國立臺灣大學工學院應用力學研究所 博士論文
Graduate Institute of Applied Mechanics College of Engineering
National Taiwan University Ph.D. Thesis
應用貝氏網路及適應性調適方法於語音情緒辨識之研究 Speech Emotion Recognition Using Bayesian Network and
Adaptive Approach Methods
游志源 Chih-Yuan Yu
指導教授:劉佩玲 博士 Advisor: Pei-Ling Liu, Ph.D.
中華民國 100 年 1 月
January, 2011
誌 謝
本論文得以順利完成,首先要感謝恩師 劉佩玲教授多年來的悉 心指導與關懷。從碩士班到博士班的求學過程中, 老師本著傳道、
授業、解惑的指導精神,除了在研究上訓練我獨立思考與解決問題 的能力外, 老師在研究上實事求是的治學態度及為人處事,亦使我 記憶深刻並永存於心,在此僅向恩師獻上衷心的敬意與感謝。
論文定稿期間,承蒙成功大學 吳宗憲教授、中正大學 余松年教 授、大同大學 包蒼龍教授、南台科大 陳有圳助理教授、崑山科大 黃 志賢助理教授、工研院 石明于博士以及廖志彬博士對於本文的指正 及提供寶貴的意見,使得本論文能夠更臻完備,也讓我在專業領域的 知識上獲益良多,在此表達本人誠摯的謝意。
在實驗室的研究生活期間,特別感謝葉柏涼學長在課業以及生活 上的相互提攜,每當研究遇到瓶頸,學長總是給於適時的鼓勵與協 助,真心的感謝您。同時亦感謝實驗室人文、力立、志峰、威靈、智 雄、士芳以及嘉文等學弟的熱心協助,在此亦一併致謝。
感謝工研院南分院在我工作服務的那段期間,提供語料作為測試 與驗證使用,同時感謝俊昇以及珠娟在實驗上的協助,淵翔、信嘉、
昇照、秦安、育賢、毅翔一起為院長盃四連霸奮戰的日子,濤哥、士 傑、鳴立、蕭大哥、蔡大哥、佳婉、紹興每個禮拜運動練球的日子,
龍哥、俊斌、時瑜、洋銘、祥傑在執行工研院計畫及技術發展時,給 予的協助與幫忙,在此也一併感謝。
最後感謝我的家人、女友欣君、紀爸爸、紀媽媽以及每一個關懷 我的朋友們,在求學的這段期間對我的支持與鼓勵,讓我能夠安心並 持之以恆的完成目標,僅將本文獻給所有關心我的人們。
中 文 摘 要:
本研究之主要目的在發展一貝氏網路自動化語音情緒辨識方 法,透過情緒語音之相關特徵參數計算,並與資料庫中各情緒之資料 作比對,將語者的情緒狀態從語音訊號中辨識出來。
首先,將語者之情緒語音訊號以統計方式計算音高(Pitch)、音框 能量(Frame energy)、共振峰(Formants)以及梅爾倒頻譜係數(Mel-scale Frequency Cepstral Coefficients, MFCC)等相關之語音情緒特徵,並以 各特徵參數在中性情緒下之資料庫平均值為正規化特徵參數因子,將 音高、音框能量以及共振峰利用正規化特徵參數因子進行正規化,得 到正規化後之特徵參數,以消除不同語者之間差異。
各特徵參數對情緒之辨識能力不同,如音高可大約分辨悲傷及中 性,快樂及生氣會被視為同一群。由於沒有任一參數可明顯分辨四種 情緒,故本研究採用分層解析的方式,先將特徵參數分群,同一群特 徵參數具有相似的情緒分類效果,並以分群結果建立多層貝氏網路 (Multi-Layered Bayesian Network, MLBN),第一層的輸入參數都只能 辨識兩群情緒,第二層的輸入參數可辨識三群情緒,較無明顯分群效 果的參數則置於第三層,以辨識四種情緒。
由於特徵參數之間具有相關性,因此,本論文將 MLBN 延伸,將 特 徵 參 數 之 相 關 性 納 入 考 量 並 提 出 多 層 共 變 異 數 貝 氏 網 路
(Multi-Layered Bayesian Network with Covariance, MLBNC)。
當語者資料不在訓練資料中時,其辨識效果通常不佳。為改善此 狀況,本研究提出適應性 MLBN 及適應性 MLBNC 語音情緒辨識調 適方法,在調適過程中,當辨識結果與語者情緒不同時,則根據語者 情緒語音所得之參數值來調整 MLBN 及 MLBNC 資料庫中各群之平 均值與標準差或共變異數,以符合語者真實的情緒狀態。
為驗證本研究所提出之方法,我們使用德國情緒語料庫 EMO-DB 當作訓練與測試語料,並以 KNN、SVM、MLBN 以及 MLBNC 分別 進行 Inside 與 Outside Test。同時,我們亦以 EMO-DB 為訓練語料,
並以工業技術研究院所自行錄製之情緒語料為測試語料,分別對 KNN、SVM、MLBN 以及 MLBNC 進行不同語系之測試。而在適應 性 MLBN 及 MLBNC 的驗證上,我們以 EMO-DB 為訓練語料,並以 工研院之情緒語料為調適與測試語料,分別對適應性 KNN、MLBN 及 MLBNC 進行調適前後的測試。
實驗結果顯示,本研究提出之 MLBN、MLBNC 與單純使用貝氏 決策之 Inside Test 辨識率分別為 81.1%、88.8%以及 70.8%,顯示透過 各參數分層分群的辨識方式,可以有效提高語音情緒之辨識率,而考 慮特徵參數間相關性之 MLBNC,其結果亦優於 MLBN。在 Outside Test 的部分,KNN、SVM 以及 MLBN 使用原始參數時,其辨識率分
別為 78.2%、89.1%以及 69.9%,而使用正規化參數時,辨識率分別 為 82.6%、91.7%以及 77.6%,顯示正規化特徵參數可以有效縮小語 者之間在特徵參數上的差異。而當訓練與測試語料為不同語系時,
KNN、SVM、MLBN 以及 MLBNC 之辨識率分別為 34.21%、46.92%、
39.33%以及 52.08%,此結果顯示,當發音方式或表達情緒方式與資 料庫有所差異時,各分類器之辨識效果均不佳。
在調適實驗部分,由調適前後之辨識結果顯示,KNN 經調適過 後,辨識率從 34.2%提升至 73.7%,而 MLBN 及 MLBNC 經調適後,
其辨識率分別從 37.8%提升至 82.4%以及 51.6%提升至 81.2%,本研 究提出之適應性 MLBN 與適應性 MLBNC 語音情緒辨識方法於資料 庫修正後,其辨識效果明顯優於適應性 KNN。而當調適次數增加時,
MLBN 及 MLBNC 經調適後,其辨識率則分別從 39.3%提升至 88.9%
以及 52.1%提升至 90.0%,顯示經由本論文所提出之調適方法,經調 適後,確實可以真正的反映語者的真實狀況,並得到良好的調適後辨 識結果。
關鍵字:語音情緒辨識、特徵參數、正規化、多層貝氏網路、多層共 變異數貝氏網路、適應性。
ABSTRACT:
The objective of this study is to develop an automatic speech emotion recognition method using Bayesian Network. By calculating the relevant features of emotion speech and comparing the features with emotion database, the speaker’s emotion state can be identified.
Firstly, we calculate the statistical features of pitch, frame energy, formants, mel-scale frequency cepstral coefficients (MFCC). Then we use the mean value of neutral emotion in corpus as normalized factor for each feature, and calculate the normalized features of pitch, frame energy and formants. The normalized features can reduce the feature difference between speakers.
