國立臺灣大學生物資源暨農學院生物環境系統工程所 博士論文
Department of Bioenvironmental Systems Engineering College of Bioresources and Agriculture
National Taiwan University Doctoral Dissertation
結合自編碼器及回饋式類神經網路 建立區域淹水預測模式之研究
A Study of Building Regional Flood Inundation Forecast Models by Hybrid Autoencoder and Recurrent Neural
Network
高毅灃 I-Feng Kao
指導教授:張斐章 博士 Advisor: Fi-John Chang, Ph.D.
中華民國 109 年 7 月 July 2020
doi:10.6342/NTU202003855
ii
謝志
自民國 98 年進入張麗秋老師研究室就讀碩士班至 109 年完成博士 論文,我在研究所 10 年的時光彷彿乘坐長途航班,幾十小時後便到了 目的地。這段航程非常充實,也讓我累積了許多寶貴經驗,而要感謝的 人更有如飛機載客量般多到難以全數列出。
在博士班期間由衷感謝指導教授張斐章老師給予充分的研究資源 與提供研究機會,除了鼓勵我跨領域選修更多機器學習,讓我能積累各 種實務經驗,尤其是在論文撰寫與圖表設計上的精闢指導讓我最後能 順利發表 SCI 期刊論文與完成博士論文。此外,非常感謝口試委員張 麗秋老師、黃文政老師、張良正老師、游保杉老師給予諸多修正建議,
讓這本論文能夠順利完成。其中特別感謝引領我進入類神經網路研究 領域的碩士班指導教授張麗秋老師,不斷提醒我在嘗試新機器學習方 法時要與本科水文學專業結合,也給予我執行計畫、撰寫報告與各式水 文應用程式的工作經驗,同時亦教導我正確的研究觀念與待人處世之 道,為博士班學業奠定了良好的基礎。
最後,特別感謝周研來博士協助規劃研究方法;沈宏榆學長提供研 究參考資料;林恒玥助理指引英文論文寫作技巧,多虧你們的協助才能 讓我的研究順利發表。此外,謝謝台大水資源資訊系統研究室的助理立 芹與士慧提供校務行政上的協助;同學 Maikel、安祺、孟信與學弟妹家 豪、佳薇、盈雅、庭玄、哲嘉、普運、嘉徽、韋德、戴禎、冠諺、佳儀、
廷軒等人在研究討論與辦公室工作上的支持;家人在生活與經濟上的 協助,使這段不長亦不短的旅途能順利達到終點。謝謝各位一路的陪伴 與包容,在此與各位分享這份得來不易的研究成果及畢業的喜悅之情。
毅灃 民國 109 年 7 月
doi:10.6342/NTU202003855
iii
摘要
淹水預報為防救災人員之重要參考資訊,惟區域淹水機制非常複 雜且數據維度極大,建立區域淹水預報係一個極具挑戰的關鍵議題,
過去有學者使用聚類的方式克服區域淹水數據維度過高的問題,但對 區域淹水特徵萃取問題尚少討論。本研究以前人的研究為基礎,思考如 何藉由特徵萃取大幅降低高維度之區域淹水資料以減少模式複雜度,
提出結合堆疊自編碼器(stacked autoencoder, SAE)及回饋式類神經網路 (recurrent neural network, RNN)之區域淹水預報模式。本研究提出之 SAE-RNN 模式利用 SAE 大幅降低區域淹水資料之維度,過程中輔以 主成分分析(principal components analysis, PCA)決定每次 SAE 堆疊過程 的隱藏層神經元個數及初始化其神經元權重,完成 4 個 SAE 模式訓練 後使 169,797 個網格資料降維成 2 至 5 維度淹水特徵編碼;淹水預報部 分係使用以編碼器-解碼器(encoder-decoder)框架及長短期記憶體(long short-term memory, LSTM)為基礎之回饋式類神經網路(RNN)模式建立 淹水特徵編碼預測模式;模式以前 24 小時雨量為輸入項,輸出未來 3 小時區域淹水特徵編碼預報結果,再透過 SAE 中的解碼器(decoder)將 預測之特徵編碼還原成區域淹水網格淹水深,完成 SAE-RNN 模式淹水 預測。本研究以宜蘭地區設計降雨及颱風暴雨紀錄所模擬之 55 場淹水 事件數據為 SAE-RNN 模式訓練、驗證及測試資料,建立 4 個使用不同 維度淹水特徵編碼之模式,預測未來 3 小時區域淹水深之測試階段 RMSE 值小於 0.09m,R2可達 0.95 以上;區域網格淹水預測結果 MAE 分布圖顯示絕對誤差小於 0.1m 之區域占全區 96%以上。根據不同 SAE- RNN 模式測試結果,發現影響 SAE-RNN 模式準確度的主因為 SAE 模 式降維還原過程的誤差,次因為 RNN 產生的預測誤差。綜合考量各模 式各項評估指標後以使用 4 維淹水特徵編碼的 SAE-RNN 模式為本研
doi:10.6342/NTU202003855
iv
究最佳區域淹水預報模式。此外,將不同區域淹水事件資料以 SAE 降 維成二維淹水特徵編碼,依時序繪製連線於平面座標上,再配合將該平 面固定間格取樣之網格座標點以 SAE 還原成區域淹水圖,使每個平面 座標網格點可關聯至特定區域淹水分布,完成可於平面圖中掌握多場 事件淹水歷程時空變化情形之視覺化圖表,同時也能顯示不同雨型對 淹水歷程變化之影響。
關鍵字:區域淹水、降維度、自編碼器、回饋式類神經網路、長短期記 憶體、資料視覺化
doi:10.6342/NTU202003855
v
Abstract
Flood forecasting is essential information in disaster management.
Because the regional flooding mechanism is very complicated, it is challenging to establish a regional flood forecast. Previous studies have used cluster analysis to overcome the problem that building a high-dimensionality regional flooding data forecasting model is difficult. However, there is an insufficient discussion on the characteristic extraction of regional flooding data. This study focuses on reducing the dimensionality of regional flooding data by feature extraction, and build regional flood inundation forecast models by hybrid Stacked autoencoder (SAE) and Recurrent neural network (RNN). During the SAE training process, this study uses Principal components analysis (PCA) to determine the number of hidden layer neurons and provide initial values of weights. In the case study of 55 flooding event physical simulation data in Yilan, 4 SAE models were completed to reduce the dimension of the regional flooding grid data from 169,797 to 5, 4, 3, or 2 and convert regional flooding data into four different dimensions of flooding characteristic codes. For forecasting the depth of regional flooding, this study uses the encoder-decoder framework and Long short-term memory (LSTM) to establish a forecast RNN model to predict the flooding characteristic codes in the future 3 hours. The input sequence of this RNN model is the rainfall information of the previous 24 hours. Finally, the SAE and RNN models are combined into SAE-RNN model, and the predicted flooding characteristic code is restored to the predicted regional flooding depth. The result of forecasting regional flood inundation shown that the RMSE less than 0.09m and the R2 more than 0.95 in the testing stage. The error distribution map of the forecast area shown that the MAE in 96% of the area is less than 0.1m. According to the results of different SAE-RNN models, this study concludes that the main factor affecting the SAE-RNN
doi:10.6342/NTU202003855
vi
model accuracy is the restoration error of SAE, the second factor is the RNN model error of forecasting flooding characteristic codes, and the SAE-RNN model with 4-dimension flooding characteristic codes is the best regional flood inundation forecast model in this case study. In addition, 2-dimension flooding characteristic codes provide a visual effect of the time and space distribution of the flooding process by line chart in the 2-dimensional coordinate plane. In this study, the decoder of SAE is used to restore the flooding characteristic codes of any coordinate as a flood map in 2- dimensional coordinate plane, which correlated the visibility between the flooding process and regional flood inundation depth distribution in the study area.
