國立臺灣大學文學院翻譯碩士學位學程 碩士論文
Graduate Program in Translation and Interpretation College of Liberal Arts
National Taiwan University Master Thesis
神經機器翻譯於時尚網站在地化之應用
Applying Neural Machine Translation to Fashion Website Localization
廖亭雲 Ting-Yun Liao
指導教授:高照明 博士 Advisor: Zhao-Ming Gao, Ph.D.
中華民國 108 年 7 月 July 2019
Acknowledgment
I would like to give heartful thanks to Professor Zhao-Ming Gao who provided helpful comments and suggestions throughout the writing of this paper. Without his encouragement and guidance, this research would not have materialized. Special thanks also go to Professor Shu-Kai Hsieh, Professor Chao-Lin Liu and Professor Yvonne Tsai whose opinions and information have helped me very much in completion of this study.
I am particularly grateful for the technical support provided by Research Assistant Hou- Wei Lin. My grateful thanks are extended to Anita Fan and Estella Yang who participated in the experiment and offered valuable feedback. Assistance given by Associate Manager Vicky Li was also greatly appreciated.
Finally, I must express my very profound gratitude to my parents and to my friends for their unfailing support and continuous encouragement throughout my years of study.
Abstract
As the number of internet users grows around the world, the demand for website localization also increases. To meet this ever-growing need, a trend has inevitably formed where automatic translation is being integrated into the workflow of localization. In recent years, the development of the internet has provided easy access to various corpora, which advances the technology of machine translation and, in turn, realizes the application of customized neural machine translation (NMT). Nevertheless, previous studies on customized NMT usually center on improving the technology itself. Thus, this research focuses on applying a customized NMT to website localization and validating its performance and effects with automatic evaluation and an experiment involving human translators. To build customized NMT, the bilingual text from shopping websites including H&M, ZARA and Burberry is compiled into a parallel corpus, which is divided into two separate corpora which train and evaluate the customized NMT. In addition to automatic evaluation, this study also carries out an experiment aiming to compare the effectiveness of the customized NMT and that of general MT which was modeled on real localization projects which involved professional translators,. The automatic evaluation result indicates that the NMT built in this research performs well. Moreover, based on the feedback from translators participating in this study, the customized NMT does exhibit positive effects on increasing translation efficiency. Due to the fact that the corpus used in this research is limited to a specific domain, the results might not be applicable to other localization fields, and further research is needed to investigate the effectiveness of customized NMT in other domains.
Keywords: neural machine translation, localization, computer-aided translation, parallel corpora
中文摘要
隨著網路使用人口成長,網站在地化的需求也持續增加,而為了以更快速度提供品 質穩定的翻譯成果,將自動翻譯融入在地化專案原有的工作流程已是必然趨勢。另 一方面,近年來由於網路發展迅速讓語料庫取得更加容易,也促進了機器翻譯技術 的發展,實現自訂神經機器翻譯模型的應用。然而目前自訂神經機器翻譯的相關研 究多半仍集中在改善技術層面,因此本研究將會將重心放在將自訂神經機器翻譯系 統應用於在地化專案,並且採用自動化方法與專業譯者參與實驗的方式評估其效能 與效果。在建立自訂神經機器翻譯系統方面,本研究從風格類似的三個快時尚品牌 網站中,分別擷取出繁體中文與英文的產品介紹文字檔,彙整成雙語平行語料庫,
再將母語料庫分為訓練與驗證兩個語料庫,用於訓練與檢驗自訂神經機器翻譯系統。
而除了採用自動化方法衡量機器翻譯的效能,本研究也招募專業譯者參與模擬實際 在地化專案的實驗,比較自訂機器翻譯與一般機器翻譯的效果。研究結果顯示,本 研究建立的自訂神經機器翻譯經過自動化方法評估可達到良好效能,而在專業譯者 的使用者經驗方面,自訂神經機器翻譯確實有一定的效果,能協助提升譯者的工作 效率。儘管本研究指出將神經機器翻譯應用於在地化專案的可行性,由於研究中選 擇的語料僅侷限在快時尚購物網站,研究結果可能無法在其他在地化領域上成立,
而適用於其他翻譯領域的自訂神經機器翻譯系統則需要將來進一步的研究。
關鍵字:神經機器翻譯、在地化、電腦輔助翻譯、平行語料庫
Table of Contents
Acknowledgment ... ii
Abstract ... iii
中文摘要 ... iv
List of Figures ... vii
List of Tables ... viii
Chapter One: Introduction ... 1
Chapter Two: Literature Review ... 6
2.1 Localization ... 7
2.2 Computer-aided Translation ... 10
2.3 Corpus-based Studies ... 11
2.4 Machine Translation ... 13
2.4.1 Rule-based machine translation ... 14
2.4.2 Corpus-based machine translation ... 15
2.4.3 Neural machine translation ... 17
2.5 Evaluation on machine translation ... 19
Chapter Three: Methodology ... 22
3.1. Corpus compilation ... 25
3.1.1 Data from H&M websites ... 25
3.1.2 Data from ZARA websites ... 27
3.1.3 Data from Burberry websites ... 28
3.1.4 Text pre-processing ... 28
3.2. Building customized NMT: OpenNMT... 29
3.3. Automatic Evaluation: BLEU ... 32
3.4. English Corpora analysis ... 33
3.4.1 Lexical characteristics ... 34
3.4.2 Composition per line ... 35
3.5. Computer-aided translation ... 35
3.5.1 Building translation memory ... 36
3.5.2 Pre-translation with CAT tools... 37
3.6 Experiment: Comparison between NMT, Google Translate and Trados ... 38
3.6.1 Selecting two groups of source text ... 39
3.6.2 Creating translation projects in Trados ... 41
3.6.3 Designing a questionnaire for feedback ... 43
3.6.4 Handing out projects and instructions ... 45
3.6.5 Retrieving results ... 47
Chapter Four: Results and Discussion ... 48
4.1 Performance of the customized NMT ... 48
4.1.1 Automatic Evaluation: BLEU ... 48
4.1.2 Training corpus analysis ... 51
4.1.3 CAT statistics analysis ... 52
4.2 Perceived effects of the customized NMT ... 57
4.3 Empirical effects of the customized NMT ... 62
4.3.1 Translators’ working time ... 63
4.3.2 Translators’ editing actions ... 65
Chapter Five: Conclusion and Limitation ... 74
5.1 Summary and reflection ... 74
5.2 Limitation ... 76
5.3 Future research ... 76
References ... 78
Appendices ... 83
List of Figures
Figure 2.1 Machine-aided human translation ... 6
Figure 2.2 Human-aided machine translation ... 7
Figure 3.1 Workflow Chart ... 24
Figure 3.2 The first layer of H&M’s English website ... 26
Figure 3.3 The first layer of H&M’s Traditional Chinese website... 27
Figure 3.4 Webpages collected from ZARA’s website ... 28
Figure 3.5 Plain text files extracted from the websites of H&M, ZARA and Burberry ... 31
Figure 3.6 Interface of the customized NMT ... 32
Figure 3.7 Upgrading .tmx file in Trados 2017 ... 37
Figure 3.8 Pre-translate statistics provided by Trados 2017 ... 38
Figure 3.9 Project 1 ... 42
Figure 3.10 Project 2 ... 42
Figure 3.11 Online recording tool: Apowersoft ... 46
Figure 4.1 Concordance search in Trados 2017 ... 57
Figure 4.2 Screenshot of the recorded video ... 63
Figure 4.3 Two-way ANOVA test on Translator A’s editing ... 71
Figure 4.4 Two-way ANOVA test on Translator B’s editing ... 72
List of Tables
Table 2.1 Interpretation of BLEU score ... 20
Table 3.1 Statistics on training and validating corpus ... 32
Table 3.3 Frequency of words in AntConc ... 34
Table 3.4 Source text word count and segment count ... 40
Table 3.5 Statistics on the two projects in Trados ... 43
Table 4.1 BLEU score of NMT and Google Translate ... 50
Table 4.2 Pre-translation Analysis by Trados 2017 ... 53
Table 4.3 Translators’ answers to the questionnaire ... 59
Table 4.4 Translators’ working time spent on each project ... 64
Table 4.5 Statistics on segment editing ... 66
Table 4.6 Statistics on editing actions ... 68
Chapter One: Introduction
Thanks to the internet, we live in a world in pursuit of efficiency.We not only ask for everything to be done faster but also better. Websites of fast fashion brands provide the best examples of this. To be competitive, in addition to providing new products every week, these companies have to update their websites to keep up-to-date. Furthermore, in order to tap into foreign markets, this digital content needs to be translated and sometimes adapted (i.e, localized) to service their consumers around the world (Schäler, 2009). In fact, any company which aims to broaden its market around the globe has a need for localization services, which has thus driven the rapid expansion of the localization industry.