Each feature has different ability of emotion recognition. For example, the normalized pitch mean can recognize sad and neutral, and happy and angry can consider as the same cluster. No features can obviously recognize the four emotions, so we use different cluster to recognize the four emotions layer by layer. We cluster the features which have similar ability of emotion recognition and establish the Multi-Layered Bayesian Network (MLBN) method for speech emotion recognition. The features of layer 1 can recognize two clusters of emotion.
The features of layer 2 can recognize three clusters of emotion. The features which have no obvious clusters are put on layer 3 and recognize the four emotions.
There are some relations between each feature. Therefore, we extend the MLBN method and establish the Multi-Layered Bayesian Network with Covariance (MLBNC) method, which consider the relations between each feature, for speech emotion recognition.
The recognition rate will be poor if the training data of recognizer did not contain speaker’s speech emotion data. Therefore, we propose adaptive MLBN and MLBNC method for speech emotion recognition. In the adaptive MLBN and MLBNC process, we adjust the mean and standard deviation or covariance of clusters in the MLBN or MLBNC database to fit speaker’s real emotion status when the recognition result is wrong.
To verify the proposed method in this research, we use German emotional database (EMO-DB) as training and testing data for inside and outside test of KNN, SVM, MLBN and MLBNC recognizer. We also use EMO-DB as training data and ITRI emotional database as testing data for different corpus test. In the adaptive tests, we use EMO-DB as training
data and ITRI emotional database as adaptive and testing data for adaptive KNN, MLBN and MLBNC recognizer.
The inside test recognition rate of MLBN, MLBNC and Bayesian Decision (BD) are 81.1%, 88.8% and 70.8% respectively. It shows that cluster of features layer by layer can effectively increase the recognition rate and it will be better when regards of the relations between each feature. In outside test, the recognition rate of KNN, SVM and MLBN are 78.2%, 89.1% and 69.9% respectively using original features and 82.6%, 91.7% and 77.6% respectively using normalized features. It shows that normalized features can reduce the feature difference between speakers and increase the recognition rate. In testing corpus is different with training, the recognition rate of KNN, SVM, MLBN and MLBNC are 34.21%, 46.92%, 39.33% and 52.08% respectively. It shows if speaker’s pronunciation or emotion presentation is different with training data, the recognition result is bad for each recognizer.
For adaptive emotion recognition test, adaptive KNN method can increase the recognition rate from 34.2% to 73.7%, adaptive MLBN method can increase from 37.8% to 82.4% and adaptive MLBNC method can increase from 51.6% to 81.2%. The proposed adaptive MLBN and
MLBNC method of this study is better than adaptive KNN method. When adjustment times increase, the recognition rate of MLBN can increase from 39.3% to 88.9% and MLBNC can increase from 52.1% to 90.0%. It shows that adaptive MLBN and MLBNC method can really reflect the real status of speaker’s emotion state and get good recognition results after appropriate adjustment.
Keywords:speech emotion recognition、features、normalization、
MLBN、MLBNC、adaptive.
目 錄:
誌謝---I 中文摘要---III ABSTRACT---VI 目錄---X 圖目錄---XIII 表目錄---XVI
第一章 導論---1
1.1 前言---1
1.2 文獻回顧---2
1.3 本文簡介---7
第二章 語音情緒特徵參數計算---9
2.1 前處理---9
2.1.1 音框(Frame)與視窗(Windows)---9
2.1.2 預強調(Pre-emphasis)---10
2.1.3 快速傅立葉轉換(Fast Fourier Transform, FFT)---11
2.2 語音特徵(Speech Feature)計算---12
2.2.1 音高(Pitch)---12
2.2.2 共振峰(Formant)---14
2.2.3 音框能量(Frame Energy)---14