Keywords: Regional flood, Dimension reduction, Autoencoder, Recurrent neural network, Long short-term memory, Data visualization
doi:10.6342/NTU202003855
vii
目錄
口試委員會審定書 ... i
謝志 ... ii
摘要 ... iii
Abstract ... v
目錄 ... vii
圖目錄 ... ix
表目錄 ... xii
縮寫說明 ... xiii
第一章 前言... 1
1.1 研究背景 ... 1
1.2 研究動機與目的 ... 2
1.3 研究方法 ... 3
1.4 論文章節架構 ... 5
第二章 文獻回顧 ... 7
2.1 類神經網路於水文應用 ... 7
2.2 回饋式類神經網路與編碼器-解碼器模型應用 ... 8
2.3 以類神經網路進行區域淹水預報 ... 12
第三章 理論概述 ... 15
3.1 序列至序列學習問題 ... 16
3.1.1 編碼器-解碼器框架 ... 17
3.2 類神經網路 ... 19
3.2.1 前饋式神經網路 ... 20
3.2.2 活化函數 ... 21
3.2.3 類神經網路優化 ... 25
3.3 堆疊自編碼器(SAE) ... 31
3.4 回饋式類神經網路(RNN) ... 35
doi:10.6342/NTU202003855
viii
3.4.1 回饋式含外變數的非線性自迴歸模式(R-NARX) ... 38
3.4.2 長短期記憶體(LSTM) ... 39
3.5 SAE-RNN 區域淹水預報模式 ... 42
3.5.1 以主成份分析協助訓練 SAE 模式 ... 42
3.5.2 以編碼器-解碼器框架建立淹水特徵編碼預測模式 ... 49
3.6 區域淹水預報模式結果評估指標 ... 53
第四章 研究案例 ... 55
4.1 研究區域 ... 55
4.2 資料蒐集 ... 58
4.3 區域淹水數據 SAE 降維 ... 65
4.4 預測區域淹水特徵編碼 ... 71
4.4.1 決定 RNN 預測模式之降雨特徵編碼維度 ... 72
4.4.2 決定 RNN 預測模式之輸入降雨序列延時 ... 75
4.4.3 不同預測時距之淹水特徵編碼預測結果 ... 76
4.5 SAE-RNN 模式預測區域淹水 ... 77
4.5.1 不同降雨類型區域淹水測試案例預測結果比較 ... 86
4.6 實際淹水事件案例驗證 ... 101
4.7 以視覺化呈現區域淹水特徵 ... 108
第五章 結論與建議 ... 111
5.1 結論 ... 111
5.2 建議 ... 112
參考文獻 ... 115
附錄 SAE-RNN 模式訓練及驗證結果 ... 123
doi:10.6342/NTU202003855
ix
圖目錄
圖 1.1 研究流程圖 ... 4
圖 2.2.1 以不同 ANN 建置之編碼器-解碼器模型 ... 11
圖 3.1 SAE-RNN 區域淹水預報模式架構圖 ... 15
圖 3.1.1 以降雨造成淹水之序列至序列學習問題資料結構 ... 17
圖 3.1.2 編碼器-解碼器框架 ... 18
圖 3.1.3 應用轉移學習將分析模式改為預報模式 ... 18
圖 3.2.1 前饋式神經網路基本結構... 21
圖 3.2.2 雙曲線正切函數 ... 22
圖 3.2.3 S 函數 ... 23
圖 3.2.4 嚴格 S 函數 ... 24
圖 3.2.5 整流線性單位函數 ... 24
圖 3.2.6 類神經網路模式優化資料分組 ... 25
圖 3.3.1 SAE 架構圖 ... 32
圖 3.3.2 SAE 第一次堆疊(𝑆𝐴𝐸1) ... 33
圖 3.3.3 SAE 第二次堆疊(𝑆𝐴𝐸2) ... 34
圖 3.3.4 SAE 第五次堆疊(𝑆𝐴𝐸5)與錢次堆疊關係示意圖 ... 35
圖 3.4.1 回饋式類神經網路基本架構 ... 35
圖 3.4.2 回饋式類神經網路於使用次數上展開示意圖 ... 36
圖 3.4.3 本研究編碼器-解碼器框架建構之淹水預報模式示意圖 ... 37
圖 3.4.4 R-NARX 模式結構 ... 39
圖 3.4.5 LSTM 神經元結構... 42
圖 3.5.1 以 PCA 協助訓練 SAE 模式示意圖 ... 43
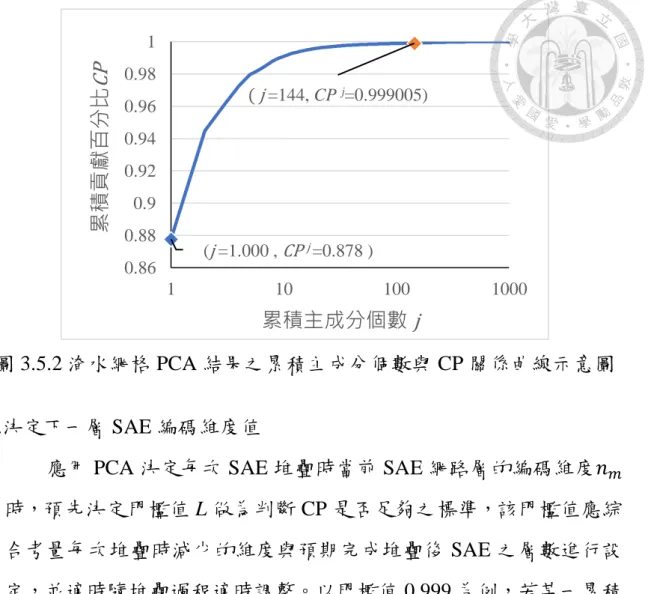
圖 3.5.2 淹水網格 PCA 結果之累積主成分個數與 CP 關係曲線示意圖 ... 45
圖 3.5.3 本研究 SAE 訓練流程圖 ... 48
圖 3.5.4 RNN 淹水特徵編碼預測模式架構圖 ... 49
圖 3.5.5 LSTM-FFNN 編碼器架構圖 ... 50
doi:10.6342/NTU202003855
x
圖 3.5.6 LSTM-R-NARX 解碼器架構圖 ... 52
圖 4.1.1 研究區域地形與河川分布... 56
圖 4.1.2 水利署製作之宜蘭縣一日暴雨 600mm 淹水潛勢分布圖 ... 57
圖 4.2.1 研究區域雨量站分布圖 ... 58
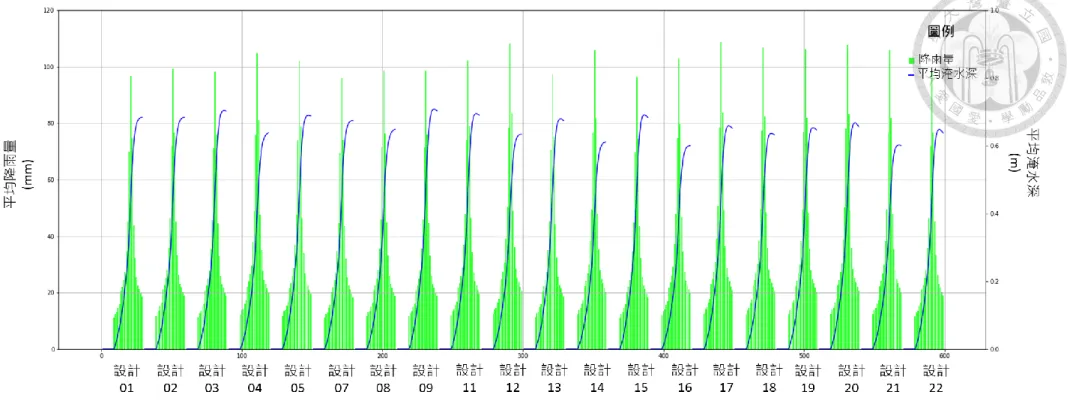
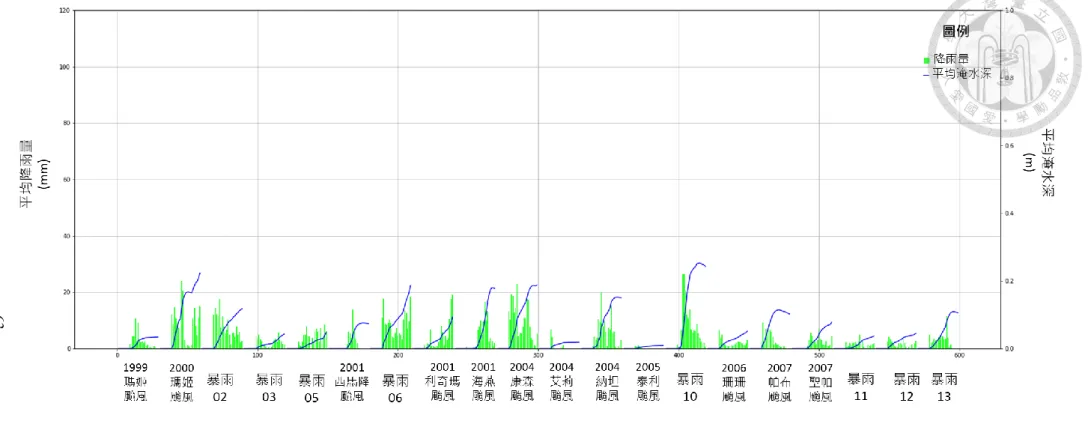
圖 4.2.2 訓練事件平均雨量及平均淹水深歷程圖(設計降雨事件) ... 62
圖 4.2.3 訓練事件平均雨量及平均淹水深歷程圖(實際降雨事件) ... 63
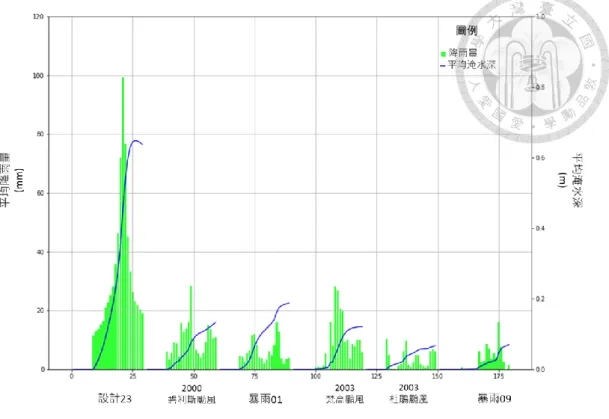
圖 4.2.4 驗證事件平均雨量及平均淹水深歷程圖 ... 64
圖 4.2.5 測試事件平均雨量及平均淹水深歷程圖 ... 64
圖 4.3.1 淹水網格數據 PCA 結果 ... 65
圖 4.3.2 𝑆𝐴𝐸1、𝑆𝐴𝐸2、𝑆𝐴𝐸3及𝑆𝐴𝐸4編碼 PCA 結果 ... 68
圖 4.3.3 𝑆𝐴𝐸5編碼 PCA 結果 ... 69
圖 4.4.1 研究案例區域淹水特徵編碼預測模式架構 ... 71
圖 4.4.2 RNN 預測淹水特徵編碼測式階段結果散佈圖 ... 74
圖 4.4.3 不同延時雨量資訊預測淹水特徵編碼結果比較圖 ... 76
圖 4.5.1 SAE-RNN 模式測試事件預報結果平均淹水深歷程圖... 80
圖 4.5.2 SAE-RNN 模式測式階段區域淹水預測結果 MAE 分布圖 ... 81
圖 4.5.3 SAE-RNN 模式測試階段區域淹水預測結果最大誤差分布圖 82 圖 4.5.4 SAE-RNN 預測結果評估指標綜合比較圖 ... 85
圖 4.5.5 設計 06 事件淹水深統計分布圖 ... 87
圖 4.5.6 SAE-RNN 模式於設計 06 預報結果平均淹水深歷程圖 ... 88
圖 4.5.7 設計 06 事件預測結果 MAE 值分布 ... 89
圖 4.5.8 設計 06 事件預測結果最大誤差分布 ... 90
圖 4.5.9 2002 雷馬遜颱風淹水深統計分布圖 ... 93
圖 4.5.10 SAE-RNN 模式於 2002 雷馬遜颱風預報結果平均淹水深歷程圖 94 圖 4.5.11 2002 雷馬遜颱風預測結果 MAE 值分布 ... 95
圖 4.5.12 2002 雷馬遜颱風預測結果最大誤差值分布 ... 96
圖 4.5.13 設計 06 與 2002 雷馬遜颱風事件降維還原最大誤差分布 .... 98
doi:10.6342/NTU202003855
xi
圖 4.5.14 SAE-RNN 預測不同類型降雨事件之淹水特徵編碼比較 .... 100
圖 4.6.1 2010 梅姬颱風累積雨量分布圖 ... 102
圖 4.6.2 2010 梅姬颱風 SAE-RNN 預報結果之淹水深平均值 ... 102
圖 4.6.3 2010 梅姬颱風 SAE-RNN 預報結果之淹水分布圖 ... 103
圖 4.6.4 2010 梅姬颱風事後調查淹水分布圖 ... 104
圖 4.6.5 2019 米塔颱風累積雨量圖 ... 106
圖 4.6.6 2019 米塔颱風累積雨量圖 ... 106
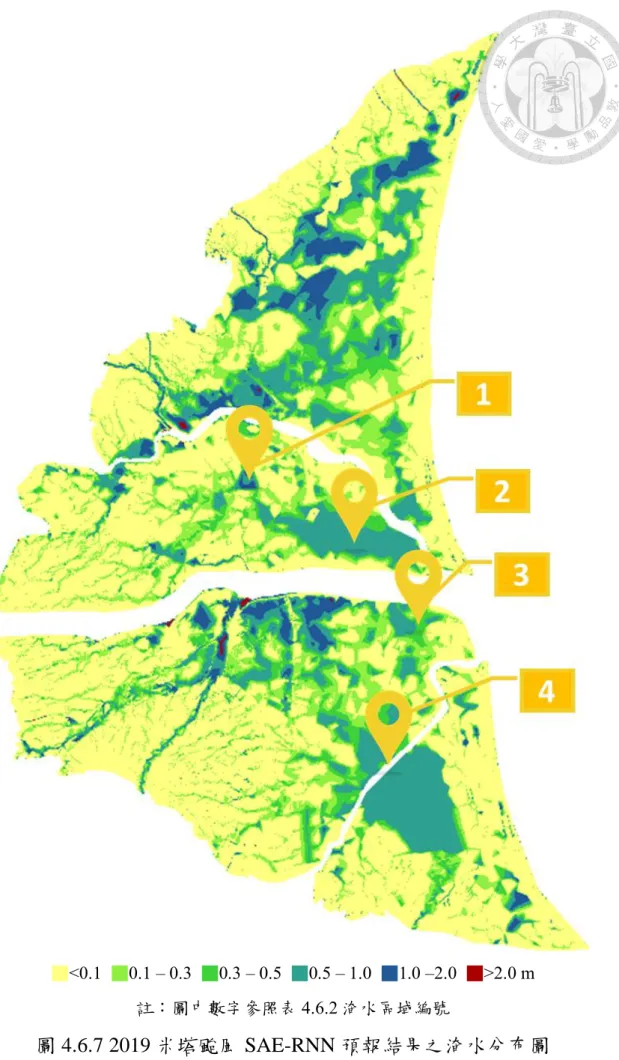
圖 4.6.7 2019 米塔颱風 SAE-RNN 預報結果之淹水分布圖 ... 107
圖 4.7.1 視覺化呈現淹水事件與淹水特徵點之關係 ... 110
附圖 1 SAE-RNN 模式訓練階段區域淹水預測結果 MAE 分布圖 ... 123