Such great demand for localization since the late 20th century has led to the wide application of computer-aided translation (CAT) tools, which are computer programs designed to “facilitating the speed and consistency of human translators” (Garcia, 2014). As localization projects involve great volumes of text and short deadlines, and the content could be highly repetitive or contain coded tags, it is necessary for translators to be equipped with the ability to use CAT tools. In a narrow sense, CAT tools do not include electronics resources such as online dictionaries and corpora, nor do machine translation systems, since, technically speaking, they generate translation rather than assist human translators. Thus, more specifically, the two key functions of CAT tools are to generate translation memories (TMs) and term bases (TBs). While the former can reference previously translated sentences and suggest a translation match with the same or similar sentence, the latter can automatically replace terminology in the source language with corresponding terms in the target language.
With CAT tools, human translators do not need to process repeated sentences or terms within
a text, which thus enhances not only work efficiency but also consistency. In theory, the amount and specificity of the data contained in a translation memory or term base determines its usability. However, in reality, it takes time and effort to build and manage domain-specific TMs and TBs, so when translators start a new project from scratch, TM and TB tools provide limited assistance.
Fortunately, the rise of corpus linguistics and machine translation systems has not only revolutionized the usage of CAT tools, but has also helped translators in more efficient ways.
Whereas corpora in the past were mainly used in linguistics studies, they are now coupled with concordancing software to serve as translation tools as well (Gao and Chiou, 2017). For instance, parallel corpora consist of original texts and translated texts. In general, this type of corpora can function as domain-specific bilingual dictionaries, and for translators, if the bilingual texts are aligned at the sentence level, the corpora can also be utilized as a translation memory (García, 2014).
Thanks to the internet, nowadays parallel bilingual texts are more accessible than ever, which lays the foundation for the development of statistical machine translation (SMT) systems. For instance, search engines like Google and Microsoft utilize their massive databases as bilingual corpora to build machine translation services such as Google Translate and Microsoft Bing Translator, which are able to pair languages according to their matching probability. Nevertheless, despite the fact that SMT can help translate most words accurately, especially domain-specific terminology, it does not perform well at the sentence level or above (Gao and Chiou, 2017). In recent years, in pursuit of higher quantity, quality and speed in translation work, more research has been done on newer technology andneural machine
translation (NMT), and large service providers like Google Translate and Microsoft Bing are also incorporating NMT systems into their MT service.
NMT can model an artificial neural network to perform machine translation. In contrast to SMT, NMT “has led to remarkable improvements, particularly in terms of human evaluation,” (Klein, Kim, Deng, Senellar & Rush, 2017) and thus has the potential to generate usable automated translation without extensive post-editing. Nevertheless, NMT is still in the early development stage, meaning more empirical studies are needed to test and improve its performance. The latest trend in NMT studies is toward customization; that is, using a collection of parallel bilingual text to build an NMT system for domain-specific translation.
In 2018, Google released a new service called “AutoML Translation” which allows users to upload data in the form of matching pairs of sentences in a source and target languages, train a customized translation model with the self-prepared data, and then translate specialized content using the trained model. Many expect this new approach on building NMT systems can achieve what general MT cannot.
In terms of MT’s application in the localization industry, as Schäler (2009) points out, the localization process will inevitably evolve into more complicated, standardized and automated activities, and translating strings will become less important. Now with the realization of customized NMT, it is possible for human translators to skip to the review and editing stages while machines tackle translation. At the same time, the development of CAT tools has largely improved the technology of translation memories and term bases, which can sufficiently support translator in post-editing automated translations. However, most of the research on NMT which focus on measuring the performance of the system itself and how to improve it tend to deemphasize the feedback from what would potentially be the ultimate
users of the software: profession translators. The question of how helpful is customized NMT for professional translators working on real localization projects in a specific domain when compared to general MT still needs to be answered.
To answer the above question, this research intends to build a customized NMT system by applying an open-source framework, OpenNMT, and then evaluate its performance. The effectiveness of the NMT system is measured by two approaches: automatic (i.e., not supervised by humans) evaluation by using the BLEU method, and an experiment with professional translators as the participants. First, the text for building an English and Traditional Chinese parallel corpus is collected from the official websites of famous fashion brands including H&M, ZARA and Burberry. Then, the bilingual corpus is divided into two corpora, a training corpus and a validating corpus. The training corpus is required so as to let the NMT learn from its example using the framework provided by OpenNMT so the trained NMT can translate an English text from the validating corpus into Traditional Chinese. The automated translation is tested by BLEU, a method for automatic evaluation of machine translation which references the bilingual texts from the validating corpus.
In parallel, a new translation project is created in the CAT tool, Trados 2017, with the English text from the validating corpus serving as the source text, and the bilingual text from the training corpus as the translation memory. The pre-translation function and analysis in Trados can provide some insight into the automatic translation generated from the customized NMT. In addition, to compare the major differences between the performance of general MT (through Google Translate) and the customized NMT, we conduct an experiment which models real translation projects and involves professional translators . Lastly, we collect feedback from the translators on their user experience in the two types of MT through
questionnaires. The whole process of the experiment is also recorded for analysis. It is expected that this research can provide some empirical evidence to support the effectiveness of the customized NMT, yet at the same time also take the first impressions of professional translators into consideration in order to measure the performance of the customized NMT.