2.2.4 梅爾頻率倒頻譜係數(Mel-frequency Cepstral coefficient, MFCC)---15
2.3 小結---16
第三章 特徵參數之統計計算與正規化---23
3.1 情緒語音資料庫---23
3.2 特徵統計計算---24
3.2.1 語音特徵平均值(Mean)與標準差(Standard deviation)-24 3.2.2 語音特徵正規化計算(Normalization)---28
3.3 小結---32
第四章 KNN 與 SVM 於語音情緒辨識之實驗與分析---50
4.1 KNN 語音情緒辨識---50
4.1.1 第 K 個最近鄰(K-Nearest Neighbor, KNN)---50
4.1.2 KNN 語音情緒辨識實驗結果與分析---51
4.2 SVM 語音情緒辨識---56
4.2.1 支持向量機(Support Vector Machine, SVM)---56
4.2.2 SVM 情緒辨識實驗結果與分析---58
4.3 小結---62
第五章 多層貝氏網路與多層共變異數貝氏網路語音情緒辨識---71
5.1 決策樹、貝氏決策與貝氏網路介紹---71
5.1.1 決策樹 (Decision Tree) ---71
5.1.2 貝氏決策(Bayes Decision)與貝氏網路(Bayesian Network) ---72
5.2 多層貝氏網路(Multi-Layer Bayesian Network, MLBN)語音情 緒辨識---75
5.2.1 語音情緒特徵分群分析---75
5.2.2 多層貝氏網路(MLBN)---83
5.2.3 多層貝氏網路(MLBN)語音情緒辨識實驗結果與分析 ---94
5.3 多層共變異數貝氏網路(Multi-Layer Bayesian Network with Covariance, MLBNC)語音情緒辨識---98
5.3.1 多層共變異數貝氏網路(MLBNC)---98
5.3.2 MLBNC 實驗結果與分析---111
5.4 蒙地卡羅模擬(Monte Carlo Simulation)與分析---115
5.5 小結---120
第六章 調適性語音情緒辨識---149
6.1 適應性 KNN 語音情緒辨識實驗與分析---149
6.2 適應性 MLBN 語音情緒辨識實驗與分析---152
6.2.1 適應性 MLBN---152
6.2.2 適應性 MLBN 實驗結果與分析---166
6.3 適應性 MLBNC 語音情緒辨識實驗與分析---171
6.3.1 適應性 MLBNC---172
6.3.2 適應性 MLBNC 實驗結果與分析---183
6.4 小結---189
第七章 結論與未來展望---211
參考文獻---218
附錄A---225
附錄B ---232
附錄C ---240
圖 目 錄:
圖 2-1 語音情緒辨識流程圖---18
圖 2-2 語音訊號音框化後之波形---18
圖 2-3 Hamming and Rectangular window ---19
圖 2-4 人耳聽覺各頻率最小音壓曲線---19
圖 2-5 預強調前後之語音波形---20
圖 2-6 預強調前後之語音頻譜---20
圖 2-7 語音之音高變化---21
圖 2-8 單一音框之共振峰示意圖---21
圖 2-9 語音之音框能量變化---22
圖 3-1 工研院情緒語音錄製環境---34
圖 3-2 不同語者在不同情緒之音高平均值分佈---35
圖 3-3 不同語者在不同情緒之原始特徵參數分佈---39
圖 3-4 正規化後音高平均值在不同語者不同情緒下之分佈---40
圖 3-5 正規化後音高標準差在不同語者不同情緒下之分佈---40
圖 3-6 正規化後各特徵參數在不同語者不同情緒下之分佈---42
圖 3-7 使用正規化特徵參數之語音情緒辨識流程---43
圖 4-1 第 K 個最近鄰(KNN)---64
圖 4-2 KNN 語音情緒辨識流程---64
圖 4-3 KNN 不同 K 值之辨識率---65
圖 4-4 二維支持向量機---65
圖 4-5 SVM 語音情緒辨識流程---66
圖 5-1 簡易交通工具分類流程---123
圖 5-2 四類別之貝氏決策示意圖---123
圖 5-3 兩類別之貝氏決策示意圖---124
圖 5-4 四種情緒類別之正規化後音高分佈---124
圖 5-5 四種情緒類別之正規化特徵參數分佈---128
圖 5-6 悲傷與其他情緒之正規化後音高平均值分佈---129
圖 5-7 多層貝氏網路語音情緒辨識架構---130
圖 5-8 多層貝氏網路第一層---131
圖 5-9 MFCC C8 平均值原始分佈及分群後分佈---131
圖 5-10 多層貝氏網路第一層分群後分佈---132
圖 5-11 多層貝氏網路第二層---133
圖 5-12 多層貝氏網路第二層分群後分佈---134
圖 5-13 多層貝氏網路第三層---135
圖 5-14 多層貝氏網路語音情緒辨識流程---135
圖 5-15 多層共變異數貝氏網路第一層---136
圖 5-16 多層共變異數貝氏網路第二層---136
圖 5-17 多層共變異數貝氏網路第三層---137
圖 5-18 MFCC C1 與 C4 平均值四情緒之特徵參數落點分佈---137
圖 5-19 MFCC C1 與 C4 平均值四情緒之雙變數常態分佈圖---138
圖 5-20 MFCC C1 與 C4 平均值四情緒之雙變數常態分佈投影----138
圖 5-21 多層共變異數貝氏網路語音情緒辨識流程---139
圖 6-1 適應性 KNN 調適流程---196
圖 6-2 適應性 MLBN 調適流程---196
圖 6-3 MLBN 第一層三種分群方式---197
圖 6-4 MLBN 第二層兩種種分群方式---198
圖 6-5 0.5時,資料庫調適後變化圖---198
圖 6-6 9 0. 時,資料庫調適後變化圖---199
圖 6-7 適應性 MLBNC 調適流程---199
圖 6-8 MLBNC 第一層三種分群方式---200
圖 6-9 MLBNC 第二層第一種分群方式---200
表 目 錄:
表 3-1 德國情緒語料庫語料數量---44
表 3-2 工業技術研究院語料庫語料數量---45
表 3-3 工業技術研究院語料庫語料詞句---46
表 3-4 使用之語音特徵參數---48
表 3-5 使用之正規化後語音特徵參數---49
表 4-1 使用正規化特徵參數 KNN Inside Test 鑑別矩陣---67
表 4-2 使用原始特徵參數 KNN Outside Test 鑑別矩陣---67
表 4-3 使用正規化特徵參數 KNN Outside Test 鑑別矩陣---68
表 4-4 KNN 不同語系測試之鑑別矩陣(正規化特徵參數)---68
表 4-5 使用正規化特徵參數 SVM Inside Test 鑑別矩陣---69
表 4-6 使用原始特徵參數 SVM Outside Test 鑑別矩陣---69
表 4-7 使用正規化特徵參數 SVM Outside Test 鑑別矩陣---70
表 4-8 SVM 不同語系測試之鑑別矩陣(正規化特徵參數)---70
表 5-1 正規化後音高平均值之正確辨識率矩陣---140
表 5-2 正規化後音高之標準差各情緒之正確辨識率矩陣---140
表 5-3 情緒類別分群與對應之特徵參數---141
表 5-4 使用正規化特徵參數 MLBN Inside Test 鑑別矩陣---142
表 5-5 使用正規化特徵參數 BD Inside Test 鑑別矩陣---142
表 5-6 使用正規化特徵參數 MLBN Outside Test 鑑別矩陣---143
表 5-7 使用原始特徵參數 MLBN Outside Test 鑑別矩陣---143
表 5-8 MLBN 不同語系測試之鑑別矩陣(正規化特徵參數)---144
表 5-9 使用正規化特徵參數 MLBNC Inside Test 鑑別矩陣---144
表 5-10 使用正規化特徵參數 MLBNC Outside Test 鑑別矩陣---145
表 5-11 MLBNC 不同語系測試之鑑別矩陣(正規化特徵參數)---145
表 5-12 KNN 蒙地卡羅模擬鑑別矩陣---146
表 5-13 SVM 蒙地卡羅模擬鑑別矩陣---146
表 5-14 MLBN 蒙地卡羅模擬鑑別矩陣---147
表 5-15 MLBNC 蒙地卡羅模擬鑑別矩陣---147
表 5-16 各分類器蒙地卡羅模擬結果---148
表 6-1 KNN 調適前後之鑑別矩陣(工研院 P1)---201
表 6-2 KNN 不同語系調適前後之鑑別矩陣(一半調適,一半測試)--202
表 6-3 MLBN 德國語料庫同語系調適前後之鑑別矩陣---203
表 6-4 使用正規化特徵參數 MLBN Dependent Test 鑑別矩陣---204