附圖 2 SAE-RNN 模式驗證階段區域淹水預測結果 MAE 分布圖 ... 124 附圖 3 SAE-RNN 模式訓練階段區域淹水預測結果最大誤差分布圖 125 附圖 4 SAE-RNN 模式驗證階段區域淹水預測結果最大誤差分布圖 126
doi:10.6342/NTU202003855
xii
表目錄
表 4.2.1 設計洪水事件雨量站 24 小時累計雨量 ... 59
表 4.2.2 雨量站不同重現期之 24 小時累計雨量 ... 60
表 4.2.3 實際降雨事件雨量站 24 小時累積雨量 ... 60
表 4.2.4 模式訓練、驗證與測試事件分組 ... 61
表 4.3.1 原始區域淹水資料 PCA 結果與 SAE 權重值個數數量推估 ... 65
表 4.3.2 SAE 模式於區域淹水資料降維與還原結果 ... 70
表 4.4.1 不同雨量特徵編碼 RNN 模式預測區域淹水特徵編碼結果 .... 73
表 4.4.2 不同延時雨量資訊預測淹水特徵編碼結果表 ... 75
表 4.4.3 RNN 模式預測多時刻區域淹水特徵編碼結果 ... 77
表 4.5.1 RNN 模式預測多時刻區域網格淹水深結果 ... 78
表 4.5.2 SAE、RNN 及 SAE-RNN 模式綜合評估值比較表 ... 84
表 4.5.3 SAE-RNN 模式於設計 06 事件預測結果 ... 87
表 4.5.4 SAE-RNN 模式於 2002 雷馬遜颱風預測結果 ... 93
表 4.5.5 設計 06 與 2002 雷馬遜颱風事件區域淹水資料降維還原結果 ... 97
表 4.6.1 2010 梅姬颱風淹水區域調查結果表 ... 102
表 4.6.2 2019 米塔颱風淹水區域調查結果表 ... 106
doi:10.6342/NTU202003855
xiii
縮寫說明
DL :Deep learning
RFFA :Regional flood frequency analysis RFF :Regional flood forecast
ANN :Artificial neural networks DNN :Deep neural network RNN :Recurrent neural network CNN :Convolutional neural network
AE :Autoencoder
SAE :Stacked autoencoder
PCA :Principle components analysis
R-NARX :Recurrent nonlinear autoregressive with exogenous input RTRL :Real-time recurrent learning
TF :Teacher forcing
FFNN :Feed forward neural network LSTM :Long short-term memory
ReLU :Rectified linear unit FC :Fully connected ED :Encoder-decoder
CP :Cumulative proportion RMSE :Root mean square error
R2 :Coefficient of determination MAE :Mean absolute error
doi:10.6342/NTU202003855
1
第一章 前言
1.1 研究背景
淹水預報是颱風暴雨期間提供防救災人員重要的參考資訊,即時 準確的預報資料有助於淹水發生時分配有限的資源與人力。在城市災 害中,由於其缺乏有效入滲、保水與排水能力之特性,使發生於城市中 的小規模淹水成為全球性普遍的挑戰(Jamali 等 2018)。在亞洲地區,
都市化程度增加和極端降雨事件也使城市淹水問題日趨嚴重,並對基 礎設施與環境帶來破壞(Luo 等,2018)。目前推估淹水方法可分為物理 驅動與資料驅動兩類,前者使用水力學平衡方程式進行演算,減少物理 平衡誤差為目標不斷的疊代更新網格點中各項流況參數,完成所有地 點之淹水深推估;後者使用淹水深數據及降雨量等影響淹水之水文數 據建立降雨-逕流模式,透過如類神經網路(artificial neural networks, ANN)等非線性轉換之複雜結構取代物理過程,以大量訓練資料及合適 的參數調整策略減少模式輸值出與目標輸出值間的誤差,完成淹水推 估。
在台灣地區,使用物理驅動模式製作以不同重現期距降雨量推估 之淹水潛勢圖是目前評估淹水發生地點的主要方法,然而費時的物理 模擬演算仍無法完全滿足分秒必爭的防災工作。為了解決此問題,使用 資料驅動模型建立精度略低,但演算時間短且符合防災需求的淹水模 式開始受到重視。近幾年由於圖形處理器通用運算 (general-purpose computing on graphics processing units, GPGPU)技術進步,縮短了複雜 與高層數的 ANN 演算時間,使資料驅動模式開始能挑戰一些難以快速 處理的問題,例如 Silver 等人(2016)應用 13 層深度神經網路(deep neural network, DNN)於圍棋遊戲,達到了電腦超越人腦的成就。雖然 ANN 具 備強大的歸納與推演能力,但在訓練具有高維度輸出值的網路模式時,
doi:10.6342/NTU202003855
2
常會遇到過多的連結權重參數以隨機亂數法初始化時不容易收斂的問 題,該情況形亦於類神經網路預測具有高維度之區域淹水網格數值時 發生。為了降低輸出值維度,利用聚類及降維方法簡化模式複雜度是一 種有效的應對手段,如 Chang 等人(2010)利用 k-means 將淹水資料先分 群簡化複雜度,再加入地文因子輸入項使單輸出模式具備預測不同網 格數值能力;沈(2013)、Chang 等人(2014)利用自組特徵映射網路(self- organization map, SOM)及總淹水體積做為不同類別之淹水特徵值,將 高維淹水網格數值轉為二維淹水拓樸圖之聚類關係後,透過預測未來 總淹水體積,並將其結果與淹水拓樸圖以線性內插方法結合,輸出區域 淹水深預測值。這些研究在輸入因子篩選與網路結構選擇以提升區域 淹水預報效果上有諸多討論,並嘗試將影響淹水之影響因子與模式結 合使其結果更趨於準確,但對於聚類分割模式預測區域後的結果整合 及淹水特徵點代表性是否足夠等問題仍有待後續研究探討。
1.2 研究動機與目的
考量以聚類結果分割區域淹水網格以建立多個區域淹水預測模式 時,不同類別邊界兩側各屬相異之模式輸出會產生數值不連續的問題,
若不分割區域淹水模式進行簡化,則難以用有物理意義之指標(例如單 一區域總淹水體積數值)代表整個區域之淹水特徵。因此,本研究提出 一種完全基於資料驅動模型概念之 ANN 區域淹水預測模式,嘗試以降 低淹水資料維度減少複雜度,並以降維後的低維數值為抽象之淹水特 徵編碼,結合具備降維及還原資料之 ANN 模式及預測未來淹水特徵點 之回饋式類神經網路(recurrent neural network, RNN)模式,成為能在不 事先分割區域淹水模式的條件下,輸出整個區域網格點淹水深的預測 模式,供未來防災應用參考。
doi:10.6342/NTU202003855
3
本研究主要目的如下:
一、 建立以統計分析為基礎之區域淹水資料降維及還原模式,使高維 區域淹水資料能降維成低維淹水特徵編碼,且該特徵編碼能夠還 原成原始資料維度,同時評估此過程造成的還原損失。
二、 建立區域淹水特徵編碼預測模式,結合前項降維還原模式完成原 始維度之區域網格淹水深預測模式。
三、 應用資料降維還原技術提出視覺化區域淹水特徵之方法,使未來 防災人員能快速了解淹水歷程中不同地區淹水深隨時間變化情 況。
1.3 研究方法
本研究以宜蘭地區蒐集之二維淹水物理模擬資料為案例,完成區 域淹水資料降維還原模式及區域淹水預測模式。使用之區域淹水資料 降維還原模式是以堆疊式自編碼器(stacked autoencoder, SAE)為基礎的 前饋式 類神 經網 路模式 ,屬 於一 種採 用堆疊 過程 建立 的自編 碼器 (autoencoder, AE)架構。AE 以隱藏層維度低於輸入及輸出層維度為主,
透過輸入與輸出具有相同維度的特性,以減少網路輸入與輸出項之間 的誤差進行監督式學習,並達到類似非監督式學習的成果。由於區域淹 水資料維度值高達 169,797,需透過多層網路逐步降維,同時整個神經 網路將有超過百萬個權重值需要調整,故以分段堆疊方式訓練網路,每 次堆疊進行訓練時以主成分分析(principle components analysis, PCA)評 估適當的降維後淹水特徵編碼之維度,並以 PCA 特徵向量作為初使神 經元權重,以避免隨機初始化對模式帶來的巨大不確定性。