Chapter Two: Literature Review
Despite the fact that this research is based on an experiment on a customized NMT, the application of CAT and corpora is also an essential part of the methodology. In Hutchins’
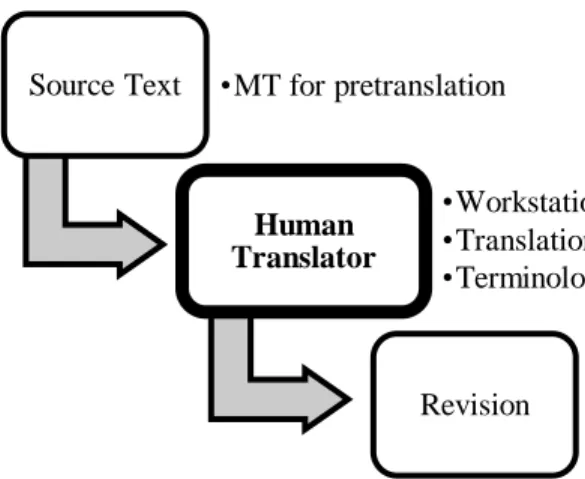
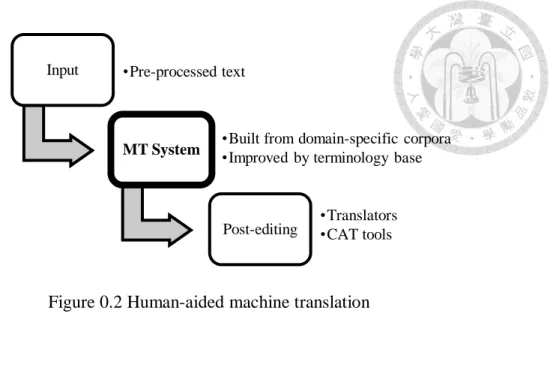
research (2005), he outlines a general introduction to machine translation, and he points out that the development of MT is a process of gradually moving from “machine-aided human translation” (Figure 2.1) to “human-aided machine translation” (Figure 2.2). The workflow of the former has human translators equipped with various computer-based tools, while the latter involves three tasks in which MT plays a primary role: machine translation, input, and post-editing. From building a domain-specific MT system, to processing the input to be compatible with the given MT system, and to post-editing the automated translation manually, both corpora and CAT tools are largely relied on in the machine-centered process. From a broader view, corpora and CAT also play a role in the process of evolving from machine- aided translation to human-aided machine translation. As such discussing MT without mentioning its relationship with corpora and CAT would be remiss. In the following sections, previous studies on localization, CAT, Corpora, MT, and the interrelation between them will be reviewed.
Source Text •MT for pretranslation
Human Translator
•Workstation
•Translation memory
•Terminology base
Revision
Figure 0.1 Machine-aided human translation
2.1 Localization
According to Schäler (2009), localization is defined as “the linguistic and cultural adaptation of digital content to the requirements and locale of a foreign market” (p.157). The definition also extends to “the provision of service and technologies for the management of multilingualism across the digital global information flow” (Schäler, 2009, p.157). Although it is not a novel concept that sellers customize products for consumers speaking different languages and living in different cultures, Schäler (2009) argues the key divide between localization and conventional translation lies in the types of materials being processed. In short, the localization as it is referred to today is a process of managing digital content.
Therefore, localization requires specific technologies, skillsets, procedures and standards, which often vary from the translation process for printed materials. In the following sections, we will introduce the development of the localization industry and the standard working procedures during localization.
In the mid-1980s, software providers began to expand their markets internationally. In
Input •Pre-processed text
MT System •Built from domain-specific corpora
•Improved by terminology base
Post-editing •Translators
•CAT tools
Figure 0.2 Human-aided machine translation
order to sell products to foreign customers, these international corporates decided to translate their products into languages used by their target consumers. As Schäler (2009) points out, localization is used as a means to meet commercial demands. In the early phase of localization, the major challenge faced by translators is that the string which needed translation usually contained both plain text and a large amount of program codes. To save the trouble with codes and help translators working on localization projects increase efficiency, large software publishers have been proactive in advancing “internalization.” As described by Schäler (2009), internalization is a process of designing (or modifying) software in a way such that the elements in a program which need to be translated and culturally adapted can be isolated in preparation for localization, and therefore the users who ultimately make use of this software can choose their preferred languages in the program. In terms of dealing with translation, these international companies have also invested in “recycling translation,” which utilizes translation memory systems to reuse past translation. Schäler (2009, p.158) indicates the application of TM and other CAT tools can be deemed as “a milestone in the history of localization.” In the ideal scenario, the work of translators during localization can be simplified to a kind of “translation” assisted by translation memories, while the sellers provide different language versions of their products, and thus generating greater revenue.
At the present stage, there is a set procedure for most localization projects, regardless of the scale, content, or target of a particular project. The various steps in the procedure are analysis, preparation, translation, engineering/testing and project review. In the analysis step, many aspects need to be considered, some of which are closely related to the work of the translators. These aspects are which parts of the product are to be localized, the word count
and rate, and what kind of tools shall be employed. During the preparation phase, a project manager refers to the analysis report to create a new project and provide a localization kit for translators. The localization kit consists of source documents, CAT tools, a style guide, query instructions, and delivery and contact details. During translation, , professional localizers should be able to leverage CAT tools specified by the manager and apply past translations and terminologies to their translation in addition to translating new content. The major difficulty faced by localizers is that, as Schäler (2009, p.159) indicates, “the pressure to produce high-quality translation within short time frames and at low cost is extremely high.”
The third phase is when the translation undergoes process engineering/testing, in which quality assurance (QA) is conducted. During this stage, the client’s reviewers identify translation issues or errors and document them in the QA report. Finally, to prevent repetitive mistakes , the whole localization project is reviewed by in-house reviewers based on the QA report,.
Considering the short life cycle of a localization project, translation inevitably has stricter time limits. Website localization is no exception. At present, localizers already have various CAT tools at their disposal to increase work efficiency. However, to further expedite localization projects , it seems the best possible solution is automation. As Hutchins (2005) points out, companies that provide information online in multiple languages only have three options: using online machine translation, outsourcing to localization agencies, or integrating automatic localization systems. Hutchins’ observation is based on not only the nature of localization, but also the relationship between CAT and MT. The following section introduces the basic features of CAT, as well as its development and its convergence with MT.
2.2 Computer-aided Translation
From the 1990s to the present, the functions of CAT tools have undergone a great deal of innovation and integration due to an increasing demand for localization. However, translation memories, which enable translators to store and reuse past translation, have always been the main feature of CAT tools since their commercialization in the mid-1990s (García, 2014; O’Hagan, 2009). A TM essentially consists of text segmentation and alignment tools. A segmentation tool is used to divide texts into shorter units. In general, these texts are segmented into sentences according to punctuation rules or specific syntactic features such as headings and bullet points. This makes it so that an alignment tool can be utilized to pair source texts and target texts segment by segment. In addition to TMs, every CAT tool is equipped with a terminology management system for building term bases or glossaries, which work similarly to a TM, differing only in that they are restricted to the term level (García, 2014).
Scholars (Bowker and Barlow, 2008; García, 2006; Shuttleworth, 2006) have been studying the pros and cons of CAT tools, especially so for TM and its impact on translators.
Although TMs to a certain degree can boost the work efficiency of translators, this technology has clear limitations due to its “unsuitability for non-repetitive texts, the inflexibility of only having matches on the sentence level, the difficulty of retrieving contextual information and the time it takes to produce useful TMs” (Shuttleworth, 2006, p.
3). TBs, which fall short in the same way on the term level, have similar restrictions.
