 dB) 77.63% 75.61% 80.15% 76.85% B 組 訊噪比 (dB) 餐廳 街道 機場 火車站 八組噪音 源平均值 乾淨 98.56% 98.16% 98.36% 98.33% 98.35% 20 93.03% 96.55% 94.69% 95.77% 95.41% 15 90.88% 94.04% 93.50% 94.14% 93.43% 10 84.46% 88.63% 88.37% 90.03% 87.50% 5 70.37% 72.61% 74.98% 76.43% 72.36% 0 44.55% 44.04% 47.75% 44.55% 42.67% -5 18.42% 20.98% 22.76% 21.44% 20.00% 平均值(20 dB~0 dB) 76.66% 79.17% 79.86% 80.18% 78.27%
4.3 結合高斯混合模型的語音增強策略
在 4.1 節中,訓練出的高斯混合模型可將語音及非語音以和閾值比較的方式 分類出來;此節中,將介紹如何處理聽覺頻譜圖上的噪音部分,並以增強後的聽覺 頻譜圖取 ACC 後做英文連續數字串的實驗。4.3.1
以權重係數降低噪音能量
對於用高斯混合模型分類出來的語音和非語音部分,我們以噪音壓抑的方式 來達到語音增強,即是將偵測到的噪音部分乘上一小於 1 的權重係數,此處我們 各取權重係數為 0.5、0.36 及 0.2 做一簡單的連續數字串測試,結果如同表 4-2 所 示,發現當權重係數在 0.36 時有最好的辨識率效果。圖 4-5(a)、圖 4-5(b) 各表 示一段數字串在環境雜訊為汽車噪音,訊噪比 10 dB 及 5 dB 下,權重係數取 0.36 的語音增強結果。 表 4-2:小量英文連續數字串---不同權重係數的辨識結果 clean 20dB 15dB 10dB 5dB 0dB -5dB Average 0.5 98.64% 97.29% 97.02% 92.41% 78.32% 42.55% 13.55% 81.52% 0.36 98.64% 97.56% 97.29% 92.14% 78.05% 46.34% 11.38% 82.28% 0.2 98.64% 96.75% 94.58% 89.16% 72.36% 34.15% 8.94% 77.40% 訊 噪 比 權 重 係 數4.3.2
實驗設定及實驗結果
在本實驗中,語料庫的使用與參數設定的部分仍和前面相同,乾淨的語料亦 經過 GMM 模型偵測及降低噪音的處理,即為匹配的模型訓練方式。 以 GMM 增強後的聽覺頻譜圖來做英文連續數字串的實驗,其實驗的結果如 表 4-3 所示。 表 4-3:英文連續數字串---GMM+ACC 的辨識結果 乾淨語料匹配訓練模式 A 組 訊噪比 (dB) 地下鐵 人聲 汽車 展覽會館 乾淨 98.62% 98.04% 97.91% 98.86% 20 97.02% 94.62% 96.63% 96.33% 15 95.33% 91.93% 94.87% 93.61% 10 91.07% 86.09% 90.16% 88.83% 5 80.01% 69.41% 77.75% 79.39% 0 46.79% 31.86% 40.71% 50.91% -5 14.18% 1.93% 14.91% 18.57% 平均值(20 dB~0 dB) 82.04% 74.78% 80.02% 81.81% B 組 訊噪比 (dB) 餐廳 街道 機場 火車站 八組噪音 源平均值 乾淨 98.62% 98.04% 97.91% 98.86% 98.36% 20 94.87% 96.49% 95.53% 96.54% 96.00% 15 92.20% 94.53% 93.59% 94.32% 93.80% 10 85.14% 90.48% 88.67% 88.83% 88.66% 5 65.77% 77.78% 74.08% 74.33% 74.82% 0 31.93% 47.97% 44.14% 43.60% 42.24% -5 3.47% 19.53% 15.12% 13.95% 12.71% 平均值(20 dB~0 dB) 73.98% 81.45% 79.20% 79.52% 79.10%在與 4.2 節中 AFE 所做的實驗結果比較,可以得知: (1) 在八種噪音源的環境下,經過 GMM 模型方式語音增強後及 AFE 降低噪音的 辨識結果,如圖 4-6 所示。由圖中可知,GMM 在人聲、餐廳、機場噪音的 環境上語音增強的效果並不好,原因是在此三種環境下,隨著訊噪比的降低, 人聲的噪音皆被誤判成”oh”,產生大量的插入錯誤,進而影響辨識的結果。 (2) 若以訊噪比的平均辨識率及總體平均辨識率來看,GMM 和 AFE 有著相近的 效果,如圖 4-7 所示。 (3) 在訊噪比為-5 dB 的情形下,AFE 仍有小量的辨識率提昇,而 GMM 在人聲和 餐廳噪音環境的辨識率平均影響下,反而較原本的辨識率還低。 在上述討論中,得知 GMM 的語音增強方式仍有進步的空間,像是一開始訓 練高斯混合模式的參數設定,訓練模型的方式,相信在適當的參數組合可以使得 GMM 模型的分群效果及噪音壓抑的結果更加提昇。 圖 4-6:八種環境雜訊在 GMM 及 AFE 語音增強策略下的比較