表 6-5 MLBN 不同語系調適前後之鑑別矩陣(一半調適,一半測試) ---205
表 6-6 調適次數增加時,MLBN 不同語系調適前後之鑑別矩陣---206
表 6-7 MLBNC 德國語料庫同語系調適前後之鑑別矩陣---207
表 6-8 MLBNC 不同語系調適前後之鑑別矩陣(一半調適,一半測試)
---208
表 6-9 調適次數增加時,MLBN 不同語系調適前後之鑑別矩陣---209
表 6-10 各分類於不同測試條件下之整體辨識結果整理---210
表 A-1 KNN Outside Test 各情緒辨識正確率(原始特徵參數)---225
表 A-2 KNN Outside Test 各情緒辨識正確率(正規化特徵參數)---226
表 A-3 SVM Outside Test 各情緒辨識正確率(原始特徵參數)---227
表 A-4 SVM Outside Test 各情緒辨識正確率(正規化特徵參數)---228
表 A-5 MLBN Outside Test 各情緒辨識正確率(原始特徵參數)---229
表 A-6 MLBN Outside Test 各情緒辨識正確率(正規化特徵參數)---230
表 A-7 MLBNC Outside Test 各情緒辨識正確率(正規化特徵參數)-231 表 B-1 正規化後音高平均值各情緒之正確辨識率矩陣---232
表 B-2 正規化後音高之標準差各情緒之正確辨識率矩陣---232
表 B-3 正規化後能量平均值各情緒之正確辨識率矩陣---232
表 B-4 正規化後能量之標準差各情緒之正確辨識率矩陣---233
表 B-5 正規化後第一共振峰平均值各情緒之正確辨識率矩陣---233
表 B-6 正規化後第一共振峰之標準差各情緒之正確辨識率矩陣---233
表 B-7 正規化後第二共振峰平均值各情緒之正確辨識率矩陣---234
表 B-8 正規化後第二共振峰之標準差各情緒之正確辨識率矩陣---234
表 B-9 正規化後第三共振峰平均值各情緒之正確辨識率矩陣---234
表 B-10 正規化後第三共振峰之標準差各情緒之正確辨識率矩陣-235
表 B-11 MFCC C1 平均值各情緒之正確辨識率矩陣---235
表 B-12 MFCC C2 平均值各情緒之正確辨識率矩陣---235
表 B-13 MFCC C3 平均值各情緒之正確辨識率矩陣---236
表 B-14 MFCC C4 平均值各情緒之正確辨識率矩陣---236
表 B-15 MFCC C5 平均值各情緒之正確辨識率矩陣---236
表 B-16 MFCC C6 平均值各情緒之正確辨識率矩陣---237
表 B-17 MFCC C7 平均值各情緒之正確辨識率矩陣---237
表 B-18 MFCC C8 平均值各情緒之正確辨識率矩陣---237
表 B-19 MFCC C9 平均值各情緒之正確辨識率矩陣---238
表 B-20 MFCC C10 平均值各情緒之正確辨識率矩陣---238
表 B-21 MFCC C11 平均值各情緒之正確辨識率矩陣---238
表 B-22 MFCC C12 平均值各情緒之正確辨識率矩陣---239
表 B-23 MFCC C13 平均值各情緒之正確辨識率矩陣---239
表 C-1 KNN 不同語系 P1 ~ P20 調適前後之辨識結果(一半調適,一半 測試)---240
表 C-2 MLBN 德國語料庫同語系 P1 ~ P20 調適前後之辨識結果----242
表 C-3 MLBN 不同語系 P1 ~ P20 調適前後之辨識結果(一半調適,一 半測試)---244
表 C-4 調適次數增加時,MLBN 不同語系 P1 ~ P20 調適前後之辨識 結果---246 表 C-5 MLBNC 德國語料庫同語系 P1 ~ P20 調適前後之辨識結果--248 表 C-6 MLBNC 不同語系 P1 ~ P20 調適前後之辨識結果(一半調適,
一半測試)---250 表 C-7 調適次數增加時,MLBN 不同語系 P1 ~ P20 調適前後之辨識
結果---252
第一章 導論
1.1 前言:
在人與人的溝通互動行為(Human communication)當中,除了文字 的內容外,語調(Prosody)、手勢(Hand gestures)以及臉部表情(Facial expression)的呈現,也是溝通行為當中,重要的資訊傳遞方式,透過 這樣的資訊傳遞,能夠讓對方明白的感受到彼此要給對方的資訊。在 溝通過程傳達的資訊內容中,除了詞面的意義外,人類可以藉由與生 俱來的感知能力,敏銳的洞悉許多隱藏在內部的事物,這些內部的相 關資訊,深深的影響著詞面上的意義,不同的表達方式與語氣代表著 不同的意思,例如一句”你這句話是什麼意思”,如果是以詢問的方式 說”你這句話是什麼意思?”,則表示希望講話者重新解釋之前話中的 意思,但如果是以” 你這句話是什麼意思!”來表示,則表示是質疑對 方講話的內容;從上述的例子中,相同的一段話,不同的說話語調會 讓聽者有不同的感受,在人類的交談中,常常透過語調、語韻以及音 量等不同的變化與修飾,將隱含的資訊附加在語句當中,希望對方能 夠從中得到講話者欲表達的資訊。
近幾年來,隨著電腦科技的日新月異,許多研究紛紛投入人機介 面(Human Machine Interface)、電腦代理人(Computer Agent)、自然語 音辨識(Natural Speech Recognition)等相關領域,這些研究使得電腦與
人之間的互動更加真實,這種人機互動的運行方式,使得人們對於電 腦的概念產生變化,電腦不再只是固定執行人給的指令,而是可以跟 人產生互動的虛擬機器人。在目前的人類生活中,電腦資訊科技已經 扮演了一個不可或缺的角色,舉凡手機、PC、NB 或車用電子,皆使 我們的生活更加便利,相信在不久的將來,智慧生活科技將在人類生 活中扮演著舉足輕重的角色,而在智慧生活科技之人機互動介面上,
機器對人類情緒的感知與理解也是智慧生活科技重要課題之一,如何 讓機器具有像人類一樣的情緒感知能力,使得機器能夠像人一樣,更 加自然與人性化,將是未來智慧生活科技人機互動上發展的重要方向 之一。
1.2 文獻回顧:
Picard[51]於 1998 年針對"Affective Computing"提出了幾個重 要的議題與方向,從電腦辨識之人類情感模型、電腦輔助學習、藝術、
娛樂、健康以及人機互動等方向上提出建議與看法,Pantic and Rothkrantz [46]於 2003 年發表的文章中,說明了情緒辨識在人機介面 上的重要性以及利用多個不同的感知方式來辨識情緒,Cowie et al.[14]
描述了在表達情緒時,語音與臉部表情的情緒特徵與反應,以及在特 定的情緒觸發條件下,語音特徵與特定情緒反應之間的對應關係,
Scherer[55]針對 2003 年語音情緒辨識的研究現況做回顧,並對語音
辨識研究之未來方向所討論與建議。目前,自動化情緒辨識方法與系 統開發已成為人機情感介面上重要的研究主題之一,對於情緒辨識的 研究,目前仍處於發展的階段,相關的研究主題主要分為幾個部分:
1.語音情緒辨識(Speech Emotion Recognition)
2.臉部影像情緒辨識(Facial Image Emotion Recognition)
3.語音臉部影像雙模情緒辨識(Audio-Visual Emotion Recognition) 4.人機互動(Human Machine Interaction)
首先,在語音情緒辨識上,Banse and Scherer[3]針對口語上,情 緒所表現之語音特徵做深入探討及研究,Cowie and Cornelius[15]則是 描述語音特徵與情緒狀態之間的關連性。由於語音情緒在辨識上,需 要以各情緒之語料建置辨識分類所需之資料庫,因此,在語料庫的建 置上,Douglas-Cowie et al.[18]建立了 100 個人之情緒資料庫,內容同 時 包 含 聲 音 與 影 像 兩 個 部 分 , Schiel et al.[56] 利 用 自 行 開 發 的 SmartKom 設備,錄製具有聲音、影像以及觸覺輸入的情緒資料庫,
Makarova and Petrushin[38]建置了包含 61 個人五種情緒之俄羅斯語 情緒資料庫 RUSLANA,Burkhardt et al.[4] 建置了包含 10 個人 800 個語句之德語情緒資料庫 EMO-DB,Wu et al.[68]則是建置了 68 個人 10 個句子 5 種情緒之華語情緒資料庫 MASC (Mandarin Affective Speech Corpus),Johnstone [30]利用互動遊戲來當作情緒觸發的機
制,並記錄當時之語音情緒反應,以此為語音情緒語料庫,Schuller et al.[59] 於 2009 年將目前研究語音情緒的九種語料(ABC, AVIC, DES, EMO-DB, eNTERFACE,SAL, SmartKom, SUSAS, and VAM)作連結,