完成以 SAE 為主的區域淹水資料降維還原模式後,進一步以回饋 式類神經網路(recurrent neural network, RNN)建立降維後淹水特徵編碼 預測模式。該模式為編碼器-解碼器(encoder-decoder, ED) 架構,以過去
doi:10.6342/NTU202003855
4
數小時雨量為輸入序列,輸出未來多時刻之淹水特徵編碼,最後結合前 段提及由 SAE 建立之還原模式將淹水特徵編碼還原成原始維度區域淹 水分布資訊,完成區域網格淹水預報模式。
最後本研究針對不同維度特徵編碼進行探討,說明用於降為的 SAE 模式與用於預測的 RNN 模式對整個區域淹水預報模式之影響,並 針對不同降雨類型所模擬的二維淹水網格數據以降維模式進行視覺化 呈現,分析不同雨型在區域淹水模擬結果之特徵。整個研究流程如圖 1.1 所示。
圖 1.1 研究流程圖
doi:10.6342/NTU202003855
5
1.4 論文章節架構
本文共分為五個章節:第一章為前言,包含研究動機與目的之說明 以及研究架構概述;第二章為文獻回顧,探討區域淹水預測方法及 RNN 與 ED 模式相關應用研究文獻;第三章為理論概述,簡介類神經網路及 本研究建構之 SAE-RNN 模式理論;第四章介紹研究案例與數據資料,
說明及討論區域淹水預測模式建置與數據分析結果;第五章為結論與 建議,總結模式建立過程中的重點並提出未來研究改進方向建議。
doi:10.6342/NTU202003855
6 doi:10.6342/NTU202003855
7
第二章 文獻回顧
洪水引發的災害在今日更加頻繁與嚴重,影響著許多人的生活並 造成損失。進行洪水預報以提供管理人員可靠的數據於警戒是應對將 發生洪水的預防措施之一(Puttinaovarat 等,2020)。在城市災害中,由 於城市缺有效入滲、保水與排水的能力,使城市中小規模淹水成為全球 性普遍的挑戰(Jamali 等 2018)。在亞洲地區,由於都市化程度增加和 極端降雨事件讓城市淹水日趨嚴重,並對基礎設施與環境帶來破壞 (Luo 等,2018)。由於全面性的都市淹水觀測設施尚不普及,歷史事件 的淹水歷程主要依靠數值模式進行模擬推估,並以少數觀測紀錄進行 校正。這些以水力學為理論基礎的淹水推估過程需要大量演算時間,無 法滿足即時淹水預測需求(沈,2013)。近年資料科學領域發展迅速,以 統計與資料驅動模型概念為主的 ANN 技術成為推估區域淹水的新模 式,其不用針對問題定義複雜數學模式與固定參數後演算速度快的優 勢使其廣泛應用於水文領域中,亦累積了相當豐富的研究文獻。
2.1 類神經網路於水文應用
類神經網路(Artificial neural networks, ANN) 可以充分模擬高度非 線性的複雜系統,其透過學習輸入與輸出資訊間的關聯性,可省略中間 物理過程中參數設定的優勢,使其非常適合應用於地表資料蒐集不易 或系統複雜的水文模式建置工作,Nourani 等人(2014)及 Chandwani 等 人(2015)對過去應用類神經網路於水文及降雨-逕流的研究有綜合性的 討論。在地下水分析中 Chang 等人(2017)使用 PCA 及 SOM 評估台灣 南部地區地下水變化趨勢特徵;在降水預報中,集水區雨量受地形、季 節、氣候等影響而在時空上具有較高不確定性,利用 ANN 具備容錯與 適合處理非線性問題之優勢,建立衛星雲圖或雷達回波等遙測資料與
doi:10.6342/NTU202003855
8
地面觀測站降雨量之間的推估或預測模式成為近年熱門的研究主題,
例如 Chang 等人,2014;Shafaei 等人,2016; Shenify 等人,2016;
Valipour 等人,2016; Nourani 等人,2017;Nanda 等人,2019。在洪 水預報與降雨-逕流模擬預測方面,由於都市洪災通常具有較短的延時,
同時降水預報不確定性較高,使用基於物理的數值模型在即時預報系 統中通常反應太慢,因此數據驅動模型變成為克服此問題的解決方法 (Berkhahn 等人,2019;Nguyen 與 Bae,2020),透過 ANN 學習降雨及 洪水資料間關聯性可避免傳統物理模式中因地文資料空間精確度不佳 帶來的尺度差異問題,同時 ANN 快速的演算時間更適合用於分秒必爭 的防救災工作,相關研究例如 Chang 等人,2014 年;Badrzadeh 等人,
2015;Chang 與 Tsai,2016 年;Nourani,2017;Chang 等人,2018;
Shoaib 等人,2018;Chang 等人,2019;Yang 等人,2019;Wang 等 人,2019;Xie 等人,2019;Chang 等人,2020;Puttinaovarat 等人,
2020;Zhou 等人,2020 C。
2.2 回饋式類神經網路與編碼器-解碼器模型應用
在對複雜系統進行模擬時,不同類型的類神經網路有各自的優缺 點,例如前饋式神經網路(feed forward neural network, FFNN)無法適當 地模擬時間序列數據,因為其輸入項均視為獨立應變數而無先後次序 的關聯性,使時間次序特性難以被模式學習,亦無法掌握輸入與輸出的 長期依賴關係。回饋式神經網路(recurrent neural network, RNN)將特定 的狀態值留到下一時刻使用,這些狀態值可能是網路隱藏層神經元輸 出值或模式輸出值,使其能掌握時間序列特徵。如果整個模式的輸出值 會回饋到輸入項中,則這類模式可被稱為回饋式含外變數的非線性自 迴歸(recurrent nonlinear autoregressive with exogenous input, R-NARX)模
doi:10.6342/NTU202003855
9
式。
近 5 年來,深度學習(deep learning, DL)技術及 DNN 逐漸受到關 注,其最大的特色就是能在困難的任務上取得不錯的效果,例如 Liu 等 人(2017)探 討了 AE、捲積類神經網 路(convolutional neural network, CNN)、深度信念網路(deep belief network, DBN)及受限玻爾茲曼機 (restricted Boltzmann machine, RBM)在語音辨識、圖項識別與電腦視覺 等應用上的實例與效果,認為 AE 可以提升學習過程的效率;Liu 等人 (2018)透過以 SAE 直接從信號中提取特徵取代人工以窮舉法選取,並 使用 ReLU 活化函數避免過擬合問題及提高小訓練集之特性,完成優 於傳統方法的變速箱故障診斷模式;Zhou 等人(2019 A)應用長短期記 憶體(long short-term memory, LSTM)預測未來 4 小時區域空氣品質。最 近 DL 技術於水文上的應用也逐漸增加,例如 Sezen 等人(2019)使用 DNN 模式建立降雨-逕流模型,使洪水退水段模擬獲得更好成效。
Kao(2020)以編碼器-解碼器(encoder-decoder, ED)模型框架及 FFNN 與 LSTM 建構以集水區雨量預測台灣石門水庫未來 6 小時入流量。
在這些 DNN 應用中最常被使用的是 ED 模型框架,該框架是序列 至序列(sequence-to-sequence, Seq2Seq)學習問題的一種解決方案,主要 特色為將模式拆解成輸入序列編碼器(encoder),中繼編碼(code)及輸出 序 列 解 碼 器 (decoder) 三 個 部 分 。 ED 模 型 將 輸 入 資 訊 透 過 編 碼 器 (encoder)轉換成具有代表性的編碼,再透過解碼器將該編碼轉換成特定 格式的輸出資訊,完成 輸入序列 (input sequence)至輸出序列(output sequence)的映射關係。只要針對不同問題之輸入輸出序列選擇適合的 神經網路結構,即可快速開發相關應用之類神經網路模式。面對時間序 列問題,最常被使用編碼器與解碼器是 RNN,其中又以 LSTM 及其衍 生的門控回饋單元(gated recurrent units, GRU)最常出現於 DL 應用文獻
doi:10.6342/NTU202003855
10
中,例如影像辨識(Fengming 等人,2017;Zhu 等人,2018)、機器翻譯 (Audhkhasi 等人,2017;Malinowski 等人,2017),空氣汙染預測(Freeman 等人,2018;Zhou 等人,2019 A;Chang 等人,2020;Zhou 等人,2020 A;Zhou 等人,2020 B)。