第五章
使用時域-頻域混合的調變濾波器的語
音增強策略
在上一章,結合高斯混合模型語音增強策略的實驗結果中,在人聲及餐廳的 噪音環境下,由於插入錯誤的大量發生,導致辨識率甚至較原本 ACC 的基本辨識 率還低。在本章中,經由聽覺感知模型的大腦聽覺模型的分析,以時域-頻域混合 的調變濾波器,重建出乾淨語音的聽覺頻譜圖,以此為模板(template),對原本聽 覺頻譜圖上的噪音部分進行處理,可降低上述兩種噪音環境的插入錯誤,並提昇 其他噪音環境下的辨識率。最後並與上一章的所介紹的 AFE 的辨識結果做比較。5.1 聽覺頻譜圖上語音部分的重建
本節介紹聽覺頻譜圖經由大腦聽覺模型,不同的時域-頻域混合的調變分析 後,重建出其中的語音部分。5.1.1
聽覺頻譜圖的重建
二維的聽覺頻譜圖在大腦聽覺階段的分析後,可以得到帶有多重解析特性的 四維結果,由於其產生的方式是一種線性運算 [12] ,我們可以對此四維結果進行 反向濾波,而得到帶有選定的時域-頻域調變特性的重建聽覺頻譜圖,如圖 5-1 所 示。 圖 5-1:經由不同的時域-頻域分析後重建出的聽覺頻譜圖5.1.2
語音重建範圍的選擇
在第二章聽覺大腦階段的介紹中,人類語音的調變能量大約出現在 rate 8 Hz 以及 scale 4 cycle/octave 以下,考慮語音隨著不同人可能有不同變動性,我們在 rate 方面,取了 2、4、8、及 16 Hz,而在 scale 方面,取了 0.5、1、2、4、8 cycle/octave。 圖 5-2 表示一段數字串在環境雜訊為展覽會場,訊噪比為 5 dB,取以上的參數組 合,再經由大腦聽覺階段重建出來的語音聽覺頻譜圖。 圖 5-2:訊噪比 5 dB 的語音經由大腦聽覺階段重建出的語音聽覺頻譜圖 由圖中可知,重建出的聽覺頻譜圖包括了大部分的語音能量,但和原來的語 音能量並不完全相同;而也有些許的噪音部分並未被濾除,我們以此為模板,來 處理重建前聽覺頻譜圖上的噪音部分。
5.2 使用調變濾波器的語音增強策略
根據選定的 rate 及 scale,我們可以重建出聽覺頻譜圖上的語音部分,此節中, 將介紹以重建的聽覺頻譜圖對原本的聽覺頻譜圖進行語音增強,並以增強後的結 果取出聽覺倒頻譜參數,做英文連續數字串的實驗。5.2.1
以閾值決定聽覺頻譜圖上的噪音
對於每一段要進行語音增強的聲音,我們皆先將其經過正規化的處理,如 3.1.1 節所描述,因此這些資料在聽覺感知模型的各階段的數值表現上會較為統一,也 方便取定一閾值,來取出聽覺頻譜圖上的噪音部分。在此我們設定閾值為 1.8,在 重建的聽覺頻譜圖上小於此閾值的部分便分類為噪音,並對原本的聽覺頻譜圖上 同樣的部分乘上權重係數,而權重係數的設定和上一章相同,為 0.36,圖 5-3(a)、 圖 5-3(b) 表示一段數字串在環境雜訊為汽車噪音,訊噪比 10 dB 及 5 dB 下,權重 係數取 0.36 的語音增強結果。5.2.2
實驗設定與實驗結果
在本實驗中,語料庫使用 AURORA-2,參數設定的部分皆和前面的聽覺倒頻 譜參數相同,乾淨的語料亦經過調變濾波器偵測及降低噪音的處理,即為匹配的 模型訓練方式。 以調變濾波器語音增強後的聽覺頻譜圖來做英文連續數字串的實驗,其實驗 的結果如表 5-1 所示。 表 5-1:英文連續數字串---經由調變濾波器+ACC 的辨識結果 乾淨語料匹配訓練模式 A 組 訊噪比 (dB) 地下鐵 人聲 汽車 展覽會館 乾淨 98.89% 98.40% 98.15% 98.95% 20 97.82% 96.40% 96.93% 96.33% 15 96.32% 94.29% 96.06% 95.06% 10 92.82% 88.12% 92.31% 91.42% 5 81.06% 69.92% 81.42% 81.86% 0 52.10% 33.89% 47.90% 52.95% -5 18.85% 4.78% 15.66% 19.47% 平均值(20 dB~0 dB) 84.02% 76.52% 82.92% 83.52% B 