To overcome these limitations, researchers have started to integrate the application of CAT into studies on SMT, as the usability of SMT has been significantly improved in recent
MT technology in order to adapt to changes in the role of a translator. Gao and Chiou (2017) have demonstrated how to use SMT, corpora and analysis tools to build a translation memory and term base for a new translation project. In fact, CAT and TM can be seen as having been derived from the same root. In the days when the capability of computers was insufficient to support the continued development of MT, the arrival of CAT tools helped provide a stepping stone to fully automatic translation (García, 2014). Stein (2018) also states while the ultimate goal of research on MT is to achieve “fully automatic high-quality translation,” research and development of CAT tools are to be promoted as well. Furthermore, some CAT tools have begun to integrate MT to address “units with lower similarities, the automatic transliteration of numbers, dates and other placeable elements” (Stein, 2018, p. 8-9). Now the evolution of CAT has reached its limit, and as Shuttleworth (2006) indicates, since TM and MT “share common problems, for which the solutions lie in the combination of the two technologies”
(p. 6), there will be more and more overlaps between the two.
2.3 Corpus-based Studies
In today’s highly competitive localization market, translators also seek assistance from electronic resources in addition to CAT tools. Zanettin (2002) and Bowker and Barlow (2008) propose that a corpus – namely, a “collection of electronic texts assembled according to explicit design criteria which usually aim at representing a larger textual population”
(Zanettin, 2002) – can be of use to professional translators. Some large reference corpora such as the British National Corpus (BNC) for British English have gained popularity outside of the linguistics circle, but corpora in such scale are difficult to build and not necessarily suitable for more specific uses. Thus, Zanettin (2002) advises translators to customize small
corpora by retrieving and organizing text information on the internet, which will result in better work efficiency and greater accuracy in terminology and phraseology.
Among all of the types of corpora, bilingual parallel corpora, which are “a collection of texts in one language alongside their translations into another language,” are the most pervasive corpora in use during translation (Bowker and Barlow, 2008). However, these corpora are more difficult to come by due to the extra effort required to align bilingual texts at the sentence level. Undoubtedly, parallel corpora can provide ample information, but extra tools are needed to truly benefit from them, such as a bilingual concordancer or translation memory. Unlike a translation memory which pairs texts segment by segment, when the texts are fully aligned in a corpus, , a concordancer can help translators “retrieve all examples of a word or phrase (or part of a word) from the corpus” (Bowker and Barlow, 2008). While translation memories are suitable for localization projects containing highly repetitive sentences, parallel corpora coupled with concordancers can be applied to match sub-sentence elements, thus functioning as a complementary tool.
Apart from serving as references, corpora can also be used to extract lexical information if supplemented with corpus processing software (Hutchins, 2005; Zanettin, 2002). The availability of monolingual comparable corpora, which consist of two or more groups of texts in the same language and belonging to the same domain, have made it possible for researchers to extract terminologies and compile term bases for specific domain. For instance, in Gao and Chiou’s studies (2017), segmentation tools, part-of-speech taggers and a corpus processing software are used to identify terminologies in English and Chinese news articles.
As Hutchins (2005) states, recent development in technology has allowed researchers to use simpler rules to build MT; which is to say, MT can be trained by the “information
about word cooccurrences derived from text corpora” (Hutchins, 2005, p.11). Moreover, terminology entries required for MT can also be extract from bilingual corpora with the assistance of corpus analysis tools. On the one hand, the wide application of corpora complements what was lacking in traditional CAT tools; on the other hand, their higher availability provides resources needed for MT research.
2.4 Machine Translation
In Hutchins’ study (2005), he provides the brief history of how machine translation systems have evolved over the years. The development of MT can be traced back to around the 1950s, when the first MT conference was held and MT was first demonstrated. Since then, the U.S. government and Georgetown University have installed some of the first MT systems and conducted related research projects. Although the results were not as good as expected, this stage laid the foundation for the progress of MT in the 1980s. Since then, the usage of MT systems has widened, especially with regards to early installations of translation software on personal computers and the introduction of translator workstations to the market. As for the online machine translation services with which the general public is more familiar, this major breakthrough in MT did not made until the 21st century. The subsequent development of the emerging technology of NMT has become a hot research topic as of late. To understand why NMT is a topic worthy of study, it is necessary to understand its differences with respect to past MT systems. According to the definition proposed by Ping (2009), based on the architecture of MT systems, there are generally two types of MT which constitute the main areas of research in MT: rule-based MT and corpus-based MT.
2.4.1 Rule-based machine translation
Rule-based MT is a system built on a variety of linguistics rules determined by developers, and can be classified as “direct” and “indirect” in terms of how they develop (Ping, 2009). Introduced before the 1980s, the direct approach is based on a bilingual dictionary and morphological analysis. In other words, this type of MT translates source text by searching the dictionary at the word level, and then reordering the translated words according to the grammar of the target language. As a result, rule-based MT built on direct approach does not accurately analyze the syntax of source texts nor does it identify the relationship between words.
In the 1980s, developers started to adopt the “indirect” approach when designing MT.
This type of MT translates texts in a three-stage method through analysis, transferring and synthesizing. Firstly, the MT analyzes the syntactic structure of source sentences and converts them into “intermediary, abstract representations of the meaning of the original”
(Ping, 2009). Then, these representations are transferred into representations which indicate the syntactic structure of the target language. Lastly, the system synthesizes the transferred representations and produces translated sentences. In contrast to the direct approach, the indirect approach can perform additional analysis on the source text and identify both sentence structure and meaning, instead of translating word for word.
However, there are still some challenges in the development of rule-based MT. Hutchins (2006) indicates that for this type of MT to work successfully, developers have to work on complicated grammar rules, and it is difficult to design a model which can apply all the grammar rules perfectly. Issues also arise from the dictionary used up by the MT system,
since every dictionary has its own limitations and cannot cover all meanings. Thus, rule- based MT has a comparatively high entry level in terms of development and application.
2.4.2 Corpus-based machine translation
In the 1990s, researchers discovered it is possible to build MT systems by applying bilingual corpora, especially collections of original and translated versions of texts. There are two types of corpus-based MT systems: example-based MT and statistical MT. The concept behind example-based MT is similar to that of translation memory in CAT tools. Based on a bilingual parallel corpus, the MT first matches the source texts with the most similar examples in the corpus, and then aligns the source text and the examples to find the corresponding parts. Lastly the corresponding parts are reordered and assembled to produce target texts. As Ping points out (2009), the main difference between TM and example-based MT is that the former requires human translators to do the task of reordering and assembling, while the latter can complete all the work automatically.
Thanks to Google Translate and Microsoft Bing Translate, statistical machine translation (SMT) has the method which the general public are most familiar, and there have been numerous studies related to the topic. In Hutchins’ presentation (2006), he describes SMT as a system based on bilingual corpora which requires “little or no linguistic
‘knowledge.’” Essentially, SMT is built on “word co-occurrences in SL and TL texts (of a corpus), relative positions of words within sentences, and length of sentences” (Hutchins, 2006, p.21). Sentences from the bilingual parallel corpus are aligned by statistical rules such as sentence length and relative positions of words. The translation process then involves two models: translation model and language model. The former model chooses the most probable
translation for a source fragment, which can be a word or a phrase, based on the frequencies of word co-occurrences in the aligned bilingual corpora. The language model organizes target fragments in the most probable order to produce translations based off the frequency of bigrams and trigrams in the target language.