水文領域中亦有許多物理傳輸過程可歸納為序列至序列問題。例 如降雨-逕流過程可以看作是降雨序列到流域排水序列的轉換,使用 LSTM 這類 RNN 模型亦能提升長時距洪水預報的準確性與可靠度。例 如 Le 等人(2019)應用於越南地區河流日常流量 1 至 3 日預測,Nash 效 率係數(Nash–Sutcliffe efficiency, NSE)值可達到 0.87 以上;Kratzert 等 人(2018)應用於流域內雪造成的儲蓄效應推估,LSTM 發揮了學習資料 長期依賴的優勢;Zhang 等人(2018)以蒸發、降水、溫度與時間為輸入 項建置基於 LSTM 之時間序列模型預測中國西北河套平原乾旱區之地 下水位,與 FFNN 相比獲得更好的準確度;Jeong 與 Park(2019)應用於 朝鮮半島地下水水位預測,使用 LSTM 建置的模型在準確度上具有優 勢;Zhou 等人(2019 B)以調適性網路模糊推論系統(Adaptive Neuro- Fuzzy Inference System, ANFIS)分別建立靜態及動態類神經網路模式預 報中國三峽水庫入流量,並以遺傳演算法(genetic algorithm, GA)及最小 平方估計器(least square estimator)對該模式參數進行優化,結果顯示動 態 ANFIS 模式可以緩解時間積延問題,並獲得準確性更高的結果。
Kao 等人(2020)提出 LSTM-ED 降雨-逕流模式以建立石門水庫預 測未來六小時入流量,此研究蒐集 2007 至 2016 年颱風期間 23 場石門 水庫入流量與集水區 10 個雨量站降雨之洪水紀錄,經補遺缺失與調整 不合理資料後整理成序列至序列模型格式,每筆學習資料均包含過去 降雨序列及未來水庫入流量序列。建立之編碼器-解碼器模式架構如圖 2.2.1 所示,5 層結構分別為輸入序列(input sequence)、編碼器(encoder)、
doi:10.6342/NTU202003855
11
編碼向量(encoded vector)、解碼器(decoder)、輸出序列(output sequence);
FFNN-ED 為編碼器與解碼器使用 FFNN 之 ED 模式,其處理輸入及輸 出序列時並不考慮其時間先後關聯性,較難以掌握資料的時間特性;
LSTM-ED 為編碼器與解碼器使用 LSTM 之 ED 模式,其具有回饋機制 的網路層結構,對處理輸入資訊而言將能透過依序讀取累積的方式使 模式更容易學習到先後次序關聯性;對生成資料的 RNN 輸出序列而 言,每次模式輸出之數值能回饋至解碼器中的架構使輸出序列中每個 值更具時間關聯性,這種處理輸入輸出序列的機制與降雨-逕流過程極 為相似,編碼器與解碼器中將 FFNN 換成 LSTM 架構後,測試資料的 預測 R2從 0.88 上升至 0.94。該研究進一步測試 FFNN-ED 與 LSTM- ED 模式於減少輸入序列時間長度時會產生的影響,結果顯示 LSTM- ED 模式不會過度依賴每一個時間步長的輸入資訊,同時可以學習到的 時間序列變化特徵,模式測試階段之結果顯示使用 LSTM 的模式在輸 入序列長度稍微減少時能取得一樣的降雨 -逕流預測性能,較使用 FFNN 的模式在多步長預測上有著更好的可靠度。
(a)FFNN-ED 模式 (b)LSTM-ED 模式
(Kao 等人,2020) 圖 2.2.1 以不同 ANN 建置之編碼器-解碼器模型
doi:10.6342/NTU202003855
12
2.3 以類神經網路進行區域淹水預報
目前以類神經網路進行區域淹水的研究大致可分為兩種類型:區 域淹水頻率分析(regional flood frequency analysis, RFFA)與區域淹水預 報(regional flood forecast, RFF)。RFFA 是一種應用統計方法從有限的數 據中估算流域內其他地點的統計分位數(quantiles),以評估區域內不同 地點的洪水發生風險(Gizaw 與 Gan 2016)。這類的研究重點在於如何將 地文因子與歷史事件淹水統計結果結合,使其可以對未有歷史洪水資 料的地區進行淹水敏感度分析與評估風險。相關研究例如 Sharifi 等人 (2018)利用氣候與土質等因子預測不同回歸周期的洪峰量;Li 等人 (2019)對 13 個包含地表物理特性與土地利用等因子結合,評估全球淹 水敏感度。
RFF 是一種以降雨量等造成洪水的因子為主,模擬或預測區域淹 水情況。藉由類神經網路學習大量觀測或數值模式模擬資料,快速建立 雨量與淹水深之間的關聯性,例如 Chang 等人(2010)開發以聚類分析為 基礎之複合型淹水模式建置區域淹水預測模式(clustering-based hybrid inundation model,CHIM),該模式使用 k-means 對網格點之淹水特性與 地文特性進行聚類,將網格點聚類成數個群集,在由群內選出一個能代 表整個群集的控制點,建立該控制點之單點淹水預測模式。為了進一步 減少同時訓練的網格點數,再從同一個群集內的其餘網格點中選取多 個地文因子具有能代表鄰近網格特性的代表點,作為該群集單點淹水 預測模式調整神經元權重的訓練樣本,之後再以雨量、控制點預測模式 結果與地文因子為輸入項,建立該群集所有網格點共用的單點預測模 式,最後整合所有群集的預測模式即完成全區之區域淹水預測模式。
CHIM 模式充分利用 ANN 在單點預測模式易於訓練的特性,將能代表 不同網格點差異的因子當作模式輸入項,並以聚類方式盡可能將相似
doi:10.6342/NTU202003855
13
的網格點以同一個 ANN 模式進行預測,解決了難以同時建立輸出多個 網格點預測模式之難題。
另一篇具有特色的文獻是 Chang 等人(2014)以 SOM 結合 R-NARX 之複合模式 SOM-R-NARX 建立區域淹水預測模式。該模式先以子集水 區或行政區進行網格分割,降低單一子區域網格的空間距離差異,再使 用 SOM 將每一小時的淹水歷程進行聚類並轉換成二維座標拓樸圖,每 個拓樸圖座標(神經元)中代表某一種淹水分布狀態,包含該子區所有網 格點於該狀態之淹水深。該模式以總淹水體積作為代表某一種淹水拓 樸圖中淹水深分布狀態之特徵值,並以 R-NARX 模式建立降雨量與該 特徵值之預測子模式。最後比較 R-NARX 預測之特徵編碼與 SOM 每 個神經元的淹水分布特徵編碼(總淹水體積),選取兩個最相似的神經 元,依特徵編碼相似度對其內涵的淹水深分布值(神經元權重)進行內插 計算,獲得該子區域之區域淹水預測結果。SOM-R-NARX 模式將區域 淹水分布轉換為具代表性之淹水拓樸圖及以總淹水體積做為淹水特徵 值,大幅度減小區域淹水資料的維度並保有物理特性,使 ANN 預測模 式只需輸出單維淹水特徵值便能由其它模式完成區域淹水預測,充分 發揮 ANN 在單點預測模式準確度高的特性。根據沈(2013)的統計資料,
SOM-R-NARX 模式與 CHIM 相比,RMSE 減少了至少 57%以上;R2提 升至少 43%以上,由此可見透過聚類等統計方法歸納統整區域淹水特 性對 ANN 學習降雨至淹水之映射關係或建置區域淹水預報模式而言 有非常大的助益。
比較這兩篇文獻與沈(2013)的比較結果,可發現 CHIM 使用了許多 水文學上影響淹水的相關因子輸入模式,在挑選因子的過程雖然能看 到不同組合對模式誤差之影響,但預報結果卻不如以 SOM 直接對區域 淹水分布情形聚類以及採用總淹水體積為特徵值的 SOM-R-NARX 模
doi:10.6342/NTU202003855
14
式佳。此一結果說明由物理為基礎推論而得的參數能有好的參考,但以 統計模式歸納及萃取之特徵更能掌握複雜的淹水分布特性。然而,
SOM-R-NARX 模式透過 SOM 將不同型態之淹水分布特性分類後,其 以總淹水體積做為特徵值需要依賴小區域內淹水深分布與總淹水體積 變化為線性關係之假設,否則將可能出現相同總淹水體積不同淹水分 布之情形。若要解除此假設條件以便預測更大範圍之區域淹水,則需要 使用二維以上之淹水特徵編碼以建立非線性之區域淹水分布與特徵編 碼間的映射關係。因此,若能以統計模式萃取更多維度代表淹水分布的 抽象特徵編碼,取代具物理意義但需要較多假設條件之特徵值,應有助 於提升神經網路學習或區域淹水預報模式。因此,本研究將以降維模式 對區域淹水資料進行特徵編碼萃取,以 ED 模型框架預測該特徵編碼 為輔,提出完全以資料驅動模型概念為主之區域淹水深預測方法。