組 訊噪比 (dB) 餐廳 街道 機場 火車站 八組噪音 源平均值 乾淨 98.89% 98.40% 98.15% 98.95% 98.60% 20 96.38% 97.10% 96.75% 97.28% 96.87% 15 93.71% 95.65% 94.69% 95.93% 95.21% 10 85.29% 91.93% 89.77% 91.18% 90.36% 5 65.67% 81.41% 74.23% 79.05% 76.83% 0 33.87% 53.60% 44.80% 49.06% 46.02% -5 4.91% 21.52% 15.63% 16.51% 14.67% 平均值(20 dB~0 dB) 74.98% 83.94% 80.05% 82.50% 81.06%在與 4.2 節中 AFE 所做的實驗結果比較,可以得知: (1) 在八種噪音源的環境下,經過調變濾波器重建方式語音增強後及 AFE 降低噪 音的辨識結果,如圖 5-4 所示。由圖中可知,調變濾波器的語音增強方式在 除了人聲、餐廳、機場噪音的環境上,都有較 AFE 明顯的辨識率增進。 (2) 在人聲、餐廳、機場的環境下,調變濾波器的語音增強效果也可與 AFE 相近。 而此三種環境在整體中辨識率較低的原因是在此三種環境下,隨著訊噪比的 降低,人聲的噪音皆被誤判成”oh”,產生大量的插入錯誤,進而影響辨識的 結果,但此插入錯誤的數目已較上一章的 GMM 的情形有所改善。 (3) 若以訊噪比的平均辨識率及總體平均辨識率來看,調變濾波器的效果除了在 訊噪比-5 dB 的情形下較 AFE 差之外,其他訊噪比的情形皆有 1~3%的提昇, 如圖 5-5 所示。 (4) 在訊噪比為-5 dB 的情形下,AFE 仍有小量的辨識率提昇,而調變濾波器的效 果在人聲和餐廳噪音環境的辨識率平均影響下,只獲得和 ACC 基本的辨識率 幾乎相同的效果。 圖 5-4:八種環境雜訊在調變濾波器及 AFE 語音增強策略下的比較
第六章
結論與未來展望
在本章中,我們將本論文的貢獻做一次更加完整的說明;並檢討本論文實驗 中結果不足的部份,提出可以修正的方向以及可以補強的地方。6.1 結論
本論文主要的研究內容是在介紹的聽覺感知模型上,擷取語音特徵參數 ACC,並建立增強語音的方法。我們先介紹了聽覺感知模型的兩個階段:頻域估 計的初期耳蝸階段以及執行時域-頻域分析的大腦聽覺階段;並從初期耳蝸階段所 輸出的聽覺頻譜圖中擷取聽覺倒頻譜參數做英文連續數字串辨認實驗,將結果與 MFCC 所做的結果做比較,並獲得 ACC 對於環境雜訊及訊噪比的健全性。 其後,以大腦聽覺階段分析出聽覺頻譜圖上的語音與噪音不同的時域-頻域特 性,來達到語音增強的效果,此階段我們提出了兩種方式來達成:高斯混合模型以 及時域-頻域混合的調變濾波器。我們並介紹歐洲電信標準協會所制訂的 AFE 來與 上面所提出的兩種語音增強策略做比較。在使用高斯混合模型的部分,以乾淨的 聽覺頻譜圖來訓練其在大腦聽覺階段上的統計特性,並以訓練出來的模型偵測出 聽覺頻譜圖上的噪音部分,再以匹配的乾淨語料模式來訓練隱藏式馬可夫模型語音辨識器,實驗結果發現雖然辨識率有所提昇,但此種語音增強策略會受到人聲 噪音的影響,導致插入錯誤的大幅增加,而降低整體辨識率的結果;而在使用時 域-頻域混合調變濾波器的部分,以濾出的聽覺頻譜圖來當做原本聽覺頻譜圖的參 照,壓抑原本聽覺頻譜圖上的噪音部分,此方法雖仍會受到人聲噪音的影響,導 致”oh”的插入錯誤的增加,但整體上的辨識率皆是有大幅的增進。從觀念上來說, 人聲噪音與人聲語音在 rate 小於 32 Hz 的條件下,皆屬可辨別(intelligible)。而大量 背景人聲噪音其高 rate 部分(基頻)會被彼此加成而破壞。因此,欲有效壓抑人聲噪 音時,必須考慮大腦高 rate 區域所提供之訊息。
6.2 未來展望
在本論文中提出的語音增強策略,是建立於聽覺感知模型上。在聽覺倒頻譜 參數的擷取上,時域上的前處理初步只使用了重疊的音框來擷取語音參數,未來 可以嘗試加入不同的前處理方式來提昇辨識率或健全性;本論文中只使用了乾淨 語料的訓練模式,之後亦可加入複合語料訓練的方式,來測試 ACC 的健全性; 而 ACC 亦可以與在時域的語音增強策略結合,可望能得到更佳的辨識效果。 而在語音增強的策略上,我們只簡單的以固定權重係數值來壓低噪音在聽覺 頻譜圖上出現的部分,而導致此方式容易受到人聲噪音的影響,未來希望能結合 語音偵測(Voice activity detection, VAD)來降低插入錯誤的個數。以上皆是我們 未來所能夠努力的目標,最後希望可以達到在低訊噪比的環境下,仍能夠有極佳 的辨識率。參考文獻