並轉換到 Valence-Arousal 空間中加以探討。
在語音情緒辨識之研究上,Scherer[54]從九種不同國家之語料 中,探討不同文化及語系之間情緒的表達方式是否有所差異,Montero et al.[41]以西班牙語建立語音情緒之模型並進行分析,Petrushin[49, 50] 使用 23 個人 700 個五種不同情緒之語料,以音高、第一、第二 共振峰、能量、以及講話速度為特徵參數,進行不同分類器之辨識實 驗,並作為情緒辨識代理人系統以及 Call Centers 之開發應用,Ang et al.[2] 利用語音訊號中之語調、語音模型以及講話者的講話方式,來 辨識憤怒與沮喪情緒,Chuang and Wu[11]利用語調及語意,並透過 PCA(Principle Component Analysis)與 SVM 來辨識說話者的情緒狀 態,Wu et al.[66]使用語意標示以及 Separable Mixture Models 來辨識 語音訊號中的情緒反應,Kwon、Schuller et al.、New et al.、Lee et al.、
Jiang and Cai 以及 Lin and Wei[33, 58, 44, 35, 29, 36]使用隱藏式馬可 夫模型(Hidden Markov Model, HMM)並以語調相關特徵來進行語音 辨識情緒,Fragopanagos and Taylor、Busso et al.以及 Iliou et al.[21, 5, 28]使用類神經網路(Neural Network, NN)來進行語音辨識情緒,Casale
et al.、Chandrakala et al.及 Kandali et al.[6, 7, 32]則使用高斯混合模型 (Gaussian Mixture Models) 及支持向量機(Support Vector Machine, SVM)來進行語音辨識情緒,Pao et al.[48]利用最短距離(Nearest class mean)分類法,並使用特徵篩選與特徵結合的方式來改善語者相關之 中文語音情緒辨識,Zhang[73] 則是使用模糊最小平方支持向量機來 進行語音情緒辨識,並使用不同之訊噪比進行實驗。
除了以分類器來做語音情緒辨識的研究外,有些研究方向則著重 於語音情緒特徵參數的計算,Lee et al.以及 Wang et al.[34, 63]利用主 成分分析(PCA)先將特徵參數作篩選後,再分別以不同之分類器做語 音情緒辨識,Wu et al.及 Meshram et al.[67, 39]利用不同時間序列的特 徵參數來進行語音情緒辨識,Espinosa et al.及 Dongrui et al.[19, 17]使 用心理學上 VAD(Valence/Activation/Dominance)三維之情緒辨識方 法,將特徵參數轉換成 VAD 值,再進行辨識, Xin et al.[69]則使用 HHT(Hilbert-Huang Transformation)方法計算新語音情緒特徵參數,稱 為 ECC 參數,並用於語音情緒辨識中。
在臉部影像情緒辨識及語音臉部影像雙模情緒辨識之研究上,
Lyons et al.[37]利用 Gabor Wavelet 來擷取臉部表情特徵,並利用 Gabor Wavelet coding 來建立臉部表情之分類器,Fasel and Luettin[20]提出一 自動臉部表情分析之方法,包含臉部圖像的正規化,臉部的動態反應
以及強度等特徵計算,Wilhelm et al.[65]使用統計與類神經網路方 法,透過影像分析來辨識使用者表情與性別,Seyedarabi et al.[60]則 利用臉部的特徵點當作追蹤點,並使用類神經網路及 FIS(Fuzzy Inference System)來進行臉部影像情緒辨識,Go et al.、Metallinou et al.、Wang et al.、Chen et al.、Das et al.、Zeng et al.以及 Mower et al.[24, 40, 64, 10, 16, 72, 42]使用臉部影像與語音雙模方式作情緒辨識。
在人機互動應用介面及其他應用系統上,Polzin and Waibel[52]
建 立 能 表 達 情 緒 之 人 機 介 面 , Fujita et al.[22] 介 紹 仿 人 機 器 人 SDR-4X,此機器人具有與人互動並學習的功能,Fujita[23]介紹能與 人互動並表達情緒寵物狗 AIBO,Álvarez et al[1]則是開發具有情緒模 型之導覽機器人。Huber et al.及 Yacoub et al.[26, 70]將語音情緒辨識 方法應用在客服系統(Call Centers)上,Niimi et al.、Iida et al.、Schroder and Grice、Yanushevskaya et al.以及 Tao et al.[45, 27, 57, 71, 62]將情緒 因子加入到語音中,使語音合成之訊號帶有情緒反應,Pao and Chen[47]則將中文之語音情緒辨識應用在中文聽障電腦輔助語言教 學系統中。
以目前語音情緒辨識的研究發展而言,辨識的效果十分仰賴資料 庫的建置,當測試的語者資料不在訓練資料庫中或測試語者所使用的 語系與訓練資料有所差異時,通常無法得到良好的辨識效果,因此,
如何透過適當的資料庫調適過程,使資料庫更貼近使用者的真實狀 態,將是本論文的重點研究之一。
1.3 本文簡介:
本論文主要在發展一自動化語音情緒辨識系統,透過情緒語音訊 號之偵測,將使用者之情緒狀態給辨識出來,在情緒之特徵參數方 面,透過音高、能量、共振峰以及梅爾倒頻譜係數之計算,並利用縮 小個人差異之正規化過程,將帶有情緒反應之語音正規化特徵參數給 計算出來,在情緒辨識方面,本論文使用 KNN、SVM 以及我們所發 展之多層貝氏網路與多層共變異數貝氏網路語音情緒辨識方法,對計 算之正規化語音情緒特徵進行辨識,並得到辨識後之情緒狀態。
此外,本論文亦提出一針對我們所發展之多層貝氏網路與多層共 變異數貝氏網路語音情緒之調適方法,此調適方法能針對使用者的真 實語音情緒狀態進行資料庫調適,並得到更貼近使用者情緒狀態的辨 識效果。
本文之內容安排如下:
第一章 導論。
第二章 介紹語音訊號之前處理過程與特徵參數之計算方式。
第三章 介紹特徵參數之統計計算與正規化計算方法,並介紹本論文 所使用之語料庫。
第四章 介紹 KNN 及 SVM 分類器,並利用 KNN 及 SVM 分類器進行 語音情緒辨識。
第五章 介紹本論文所發展之多層貝氏網路與多層共變異數貝氏網路 語音情緒辨識方法,並進行語音情緒辨識。
第六章 發展多層貝氏網路與多層共變異數貝氏網路語音情緒辨識之 調適方法,並進行適應性實驗。
第七章 總結全文並對未來研究方向提出建議。
第二章 語音情緒特徵參數計算
一般而言,語音情緒辨識的主要流程如圖 2-1 所示,首先,將欲 辨識情緒之語音訊號經由訊號擷取裝置(麥克風),得到語音之類比訊 號,經由 A/D 轉換後,將類比訊號轉換成離散時間序列,接著,將 所得之離散時間序列經過前處理(Pre-processing),並將處理過後的離 散數位序列經由相關的特徵計算,得到此語音訊號之對應情緒特徵,
最後,將此語音訊號所對應之情緒特徵與建置之資料庫作比對,找出 相對應之情緒類別。在本章之內容當中,將主要針對情緒辨識流程中 的前置處理以及特徵擷取計算的部分,作更詳細的敘述。
2.1 前處理
2.1.1 音框(Frame)與視窗(Windows)
由於語音訊號為一時變性(Time varying)訊號,訊號隨時間的變化 非常快速,因此,在處理上,通常會取一小段語音訊號來做處理分析,
此種分析方式稱為短時距分析(Short-term analysis),而此一小段語音 訊號則稱為音框(Frame),如圖 2-2 所示。一般而言,音框的長度通常 為 10 ~ 30 毫秒(ms),音框的移動距離會取音框長度的一半,約 5 ~ 15 毫秒,讓音框與音框之間有所重疊,這樣比較能夠看到語音特徵改變 的延續性,取音框的數學表示式如 (2.1.1)式所示。
n m
x n m
w nfx ; ; (2.1.1) 其中,m 為音框編號,x
n;m
為第 m 個音框之語音訊號序列,w
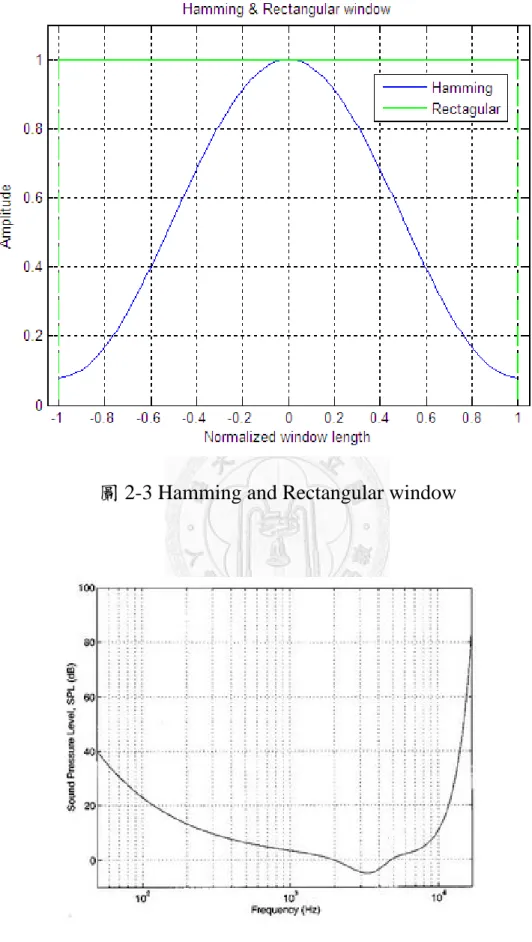
n 為視窗的加權,一般常用的加權視窗如矩形窗(Rectangular window) 與漢明窗(Hamming window)[25],其數學式與圖分別如(2.1.2)、(2.1.3) 及圖2-3所示:
otherwise N n n
w 0
1 0
1 (2.1.2)
otherwise
N N n
n n
w
0
1 1 0
cos 2 46 . 0 54 .