Hutchins (2006) describes SMT as a “direct approach” that replaces a fragment in a source language with a fragment in a target language in the most probable sequence. In other words, it can be said that the size of a training corpora plays an essential role in SMT, and this is where the most obvious advantage of SMT lies. As Stein (2018, p.14) indicates, in contrast to rule-based MT, “SMT systems produce better translations in terms of word choice, disambiguation, etc.” Any types of word combinations can be translated, as long as they are included in the corpora in a certain number “to be identified statistically.” Thus, Stein (2018, p.14) concludes that the idea behind SMT is that “bigger corpora means better results.”
However, although studies on SMT have extended from word-based, phrase-based to syntax-based, there are still some issues mostly arising from training corpora which remain unresolved. As mentioned before, the size of the training corpus for SMT matters, and other scholars such as Ping (2009) also point out the success of SMT is basically determined by the training corpus. For instance, if most of the data used for compiling a training corpus comes from the internet, which is the most efficient way to collect a huge amount of bilingual texts, it is difficult to control the quality, resulting in unstable results when using the SMT program. Apart from this, Stein (2018) also argues that when SMT deals with certain language pairs, many problems stem from differences in grammar like “inflection, word order, use of pronouns, number and kind of temporal forms, etc.”
In Gao and Chiou’s research (2017), the scholars acknowledge that SMT can serve as a supplement to CAT tools when there is insufficient relevant past translation. Although Google Translate has shown in studies its usefulness for translating terminology and proper nouns, Gao and Chiou discovered the SMT system cannot “identify the beginning and ending of a multiword unit” and often provides translation in simplified Chinses based on probability.
As a result, human translators usually need to pay extra attention to pre-editing such as simplifying input, in order to improve the productivity of SMT and achieve the goal of
“human-aided machine translation.”
Stein (2018, p.15) summarizes the recent development of MT with the observation that,
“the use of linguistic information and statistical data, has become one of the most researched fields in MT over the last decade.” Combining the strengths of different MT systems not only increases the translation quality of MT but also opens up the possibility for research on MT for rare language pairs; regardless, a real breakthrough has yet to be achieved. This hybrid approach leads to shifting the research focus to identifying appropriate language resources to build MT systems, and especially MT for a specific domain, since “it turns out that the automatic translation of specialized domains is more reliable” (Stein, 2018, p.16).
2.4.3 Neural machine translation
According to Luong, Cho and Manning (2016), nowadays there is a considerable demand for machine translation, especially in the fields of “humanity and commerce.”
However, although the ultimate goal is to realize “fully automatic high-quality MT,” at the present stage, only “user- or platform-initiated low-quality translation” or “author-initiated high quality translation” are available. The first category includes translation service
provided by Google Translate or Bing Translator, while the other category requires post- editing from human translators or MT as supplementary tools for translators. As the technology of MT evolves, , the quality of automatic translation from statistical machine translation to neural machine translation has improved, but there are still obstacles that need to be overcome.
As Luong, Cho and Manning (2016) state, NMT was a “fringe research activity” back in 2014, which then became a widely-acknowledged research approach for general MT in 2016. Luong, Cho, and Manning (2016, p. 14) define NMT as “the approach of modeling the entire MT process via one big artificial neural network”. Simply put, NMT is a two-layered neural encoder-decoder architecture; the encoder network can receive an input source sentence and transform it into a series of vectors, each representing an input word, and then based on this series of vectors, the decoder network generates a translated text.
The emerging technology of neural machine translation is reported to perform better than SMT at the sentence level. Research (Kinoshit, Oshio and Mitsuhashi, 2017) has been conducted on comparing the performance of SMT and NMT with large parallel corpora, and the researchers indicate NMT scores higher both in BLEU – an automatic evaluation framework for machine translation (Papineni, Roukos, Ward and Zhu, 2002) – and human evaluation. The advantages of NMT are explained in the documentation of Google’s AutoML Translation service (2019).When rule-based MT was the mainstream approach to process natural language, it required professional programmers to instruct the computer step by step.
Now with large parallel corpora available, it is possible to get the machine learn by itself the language rules from examples using a certain framework. This new approach led to the
application of customized NMT. Trained with a domain-specific corpus, customized NMT can achieve what general MT cannot in the translation of a specific domain.
2.5 Evaluation on machine translation
Although human evaluation on MT can cover all aspects of translation quality, it requires time and effort. To better examine the performance of MT, Papineni, Roukos, Ward and Zhu propose an automatic method called BLEU (bilingual evaluation understudy) to assist developers. Simply put, this method consists of two components: a numerical
"translation closeness" metric, and a corpus of good quality human reference translations (Papineni, Roukos, Ward, Henderson and Reeder, 2002). BLEU is able to calculate the similarity of automated translation and reference translation by finding how many matching n-grams exist between the two texts at the sentence level. Apart from n-grams, sentence length is also put into consideration, since amore similar sentence length is an indicator of a better translation. According to the study (Papineni, et al., 2002), BLEU shows the ability to differentiate not only good and bad automated translations, but also ideal and poor human translation. The results of the automatic evaluation are statistically similar to the judgement of human participants in the study.
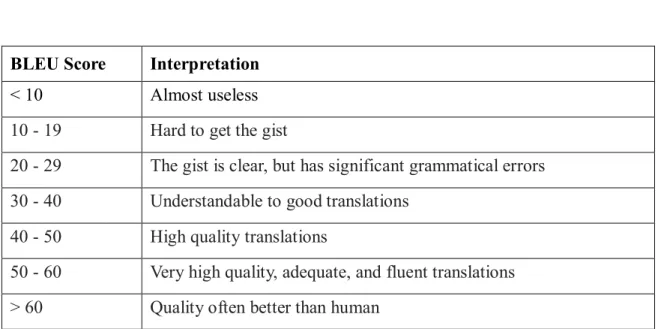
The score provided by BLEU is between 0 to 1. A score of 1 occurs when the translation is perfectly identical to the reference text. For the sake of convenience, a BLEU score is sometimes not presented as decimals but percentages. It is noteworthy that there is no strict standard to interpret a BLUE score. For instance, the documentation “Evaluating models”
published by Google’s AutoML Translation (2019) suggests using the following table (Table
2.1) as a rough guideline, while Lavie (2011) simply proposes that a BLEU score over 30 should be deemed as “understandable translation” and a score over 50 as “good and fluent translation.”
BLEU Score Interpretation
< 10 Almost useless 10 - 19 Hard to get the gist
20 - 29 The gist is clear, but has significant grammatical errors 30 - 40 Understandable to good translations
40 - 50 High quality translations
50 - 60 Very high quality, adequate, and fluent translations
> 60 Quality often better than human
Table 0.1 Interpretation of BLEU score
However, scholars have pointed out that although BLEU has its advantages in that it saves time and effort, its results do not necessarily correspond to the evaluation of professional translators (Kinoshit and Mitsuhashi, 2017), and that the differences of language pairs might also cause larger variations in BLEU scores (Junczys-Dowmunt, et al., 2016).
For instance, all words areweighted equally in BLEU, meaning that it cannot identify the extent of a mistranslation. Also, the automated evaluation is based on matching “exact words,”
so synonyms are considered as translation errors. BLEU is a method designed for MT developers to effectively measure and improve their systems, and does not necessarily meet the needs of language analysts. As Lavie (2011, p.40) points out, BLEU scores are not “easily
interpretable by most translation professionals.” Lavie (2011, p.50) also argues that compared to other automated metrics such as the Metric for Evaluation of Translation with Explicit Ordering (METEOR), BLEU does not show better “correlation with human judgement.”