doi:10.6342/NTU202003855
15
第三章 理論概述
本研究使用 ANN 建置區域淹水預測模式,可分為區域淹水資料降 維成淹水特徵編碼及預測特徵編碼及還原成區域淹水分布兩部分。淹 水資料降維與還原使用 ANN 基礎之 SAE 進行降維度,並以 PCA 分析 SAE 最佳隱藏層神經元個數並協助 SAE 神經元權重初始化,使其架構 精簡且更容易於訓練階段收斂。淹水預測使用 RNN 基礎之 LSTM 及 ED 框架建構多時刻淹水特徵編碼預測模式,再與前述之 SAE 結合成 SAE-RNN 預測模式。SAE-RNN 整體架構如圖 3.1 所示,包含萃取區 域淹水特徵的降維及還原模式 SAE,以及預測淹水特徵編碼之 RNN 並 還原成原始區域淹水資料維度之 SAE-RNN 預報模式兩部分。其中 SAE 以區域網格淹水深進行訓練,降維後的淹水特徵編碼由輸入雨量資訊 之 RNN 模式進行 t+n 時刻預測。最後結合兩者輸出未來 t+n 時刻區域 網格淹水深預報結果。
圖 3.1 SAE-RNN 區域淹水預報模式架構圖
doi:10.6342/NTU202003855
16
3.1 序列至序列學習問題
在資料科學研究中,序列(sequences)泛指長度不固定的資料,而序 列至序列學習問題(sequence-to-sequence learning problem)即是如何將 輸入序列(input sequence)映射到輸出序列(output sequence)之問題。以水 文降雨-逕流過程為例,每一場降雨延時不一致的事件紀錄是輸入序列;
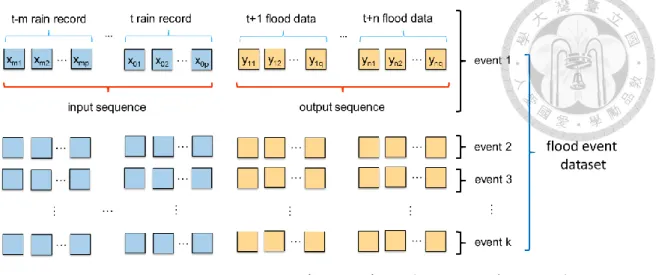
每場流量歷程長度不同的洪水事件紀錄是輸出序列,讓模式學習由降 雨轉換為逕流量的問題即為序列至序列學習問題。依此類推,降雨推 估、洪水預報、地下水變化趨勢分析等應用亦屬於序列至序列學習問 題。一個序列至序列學習問題的資料集(dataset)由多個樣本(sample)所 組成,每個樣本包含一個輸入序列 X 與一個輸出序列 Y,每個序列由 多個 d 維度的向量組成,如 3-1 及 3-2 式所示:
𝑋 = (𝑥1, 𝑥2, . . . , 𝑥𝑇) (3-1) 𝑌 = (𝑦1, 𝑦2, . . . , 𝑦𝐿) (3-2)
𝑇, 𝐿 ∈ 𝑁 𝑥𝑇 ∈ 𝑅𝑑𝑖, 𝑦𝐿 ∈ 𝑅𝑑𝑜
式中𝑥為輸入序列 X 中𝑑𝑖維度向量;𝑦是輸出序列 Y 中𝑑𝑜維度向量。以 多個雨量站紀錄推估區域網格淹水深為例,不同事件有不同的降雨延 時與淹水時長,但有固定數目之雨量站與淹水點。例如輸入序列為降雨 延時 m 小時,p 個測站的暴雨事件紀錄;輸出序列可為淹水時長 n 小 時,q 個淹水點的洪水事件紀錄,其數據結構如圖 3.1.1 所示。
doi:10.6342/NTU202003855
17
圖 3.1.1 以降雨造成淹水之序列至序列學習問題資料結構
傳統的 ANN 模式要求須有固定個數的輸入與輸出項目個數,才能 建立輸入值映射到輸出值間的映射關係,因此第一步即是先將輸入序 列或輸出序列轉換成模式可以接受的格式。這個轉換過程過去通常是 由人進行資料抽取,例如由試誤法(try and error method)及 gamma test (Jones,2002;Chang 等,2014)從輸入序列中尋找適合模式學習的輸入 時間長度及輸出範本格式,對模式是否可成功學習是非常關鍵的一步。
在深度學習技術逐漸成熟與電腦硬體增加演算速度後,透過機器學習 技術協助處理人為抽取資料特徵的做法漸漸成為主流。有些序列至序 列學習問題具有相同或類似的輸入序列,例如預報流量與淹水深均需 要雨量資訊;有些問題具有相同的輸出序列,例如推估降雨機率或淹水 機率均是輸出 0 至 1 的數值,因此序列至序列學習模型可以被歸納為 一種編碼器-解碼器(encoder-decoder, ED)框架,透過選擇或抽換適合處 理特定序列的編碼器或解碼器之 ANN 結構,使複雜的模型可以透過轉 移學習(transform learning)技巧快速有效的完成開發。
3.1.1 編碼器-解碼器框架
ED 框架是近年來許多研究人員用來解決複雜任務的方法(Asadi 與
doi:10.6342/NTU202003855
18
Safabakhsh,2020)。其主要概念為利用編碼器(encoder)將輸入序列轉換 成該序列之抽象特徵,適合解碼器(decoder)映射到輸出序列之編碼向量 (code vector),再透過解碼器將抽象特徵之編碼向量轉換成符合需求格 式之輸出序列。整體過程如圖 3.1.2 所示。
圖 3.1.2 編碼器-解碼器框架
在機器學習研究與應用中,編碼器與解碼器常以 ANN 模式為主 體,根據不同的資料序列型態選用不同類型的 ANN。例如時間序列常 以 RNN 或一維 CNN 萃取時間連續性特徵;圖像或照片常以二維 CNN 萃取平面空間特徵;沒有明顯關聯性的多維資料常以 FFNN 作為編碼 器或解碼器。為了加速複雜模式開發過程,使用已訓練的編碼器或解碼 器是一種常見的轉移學習技巧。以區域淹水特性分析模式透過轉移學 習方法轉換為淹水預報模式為例(圖 3.1.3),區域淹水分析模式中解碼 器 1 的作用是將淹水特徵還原為淹水資料格式,與淹水預報模式輸出 的淹水數據格式相符,如果淹水預報模式直接使用淹水分析模式的解 碼器 1,並建置預測淹水特徵之編碼器 2,即可大幅減少開發時間。
圖 3.1.3 應用轉移學習將分析模式改為預報模式
doi:10.6342/NTU202003855
19
3.2 類神經網路
類神經網路(artificial neural network , ANN)屬人工智慧(artificial intelligence, AI)領域中,一種模仿人類腦細胞神經網路的演算技術。例 如複雜且含有雜訊的辨識及分類問題,對傳統電腦資訊理論是一件非 常複雜且困難的問題,但對生物來說,通常都能容易地解決,因此許多 學者嘗試使用模仿生物的神經系統模型—ANN,來解決過去不易處理 的問題(張與張,2015)。ANN 由多個非線性的運算單元(或稱神經元, neuron)與運算單元間的眾多連結(links)所組成,並以電腦的軟硬體來模 擬生物神經網路的資訊系統,具有可從人類專家解決問題的實例中之 學習能力,ANN 之應用並不需前提假設,只要有充足的歷史資料作為 學習範本,即可利用其非線性函數的轉換,有效地對大量資料進行分 析。ANN 有許多與人類大腦功能相似的特性,其中最重要的三項有:
1. 學習(learning)
ANN 的學習過程可藉由建立神經元間的連結模式、修正神經元 間的權重、調整神經元活化函數中的門檻值等方式達成。另外學習形 式可分成即時線上學習(on-line learning)與離線學習(off-line learning) 兩種。前者依據新增或即時的資訊,不斷地調整網路連結權重值,使 其適應即時環境變化;後者先將一整批的訓練資料(training data)用 於修正網路連結權重後,才開始線上使用。
2. 回想(recall)
當 ANN 接受到一個輸入刺激,進而依據網路架構產生一個輸出 值,此過程稱為回想過程。影響 ANN 的效能與強健度的關鍵,就在 於回想過程是否快速有效。
3. 歸納推演(generalization)
歸納推演是從一個系統中局部觀察描述出其整體特性的過程,例
doi:10.6342/NTU202003855
20
如從特殊例子推演到整體的事件,或是從範例的認知去定義出物件的 種類等。ANN 對於輸入資料,具有萃取其特徵的能力,即是說它可 對於從未出現在訓練範例中的輸入做出正確的回應。
3.2.1 前饋式神經網路
前饋式神經網路(feed forward neural network, FFNN)為眾多類神經 網路模式之一,以監督式學習方式將運算後輸出的結果與目標輸出值 間的誤差反向傳遞,藉由調整網路連結權重,使得輸出與輸入之間的誤 差達到最小,來處理輸入資料與輸出資料之間映射的非線性問題。一般 常用的 FFNN 架構如圖 3.2.1 所示之三層結構的神經網路,包含輸入 層、隱藏層及輸出層。FFNN 輸入層僅做為模式輸入介面,只將輸入資 訊往後傳遞,不對輸入資訊做特別處理。隱藏層及輸出層常使用全連結 (fully connected, FC)層,即每個神經元與前一層所有神經元均有連結。