[1]. Neural System Laboratory, http://www.isr.umd.edu/Labs/NSL/. [2]. Hidden Markov Model Toolkit, http://htk.eng.cam.ac.uk/.
[3]. S. A. Shamma, H. Versnel, and N. Kowalski, “Ripple analysis in the ferret auditory cortex: I. Response characteristics of single units to sinusoidally rippled spectra,” J. Auditory Neuroscience, vol. 1, no. 2, pp. 233–254, 1995.
[4]. S. A. Shamma and H. Versnel, “Ripple analysis in the ferret auditory cortex: II. Prediction of unit response to arbitrary profiles,” J. Auditory Neuroscience, vol. 1, no. 2, pp. 255–270, 1995.
[5]. J. Simon, D. A. Depireux, and S. A. Shamma, “Representation of complex spectra in auditory cortex,” in Psychophysical and Physiological Advances in Hearing.
Proceedings of the 11th International Symposium on Hearing, A. R. Palmer, A.
Ress, A. Q. Summerfield, and R. Meddis, Eds. London: Whurr Publishers, pp. 513–520, 1998.
[6]. K. Wang and S. A. Shamma, “Self-normalization and noise-robustness in early auditory representations,” IEEE Trans. Speech Audio Processing, vol. 2, no. 3, pp. 421–435, 1994.
[7]. AURORA Database, http://www.elda.org/article52.html.
[8]. H.G. Hirsch, D. Pearce, “The AURORA Experimental Framework for the Performance Evaluation of Speech Recognition Systems under Noisy Conditions,” ISCA ITRW ASR2000, Paris, France, September 18-20, 2000.
[9]. VOICEBOX, http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html.
[10]. D.S. Kim, “A Cue for Objective Speech Quality Estimation in Temporal Envelope Representations,” IEEE Signal Processing Letters, vol. 11, no. 10, pp. 849-852,
[11]. ETSI, “Speech Processing, Transmission and Quality Aspects (STQ); Distributed speech recognition; Advanced front-end feature extraction algorithm; Compression algorithms,” ETSI Standard ES 202 050 v1.1.3, November 2003.
[12]. T. Chi, P. Ru and S. A. Shamma, “Multiresolution spectrotemporal analysis of complex sounds,“ Journal of the Acoustical Society of America, vol. 118, no. 2, pp. 887-906, August 2005.