0
(2.1.3)
2.1.2 預強調(Pre-emphasis)
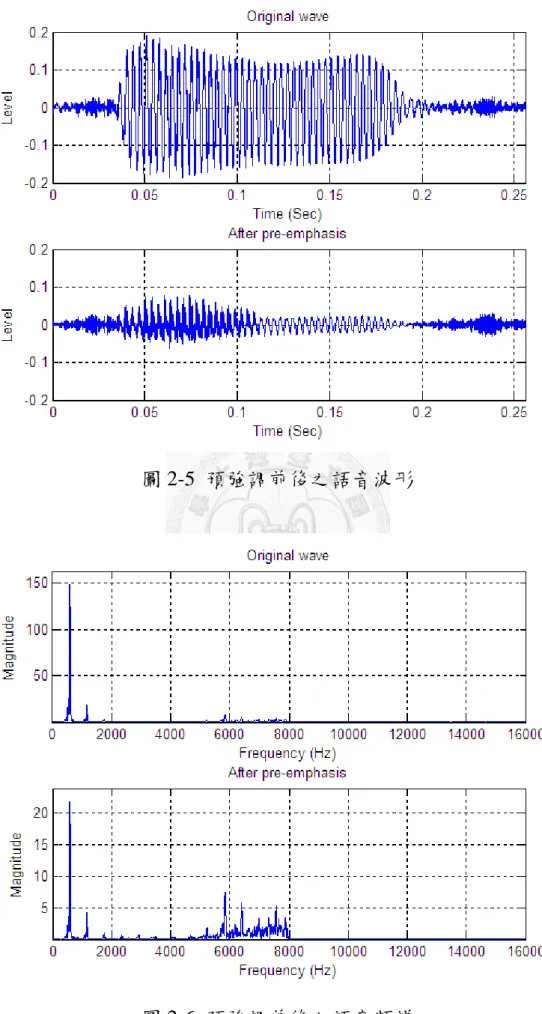
由於人耳聽覺在不同頻率所能接收的最小音強(Intensity)不同,如 圖 2-4所示,人耳對於1kHz到 5kHz的聲音最為敏感,但對於1kHz 以下與5kHz 以上的聲音,就需要較大的音強才聽的到,這條臨界曲 線稱為聽覺閥(Hearing threshold)。而預強調的最主要工作就是強化高 頻訊號部分,使得預強調後的語音訊號能更貼近人類的聽覺系統,其 作法為將訊號經過一高通濾波器(High pass filter),調整高頻成分的權 重(Weight),其計算式如式(2.1.4)所示:
z 1az1H (2.1.4)
zH 為濾波器頻率響應之z轉換,經過預強調的音頻訊號,可表 示成:
1
1
1
2 n S n aS n
S (2.1.5) 其中 n 為訊號之取樣數,S2
n 為經過預強調後的輸出訊號。圖 2-5 為某一段音頻訊號及其經過預強調之結果,圖 2.1-5 為預強調前 後語音訊號的頻譜結果,由結果可以看出,在預強調之後,原本所抑 制的高頻能量值將被增強,以符合人類的聽覺系統。2.1.3 快速傅立葉轉換(Fast Fourier Transform, FFT)
由於語音訊號在時域(Time domain)上的多變性與時變性,一般而 言,在時域上不容易找出語音相關特徵參數,通常的作法是將訊號從 時域轉換到頻域(Frequency domain)上,然後在頻域上找出語音的相關 特徵參數。由於語音訊號為數位訊號,因此,在時域轉換到頻域的過 程中,需使用到離散傅立葉轉換(Discrete Fourier Transform, DFT),離 散傅立葉轉換的定義如下:設一點數為 N 的有限離散訊號x
n ,1
0n N ,其離散傅立葉轉換為X
k ,轉換式形式為:
0,1, , 11
0 1
0
2
x nW k N
e n x k
X
N
n
nk N
n
Nnk i
(2.1.6) 離散逆轉換為
1
1 1
0,1, , 10 1
0
2
X k W k N
e N k N X
n x
N
n
nk N
n
Nnk i
(2.1.7) 其中W ei2 N。將上列兩式改寫成矩陣形式,如(2.1.8)式及(2.1.9) 式所示:
x W
X nk (2.1.8)
X W
x nk
N
1
(2.1.9) 式中X與x都是N維向量,W 與nk W 為nk N 維矩陣。N
離散傅立葉轉換讓傅立葉轉換能實際應用於電腦上,但卻因為計 算量太大,使得應用上受到限制。要計算N 點的X
k 需要N2次的複數乘法以及N
N 1
次的複數加法,且因為一次複數乘法等於四次實 數相乘與兩次實數相加,一次複數相加等於兩次實數相加,當 N 很 大時,其計算量相當可觀。舉例來說,若處理點數為1024 點的訊號,需要做1048576次的複數相乘,也就是 4194304次的實數相乘,計算 量相當驚人。
由於計算量過大,離散傅立葉轉換並未被廣泛使用,直到 1965 年由 Cooly 和 Tukey 提出了快速傅立葉轉換(Fast Fourier Transform, FFT)的計算方法[12],這才使得離散傅立葉轉換被大量應用於工程分 析上,FFT 的計算方式是利用W 的週期性與對稱性來減少計算量,
其詳細推導過程可以參考數位訊號處理的相關書籍。
2.2 語音特徵(Speech Feature)計算
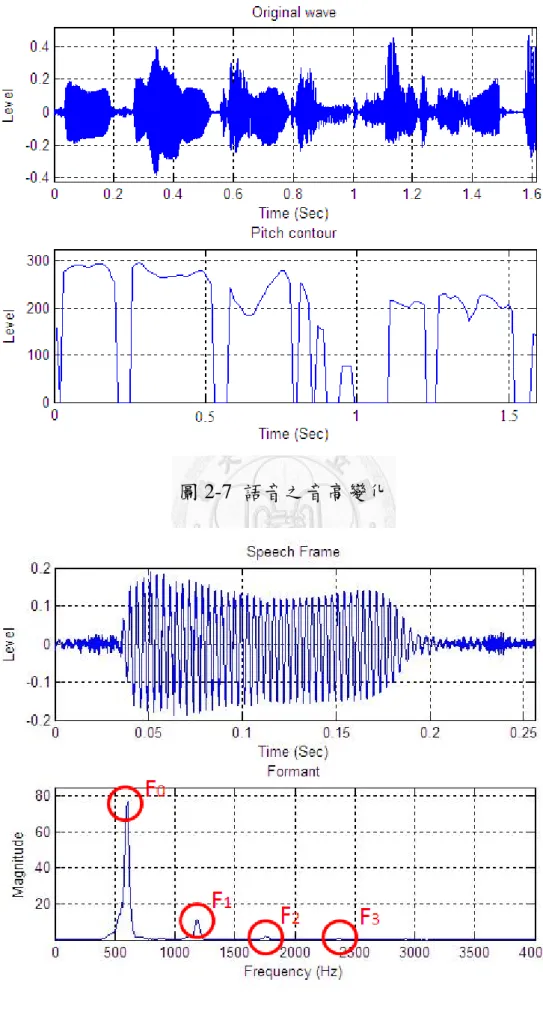
2.2.1 音高(Pitch)
在一段語音信號的形成過程中,首先會先由聲音源(Sound source) 發出一定頻率的弦波訊號後,接著聲音經由口腔、舌和嘴唇等所形成
的濾波器(Filters),將聲源信號做調變,便可以發出不同聲調的聲音。
而所謂的音高(或者稱為基頻, Pitch),意指發音源最原始的振動頻 率;通常要精確的去找出音高是不太容易的事,一般常用的方法,有 自相關函數分析(Autocorrelation Function Analysis) [53]、倒頻譜演算 法(Cepstrum Algorithm) [43]以及小波轉換(Wavelet Transform)[31]等。
音高為語音辨識中重要的特徵之一,只有在有聲語音(Voiced signal)中,才會有音高的存在,而人類的情緒則是隱藏於有聲的語音 信號中,圖 2-7為一段語音訊號經由自相關函數分析所計算出來的音 高輪廓(Pitch contour),本文之音高計算將採用自相關函數分析作為音 高的計算方法,其主要步驟如下:
(1)、取出一段經過音框化之語音訊號,將此語音訊號序列經過快速 傅立葉轉換後,得到一頻譜參數序列。
n m
FFT
x
nFSpectrum ; (2.2.1) 其中m表示第m個音框,x
n 表示第m個音框內的語音訊號序列。(2)、設定一頻寬(50~1000Hz),將此頻率範圍內之音框頻譜做自相關 分析,如式(2.2.2)所示。
1
1
; )
; (
; _
n
i
m i
FSpectrum m
i FSpectrum
m i FSpectrum ACF
(2.2.2)
(3)、找出自相關分析ACF_FSpectrum
i;m 除了第一個值外,最大值 的位置,並由式(2.2.3)計算出對應的頻率。
1
k N
pitch Fs (2.2.3)
其中,N為音框長度,k表示除了第一個值外,最大值的位置點。
2.2.2 共振峰(Formant)
人類的聲帶振動經過聲道以及口腔後,會產生共振發出聲音,取 一段經音框化後之音頻訊號,將音頻訊號利用快速傅立葉轉換將訊號 轉換到頻譜上,將傅立葉轉換之頻譜取其包絡線,可得到一條較為緩 和的頻譜曲線,在曲線上可以看到若干個高點,這些高點代表能量集 中的頻率位置,這些能量集中的位置就是共振峰(Formant)之所在位 置。如圖 2-8 所示,第一個高點通常為音高位置,標示為 F0,第二 個高點稱為第一共振峰,標示為 F1,第三個高點稱為第二共振峰,
標示為 F2,依次類推。如果發出的聲音是聲帶不動的輔音,則在頻 譜上就看不到基頻與共振峰,而且能量會比較集中在高頻處。