界於輸入層與輸出層間的隱藏層主要用途為對輸入資訊進行非線性轉 換,其層數依需求或問題複雜度可為零層(即沒有隱藏層)到數層,每一 層神經元個數亦可有不同設定。輸出層為 FFNN 的輸出介面,主要用 途為將隱藏層中的訊息轉換為模式輸出格式,例如在分類問題上是 0 至 1 的類別隸屬度;在回歸問題上可能是任何有理數(rational number)。此 外,若 FFNN 僅有一層輸出層,則 可稱為單層感知器(single layer perceptron),該概念於 1958 年由 Rosenblatt 提出,屬於形式最簡單之 FFNN。
doi:10.6342/NTU202003855
21
圖 3.2.1 前饋式神經網路基本結構
神經元(neural)為 ANN 基本運算單元,常見的運算方式為對每一筆 輸入資訊乘上一調整權重值(weight)後累加,再加一個偏權值(bias)後輸 出到下一層,其運算過程與一次多項式類似,如 3-3 式所示。
𝑦𝑗𝑛 = 𝑓 (∑ 𝑤𝑖𝑗𝑦𝑖𝑛−1 + 𝑏𝑗𝑛
𝑖
) (3-3)
式中𝑦𝑗𝑛為第 n 層第 j 個神經元輸出值, f 為活化函數(activation function),
𝑦𝑖𝑛−1為 n-1 層第 i 個神經元輸出值,𝑤𝑖𝑗第 n 層第 j 個神經元與第 n-1 層 第 i 個神經元間的連結權重,𝑏𝑗𝑛第 n 層第 j 個神經元的偏權值(bias)。
3.2.2 活化函數
活化函數是類神經網路具有模擬複雜問題的關鍵,原本經由神經 元線性疊加計算的數值經由非線性活化函數轉換後可讓整個網路具有
doi:10.6342/NTU202003855
22
非線性轉換能力,一般而言會依神經元輸出值需求或其在網路中的位 置決定使用何種活化函數。本研究使用的活化函數有以下幾種:
1. 雙曲線正切函數(tanh)
雙曲線正切函數輸出值範圍界於-1 至 1 間,中心對稱於 0 原 點,同時曲線在輸入值-1 至 1 間距有較大變化使非線性擬合 (fitting)能力佳,輸入值超過-3 至 3 以外的區間輸出值趨近於 1 使 神經元輸出更為穩定,是非常適合於 ANN 中使用的活化函數。
主要缺點為計算量較大,以及微分值小於 0 會有訓練時於倒傳遞 誤差梯度過程發生梯度消失問題(vanishing gradient problem),較 不適合在多層網路中大量使用。此函數圖形如圖 3.2.2 所示,計 算如 3-4 式:
𝑓(𝑥) =𝑒𝑥 − 𝑒−𝑥
𝑒𝑥+ 𝑒−𝑥 (3-4)
(a)一般形式 (b)微分形式 圖 3.2.2 雙曲線正切函數
2. S 函數(sigmoid)
S 函數輸出值範圍界於-1 至 1 間,中心對稱於(0, 0.5),與雙 曲線正切函數主要差異在於計算較少,輸入值與輸出值變化特性 與雙曲線正切函數相似,常用於早期 FFNN 中取代雙曲線正切函
doi:10.6342/NTU202003855
23
數。其缺點為輸出值大於 0 的特性使使倒傳遞誤差梯度時非正即 負而產生震盪,可配合批次(batch)訓練累積多次修正再取其平均 值調整權重以避免數值震盪過大問題;函數微分小於 1 使其與雙 曲線正切函數一樣有梯度消失問題,較不適合在多層網路中大量 使用。此函數圖形如圖 3.2.3 所示,計算如 3-5 式:
𝑓(𝑥) = 𝑒𝑥
𝑒𝑥+ 1 (3-5)
(a)一般形式 (b)微分形式 圖 3.2.3 S 函數
3. 嚴格 S 函數(hard sigmoid)
嚴格 S 函數是 S 函數的計算簡化版本,輸出值範圍界於-1 至 1 間,中心對稱於(0, 0.5),除了輸入值與輸出值變化特性在輸入 值接近 0 時的斜率為定值外,其餘特性與 S 函數相似,適合用在 訓練樣本非常多或神經元數量非常大的案例中。此函數圖形如圖 3.2.4 所示,計算如 3-6 式:
𝑓(𝑥) = max[0, min(1, 0.2𝑥 + 0.5)] (3-6)
doi:10.6342/NTU202003855
24
(a)一般形式 (b)微分形式 圖 3.2.4 嚴格 S 函數
4. 整流線性單位函數
整流線性單位函數(rectified linear unit, ReLU)輸入值小於 0 時輸出值為 0,其餘情況輸出值等於輸入值。雖然函數在原點 0 不可微分,但連續的特性不影響其於電腦程式中計算的方便性。
輸入值為負數時輸出 0 是其唯一的非線性特徵,雖然變化單調但 透過多層網路神經元串聯依然能模擬複雜數學函數。ReLU 微分 為 1 使其沒有梯度消失問題,常應用於具有多層結構之 DNN 模 式中。此函數圖形如圖 3.2.5 所示,計算如 3-7 式:
𝑓(𝑥) = max(0, 𝑥) (3-7)
(a)一般形式 (b)微分形式 圖 3.2.5 整流線性單位函數
5. 線性輸出(linear)
doi:10.6342/NTU202003855
25
若神經元不使用任何活化函數即為線性輸出,一般用於模擬 回歸問題的 ANN 模式輸出層神經元中。如果一個 FFNN 模式無 任何活化函數,所有神經元均為線性輸出,則此 FFNN 模式可歸 納統整為多變量線性回歸(multiple regression)模式。
3.2.3 類神經網路優化
ANN 模式需要藉由範本(sample)調整網路神經元參數(parameters),
才能使模式輸出值與目標輸出值一致,此過程稱為優化(optimize)。在 優化開始前會先將可使用的資料如圖 3.2.6(a)分為訓練資料與測試資料 兩組,前者用於 ANN 神經元參數優化,後者用於測試完成優化之 ANN 模式性能。此外,在訓練資料中又會分為訓練範本與驗證範本,分別用 於優化器(optimizer)調整神經元參數與驗證每次調整後的 ANN 模式性 能,以決定是否繼續優化。若可用於優化的資料不足使模式無法有效收 斂,則會採用交叉驗證(cross-validation)的方式進行模式驗證,方法為將 訓練資料分為 k 個資料集,每個資料集輪流做為驗證資料,其餘則用 於模式訓練,共建立 k 個獨立模式,最後以所有模式測試資料評估指 標的平均值來評價整體模式架構之優劣。圖 3.2.6(b)為建立 4 個獨立模 式的交叉驗證範例,該範例中資料集 1 至 4 輪流做為訓練及驗證範本,
資料集 5 固定做為測試範本。
(a)正常分組 (b)交叉驗證分組 圖 3.2.6 類神經網路模式優化資料分組
doi:10.6342/NTU202003855
26
優化過程一般而言可以分成初始化、訓練與驗證三階段,除了初始 化只在最開始進行一次外,優化過程中每次疊代(epoch)都會重複一次 訓練與驗證階段,並根據驗證階段結果決定是否繼續或結束優化過程。
1. 初始化(initialization)
在開始優化 ANN 前須對模式中的連結權重值等參數初始化,
選擇適當的初始化方法亦是網路是否能順利優化的關鍵之一,常用 的初始化方式可分為指定常數法,隨機亂數法與轉移(transform)參 數法三種,同一個網路層中相同類型的參數常使用相同的方法初始 化。這些初始化方法中指定常數法即為將參數初始化為 0、1 或其 它常數值,例如偏權值常以 0 初始化;隨機亂數法將參數以選定之 機率分布隨機值初始化,常用的機率分布函數有均勻分布(uniform distribution)及常態分布(normal distribution)兩種,此初始化法常用 於連結權重初始化;轉移參數法將其他模式相同維度與數量的參數 複製到目前網路中,其參數來源可能是另一個已訓練的 ANN 模式 或其他任何模式。例如本研究使用 PCA 結果中的特徵向量做為 SAE 神經網路初始化參數來源即為轉移參數法之應用。此外,決定 網路架構後還有超參數(hyperparameter)需要在初始化階段決定,例 如網路層中的神經元個數、優化方法中的學習數率(learning rate)、
訓練過程中的批次大小(batch size)、疊代次數或其他不可訓練的模 式參數。
2. 訓練 (training)
訓練指的是使用優化器(optimizer)調整已初始化的 ANN 參數,
是整個 ANN 模式優化最關鍵的步驟。一般使用以梯度下降法 (gradient descent)為基礎建立的優化器進行調整,即往該參數對誤差 函數(loss function)梯度下降方向進行修正,如 3-8 式:
doi:10.6342/NTU202003855
27
𝑥𝑛+1 = 𝑥𝑛 − 𝜂∇𝐹(𝑥𝑛) (3-8) 式中𝑥𝑛為第 n 次未調整參數值;𝑥𝑛+1為調整後的參數值;𝜂為學習 速率,即每次要調整的幅度權重值;∇𝐹(𝑥𝑛)為誤差函數於此參數的 梯度值。為了避免每輸入一筆訓練資料即進行網路神經元參數調整 所造成的震盪問題,一次輸入多筆訓練資料為一個批次(batch),再 參考該批次內修正量之平均誤差修正參數,則可有效解決此震盪問 題,此種訓練方式稱為批次學習(batch learning),一個批次的大小 (batch size)為模式超參數之一,常以經驗或試誤法決定。