At this point, most of the studies on machine translation and its automatic evaluation have centered around how to improve the technology itself and the related tools. Feedback from users such as professional translators on machine translation is rarely included in the discussion. Thus, in addition to following the methods of past research on building and evaluating a customized NMT system, this research intends to examine this technology from the perspective of professional translators. By combining the two approaches, it is expected that this paper will be able to investigate into the performance of the customized NMT in a more comprehensive way, yet at the same time also answer the question of whether or not the NMT is useful for professional translators.
Chapter Three: Methodology
According to previous studies, although CAT tools are prevalent in the localization industry, their development has hit a bottleneck. As a result, adding machine translation to a translator’s workflow was bound to happen. However, most of the research related to MT focuses on how to improve the technology itself to enhance translation efficiency, yet rarely takes the needs of professional translators into consideration. Thus, this research aims to examine how helpful the latest MT technology is for profession translators who possess the ability to operate CAT tools. For this purpose, it is necessary to answer the following questions: How does the proposed customized NMT perform? How do professional translators perceive the effects of the proposed NMT? What are the empirical effects of the proposed NMT? Lastly, what is the current ideal tool combination for professional translators?
In order to answer these questions, this research combines a collection of tools to conduct an experiment (see Figure 3.1). The first step is to compile a corpus in which English and Traditional Chinese parallel texts are collected from the official websites of the popular fashion brands H&M, ZARA and Burberry. Then, the bilingual corpus is split into two corpora, a training corpus and a validating corpus. The training corpus is applied to build an NMT system from scratch by adopting the framework of OpenNMT. The trained NMT is then used to translate the English text from the validating corpus into Traditional Chinese.
The automated translation is tested by BLEU – a method for automatic evaluation of machine translation – which references the bilingual texts from the validating corpus. In addition, the English text from the training corpus is further analyzed with a corpus analysis tool to identify some of the factors which might affect the performance of the customized NMT.
At the same time, a new translation project is created in the CAT tool, Trados 2017, with English text from the validating corpus serving as the source text, and the bilingual text from the training corpus to serve as a translation memory. The pre-translation function and analysis in Trados can provide some insight into the automatic translation generated from the customized NMT. Lastly, in order to compare the usefulness of the most common NMT, Google Translate and the customized NMT, an experiment modeling real translation projects and involving professional translators is conducted. The two groups of source text for the two separate translation projects are selected from the English text from the validating corpus.
With the support of the translation memory built from bilingual training corpus and machine translation from NMT or Google Translate, the participating translators have to complete the two projects and answer a feedback questionnaire. It is expected that the result of this experiment can reveal how and why these tools are useful for professional translators.
Figure 0.1 Workflow Chart
3.1. Corpus compilation
For the purposes of modeling a real localization project and efficiently collecting sufficient texts to train an NMT system, international fashion brands such as ZARA, H&M and Burberry, which have multiple language versions for their websites and update their webpages frequently, are the ideal sources of data. Since only plain text files are needed to build corpora and train NMT, as well as to compile TM and TB, web crawler tools are used to collect English and Traditional Chinese texts from the shopping websites. The crawler tools can find the English texts’ corresponding Traditional Chinese translation by identifying the same elements across webpages in different languages, ensuring that the bilingual texts are extracted from the websites in a fully aligned format. It took about six months (from January 2018 to August 2018) to gather sufficient bilingual text from the three websites.
3.1.1 Data from H&M websites
H&M websites are structured with two layers: product lists and product descriptions.
By connecting to the webpage URLs of product lists and analyzing the HTML codes returned by the URLs, every URL from each product, which is in the second layer, can be collected.
Then, by connecting to the URL of each product, English and Traditional Chinese product descriptions can be extracted from the websites to compile the corpora for training a machine translation system.
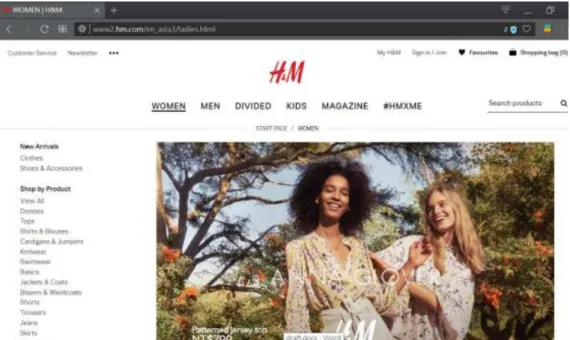
First, the program “get_urls.py1” is used to acquire the first layer of URLs, which are four product lists containing different types of product URLs: WOMEN, MEN, DIVIDED,
1 I would like to thank Research Assistant, Hou-Wei Lin, for providing technical support for operating
and KIDS. As a result, the first layer of URLs is “http://www2.hm.com/en_asia3/XX/shop- by-product/view-all.html,” in which “XX” can be replaced by “ladies”, “men”, “divided”, or
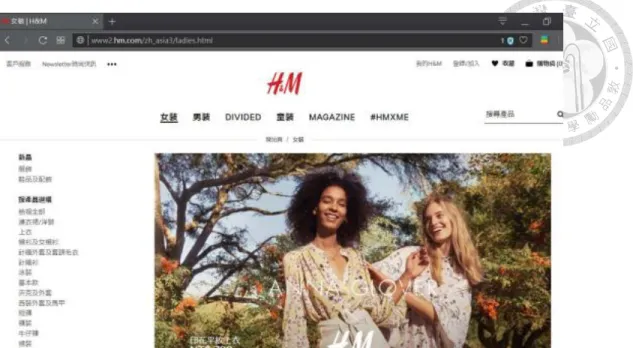
“kids” (see Figure 3.2). The same rule applies to the Traditional Chinese website, but the first layer of URLs needs to be changed into “http://www2.hm.com/zh_asia3/XX/shop-by- product/view-all.html” (see Figure 3.3).
Figure 0.2 The first layer of H&M’s English website
Figure 0.3 The first layer of H&M’s Traditional Chinese website
3.1.2 Data from ZARA websites
The websites of ZARA are more complicatedly constructed, so another software, HTTrack WEBSITE COPIER, is used to extract bilingual texts. The software allows users to download selected webpages, and in this case, only URLs which start with “-p” followed by a two-digit number and end with a number are collected. In other words, only webpages containing product information are chosen for downloading. The results are shown in Figure 3.4.
Figure 0.4 Webpages collected from ZARA’s website
3.1.3 Data from Burberry websites
After collecting data from the websites mentioned above, it was estimated that more bilingual texts would be needed to build a more effective NMT system. As a result, Burberry is chosen to serve as another data source since it is one of the few international brands which provides adequate traditional Chinese content on its official website. The same methods used in extracting texts from H&M and ZARA websites are both applied to collect 10000 more lines of bilingual texts from the Burberry websites. It should be noted the English text collected from Burberry’s website is written in British English, which might result in different spellings for the same word in American English. Moreover, this luxury brand has a different market position from ZARA and H&M in terms of pricing and product features, which could result in varied word choice and text styles in the corpus.