2.2.3 音框能量(Frame Energy)
在語音特徵中,聲音強度的變化是相當重要的訊息,聲音強度與 波形振幅有關,振幅越大音強越大,在固定音框長度的情況下,音框 能量可以以式(2.2.4)表示
m
N mL n
n x m
En
1
2 (2.2.4) 其中,m為音框編號,音框與音框相距為 L。
由於人耳對音強的感知並非線性,而是接近於對數的曲線,所以
一般時候我們會將能量以對數方式表示,
m
N mL n
n x m
En
1
log 2 (2.2.5) 我們從訊號起始端開始,第一個音框編號為 1,以此類推,我們 可以得到一音框能量變化的序列,圖 2-9為一語音訊號的音框能量曲 線,
2.2.4 梅爾頻率倒頻譜係數(Mel-frequency Cepstral coefficient, MFCC)
人耳在頻域上的感知並非全頻域有相同的敏感度,在正常的情況 下,對於低頻有較高的解析度,也就是在低頻可以分辨較小的頻率差 異,此外還有臨界頻帶的現象,在1kHz 頻率以下的臨界頻帶寬度約 為 100Hz,1kHz 頻率以上的臨界頻帶寬度成指數增加。因此,配合 人耳聽覺特性,在頻域中以梅爾(Mel-frequency)劃分頻帶,將屬於一 個頻帶中的頻率成分,合在一起當作一個能量強度,然後將這些頻帶 強度,以離散餘弦轉換(DCT),轉換成倒頻譜,其轉換方法如下,首 先,設計一組梅爾頻率的帶通濾波器,來得到通過帶通的音強,用以 計算倒頻譜,圖 2-10 為三角形濾波器所組成的梅爾濾波器組,梅爾 頻率刻度是以 1kHz 以下為等間距,1kHz以上為對數間隔,在 4kHz 範圍內設計成20 個頻帶,其中心頻率設定成;100,200,300,400, 500,600,700,800,900,1000,1148,1318,1514,1737,1995, 2291,2630,3020,3467,4000Hz。以數學式表示,第 m 個濾波器
的函數式如下:
m Mk f
f k f f
f
k f
f k f f
f f k
f k
k B
m
m m
m m
m
m m
m m
m m
m
1
0 0
1
1 1
1
1 1
1 1
(2.2.6)
kBm 表示是第 m 個頻帶的三角形濾波器,f 為第 m 個頻帶的中m 心頻率,fm1與 fm1就是前後兩個頻帶的中心頻率,M 為全部的頻帶 數目。
將各頻率的能量,乘上三角形濾波器,然後累加起來,就是通過 這個濾波器的能量,取對數值,得到:
k
m k
B k X m
Y log 2 (2.2.7) 對全部 M 個濾波器輸出的對數能量,做離散餘弦轉換(Discrete Cosine Transform, DCT),得到梅爾頻率倒頻譜。
M
m
x M
m n m
M Y n c
1
12 1 cos
(2.2.8)
ncx 就 是 訊 號 x
n 的 梅 爾 倒 頻 譜 係 數 (Mel-frequency Cepstral Coefficient, MFCC),在本論文中只用前 13 個,即n1,2,...13來作為 語音的頻譜特徵。2.3 小結
在本章的內容中,主要針對特徵擷取前的分析以及之後的特徵擷
取計算,由於人類對於不同振幅以及頻率,也就是音量以及音調的感 知是相當敏感的,且人耳對於聲音的接收也是透過頻率的轉換來接 收,因此,頻譜上的特徵計算在情緒特徵擷取上是相當重要的;而由 於語音訊號常常伴隨著雜訊,而雜訊在頻譜上往往與語音訊號是互相 重疊的,因此,環境與麥克風的品質亦深深影響語音的特徵擷取。此 外,人與人之間在語音特徵上的差異也是造成目前語音情緒辨識率不 佳的問題所在,如何縮小人與人之間在語音特徵上的差異,並經由適 當的調適方法來改善辨識上的問題,將是本研究發展的另外一個課題 所在,以下章節將持續針對縮小特徵差異、辨識分類器以及調適方法 作更深入的探討。
圖 2-1 語音情緒辨識流程圖
圖 2-2 語音訊號音框化後之波形
圖 2-3 Hamming and Rectangular window
圖 2-4 人耳聽覺各頻率最小音壓曲線
圖 2-5 預強調前後之語音波形
圖 2-6 預強調前後之語音頻譜
圖 2-7 語音之音高變化
圖 2-8 單一音框之共振峰示意圖
圖 2-9 語音之音框能量變化
圖 2-10 三角形濾波器組成的梅爾頻率濾波器組
第三章 特徵參數之統計計算與正規 化
在語音情緒辨識的流程中,其中一個重要的環節就是如何從現有 的資訊中找出線索,並與資料庫作比對,前面一章所講到的特徵計 算,對一段長度約 3 秒的語音訊號而言,計算出來的特徵參數是非常 多的,因此,在特徵計算與資料庫特徵建置上,本文將採用統計的方 式來得到相關的特徵。此外,由於不同語者在語音特徵上的差異,容 易造成辨識的困難,因此,本章亦將提出一正規化的計算方法,縮小 不同語者在語音特徵上的差異,期望對後續的辨識分類有所助益。
3.1 情緒語音資料庫
本論文所使用之情緒語音語料庫是 W. F. Sendlmeier 等人於 Technical University of Berlin 所蒐集的情緒語料庫,此情緒語料庫為 開放資源,內容包含十名演員(五名男士及五名女士),分別就十個單 字與五個句子,以不同情緒發音,語料庫中包含悲傷 62 筆、中性 79 筆、快樂 71 筆及生氣 127 筆,共 339 筆語料(如表 3-1 所示),主要當 作 訓 練 與 辨 識 用 。 此 外 , 本 文 亦 使 用 工 業 技 術 研 究 院 (Industrial Technology Research Institute, ITRI)所自行錄製之情緒語料庫,此情緒 語料庫為工研院版權所有,內容包含女性十名,男性十名,每名語者
四種情緒各 30 筆語料(如表 3-2 所示),各情緒之語料語句則如表 3-3 所列,錄製環境如圖 3-1 所示,錄音設備則包含 RODE NT-3 麥克風、 E-MU 0404 USB 外接音效卡及一台桌上型 PC,錄音軟體則是利用自 行撰寫之 MATLAB 程式,以單聲道、取樣頻率 16kHz 及取樣解析度 16bit 錄製語料,在錄製的過程中,會先讓錄音語者聆聽事先以語音 情緒表達能力較高之語者所先行錄製之語音情緒範例,並解釋各情緒 的可能表現方式,接著,會讓錄音語者對欲錄製的情緒類別試講數 次,待情緒表達明確後,再進行錄音語者之情緒語音錄製,在錄製的 過程中,若錄音語者情緒表達不明顯時,則會對該語句進行重錄,直 至情緒表現明確為止。