3. 驗證
此階段主要的目的是檢視 ANN 模式經過優化器及訓練範本調 整後的性能,一般而言驗證範本會與訓練範本有相似的資料分布特 性,使其能正確評估訓練結果,以便決定是否繼續優化模式或停止。
此外,為了使網路參數優化更有效率及避免落入局部最小值 (Local minimum),已有許多改進梯度下降法優化參數之策略,本研究有使用 的策略如下:
1. 隨機梯度下降(stochastic gradient descent):
在每一次疊代過程中,以隨機方式排序訓練資料中批次的順 序,使每次訓練時修正過程具有差異,避免因相同順序的訓練資料 重複疊代而落入局部最小值。
2. 加入慣性項(momentum):
將前一次參數調整的修正量加入,可使搜尋過程中更有機會跳 出局部最佳解並減少震盪,如 3-9 與 3-10 式:
𝑣𝑛 = 𝛾𝑣𝑛−1+ 𝜂∇𝐹(𝑥𝑛) (3-9) 𝑥𝑛+1 = 𝑥𝑛 − 𝑣𝑛 (3-10) 式中𝑣𝑛為第 n 個參數的一階矩(1st moment),即為以過去梯度累計
doi:10.6342/NTU202003855
28
值𝑣𝑛−1與目前誤差函數於此參數的梯度∇𝐹(𝑥𝑛)分別乘上調整超參 數𝛾及學習速率𝜂之結果,其意義為過去疊代過程中誤差梯度的滑動 平均值(moving average)。其餘符號與 3-8 式相同。當梯度過大時可 能會有不斷跳過最佳解位置而來回震盪問題,透過加入𝑣𝑛−1使參數 修正量減少可達到抑制震盪效果;當梯度過小時誤差改善幅度可能 太慢,透過加入𝑣𝑛−1可加大修正量以加速優化過程。
3. 使用變動學習速率:
每一次調整參數時以自適應(adaptive)的方式調整學習速率,其 變動方式為每次更新參數時與之前疊代誤差相比較,於誤差量下降 時增加學習速率以加速收;誤差量上升時降低學習速率避免震盪。
根據上述三點,選用 Adam 演算法(Kingma 與 Ba,2014)做為本研 究 SAE 及 RNN 模式優化器。Adam 為適應性矩估計(adaptive moment estimation)之縮寫,適合解決 ANN 中大量參數要調整問題。Adam 屬於 一種隨機梯度下降法的延伸演算法,透過計算每個參數的一階梯度 (∇𝐹)與二階梯度(∇2𝐹)於過去疊代的移動平均值,為不同參數提供獨立 的自適應性變動學習速率,使其在各種非穩態或線性的類神經網路參 數優化過程中更容易使收斂。Adam 調整參數的方法如 3-11 至 3-18 式 所示,首先以 3-11 式計算誤差梯度:
𝑔𝑛 = ∇𝐹(𝑥𝑛) (3-11) 式中𝑔𝑛為每次調整第 n 個參數的誤差梯度,其於符號與 3-8 式相同。
接著以 3-12 式及 3-13 式計算一階矩(1st moment)與二階矩(2nd moment),
其概念與 3-9 式相似:
𝑚𝑛 = 𝛽1𝑛𝑚𝑛−1+ (1 − 𝛽1𝑛)𝑔𝑛 (3-12) 𝑣𝑛 = 𝛽2𝑛𝑣𝑛−1+ (1 − 𝛽2𝑛)𝑔𝑛2 (3-13) 式中𝑚𝑛與𝑣𝑛分別為第 n 個參數過去一階矩與二階矩,𝛽1𝑛與𝛽2𝑛為第 n 個
doi:10.6342/NTU202003855
29
參數過去一階矩與目前梯度的權重參數,介於 0 至 1 之間,文獻建議 𝛽1𝑛與𝛽2𝑛設定為 0.9 與 0.999。接著以 3-14 式及 3-15 式進行初始梯度偏 差校正(bias-corrected of first moment):
𝑚̂𝑛 = 𝑚𝑛
1 − 𝛽1𝑛 (3-14) 𝑣̂𝑛 = 𝑣𝑛
1 − 𝛽2𝑛 (3-15) 3-14 式及 3-15 式分別與 3-12 式及 3-13 式結合後為 3-16 式及 3-17 式,
可使第一次疊代𝑚𝑛與𝑣𝑛為 0 時𝛽1𝑛與𝛽2𝑛不會影響𝑔𝑛修正網路參數:
𝑚̂𝑛 = 𝛽1𝑛
1 − 𝛽1𝑛𝑚𝑛−1+ 𝑔𝑛 (3-16) 𝑣̂𝑛 = 𝛽2𝑛
1 − 𝛽2𝑛𝑣𝑛−1+ 𝑔𝑛2 (3-17) 最後第 n 個參數更新結果如 3-18 式:
𝑥𝑛+1 = 𝑥𝑛 − 𝜂𝑚̂𝑛
√𝑣̂𝑛+ 𝜀 (3-18) 式中𝜀為一個很小的值以避免除以 0 的情況發生。其中分母內的𝑣̂𝑛為變 動學習速率效果,可以使誤差梯度大的陡降區間減少調整量以避免震 盪;在梯度小的平緩區間加大調整量使優化過程更快收斂。𝑚̂𝑛為加入 慣性項效果,可使優化過程更有機會跳出局部最佳解並減少震盪。
此外,在訓練過程中範本不足或疊代次數過多時容易會發生過度 擬合(over fitting),即模式過度描述訓練資料輸入與輸出值間的關係,
使訓練結果理想但驗證結果不如預期的情況。為了避免過度擬合,本研 究使用的方法如下:
1. 提早結束訓練(early stopping):
當訓練過程中發生驗證資料誤差不再下降,反而開始持續上升 時,繼續訓練可能造成模式有過度擬合的問題,若設定檢查條件及
doi:10.6342/NTU202003855
30
儲存最佳參數,適時提早結束訓練階段,則能避免過度擬合的情況 發生。
2. 使用 Dropout 技術:
Dropout 為 Srivastava 等人(2014)提出的一種避免過度擬合技 術,方法為設定拿掉率(dropout rate),於訓練階段以隨機選取法使 隱藏層中一定數量的神經元暫時被拿掉(drop out),降低網路模型複 雜度,減少訓練階段模式擬合能力。由於採隨機方式拿掉,可避免 某一神經元參數被過度調整。驗證階段時恢復所有神經元連結,此 時下一層神經元接收到的值會增加,需乘以拿掉率以修正增加情 形。整體運算過程如 3-19 及 3-20 式所示:
{net′ = 𝑟1𝑤1𝑥1+ 𝑟2𝑤2𝑥2+ ⋯ + 𝑟𝑛𝑤𝑛𝑥𝑛+ 𝑏fortraining
net′ = 𝐷𝑟(𝑤1𝑥1 + 𝑤2𝑥2 + ⋯ + 𝑤𝑛𝑥𝑛) + 𝑏forotherstage (3-19)
y = 𝑓(𝑛𝑒𝑡′) (3-20)
式中net′為更改後之網路輸出值;𝐷𝑟為拿掉率,數值可介於 0 至 1 之間,一般不超過 0.5;𝑟𝑛為第 n 個連結隨機拿掉的遮罩,值可能 為 0 或 1,分別代表拿掉或保留。最後以 3-20 式計算神經元之輸出 值 y,其中𝑓為活化函數。
3. 加入正則項(regularizer):
於訓練階段神經元參數可調整範圍越大則代表模式擬合訓練 資料的能力越好,也容易造成過度擬合問題,因此在損失函數中增 加計算所有神經元參數值大小的正則項,則可以抑制參數值過大的 情形發生。一般常用的正則項有 L1與 L2兩種,前者為所有神經元 參數的絕對值總和;後者為所有神經元參數的平方和,如 3-21 至 3-23 式所示:
𝐿1 = ∑ |𝑤𝑗|
𝑛
𝑗=1 (3-21)
doi:10.6342/NTU202003855
31
𝐿2 = ∑ 𝑤𝑗2
𝑛
𝑗=1 (3-22)
𝐹̂(𝑥𝑛) = 𝐹(𝑥𝑛) + 𝛽1𝐿1 + 𝛽2𝐿2 (3-23) 式中𝐹̂(𝑥𝑛)為加入正則項後的損失函數;𝛽1與𝛽2為正則項調整值,
為模式超參數之一,常以經驗或試誤法決定。
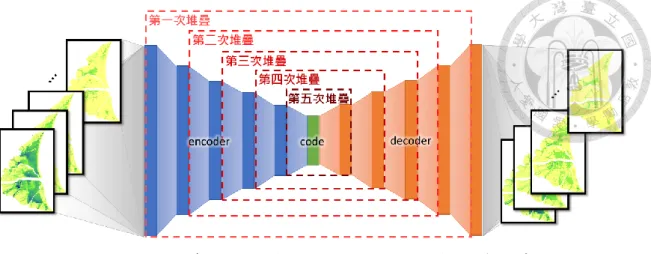
3.3 堆疊自編碼器(SAE)
堆疊自編碼器(Stacked autoencoder, SAE)是一種改良訓練方式的自 編碼器(autoencoder, AE)模式,亦屬於 ANN 模式的一種,為具有多層 隱藏層及對稱結構的 FFNN 或 DNN,其中堆疊是指 SAE 訓練過程中 隱藏層逐步增加的建構方式。一般而言,SAE 輸入與輸出層維度一致,
模式訓練目的是將輸出值近似於輸入值,因此,SAE 可用監督式學習 的方法達到無監督式學習的效果,又因 SAE 隱藏層維度常小於輸入層 與輸出層,使其具有對輸入資料進行降維之功能。
SAE 屬於編碼器-解碼器框架,具有編碼器(encoder)、編碼(code, C) 與解碼器(decoder)等三個主要部分,架構如圖 3.3.1 所示,可用 3-24 至 3-27 式表示,並以 3-28 式為損失函數(loss function):
𝑒𝑛𝑐𝑜𝑑𝑒𝑟: 𝑅𝑛 → 𝑅𝑑 (3-24) 𝑑𝑒𝑐𝑜𝑑𝑒𝑟: 𝑅𝑑 → 𝑅𝑛 (3-25)
𝑑, 𝑛 ∈ 𝑅
𝐶 = 𝑒𝑛𝑐𝑜𝑑𝑒𝑟(𝑋) (3-26) 𝑋′ = 𝐴𝐸(𝑋) = 𝑑𝑒𝑐𝑜𝑑𝑒𝑟(𝑒𝑛𝑐𝑜𝑑𝑒𝑟(𝑋)) (3-27)
𝑋 ∈ 𝑅𝑛, 𝐶 ∈ 𝑅𝑑
𝐿(𝑋, 𝑋′) = ‖𝑋 − 𝑋′‖2 (3-28) 上式中 X 與 C 分別屬於維度為 n 與 d 的實數向量,𝑋′代表經 AE 計算 後的模式輸出值,即為將 X 轉換成 C 再還原的結果。編碼器與解碼器
doi:10.6342/NTU202003855