3.1.4 Text pre-processing
Each webpage consists of three to six lines of data, in which there is a line for the product name, one or more lines for product descriptions and a line for the material of the product. In the three websites, the same product in different colors results in repetitive data, so the program “parse_urls.py” is used to delete repeated product pages. Lastly, the text data in each selected webpage is extracted through the program “read_sorted_urls.py,” which can provide plain text files for the usage of this research. In total, this bilingual corpus contains 82815 lines, in which there are 723147 English words and 119251 Traditional Chinese words, both including numbers and punctuations.
3.2. Building customized NMT: OpenNMT
This research adopts the open-source neural machine translation framework, OpenNMT, which provides a complete library that allows users to train and deploy a new NMT model simply by importing the source and target files (OpenNMT, 2017). Google’s AutoML Translation was not available yet since this research was conducted in 2018. Currently, OpenNMT is a more accessible open-source tool. The NMT adopted here is a sequence-to- sequence model, and the mechanism behind this is to “encode the source sequence using some type of encoder and then to output the target sequence with a decoder” (Levin, Dhanuka and Khalilov, 2017). The aim is to train the encoder and decoder together so that they are able to translate source sentences into target sentences. In this research, the encoder and the decoder are two layers of long short-term memory (LSTM) recurrent neural nets. Although it is expected that adding more layers of LSTM can improve the performance of the customized NMT, the preliminary test result shows the opposite, so a two-layer LSTM setting
is applied. It should also be noted that when building the customized NMT, default configurations and parameters are used.
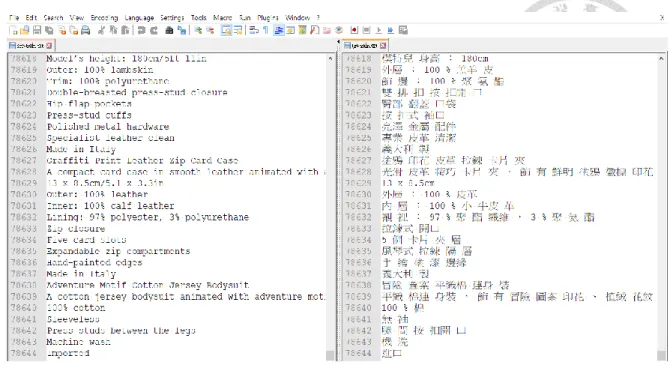
According to the tutorial on GitHub (2018), using OpenNMT requires three steps: pre- processing the data, training the model, and translating sentences. Beforehand, it is necessary to ensure the training files are presented as one sentence per line and every word is separated by a space(i.e., sentence and word segmentation). As the English texts and Traditional Chinese texts are already aligned and paired segment by segment when extracting bilingual data, , there is no need for sentence segmentation. Nevertheless, while English words are naturally separated by a space, Chinese words do not have an equivalent indicator of separation which a computer can recognize. As a result, a word segmentation system for Chinese, NAER Segmentor (National Academy for Educational Research, 2014), is used to solve this problem. As Figure 3.5 shows, the bilingual text is already aligned, and the Chinese text is segmented into word units separated by a space. Although the segmentation is not perfectly correct, it should be noted the system segments Traditional Chinese text in a consistent manner. Thus, repeated similar errors in segmentation are unlikely to cause difficulties for the proposed NMT to learn the relation between Chinese words or between the bilingual word units. There are certainly other segmentation tools for Chinese such as Jeiba and Transformer, but considering the corpus used in this research consists of a smaller amount of Traditional Chinese text, it is assumed that NAER Segmentor can perform better in terms of accuracy.
Figure 0.5 Plain text files extracted from the websites of H&M, ZARA and Burberry
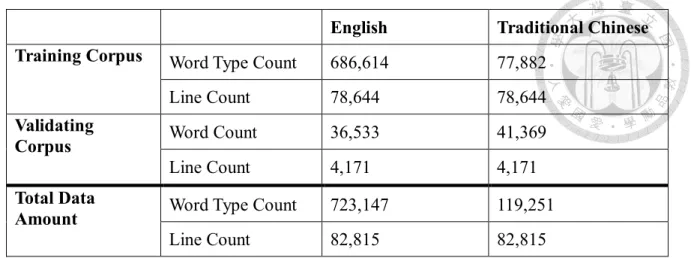
By using the tools mentioned above, 82,815 lines of bilingual texts are collected, containing 723,147 English word types and 119,251 Traditional Chinese word types, in which punctuation marks are not calculated. Please note that a Chinese word type does not necessarily equal to a single Chinese character. The parallel corpus compiled previously is then divided into two corpora, the training corpus and the validating corpus. The former is used to train the customized NMT, while the latter serves as a reference translation in BLEU, an automatic evaluation method for machine translation used to assess the effectiveness of the NMT. In other words, after training, the effectiveness of the NMT is measured against the second bilingual parallel corpus. The following table shows the statistics of the two corpora.
English Traditional Chinese Training Corpus Word Type Count 686,614 77,882
Line Count 78,644 78,644
Validating
Corpus Word Count 36,533 41,369
Line Count 4,171 4,171
Total Data
Amount Word Type Count 723,147 119,251
Line Count 82,815 82,815
Table 0.1 Statistics on training and validating corpus
For the sake of convenience , the trained NMT is then presented as a simple interface for searching English texts’ Traditional Chinese translation. As Figure 3.6 shows, the Traditional Chinese translation is segmented word by word.
Figure 0.6 Interface of the customized NMT
3.3. Automatic Evaluation: BLEU
After the translation is generated by the trained NMT, BLEU is used to evaluate the
professional human translation, the better it is” (Papineni et al., 2002). That is, BLEU measures the automated translation’s similarity to a reference human translation by comparing the n-grams in the two texts and counting the matches sentence by sentence.
Theoretically, more matches indicate a better translation. Then, the system provides a numerical metric to determine the quality of the automated translation. The score provided by BLEU is between 0 to 1, but a score of 1 only occurs when the translation is perfectly identical to the reference text.
Papineni et al. (2002) point out that when automatic translation is measured against more reference translations, it scores higher in the BLEU system. Thus, whereas the validating corpus compiled in the previous steps consists of three different sources of texts, the corpus is treated as one single reference when calculating the BLEU score of the NMT- generated translation. This research adopts the MTEval toolkit to run the machine translation evaluation metrics, and the BLEU score achieved was 0.741479. The score represents the total average calculated with the average of 1-4 gram in each segment.
3.4. English Corpora analysis
For the convenience of discussion in the later steps, analysis has been done on the English training and validating corpora in order to identify some of its characteristics which might determine the final results of this research. The tools used in this step include AntConc, Notepad++ and Microsoft Excel. AntConc is a “freeware, multiplatform tool for carrying out corpus linguistics research” (AntConc Readme Help File, 2019) and is utilized to analyze the lexical aspects of the English texts. Some basic calculations on the composition of each line are also made with the help of Excel and Notepad++.
3.4.1 Lexical characteristics
In AntConc, the Word List function “counts all the words in the corpus and presents them in an ordered list” (AntConc Readme Help File, 2019). Although the function is mainly used to “quickly find which words are the most frequent in a corpus” (AntConc Readme Help File, 2019), the goal of this function is to identify the Word Types and Word Tokens in the English corpus. The term “Word Types” refer to the number of unique words, while “Word Tokens” represent the total word count in the corpus. By default, AntConc does not count punctuation as a token. Furthermore, AntConc also shows the frequency of each word type in both corpora. As in Figure 3.7, the word types ranking from 3,194 to the end of the list, 3,859, only appear once in one of the corpora. That is, 676 words among 3,859 word types are either new vocabulary shown in the validating corpus, or one-time information in the training corpus.