3.2 特徵統計計算
3.2.1 語音特徵平均值(Mean)與標準差(Standard deviation)
針對一段長度 1.5 ~ 3 秒,取樣頻率 16kHz 的語音訊號而言,若 音框長度為 256 點,音框與音框之間重疊的部分為 128 點,其一段語 音訊號的音框數約為 188 ~ 376 個,因此,將計算所得之語音參數利 用統計方式,計算出與統計分布情況有關的統計量值,如:最小值、
最大值、中間值及標準差等統計參數,並利用設定閥值(Threshold)的 方式,將雜訊或不必要的資料去除,以得到與情緒相關性較大的統計 量值,是本文採用的特徵計算方法。以下將針對資料庫中不同語音特
徵的計算與處理方式作說明:
首先,計算資料庫中的音高特徵,將每一段資料庫中的語音訊 號,以音框長度 256 點,音框與音框之間重疊部分 128 點,計算出每 一 個 音 框 的 音 高 值 , 接 著 , 設 定 音 高 的 上 閥 值 (Upper bound) 為 550Hz,下閥值(Lower bound)為 75Hz,如式(3.2.1)所示,這是由於人 類發音的母音音高通常介於 75 ~ 550Hz 之間,利用閥值的限制,可 以去除非語音以及環境雜訊的干擾。
0 otherwise
550 75
if
,
, ,
m P m
m P P
E j i E
j E i
j
i (3.2.1) 其中,
E 表示情緒類別,i 表示第 i 個人的語音,j 表示在 Person i 及情緒類別
E 下,第 j 筆語音情緒資料,m 則表示那一筆語音情緒 資料中第 m 個音框的音高值,舉例來說,P3 ,H2
100 表示第 3 個人中,情緒類別為”快樂”資料下,第 2 筆資料第 100 個音框的音高值。
此外,我們建立一個以Pi , Ej
m 為判斷基準的旗標(Flag),並藉此 旗標來決定此音框是否為說話音框的根據,其算式如(3.2.2)所示:
0 otherwise 0
if
1 ,
,
m m P
flag
E j E i
j
i (3.2.2) 當 flagi ,Ej
m 1表示此音框為說話音框, flagi ,Ej
m 0則否,
mflagi ,Ej 中各符號的意義與Pi , Ej
m 相同。接著,將有語音部分的音高值以統計方式,計算其平均值(Mean)
與標準差(Standard deviation),其算式如(3.2.3)及(3.2.4)所示:
1
( ), 1
, P, m flag m
P N iEj
n
m E j i E
j
i
(3.2.3)
n
m
E j i E
j i E
j i
P P m P
N 1
2 , ,
, ,
1 (3.2.4)
其中,N 表示 flagi ,Ej
m 1之音框總數。最後,我們得到音高的 平均值與標準差,資料庫中的每一筆情緒語音皆會得到一個音高的平 均值與標準差,舉例來說,在 Person i 中,我們有四種情緒(喜、怒、哀以及中性)各五筆資料,將音高的平均值設為第一個特徵參數,標 準差設為第二參數,則我們的資料庫中第一個特徵參數將有四個類 別,而每個類別則分別有五個音高平均值特徵值,第二個特徵也同樣 具有四個類別,每個類別分別有五個音高標準差特徵值,以此類推,
以下的各個特徵參數將以同樣的統計計算方式建立資料庫。
接著,計算音框能量及音框能量標準差兩個特徵參數,先計算每 一個音框的能量序列Eni , Ej
m ,當 flagi ,Ej
m 1時,將所對應之音框 能量以統計方式,計算其平均值,得到平均音框能量En iE,j 及其標準 差En , E,i j,如式(3.2.5)及(3.2.6)所示。 1
( ) 1,, 1
,
, En m flag m
En N iEj
n
m E
j i E
j
i (3.2.5)
n
m
E j i E
j i E
j i
En En m En
N 1
2 , 2
, ,
,
1 (3.2.6)
接下來,與音高以及音框能量之計算方式相同,計算語音當中的
共振峰值,並取出與情緒關連性較大的第一至第三共振峰值( 1F ~ 3
F ),將第一至第三共振峰值以統計方式,計算其平均值與標準差,
其算式如(3.2.7) ~ (3.2.12)所示
1 1
( ) 11 ,
1
,
, F m flag m
F N iEj
n
m E
j i E
j
i (3.2.7)
n
m
E j i E
j i E
j i
F F m F
N 1
2 , 2
, ,
,
1 1 1 1
(3.2.8)
1 2
( ) 12 ,
1
,
, F m flag m
F N iEj
n
m E
j i E
j
i (3.2.9)
n
m
E j i E
j i E
j i
F F m F
N 1
2 , 2
, ,
,
2 1 2 2
(3.2.10)
1 3
( ) 13 ,
1
,
, F m flag m
F N iEj
n
m E
j i E
j
i (3.2.11)
n
m
E j i E
j i E
j i
F F k F
N 1
2 , 2
, ,
,
3 1 3 3
(3.2.12)
最後,計算梅爾頻率倒頻譜係數(MFCC),並取前 13 個係數當作 語音情緒辨識之特徵參數,同樣的,以音高所得到之旗標 flagi , Ej
m 來 當作 MFCC 取捨的依據,將 flagi ,Ej
m 1時,所對應之音框的 MFCC 各 係 數 以 統 計 方 式 , 計 算 其 平 均 值 , 得 到 MFCC CE1,i,j , E j i
MFCCC2,, ,……,MFCC CE13,i,j,如式(3.2.13)所示,MFCC CtE,i,j中各符 號的意義與Pi , Ej
m 相同,i 表示第 i 個人的語音,
E 表示情緒類別,j 表示在 Person i 及情緒類別