3.4.2 Composition per line
The “line” referred to here is defined as a segment of information collected from the websites. In other words, a single line might include more than one sentence, which is delineated through the use of a period. The word count per line in both corpora seems to vary, since all the lines are directly copied from the websites and do not undergo further segmentation. In order to understand the composition of each line in the corpora, all the English texts are copied and pasted to Excel, in which each cell contains a single line. The word count without punctuation in each cell can be calculated by using the following function:
=IF(LEN(TRIM(text))=0,0,LEN(TRIM(text))-LEN(SUBSTITUTE(text," ",""))+1)
The word count is then sorted from high to low in Excel, and the results show the minimum word per line is 1, while the maximum words per line is 93. Nevertheless, further analysis on the average word count per “sentence” cannot be carried out because although there are complete sentences ending with a period, there are also lines including only short phrases or even a single word without any punctuation.
3.5. Computer-aided translation
In order to interpret the performance of the customized NMT in a more comprehensive way, this research also utilizes CAT tools to pre-translate the same text as the NMT. By applying the pre-translation function of the tool, it is expected to gain more understanding on the similarity between the training and validating corpora and how it might affect the performance of the NMT. Also, through this method, the differences between the CAT tools and the customized NMT can be clearly identified.
3.5.1 Building translation memory
The most helpful function a CAT tools provides for a translation project is its translation memory system. For this research, the bilingual training data collected from the websites is also used to compile a translation memory. Since the bilingual text is already segment- aligned, it is easy to convert the text into a translation memory file through various tools.
First, the bilingual text is copied and pasted to Excel and saved as an .xlsx file, where the first column is the English text while the second column is Traditional Chinese. Then the .xlsx file is uploaded to the online tools provided by Translatum and converted into a .tmx file. Although .tmx is a format compatible with most of the CAT tools, to make the translation
memory work in a particular CAT system like SDL Trados Studio 2017, a further step of upgrading the .tmx file to a .sdltm file in Trados is needed.
3.5.2 Pre-translation with CAT tools
The next step is to create a new translation project in Trados 2017. The source language
and target language are set as English and Traditional Chinese respectively, and then the English text from the validating corpus is imported as the source text. Since the translation memory is already compiled in the previous step, it can be directly added to the new project in Trados. Before the translation and editing start, Trados provides some matching statistics for the translator’s references. The feature compares the similarity between the source text and the TM, revealing the word count of the source text that actually needs to be translated.
Figure 0.7 Upgrading .tmx file in Trados 2017
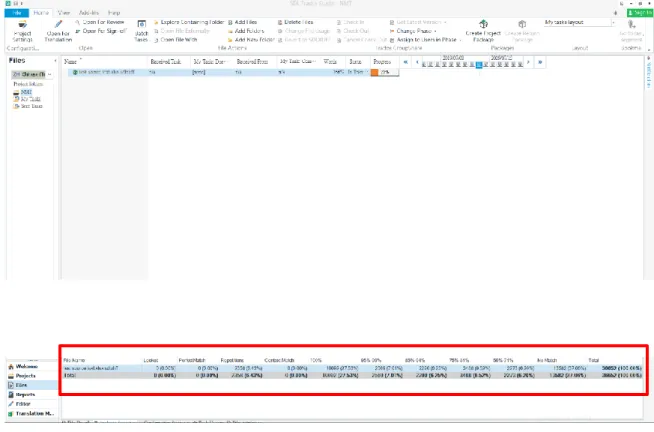
Trados divides matching rates into seven groups: Repetition, 100%, 95%-99%, 85%-94%, 75%-84%, 50%-74% and No Match. As the following figure shows, Trados provides options for showing the matching rate of “segments” or “words” in percentages, but the way in which the matching rates are calculated in Trados is unknown to the users. The advantages of Trados include providing a clear view for the differences between a source segment and a similar segment from the TM, and it is more convenient for editing. As a result, the following experiment also utilizes Trados as the main tool.
3.6 Experiment: Comparison between NMT, Google Translate and Trados
Figure 0.8 Pre-translate statistics provided by Trados 2017
In order to identify how helpful the NMT proposed by this research is for professional translators, it is necessary to integrate the automated translation generated by NMT into a translation project and have professional translators working on the project. In the following experiment, the English texts in the validating corpus are used to create a new project in Trados and serve as the source text. Participants of the experiment, all of whom are professional translators, are asked to translate the selected segments with the help of a translation memory and machine translation. The participants have to complete two different projects. The two projects are created with different groups of selected English text. One project is supplemented with NMT translation, while the other uses Google Translate. The two projects contain segments similar in word count and length, and are equipped with the same translation memory which was built in the previous steps. After completing the two projects, participating translators are asked to answer a question about the roles these tools play in their working processes. The following sections describe in detail how and why this experiment is designed and carried out.
3.6.1 Selecting two groups of source text
The first factor to consider when selecting English segments as the source text is the total word count and segment lengths. Since the participating translators are expected to concentrate continuously on the two projects, the total word count of each project is set at around 200 words, which take roughly half an hour to translate. In addition, longer segments containing more than two sentences, which we determine by the presence of periods, are removed from the experiment to prevent participants from spending too much time on the
same segment. The main purpose is to ensure that even though the two projects are created with different groups of English text, each source segment is almost equally understandable.
Next, to create two translation projects that both require the experiment participants to make the most of MT and translation memory and minimize the usage of other internet resources like search engines, the matching rates provided by Trados’ pre-translation analysis are used to exclude segments not suitable for this experiment. For instance, 100% matches and segments with matching rate lower than 30% are not considered, because the former can be confirmed as the correct translation without the help of any tools, while the later contains too much new information that neither CAT nor MT provide adequate assistance. By examining the rest of the text thoroughly, we observed that there are six scenarios which the participants might face: Trados failing to process 100% matches, Trados failing to replace a small part of a segment with the correct translation, Trados contradicting the translator’s judgement, NMT combining various sources to provide usable translations, NMT combining various sources to provide translation identical with the texts from, the websites, and NMT mistranslating 100% matches. Further explanations are provided in the next chapter.
Source text word count (Excel) Number of segments (Excel)
Group 1 225 13
Group 2 198 12
Table 0.3 Source text word count and segment count
3.6.2 Creating translation projects in Trados
The two groups of text complied in the previous step are saved as two separate Excel files first so they can be imported to Trados as the source text for two different projects. In the process of creating two new projects, the translation memory built in Section 5.1 is also added to the projects. The final step is to copy and paste the translation generated by NMT and by Google Translate to the target segments of the two projects. As the Figure 3.9 and Figure 3.10 show, Project 1 and Project 2 contain different groups of source text and target text for reference, but the applied TM is the same file. Because the translation memory is created directly from the training corpus, there is a space between each Chinese “word unit.”
The machine translation provided in Project 1, which is generated from the trained NMT, is also displayed in the same format. Moreover, it is observed that Trados tends to segment text based on periods, so there is a difference in the number of segments in each project in Trados (see Table 5).
Figure 0.9 Project 1
Figure 0.10 Project 2